
Chapter 9. Putting Evolutionary Architecture into Practice
Finally, we look at the steps required to implement the ideas around evolutionary architecture. This includes both technical and business concerns, including organization and team impacts. We also suggest where to start and how to sell these ideas to your business.
Organizational Factors
The impact of software architecture has a surprisingly wide breadth on a variety of factors not normally associated with software, including team impacts, budgeting, and a host of others. Let’s look at a common set of factors that impact your ability to put evolutionary architecture into practice.
Don’t Fight Conway’s Law
In April 1968, Melvin Conway submitted a paper to Harvard Business Review titled “How Do Committees Invent?”. In this paper, Conway introduced the notion that the social structures, particularly the communication paths between people, inevitably influence final product design.
As Conway describes, in the very early stage of the design, a high-level understanding of the system is made to understand how to break down areas of responsibility into different patterns. The way that a group breaks down a problem affects choices that they can make later.
He codified what has become known as Conway’s Law:
Organizations which design systems … are constrained to produce designs which are copies of the communication structures of these organizations.
Melvin Conway
As Conway notes, when technologists break down problems into smaller chunks to delegate, they introduce coordination problems. In many organizations, formal communication structures or rigid hierarchy appears to solve this coordination problem but often leads to inflexible solutions. For example, in a layered architecture where the team is separated by technical function (user interface, business logic, etc.), solving common problems that cut vertically across layers increases coordination overhead. People who have worked in startups and then have joined large multinational corporations have likely experienced the contrast between the nimble, adaptable culture of the former and the inflexible communication structures of the latter. A good example of Conway’s Law in action might be trying to change the contract between two services, which could be difficult if the successful change of a service owned by one team requires the coordinated and agreed-upon effort of another.
In his paper, Conway was effectively warning software architects to pay attention not only to the architecture and design of the software, but also to the delegation, assignment, and coordination of the work between teams.
In many organizations, teams are divided according to their functional skills. Some common examples include:
- Frontend developers
-
A team with specialized skills in a particular UI technology (e.g., HTML, mobile, desktop)
- Backend developers
-
A team with unique skills in building backend services, sometimes API tiers
- Database developers
-
A team with unique skills in building storage and logic services
Consider the common structure/team alignment illustrated in Figure 9-1.
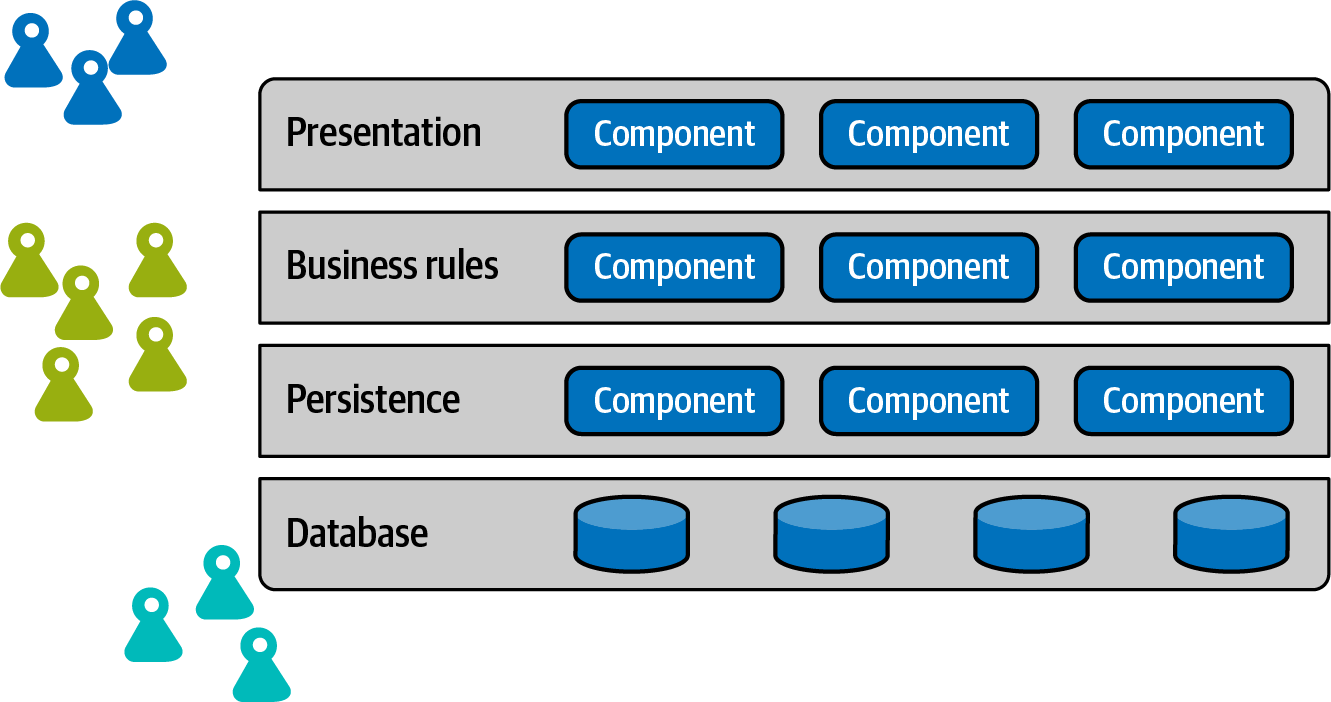
Figure 9-1. Layered architectures facilitate separating team members by technical capabilities
This team organization works relatively well if companies utilize a layered architecture based on similar technical layers, modeled after observations in “Don’t Fight Conway’s Law”. However, if a team switches to a distributed architecture such as microservices yet keeps the same organization, the side effect is increased messaging between layers, as illustrated in Figure 9-2.

Figure 9-2. Building microservices yet maintaining layers increases communication overhead
In Figure 9-2, changes to domain concepts like CatalogCheckout requires coordination between all the technical parts of the domain, increasing the overhead and slowing development.
In organizations with functional silos, management divides teams to make their human resources department happy without much regard to engineering efficiency. Although each team may be good at their part of the design (e.g., building a screen, adding a backend API or service, or developing a new storage mechanism), to release a new business capability or feature all three teams must be involved in building the feature. Teams typically optimize for efficiency for their immediate tasks rather than the more abstract, strategic goals of the business, particularly when under schedule pressure. Instead of delivering an end-to-end feature value, teams often focus on delivering components that may or may not work well with each other.
As Conway noted in his paper, every time a delegation is made and somebody’s scope of inquiry is narrowed, the class of design alternatives which can be effectively pursued is also narrowed. Stated another way, it’s hard for someone to change something if the thing she wants to change is owned by someone else. Software architects should pay attention to how work is divided and delegated to align architectural goals with team structure.
Many companies that build architectures such as microservices structure their teams around service boundaries rather than siloed technical architecture partitions. In the ThoughtWorks Technology Radar, we call this the Inverse Conway Maneuver. Organization of teams in such a manner is ideal because team structure will impact myriad dimensions of software development and should reflect the problem size and scope. For example, when building a microservices architecture, companies typically structure teams that resemble the architecture by cutting across functional silos and including team members who cover every angle of the business and technical aspects of the architecture. Modeling the team to resemble the architecture appears in Figure 9-3.
Separating teams to resemble architecture is becoming increasingly common as teams realize the benefits of mapping teams to architecture.
Tip
Structure teams to look like your target architecture, and it will be easier to achieve that architecture.

Figure 9-3. Using the Inverse Conway Maneuver to simplify communication
Teams structured around domains rather than technical capabilities have several advantages when it comes to evolutionary architecture and exhibit some common characteristics.
Default to cross-functional teams
Domain-centric teams tend to be cross-functional, meaning every product role is covered by someone on the team. The goal of a domain-centric team is to eliminate operational friction. In other words, the team has all the roles needed to design, implement, and deploy their service, including traditionally separate roles like operations. But these roles must change to accommodate this new structure, which includes the following roles:
- Architecture
-
Design architecture to eliminate inappropriate coupling that complicates incremental change. Notice that this doesn’t require an exotic architecture like microservices. A well-designed modular monolithic application may display the same ability to accommodate incremental change (although architects must design the application explicitly to support this level of change).
