
2.7. Concluding Remarks
In this chapter, various biometric identification models are reviewed and key design issues and tradeoffs for biometric authentication systems are explored. As vital background information for later chapters, several commonly used feature extraction algorithms for visual-based and audio-based biometric systems are described. In real-world situations, most people divide the BI model selection problem into optimization of the feature extraction algorithms and then optimization of pattern classification algorithms, under the constraints of compatibility, data storage, speed, and data availability. Various existing feature extraction and pattern classification methods are investigated. The tradeoff between the feature extractor and the pattern classifier in the BI models is also addressed.
Problems
A function is scale-invariant if φ(αy) = φ(y). Verify that the kurtosis function k(y) is scale-invariant.
Deflation Procedure. The deflation involves the removal of the already extracted independent component(s) from the original space x(t). Assuming that the first IC-extracting vector W1 is already derived from Eq. 2.3.1. Then, let us define
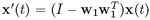 , which in effect spans only a (deflated) (n — l)-dimensional subspace. The second most discriminative independent component can be found from the deflated subspace. Mathematically, the aim is to find a vector w2 such that
, which in effect spans only a (deflated) (n — l)-dimensional subspace. The second most discriminative independent component can be found from the deflated subspace. Mathematically, the aim is to find a vector w2 such that  yields the minimum kurtosis:
yields the minimum kurtosis:Equation 2.7.1
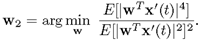
Furthermore, to better ensure numerical stability, the following SVD approach is proposed in the KuicNet algorithm [189]. By the SVD property, [Worth|w] in the following SVD factorization forms a unitary matrix:
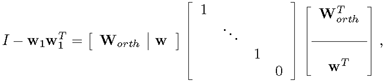
where Worth is an n × (n - 1) matrix, corresponding to the (n - 1) singular vectors. Now let's define a new (n - l)-dimensional vector process: v(t) =
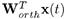 , and find a vector
, and find a vector 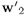 such that
such that  has a minimum kurtosis; that is,
has a minimum kurtosis; that is,Equation 2.7.2
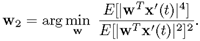
Show that the second IC-extracting vector w2 can be derived from
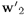 . In fact, verify that
. In fact, verify that
Show that, by a recursive procedure, all of the other components {wj, j > 2} can be similarly derived.
Write a MatLab program for sequential extraction of the independent components based on the deflation procedure.
Among various potential applications of face recognition techniques, significant differences exist in terms of image quality and the availability of a well-defined matching criterion. A small number of exemplar applications are listed here:
Credit card and ID cards (including driver's license, passport, etc.)
Bank security
Photo matching
Public surveillance
Expert/witness identification
Note that the first three applications involve matching one face image to another, while the last two applications involve finding a face resembling the human recollection of a facial image [52]. Among these applications, which is the most advantageous in terms of controlled image, controlled segmentation, and good quality images? Also, which application (s) bears the most disadvantages in terms of
the lack of an existing database
a potentially huge database
uncontrolled segmentation
low image quality
Among the applications listed in Problem 3, select application(s) where recognition is more desirable than verification.
Among the list of applications in Problem 3, select the application(s) where distributed systems are more desirable than centralized systems. That is, which application(s) have the potential to make a best use of a geographically localized search. Explain the situations where data can be stored locally and where data should be stored centrally.
Face recognition techniques can be classified into two groups: (1) static matching and (2) dynamic matching, depending on the availability of video images. Among the list itemized in Problem 3, select the application(s) that could effectively make use of the dynamic matching technology. Explain why.
Given controlled imaging conditions, segmentation/location of a face is usually straightforward. Among the applications listed in Problem 3, select the application(s) which are potentially easiest for segmentation/location of a face. Which are potentially the most difficult? Explain why.
Although imaging conditions are controlled for many key applications, feature extraction and face matching must take into account variations in the face due to aging, hair loss, hair growth, and so on. Suggest plausible solutions to tackle these problems.
Image segmentation is important for image analysis and face recognition. The contour of a segmented object offers a more reliable representation than the grey levels of image pixels. Prominent examples for contour representations include chain codes, B-spline representation, and Fourier descriptors (described next). For the Fourier descriptors, a trace function is expressed by a complex function
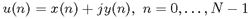
whose discrete Fourier transform representation is

