
A reliable system is one that ensures correct operation in the face of failure, with high probability. This entails the following things:
- Continuous self-monitoring of the system
- Detection of failure or corruption in a component
- Fixing the problem and/or failing over to a working component
Although various practices have evolved in the industry to ensure reliability, redundancy and failover are commonly (or even universally) used.
In the context of a Fabric application of the kind we built in Section I, this has certain implications. Recall that Fabric has many different components that must work in concert (though in a loosely-coupled manner) to ensure successful operation. The ordering service is one such key component that, if it were to fail, would completely stall the transaction pipeline. Therefore, when building a production version of, say, our trade application, you must ensure that the orderer has enough redundancy built in. In practice, if your orderer is a Kafka cluster, this means ensuring that there are enough Kafka nodes (brokers) to take up the slack should one or more fail.
Similarly, the reliability of peers for endorsement and commitment is key to ensuring transaction integrity. Although blockchains, being shared replicated ledgers, are designed to be somewhat robust to peer failures, their vulnerabilities may vary depending on the application. If an endorsing peer fails, and if its signature is necessary to satisfy the transaction endorsement policy, transaction requests cannot be created. If an endorsing peer misbehaves, and produces incorrect execution results, the transaction will fail to get committed. In either case, the throughput of the system will reduce or fall to zero. To prevent this from happening, you should ensure that there is adequate redundancy built into the set of peers within each organization, especially the ones that are key to satisfying an endorsement policy. The following diagram illustrates a possible mechanism whereby transaction proposals are made to multiple peers, and absent or incorrect responses are discarded using a majority rule:
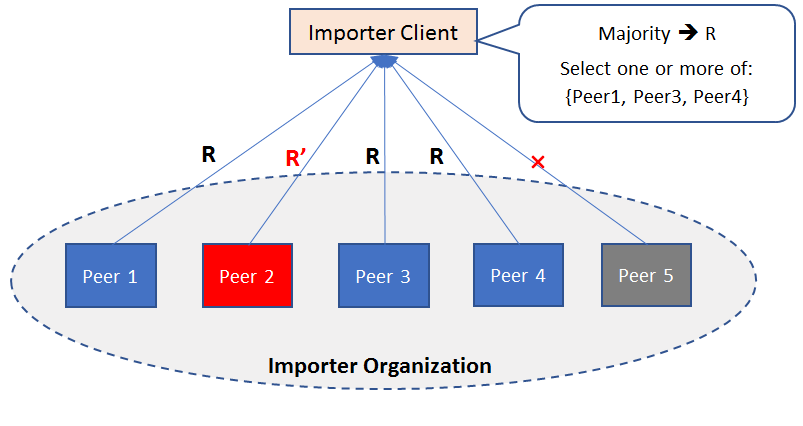
The level of reliability one gets from a system depends on the amount of resources devoted to monitoring and failover. For example, five peers in the preceding diagram are sufficient to counter two peer failures, but this now requires four more peers in the organization than what we used in our example network. To determine and ensure that your network yields the expected level of reliability, you will need to run integration tests on your complete system over a period of time.