
9. Generation: Pushing the Specification Level Upwards
The programmer at wit’s end ... can often do best by disentangling himself from his code, rearing back, and contemplating his data. Representation is the essence of programming.
The Mythical Man-Month, Anniversary Edition (1975–1995), p. 103
—Fred Brooks
In Chapter 1 we observed that human beings are better at visualizing data than they are at reasoning about control flow. We recapitulate: To see this, compare the expressiveness and explanatory power of a diagram of a fifty-node pointer tree with a flowchart of a fifty-line program. Or (better) of an array initializer expressing a conversion table with an equivalent switch statement. The difference in transparency and clarity is dramatic.1
1 For further development of this point see [Bentley].
Data is more tractable than program logic. That’s true whether the data is an ordinary table, a declarative markup language, a templating system, or a set of macros that will expand to program logic. It’s good practice to move as much of the complexity in your design as possible away from procedural code and into data, and good practice to pick data representations that are convenient for humans to maintain and manipulate. Translating those representations into forms that are convenient for machines to process is another job for machines, not for humans.
Another important advantage of higher-level, more declarative notations is that they lend themselves better to compile-time checking. Procedural notations inherently have complex runtime behavior which is difficult to analyze at compile time. Declarative notations give the implementation much more leverage for finding mistakes, by permitting much more thorough understanding of the intended behavior.
—Henry Spencer
These insights ground in theory a set of practices that have always been an important part of the Unix programmer’s toolkit—very high-level languages, data-driven programming, code generators, and domain-specific minilanguages. What unifies these is that they are all ways of lifting the generation of code up some levels, so that specifications can be smaller. We’ve previously noted that defect densities tend to be nearly constant across programming languages; all these practices mean that whatever malign forces generate our bugs will get fewer lines to wreak their havoc on.
In Chapter 8 we discussed the uses of domain-specific minilanguages. In Chapter 14 we’ll make the argument for very-high-level languages. In this chapter we’ll look at some design studies in data-driven programming and a few examples of ad-hoc code generation; we’ll look at some code-generation tools in Chapter 15. As with minilanguages, these methods can enable you to drastically cut the line count of your programs, and correspondingly lower debugging time and maintenance costs.
9.1 Data-Driven Programming
When doing data-driven programming, one clearly distinguishes code from the data structures on which it acts, and designs both so that one can make changes to the logic of the program by editing not the code but the data structure.
Data-driven programming is sometimes confused with object orientation, another style in which data organization is supposed to be central. There are at least two differences. One is that in data-driven programming, the data is not merely the state of some object, but actually defines the control flow of the program. Where the primary concern in OO is encapsulation, the primary concern in data-driven programming is writing as little fixed code as possible. Unix has a stronger tradition of data-driven programming than of OO.
Programming data-driven style is also sometimes confused with writing state machines. It is in fact possible to express the logic of a state machine as a table or data structure, but hand-coded state machines are usually rigid blocks of code that are far harder to modify than a table.
An important rule when doing any kind of code generation or data-driven programming is this: always push problems upstream. Don’t hack the generated code or any intermediate representations by hand—instead, think of a way to improve or replace your translation tool. Otherwise you’re likely to find that hand-patching bits which should have been generated correctly by machine will have turned into an infinite time sink.
At the upper end of its complexity scale, data-driven programming merges into writing interpreters for p-code or simple minilanguages of the kind we surveyed in Chapter 8. At other edges, it merges into code generation and state-machine programming. The distinctions are not actually that important; the important part is moving program logic away from hardwired control structures and into data.
9.1.1 Case Study: ascii
I maintain a program called ascii, a very simple little utility that tries to interpret its command-line arguments as names of ASCII (American Standard Code for Information Interchange) characters and report all the equivalent names. Code and documentation for the tool are available from the project page <http://www.catb.org/~esr/ascii>. Here is an illustrative screenshot:
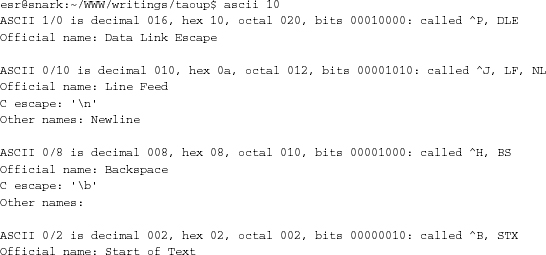
One indication that this program was a good idea is the fact that it has an unexpected use—as a quick CLI aid to converting between decimal, hex, octal, and binary representations of bytes.
