
![]()
Applications are made up of business logic, interaction with other systems, user interfaces . . . and data. Most of the data that our applications manipulate have to be stored in databases, retrieved, and analyzed. Databases are important: they store business data, act as a central point between applications, and process data through triggers or stored procedures. Persistent data are everywhere, and most of the time they use relational databases as the underlying persistence engine (as opposed to schemaless databases). Relational databases store data in tables made of rows and columns. Data are identified by primary keys, which are special columns with uniqueness constraints and, sometimes, indexes. The relationships between tables use foreign keys and join tables with integrity constraints.
All this vocabulary is completely unknown in an object-oriented language such as Java. In Java, we manipulate objects that are instances of classes. Objects inherit from others, have references to collections of other objects, and sometimes point to themselves in a recursive manner. We have concrete classes, abstract classes, interfaces, enumerations, annotations, methods, attributes, and so on. Objects encapsulate state and behavior in a nice way, but this state is only accessible when the Java Virtual Machine (JVM) is running: if the JVM stops or the garbage collector cleans its memory content, objects disappear, as well as their state. Some objects need to be persistent. By persistent data, I mean data that are deliberately stored in a permanent form on magnetic media, flash memory, and so forth. An object that can store its state to get reused later is said to be persistent.
The principle of object-relational mapping (ORM) is to bring the world of database and objects together. It involves delegating access to relational databases to external tools or frameworks, which in turn give an object-oriented view of relational data, and vice versa. Mapping tools have a bidirectional correspondence between the database and objects. Several frameworks achieve this, such as Hibernate, TopLink, and Java Data Objects (JDO), but Java Persistence API (JPA) is the preferred technology and is part of Java EE 7.
This chapter is an introduction to JPA, and in the two following chapters I concentrate on ORM and querying and managing persistent objects.
Understanding Entities
When talking about mapping objects to a relational database, persisting objects, or querying objects, the term “entity” should be used rather than “object.” Objects are instances that just live in memory. Entities are objects that live shortly in memory and persistently in a database. They have the ability to be mapped to a database; they can be concrete or abstract; and they support inheritance, relationships, and so on. These entities, once mapped, can be managed by JPA. You can persist an entity in the database, remove it, and query it using a query language Java Persistence Query Language, or JPQL). ORM lets you manipulate entities, while under the covers the database is being accessed. And, as you will see, an entity follows a defined life cycle. With callback methods and listeners, JPA lets you hook some business code to life-cycle events.
As a first example, let’s start with the simplest entity that we can possibly have. In the JPA persistence model, an entity is a Plain Old Java Object (POJO). This means an entity is declared, instantiated, and used just like any other Java class. An entity has attributes (its state) that can be manipulated via getters and setters. Listing 4-1 shows a simple entity.
Listing 4-1. Simple Example of a Book Entity
@Entity
public class Book {
@Id @GeneratedValue
private Long id;
private String title;
private Float price;
private String description;
private String isbn;
private Integer nbOfPage;
private Boolean illustrations;
public Book() {
}
// Getters, setters
}
The example in Listing 4-1 represents a Book entity from which I’ve omitted the getters and the setters for clarity. As you can see, except for some annotations, this entity looks exactly like any Java class: it has several attributes (id, title, price, etc.) of different types (Long, String, Float, Integer, and Boolean), a default constructor, and getters and setters for each attribute. So how does this map to a table? The answer is thanks to annotations.
For a class to be an entity it has be to annotated with @javax.persistence.Entity, which allows the persistence provider to recognize it as a persistent class and not just as a simple POJO. Then, the annotation @javax.persistence.Id defines the unique identifier of this object. Because JPA is about mapping objects to relational tables, objects need an ID that will be mapped to a primary key. The other attributes in Listing 4-1 (title, price, description, etc.) are not annotated, so they will be made persistent by applying a default mapping.
This example of code has only attributes, but, as you will later see, an entity can also have business methods. Note that this Book entity is a Java class that does not implement any interface or extend any class. In fact, to be an entity, a class must follow these rules.
- The entity class must be annotated with @javax.persistence.Entity (or denoted in the XML descriptor as an entity).
- The @javax.persistence.Id annotation must be used to denote a simple primary key.
- The entity class must have a no-arg constructor that has to be public or protected. The entity class may have other constructors as well.
- The entity class must be a top-level class. An enum or interface cannot be designated as an entity.
- The entity class must not be final. No methods or persistent instance variables of the entity class may be final.
- If an entity instance has to be passed by value as a detached object (e.g., through a remote interface), the entity class must implement the Serializable interface.
![]() Note In previous versions of Java EE, the persistent component model was called Entity Bean, or to be more precise, Entity Bean CMP (Container-Managed Persistence), and was associated with Enterprise JavaBeans. This model of persistence lasted from J2EE 1.3 until 1.4, but was heavyweight and finally replaced by JPA since Java EE 5. JPA uses the term “Entity” instead of “Entity Bean.”
Note In previous versions of Java EE, the persistent component model was called Entity Bean, or to be more precise, Entity Bean CMP (Container-Managed Persistence), and was associated with Enterprise JavaBeans. This model of persistence lasted from J2EE 1.3 until 1.4, but was heavyweight and finally replaced by JPA since Java EE 5. JPA uses the term “Entity” instead of “Entity Bean.”
The principle of ORM is to delegate to external tools or frameworks (in our case, JPA) the task of creating a correspondence between objects and tables. The world of classes, objects, and attributes can then be mapped to relational databases made of tables containing rows and columns. Mapping gives an object-oriented view to developers who can transparently use entities instead of tables. And how does JPA map objects to a database? Through metadata.
Associated with every entity are metadata that describe the mapping. The metadata enable the persistence provider to recognize an entity and to interpret the mapping. The metadata can be written in two different formats.
- Annotations: The code of the entity is directly annotated with all sorts of annotations that are described in the javax.persistence package.
- XML descriptors: Instead of (or in addition to) annotations, you can use XML descriptors. The mapping is defined in an external XML file that will be deployed with the entities. This can be very useful when database configuration changes depending on the environment, for example.
The Book entity (shown in Listing 4-1) uses JPA annotations so the persistence provider can synchronize the data between the attributes of the Book entity and the columns of the BOOK table. Therefore, if the attribute isbn is modified by the application, the ISBN column will be synchronized (if the entity is managed, if the transaction context is set, etc.).
