
Chapter 6. Evolutionary Data
Relational and other types of data stores are ubiquitous in modern software projects, a form of coupling that is often more problematic than architectural coupling. Data teams are generally not as accustomed to engineering practices such as unit testing and refactoring (which is gradually improving). Also, databases often become integration points, making data teams reluctant to make changes due to potential rippling side effects.
Data is an important dimension to consider when creating an evolvable architecture. Architectures like microservices require much more architectural consideration of data partitioning, dependencies, transactionality, and a host of other issues that were formerly only the realm of data teams. It is beyond the scope of this book to cover all the aspects of evolutionary database design. Fortunately, our co-author Pramod Sadalage, along with Scott Ambler, wrote Refactoring Databases, subtitled Evolutionary Database Design. We cover only the parts of database design that impact evolutionary architecture and encourage readers to read that book.
Evolutionary Database Design
Evolutionary design in databases occurs when developers can build and evolve the structure of the database as requirements change over time. Database schemas are abstractions, similar to class hierarchies. As the underlying real world changes, those changes must be reflected in the abstractions developers and data teams build. Otherwise, the abstractions gradually fall out of synchronization with the real world.
Evolving Schemas
How can architects build systems that support evolution but still use traditional tools like relational databases? The key to evolving database design lies in evolving schemas alongside code. Continuous Delivery addresses the problem of how to fit the traditional data silo into the continuous feedback loop of modern software projects. Developers must treat changes to database structure the same way they treat source code: tested, versioned, and incremental:
- Tested
-
The data team and developers should rigorously test changes to database schemas to ensure stability. If developers use a data mapping tool like an object-relational mapper (ORM), they should consider adding fitness functions to ensure the mappings stay in sync with the schemas.
- Versioned
-
Developers and the data team should version database schemas alongside the code that utilizes it. Source code and database schemas are symbiotic—neither functions without the other. Engineering practices that artificially separate these two necessarily coupled things cause needless inefficiencies.
- Incremental
-
Changes to the database schemas should accrue just as source code changes build up: incrementally as the system evolves. Modern engineering practices eschew manual updates of database schemas, preferring automated migration tools instead.
Database migration tools are utilities that allow developers (or the data team) to make small, incremental changes to a database that are automatically applied as part of a deployment pipeline. They exist along a wide spectrum of capabilities from simple command-line tools to sophisticated proto-IDEs. When developers need to make a change to a schema, they write small database migration (aka delta) scripts, as illustrated in Example 6-1.
Example 6-1. A simple database migration
CREATETABLEcustomer(idBIGINTGENERATEDBYDEFAULTASIDENTITY(STARTWITH1)PRIMARYKEY,firstnameVARCHAR(60),lastnameVARCHAR(60));
The migration tool takes the SQL snippet shown in Example 6-1 and automatically applies it to the developer’s instance of the database. If the developer later realizes they want to add date of birth, rather than changing the original migration they can create a new one that modifies the original structure, as shown in Example 6-2.
Example 6-2. Adding date of birth to existing table using a migration
ALTERTABLEcustomerADDCOLUMNdateofbirthDATETIME;
Once developers have run migrations, the migrations are considered immutable—changes are modeled after double-entry bookkeeping. For example, suppose that Danielle the developer ran the migration in Example 6-2 as the 24th migration on a project. Later, she realizes dateofbirth isn’t needed after all. She could just remove the 24th migration, and hence, the dateofbirth column. However, any code written after Danielle ran the migration will assume the presence of the dateofbirth column and will no longer work if the project needs to back up to an intermediate point (e.g., to fix a bug). Also, any other environment where this change was already applied will have the column and create a schema mismatch. Instead, she could remove the column by creating a new migration.
In Example 6-2, the developer modifies the existing schema to add a new column. Some migration tools support undo capabilities as well, as shown in Example 6-3. Supporting undo allows developers to easily move forward and backward through the schema versions. For example, suppose a project is on version 101 in the source code repository and needs to return to version 95. For the source code, developers merely check out version 95 from version control. But how can they ensure the database schema is correct for version 95 of the code? If they use migrations with undo capabilities, they can “undo” their way backward to version 95 of the schema, applying each migration in turn to regress to the desired version.