The main logic of this program could have been coded as a 128-branch case statement. This would, however, have made the code bulky and difficult to maintain. It would also have tangled parts that change relatively rapidly (like the list of slang names for characters) with parts that change slowly or not at all (like the official names), putting them both in the same legend string and making errors during editing much more likely to touch data that ought to be stable.
Instead, we apply data-driven programming. All the character name strings live in a table structure that is quite a bit larger than any of the functions in the code (indeed, counted in lines it is larger than any three of the functions in the program). The code merely navigates the table and does low-level tasks like radix conversions. The initializer actually lives in the file nametable.h, which is generated in a way we’ll describe later in this chapter.
This organization makes it easy to add new character names, change existing ones, or delete old names by simply editing the table, without disturbing the code.
(The way the program is built is good Unix style, but the output format is questionable. It’s hard to see how the output could usefully become the input of any other program, so it does not play well with others.)
9.1.2 Case Study: Statistical Spam Filtering
One interesting case of data-driven programming is statistical learning algorithms for detecting spam (unsolicited bulk email). A whole class of mail filter programs (those easily findable by Web search include popfile, spambayes, and bogofilter) use a database of word correlations to replace the elaborate pattern-matching conditional logic of pattern-matching spam filters.
Programs like these became common on the Internet very rapidly following Paul Graham’s landmark paper A Plan for Spam [Graham] in 2002. While the explosion was triggered by the increasing cost of the pattern-matching arms race, the statistical-filtering idea was adopted first and fastest by Unix shops. In part, this was certainly because almost all the Internet service providers (who are most burdened by spam, and thus had most incentive to adopt effective new techniques) are Unix shops—but undoubtedly the harmony with some traditional themes in Unix software design helped as well.
Conventional spam filters require that a system administrator, or some other responsible party, maintain information on patterns of text found in spam—names of sites that emit nothing but spam, come-on phrases often used by pornography sites or Internet scam artists, and the like. In his paper, Graham noted accurately that computer programmers like the idea of pattern-matching filters, and sometimes have difficulty seeing past that approach, because it offers them so many opportunities to be clever.
Statistical spam filters, on the other hand, work by collecting feedback about what the user judges to be spam versus nonspam. That feedback is processed into databases of statistical correlation coefficients or weights connecting words or phrases to the user’s spam/nonspam classification. The most popular algorithms use minor variants of Bayes’s Theorem on conditional probabilities, but other techniques (including various sorts of polynomial hashing) are also employed.
In all these programs, the correlation check is a relatively trivial mathematical formula. The weights fed into the formula along with the message being checked serve as implicit control structure for the filtering algorithm.
The problem with conventional pattern-matching spam filters is that they are brittle. Spammers are constantly gaming against the filter-rule databases, forcing the filter maintainers to constantly reprogram their filters to stay ahead in the arms race. Statistical spam filters generate their own filter rules from the user feedback.
In fact, experience with statistical filters seems to show that the particular learning algorithm used is far less important than the quality of the spam and nonspam data sets from which the learning algorithm computes its weights. So the results of statistical filters really are driven more by the shape of the data than by the algorithm.
A Plan for Spam was something of a bombshell because its author argued convincingly that a simple, even crude, statistical approach gave a lower rate of nonspam being erroneously classified as spam than either elaborate pattern-matching techniques or the human eyeball could manage. For Unix programmers, seeing past the lure of clever pattern-matching was far easier than in other programming cultures without as strong an attachment to “Keep It Simple, Stupid!”
9.1.3 Case Study: Metaclass Hacking in fetchmailconf
The fetchmailconf(1) dotfile configurator shipped with fetchmail(1) contains an instructive example of advanced data-driven programming in a very high-level, object-oriented language.
In October 1997 a series of questions on the fetchmail-friends mailing list made it clear that end-users were having increasing troubles generating configuration files for fetchmail. The file uses a simple, classically-Unixy free-format syntax, but can become forbiddingly complicated when a user has POP3 and IMAP accounts at multiple sites. See Example 9.1 for a somewhat simplified version of the fetchmail author’s configuration file.
