
Chapter 5
Approaches for High-Performance Big Data Processing
Applications and Challenges
Ouidad Achahbar, Mohamed Riduan Abid, Mohamed Bakhouya, Chaker El Amrani, Jaafar Gaber, Mohammed Essaaidi, and Tarek A. El Ghazawi
Abstract
Social media websites, such as Facebook, Twitter, and YouTube, and job posting websites like LinkedIn and CareerBuilder involve a huge amount of data that are very useful to economy assessment and society development. These sites provide sentiments and interests of people connected to web communities and a lot of other information. The Big Data collected from the web is considered as an unprecedented source to fuel data processing and business intelligence. However, collecting, storing, analyzing, and processing these Big Data as quickly as possible create new challenges for both scientists and analytics. For example, analyzing Big Data from social media is now widely accepted by many companies as a way of testing the acceptance of their products and services based on customers’ opinions. Opinion mining or sentiment analysis methods have been recently proposed for extracting positive/negative words from Big Data. However, highly accurate and timely processing and analysis of the huge amount of data to extract their meaning require new processing techniques. More precisely, a technology is needed to deal with the massive amounts of unstructured and semistructured information, in order to understand hidden user behavior. Existing solutions are time consuming given the increase in data volume and complexity. It is possible to use high-performance computing technology to accelerate data processing, through MapReduce ported to cloud computing. This will allow companies to deliver more business value to their end customers in the dynamic and changing business environment. This chapter discusses approaches proposed in literature and their use in the cloud for Big Data analysis and processing.
5.1 Introduction
Societal and technological progress have brought a widespread diffusion of computer services, information, and data characterized by an ever-increasing complexity, pervasiveness, and social meaning. Ever more often, people make use of and are surrounded by devices enabling the rapid establishment of communication means on top of which people may socialize and collaborate, supply or demand services, and query and provide knowledge as it has never been possible before [1]. These novel forms of social services and social organization are a promise of new wealth and quality for all. More precisely, social media, such as Facebook, Twitter, and YouTube, and job posting websites like LinkedIn and CareerBuilder are providing a communication medium to share and distribute information among users.
These media involve a huge amount of data that are very useful to economy assessment and society development. In other words, the Big Data collected from social media is considered as an unprecedented source to fuel data processing and business intelligence. A study done in 2012 by the American Multinational Corporation (AMC) has estimated that from 2005 to 2020, data will grow by a factor of 300 (from 130 exabytes to 40,000 exabytes), and therefore, digital data will be doubled every 2 years [2]. IBM estimates that every day, 2.5 quintillion bytes of data are created, and 90% of the data in the world today has been created in the last 2 years [3]. In addition, Oracle estimated that 2.5 zettabytes of data were generated in 2012, and this will grow significantly every year [4].
The growth of data constitutes the “Big Data” phenomenon. Big Data can be then defined as a large amounts of data, which requires new technologies and architectures so that it becomes possible to extract value from them by a capturing and analysis process. Due to such a large size of data, it becomes very difficult to perform effective analysis using existing traditional techniques. More precisely, as Big Data grows in terms of volume, velocity, and value, the current technologies for storing, processing, and analyzing data become inefficient and insufficient. Furthermore, unlike data that are structured in a known format (e.g., rows and columns), data extracted, for example, from social media, have unstructured formats and are very complex to process directly using standards tools. Therefore, technologies that enable a scalable and accurate analysis of Big Data are required in order to extract value from it.
A Gartner survey stated that data growth is considered as the largest challenge for organizations [5]. With this issue, analyzing and high-performance processing of these Big Data as quickly as possible create new challenges for both scientists and analytics. However, high-performance computing (HPC) technologies still lack the tool sets that fit the current growth of data. In this case, new paradigms and storage tools were integrated with HPC to deal with the current challenges related to data management. Some of these technologies include providing computing as a utility (cloud computing) and introducing new parallel and distributed paradigms. Recently, cloud computing has played an important role as it provides organizations with the ability to analyze and store data economically and efficiently. For example, performing HPC in the cloud was introduced as data has started to be migrated and managed in the cloud. For example, Digital Communications Inc. (DCI) stated that by 2020, a significant portion of digital data will be managed in the cloud, and even if a byte in the digital universe is not stored in the cloud, it will pass, at some point, through the cloud [6].
Performing HPC in the cloud is known as high-performance computing as a service (HPCaaS). Therefore, a scalable HPC environment that can handle the complexity and challenges related to Big Data is required [7]. Many solutions have been proposed and developed to improve computation performance of Big Data. Some of them tend to improve algorithm efficiency, provide new distributed paradigms, or develop powerful clustering environments, though few of those solutions have addressed a whole picture of integrating HPC with the current emerging technologies in terms of storage and processing.
This chapter introduces the Big Data concepts along with their importance in the modern world and existing projects that are effective and important in changing the concept of science into big science and society too. In this work, we will be focusing on efficient approaches for high-performance mining of Big Data, particularly existing solutions that are proposed in the literature and their efficiency in HPC for Big Data analysis and processing. The remainder of this chapter is structured as follows. The definition of Big Data and related concepts are introduced in Section 5.2. In Section 5.3, existing solutions for data processing and analysis are presented. Some remaining issues and further research directions are presented in Section 5.4. Conclusions and perspectives are presented in Section 5.5.
