
Chapter 18
Semantic-Based Heterogeneous Multimedia Big Data Retrieval
Kehua Guo and Jianhua Ma
Abstract
Nowadays, data heterogeneity is one of the most critical features for multimedia Big Data; searching heterogeneous multimedia documents reflecting users’ query intent from a Big Data environment is a difficult task in information retrieval and pattern recognition. This chapter proposes a heterogeneous multimedia Big Data retrieval framework that can achieve good retrieval accuracy and performance. The chapter is organized as follows. In Section 18.1, we address the particularity of heterogeneous multimedia retrieval in a Big Data environment and introduce the background of the topic. Then literatures related to current multimedia retrieval approaches are briefly reviewed, and the general concept of the proposed framework is introduced briefly in Section 18.2. In Section 18.3, the description of this framework is given in detail including semantic information extraction, representation, storage, and multimedia Big Data retrieval. The performance evaluations are shown in Section 18.4, and finally, we conclude the chapter in Section 18.5.
18.1 Introduction
Multimedia retrieval is an important technology in many applications such as web-scale multimedia search engines, mobile multimedia search, remote video surveillance, automation creation, and e-government [1]. With the widespread use of multimedia documents, our world will be swamped with multimedia content such as massive images, videos, audios, and other content. Therefore, traditional multimedia retrieval has been switching into a Big Data environment, and the research into solving some problems according to the features of multimedia Big Data retrieval attracts considerable attention.
At present, multimedia retrieval from Big Data environments is facing two problems: The first is document type heterogeneity. The multimedia content generated from various applications may be huge and unstructured. For example, the different types of multimedia services will generate images, videos, audios, graphics, or text documents. Such heterogeneity makes it difficult to execute a heterogeneous search. The second is intent expression. In multimedia retrieval, the query intent generally can be represented by text. However, the text can only express very limited query intent. Users do not want to enter too many key words, but short text may lead to ambiguity. In many cases, the query intent may be described by content (for example, we can search some portraits that are similar to an uploaded image), but content-based retrieval may ignore personal understanding because semantic information cannot be described by physical features such as color, texture, shape, and so forth. Therefore, the returned results may be far from satisfying users’ search intent.
These features have become new challenges in the research of Big Data–based multimedia information retrieval. Therefore, how to simultaneously consider the type heterogeneity and user intent in order to guarantee good retrieval performance and economical efficiency has been an important issue.
Traditional multimedia retrieval approaches can be divided into three classes: text-based, content-based, and semantic-based retrieval [1,2]. The text-based approach has been widely used in many commercial Internet-scale multimedia search engines. In this approach, a user types some key words, and then the search engine searches for the text in a host document and returns the multimedia files whose surrounding text contains the key words. This approach has the following disadvantages: (1) Users can only type short or ambiguous key words because the users’ query intent usually cannot be correctly described by text. For example, when a user inputs the key word “Apple,” the result may contain fruit, a logo, and an Apple phone. (2) To a multimedia database that stores only multimedia documents and in which the surrounding text does not exist, the text-based approach will be useless. For example, if a user stores many animation videos in the database, he/she can only query the videos based on simple information (e.g., filename), because the text related to them is limited.
Another multimedia retrieval approach is content based. In this approach, a user uploads a file (e.g., an image); the search engine searches for documents that are similar to it using content-based approaches. This approach will suffer from three disadvantages: (1) This approach cannot support heterogeneous search (e.g., upload an image to search for audio). (2) The search engine will ignore the users’ query intent and cannot get similar results satisfying users’ search intent. (3) The computation time of feature attraction will cost much computation resources.
The third approach is semantic based. In this approach, semantic features of multimedia documents are described by an ontology method and stored in the server’s knowledge base; when the match requirement arrives, the server will execute retrieval in the knowledge base. However, if the multimedia document leaves the knowledge base, the retrieval process cannot be executed unless the semantic information is rebuilt.
This chapter is summarized from our recent work [1,2]. In this chapter, we use the semantic-based approach to represent users’ intent and propose a storage and retrieval framework supporting heterogeneous multimedia Big Data retrieval. The characteristics of this framework are as follows: (1) It supports heterogeneous multimedia retrieval. We can upload a multimedia document with any multimedia type (such as image, video, or audio) to obtain suiTable documents with various types. (2) There is convenience in interaction. This framework provides retrieval interfaces similar to traditional commercial search engines for convenient retrieval. (3) It saves data space. We store the text-represented semantic information in the database and then provide links to the real multimedia documents instead of directly processing multimedia data with large size. (4) There is efficiency with economic processing. We use a NoSQL database on some inexpensive computers to store the semantic information and use an open-sourced Hadoop tool to process the retrieval. The experiment results show that this framework can effectively search the heterogeneous multimedia documents reflecting users’ query intent.
18.2 Related Work
In the past decades, heterogeneous multimedia retrieval was done mainly using text-based approaches. But, in fact, this retrieval is only based on the text surrounding multimedia documents in host files (e.g., web pages). Although we can type key words to obtain various types of multimedia documents, these methods do not intrinsically support heterogeneous retrieval. If the text does not exist, the retrieval cannot be executed.
In a Big Data environment, information retrieval encounters some particular problems because of the data complexity, uncertainty, and emergence [3]. At present, research is focusing on the massive data capture, indexing optimization, and improvement of retrieval [4]. In a Big Data process, NoSQL technology is useful to store the information, which can be represented in map format. Apache HBase is a typical database to realize the NoSQL idea that simplifies the design, provides horizontal scaling, and gives finer control over availability. The features of HBase are outlined in the original Google File System [5] and BigTable [6]. Tables in HBase can serve as the input and output for MapReduce [7] jobs running in Hadoop [8] and may be accessed through some typical application program interfaces (APIs), such as Java [9].
The research on heterogeneous multimedia retrieval approaches has mainly concentrated on how to combine the text-based approach with other methods [10,11]. Although it is more convenient for users to type text key words, content-based retrieval (e.g., images) has been widely used in some commercial search engines (e.g., Google Images search). However, it is very difficult to execute heterogeneous retrieval based on multimedia content [12,13]. For example, given a video and audio document relevant to the same artist, it is difficult to identify the artist or extract other similar features from the binary data of the two documents because their data formats are different. Therefore, full heterogeneous multimedia retrieval has not been achieved.
The approach proposed in this chapter mainly uses semantic information to support heterogeneous multimedia retrieval. Feature recognition is based on not only the low-level visual features, such as color, texture, and shape, but also full consideration of the semantic information, such as event, experience, and sensibility [14,15]. At present, the semantic information extraction approaches generally use the model of text semantic analysis, which constructs the relation between a text phrase and visual description in latent space or a random field. For an image, a bag-of-words model [16] is widely used to express visual words. Objects can be described by visual words to realize semantic learning. In addition, a topic model is widely used for the semantic extraction. The typical topic models are probabilistic latent semantic analysis (PLSA) [17] and latent Dirichlet allocation (LDA) [18]. Based on these models, many semantic learning approaches have been proposed. A study [19] proposed an algorithm to improve the training effect of image classification in high-dimension feature space. Previous works [20,21] have proposed some multiple-class annotation approaches based on supervision.