The complex coefficients a(k) are called the Fourier descriptors (FDs) [273]. Two shapes are considered similar if their (normalized) FDs have a short distance. The FDs are invariant with respect to many geometric transformations. For example, the FDs can be used to match similar shapes even if they are of different size and orientation. Show that
normalized FDs are invariant to scaling.
the magnitudes of the FDs |a(k)| for all k's except k = 1 have invariant properties with respect to starting point, rotation, and reflection.
the magnitudes of FDs are invariant to shift.
A face recognition system uses the distances between various facial features to identify people. The feature extractor contains a bank of local feature detection filters to detect the positions of the nose, mouth, chin, and eyes. The feature vector that feeds into the recognizer is formed by the distance measures between those detected points. The recognizer is an MLP with 10 hidden neurons (see Section 5.4 for detailed discussions on MLPs). Suppose the processing time for each local feature detector is the same—that is, t(Fi(x)) = F for all i—and the processing time for each neuron in the MLP is also the same, that is, t(Cj(x)) = C for all j. Assume that C equals to 0.2F.
If one downsizes the feature extractor to eye and nose detection alone, while keeping the recognizer the same, can the identification time be reduced?
Suppose one needs to increase the number of hidden nodes in the MLP to maintain the same recognition rate. If the number of hidden nodes is linearly proportional to the reciprocal of the dimension of the input feature vectors, can the identification time be reduced with eyes and nose detection only?
Template-based visual feature extraction often decomposes the input image into several levels of low- and high-spatial frequency components (e.g., FFT, wavelets).
Describe the pros and cons of using low- or high-frequency information for recognition.
If the object is (1) poorly illuminated or (2) photographed by a low-quality camera, what can be done to maintain image invariance?
A centralized speaker verification system uses 1024-center Gaussian mixture speaker models to characterize client speakers and a 1024-center universal background model to characterize impostors. The feature extractor of the system computes 12-dimensional MFCCs and their first derivative every 15ms. How would you reduce the computation requirements when verification is to be done locally on a handheld device?
Assuming that an e-banking system has 100, 000 users, estimate the storage requirements using your favorite speaker verification technology (please specify) as a means of enhancing access-control security. Repeat the preceding but use your favorite face recognition technology.
The vocal tract can be modeled by an all-pole filter of the form
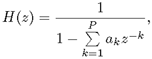
where ak (k = 1,..., P) are the prediction coefficients.
By minimizing the error between the speech signal s(n) and its predicted value, show that
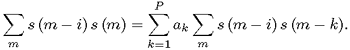
Hence, show that the LP coefficients {ak; k = 1,..., P} are the solutions of the matrix equation
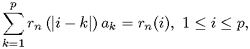
where

is the autocorrelation function of speech signal s(n) at lag i - k, and N is the frame size.
Determine the LP coefficients {ak; k = 1,..., P} when s(0) = -1.0, s(l) = 1.0, s(2) = s(3) = ··· = s(N - 1) = 0.0, and P = 2.
Plot the frequency response of H(z).
Hence, determine the formant frequency (or frequencies) of s(n), assuming that the sampling frequency of s(n) is 8kHz.
Suggest an appropriate value for P so that the first three formant frequencies of speech signals can be accurately modeled.
Answer the following questions based on a vocal-tract filter of the form
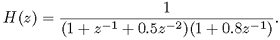
Determine the poles of H(z).
Plot the poles on a z-plane.
Assume that the sampling frequency is 8kHz. Determine the resonance frequencies.
Sketch the frequency response of H(z) (i.e., plot | H(ejω)| against ω).
Identify the type of sounds (voiced or unvoiced) whose spectra are best modeled by |H(ejω)| and give a brief explanation.
In linear-prediction analysis, the transfer function of the inverse filter can be written as

where ak (k = 1,..., p) are the predictor coefficients. If all the zeros of A(z) are inside the unit circle, log A(z) can be expressed as:

where cn is the cepstrum of A(z).
By differentiating log A(z) with respect to z-1, show that

Hence show that
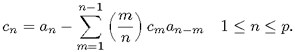
Hence, express the cepstrum of the vocal-tract filter H(z) in terms of an, where H(z) = 1/A(z).
The cepstral coefficients of a speech signal s(n) can be obtained by using the definition of cepstrum:
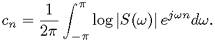
Alternatively, they can be derived from the predictor coefficients ak (k = 1,..., p) according to the results in Problem 18b and Problem 18c. Comment on the differences between the cepstral coefficients derived from these two approaches.
The spectral similarity measure between two spectra, S1(ω) and S2(ω), is defined as

Show that

where c1(n) and c2(n) are the complex Cepstral coefficients of S1(ω) and S2(ω), respectively. Hint: Use the relationship

where
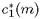 and
and  are the complex conjugates of c1(m) and c2(m), respectively.
are the complex conjugates of c1(m) and c2(m), respectively.Given that c(n) → 0 when n → ∞, show that the distance between two spectra is approximately equal to the Euclidean distance between the two corresponding cepstral vectors; that is, show that
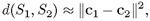
where ci = [c1 c2 ··· CL]T for some finite integer L.
Hence, discuss the advantages of using cepstral vectors for speech/speaker recognition.
Explain why the frame size for the spectral analysis of speech is usually set to 20ms to 30ms.
Compare the Hamming window against the rectangular window in the context of their magnitude spectra. Explain the possible advantage(s) of using the Hamming window in spectral analysis of speech.