
9.6. Speaker Verification Based on Articulatory Features
Most traditional speaker verification systems are based on the modeling of short-term spectral information [306]. These systems compute the ratio of the likelihood of the genuine speaker model to the likelihood of the impostor model given some spectral features extracted from a claimant. The resulting likelihood ratio is compared against a threshold for decision making. The advantage of using short-term spectral information is that promising results are obtainable from a limited amount of training data. However, spectral information is only one of many sources suitable for speaker verification. For example, in addition to the spectral information, humans make use of high-level information, such as dialect and lexical characteristics [81], to recognize speakers. Although these characteristics are closely related to the unique speech production process, they are usually ignored by most speaker verification systems. Mainly, this is because obtaining such information reliably from speech signals remains a challenging research problem.
In recent years, researchers have started to investigate the use of high-level speaker information for speaker verification [309]. Such information includes (1) prosodic features obtained from pitch and energy tracking and (2) phonetic features derived from phone sequences using speech recognizers and language models. Recent research has shown that using high-level features alone can achieve reasonably good speaker recognition performance [309]. It has also been shown that a significant improvement in speaker recognition accuracy can be obtained when the features are combined with spectral features using a simple perceptron fusion [42].
In addition to the high-level features mentioned here, properties arising from the speech production process can be used for recognizing speakers. Speech is produced by a sequential movement of articulators in the vocal tract excited by an air stream originating from the lungs. The combined effects of articulation and excitation, which give rise to the produced speech, are the origin of unique speaker characteristics [81] and the source of high-level features. Gupta et al. [122] have demonstrated that features derived from glottal excitation are useful for speaker verification; however, glottal features be derived only from voiced speech.
Combining the movement or position of articulators with glottal features for speaker verification might alleviate the shortcomings of glottal features. Specifically, articulatory features (AFs) can be used to capture the position and movement of articulators during speech production for speaker verification. AFs have been adopted as an alternative, or a supplementary feature, for automatic speech recognition (see references [88, 103, 181, 202, 312]) and confidence measures [203]. The studies have demonstrated the usefulness of AFs, either used alone or together with spectral features such as MFCCs.
In an early 2004 study, Leung et al. [201], five important speech production properties, including the manner and place of articulation, voicing of speech, lip rounding, and tongue position, were considered as features for verifying speakers. For each property, a classifier was used to determine the probability of different classes given a sequence of spectral features. The outputs of the five classifiers, which can be considered as the abstract representation of the five speech production properties, were concatenated to form the AF vectors for speaker verification. It was found that AFs are complementary to spectral features and that a significant reduction in EERs can be achieved when they are used together with spectral features in a speaker verification system.
9.6.1. Articulatory Feature Extraction
To extract AFs from speech, a set of articulatory classifiers are taught the mappings between the acoustic signals and the articulatory states. Either images (e.g., an X-ray that records the actual articulatory positions [400]) or mappings between phonemes and their corresponding articulatory properties [2, 50] can be used to train the AF classifiers. Images that track real articulatory positions can help reduce the correlation between the extracted AFs and speech data; however, collecting sufficient data to run large-scale experiments is too expensive. Consequently, it is more common to use phoneme-to-articulatory state mappings [181] to extract AFs. The average AFs classification rate can be more than 80% under matched conditions [2, 50], and the mapping approach has been adopted in many speech recognition systems [88, 181, 202, 312].
A mapping approach similar to that of Kirchhoff [181] was adopted for this work (i.e., AFs were extracted from acoustic signals using phoneme-to-articulatory mappings). Specifically, to obtain the AFs a sequence of acoustic vectors were fed to five classifiers in parallel, where each classifier represents a different articulatory property. The outputs of these classifiers (the posterior probabilities) were concatenated to form the AF vectors. As a result, the extracted AFs can be considered an intermediate representation of the acoustic signals.
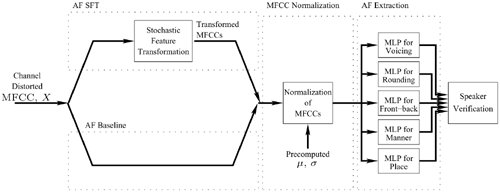
In this verification system, five different articulatory properties are used, as tabulated in the first column of Table 9.17. For each property, a multi-layer perceptron (MLP) estimates the probability distributions of its predefined output classes (see second column of table). The AF extraction process is illustrated in the right-dotted box of Figure 9.27.