5.2 Big Data Definition and Concepts
Social media websites involve a huge amount of data that are very useful to economy assessment and society development. Big Data is then defined as large and complex data sets that are generated from different sources including social media, online transactions, sensors, smart meters, and administrative services [8]. With all these sources, the size of Big Data goes beyond the ability of typical tools of storing, analyzing, and processing data. Literature reviews on Big Data divide the concept into four dimensions: volume, velocity, variety, and value [8]. In other words, (1) the size of data generated is very large, and it goes from terabytes to petabytes; (2) data grows continuously at an exponential rate; (3) data are generated in different forms: structured, semistructured, and unstructured data, which require new techniques that can handle data heterogeneity; and (4) the challenge in Big Data is to identify what is valuable so as to be able to capture, transform, and extract data for analysis. Data incorporates information of great benefit and insight for users. For example, many social media websites provide sentiments and opinions of people connected to web communities and a lot of other information. Sentiments or opinions are clients’ personal judgments about something, such as whether the product is good or bad [9]. Sentiment analysis or opinion mining is now widely accepted by companies as an important core element for automatically detecting sentiments. For example, this research field has been active since 2002 as a part of online market research tool kits for processing of large numbers of texts in order to identify clients’ opinions about products.
In past years, many machine learning algorithms for text analysis have been proposed. They can be classified into two main families: linguistic and nonlinguistic. Linguistic-based algorithms use knowledge about language (e.g., syntactic, semantic) in order to understand and analyze texts. Nonlinguistic-based algorithms use a learning process from training data in order to guess correct sentiment values. However, these algorithms are time consuming, and plenty of efforts have been dedicated to parallelize them to get better speed. Therefore, new technologies that can support the volume, velocity, variety, and value of data were recently introduced. Some of the new technologies are Not Only Structured Query Language (NoSQL), parallel and distributed paradigms, and new cloud computing trends that can support the four dimensions of Big Data. For example, NoSQL is the transition from relational databases to nonrelational databases [10]. It is characterized by the ability to scale horizontally, the ability to replicate and to partition data over many servers, and the ability to provide high-performance operations. However, moving from relational to NoSQL systems has eliminated some of the atomicity, consistency, isolation, and durability (ACID) transactional properties [11]. In this context, NoSQL properties are defined by consistency, availability, and partition (CAP) tolerance [12] theory, which states that developers must make trade-off decisions between consistency, availability, and partitioning. Some examples of NoSQL tools are Cassandra [13], HBase [14], MongoDB [15], and CouchDB [16].
In parallel to these technologies, cloud computing becomes the current innovative and emerging trend in delivering information technology (IT) services that attracts the interest of both academic and industrial fields. Using advanced technologies, cloud computing provides end users with a variety of services, starting from hardware-level services to the application level. Cloud computing is understood as utility computing over the Internet. This means that computing services have moved from local data centers to hosted services that are offered over the Internet and paid for based on a pay-per-use model [17]. As stated in References 18 and 19, cloud deployment models are classified as follows: software as a service (SaaS), platform as a service (PaaS), and infrastructure as a service (IaaS). SaaS represents application software, operating systems (OSs), and computing resources. End users can view the SaaS model as a web-based application interface where services and complete software applications are delivered over the Internet. Some examples of SaaS applications are Google Docs, Microsoft Office Live, Salesforce Customer Relationship Management (CRM), and so forth. PaaS allows end users to create and deploy applications on a provider’s cloud infrastructure. In this case, end users do not manage or control the underlying cloud infrastructure like the network, servers, OSs, or storage. However, they do have control over the deployed applications by being allowed to design, model, develop, and test them. Examples of PaaS are Google App Engine, Microsoft Azure, Salesforce, and so forth. IaaS consists of a set of virtualized computing resources such as network bandwidth, storage capacity, memory, and processing power. These resources can be used to deploy and run arbitrary software, which can include OSs and applications. Examples of IaaS providers are Dropbox, Amazon Web Services (AWS), and so forth.
As illustrated in Table 5.1, there are many other providers who offer cloud services with different features and pricing [20]. For example, Amazon (AWS) [21] offers a number of cloud services for all business sizes. Some AWS services are Elastic Compute Cloud; Simple Storage Service; SimpleDB (relational data storage service that stores, processes, and queries data sets in the cloud); and so forth. Google [22] offers high accessibility and usability in its cloud services. Some of Google’s services include Google App Engine, Gmail, Google Docs, Google Analytics, Picasa (a tool used to exhibit products and upload their images in the cloud), and so forth.
Examples of Services Provided in Cloud Computing Environment
|
Deployment Models |
Types |
Examples |
|
Software as a service |
Gmail, Google Docs, finance, collaboration, communication, business, CRM |
Zaho, Salesforce, Google Apps |
|
Platform as a service |
Web 2 application runtime, developer tools, middleware |
Windows Azure, Aptana, Google App Engine |
|
Infrastructure as a service |
Servers, storage, processing power, networking resources |
Amazon Web Services, Dropbox, Akamai |
Sourc e : Youssef, A. E., J. Emerg. Trends Comput. Inf. Sci ., 3, 2012.
