
2.6. Audio-Based Feature Extraction and Pattern Classification
Audio-based feature extraction consists of parameterizing speech signals into a sequence of feature vectors, which are less redundant for statistical modeling. Although speech signals are nonstationary, their short-term segments can be considered to be stationary. This means that classical signal processing techniques, such as spectral and cepstral analysis, can be applied to short segments of speech on a frame-by-frame basis.
It is well known that the physiological and behavioral characteristics of individual speakers are different. While the physiological differences (e.g., vocal tract shape) result in the variation of low-level spectral features among speakers, the behavioral differences (e.g., voice source, speaking rate, use of words) contribute to the variation in the high-level, suprasegmental features.
2.6.1. Low-Level Features
Short-term spectral measurements are currently the most common feature extraction method for speaker recognition. In this approach, time-domain speech signals are divided into a number of overlapping frames, with frame sizes of 20ms to 30ms. For each frame, either linear predictive-based cepstral parameters or filter-bank-based cepstral parameters are extracted.
LP-Based Cepstral Parameters
Linear prediction (LP) analysis [228] is based on the assumption that the current sample of speech signals s(n) can be predicted from the past P speech samples;
![]()
where ![]() are called the LP coefficients. It is also assumed that the excitation source Gu(n), where G is the gain and u(n) is the normalized excitation, can be separated from the vocal tract. These two assumptions lead to a simple source-filter model where the vocal tract is represented by an IIR filter of the form
are called the LP coefficients. It is also assumed that the excitation source Gu(n), where G is the gain and u(n) is the normalized excitation, can be separated from the vocal tract. These two assumptions lead to a simple source-filter model where the vocal tract is represented by an IIR filter of the form
Equation 2.6.1
![]()
In the time-domain, the output s(n) of this IIR filter is a linear regression of its (finite) past output values and the present input Gu(n):
![]()
The goal of LP analysis is to determine a set of LP coefficients a = {a1,..., ap} for each frame of speech such that the frequency response of Eq. 2.6.1 is as close to the frequency spectrum of the speech signal as possible (i.e., |H(ω)| ≈ |S(ω)|). This is achieved by minimizing the sum of the prediction error for each frame. Specifically, for speech frame ![]() starting at sample n, compute this:
starting at sample n, compute this:
Equation 2.6.2
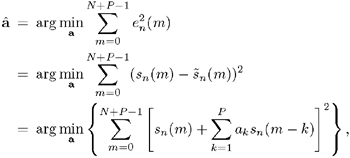
where â = {â1,..., âp}, m = 0,..., N + P - 1 is the index for accessing the speech samples in the current frame and N is the number of samples per frame. The solution to this minimization problem (see Problem 15) is a matrix equation of the form:
Equation 2.6.3
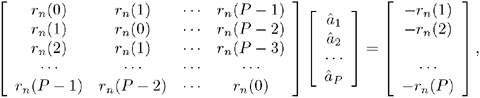
where rn(k) is an autocorrelation function
![]()
As a numerical example, let s(0) = 2.0, s(l) = -1) = -1.0, s(2) = 1.0, and s(3) = s(4) = ··· = s(N - 1) = 0.0 and P = 2.[1] Thus,
[1] For notation simplicity, the subscript n has been dropped.

Substituting r(1), r(2), and r(3) into Eq. 2.6.3, the following LP coefficients is obtained:
![]()
Hence, the transfer function of the vocal tract filter is
![]()
Although LP coefficients represent the spectral envelope of the speech signals, it was found that smoothing the LP-based spectral envelopes by cepstral processing can provide a more consistent representation of a speaker's vocal tract characteristics from one utterance to another [13]. The cepstral coefficients cn can be computed directly from LP coefficients ak [228] as follows (see also Problem 18):
Equation 2.6.4
![]()
Equation 2.6.5
![]()
Equation 2.6.6
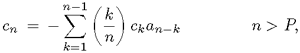
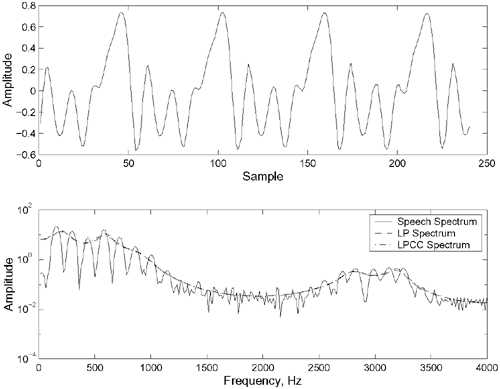
where G is the estimated model gain and P is the prediction order. Figure 2.9 depicts the process of obtaining the LP-based cepstral parameters. As the coefficients are derived from LP analysis, they are referred to as LP-derived cepstral coefficients (LPCCs) in the literature. Figure 2.10 compares the spectrum, the LP-spectral envelope, and the LPCC-spectral envelope of a voiced speech frame. Evidently, the envelopes created by both the LP coefficients and the LPCCs are able to track the peaks (formants) of the speech spectrum. Because different individuals produce speech with different formants (even for the same class of sounds), LPCCs can be used as a feature for speaker recognition.

