
8. Minilanguages: Finding a Notation That Sings
A good notation has a subtlety and suggestiveness which at times makes it almost seem like a live teacher.
The World of Mathematics (1956)
—Bertrand Russell
One of the most consistent results from large-scale studies of error patterns in software is that programmer error rates in defects per hundreds of lines are largely independent of the language in which the programmers are coding.1 Higher-level languages, which allow you to get more done in fewer lines, mean fewer bugs as well.
1 Les Hatton reports by email on the analysis in his book in preparation, Software Failure: “Provided you use executable line counts for the density measure, the injected defect densities vary less between languages than they do between engineers by about a factor of 10”.
Unix has a long tradition of hosting little languages specialized for a particular application domain, languages that can enable you to drastically reduce the line count of your programs. Domain-specific language examples include the numerous Unix typesetting languages (troff, eqn, tbl, pic, grap), shell utilities (awk, sed, dc, bc), and software development tools (make, yacc, lex). There is a fuzzy boundary between domain-specific languages and the more flexible sort of application run-control file (sendmail, BIND, X); another with data-file formats; and another with scripting languages (which we’ll survey in Chapter 14).
Historically, domain-specific languages of this kind have been called ’little languages’ or ’minilanguages’ in the Unix world, because early examples were small and low in complexity relative to general-purpose languages (all three terms for the category are in common use). But if the application domain is complex (in that it has lots of different primitive operations or involves manipulation of intricate data structures), an application language for it may have to be rather more complex than some general-purpose languages. We’ll keep the traditional term ’minilanguage’ to emphasize that the wise course is usually to keep these designs as small and simple as possible.
The domain-specific little language is an extremely powerful design idea. It allows you to define your own higher-level language to specify the appropriate methods, rules, and algorithms for the task at hand, reducing global complexity relative to a design that uses hardwired lower-level code for the same ends. You can get to a minilanguage design in at least three ways, two of them good and one of them dangerous.
One right way to get there is to realize up front that you can use a minilanguage design to push a given specification of a programming problem up a level, into a notation that is more compact and expressive than you could support in a general-purpose language. As with code generation and data-driven programming, a minilanguage lets you take practical advantage of the fact that the defect rate in your software will be largely independent of the level of the language you are using; more expressive languages mean shorter programs and fewer bugs.
The second right way to get to a minilanguage design is to notice that one of your specification file formats is looking more and more like a minilanguage—that is, it is developing complex structures and implying actions in the application you are controlling. Is it trying to describe control flow as well as data layouts? If so, it may be time to promote that control flow from being implicit to being explicit in your specification language.
The wrong way to get to a minilanguage design is to extend your way to it, one patch and crufty added feature at a time. On this path, your specification file keeps sprouting more implied control flow and more tangled special-purpose structures until it has become an ad-hoc language without your noticing it. Some legendary nightmares have been spawned this way; the example every Unix guru will think of (and shudder over) is the sendmail.cf configuration file associated with the sendmail mail transport.
Sadly, most people do their first minilanguage the wrong way, and only realize later what a mess it is. Then the question is: how to clean it up? Sometimes the answer implies rethinking the entire application design. Another notorious example of language-by-feature creep was the editor TECO, which grew first macros and then loops and conditionals as programmers wanted to use it to package increasingly complex editing routines. The resulting ugliness was eventually fixed by a redesign of the entire editor to be based on an intentional language; this is how Emacs Lisp (which we’ll survey below) evolved.
All sufficiently complicated specification files aspire to the condition of minilanguages. Therefore, it will often be the case that your only defense against designing a bad minilanguage is knowing how to design a good one. This need not be a huge step or involve knowing a lot of formal language theory; with modern tools, learning a few relatively simple techniques and bearing good examples in mind as you design should be sufficient.
In this chapter we’ll examine all the kinds of minilanguages normally supported under Unix, and try to identify the kinds of situation in which each of them represents an effective design solution. This chapter is not meant to be an exhaustive catalog of Unix languages, but rather to bring out the design principles involved in structuring an application around a minilanguage. We’ll have much more to say about languages for general-purpose programming in Chapter 14.
We’ll need to start by doing a little taxonomy, so we’ll know what we’re talking about later on.
8.1 Understanding the Taxonomy of Languages
All the languages in Figure 8.1 are described in case studies, either in this chapter or elsewhere in this book. For the general-purpose interpreters near the right-hand side, see Chapter 14.
Figure 8.1. Taxonomy of languages.
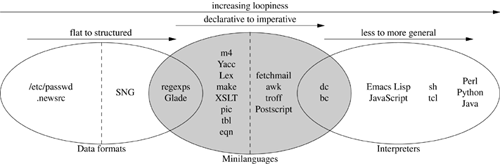
In Chapter 5 we looked at Unix conventions for data files. There’s a spectrum of complexity in these. At the low end are files that make simple associations between names and properties; the /etc/passwd and .newsrc formats are good examples. Further up the scale we start to get formats that marshal or serialize data structures; the PNG and SNG formats are (equivalent) good examples of this.
A structured data-file format starts to border on being a minilanguage when it expresses not just structure but actions performed on some interpretive context (that is, memory that is outside the data file itself). XML markups tend to straddle this border; the example we’ll look at here is Glade, a code generator for building GUI interfaces. Formats that are both designed to be read and written by humans (rather than just programs) and are used to generate code, are firmly in the realm of minilanguages. yacc and lex are the classic examples. We’ll discuss glade, yacc and lex in Chapter 9.
The Unix macro processor, m4, is another very simple declarative minilanguage (that is, one in which the program is expressed as a set of desired relationships or constraints rather than explicit actions). It has often been used as a preprocessing stage for other minilanguages.
Unix makefiles, which are designed to automate build processes, express dependency relationships between source and derived files2 and the commands required to make each derived file from its sources. When you run make, it uses those declarations to walk the implied tree of dependencies, doing the least work necessary to bring your build up to date. Like yacc and lex specifications, makefiles are a declarative minilanguage; they set up constraints that imply actions performed on an interpretive context (in this case, the portion of the file system where the source and generated files live). We’ll return to makefiles in Chapter 15.
2 For less technical readers: the compiled form of a C program is derived from its C source form by compilation and linkage. The PostScript version of a troff document is derived from the troff source; the command to make the former from the latter is a troff invocation. There are many other kinds of derivation; makefiles can express almost all of them.
XSLT, the language used to describe transformations of XML, is at the high end of complexity for declarative minilanguages. It’s complex enough that it’s not normally thought of as a minilanguage at all, but it shares some important characteristic of such languages which we’ll examine when we look at it in more detail below.
