
Chapter 16
Privacy-Preserving Big Data Management
The Case of OLAP
Alfredo Cuzzocrea
Abstract
This chapter explores the emerging context of privacy-preserving OLAP over Big Data, a novel topic that is playing a critical role in actual Big Data research, and proposes an innovative framework for supporting intelligent techniques for computing privacy-preserving OLAP aggregations on data cubes. The proposed framework originates from the evidence stating that state-of-the-art privacy-preserving OLAP approaches lack strong theoretical bases that provide solid foundations to them. In other words, there is not a theory underlying such approaches, but rather an algorithmic vision of the problem. A class of methods that clearly confirm to us the trend above is represented by the so-called perturbation-based techniques, which propose to alter the target data cube cell-by-cell to gain privacy-preserving query processing. This approach exposes us to clear limits, whose lack of extendibility and scalability is only the tip of an enormous iceberg. With the aim of fulfilling this critical drawback, this chapter describes and experimentally assesses a theoretically-sound accuracy/privacy-constrained framework for computing privacy-preserving data cubes in OLAP environments. The benefits derived from our proposed framework are twofold. First, we provide and meaningfully exploit solid theoretical foundations to the privacy-preserving OLAP problem that pursue the idea of obtaining privacy-preserving data cubes via balancing accuracy and privacy of cubes by means of flexible sampling methods. Second, we ensure the efficiency and the scalability of the proposed approach, as confirmed to us by our experimental results, thanks to the idea of leaving the algorithmic vision of the privacy-preserving OLAP problem.
16.1 Introduction
One among the most challenging topics in Big Data research is represented, without doubt, by the issue of ensuring the security and privacy of Big Data repositories (e.g., References 1 and 2). To become convinced about this, consider the case of cloud systems [3,4], which are very popular now. Here, cloud nodes are likely to exchange data very often. Therefore, the privacy breach risk arises, as distributed data repositories can be accessed from a node to another one, and hence, sensitive information can be inferred.
Another relevant data management context for Big Data research is represented by the issue of effectively and efficiently supporting data warehousing and online analytical processing (OLAP) over Big Data [5–7], as multidimensional data analysis paradigms are likely to become an “enabling technology” for analytics over Big Data [8,9], a collection of models, algorithms, and techniques oriented to extract useful knowledge from cloud-based Big Data repositories for decision-making and analysis purposes.
At the convergence of the three axioms introduced here (i.e., security and privacy of Big Data, data warehousing and OLAP over Big Data, analytics over Big Data), a critical research challenge is represented by the issue of effectively and efficiently computing privacy-preserving OLAP data cubes over Big Data [10,11]. It is easy to foresee that this problem will become more and more important in future years, as it not only involves relevant theoretical and methodological aspects, not all explored by actual literature, but also regards significant modern scientific applications, such as biomedical tools over Big Data [12,13], e-science and e-life Big Data applications [14,15], intelligent tools for exploring Big Data repositories [16,17], and so forth.
Inspired by these clear and evident trends, in this chapter, we focus the attention on privacy-preserving OLAP data cubes over Big Data, and we provide two kinds of contributions:
- We provide a complete survey of privacy-preserving OLAP approaches available in literature, with respect to both centralized and distributed environments.
- We provide an innovative framework that relies on flexible sampling-based data cube compression techniques for computing privacy-preserving OLAP aggregations on data cubes.
16.1.1 Problem Definition
Given a multidimensional range R of a data cube A, an aggregate pattern over R is defined as an aggregate value extracted from R that is capable of providing a “description” of data stored in R. In order to capture the privacy of aggregate patterns, in this chapter, we introduce a novel notion of privacy OLAP. According to this novel notion, given a data cube A, the privacy preservation of A is modeled in terms of the privacy preservation of aggregate patterns defined on multidimensional data stored in A. Therefore, we say that a data cube A is privacy preserving iff aggregate patterns extracted from A are privacy preserving. Contrary to our innovative privacy OLAP notion, previous privacy-preserving OLAP proposals totally neglect this even-relevant theoretical aspect and, inspired by well-established techniques that focus on the privacy preservation of relational tuples [18,19], mostly focus on the privacy preservation of data cells (e.g., Reference 20) accordingly. Despite this, OLAP deals with aggregate data and neglects individual information. Therefore, it makes more sense to deal with the privacy preservation of aggregate patterns rather than the privacy preservation of data cube cells.
Given a multidimensional range R of a data cube A, AVG(R), that is, the average value of data cells in R, is the simplest aggregate pattern one could think about. It should be noted that this pattern could be inferred with a high degree of accuracy starting from (1) the knowledge about the summation of items in R, SUM(R) (which could be public for some reason—e.g., the total amount of salaries of a certain corporate department) and (2) the estimation of the number of items in R, COUNT(R) (which, even if not disclosed to external users, could be easily estimated—e.g., the total number of employees of the department). In turn, basic aggregate patterns like AVG can be meaningfully combined to progressively discover (1) more complex aggregate patterns (e.g., Reference 21 describes a possible methodology for deriving complex OLAP aggregates from elementary ones) to be exploited for trend analysis of sensitive aggregations and prediction purposes or, contrary to this, (2) aggregations of coarser hierarchical data cube levels until the privacy of individual data cells is breached. From the latter amenity, it follows that the results of Reference 20, which conventionally focuses on the privacy preservation of data cube cells, are covered by our innovative privacy OLAP notion.
Inspired by these considerations, in this chapter, we provide a pioneering framework that encompasses flexible sampling-based data cube compression techniques for computing privacy-preserving OLAP aggregations on data cubes while allowing approximate answers to be efficiently evaluated over such aggregations. This framework addresses an application scenario where, given a multidimensional data cube A stored in a producer data warehouse server, a collection of multidimensional portions of A defined by a given (range) query workload QWL of interest must be published online for consumer OLAP client applications. Moreover, once published, the collection of multidimensional portions is no longer connected to the data warehouse server, and updates are handled from scratch at each new online data delivery. The query workload QWL is cooperatively determined by the data warehouse server and OLAP client applications, mostly depending on OLAP analysis goals of client applications and other parameters such as business processes and requirements, frequency of accesses, and locality. OLAP client applications wish to retrieve summarized knowledge from A via adopting a complex multiresolution query model whose components are (1) queries of QWL and (2) for each query Q of QWL, subqueries of Q (i.e., in a multiresolution fashion). To this end, for each query Q of QWL, an accuracy grid G(Q)
16.1.2 Chapter Organization
The remaining part of this chapter is organized as follows. In Section 16.2, we provide a comprehensive overview on actual proposals that focus on privacy-preserving OLAP over Big Data, both in centralized and distributed environments. In Section 16.3, we provide the fundamental definitions and formal tools of our proposed privacy-preserving OLAP framework. Section 16.4 contains results on managing overlapping query workloads defined over privacy-preserving OLAP data cubes. Section 16.5 defines metrics for modeling and measuring the accuracy of privacy-preserving OLAP data cubes, whereas Section 16.6 defines metrics for modeling and measuring the privacy of privacy-preserving OLAP data cubes as well. Section 16.7 introduces the accuracy and privacy thresholds of the proposed privacy-preserving OLAP framework. In Section 16.8, we focus our attention on so-called accuracy grids and multiresolution accuracy grids, a family of conceptual tools for handing accuracy and privacy of privacy-preserving OLAP data cubes. Section 16.9 contains the core algorithm of our proposed privacy-preserving OLAP framework. In Section 16.10, we provide a comprehensive experimental assessment and analysis of algorithms embedded in our proposed privacy-preserving OLAP framework. Finally, in Section 16.11 we derive conclusions from our research and set a basis for future efforts in the investigated area.
16.2 Literature Overview and Survey
In our proposed research, two contexts are relevant, namely, privacy-preserving OLAP in centralized environments and privacy-preserving OLAP in distributed environments. Here, we provide a survey on both areas.
16.2.1 Privacy-Preserving OLAP in Centralized Environments
Despite the above-discussed in Section 16.1 privacy-preserving issues in OLAP, today’s OLAP server platforms lack effective countermeasures to face relevant-in-practice limitations deriving from privacy breaches. Contrary to this actual trend, privacy-preserving issues in statistical databases, which represent the theoretical foundations of privacy-preserving OLAP, have been deeply investigated during past years [25], and a relevant number of techniques developed in this context are still waiting to be studied, extended, and integrated within the core layer of OLAP server platforms. Basically, privacy-preserving techniques for statistical databases can be classified into two main classes: restriction-based techniques and perturbation-based techniques. The first ones propose restricting the number of classes of queries that can be posed to the target database (e.g., Reference 26); the second ones propose adding random noise at various levels of the target database, ranging from schemas [27] to query answers [28]. Auditing query techniques aims at devising intelligent methodologies for detecting which queries must be forbidden, in order to preserve privacy. Therefore, these approaches have been studied in the broader context of restriction-based privacy-preserving techniques. Recently, some proposals on auditing techniques in OLAP appeared. Among these proposals, noticeable ones are Reference 29, which makes use of an information theoretic approach, and Reference 30, which exploits integer linear programming (ILP) techniques. Nevertheless, due to different, specific motivations, both restriction-based and perturbation-based techniques are not effective and efficient in OLAP. Restriction-based techniques are quite ineffective in OLAP since the nature of OLAP analysis is intrinsically interactive and based on a wide set of operators and query classes. Perturbation-based techniques, which process one data cube cell at a time, are quite inefficient in OLAP since they introduce excessive computational overheads when executed on massive data cubes. It should be noted that the latter drawback derives from the lack of a proper notion of privacy OLAP, as highlighted in Section 16.1.1.