Example 6-3. Adding date of birth and undo migration to existing table
ALTERTABLEcustomerADDCOLUMNdateofbirthDATETIME;--//@UNDOALTERTABLEcustomerDROPCOLUMNdateofbirth;
However, most teams have moved away from building undo capabilities for three reasons. First, if all the migrations exist, developers can build the database just up to the point they need without backing up to a previous version. In our example, developers would build from 1 to 95 to restore version 95. Second, why maintain two versions of correctness, both forward and backward? To confidently support undo, developers must test the code, sometimes doubling the testing burden. Third, building comprehensive undo sometimes presents daunting challenges. For example, imagine that the migration dropped a table—how would the migration script preserve all data in the case of an undo operation? Prefix the table with DROPPED_ and keep it around? This will quickly get complicated because of all the changes happening around the table, and soon the data in the DROPPED table will not be relevant anymore.
Database migrations allow both database admins and developers to manage changes to schema and code incrementally, by treating each as parts of a whole. By incorporating database changes into the deployment pipeline feedback loop, developers have more opportunities to incorporate automation and earlier verification into the project’s build cadence.
Shared Database Integration
A common integration pattern highlighted here is Shared Database Integration, which uses database as a sharing mechanism for data, as illustrated in Figure 6-1.

Figure 6-1. Using the database as an integration point
In Figure 6-1, the three applications share the same relational database. Projects frequently default to this integration style—every project is using the same relational database because of governance, so why not share data across projects? Architects quickly discover, however, that using the database as an integration point fossilizes the database schema across all sharing projects.
What happens when one of the coupled applications needs to evolve capabilities via a schema change? If ApplicationA makes changes to the schema, this could potentially break the other two applications. Fortunately, as discussed in the aforementioned Refactoring Databases book, a commonly utilized refactoring pattern is used to untangle this kind of coupling: the Expand/Contract pattern. Many database refactoring techniques avoid timing problems by building a transition phase into the refactoring, as illustrated in Figure 6-2.

Figure 6-2. The Expand/Contract pattern for database refactoring
Using this pattern, developers have a starting state and an ending state, maintaining both the old and new states during the transition. This transition state allows for backward compatibility and also gives other systems in the enterprise enough time to catch up with the change. For some organizations, the transition state can last from a few days to months.
Here is an example of Expand/Contract in action. Consider the common evolutionary change of splitting a name column into firstname and lastname, which PenultimateWidgets needs to do for marketing purposes. For this change, developers have the start state, the expand state, and the final state, as shown in Figure 6-3.

Figure 6-3. The three states of Expand/Contract refactoring
In Figure 6-3, the full name appears as a single column. During the transition, the PenultimateWidgets data team must maintain both versions to prevent breaking possible integration points in the database. They have several options for how we proceed to split the name column into firstname and lastname.
Option 1: No integration points, no legacy data
In this case, the developers have no other systems to think about and no existing data to manage, so they can add the new columns and drop the old column, as shown in Example 6-4.
Example 6-4. Simple case with no integration points and no legacy data
ALTERTABLEcustomerADDfirstnameVARCHAR2(60);ALTERTABLEcustomerADDlastnameVARCHAR2(60);ALTERTABLEcustomerDROPCOLUMNname;
For Option 1, the refactoring is straightforward: the data team can make the relevant change and get on with life.
Option 2: Legacy data, but no integration points
In this scenario, developers assume existing data to migrate to new columns but they have no external systems to worry about. They must create a function to extract the pertinent information from the existing column to handle migrating the data, as shown in Example 6-5.
Example 6-5. Legacy data but no integrators
ALTERTABLECustomerADDfirstnameVARCHAR2(60);ALTERTABLECustomerADDlastnameVARCHAR2(60);UPDATECustomersetfirstname=extractfirstname(name);UPDATECustomersetlastname=extractlastname(name);ALTERTABLEcustomerDROPCOLUMNname;
This scenario requires the data team to extract and migrate the existing data but is otherwise straightforward.
