
Chapter 3. Engineering Incremental Change
In 2010, Jez Humble and Dave Farley released Continuous Delivery, a collection of practices to enhance engineering efficiency in software projects. They provided the mechanism for building and releasing software via automation and tools but not the structure of how to design evolvable software. Evolutionary architecture assumes these engineering practices as being prerequisites but addresses how to utilize them to help design evolvable software.
Our definition of evolutionary architecture is one that supports guided, incremental change across multiple dimensions. By incremental change, we mean the architecture should facilitate change through a series of small changes. This chapter describes architectures that support incremental change along with some of the engineering practices used to achieve incremental change, an important building block of evolutionary architecture. We discuss two aspects of incremental change: development, which covers how developers build software, and operational, which covers how teams deploy software.
This chapter covers the characteristics, engineering practices, team considerations, and other aspects of building architectures that support incremental change.
Incremental Change
Here is an example of the operational side of incremental change. We start with the fleshed-out example of incremental change from Chapter 1, which includes additional details about the architecture and deployment environment. PenultimateWidgets, our seller of widgets, has a catalog page backed by a microservices architecture and engineering practices, as illustrated in Figure 3-1.

Figure 3-1. Initial configuration of PenultimateWidgets’ component deployment
PenultimateWidgets’ architects have implemented microservices that are operationally isolated from other services. Microservices implement a share nothing architecture: each service is operationally distinct to eliminate technical coupling and therefore promote change at a granular level. PenultimateWidgets deploys all its services in separate containers to trivialize operational changes.
The website allows users to rate different widgets with star ratings. But other parts of the architecture also need ratings (customer service representatives, shipping provider evaluation, etc.), so they all share the star rating service. One day, the star rating team releases a new version alongside the existing one that allows half-star ratings—a significant upgrade, as shown in Figure 3-2.

Figure 3-2. Deploying with an improved star rating service showing the addition of the half-star rating
The services that utilize ratings aren’t required to migrate to the improved rating service but can gradually transition to the better service when convenient. As time progresses, more parts of the ecosystem that need ratings move to the enhanced version. One of PenultimateWidgets’ DevOps practices is architectural monitoring—monitoring not only the services but also the routes between services. When the operations group observes that no one has routed to a particular service within a given time interval, they automatically disintegrate that service from the ecosystem, as shown in Figure 3-3.

Figure 3-3. All services now use the improved star rating service
The mechanical ability to evolve is one of the key components of an evolutionary architecture. Let’s dig one level deeper in the abstraction above.
PenultimateWidgets has a fine-grained microservices architecture, where each service is deployed using a container—such as Docker—and using a service template to handle infrastructure coupling. Applications within PenultimateWidgets consist of routes between instances of running services—a given service may have multiple instances to handle operational concerns like on-demand scalability. This allows architects to host different versions of services in production and control access via routing. When a deployment pipeline deploys a service, it registers itself (location and contract) with a service discovery tool. When a service needs to find another service, it uses the discovery tool to learn the location and version suitability via the contract.
When the new star rating service is deployed, it registers itself with the service discovery tool and publishes its new contract. The new version of the service supports a broader range of values—specifically, half-point values—than the original. That means the service developers don’t have to worry about restricting the supported values. If the new version requires a different contract for callers, it is typical to handle that within the service rather than burden callers with resolving which version to call. We cover that contract strategy in “Version Services Internally”.
When the team deploys the new service, they don’t want to force the calling services to upgrade to the new service immediately. Thus, the architect temporarily changes the star-service endpoint into a proxy that checks to see which version of the service is requested and routes to the requested version. No existing services must change to use the rating service as they always have, but new calls can start taking advantage of the new capability. Old services aren’t forced to upgrade and can continue to call the original service as long as they need it. As the calling services decide to use the new behavior, they change the version they request from the endpoint. Over time, the original version falls into disuse, and at some point, the architect can remove the old version from the endpoint when it is no longer needed. Operations is responsible for scanning for services that no other services call anymore (within some reasonable threshold) and for garbage collecting the unused services. The example shown in Figure 3-3 shows evolution in the abstract; a tool that implements this style of cloud-based evolutionary architecture is Swabbie.
All the changes to this architecture, including the provisioning of external components such as the database, happen under the supervision of a deployment pipeline, removing the responsibility of coordinating the disparate moving parts of the deployment from DevOps.