Recently, HPC has been adopted to provide high computation capabilities, high bandwidth, and low-latency networks in order to handle the complexity of Big Data. HPC fits these requirements by implementing large physical clusters. However, traditional HPC faces a set of challenges, which consist of peak demand, high capital, and high expertise, to acquiring and operating the physical environment [23]. To deal with these issues, HPC experts have leveraged the benefits of new technology trends including cloud technologies and large storage infrastructures. Merging HPC with these new technologies has led to a new HPC model, HPCaaS. HPCaaS is an emerging computing model where end users have on-demand access to pre-existing needed technologies that provide high performance and a scalable HPC computing environment [24]. HPCaaS provides unlimited benefits because of the better quality of services provided by the cloud technologies and the better parallel processing and storage provided by, for example, the Hadoop Distributed File System (HDFS) and MapReduce paradigm. Some HPCaaS benefits are stated in Reference 23 as follows: (1) high scalability, in which resources are scaling up as to ensure essential resources that fit users’ demand in terms of processing large and complex data sets; (2) low cost, in which end users can eliminate the initial capital outlay, time, and complexity to procure HPC; and (3) low latency, by implementing the placement group concept that ensures the execution and processing of data in the same server.
There are many HPCaaS providers in the market. An example of an HPCaaS provider is Penguin Computing [25], which has been a leader in designing and implementing high-performance environments for over a decade. Nowadays, it provides HPCaaS with different options: on demand, HPCaaS as private services, and hybrid HPCaaS services. AWS [26] is also an active HPCaaS in the market; it provides simplified tools to perform HPC over the cloud. AWS allows end users to benefit from HPCaaS features with different pricing models: On-Demand, Reserved [27], or Spot Instances [28]. HPCaaS on AWS is currently used for computer-aided engineering, molecular modeling, genome analysis, and numerical modeling across many industries, including oil and gas, financial services, and manufacturing [21]. Other leaders of HPCaaS in the market are Microsoft (Windows Azure HPC) [29] and Google (Google Compute Engine) [30].
For Big Data processing, two main research directions can be identified: (1) deploying popular tools and libraries in the cloud and providing the service as SaaS and (2) providing computing and storage resources as IaaS or HPCaaS to allow users to create virtual clusters and run jobs.
5.3 Cloud Computing for Big Data Analysis
Recent efforts have investigated cloud computing platforms either to create parallel versions in the form of libraries and statistic tools or to allow users to create clusters on these platforms and run them in the cloud [31]. This section highlights existing work in both directions, data analytics tools as SaaS and computing as IaaS.
5.3.1 Data Analytics Tools as SaaS
Data analytics solutions provide optimized statistical toolboxes that include parallel algorithms (e.g., Message Passing Interface [MPI], Hadoop) for data analysis. Furthermore, users also can write their algorithms and run them in parallel over computer clusters. For example, the Apache Mahout (https://mahout.apache.org/) is a project of the Fondation Apache aiming to build scalable machine learning libraries using Apache Hadoop and the MapReduce paradigm. These libraries are self-contained and highly optimized in order to get better performance while making them easy to use. In other words, these libraries include optimized algorithms (e.g., clustering, classification, collaborative filtering), making them among the most popular libraries for machine learning projects.
GraphLab (http://graphlab.org/projects/index.html) is another project from Carnegie Mellon University with the main aim to develop new parallel machine learning algorithms for graph programming Application Programming Interface (API). It is a graph-based high-performance framework that includes different machine learning algorithms for data analysis. It includes several libraries and algorithms, for example, feature extraction (e.g., linear discriminant analysis); graph analytics (e.g., PageRank, triangle counting); and clustering (e.g., K-means). Jubatus (http://jubat.us/en/) is another open-source machine learning and distributed computing framework that provides several features, such as classification, recommendation, regression, and graph mining.
The IBM Parallel Machine Learning Toolbox (PML, https://www.research.ibm.com/haifa/projects/verification/ml_toolbox/index.html) was developed, similar to the MapReduce programming model and Hadoop system, to allow users with little knowledge in parallel and distributed systems to easily implement parallel algorithms and run them on multiple processor environments or on multithreading machines. It also provides preprogrammed parallel algorithms, such as support vector machine classifiers, linear and transform regression, nearest neighbors, K-means, and principal component analysis (PCA). NIMBLE is another tool kit for implementing parallel data mining and machine learning algorithms on MapReduce [32]. Its main aim is to allow users to develop parallel machine learning algorithms and run them on distributed- and shared-memory machines.
Another category of machine learning systems has been developed and uses Hadoop as a processing environment for data analysis. For example, the Kitenga Analytics (http://software.dell.com/products/kitenga-analytics-suite/) platform provides analytical tools with an easy-to-use interface for Big Data sophisticated processing and analysis. It combines Hadoop, Mahout machine learning, and advanced natural language processing in a fully integrated platform for performing fast content mining and Big Data analysis. Furthermore, it can be considered as the first Big Data search and analytics platform to integrate and process diverse, unstructured, semistructured, and structured information. Pentaho Business Analytics (http://www.pentaho.fr/explore/ pentaho-business-analytics/) is another platform for data integration and analysis. It offers comprehensive tools that support data preprocessing, data exploration, and data extraction together with tools for visualization and for distributed execution on the Hadoop platform. Other systems, such as BigML (https://bigml.com/), Google Prediction API (https://cloud.google.com/products/prediction-api/), and Eigendog, recently have been developed by offering services for data processing and analysis. For example, Google Prediction API is Google’s cloud-based machine learning tool used for analyzing data. However, these solutions cannot be used for texts that are extracted, for example, from social media and social networks (e.g., Twitter, Facebook).