More recently, Reference 31 proposes a cardinality-based inference control scheme that aims at finding sufficient conditions for obtaining safe data cubes, that is, data cubes such that the number of known values is under a tight bound. In line with this research, Reference 32 proposes a privacy-preserving OLAP approach that combines access and inference control techniques [28]: (1) the first one is based on the hierarchical nature of data cubes modeled in terms of cuboid lattices [33] and multiresolution of data, and (2) the second one is based on directly applying restriction to coarser aggregations of data cubes and then removing remaining inferences that can be still derived. References 31 and 32 are not properly comparable with our work, as they basically combine a technique inspired from statistical databases with an access control scheme, which are both outside the scope of this chapter. Reference 34 extends results of Reference 32 via proposing the algorithm FMC, which still works on the cuboid lattice to hide sensitive data that cause inference. Finally, Reference 20 proposes a random data distortion technique, called zero-sum method, for preserving the privacy of data cells while providing accurate answers to range queries. To this end, Reference 20 iteratively alters the values of data cells of the target data cube in such a way as to maintain the marginal sums of data cells along rows and columns of the data cube equal to zero. According to motivations given in Section 16.1.1, when applied to massive data cubes, Reference 20 clearly introduces excessive overheads, which are not comparable with low computational requirements due to sampling-based techniques like ours. In addition to this, in our framework, we are interested in preserving the privacy of aggregate patterns rather than the one of data cells, which, however, can be still captured by introducing aggregate patterns at the coarser degree of aggregation of the input data cube, as stated in Section 16.1.1. In other words, Reference 20 does not introduce a proper notion of privacy OLAP but only restricts the analysis to the privacy of data cube cells. Despite this, we observe that, from the client-side perspective, Reference 20 (1) solves the same problem we investigate, that is, providing privacy-preserving (approximate) answers to OLAP queries against data cubes, and (2) contrary to References 32 and 35, adopts a “data-oriented” approach, which is similar in nature to ours. For these reasons, in our experimental analysis, we test the performance of our framework against the one of Reference 20, which, apart from being the state-of-the-art perturbation-based privacy-preserving OLAP technique, will be hereby considered as the comparison technique for testing the effectiveness of the privacy-preserving OLAP technique we propose.
16.2.2 Privacy-Preserving OLAP in Distributed Environments
While privacy-preserving distributed data mining has been widely investigated, and a plethora of proposals exists (e.g., References 36–40), the problem of effectively and efficiently supporting privacy-preserving OLAP over distributed collections of data repositories, which is relevant in practice, has been neglected so far.
Distributed privacy preservation techniques over OLAP data cubes solve the problem of making privacy-preserving distributed OLAP data cubes or, under an alternative interpretation, making a privacy-preserving OLAP data cube model over distributed data sources. Deriving problems is similar but different in nature. As regards the first problem, to the best of our knowledge, in the literature, there does not exist any proposal that deals with it, whereas concerning the second problem, Reference 35 is the state-of-the-art result existent in literature.
By looking at the active literature, while a plethora of initiatives focusing on privacy-preserving distributed data mining [41] exists, References 36–40 being some noticeable ones, to the best of our knowledge, only References 35, 42, and 43 deal with the yet-relevant problem of effectively and efficiently supporting privacy-preserving OLAP over distributed data sources, specifically falling in the second scientific context according to the provided taxonomy. Reference 35 defines a privacy-preserving OLAP model over data partitioned across multiple clients using a randomization approach, which is implemented by the so-called retention replacement perturbation algorithm, on the basis of which (1) clients perturb tuples with which they participate to the partition in order to gain row-level privacy and (2) a server is capable of evaluating OLAP queries against perturbed tables via reconstructing original distributions of attributes involved by such queries. In Reference 35, the authors demonstrate that the proposed distributed privacy-preserving OLAP model is safe against privacy breaches. Reference 42 is another distributed privacy-preserving OLAP approach that is reminiscent of ours. More specifically, Reference 42 pursues the idea of obtaining a privacy-preserving OLAP data cube model from distributed data sources across multiple sites via applying perturbation-based techniques on aggregate data that are retrieved from each singleton site as a baseline step of the main (distributed) OLAP computation task. Finally, Reference 43 focuses the attention on the significant issue of providing efficient data aggregation while preserving privacy over wireless sensor networks. The proposed solution is represented by two privacy-preserving data aggregation schemes that make use of innovative additive aggregation functions, these schemes being named cluster-based private data aggregation (CPDA) and slice-mix-aggregate (SMART). Proposed aggregation functions fully exploit topology and dynamics of the underlying wireless sensor network and bridge the gap between collaborative data collection over such networks and data privacy needs.
16.3 Fundamental Definitions and Formal Tools
A data cube A defined over a relational data source S
Given an |ℱ|
Given a query Q against a data cube A, the query region of Q, denoted by R(Q), is defined as the subdomain of A bounded by the ranges Rk0,Rk1,…,Rkm−1
Given an m-dimensional query Q, the accuracy grid G(Q)
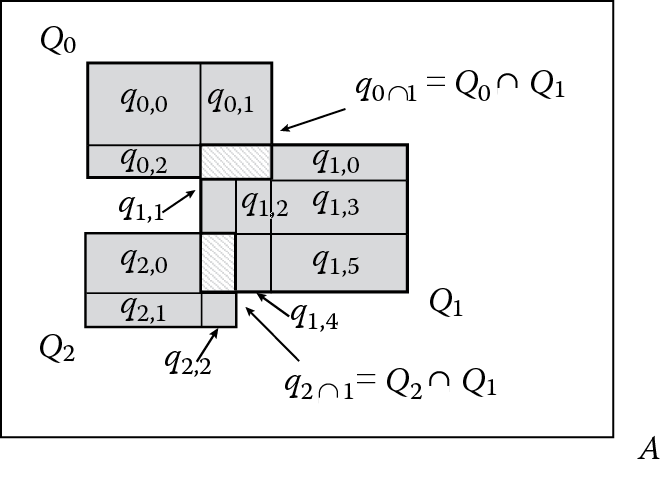
Building the nonoverlapping query workload (plain lines) from an overlapping query workload (bold lines).
Based on the latter definitions, in our framework, we consider the broader concept of extended range query Q+, defined as a tuple Q+=〈Q, G(Q)〉
Given an n-dimensional data domain D, we introduce the volume of D, denoted by ||D||, as follows: ||D||=|d0|×|d1|×…×|dn−1|, such that |di| is the cardinality of the dimension di of D. This definition can also be extended to a multidimensional data cube A, thus introducing the volume of A, ||A||, and to a multidimensional range query Q, thus introducing the volume of Q, ||Q||.
Given a data cube A, a range query workload QWL against A is defined as a collection of (range) queries against A, as follows: QWL = {Q0, Q1,…, Q|QWL|−1}, with R(Qk) ⊆ R(A) ∀ Qk ∈ QWL. An example query workload is depicted in Figure 16.1.
Given a query workload QWL = {Q0, Q1,…, Q|QWL|−1}, we say that QWL is nonoverlapping if there do not exist two queries Qi and Qj belonging to QWL such that R(Qi) ∩ R(Qj) ≠ ∅. Given a query workload QWL = {Q0, Q1,…, Q|QWL|−1}, we say that QWL is overlapping if there exist two queries Qi and Qj belonging to QWL such that R(Qi) ∩ R(Qj) ≠ ∅. Given a query workload QWL = {Q0, Q1,…, Q|QWL|−1}, the region set of QWL, denoted by R(QWL), is defined as the collection of regions of queries belonging to QWL, as follows: R(QWL) = {R(Q0), R(Q1),…, R(Q|QWL|−1)}.
16.4 Dealing with Overlapping Query Workloads
When overlapping query workloads are considered, we adopt a unifying strategy that allows us to handle nonoverlapping and overlapping query workloads in the same manner. As we will better discuss in Section 16.9, this approach involves several benefits in all the phases of our privacy-preserving OLAP technique. In this respect, given an overlapping query workload QWL, our aim is to obtain a nonoverlapping query workload QWLʹ from QWL such that QWLʹ is equivalent to QWL, that is, (1) QWLʹ provides the same information content as QWL, and (2) QWL can be totally reconstructed from QWLʹ. To this end, for each query Qi of QWL without any intersection with other queries in QWL, we simply add Qi to QWLʹ and remove Qi from QWL. Contrary to this, for each query Qj of QWL having at least one non-null intersection with other queries in QWL, we (1) extract from Qj two new subsets of queries (defined next), denoted by τ1(Qj) and τ2(Qj); (2) add τ1(Qj) and τ2(Qj) to QWLʹ; and (3) remove Qj from QWL. Specifically, τ1(Qj) contains the subqueries of Qj defined by intersection regions of Qj, and τ2(Qj) contains the subqueries of Qj defined by regions of Qj obtained via prolonging the ranges of subqueries in τ1(Qj) along the dimensions of Qj. As an example, consider Figure 16.1, where the nonoverlapping query workload QWLʹ extracted from an overlapping query workload QWL = {Q0, Q1, Q2} is depicted. Here, we have the following: (1) τ1(Q0) = {q0∩1}—note that q0∩1 ≡ Q0 ∩ Q1; (2) τ2(Q0) = {q0,0, q0,1, q0,2}; (3) τ1(Q1) = {q0∩1, q2∩1}—note that q2∩1 ≡ Q2 ∩ Q1; (4) τ2(Q1) = {q1,0, q1,1, q1,2, q1,3, q1,4, q1,5}; (5) τ1(Q2) = {q2∩1}; and (6) τ2(Q2) = {q2,0, q2,1, q2,2}. Therefore, QWLʹ = τ1(Q0) ∪ τ2(Q0) ∪ τ1(Q1) ∪ τ2(Q1) ∪ τ1(Q2) ∪ τ2(Q2).