In the field of unsupervised learning, a study [22] has proposed a normalized cut clustering algorithm. Another study [23] presented an improved PLSA model. In addition, some researchers have combined relative feedback and machine learning. One study [24] used feedback and obtained a model collaborative method to extract the semantic information and get recognition results with higher precision. Another [25] used a support vector machine (SVM) active learning algorithm to handle feedback information; the users could choose the image reflecting the query intent.
In the field of system development, one study [26] used the hidden Markov model (HMM) to construct an automatic semantic image retrieval system. This approach could express the relation of image features after being given a semantic class. A Digital Shape Workbench [27–29] provided an approach to realize sharing and reuse of design resources and used ontology technology to describe the resources and high-level semantic information of three-dimensional models. In this system, ontology-driven annotation of the Shapes method and ShapeAnnotator were used for user interaction. Based on this work, another study [30] investigated the ontology expression to virtual humans, covering the features, functions, and skills of a human. Purdue University is responsible for the conception of the Engineering Ontology and Engineering Lexicon and proposed a calculable search framework [31]. A study [32] used the Semantic Web Rule Language to define the semantic matching. Another [33] proposed a hierarchical ontology-based knowledge representation model.
In current approaches, semantic features and multimedia documents are stored in the server’s rational database, and we have to purchase expensive servers to process the retrieval. On the one hand, if the multimedia document is not stored in the knowledge base, the retrieval process cannot be conducted unless the semantic information is rebuilt. On the other hand, multimedia data with large size will cost much storage space. So, our framework presents an effective and economical framework that uses an inexpensive investment to store and retrieve the semantic information from heterogeneous multimedia data. In this framework, we do not directly process multimedia data with large size; in HBase, we only store the ontology-represented semantic information, which can be parallel-processed in distributed nodes with a MapReduce-based retrieval algorithm.
In our framework, we apply some valuable assets to facilitate the intent-reflective retrieval of heterogeneous multimedia Big Data. Big Data processing tools (e.g., Hadoop) are open source and convenient in that they can be freely obtained. For example, Hadoop only provides a programming model to perform distributed computing, and we can use the traditional retrieval algorithm after designing the computing model that is suiTable for the MapReduce programming specification. In addition, the semantic information of the multimedia documents can also be easily obtained and saved because of the existence of many computing models. For example, we can provide the semantic information to the multimedia documents through annotating by social user and describe the semantic information by ontology technology. These technologies have been widely used in various fields.
18.3 Proposed Framework
18.3.1 Overview
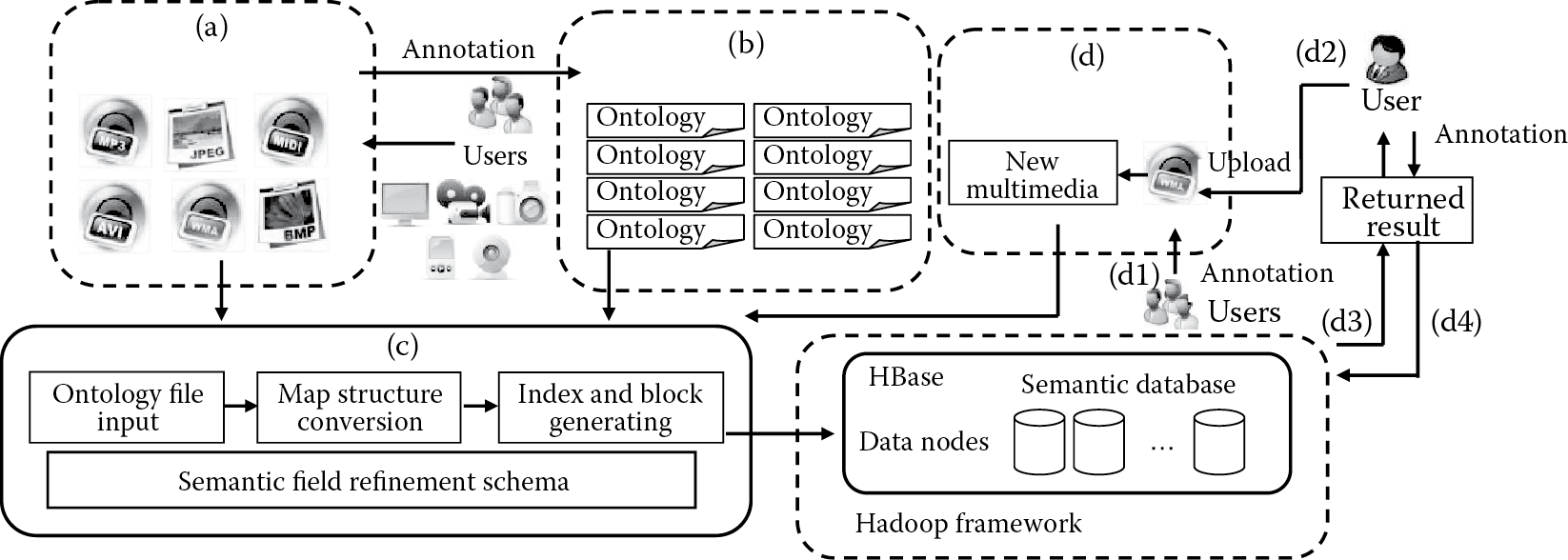
This section will present our framework on how to combine the semantic information and multimedia documents to perform Big Data retrieval. Our framework adopts a four-step architecture, shown in Figure 18.1. The architecture mainly consists of semantic annotation (Figure 18.1a), semantic representation (Figure 18.1b), NoSQL-based semantic storage (Figure 18.1c), and heterogeneous multimedia retrieval (Figure 18.1d) steps.
In the semantic annotation step, each multimedia document will be annotated by social users according to their personal understanding. The multimedia types may include images, videos, audio, and text with various formats. The multimedia content will be obtained from various generating sources, such as web crawling, sensor collection, user generation, and so forth. After the semantic extraction, the text annotations provided by users will be represented by ontology in the second step. A weight adjustment schema is used to adjust the weight of every semantic field in the ontology.
In the third step, the ontology file will be saved into a NoSQL-based storage linked to the real multimedia data with the location information. In order to better adapt to the NoSQL-based Big Data processing tool, we will use the map (key/value) structure conversion process to normalize the storage format of the multimedia location and its corresponding semantic information. After the new structures are generated, we will generate the index and storage block, according to which the ontology will be saved into the NoSQL-based distributed semantic database managed by HBase.
The fourth step is the retrieval process. In this step, the user can upload an annotated multimedia document with arbitrarily arbitrary format to execute heterogeneous multimedia retrieval (Figure 18.1d1–d2). In this case, the engine will return the results by matching the annotations of an uploaded document with semantic information in the database (Figure 18.1d3). Finally, users will be asked to give additional annotations to the multimedia document they selected (Figure 18.1d4) to make the annotations more abundant and accurate.
18.3.2 Semantic Annotation
In this framework, multimedia documents will be semantically annotated by several users, and the semantic information will be saved into HBase. The users can annotate a multimedia document in the interfaces provided by software tools. All the annotations will be described by text.
For annotation users, we have developed software named SemanticMultimediaViewer (SMV) [1], which can read, analyze, and annotate semantic multimedia documents. This software, running on PC or mobile devices, can save new documents to a multimedia database. The interface is shown in Figure 18.2.
