
Chapter 10. Attributes
Data is a precious thing and will last longer than the systems themselves.
—Tim Berners-Lee
Civilization advances by extending the number of important operations which we can perform without thinking of them.
—Alfred North Whitehead
There are two layers that will be considered in this chapter: the Attribute Protocol Layer and the Generic Attribute Profile Layer. Both are so closely related that it is useful to discuss them at the same time. When Bluetooth low energy was created in the Bluetooth Special Interest Group (SIG), the concepts behind Attribute Protocol were originally created within a non-core working group before being integrated into the core specification. However, at the time of integration an architectural decision was made to split the document into an abstract protocol and a generic profile. Although this is a useful abstraction to make from the specification point of view, it is not useful when attempting to understand how attributes work. The abstraction of generic attribute profile away from the attribute protocol can theoretically allow other generic profiles to be placed above the attribute protocol. And although this is possible, it’s not something that is being considered currently.
10.1. Background
When Bluetooth low energy was first designed, there was a big question about what protocol to use. The protocol had to be very simple because any complexity would increase the cost and memory requirements for that protocol. It was also desirable to use the minimum number of protocols as possible. As a result, it was considered that using a single protocol for everything would be the best initial approach. This goal was not entirely met; Bluetooth low energy uses three protocols: Logical Link Control and Adaptation Protocol (L2CAP), Security Manager Protocol (SM), and Attribute Protocol (AP).
The goal was to reduce the number of protocols to a minimum, and each and every service above the Generic Attribute Profile (GATT), including the Generic Access Profile for name and appearance discovery, uses the AP. This allows additional services to be created, built on top of the GATT, for minimal additional cost.
10.1.1. Protocol Proliferation Is Wrong
You might be questioning why protocols are such a bad thing. The whole of computing, and in some senses the rest of the world, revolves around protocols. Most activities have their own protocol: to download a Web page, the Hypertext Transfer Protocol (HTTP) is used; to transfer a file, the File Transfer Protocol (FTP) is used; to log in to another computer securely, the Secure-Shell protocol (SSH) is used. Each protocol is optimized for its own application area. It is not efficient to transmit a large group of files by using HTTP, and it is not efficient to log in to computers by using FTP.
The big difference between Bluetooth low energy and the plethora of Internet protocols is that Bluetooth low energy is not trying to transfer such a wide range of data types. Given that it is not about transferring large quantities of data or streaming music, a single protocol can be designed that only has to deal with the limited set of data types that Bluetooth low energy targets. This protocol is called the Attribute Protocol; it is the foundation and building block for the whole of Bluetooth. To understand Attribute Protocol is to understand Bluetooth low energy.
10.1.2. Data, Data, Everywhere...
When Bluetooth low energy was first discussed, it was clear that as any communications system, it is all about data. Lots of things have data, and Bluetooth low energy is a means by which lots of other devices can access and use this data. This data could be anything: the signal strength of your mobile phone; the state of the battery in your toys; your weight; how many times you’ve opened the fridge today; how far you’ve bicycled this morning; what time it is; how much talk time you have on your headset; the latest news headline; who has just sent you a text message; if the chair is being sat upon at the moment; who is in the meeting room; how long you’ve spoken on your phone this month—anything!
As Figure 10–1 demonstrates, a Bluetooth proximity device might expose its transmit power level, which is an alert level used to notify the user when the connection is lost. It might also have a device name so that the user can more easily identify the device. Finally, because the device is battery powered, it might also expose its current battery level.

Figure 10–1. Some examples of the types of data that Bluetooth low energy devices might have
The important concept about data that you need to understand is that some devices have it, and other devices want to use it. In Bluetooth low energy, this distinction is very important because it determines which devices are considered to be servers and which are clients. A device that has data is a server; a device that is using the data from another device is a client. This relationship is illustrated in Figure 10–2.

Figure 10–2. Servers have data; clients use this data
10.1.3. Data and State
There is another important concept that you need to understand. There is a significant difference between data and state. Data is a value that represents something, such as a fact or a measurement. Data could be the temperature of the room as measured by the thermometer, or it could be temperature of the room as read by the heating system; thus multiple devices can “know” data. State is a value that represents the status or condition of a device: what it is doing, how it is operating. This state is only known on one device; one device is said to hold this state information. The thermostat measures the room temperature and is therefore said to reflect the state of the temperature for that room.
In this book, “state” refers to the information (data) that resides on the server; “data” refers to that information (again, the data) as it is in transit from the server to the client or held on the client. So, a server is a device that holds a collection of state information. A client is a device that reads or writes this state information, perhaps caching it locally as data. The data on the client is not authoritative because the server’s state could have changed since the client last received data from it. When reading the following sections, remember that devices have state, and that the state will be on the server.
10.1.4. Kinds of State
Bluetooth low energy uses three different kinds of state: external, internal, and abstract.
Current physical measurements represent the state of a physical sensor or similar interface. For example, let’s consider a bathroom scale. As shown in Figure 10–3, measurements for this device might include the current temperature of the room, the current battery state of the weighing scales, or the weight of the person who last used the scale. These are all known as external state; state that every time you read it might result in a different value because it is being measured by using an external sensor.
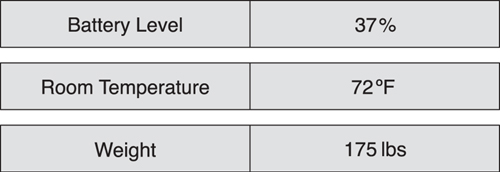
Figure 10–3. Physical measurements
The next type of state is internal state (see Figure 10–4). Some devices have state machines that represent their current internal state. They don’t represent the external state of a sensor, but how the device is currently functioning. This could include things such as the state of the call on the phone, whether time is currently being synchronized by using a GPS receiver, or if the light is still changing brightness due to an earlier dimming command.
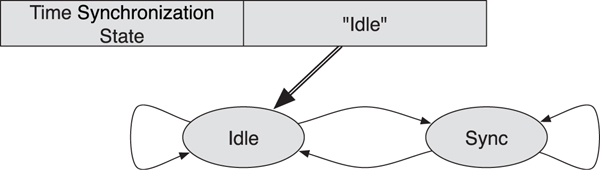
Figure 10–4. Internal state
The last type of state is an abstract state (see Figure 10–5). This is state information that is only relevant at a momentary point in time; it does not represent the current external or internal state of the device. Examples of this type of state include a way to command a light to toggle its on/off state, a way to request a device to immediately alert, or a way for a device to control when time is synchronized and how to cancel an in-progress synchronization. In the Attribute Protocol, these are known as control points. Typically, these are attributes that cannot be read; they can be written or notified.

Figure 10–5. Abstract state
10.1.5. State Machines
The most interesting aspect of the Attribute Protocol and the types of state that can be exposed is that it explicitly supports exposing finite state machines. A state machine represents the internal state for the device. A state machine also has one or more external inputs into the machine. These external inputs are momentary commands that move the state machine from one state to another, as determined by other state information or behavior; this is an abstract state, or control point.
By using the combination of internal state and control points, it is possible to fully expose the workings and behavior of a finite state machine on a device. This is interesting from two points of view. First, by exposing finite state machines, their inputs, and their current state, the behavior of a device can be exposed explicitly. By exposing inputs, other devices can interact with this device. Second, it is possible to define the full behavior of a finite state machine, including invalid behavior. By doing this, any device can send an input on any control point into a state machine, and the behavior defined for that state machine will still define what will happen.
Consider for a moment a very simple state machine for a light. The light can be considered to have a finite state machine with two states: on and off, as illustrated in Figures 10–6 and 10–7. It could be possible to read its current state and also write this state to change the light’s state. However, it is also useful to consider that this state machine has three possible inputs: turn on, turn off, and toggle. Most of the state machine inputs can map to a valid and logical next state. For example, sending turn on to a light that is off will turn it on, sending turn off to a light that is on will turn it off. However, sending turn on to a light that is on will keep it on even though this might be considered an invalid behavior. Similarly, sending turn off to a light that is off will keep it off. Also, sending toggle to a light that was on will turn it off. Sending toggle to a light that was off will turn it on.
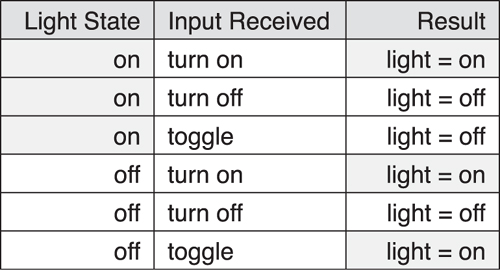
Figure 10–6. An example of state transitions for a light

Figure 10–7. An example of a light state machine
The interesting thing about the toggle input is that it significantly reduces the volume of traffic that needs to be sent over the radio to change the light’s state. Without exposing this abstract control point, a light switch would need to first read the current light state, toggle this data internally, and then write the new value to the light state. This requires a minimum of three different messages to be sent: a request for the current light state, a response including that light state, and a command to set the light state to a new value. By adding the toggle command to the light’s finite state machine, it is possible to remove most of these messages by just commanding the light state machine’s abstract control point to accept the toggle command. The light switch can then send a single toggle command to the light. The light does the toggling of the light state on the server; the light switch doesn’t need to know the old or new state.
Exposing a state machine is therefore more efficient in terms of messages that need to be sent over the radio, but is also more interoperable because it is impossible to command a state machine into a state that has not been defined by the behavior of this state machine. Therefore, by defining all possible states, and the behavior of all inputs in all possible states, an interoperable and optimal protocol can be used.
10.1.6. Services and Profiles
The most interesting architectural change between Bluetooth classic and Bluetooth low energy is the service and profile architecture. In Bluetooth classic, most profiles also include protocols, defined behavior, and interoperability guidelines. These classic profiles are therefore highly complex and encompass many different concepts. The biggest problem is that the profiles define just two types of device, one at either end of the link. The behavior of each device is then explicitly defined. At first glance, this might appear to be a very useful thing to do. If you have a phone and a Bluetooth car kit, it would be very useful to define what each device must do and how it interacts with the other device to enable a given use case. Unfortunately, this has a few problems.
The first problem with existing profiles is that the behavior of a given device in the network is not explicitly defined on its own. This means that even though the behavior of the two devices is defined, it is sometimes not explicitly clear what the behavior of each individual device should be.
This leads to ambiguities wherein each device believes it is the other device’s job to carry out an action, and thus the action never gets done. For example, the Hands-Free Profile (HFP) says, “either the HF or the AG shall initiate the establishment of an Audio Connection whenever necessary.” So, which device initiates the audio connection, the HF or the AG? What happens if they both attempt to do this at the same time? This is an interoperability nightmare.
The obvious solution to this is to define the behavior of each device separately, to make it explicit what each device should do.
The second problem with existing profiles is that it is almost impossible to use the profile in a way that was not initially envisioned. Because profiles define how the two devices interoperate with one another, it is very difficult to then make it work with a slightly different device. Even within profiles, this becomes difficult. For example, the hands-free profile defines a phone and a car kit, yet the most-implemented use case is a phone with a headset; the phone doesn’t know it is talking with a car kit or a headset and therefore continuously sends user interface status updates to the other device because it might be a car kit. This wastes power because a headset really doesn’t care about the signal strength going from four bars to three bars. The obvious solution to this is to define the behavior of each device without the need to know the device’s functionality.
In Bluetooth low energy, these problems have been tackled by taking a radically different approach. First, because we have a pure client-server architecture, we have separate documents that describe the behavior for a given use case on the server and on a client. The server’s behavior is defined in a service specification, whereas the client’s behavior is defined in a profile specification. As illustrated in Figure 10–8, this means that the service specification defines the state that is exposed in the server by using an attribute database as well as the behavior that is available through these attributes.
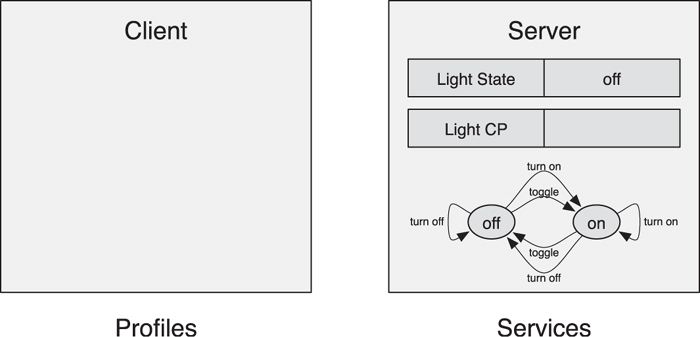
Figure 10–8. The profile/service architecture
Some attributes on a service might be readable, returning either historical or current data. Some attributes might be writable and make it possible for commands to be sent to the service. Some attributes expose the state of a finite state machine that when combined with control points provide fully exposable behavior. The profile specifications define how to use one or more services to enable a given use case (for example, how to configure the attributes exposed for a service in an attribute database on the server to ask the service do something that client needs it to do).