16.5 Metrics for Modeling and Measuring Accuracy
As accuracy metrics for answers to queries of the target query workload QWL, we make use of the relative query error between exact and approximate answers, which is a measure of quality for approximate query answering techniques in OLAP that is well recognized in literature (e.g., Reference 24).
Formally, given a query Qk of QWL, we denote as A(Qk) the exact answer to Qk (i.e., the answer to Qk evaluated over the original data cube A) and as ˜A(Qk)
EQ(Qk) can be extended to the whole query workload QWL, thus introducing the average relative query error ˉEQ(QWL)
Based on the previous definition of ||QWL||, the average relative query error ˉEQ(QWL)
16.6 Metrics for Modeling and Measuring Privacy
Since we deal with the problem of ensuring the privacy preservation of OLAP aggregations, our privacy metrics take into consideration how sensitive knowledge can be discovered from aggregate data and try to limit this possibility. On a theoretical plane, this is modeled by the privacy OLAP notion introduced in Section 16.1.1.
To this end, we first study how sensitive aggregations can be discovered from the target data cube A. Starting from the knowledge about A (e.g., range sizes, OLAP hierarchies, etc.) and the knowledge about a given query Qk belonging to the query workload QWL [i.e., the volume of Qk, ||Qk|| and the exact answer to Qk, A(Qk)], it is possible to infer knowledge about sensitive ranges of data contained within R(Qk). For instance, it is possible to derive the average value of the contribution throughout which each basic data cell of A within R(Qk) contributes to A(Qk), which we name singleton aggregation I(Qk). I(Qk) is defined as follows: I(Qk)=A(Qk)‖Qk‖ .
In order to provide a clearer practical example of privacy breaches deriving from the proposed singleton aggregation model in real-life OLAP application scenarios, consider a three-dimensional OLAP data cube A characterized by the set of dimensions ℱ={Region, Product, Time} and the set of measures ℳ={Sale} . Assume that A stores data about sales performed in stores located in Italy. In the running example, for the sake of simplicity, consider again the SQL aggregation operator AVG. If malicious users know the AVG value of the range R of A : R = 〈SouthItaly, [ElectricProducts : OfficeProducts], [2008:2009]〉, say AVG(R) = 23,500K€, and the volume of R, say ||R|| = 1000, they will easily infer that, during the time interval between the 2008 and 2009, each store located in South Italy has originated a volume of sales of about 23,500€ (suppose that data are uniformly distributed) for electric and office products. This sensitive knowledge, also combined with the knowledge about the hierarchies defined on dimensions of A, for example, H(Region): Italy ← {North Italy, Central Italy, South Italy, Insular Italy} ← … ← South Italy ← {Abruzzo, Molise, Campania, Puglia, Basilicata, Calabria} ← …, can allow malicious users to infer sensitive sale data about specific individual stores located in Calabria related to specific individual classes of products and specific individual days, just starting from aggregate values of sale data of stores located in the whole of Italy during 2008 and 2009 (!).
Coming back to the singleton aggregation model, it is easy to understand that, starting from the knowledge about I(Qk), it is possible to progressively discover aggregations of a larger range of data within R(Qk), rather than the one stored within the basic data cell, thus inferring sensitive knowledge that is even more useful. Also, by exploiting OLAP hierarchies and the well-known ROLL-UP operator, it is possible to discover aggregations of ranges of data at higher degrees of such hierarchies. It should be noted that the singleton aggregation model, I(Qk), indeed represents an instance of our privacy OLAP notion targeted to the problem of preserving the privacy of range-SUM queries (the focus of our chapter). As a consequence, I(Qk) is essentially based on the conventional SQL aggregation operator AVG. Despite this, the underlying theoretical model we propose is general enough to be straightforwardly extended to deal with more sophisticated privacy OLAP notion instances, depending on the particular class of OLAP queries considered. Without loss of generality, given a query Qk belonging to an OLAP query class C , in order to handle the privacy preservation of Qk, we only need to define the formal expression of the related singleton aggregation I(Qk) (like the previous one for the specific case of range-SUM queries). Then, the theoretical framework we propose works in the same way.
Secondly, we study how OLAP client applications can discover sensitive aggregations from the knowledge about approximate answers and, similarly to the previous case, from the knowledge about data cube and query metadata. Starting from the knowledge about the synopsis data cube Aʹ and the knowledge about the answer to a given query Qk belonging to the query workload QWL, it is possible to derive an estimation on I(Qk), denoted by ˜I(Qk) , as follows: ˜I(Qk)=˜A(Qk)S(Qk) , such that S(Qk) is the number of samples effectively extracted from R(Qk) to compute Aʹ (note that S(Qk) < ||Qk||). The relative difference between I(Qk) and ˜I(Qk) , named relative inference error and denoted by EI(Qk), gives us metrics for the privacy of ˜A(Qk) , which is defined as follows: EI(Qk)=|I(Qk)−˜I(Qk)|max{I(Qk),1} .
Indeed, while OLAP client applications are aware about the definition and metadata of both the target data cube and queries of the query workload QWL, the number of samples S(Qk) (for each query Qk in QWL) is not disclosed to them. As a consequence, in order to model this aspect of our framework, we introduce the user-perceived singleton aggregation, denoted by ˜IU(Qk) , which is the effective singleton aggregation perceived by external applications based on the knowledge made available to them. ˜IU(Qk) is defined as follows: ˜IU(Qk)=˜A(Qk)‖Qk‖ .
Based on ˜IU(Qk) , we derive the definition of the relative user-perceived inference errorEUI(Qk) , as follows: EUI(Qk)=|I(Qk)−˜IU(Qk)|max{I(Qk),1} .
Since S(Qk) < ||Qk||, it is trivial to demonstrate that ˜IU(Qk) provides a better estimation of the singleton aggregation of Qk than that provided by ˜I(Qk) , as ˜IU(Qk) is evaluated with respect to all the items contained within R(Qk) (i.e., ||Qk||), whereas ˜I(Qk) is evaluated with respect to the effective number of samples extracted from R(Qk) [i.e., S(Qk)]. In other words, ˜IU(Qk) is an upper bound for ˜I(Qk) . Therefore, in our framework, we consider ˜I(Qk) to compute the synopsis data cube, whereas we consider ˜IU(Qk) to model inference issues on the OLAP client application side.
EUI(Qk) can be extended to the whole query workload QWL by considering the average relative inference error ˉEI(QWL) that takes into account the contributions of relative inference errors EI(Qk) of all the queries Qk in QWL. Similarly to what was done for the average relative query error ˉEQ(QWL) , we model ˉEI(QWL) as follows: ˉEI(QWL)=|QWL|−1∑k=0‖Qk‖‖QWL‖⋅EI(Qk) , that is, ˉEI(QWL)=|QWL|−1∑k=0‖Qk‖|QWL|−1∑j=0‖Qj‖⋅|I(Qk)−˜IU(Qk)|max{I(Qk),1} , under the constraint |QWL|−1∑k=0‖Qk‖‖QWL‖=1 .
Note that, ˉEI(QWL) is defined in dependence on ˜IU(Qk) rather than ˜I(Qk) . For the sake of simplicity, here and in the remaining part of the chapter, we assume EI(Qk)≡EUI(Qk) .
The concepts and definitions allow us to introduce the singleton aggregation privacy-preserving model X=〈I(⋅),˜I(⋅),˜IU(⋅)〉 , which is a fundamental component of the privacy-preserving OLAP framework we propose. X properly realizes our privacy OLAP notion.
Given a query Qk ∈ QWL against the target data cube A, in order to preserve the privacy of Qk under our privacy OLAP notion, we must maximize the inference error EI(Qk) while minimizing the query error EQ(Qk). While the definition of EQ(Qk) can be reasonably considered as an invariant of our theoretical model, the definition of EI(Qk) strictly depends on X . Therefore, given a particular class of OLAP queries C , in order to preserve the privacy of queries of kind C , we only need to appropriately define X . This nice amenity states that the privacy-preserving OLAP framework we propose is orthogonal to the particular class of queries considered and can be straightforwardly adapted to a large family of OLAP query classes.
16.7 Accuracy and Privacy Thresholds
Similarly to related proposals that appeared in literature recently [20], in our framework, we introduce the accuracy threshold ΦQ and the privacy threshold ΦI. ΦQ and ΦI give us an upper bound for the average relative query error ˉEQ(QWL) and a lower bound for the average relative inference error ˉEI(QWL) of a given query workload QWL against the synopsis data cube Aʹ. As stated in Section 16.1.1, ΦQ and ΦI allow us to meaningfully model and treat the accuracy/privacy constraint by means of rigorous mathematical/statistical models.