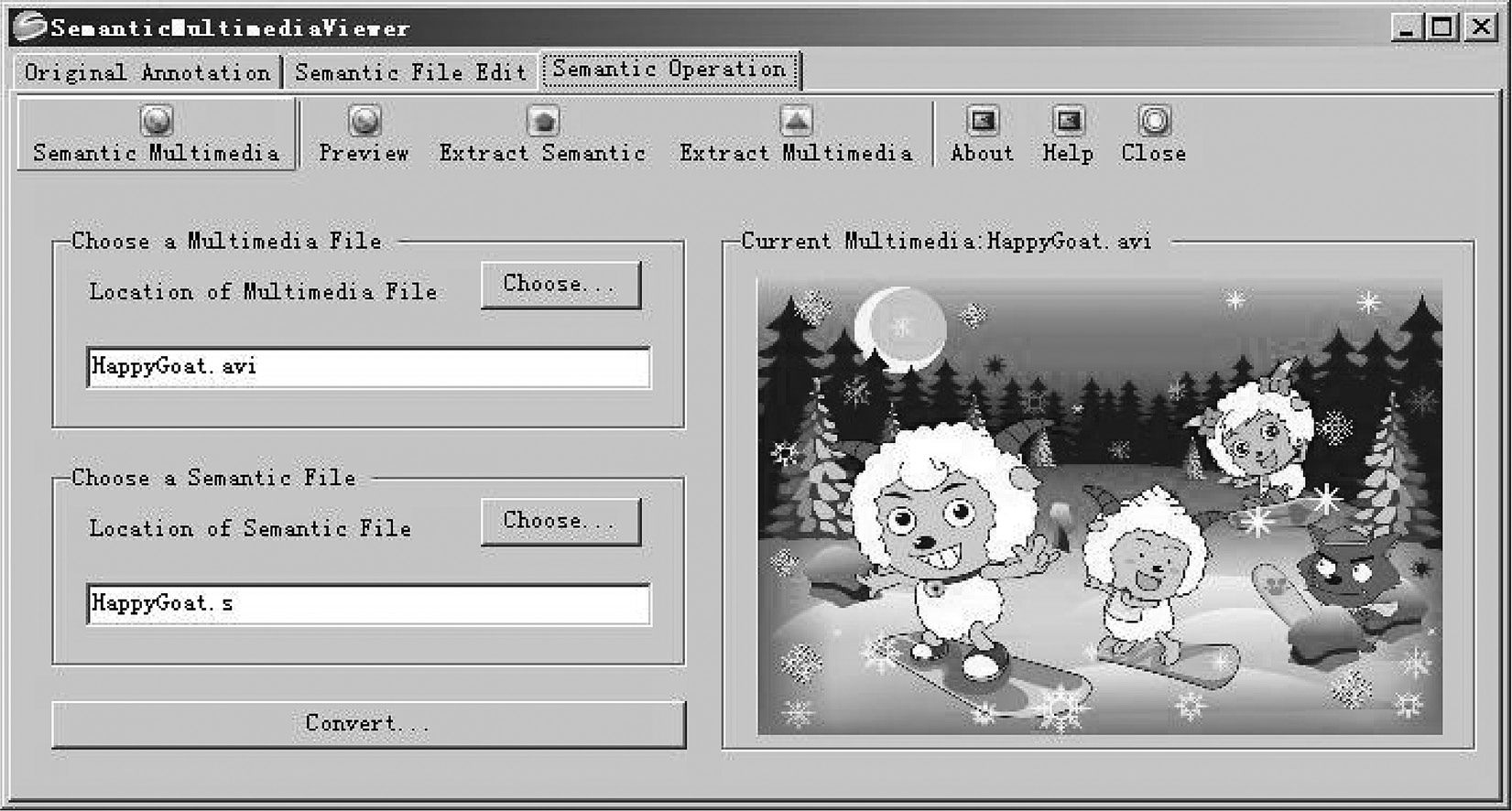
The interface of SMV. (From Guo, K. et al., Wirel. Pers. Commun., 72, 2013; Guo, K. and Zhang, S., Comput. Math. Methods Med., 2013, 2013.)
In SMV, the users can choose the “Original Annotation” tab page to annotate any multimedia document. This tab page provides three functions. Firstly, the users can open a multimedia file (image, video, audio, etc.) and preview the content of the multimedia. Secondly, the tab page provides an interface to allow the user to annotate the opened multimedia file. Finally, the software can save the information as a semantic file when the user chooses to save the annotations. The “Semantic File Edit” tab page provides two functions. One is to open a semantic file and preview the content of the semantic information. The other is to insert, delete, or update the ontology in the semantic file and save the modification to the semantic file. In our framework, the tab page “Semantic Operation” will not be used.
We define m as a multimedia document and C as the set of all the multimedia documents (including images, videos, audio, etc.) satisfying C = {m1, m2,…,mN} (where N is the number of multimedia documents). For arbitrary mi ∈ C, mi will be saved in a hard disk. The location information of mi is saved in HBase linked to the real file. Semantic annotations will provide meaningful key words reflecting users’ personal understanding of mi.
Define set Ami as the annotation set of mi satisfying Ami = {a1,a2,…,an} (where n is the number of annotations for mi). For arbitrary mi ∈ C, users will give many annotations. However, not all the annotations can accurately represent the semantic information of mi. Therefore, we assign every ai ∈ Ami a weight. Therefore, for arbitrary mi ∈ C, the final annotation matrix of Ami will be defined as
(18.1)
where ai is the ith annotation and wi is the corresponding weight. Therefore, all the annotation matrices for the multimedia documents can be defined as A = {Am1, Am2,…, AmN}. After the semantic annotation, for arbitrary mi ∈ C, we assign the initial value of wi as .
It is evident that wi for every annotation could not be constant after retrieval. Obviously, more frequently used annotations during the retrieval process can better express semantic information; they should be assigned a greater weight. We design an adjustment schema as follows:
(18.2)
The value of ki satisfies the following:
(18.3)
The initial weight assignment and the adjustment process need to check all the semantic information in the database, and this work will cost much computational resources. To solve this problem, we can execute this process only once the search engine is built. In addition, the adjustment process can be performed in a background thread.
18.3.3 Optimization and User Feedback
During the use of this framework, for arbitrary mi ∈ C, the annotation matrix Ami stems from the understanding of different users. The cardinality of Ami will become progressively greater. In Ami, wrong or less frequently used annotations will inevitably be mixed, which will waste much retrieving resources and storage space. In order to solve this problem, we define an optimization approach to eliminate the annotations that may be useless. We use a weight adjustment schema to adjust the weight of every semantic field.
This process is called annotation refinement. The purpose is to retain most of the high-frequency annotations and eliminate the annotations with less use. For arbitrary mi ∈ C, we will check Ami and remove the ith row when ai satisfies
(18.4)
The initial weight assignment and the adjustment schema need to check all the semantic documents in HBase, and this work will cost much computational resources. To solve this problem, the adjustment process can be performed in a background thread.
After retrieval, this framework will return some multimedia documents. This framework supports user feedback, so for a particular returned document, the user can add additional annotations to enrich the semantic information. For these annotations, the initial weight will be 1/n too.
In summary, as the retrieval progresses, the annotations will be more and more abundant. But rarely used annotations will also be removed. There will be some new annotations added into the annotation matrix Ami because of the user feedback. Therefore, this framework is a dynamic framework; the longer it is used, the more accurate the results we can obtain.