The main advantage of this split is that the server has a known and defined behavior. It does what it does, as defined by the service specification, without any interest in how the client is using it. This means that the service can be individually unit tested and that it is independent of the client. Any client can use that service if it needs to do so. For example, if there is a time service, this service could be used by one client to obtain the current time; it could be used by another client to read the current time periodically to determine it’s own clock drift; it could be used by another client to request that a GPS receiver is used to obtain the most accurate time possible. The time service doesn’t care what the client is doing; it just does it.
For example, as demonstrated in Figure 10–9, a light can expose a Light Service with two pieces of data: the current physical light state, and the abstract light control point to allow a client to control the state of the light. A light switch would implement the light profile that knows how to find the light service, how to read the current light state, and how to control the light state. The light switch knows the behavior that is exposed because this must be the same for every instance of the light service.
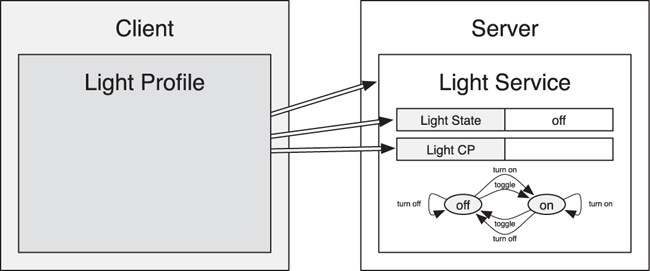
Figure 10–9. An example of a light profile and service
The client is also at an advantage using this system. The profiles are written without defining the behavior of the server—these are defined by the services—and therefore very much simpler. The client profiles are in essence a set of rules for discovering, connecting, configuring, and using services. They also include standard procedures for performing various actions that are required by the client. The clients, and their profiles, can use any combination of services to achieve their goals. For example, a client could combine the use of the time service with a temperature service to allow temperature to be monitored over time, without the need to have a real-time clock in the client and without the need to collect this data in real time.
Take, for example, a home security system that knows that the house is unoccupied, but the homeowners would like the house to appear to be occupied by turning on and off lights randomly. This could be accomplished by defining a new profile that implemented some very simple sets of instructions, as illustrated in the following script:
loop forever:
wait <random period from 10 seconds to 3 hours>
connect to a light:
send "toggle" to control point
disconnect
Alternatively, if you were managing an office and wanted to make sure all the lights were off when people were not at work, this could be implemented in yet another profile that is represented by this set of instructions:
loop forever:
wait <until start of next working day>
connect to lights:
send "on" to control point
disconnect
wait <until end of working day>
connect to lights:
send "off" to control point
disconnect
It is this combination of multiple services in the client that is one of the most powerful concepts in Bluetooth low energy. Each individual service can be kept very simple; it is the combination of services that provides the complexity and richness of the system. For this to be true, services must be atomic. Atomic in this context means that the services perform only one set of actions. By making services atomic, they can be reused by multiple clients, all doing different things.
This allows the first problem identified with classic profiles to be solved—it is almost impossible to define a classic profile that has explicit state. By defining the services as separate specifications, it is possible to keep them atomic so that the quantity of behavior in each service is very small. The small quantity of behavior means it is very much easier to define explicitly what a service does, and, therefore, it is also easier to test this by using standard unit testing methodologies. This means that atomic services have explicit state, and that this state can be relied upon by clients.
This approach also solves the second problem identified with classic profiles—it is almost impossible to use a classic profile in a way that was not envisioned. By splitting the use cases into services that are atomic with known behavior, it is possible to define clients that can use these services. Clients can use these either in isolation or in combination with other services. Because the services have explicit behavior, the complexity of combining services is minimized. Also, because each service is atomic, there is no “bleeding” of behavior from one service to another. Each service is separate, and its behavior is not dependent upon the state of another service. This means that services can be combined in any order that is conceivable.
This also means that clients can use services on a device in novel ways. There is no actual need for profiles; it is the services that define how devices interoperate, profiles just define the standard ways that this can be done for a given use case. Therefore, a device can determine that it can combine not only the temperature service and time service but also the solar panel’s power generation service to determine the current weather. This is probably not a profile or use case that would be defined by the Bluetooth SIG, but it could be something that a manufacturer might wish to do. By splitting the behavior of the server into services, it is possible to combine this behavior in interesting, novel, and useful ways in any client.
10.2. Attributes
To understand the Attribute Protocol, you first must understand an attribute. Defined broadly, an attribute is a piece of labeled, addressable data. In the following subsections, we’ll look more closely at what this means and how you can use attributes in a practical sense.
10.2.1. Attribute
Figure 10–10 shows that an attribute is composed of three values: the attribute handle, the attribute type, and the attribute value.

Figure 10–10. The structure of an attribute
10.2.2. The Attribute Handle
A device can contain many attributes. For example, a temperature sensor might contain an attribute for the temperature, one for the device name, and one for the battery state. It could be considered that the attribute type would be sufficient to identify a given attribute; for example, just asking for the temperature should return the temperature, asking for the device name should return the device name, and so on. However, what if the device contains two temperature sensors: an indoor temperature sensor and an outdoor temperature sensor? In this case, you cannot just read the temperature sensor; you need to read the first or second temperature attribute. This problem becomes much more complex when you consider that you could have an arbitrary number of temperature sensors.1
To solve the this problem, instead of addressing attributes by their type, you use a 16-bit address called the attribute handle. Valid handles are 0x0001 to 0xFFFF. Handle 0x0000 is an invalid handle and cannot be used to address an attribute. You can consider these handles to be the memory address, port number, or hardware register address for the attribute value, depending on your particular background in software, hardware, or embedded engineering.
10.2.3. Attribute Type
There are many different types of data that can be exposed: temperature, pressure, volume, distance, power, time, charge, Boolean on/off state, state machine states, and so on. The type of the data that is exposed is called the attribute type. Given the different possible types of data that can be exposed, a 128-bit number is used to identify the type of the attribute. This unique identifier is known as a Universally Unique Identifier (UUID).2
UUIDs are huge. A 128-bit UUID requires 16 bytes of data to be sent between devices so that each device can identify the type of the data. To enable the efficient transfer of data types between devices, the Bluetooth SIG has defined a single 128-bit UUID, called the Bluetooth Base UUID that can be combined with a small 16-bit number. The use of a defined Bluetooth Base UUID means that this UUID and any derived UUID still follow the rules for allocating UUIDs. It also means that when sending UUIDs between devices for well-known values, only the short version of the UUID can be sent and then recombined with the Bluetooth Base UUID when it is received.
The Bluetooth Base UUID is defined as the following:
00000000 − 0000 − 1000 − 8000 − 00805F 9B34F B
When a short 16-bit Bluetooth UUID is sent, say the value 0x2A01, the full 128-bit UUID would be the following:
00002A01 − 0000 − 1000 − 8000 − 00805F 9B34F B
When referring to these 16-bit Bluetooth UUIDs, the values of the short UUIDs are very rarely used. Instead, a name of these values is used, surrounded by guillemets (“≪” and “≫”). So, for example, the name ≪Includes≫ is a 16-bit Bluetooth UUID that has the value 0x2802. There are many 16-bit Bluetooth UUIDs that are defined. The UUID itself does not define the usage of the UUIDs, but the UUIDs that are used by Bluetooth low energy are arranged into the following groups for human readability when debugging:
• 0x1800 through 0x26FF are for Service UUIDs
• 0x2700 through 0x27FF are for Units
• 0x2800 through 0x28FF are for Attribute Types
• 0x2900 through 0x29FF are for Characteristic Descriptors
• 0x2A00 through 0x7FFF are for Characteristic Types
10.2.4. Attribute Value
The state data that a device exposes is available in an attribute value. Each attribute has a value that can be any size from 0 bytes to a maximum of 512 bytes in length, although the size is fixed for some attribute types. The value of the attribute is not significant to the Attribute Protocol, but it is significant to the layers above that include the Generic Attribute Profile and GATT-based services and profiles.
10.2.4.1. Service UUIDs
Each service can be identified by using a UUID. This can be either a 16-bit UUID or a full 128-bit UUID. There are 3,840 services that can be allocated by using a 16-bit UUID, and an almost infinite number3 of proprietary services by using 128-bit UUIDs.
10.2.4.2. Units
Many of the values that are exposed represent physical values measured by a sensor. Therefore, it’s useful to also define unit UUIDs for each of these possible types of value. The units are derived from the Bureau International des Poids et Mesures, otherwise known as the International System of Units (abbreviated SI from the original French, Système International d’Unités). This allows values captured from a Bluetooth low energy sensor to be used in other systems that also use the same SI units. It should be noted that even though the SI units are defined around the metric system, imperial units are also defined. So, even though velocity can be represented in meters per second, it can also be represented in kilometers per hour (km/h) or miles per hour (mph).
10.2.4.3. Attribute Types
The most fundamental attribute types are allocated UUIDs from the Attribute Type UUID range. These are typically used for the attribute types defined by the Generic Attribute Profile, and not a service. The following attribute types are defined:
• Primary Service
• Secondary Service
• Include
• Characteristic
10.2.4.4. Characteristic Descriptor
Some data exposed by a service might include additional data. This additional data is labeled by using Characteristic Descriptors. An example of a descriptor would be a value that describes the format (the unit and representation) of an associated value.
10.2.4.5. Characteristic Types
This range of 16-bit UUIDs is the most used group of attribute types. Each unique type of value that is exposed by a service is allocated a Characteristic Type UUID. This allows a client to discover all the different types of data that a server has. Each characteristic type has a defined format and representation. There are a possible 22,015 characteristic types that can be defined, without having to resort to the almost unlimited number of 128-bit UUIDs that can also be used.
10.2.5. Databases, Servers, and Clients
A collection of attributes is called a database. A database can be very small and simple, the minimum being just six attributes,4 or very large and complex. The complexity of the attribute database, however, is not at the attribute layer, it’s how those attributes are used in services and profiles.
The database is always contained in an attribute server; an attribute client uses the Attribute Protocol to communicate with the attribute server. There is only ever one attribute server on each device, regardless of whether Bluetooth low energy or Bluetooth classic is used to make a connection with the other device. Because there is only one attribute server on each device, there is only one attribute database on each device. For a Bluetooth low energy device, the attribute database includes a Generic Access Profile service that is mandatory to support. This means that every Bluetooth low energy device includes an attribute server and an attribute database (see Figure 10–11).

Figure 10–11. An example of an attribute database
This means that the cost of exposing a small amount of information on a device—for instance, say just the battery state—is very small. This is because every device already includes an attribute database, so the only cost of adding in a service to expose this information is just the cost of three or more additional attributes. Given that each device starts with six attributes as a minimum, adding an extra three attributes for the battery service is fairly trivial.
10.2.6. Attribute Permissions
Some attributes in an attribute server contain information that can only be read or written. To facilitate these restrictions upon access, each and every attribute in an attribute database also has permissions. Permissions themselves can be split into three basic types: access permissions, authentication permissions, and authorization permissions. Access permissions determine what types of requests can be performed on a particular attribute. Going back to our earlier examples, the state of the light might be readable and writable, the state of a phone call might only be readable, whereas the light control point might be writable only. Similarly, the state of a light might be readable to anybody but can only be written by trusted devices, the state of a phone call will require authorization to read its state, and the light control point will require authentication to write its state.
It should be noted now that attribute permissions only apply to the attribute value. They do not apply to the attribute handle or attribute type. Every device has permission to discover all the attributes that a device exposes, including their handles and their types. This is to allow devices to determine if a device supports something that it can use before authenticating and obtaining authorization. For example, it is possible to determine if a device supports the light control point attribute without authenticating. This makes the initial device and service discovery very user-friendly, while protecting the private and confidential information exposed by that device in those services.