Option 3: Existing data and integration points
This is the most complex and, unfortunately, most common scenario. Companies need to migrate existing data to new columns while external systems depend on the name column, which the other teams cannot migrate to use the new columns in the desired time frame. The required SQL appears in Example 6-6.
Example 6-6. Complex case with legacy data and integrators
ALTERTABLECustomerADDfirstnameVARCHAR2(60);ALTERTABLECustomerADDlastnameVARCHAR2(60);UPDATECustomersetfirstname=extractfirstname(name);UPDATECustomersetlastname=extractlastname(name);CREATEORREPLACETRIGGERSynchronizeNameBEFOREINSERTORUPDATEONCustomerREFERENCINGOLDASOLDNEWASNEWFOREACHROWBEGINIF:NEW.NameISNULLTHEN:NEW.Name:=:NEW.firstname||' '||:NEW.lastname;ENDIF;IF:NEW.nameISNOTNULLTHEN:NEW.firstname:=extractfirstname(:NEW.name);:NEW.lastname:=extractlastname(:NEW.name);ENDIF;END;
To build the transition phase in Example 6-6, the data team adds a trigger in the database that moves data from the old name column to the new firstname and lastname columns when the other systems are inserting data into the database, allowing the new system to access the same data. Similarly, developers or the data team concatenate the firstname and lastname columns into a name column when the new system inserts data so that the other systems have access to their properly formatted data.
Once the other systems modify their access to use the new structure (with separate first and last names), the contraction phase can be executed and the old column dropped:
ALTERTABLECustomerDROPCOLUMNname;
If a lot of data exists and dropping the column will be time-consuming, the data team can sometimes set the column to “not used” (if the database supports this feature):
ALTERTABLECustomerSETUNUSEDname;
After dropping the legacy column, if a read-only version of the previous schema is needed, the data team can add a functional column so that read access to the database is preserved:
ALTERTABLECUSTOMERADD(nameAS(generatename(firstname,lastname)));
As illustrated in each scenario, the data team and developers can utilize the native facilities of databases to build evolvable systems.
Expand/Contract is a subset of a pattern called Parallel Change, a broad pattern used to safely implement backward-incompatible changes to an interface.
Inappropriate Data Entanglement
Data and databases form an integral part of most modern software architectures—developers who ignore this key aspect when trying to evolve their architecture suffer.
Databases and the data team form a particular challenge in many organizations because, for whatever reason, their tools and engineering practices are antiquated compared to the traditional development world. For example, the tools the data team uses daily are extremely primitive compared to any developer’s IDE. Features that are common for developers don’t exist for data teams: refactoring support, out-of-container testing, unit testing, dependency tracking, linting, mocking and stubbing, and so on.
The data structures in the databases are coupled with application code, and it’s difficult for the data team to refactor the database without involvement of the users of the data structures, such as application developers; Extract, Transform, and Load developers; and report developers. Since involvement of different teams, resource coordination, and prioritization from the product team are necessary, the database refactoring becomes complex to execute and often gets deprioritized, leading to suboptimal database structures and abstractions.
Two-Phase Commit Transactions
When architects discuss coupling, the conversation usually revolves around classes, libraries, and other aspects of the technical architecture. However, other avenues of coupling exist in most projects, including transactions; this is true in both monolithic and distributed architectures.
Transactions are a special form of coupling because transactional behavior doesn’t appear in traditional technical architecture-centric tools. Architects can easily determine the afferent and efferent coupling between classes with a variety of tools. They have a much harder time determining the extent of transactional contexts. Just as coupling between schemas harms evolution, transactional coupling binds the constituent parts together in concrete ways, making evolution more difficult.
Transactions appear in business systems for a variety of reasons. First, business analysts love the idea of transactions—an operation that stops the world for some context briefly—regardless of the technical challenges. Global coordination in complex systems is difficult, and transactions represent a form of it. Second, transactional boundaries often tell how business concepts are really coupled together in their implementation. Third, the data team may own the transactional contexts, making it hard to coordinate breaking the data apart to resemble the coupling found in the technical architecture.