18.3.4 Semantic Representation
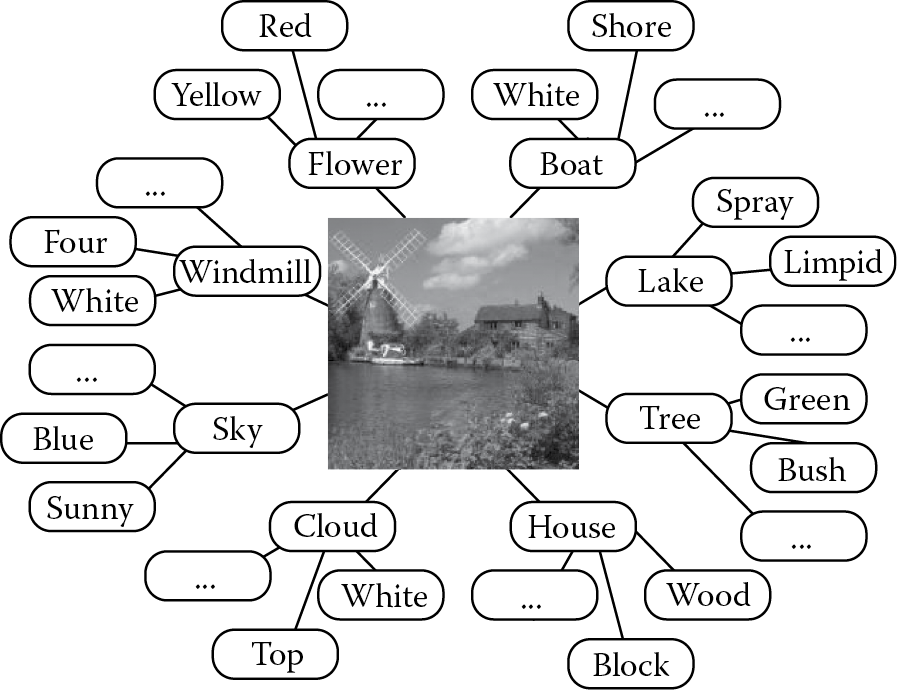
This framework uses ontology technology to describe the multimedia semantic information. In the ontology representation, each node describes one certain semantic concept, and the ontology representation satisfies a recursive and hierarchical structure. The ontology nodes at the first level are used to represent the most obvious features. The second and other levels of semantic annotations will be provided based on the previous levels. All the information is annotated by the users in the original annotation or feedback progress. Figure 18.3 shows the annotation structure of an image.
This framework adopts a composite pattern as the data structure to represent the relation of annotations. In a composite pattern, objects can be composed as a tree structure to represent the part and whole hierarchy. This pattern regards simple and complex elements as common elements. A client can use the same method to deal with complex elements as simple elements, so that the internal structure of the complex elements will be independent with the client program. The data structure using composite pattern is shown in Figure 18.4 [1].
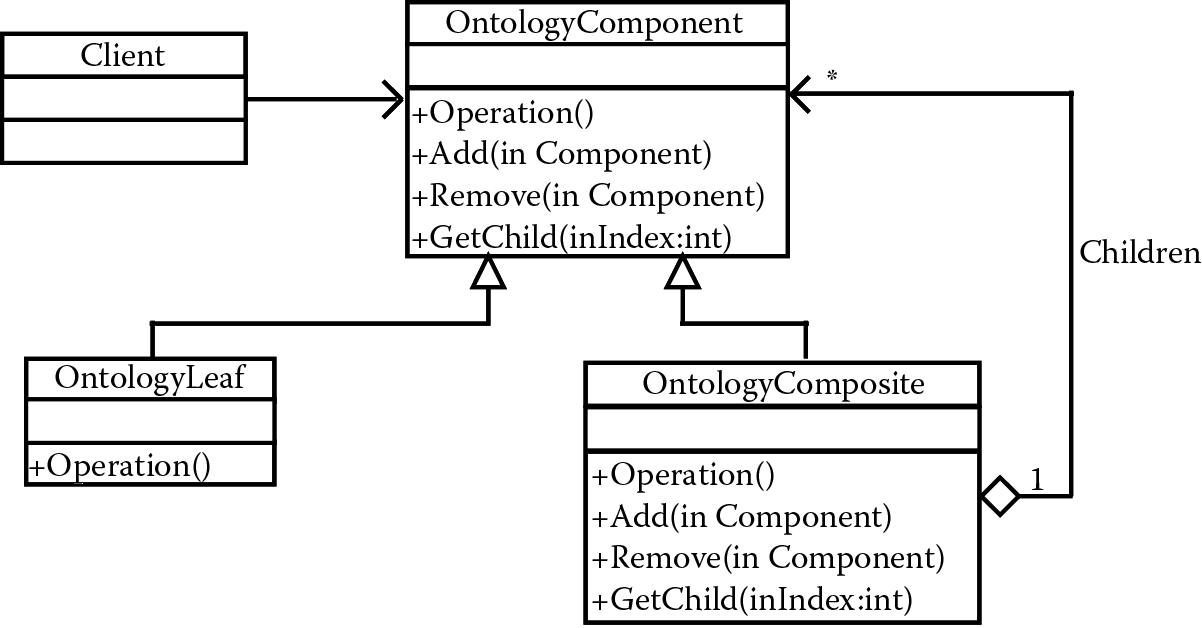
Ontology structure based on composite pattern. (From Guo, K. et al., Wirel. Pers. Commun., 72, 779–793, 2013; Guo, K. and Zhang, S., Comput. Math. Methods Med., 2013, 1–7, 2013.)
In this structure, OntologyComponent is a declared object interface in the composition. In many cases, this interface will implement all the default methods that are shared by all the ontologies. OntologyLeaf represents the leaf node object in the composition, and these nodes have no children nodes. In OntologyComposite, the methods of branch nodes will be defined to store the children components; the operations relative to children components will be implemented in the OntologyComponent interface. Therefore, a composite pattern allows the user to use ontology as a consistency method.
18.3.5 NoSQL-Based Semantic Storage
NoSQL databases have been widely used in industry, including Big Data and real-time web applications. We use NoSQL technology to store the semantic information and the multimedia location, which are represented in map format. A NoSQL database presents all the semantic information in a highly optimized key/value format. We can store and retrieve data using models, which employs less constrained consistency than traditional relational databases such as Oracle, Microsoft SQL Server, and so forth. In this chapter, when using this mechanism, we select Apache HBase to simplify storage.
In a Big Data environment, the velocity and cost efficiency are the most important factors in processing heterogeneous multimedia. In Hadoop, HBase is regarded as the data storage solution, which uses the idea of NoSQL. To facilitate the following data processing in MapReduce, the data structure is required to be changed into (key, value) pairs because the map function takes a key/value pair as input. HBase stores the files with some blocks in data nodes, the size of a block is a fixed value (e.g., 64 MB), and the corresponding multimedia semantic information will be recorded in each block. The file structure is shown in Figure 18.5 [34].
