
DevOps deals with the entire software development life cycle, starting from requirements gathering through post-production monitoring. The main DevOps concepts and approaches were covered in Chapter 1. In this chapter, we will look at various DevOps architectures.
The DevOps Approach for Web Applications
The DevOps approach for web application development follows the traditional model of requirements management, version control, branching and merging strategy, and continuous integration and deployment. Sometimes, this gets extended further into a continuous monitoring and feedback loop as well. In addition to the base components, most of the time the tool integration required in each process step varies from application to application.
The tools and technologies integrated across the DevOps pipeline are based on the technology stack and the requirements of the customer. XebiaLabs publishes a list of the leading DevOps tools used across the pipeline (https://digital.ai/periodic-table-of-devops-tools), categorized by different usages. This is a great reference for DevOps architects.
Requirements management: Azure Boards
Version control: Azure Repo or GitLab
- Continuous integration: Azure Pipeline for the build automation
Jasmine and Karma for unit testing
WhiteSource for open source vulnerability analysis
Nunit/SOAP UI/Postman for unit testing of the API
Sonar for code analysis
- Continuous deployment: Azure Release Pipeline
ARM/Terraform/Pulumi for infrastructure provisioning
Protractor and Karma for end-to-end testing
Selenium for functional testing
Continuous monitoring: Azure Monitor or specifically Application Insight for monitoring
This is just the basic setup for modern application development, and the list of tool integration varies based on the customer requirements.
Microservices

Microservices architecture
The DevOps Approach for Databases
There are a number of data platform tools and technologies, such as Oracle Database, Azure Data Lake Store, SSIS packages, Azure SQL, and Cosmos DB, dealing with various data requirements. To store data, there are multiple data stores, both SQL and NoSQL based. Azure DevOps supports various types of databases and associated platforms such as SSIS packages, data lake deployments, and so on.
SQL Server database
SQL Server database DevOps starts from the database project creation using Visual Studio. Visual Studio supports the development of schema files and the unit testing of the SQL schema. Moreover, proper version control using Azure Repos will be handled through Visual Studio. The database project supports the configuration of the pre-conditions and post-conditions required at deployment time. These conditions will be used to execute the cleanup activities, user creation, and other common environment-specific configurations.

DevOps, SQL database
Moreover, MySQL deployment supports using MySQL tasks and YAML scripts in the Azure DevOps pipeline. SSIS packages are supported in Azure DevOps, and the package generated is similar to DACPAC with an extension of .ispac. Azure offers another pipeline called the Data Factory Pipeline for Azure Data Factory with all the required support for data cleaning, transformation, etc.
The DevOps Approach for Machine Learning Models

ML pipeline
- 1.
Plan: Identify the requirements for a model, and decide on the algorithm and technology and implementation plan.
- 2.
Develop the model: Develop the model using specific algorithms and languages such as Python or R.
- 3.
Train the model: Feed the training data and train the model. Model training varies based on various factors such as the type of algorithm used: supervised, semisupervised or unsupervised, data volume, expected accuracy, and so on.
- 4.
Package the model: Package the model for deployment. DevOps activities start from here.
- 5.
Validate the model: Validate the model in an environment.
- 6.
Deploy the model: Deploy the model to target environment and feed the real data on which the model needs to act on.
- 7.
Monitor the model: Monitor the accuracy, response, performance, etc., of the deployed model. If required, retrain the model using additional data.
Manual deployment
Azure DevOps and deployment as a container in app service
Azure DevOps and deployment via Azure Container Instance (ACI)
Azure DevOps and deployment via Azure Kubernetes Services (AKS)
Azure Machine Learning Workspace Pipeline
Manual deployment requires developers to package and deploy the model to Azure services. This is not a recommended option. Azure DevOps and Azure ML Workspace Pipeline are the two options recommended based on the target users.
ML Approaches
Scenario | User | Azure Offering | Strengths |
|---|---|---|---|
Model orchestration | Data scientist | Azure Machine Learning Pipelines | Distribution, caching, code-first, reuse |
Data orchestration | Data engineer | Azure Data Factory Pipelines | Strongly typed movement, data-centric activities |
Code and app orchestration | App Developer/Ops | Azure DevOps Pipelines | Most open and flexible activity support, approval queues, phases with gating |
If the user is a data scientist, then use the end-to-end ML pipeline via Azure Machine Learning Pipelines. This approach is called machine learning operationalization (MLOps).