The following access permissions are defined:
• Readable
• Writable
• Readable and Writable
When an attribute is read, the access permissions are checked to determine if the value of the attribute is readable. If it cannot be read, an error will be returned stating that the client cannot read this attribute value. Similarly, when an attribute is written, the access permissions are checked and if the value of the attribute cannot be written, an error stating that the client cannot write this attribute value will be returned.
The following authentication permissions are defined:
• Authentication required
• No authentication required
When an attribute is accessed, either for read or write, the authentication permissions are checked to determine if the attribute requires authentication. If it does require authentication, the client that sent the request is authenticated with this device. If the attribute does not require authentication, the value should be accessible, subject to other permission constraints. If the attribute does require authentication, only the clients that have previously authenticated will be allowed access. If a client is not authenticated with the device and it attempts to access an attribute that requires authentication, then an error stating that there is insufficient authentication will be returned.
If a client receives the insufficient authentication error, it can do one of two things: it can ignore the request and pass the error up to the application; or it can attempt to authenticate the client by using the SM and resend the request. It should be noted that the error code does not communicate the required level of authentication. Therefore, the client might need to either request authentication or raise the authentication level to gain access to the attribute value.
The interesting side effect of this behavior is that the client is in complete control over when and how authentication is performed. The server also doesn’t need to hold the state of the received request. In Bluetooth classic, authentication is typically performed on the creation of an L2CAP channel. When the responder receives the channel request to a channel that requires authentication, it stores this request, sends back a pending response, initiates security procedures, and then finally resumes the original request. This is both complex and memory intensive. In Bluetooth low energy, the server simply responds as best it can to each and every request; the client contains the complexity of ensuring that authentication is performed, reissuing the original request again when necessary.
The following authorization permissions are defined:
• No authorization
• Authorization
Authorization is subtly different from authentication. It triggers similar behavior; an error response is sent with the error code insufficient authorization whenever an attribute access is attempted and the client is not authorized. However, this is an error that the client cannot resolve.
Authorization is a property of the server; the server either authorizes a client to access a set of attributes, or it does not. Therefore, it is up to the server to authorize clients. More important, the client has no signaling available to prompt the server to ask the user to authorize the client. Therefore, whenever a client attempts to access a given attribute that requires authorization, the server might prompt the user to authorize that client. The server might also immediately reject the request. The client would then need to wait before reattempting the request. Typically, the user of the client device will trigger the retry after he has configured the other devices to add the client to the list of authorized devices.
10.2.7. Accessing Attributes
Each attribute in an attribute database can be accessed by using one of the following five basic types of messages:
• Find Requests
• Read Request
• Write Request
• Write Command
• Notification
• Indication
Using Find Requests, a client can find attributes in an attribute database such that the more efficient handle-based requests can be used.
The Read Request is sent to read an attribute value. These either use one or more attribute handles or a range of attribute handles and an attribute type to determine which attribute value to read.
The Write Request is sent to write an attribute value. These always use an attribute handle and the value to write. It is also possible to prepare multiple values to be written before executing these writes in a single atomic operation.
Each of these requests always causes the attribute server to send a single response. If more data is required, another request must be sent by the client. For example, if the attribute value is very long and cannot fit into a single Read Response, the client can request the additional parts of the attribute value by using another Read Blob Request.
To minimize the complexity of the server, only one request can be sent at a time. Another request can only be sent after the previous response has been received.
It is also possible to use the Write Command to write an attribute value. This never causes a response. Because it does not have a response, this command can be sent at any time. This means that it is useful to write commands into a control point of an exposed state machine.
There are two additional types of messages, both of which are initiated by the server and send attribute values unprompted to the client. The Notification can be sent at any time and includes the attribute handle of the attribute that is being notified and the current attribute value of this attribute. The Indication is the same, having the same attribute handle and attribute value, but always causes an attribute confirmation to be sent back. These confirmations both acknowledge that the indicated value has been received but also that another Indication can be sent, whereas Notifications can be sent at any time.
10.2.8. Atomic Operations and Transactions
Each Attribute Protocol message that is sent from a client to a server, and vice versa, is sent as part of a single transaction. A transaction is either a single request followed by a single response or a single indication followed by a single confirmation. Transactions are important because they limit the amount of information that needs to be saved between successive transactions. This means that if a device receives a request, it doesn’t need to save any information about that request to process the next request.
The other important aspect about the transaction model is that a new transaction can’t be started until the last transaction has completed. For example, if a device sends a Read Request for an attribute, it can’t send another until it has received the response from the last request. These transactions are only relative to a single device. A device that starts a transaction cannot initiate another transaction, but it can still process requests from peer devices.
There are a couple of exceptions to this simple rule: Commands and Notifications, and Prepare/Execute writes.
10.2.8.1. Commands and Notifications
There are two Attribute Protocol messages called Commands and Notifications with which a device can send a message to another device without having to await a response before sending another Command or Notification. These are useful when you must send a particular Command or Notification but are currently in the middle of another transaction. For example, suppose that you have have sent a Read Request to a particular device and are awaiting a response, and then you need to write a value on the same peer device. To do that, you would use a Write Command.
Commands and Notifications do not require a response or confirmation. This means that the sending device has no way of knowing if the message has been received and processed. For some applications, this is not acceptable, and a request/response or indication/confirmation is required. For some applications, however, this is perfectly acceptable. An interesting side effect of the lack of a response or confirmation is that the there is no limit to the number of these messages that a device can send. Effectively, a device can flood the peer device with Commands or Notifications. To protect against this, a device can drop any Command or Notification that it receives if it doesn’t have the buffer space to store or process it. Therefore, these messages must be considered to be unreliable.
10.2.8.2. Prepare Write Requests and Execute Write Requests
The second exception to the preceding transaction rules is the Prepare Write Request and the Execute Write Request messages. Using these messages, a device can prepare a whole sequence of writes and then execute them as a single transaction. From the transaction point of view, each Prepare Write Request and response is a separate transaction. It is possible to interleave other requests in the middle of the complete sequence of prepares and execute.
There are two interesting side effects of this command: long writes and verification of writes. Each Prepare Write Request not only includes the handle of the attribute that will be written along with a value, but also the offset into that attribute’s value where this part of the value will be written. This means that you can use a sequence of Prepare Write Requests to write a single, very large attribute for each part of the attribute value in a single execution.
The other interesting side effect is that the prepare write response includes the attribute handle, offset, and part value that was placed into the Prepare Write Request. This might at first appear to be a waste of bandwidth, but because values in the response will be the same as in the request, this protects against something going wrong.
Bluetooth low energy is sometimes a little protective of data; all bits in the payload are protected with a 24-bit cyclic redundancy check (CRC) that can detect up to 5 bit errors. If a packet is received that has 6 bit errors, there is a very small probability that the CRC will falsely accept this packet. The next guard is the 32-bit message integrity check (MIC) value that is included in every encrypted packet. This should reject a packet that has falsely passed the CRC value, but there is absolutely no guarantee that it will not also falsely pass an invalid packet. Therefore, there is an extremely small chance that a packet can be received that has falsely passed the checks.
Sometimes even a very small chance is too large. For example, if you are using Bluetooth low energy to control the sewage outflow valve of a city, you really don’t want to write “close” only to discover that the valve received it as “fully open” and flooded the park and children’s play area with... err, sewage.
It is for this reason that the prepare response includes the same data that was in the request. The fact that a packet is sent in two different directions, typically by using two different radio channels, each using different encryption packet counters, means that the chance that the same data in the response has been corrupted in the same way as the request is as close to zero as you could possibly make it. And, of course, if the response was wrong, then you can cancel the whole sequence of prepared writes by using the “cancel” code in the Execute Write Request and then start preparing to write again.
10.3. Grouping
The Generic Attribute Protocol only defines a flat structure of attributes. Each attribute has an address—its handle. However, modern data organization methodologies require significantly more structure than this simple flat structure. This is what the Attribute Profile enables. Instead of just a set of attributes, the Attribute Profile defines groups of attributes.
To understand why this is necessary, let’s analyze how this could be done. It’s possible to have “pages” of attributes. Each page would have a defined set of values. A page would be defined for each use case; for example, one page would describe the device, another page would be used if the device has a battery, and another page would expose the temperature. This is interesting if the devices are complicated. What happens when you have two batteries? What if there are two temperature sensors?
The biggest leap in software engineering over the last few decades has been the slow introduction of object-oriented paradigms. This essentially groups the data that describes an entity with the methods that you can use to control the data’s behavior. The main benefit of using an object-oriented architecture is that each object is self-contained.
Let me take a moment to define some terminology. When talking about object-oriented programming, you might think of interfaces, classes, and objects. An interface is a description of external behavior. A class is an implementation of that interface. An object is an instantiation of that class. For example, a car is an instance of an automobile class that implements the driving interface, Not all car objects look the same; they can be implemented differently, but critically, they all have the same basic driving interface, such as the steering wheel, the accelerator pedal, and the brake pedal. The driving interface is the same, but the class that implements this interface can be different, and this can be instantiated many times, as is evident in traffic congestion.
Within Bluetooth low energy, grouping is used for both services and characteristics. A service is grouped by using a service declaration; a characteristic is grouped by using a characteristic declaration.
A service is a grouping of one or more characteristics; a characteristic is a grouping of one or more attributes.
10.4. Services
In software engineering, if you define and implement behavior for a given class, as long as the interface to that class is fixed, other parts of the system can reuse an object based on that class. This also means that if there is a bug in that class, you can fix it once, and all the other parts of the system can benefit immediately from that fix.
To ensure that classes are reusable, you must define an abstract interface that is immutable. Immutability is a strong word that means “unchanging over time.” This immutability is the only thing that ensures the long-term viability of an interface. If interfaces were mutable, the user of that object would need to spend more time working out what interface that object has rather than actually doing what it needs to do.
Object-oriented systems typically use inheritance to enable changes to interfaces; a new class with a new interface inherits the behavior of an old class and then adds to or changes this behavior, as required. By ensuring that interfaces are immutable, they can be reused successfully for many years.
In Bluetooth low energy, the Generic Attribute Profile defines two basic forms of grouping: services and characteristics. A service is the equivalent of an object that has an immutable interface. Services typically include one or more characteristics, and can also reference other services. A characteristic is a unit of data or exposed behavior. These characteristics are self-describing, such that generic clients can read and display these characteristics.
Thus, a service is just a collection of characteristics and some behavior that is exposed through these characteristics (see Figure 10–12). The set of characteristics and their associated behavior encompasses the immutable interface for the service.
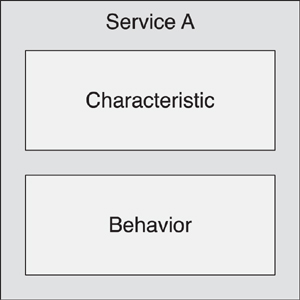
Figure 10–12. An immutable service interface is composed of characteristics and behaviors
However, as Figure 10–13 illustrates, services can reference other services. And it is this simple concept that imbues enormous power to this architecture. A reference is just that—one service can point to another service. The reference can say many things: this service is used to extend the behavior of the original service; this service uses the other service; this service and the other service are combined together into a much bigger set of services. Let us examine each of these references in term.

Figure 10–13. Service A references Service B
10.4.1. Extending Services
Service A, which has been used for many years, now needs to be extended. Because Service A is immutable, we cannot simply add new behavior to the original service. Therefore, it’s necessary to extend without altering the original service. To do that, we define a new service, Service AB, which contains the additional behavior required, as shown in Figure 10–14. However, to maintain backward compatibility for the many millions or billions of existing devices that only support Service A, we must also include an instance of that Service in every device that implements Service AB.
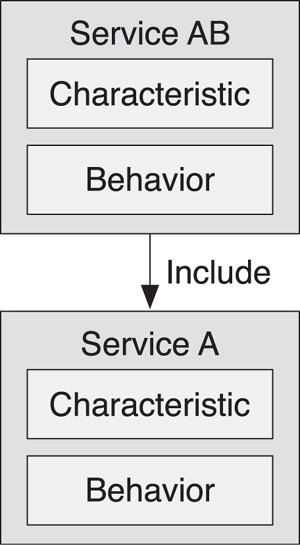
Figure 10–14. Service AB extends Service A
Now, suppose that we have two instances of Service AB, AB:1, and AB:2, on a device. We would also need two instances of Service A, A:1, and A:2 on the device. But which Service A belongs to which Service AB? To solve this problem, a reference needs to be made from each Service AB to the particular instance of Service A that it is explicitly extending (see Figure 10–15).