As Figure 4-1 shows, the Book entity is mapped in a BOOK table, and each column is named after the attribute of the class (e.g., the isbn attribute of type String is mapped to a column named ISBN of type VARCHAR). These default mapping rules are an important part of the principle known as configuration by exception.
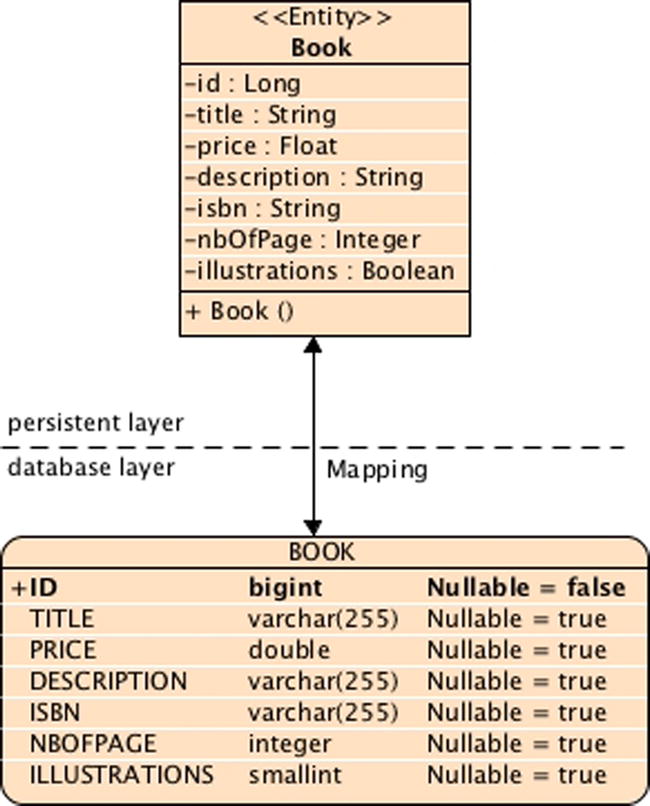
Figure 4-1. Data synchronization between the entity and the table
Java EE 5 introduced the idea of configuration by exception (sometimes referred to as programming by exception or convention over configuration) and is still heavily used today in Java EE 7. This means, unless specified differently, the container or provider should apply the default rules. In other words, having to supply a configuration is the exception to the rule. This allows you to write the minimum amount of code to get your application running, relying on the container and provider defaults. If you don’t want the provider to apply the default rules, you can customize the mapping to your own needs using metadata. In other words, having to supply a configuration is the exception to the rule.
Without any annotation, the Book entity in Listing 4-1 would be treated just like a POJO and not be persisted. That is the rule: if no special configuration is given, the default should be applied, and the default for the persistence provider is that the Book class has no database representation. But because you need to change this default behavior, you annotate the class with @Entity. It is the same for the identifier. You need a way to tell the persistence provider that the id attribute has to be mapped to a primary key, so you annotate it with @Id, and the value of this identifier is automatically generated by the persistence provider, using the optional @GeneratedValue annotation. This type of decision characterizes the configuration-by-exception approach, in which annotations are not required for the more common cases and are only used when an override is needed. This means that, for all the other attributes, the following default mapping rules will apply:
- The entity name is mapped to a relational table name (e.g., the Book entity is mapped to a BOOK table). If you want to map it to another table, you will need to use the @Table annotation, as you’ll see later in the “Elementary Mapping” section of the next chapter.
- Attribute names are mapped to a column name (e.g., the id attribute, or the getId() method, is mapped to an ID column). If you want to change this default mapping, you will need to use the @Column annotation.
- JDBC rules apply for mapping Java primitives to relational data types. A String will be mapped to VARCHAR, a Long to a BIGINT, a Boolean to a SMALLINT, and so on. The default size of a column mapped from a String is 255 (a String is mapped to a VARCHAR(255)). But keep in mind that the default mapping rules are different from one database to another. For example, a String is mapped to a VARCHAR in Derby and a VARCHAR2 in Oracle. An Integer is mapped to an INTEGER in Derby and a NUMBER in Oracle. The information of the underlying database is provided in the persistence.xml file, which you’ll see later.
Following these rules, the Book entity will be mapped to a Derby table that has the structure described in Listing 4-2.
Listing 4-2. Script Creating the BOOK Table Structure
CREATE TABLE BOOK (
ID BIGINT NOT NULL,
TITLE VARCHAR(255),
PRICE FLOAT,
DESCRIPTION VARCHAR(255),
ISBN VARCHAR(255),
NBOFPAGE INTEGER,
ILLUSTRATIONS SMALLINT DEFAULT 0,
PRIMARY KEY (ID)
)
JPA 2.1 has an API and a standard mechanism to generate the database automatically from the entities and generate scripts such as Listing 4-2. This feature is very convenient when you are in development mode. However, most of the time you need to connect to a legacy database that already exists.
Listing 4-1 shows an example of a very simple mapping. As you will see in the next chapter, the mapping can be much richer, allowing you to map all kinds of things from objects to relationships. The world of object-oriented programming abounds with classes and associations between classes (and collections of classes). Databases also model relationships, only differently: using foreign keys or join tables. JPA has a set of metadata to manage the mapping of relationships. Even inheritance can be mapped. Inheritance is commonly used by developers to reuse code, but this concept is natively unknown in relational databases (as they have to emulate inheritance using foreign keys and constraints). Even if inheritance mapping throws in several twists, JPA supports it and gives you three different strategies to choose from.
![]() Note JPA is aimed at relational databases. The mapping metadata (annotations or XML) are designed to map entities to structured tables and attributes to columns. The new era of NoSQL (Not Only SQL) databases (or schemaless) has emerged with different storage structures: key-values, column, document, or graph. At the moment JPA is not able to map entities to these structures. Hibernate OGM is an open source framework that attempts to address this issue. EclipseLink also has some extensions to map NoSQL structures. Hibernate OGM or EclipseLink extensions are beyond the scope of this book, but you should have a look at them if you plan to use NoSQL databases.