In Chapter 5, we discussed the architectural quantum boundary concept: the smallest architectural deployable unit, which differs from traditional thinking about cohesion by encompassing dependent components like databases. The binding created by databases is more imposing than traditional coupling because of transactional boundaries, which often define how business processes work. Architects sometimes err in trying to build an architecture with a smaller level of granularity than is natural for the business. For example, microservices architectures aren’t particularly well suited for heavily transactional systems because the goal service quantum is so small.
Architects must consider all the coupling characteristics of their application: classes, package/namespace, library and framework, data schemas, and transactional contexts. Ignoring any of these dimensions (or their interactions) creates problems when trying to evolve an architecture. In physics, the strong nuclear force that binds atoms together is one of the strongest forces yet identified. Transactional contexts act like a strong nuclear force for architecture quanta.
Note
Database transactions act as a strong nuclear force, binding quanta together.
While systems often cannot avoid transactions, architects should try to limit transactional contexts as much as possible because they form a tight coupling knot, hampering the ability to change some components or services without affecting others. More importantly, architects should take aspects like transactional boundaries into account when thinking about architectural changes.
As we will discuss in Chapter 9, when migrating a monolithic architectural style to a more granular one, start with a small number of larger services first. When building a greenfield microservices architecture, developers should be diligent about restricting the size of service and data contexts. However, don’t take the term microservices too literally—each service doesn’t have to be small; rather, it should capture a useful bounded context.
When restructuring an existing database schema, it is often difficult to achieve appropriate granularity. Many data teams spend decades stitching a database schema together and have no interest in performing the reverse operation. Often, the necessary transactional contexts to support the business define the smallest granularity developers can make into services. While architects may aspire to create a smaller level of granularity, their efforts slip into inappropriate coupling if it creates a mismatch with data concerns. Building an architecture that structurally conflicts with the problem developers are trying to solve represents a damaging version of metawork, described in “Migrating Architectures”.
Age and Quality of Data
Another dysfunction that manifests in large companies is the fetishization of data and databases. We have heard more than one CTO say, “I don’t really care that much about applications because they have a short lifespan, but my data schemas are precious because they live forever!” While it’s true that schemas change less frequently than code, database schemas still represent an abstraction of the real world. While inconvenient, the real world has a habit of changing over time. The data team that believes that schemas never change is ignoring reality.
But if the data teams never refactor the database to make schema changes, how do they make changes to accommodate new abstractions? Unfortunately, adding another join table is a common process the data team uses to expand schema definitions. Rather than make a schema change and risk breaking existing systems, they just add a new table, joining it to the original using relational database primitives. While this works in the short term, it obfuscates the real underlying abstraction: in the real world, one entity is represented by multiple things. Over time, the data teams that rarely genuinely restructure schemas build an increasingly fossilized world, with byzantine grouping and bunching strategies. When the data team doesn’t restructure the database, it’s not preserving a precious enterprise resource; it’s creating the concretized remains of every version of the schema, overlaid upon one another via join tables.
Legacy data quality presents another huge problem. Often, the data has survived many generations of software, each with its own persistence quirks, resulting in data that is inconsistent at best and garbage at worst. In many ways, trying to keep every scrap of data couples the architecture to the past, forcing elaborate workarounds to make things operate successfully.
Before trying to build an evolutionary architecture, make sure developers can evolve the data as well, both in terms of schema and quality. Poor structure requires refactoring, and data teams should perform whatever actions are necessary to baseline the quality of data. We prefer fixing these problems early rather than building elaborate, ongoing mechanisms to handle these problems in perpetuity.
Legacy schemas and data have value, but they also represent a tax on the ability to evolve. Architects, data teams, and business representatives need to have frank conversations about what represents value to the organization—keeping legacy data forever or the ability to make evolutionary change. Look at the data that has true value and preserve it, and make the older data available for reference but out of the mainstream of evolutionary development.