The spectrum of minilanguages ranges from declarative (with implicit actions) to imperative (with explicit actions). The run-control syntax of fetchmail(1) can be viewed as either a very weak imperative language or a declarative language with implied control flow. The troff and PostScript typesetting languages are imperative languages with a lot of special-purpose domain expertise baked into them.
Some task-specific imperative minilanguages start to border on being general-purpose interpreters. They reach this level when they are explicitly Turing-complete—that is, they can do both conditionals and loops (or recursion)3 with features that are designed to be used as control structures. Some languages, by contrast, are only accidentally Turing-complete—they have features that can be used to implement control structures as a sort of side effect of what they are actually designed to do.
3 Any Turing-complete language could theoretically be used for general-purpose programming, and is theoretically exactly as powerful as any other Turing-complete language. In practice, some Turing-complete languages would be far too painful to use for anything outside a specified and narrow problem domain.
The bc(1) and dc(1) interpreters we looked at in Chapter 7 are good examples of specialized imperative minilanguages that are explicitly Turing-complete.
We are over the border into general-purpose interpreters when we reach languages like Emacs Lisp and JavaScript that are designed to be full programming languages run in specialized contexts. We’ll have more to say about these when we discuss embedded scripting languages later on.
The spectrum in interpreters is one of increasing generality; the flip side of this is that a more general-purpose interpreter embodies fewer assumptions about the context in which it runs. With increasing generality there usually comes a richer ontology of data types. Shell and Tcl have relatively simple ontologies; Perl, Python, and Java more complex ones. We’ll return to these general-purpose languages in Chapter 14.
8.2 Applying Minilanguages
Designing with minilanguages involves two distinct challenges. One is having existing minilanguages handy in your toolkit, and recognizing when they can be applied as-is. The other is knowing when it is appropriate to design a custom minilanguage for an application. To help you develop both aspects of your design sense, about half of this chapter will consist of case studies.
8.2.1 Case Study: sng
In Chapter 6 we looked at sng(1), which translates between PNG and an editable all-text representation of the same bits. The SNG data-file format is worth reexamining for contrast here because it is not quite a domain-specific minilanguage. It describes a data layout, but doesn’t associate any implied sequence of actions with the data.
SNG does, however, share one important characteristic with domain-specific minilanguages that binary structured data formats like PNG do not—transparency. Structured data files make it possible for editing, conversion, and generation tools to cooperate without knowing about each others’ design assumptions other than through the medium of the minilanguage. What SNG adds is that, like a domain-specific minilanguage, it’s designed to be easy to parse by eyeball and edit with general-purpose tools.
8.2.2 Case Study: Regular Expressions
A kind of specification that turns up repeatedly in Unix tools and scripting languages is the regular expression (’regexp’ for short). We consider it here as a declarative minilanguage for describing text patterns; it is often embedded in other minilanguages. Regexps are so ubiquitous that the are hardly thought of as a minilanguage, but they replace what would otherwise be huge volumes of code implementing different (and incompatible) search capabilities.
This introduction skates over some details like POSIX extensions, back-references, and internationalization features; for a more complete treatment, see Mastering Regular Expressions [Friedl].
Regular expressions describe patterns that may either match or fail to match against strings. The simplest regular-expression tool is grep(1), a filter that passes through to its output every line in its input matching a specified regexp. Regexp notation is summarized in Table 8.1.
There are a number of minor variants of regexp notation:
- Glob expressions. This is the limited set of wildcard conventions used by early Unix shells for filename matching. There are only three wildcards:
*, which matches any sequence of characters (like.*in the other variants);?, which matches any single character (like.in the other variants); and[...], which matches a character class just as in the other variants. Some shells (csh,bash,zsh) later added{}for alternation. Thus,x{a,b}cmatchesxacorxbcbut notxc. Some shells further extend globs in the direction of extended regular expressions. - Basic regular expressions. This is the notation accepted by the original grep(1) utility for extracting lines matching a given regexp from a file. The line editor ed(1), the stream editor sed(1), also use these. Old Unix hands think of these as the basic or ’vanilla’ flavor of regexp; people first exposed to the more modern tools tend to assume the extended form described next.
- Extended regular expressions. This is the notation accepted by the extended grep utility egrep(1) for extracting lines matching a given regexp from a file. Regular expressions in Lex and the Emacs editor are very close to the egrep flavor.
- Perl regular expressions. This is the notation accepted by Perl and Python regexp functions. These are quite a bit more powerful than the egrep flavor.
Table 8.1. Regular-expression examples.

Now that we’ve looked at some motivating examples, Table 8.2 is a summary of the standard regular-expression wildcards. Note: we’re not including the glob variant in this table, so a value of “All” implies only all three of the basic, extended/Emacs, and Perl/Python variants.4
4 The POSIX standard for regular expressions introduces some symbolic ranges like [[:lower;;]] and [[:digit:]], and some specific tools have extra wildcards not covered here, but these will suffice to interpret most regexps.
Table 8.2. Introduction to regular-expression operations.

Design practice in new languages with regexp support has stabilized on the Perl/Python variant. It is more transparent than the others, notably because backlash before a non-alphanumeric character always means that character as a literal, so there is much less confusion about how to quote elements of regexps.
Regular expressions are an extreme example of how concise a minilanguage can be. Simple regular expressions express recognition behavior that would otherwise have to be implenented with hundreds of lines of fussy, bug-prone code.
8.2.3 Case Study: Glade
Glade is an interface builder for the open-source GTK toolkit library for X.5 Glade allows you to develop a GUI interface by interactively picking, placing, and modifying widgets on an interface panel. The GUI editor produces an XML file describing the interface; this, in turn, can be fed to one of several code generators that will actually grind out C, C++, Python or Perl code for the interface. The generated code then calls functions you write to supply behavior to the interface.
5 For non-Unix programmers, an X toolkit is a graphics library that supplies GUI widgets (like labels, buttons, and pull-down menus) to the programs that link to it. Under most other graphical operating systems, the OS supplies one toolkit that everyone uses. Unix and X support multiple toolkits; this is part of the separation of policy from mechanism that we called out as a design goal of X in Chapter 1. GTK and Qt are the two most popular open-source X toolkits.
Glade’s XML format for describing GUIs is a good example of a simple domain-specific minilanguage. See Example 8.1 for a “Hello, world!” GUI in Glade format.
Example 8.1. Glade “Hello, World”.