Once they have defined fitness functions, architects must ensure that they are evaluated in a timely manner. Automation is the key to continual evaluation. A deployment pipeline is often used to evaluate tasks like this. Using a deployment pipeline, architects can define which, when, and how often fitness functions execute.
Deployment Pipelines
Continuous Delivery describes the deployment pipeline mechanism. Similar to a continuous integration server, a deployment pipeline “listens” for changes, then runs a series of verification steps, each with increasing sophistication. Continuous Delivery practices encourage using a deployment pipeline as the mechanism to automate common project tasks, such as testing, machine provisioning, deployments, and so forth. Open source tools such as GoCD facilitate building these deployment pipelines.
A typical deployment pipeline automatically builds the deployment environment (a container like Docker or a bespoke environment generated by a tool like Puppet, or Chef) as shown in Figure 3-4.
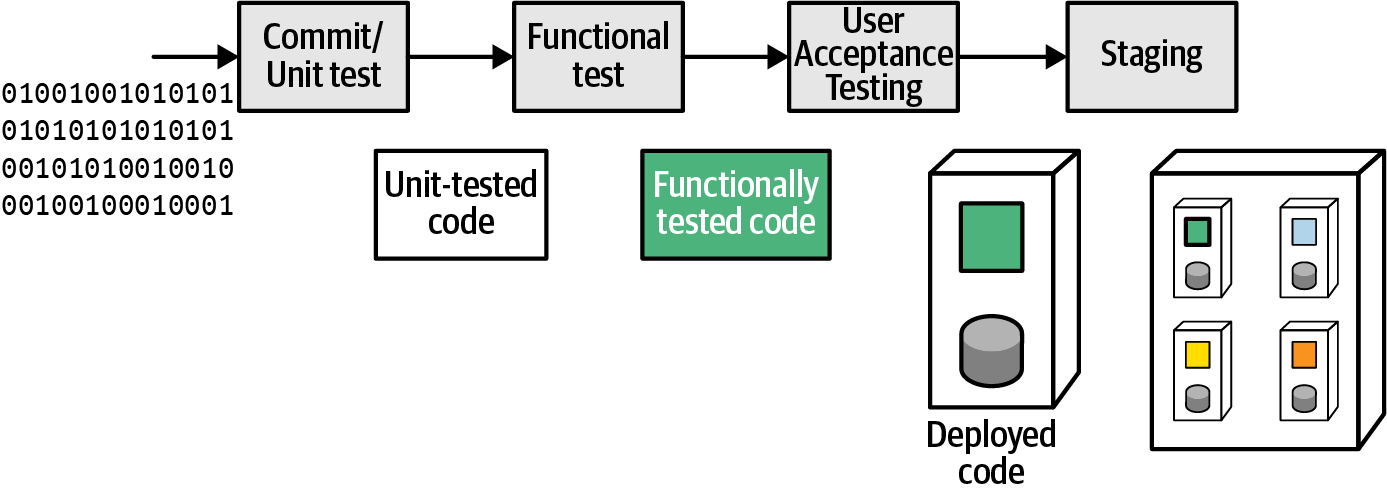
Figure 3-4. Deployment pipeline stages
By building the deployment image that the deployment pipeline executes, developers and operations have a high degree of confidence: the host computer (or virtual machine) is declaratively defined, and it’s a common practice to rebuild it from nothing.
The deployment pipeline also offers an ideal way to execute the fitness functions defined for an architecture: it applies arbitrary verification criteria, has multiple stages to incorporate differing levels of abstraction and sophistication of tests, and runs every single time the system changes in any way. A deployment pipeline with fitness functions added is shown in Figure 3-5.

Figure 3-5. A deployment pipeline with fitness functions added as stages
Figure 3-5 shows a collection of atomic and holistic fitness functions, with the latter in a more complex integration environment. Deployment pipelines can ensure the rules defined to protect architectural dimensions execute each time the system changes.
In Chapter 2, we described PenultimateWidgets’ spreadsheet of requirements. Once the team adopted some of the Continuous Delivery engineering practices, they realized that the architecture characteristics for the platform work better in an automated deployment pipeline. To that end, service developers created a deployment pipeline to validate the fitness functions created both by the enterprise architects and by the service team. Now, each time the team makes a change to the service, a barrage of tests validate both the correctness of the code and its overall fitness within the architecture.