Case Study: Evolving PenultimateWidgets’ Routing
PenultimateWidgets has decided to implement a new routing scheme between pages, providing a navigational breadcrumb trail to users. Doing so means changing the way routing between pages has been done (using an in-house framework). Pages that implement the new routing mechanism require more context (origin page, workflow state, etc.), and thus require more data.
Within the routing service quantum, PenultimateWidgets currently has a single table to handle routes. For the new version, developers need more information, so the table structure will be more complex. Consider the starting point illustrated in Figure 6-4.
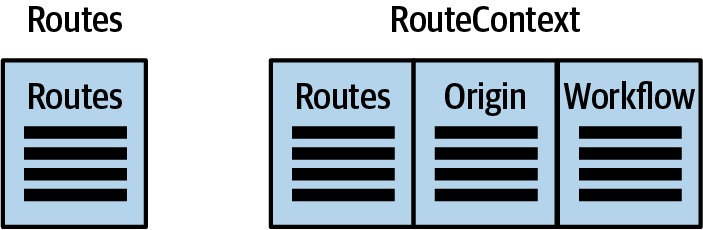
Figure 6-4. Starting point for new routing implementation
Not all pages at PenultimateWidgets will implement the new routing at the same time because different business units work at different speeds. Thus, the routing service must support both the old and new versions. We will see how that is handled via routing in Chapter 7. In this case, we must handle the same scenario at the data level.
Using the Expand/Contract pattern, a developer can create the new routing structure and make it available via the service call. Internally, both routing tables have a trigger associated with the route column so that changes to one are automatically replicated to the other, as shown in Figure 6-5.

Figure 6-5. The transitional state, where the service supports both versions of routing
As seen in Figure 6-5, the service can support both APIs as long as developers need the old routing service. In essence, the application now supports two versions of routing information.
When the old service is no longer needed, the routing service developers can remove the old table and the trigger, as shown in Figure 6-6.
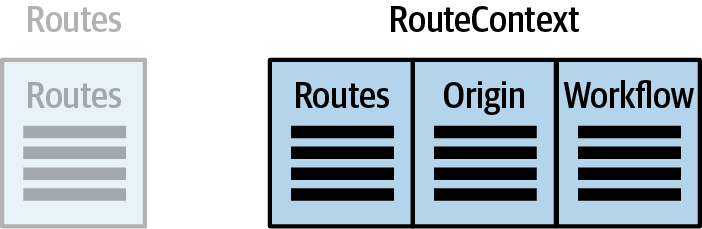
Figure 6-6. The ending state of the routing tables
In Figure 6-6, all services have migrated to the new routing capability, allowing the old service to be removed. This matches the workflow shown in Figure 6-2.
The database can evolve right alongside the architecture as long as developers apply proper engineering practices such as continuous integration, source control, and so on. This ability to easily change the database schema is critical: a database represents an abstraction based on the real world, which can change unexpectedly. While data abstractions resist change better than behavior, they must still evolve. Architects must treat data as a primary concern when building an evolutionary architecture.
Refactoring databases is an important skill and craft for the data team and developers to hone. Data is fundamental to many applications. To build evolvable systems, developers and the data team must embrace effective data practices alongside other modern engineering practices.
From Native to Fitness Function
Sometime choices in software architecture cause issues in other parts of the ecosystem. When architects embraced microservices architectures, which suggests one database per bounded context, it changed data teams’ traditional perspective about databases: they are more accustomed to a single relational database, along with the conveniences those tools and model provide. For example, data teams pay close attention to referential integrity, to ensure the correctness of the connecting points of the data structure.
But what happens when architects want to break databases into a data-per-service architecture like microservices—how can they convince skeptical data teams that the advantages of microservices outweigh giving up some of their trusted mechanisms?
Because it is a form of governance, architects can reassure data teams by wiring continuous fitness functions into the build to ensure important pieces maintain integrity and address other issues.