- Business analysts
-
In products with high areas of domain complexity, due to complex rules, configuration, or product history, business analysts (BAs) support the rest of the team with expertise. In cross-functional teams, BAs are now co-located with the team to provide fast feedback on proposed changes.
- Data
-
Database administrators, data analysts, and data scientists must deal with new granularity, transaction, and system of record issues.
- Developers
-
A fully cross-functional team for a complicated tech stack often requires developers to be more T-shaped or “full-stack,” working in other areas they might have avoided in their silos. For example, backend developers might do some mobile or web development or vice versa.
- Designers
-
Designers in cross-functional teams can work closely with their team on user-facing features but may need to spend more time with other designers from other cross-functional teams contributing to the same product to guarantee consistency across the user interface.
- Operations
-
Slicing up services and deploying them separately (often alongside existing services and deployed continuously) is a daunting challenge for many organizations with traditional IT structures. Naïve old-school architects believe that component and operational modularity are the same thing, but this is often not the case in the real world. Automating DevOps tasks like machine provisioning and deployment is critical to success.
- Product managers
-
Often described as the “CEO” for a product, most product managers (PMs) prioritize customer needs and business outcomes for a certain product area such as the “Growth” or Customer Registration area, Payment area, or Customer Support. In a cross-functional setup, a PM no longer needs to coordinate with many technical teams as they should have all the skills necessary to deliver on their product area. Working in cross-functional teams gives the PM more time to coordinate with others PMs or internal stakeholders to deliver a seamless end-to-end product.
- Testing
-
Testers must become accustomed to the challenges of integration testing across domains, such as building integration environments, creating and maintaining contracts, and so on.
One goal of cross-functional teams is to eliminate coordination friction. On traditional siloed teams, developers often must wait on a DBA to make changes or wait for someone in operations to provide resources. Making all the roles local eliminates the incidental friction of coordination across silos.
While it would be luxurious to have every role filled by qualified engineers on every project, most companies aren’t that lucky. Key skill areas are always constrained by external forces like market demand. So, many companies aspire to create cross-functional teams but cannot because of resources. In those cases, constrained resources may be shared across projects. For example, rather than have one operations engineer per service, perhaps they rotate across several different teams.
By modeling architecture and teams around the domain, the common unit of change is now handled within the same team, reducing artificial friction. A domain-centric architecture may still use layered architecture for its other benefits, such as separation of concerns. For example, the implementation of a particular microservice might depend on a framework that implements the layered architecture, allowing that team to easily swap out a technical layer. Microservices encapsulate the technical architecture inside the domain, inverting the traditional relationship.
Having small, cross-functional teams also takes advantage of human nature. Amazon’s “two-pizza team” mimics small-group primate behavior. Most sports teams have around 10 players, and anthropologists believe that preverbal hunting parties were also around this size. Building highly responsible teams leverages innate social behavior, making team members more responsible. For example, suppose a developer in a traditional project structure wrote some code two years ago that blew up in the middle of the night, forcing someone in operations to respond to a pager in the night and fix it. The next morning, our careless developer may not even realize they accidentally caused a panic in the middle of the night. On a cross-functional team, if the developer wrote code that blew up in the night and someone from his team had to respond to it, the next morning our hapless developer would have to look across the table at the sad, tired eyes of the team member they inadvertently affected. It should make our errant developer want to be a better teammate.
Creating cross-functional teams prevents finger pointing across silos and engenders a feeling of ownership in the team, encouraging team members to do their best work.
Organize teams around business capabilities
Organizing teams around domains implicitly means organizing them around business capabilities. Many organizations expect their technical architecture to represent its own complex abstraction, loosely related to business behavior because architects’ traditional emphasis has been around purely technical architecture, that is typically segregated by functionality. A layered architecture is designed to make swapping technical architecture layers easier, not make working on a domain entity like
Customer easier. Most of this emphasis was driven by external factors. For example, many architectural styles of the past decade focused heavily on maximizing shared resources because of expense.
Architects have gradually detangled themselves from commercial restrictions via the embrace of open source in all corners of most organizations. Shared resource architecture has inherent problems around inadvertent interference between parts. Now that developers have the option of creating custom-made environments and functionality, it is easier for them to shift emphasis away from technical architectures and focus more on domain-centric ones to better match the common unit of change in most software projects.
Tip
Organize teams around business capabilities, not job functions.
Balance cognitive load with business capabilities
Since we wrote the first edition of this book, our industry has uncovered better approaches for team design optimized for the continuous flow of value. In their book, Team Topologies: Organizing Business and Technology Teams for Fast Flow, Manuel Pais and Matthew Skelton refer to four different team patterns:
- Stream-aligned teams
-
are aligned to a flow of work from (usually a segment of) the business domain.
- Enabling teams
-
help stream-aligned teams overcome obstacles and detect missing capabilities such as learning new skills/technologies.
- Complicated subsystem teams
-
own a part of the business domain that demands significant mathematics/calculation/technical expertise.
- Platform teams
-
are a grouping of other team types that provide a compelling internal product to accelerate delivery by stream-aligned teams.
In their model, using stream-aligned teams maps to our recommendation of aligning teams around “Business Capabilities” with a small caveat: team design must also account for cognitive load. A team with an excessive cognitive load, either from a complex domain area or from a complex set of technologies, will struggle to deliver. As an example, if you have ever worked with processing payments, there is a high domain cognitive load caused by payment scheme–specific rules and exceptions. Dealing with one payment scheme might be manageable for a single team, but if that team has to maintain five or six concurrent payment schemes, they are likely to exceed their team cognitive load even without considering additional technical complexity.
The response to this might be to try to have multiple stream-aligned teams or, where needed, a complicated subsystem team. For example, you might have a single stream-aligned team taking care of the end-to-end user journey for processing a payment, and then additionally have a complicated system team for a specific payment scheme (e.g., Mastercard or Visa).
The book Team Topologies reinforces the idea we should arrange teams around the domain’s business capabilities but also need to take into account cognitive load.
Think product over project
One mechanism many companies use to shift their team emphasis is to model their work around products rather than projects. Software projects have a common workflow in most organizations. A problem is identified, a development team is formed, and they work on the problem until “completion,” at which time they turn the software over to operations for care, feeding, and maintenance for the rest of its life. Then the project team moves on to the next problem.
This causes a slew of common problems. First, because the team has moved on to other concerns, bug fixes and other maintenance work is often difficult to manage. Second, because the developers are isolated from the operational aspects of their code, they care less about things like quality. In general, the more layers of indirection between a developer and their running code, the less connection they have to that code. This sometimes leads to an “us versus them” mentality between operational silos, which isn’t surprising, as many organizations have incentivized workers to exist in conflict. Third, the concept of “project” has a temporal connotation: projects end, which affects the decision process of those who work on it.
Thinking of software as a product shifts the company’s perspective in three ways. First, products live forever, unlike the lifespan of projects. Cross-functional teams (frequently based on the Inverse Conway Maneuver) stay associated with their product. Second, each product has an owner who advocates for its use within the ecosystem and manages things like requirements. Third, because the team is cross-functional, each role needed by the product is represented: PMs, BAs, designers, developers, QA, DBA, operations, and any other required roles.
The real goal of shifting from a project to a product mentality concerns long-term company buy-in. Product teams take ownership responsibility for the long-term quality of their product. Thus, developers take ownership of quality metrics and pay more attention to defects. This perspective also helps provide a long-term vision to the team. The book Project to Product: How to Survive and Thrive in the Age of Digital Disruption with the Flow Framework by Mik Kersten (IT Revolution Press) covers the organizational changes and a framework for guiding an organization through this cultural and structural change.
Avoid excessively large teams
Many companies have found anecdotally that large development teams don’t work well, and J. Richard Hackman, a famous expert on team dynamics, offers an explanation as to why. It’s not the number of people but the number of connections they must maintain. He uses the formula shown in Equation 9-1 to determine how many connections exist between people, where n is the number of people.
Equation 9-1. Number of connections between people
In Equation 9-1, as the number of people grows, the number of connections grows rapidly, as shown in Figure 9-4.