Figure 9.27. System block diagram of speaker verification using AFs extracted from MFCCs or using MFCCs after SFT. The normalization parameters, μ and σ, are determined from the clean MFCCs (i.e., senh). The thick arrows represent multidimension inputs and outputs. Each AF-MLP takes 9 consecutive, 12-dimensional normalized MFCCs as input. The number of outputs for the voicing, rounding, front-back, manner, and place MLPs are 2, 3, 3, 5, and 9, respectively.
| Articulatory Properties | Class | Number of Classes |
|---|---|---|
| Voicing | Voiced, unvoiced | 2 |
| Front-back | Front, back, nil | 3 |
| Rounding | Rounded, not rounded, nil | 3 |
| Manner | Vowel, stop, fricative, nasal, approximant-lateral | 5 |
| Place | High, middle, low, labial, dental, coronal, palatal, velar, glottal | 9 |
The inputs to these five AF-MLPs are identical, while their output numbers are equal to the number of AF classes listed in the last column of Table 9.17. To ensure a more accurate estimation of the AF values, multiple frames of MFCCs served as inputs to the AF-MLPs. More specifically, for the t-th frame of an utterance, a block of "normalized" MFCCs at frames ![]() (where n = 8 in this work) is presented to the AF-MLPs. Rather than feeding the MFCCs directly to the AF-MLPs, they are normalized to zero mean and unit variance. The normalization parameters, a mean vector μ, and a standard deviation vector σ—each with dimension the same as that of the MFCCs—are obtained globally from the training data. Given an MFCC vector xt, the normalization for dimension i is done by applying
(where n = 8 in this work) is presented to the AF-MLPs. Rather than feeding the MFCCs directly to the AF-MLPs, they are normalized to zero mean and unit variance. The normalization parameters, a mean vector μ, and a standard deviation vector σ—each with dimension the same as that of the MFCCs—are obtained globally from the training data. Given an MFCC vector xt, the normalization for dimension i is done by applying
Equation 9.6.1
![]()
The normalization aims to remove the variations of input features among different dimensions so that the determination of MLP weights will not be dominated by those input features with large magnitude.
The AF-MLPs can be trained from speech data with time-aligned phonetic labels. The alignments can be obtained from transcriptions or from Viterbi decoding using phoneme models. With the phoneme labels, articulatory classes can then be derived from the mappings between phonemes and their states of articulation [181].
9.6.2. AF-Based Speaker Verification
Figure 9.28 illustrates the procedures of phone-based speaker verification using AFs as features. The procedures can be divided into four steps. First, the most likely handset is identified by the handset selector (described in Section 9.4.2); second, the MFCCs are normalized using the parameters of the selected handset; third, the normalized MFCCs are fed to five AF-MLPs to determine the AFs; finally, the AFs are used as speaker features for speaker verification. The aim of identifying the handset before extracting the AFs is to determine the most likely handset so that handset-specific compensation can be applied to the MFCCs.
Figure 9.28. Combination of handset identification, handset-specific normalization, and AF extraction for robust speaker verification. The thick arrows represent the multidimension inputs and outputs. The number of inputs and outputs of the AF-MLPs are the same as those described in Figure 9.27.

Handset-Specific Normalization
As given in Eq. 9.6.1, the means and variances of the spectral vectors estimated from the clean training data are used to normalize the MFCCs. These parameters, however, may be varied across different handsets. Therefore, the AFs of channel-distorted speech cannot be correctly determined if the means and variances of clean MFCCs are used for normalizing the channel-distorted MFCCs. To compensate for the distortion caused by different handsets, handset-dependent normalization parameters (μh, σh) are needed.
As illustrated in Figure 9.28, the normalization parameters of the identified handset, h, are used to normalize the distorted MFCCs:
Equation 9.6.2
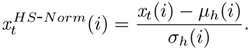
Eq. 9.6.2 is referred to as HS-Norm hereafter in this section. The handset-normalized MFCCs are then fed to the five AF-MLPs to determine the AFs. Because the MFCCs are now transformed to a range close to clean training speech, the variation of MFCCs due to handset differences can be minimized.
In addition to normalizing the MLP inputs, HS-Norm can also be applied to GMM-based verification systems to minimize the channel effect caused by different handsets. As suggested in Viikki and Laurila [361], applying a segmental means-and-variances normalization to the feature vectors regardless of the noise conditions can significantly enhance the channel robustness. Unlike the segmental feature normalization of that 1997 study [361], however, the normalization parameters in HS-Norm are handset-dependent, which makes HS-Norm more amenable to the compensation of handset-dependent channel distortion. Compared to SFT, which only shifts the feature means according to the identified channel, HS-Norm does a better feature compensation job because both feature means and variances are considered. Therefore, HS-Norm should be more effective than SFT in channel compensation.
Speaker Verification
As Table 9.17 shows, there are a total of 22 articulatory classes, which result in a 22-dimensional AF vector for each frame. For each testing utterance from a claimant, a sequence of 22-dimensional AF vectors Y were fed to a speaker model (Ms) and a background model (Mb) to obtain a verification score S(Y):
Equation 9.6.3
![]()
Similar to spectral feature-based speaker verification, speaker-independent EER is obtained from S(Y).