Figure 10–15. Two instances of Service AB extending Service A
An old device that only understands Service A will still find the two old Service A instances and use them as before; the old device will ignore the other Service AB instances and, therefore, will only be able to use the nonextended behavior.
A new device that understands both Service AB and Service A will find the Service AB instances and follow the references to their Service A instances. As such, the new device will be able to use the new behavior that is defined in Service AB.
A new device that is talking with an old device will attempt to find Service AB, fail, and then find Service A; the new, therefore, will be able to automatically fall back to the interoperable behavior that was defined in Service A.
This appears complex, but it’s actually much simpler than the alternative: Service A would be extended into a new version, with feature bits to determine which features a particular service supports and possibly very complex behavior because each possible combination of features would need to be tested. The extension methodology means that each service is self-contained and immutable, and the relationship between services is explicitly exposed. A device using the services can determine its behavior. Legacy compatibility is also guaranteed by the immutability of the original server.
10.4.2. Reusing Another Service
An additional method for reusing another service is to reference it. This is actually the simplest reference that can be made. One service, Service A, wants to use the behavior and state information from another service, Service B. To do this, Service A only needs to reference Service B. This is not reuse in the classic object-oriented sense; it is more like a generic pointer to another instance of a class.
This is useful because there may be many instances of both the referencing service as well as the referenced services: Service A:1, Service A:2, Service B:1, Service B:2, as depicted in Figure 10–16. Without the reference, it would be impossible to determine if A:1 reused B:1 or B:2, or if A:2 reused B:1 or B:2. By including a reference to the other service, the particular instance of the service that is being reused will be known.

Figure 10–16. Service A reuses behavior and characteristics of Service B
10.4.3. Combining Services
The final reference style is more complex than the other two in that it implies a separation of interface from implementation. Sometimes, it is necessary to have two independent service instances that are related to one another and have additional behavior when combined. To do this by using services, a third service must be defined that references both the original two services. For example, consider two instances of a service, Service A:1 and Service A:2, that need to be merged together and have additional “combinatorial” behavior. You can do this by instantiating a third service, Service C, that references both A1 and A2, as demonstrated in Figure 10–17.

Figure 10–17. Service C combines the behavior of two instances of Service A
Service C can expose the behavior that is required when dealing with both A:1 and A:2; it encapsulates the combined service behavior. For example, a light service and a daylight sensor service could be combined to give a service of a light that could only be switched on when there was no daylight.5 The state machine of the combined service has extra states deriving from combinations of the state of the two basic services it references. The independent A:1 and A:2 services still have their own immutable behavior. This implies that Service C must very clearly distinguish the difference between the behavior associated with the combined services and the behavior of the independent services.
10.4.4. Primary or Secondary
One final concept to understand for services is that they can come in two different “flavors.” Services can either be primary or secondary services. As you can clearly gather from the preceding description of the services and how they are designed, it is sometimes necessary to set up services that expose the external behavior of the device, and sometimes it is necessary to set up services that expose a block of functionality that can be reused many times in many different ways yet is never actually used or understood by the end user.
A service that exposes what a device does is typically a primary service. For example, if you have a device that supports Service B, Service B would be instantiated as a primary service. If you need some additional information for this device, which is available in Service D, but that information is not associated with what the device does, Service D would be instantiated as a secondary service (see Figure 10–18). So, a secondary service is an encapsulation of behavior and characteristics that are not something that a user would need to understand.
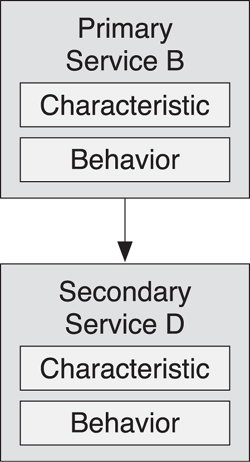
Figure 10–18. The relationship between primary and secondary services
Primary services can be found quickly and efficiently by using the Attribute Protocol. They can have either a “parent” service or be a stand-alone service. Secondary services can only be found by reference and must always have another service that points to them. This implies that a tree of services can be created, with a primary service at the top of each tree and each branch pointing to either primary or secondary services, and each branch from each of these being yet more primary or secondary services.
A primary service can point to another primary service, as illustrated in Figure 10–19. For example, the service extension would allow a new “version” of a service to be exposed and enable backward compatibility between these services.
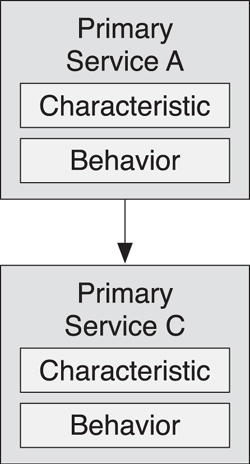
Figure 10–19. Primary services
A primary service can point to a secondary service so that it can reuse the behavior exposed in a secondary service. A secondary service can point to another secondary service or another primary service. Pointing from one secondary service to another secondary service is fairly rare because secondary services are typically leaf nodes in a service tree. Pointing from a secondary service to another primary service is extremely rare, but possible.
Primary services have one final advantage. When a client is looking for a particular service, it is possible to look for primary services very quickly. This can be further enhanced by only allowing a single instance of a given primary service on a device. For example, if a service is defined that can only have one instance of itself on a device, a quick search for that service by a client device would definitely determine whether that service exists.
This optimization has a significant benefit: A simple client that is only looking for one instance of a primary service can achieve that objective with the absolute minimum of fuss. Simple clients don’t need to read the complete list of services in a device or determine their relationships to be able to use simple services. Without this optimization, every single simple client would need to walk the complete service tree to determine how it can use the services exposed on a device to best effect. This is a huge waste of valuable resources, both in terms of power for communication and memory to store all intermediate results and computations.
10.4.5. Plug-and-Play Client Applications
The other interesting aspect of the service model is that it is possible to take the set of service trees in a device and search for applications that can exploit these service trees. To do this, the generic client would begin by performing a complete service enumeration, first of the primary services and then following the relationships to other referenced services. Once this tree has been built up, it is possible to pass this “forest” of services to an application store to obtain the list of applications that are known to work with all, or part, of this forest.
Some applications might support just a single primary service. Some applications might support a primary service that extends another primary service, perhaps as an extension of the original service, and perhaps as a second version of the application. Some applications might support more than one service tree. These applications might be able to either present the information from these services in an interesting all-in-one application or combine this information together on the client in innovative ways.
For example, given a server that supports the services illustrated in Figures 10–18 and 10–19, it would support the primary Service A, including another primary Service C, the primary Service B including secondary Service D, and the primary Service C on its own: A(C), B (D), C. The client can then use this information to determine which applications support this set of services. The list of services for each App is then checked against this set to determine which applications can support this device. Some applications might only support a single service (App1 supporting C), whereas others might support the extended service A that includes C. Other apps might support both the A(C) and B service trees, App6, whereas others might support the additional secondary service D included from B, App7 (see Figure 10–20).
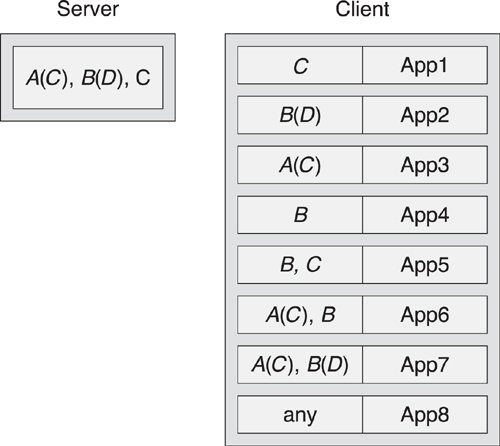
Figure 10–20. Services on a server mapped to applications on a client
Another approach is to use a generic application, App8, that can talk with any service. These client applications will typically not be able to interact as well as a specifically written application, but they might be able to support devices for which the client has no specific application already written.
This generic client behavior is explicitly supported by using the combination of services and a pure client-server model. However, the key element that makes this possible is the immutable services. Without services that have a known immutable behavior, generic client applications could not be written that can use this behavior.
The whole system has been designed for the maximum flexibility by limiting each individual part of the system to minimum flexibility. It is the combination of these individual immutable parts that provides the richness and ultimate flexibility required by products in the market.
10.4.6. Service Declaration
A service is grouped by using a service declaration (see Figure 10–21). This is an attribute with the attribute type of Primary Service or Secondary Service. All attributes that follow this service declaration and occur before the next service declaration are considered grouped with this service; they belong to this service.
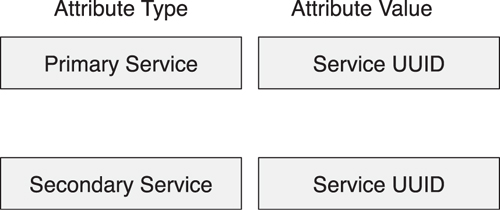
Figure 10–21. Primary and secondary service declaration
As defined earlier, a primary service is one that encapsulates what the device does. A secondary service is one that helps the primary service achieve its behavior. All secondary services are referenced from a primary service. The reason for this is very simple; it retains simplicity of the client.
Simple clients are devices that have no user interface but can still use services on a peer device. A simple device can just search for the primary services and find the services that it needs. It does not need to walk the complete tree of services that a device might expose. In fact, the Attribute Protocol is optimized for simple clients by allowing them to search for a specific primary service.
Some services have helper services that assist them in exposing their behavior or state. For example, most medical devices will include device information; there is no need for each medical service to define their own device information. Similar device information is also required in the automation and battery scenarios. By defining this information in a service, the device information service only needs to be defined once and can then be used many times. This also makes it possible for those simple clients to not concern themselves with such information; they just ignore those secondary services when looking for their primary services.
The service declaration’s value is a Service UUID. This is either a 16-bit Blue-tooth UUID or a 128-bit UUID. Any service that a device does not understand can be safely ignored. For example, if a device includes a secondary service that has a 16-bit or 128-bit UUID that this device does not understand, all the attributes that are grouped with this service declaration can be ignored. To help with this, the Attribute Protocol allows the range of attribute handles for services to be discovered. Only known services will be processed further.
10.4.7. Including Services
Secondary services must be discovered separately. To do this, each service can have zero or more Include attributes. Include declarations always immediately follow the service declaration and come before any other attributes for the service. The Include definitions also encompass the handle range for the referenced service, along with the Service UUID for the included service (see Figure 10–22). This allows very quick discovery of the referenced services, their grouped attributes, and the type of the service. It does not state if this referenced service is a primary or a secondary service because this is not relevant.
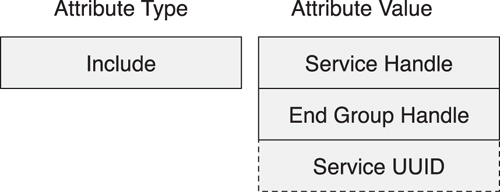
Figure 10–22. The structure of the Include declaration
Given that four octets are used for handles in the Include value, a Service UUID that is a full 128-bit UUID will not fit into the standard response packets used to find the included services. Therefore, when the included service has a 128-bit UUID, the Service UUID is not a part of this declarations value. This means that an additional Attribute Protocol read is required to find the type of the service being included.
If the type of a referenced service—either primary or secondary—does not matter, a primary service can reference another primary service or a secondary service, and a secondary service can reference another secondary or primary service.
The preceding example that presented four services A(C), B(D) would be created by using the database illustrated in Figure 10–23.
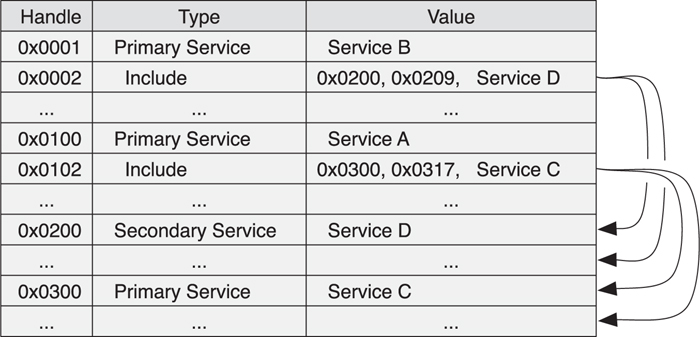
Figure 10–23. An example of an attribute database of Services A(C), B(D)
A primary service that was originally published that was later extended with another primary service would need to reference the original service. This original primary service cannot be changed to a secondary service because that would mean old clients would not be able to find that old service.
