
4
XPath
In Chapters 2 and 3 we introduced and illustrated how HTML/XML documents use markup to store information and create the visual appearance of the webpage when opened in the browser. We also explained how to use a scripting language like R to transform the source code underlying web documents into modifiable data objects called the DOM with the use of dedicated parsing functions (Sections 2.4 and 3.5.1). In a typical data analysis workflow, these are important, but only intermediate steps in the process of assembling well-structured and cleaned datasets from webpages. Before we can take full advantage of the Web as a nearly endless data source, a series of filtering and extraction steps follow once the relevant web documents have been identified and downloaded. The main purpose of these steps is to recast information that is encoded in formats using markup language into formats that are suitable for further processing and analysis with statistical software. Initially, this task comprises asking what information we are interested in and identifying where the information is located in a specific document. Once we know this, we can tailor a query to the document and obtain the desired information. Additionally, some data reshaping and exception handling is often necessary to cast the extracted values into a format that facilitates further analysis.
This chapter walks you through each of these steps and helps you to build an intuition for querying tree-based data structures like HTML/XML documents. We will see that accessing particular information from HTML/XML documents is straightforward using the concise, yet powerful path statements provided by the XML Path language (short XPath), a very popular web technology and W3C standard (W3C 1999). After introducing the basic logic underlying XPath, we show how to leverage the full power of its vocabulary using predicates, operators, and custom extractor functions in an application to real documents. We further explore how to work with namespace properties (Section 4.3.2). The chapter concludes with a pointer to helpful tools (Section 4.3.3) and a more high-level discussion about general problems in constructing efficient and robust extraction code for HTML/XML documents (Section 4.3.3).
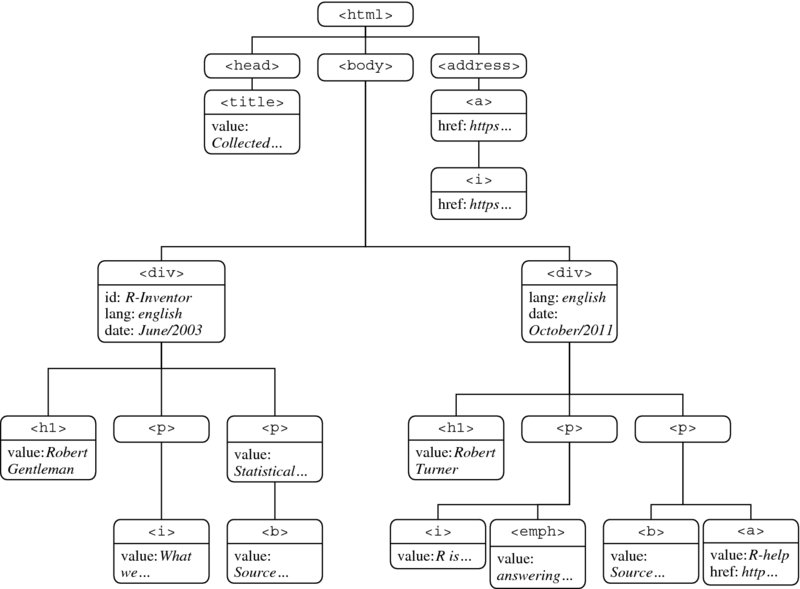
Figure 4.1 A tree perspective on parsed_doc
4.1 XPath—a query language for web documents
XPath is a query language that is useful for addressing and extracting parts from HTML/XML documents. XPath is best categorized as a domain-specific language, which indicates that its field of application is a rather narrow one—it is simply a very helpful tool for selecting information from marked up documents such as HTML, XML, or any variant of it such as SVG or RSS (see Sections 3.4.3 and 3.4.3). XPath is also a W3C standard, which means that the language is subjected to constant maintenance and widely employed in modern web applications. Among the two versions of XPath that are in current use, we apply XPath 1.0 as it provides sufficiently powerful statements and is implemented in the XML package for R.
As a stylized, running example, we revisit fortunes.html—a simple HTML file that includes short quotes of R wisdoms. A first, necessary step prior to applying XPath is to parse the document and make its content available in the workspace of the R session, since XPath only works on the DOM representation of a document and cannot be applied on the native code. We begin by loading the XML package and use htmlParse() to parse the file into the object parsed_doc:
R> library(XML)
R> parsed_doc <- htmlParse(file ="fortunes.html")
The document is now available in the workspace and we can examine its content using XML’s print() method on the object:
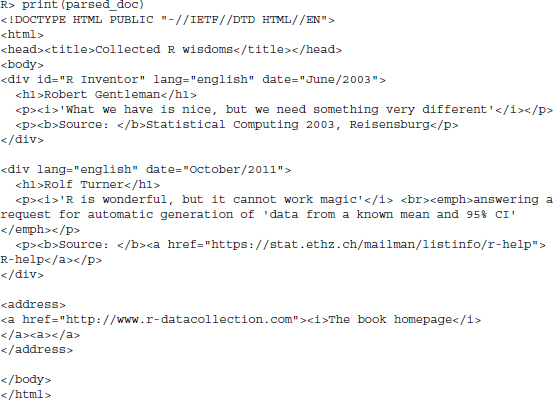
Before proceeding, we would like to restate a crucial idea from Chapter 2 that will be helpful in understanding the basic logic of XPath statements. HTML/XML documents use tags to markup information and the nestedness of the tags describe a hierarchical order. One way to depict this hierarchical order of tags is by means of a tree as it is portrayed in Figure 4.1. In the tree, edges represent the nestedness of a lower-level node inside a higher-level node. Throughout this chapter we will not only refer to this image but also adopt graph language to describe the location of the tags in the document as well as their relations. Therefore, if we refer to the <div> node, we mean the entire information that is encapsulated within the div tags, that is, the value of the node, its set of attributes as well as their values, and its children nodes. When we use the word node set, we refer to a selection of multiple nodes.