Note JPA is aimed at relational databases. The mapping metadata (annotations or XML) are designed to map entities to structured tables and attributes to columns. The new era of NoSQL (Not Only SQL) databases (or schemaless) has emerged with different storage structures: key-values, column, document, or graph. At the moment JPA is not able to map entities to these structures. Hibernate OGM is an open source framework that attempts to address this issue. EclipseLink also has some extensions to map NoSQL structures. Hibernate OGM or EclipseLink extensions are beyond the scope of this book, but you should have a look at them if you plan to use NoSQL databases.
JPA allows you to map entities to databases and also to query them using different criteria. JPA’s power is that it offers the ability to query entities and their relationships in an object-oriented way without having to use the underlying database foreign keys or columns. The central piece of the API responsible for orchestrating entities is the javax.persistence.EntityManager. Its role is to manage entities, read from and write to a given database, and allow simple CRUD (create, read, update, and delete) operations on entities as well as complex queries using JPQL. In a technical sense, the entity manager is just an interface whose implementation is done by the persistence provider (e.g., EclipseLink). The following snippet of code shows you how to obtain an entity manager and persist a Book entity:
EntityManagerFactory emf = Persistence.createEntityManagerFactory("chapter04PU");
EntityManager em = emf.createEntityManager();
em.persist(book);
In Figure 4-2, you can see how the EntityManager interface can be used by a class (here Main) to manipulate entities (in this case, Book). With methods such as persist() and find(), the entity manager hides the JDBC calls to the database and the INSERT or SELECT SQL (Structured Query Language) statement.
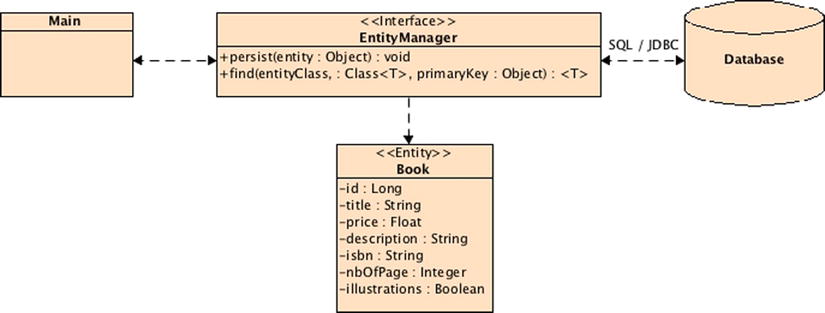
Figure 4-2. The entity manager interacts with the entity and the underlying database
The entity manager also allows you to query entities. A query in this case is similar to a database query, except that, instead of using SQL, JPA queries over entities using JPQL. Its syntax uses the familiar object dot (.) notation. To retrieve all the books that have the title H2G2, you can write the following:
SELECT b FROM Book b WHERE b.title = 'H2G2'
Notice that title is the name of the Book attribute, not the name of a column in a table. JPQL statements manipulate objects and attributes, not tables and columns. A JPQL statement can be executed with dynamic queries (created dynamically at runtime) or static queries (defined statically at compile time). You can also execute native SQL statement and even stored procedures. Static queries, also known as named queries, are defined using either annotations (@NamedQuery) or XML metadata. The previous JPQL statement can, for example, be defined as a named query on the Book entity. Listing 4-3 shows a Book entity defining the findBookH2G2 named query using the @NamedQuery annotation (more on queries in Chapter 6).
Listing 4-3. Book Entity with a findBookH2G2 Named Query
@Entity
@NamedQuery(name = "findBookH2G2", →
query = "SELECT b FROM Book b WHERE b.title ='H2G2'")
public class Book {
@Id @GeneratedValue
private Long id;
private String title;
private Float price;
private String description;
private String isbn;
private Integer nbOfPage;
private Boolean illustrations;
// Constructors, getters, setters
}
The EntityManager can be obtained in a standard Java class using a factory. Listing 4-4 shows such a class creating an instance of the Book entity, persisting it into a table, and calling a named query. It follows steps 1 through 5.
- Creates an instance of the Book entity: Entities are annotated POJOs, managed by the persistence provider. From a Java viewpoint, an instance of a class needs to be created through the new keyword as with any POJO. It is important to emphasize that, up to this point in the code, the persistence provider is not aware of the Book object.
- Obtains an entity manager and a transaction: This is the important part of the code, as an entity manager is needed to manipulate entities. First, an entity manager factory is created for the "chapter04PU" persistence unit. This factory is then employed to obtain an entity manager (the em variable), used throughout the code to get a transaction (tx variable), and persist and retrieve a Book.
- Persists the book to the database: The code starts a transaction (tx.begin()) and uses the EntityManager.persist() method to insert a Book instance. When the transaction is committed (tx.commit()), the data is flushed to the database.
- Executes the named query: Again, the entity manager is used to retrieve the book using the findBookH2G2 named query.
- Closes the entity manager and the entity manager factory.
Listing 4-4. A Main Class Persisting and Retrieving a Book Entity
public class Main {
public static void main(String[] args) {
// 1-Creates an instance of book
Book book = new Book("H2G2", "The Hitchhiker's Guide to the Galaxy", 12.5F, →
"1-84023-742-2", 354, false);
// 2-Obtains an entity manager and a transaction
EntityManagerFactory emf = Persistence.createEntityManagerFactory("chapter04PU");
EntityManager em = emf.createEntityManager();
// 3-Persists the book to the database
EntityTransaction tx = em.getTransaction();
tx.begin();
em.persist(book);
tx.commit();
// 4-Executes the named query
book = em.createNamedQuery("findBookH2G2", Book.class).getSingleResult();
// 5-Closes the entity manager and the factory
em.close();
emf.close();
}
}
Notice in Listing 4-4 the absence of SQL queries or JDBC calls. As shown in Figure 4-2 the Main class interacts with the underlying database through the EntityManager interface, which provides a set of standard methods that allow you to perform operations on the Book entity. Behind the scenes, the EntityManager relies on the persistence provider to interact with the databases. When you invoke the EntityManager method, the persistence provider generates and executes a SQL statement through the corresponding JDBC driver.