Another common practice in evolutionary architecture projects is continuous deployment—using a deployment pipeline to put changes into production contingent on successfully passing the pipeline’s gauntlet of tests and other verifications. While continuous deployment is ideal, it requires sophisticated coordination: developers must ensure changes deployed to production on an ongoing basis don’t break things.
To solve this coordination problem, a fan-out operation is commonly used in deployment pipelines in which the pipeline runs several jobs in parallel, as shown in Figure 3-6.

Figure 3-6. Deployment pipeline fan-out to test multiple scenarios
As shown in Figure 3-6, when a team makes a change, they have to verify two things: they haven’t negatively affected the current production state (because a successful deployment pipeline execution will deploy code into production) and their changes were successful (affecting the future state environment). A deployment pipeline fan-out allows tasks (testing, deployment, etc.) to execute in parallel, saving time. Once the series of concurrent jobs illustrated in Figure 3-6 completes, the pipeline can evaluate the results and, if everything is successful, perform a fan-in, consolidating to a single thread of action to perform tasks like deployment. Note that the deployment pipeline may perform this combination of fan-out and fan-in numerous times whenever the team needs to evaluate a change in multiple contexts.
Another common issue with continuous deployment is business impact. Users don’t want a barrage of new features showing up on a regular basis and would rather have them staged in a more traditional way, such as in a “Big Bang” deployment. A common way to accommodate both continuous deployment and staged releases is to use feature toggles. A feature toggle is typically a condition in code that enables or disables a feature, or switches between two implementations (e.g., new and old). The simplest implementation of a feature toggle is an if-statement that inspects an environment variable or configuration value and shows or hides a feature based on the value of that environment variable. You also can have more complex feature toggles that provide the ability to reload configurations and enable or disable features at runtime. By implementing code behind feature toggles, developers can safely deploy new changes to production without worrying that users see their changes prematurely. In fact, many teams performing continuous deployment utilize feature toggles so that they can separate operationalizing new features from releasing them to consumers.
Using deployment pipelines in engineering practices, architects can easily apply project fitness functions. Figuring out which stages are needed is a common challenge for developers designing a deployment pipeline. However, once the fitness functions inside a deployment pipeline are in place, architects and developers have a high level of confidence that evolutionary changes won’t violate the project guidelines. Architectural concerns are often poorly elucidated and sparsely evaluated, often subjectively; creating them as fitness functions allows better rigor and therefore better confidence in the engineering practices.
Case Study: Adding Fitness Functions to PenultimateWidgets’ Invoicing Service
Our exemplar company, PenultimateWidgets, has an architecture that includes a service to handle invoicing. The invoicing team wants to replace outdated libraries and approaches but wants to ensure these changes don’t impact other teams’ ability to integrate with them.
The invoicing team identified the following needs:
- Scalability
-
While performance isn’t a big concern for PenultimateWidgets, the company handles invoicing details for several resellers, so the invoicing service must maintain availability service-level agreements.
- Integration with other services
-
Several other services in the PenultimateWidgets ecosystem use invoicing. The team wants to make sure integration points don’t break while making internal changes.
- Security
-
Invoicing means money, and security is an ongoing concern.
- Auditability
-
Some state regulations require that changes to taxation code be verified by an independent accountant.
The invoicing team uses a continuous integration server and recently upgraded to on-demand provisioning of the environment that runs their code. To implement evolutionary architecture fitness functions, they implement a deployment pipeline to replace the continuous integration server, allowing them to create several stages of execution, as shown in Figure 3-7.

Figure 3-7. PenultimateWidgets’ deployment pipeline
PenultimateWidgets’ deployment pipeline consists of six stages:
- Stage 1: Replicate CI
-
The first stage replicates the behavior of the former CI server, running unit and functional tests.
- Stage 2: Containerize and deploy
-
Developers use the second stage to build containers for their service, allowing deeper levels of testing, including deploying the containers to a dynamically created test environment.
- Stage 3: Execute atomic fitness functions
-
In the third stage, atomic fitness functions, including automated scalability tests and security penetration testing, are executed. This stage also runs a metrics tool that flags any code within a certain package that developers changed, pertaining to auditability. While this tool doesn’t make any determinations, it assists a later stage in narrowing in on specific code.
- Stage 4: Execute holistic fitness functions
-
The fourth stage focuses on holistic fitness functions, including testing contracts to protect integration points and some further scalability tests.
- Stage 5a: Conduct a security review (manual)
-
This stage includes a manual stage by a specific security group within the organization to review, audit, and assess any security vulnerabilities in the codebase. Deployment pipelines allow the definition of manual stages, triggered on demand by the relevant security specialist.