Figure 9-4. As the number of people grows, the connections grow rapidly
In Figure 9-4, when the number of people on a team reaches 14, they must manage 91 links; when it reaches 50 team members, the number of links is a daunting 1,225. Thus, the motivation to create small teams revolves around the desire to cut down on communication links. And these small teams should be cross-functional to eliminate artificial friction imposed by coordinating across silos, which often accidentally drives up the number of collaborators on a project.
Each team shouldn’t have to know what other teams are doing, unless integration points exist between the teams. Even then, fitness functions should be used to ensure integrity of integration points.
Tip
Strive for a low number of connections between development teams.
Team coupling characteristics
The way firms organize and govern their own structures significantly influences the way software is built and architected. In this section, we explore the different organizational and team aspects that make building evolutionary architectures easier or harder. Most architects don’t think about how team structure affects the coupling characteristics of the architecture, but it has a huge impact.
Culture
Culture, (n.): The ideas, customs, and social behavior of a particular people or society.
Oxford English Dictionary
Architects should care about how engineers build their system and watch out for the behaviors their organization rewards. The activities and decision-making processes architects use to choose tools and create designs can have a big impact on how well software endures evolution. Well-functioning architects take on leadership roles, creating the technical culture and designing approaches for how developers build systems. They teach and encourage in individual engineers the skills necessary to build evolutionary architecture.
An architect can seek to understand a team’s engineering culture by asking questions like:
-
Does everyone on the team know what fitness functions are and consider the impact of new tool or product choices on the ability to evolve new fitness functions?
-
Are teams measuring how well their system meets their defined fitness functions?
-
Do engineers understand cohesion and coupling? What about connascence?
-
Are there conversations about what domain and technical concepts belong together?
-
Do teams choose solutions not based on what technology they want to learn but based on its ability to make changes?
-
How are teams responding to business changes? Do they struggle to incorporate small business changes, or are they spending too much time on them?
Adjusting the behavior of the team often involves adjusting the process around the team, as people respond to what is asked of them to do.
Tell me how you measure me, and I will tell you how I will behave.
Dr. Eliyahu M. Goldratt (The Haystack Syndrome)
If a team is unaccustomed to change, an architect can introduce practices that start making that a priority. For example, when a team considers a new library or framework, the architect can ask the team to explicitly evaluate, through a short experiment, how much extra coupling the new library or framework will add. Will engineers be able to easily write and test code outside of the given library or framework, or will the new library and framework require additional runtime setup that may slow down the development loop?
In addition to the selection of new libraries or frameworks, code reviews are a natural place to consider how well newly changed code supports future changes. If there is another place in the system that will suddenly use another external integration point, and that integration point will change, how many places would need to be updated? Of course, developers must watch out for overengineering, prematurely adding additional complexity or abstractions for change. The Refactoring book contains relevant advice:
The first time you do something, you just do it. The second time you do something similar, you wince at the duplication, but you do the duplicate thing anyway. The third time you do something similar, you refactor.
Many teams are driven and rewarded most often for delivering new functionality, with code quality and the evolvable aspect considered only if teams make it a priority. An architect who cares about evolutionary architecture needs to watch out for team actions that prioritize design decisions that help with evolvability or find ways to encourage it.
Culture of Experimentation
Successful evolution demands experimentation, but some companies fail to experiment because they are too busy delivering to plans. Successful experimentation is about regularly running small activities to try out new ideas (both from a technical and product perspective) and to integrate successful experiments into existing systems.
The real measure of success is the number of experiments that can be crowded into 24 hours.
Thomas Alva Edison
Organizations can encourage experimentation in a variety of ways:
- Bringing ideas from outside
-
Many companies send their employees to conferences and encourage them to find new technologies, tools, and approaches that might solve a problem better. Other companies bring in external advice or consultants as sources of new ideas.
- Encouraging explicit improvement
-
Toyota is most famous for its culture of kaizen, or continuous improvement. Everyone is expected to continually seek constant improvements, particularly those closest to the problems and empowered to solve them.
- Implementing spike and stabilize
-
A spike solution is an extreme programming practice where teams generate a throwaway solution to quickly learn a tough technical problem, explore an unfamiliar domain, or increase confidence in estimates. Using spike solutions increases learning speed at the cost of software quality; no one would want to put a spike solution straight into production because it would lack the necessary thought and time to make it operational. It was created for learning, not as the well-engineered solution.
- Creating innovation time
-
Google is well known for its 20% time, where employees can work on any project for 20% of their time. Other companies organize Hackathons and allow teams to find new products or improvements to existing products. Atlassian holds regular 24-hour sessions called ShipIt days.
- Following set-based development
-
Set-based development focuses on exploring multiple approaches. At first glance, multiple options appear costly because of extra work, but in exploring several options simultaneously, teams end up with a better understanding of the problem at hand and discover real constraints with tooling or approach. The key to effective set-based development is to prototype several approaches in a short period (i.e., less than a few days) to build more concrete data and experience. A more robust solution often appears after taking into account several competing solutions.
- Connecting engineers with end users
-
Experimentation is successful only when teams understand the impact of their work. In many firms with an experimentation mindset, teams and product people see firsthand the impact of decisions on customers and are encouraged to experiment to explore this impact. A/B testing is one such practice companies use with this experimentation mindset. Another practice companies implement is sending teams and engineers to observe how users interact with their software to achieve a certain task. This practice, taken from the pages of the usability community, builds empathy with end users, and engineers often return with a better understanding of user needs, and with new ideas to better fulfill them.
CFO and Budgeting
Many traditional functions of enterprise architecture, such as budgeting, must reflect changing priorities in an evolutionary architecture. In the past, budgeting was based on the ability to predict long-term trends in a software development ecosystem. However, as we’ve suggested throughout this book, the fundamental nature of dynamic equilibrium destroys predictability.
In fact, an interesting relationship exists between architectural quanta and the cost of architecture. As the number of quanta rises, the cost per quantum goes down, until architects reach a sweet spot, as illustrated in Figure 9-5.

Figure 9-5. The relationship between architectural quanta and cost
In Figure 9-5, as the number of architectural quanta rises, the cost of each diminishes because of several factors. First, because the architecture consists of smaller parts, the separation of concerns should be more discrete and defined. Second, rising numbers of physical quanta require automation of their operational aspects because, beyond a certain point, it is no longer practical for people to handle chores manually.
However, it is possible to make quanta so small that the sheer numbers become more costly. For example, in a microservices architecture, it is possible to build services at the granularity of a single field on a form. At that level, the coordination cost between each small part starts dominating other factors in the architecture. Thus, at the extremes of the graph, the sheer number of quanta drives benefit per quantum down.
In an evolutionary architecture, architects strive to find the sweet spot between the proper quantum size and the corresponding costs. Every company is different. For example, a company in an aggressive market may need to move faster and therefore desire a smaller quantum size. Remember, the speed at which new generations appear is proportional to cycle time, and smaller quanta tend to have shorter cycle times. Another company may find it pragmatic to build a monolithic architecture for simplicity.
As we face an ecosystem that defies planning, many factors determine the best match between architecture and cost. This reflects our observation that the role of architects has expanded: Architectural choices have more impact than ever.
Rather than adhere to decades-old “best practice” guidelines about enterprise architecture, modern architects must understand the benefits of evolvable systems along with the inherent uncertainty that goes with them.
The Business Case
We cover a lot of technical details throughout this book, but unless you can show business value from this approach, it appears to nontechnologists as metawork. Thus, architects should be able to make the case that evolutionary architecture can improve both confidence in change and automated governance. However, more direct benefits exist in the kinds of capabilities this architectural approach enables.
Architects can sell the idea of evolutionary architecture by talking to business stakeholders in terms they understand and appreciate (rather than the nuances of architectural plumbing): talk to them about A/B testing and the ability to learn from customers. Underlying these advanced interaction techniques are the supporting mechanics and structure of evolutionary architecture, including the ability to perform hypothesis-, and data-driven development.
Hypothesis- and Data-Driven Development
The GitHub example in “Case Study: Architectural Restructuring While Deploying 60 Times
per Day” using the Scientist framework is an example of data-driven development—allow data to drive changes and focus efforts on technical change. A similar approach that incorporates business rather than technical concerns is hypothesis-driven development.