Which JDBC driver should you use? How should you connect to the database? What’s the database name? This information is missing from our previous code. When the Main class (Listing 4-4) creates an EntityManagerFactory, it passes the name of a persistence unit as a parameter; in this case, it’s called chapter04PU. The persistence unit indicates to the entity manager the type of database to use and the connection parameters, which are defined in the persistence.xml file, shown in Listing 4-5, that have to be accessible in the class path.
Listing 4-5. The persistence.xml File Defining the Persistence Unit
<?xml version="1.0" encoding="UTF-8"?>
<persistence xmlns=" http://xmlns.jcp.org/xml/ns/persistence "
xmlns:xsi=" http://www.w3.org/2001/XMLSchema-instance "
xsi:schemaLocation=" http://xmlns.jcp.org/xml/ns/persistence →
http://xmlns.jcp.org/xml/ns/persistence/persistence_2_1.xsd "
version="2.1">
<persistence-unit name=" chapter04PU " transaction-type="RESOURCE_LOCAL">
<provider>org.eclipse.persistence.jpa.PersistenceProvider</provider>
<class>org.agoncal.book.javaee7.chapter04. Book </class>
<properties>
<property name="javax.persistence.schema-generation-action" value="drop-and-create"/>
<property name="javax.persistence.schema-generation-target" value="database"/>
<property name="javax.persistence.jdbc.driver" →
value="org.apache.derby.jdbc.ClientDriver"/>
<property name="javax.persistence.jdbc.url" →
value="jdbc:derby:// localhost:1527 / chapter04DB ;create=true"/>
<property name="javax.persistence.jdbc. user " value="APP"/>
<property name="javax.persistence.jdbc. password " value="APP"/>
</properties>
</persistence-unit>
</persistence>
The chapter04PU persistence unit defines a JDBC connection for the chapter04DB Derby database running on localhost and port 1527. It connects with a user (APP) and a password (APP) at a given URL. The <class> tag tells the persistence provider to manage the Book class (there are other tags to implicitly or explicitly denote managed persistence classes such as <mapping-file>, <jar-file>, or <exclude-unlisted-classes>). Without a persistent unit, entities can be manipulated as POJOs without having persistent repercussions.
Entity Life Cycle and Callbacks
Entities are just POJOs. When the entity manager manages the POJOs, they have a persistence identity (a key that uniquely identifies an instance equivalent to a primary key), and the database synchronizes their state. When they are not managed (i.e., they are detached from the entity manager), they can be used like any other Java class. This means that entities have a life cycle, as shown in Figure 4-3. When you create an instance of the Book entity with the new operator, the object exists in memory, and JPA knows nothing about it (it can even end up being garbage collected). When it becomes managed by the entity manager, the BOOK table maps and synchronizes its state. Calling the EntityManager.remove() method deletes the data from the database, but the Java object continues living in memory until it gets garbage collected.
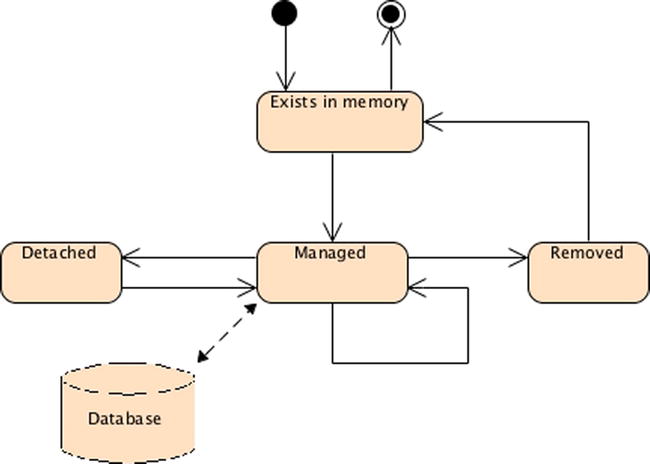
Figure 4-3. The life cyle of an entity
The operations made to entities fall into four categories—persisting, updating, removing, and loading—which correspond to the database operations of inserting, updating, deleting, and selecting, respectively. Each operation has a “pre” and “post” event (except for loading, which only has a “post” event) that can be intercepted by the entity manager to invoke a business method. As you will see in Chapter 6, you will have @PrePersist and @PostPersist annotations, and so on. JPA allows you to hook business logic to the entity when these events occur. These annotations can be set on entity methods (a.k.a. callback methods) or in external classes (a.k.a. listeners). You can think of callback methods and listeners as analogous triggers in a relational database.
Integration with Bean Validation
Bean Validation, which was explained in the previous chapter, has several hooks into Java EE. One of them is its integration with JPA and the entity life cycle. Entities may include Bean Validation constraints and be automatically validated. In fact, automatic validation is achieved because JPA delegates validation to the Bean Validation implementation upon the pre-persist, pre-update, and pre-remove entity life-cycle events. Of course, validation can still be achieved manually, by calling the validate method of a Validator on an entity if needed.
Listing 4-6 shows a Book entity with two Bean Validation constraints (@NotNull and @Size). If the title attribute is null and you want to persist this entity (by invoking EntityManager.persist()), the JPA runtime will throw a ConstraintViolation exception and the data will not be inserted in the database.
Listing 4-6. An Entity with Bean Validation Annotations
@Entity
public class Book {
@Id @GeneratedValue
private Long id;
@NotNull
private String title;
private Float price;
@Size(min = 10, max = 2000)
private String description;
private String isbn;
private Integer nbOfPage;
private Boolean illustrations;
// Constructors, getters, setters
}
JPA 1.0 was created with Java EE 5 to solve the problem of data persistence. It brought the object-oriented and relational models together. In Java EE 7, JPA 2.1 follows the same path of simplicity and robustness and adds new functionalities. You can use this API to access and manipulate relational data from EJBs, web components, and Java SE applications.
JPA is an abstraction above JDBC that makes it possible to be independent of SQL. All classes and annotations of this API are in the javax.persistence package. The main components of JPA are
- ORM, which is the mechanism to map objects to data stored in a relational database.
- An entity manager API to perform database-related operations, such as CRUD.
- The JPQL, which allows you to retrieve data with an object-oriented query language.
- Transactions and locking mechanisms which Java Transaction API (JTA) provides when accessing data concurrently. JPA also supports resource-local (non-JTA) transactions.
- Callbacks and listeners to hook business logic into the life cycle of a persistent object.