9.6.3. Fusion of Spectral and Articulatory Features
Because the spectral features (MFCCs) and articulatory features focus on different aspects of speech, fusion of these features is expected to provide better performance than using individual features. Recent experimental results (see [201]) on the fusion of spectral and articulatory features for phone-based speaker verification are reported next.
Corpus
In this work, the HTIMIT corpus [304] was used for performance evaluation. HTIMIT was constructed by playing a gender-balanced subset of the TIMIT corpus through nine phone handsets and a Sennheizer head-mounted microphone. This setup introduces real handset-transducer distortion in a controlled manner but without losing the time-aligned phonetic transcriptions of the TIMIT corpus. This feature makes HTIMIT ideal for studying the handset variability in speech and speaker recognition systems [291]. It also facilitates the training of AF-MLPs by mapping the time-aligned phoneme labels to their corresponding articulatory classes.
Speaker Enrollment
A disjointed, gender-balanced speaker set and a disjointed, gender-balanced imposter set, consisting of 100 client speakers and 50 impostors, respectively, were selected from the HTIMIT corpus.
For the system that uses spectral features only (hereafter referred to as the MFCC system), twelfth-order MFCCs were computed every 14ms using a Hamming window of 28ms. For the system that uses AFs as features (hereafter referred to as AF system), 22-dimensional AF vectors were obtained from the five AF-MLPs, each with 108 input nodes (9 frames of 12-dimensional MFCCs) and 50 hidden nodes. The MLPs were trained using the Quicknet [104]. Training data includes all sentences collected using the senh microphone of all speakers in HTIMIT, excluding speakers from the speaker set and the impostor set.
For each system, a 64-center universal background model Mb was trained using the SA and SX utterances from all speakers in the speaker set. For each speaker in the speaker set, a speaker model Ms was adapted from Mb using MAP adaptation [306]. Only the SA and SX sentences collected using the head-mounted microphone (senh) were used for enrollment and adaptation.
Robustness Enhancement
For the MFCC system, cepstral mean subtraction (CMS), stochastic feature transformation (SFT), and handset-specific normalization (HS-Norm) were adopted to enhance the robustness to handset mismatches. Except for CMS, where the channel compensation was handset-independent, a handset selector ![]() was first applied to each testing utterance to identify the most likely handset. The SFT or HS-Norm corresponding to the identified handset was then applied to the distorted MFCC vectors. For each handset, the SX and SA sentences of 10 speakers, randomly chosen from the training data, were used to estimate the SFT and HS-Norm parameters.
was first applied to each testing utterance to identify the most likely handset. The SFT or HS-Norm corresponding to the identified handset was then applied to the distorted MFCC vectors. For each handset, the SX and SA sentences of 10 speakers, randomly chosen from the training data, were used to estimate the SFT and HS-Norm parameters.
The handset selector in the AF system was also MFCC-based, and ![]() are identical to those of the MFCC system. Both the verification performance of AFs extracted from MFCCs and from MFCCs with CMS were evaluated. However, most of the channel characteristics in MFCCs would be removed if CMS was applied, which reduced the accuracy of the handset selector. If required, CMS was performed after handset selection and before AF extraction.
are identical to those of the MFCC system. Both the verification performance of AFs extracted from MFCCs and from MFCCs with CMS were evaluated. However, most of the channel characteristics in MFCCs would be removed if CMS was applied, which reduced the accuracy of the handset selector. If required, CMS was performed after handset selection and before AF extraction.
System Fusion
Although both the AF and MFCC systems take MFCCs as input, they attempt to capture two different information sets from the speech signals. The MFCC system attempts to capture the acoustic characteristics, and the AF system attempts to capture the articulatory properties. Therefore, fusing these two systems should result in a better performance than the individual systems can provide.
In this work, utterance scores, as given in Eq. 9.6.3, obtained from the MFCC system and the AF system were linearly combined to produce the fusion scores
Equation 9.6.4
![]()
where waf is a handset-dependent fusion weight. The fusion weight was determined from data used for estimating the normalization parameters and the SFT parameters of each handset type.