In our application scenario, ΦQ and ΦI are cooperatively negotiated by the data warehouse server and OLAP client applications. The issue of determining how to set these parameters is a nontrivial engagement. Intuitively enough, regarding the accuracy of answers, it is possible to (1) refer to the widely accepted query error threshold belonging to the interval [15, 20]% that, according to results of a plethora of research experiences in the context of approximate query answering techniques in OLAP (e.g., see Reference 44), represents the current state of the art and (2) use it as a baseline to trade off the parameter ΦQ. Regarding the privacy of answers, there are no immediate guidelines to be considered since privacy-preserving techniques for advanced data management (like OLAP) are relatively new; hence, we cannot refer to any widely accepted threshold like what happens with approximate query answering techniques. As a result, the parameter ΦI can be set according to a two-step approach where first the accuracy constraint is accomplished in the dependence of ΦQ, and then ΦI is consequently set by trying to maximize it (i.e., augmenting the privacy of answers) as much as possible, thus following a best-effort approach.
16.8 Accuracy Grids and Multiresolution Accuracy Grids: Conceptual Tools for Handling Accuracy and Privacy
From Sections 16.1.1 and 16.7, it follows that, in our framework, the synopsis data cube Aʹ stores OLAP aggregations satisfying the accuracy/privacy constraint with respect to queries of the target query workload QWL. Hence, computing Aʹ via sampling the input data cube A is the most relevant task of the privacy-preserving OLAP framework we propose.
To this end, we adopt the strategy of sampling query regions according to the partitioned representation defined by their accuracy grids. This strategy is named accuracy grid–constrained sampling. On the basis of this strategy, samples are extracted from cells of accuracy grids, according to a vision that considers the elementary cell of accuracy grids as the atomic unit of our reasoning. This assumption is well founded under the evidence of noticing that, given a query Qk of QWL and the collection of its subqueries qk,0, qk,1, …, qk,m−1 defined by the accuracy grid G(Qk) of Qk, sampling the (sub)query regions R(qk,0), R(qk,1), …, R(qk,m−1) of R(Qk) allows us to (1) efficiently answer subqueries qk,0, qk,1, …, qk,m−1, as sampling is accuracy grid constrained, and at the same time, (2) efficiently answer the super-query Qk, being the answer to Qk given by the summation of the answers to qk,0, qk,1, …, qk,m−1 (recall that we consider range-SUM queries). It is a matter of fact to note that the alternative solution of sampling the super-query Qk directly, which we name region-constrained sampling, would expose us to the flaw of being unable to efficiently answer the subqueries qk,0, qk,1, …, qk,m−1 of Qk, since there could exist the risk of having (sub)regions of Qk characterized by high density of samples and (sub)regions of Qk characterized by low density of samples.
It is important to further highlight that, similarly to the privacy OLAP notion (see Section 16.7), the proposed sampling strategy depends on the particular class of OLAP queries considered, that is, range-SUM queries. If different OLAP queries must be handled, different sampling strategies must be defined accordingly.
Similarly to what was done with the accuracy of answers, we exploit amenities offered by accuracy grids to accomplish the privacy constraint as well. In other words, just like accuracy, privacy of answers is handled by means of the granularity of accuracy grids and still considering the elementary cell of accuracy grids as the atomic unit of our reasoning.
To become convinced of the benefits coming from our sampling strategy, consider Figure 16.2, where a data cube A and a query Qk are depicted along with 63 samples (represented by blue points) extracted from R(Qk) by means of two different strategies: (1) accuracy grid–constrained sampling (Figure 16.2a) and (2) region-constrained sampling (Figure 16.2b). As shown in Figure 16.2, accuracy grid–constrained sampling allows us to avoid “favorite” regions in the synopsis data cube Aʹ being obtained, that is, regions for which the total amount of allocated space (similarly, the total number of extracted samples) is much greater than that of other regions in Aʹ. It is easy to understand that the latter circumstance, which could be caused by the alternative strategy (i.e., region-constrained sampling), arbitrarily originates regions in Aʹ for which the accuracy error is low and the inference error is high (which is a desiderata in our framework), and regions for which the accuracy error is very high and the inference error is very low (which are both undesired effects in our framework). The final, global effect of such a scenario results in a limited capability of answering queries by satisfying the accuracy/privacy constraint. Contrary to the latter scenario, accuracy grid–constrained sampling aims at obtaining a fair distribution of samples across Aʹ, so that a large number of queries against Aʹ can be accommodated by satisfying the accuracy/privacy constraint.
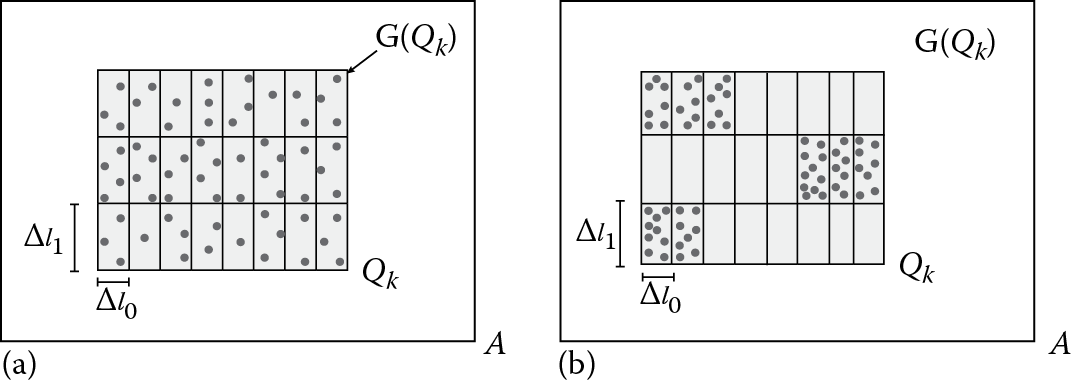
Two sampling strategies: (a) accuracy grid–constrained sampling and (b) region-constrained sampling.
When overlapping query workloads are considered, intersection (query) regions pose the issue of dealing with the overlapping of different accuracy grids, which we name multiresolution accuracy grids, meaning that such grids partition the same intersection region of multiple queries by means of cells at different granularities. As much as granularities of such cells are different, we obtain “problematic” settings to be handled where subqueries have very different volumes, so that, due to geometrical issues, handling both accuracy and privacy of answers as well as dealing with the sampling phase become more questioning. It should be noted that, contrary to what happens with overlapping queries, accuracy grids of nonoverlapping queries originate subqueries having volumes that are equal one to another, so that we obtain facility at both modeling and reasoning tasks.
To overcome issues deriving from handling multiresolution accuracy grids, we introduce an innovative solution that consists in decomposing nonoverlapping and overlapping query workloads in sets of appropriately selected subqueries, thus achieving the amenity of treating both kinds of query workloads in a unified manner. The baseline operation of this process is represented by the decomposition of a query Qk of the target query workload QWL. Given an I0,k × I1,k query Qk and its accuracy grid G(Qk)=〈∆ℓ0,k,∆ℓ1,k〉 , the query decomposition process generates a set of subqueries ζ(Qk) on the basis of the nature of Qk. In more detail, if Qk is nonoverlapping, then Qk is decomposed in I0,k∆ℓ0,k⋅I1,k∆ℓ1,k subqueries given by cells in G(Qk) , such that each subquery has volume equal to Δℓ0,k × Δℓ1,k. Otherwise, if Qk is overlapping, that is, there exists another query Qh in QWL such that R(Qk) ∩ R(Qh) ≠ ∅, the query decomposition process works as follows: (1) The intersection region of Qk and Qh, denoted by RI(Qk,Qh), is decomposed in the set of subqueries ζ(Qk,Qh) given by the overlapping of G(Qk) and G(Qh) . (2) Let π(Qk) be the set of subqueries in ζ(Qk) (computed considering Qk as nonoverlapping) that partially overlap RI(Qk,Qh), and π(Qh) be the analogous set for Qh; π(Qk) and π(Qh) are decomposed in sets of subqueries obtained by considering portions of subqueries in π(Qk) and π(Qh) that are completely contained by the regions R(Qk) − RI(Qk,Qh) and R(Qh) − RI(Qk,Qh), respectively, thus obtaining the sets of border queries μ1(Qk) and μ1(Qh). (3) Let ω(Qk) be the set of subqueries in ζ(Qk) that are completely contained by the region R(Qk) − RI(Qk,Qh) − μ1(Qk), and ω(Qh) be the analogous set for Qh; ω(Qk) and ω(Qh) are decomposed in sets of subqueries given by G(Qk) and G(Qh) , respectively, thus obtaining the sets μ2(Qk) and μ2(Qh). (4) Finally, the set of subqueries originated by the decomposition of the overlapping queries Qk and Qh, denoted by ζI(Qk,Qh), is obtained as follows: ζI(Qk,Qh) = ζ(Qk,Qh) ∪ μ1(Qk) ∪ μ1(Qh) ∪ μ2(Qk) ∪ μ2(Qh). Given a query workload QWL, QWL is decomposed by iteratively decomposing its queries Q0, Q1, …, Q|QWL|−1 according to the query decomposition process described for a given (singleton) query.
16.9 An Effective and Efficient Algorithm for Computing Synopsis Data Cubes
From the Sections 16.3–16.8, it follows that our privacy-preserving OLAP technique, which is finally implemented by greedy algorithm computeSynDataCube, encompasses three main phases: (1) allocation of the input storage space B, (2) sampling of the input data cube A, and (3) refinement of the synopsis data cube Aʹ. In this section, we present in detail these phases and finally conclude with algorithm computeSynDataCube.