Figure 2.10. Comparison of the spectrum, LP-spectral envelope, and LPCC-spectral envelope of a frame of voiced speech. Top, time-domain speech signal; bottom, frequency spectra.
Filter-Bank-Based Cepstral Parameters
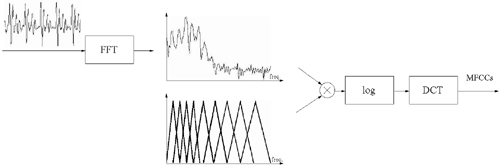
Similar to the LPCCs described before, filter-bank-based cepstral parameters are also derived from speech signals on a frame-by-frame basis. However, unlike LP analysis, a number of triangular filters with different center frequencies and bandwidth are applied to the speech signals. Each of these filters extracts the average of the frequency spectrum in a particular frequency band. Typically, the Mel scale, which is an auditory scale similar to the frequency scale of the human ear, is used for positioning the filters. The outputs of these filters form a spectral envelope, and a discrete cosine transform is applied to the filters' output to obtain the cepstral coefficients [69]:
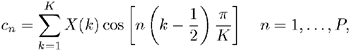
where X(k) is the logarithm of the k-th filter bank's output, K is the number of filter banks, and P is the number of cepstral coefficients for recognition. Because the Mel scale is used in the processing, the coefficients are referred to as Mel-frequency cepstral coefficients (MFCCs). Figure 2.11 depicts the process of extracting the MFCCs.
Dynamic Parameters
In speech recognition, the first- and second-order LPCCs or MFCCs are also computed by using polynomial approximation as follows [107]:
![]()
where L is typically equal to 3. Similar dynamic features are also extracted from the log-energy. Together with the cepstral coefficients cn, n = 1,..., P, a feature vector will contain 39 (=12 + 12 + 12 + 1 + 1 + 1) elements if P = 12. The dynamic features are important for speech recognition because the rate of change of spectral shape and energy could be different from phones to phones. Incorporating these parameters into the feature vectors can certainly help improve the performance of large-vocabulary continuous-speech recognition systems, as most of these systems use phone-based hidden Markov models [395].
In speaker recognition, the change in energy and rate of energy change may not be as significant as those in speech recognition. This is especially the case in text-independent speaker recognition, where the energy profile of utterances could be very different, even though they are produced by the same speaker. Therefore, Gaussian mixture models (see Chapter 5), instead of hidden Markov models, are usually used for modeling the vocal tract characteristics of individual speakers, and the order of presenting the feature vectors to the models is irrelevant. On the other hand, energy and energy profile play an important role in text-dependent speaker recognition because it is possible to use phone- or word-based speaker models. During a verification session, the claimant is asked to utter a prompted phrase, and the energy profile can help the spectral features detect the misalignment between the prompted phrase and utterance.
2.6.2. High-Level Features
The low-level features described before assume that every 10ms to 20ms of speech can be treated independently. These features work well when the amount of recorded speech is in the order of seconds. However, if the amount of recorded speech increases to the 10s of seconds, or even in the order of minutes, extracting features that span a longer time scale will become attractive. It is commonly believed that, apart from using spectral contents, humans also recognize speakers based on their speaking style, speaking rate, prosody, rhythm, intonation, accent, word and phrase usage, frequency of occurrence of specific words, and so on. These high-level features will be very useful for automatic speaker recognition if they can be extracted reliably.
Early attempts to use high-level features date back to the early 1970s. For example, in Atal [12], pitch contours were used as speaker features. Although it has become clear that using pitch contours alone is not very effective, pitch-based information contained in the MFCCs of the LP-residual signals can be added to the static MFCCs for speaker recognition [290, 292, 398]. The idea comes from speech coding in which the construction of the LP-residual plays an important role in enhancing the quality of coded speech. Other high-level features that have been used for speaker recognition include idiolectal and prosodic information [82, 374]. Building speaker recognition systems that can make use of this information, however, requires a large prosodic database, which may be difficult to achieve in practice.