Recently, an increased interest has been devoted to text mining and natural language processing approaches. These solutions are delivered to users as cloud-based services. It is worth noting that the main aim of text mining approaches is to extract features, for example, concept extraction and sentiment or opinion extraction. However, the size and number of documents that need to be processed require the development of new solutions. Several solutions are provided via web services. For example, AlchemyAPI (http://www.alchemyapi.com/) provides natural language processing web services for processing and analyzing vast amounts of unstructured data. It can be used for performing key word/entity extraction and sentiment analysis on large amounts of documents and tweets. In other words, it uses linguistic parsing, natural language processing, and machine learning to analyze and extract semantic meaning (i.e., valuable information) from web content.
5.3.2 Computing as IaaS
Providing high-performance data analysis allows users to avoid installing and managing their own clusters. This can be done by offering computing clusters using public providers. In fact, a high-performance platform is easy to create and effortless to maintain. These solutions provide users the possibility to experiment with complex algorithms on their customized clusters on the cloud.
It is worth noting that performing HPC in the cloud was introduced as data has started to be migrated and managed in the cloud. As stated in Section 5.2, performing HPC in the cloud is known as HPCaaS.
In short, HPCaaS offers high-performance, on-demand, and scalable HPC environments that can handle the complexity and challenges related to Big Data [7]. One of the most known and adopted parallel and distributed systems is the MapReduce model that was developed by Google to meet the growth of their web search indexing process [33]. MapReduce computations are performed with the support of a data storage system known as Google File System (GFS). The success of both GFS and MapReduce inspired the development of Hadoop, which is a distributed and parallel system that implements MapReduce and HDFS [34]. Nowadays, Hadoop is widely adopted by big players in the market because of its scalability, reliability, and low cost of implementation. Hadoop is also proposed to be integrated with HPC as an underlying technology that distributes the work across an HPC cluster [35,36]. With these solutions, users no longer need high skills in HPC-related fields in order to access computing resources.
Recently, several cloud-based HPC clusters have been provided to users together with software packages (e.g., Octave, R system) for data analysis [31]. The main objective is to provide users with suitable environments that are equipped with scalable high-performance resources and statistical software for their day-to-day data analysis and processing. For example, Cloudnumbers.com (http://www.scientific-computing.com/products/product_details.php?product_id=1086) is a cloud-based HPC platform that can be used for time-intensive processing of Big Data from different domains, such as finance and social science. Furthermore, a web interface can be used by users to create, monitor, and easily maintain their work environments. Another similar environment to Cloudnumbers.com is Opani (http://opani.com), which provides additional functionalities that allow users to adapt resources according to data size. While these solutions are scalable, high-level expertise statistics are required, and thus, there are a limited number of providers in this category of solutions. To overcome this drawback, some solutions have been proposed to allow users to build their cloud Hadoop clusters and run their applications. For example, RHIPE (http://www.datadr.org/) provides a framework that allows users to access Hadoop clusters and launch map/reduce analysis of complex Big Data. It is an environment composed of R, an interactive language for data analysis; HDFS; and MapReduce. Other environments, such as Anaconda (https://store.continuum.io/cshop/anaconda/) and Segue (http://code.google.com/p/segue/), were developed for performing map/reduce jobs on top of clusters for Big Data analysis.
5.4 Challenges and Current Research Directions
Big Data are ubiquitous in many domains such as social media, online transactions, sensors, smart meters, and administrative services. In the past few years, many solutions have been proposed and developed to improve computation performance of Big Data. Some of them tend to improve algorithm efficiency, provide new distributed paradigms, or develop powerful clustering environments. For example, machine learning provides a wide range of techniques, such as association rule mining, decision trees, regression, support vector machines, and other data mining techniques [37].
However, few of those solutions have addressed the whole picture of integrating HPC with the current emerging technologies in terms of storage and processing of Big Data, mainly those extracted from social media. Some of the most popular technologies currently used in hosting and processing Big Data are cloud computing, HDFS, and Hadoop MapReduce [38]. At present, the use of HPC in cloud computing is still limited. The first step towards this research was done by the Department of Energy National Laboratories (DOE), which started exploring the use of cloud services for scientific computing [24]. Besides, in 2009, Yahoo Inc. launched partnerships with major top universities in the United States to conduct more research about cloud computing, distributed systems, and high computing applications.
Recently, there have been several studies that evaluated the performance of high computing in the cloud. Most of these studies used Amazon Elastic Compute Cloud (Amazon EC2) as a cloud environment [26,39–42]. Besides, only few studies have evaluated the performance of high computing using the combination of both new emerging distributed paradigms and the cloud environment [43]. For example, in Reference 39, the authors have evaluated HPC on three different cloud providers: Amazon EC2, GoGrid cloud, and IBM cloud. For each cloud platform, they ran HPC on Linux virtual machines (VMs), and they came to the conclusion that the tested public clouds do not seem to be optimized for running HPC applications. This was explained by the fact that public cloud platforms have slow network connections between VMs. Furthermore, the authors in Reference 26 evaluated the performance of HPC applications in today’s cloud environments (Amazon EC2) to understand the trade-offs in migrating to the cloud. Overall results indicated that running HPC on the EC2 cloud platform limits performance and causes significant variability. Besides Amazon EC2, research [44] has evaluated the performance–cost trade-offs of running HPC applications on three different platforms. The first and second platforms consisted of two physical clusters (Taub and Open Cirrus cluster), and the third platform consisted of Eucalyptus with kernel-based virtualization machine (KVM) virtualization. Running HPC on these platforms led authors to conclude that the cloud is more cost effective for low-communication-intensive applications.