16.9.1 Allocation Phase
Given the input data cube A, the target query workload QWL, and the storage space B, in order to compute the synopsis data cube Aʹ, the first issue to be considered is how to allocate B across query regions of QWL. Given a query region R(Qk), allocating an amount of storage space to R(Qk), denoted by B(Qk), corresponds to assigning to R(Qk) a certain number of samples that can be extracted from R(Qk), denoted by N(Qk). To this end, during the allocation phase of algorithm computeSynDataCube, we assign more samples to those query regions of QWL having skewed (i.e., irregular and asymmetric) data distributions (e.g., Zipf ) and fewer samples to those query regions having uniform data distributions. The idea underlying such an approach is that few samples are enough to “describe” uniform query regions, due to the fact that data distributions of such regions are “regular,” whereas we need more samples to “describe” skewed query regions, due to the fact that data distributions of such regions are, contrary to the previous case, not “regular.” Specifically, we face the deriving allocation problem by means of a proportional storage space allocation scheme, which allows us to efficiently allocate B across query regions of QWL via assigning a fraction of B to each region. This allocation scheme has been preliminarily proposed in Reference 45 for the different context of approximate query answering techniques for two-dimensional OLAP data cubes, and in this work, it is extended to deal with multidimensional data cubes and (query) regions.
First, if QWL is overlapping, we compute its corresponding nonoverlapping query workload QWLʹ (see Section 16.4). Hence, in both cases (i.e., QWL is overlapping and not), a set of regions R(QWL) = {R(Q0), R(Q1), …, R(Q|QWL|1)} is obtained. Let R(Qk) be a region belonging to R(QWL); the amount of storage space allocated to R(Qk), B(Qk), is determined according to a proportional approach that considers (1) the nature of the data distribution of R(Qk) and geometrical issues of R(Qk) and (2) the latter parameters of R(Qk) in proportional comparison with the same parameters of all the regions in R(QWL), as follows: B(Qk)=⌊φ(R(Qk))+Ψ(R(Qk))⋅ξ(R(Qk))|QWL|−1∑h=0φ(R(Qk))+|QWL|−1∑h=0Ψ(R(Qk))⋅ξ(R(Qk))⋅B⌋ , such that [45] (1) Ψ(R) is a Boolean characteristic function that, given a region R, allows us to decide if data in R are uniform or skewed; (2) φ(R) is a factor that captures the skewness and the variance of R in a combined manner; and (3) ξ(R) is a factor that provides the ratio between the skewness of R and its standard deviation, which, according to Reference 46, allows us to estimate the skewness degree of the data distribution of R. The previous formula can be extended to handle the overall allocation of B across regions of QWL, thus achieving the formal definition of our proportional storage space allocation scheme, denoted by W(A,R(Q0),R(Q1),…,R(Q|QWL|−1),B) , via the following system:
{B(Q0)=⌊φ(R(Q0))+Ψ(R(Q0))⋅ξ(R(Q0))|QWL|−1∑k=0φ(R(Qk))+|QWL|−1∑k=0Ψ(R(Qk))⋅ξ(R(Qk))⋅B⌋⋯B(Q|QWL|−1)=⌊φ(R(Q|QWL|−1))+Ψ(R(Q|QWL|−1))⋅ξ(R(Q|QWL|−1))|QWL|−1∑k=0φ(R(Qk))+|QWL|−1∑k=0Ψ(R(Qk))⋅ξ(R(Qk))⋅B⌋|QWL|−1∑k=0B(Qk)≤B (16.1)
In turn, for each query region R(Qk) of R(QWL), we further allocate the amount of storage space B(Qk) across the subqueries of Qk, qk,0, qk,1,…, qk,m−1, obtained by decomposing Qk according to our decomposition process (see Section 16.8), via using the same allocation scheme (Equation 16.1). Overall, this approach allows us to obtain a storage space allocation for each subquery qk,i of QWL in terms of the maximum sample number N(qk,i)=⌊B(qk,i)32⌋ that can be extracted from qk,i,* B(qk,i) being the amount of storage space allocated to qk,i.
It should be noted that the described approach allows us to achieve an extremely accurate level of detail in handling accuracy/privacy issues of the final synopsis data cube Aʹ. To become convinced of this, recall that the granularity of OLAP client applications is that one of queries (see Section 16.1.1), which is much greater than that one of subqueries (specifically, the latter depends on the degree of accuracy grids) we use as the atomic unit of our reasoning. Thanks to this difference between granularity of input queries and accuracy grid cells, which, in our framework, is made “conveniently” high, we finally obtain a crucial information gain that allows us to efficiently accomplish the accuracy/privacy constraint.
16.9.2 Sampling Phase
Given an instance of our proportional allocation scheme (Equation 16.1), W , during the second phase of algorithm computeSynDataCube, we sample the input data cube A in order to obtain the synopsis data cube Aʹ, in such a way as to satisfy the accuracy/privacy constraint with respect to the target query workload QWL. To this end, we apply a different strategy in dependence on the fact that query regions characterized by uniform or skewed distributions are handled, according to similar insights that have inspired our allocation technique (see Section 16.9.1). Specifically, for a skewed region R(qk,i), given the maximum number of samples that can be extracted from R(qk,i), N(qk,i), we sample the N(qk,i) outliers of qk. It is worth noticing that, for skewed regions, the sum of outliers represents an accurate estimation of the sum of all the data cells contained within such regions. Also, it should be noted that this approach allows us to gain advantages with respect to approximate query answering as well as the privacy preservation of sensitive ranges of multidimensional data of skewed regions. Contrary to this, for a uniform region R(qk,i), given the maximum number of samples that can be extracted from R(qk,i), N(qk,i), let (1) ˉCR(qk,i) be the average of values of data cells contained within R(qk,i); (2) U(R(qk,i) ,ˉCR(qk,i) ) be the set of data cells C in R(qk,i) such that value(C) > ˉCR(qk,i) , where value(C) denotes the value of C; and (3) ˉC↑R(qk,i) be the average of values of data cells in U(R(qi,k) ,ˉCR(qk,i) ). We adopt the strategy of extracting N(qk,i) samples from R(qk,i) by selecting them as the N(qk,i) closer-to-ˉC↑R(qk,i) data cells C in R(qk,i) such that value (C) > ˉCR(qk,i) . Just like previous considerations given for skewed regions, it should be noted that the described sampling strategy for uniform regions allows us to meaningfully trade off the need for efficiently answering range-SUM queries against the synopsis data cube and the need for limiting the number of samples to be stored within the synopsis data cube.
In order to satisfy the accuracy/privacy constraint, the sampling phase aims at accomplishing (decomposed) accuracy and privacy constraints separately, based on a two-step approach. Given a query region R(Qk), we first sample R(Qk) in such a way as to satisfy the accuracy constraint, and then, we check if samples extracted from R(Qk) also satisfy, beyond the accuracy constraint, the privacy constraint. As mentioned in Section 16.7, this strategy follows a best-effort approach aiming at minimizing computational overheads due to computing the synopsis data cube, and it is also the conceptual basis of guidelines for setting the thresholds ΦQ and ΦI.
Moreover, our sampling strategy aims at obtaining a tunable representation of the synopsis data cube Aʹ, which can be progressively refined until the accuracy/privacy constraint is satisfied as much as possible. This means that, given the input data cube A, we first sample A in order to obtain the current representation of Aʹ. If such a representation satisfies the accuracy/privacy constraint, then the final representation of Aʹ is achieved and used at query time to answer queries instead of A. Otherwise, if the current representation of Aʹ does not satisfy the accuracy/privacy constraint, then we perform “corrections” on the current representation of Aʹ, thus refining such representation in order to obtain a final representation that satisfies the constraint, on the basis of a best-effort approach. What we call the refinement process (described in Section 16.9.3) is based on a greedy approach that “moves”† samples from regions of QWL whose queries satisfy the accuracy/privacy constraint to regions of QWL whose queries do not satisfy the constraint, yet ensuring that the former do not violate the constraint.
Given a query Qk of the target query workload QWL, we say that Qk satisfies the accuracy/privacy constraint iff the following inequalities simultaneously hold: {EQ(Qk)≤ΦQEI(Qk)≥ΦI .
In turn, given a query workload QWL, we decide about its satisfiability with respect to the accuracy/privacy constraint by inspecting the satisfiability of queries that compose QWL. Therefore, we say that QWL satisfies the accuracy/privacy constraint iff the following inequalities simultaneously hold: {ˉEQ(QWL)≤ΦQˉEI(QWL)≥ΦI .
Given the target query workload QWL, the criterion of our greedy approach used during the refinement process is the minimization of the average relative query error, ˉEQ(QWL) , and the maximization of the average relative inference error, ˉEI(QWL) , within the minimum number of movements that allows us to accomplish both the goals simultaneously [i.e., minimizing ˉEQ(QWL) and maximizing ˉEI(QWL) ]. Furthermore, the refinement process is bounded by a maximum occupancy of samples moved across queries of QWL, which we name total buffer size and denote as ℒA′,QWL . ℒA′,QWL depends on several parameters, such as the size of the buffer, the number of sample pages moved at each iteration, the overall available swap memory, and so forth.