Machine Learning Operationalization
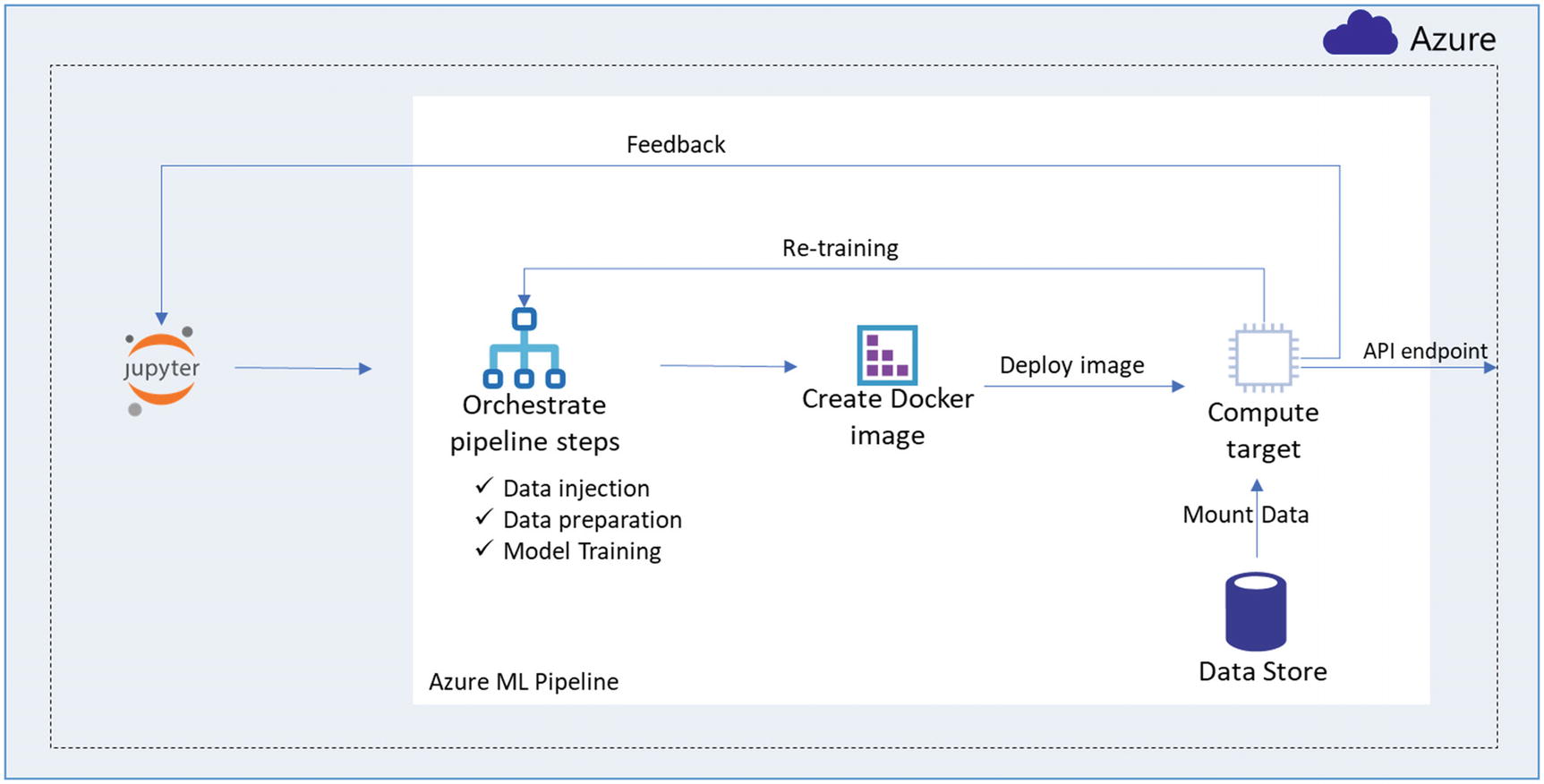
The orchestration step is important; it deals with the core activities of data injection, data cleaning, transformation, training, and so on. “Create Docker image” will create a Docker container that the user can deploy to a compute target. Under “Compute target,” the user can select either a CPU-based virtual machine or a GPU-enabled virtual machine. If the models are based on a neural network or require GPU capability, then select the GPU-based compute target. Mainly, this flow is used by data scientists, who deal with the ML life cycle.
Azure DevOps

Azure DevOps and AKS
Azure DevOps Pipelines stores the container image in Azure Container Registry and deploys it to AKS using the release pipeline. To implement further security, we can configure ingress controllers to handle the security and routing for the models. In general, models will be protected using internal IPs and exposed for external consumption through APIs. In this case, the APIs will be configured in the ingress controller. Additional layers for the API management and app services will be added based on the system requirements. It is not recommended to expose the ingress controllers outside the Azure, instead configure API Management in front of Ingress controller to handle the incoming requests and apply security validation.