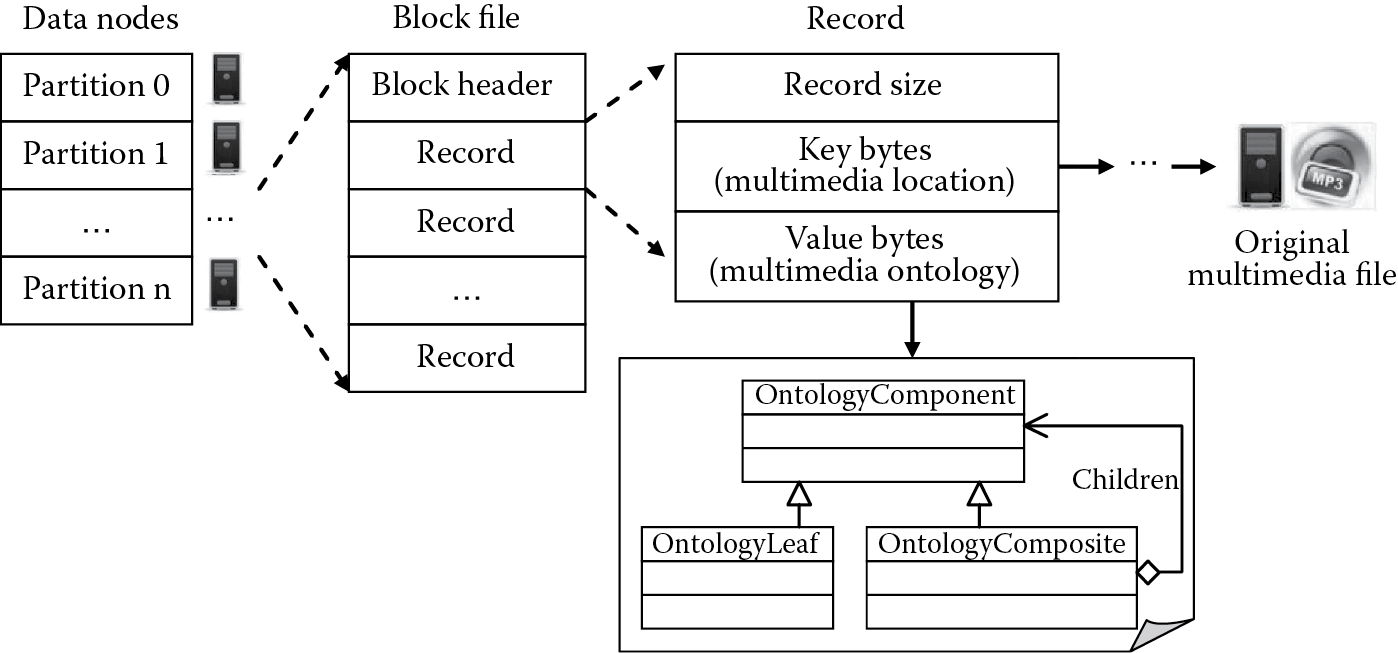
We can see from Figure 18.5 that the block files do not store the multimedia data, in order to reduce the network load during the job dispatching between data nodes. For the record, the key is the location of the original multimedia file, and the value is the ontology content of the multimedia document. The ontology information will be represented as a byte array.
18.3.6 Heterogeneous Multimedia Retrieval
In the retrieval process, firstly, we specify a mapper function, which processes a key/value pair to generate a set of intermediate key/value pairs. Secondly, we design a reducer function that processes intermediate values associated with the same intermediate key.
The user can upload some multimedia documents to execute the retrieval. Similarly, these documents will be assigned semantic information through social annotation. The semantic information will be represented as an ontology and converted into a map structure. In the queries, we assign every query a QueryId and QueryOntology; the returned result will be formed as a ReturnedList. The process of MapReduce-based retrieval is shown in Figure 18.6 [34].
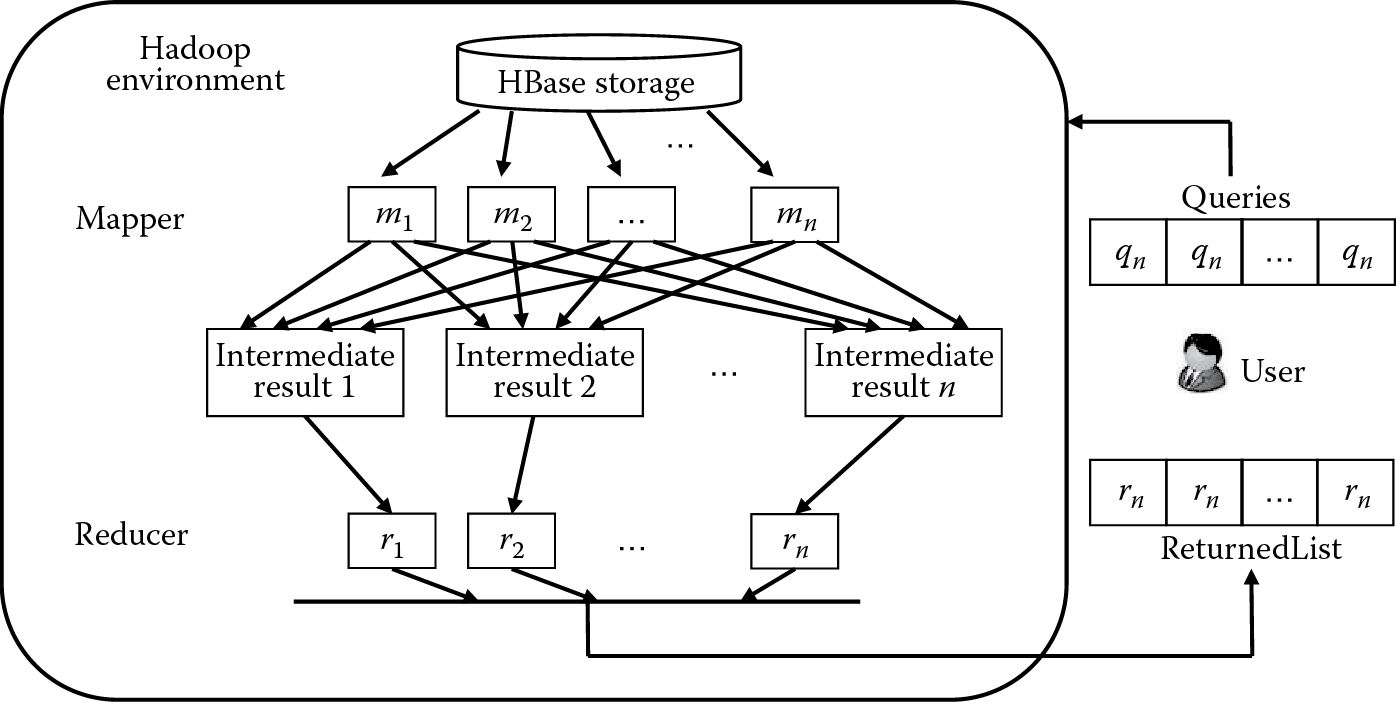
The process of MapReduce-based retrieval. (From Guo, K. et al., J. Syst. Software, 87, 2014.)
In Figure 18.6, the queries will be submitted to the Hadoop environment, and then the mapper and reducer will run. All the returned records will be put into a list. In the queries and returned list, the information will be represented as a byte array. The mapper function takes pairs of record keys (multimedia location) and record values (ontology information). For each pair, a retrieval engine runs all queries and outputs for each matching query using a similarity function. The MapReduce tool runs the mapper functions in parallel on each machine. When the map step finishes, the MapReduce tool groups the intermediate output according to every QueryId. For each corresponding QueryId, the reducer function that runs locally on each machine will simply take the result whose similarity is above the average value and output it into the ReturnedList.