In the week between Christmas 2013 and New Year’s Day 2014, Facebook encountered a problem: more photos were uploaded to Facebook in that week than all the photos on Flickr, and more than a million of them were flagged as offensive. Facebook allows users to flag photos they believe are potentially offensive and then reviews them to determine objectively if they are. But this dramatic increase in photos created a problem: there was not enough staff to review the photos.
Fortunately, Facebook has modern DevOps and the ability to perform experiments on its users. When asked about the chances a typical Facebook user has been involved in an experiment, one Facebook engineer claimed, “Oh, 100%—we routinely have more than 20 experiments running at a time.” Engineers used this experimental capability to ask users follow-up questions about why photos were deemed offensive and discovered many delightful quirks of human behavior. For example, people don’t like to admit that they look bad in a photo but will freely admit that the photographer did a poor job. By experimenting with different phrasing and questions, the engineers could query their actual users to determine why they flagged a photo as offensive. In a relatively short amount of time, Facebook shaved off enough false positives to restore offensive photos to a manageable problem by building a platform that allowed for experimentation.
In the book Lean Enterprise (O’Reilly), the authors describe the modern process of hypothesis-driven development. Under this process, rather than gathering formal requirements and spending time and resources building features into applications, teams should leverage the scientific method instead. Once teams have created the minimal viable product version of an application (whether as a new product or by performing maintenance work on an existing application), they can build hypotheses during new feature ideation rather than requirements. Hypothesis-driven development hypotheses are couched in terms of the hypothesis to test, what experiments can determine the results, and what validating the hypothesis means to future application development.
For example, rather than change the image size for sales items on a catalog page because a business analyst thought it was a good idea, state it as a hypothesis instead: if we make the sales images bigger, we hypothesize that it will lead to a 5% increase in sales for those items. Once the hypothesis is in place, run experiments via A/B testing—one group with bigger sales images and one without—and tally the results.
Even agile projects with engaged business users incrementally build themselves into a bad spot. An individual decision by a business analyst may make sense in isolation, but when combined with other features may ultimately degrade the overall experience. In an excellent case study, the mobile.de team followed a logical path of accruing new features haphazardly to the point where sales were diminishing, at least in part because their UI had become so convoluted, as is often the result of development continuing on mature software products. Different philosophical approaches included more listings, better prioritization, and better grouping. To help them make this decision, they built three versions of the UI and allowed their users to decide.
The engine that drives agile software methodologies is the nested feedback loop: testing, continuous integration, iterations, and so on. And yet, the part of the feedback loop that incorporates the ultimate users of the application has eluded teams. Using hypothesis-driven development, we can incorporate users in an unprecedented way, learning from behavior and building what users really find valuable.
Hypothesis-driven development requires the coordination of many moving parts: evolutionary architecture, modern DevOps, modified requirements gathering, and the ability to run multiple versions of an application simultaneously. Service-based architectures (like microservices) usually achieve side-by-side versions by intelligent routing of services. For example, one user may execute the application using a particular constellation of services while another request may use an entirely different set of instances of the same services. If most services include many running instances (for scalability, for example), it becomes trivial to make some of those instances slightly different with enhanced functionality and to route some users to those features.
Experiments should run long enough to yield significant results. Generally, it is preferable to find a measurable way to determine better outcomes rather than annoy users with things like pop-up surveys. For example, does one hypothesized workflow allow the user to complete a task with fewer keystrokes and clicks? By silently incorporating users into the development and design feedback loop, you can build much more functional software.
Fitness Functions as Experimental Media
One common use of fitness functions by architects is to answer hypotheses. Architects have many decisions that have never existed here or anywhere in this particular manifestation, leading to educated guesses about architecture concerns. However, once teams have implemented a solution, the architect can use fitness functions to validate hypotheses. Here are several examples derived from real-world projects.
Case study: UDP communications
PenultimateWidgets has an ecosystem with a large number of ETL (Extract, Transform, and Load) jobs and batch processes. The team created a custom monitoring tool to ensure the execution of tasks, such as Send Reports, Consolidate Information, and so on, as shown in Figure 9-6.
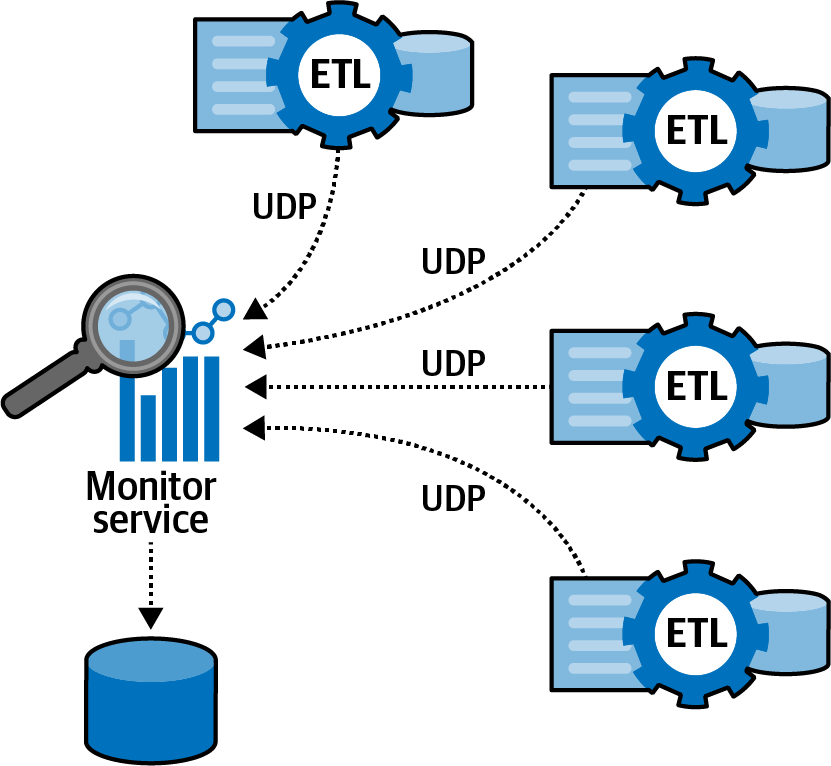
Figure 9-6. Custom monitoring tool for ETL communication
Architects designed the system in Figure 9-6 to use a UDP protocol between the ETL jobs and the monitoring service. Sometimes the completion messages would get lost, leading the team to raise an alert that the task was unfinished, which then led them to assign a person to manage that false positive. The architects decided to build a fitness function to answer the question: what percentage of messages are not being covered by the custom monitoring tool? If the number is greater than 10%, the decision is to replace the monitoring tool with a more standard implementation.
To test the hypothesis that the custom tool wasn’t as reliable as the creators assumed, the team built a fitness function to:
-
Calculate the estimated number of messages from all the applications and the frequency of the messages in a controlled environment (like PreProd or UAT) via monitoring
-
Create a
Mock Serviceto simulate that number of requests -
Use the
Mock Serviceto read the processed messages from theMonitorServicedatabase, to get a metric about the percentage of lost messages and maximum number of messages the application can handle without crashing, and store that information in a JSON file -
Process the JSON file with an analytics tool such as Pandas to create results
The fitness function solution appears in Figure 9-7.