16.9.3 Refinement Phase
In the refinement process, the third phase of algorithm computeSynDataCube, given the current representation of Aʹ that does not satisfy the accuracy/privacy constraint with respect to the target query workload QWL, we try to obtain an alternative representation of Aʹ that satisfies the constraint, according to a best-effort approach. To this end, the refinement process encompasses the following steps: (1) sort queries in QWL according to their “distance” from the satisfiability condition, thus obtaining the ordered query set QWLP ; (2) select from QWLP a pair of queries QT and Qℱ such that (ii.j) QT is the query of QWLP having the greater positive distance from the satisfiability condition, that is, QT is the query of QWLP that has the greater surplus of samples that can be moved toward queries in QWLP that do not satisfy the satisfiability condition, and (ii.jj) Qℱ is the query of QWLP having the greater negative distance from the satisfiability condition, that is, Qℱ is the query of QWLP that is in most need of new samples; (3) move enough samples from QT to Qℱ in such a way as to satisfy the accuracy/privacy constraint on Qℱ while, at the same time, ensuring that QT does not violate the constraint; and (4) repeat steps 1, 2, and 3 until the current representation of Aʹ satisfies, as much as possible, the accuracy/privacy constraint with respect to QWL, within the maximum number of iterations bounded by ℒA′,QWL . Regarding step 3, moving ρ samples from QT to Qℱ means (1) removing ρ samples from R(QT) , thus obtaining an additional space, named B(ρ); (2) allocating B(ρ) to R(Qℱ) ; and (3) resampling R(Qℱ) by considering the additional number of samples that have become available—in practice, this means extracting from R(Qℱ) further ρ samples.
Let S*(Qk) be the number of samples of a query Qk ∈ QWL satisfying the accuracy/privacy constraint. From the formal definitions of EQ(Qk) (see Section 16.5), I(Qk), ˜I(Qk) , and EI(Qk) (see Section 16.6), and the satisfiability condition, it could be easily demonstrated that S*(Qk) is given by the following formula: S*(Qk)=(1−ΦQ)(1−ΦI)⋅‖Qk‖ .
Let Seff(Qℱ) and Seff(QT) be the numbers of samples effectively extracted from R(Qℱ) and R(QT) , respectively, during the previous sampling phase. Note that Seff(Qℱ)<S*(Qℱ) and Seff(QT)≥S*(QT) . It is easy to prove that the number of samples to be moved from QT to Qℱ such that Qℱ satisfies the accuracy/privacy constraint and QT does not violate the constraint, denoted by Smov(QT,Qℱ) , is finally given by the following formula: Smov(QT,Qℱ)=S*(Qℱ)−Seff(Qℱ) , under the constraint Smov(QT,Qℱ)<Seff(QT)−S*(QT) .
Without going into detail, it is possible to demonstrate that, given (1) an arbitrary data cube A, (2) an arbitrary query workload QWL, (3) an arbitrary pair of thresholds ΦQ and ΦI, and (4) an arbitrary storage space B, it is not always possible to make QWL satisfiable via the refinement process. From this evidence, our idea of using a best-effort approach makes sense perfectly.
16.9.4 The computeSynDataCube Algorithm
Main greedy algorithm computeSynDataCube is described by the pseudocode listed in Figure 16.3, wherein (1) allocateStorageSpace implements the proportional storage space allocation scheme (Equation 16.1), (2) sampleDataCube implements the sampling strategy, (3) check tests the satisfiability of the target query workload against the current representation of the synopsis data cube, and (4) refineSynDataCube is in charge of refining the current representation of the synopsis data cube.

16.10 Experimental Assessment and Analysis
In order to test the effectiveness of our framework throughout studying the performance of algorithm computeSynDataCube, we conducted an experimental evaluation where we tested how the relative query error (similarly, the accuracy of answers) and the relative inference error (similarly, the privacy of answers) due to the evaluation of populations of randomly generated queries, which model query workloads of our framework, over the synopsis data cube range with respect to the volume of queries. The latter is a relevant parameter costing computational requirements of any query processing algorithm (also referred as selectivity—e.g., Reference 44). According to motivations given in Section 16.2.1, we considered the zero-sum method [20] as the comparison technique.
In our experimental assessment, we engineered three classes of two-dimensional data cubes: synthetic, benchmark, and real-life data cubes. For all these data cubes, we limited the cardinalities of both dimensions to a threshold equal to 1000, which represents a reliable value modeling significant OLAP applications (e.g., Reference 44). In addition to this, data cubes of our experimental framework expose different sparseness coefficients s, which measures the percentage number of non-null data cells with respect to the total number of data cells of a data cube. As has been widely known since early experiences in OLAP research [47], the sparseness coefficient holds a critical impact on every data cube processing technique, thus including privacy-preserving data cube computation as well.
In particular, synthetic data cubes store two kinds of data: uniform data and skewed data, the latter being obtained by means of a Zipf distribution [48]. The benchmark data cube we considered has been built from the TPC-H data set [49], the real-life one from the Forest CoverType (FCT) data set [50]. Both data sets are well known in the data warehousing and OLAP research community. The final sparseness of the TPC-H and FCT data cube, respectively, has been easily artificially determined within the same OLAP data cube aggregation routine. The benefits derived from using different kinds of data cubes are manifold, among which we recall the following: (1) The algorithm can be tested against different data distributions, thus stressing the reliability of the collection of techniques we propose (i.e., allocation, sampling, refinement), which, as described in Section 16.9, inspect the nature of input data to compute the final synopsis data cube. (2) Parameters of data distributions characterizing the data cubes can be controlled easily, thus obtaining a reliable experimental evaluation. Selectivity of queries has been modeled in terms of a percentage value of the overall volume of synthetic data cubes, and for each experiment, we considered queries with selectivity increasing in size, in order to stress our proposed techniques under the ranging of an increasing input.
Regarding compression issues, we imposed a compression ratio r, which measures the percentage occupancy of the synopsis data cube Aʹ, size(Aʹ), with respect to the occupancy of the input data cube A, size(A), equal to 20%, which is a widely accepted threshold for data cube compression techniques (e.g., Reference 44). To simplify, we set the accuracy and privacy thresholds in such a way as not to trigger the refinement process. This is also because Reference 20 does not support any “dynamic” computational feature (e.g., tuning of the quality of the random data distortion technique), so that it would have been particularly difficult to compare the two techniques under completely different experimental settings. On the other hand, this aspect puts in evidence the innovative characteristics of our privacy-preserving OLAP technique with respect to Reference 20, which is indeed a state-of-the-art proposal in perturbation-based privacy-preserving OLAP techniques.
Figure 16.4 shows experimental results concerning relative query errors of synopsis data cubes built from uniform, skewed, TPC-H, and FCT data, and for several values of s. Figure 16.5 shows instead the results concerning relative inference errors on the same data cubes. In both Figures, our approach is labeled as G, whereas the approach in Reference 20, is labeled as Z. Obtained experimental results confirm the effectiveness of our algorithm, also in comparison with Reference 20, according to the following considerations. First, relative query and inference errors decrease as selectivity of queries increases, that is, the accuracy of answers increases and the privacy of answers decreases as selectivity of queries increases. This is because the more the data cells involved by a given query Qk, the more the samples extracted from R(Qk) are able to “describe” the original data distribution of R(Qk) (this also depends on the proportional storage space allocation scheme [Equation 16.1]), so that accuracy increases. At the same time, more samples cause a decrease in privacy, since they provide accurate singleton aggregations and, as a consequence, the inference error decreases. Secondly, when s increases, we observe a higher query error (i.e., accuracy of answers decreases) and a higher inference error (i.e., privacy of answers increases). In other words, data sparseness influences both accuracy and privacy of answers, with a negative effect in the first case (i.e., accuracy of answers) and a positive effect in the second case (i.e., privacy of answers). This is because, similarly to the results of Reference 20, we observe that privacy-preserving techniques, being essentially based on mathematical/statistical models and tools, strongly depend on the sparseness of data, since the latter, in turn, influences the nature and, above all, the shape of data distributions kept in databases and data cubes. Both these pieces of experimental evidence further corroborate our idea of trading off accuracy and privacy of OLAP aggregations to compute the final synopsis data cube. Also, by comparing experimental results on uniform, skewed, TPC-H, and FCT (input) data, we observe that our technique works better on uniform data, as expected, while it decreases the performance on benchmark and real-life data gracefully. This is due to the fact that uniform data distributions can be approximated better than skewed, benchmark, and real-life ones. On the other hand, experimental results reported in Figure 16.4 and Figure 16.5 confirm to us the effectiveness and, above all, the reliability of our technique even on benchmark and real-life data one can find in real-world application scenarios. Finally, Figure 16.4 and Figure 16.5 clearly state that our proposed privacy-preserving OLAP technique outperforms the zero-sum method [20]. This achievement is another relevant contribution of our research.