The AKS setup is used to train ML models; please refer to the reference architecture from Microsoft at https://azure.microsoft.com/en-in/solutions/architecture/machine-learning-with-aks/.
The DevOps Approach for COTS Applications
Commercial-off-the-shelf (COTS) applications are software products that are ready to use for a specific purpose. For example, SAP, Salesforce, and CRM are some COTS applications. The DevOps implementation in COTS applications is different from a traditional application, meaning an application specific to one customer’s need.
SAP
DevOps for COTS depends on the application support for implementing DevOps. In general, implementation of end to end DevOps for COTS is not possible completely. Currently, most of the COTS development and deployment involves few manual tasks, which will not be handled by the DevOps tools. Some of the major COTS players like SAP and Saleforce, changing the process for custom implementation and deployment to align with DevOps. We can implement some aspects of DevOps but still involve some manual elements to accomplish the complete release cycle.
The DevOps Approach for the Support Team
How we can include the support team as part of the DevOps ecosystem?
What are the advantages or limitations with this approach?
Is it feasible to include a support team?
How will be the L1, L2, and L3/L4 teams align to DevOps principles?
DevOps is defined as the collaboration of people to release value in a faster way using appropriate processes and technology adoption. The main concept of DevOps is people, especially the team culture. DevOps eliminates silos between dev and ops using practices such as smaller, much more frequent releases and blameless post-mortems, in combination with technologies and tools that empower transparent communication and cooperation across teams.

BizDevOps
The DevOps team without a support ecosystem may be able to deliver value faster to the client. But client satisfaction mainly depends on how quickly the issues or challenges are addressed. If you deliver hundreds of amazing features to the client but take more time to fix bugs and release, fail to respond to a production outage in a timely fashion, or make an effort to reduce application downtime for the business, this will impact the client satisfaction inversely.
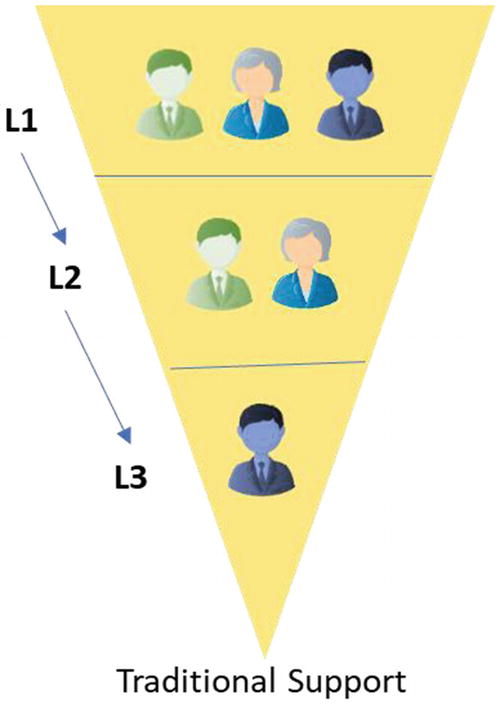
Traditional support model
Delay in ticket handling
Tiered approach
Less collaboration
Ticket bouncing
Triage by nonexperts
Siloed teams
Less involvement in core development activities
Under-utilized skillset
No change in operation
No rotation
Traditional team
Intelligent Swarming Support Model
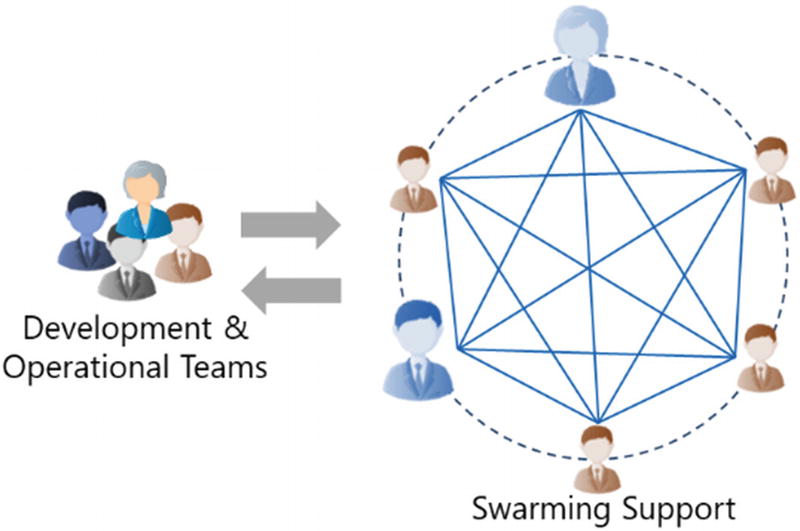
Swarming model
In the swarming support model, expert teams are formed as swarm teams. There may be one or more swarm teams to handle the support tickets. If the L1 support is not automated fully, then there may be one swarm team to support the L1 tickets and help in automation. The L2/L3/L4 areas will be handled by a single team of experts who understand the application functionality and technology.