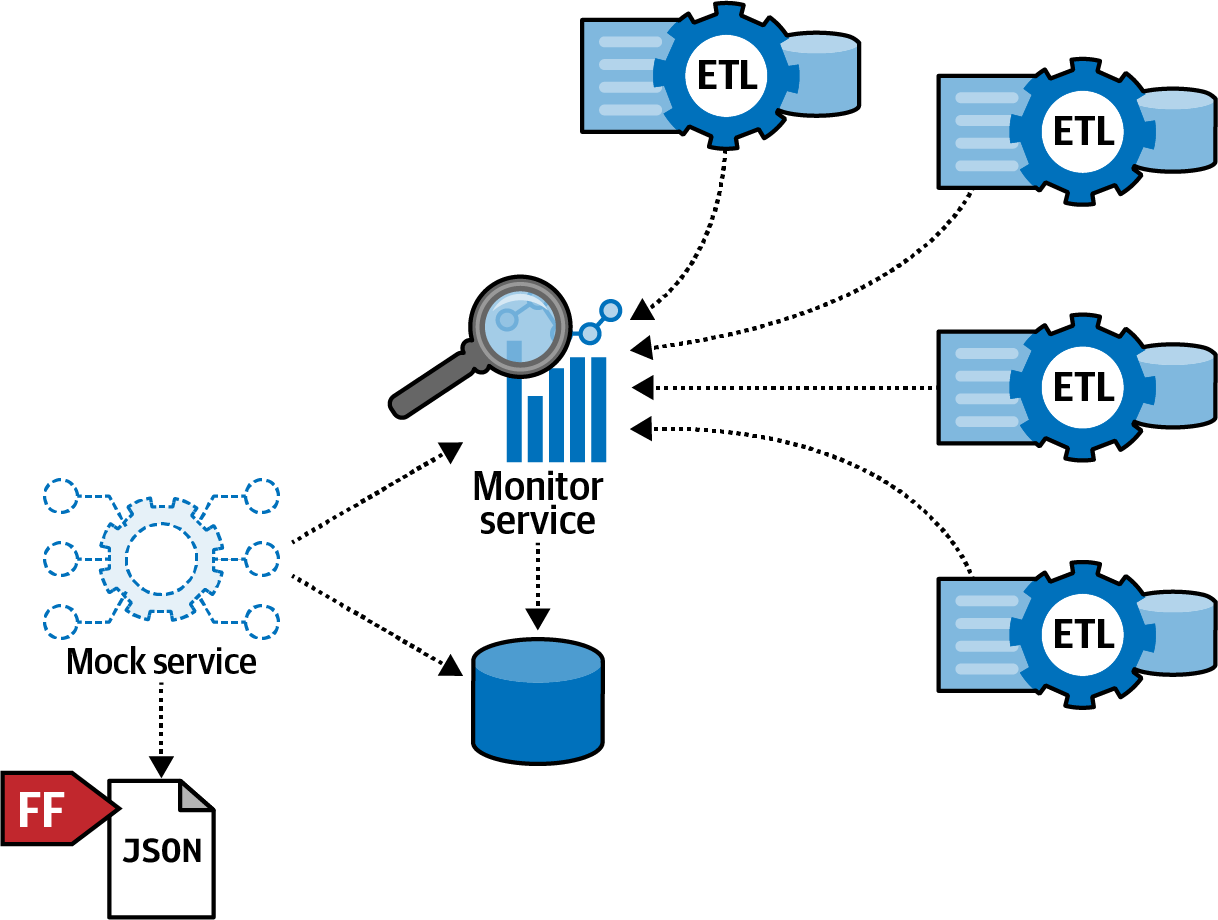
Figure 9-7. Fitness function to test hypothesis
After processing, the team concluded that fully 40% of messages were lost at high scale, calling the reliability of the custom solution into question and leading the team to decide to change the implementation.
Case study: Security dependencies
PenultimateWidgets has a dreaded security breach in some of its library dependencies, leading the team to implement a lengthly manual process upon application change to validate the software supply chain. However, this review process harmed the team’s ability to move as quickly as their market demands.
To improve the feedback time on security checks, the team built a stage in their continuous integration pipeline to scan the library dependency list, validating each version against a real-time updated block list, and raising an alert if any project uses an affected library, as shown in Figure 9-8.

Figure 9-8. Security scanning during continuous integration
The fitness function shown in Figure 9-8 illustrates how teams can utilize holistic governance of important aspects of their ecosystem. Security is a critical fast-feedback requirement in organizations, and automating security checks provides the fastest possible feedback. Automation doesn’t replace people in the feedback loop. Rather, it allows teams to automate regression and other automatable tasks, freeing people for more creative approaches that only a human can imagine.
Case study: Concurrency fitness function
PenultimateWidgets was using the Strangler Fig pattern—slowly replacing functionality one discrete behavior at a time. Thus, the team created a new microservice to handle a specific part of the domain. The new service runs in production, using the double-writing strategy but maintaining the source of truth in the legacy database. Because the team had not written this type of service before, the architects estimated based on preliminary data that the scaling factor should be 120 requests/second. However, the service frequently crashed, even though measurements showed that they could handle up to 300 requests/second. Does the team need to increase the auto-scaling factor or is something else creating the problem? The problem is illustrated in Figure 9-9.

Figure 9-9. Verifying levels of concurrency
As shown in Figure 9-9, the team created a fitness function to measure the real performance in the production system. This fitness function:
-
Calculates the number of incoming calls in production to verify the maximum number of requests that the service needs to support and what would be the auto-scaling factor to guarantee availability with horizontal scaling
-
Create a New Relic Query to get the number of calls per second in production
-
Make new load and concurrency tests using the new number of requests per second
-
Monitor the memory and CPU, and define the stress point
-
Put that fitness function in the pipeline to guarantee availability and performance over time
After running the fitness function, the team realized that the average number of calls was 1,200 per second, greatly exceeding their estimate. Thus, the team updated the scaling factor to reflect reality.
Case study: Fidelity fitness function
The same team from the previous example faced a common problem when teams used the Strangler Fig pattern—how can they be sure that the new system replicates the behavior of the old system? They built what we call a fidelity fitness function, one that allows teams to selectively replace chunks of functionality one piece at a time. Most of these fitness functions are inspired by the example shown in Example 4-11, which allows the ability to run two versions of code side by side (which thresholds) to ensure the new replicates the old.
The fidelity fitness function the team implemented appears in Figure 9-10.
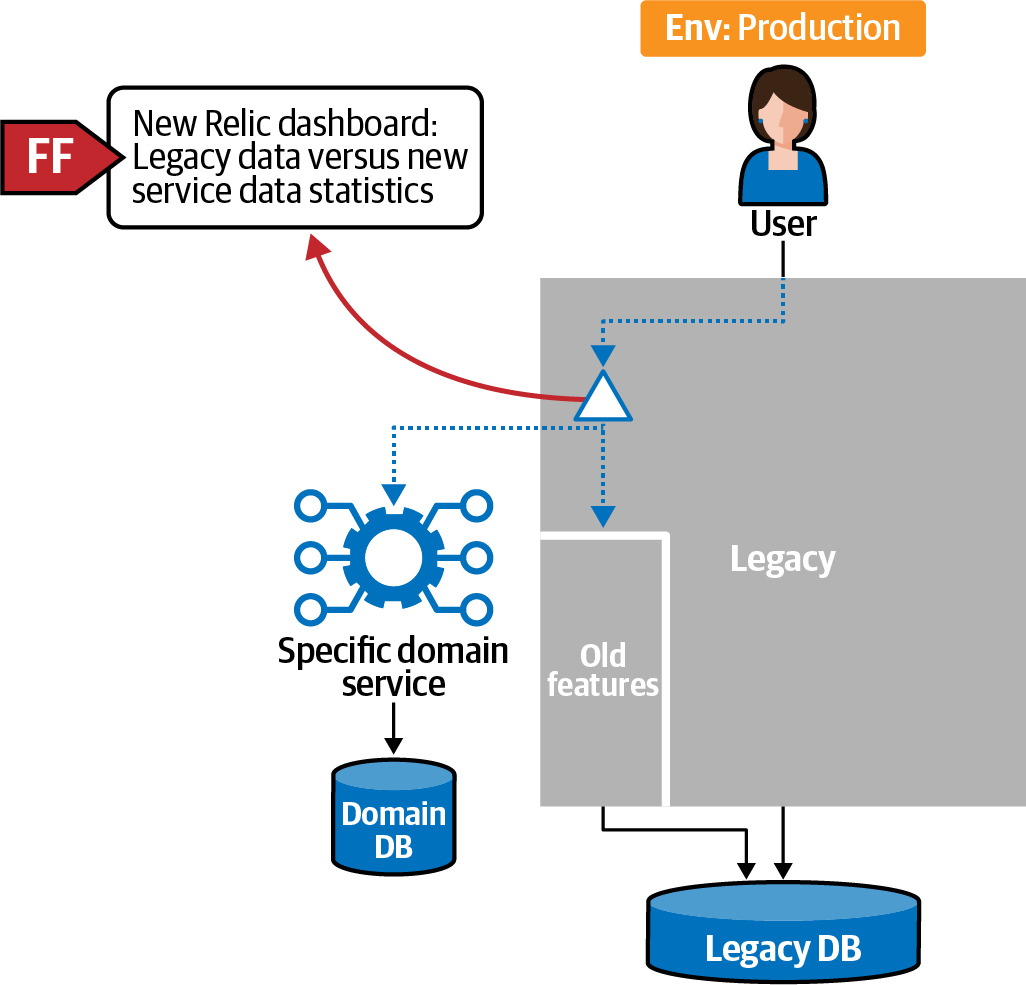
Figure 9-10. Fidelity fitness function to ensure equivalent responses
The team implemented the fitness function to ensure consistency. However, they realized a side benefit as well: they also identified some data that came from sources they had not documented, leading them to a better holistic understanding of data dependencies in the (poorly documented) legacy system.