- Stage 5b: Conduct audits (manual)
-
PenultimateWidgets is based in a state that mandates specific auditing rules. The invoicing team builds this manual stage into their deployment pipeline, which offers several benefits. First, treating auditing as a fitness function allows developers, architects, auditors, and others to think about this behavior in a unified way—a necessary evaluation to determine the system’s correct function. Second, adding the evaluation to the deployment pipeline allows developers to assess the engineering impact of this behavior compared to other automated evaluations within the deployment pipeline.
For example, if the security review happens weekly but auditing happens only monthly, the bottleneck to faster releases is clearly the auditing stage. By treating both security and audit as stages in the deployment pipeline, decisions concerning both can be addressed more rationally: Is it of value to the company to increase release cadence by having consultants perform the necessary audit more often?
- Stage 6: Deploy
-
The last stage is deployment into the production environment. This is an automated stage for PenultimateWidgets and is triggered only if the two upstream manual stages (security review and audit) report success.
Interested architects at PenultimateWidgets receive an automatically generated report each week about the success/failure rate of the fitness functions, helping them gauge health, cadence, and other factors.
Case Study: Validating API Consistency in an Automated Build
PenultimateWidgets architects have designed an API encapsulating the internal complexity of their accounting systems into a cleaner interface that the remainder of the company (and partner companies) use. Because they have many integration consumers, when rolling out changes they want to be careful not to create inconsistencies or breakages with previous versions.
To that end, the architects designed the deployment pipeline shown in Figure 3-8.
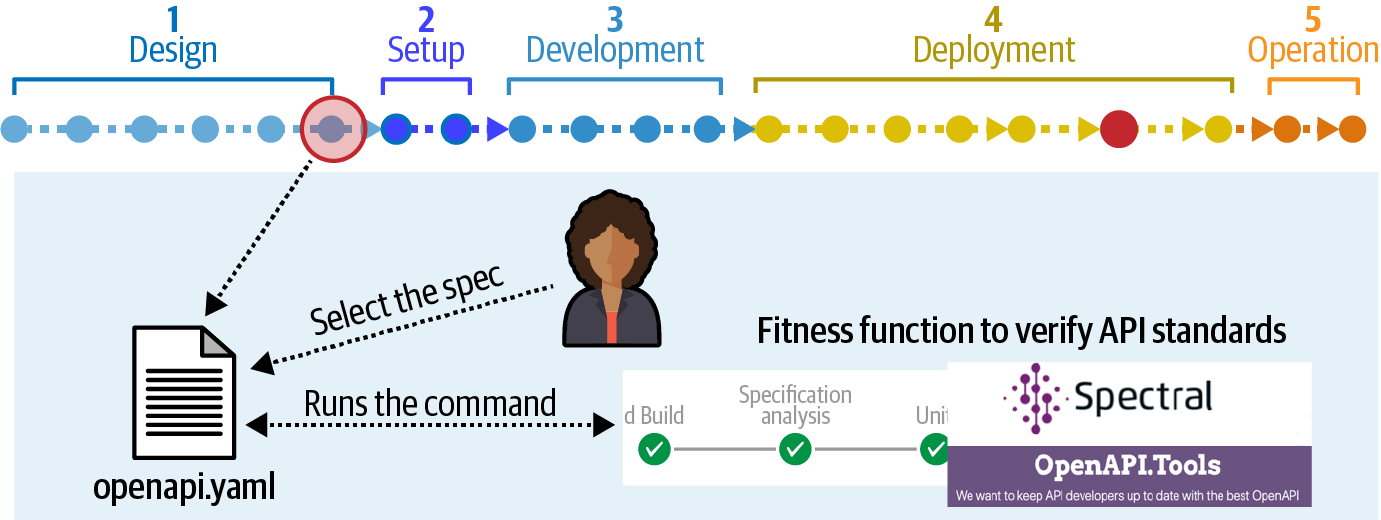
Figure 3-8. A consistency fitness function as part of a deployment pipeline
In Figure 3-8, the five stages of the deployment pipeline are:
- Stage 1: Design
-
Design artifacts, including new and changed entries for the integration API.
- Stage 2: Setup
-
Set up the operational tasks required to run the rest of the tests and other verifications in the deployment pipeline, including tasks such as containerization and database migrations.