4.2 Identifying node sets with XPath
4.2.1 Basic structure of an XPath query
To get started, let us put ourselves to the task of extracting information from the <i> nodes, that is, text that is written in italics, which contain the actual quotes. A look at either HTML code or the document tree in Figure 4.1 reveals that there are two nodes of interest and they are both located at the lowest level of the document. In XPath, we can express this hierarchical order by constructing a sequence of nodes separated by the / (forward slash). This is called a hierarchical addressing mechanism and it is similar to a location path on a local file system. The resemblance is not accidental but results from a similar hierarchical organization of the underlying document/file system. Just like folders can be nested inside other folders on a local hard drive, the DOM treats an XML document as a tree of nodes, where the nestedness of nodes within other nodes creates a node hierarchy.
For our HTML file we can describe the position of the <i> nodes by describing the sequence of nodes that lead to it. The XPath that represents this position is “/html/body/div/p/i.” This statement reads from left to right: Start at the root node <html>—the top node in a tree is also referred to as the root note—proceed to the <body> node, the <div> node, the <p> node, and finally the <i> node. To apply this XPath we use XML’s xpathSApply() function. Essentially, xpathSApply() allows us to conduct two tasks in one step. First, the function returns the complete node set that matches the XPath expression. Second, if intended, we can pass an extractor function to obtain a node's value, attribute, or attribute value.1 In our case, we set xpathSApply()’s first argument doc to the parsed document and the second argument path to the XPath statement that we wish to apply:
R> xpathSApply(doc = parsed_doc, path ="/html/body/div/p/i")
[[1]]
<i>’What we have is nice, but we need something very different’</i>
[[2]]
<i>’R is wonderful, but it cannot work magic’</i>
In the present case, the specified path is valid for two <i> nodes. Thus, the XPath query extracts more than one node at once if it describes a valid path for multiple nodes. The path that we just applied is called an absolute path. The distinctive feature about absolute paths is that they always emanate from the root node and describe a sequence of consecutive nodes to the target node. As an alternative we can construct shorter, relative paths to the target node. Relative paths tolerate “jumps” between nodes, which we can indicate with //. To exemplify, consider the following path:
R> xpathSApply(parsed_doc,"//body//p/i")
[[1]]
<i>’What we have is nice, but we need something very different’</i>
[[2]]
<i>’R is wonderful, but it cannot work magic’</i>
This statement reads as follows: Find the <body> node at some level of the document's hierarchy—it does not have to be the root—then find one or more levels lower in the hierarchy a <p> node, immediately followed by an <i> node. We obtain the same set of <i> nodes as previously. An even more concise path for the <i> nodes would be the following:
R> xpathSApply(parsed_doc,"//p/i")
[[1]]
<i>’What we have is nice, but we need something very different’</i>
[[2]]
<i>’R is wonderful, but it cannot work magic’</i>
These three examples help to stress an important point in XPath's design. There are virtually always several ways to describe the same node set by means of different XPath statements. So why do we construct a long absolute path if a valid relative path exists that returns the same information? xpathSApply() traverses through the complete document and resolves node jumps of any width and at any depth within the document tree. The appeal of relative paths derives from their shortness, but there are reasons for favoring absolute paths in some instances. Relative path statements result in complete traversals of the document tree, which is rather expensive computationally and decreases the efficiency of the query. For the small HTML file we consider here, computational efficiency is of no concern. Nonetheless, the additional strain will become noticeable in the speed of code execution when larger file sizes or extraction tasks for multiple documents are concerned. Hence, if speed is an issue to your code execution, it is advisable to express node locations by absolute paths.
Beyond pure path logic, XPath allows the incorporation of symbols with special meaning in the expressions. One such symbol is the wildcard operator *. The wildcard operator matches any (single) node with arbitrary name at its position. To return all <i> nodes from the HTML file we can use the operator between the <div> and <i> node to match the <p> nodes:
R> xpathSApply(parsed_doc,"/html/body/div/*/i")
[[1]]
<i>’What we have is nice, but we need something very different’</i>
[[2]]
<i>’R is wonderful, but it cannot work magic’</i>
Two further elements that we repeatedly make use of are the . and the .. operator. The . operator selects the current nodes (or self-axis) in a selected node set. This operation is occasionally useful when using predicates. We postpone a detailed exploration of the . operator to Section 4.2.3, where we discuss predicates. The .. operator selects the node one level up the hierarchy from the current node. Thus, if we wish to select the <head> node we could first locate its child <title> and then go one level up the hierarchy:
R> xpathSApply(parsed_doc,"//title/..")