ORM solutions have been around for a long time, even before Java. Products such as TopLink originally started with Smalltalk in 1994 before switching to Java. Commercial ORM products like TopLink have been available since the earliest days of the Java language. They were successful but were never standardized for the Java platform. A similar approach to ORM was standardized in the form of JDO, which failed to gain any significant market penetration.
In 1998, EJB 1.0 was created and later shipped with J2EE 1.2. It was a heavyweight, distributed component used for transactional business logic. Entity Bean CMP was introduced as optional in EJB 1.0, became mandatory in EJB 1.1, and was enhanced through versions up to EJB 2.1 (J2EE 1.4). Persistence could only be done inside the container through a complex mechanism of instantiation using home, local, or remote interfaces. The ORM capabilities were also very limited, as inheritance was difficult to map.
Parallel to the J2EE world was a popular open source solution that led to some surprising changes in the direction of persistence: Hibernate, which brought back a lightweight, object-oriented persistent model.
After years of complaints about Entity CMP 2.x components and in acknowledgment of the success and simplicity of open source frameworks such as Hibernate, the persistence model of the Enterprise Edition was completely rearchitected in Java EE 5. JPA 1.0 was born with a very lightweight approach that adopted many Hibernate design principles. The JPA 1.0 specification was bundled with EJB 3.0 (JSR 220). In 2009 JPA 2.0 (JSR 317) shipped with Java EE 6 and brought new APIs, extended JPQL, and added new functionalities such as second-level cache, pessimistic locking, or the criteria API.
Today, with Java EE 7, JPA 2.1 follows the path of ease of development and brings new features. It has evolved in the JSR 338.
What’s New in JPA 2.1?
If JPA 1.0 was a revolution from its Entity CMP 2.x ancestor because a completely new persistence model, JPA 2.0, was a continuation of JPA 1.0, and today JPA 2.1 follows the same steps and brings many new features and improvements.
- Schema generation: JPA 2.1 has standardized database schema generation by bringing a new API and a set of properties (defined in the persistence.xml).
- Converters: These are new classes that convert between database and attributes representations.
- CDI support: Injection is now possible into event listeners.
- Support for stored procedures: JPA 2.1 allows now dynamically specified and named stored procedure queries.
- Bulk update and delete criteria queries: Criteria API only had select queries; now update and delete queries are also specified.
- Downcasting: The new TREAT operator allows access to subclass-specific state in queries.
Table 4-1 lists the main packages defined in JPA 2.1 today.
Table 4-1. Main JPA Packages
| Package | Description |
|---|---|
| javax.persistence | API for the management of persistence and object/relational mapping |
| javax.persistence.criteria | Java Persistence Criteria API |
| javax.persistence.metamodel | Java Persistence Metamodel API |
| javax.persistence.spi | SPI for Java Persistence providers |
EclipseLink 2.5 is the open source reference implementation of JPA 2.1. It provides a powerful and flexible framework for storing Java objects in a relational database. EclipseLink is a JPA implementation, but it also supports XML persistence through Java XML Binding (JAXB) and other means such as Service Data Objects (SDO). It provides support not only for ORM but also for object XML mapping (OXM), object persistence to enterprise information systems (EIS) using Java EE Connector Architecture (JCA), and database web services.
EclipseLink’s origins stem from the Oracle TopLink product given to the Eclipse Foundation in 2006. EclipseLink is the JPA reference implementation and is the persistence framework used in this book. It is also referred to as the persistence provider, or simply the provider.
At the time of writing this book EclipseLink is the only JPA 2.1 implementation. But Hibernate and OpenJPA will soon follow and you will have several implementations to choose from.
Putting It all Together
Now that you know a little bit about JPA, EclipseLink, entities, the entity manager, and JPQL, let’s put them all together and write a small application that persists an entity to a database. The idea is to write a simple Book entity with Bean Validation constraints and a Main class that persists a book. You’ll then compile it with Maven and run it with EclipseLink and a Derby client database. To show how easy it is to integration-test an entity, I will show you how to write a test class (BookIT) with JUnit 4 and use the embedded mode of Derby for persisting data using an in-memory database.
This example follows the Maven directory structure, so classes and files described in Figure 4-4 have to be placed in the following directories:
- src/main/java: For the Book entity and the Main class;
- src/main/resources: For the persistence.xml file used by the Main and BookIT classes as well as the insert.sql database loading script;
- src/test/java: For the BookIT class, which is used for integration testing; and
- pom.xml: For the Maven POM, which describes the project and its dependencies on other external modules and components.

Figure 4-4. Putting it all together
Writing the Book Entity
The Book entity, shown in Listing 4-7, needs to be developed under the src/main/java directory. It has several attributes (a title, a price, etc.) of different data types (String, Float, Integer, and Boolean), some Bean Validation annotations (@NotNull and @Size), as well as some JPA annotations.
- @Entity informs the persistence provider that this class is an entity and that it should manage it.
- The @NamedQueries and @NamedQuery annotations define two named-queries that use JPQL to retrieve books from the database.
- @Id defines the id attribute as being the primary key.
- The @GeneratedValue annotation informs the persistence provider to autogenerate the primary key using the underlying database id utility.
Listing 4-7. A Book Entity with a Named Query
package org.agoncal.book.javaee7.chapter04 ;
@Entity
@NamedQueries ({
@NamedQuery (name = "findAllBooks", query = "SELECT b FROM Book b"),
@NamedQuery(name = "findBookH2G2", query = "SELECT b FROM Book b WHERE b.title ='H2G2'")
})
public class Book {
@Id @GeneratedValue
private Long id;
@NotNull
private String title;
private Float price;
@Size(min = 10, max = 2000)
private String description;
private String isbn;
private Integer nbOfPage;
private Boolean illustrations;
// Constructors, getters, setters
}
Note that for better readability I’ve omitted the constructor, getters, and setters of this class. As you can see in this code, except for a few annotations, Book is a simple POJO. Now let’s write a Main class that persists a book to the database.