- Stage 3: Development
-
Develop the testing environment for unit, functional, and user acceptance testing, as well as architectural fitness functions.
- Stage 4: Deployment
-
If all upstream tasks were successful, deploy to production under a feature toggle that controls the exposure of new features to users.
- Stage 5: Operation
-
Maintain continuous fitness functions and other monitors.
In the case of API changes, the architects designed a multipart fitness function. Stage 1 of the verification chain starts with the design and definition of the new API, published in openapi.yaml. The team verifies the structure and other aspects of the new specification using Spectral and OpenAPI.Tools.
The next stage in the deployment pipeline appears at the start of the development phase, illustrated in Figure 3-9.
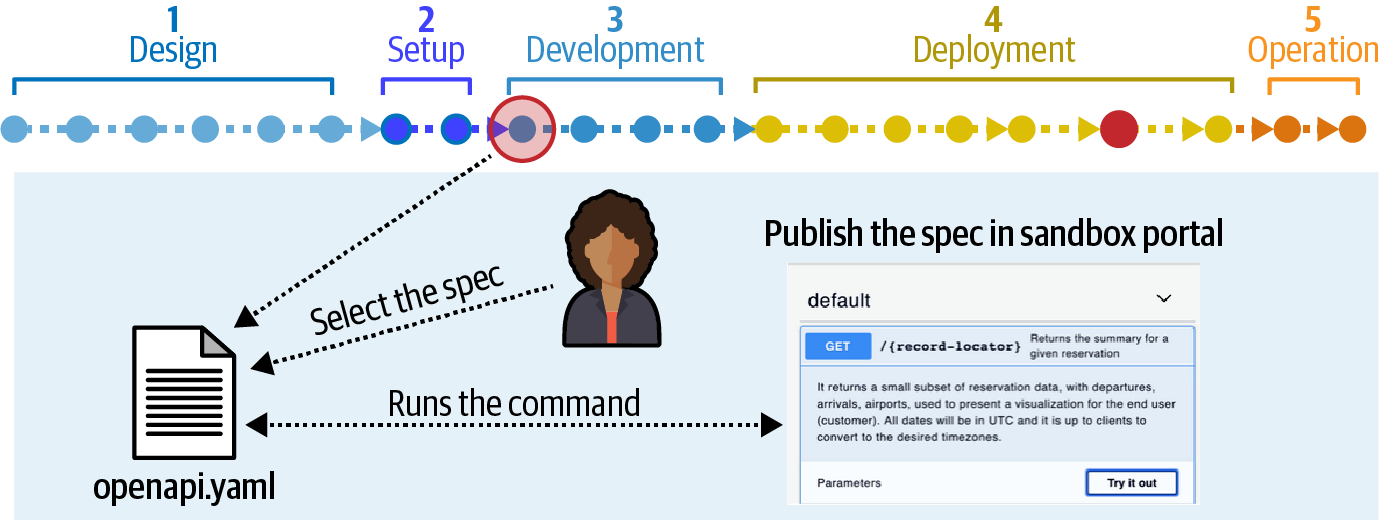
Figure 3-9. Second stage of consistency verification
In Stage 2, shown in Figure 3-9, the deployment pipeline selects the new specification and publishes it to a sandbox environment to allow testing. Once the sandbox environment is live, the deployment pipeline runs a series of unit and functional tests to verify the changes. This stage verifies that the applications underlying the APIs still function consistently.
Stage 3, shown in Figure 3-10, tests integration architecture concerns using Pact, a tool that allows cross-service integration testing to ensure integration points are preserved, an implementation of a common concept known as consumer-driven contracts.
Consumer-driven contracts, which are atomic integration architecture fitness functions, are a common practice in microservices architectures. Consider the illustration shown in Figure 3-11.