2.6.3. Robustness in Speech Features
As a result of the proliferation of e-banking and e-commerce, recent research on speaker verification has focused on verifying speakers' identity over the phone. A challenge of phone-based speaker verification is that transducer variability could result in acoustic mismatches between the speech data gathered from different handsets. The recent popularity of mobile and Internet phones further complicates the problem because speech coders in these phones also introduce acoustic distortion into speech signals. The sensitivity to handset variations and speech coding algorithms means that handset compensation techniques are essential for practical speaker verification systems. Therefore, the ability to extract features free from environmental distortion is of primary importance.
Efforts to address reliability issues in speech-based biometrics have centered on two main areas: channel mismatch equalization and background noise compensation.
Channel Mismatch Equalization
In the practical application of speaker recognition, speech is typically collected under different acoustic environments and communication channels, causing mismatches between speech gathered during enrollment and during verification. Three main schools of thought have been used to address this problem. The first looks at the local spectral characteristics of a given frame of speech. Early attempts included cepstral weighting [351] and bandpass liftering [172]. These approaches, however, assume that all frames are subject to the same distortion. This assumption has been avoided by more recent proposals, such as adaptive component weighting [11] and pole-zero postfiltering [406]. However, the experiments in these studies have limitations because the speech corpora (KING and TIMIT with channel simulators) they used do not allow for proper examination of handset variability. More effort must be made to investigate whether these approaches are sensitive to handset variation.
The second school exploits the temporal variability of feature vectors. Typical examples include cepstral mean subtraction [13], pole-filtered cepstral mean subtraction [258], delta cepstrum [107], relative spectral processing [134], signal bias removal [294], and the modified-mean cepstral mean normalization with frequency warping [112]. Although these methods have been successfully used in reducing channel mismatches, they have limitations because they assume that the channel effect can be approximated by a linear filter. Most phone handsets, however, exhibit energy-dependent frequency responses [308] for which a linear filter may be a poor approximation. Therefore, a more complex representation of handset characteristics is required.
The third school uses affine transformation to correct the mismatches [229], where speaker models can be trained on clean speech and operated on environmentally distorted speech without retraining. This approach has the advantage that both convolutional distortion and additive noise can be compensated for simultaneously. Additional computation is required during verification, however, to compute the transformation matrices.
Background Noise Compensation
It has been shown that approximately 40% of phone conversations contain competing speech, music, or traffic noise [79]. This figure suggests the importance of background noise compensation in phone-based speaker verification. Early approaches include spectral subtraction [30] and projection-based distortion measures [231]. More recently, statistical-based methods (e.g., the noise integration model [317] and signal bias removal [294]) have been proposed. The advantage of using statistical methods is that clean reference templates are no longer required. This property is particularly important to phone-based applications because clean speech is usually not available.
Joint Additive and Convolutional Bias Compensation
There have been several proposals aimed at addressing the problem of convolutional distortion and additive noise simultaneously. In addition to the affine transformation mentioned before, these proposals include stochastic pattern matching [332], parallel model combination [111], state-based compensation for continuous-density hidden-Markov models [4], and maximum likelihood estimation of channels' autocorrelation functions and noise [405]. Although these techniques have been successful in improving speech recognition performance, caution must be taken when they are applied to speaker recognition. This is because adapting a speaker model to new environments will affect its capability in recognizing speakers [18].
2.6.4. Classification Schemes for Speech-Based Biometrics
Similar to the visual-based biometrics described in Section 2.5, feature extraction in audio-based biometrics is followed by pattern classification in which the characteristics of individual speakers are modeled. For verification applications, a number of decision strategies have been developed to improve system performance.
Speaker Modeling
The choice of speaker models depends mainly on whether the verification is text-dependent or text-independent. In the former, it is possible to compare the claimant's utterance with that of the reference speaker by aligning the two utterances at equivalent points in time using dynamic time warping (DTW) techniques [107]. An alternative is to model the statistical variation in the spectral features. This is known as hidden-Markov modeling (HMM), which has been shown to outperform the DTW-based methods [259]. In text-independent speaker verification, methods that look at long-term speech statistics [232], or consider individual spectral vectors as independent of one another, have been proposed. The latter includes vector quantization (VQ) [342], Gaussian mixture models (GMMs) [301], and neural networks [222, 265].
Decision Strategies
Research has shown that normalizing speaker scores can reduce error rates. Early work includes the likelihood ratio scoring proposed by Higgins et al. [136] and the cohort normalized scoring proposed by Rosenberg et al. [318]. Subsequent work based on likelihood normalization [215, 235] and minimum verification error training [320] also shows that including an impostor model not only improves speaker separability but also allows the decision threshold to be easily set. Rosenberg and Parthasarathy [319] established some principles for constructing impostor models and showed that those with speech closest to the reference speaker's model perform the best. Their result, however, differs from that of Reynolds [302], who found that a gender-balanced, randomly selected impostor model performs better, suggesting that more work is required in this area.