A valid specification in Glade format implies a repertoire of actions by the GUI in response to user behavior. The Glade GUI treats these specifications as structured data files; Glade code generators, on the other hand, use them to write programs implementing a GUI. For some languages (including Python), there are runtime libraries that allow you to skip the code-generation step and simply instantiate the GUI directly at runtime from the XML specification (interpreting Glade markup, rather than compiling it to the host language). Thus, you get the choice of trading space efficiency for startup speed or vice versa.
Once you get past the verbosity of XML, Glade markup is a fairly simple language. It does just two things: declare GUI-widget hierarchies and associate properties with widgets. You don’t actually have to know a lot about how glade works to read the specification above. In fact, if you have any experience programming in GUI toolkits, reading it will immediately give you a fairly good visualization of what glade does with the specification. (Hands up everyone who predicted that this particular specification will give you a single button widget in a window frame.)
This kind of transparency and simplicity is the mark of a good minilanguage design. The mapping between the notation and domain objects is very clear. The relationships between objects are expressed directly, rather than through name references or some other sort of indirection that you have to think to follow.
The ultimate functional test of a minilanguage like this one is simple: can I hack it without reading the manual? For a significant range of cases, the Glade answer is yes. For example, if you know the C-level constants that GTK uses to describe window-positioning hints, you’ll recognize GTK_WIN_POS_NONE as one and instantly be able to change the positioning hint associated with this GUI.
The advantage of using Glade should be clear. It specializes in code generation so you don’t have to. That’s one less routine task you have to hand-code, and one fewer source of hand-coded bugs.
More information, including source code and documentation and links to sample applications, is available at the Glade project page <http://glade.gnome.org/>. Glade has been ported to Windows.
8.2.4 Case Study: m4
The m4(1) macro processor interprets a declarative minilanguage for describing transformations of text. An m4 program is a set of macros that specifies ways to expand text strings into other strings. Applying those declarations to an input text with m4 performs macro expansion and yields an output text. (The C preprocessor performs similar services for C compilers, though in a rather different style.)
Example 8.2 shows an m4 macro that directs m4 to expand each occurrence of the string “OS” in its input into the string “operating system” on output. This is a trivial example; m4 supports macros with arguments that can be used to do more than transform one fixed string into another. Typing info m4 at your shell prompt will probably display on-line documentation for this language.
Example 8.2. A sample m4 macro.
![]()
The m4 macro language supports conditionals and recursion. The combination can be used to implement loops, and this was intended; m4 is deliberately Turing-complete. But actually trying to use m4 as a general-purpose language would be deeply perverse.
The m4 macro processor is usually employed as a preprocessor for minilanguages that lack a built-in notion of named procedures or a built-in file-inclusion feature. It’s an easy way to extend the syntax of the base language so the combination with m4 supports both these features.
One well-known use of m4 has been to clean up (or at least effectively hide) another minilanguage design that was called out as a bad example earlier in this chapter. Most system administrators now generate their sendmail.cf configuration files using an m4 macro package supplied with the sendmail distribution. The macros start from feature names (or name/value pairs) and generate the corresponding (much uglier) strings in the sendmail configuration language.
Use m4 with caution, however. Unix experience has taught minilanguage designers to be wary of macro expansion,6 for reasons we’ll discuss later in the chapter.
6 Whether or not “macro expansion” should be spelled “macroexpansion” is a matter for some dispute. The latter is found mainly among Lisp programmers.
8.2.5 Case Study: XSLT
XSLT, like m4 macros, is a language for describing transformations of a text stream. But it does much more than simple macro substitution; it describes transformations of XML data, including query and report generation. It is the language used to write XML stylesheets. For practical applications, see the description of XML document processing in Chapter 18. XSLT is described by a World Wide Web Consortium standard and has several open-source implementations.
XSLT and m4 macros are both purely declarative and Turing-complete, but XSLT supports only recursions and not loops. It is quite complex, certainly the most difficult language to master of any in this chapter’s case studies—and probably the most difficult of any language mentioned in this book.7
7 It is not clear that XSLT could be any simpler and still do its job, however, so we cannot characterize it as a bad design.
Despite its complexity, XSLT really is a minilanguage. It shares important (though not universal) characteristics of the breed:
• A restricted ontology of types, with (in particular) no analog of record structures or arrays.
• Restricted interface to the rest of the world. XSLT processors are designed to filter standard input to standard output, with a limited ability to read and write files. They can’t open sockets or run subcommands.
Example 8.3. A sample XSLT program.

The program in Example 8.3 transforms an XML document so that each attribute of every element is transformed into a new tag pair directly enclosed by that element, with the attribute value as the tag pair’s content.
We’ve included a glance at XSLT here partly to illustrate the point that ’declarative’ does not imply either ’simple’ or ’weak’, and mostly because if you have to work with XML documents, you will someday have to face the challenge that is XSLT.
XSLT: Mastering XML Transformations [Tidwell] is a good introduction to the language. A brief tutorial with examples is available on the Web.8
8 XSL Concepts and Practical Use <http://nwalsh.com/docs/tutorials/xsl/xsl/slides.html>.
8.2.6 Case Study: The Documenter’s Workbench Tools
The troff(1) typesetting formatter was, as we noted in Chapter 2, Unix’s original killer application. troff is the center of a suite of formatting tools (collectively called Documenter’s Workbench or DWB), all of which are domain-specific minilanguages of various kinds. Most are either preprocessors or postprocessors for troff markup. Open-source Unixes host an enhanced implementation of Documenter’s Workbench called groff(1), from the Free Software Foundation.
We’ll examine troff in more detail in Chapter 18; for now, it’s sufficient to note that it is a good example of an imperative minilanguage that borders on being a full-fledged interpreter (it has conditionals and recursion but not loops; it is accidentally Turing-complete).
The postprocessors (’drivers’ in DWB terminology) are normally not visible to troff users. The original troff emitted codes for the particular typesetter the Unix development group had available in 1970; later in the 1970s these were cleaned up into a device-independent minilanguage for placing text and simple graphics on a page. The postprocessors translate this language (called “ditroff” for “device-independent troff”) into something modern imaging printers can actually accept—the most important of these (and the modern default) is PostScript.
The preprocessors are more interesting, because they actually add capabilities to the troff language. There are three common ones: tbl(1) for making tables, eqn(1) for typesetting mathematical equations, and pic(1) for drawing diagrams. Less used, but still live, are grn(1) for graphics, and refer(1) and bib(1) for formatting bibliographies. Open-source equivalents of all of these ship with groff. The grap(1) preprocessor provided a rather versatile plotting facility; there is an open-source implementation separate from groff.