[[1]]
<head>
<title>Collected R wisdoms</title>
</head>
Lastly, we sometimes want to conduct multiple queries at once to extract elements that lie at different paths. There are two principal methods to do this. The first method is to use the pipe operator ∣ to indicate several paths, which are evaluated individually and returned together. For example, to select the <address> and the <title> nodes, we can use the following statement:
R> xpathSApply(parsed_doc,"//address | //title")
[[1]]
<title>Collected R wisdoms</title>
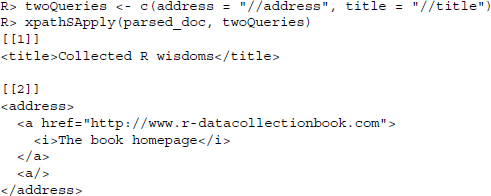
Another option is to store the XPath queries in a vector and pass this vector to xpathSApply(). Here, we first generate a named vector twoQueries where the elements represent the distinct XPath queries. Passing twoQueries to xpathSApply() we get
4.2.2 Node relations
The XPath syntax introduced so far is sufficiently powerful to select some of the nodes in the document, but it is of limited use when the extraction tasks become increasingly complex. Connected node sequences simply lack expressiveness, which is required for singling out specific nodes from smaller node subsets. This issue is nicely illustrated by the queries that we used to identify the <i> nodes in the document. Assume we would like to identify the <i> node that appears within the second section element <div>. With the syntax introduced so far, no path can be constructed to return this single node since the node sequence to this node is equally valid for the <i> nodes within the first section of the document.
In this type of situation, we can make use of XPath's capability to exploit other features of the document tree. One such feature is the position of a node relative to other nodes in the document tree. These relationships between nodes are apparent in Figure 4.1. Most nodes have nodes that precede or follow their path, an information that is often unique and thus differentiates between nodes. As is usual in describing tree-structured data formats, we employ notation based on family relationships (child, parent, grandparent, …) to describe the between-node relations. This feature allows analysts to extract information from a specific target node with an unknown name solely based on the relationship to another node with a known name. The construction of a proper XPath statement that employ this feature follows the pattern node1/relation::node2, where node2 has a specific relation to node1. Let us try to apply this technique on the problem discussed above, selecting the second <div> node in the document. We learn from Figure 4.1 that only the second <div> node has an <a> node as one of its grandchildren. This constitutes a unique feature of the second <div> node that we can extract as follows:
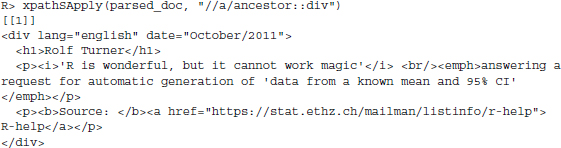
Here, we first select the <a> nodes in the document and then subselect among this set all ancestor nodes with name div. Comparing the resulting node set to the results from above, we find that a smaller set is returned. If we were interested on extracting only the text in italics from this node set, we can make a straightforward extension to this expression. To proceed from the thus selected <div> node to all the <i> that come one or more levels lower in the hierarchy, we add //i to the expression:
R> xpathSApply(parsed_doc,"//a/ancestor::div//i")
[[1]]
<i>’R is wonderful, but it cannot work magic’</i>
As a testament to XPath's capability to reflect complex relationships between nodes, consider the following statement:
R> xpathSApply(parsed_doc,"//p/preceding-sibling::h1")
[[1]]
<h1>Robert Gentleman</h1>
[[2]]
<h1>Rolf Turner</h1>
Here, we first select all the <p> nodes in the document and then all the <h1> siblings that precede these nodes.2
Generally, XPath statements are limitless with respect to their length and the number of special symbols used in it. To illustrate the combination of the wildcard operator with another node relation, consider the following statement:
R> xpathSApply(parsed_doc,"//title/parent::*")
[[1]]
<head>
<title>Collected R wisdoms</title>
</head>
The parent selects nodes in the tree that appear one level higher with respect to the reference node <title. The wildcard operator is used to express indifference regarding the node names. In combination, this statement returns every parent node for every <title> node in the document. For a full list of available relations, take a look at Table 4.1. A visual impression of all available node relationships is displayed in Figure 4.2.
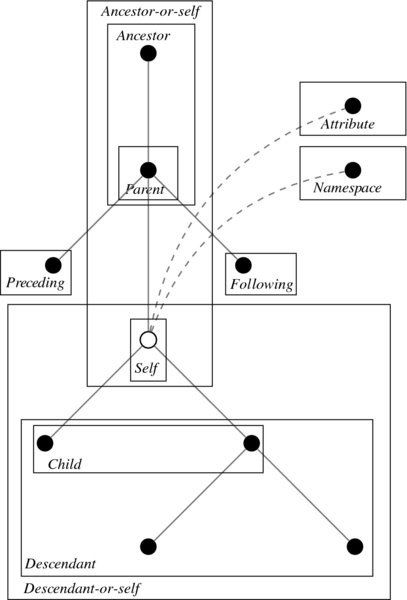
Figure 4.2 Visualizing node relations. Descriptions are presented in relation to the white node
Table 4.1 XPath axes
| Axis name | Result |
| ancestor | Selects all ancestors (parent, grandparent, etc.) of the current node |
| ancestor-or-self | Selects all ancestors (parent, grandparent, etc.) of the current node and the current node itself |
| attribute | Selects all attributes of the current node |
| child | Selects all children of the current node |
| descendant | Selects all descendants (children, grandchildren, etc.) of the current node |
| descendant-or-self | Selects all descendants (children, grandchildren, etc.) of the current node and the current node itself |
| following | Selects everything in the document after the closing tag of the current node |
| following-sibling | Selects all siblings after the current node |
| namespace | Selects all namespace nodes of the current node |
| parent | Selects the parent of the current node |
| preceding | Selects all nodes that appear before the current node in the document except ancestors, attribute nodes, and namespace nodes |
| preceding-sibling | Selects all siblings before the current node |
| self | Selects the current node |
4.2.3 XPath predicates
Beside exploiting relationship properties of the tree, we can use predicates to obtain and process numerical and textual properties of the document. Applying these features in a conditioning statement for the node selection adds another level of expressiveness to XPath statements. Put simply, predicates are nothing but simple functions that are applied to a node's name, value, or attribute, and which evaluate whether a condition (or set of conditions) is true or false. Internally, a predicate returns a logical response. Nodes where the response is true are selected. Their general use is as follows: After a node (or node set) we specify the predicate in square brackets, for example, node1[predicate]. We select all <node1> nodes in the document that comply with the condition formulated by the predicate. As a complete coverage of all predicates is neither possible nor helpful for this introduction, we restrict our attention to the most frequent—and in our view most helpful—predicates in XPath. We have listed some of the available predicates in Table 4.2. Our goal is not to provide an exhaustive examination of this topic, but to convey the inherent logic in applying predicates. We will see that some predicates work in combination with so-called operators. A complete overview of available operators is presented in Table 4.3.