Example 9.1. Example of fetchmailrc syntax.

The design objective of fetchmailconf was to completely hide the control file syntax behind a fashionable, ergonomically-correct GUI replete with selection buttons, slider bars and fill-out forms. But the beta design had a problem: it could easily generate configuration files from the user’s GUI actions, but could not read and edit existing ones.
The parser for fetchmail’s configuration file syntax is rather elaborate. It’s actually written in yacc and lex, the two classic Unix tools for generating language-parsing code in C. For fetchmailconf to be able to edit existing configuration files, it at first appeared that it would be necessary to replicate that elaborate parser in fetchmailconf’s implementation language—Python.
This tactic seemed doomed. Even leaving aside the amount of duplicative work implied, it is notoriously hard to be certain that two parsers in two different languages accept the same grammar. Keeping them synchronized as the configuration language evolved bid fair to be a maintenance nightmare. It would have violated the SPOT rule we discussed in Chapter 4 wholesale.
This problem stumped me for a while. The insight that cracked it was that fetchmailconf could use fetchmail’s own parser as a filter! I added a --configdump option to fetchmail that would parse .fetchmailrc and dump the result to standard output in the format of a Python initializer. For the file above, the result would look roughly like Example 9.2 (to save space, some data not relevant to the example is omitted).
Example 9.2. Python structure dump of a fetchmail configuration.


The major hurdle had been leapt. The Python interpreter could then evaluate the fetchmail --configdump output and read the configuration available to fetchmailconf as the value of the variable ’fetchmail’.
But this wasn’t quite the last obstacle in the race. What was really needed wasn’t just for fetchmailconf to have the existing configuration, but to turn it into a linked tree of live objects. There would be three kinds of objects in this tree: Configuration (the top-level object representing the entire configuration), Site (representing one of the servers to be polled), and User (representing user data attached to a site). The example file describes three site objects, each with one user object attached to it.
The three object classes already existed in fetchmailconf. Each had a method that caused it to pop up a GUI edit panel to modify its instance data. The last remaining problem was to somehow transform the static data in this Python initializer into live objects.
I considered writing a glue layer that would explicitly know about the structure of all three classes and use that knowledge to grovel through the initializer creating matching objects, but rejected that idea because new class members were likely to be added over time as the configuration language grew new features. If the object-creation code were written in the obvious way, it would once again be fragile and tend to fall out of synchronization when either the class definitions or the initializer structure dumped by the --configdump report generator changed. Again, a recipe for endless bugs.
The better way would be data-driven programming—code that would analyze the shape and members of the initializer, query the class definitions themselves about their members, and then impedance-match the two sets.
Lisp and Java programmers call this introspection; in some other object-oriented languages it’s called metaclass hacking and is generally considered fearsomely esoteric, deep black magic. Most object-oriented languages don’t support it at all; in those that do (Perl and Java among them), it tends to be a complicated and fragile undertaking. But Python’s facilities for introspection and metaclass hacking are unusually accessible.
See Example 9.3 for the solution code, from near line 1895 of the 1.43 version.
Example 9.3. copy_instance metaclass code.

Most of this code is error-checking against the possibility that the class members and --configdump report generation have drifted out of synchronization. It ensures that if the code breaks, the breakage will be detected early—an implementation of the Rule of Repair. The heart of this function is the last two lines, which set attributes in the class from corresponding members in the dictionary. They’re equivalent to this:
![]()
When your code is this simple, it is far more likely to be right. See Example 9.4 for the code that calls it.
Example 9.4. Calling context for copy_instance.

The key point to extract from this code is that it traverses the three levels of the initializer (configuration/server/user), instantiating the correct objects at each level into lists contained in the next object up. Because copy_instance is data-driven and completely generic, it can be used on all three levels for three different object types.
This is a new-school sort of example; Python was not even invented until 1990. But it reflects themes that go back to 1969 in the Unix tradition. If meditating on Unix programming as practiced by his predecessors had not taught me constructive laziness—insisting on reuse, and refusing to write duplicative glue code in accordance with the SPOT rule—I might have rushed into coding a parser in Python. The first key insight that fetchmail itself could be made into fetchmailconf’s configuration parser might never have happened.