10.5. Characteristics
Grouping attributes together within a service demonstrates how these attributes can be combined to provide a consistent interface to a block of behavior. The architecture of Bluetooth low energy also makes it possible to group attributes to allow the state and behavior of a service to be exposed.
A characteristic is just a single value. It could be current temperature, how far somebody has ridden their bicycle, or the state of the time synchronization finite state machine. However, a characteristic is much more than that. A characteristic needs to expose what type of data a value represents, whether a value can be read or written, how to configure the value to be indicated or notified or broadcast, and expose what a value means.
To do this, a characteristic is composed of three basic elements:
• Declaration
• Value
• Descriptor(s)
A declaration is the start of a characteristic; it groups all the other attributes for this characteristic. The value attribute contains the actual value for this characteristic. The descriptors hold additional information or configuration for this characteristic.
One question that is always asked at this point is why is the value an attribute within a characteristic and not just an attribute in its own right? The answer is actually fairly complex. A characteristic is not just a value; it has permissions, additional configuration, and descriptive data that is useful to consider as part of this characteristic. It could have been possible to add additional semantics to the Attribute Protocol to access this information, but this would have made the protocol more complex for the minority of cases for which this is really necessary.
Instead, a decision was made to keep the flat structure of attributes, as exposed by the protocol, separate from the structure of the device and its characteristics, as defined by the Generic Attribute Profile. This means that it is more complex to obtain certain information about some characteristics, but much easier to find the required information for most characteristics.
Simply put, a characteristic is composed of a characteristic declaration, the characteristic value, and zero or more descriptors.
10.5.1. Characteristic Declaration
To start a characteristic, a Characteristic attribute is used. This contains three fields: characteristic properties, the handle of the value attribute, and the type of the characteristic, as shown in Figure 10–24.
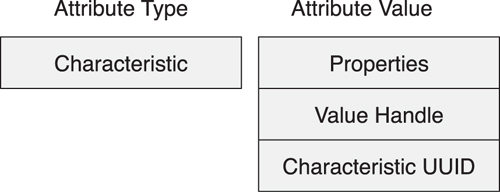
Figure 10–24. Characteristic Declaration
The characteristic properties determine if the characteristic value attribute can be read, written, notified, indicated, broadcast, commanded, or authenticated in a signed write. If the bit is set in this field, the associated procedure can be used to access the value of the characteristic value. Additionally, if the characteristic has the broadcast bit set, the server characteristic configuration descriptor must also exist. Similarly, if the characteristic has the notify or indicate bit set, the client characteristic configuration descriptor must exist.
There is also an extended properties bit in this field. This was added because there were additional properties to include in the 8-bit field, and the length of this field as the maximum size of this Descriptors value was already met. These additional properties are in the characteristic extended properties descriptor. There are only two additional properties: reliable write support and writable auxiliaries. The writable auxiliaries is the most interesting bit because this determines whether the characteristic user description descriptor can be written.
The characteristic value handle field is the handle of the attribute that contains the value for the characteristic. This is needed so that a very quick search for the characteristic can be performed by a client that returns only characteristic declarations. With this declaration, the attribute that holds the value is immediately available. If this field did not exist, the client would then need to perform an additional search for attributes and effectively guess which attribute after the declaration was the value. At the moment, the value attribute is the very next attribute after the characteristic declaration, but by including the handle for the value attribute in the declaration, this practice could be changed in the future.
The final field is the characteristic UUID. This holds the UUID that is used to identify the type of the characteristic value. This UUID must be the same as the type of the attribute that holds the characteristic value. Effectively, this means that this is a duplication of information that could be determined by sending more requests to the server. However, this would require more over-the-air protocol messages to be sent, wasting power. It is more efficient to include the type information in the declaration directly.
On occasion, it has been questioned why the characteristic value attribute’s type is not a static UUID such as Value. This would reduce the previously described problem; however, there are other optimizations that can be performed, indicating that this would not be an ideal solution (see Figure 10–25). For a simple client that only wants to retrieve the battery state of a device, it would be much more efficient to just ask for the battery state rather than search for the characteristic that has the battery state UUID in one of its fields. It is these simple optimizations that have determined the structure of the declaration, as demonstrated in the following:
// The complicated way
service_range = discover_primary_service_by_UUID («Battery_Service»)
chars = discover_all_characteristics_of_a_service (service_range)
foreach char in chars:
if char.uuid == «Battery Level»:
battery_level = read_characteristic_value (char.handle)
// The easy way
battery_level = read_characteristic_value_by_UUID («Battery Level»)
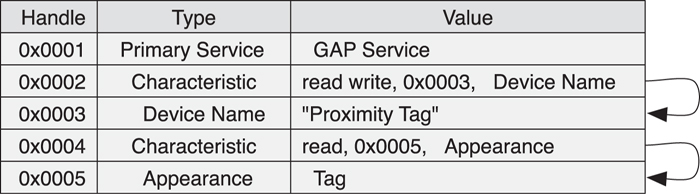
Figure 10–25. Characteristic example
10.5.2. Characteristic Value
The characteristic value is an attribute with the type that must match the characteristic declaration’s characteristic UUID field. Apart from that, it is an ordinary attribute. The biggest difference is that the types of actions that can be performed on this characteristic value attribute are exposed in the characteristic declarations properties field and additionally might be in the characteristic extended properties descriptor.
For each characteristic, a specification document can be found that describes the format of the characteristic. Also, characteristics themselves have no behavior, so the service specification with which this characteristic is grouped should be examined to determine the behavior exposed by this instance of the characteristic.
10.5.3. Descriptors
There can be any number of descriptors on a characteristic. Most descriptors are optional, although, as just explained, they might be required depending on the characteristic declaration. Some descriptors might also be required by a service specification.
The following descriptors can be included in a characteristic:
• Characteristic Extended Properties
• Characteristic User Description
• Client Characteristic Configuration
• Server Characteristic Configuration
• Characteristic Presentation Format
• Characteristic Aggregation Format
10.5.3.1. The Characteristic Extended Properties Descriptor
This is the descriptor that is used to capture the additional extended properties. At the moment, only two are detailed: the ability to perform reliable writes on the value and the ability to write the Characteristic User Description descriptor.
10.5.3.2. The Characteristic User Description Descriptor
Using this descriptor, a device can associate a text string with a characteristic. This is most useful with devices for which users can perform this configuration themselves. For example, the user could configure a thermostat to describe which room in the building the device is measuring. Some devices might include multiple temperature sensors, so having this configuration at the characteristic level is essential for the ultimate configurability.
10.5.3.3. The Client Characteristic Configuration Descriptor
If a characteristic is notifiable or indicatable, this descriptor must exist. It is a twobit value, with one bit for notifications and the other for indications. Notification and Indication are complementary procedures, so it is impossible to set both of these bits at the same time. How the value is notified or indicated is not defined in the core specifications; this is defined by the service specifications.
10.5.3.4. The Server Characteristic Configuration Descriptor
This descriptor is very similar to the Client Characteristic Configuration descriptor, except that it has one bit for broadcast. This is a single bit, and setting it causes the device to broadcast some data associated with the service in which this characteristic is grouped. Again, the timing of this broadcast is determined by the service.
Interestingly, it is not possible to broadcast a single characteristic. Instead, the service for which this characteristic is grouped defines what data is broadcast when this bit is set. Some services might define that multiple characteristics can be broadcast; it is up to the service to define how an observer can determine which characteristics are broadcast by the service.
It might appear at first to be rather strange that there is bit in a characteristic that can turn on the broadcast of this characteristic, without having the ability to actually broadcast the characteristic directly. This is because characteristics themselves do not have behavior; thus, the meaning of broadcast characteristic data without the context of a service is meaningless. Just receiving “Temperature : 20.5°C” doesn’t mean much. Receiving “Room Temperature Service : 20.5°C” or “Car Engine Service : 65°C” gives that temperature the needed context.
10.5.3.5. The Characteristic Presentation Format Descriptor
One of the goals for the Generic Attribute Profile was to enable generic clients. A generic client is defined as a device that can read the values of a characteristic and display them to the user without understanding what they mean. A generic client could connect to a refrigerator and display the inside temperature without understanding that a value above 10°C is probably bad. In contrast, a profile defines how a client can interoperate with a temperature service in a refrigerator and what to do when the temperature goes out of a valid range.
For generic clients to work, they must be able to find characteristics that can be displayed to the user and then understand their characteristic values enough to display them to the user. The characteristic declaration having a known attribute type is one aspect of being able to find all the characteristics within a device. Generally, characteristics that are readable are also useful. The most important aspect that denotes if a characteristic can be used by a generic client is the Characteristic Presentation Format descriptor. If this exists, it’s possible for the generic client to display its value, and it is safe to read this value.
The presentation format is a multiple-field value that contains the following fields:
• Format
• Exponent
• Unit
• Namespace
• Description
The format is an enumeration of the standard data types that determine how the value is structured. There are formats for Boolean and unsigned 2-bit and 4-bit formats. There are formats for both unsigned and signed integer values with sizes ranging from 8 to 128 bits. There are two sized standard IEEE-754 floating-point numbers, such as are used in most high-end computers. There are two sized integer-based fixed-point numbers that are used primarily by medical devices. Finally, there are two string representations using both UTF-8 and UTF-16 encodings. If the format of the characteristic doesn’t fit into one of these buckets, the opaque structure can be used, or an aggregate format should be used, as defined in the following description.
After the format comes the exponent. This field is only valid for the integer values; it determines a fixed exponent that can be applied to the integer value before it is rendered to the user. This is a base 10 exponent, which makes it possible to perform the placement of the decimal point in the final output routine, rather than using complex mathematics. The value that the characteristic value represents can be expressed by using the following formula:
displayed value = characteristic value * 10exponent
For example, if the characteristic value is 0xFD94, and the presentation format is a signed 16-bit integer with an exponent of −2, the displayed value will be as follows:
−620 * 10−2 = −620 * 0.01 = −6.20
The next field in the presentation format is the unit field. The unit is a UUID defined in the assigned numbers document. Many units are defined. For example, in the preceding example, if the unit is Temperature Celsius, the displayed value will be −6.2°C. It is obviously assumed that a generic client knows what each of these unit UUIDs are.
The final two fields should be considered as a single value. The namespace and description fields determine additional information about the value. The namespace field is a single byte that determines which organization controls the description field. The description field is a 16-bit unsigned number.
The description field is really just a single “adjective” that can be applied to the characteristic so that the user can determine which value is associated with a particular property of the device. As an example, consider a thermometer that has both inside and outside temperature probes. This would expose two temperature characteristics, the only difference being the description field of the Characteristic Presentation Format descriptor being either “inside” or “outside.”
The description and unit fields are used as a lookup to a string localized to the user’s language. Therefore, for a characteristic that has the unit of “weight (kg)” and a description of “hanging”, this localized string would be one of “hanging weight”, “hengende vekt”, “vjeŠanje teŽina”, “riippuva paino”, “penjant de pes”, depending on the user’s language.
10.5.3.6. The Characteristic Aggregation Format Descriptor
Some characteristic values are more complex than just a single value. For example, look at the standard denotation of a position on the planet earth. This is composed of two values concatenated together into a single “value.” The position value is an aggregation of a latitude value and a longitude value. To allow for such complex characteristic values, the Characteristic Aggregate Format descriptor allows multiple presentation format descriptors to be referenced so that the individual fields of the value can be illustrated.
Using the preceding example, the characteristic would have two Characteristic Presentation Format descriptors (one for the latitude and one for the longitude) and the Characteristic Aggregation Format descriptor that references these two Characteristic Presentation Formation descriptors in their correct order. A generic client can then correctly deconstruct the format of the characteristic value and display the value to the user.
It should be noted that there is no requirement for these Characteristic Presentation Format descriptors that are referenced from the Characteristic Aggregate Format to be in the same characteristic. They might not even be in the same service or device. They are just referenced presentation formats; the characteristic within which they are grouped has no meaning for the aggregate format.
10.6. The Attribute Protocol
The Attribute Protocol is a very simple protocol by which an attribute client can find and access attributes on an attribute server. It is structured as six basic operations:
• Request
• Response
• Command
• Indication
• Confirmation
• Notification
The client sends a request to the server to request that the server do something and send back a response, as depicted in Figure 10–26. A client can send only one request at a time. This reduces the complexity on the server, reducing the memory requirements, and thereby making it possible to implement an attribute server using very little code. For each request, there can be only two possible responses: a response that is directly associated with the request, or an error response that gives information about why the request failed.