Table 4.2 Overview of some important XPath functions
| Function | Description | Example |
| name(<node>) | Returns the name of <node> or the first node in a node set | //*[name()=’title’]; Returns: <title> |
| text(<node>) | Returns the value of <node> or the first node in a node set | //*[text()=’The book homepage’]; Returns: <i> with value The book homepage |
| @attribute | Returns the value of a node's attribute or of the first node in a node set | //div[@id=’R Inventor’]; Returns: <div> with attribute id value R Inventor |
| string-length(str1) | Returns the length of str1. If there is no string argument, it returns the length of the string value of the current node | //h1[string-length()>11]; Returns: <h1> with value Robert Gentleman |
| translate(str1, str2, str3) | Converts str1 by replacing the characters in str2 with the characters in str3 | //div[translate(./@date, ’2003’, ’2005’)=’June/2005’]; Returns: first <div> node with date attribute value June/2003 |
| contains(str1,str2) | Returns TRUE if str1 contains str2, otherwise FALSE | //div[contains(@id, ’Inventor’)]; Returns: first <div> node with id attribute value R Inventor |
| starts-with(str1,str2) | Returns TRUE if str1 starts with str2, otherwise FALSE | //i[starts-with(text(), ’The’)]; Returns: <i> with value The book homepage |
| substring-before (str1,str2) | Returns the start of str1 before str2 occurs in it | //div[substring-before(@date, ’/’)=’June’]; Returns: <div> with date attribute value June/2003 |
| substring-after (str1,str2) | Returns the remainder of str1 after str2 occurs in it | //div[substring-after(@date, ’/’)=2003]; Returns: <div> with date attribute value June/2003 |
| not(arg) | Returns TRUE if the boolean value is FALSE, and FALSE if the boolean value is TRUE | //div[not(contains(@id, ’Inventor’))]; Returns: the <div> node that does not contain the string Inventor in its id attribute value |
| local-name(<node>) | Returns the name of the current <node> or the first node in a node set—without the namespace prefix | //*[local-name()=’address’]; Returns: <address> |
| count(<node>) | Returns the count of a nodeset <node> | //div[count(.//a)=0]; Result: The second <div> with one <a> child |
| position(<node>) | Returns the index position of <node> that is currently being processed | //div/p[position()=1]; Result: The first <p> node in each <div> node |
| last() | Returns the number of items in the processed node list <node> | //div/p[last()]; Result: The last <p> node in each <div> node |
Table 4.3 XPath operators
| Operators | Description | Example |
| ∣ | Computes two node sets | //i | //b |
| + | Addition | 5 + 3 |
| - | Subtraction | 8 - 2 |
| * | Multiplication | 8 * 5 |
| div | Division | 8 div 5 |
| = | Equal | count = 27 |
| != | Not equal | count != 27 |
| < | Less than | count < 27 |
| ⩽ | Less than or equal to | count <= 27 |
| > | Greater than | count > 27 |
| ⩾ | Greater than or equal to | count >= 27 |
| or | Or | count = 27 or count = 28 |
| and | And | count > 26 and count < 30 |
| mod | Modulo (division remainder) | 7 mod 2 |
Source: Adapted from http://www.w3schools.com/xpath/xpath_operators.asp
4.2.3.1 Numerical predicates
XPath offers the possibility to take advantage of implied numerical properties of documents, such as counts or positions. There are several predicates that return numerical properties, which can be used to create conditional statements. The position of a node is an important numerical characteristic that we can easily implement. Let us collect the <p> nodes that appear on first position:
R> xpathSApply(parsed_doc,"//div/p[position()=1]")
[[1]]
<p>
<i>’What we have is nice, but we need something very different’</i>
</p>
[[2]]
<p><i>’R is wonderful, but it cannot work magic’</i> <br/><emph>answering a
request for automatic generation of ’data from a known mean and 95% CI’
</emph></p>
The predicate we use is position() in combination with the equal operator =.3 The statement returns two nodes. The position predicate does not evaluate which <p> node is on first position among all <p> nodes in the document but on first position in each node subset relative to its parent. If we wish to select the last element of a node set without knowing the number of nodes in a subset in advance, we can use the last() operator:
R> xpathSApply(parsed_doc,"//div/p[last()]")
[[1]]
<p><b>Source: </b>Statistical Computing 2003, Reisensburg</p>
[[2]]
<p>
<b>Source: </b>
<a href="https://stat.ethz.ch/mailman/listinfo/r-help">R-help</a>
</p>
Output from numerical predicates may be further processed with mathematical operations. To select the next to last <p> nodes, we extend the previous statement:
R> xpathSApply(parsed_doc,"//div/p[last()-1]")
[[1]]
<p>
<i>’What we have is nice, but we need something very different’</i>
</p>
[[2]]
<p><i>’R is wonderful, but it cannot work magic’</i> <br/><emph>answering a request for automatic generation of ’data from a known mean and 95% CI’</emph></p>
A count is another numerical property we can use as a condition for node selection. One of the most frequent uses of counts is selecting nodes based on their number of children nodes. An implementation of this logic is the following:
R> xpathSApply(parsed_doc,"//div[count(.//a)>0]")
[[1]]
<div lang="english" date="October/2011">
<h1>Rolf Turner</h1>
<p><i>’R is wonderful, but it cannot work magic’</i> <br/><emph>answering a
request for automatic generation of ’data from a known mean and 95% CI’
</emph></p>
<p><b>Source: </b><a href="https://stat.ethz.ch/mailman/listinfo/r-help">
R-help</a></p>
</div>
Piece by piece, the statement reads as follows. We start by selecting all the <div> nodes in the document (//div). We refine the selection by using the count() predicate, which takes as argument the thing we need to count. In this case we count the number of <a> nodes that precede the selected <div> nodes (.//a). The . element is used to condition on the previous selection. Internally, this results in another node set, which we then pass to the count() function. Combining the operator with a value >0, we ask for those <div> nodes in the document that have more than zero <a> nodes as children. Besides nodes, we can also condition on the number of attributes in a node:
R> xpathSApply(parsed_doc,"//div[count(./@*)>2]")
[[1]]
<div id="R Inventor" lang="english" date="June/2003">
<h1>Robert Gentleman</h1>
<p><i>’What we have is nice, but we need something very different’</i></p>
<p><b>Source: </b>Statistical Computing 2003, Reisensburg</p>
</div>
The @ element retrieves the attributes from a selected node. Here, the ./@* expression returns all the attributes—regardless of their name—from the currently selected nodes. We pass these attributes to the count function and evaluate whether the number of attributes is greater than 2. Only the nodes returning TRUE for this function are selected.
The number of characters in the content of an element is another kind of count we can obtain and use to condition node selection. This is particularly useful if all we know about our extraction target is that the node contains some greater amount of text. It is implemented as follows:
R> xpathSApply(parsed_doc,"//*[string-length(text())>50]")
[[1]]
<i>’What we have is nice, but we need something very different’</i>
[[2]]
<emph>answering a request for automatic generation of ’data from a known mean and 95% CI’</emph>
We first obtain a node set of all the nodes in the document (//*). On this set, we impose the condition that the content of these nodes (as returned by text()) must contain more than 50 characters.
It is sometimes useful to invert the node selection and return all nodes for which the predicate does not return TRUE. XPath includes a couple of functions that allow employing Boolean logic in the query. To express an inversion of a node set, one can use the Boolean not function to select all nodes that are not selected by the query. To select all <div> with two or fewer attributes, we can write
R> xpathSApply(parsed_doc,"//div[not(count(./@*)>2)]")
[[1]]
<div lang="english" date="October/2011">
<h1>Rolf Turner</h1>
<p><i>’R is wonderful, but it cannot work magic’</i> <br/><emph>answering a
request for automatic generation of ’data from a known mean and 95% CI’
</emph></p>
<p><b>Source: </b><a href="https://stat.ethz.ch/mailman/listinfo/r-help">R-help</a></p>
</div>
4.2.3.2 Textual predicates
Since HTML/XML files or any of their variants are plain text files, textual properties of the document are useful predicates for node selection. This might come in handy if we need to pick nodes on the basis of text in their names, content, attributes, or attributes’ values. Besides exact matching, working with strings often requires tools for partial matching of substrings. While XPath 1.0 is sufficiently powerful in this respect, version 2.0 has seen huge improvements with the implementation of a complete library of regular expression predicates (for an introduction to string manipulation techniques see Chapter 8). Nonetheless, XPath 1.0 fares well enough in most situations, so that switching to other XPath implementations is not necessary. To begin, let us explore methods to perform exact matches for strings. We already introduced the = operator for equalizing numerical values, but it works just as well for exact string matching. To select all <div> nodes in the document, which contain quotes written in October 2011, that is, contain an attribute date with the value October/2011, we can write
R> xpathSApply(parsed_doc,"//div[@date=’October/2011’]")
[[1]]
<div lang="english" date="October/2011">
<h1>Rolf Turner</h1>
<p><i>’R is wonderful, but it cannot work magic’</i> <br/><emph>answering a
request for automatic generation of ’data from a known mean and 95% CI’
</emph></p>
<p><b>Source: </b><a href="https://stat.ethz.ch/mailman/listinfo/r-help">R-help</a></p>
</div>
We first select all the <div> nodes in the document and then subselect those that have an attribute date with the value October/2011. In many instances, exact matching for strings as implied by the equal sign is an exceedingly strict operation. One way to be more liberal is to conduct partial matching for strings. The general use of these methods is as follows: string_method(text1, ’text2’), where text1 refers to a text element in the document and text2 to a string we want to match it to. To select all nodes in a document that contain the word magic in their value, we can construct the following statement:
R> xpathSApply(parsed_doc,"//*[contains(text(), ’magic’)]")
[[1]]
<i>’R is wonderful, but it cannot work magic’</i>
In this statement we first select all the nodes in the document and condition this set using the contains() function on whether the value contains the word magic as returned by text(). Please note that all partial matching functions are case sensitive, so capitalized versions of the term would not be matched. To match a pattern to the beginning of a string, the starts_with() function can be used. The following code snippet illustrates the application of this function by selecting all the <div> nodes with an attribute id, where the value starts with the letter R:
R> xpathSApply(parsed_doc,"//div[starts-with(./@id, ’R’)]")
[[1]]
<div id="R Inventor" lang="english" date="June/2003">
<h1>Robert Gentleman</h1>
<p><i>’What we have is nice, but we need something very different’</i></p>
<p><b>Source: </b>Statistical Computing 2003, Reisensburg</p>
</div>
ends_with() is used to match a string to the end of a string. It is frequently useful to preprocess node strings before conducting matching operations. The purpose of this step is to normalize node values, attributes, and attribute values, for example, by removing capitalization or replacing substrings. Let us try to extract only those quotes that have been published in 2003. As we see in the source code, the <div> nodes contain a date attribute, which holds information about the year of the quote. To condition our selection on this value, we can issue the following expression:
R> xpathSApply(parsed_doc,"//div[substring-after(./@date, ’/’)=’2003’]//i")
[[1]]
<i>’What we have is nice, but we need something very different’</i>
Let us consider the statement piece by piece. We first select all the <div> nodes in the document (//div). The selection is further conditioned on the returned attribute value from the predicate. In the predicate we first obtain the date value for all the selected nodes (./@date). This yields the following vector: June/2003, October/2011. The values are passed to the substring-after() function where they are split according to the /, specified as the second argument. Internally, the function outputs 2003, 2011. We then conduct exact matching against the value 2003, which selects the <div> node we are looking for. Finally, we move down to the <i> node by attaching //i to the expression.
4.3 Extracting node elements
So far, we have used xpathSApply() to return nodes that match specified XPath statements. We learned that the function returns a list object that contains the nodes’ name, value, and attribute values (if specified). We usually do not care for the node in its entirety, but need to extract a specific information from the node, for example, its value. Fortunately, this task is fairly straightforward to implement. We simply pass an extractor function to the fun argument in the function call. The XML package offers an extensive set of these functions to select the pieces of information we are interested in. A complete overview of all extractor functions is presented in Table 4.4. For example, in order to extract the value of the <title> node we can simply write
R> xpathSApply(parsed_doc,"//title", fun = xmlValue)
[1]"Collected R wisdoms"
Table 4.4 XML extractor functions
| Function | Argument | Return value |
| xmlName | Node name | |
| xmlValue | Node value | |
| xmlGetAttr | name | Node attribute |
| xmlAttrs | (All) node attributes | |
| xmlChildren | Node children | |
| xmlSize | Node size |
Instead of a list with complete node information, xpathSApply() now returns a vector object, which only contains the value of the node set that matches the XPath statement. For nodes without value information, the functions would return an NA value. Beside the value, we can also extract information from the attributes. Passing xmlAttrs() to the fun argument will select all attributes that are in the selected nodes:
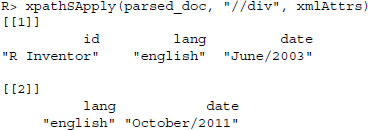
In most applications we are interested in specific rather than all node attributes. To select a specific attribute from a node, we use xmlGetAttr() and add the attribute name:
R> xpathSApply(parsed_doc,"//div", xmlGetAttr,"lang")
[1]"english""english"
4.3.1 Extending the fun argument
Processing returned node sets from XPath can easily extend beyond mere feature extraction as introduced in the last section. Rather than extracting information from the node, we can adapt the fun argument to perform any available numerical or textual operation on the node element. We can build novel functions for particular purposes or modify existing extractor functions for our specific needs and pass them to xpathSApply(). The goal of further processing can either lie in cleansing the numeric or textual content of the node, or some kind of exception handling in order to deal with extraction failures.