Writing the Main Class
The Main class, shown in Listing 4-8, is under the same package as the Book entity. It commences by creating a new instance of Book (using the Java keyword new) and sets some values to its attributes. There is nothing special here, just pure Java code. It then uses the Persistence class to get an instance of an EntityManagerFactory that refers to a persistence unit called chapter04PU, which I’ll describe later in the section “Writing the Persistence Unit.” This factory creates an instance of an EntityManager (em variable). As mentioned previously, the entity manager is the central piece of JPA in that it is able to create a transaction, persist the book object using the EntityManager.persist() method, and then commit the transaction. At the end of the main() method, both the EntityManager and EntityManagerFactory are closed to release the provider’s resources
Listing 4-8. A Main Class Persisting the Book Entity
package org.agoncal.book.javaee7.chapter04 ;
public class Main {
public static void main(String[] args) {
// Creates an instance of book
Book book = new Book ("H2G2", "The Hitchhiker's Guide to the Galaxy", 12.5F, →
"1-84023-742-2", 354, false);
// Obtains an entity manager and a transaction
EntityManagerFactory emf = Persistence .createEntityManagerFactory(" chapter04PU ");
EntityManager em = emf.createEntityManager();
// Persists the book to the database
EntityTransaction tx = em.getTransaction();
tx.begin();
em.persist(book);
tx.commit();
// Closes the entity manager and the factory
em.close();
emf.close();
}
}
Again, for readability I’ve omitted exception handling. If a persistence exception occurs, you would have to roll back the transaction, log a message, and close the EntityManager in the finally block.
Writing the BookIT Integration Test
One complaint made about the previous versions of Entity CMP 2.x was the difficulty of integration testing persistent components. One of the major selling points of JPA is that you can easily test entities without requiring a running application server or live database. But what can you test? Entities themselves usually don’t need to be tested in isolation. Most methods on entities are simple getters or setters with only a few business methods. Verifying that a setter assigns a value to an attribute and that the corresponding getter retrieves the same value does not give any extra value (unless a side effect is detected in the getters or the setters). So unit testing an entity has limited interest.
What about testing the database queries? Making sure that the findBookH2G2 query is correct? Or injecting data into the database and testing complex queries bringing multiple values? These integration tests would need a real database with real data, or you would unit test in isolation with mocks to simulate a query. Using an in-memory database and JPA transactions is a good compromise. CRUD operations and JPQL queries can be tested with a very lightweight database that doesn’t need to run in a separate process (just by adding a jar file to the class path). This is how you will run our BookIT class, by using the embedded mode of Derby.
Maven uses two different directories, one to store the main application code and another for the test classes. The BookIT class, shown in Listing 4-9, goes under the src/test/java directory and tests that the entity manager can persist a book and retrieve it from the database and checks that Bean Validation constraints are raised.
Listing 4-9. Test Class That Creates and Retrieves Books from the Database
public class BookIT {
private static EntityManagerFactory emf = →
Persistence.createEntityManagerFactory(" chapter04TestPU ");
private EntityManager em;
private EntityTransaction tx;
@Before
public void initEntityManager() throws Exception {
em = emf.createEntityManager();
tx = em.getTransaction();
}
@After
public void closeEntityManager() throws Exception {
if (em != null) em.close();
}
@Test
public void shouldFindJavaEE7Book () throws Exception {
Book book = em. find (Book.class, 1001 L);
assertEquals("Beginning Java EE 7", book.getTitle());
}
@Test
public void shouldCreateH2G2Book () throws Exception {
// Creates an instance of book
Book book = new Book("H2G2", "The Hitchhiker's Guide to the Galaxy", 12.5F, →
"1-84023-742-2", 354, false);
// Persists the book to the database
tx.begin();
em.persist(book);
tx.commit();
assertNotNull("ID should not be null", book.getId());
// Retrieves all the books from the database
book = em.createNamedQuery(" findBookH2G2 ", Book.class).getSingleResult();
assertEquals("The Hitchhiker's Guide to the Galaxy", book.getDescription());
}
@Test(expected = ConstraintViolationException .class)
public void shouldRaiseConstraintViolationCauseNullTitle () {
Book book = new Book( null , "Null title, should fail", 12.5F, →
"1-84023-742-2", 354, false);
em.persist(book);
}
}
Like the Main class, BookIT in Listing 4-9 needs to create an EntityManager instance using an EntityManagerFactory. To initialize these components, you can use the JUnit 4 fixtures. The @Before and @After annotations allow executions of some code before and after a test is executed. That’s the perfect place to create and close an EntityManager instance and get a transaction.
The shouldFindJavaEE7Book() test case relies on data already being present in the database (more on insert.sql script later) as it finds the book with id 1001 and checks that the title is "Beginning Java EE 7". The shouldCreateH2G2Book() method persists a book (using the EntityManager.persist() method) and checks whether the id has been automatically generated by EclipseLink (with assertNotNull). If so, the findBookH2G2 named query is executed and checks whether the returned book has "The Hitchhiker's Guide to the Galaxy" as its description. The last test case creates a Book with a null title, persists it, and checks that a ConstraintViolationException has been thrown.
Writing the Persistence Unit
As you can see in the Main class (Listing 4-8), the EntityManagerFactory needs a persistence unit called chapter04PU. And the integration test BookIT (Listing 4-9) uses a different persistent unit (chapter04TestPU). These two persistence units have to be defined in the persistence.xml file under the src/main/resources/META-INF directory (see Listing 4-10). This file, required by the JPA specification, is important as it links the JPA provider (EclipseLink in our case) to the database (Derby). It contains all the necessary information to connect to the database (URL, JDBC driver, user, and password) and informs the provider of the database schema-generation mode (drop-and-create means that tables will be dropped and then created). The <provider> element defines the persistence provider, in our case, EclipseLink. The persistence units list all the entities that should be managed by the entity manager. Here, the <class> tag refers to the Book entity.
The two persistent units differ in the sense that chapter04PU uses a running Derby database and chapter04TestPU an in memory one. Notice that both use the load script insert.sql to insert data into the database at runtime.