Building Enterprise Fitness Functions
In an evolutionary architecture, the role of the enterprise architect revolves around guidance and enterprise-wide fitness functions. Microservices architectures reflect this changing model. Because each service is operationally decoupled from the others, sharing resources isn’t a consideration. Instead, architects provide guidance around the purposeful coupling points in the architecture (such as service templates) and platform choices. Enterprise architecture typically owns this shared infrastructure function and constrains platform choices to those supported consistently across the enterprise.
Case Study: Zero-Day Security Vulnerability
What does a company do when a zero-day exploit is discovered in one of the development frameworks or libraries it uses? Many scanning tools exist to search for known vulnerabilities at the network packet level, but they often don’t have the proper hooks to test the right thing in a timely manner. A dire example of this scenario affected a major financial institution a few years ago. On September 7, 2017, Equifax, a major credit scoring agency in the United States, announced that a data breach had occurred. Ultimately, the problem was traced to a hacking exploit of the popular Struts web framework in the Java ecosystem (Apache Struts vCVE-2017-5638). The foundation issued a statement announcing the vulnerability and released a patch on March 7, 2017. The Department of Homeland Security contacted Equifax and similar companies the next day, warning them of this problem, and they ran scans on March 15, 2017, which found most of the affected systems…most, not all. Thus, the critical patch wasn’t applied to many older systems until July 29, 2017, when Equifax’s security experts identified the hacking behavior that led to the data breach.
In a world with automated governance, every project runs a deployment pipeline, and the security team has a “slot” in each team’s deployment pipeline where they can deploy fitness functions. Most of the time, these will be mundane checks for safeguards like preventing developers from storing passwords in databases and similar regular governance chores. However, when a zero-day exploit appears, having the same mechanism in place everywhere allows the security team to insert a test in every project that checks for a certain framework and version number; if it finds the dangerous version, it fails the build and notifies the security team. Increasingly, teams worry about software supply chain issues—what is the provenance of the libraries and frameworks of (particularly) open source tools? Unfortunately, numerous stories exist describing developer tools acting as an attack vector. Thus, teams need to pay attention to metadata about dependencies. Fortunately, a number of tools have appeared to address tracking and automating software supply chain governance, such as snyk and Dependabot, used by GitHub.
Teams configure deployment pipelines to awaken them for any change to the ecosystem: code, database schema, deployment configuration, and fitness functions. Changes to dependencies allow the security team to monitor possible vulnerabilities, providing a hook to the correct information at the proper time.
If each project uses a deployment pipeline to apply fitness functions as part of their build, enterprise architects can insert some of their own fitness functions. This allows each project to verify cross-cutting concerns, such as scalability, security, and other enterprise-wide concerns, on a continual basis, discovering flaws as early as possible. Just as projects in microservices share service templates to unify parts of technical architecture, enterprise architects can use deployment pipelines to drive consistent testing across projects.
Mechanisms like this allow enterprises to universally automate important governance tasks, and create opportunities to create governance around critical and important aspects of software development. The sheer number of moving parts in modern software requires automation to create assurances.
Carving Out Bounded Contexts Within Existing Integration Architecture
In “Reuse Patterns”, we discussed the issues around architects trying to achieve reuse without creating brittleness. A specific example of this issue often arises in reconciling enterprise-level reuse and isolation via bounded contexts and architecture quanta, often exemplified in a data layer, as illustrated in Figure 9-11.

Figure 9-11. Bounded context identified within existing architecture layers
A common architecture pattern is the layered architecture, where architects partition components based on technical capabilities—presentation, persistence, and so on. The goal of the layered architecture is separation of concerns, which (hopefully) leads to higher degrees of reuse. Technical partitioning describes building architectures based on technical capabilities; it was the most common architecture style for many years.
However, after the advent of DDD, architects started designing architectures inspired by it, especially bounded context. In fact, the two most common new topologies architects build solutions with are modular monoliths and microservices, both heavily based on DDD.
However, these two patterns are fundamentally incompatible—layered architecture promotes separation of concerns and facilitates reuse across different contexts, which is one of the stated benefits of the layered approach. However, as we have illustrated, that kind of cross-cutting reuse is decried by both the connecting property of locality and the principle behind bounded context.
So how do organizations reconcile this conflict? By supporting separation of concerns without allowing the damaging side effects of cross-cutting reuse. This is in fact yet another example of having an architectural principle that requires governance, leading to fitness functions to augment the structure.
Consider the architecture illustrated in Figure 9-12.
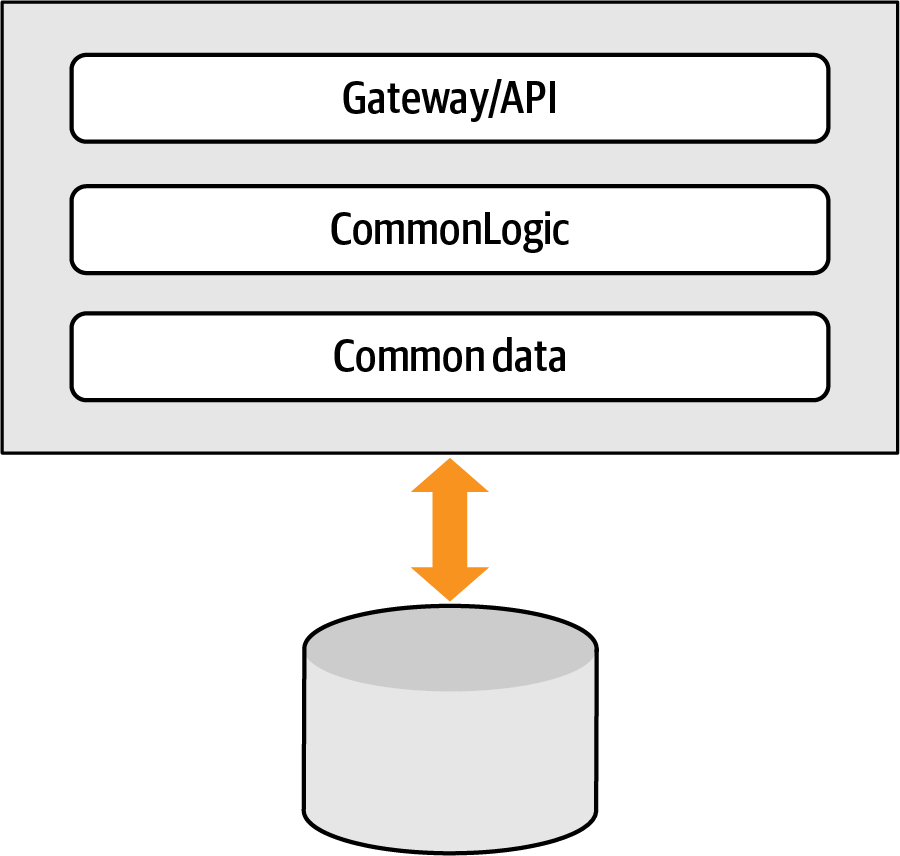
Figure 9-12. A traditional layered architecture, both components and monolithic database
In Figure 9-12, the architects have partitioned the architecture in terms of technical capabilities—the actual layers aren’t important. However, during a DDD exercise, the team identifies the parts of an application with the integration architecture that should be isolated as a bounded context, illustrated in Figure 9-13.