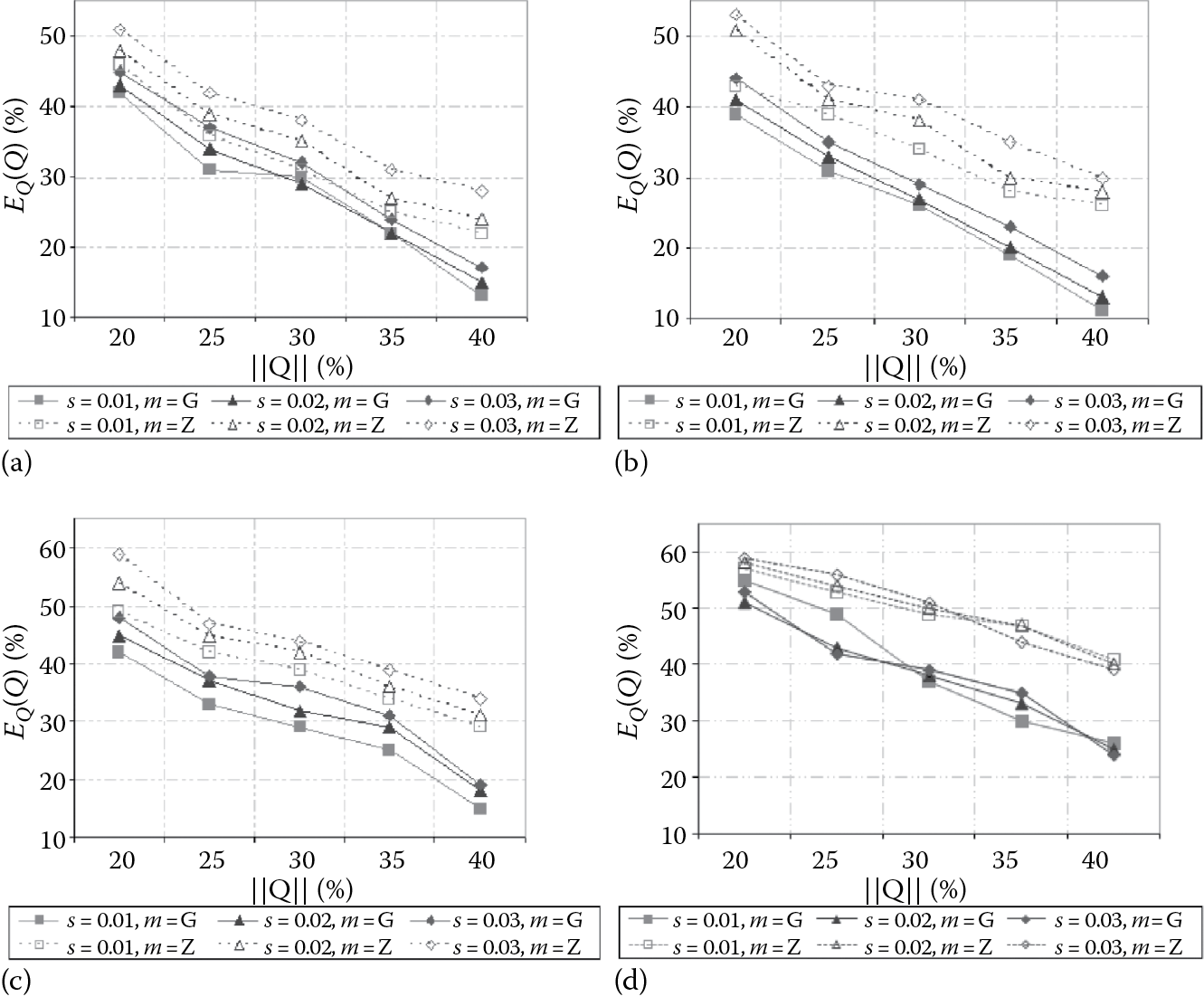
Relative query errors of synopsis data cubes built from (a) uniform, (b) skewed, (c) TPC-H, and (d) FCT data cubes for several values of s (r = 20%).
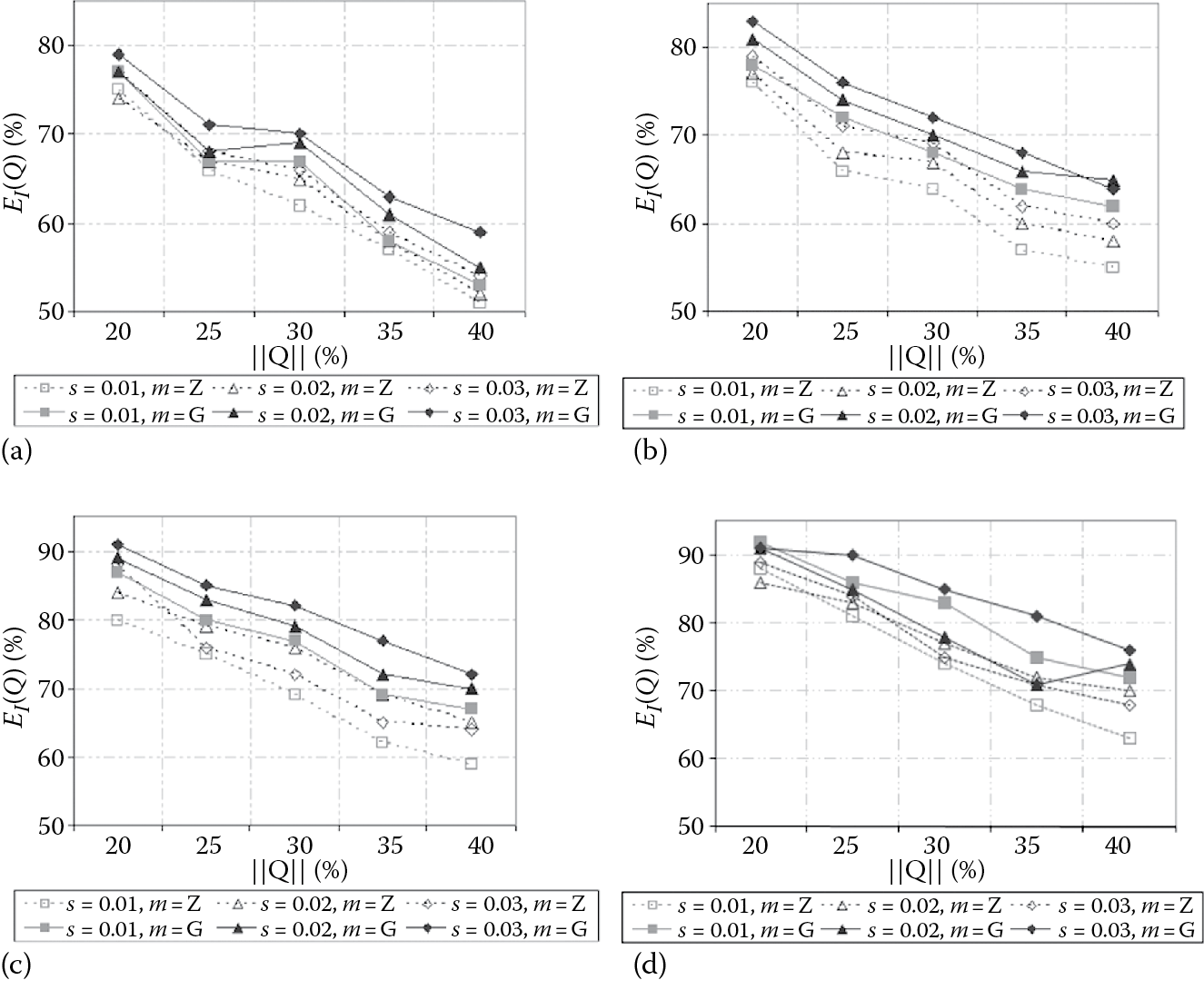
Relative inference errors of synopsis data cubes built from (a) uniform, (b) skewed, (c) TPC-H, and (d) FCT data cubes for several values of s (r = 20%).
16.11 Conclusions and Future Work
In this chapter, we have discussed principles and fundamentals of privacy-preserving OLAP over Big Data, both in centralized and distributed environments, and we have proposed a complete framework for efficiently supporting privacy-preserving OLAP aggregations on data cubes, along with its experimental assessment. We rigorously presented theoretical foundations as well as intelligent techniques for processing data cubes and queries, and algorithms for computing the final synopsis data cube whose aggregations balance, according to a best-effort approach, accuracy and privacy of retrieved answers. An experimental evaluation conducted on several classes of data cubes has clearly demonstrated the benefits deriving from the privacy-preserving OLAP technique we propose, also in comparison with a state-of-the-art proposal.
Future work is mainly oriented toward extending the actual capabilities of our framework in order to encompass the following features: (1) intelligent update management techniques (e.g., what happens when a query workload’s characteristics change dynamically over time), perhaps inspired by well-known principles of self-tuning databases; (2) assuring the robustness of the framework with respect to coalitions of attackers; (3) integrating the proposed framework within the core layer of next-generation data warehousing and data mining server systems; and (4) building useful real-life case studies in emerging application scenarios (e.g., analytics over complex data [51,52]).
References
1. C. Wu and Y. Guo, “Enhanced User Data Privacy with Pay-by-Data Model,” in: Proceedings of BigData Conference, 53–57, 2013.
2. M. Jensen, “Challenges of Privacy Protection in Big Data Analytics,” in: Proceedings of BigData Congress, 235–238, 2013.
3. M. Li et al., “MyCloud: Supporting User-ConFigured Privacy Protection in Cloud Computing,” in: Proceedings of ACSAC, 59–68, 2013.
4. S. Betgé-Brezetz et al., “End-to-End Privacy Policy Enforcement in Cloud Infrastructure,” in: Proceedings of CLOUDNET, 25–32, 2013.