18.4 Performance Evaluation
18.4.1 Running Environment and Software Tools
We developed and deployed our framework on the basis of 10 computers as the data nodes, which can simulate the parallel and distributed system. Every node is a common PC (2.0 GHz CPU, 2 GB RAM), on which are installed Ubuntu Linux and Hadoop 2.0 together with the supporting tools (e.g., Java SDK 6.0, OpenSSH, etc.). We numbered the nodes from 01 to 10 and took node 01 as the master node, and all the nodes were arranged as slave nodes. Therefore, in total, this parallel system has 10 machines, 10 processors, 20 GB memory, 10 disks, and 10 slave data modes. All the experiments were conducted in such a simulated environment. Figure 18.7 shows the running framework in the experiments.
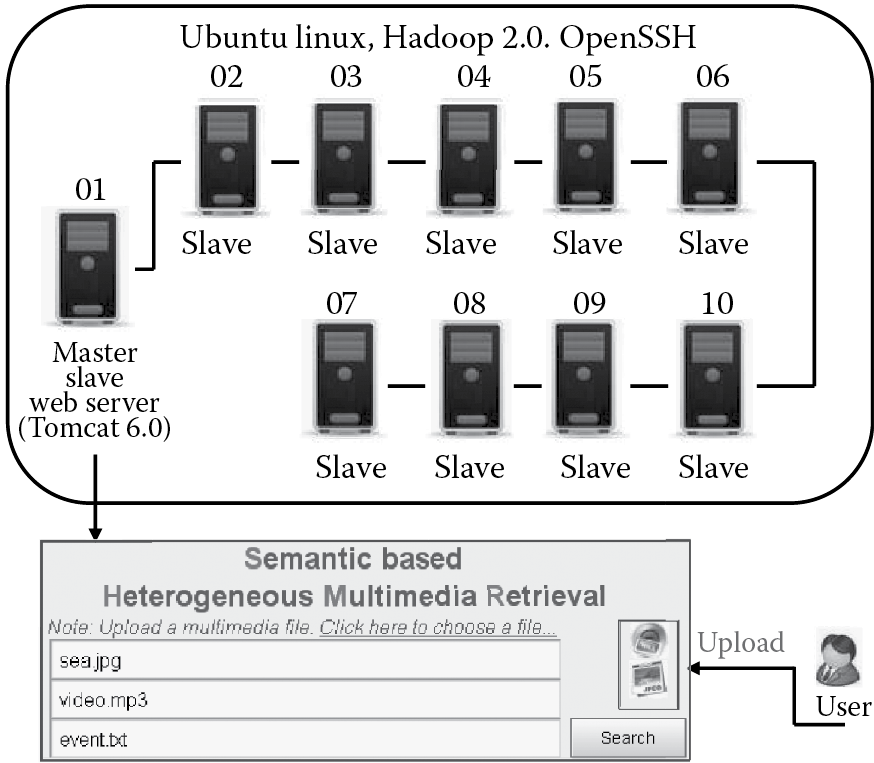
Running framework of performance evaluation. (From Guo, K. et al., J. Syst. Software, 87, 2014.)
In this chapter, we developed some other software tools to verify the effectiveness of our framework. These tools include the following: (1) An annotation interface is used for the users to provide the annotations to the multimedia documents. We developed SMV for PC and mobile device users [1]. (2) Our framework provides a convenient operating interface, which is very similar to the traditional commercial search engines (e.g., Google Images search). Users can upload multimedia documents in the interface and submit the information to the server. The interface was developed using HTML5, and it can run on a typical terminal. (3) For the web server, the search engine was deployed in Tomcat 6.0. In the cluster, the background process was executed every 24 h. Table 18.1 shows the introduction of software tools.
Introduction of Software Tools
|
Software T ool |
Development E nvironment |
Running Environment |
|
SMV |
Microsoft Foundation Classes for PC users Android 5.0 for mobile device users |
Mobile device: 1.2 GHz CPU, 1 GB RAM PC: 2 GHz CPU, 2 GB RAM |
|
User interface |
HTML5 for browser users and mobile device users |
|
|
Search engine |
Java Enterprise Edition 5.0 |
PC: 2 GHz CPU, 2 GB RAM |
|
Server |
Tomcat 6.0 |
PC: 2 GHz CPU, 2 GB RAM |
|
Development tools |
MyEclipse 8.5 Java Enterprise Edition 5.0 |
PC: 2 GHz CPU, 2 GB RAM |
How to construct the data set is an important problem in the experiment. Some general databases have been proposed. However, these databases can only perform the experiments aiming at one particular multimedia type (e.g., image files). Heterogeneous multimedia retrieval requires a wide variety of files such as images, videos, audio, and so forth. So these databases are not suiTable for performing the experiments. In this chapter, we have constructed a multimedia database containing various multimedia types including images, videos, audio, and text documents. In the experiment, we used a multimedia database containing 50,000 multimedia documents, including 20,000 images, 10,000 videos, 10,000 audio files, and 10,000 text documents. All the semantic information of the multimedia documents were provided through the users manually annotating and analyzing the text from the host file (e.g., web page) where the documents are downloaded.
18.4.2 Performance Evaluation Model
In this section, a performance evaluation model is designed to measure the performance of our framework. These models are based on the following three criteria: precision ratio, time cost, and storage cost.
- Precision ratio. Precision ratio is a very common measurement for evaluating retrieval performance. In the experiment, we slightly modify the traditional definition of precision ratio. For each retrieval process, we let the user choose multimedia documents that reflect his/her query intent. We define the set of retrieved results as Rt = {M1, M2,…, Mt} (where t is the number of retrieved multimedia documents) and define the set of all the multimedia documents reflecting users’ intent as Rl = {M1, M2,…,Ml} (where l is the number of relevant documents).
The precision ratio is computed by the proportion of retrieved relevant documents to total retrieved documents. Therefore, the modified precision ratio p can be defined as follows:
(18.5)
The way to determine whether an image reflects the query intent is important. In this chapter, we make the judgment based on the users. However, because the database is large, the user can select results in the first few pages to evaluate the precision ratio.
- Time cost. Time cost includes two factors. The first factor is data process time cost. In our framework, several background processes will cost time. We define the background process time as follows:
tb = tpre + tref (18.6)
where tpre is the preprocess time (convert the semantic and multimedia location to map structure) and satisfies
(18.7)
tref represents the annotation refinement time (eliminate the redundant or error semantic information and add the new semantic information in the feedback).
The second factor is retrieval time. We define tr as the time cost for retrieval. In fact, tr includes extraction time (extract the semantic information from the HBase) and the matching time (match the semantic similarity of the sample document with the stored documents).
- Storage cost. Because the HBase will store the map information, the storage cost will be taken into consideration. The rate of increase for storage ps is defined as follows:
ps = sont/sorg (18.8)
where sont is the size of semantic information of the multimedia documents and sorg is the size of original multimedia documents,
(18.9)
18.4.3 Precision Ratio Evaluation
In the experiment, we first upload a multimedia document to the search engine to search for multimedia documents similar to it. The uploaded file will be annotated by some other users. After uploading the file in the interface, the system will search for all the records whose semantic information is similar to that of the sample document. The time cost includes extracting semantic information from the sample file and matching the semantic information with multimedia documents in HBase.