The second insight (that copy_instance could be generic) proceeded from the Unix tradition of looking assiduously for ways to avoid hand-hacking. But more specifically, Unix programmers are very used to writing parser specifications to generate parsers for processing language-like markups; from there it was a short step to believing that the rest of the job could be done by some kind of generic tree-walk of the configuration structure. Two separate stages of data-driven programming, one building on the other, were needed to solve the design problem cleanly.
Insights like this can be extraordinarily powerful. The code we have been looking at was written in about ninety minutes, worked the first time it was run, and has been stable in the years since (the only time it has ever broken is when it threw an exception in the presence of genuine version skew). It’s less than forty lines and beautifully simple. There is no way that the naïve approach of building an entire second parser could possibly have produced this kind of maintainability, reliability or compactness. Reuse, simplification, generalization, orthogonality: this is the Zen of Unix in action.
In Chapter 10, we’ll examine the run-control syntax of fetchmail as an example of the standard shell-like metaformat for run-control files. In Chapter 14 we’ll use fetchmailconf as an example of Python’s strength in rapidly building GUIs.
9.2 Ad-hoc Code Generation
Unix comes equipped with some powerful special-purpose code generators for purposes like building lexical analyzers (tokenizers) and parsers; we’ll survey these in Chapter 15. But there are much simpler, lighter-weight sorts of code generation we can use to make life easier without having to know any compiler theory or write (error-prone) procedural logic.
Here are a couple of simple case studies to illustrate this point:
9.2.1 Case Study: Generating Code for the ascii Displays
Called without arguments, ascii generates a usage screen that looks like Example 9.5.
Example 9.5. ascii usage screen.
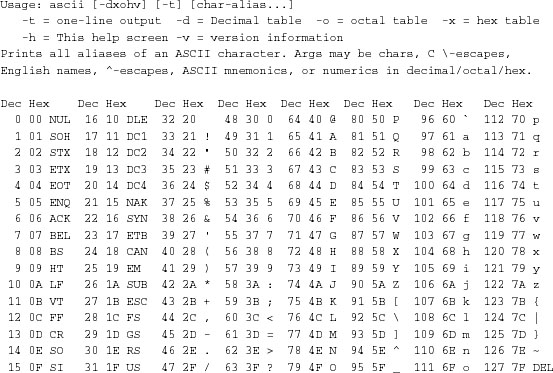
This screen is carefully designed to fit in 23 rows and 79 columns, so that it will fit in a 24×80 terminal window.
This table could be generated at runtime, on the fly. Grinding out the decimal and hex columns would be easy enough. But between wrapping the table at the right places and knowing when to print mnemonics like NUL rather than characters, there would have been enough odd corner cases to make the code distinctly unpleasant. Furthermore, the columns had to be unevenly spaced to make the table fit in 79 columns. But any Unix programmer would reflexively express it as a block of data before finding out these things.
The most naïve way to generate the usage screen would have been to put each line into a C initializer in the ascii.c source code, and then have all lines be written out by code that steps through the initializer. The problem with this method is that the extra data in the C initializer format (trailing newline, string quotes, comma) would make the lines longer than 79 characters, causing them to wrap and making it rather difficult to map the appearance of the code to the appearance of the output. This, in turn, would make the display difficult to edit, which was annoying when I was tinkering it to fit in 24×80 screen cells.
A more sophisticated method using the string-pasting behavior of the ANSI C preprocessor collided with a variant of the same problem. Essentially, any way of inlining the usage screen explicitly would involve punctuation at start and end of line that there’s no room for.2 And copying the table to the screen from a file at runtime seemed like a fragile expedient; after all, the file could get lost.
2 Scripting languages tend to solve this problem more elegantly than C does. Investigate the shell’s here documents and Python’s triple-quote construct to find out how.
Here’s the solution. The source distribution contains a file that just contains the usage screen, exactly as listed above and named splashscreen. The C source contains the following function:

And splashscreen.h is generated by a makefile production:
![]()
So when the program is built, the splashscreen file is automatically massaged into a series of output function calls, which are then included by the C preprocessor in the right function.
By generating the code from data, we get to keep the editable version of the usage screen identical to its display appearance. This promotes transparency. Furthermore, we could modify the usage screen at will without touching the C code at all, and the right thing would automatically happen on the next build.