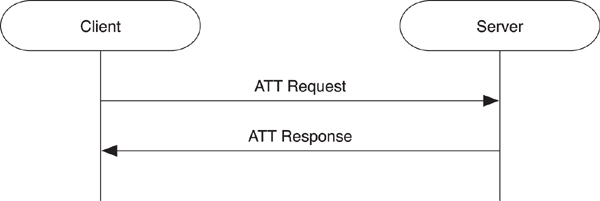
Figure 10–26. An Attribute Protocol request
A client also sends a command to a server but receives no response, as demonstrated in Figure 10–27. The client uses commands when it wants the server to perform an action but there is no need for a immediate response, for example, when the client commands the server to change the television channel. A command can also be used when the response might be delayed and therefore would be delivered in the form of indications or notifications.

Figure 10–27. An Attribute Protocol command
Indications are sent by a server to a client to inform the client that a particular attribute has a given value (see Figure 10–28). Indications are similar to requests in that a confirmation response is required by the client. Also, the server can send only one indication at a time, meaning that only after receiving a confirmation for a previous indication can the next indication be sent.

Figure 10–28. An Attribute Protocol indication
The server sends notifications to a client to inform the client that a value of a particular attribute has a given value (see Figure 10–29). Notifications don’t require a response. In this way, they are similar to commands.

Figure 10–29. An Attribute Protocol notification
Because commands and notifications have no response or confirmation, there are no restrictions on how often they can be sent. If too many commands or notifications are sent, such that the server or client cannot process them all, the receiver of the messages can discard them. They are therefore unreliable. Requests and indications are therefore considered to be reliable because they all must elicit a response acknowledging that the receiving side has at least processed the request or indication.
10.6.1. Protocol Messages
Figure 10–30 provides a list of all the Attribute Protocol PDUs. For most messages, there are both a Request and a Response PDU. For example, the Read message has a Read Request PDU and Read Response PDU. For each of these, there is a set of parameters, which are summarized here.
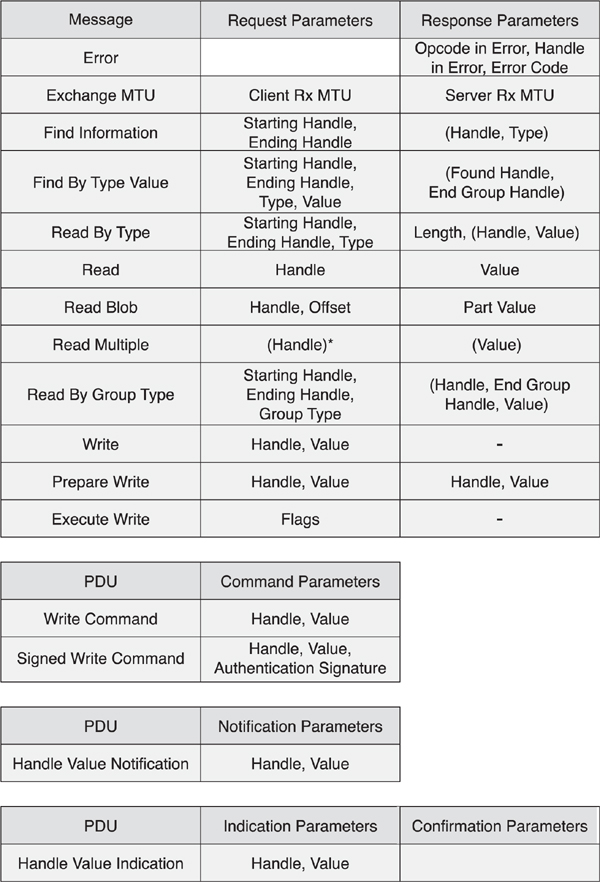
Figure 10–30. Attribute PDUs
The following sections refer to the example attribute database that is shown in Figure 10–11.
10.6.2. The Exchange MTU Request
The Attribute Protocol has a default maximum transmission unit (MTU) of 23 octets on a Bluetooth low energy link. If a device wants to send larger packets, it must negotiate a higher MTU size. Only the client can initiate this request. However, given that many devices have both client and server functionality, this should not be a critical issue. The client request includes the client receiver’s MTU size; the server request includes the server receiver’s MTU size. These two values cannot not be the same value. The MTU size that a link uses can be calculated by taking the minimum of both the client Rx MTU and the server Rx MTU.
This value is not negotiated. In fact, the values sent in the Exchange MTU Request and Exchange MTU Response are fixed values so that the implementation is made as easy as possible. A device that is both a client and a server must use the same value for its client Rx MTU and server Rx MTU, meaning that regardless of which device initiates the MTU exchange, the same MTU results. This means that in the event that both devices initiate the procedure at the same time, the result is the same as if one or the other had started it at different times. This restriction also means that there is no point in starting another MTU exchange at a later time during a connection because the result will always be the same.
For very simple devices that don’t support anything more than the default MTU, the server can always respond with a service Rx MTU of 23, and nothing changes. Obviously, a client would not initiate an MTU exchange if it only supports the default MTU. This implies that all devices must support at least the default MTU.
10.6.3. The Find Information Request
The Find Information Request and response are used to find handle and type information for a sequence of attributes (see Figure 10–31). This is the only message that enables a client to discover the types of any attributes.
Figure 10–31. The Find Information Request
The Find Information Request includes two handles: a starting handle and an ending handle. These define the range of attribute handles used for this request. To find all value attributes, the request would have the starting handle set to 0x0001 and the ending handle set to 0xFFFF. Typically, the response can only include a few attributes within this range of handles at a time; therefore, a sequence of these Find Information Requests must be performed to find all the attributes, with the starting handle one higher than the last found attribute.
The Find Information Response contains handle-type pairs. There are two possible formats for this because there are two sizes of UUID used in Bluetooth low energy. One format is for 16-bit UUIDs that allows up to 5 attribute handle-type pairs to be included in a single Find Information Response. The other format is for 128-bit UUIDs that can only contain a single handle-type pair in the response. Obviously, with a larger MTU than the default, the number of handle-type pairs that can be included increases.
The other interesting thing about the response is that it cannot include both 16-bit and 128-bit UUIDs in the same response packet. To do this would have required an extra byte for each handle-type pair, reducing the number of 16-bit UUIDs that could have been included in a default MTU response to just 4. Given that most UUIDs in a standard attribute server will be 16-bit UUIDs, and it is also not possible to include both a 16-bit UUID and a 128-bit UUID in a single response, it was not considered useful to provide this flexibility.
10.6.4. The Find By Type Value Request
The Find By Type Value Request and response can find all the attributes with a given type and value. The request includes two handles: a starting handle and an ending handle. These define the range of attribute handles used for this request. Any attribute with a handle of starting handle up to and including ending handle that has the same type and same value as the request is returned in the response.
The response includes one or more handles for each attribute that is found. If the type in the request is considered a grouping attribute, one of Primary Service, Secondary Service, or Characteristic, the handle of the last attribute within this group is also included in the response. Unfortunately, because the format of the characteristic declaration does not have a static value for a given characteristic, it is not possible to use this request to search for characteristics.
The primary use of this request is to find a specific primary service. A client can send a Find By Type Value Request with the type set to Primary Service and the value set to the UUID of the service. The response then includes the handle range of each instance of this primary service that is found. Some services are specified such that they cannot exist in a server more than once; therefore, this request would only return a single handle range for that service.
It is possible to use this request to find secondary services; however, this is not something that is used by Bluetooth low energy today. Secondary services are always included from other services, so the Read By Type Request is used to discover these services.
10.6.5. The Read By Type Request
The Read By Type Request reads the value of an attribute within a range of handles. The client uses this when it knows only the type, not the handle. The request includes a starting handle and ending handle. It also includes the type of the attribute to be read. The response includes pairs of handles and values.
Each attribute within the handle range that has the requested type is returned. The response is a set of attribute handles and their associated values. The response is optimized for attributes that have the same size values. For example, when reading all the includes of a service, the Include attributes might all have the same sized values; thus, a single response is returned. If the attributes have different sized values, only the first one or first few that have the same length of value will be returned in the first response. If the attributes have the same sized values, but only some fit into a single response, only the ones that fit into the response will be returned. The request will then have to be repeated with an updated starting handle to obtain further requests.
The Read By Type Request is used for searching for included services as well as discovering all the characteristics of a service by using the Characteristic type. It is also used to read the value of a characteristic with a known type. For example, if you just want to quickly read the battery level of a device, a quick method is to use a read by type request, with the type set to Battery Level. The response will then include the handles of the characteristic values for the battery state along with its values. This allows a client to read out some data very quickly by sending a quick request to it and get that attribute type’s value without extensive characteristic discovery.
10.6.6. The Read Request
The Read Request is probably the simplest request in the Attribute Protocol. The request includes a handle, and the response returns the value of the attribute identified by that handle. This is only useful when the attribute handle is known, but assuming that this knowledge is available on the client, the value of that attribute is read.
10.6.7. The Read Blob Request
Sometimes, the value of an attribute is longer than can be contained within a Read Response. In this situation, the Read Blob Request can be used to read the additional bytes of an attribute’s value. The word blob comes from the database term meaning Binary Long Object. The Read Blob Request includes not only the attribute handle but also a zero-based offset into the attribute value. The response contains as much of the value of the attribute as from the given attribute offset.
This request can be used after the Read Response has returned the first 22 octets of an attribute when the client expects a longer attribute value. That Read Blob Request uses the same attribute handle but with an offset of 22. The response includes part of the value of this attribute from offset 22 to the byte at offset 43. This can continue until the complete attribute value has been read.
This is used when reading long characteristic values and reading long characteristic descriptors.
10.6.8. The Read Multiple Request
The Read Multiple Request reads multiple attribute values in a single operation. The request includes a set of one or more attribute handles. The response includes the values of these attribute handles in the order that they were requested. This is optimized to read multiple attributes of a known size. For example, weight scale might measure an individual’s weight as well as a body mass index; both of these values can be read in a single request.
Because there is no delimitation between the values in the response, variable-length attribute values cannot be used, with a single exception. The last attribute requested can have a variable length. This means that if a client requests a read of three attributes in a single-read multiple request, the first two attributes must have a fixed size, whereas the last attribute can have a variable length.
If a client requests multiple attributes whose values would extend beyond the end of the response packet, the values that don’t fit into the response will be silently dropped.
10.6.9. The Read By Group Type Request
The last read request is the Read By Group Type Request. This is very similar to the Read By Type Request in that it takes a range of handles that the read will be considered over as well as an attribute type. The difference is that the attribute type must be a grouping attribute type, and the response includes the handle of the read attribute, the last attribute for that grouping attribute, as well as the value.
This means that if the grouping type is a Primary Service, it will return not only all the primary service declaration attribute handles but also the last attribute within that primary service and the value of the primary service declaration. A single request can therefore be used to discover all the primary services within a device, and the handle ranges of all the attributes associated with those services, and the type of those services.
As with the other responses where pairs of handles and values are returned, if the values have a variable length, only the first attributes with the same length will be returned in a single response. Therefore, it is necessary for the client to send the request again, updating the starting handle to find the next attribute of interest.
10.6.10. The Write Request
The Write Request is analogous to the Read Request. The request includes a handle and the value to be written into that attribute. The response acknowledges that the value was written.
10.6.11. The Write Command
The Write Command is similar to the Write Request, except there is no response sent. The Write Command contains the handle of the attribute to be written along with the value that is to be written.
Use this command when there is no need for a response. Also, because this command can be sent at any time, even after another request has already been sent and an associated response has not yet been received, this command is also useful in situations for which the latency of sending the command is very important.
10.6.12. The Signed Write Command
The Signed Write Command is very similar to the Write Command except that it also includes an authentication signature. This way, the sender can authenticate itself along with the handle and value being commanded to the server without the need to encrypt the link. This is most useful when the cost of starting encryption would either significantly increase the latency of the data connection or increase the cost of sending a small bit of data when the data does not have to be confidentially delivered.
The authentication signature is composed of a SignCounter and a message authentication code. The SignCounter must be a different value for each message sent between the two devices, regardless of whether the link was disconnected between messages being sent. The message authentication code is the result of the CMAC function as defined in the NIST special publication 800-38B, using a Connection Signature Resolving Key (CSRK) that can be distributed when two devices bond.