To measure the performance, we use the images, videos, audio, and text as the sample documents to execute the retrieval. For every sample type, we perform 10 different retrievals using 10 different documents, which are numbered from 01 to 10. The precision ratios are listed in Figure 18.8.
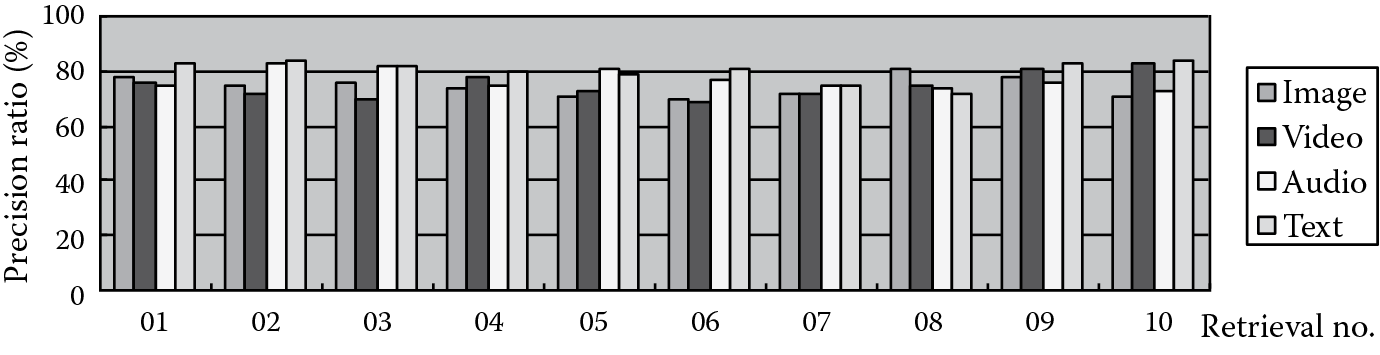
We can see from Figure 18.8 that our framework achieves good retrieval precision ratios. In order to demonstrate the performance of the heterogeneous retrieval, we specially record the precision ratios of using one type to search for the four types (e.g., use an image to search for images, videos, audio, and text documents). For every document type, we perform 10 different retrievals using 10 different sample documents and compute the average precision ratios. The average precision ratios are illustrated in Figure 18.9.
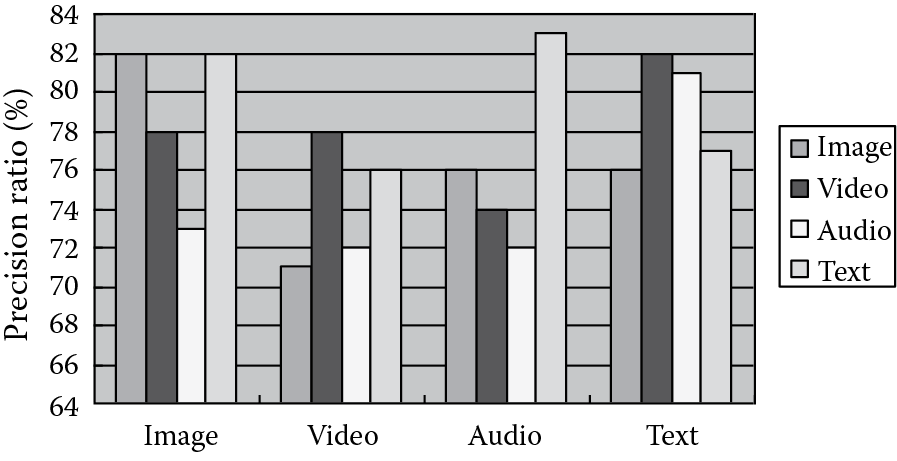
Figure 18.9 indicates that even in the retrieval process between different multimedia types, the precision ratios are not reduced. This is because this framework completely abandons physical feature extraction and executes the retrieval process based only on semantic information.
However, we cannot ignore that some traditional technologies supporting content-based retrieval have good performances too. For example, Google Images search actually can get perfect results reflecting users’ intent in content-based image retrieval. However, it has the following disadvantages in comparison with this framework: (1) This search pattern cannot support heterogeneous retrieval, because of the physical feature extraction. (2) Compared with physical features, annotations can better represent the users’ query intent, so our framework can get more accurate results in case of the semantic multimedia retrieval. If the documents contain more abundant annotations, the retrieval performance will be better. In addition, our framework has the advantage of good speed because of skipping the physical feature extraction.
18.4.4 Time and Storage Cost
In order to carry out the retrieval process, we have to perform several background processes whose time cost is tb, which includestpre and tref. Table 18.2 shows the time cost of the background processes.
We can see from Table 18.2 that tpre, tref will cost some seconds (tb costs about 132 s for image type, 91 s for video type, 71 s for audio type, and 102 s for text type). However, the background processes are not always executed. In the server, the background process will be executed every 24 h in background thread, so this time cost can be accepTable.
Time Cost of Background Processes (s)
|
Multimedia T ype |
tpre |
tref |
tb |
|
Image |
93 |
39 |
132 |
|
Video |
63 |
28 |
91 |
|
Audio |
52 |
19 |
71 |
|
Text |
78 |
24 |
102 |
Now we will measure the retrieval time tr. We specially record the time cost of 16 retrieval processes. For every document type (image, video, audio, and text), we perform four different retrievals (the samples are numbered from 01 to 04). In every retrieval, tr will be recorded respectively. The detailed time cost of 16 retrieval experiments is listed in Figure 18.10.
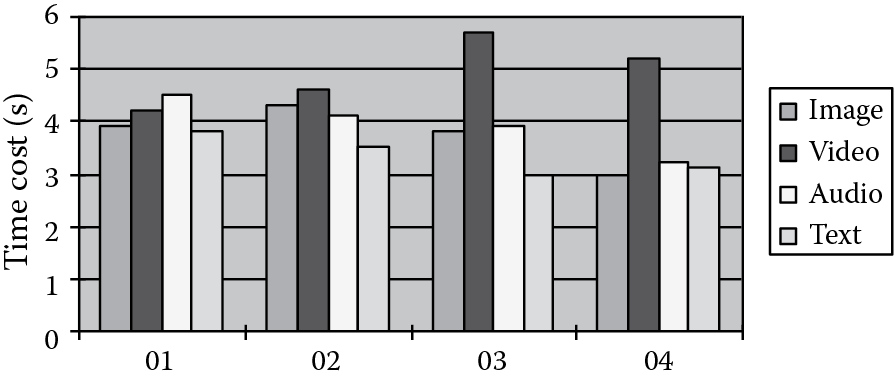
Figure 18.10 shows that the semantic information extraction only costs a very short time; this is because we only need to read the sample document and directly extract the semantic segment from it. After the extraction, the retrieval process will be similar to the text-based retrieval, and Table 18.2 indicates that this process can be executed in accepTable time.
The storage cost will be taken into consideration because the HBase will store the semantic information. Table 18.3 shows the storage space cost.
We can see from Table 18.3 that the semantic information file size has almost not increased for image, video, and audio (ps is about 1.56% for image, 0.18% for video, and 0.32% for audio type); this is because the semantic information is represented as text and the size of semantic files is small. However, the semantic information file size occupies 15.23% for text type; this is because the semantic information in a text file is abundant.