For similar reasons, the initializer that holds the name synonym strings is also generated via a sed script in the makefile, from a file called nametable in the ascii source distribution. Most of nametable is simply copied into the C initializer. But the generation process would make it easy to adapt this tool for other 8-bit character sets such as the ISO-8859 series (Latin-1 and friends).
This is an almost trivial example, but it nevertheless illustrates the advantages of even simple and ad-hoc code generation. Similar techniques could be applied to larger programs with correspondingly greater benefits.
9.2.2 Case Study: Generating HTML Code for a Tabular List
Let’s suppose that we want to put a page of tabular data on a Web page. We want the first few lines to look like Example 9.6.
Example 9.6. Desired output format for the star table.
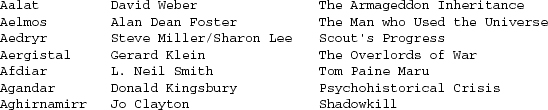
The thick-as-a-plank way to handle this would be to hand-write HTML table code for the desired appearance. Then, each time we want to add a name, we’d have to hand-write another set of <tr> and <td> tags for the entry. This would get very tedious very quickly. But what’s worse, changing the format of the list would require hand-hacking every entry.
The superficially clever way to handle this would be to make this data a three-column relation in a database, then use some fancy CGI3 technique or a database-capable templating engine like PHP to generate the page on the fly. But suppose we know that the list will not change very often, don’t want to run a database server just to be able to display this list, and don’t want to load the server with unnecessary CGI traffic?
3 Here, CGI refers not to Computer Graphic Inagery but to the Common Gateway Interface used for live Web content.
There’s a better solution. We put the data in a tabular flat-file format like Example 9.7.
Example 9.7. Master form of the star table.
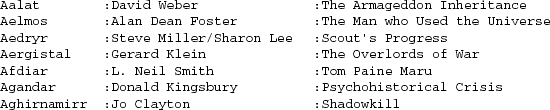
We could in a pinch have done without the explicit colon field delimiters, using the pattern consisting of two or more spaces as a delimiter, but the explicit delimiter protects us in case we press spacebar twice while editing a field value and fail to notice it.
We then write a script in shell, Perl, Python, or Tcl that massages this file into an HTML table, and run that each time we add an entry. The old-school Unix way would revolve around the following nigh-unreadable sed(1) invocation
sed -e 's,^,<tr><td>,' -e 's,$,</td></tr>,' -e 's,:,</td><td>,g'
or this perhaps slightly more scrutable awk(1) program:
awk -F: '{printf("<tr><td>%s</td><td>%s</td><td>%s</td></tr>
",
$1, $2, $3)}'
(If either of these examples interests but mystifies, read the documentation for sed(1) or awk(1). We explained in Chapter 8 that the latter has largely fallen out of use. The former is still an important Unix tool that we haven’t examined in detail because (a) Unix programmers already know it, and (b) it’s easy for non-Unix programmers to pick up from the manual page once they grasp the basic ideas about pipelines and redirection.)
A new-school solution might center on this Python code, or on equivalent Perl:
for row in map(lambda x:x.rstrip().split(':'),sys.stdin.readlines()):
print "<tr><td>" + "</td><td>".join(row) + "</td></tr>"
These scripts took about five minutes each to write and debug, certainly less time than would have been required to either hand-hack the initial HTML or create and verify the database. The combination of the table and this code will be much simpler to maintain than either the under-engineered hand-hacked HTML or the over-engineered database.
A further advantage of this way of solving the problem is that the master file stays easy to search and modify with an ordinary text editor. Another is that we can experiment with different table-to-HTML transformations by tweaking the generator script, or easily make a subset of the report by putting a grep(1) filter before it.
I actually use this technique to maintain the Web page that lists fetchmail test sites; the example above is science-fictional only because publishing the real data would reveal account usernames and passwords.
This was a somewhat less trivial example than the previous one. What we’ve actually designed here is a separation between content and formatting, with the generator script acting as a stylesheet. (This is yet another mechanism-vs.-policy separation.)
The lesson in all these cases is the same. Do as little work as possible. Let the data shape the code. Lean on your tools. Separate mechanism from policy. Expert Unix programmers learn to see possibilities like these quickly and automatically. Constructive laziness is one of the cardinal virtues of the master programmer.