The SignCounter is a 32-bit value, which means that there are 4 billion possible signed writes to be performed before the devices need to distribute a new CSRK. Because the SignCounter protects against replay attacks, a Signed Write Command that is received with the same SignCounter must be ignored. The message authentication code is a 64-bit value that is appended after the handle, value, and SignCounter. It should be noted that this requires that the server stores the last SignCounter for each client.
10.6.13. The Prepare Write Request and Execute Write Request
The Prepare Write Request and Execute Write Request are used for two purposes. First, they provide the ability to write long attribute values. Second, they allow multiple values to be written as a single-executed atomic operation.
The attribute server contains a single prepare write queue in which Prepare Write Requests are stored. The size of the queue is implementation dependent, but typically, it is large enough for all the expected services that require prepared writes. The values that are prepared are not written into the attributes until an Execute Write Request is received that gives the go-ahead to execute these prepared writes.
The Prepare Write Request includes the handle, offset, and part attribute value in a similar way as that of the Read Blob Request. This means that the client can either prepare the values of several attributes in the queue or prepare all the parts of an attribute value to be written in the queue. This way, a client can be sure that all the parts of an attribute can be written on the server before the prepare queue is actually executed.
The Prepare Write Response also includes the handle, offset, and part attribute value from the request. This is pure paranoia to ensure that the data gets through reliably. The client can check the fields in the response, with the values it placed into the request, to ensure that the prepared data is received correctly. For some applications, this is certainly a level of verification that is needed. As per the earlier sewage valve example, it is better to send a message twice—and check it—than to flood the children’s play park with untreated effluent because of a single bit error.
To see how careful a client can be about writing a single byte of data to a server, we need to examine how much protection there can be on this data. When a client sends a Prepare Write Request to a server on an encrypted link, there is a 24-bit CRC making sure that there are no bit errors as well as a 32-bit MIC value to ensure that it was sent from the correct client. The prepare write response is also protected with the same 24-bit CRC and 32-bit MIC values.
This means that a single Prepare Write Request of a 1-byte attribute value is being protected by 112 bits of error-checking values: a ratio of 14 protection bytes to the single data byte. In addition, if the client is not happy with the Prepare Write Response, it can just send a quick Execute Write Request with the flags set to “cancel” the Prepare Write Queue and start preparing the value again.
Once all the prepared writes have been sent, the server has a queue of prepared writes ready to execute. The client can then send the Execute Write Request with the flags set to immediately write all prepared values. The server will then write all these values in a single atomic operation. The attributes are written in the order in which they were prepared. If the client prepared the same attribute multiple times, the server will write these values in order. This means that if the prepare queue is used to configure a hardware state for which the hardware must be disabled, configured, and then reenabled, this can all be done with in a single prepare queue by writing “disable” to the appropriate attribute, writing the configuration attributes, and then writing “enable” at the end of the prepare queue. The execution of this prepared queue will therefore complete the reconfiguration in an atomic operation.
10.6.14. The Handle Value Notification
When the server wants to send a quick attribute state update to the client, it can send a Handle Value Notification. This is one of only two messages that the server can send to the client, and the only one that doesn’t have a message sent in reply. Therefore, the server can send it at any time and it is also considered to be unreliable.
The Handle Value Notification has an attribute handle and a value. The notification is therefore a message from the server to the client that this attribute now has this value. This message is one of the most important messages in the Attribute Protocol. It not only allows the server to efficiently keep the client up to date with the current state of its attribute database, but it is also used to notify the client of the changes in a finite state machine.
Without notifications, a client would need to constantly poll the server to determine if the attribute value had changed. Once notifications are configured, the client just waits for the server to notify it when the value has updated. It should be noted that this also means that the client is be notified of the new value more quickly than if it were polling periodically.
Typically, the configuration of notifications within a server is stored for all bonded devices. This has the advantage that when a client reconnects to a device, the server in that device can instantly notify the client of its state. For example, the battery level of a device could be configured for notification; whenever the client reconnects to the device and the battery level has changed, the client is instantly notified.
Because these notifications don’t have any confirmations, they can be sent at any time, regardless of any other transactions that are active at the same time. This means that even if the client and server are in the middle of a complex interaction involving requests and indications, a notification can always be sent. As such, notifications are very useful for information that needs to be sent to the client now.
10.6.15. The Handle Value Indication
A Handle Value Indication is very similar to the Handle Value Notification; it has the same fields of attribute handle and value, but it must be confirmed upon receipt in the client. The server can only send one of these indications at a time, and it will only send the next indication when the last indication has been confirmed.
The handle value confirmation doesn’t have any data within it. It is used for flow control. Because of the confirmation, the indications can be considered to be reliable. Once the server has received the confirmation, the server can be assured that the client has received the indication.
10.6.16. Error Response
An Error Response can be sent by a device whenever a request asks for something that cannot be achieved. For example, if a device asks for an attribute to be written by using a write request, but that attribute is read-only, instead of sending a write response saying that everything was good, an Error Response is sent giving the reason the request failed.
The Error Response includes all the information about the request that caused the error, the attribute on which the request failed, and why the error was generated in the first place. Whenever a client receives an error response, it must assume that this error response is for the last request that it sent. Therefore, the Error Response is another way to close the request’s transaction along with its own response message. This means that for each request that can be sent, there are always two possible responses, the failure error response case and the success response case. For example, a Read Request can either have an Error Response or a Read Response sent in reply.
The following are the different reasons an error can be sent:
• Invalid Handle The attribute handle in the request was invalid and does not exist on the server. This could be because a read or write was requested using an attribute handle that is not used or allocated by that server. It can also be sent when an attribute handle in the request was set to 0x0000.
• Read Not Permitted The attribute does not allow the reading of the attribute value. For example, a control point write-only attribute will send this error if a client attempted to read this value.
• Write Not Permitted The attribute does not allow the writing of the attribute value. For example, attempting to write a read-only attribute value will send this error.
• Invalid PDU The request that is sent is not understood by the server. This is typically sent when the client has sent a request that is badly formatted. For example, a Read Request should have a two-octet handle as its single parameter. If the Read Request does not have two octets of parameters, this error is sent.
• Insufficient Authentication The request to read or write an attribute’s value cannot be completed because the two devices have not authenticated one another. To perform authentication, the connection can be encrypted, or if no bond exists for that device, the Security Manager pairing procedures can be used to pair and then bond the devices.
• Request Not Supported The request that is sent is known to the server but it has chosen not to implement it at this time. This can be used for both known requests that the server did not implement as well as future requests that it does not currently understand. This error can be the default error on any request that is not implemented in a device.
• Invalid Offset The request includes an offset, but the offset given was invalid. When reading long attributes, the offset is used to read the parts of the attribute value one block of bytes at a time. If the offset used is greater than the length of the attribute value, the offset would be considered invalid. An offset the same as the length of the attribute value does not give this error; instead, it would respond with zero-length part value in the response.
• Insufficient Authorization The request to read or write an attribute’s value cannot be completed because the server has not authorized the client to have access to that value. Authorization is a server local feature. The server needs to determine how to allow the user to authorize that client. For example, on a phone or a computer, this could be done by prompting the user and asking her if she grants access to the requested data.
• Prepare Queue Full The Prepare Write Request cannot be accepted because the memory used to hold the queue of pending writes is already full. The prepare queue is a finite size and should be sufficiently large to handle all the services that the device supports. However, a client might attempt to do too much in a single prepared queue and therefore would fail.
• Attribute Not Found The sought-after attribute was not found. This is only used when searching over a range of attributes when looking for a specific attribute type or types. This means that only the Find Information Request, Find By Type Value Request, Read By Type Request, and Read By Group Type Request can generate this error. For the Find Information Request, this means that there were no attributes found within the handle range. For the Find By Type Value Request, Read By Type Request, and Read By Group Type Request, this means that there were no attributes of the given type found within the handle range.
• Attribute Not Long The attribute referenced in the Read Blob Request is not a long attribute and therefore the request is rejected and the client should use the Read Request instead. This error is only relevant to fixed-length attribute values, which are shorter than the current MTU size where the Read Blob Request is used. For this reason, it is much simpler to use a Read Request to read the first 22 octets of an attribute value and then use the Read Blob Request to read the remaining octets.
• Insufficient Encryption Key Size This error is generated when the link is encrypted and has sufficient authentication and authorization, but the encryption key size negotiated during pairing is weaker than that required by the service. There are some attribute values where very strong encryption keys are necessary to fully protect the confidentiality of the data.
• Invalid Attribute Value Length The attribute value used in the write request or from the prepare queue during the execution of that prepare queue is the wrong length. If an attribute value has a fixed size (for example, two bytes) and the write attempts to change this to a different size (for example, one or three bytes), then this error is generated.
• Unlikely Error This is probably the best error code that exists. It basically means that something unexplained happened that doesn’t fit any other error code. The problem with this error code is that if the error was describable, an error code could be created for it. Given that the error generating this was not thought of ahead of time, it really is an unlikely error.
• Insufficient Encryption The attribute value can be read or written but the link is not encrypted. There are some attribute values for which the confidentiality of an encrypted link is required.
• Unsupported Group Type The attribute type that was included in the request was not considered a group type by the server. Only group types that are known by the server can be used in Read By Group Type Request.
• Insufficient Resources The server has insufficient resources to accept or process this particular request. For example, some services might use this error code when configuring a device to broadcast data when the quantity of data that is already being broadcast in addition to the requested broadcast data is too large.
• Application Errors The request did something with an attribute of a service that was not allowed, and the service allocated its own error code to report what went wrong. This is a range of error codes, from 128 to 255, and the actual meaning is defined in the service specification in which the attribute is grouped. A typical application error would be that the value written into a characteristic was invalid.
It should be noted that an error response terminates the request. If the client fixes the error, perhaps by authorizing or performing a procedure that authenticates the link, the client will have to repeat the request. There is no “pending” response. Pending responses assume that the server can hold state about the request while it sorts out the problem. In Bluetooth low energy, the client is always the more complex device so it must resolve the problems and hold the state again. It also means that a client can send any request to the server, knowing that it can always receive an error, and then move on to the next attribute if it is unable to fix the problem causing the error.
10.7. The Generic Attribute Profile
The final piece of the attribute puzzle is the Generic Attribute Profile (GATT) procedures. The Attribute Protocol defines how a client and server can send standard messages between one another. The GATT procedures define standard ways that services, characteristics, and their descriptors can be discovered and then used. The GATT procedures can be considered to be split into three basic types:
• Discovery procedures
• Client-initiated procedures
• Server-initiated procedures
There is one additional type of procedure that doesn’t fit into any of these groups. This is the Exchange MTU procedure that uses the Exchange MTU Request from the Attribute Protocol to determine the MTU size that is used for any subsequent messages. This procedure does not have to be used; therefore, the default MTU of 23 octets would be used.
10.7.1. The Discovery Procedures
There are four basic things that need to be discovered. First, the client needs to discover the primary services. Once the primary services have been discovered, all the other information on a server that is grouped with this primary service can be discovered. The client can then use the range of handles for each interesting primary service to discover the referenced secondary services, the characteristics that are actually exposed by this instance of the service. For each characteristic found, the set of descriptors can then be discovered. Only after all this is complete can the services be “used” by client and server-initiated procedures such as reading or writing characteristic values or descriptors.
10.7.2. The Discovering Services
There are three ways to discover services:
• Discover All Primary Services
• Discover Primary Service By Service UUID
• Find Included Services
10.7.2.1. Discover All Primary Services
When a client connects to a device and wants to find all the primary services exposed on the device to determine what it can do, it uses the Read By Group Type Request with the handle range set to 0x0001 : 0xFFFF and the attribute type set to Primary Service. The server responds with the one or more primary services that it finds. The response includes not only the handle of the service declaration but also the last handle for the attributes of this service. The response also includes the value of the service declaration so that the client can determine that it understands each service.
Unless the last handle of the last service is 0xFFFF or an Error Response was received, the client sends another Read By Group Type Request with the starting handle updated to be one greater than the last handle of the last service in the previous response. This way, the client can enumerate all the services on a device.
It should be noted that the Read By Group Type Response cannot return both services with 16-bit UUIDs and 128-bit UUIDs in a single response. Therefore, the server will return all 16-bit UUIDs before an attribute with a 128-bit UUID in one response, and then the 128-bit service in the next response, and the remainder of the 16-bit UUIDs in subsequent responses. This is optimized for the more common 16-bit UUIDs used by standard services. To help with this, 16-bit UUID–based services are recommended to have lower numbered handles.