5. M. Weidner, J. Dees and P. Sanders, “Fast OLAP Query Execution in Main Memory on Large Data in a Cluster,” in: Proceedings of BigData Conference, 518–524, 2013.
6. A. Cuzzocrea, R. Moussa and G. Xu, “OLAP*: Effectively and Efficiently Supporting Parallel OLAP over Big Data,” in: Proceedings of MEDI, 38–49, 2013.
7. A. Cuzzocrea, L. Bellatreche and I.-Y. Song, “Data Warehousing and OLAP Over Big Data: Current Challenges and Future Research Directions,” in: Proceedings of DOLAP, 67–70, 2013.
8. A. Cuzzocrea, “Analytics over Big Data: Exploring the Convergence of Data Warehousing, OLAP and Data-Intensive Cloud Infrastructures,” in: Proceedings of COMPSAC, 481–483, 2013.
9. A. Cuzzocrea, I.-Y. Song and K.C. Davis, “Analytics over Large-Scale Multidimensional Data: The Big Data Revolution!,” in: Proceedings of DOLAP, 101–104, 2011.
10. A. Cuzzocrea and V. Russo, “Privacy Preserving OLAP and OLAP Security,” J. Wang (ed.), Encyclopedia of Data Warehousing and Mining, 2nd ed., IGI Global, Hershey, PA 1575–1581, 2009.
11. A. Cuzzocrea and D. Saccà, “Balancing Accuracy and Privacy of OLAP Aggregations on Data Cubes,” in: Proceedings of the 13th ACM International Workshop on Data Warehousing and OLAP, 93–98, 2010.
12. X. Chen et al., “OWL Reasoning over Big Biomedical Data,” in: Proceedings of BigData Conference, 29–36, 2013.
13. M. Paoletti et al., “Explorative Data Analysis Techniques and Unsupervised Clustering Methods to Support Clinical Assessment of Chronic Obstructive Pulmonary Disease (COPD) Phenotypes,” Journal of Biomedical Informatics 42(6), 1013–1021, 2009.
14. Y.-W. Cheah et al., “Milieu: Lightweight and Configurable Big Data Provenance for Science,” in: Proceedings of BigData Congress, 46–53, 2013.
15. A.G. Erdman, D.F. Keefe and R. Schiestl, “Grand Challenge: Applying Regulatory Science and Big Data to Improve Medical Device Innovation,” IEEE Transactions on Biomedical Engineering 60(3), 700–706, 2013.
16. D. Cheng et al., “Tile Based Visual Analytics for Twitter Big Data Exploratory Analysis,” in: Proceedings of BigData Conference, 2–4, 2013.
17. N. Ferreira et al., “Visual Exploration of Big Spatio-Temporal Urban Data: A Study of New York City Taxi Trips,” IEEE Transactions on Visualization and Computer Graphics 19(12), 2149–2158, 2013.
18. L. Sweeney, “k-Anonymity: A Model for Protecting Privacy,” International Journal on Uncertainty Fuzziness and Knowledge-based Systems 10(5), 557–570, 2002.
19. A. Machanavajjhala et al., “L-diversity: Privacy beyond k-Anonymity,” ACM Transactions on Knowledge Discovery from Data 1(1), art. no. 3, 2007.
20. S.Y. Sung et al., “Privacy Preservation for Data Cubes,” Knowledge and Information Systems 9(1), 38–61, 2006.
21. J. Han et al., “Efficient Computation of Iceberg Cubes with Complex Measures,” in: Proceedings of ACM SIGMOD, 1–12, 2001.
22. A. Cuzzocrea and W. Wang, “Approximate Range-Sum Query Answering on Data Cubes with Probabilistic Guarantees,” Journal of Intelligent Information Systems 28(2), 161–197, 2007.
23. A. Cuzzocrea and P. Serafino, “LCS-Hist: Taming Massive High-Dimensional Data Cube Compression,” in: Proceedings of the 12th International Conference on Extending Database Technology, 768–779, 2009.
24. A. Cuzzocrea, “Overcoming Limitations of Approximate Query Answering in OLAP,” in: IEEE IDEAS, 200–209, 2005.
25. N.R. Adam and J.C. Wortmann, “Security-Control Methods for Statistical Databases: A Comparative Study,” ACM Computing Surveys 21(4), 515–556, 1989.
26. F.Y. Chin and G. Ozsoyoglu, “Auditing and Inference Control in Statistical Databases,” IEEE Transactions on Software Engineering 8(6), 574–582, 1982.
27. J. Schlorer, “Security of Statistical Databases: Multidimensional Transformation,” ACM Transactions on Database Systems 6(1), 95–112, 1981.
28. D.E. Denning and J. Schlorer, “Inference Controls for Statistical Databases,” IEEE Computer 16(7), 69–82, 1983.
29. N. Zhang, W. Zhao and J. Chen, “Cardinality-Based Inference Control in OLAP Systems: An Information Theoretic Approach,” in: Proceedings of ACM DOLAP, 59–64, 2004.
30. F.M. Malvestuto, M. Mezzini and M. Moscarini, “Auditing Sum-Queries to Make a Statistical Database Secure,” ACM Transactions on Information and System Security 9(1), 31–60, 2006.
31. L. Wang, D. Wijesekera and S. Jajodia, “Cardinality-based Inference Control in Data Cubes,” Journal of Computer Security 12(5), 655–692, 2004.
32. L. Wang, S. Jajodia and D. Wijesekera, “Securing OLAP Data Cubes against Privacy Breaches,” in: Proceedings of IEEE SSP, 161–175, 2004.
33. J. Gray et al., “Data Cube: A Relational Aggregation Operator Generalizing Group-By, Cross-Tab, and Sub-Totals,” Data Mining and Knowledge Discovery 1(1), 29–53, 1997.
34. M. Hua et al., “FMC: An Approach for Privacy Preserving OLAP,” in: Proceedings of the 7th International Conference on Data Warehousing and Knowledge Discovery, LNCS Vol. 3589, 408– 417, 2005.
35. R. Agrawal, R. Srikant and D. Thomas, “Privacy-Preserving OLAP,” in: Proceedings of the 2005 ACM International Conference on Management of Data, 251–262, 2005.
36. J. Vaidya and C. Clifton, “Privacy Preserving Association Rule Mining in Vertically Partitioned Data,” in: Proceedings of the 8th ACM International Conference on Knowledge Discovery and Data Mining, 639–644, 2002.
37. M. Kantarcioglu and C. Clifton, “Privacy-Preserving Distributed Mining of Association Rules on Horizontally Partitioned Data,” IEEE Transactions on Knowledge and Data Engineering 16(9), 1026–1037, 2004.
38. J. Vaidya and C. Clifton, “Privacy-Preserving K-Means Clustering over Vertically Partitioned Data,” in: Proceedings of the 9th ACM International Conference on Knowledge Discovery and Data Mining, 206–215, 2003.
39. G. Jagannathan, K. Pillaipakkamnatt and R. Wright, “A New Privacy-Preserving Distributed K-Clustering Algorithm,” in: Proceedings of the 2006 SIAM International Conference on Data Mining, 492–496, 2006.
40. G. Jagannathan and R. Wright, “Privacy-Preserving Distributed K-Means Clustering over Arbitrarily Partitioned Data,” in: Proceedings of the 11th ACM International Conference on Knowledge Discovery and Data Mining, 593–599, 2002.
41. C. Clifton et al., “Tools for Privacy Preserving Distributed Data Mining,” SIGKDD Explorations 4(2), 28–34, 2002.
42. Y. Tong et al., “Privacy-Preserving OLAP based on Output Perturbation Across Multiple Sites,” in: Proceedings of the 2006 International Conference on Privacy, Security and Trust, AICPS Vol. 380, 46, 2006.
43. W. He et al., “PDA: Privacy-Preserving Data Aggregation in Wireless Sensor Networks,” in: Proceedings of the 26th IEEE Annual Conference on Computer Communications, 2045–2053, 2007.
44. A. Cuzzocrea, “Accuracy Control in Compressed Multidimensional Data Cubes for Quality of Answer-based OLAP Tools,” in: Proceedings of the 18th IEEE International Conference on Scientific and Statistical Database Management, 301–310, 2006.
45. A. Cuzzocrea, “Improving Range-Sum Query Evaluation on Data Cubes via Polynomial Approximation,” Data & Knowledge Engineering 56(2), 85–121, 2006.
46. A. Stuart and K.J. Ord, Kendall’s Advanced Theory of Statistics, Vol. 1: Distribution Theory, 6th ed., Oxford University Press, New York City, 1998.
47. S. Agarwal et al., “On the Computation of Multidimensional Aggregates,” in: Proceedings of VLDB, 506–521, 1996.
48. G.K. Zipf, Human Behaviour and the Principle of Least Effort: An Introduction to Human Ecology, Addison-Wesley, Boston, MA, 1949.
49. Transaction Processing Council, TPC Benchmark H, available at http://www.tpc.org/tpch/.
50. UCI KDD Archive, The Forest CoverType Data Set, available at http://kdd.ics.uci.edu/databases/covertype/covertype.html.
51. K. Beyer et al., “Extending XQuery for Analytics,” in: Proceedings of the 2005 ACM International Conference on Management of Data, 503–514, 2005.
52. R.R. Bordawekar and C.A. Lang, “Analytical Processing of XML Documents: Opportunities and Challenges,” SIGMOD Record 34(2), 27–32, 2005.