Evaluation of HPC without relating it to new cloud technologies was also performed using different virtualization technologies [45–48]. For example, in Reference 45, the authors performed an analysis of virtualization techniques including VMware, Xen, and OpenVZ. Their findings showed that none of the techniques matches the performance of the base system perfectly; however, OpenVZ demonstrates high performance in both file system performance and industry-standard benchmarks. In Reference 46, the authors compared the performance of KVM and VMware. Overall findings showed that VMware performs better than KVM. Still, in a few cases, KVM gave better results than VMware. In Reference 47, the authors conducted quantitative analysis of two leading open-source hypervisors, Xen and KVM. Their study evaluated the performance isolation, overall performance, and scalability of VMs for each virtualization technology. In short, their findings showed that KVM has substantial problems with guests crashing (when increasing the number of guests); however, KVM still has better performance isolation than Xen. Finally, in Reference 48, the authors have extensively compared four hypervisors: Hyper-V, KVM, VMware, and Xen. Their results demonstrated that there is no perfect hypervisor. However, despite the evaluation of different technologies, HPCaaS still needs more investigation to decide on appropriate environments for Big Data analysis.
In our recent work, different experiments have been conducted on three different clusters, Hadoop physical cluster (HPhC), Hadoop virtualized cluster using KVM (HVC-KVM), and Hadoop virtualized cluster using VMware Elastic sky X Integrated (HVC-VMware ESXi), as illustrated in Figure 5.1 [49].
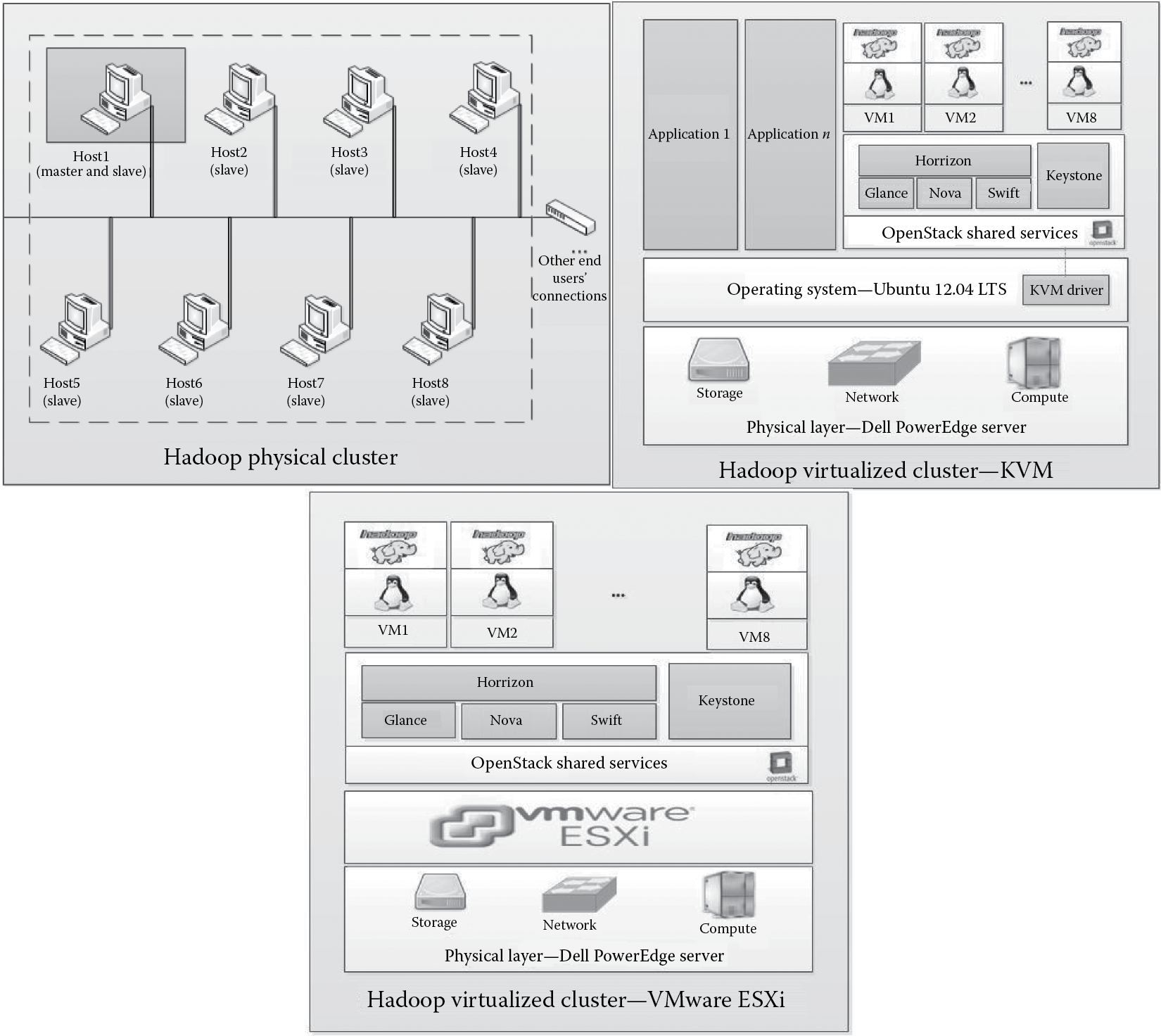
Hadoop physical and virtualized clusters. LTS, long term support. (From Achahbar, O., The Impact of Virtualization on High Performance Computing Clustering in the Cloud, Master’s thesis report, Al Akhawayn University in Ifrane, Morocco, 2014.)