18.5 Discussions and Conclusions
In this chapter, a new approach supporting heterogeneous multimedia retrieval and reflecting users’ retrieval intent has been proposed. We designed the framework and described semantic annotation, ontology representation, ontology storage, a MapReduce-based retrieval process, and a performance evaluation model. Experiment results show that this framework can achieve good performance in heterogeneous multimedia retrieval reflecting the users’ intent.
In this framework, we only need to purchase some cheap computers to perform the semantic storage and retrieval process. Because investment in high-performance server hardware is more expensive than organizing cheap computers into a distributed computing environment, our framework can help us to reduce the cost of hardware investment. Also, in our framework, we use some open-source tools such as Ubuntu Linux, Java SDK, and Hadoop tools. The operating system and software tools can be freely downloaded from the corresponding websites. This will save the investment of software. In addition, Apache Hadoop provides simplified programming models for reliable, scalable, distributed computing. It allows the distributed processing of large data sets across clusters of computers using simple programming models; the programmer can use Hadoop and MapReduce with low learning cost. Therefore, the investment cost is very economical for heterogeneous multimedia Big Data retrieval using our framework.
Acknowledgments
This work is supported by the Natural Science Foundation of China (61202341, 61103203) and the China Scholarship (201308430049).
References
1. K. Guo, J. Ma, G. Duan. DHSR: A novel semantic retrieval approach for ubiquitous multimedia. Wireless Personal Communications, 2013, 72(4): 779–793.
2. K. Guo, S. Zhang. A semantic medical multimedia retrieval approach using ontology information hiding. Computational and Mathematical Methods in Medicine, 2013, 2013(407917): 1–7.
3. C. Liu, J. Chen, L. Yang et al. Authorized public auditing of dynamic Big Data storage on cloud with efficient verifiable fine-grained updates. IEEE Transactions on Parallel and Distributed Systems, 2014, 25(9): 2234–2244.
4. J.R. Smith. Minding the gap. IEEE MultiMedia, 2012, 19(2): 2–3.
5. S. Ghemawat, H. Gobioff, S.T. Leung. The Google file system. ACM SIGOPS Operating Systems Review. ACM, 2003, 37(5): 29–43.
6. F. Chang, J. Dean, S. Ghemawat et al. BigTable: A distributed storage system for structured data. ACM Transactions on Computer Systems, 2008, 26(2): 1–26, Article no. 4.
7. J. Dean, S. Ghemawat. MapReduce: Simplified data processing on large clusters. Communications of the ACM, 2008, 51(1): 107–113.
8. Apache Hadoop. Available at http://hadoop.apache.org/.
9. Apache Hbase. Available at http://en.wikipedia.org/wiki/HBase.
10. R. Zhao, W.I. Grosky. Narrowing the semantic gap-improved text-based web document retrieval using visual features. IEEE Transactions on Multimedia, 2002, 4(2): 189–200.
11. Y. Yang, F. Nie, D. Xu et al. A multimedia retrieval architecture based on semi-supervised ranking and relevance feedback. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2012, 34(4): 723–742.
12. A. Smeulders, M. Worring, S. Santini et al. Content-based image retrieval at the end of the early years. IEEE Transactions Pattern Analysis and Machine Intelligence, 2000, 22(12): 1349–1380.
13. G. Zhou, K. Ting, F. Liu, Y. Yin. Relevance feature mapping for content-based multimedia information retrieval. Pattern Recognition, 2012, 45(4): 1707–1720.
14. R.C.F. Wong, C.H.C. Leung. Automatic semantic annotation of real-world web images. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2008, 30(11): 1933–1944.
15. A. Gijsenij, T. Gevers. Color constancy using natural image statistics and scene semantics. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2010, 33(4): 687–698.
16. W. Lei, S.C.H. Hoi, Y. Nenghai. Semantics-preserving bag-of-words models and applications. IEEE Transactions on Image Processing, 2010, 19(7): 1908–1920.
17. T. Hofmann. Unsupervised learning by probabilistic latent semantic analysis. Machine Learning, 2001, 42(1–2): 177–196.
18. D.M. Blei, A.Y. Ng, M.I. Jordan. Latent Dirichlet allocation. Journal of Machine Learning Research, 2003, 3(1): 993–1022.
19. Y. Gao, J. Fan, H. Luo et al. Automatic image annotation by incorporating feature hierarchy and boosting to scale up SVM classifiers. In Proceedings of the 14th ACM International Conference on Multimedia, Santa Barbara, CA, 2006: 901–910.
20. G. Carneiro, A. Chan, P. Moreno, N. Vasconcelos. Supervised learning of semantic classes for image annotation and retrieval. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2007, 29(3): 394–410.
21. N. Rasiwasia, P.J. Moreno, N. Vasconcelos. Bridging the gap: Query by semantic example. IEEE Transactions on Multimedia, 2007, 9(5): 923–938.
22. J. Shi, J. Malik. Normalized cuts and image segmentation. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2000, 22(8): 888–905.
23. F. Monay, D. Gatica-Perez. Modeling semantic aspects for cross-media image indexing. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2007, 29(10): 1802–1817.
24. D. Djordjevic, E. Izquierdo. An object and user driven system for semantic-based image annotation and retrieval. IEEE Transactions on Circuits and Systems for Video Technology, 2007, 17(3): 313–323.
25. S.C.H. Hoi, J. Rong, J. Zhu, M.R. Lyu. Semi-supervised SVM batch mode active learning for image retrieval. In Proceedings of 2008 IEEE Conference on Computer Vision and Pattern Recognition, Anchorage, AK, IEEE Computer Society, 2008: 1–7.
26. J. Li, J.Z. Wang. Automatic linguistic indexing of pictures by a statistical modeling approach. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2003, 25(9): 1075–1088.
27. R. Albertoni, R. Papaleo, M. Pitikakis. Ontology-based searching framework for digital shapes. Lecture Notes in Computer Science, 2005, 3762: 896–905.
28. M. Attene, F. Robbiano, M. Spagnuolo. Part-based annotation of virtual 3d shapes. In Proceedings of International Conference on Cyberworlds, Hannover, Germany, IEEE Computer Society Press, 2007: 427–436.
29. M. Attene, F. Robbiano, M. Spagnuolo, B. Falcidieno. Semantic annotation of 3d surface meshes based on feature characterization. Lecture Notes in Computer Science, 2009, 4816: 126–139.
30. M. Gutiérrez, A. García-Rojas, D. Thalmann. An ontology of virtual humans incorporating semantics into human shapes. The Visual Computer, 2007, 23(3): 207–218.
31. Z.J. Li, V. Raskinm, K. Ramani. Developing ontologies for engineering information retrieval. IASME Transactions Journal of Computing and Information Science in Engineering, 2008, 8(1): 1–13.
32. X.Y. Wang, T.Y. Lv, S.S. Wang. An ontology and swrl based 3d model retrieval system. Lecture Notes in Computer Science, 2008, 4993: 335–344.
33. D. Yang, M. Dong, R. Miao. Development of a product configuration system with an ontology-based approach. Computer-Aided Design, 2008, 40(8): 863–878.
34. K. Guo, W. Pan, M. Lu, X. Zhou, J. Ma. An effective and economical architecture for semantic-based heterogeneous multimedia big data retrieval. Journal of Systems and Software, 2014, 87 pp.