Some other preprocessors have no open-source implementation and are no longer in common use. Best known of these was ideal(1), for graphics. A younger sibling of the family, chem(1), draws chemical structural formulas; it is available as part of Bell Labs’s netlib code.9
Each of these preprocessors is a little program that accepts a minilanguage and compiles it into troff requests. Each one recognizes the markup it is supposed to interpret by looking for a unique start and end request, and passes through unaltered any markup outside those (tbl looks for .TS/.TE, pic looks for .PS/.PE, etc.). Thus, most of the preprocessors can normally be run in any order without stepping on each other. There are some exceptions: in particular, chem and grap both issue pic commands, and so must come before it in the pipeline.
![]()
The preceding is a full-Monty example of a Documenter’s Workbench processing pipeline, for a hypothetical thesis incorporating chemical formulas, mathematical equations, tables, bibliographies, plots, and diagrams. (The cat(1) command simply copies its input or a file argument to its output; we use it here to emphasize the order of operations.) In practice modern troff implementations tend to support command-line options that can invoke at least tbl(1), eqn(1) and pic(1), so it isn’t necessary to write such an elaborate pipeline. Even if it were, these sorts of build recipes are normally composed just once and stashed away in a makefile or shellscript wrapper for repeated use.
The document markup of Documenter’s Workbench is in some ways obsolete, but the range of problems these preprocessors address gives some indication of the power of the minilanguage model—it would be extremely difficult to embed equivalent knowledge into a WYSIWYG word processor. There are some ways in which modern XML-based document markups and toolchains are still, in 2003, playing catch-up with capabilities that Documenter’s Workbench had in 1979. We’ll discuss these issues in more detail in Chapter 18.
The design themes that gave Documenter’s Workbench so much power should by now be familiar ones; all the tools share a common text-stream representation of documents, and the formatting system is broken up into independent components that can be debugged and improved separately. The pipeline architecture supports plugging in new, experimental preprocessors and postprocessors without disturbing old ones. It is modular and extensible.
The architecture of Documenter’s Workbench as a whole teaches us some things about how to fit multiple specialist minilanguages into a cooperating system. One preprocessor can build on another. Indeed, the Documenter’s Workbench tools were an early exemplar of the power of pipes, filtering, and minilanguages that influenced a lot of later Unix design by example. The design of the individual preprocessors has more lessons to teach about what effective minilanguage designs look like.
One of these lessons is negative. Sometimes users writing descriptions in the minilanguages do unclean things with low-level troff markup inserted by hand. This can produce interactions and bugs that are hard to diagnose, because the generated troff coming out of the pipeline is not visible—and would not be readable if it were. This is analogous to the sorts of bugs that happen in code that mixes C with snippets of in-line assembler. It might have been better to separate the language layers more completely, if that were possible. Minilanguage designers should take note of this.
All the preprocessor languages (though not troff markup itself) have relatively clean, shell-like syntaxes that follow many of the conventions we described in Chapter 5 for the design of data-file formats. There are a few embarrassing exceptions; notably, tbl(1) defaults to using a tab as a field separator between table columns, replicating an infamous botch in the design of make(1) and causing annoying bugs when editors or other tools invisibly change the composition of whitespace.
While troff itself is a specialized imperative language, one theme that runs through at least three of the Documenter’s Workbench minilanguages is declarative semantics: doing layout from constraints. This is an idea that shows up in modern GUI toolkits as well—that, instead of giving pixel coordinates for graphical objects, what you really want to do is declare spatial relationships among them (“widget A is above widget B, which is to the left of widget C”) and have your software compute a best-fit layout for A, B, and C according to those constraints.
The pic(1) program uses this approach to lay out elements for diagrams. The language taxonomy diagram at Figure 8.1 was produced with the pic source code in Example 8.410 run through pic2graph, one of our case studies in Chapter 7.
10 It is also quite traditional for Unix books that describe pic(1) to include their own illustrations as coding examples.
Example 8.4. Taxonomy of languages—the pic source.


This is a very typical Unix minilanguage design, and as such has some points of interest even on the purely syntactic level. Notice how much it looks like a shell program: # leads comments, and the syntax is obviously token-oriented with the simplest possible convention for strings. The designer of pic(1) knew that Unix programmers expect minilanguage syntaxes to look like this unless there is a strong and specific reason they should not. The Rule of Least Surprise is in full operation here.
It probably doesn’t take a lot of effort to discern that the first line of code is a macro definition; the later references to smallellipse() encapsulate a repeated design element of the diagram. Nor will it take much scrutiny to deduce that box invis declares a box with invisible borders, actually just a frame for text to be stacked inside. The arrow command is equally obvious.
With these as clues and one eye on the actual diagram, the meaning of the remaining pieces of the syntax (position references like M.s and constructions like last arrow or at 0.25 between M.e and I.e or the addition of vector offsets to a location) should become rapidly apparent. As with Glade markup and m4, an example like this one can teach a good bit of the language without any reference to a manual (a compactness property troff(1) markup, unfortunately, does not have).
The example of pic(1) reflects a common design theme in minilanguages, which we also saw reflected in Glade—the use of a minilanguage interpreter to encapsulate some form of constraint-based reasoning and turn it into actions. We could actually choose to view pic(1) as an imperative language rather than a declarative one; it has elements of both, and the dispute would quickly grow theological.
The combination of macros with constraint-based layout gives pic(1) the ability to express the structure of diagrams in a way that more modern vector-based markups like SVG cannot. It is therefore fortunate that one effect of the Documenter’s Workbench design is to make it relatively easy to keep pic(1) useful outside the DWB context. The pic2graph script we used as a case study in Chapter 7 was an ad-hoc way to accomplish this, using the retrofitted PostScript capability of groff(1) as a half-way step to a modern bitmap format.
A cleaner solution is the pic2plot(1) utility distributed with the GNU plotutils package, which exploited the internal modularity of the GNU pic(1) code. The code was split into a parsing front end and a back end that generated troff markup, the two communicating through a layer of drawing primitives. Because this design obeyed the Rule of Modularity, pic2plot(1) implementers were able to split off the GNU pic parsing stage and reimplement the drawing primitives using a modern plotting library. Their solution has the disadvantage, however, that text in the output is generated with fonts built into pic2plot that won’t match those of troff.
8.2.7 Case Study: fetchmail Run-Control Syntax
See Example 8.5 for an example.
Example 8.5. Synthetic example of a fetchmailrc.

This run-control file can be viewed as an imperative minilanguage. There is an implied flow of execution: cycle through the list of poll commands repeatedly (sleeping for a while at the end of each cycle), and for each site entry collect mail for each associated user in sequence. It is far from being general-purpose; all it can do is sequence the program’s polling behavior.