Figure 9-13. An embedded bounded context within another architecture
In Figure 9-13, the team has identified the bounded context (shaded area) within the technical layers. While further separating the parts of the domain based on technical features doesn’t harm anything, teams also need to prevent applications from coupling to their implementation details.
Thus, the team builds fitness functions to prevent cross-bounded context communication, as illustrated in Figure 9-14.
The team builds fitness functions in each appropriate place to prevent accidental coupling. Of course, returning to a common theme in this book, we can’t specify exactly what those fitness functions will look like—it will depend on the assets the teams want to protect. However, the overarching goal should be clear: prevent violating the bounded context by violating the locality principle of connascence.

Figure 9-14. Carving out a bounded context within a layered architecture
Where Do You Start?
Many architects with existing architectures that resemble Big Balls of Mud struggle with where to start adding evolvability. While appropriate coupling and use of modularity are some of the first steps you should take, sometimes there are other priorities. For example, if your data schema is hopelessly coupled, determining how DBAs can achieve modularity might be the first step. Here are some common strategies and reasons to adopt the practices around building evolutionary architectures.
Low-Hanging Fruit
If an organization needs an early win to prove the approach, architects may choose the easiest problem that highlights the evolutionary architecture approach. Generally, this will be part of the system that is already decoupled to a large degree and hopefully not on the critical path to any dependencies. Increasing modularity and decreasing coupling allows teams to demonstrate other aspects of evolutionary architecture, namely fitness functions and incremental change. Building better isolation allows more focused testing and the creation of fitness functions. Better isolation of deployable units makes building deployment pipelines easier and provides a platform for building more robust testing.
Metrics are a common adjunct to the deployment pipeline in incremental change environments. If teams use this effort as a proof of concept, developers should gather appropriate metrics for both before and after scenarios. Gathering concrete data is the best way for developers to vet the approach; remember the adage that demonstration defeats discussion.
This “easiest first” approach minimizes risk at the possible expense of value, unless a team is lucky enough to have easy and high value align. This is a good strategy for companies that are skeptical and want to dip their toes in the metaphorical water of evolutionary architecture.
Highest Value First
An alternative approach to “easiest first” is “highest value first”: find the most critical part of the system and build evolutionary behavior around it first. Companies may take this approach for several reasons. First, if architects are convinced that they want to pursue an evolutionary architecture, choosing the highest-value portion first indicates commitment. Second, for companies still evaluating these ideas, their architects may be curious as to how applicable these techniques are within their ecosystem. Thus, by choosing the highest-value part first, they demonstrate the long-term value proposition of evolutionary architecture. Third, if architects have doubts that these ideas can work for their application, vetting the concepts via the most valuable part of the system provides actionable data as to whether they want to proceed.
Testing
Many companies lament the lack of testing their systems have. If developers find themselves in a codebase with anemic or no testing, they may decide to add some critical tests before undertaking the more ambitious move to evolutionary architecture.
It is generally frowned upon for developers to undertake a project that only adds tests to a codebase. Management looks upon this activity with suspicion, especially if new-feature implementation is delayed. Rather, architects should combine increasing modularity with high-level functional tests. Wrapping functionality with unit tests provides better scaffolding for engineering practices such as test-driven development (TDD) but takes time to retrofit into a codebase. Instead, developers should add coarse-grained functional tests around some behavior before restructuring the code, allowing you to verify that the overall system behavior hasn’t changed because of the restructuring.
Testing is a critical component to the incremental change aspect of evolutionary architecture, and fitness functions leverage tests aggressively. Thus, at least some level of testing enables these techniques, and a strong correlation exists between comprehensiveness of testing and ease of implementing an evolutionary architecture.
Infrastructure
New capabilities come slowly to some companies, and the operations group is a common victim of lack of innovation. For companies that have a dysfunctional infrastructure, getting those problems solved may be a precursor to building an evolutionary architecture. Infrastructure issues come in many forms. For example, some companies outsource all their operational responsibilities to another company and thus don’t control that critical piece of their ecosystem; the difficultly of DevOps rises by orders of magnitude when saddled with the overhead of cross-company coordination.
Another common infrastructure dysfunction is an impenetrable firewall between development and operations, where developers have no insight into how code eventually runs. This structure is common in companies rife with politics across divisions, where each silo acts autonomously.
Lastly, architects and developers in some organizations have ignored good practices and consequently built massive amounts of technical debt that manifests within infrastructure. Some companies don’t even have a good idea of what runs where and other basic knowledge of the interactions between architecture and infrastructure.
Ultimately, the advice parallels the annoying-but-accurate consultant’s answer of It Depends! Only architects, developers, DBAs, DevOps, testing, security, and the other host of contributors can ultimately determine the best road map toward evolutionary architecture.
Case Study: Enterprise Architecture at PenultimateWidgets
PenultimateWidgets is considering revamping a major part of its legacy platform, and a team of enterprise architects generated a spreadsheet listing all the properties the new platform should exhibit: security, performance metrics, scalability, deployability, and a host of other properties. Each category contained 5 to 20 cells, each with some specific criteria. For example, one of the uptime metrics insisted that each service offer five nines (99.999) of availability. In total, they identified 62 discrete items.
But they realized some problems with this approach. First, would they verify each of these 62 properties on projects? They could create a policy, but who would verify that policy on an ongoing basis? Verifying all these things manually, even on an ad hoc basis, would be a considerable challenge.
Second, would it make sense to impose strict availability guidelines across every part of the system? Is it critical that the administrator’s management screens offer five nines? Creating blanket policies often leads to egregious overengineering.
To solve these problems, the enterprise architects defined their criteria as fitness functions and created a deployment pipeline template for each project to start with. Within the deployment pipeline, the architects designed fitness functions to automatically check critical features such as security, leaving individual teams to add specific fitness functions (like availability) for their service.
Future State?
What is the future state of evolutionary architecture? As teams become more familiar with the ideas and practices, they will subsume them into business as usual and start using these ideas to build new capabilities, such as data-driven development.
Much work must be done around the more difficult kinds of fitness functions, but progress is already occurring as organizations solve problems and make many of their solutions freely available. In the early days of agility, people lamented that some problems were just too hard to automate, but intrepid developers kept chipping away and now entire data centers have succumbed to automation. For instance, Netflix has made tremendous innovations in conceptualizing and building tools like the Simian Army, supporting holistic continuous fitness functions (but not yet calling them that).
There are a couple of promising areas.
Fitness Functions Using AI
Gradually, large, open source, artificial intelligence frameworks are becoming available for regular projects. As developers learn to utilize these tools to support software development, we envision fitness functions based on AI that look for anomalous behavior. Credit card companies already apply heuristics such as flagging near-simultaneous transactions in different parts of the world; architects can start to build investigatory tools to look for odd behaviors in architecture.
Generative Testing
A practice common in many functional programming communities gaining wider acceptance is the idea of generative testing. Traditional unit tests include assertions of correct outcomes within each test case. However, with generative testing, developers run a large number of tests and capture the outcomes, then use statistical analysis on the results to look for anomalies. For example, consider the mundane case of boundary-checking ranges of numbers. Traditional unit tests check the known places where numbers break (negatives, rolling over numerical sizes, etc.) but are immune to unanticipated edge cases. Generative tests check every possible value and report on edge cases that break.
Why (or Why Not)?
No silver bullets exist, including in architecture. We don’t recommend that every project take on the extra cost and effort of evolvability unless it benefits them.
Why Should a Company Decide to Build an Evolutionary Architecture?
Many businesses find that the cycle of change has accelerated over the past few years, as reflected in the aforementioned Forbes observation that every company must be competent at software development and delivery. Let’s look at some reasons why using evolutionary architectures makes sense.
Predictable versus evolvable
Many companies value long-term planning for resources and other strategic matters; companies obviously value predictability. However, because of the dynamic equilibrium of the software development ecosystem, predictability has expired. Enterprise architects may still make plans, but they may be invalidated at any moment.