Two main benchmarks, TeraSort and HDFS I/O saturation (TestDFSIO) benchmarks [50], were used to study the impact of machine virtualization on HPCaaS. TeraSort does considerable computation, networking, and storage input/output (I/O) and is often considered to be representative of real Hadoop workloads. The TestDFSIO benchmark is used to check the I/O rate of a Hadoop cluster with write and read operations. Such a benchmark can be helpful for testing HDFS by checking network performance and testing hardware, OS, and Hadoop setup. For example, Figure 5.2 shows some experimental results obtained when running TeraSort benchmark and TestDFSIO-Write on HPhC. Figure 5.2 shows that it needs much time to sort large data sets like 10 and 30 GB. However, scaling the cluster to more nodes led to significant time reduction in sorting data sets. Figure 5.2 shows that as the number of VMs increases, the average time decreases when writing different data set sizes. In fact, the Hadoop VMware ESXi cluster performs better at sorting Big Data sets (more computations), and the Hadoop KVM cluster performs better at I/O operations.
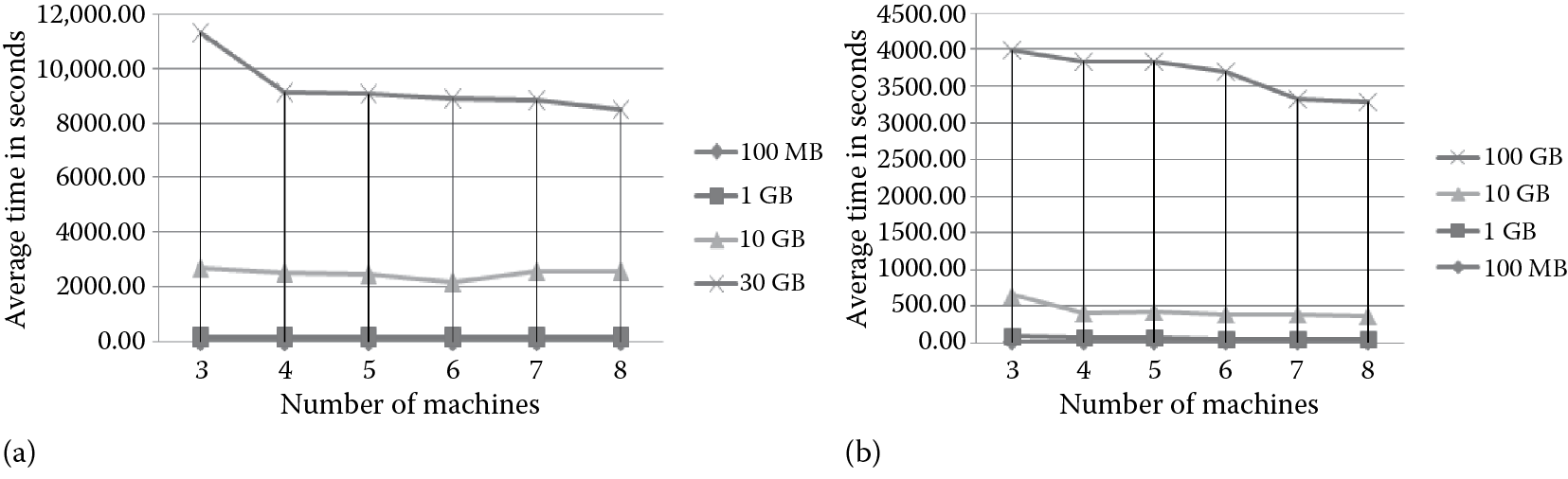
Performance on Hadoop physical cluster of (a) TeraSort and (b) TestDFSIO-Write. (From Achahbar, O., The Impact of Virtualization on High Performance Computing Clustering in the Cloud, Master’s thesis report, Al Akhawayn University in Ifrane, Morocco, 2014.)
Furthermore, while several parallel machine algorithms have been developed and integrated into the cloud environments using traditional HPC architectures, still other techniques are not fully exploited in emerging technologies such as graphics processing units (GPUs) [51]. It is worth noting that GPU-based computing is a huge shift of paradigm in parallel computing that promises a dramatic increase in performance. GPUs are designed for computing-intensive applications; they allow for the execution of threads on a larger number of processing elements. Having a large number of threads makes it possible to surpass the performance of current multicore CPUs.