As with pic(1), one could choose to view this minilanguage as either declarations or a very weak imperative language, and argue endlessly over the distinction. On the one hand, it has neither conditionals nor recursion nor loops; in fact, it has no explicit control structures at all. On the other hand, it does describe actions rather than just relationships, which distinguishes it from a purely declarative syntax like Glade GUI descriptions.
Run-control minilanguages for complex programs often straddle this border. We’re making a point of this fact because not having explicit control structures in an imperative minilanguage can be a tremendous simplification if the problem domain lets you get away with it.
One notable feature of .fetchmailrc syntax is the use of optional noise keywords that are supported simply in order to make the specifications read a bit more like English. The ’with’ keywords and single occurrence of ’options’ in the example aren’t actually necessary, but they help make the declarations easier to read at a glance.
The traditional term for this sort of thing is syntactic sugar; the maxim that goes with this is a famous quip that “syntactic sugar causes cancer of the semicolon”.11 Indeed, syntactic sugar needs to be used sparingly lest it obscure more than help.
11 The line is owed to Alan Perlis, who did some of the pioneering work in software modularity around 1970. The semicolon in question was the statement separator or terminator in various Algol-descended languages, including Pascal and C.
In Chapter 9 we’ll see how data-driven programming helps provide an elegant solution to the problem of editing fetchmail run-control files through a GUI.
8.2.8 Case Study: awk
The awk minilanguage is an old-school Unix tool, formerly much used in shellscripts. Like m4, it’s intended for writing small but expressive programs to transform textual input into textual output. Versions ship with all Unixes, several in open source; the command info gawk at your Unix shell prompt is quite likely to take you to on-line documentation.
Programs in awk consist of pattern/action pairs. Each pattern is a regular expression, a concept we’ll describe in detail in Chapter 9. When an awk program is run, it steps through each line of the input file. Each line is checked against every pattern/action pair in order. If the pattern matches the line, the associated action is performed.
Each action is coded in a language resembling a subset of C, with variables and conditionals and loops and an ontology of types including integers, strings, and (unlike C) dictionaries.12
12 For those who have never programmed in a modern scripting language, a dictionary is a lookup table of key-to-value associations, often implemented through a hash table. C programmers spend a lot of their coding time implementing dictionaries in various elaborate ways.
The awk action language is Turing-complete, and can read and write files. In some versions it can open and use network sockets. But awk has primarily seen use as a report generator, especially for interpreting and reducing tabular data. It is seldom used standalone, but rather embedded in scripts. There is an example awk program in the case study on HTML generation included in Chapter 9.
A case study of awk is included to point out that it is not a model for emulation; in fact, since 1990 it has largely fallen out of use. It has been superseded by new-school scripting languages—notably Perl, which was explicitly designed to be an awk killer. The reasons are worthy of examination, because they constitute a bit of a cautionary tale for minilanguage designers.
The awk language was originally designed to be a small, expressive special-purpose language for report generation. Unfortunately, it turns out to have been designed at a bad spot on the complexity-vs.-power curve. The action language is noncompact, but the pattern-driven framework it sits inside keeps it from being generally applicable—that’s the worst of both worlds. And the new-school scripting languages can do anything awk can; their equivalent programs are usually just as readable, if not more so.
Awk has also fallen out of use because more modern shells have floating point arithmetic, associative arrays, RE pattern matching, and substring capabilities, so that equivalents of small awk scripts can be done without the overhead of process creation.
—David Korn
For a few years after the release of Perl in 1987, awk remained competitive simply because it had a smaller, faster implementation. But as the cost of compute cycles and memory dropped, the economic reasons for favoring a special-purpose language that was relatively thrifty with both lost their force. Programmers increasingly chose to do awklike things with Perl or (later) Python, rather than keep two different scripting languages in their heads.13 By the year 2000 awk had become little more than a memory for most old-school Unix hackers, and not a particularly nostalgic one.
13 I was at one time an awk wizard, but I had to be reminded by someone else that the language was applicable to the HTML-generation problem where this book’s only awk example occurs.
Falling costs have changed the tradeoffs in minilanguage design. Restricting your design’s capabilities to buy compactness may still be a good idea, but doing so to economize on machine resources is a bad one. Machine resources get cheaper over time, but space in programmers’ heads only gets more expensive. Modern minilanguages can either be general but noncompact, or specialized but very compact; specialized but noncompact simply won’t compete.
8.2.9 Case Study: PostScript
PostScript is a minilanguage specialized for describing typeset text and graphics to imaging devices. It is an import into Unix, based on design work done at the legendary Xerox Palo Alto Research Center along with the earliest laser printers. For years after its first commercial release in 1984, it was available only as a proprietary product from Adobe, Inc., and was primarily associated with Apple computers. It was cloned under license terms very close to open-source in 1988, and has since become the de-facto standard for printer control under Unix. A fully open-source version is shipped with most most modern Unixes.14 A good technical introduction to PostScript is also available.15
14 There is a GhostScript Project site <http://www.cs.wisc.edu/~ghost/>.
15 A First Guide To PostScript <http://www.cs.indiana.edu/docproject/programming/postscript/postscript.html>.
PostScript bears some functional resemblance to troff markup; both are intended to control printers and other imaging devices, and both are normally generated by programs or macro packages rather than being hand-written by humans. But where troff requests are a jumped-up set of format-control codes with some language features tacked on as an afterthought, PostScript was designed from the ground up as a language and is far more expressive and powerful. The main thing that makes Postscript useful is that algorithmic descriptions of images written in it are far smaller than the bitmaps they render to, and so take up less storage and communication bandwidth.
PostScript is explicitly Turing-complete, supporting conditionals and loops and recursion and named procedures. The ontology of types includes integers, reals, strings, and arrays (each element of an array may be of any type) but no equivalent of structures. Technically, PostScript is a stack-based language; arguments of PostScript’s primitive procedures (operators) are normally popped off a push-down stack of arguments, and the result(s) are pushed back onto it.
There are about 40 basic operators out of a total of around 400. The one that does most of the work is show, which draws a string onto the page. Others set the current font, change the gray level or color, draw lines or arcs or Bezier curves, fill closed regions, set clipping regions, etc. A PostScript interpreter is supposed to be able to interpret these commands into bitmaps to be thrown on a display or print medium.
Other PostScript operators implement arithmetic, control structures, and procedures. These allow repetitive or stereotyped images (such as text, which is composed of repeated letterforms) to be expressed as programs that combine images. Part of the utility of PostScript comes from the fact that PostScript programs to print text or simple vector graphics are much less bulky than the bitmaps the text or vectors render to, are device-resolution independent, and travel more quickly over a network cable or serial line.