Even companies in staid, established industries shouldn’t ignore the perils of systems that cannot evolve. The taxi industry was a multicentury, international institution when it was rocked by ride-sharing companies that understood and reacted to the implications of the shifting ecosystem. The phenomenon known as The Innovators Dilemma predicts that companies in well-established markets are likely to fail as more agile startups address the changing ecosystem better.
Building evolvable architecture takes extra time and effort, but the reward comes when the company can react to substantive shifts in the marketplace without major rework. Predictability will never return to the nostalgic days of mainframes and dedicated operations centers. The highly volatile nature of the development world increasingly pushes all organizations toward incremental change.
Scale
For a while, the best practice in architecture was to build transactional systems backed by relational databases, using many of the features of the database to handle coordination. The problem with that approach is scaling—it becomes hard to scale the backend database. Lots of byzantine technologies spawned to mitigate this problem, but they were only Band-Aids to the fundamental problem of scale: coupling. Any coupling point in an architecture eventually prevents scale, and relying on coordination at the database level eventually hits a wall.
Amazon faced this exact problem. The original site was designed with a monolithic frontend tied to a monolithic backend modeled around databases. When traffic increased, the team had to scale up the databases. At some point, they reached the limits of database scale, and the impact on the site was decreasing performance—every page loaded more slowly.
Amazon realized that coupling everything to one thing (whether a relational database, enterprise service bus, etc.) ultimately limited scalability. By redesigning the architecture in more of a microservices style that eliminated inappropriate coupling, Amazon allowed its overall ecosystem to scale.
A side benefit of that level of decoupling is enhanced evolvability. As we have illustrated throughout the book, inappropriate coupling represents the biggest challenge to evolution. Building a scalable system also tends to correspond to an evolvable one.
Advanced business capabilities
Many companies look with envy at Facebook, Netflix, and other cutting-edge technology companies because they have sophisticated features. Incremental change allows well-known practices such as hypotheses and data-driven development. Many companies yearn to incorporate their users into their feedback loop via multivariate testing. A key building block for many advanced DevOps practices is an architecture that can evolve. For example, developers find it difficult to perform A/B testing if a high degree of coupling exists between components, making isolation of concerns more daunting. Generally, an evolutionary architecture allows a company better technical responsiveness to inevitable but unpredictable changes.
Cycle time as a business metric
In “Deployment Pipelines”, we made the distinction between Continuous Delivery, where at least one stage in the deployment pipeline performs a manual pull, and continuous deployment, where every stage automatically promotes to the next upon success. Building continuous deployment takes a fair amount of engineering sophistication—why would a company go quite that far?
Because cycle time has become a business differentiator in some markets. Some large conservative organizations view software as overhead and thus try to minimize cost. Innovative companies see software as a competitive advantage. For example, if AcmeWidgets has created an architecture where the cycle time is three hours, and PenultimateWidgets still has a six-week cycle time, AcmeWidgets has an advantage it can exploit.
Many companies have made cycle time a first-class business metric, mostly because they live in a highly competitive market. All markets eventually become competitive in this way. For example, in the early 1990s, some big companies were more aggressive in moving toward automating manual workflows via software and gained a huge advantage as all companies eventually realized that necessity.
Isolating architectural characteristics at the quantum level
Thinking of traditional nonfunctional requirements as fitness functions and building a well-encapsulated architectural quantum allows architects to support different characteristics per quantum, one of the benefits of a microservices architecture. Because the technical architecture of each quantum is decoupled from other quanta, architects can choose different architectures for different use cases. For example, developers on one small service may choose a microkernel architecture because they want to support a small core that allows incremental addition. Another team of developers may choose an event-driven architecture for their service because of scalability concerns. If both services were part of a monolith, architects would have to make trade-offs to attempt to satisfy both requirements. By isolating technical architecture at a small quantum level, architects are free to focus on the primary characteristics of a singular quantum, not analyzing the trade-offs for competing priorities.
Adaptation versus evolution
Many organizations fall into the trap of gradually increasing technical debt and reluctance to make needed restructuring modifications, which in turns makes systems and integration points increasingly brittle. Companies try to pave over this brittleness with connection tools like service buses, which alleviates some of the technical headaches but doesn’t address deeper logical cohesion of business processes. Using a service bus is an example of adapting an existing system to use in another setting. But as we’ve highlighted previously, a side effect of adaptation is increased technical debt. When developers adapt something, they preserve the original behavior and layer new behavior alongside it. The more adaptation cycles a component endures, the more parallel behavior there is, increasing complexity, hopefully strategically.
The use of feature toggles offers a good example of the benefits of adaptation. Often, developers use toggles when trying several alternatives via hypotheses-driven development, testing their users to see what resonates best. In this case, the technical debt imposed by toggles is purposeful and desirable. Of course, the engineering best practice around these types of toggles is to remove them as soon as the decision is resolved.
Alternatively, evolving implies fundamental change. Building an evolvable architecture entails changing the architecture in situ, protected from breakages via fitness functions. The end result is a system that continues to evolve in useful ways without an increasing legacy of outdated solutions lurking within.
Why Would a Company Choose Not to Build an Evolutionary Architecture?
We don’t believe that evolutionary architecture is the cure for all ailments! Companies have several legitimate reasons to pass on these ideas. Here are some common reasons.
Can’t evolve a Big Ball of Mud
One of the key “-ilities” architects neglect is feasibility—should the team undertake this project? If an architecture is a hopelessly coupled Big Ball of Mud, making it possible to evolve it cleanly will take an enormous amount of work—likely more than rewriting it from scratch. Companies loathe throwing anything away that has perceived value, but often a rework is more costly than a rewrite.
How can companies tell if they’re in this situation? The first step to converting an existing architecture into an evolvable one is modularity. Thus, a developer’s first task requires finding whatever modularity exists in the current system and restructuring the architecture around those discoveries. Once the architecture becomes less entangled, it becomes easier for architects to see underlying structures and make reasonable determinations about the effort needed for restructuring.
Other architectural characteristics dominate
Evolvability is only one of many characteristics architects must weigh when choosing a particular architecture style. No architecture can fully support conflicting core goals. For example, building high performance and high scale into the same architecture is difficult. In some cases, other factors may outweigh evolutionary change.
Most of the time, architects choose an architecture for a broad set of requirements. For example, perhaps an architecture needs to support high availability, security, and scale. This leads toward general architecture patterns, such as monolith, microservices, or event-driven patterns. However, a family of architectures known as domain-specific architectures attempt to maximize a single characteristic. Having built their architecture for such a specific purpose, evolving it to accommodate other concerns would present difficulties (unless developers are extraordinarily lucky and architectural concerns overlap). Thus, most domain-specific architectures aren’t concerned with evolution because their specific purpose overrides other concerns.
Sacrificial architecture
Martin Fowler defined a sacrificial architecture as one designed to be thrown away. Many companies need to build simple versions initially to investigate a market or prove viability. Once proven, they can build the real architecture to support the characteristics that have manifested.
Many companies do this strategically. Often, companies build this type of architecture when creating a minimum viable product to test a market, anticipating building a more robust architecture if the market approves. Building a sacrificial architecture implies that architects aren’t going to try to evolve it but rather replace it at the appropriate time with something more permanent. Cloud offerings make this an attractive option for companies experimenting with the viability of a new market or offering.
Summary
Building evolutionary architectures isn’t a silver-bullet set of tools architects can download and run. Rather, it is a holistic approach to governance in architecture, based on the cumulative experience we have learned about software engineering. Real software engineering will rely on automation plus incremental change, both features of evolutionary architecture.
Remember that often turnkey tools won’t exist for your ecosystem. So the key question is, “Is the information I need available somewhere?” If so, then a simple handcrafted scripting tool can gather and aggregate that disparate data to provide architectural value.
Architects don’t have to implement an elaborate set of fitness functions. Just like domain testing via unit tests, architects should focus on high-value fitness functions that justify the effort to create and maintain them. There is no absolute end state for evolution in an architecture, only degrees of value added via these approaches.
To evolve a software system, architects must have confidence in the structural design and engineering practices working synergistically. Controlling coupling and automating verification is the key to building well-governed architectures that can evolve via domain, technical changes, or both.