GPU programming is now a much richer environment than it used to be a few years ago. On top of the two major programming languages, Compute Unified Device Architecture (CUDA) [52] and Open Computing Language (OpenCL), libraries have been developed that allow fast access to the computing power of GPUs without detailed knowledge or programming of GPU hardware. GPUs [53] could be used as accelerators for Big Data analytics such as in social media, statistical analysis in sensor data streams, predictive models, and so forth. GPUs could also be integrated in cloud computing and provide GPU-accelerated cloud services for Big Data. For example, since GPUs are not expensive and have performed better than multicore machines, they can serve as a practical infrastructure for cloud environments. Also, most efforts have been dedicated to machine learning techniques (e.g., association rule mining), and little work has been done for accelerating other algorithms related to text mining and sentiment analysis. These techniques are data and computationally intensive, making them good candidates for implementation in cloud environments. Generally, experimental results demonstrate that vitalized clusters can perform much better than physical clusters when processing and handling HPC.
5.5 Conclusions and Perspectives
In this chapter, approaches proposed in literature and their use in the cloud for Big Data analysis and processing are presented. More precisely, we have first introduced the Big Data technology and its importance in different fields. We focused mainly on approaches for high-performance mining of Big Data and their efficiency in HPC for Big Data analysis and processing. We highlighted existing work on data analytics tools such as SaaS and computing such as IaaS. Some remaining research issues and directions are introduced together with some results from our recent work, especially the introduction of HPC in cloud environments. Future work will focus on studying the impact of cloud open sources on improving HPCaaS and conducting experiments using real machine learning and text mining applications on HPCaaS.
References
1. V. De Florio, M. Bakhouya, A. Coronato and G. Di Marzo, “Models and Concepts for Socio-Technical Complex Systems: Towards Fractal Social Organizations,” Systems Research and Behavioral Science, vol. 30, no. 6, pp. 750–772, 2013.
2. J. Gantz and D. Reinsel, “The Digital Universe in 2020: Big Data, Bigger Digital Shadows, and Biggest Growth in the Far East,” IDC IVIEW, 2012, pp. 1–16.
3. M. K. Kakhani, S. Kakhani, and S. R. Biradar, “Research Issues in Big Data Analytics,” International Journal of Application or Innovation in Engineering and Management, vol. 2, no. 8, pp. 228–232, 2013.
4. C. Hagen, “Big Data and the Creative Destruction of Today’s,” ATKearney, 2012.
5. Gartner, Inc., “Hunting and Harvesting in a Digital World,” Gartner CIO Agenda Report, 2013, pp. 1–8.
6. J. Gantz and D. Reinsel, “The Digital Universe Decade—Are You Ready?” IDC IVIEW, 2010, pp. 1–15.
7. Ch. Vecchiola, S. Pandey and R. Buyya, “High-Performance Cloud Computing: A View of Scientific Applications,” in the 10th International Symposium on Pervasive Systems, Algorithms and Networks I-SPAN 2009, IEEE Computer Society, 2009, pp. 4–16.
8. J.-P. Dijcks, “Oracle: Big Data for the Enterprise,” white paper, Oracle Corp., 2013, pp. 1–16.
9. B. Pang and L. Lee, “Opinion Mining and Sentiment Analysis,” Foundations and Trends in Information Retrieval, vol. 2, no. 1–2, pp. 1–135, 2008.
10. Oracle Corporation, “Oracle NoSQL Database,” white paper, Oracle Corp., 2011, pp. 1–12.
11. S. Yu, “ACID Properties in Distributed Databases,” Advanced eBusiness Transactions for B2B-Collaborations, 2009.
12. S. Gilbert and N. Lynch, “Brewer’s Conjecture and the Feasibility of Consistent, Available, Partition-Tolerant Web Services,” ACM SIGACT News, vol. 33, no. 2, p. 51, 2002.
13. A. Lakshman and P. Malik, “Cassandra—A Decentralized Structured Storage System,” ACM SIGOPS Operating Systems Review, vol. 44, no. 2, pp. 35–40, 2010.
14. G. Lars, HBase: The Definitive Guide, 1st edition, O’Reilly Media, Sebastopol, CA, 556 pp., 2011.
15. MongoDB. Available at http://www.mongodb.org/.
16. Apache CouchDBTM. Available at http://couchdb.apache.org/.
17. D. Boulter, “Simplify Your Journey to the Cloud,” Capgemini and SOGETI, 2010, pp. 1–8.
18. P. Mell and T. Grance, “The NIST Definition of Cloud Computing,” National Institute of Standards and Technology, 2011, pp. 1–3.
19. A. E. Youssef, “Exploring Cloud Computing Services and Applications,” Journal of Emerging Trends in Computing and Information Sciences, vol. 3, no. 6, pp. 838–847, 2012.
20. A. T. Velte, T. J. Velte, and R. Elsenpeter, Cloud Computing, A Practical Approach, 1st edition, McGraw-Hill Osborne Media, New York, 352 pp., 2009.
21. Amazon Web Services. Available at http://aws.amazon.com/.
22. Google Cloud Platform. Available at https://cloud.google.com/.
23. J. Bernstein and K. McMahon, “Computing on Demand—HPC as a Service,” pp. 1–12, Penguin On Demand. Available at http://www.penguincomputing.com/files/whitepapers/PODWhitePaper.pdf.
24. Y. Xiaotao, L. Aili and Z. Lin, “Research of High Performance Computing with Clouds,” in the Third International Symposium on Computer Science and Computational Technology (ISCSCT), 2010, pp. 289–293.