Historically, PostScript’s stack-based interpretation resembles a language called FORTH, originally designed to control telescope motors in real time, which was briefly popular in the 1980s. Stack-based languages are famous for supporting extremely tight, economical coding and infamous for being difficult to read. PostScript shares both traits.
PostScript is often implemented as firmware built into a printer. The open-source implementation Ghostscript can translate PostScript to various graphics formats and (weaker) printer-control languages. Most other software treats PostScript as a final output format, meant to be handed to a PostScript-capable imaging device but not edited or eyeballed.
PostScript (either in the original or the trivial variant EPSF, with a bounding box declared around it so it can be embedded in other graphics) is a very well designed example of a special-purpose control language and deserves careful study as a model. It is a component of other standards such as PDF, the Portable Document Format.
8.2.10 Case Study: bc and dc
We first examined bc(1) and dc(1) in Chapter 7 as a case study in shellouts. They are examples of domain-specific minilanguages of the imperative type.
dc is the oldest language on Unix; it was written on the PDP-7 and ported to the PDP-11 before Unix [itself] was ported.
—Ken Thompson
The domain of these two languages is unlimited-precision arithmetic. Other programs can use them to do such calculations without having to worry about the special techniques needed to do those calculations.
In fact, the original motivation for dc had nothing to do with providing a general-purpose interactive calculator, which could have been done with a simple floating-point program. The motivation was Bell Labs’ long interest in numerical analysis: calculating constants for numerical algorithms, accurately is greatly aided by being able to work to much higher precision than the algorithm itself will use. Hence dc’s arbitrary-precision arithmetic.
—Henry Spencer
Like SNG and Glade markup, one of the strengths of both of these languages is their simplicity. Once you know that dc(1) is a reverse-Polish-notation calculator and bc(1) an algebraic-notation calculator, very little about interactive use of either of these languages is going to be novel. We’ll return to the importance of the Rule of Least Surprise in interfaces in Chapter 11.
These minilanguages have both conditionals and loops; they are Turing-complete, but have a very restricted ontology of types including only unlimited-precision integers and strings. This puts them in the borderland between interpreted minilanguages and full scripting languages. The programming features have been designed not to intrude on the common use as a calculator; indeed, most dc/bc users are probably unaware of them.
Normally, dc/bc are used conversationally, but their capacity to support libraries of user-defined procedures gives them an additional kind of utility—programmability. This is actually the most important advantage of imperative minilanguages, one that we observed in the case study of the Documenter’s Workbench tools to be very powerful whether or not a program’s normal mode is conversational; you can use them to write high-level programs that embody task-specific intelligence.
Because the interface of dc/bc is so simple (send a line containing an expression, get back a line containing a value) other programs and scripts can easily get access to all these capabilities by calling these programs as slave processes. Example 8.6 is one famous example, an implementation of the Rivest-Shamir-Adelman public-key cipher in Perl that was widely published in signature blocks and on T-shirts as a protest against U.S. export retrictions on cryptography, c. 1995; it shells out to dc to do the unlimited-precision arithmetic required.
Example 8.6. RSA implementation using dc.
![]()
8.2.11 Case Study: Emacs Lisp
Rather than merely being run as a slave process to accomplish specific tasks, a special-purpose interpreted language can become the core of an entire architecture; we’ll consider the advantages and disadvantages of this approach in Chapter 13. troff requests were an early example; today, the Emacs editor is one of the best-known and most powerful modern ones. It’s built around a dialect of Lisp with primitives for both describing actions on editing buffers and controlling slave processes.
The fact that Emacs is built around a powerful language for describing editing actions or front ends for other programs means that it can be used for many other things besides ordinary editing. We’ll examine the applications of Emacs’s task-specific intelligence for day-to-day program development (compilation, debugging, version control) in Chapter 15. Emacs ’modes’ are user-defined libraries—programs written in Emacs Lisp that specialize the editor for a particular job—usually, but not necessarily, one related to editing.
Thus there are specialized modes that know the syntax of a large number of programming languages, and of markup languages like SGML, XML, and HTML. But many people also use Emacs modes to send and receive email (these use Unix system mail utilities as slaves) or Usenet news. Emacs can browse the web, or act as a front-end for various chat programs. There is also a calendaring package, Emacs’s own calculator program, and even a fairly wide selection of games written as Emacs Lisp modes (including a descendant of the famous ELIZA program that simulates a Rogersian psychiatrist).16
16 One of the silliest things you can do with a modern Unix machine is run the Eliza mode of Emacs against random quotes from Zippy the Pinhead. M-x psychoanalyze-pinhead; type control-G when you’ve had enough.
8.2.12 Case Study: JavaScript
JavaScript is an open-source language designed to be embedded in C programs. Though it is also embedded in web servers, its original and best-known manifestation is client-side JavaScript, which allows you to embed executable code in Web pages to be run by any JavaScript-capable browser. That is the version we will survey here.
JavaScript is a fully Turing-complete interpreted language with integers, real numbers, booleans, strings, and lightweight dictionary-based objects resembling those of Python. Values are typed, but variables can hold any type; conversions between types are automatic in many contexts. Syntactically JavaScript resembles Java with some influence from Perl, and features Perl-like regular expressions.
Despite all these features, client-side JavaScript is not quite a general-purpose language. Its capabilities are severely restricted to prevent attacks on the browser user through Web pages containing JavaScript code. It can accept input from the user and generate or modify Web pages, but it cannot directly alter the contents of disk files and cannot open its own network connections.
Over time, the JavaScript language has become more general and less bound to its client-side environment. This is something that can be expected to happen to any successful specialized language as its possibilities unfold in the minds of developers and users. Client JavaScript now interacts with its environment by reading and writing values in a single special object called the browser DOM (Document Object Model). The language still has some legacy APIs to the browser that don’t go through the DOM, but these are deprecated, not present in the ECMA-262 standard for JavaScript, and may not be supported in future versions.
The standard reference for JavaScript is JavaScript: The Definitive Guide [FlanaganJavaScript]. Source code is downloadable.17 JavaScript makes an interesting study for two reasons. First, it’s about as close to being a general-purpose language as one can get without actually being there. Second, the binding between client-side JavaScript and its browser environment via a single DOM object is well designed, and could serve as a model for other embedding situations.