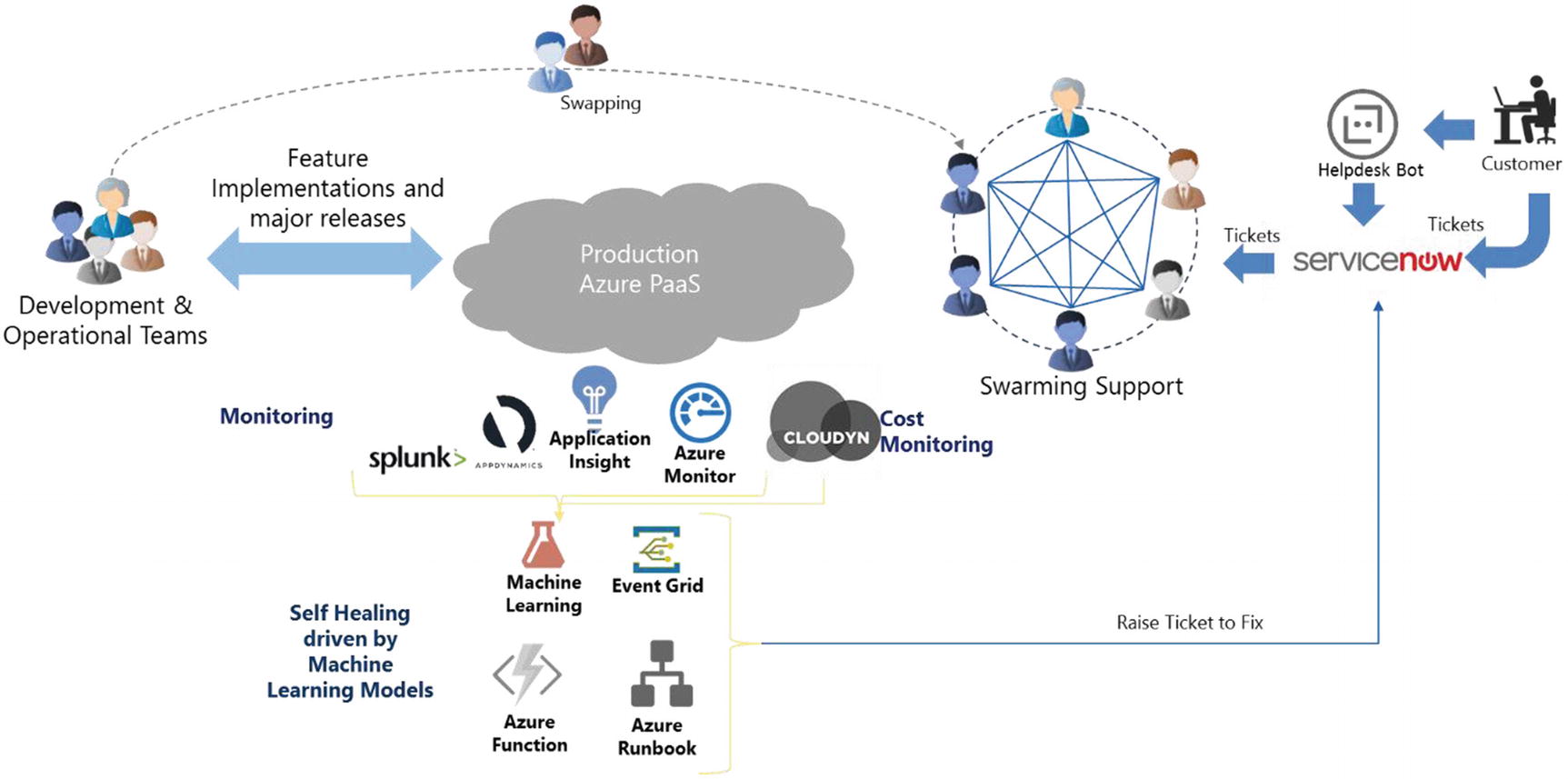
Intelligent swarming support model
Swiftness in solving tickets
Flat team
Quick collaboration
One owner
Experts handle the tickets
Single team; swapping with core team
Higher team satisfaction
Proper skill utilization
Culture and process change
Rotation between support and core team
Proper team combination for successful implementation
Summary
The DevOps approach and architecture vary from application to application, but the basic components are the same. More and more COTS applications are starting to support external DevOps tools to integrate with the core deployment model. A proper DevOps architecture helps manage the release of value quickly in an agile manner.