To illustrate the concept in a first application, let us attempt to extract all quotes from the document and convert the symbols to lowercase during the extraction process. We can use base R’s tolower() function, which transforms strings to lowercase. We begin by writing a function called lowerCaseFun(). In the function, we simply feed the information from the node value to the tolower() function and return the transformed text:
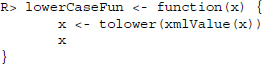
Adding the function to xpathSApply()’s fun argument, yields:
R> xpathSApply(parsed_doc,"//div//i", fun = lowerCaseFun)
[1]"’what we have is nice, but we need something very different’"
[2]"’r is wonderful, but it cannot work magic’"
The returned vector now consists of all the transformed node values and spares us an additional postprocessing step after the extraction. A second and a little more complex postprocessing function might include some basic string operations that employ functionality from the stringr package. Again, we begin by writing a function that loads the stringr package, collects the date and extracts the year information4:
Passing this function to the fun argument in xpathSApply() yields:
R> xpathSApply(parsed_doc,"//div", dateFun)
[1]"2003""2011"
We can also use the fun argument to cope with situations where an XPath statement returns an empty node set. In XML’s DOM the NULL object is used to indicate a node that does not exist. We can employ a custom function that includes a test for the NULL object and makes further processing dependent on positive or negative evaluation of this test:

The first line in this custom function saves the node's id value into a new object id. Conditional on this value being NULL, we either return not specified or the id value in the second line. To see the results, let us pass the function to xpathSApply():
R> xpathSApply(parsed_doc,"//div", idFun)
[1]"R Inventor""not specified"
4.3.1.1 Using variables in XPath expressions
The previous examples were simple enough to allow querying all information with a single, fixed XPath expression. Occasionally, though, it becomes inevitable to treat XPath expressions themselves as variable parts of the extraction program. Data analysts often find that a specific type of information is encoded heterogeneously across documents, and hence, constructing a valid XPath expression for all documents may be impossible, especially when future versions of a site are expected to change. To illustrate this, consider extracting information from the XML file technology.xml, which we introduced in Section 3.5.1. Previously, we extracted the Apple stock from this file, but now we tackle the problem of pulling out all companies’ stock information. The problem is that the target closing stock information (<close>) is encapsulated in parent nodes with different names (Apple, Google, IBM). Instead of creating separate query functions for each company, we can help ourselves by using the sprintf() function to create flexible XPath expressions. We start by parsing the document again and building a character vector with the relevant company names:
R> parsed_stocks <- xmlParse(file ="technology.xml")
R> companies <- c("Apple","IBM","Google")
Next, we use sprintf() to create the queries. Inside the function, we set the basic template of the XPath expression. The string %s is used to indicate the variable part, where s stands for a string variable. The object companies indicates the elements we want to substitute for %s:
![]()
We can proceed as usual by first laying out an extractor function…

… and then passing this extractor function to xpathSApply(). Here, we additionally convert the output to a more convenient data frame format and change the vector type:

4.3.2 XML namespaces
In our introduction to XML technologies in Chapter 3, we introduced namespaces as a feature to create uniquely identified nodes in a web document. Namespaces become an indispensable part of XML when different markup vocabularies are used inside a single document. Such may be the result of merging two different XML files into a single document. When the constituent XML files employ similar vocabulary, namespaces help to resolve ambiguities and prevent name collisions.
Separate namespaces pose a problem to the kinds of XPath statements we have been considering so far, since XPath ordinarily considers the default namespace. In this section we learn how to specify the namespace under which a specific node set is defined and thus extract the elements of interest. Let us return to the example we used in our introduction to XML namespaces (Section 3.4). The file books.xml not only contains an HTML title but also information on a book enclosed in XML nodes. We start by parsing the document with xmlParse() and print its contents to the screen:
For the sake of the example, let us assume we are interested in extracting information from the <title> node, which holds the text string JavaScript: The Good Parts. We can start by issuing a call to all <title> nodes in the document and retrieve their values:
R> xpathSApply(parsed_xml,"//title", fun = xmlValue)
list()
Evidently, the call returns an empty list. The key problem is that neither of the two <title> nodes in the document has been defined under the default namespace on which standard XPath operates. The specific namespaces can be inspected in the xmlns statements in the attributes of the <root> node. Here, two separate namespaces are declared, which are referred to by the letters h and t. One way to bypass the unique namespaces is to make a query directly to the local name of interest:
![]()
Here, we first select all the nodes in the document and then subselect all the nodes with local name title. To conduct namespace-aware XPath queries on the document, we can extend the function and use the namespaces argument in the xpathSApply() function to refer to the particular namespace under which the second <title> node has been defined. We know that the namespace information appears in the <root> node. We can pass the second namespace string to the namespaces argument of the xpathSApply() function:

Similarly, if we were interested in extracting information from the <title> node under the first namespace, we would simply change the URI:

These methods require the namespaces under which the nodes of interest have been declared to be known in advance. The literal specification of the URI can be circumvented if we know where in the document the namespace definition occurs. Namespaces are always declared as attribute values of an XML element. For the sample file, the information appears in the <root> node's xmlns attribute. We capitalize on this knowledge by extracting the namespace URI for the second namespace using the xmlNamespaceDefinitions() function:
R> nsDefs <- xmlNamespaceDefinitions(parsed_xml)[[2]]
R> ns <- nsDefs$uri
R> ns
[1]"http://funnybooknames.com/crockford"
Having stored the information in a new object, the namespace URI can be passed to the XPath query in order to extract information from the <title> node under that namespace:
R> xpathSApply(parsed_xml,"//x:title", namespaces = c(x = ns), xmlValue)
[1]"JavaScript: The Good Parts"
4.3.3 Little XPath helper tools
XPath's versatility comes at the cost of a steep learning curve. Beginners and experienced XPath users may find the following tools helpful in verifying and constructing valid statements for their extraction tasks:
SelectorGadget
SelectorGadget (http://selectorgadget.com) is an open-source bookmarklet that simplifies the generation of suitable XPath statements through a point-and-click approach. To make use of its functionality, visit the SelectorGadget website and create a bookmark for the page. On the website of interest, activate SelectorGadget by clicking on the bookmark. Once a tool bar on the bottom left appears, SelectorGadget is activated and highlights the page's DOM elements when the cursor moves across the page. Clicking an element adds it to the list of nodes to be scraped. From this selection, SelectorGadget creates a generalized statement that we can obtain by clicking on the XPath button. The XPath expression can then be passed to xpathSApply()’s path argument. Please note that in order to use the generated XPath expressions in xpathSApply(), you need to be aware that the type of quotation mark that embrace the XPath expression may not be used inside the expression (e.g., for the attribute names). Replace them either with double (" ") or single (‘’) quotation marks.