17 Open-source JavaScript implementations in C and Java are available <http://www.mozilla.org/js/>.
8.3 Designing Minilanguages
When is designing a minilanguage appropriate? We’ve observed that minilanguages offer a way to push problem specifications to a higher level, and seen how this operates in several case studies. The flip side of this observation is that a minilanguage is likely to be a good approach whenever the domain primitives in your application area are simple and stereotyped, but the ways in which users are likely to want to apply them are fluid and varying.
For some related ideas, find a description of the Alternate Hard And Soft Layers <http://www.c2.com/cgi/wiki?AlternateHardAndSoftLayers> and Scripted Components <http://www.doc.ic.ac.uk/~np2/patterns/scripting/scripting.html> design patterns.
An interesting survey of design styles and techniques in minilanguages is Notable Design Patterns for Domain-Specific Languages [Spinellis].
8.3.1 Choosing the Right Complexity Level
The first important thing to bear in mind when designing a minilanguage is, as usual, to keep it as simple as possible. The taxonomy diagram we used to organize the case studies implies a hierarchy of complexity; you want to keep your design as far toward the left-hand edge as possible. If you can get away with designing a structured data file rather than a minilanguage that is going to modify external data when it’s interpreted, by all means do so.
One very pragmatic reason to stick with structured data rather than a minilanguage is that in a networked world, embedded minilanguage facilities are subject to abuses that can be inconvenient or even dangerous. JavaScript is a prime example in the ’inconvenient’ category; its designers didn’t anticipate that it would be used for pop-up advertisements so obnoxious as to create a demand for browser features that suppress JavaScript interpretation.
Microsoft Word macro viruses show how this sort of thing can become actively dangerous, a security hole that costs billions of dollars in downtime and lost productivity annually. It is instructive to note that despite the existence of at least twenty million Unix users worldwide18 there has never been any Unix equivalent of Windows’s frequent macro-virus outbreaks. There are a number of reasons for this, including the fundamentally better security design of Unix; but at least one is the fact that Unix mail agents do not default to executing live content in any document that the user views.19
18 20M is a conservative estimate based on mid-2003 figures from the Linux Counter and elsewhere.
19 Kmail, which we looked at in Chapter 6, won’t even chase off-site links in HTML for this reason.
If there is any way that your application’s users might end up running programs from untrusted sources, risky features of your application minilanguage might end up having to be suppressed. Languages like Java and JavaScript are explicitly sandboxed—that is, they have limited access to their environment not merely to simplify their design but to try to prevent potentially destructive operations by buggy or malicious code.
On the other hand, a lot of bad designs have been botched by designers who failed to face up to the fact that they really needed a minilanguage rather than a data-file format. Too often, language-like features get pasted on as an afterthought. The two most common symptoms of this problem are weak, ad-hoc control structures and poor or nonexistent facilities for declaring procedures.
It’s risky to design minilanguages that are only accidentally Turing-complete. If you do this the odds are good that, sometime in the future, some clever fellow is going to think he needs to press your language into doing loops and conditionals for him. Because these are only available in an obfuscated way, he’ll produce obfuscated code. The results may be serviceable in the short term, but are likely to be a nightmare for those who come after him.
Minilanguage design is both powerful and esthetically rewarding, but it’s also full of similar traps. There are kinds of design in which it is appropriate to take the bottom-up approach of pasting together a bunch of low-level services and worrying about their organization after you have explored the problem domain for a while. One of the virtues of minilanguages is that they can help you get a good design out of bottom-up programming by allowing you to defer some top-down decisions into the control flow of programs in your minilanguage. But if you take a bottom-up approach to the minilanguage design itself, you are likely to end up with an ugly syntax reflecting a weak language and a poorly-thought-out implementation.
There are many places in a minilanguage design where small choices make a large difference in the useability and ease of the tool:
As a language designer, it is a good principle to consider the alternatives to giving an error message. When there is true ambiguity in the intent of the programmer an error message is appropriate, but in many cases the intent is clear, and making the language silently do the right thing is a great boon. A good example is C accommodating an extra comma at the end of an array initializer list, which makes both editing and machine generation of array initializers much easier. Anti-examples are the pickiness of various HTML readers, especially their habit of silently discarding parts of your document because of trivial nesting errors.
—Steve Johnson
On this issue, as elsewhere, there is no substitute for good taste and engineering judgment. If you’re going to design a minilanguage, don’t do it halfway. Declarative minilanguages should have a clear, consistent language-like syntax designed to be readable by humans. Imperative ones should add a full range of control structures adapted from language models you can expect your users to be familiar with. Think about the language as a language; ask yourself esthetic questions like “Will this be comfortable to program in?” and even “Will it be pleasant to look at?” Here, as elsewhere in software design, David Gelernter’s maxim is apt: beauty is the ultimate defense against complexity.
8.3.2 Extending and Embedding Languages
One fundamentally important question is whether you can implement your minilanguage by extending or embedding an existing scripting language. This is often the right way to go for an imperative minilanguage, but much less appropriate for a declarative one.
Sometimes it’s possible to write your imperative language simply by coding service functions in an interpreted language, which we’ll call the ’host’ language for purposes of this discussion. Your minilanguage programs are then just scripts that load your service library and use the host language’s control structures and other facilities as a framework. Every facility the host language supplies is one you don’t have to write.
This is the easiest way to write a minilanguage. Old-school Lisp programmers (including me) love this technique and use it heavily. It underlies the design of the Emacs editor, and has been rediscovered in the new-school scripting languages like Tcl, Python, and Perl. There are drawbacks to it, however.
Your host language may be unable to interface to a code library that you need. Or, internally, its ontology of data types may be inadequate for the kind of computation you need to do. Or, after measuring the performance of a prototype, you discover that it’s too slow. When any of these things happen, your solution is usually going to involve coding in C (or C++) and integrating the results into your minilanguage.
The option of extending a scripting language with C code, or of embedding a scripting language in a C program, relies on the existence of scripting languages designed for it. You extend a scripting language by telling it to dynamically load a C library or module in such a way that the C entry points become visible as functions in the extended language. You embed a scripting language in a C program by sending commands to an instance of the interpreter and receiving the results back as values in C.
Both techniques also rely on the ability to move data between the type ontology of C and the type ontology of your scripting language. Some scripting languages are designed from the ground up to support this. One such is Tcl, which we’ll cover in Chapter 14. Another is Guile, an open-source dialect of the Lisp variant Scheme. Guile is shipped as a library and specifically designed to be embedded in C programs.