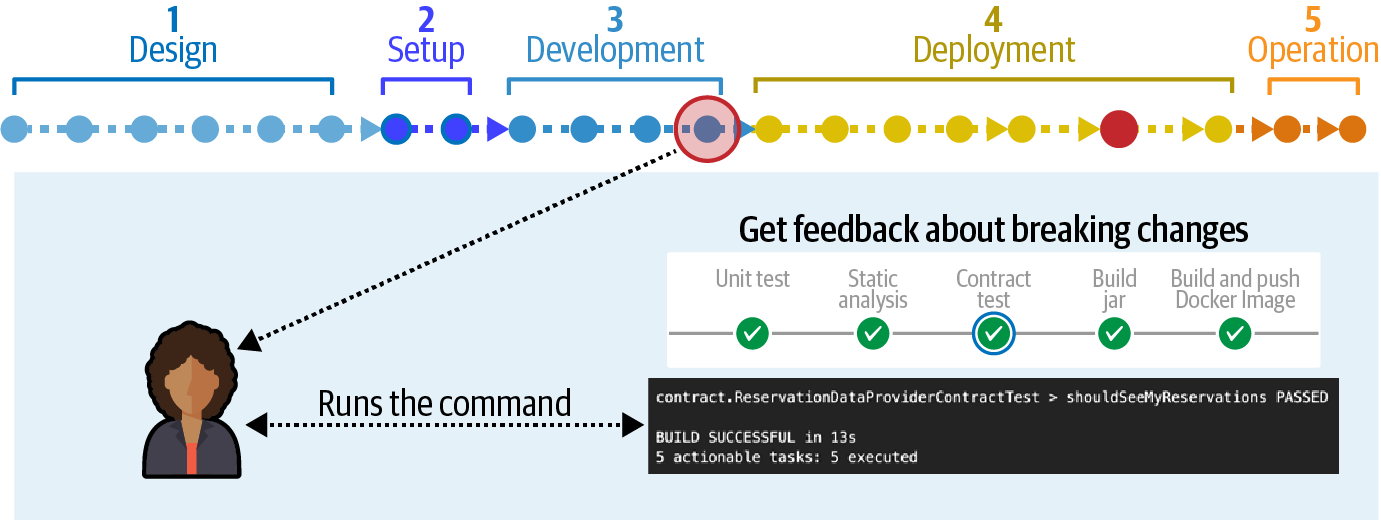
Figure 3-10. Third stage of consistency verification, for integration architecture

Figure 3-11. Consumer-driven contracts use tests to establish contracts between a provider and consumer(s)
In Figure 3-11, the provider team is supplying information (typically data in a lightweight format like JSON) to each of the consumers, C1 and C2. In consumer-driven contracts, the consumers of information put together a suite of tests that encapsulate what they need from the provider and hand off those tests to the provider, who promises to keep the tests passing at all times. Because the tests cover the information needed by the consumer, the provider can evolve in any way that doesn’t break these fitness functions. In the scenario shown in Figure 3-11, the provider runs tests on behalf of all three consumers in addition to their own suite of tests. Using fitness functions like this is informally known as an engineering safety net. Maintaining integration protocol consistency shouldn’t be done manually when it is easy to build fitness functions to handle this chore.
One implicit assumption included in the incremental change aspect of evolutionary architecture is a certain level of engineering maturity among the development teams. For example, if a team is using consumer-driven contracts but they also have broken builds for days at a time, they can’t be sure their integration points are still valid. Using engineering practice to police practices via fitness functions relieves lots of manual pain from developers but requires a certain level of maturity to be successful.
In the last stage, the deployment pipeline deploys the changes into production, allowing A/B testing and other verification before it officially goes live.
Summary
A couple of us worked in engineering disciplines outside software, such as Neal, who started his university career in the more traditional engineering discipline. Before switching to computer science, he got a good dose of the advanced mathematics that structural engineers use.
Traditionally, many people tried to equate software development to other engineering disciplines. For example, the waterfall process of complete design up front followed by mechanical assembly has proved particularly ill-suited to software development. Another question that frequently arises: when are we going to get the same kind of mathematics in software, similar to the kind of advanced math they have in structural engineering?
We don’t think that software engineering will rely on math as much as other engineering disciplines because of the distinct differences between design and manufacturing. In structural engineering, manufacturing is intensely expensive and unforgiving of design flaws, necessitating a huge catalog of predictive analysis during the design phase. Thus, the effort is split between design and manufacturing. Software, however, has a completely different balance. Manufacturing in software equals compilation and deployment, activities that we have increasingly learned to automate. Thus, in software, virtually all the effort lies with design, not manufacturing; design encompasses coding and virtually every other thing we think of as “software development.”
However, the things we manufacture are also vastly different. Modern software consists of thousands or millions of moving parts, all of which can be changed virtually arbitrarily. Fortunately, teams can make that design change and virtually instantly redeploy (in essence, remanufacture) the system.
The keys to a true software engineering discipline lie in incremental change with automated verification. Because our manufacturing is essentially free but extremely variable, the secret to sanity in software development lies with confidence in making changes, backed up by automated verification—incremental change.