Listing 4-10. persistence.xml File
<?xml version="1.0" encoding="UTF-8"?>
<persistence xmlns=" http://xmlns.jcp.org/xml/ns/persistence "
xmlns:xsi=" http://www.w3.org/2001/XMLSchema-instance "
xsi:schemaLocation=" http://xmlns.jcp.org/xml/ns/persistence →
http://xmlns.jcp.org/xml/ns/persistence/persistence_2_1.xsd "
version="2.1">
<persistence-unit name=" chapter04PU " transaction-type="RESOURCE_LOCAL">
<provider>org.eclipse.persistence.jpa.PersistenceProvider</provider>
<class>org.agoncal.book.javaee7.chapter04.Book</class>
<properties>
<property name="javax.persistence.schema-generation-action" value=" drop-and-create "/>
<property name="javax.persistence.schema-generation-target" →
value=" database-and-scripts "/>
<property name="javax.persistence.jdbc.driver" →
value=" org.apache.derby.jdbc.ClientDriver "/>
<property name="javax.persistence.jdbc.url" →
value=" jdbc:derby://localhost:1527/chapter04DB;create=true "/>
<property name="javax.persistence.jdbc.user" value="APP"/>
<property name="javax.persistence.jdbc.password" value="APP"/>
<property name="javax.persistence.sql-load-script-source" value=" insert.sql "/>
</properties>
</persistence-unit>
<persistence-unit name=" chapter04TestPU " transaction-type="RESOURCE_LOCAL">
<provider>org.eclipse.persistence.jpa.PersistenceProvider</provider>
<class>org.agoncal.book.javaee7.chapter04.Book</class>
<properties>
<property name="javax.persistence.schema-generation-action" value="drop-and-create"/>
<property name="javax.persistence.schema-generation-target" value="database"/>
<property name="javax.persistence.jdbc.driver" →
value=" org.apache.derby.jdbc.EmbeddedDriver "/>
<property name="javax.persistence.jdbc.url" →
value=" jdbc:derby:memory:chapter04DB;create=true "/>
<property name="javax.persistence.sql-load-script-source" value=" insert.sql "/>
</properties>
</persistence-unit>
</persistence>
Writing an SQL Script to Load Data
Both persistence units defined in Listing 4-10 load the insert.sql script (using the javax.persistence.sql-load-script-source property). This means that the script in Listing 4-11 is executed for database initialization and inserts three books.
Listing 4-11. insert.sql File
INSERT INTO BOOK(ID, TITLE, DESCRIPTION, ILLUSTRATIONS, ISBN, NBOFPAGE, PRICE) values →
(1000, 'Beginning Java EE 6', 'Best Java EE book ever', 1, '1234-5678', 450, 49)
INSERT INTO BOOK(ID, TITLE, DESCRIPTION, ILLUSTRATIONS, ISBN, NBOFPAGE, PRICE) values →
( 1001 , 'Beginning Java EE 7 ', 'No, this is the best ', 1, '5678-9012', 550, 53)
INSERT INTO BOOK(ID, TITLE, DESCRIPTION, ILLUSTRATIONS, ISBN, NBOFPAGE, PRICE) values →
(1010, 'The Lord of the Rings', 'One ring to rule them all', 0, '9012-3456', 222, 23)
If you look carefully at the BookIT integration test (method shouldFindJavaEE7Book) you’ll see that the test expects the book id 1001 to be in the database. Thanks to the database initialization, this is done before the tests are run.
Compiling and Testing with Maven
We have all the ingredients to compile and test the entity before running the Main application: the Book entity, the BookIT integration test, and the persistence units binding the entity to the Derby database. To compile this code, instead of using the javac compiler command directly, you will use Maven. You must first create a pom.xml file that describes the project and its dependencies such as the JPA and Bean Validation API. You also need to inform Maven that you are using Java SE 7 by configuring the maven-compiler-plugin as shown in Listing 4-12.
Listing 4-12. Maven pom.xml File to Compile, Test, and Execute the Application
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns=" http://maven.apache.org/POM/4.0.0 " →
xmlns:xsi=" http://www.w3.org/2001/XMLSchema-instance " →
xsi:schemaLocation=" http://maven.apache.org/POM/4.0.0 →
http://maven.apache.org/xsd/maven-4.0.0.xsd ">
<modelVersion>4.0.0</modelVersion>
<parent>
<artifactId>parent</artifactId>
<groupId>org.agoncal.book.javaee7</groupId>
<version>1.0</version>
</parent>
<groupId>org.agoncal.book.javaee7</groupId>
<artifactId>chapter04</artifactId>
<version>1.0</version>
<dependencies>
<dependency>
<groupId>org.eclipse.persistence</groupId>
<artifactId> org.eclipse.persistence.jpa </artifactId>
<version>2.5.0</version>
</dependency>
<dependency>
<groupId>org.hibernate</groupId>
<artifactId> hibernate-validator </artifactId>
<version>5.0.0</version>
</dependency>
<dependency>
<groupId>org.apache.derby</groupId>
<artifactId> derbyclient </artifactId>
<version>10.9.1.0</version>
</dependency>
<dependency>
<groupId>org.apache.derby</groupId>
<artifactId> derby </artifactId>
<version>10.9.1.0</version>
<scope> test </scope>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.11</version>
<scope>test</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId> maven-compiler-plugin </artifactId>
<version>2.5.1</version>
<configuration>
<source> 1.7 </source>
<target>1.7</target>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId> maven-failsafe-plugin </artifactId>
<version>2.12.4</version>
<executions>
<execution>
<id>integration-test</id>
<goals>
<goal> integration-test </goal>
<goal>verify</goal>
</goals>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.codehaus.mojo</groupId>
<artifactId> exec-maven-plugin </artifactId>
<version>1.2.1</version>
<executions>
<execution>
<goals>
<goal>java</goal>
</goals>
</execution>
</executions>
<configuration>
<mainClass> org.agoncal.book.javaee7.chapter04.Main </mainClass>
</configuration>
</plugin>
</plugins>
</build>
</project>
First, to be able to compile the code, you need the JPA API that defines all the annotations and classes that are in the javax.persistence package. You will get these and the EclipseLink runtime (i.e., the persistence provider) through the org.eclipse.persistence.jpa artifact ID. As seen in the previous chapter, the Bean Validation API is in the hibernate-validator artifact. You then need the JDBC drivers to connect to Derby. The derbyclient artifact ID refers to the jar that contains the JDBC driver to connect to Derby running in server mode (the database runs in a separate process and listens to a port) and the derby artifact ID contains the classes to use Derby as an embedded database. Note that this artifact ID is scoped for testing (<scope>test</scope>) and as well as the artifact for JUnit 4.