Results
Table 9.18 summarizes the EERs obtained from the approaches discussed before. Each EER is determined by concatenating the utterance scores of all SI sentences from 100 speakers and 50 impostors. For each approach, two sets of EERs are obtained. The EERs and the relative reductions (Rel. Red.) under the Average column are the average of EERs individually obtained from the nine mismatched handsets (i.e., excluding senh). Those under the Global column are the global EERs obtained by merging the utterance scores of the nine mismatched handsets. The results are organized into three sections in Table 9.18, where the EERs of the MFCC systems, the AF systems, and the fusion of the two systems are listed in Rows 1 through 4, Rows 5 through 9, and Rows 10 through 12, respectively.
| Row | Features | Average | Global | ||
|---|---|---|---|---|---|
| EER (%) | Rel. Red. (%) | EER (%) | Rel. Red. (%) | ||
| 1 | MFCC baseline | 23.84 | - | 23.77 | - |
| 2 | MFCC CMS | 12.80 | - | 13.10 | - |
| 3 | MFCC SFT | 8.31 | - | 9.30 | - |
| 4 | MFCC HS-Norm | 8.15 | - | 8.45 | - |
| 5 | AF baseline | 30.93 | - | 30.89 | - |
| 6 | AF CMS | 20.73 | - | 20.53 | - |
| 7 | AF CMS + HS-Norm | 18.39 | - | 18.85 | - |
| 8 | AF SFT | 15.63 | - | 16.00 | - |
| 9 | AF HS-Norm | 14.57 | - | 14.66 | - |
| 10 | 3 + 9 | 7.85 | 5.54 | 8.50 | 8.60 |
| 11 | 4 + 9 | 7.70 | 5.52 | 8.07 | 4.50 |
| 12 | 2 + 7 | 11.76 | 8.13 | 12.63 | 3.59 |
Evidently, for the MFCC system, MFCC SFT and MFCC HS-Norm, which adopt the handset-specific compensation, outperform MFCC baseline and MFCC CMS. In particular, MFCC HS-Norm achieves the lowest EER, which gives an average EER of 8.15% and a global EER of 8.45%. When compared to the EERs obtained from MFCC CMS, which is the simplest robustness enhancement approach, these error rates represent a relative reduction of 36.33% and 35.50% for average EER and global EER, respectively. MFCC SFT achieves a slightly less significant error reduction: a 35.08% in average EER and a 29.01% in global EER. This demonstrates that HS-Norm is better than SFT for enhancing channel robustness.
For the AF system, the verification results based on the AFs extracted from the MFCCs and from the MFCCs with CMS are named AF baseline and AF CMS in Table 9.18, respectively. AF SFT represents verification using AFs extracted from MFCCs with SFT. Because of the nature of MLP training, Eq. 9.6.1 is used to normalize the MFCCs before feeding them into the MLPs. For AF baseline, AF CMS, and AF SFT, the feature means and variances determined from the training data (i.e., senh) were used to normalize the MFCCs (or the stochastically transformed MFCCs), as shown in Figure 9.27; in AF HS-Norm and AF CMS + HS-Norm, on the other hand, handset-specific normalization was applied to the MFCCs and the MFCCs with CMS, respectively, as illustrated in Figure 9.28.
The results for AFs suggest that the lowest EERs (both average and global) can be obtained from extracting AFs from handset-normalized MFCCs rather than from the stochastically transformed MFCCs or from the CMS MFCCs. This is consistent with the results obtained from the MFCC system. During the AF extraction, the application of HS-Norm significantly reduces the EERs from 30.93% to 14.57% (average) and from 30.89% to 14.66% (global). Even if the AFs are extracted from the CMS MFCCs, applying HS-Norm can still reduce the EERs from 20.73% to 18.39% (average) and from 20.53% to 18.85% (global). This represents an error reduction of 11.29% and 8.18% for average and global EERs, respectively.
The individual MFCC and AF systems that give the lowest EER were fused together. After trying all possible combinations, the three fusions that give the lowest EERs, and their corresponding EER reduction relative to the respective MFCC systems, are summarized in Table 9.18. These include the fusion of MFCC SFT and AF HS-Norm, the fusion of MFCC HS-Norm and AF HS-Norm, and the fusion of MFCC CMS and AF CMS + HS-Norm. Of the three fusions, EERs lower than the individual systems were obtained. The relative error reductions range from 5.52% to 8.13% for the average EERs and from 3.59% to 8.60% for the global EERs. Of the three fusions, the lowest EER was obtained from the fusion of MFCC HS-Norm and AF HS-Norm, which yields 7.70% for the average EER and 8.07% for the global EER. These represent an EER reduction of 5.52% (average) and 4.50% (global). This suggests that the acoustic characteristics represented by the MFCCs and the articulatory properties represented by the AFs are partially complementary, although they are from the same source.
The global DET curves (see Martin et al. [233]) using all testing utterances from the nine mismatched handsets and the DET curves obtained from the el3 handset are shown in Figure 9.29. The curves also agree with the EERs listed in Table 9.18.
Figure 9.29. DET plots of speaker verification using the MFCCs, AFs, and fusion of the two features based on various channel compensation approaches. For ease of comparison, methods in the legend are arranged in descending order of EERs. The DET plots are generated using (a) all testing utterances from all of the 9 mismatched handsets and (b) testing utterances from the el3 handset.