10.7.2.2. Discover Primary Service By Service UUID
Sometimes, a client just wants to use a particular service and doesn’t want or need to enumerate any other services. For example, a light switch would only need to discover the Light Service and wouldn’t care about any other services that this device exposes. To help with these “simple clients,” a special procedure is used that is optimized for discovering primary services that have a known type.
The client sends a Find By Type Value Request to the server with the handle range set to 0x0001 : 0xFFFF, the type set to Primary Service, and the value set to the service type that is wanted, for example, Light Service. The server responds with the handle ranges for each light service that is found.
Some services will be defined such that they are “singleton” services; they can only be instantiated once on any given server. For these services, the response will only ever include a single handle range. Other services will allow themselves to be instantiated multiple times; thus, the response will have multiple handle ranges, one for each service.
It might be possible—although unlikely—that the number of instances of a given service on a device will exceed the eight service handle ranges that can be included in a single response. In this case, the same updating of the starting handle that was used earlier is used to find the other services.
10.7.2.3. Find Included Services
Once the primary services are discovered, secondary services and other referenced services can then be discovered. This involves looking for an Include declaration by using the Read By Type Request. This time, the starting handle and ending handle would be set to the handle range of each service previously found. Typically, only two references can be returned in a single response. Therefore, the request needs to be sent with the starting handle set to one higher than the last handle returned.
Once referenced services have been discovered, the references to these services can also be discovered by using the same procedures.
10.7.3. Characteristic Discovery
Once the services have been discovered, the characteristics of each service can then be discovered. To discover characteristics, both characteristic discovery and characteristic descriptor discovery must be performed.
10.7.3.1. Discover All Characteristics of a Service
To perform characteristic discovery, Read By Type Request is used with the handle range set to the handle range for the service and the type set to Characteristic. This allows all the characteristic declarations to be discovered and read.
Within a service, the mandatory characteristics should be ordered first, followed by any optional characteristics. This allows a client that is looking for the one mandatory characteristic in a service to terminate this procedure early.
For each characteristic in a service, the characteristic declaration is returned, together with the handle of this characteristic. The declaration includes its properties, the handle of the attribute that contains the characteristic’s value, and the type of this characteristic. This means that once you have discovered the characteristic declaration, you can determine what this characteristic represents, what you can do with this characteristic, and the handle for the subsequent read or write procedures.
10.7.3.2. Discover All Characteristic Descriptors
Once each characteristic’s declaration has been discovered, it is then possible to find all the descriptors for each characteristic. This is done by using the Find Information Request with the handle range set to the handle range for each characteristic declaration grouped with the characteristic.
It is not possible to find the handles of all the attributes that are grouped with the characteristic declaration directly. It is possible to determine the handles of all the characteristic declarations within a service, and with this knowledge, determine the handles associated with a given characteristic. For example, if you have a service that has a declaration at handle 0x0100, and the end handle for this service is 0x010F, with characteristic declarations at 0x0102 and 0x0108, the attribute handles for the attributes grouped with the first characteristic of this service would be in the range 0x0103 to 0x0107, and for the second characteristic, they would be in the range 0x0109 to 0x010F.
The Find Information Response includes the handles and types of all the descriptors for the characteristic. Any characteristic descriptor that is not understood by the client can be safely ignored. Any characteristic descriptor that is understood by the client can be used to either understand the characteristic further, or configure the behavior of the characteristic. For example, the client could use the Characteristic Presentation Format to understand how to display the value on the client’s display. The client could use the Client Characteristic Configuration Descriptor to configure the characteristic to be notified or indicated.
10.7.4. Client-Initiated Procedures
There are four things that a client can do with a characteristic:
• Reading characteristic value
• Writing characteristic value
• Reading characteristic descriptors
• Writing characteristic descriptors
10.7.4.1. Read (Long) Characteristic Values
After the characteristics of a service have been discovered, the value of the characteristic can be read. The value is stored in an attribute that is pointed to by a handle in the characteristic declaration. The type of this attribute is also the same as the characteristic UUID from the characteristic declaration. This means that once the characteristic descriptor has been discovered by using the characteristic discovery procedures described earlier, the characteristic value can be read by using either a Read Request or a Read Blob Request.
The difference between using a Read Request or a Read Blob Request is very subtle and can cause confusion. Attributes can have a fixed length, and if this fixed length is less than the attribute protocol’s MTU, the Read Request can be used to read the characteristic value. If the attribute has a fixed length but this length is longer than the attribute protocol’s MTU, first a Read Request would be used to obtain the first 22 octets of the characteristic’s value, followed by one or more Read Blob Request messages to obtain the remaining parts of the characteristic’s value.
If the characteristic value can have a variable length, for example, a string, then it must be assumed that the value is longer, and then the Read Request followed by Read Blob Request messages must be used to read the complete value. This procedure can terminate early if the variable length value is shorter than expected. For example, if the characteristic value is 21 octets in length, only a single Read Request will be necessary; if the characteristic value is 22 octets in length, a Read Request followed by a Read Blob Request will be necessary, with the Read Blob Response containing no additional octets of value. Therefore, it is not possible to know if the Read Response or any Read Blob Response contains the last octet of the attribute value or is just full up because it has exactly the right length. Thus, the client keeps issuing a Read Blob Request until it receives a Read Blob Response containing less than 22 octets of data.
10.7.4.2. Read Using Characteristic UUID
There are some instances for which you just want to read the value of a characteristic, without having to first find all the characteristic declarations within a service and then read the value. For example, to read the battery level, it would be much more efficient to just request the value of the Battery Level characteristic. This can be done by using the Read By Type Request with the type set to the required characteristic UUID.
10.7.4.3. Read Multiple Characteristic Values
It is also possible to read multiple characteristic values at the same time. This does require that the handles of each of the characteristic’s values are known. The biggest issue with this procedure is that each of the values must have a known size. This is because there are no frame boundaries on each value. The Read Multiple Request is used to perform this procedure.
However, even when taking this restriction into consideration, it can also provide some interesting possibilities. The last characteristic value requested can have a variable size because the size of this value is determined by the size of the attribute protocol packet.
10.7.4.4. Write (Long) Characteristic Value
To write characteristic values, the Write Request is used. This can only be used to write short characteristic values; by default, less than or equal to 20 octets in length. To use this, the characteristic value’s attribute handle must have been discovered.
If the attribute value that is to be written is longer than 20 octets, a different procedure will need to be used. This involves using both the Prepare Write Request to prepare the long value to be written, followed by the Execute Write Request to actually write the value. It might appear to be overkill from a protocol point of view to use the same procedure to write long characteristic values as is used for reliable writes, but there is a very good reason for this. The Attribute Protocol is atomic in operation only for a single request. If the long attribute write occurred over multiple requests, causing the value to be partially changed between each request, any other device trying to read the value would possibly read an invalid value. By using the prepare write queue to prestore the long value to be written and then executing this write in a single Execute Write Request, the atomic nature of the write can be ensured.
10.7.4.5. Characteristic Value Reliable Writes
When attempting to write values with the maximum reliability, the Characteristic Value Reliable Writes procedure is used. This procedure can also be used for writing multiple characteristic values at the same time in an atomic operation. For example, when moving a machining tool to a new position in 2-D space, if the x and y values were written in sequential requests, two straight lines would be created, one horizontal and one vertical. However, if both the x and y values were prepared and then executed in a single atomic operation, a single line would be created.
The procedure uses the same Prepare Write Request and Execute Write Request that is used in the Write Long Characteristic Value procedure, with one additional check. For each value that is prepared, the Prepare Write Response is compared with the request to ensure that the handle and value in the response are the same as those used in the request. As explained in Section 10.6.13, this ensures the maximum security against single bit errors. If the handle and value are different, the Execute Write Request is used with the flags parameter set to cancel the prepare queue. Consequently, all the values that were prepared will have to be prepared again.
10.7.4.6. (Signed) Writing Without Response
Sometimes, a value needs to be written very quickly and a response is not required at the protocol level. This procedure uses the Write Command to send the value to be written to the characteristic value’s attribute. There is no response with this command; therefore, it is assumed that if a response is required, it would be delivered through another characteristic being notified, or is out of band, or not required.
For example, when turning a light on, it is not necessary to receive a response from the peer device over the Attribute Protocol because the user will see the light turn on. Another reason for using this procedure is when the response might not be available immediately. For example, a time synchronization service might expose a characteristic that can be written without response to start the synchronization process. When the synchronization has completed, the newly updated time value can be notified to complete the process. The final reason for using this procedure is when the response would be too complex to fit into a single message. For example, a message server could expose the state of a single message and have a characteristic that can be written without response to change which message is exposed. There is no reason to have a response to the write because the value of the associated characteristics will have been updated by the time those values are read.
For some devices, the data that is written needs to authenticate the initiator of this message. To do this, the Signed Write Command is used. Again, this does not have a response, so it can be used in exactly the same situations as a Write Command, but with the additional security that authentication provides.
For example, the television would like to know that the remote control that just sent the “power off” message was the remote control that is bonded with the television. Typically, this would have required the full encryption of the link to ensure authentication. Encryption takes time to set up and requires many resources on devices to create cipher streams for encrypting each message. For some applications, the time taken to encrypt the link will push the latency requirements of the application outside the latencies that can be tolerated. The Signed Write Without Response procedure solves this. The message can be authenticated before the link is established, and then sent on an unencrypted link as the very first message on the link. This significantly reduces the latency for the message being transmitted to the other device but does not stop eavesdroppers from listening to this transaction. However, if this message is just to say “turn on” or “turn off” a device, there is no confidential information in this message.
10.7.4.7. Read/Write (Long) Characteristic Descriptors
Characteristic descriptors are not the same as the characteristic value, but the procedures to access them are very similar to the procedures used to read and write the characteristic values.
For reading the descriptors, the Read Request and Read Blob Request are used. For writing the descriptors, the Write Request and Prepare Write Request/Execute Write Request are used.
10.7.5. Server-Initiated Procedures
Not all procedures are initiated by the client. Some are initiated by the server, including notifications and indications. Typically, the client will configure the server to send these messages or cause the server to send the messages because it commanded the server to do something that generates these messages.
There are two types of GATT procedures that are server initiated:
• Notifications
• Indications
10.7.5.1. Notifications
A notification is a server-initiated message that can be sent at any time by a server to a client. These messages have no flow control mechanisms, so a client might not have enough buffer space to hold all the received messages and is allowed to drop them. It is useful to consider notifications as unreliable messages. Notification uses the Handle Value Notification message.
10.7.5.2. Indications
An indication is a server-initiated message that can be sent at any time by a server to a client. These messages have flow control and therefore a server cannot send an indication until the last indication was confirmed as received by the client. These indications are therefore considered to be reliable messages. Indications use the Handle Value Indication message as well as the Handle Value Confirmation message sent by the client to acknowledge the receipt of the indication.
10.7.6. Mapping ATT PDUs to GATT Procedures
• Exchange MTU Request is used in the Exchange MTU procedure in GATT.
• Find Information Request is used in the Discover All Characteristic Descriptors procedure in GATT.
• Find By Type Value Request is used in the Discover Primary Services By Service UUID procedure in GATT.
• Read By Type Request is used in the Find Included Services, Discover All Characteristics of a Service, Discover Characteristics by UUID, and Read Using Characteristic UUID procedures in GATT.
• Read Request is used in the Read Characteristic Value and Read Characteristic Descriptors procedures in GATT.
• Read Blob Request is used in the Read Long Characteristic Values and Read Long Characteristic Descriptors procedures in GATT.
• Read Multiple Request is used in the Read Multiple Characteristic Values procedure in GATT.
• Read By Group Type Request is used in the Discover All Primary Services procedure in GATT.
• Write Request is used in the Write Characteristic Value and Write Characteristic Descriptor procedures in GATT.
• Write Command is used in the Write Without Response procedure in GATT.
• Signed Write Command is used in the Signed Write Without Response procedure in GATT.
• Prepare Write Request and Execute Write Request is used in the Write Long Characteristic Value, Characteristic Value Reliable Writes, and Write Long Characteristic Descriptors procedures in GATT.
• Handle Value Notification is used in the Notification procedure in GATT.
• Handle Value Indication is used in the Indication procedure in GATT.