25. Self-service POD Portal. Available at http://www.penguincomputing.com/services/hpc-cloud/pod.
26. K. R. Jackson, “Performance Analysis of High Performance Computing Applications on the Amazon Web Services Cloud,” in Cloud Computing Technology and Science (CloudCom), 2010 IEEE Second International Conference on, 2010, pp. 159–168.
27. Amazon Cloud Storage. Available at http://aws.amazon.com/ec2/reserved-instances/.
28. Amazon Cloud Drive. Available at http://aws.amazon.com/ec2/spot-instances/.
29. Microsoft High Performance Computing for Developers. Available at http://msdn.microsoft.com/en-us/library/ff976568.aspx.
30. Google Cloud Storage. Available at https://cloud.google.com/products/compute-engine.
31. D. Pop, “Machine Learning and Cloud Computing: Survey of Distributed and SaaS Solutions,” Technical Report Institute e-Austria Timisoara, 2012.
32. A. Ghoting, P. Kambadur, E. Pednault and R. Kannan, “NIMBLE: A Toolkit for the Implementation of Parallel Data Mining and Machine Learning Algorithms on MapReduce,” in KDD, 2011.
33. J. Dean and S. Ghemawat, “MapReduce: Simple Data Processing on Large Clusters,” in OSDI, 2004, pp. 1–12.
34. Hadoop. Available at http://hadoop.apache.org/.
35. S. Krishman, M. Tatineni and C. Baru, “myHaddop—Hadoop-on-Demand on Traditional HPC Resources,” in the National Science Foundation’s Cluster Exploratory Program, 2011, pp. 1–7.
36. E. Molina-Estolano, M. Gokhale, C. Maltzahn, J. May, J. Bent and S. Brandt, “Mixing Hadoop and HPC Workloads on Parallel Filesystems,” in the 4th Annual Workshop on Petascale Data Storage, 2009, pp. 1–5.
37. S. R. Upadhyaya, “Parallel Approaches to Machine Learning—A Comprehensive Survey,” Journal of Parallel and Distributed Computing, vol. 73, pp. 284–292, 2013.
38. C. Cranor, M. Polte and G. Gibson, “HPC Computation on Hadoop Storage with PLFS,” Parallel Data Laboratory at Carnegie Mellon University, 2012, pp. 1–9.
39. S. Zhou, B. Kobler, D. Duffy and T. McGlynn, “Case Study for Running HPC Applications in Public Clouds,” in Science Cloud ’10, 2012.
40. E. Walker, “Benchmarking Amazon EC2 for High-Performance Scientific Computing,” Texas Advanced Computing Center at the University of Texas, 2008, pp. 18–23.
41. J. Ekanayake and G. Fox, “High Performance Parallel Computing with Clouds and Cloud Technologies,” School of Informatics and Computing at Indiana University, 2009, pp. 1–20.
42. Y. Gu and R. L. Grossman, “Sector and Sphere: The Design and Implementation of a High Performance Data Cloud,” National Science Foundation, 2008, pp. 1–11.
43. C. Evangelinos and C. N. Hill, “Cloud Computing for Parallel Scientific HPC Applications: Feasibility of Running Coupled Atmosphere-Ocean Climate Models on Amazon’s EC2,” Department of Earth, Atmospheric and Planetary Sciences at Massachusetts Institute of Technology, 2009, pp. 1–6.
44. A. Gupta and D. Milojicic, “Evaluation of HPC Applications on Cloud,” Hewlett-Packard Development Company, 2011, pp. 1–6.
45. C. Fragni, M. Moreira, D. Mattos, L. Costa, and O. Duarte, “Evaluating Xen, VMware, and OpenVZ Virtualization Platforms for Network Virtualization,” Federal University of Rio de Janeiro, 2010, 1 p. Available at http://www.gta.ufrj.br/ftp/gta/TechReports/FMM10b.pdf.
46. N. Yaqub, “Comparison of Virtualization Performance: VMWare and KVM,” Master Thesis, DUO Digitale utgivelser ved UiO, Universitetet i Oslo, Norway, 2012, pp. 30–44. Available at http://urn.nb.no/URN:NBN:no-33642.
47. T. Deshane, M. Ben-Yehuda, A. Shah and B. Rao, “Quantitative Comparison of Xen and KVM,” in Xen Summit, 2008, pp. 1–3.
48. J. Hwang, S. Wu and T. Wood, “A Component-Based Performance Comparison of Four Hypervisors,” George Washington University and IBM T.J. Watson Research Center, 2012, pp. 1–8.
49. O. Achahbar, “The Impact of Virtualization on High Performance Computing Clustering in the Cloud,” Master Thesis Report, Al Akhawayn University in Ifrane, Morocco, 2014.
50. M. G. Noll, “Benchmarking and Stress Testing and Hadoop Cluster with TeraSort, Test DFSIO & Co.,” 2011.
51. E. Wu and Y. Liu, “Emerging Technology about GPGPU,” APCCAS. IEEE Asia Pacific Conference on Circuits and Systems, 2008.
52. NVIDIA, “NVIDIA CUDA Compute Unified Device Architecture: Programming Guide,” Version 2.3, July 2009. Available at http://www.cs.ucla.edu/~palsberg/course/cs239/papers/CudaReferenceManual_2.0.pdf.
53. W. Fang, “Parallel Data Mining on Graphics Processors,” Technical Report HKUST-CS08-07, October 2008.