It is possible (though in 2003 still rather painful and difficult) to extend or embed Perl. It is very easy to extend Python and only slightly more difficult to embed it; C extension is especially heavily used in the Python world. Java has an interface to call ’native methods’ in C, though the practice is explicitly discouraged because it tends to break portability. Most versions of shell are not designed for embeddability and extension, but the Korn shell (ksh93 and later versions) is a notable exception.
There are lots of bad reasons not to piggyback your imperative minilanguage on an existing scripting language. One of the few good ones is that you actually want to implement your own custom grammar for error checking. If that’s the case, then see the advice about yacc and lex below.
8.3.3 Writing a Custom Grammar
For declarative minilanguages, one major question is whether or not you should use XML as a base syntax and specify your grammar as an XML document type. This may well be the right thing for elaborately structured declarative minilanguages, but the same caveats we noted in Chapter 5 about the design of data-file formats apply—XML might be overkill. If you don’t use XML, follow the Rule of Least Surprise by supporting the Unix conventions we described for data files (simple token-oriented syntax, supporting C backslash conventions, etc.).
If you do need a custom grammar, yacc and lex (or their local equivalent in the language you’re using) should probably be your best friends, unless the grammar of your language is so simple that hand-coding a recursive-descent parser is trivial. Even then, yacc may give you better error recovery, and a yacc specification will be easier to modify as the language syntax evolves. See Chapter 9 for a look at the yacc- and lex-derived tools available in different implementation languages.
Even if you decide you must implement your own syntax, consider what mileage you can get from reusing existing tools. If you need a macro facility, consider whether preprocessing with m4(1) might be the right answer—but consider the cautions in the next section first.
8.3.4 Macros—Beware!
Macro expansion facilities were a favored tactic for language designers in early Unix; the C language has one, of course, and we have seen them show up in some of the more complex special-purpose minilanguages like pic(1). The m4 preprocessor provides a generic tool for implementing macro-expanding preprocessors.
Macro expansion is easy to specify and implement, and you can do a lot of cute tricks with it. Those early designers appear to have been influenced by experience with assemblers, in which macro facilities were often the only device available for structuring programs.
The strength of macro expansion is that it knows nothing about the underlying syntax of the base language, and can be used to extend that syntax. Unfortunately, this power is very easily abused to produce code that is opaque, surprising, and a fertile source of hard-to-characterize bugs.
In C, the classic example of this sort of problem is a macro such as this:
#define max(x, y) x > y ? x : y
There are at least two problems with this macro. One is that it can produce surprising results if either of the arguments is an expression including an operator of lower precedence than > or ?:. Consider the expression max(a = b, ++c). If the programmer has forgotten that max is a macro, he will be expecting the assignment a = b and the preincrement operation on c to be executed before the resulting values are passed as arguments to max.
But that’s not what will happen. Instead, the preprocessor will expand this expression to a = b > ++c ? a = b : ++c, which the C compiler’s precedence rules make it interpret as a = (b > ++c ? a = b : ++c). The effect will be to assign to a!
This sort of bad interaction can be headed off by coding the macro definition more defensively.
#define max(x, y) ((x) > (y) ? (x) : (y))
With this definition, the expansion would be ((a = b) > (++c) ? (a = b) : (++c)). This solves one problem—but notice that c may be incremented twice! There are subtler versions of this trap, such as passing the macro a function-call with side effects.
In general, interactions between macros and expressions with side effects can lead to unfortunate results that are hard to diagnose. C’s macro processor is a deliberately lightweight and simple one; more powerful ones can actually get you in worse trouble.
The TEX formatting language (see Chapter 18) well illustrates the general problem. TEX is intentionally Turing-complete (it has conditionals, loops, and recursion), but while it can be made to do amazing things, TEX code tends to be unreadable and painful to debug. The sources for LATEX, the the most widely used TEX macro package, are an instructive example: they’re in very good TEX style, but even so are extremely difficult to follow.
A minor problem, compared to this one, is that macro expansion tends to screw up error diagnostics. The base language processor generates its error reports relative to the macro expanded text, not the original the programmer is looking at. If the relationship between the two has been obfuscated by macro expansion, the emitted diagnostic can be very difficult to associate with the actual location of the error.
This is especially a problem with preprocessors and macros that can have multiline expansions, conditionally include or exclude text, or otherwise change line numbers in the expanded text.
Macro expansion stages that are built into a language can do their own compensation, fiddling line numbers to refer back to the preexpanded text. The macro facility in pic(1) does this, for example. This problem is more difficult to solve when the macro expansion is done by a preprocessor.
The C preprocessor addresses this problem by emitting #line directives whenever it does an inclusion or multiline expansion. The C compiler is expected to interpret these and adjust the line numbers in its error reports accordingly. Unfortunately, m4 has no such facility.
These are reasons to use macro expansion with extreme caution. One of the long-term lessons of the Unix experience is that macros tend to create more problems than they solve. Modern language and minilanguage designs have moved away from them.
8.3.5 Language or Application Protocol?
Another important question you need to ask is whether your minilanguage engine will be called interactively by other programs, as a slave process. If so, your design should probably look less like a conversational language for human interaction and more like the kind of application protocols we looked at in Chapter 5.
The main difference is how carefully marked the boundaries of transactions are. Human beings are good at spotting where conversational output from a CLI ends, and where the prompt for the next input is. They can use context to tell what’s significant and what should be ignored. Computer programs have much more trouble with this. Without either unambiguous end markers on output or advance knowledge of the length of the output, they can’t tell when to stop reading.
Even worse is when a program’s input is buffered (often inadvertently, as by stdio). A program that stops overtly reading at the right place can nonetheless eat past it.
—Doug McIlroy
Programs in which master processes are trying to do interactive things with slaved minilanguages that are not carefully designed around this problem are prone to deadlock as the master and slave fall out of synchronization (a problem we first noted in Chapter 7).
There are workarounds for driving minilanguages that are not so carefully designed. The prototype for most of them is the Tcl expect package. This package assists conversation with CLIs. It’s built around the following operation: read from slave until either a given regular-expression pattern is matched or a specified timeout elapses. With this (and, of course, a send-to-slave operation) it’s often possible to construct master programs to do reliable dialogues with slave processes even when the latter have not been tailored for the role.
Workalikes of the expect package in other languages are available; a Web search for the name of your favorite language with the added keywords “Tcl expect” is quite likely to turn up something useful. As a minilanguage designer, however, you would be unwise to assume that all your users will be expect gurus. Even if they are, this is an extra glue layer and a place for things to go wrong.
Be aware of this issue when designing your minilanguage. It may be a good idea to add an option that changes its conversational behavior to make it respond more like an application protocol, with unambiguous end-of-output delimiters and an analog of byte stuffing.