To compile the classes, open a command-line interpreter in the root directory that contains the pom.xml file and enter the following Maven command:
$ mvn compile
You should see the BUILD SUCCESS message informing you that the compilation was successful. Maven creates a target subdirectory with all the class files as well as the persistence.xml file. To run the integration tests you also rely on Maven by entering the following command:
$ mvn integration-test
You should see some logs about Derby creating a database and tables in memory. The BookIT class is then executed, and a Maven report should inform you that the three test cases are successful:
Results :
Tests run: 3 , Failures: 0, Errors: 0, Skipped: 0
[INFO] ------------------------------------------------------------------------
[INFO] BUILD SUCCESS
[INFO] ------------------------------------------------------------------------
[INFO] Total time: 5.192s
[INFO] Finished
[INFO] Final Memory: 18M/221M
[INFO] ------------------------------------------------------------------------
Running the Main Class with Derby
Before executing the Main class, you need to start Derby. The easiest way to do this is to go to the $DERBY_HOME/bin directory and execute the startNetworkServer script. Derby starts and displays the following messages in the console:
Security manager installed using the Basic server security policy.
Apache Derby Network Server - 10.9.1.0 - (802917) started and ready to accept
connections on port 1527
The Derby process is listening on port 1527 and waiting for the JDBC driver to send any SQL statement. To execute the Main class, you can use the java interpreter command or use the exec-maven-plugin as follows:
$ mvn exec:java
When you run the Main class, several things occur. First, Derby will automatically create the chapter04DB database once the Book entity is initialized. That is because in the persistence.xml file you’ve added the create=true property to the JDBC URL.
<property name="javax.persistence.jdbc.url" →
value="jdbc:derby://localhost:1527/chapter04DB; create=true "/>
This shortcut is very useful when you are in development mode, as you do not need any SQL script to create the database. Then, the javax.persistence.schema-generation-action property informs EclipseLink to automatically drop and create the BOOK table. Finally, the book is inserted into the table (with an automatically generated ID).
Let’s use Derby commands to display the table structure: enter the ij command in a console (as explained in Appendix A, the $DERBY_HOME/bin directory has to be in your PATH variable). This runs the Derby interpreter, and you can execute commands to connect to the database, show the tables of the chapter04DB database (show tables), check the structure of the BOOK table (describe book), and even show its content by entering SQL statements such as SELECT * FROM BOOK.
$ ij
version 10.9.1.0
ij> connect 'jdbc:derby://localhost:1527/chapter04DB';
ij> show tables;
TABLE_SCHEM |TABLE_NAME |REMARKS
------------------------------------------------------------------------
APP | BOOK |
APP | SEQUENCE |
ij> describe book;
COLUMN_NAME |TYPE_NAME|DEC&|NUM&|COLUM&|COLUMN_DEF|CHAR_OCTE&|IS_NULL&
------------------------------------------------------------------------
ID |BIGINT |0 |10 |19 |NULL |NULL |NO
TITLE |VARCHAR |NULL|NULL|255 |NULL |510 |YES
PRICE |DOUBLE |NULL|2 |52 |NULL |NULL |YES
ILLUSTRATIONS |SMALLINT |0 |10 |5 |0 |NULL |YES
DESCRIPTION |VARCHAR |NULL|NULL|255 |NULL |510 |YES
ISBN |VARCHAR |NULL|NULL|255 |NULL |510 |YES
NBOFPAGE |INTEGER |0 |10 |10 |NULL |NULL |YES
Coming back to the code of the Book entity (Listing 4-7), because you’ve used the @GeneratedValue annotation (to automatically generate an ID), EclipseLink has created a sequence table to store the numbering (the SEQUENCE table). For the BOOK table structure, JPA has followed certain default conventions to name the table and the columns after the entity name and attributes (e.g., Strings are mapped to VARCHAR(255)).
In the persistence.xml file described in Listing 4-10 we have informed EclipseLink to generate the schema database as well as creating the drop and create scripts, thanks to the following property:
<property name="javax.persistence.schema-generation. database .action" →
value=" drop-and-create "/>
<property name="javax.persistence.schema-generation. scripts .action" →
value=" drop-and-create "/>
By default the provider will generate two SQL scripts: createDDL.jdbc (Listing 4-13) with all the SQL statements to create the entire database and the dropDDL.jdbc (Listing 4-14) to drop all the tables. This is useful when you need to execute scripts to create a database in your continuous integration process.
Listing 4-13. The createDDL.jdbc Script
CREATE TABLE BOOK (ID BIGINT NOT NULL, DESCRIPTION VARCHAR(255), →
ILLUSTRATIONS SMALLINT DEFAULT 0, ISBN VARCHAR(255), NBOFPAGE INTEGER, →
PRICE FLOAT, TITLE VARCHAR(255), PRIMARY KEY (ID))
CREATE TABLE SEQUENCE (SEQ_NAME VARCHAR(50) NOT NULL, SEQ_COUNT DECIMAL(15), →
PRIMARY KEY (SEQ_NAME))
INSERT INTO SEQUENCE (SEQ_NAME, SEQ_COUNT) values ('SEQ_GEN', 0)
Listing 4-14. The dropDDL.jdbc Script
DROP TABLE BOOK
DELETE FROM SEQUENCE WHERE SEQ_NAME = 'SEQ_GEN'
Summary
This chapter contained a quick overview of JPA 2.1. Like most of the other Java EE 7 specifications, JPA focuses on a simple object architecture, leaving its ancestor, a heavyweight component model (a.k.a. EJB CMP 2.x), behind. The chapter also covered entities, which are persistent objects that map metadata through annotations or XML.
Thanks to the “Putting It All Together” section, you have seen how to run a JPA application with EclipseLink and Derby. Integration testing is an important topic in projects, and, with JPA and in memory databases such as Derby, it is now very easy to test persistence.
In the following chapters, you will learn more about the main JPA components. Chapter 5 will show you how to map entities, relationships, and inheritance to a database. Chapter 6 will focus on the entity manager API, the JPQL syntax, and how to use queries and locking mechanisms as well as explaining the life cycle of entities and how to hook business logic in callback methods in entities and listeners.