Web Developer Tools
Many modern browsers contain a suite of developer tools to help inspect elements in the webpage and create valid XPath statements that can be passed to XML’s node retrieval functions. Beyond information on the current DOM, developer tools also allow tracing changes to DOM elements in dynamic webpages. We will make use of these tools in Section 6.3.
Summary
In this chapter we made a broad introduction to the XPath language for querying XML documents. We hope to have shown that XPath constitutes an indispensable investment for data analysts who want to work with data from webpages in a productive and efficient manner. With the tools introduced at the end of this chapter, many extraction problems may even be solved through simply clicking elements and pasting the returned expression. Despite their helpfulness, these tools may fail for rather intricate extraction problems, and, thus, knowing how to build expressions from scratch remains a necessary skill. We also would like to assert that the construction of an applicable XPath statement is rarely a one-shot affair but requires an iterative learning process. This process can be described as a cycle of three steps. In the construction stage, we assemble an XPath statement that is believed to return the correct information. In the testing stage, we apply the XPath, observe the returned node set or error message, and find that perhaps the returned node set is too broad or too narrow. The learning stage is a necessary stage when the XPath query has failed. Learning from this failure, we might infer a more suitable XPath expression, for example, by making it more strict or more lax in order to obtain only the desired information. Going back to step number one, we apply the refined XPath to check whether it now yields the correct set of nodes. For many extraction problems we find that multiple traverses through this cycle are necessary to build confidence in the robustness of the programmed extraction routine. We are going to elaborate on the XPath scraping strategy again in Section 9.2.2.
The issue of XPath robustness is exacerbated when the code is to work on unseen instances of a webpage, for example, when the extraction code is automatically executed daily (see Section 11.2). Inevitably, websites undergo changes to their structure; elements are removed or shifted, new features are implemented, visual appearances are modified, which ultimately affect the page's contents as well. This is especially true for popular websites. But we will see that certain dispositions can be made in the XPath statements and auxiliary code design to increase robustness and warn the analyst when the extraction fails. One possibility is to rely on textual predicates when textual information should be extracted from the document. Adding information to the query on the substantive interest can add necessary robustness to the code.
Further reading
A full exploration of XPath and the XML package is beyond the scope of this chapter. For an extensive overview of the XML package, interested readers are referred to Nolan and Temple Lang (2014). A more concise introduction to the package is provided by Temple Lang (2013c). Tennison provides a comprehensive overview of XPath 1.0 (Tennison 2001). Another helpful overview of XPath 1.0 and 2.0 methods can be found in Holzner (2003). For an excellent online documentation on web technologies, including XPath, consult Mozilla Developer Network (2013).
Problems
-
What makes XPath a domain-specific language?
-
XPath is the XML Path language, but it also works for HTML documents. Explain why.
-
Return to the fortunes1.html file and consider the following XPath expression: //a[text()[contains(., ’R-help’)]]…. Replace … to get the <h1> node with value “Robert Gentleman.”
-
Construct a predicate with the appropriate string functions to test whether the month of a quote is October.
-
Consider the following two XPath statements for extracting paragraph nodes from a HTML file. 1. //div//p, 2. //p. Decide which of the two statements makes a more narrow request. Explain why.
-
Verify that for extracting the quotes from fortunes.html the XPath expression //i does not return the correct results. Explain why not.
-
The XML file potus.xml contains biographical information on US presidents. Parse the file into an object of the R session.
- Extract the names of all the presidents.
- Extract the names of all presidents, beginning with the 40th term.
- Extract the value of the <occupation> node for all Republican presidents.
- Extract the <occupation> node for all Republican presidents that are also Baptists.
- The <occupation> node contains a string with additional white space at the beginning and the end of the string. Remove the white space by extending the extractor function.
- Extract information from the <education> nodes. Replace all instances of “No formal education” with NA.
- Extract the <name> node for all presidents whose terms started in or after the year 1960.
-
The State of Delaware maintains a repository of datasets published by the Delaware Government Information Center and other Delaware agencies. Take a look at Naturalizations.xml (included in the chapter's materials at http://www.r-datacollection.com). The file contains information about naturalization records from the Superior Court. Convert the data into an R data frame.
-
The Commonwealth War Graves Commission database contains geographical information on burial plots and memorials across the globe for those who lost their lives as a result of World War I. The data have been recast as a KML document, an XML-type data structure. Take a look at cwgc-uk.kml (included in the chapter's materials). Parse the data and create a data frame from the information on name and coordinates. Plot the distribution on a map.
-
Inspect the SelectorGadget (see Section 4.3.3). Go to http://planning.maryland.gov/ Redistricting/2010/legiDist.shtml and identify the XPath expression suited to extract the links in the bottom right table named Maryland 2012 Legislative District Maps (with Precincts) using SelectorGadget.