Referential Integrity
Referential integrity is a form of governance, at the data schema level rather than architecture coupling. However, to an architect, both impact the ability to evolve the application by increasing coupling. For example, many cases exist where data teams are reluctant to break up tables into separate databases because of referential integrity, but that coupling prevents both services coupled to it from changing.
Referential integrity in databases refers to primary keys and their linkages. In distributed architectures, teams also have unique identifiers for entities, frequently expressed as GUIDs or some other random sequence. Thus, architects must write fitness functions to ensure that if, for example, a particular item is deleted by the owner of the information, that deletion is propagated to other services that might still reference the deleted entity. A number of patterns in event-driven architecture address these kinds of background tasks; one such example appears in Figure 6-7.

Figure 6-7. Using event-based data synchronization to handle referential integrity
In Figure 6-7, when the user interface rejects a trade via the Trader Blotter service, it propagates a message on a durable message queue that all interested services monitor, updating or deleting the changes as needed.
While referential integrity in databases is powerful, it sometimes creates undesirable coupling, which must be weighed against the benefits.
Data Duplication
When teams become accustomed to a single relational database, they don’t often think of the two operations—read and write—as separate. However, microservices architectures force teams to think more carefully about which services can update information versus which services can just read it. Consider the common scenario faced by many teams new to microservices, illustrated in Figure 6-8.
A number of the services need access to several key parts of the system, for Reference, Audit Tables, Configuration, and Customer. How should the team handle this need? The solution shown in Figure 6-8 shares the tables with all the interested services, which is convenient but violates one of the tenets of microservices architectures to avoid coupling services to a common database. If the schema for any of these tables changes, it will ripple out to the coupled services, potentially requiring them to change.

Figure 6-8. Managing shared information in a distributed architecture
An alternative approach appears in Figure 6-9.

Figure 6-9. Modeling shared information as a service
In Figure 6-9, following the philosophy behind microservices, we model each shared bit of information as a distinct service. However, this exposes one of the problems in microservices—too much interservice communication, which can impact performance.
A common approach by many teams is to carefully consider who should own data (i.e., who can update it) versus who can read some version of it. The solution shown in Figure 6-10 uses in-process caching for read access.

Figure 6-10. Using caching for read-only access
In Figure 6-10, the service components on the left “own” the data. However, on startup, each interested service reads and caches the data of interest, with an appropriate update frequency for cached information. If one of the righthand services needs to update the shared value, it does so via a request to the owning service, which can then publish the changes.
Architects use a variety of approaches to manage data access versus updates in modern architectures. Examples include change control, connection management scalability, fault tolerance, architectural quanta, database-type optimization, database transactions, and data relationships, which is covered in more detail in Software Architecture: The Hard Parts (O’Reilly).
Replacing Triggers and Stored Procedures
Another common mechanism data teams rely on are stored procedures, written in the native SQL for the database. While this is a powerful and performant option for manipulating data, it suffers from some challenges in modern software engineering practices. For example, stored procedures are hard to unit test, often have poor refactoring support, and separate behavior from the other behavior in source code.
Migrating to microservices often causes data teams to refactor stored procedures because the data in question no longer resides in a single database. In that case, the behavior must move to code, and teams must address issues such as data volume and transport. In modern NoSQL databases there may be triggers or serverless functions that trigger based on some data change. All of the database code has to be refactored.
Architects can use the same Expand/Contract pattern to extract behavior currently in stored procedures into application code, using the Migrate Method from Database pattern as shown Figure 6-11.

Figure 6-11. Extracting database code into services
During the expand phase, developers add the replacement method in the Widgets Administration service, and developers refactor other services to call the Widgets Administration service. Initially, the new method acts as a pass-through to the stored procedure until the team can invisibly replace the functionality in well-tested code. During this period, the application supports calls to either the service or the stored procedure. In the contract phase, architects can use a fitness function to make sure all dependencies have migrated to calling the service and subsequently drop the stored procedure. This is the database version of the Strangler Fig pattern.
Another option might be to avoid refactoring the stored procedure and build a broader data context instead, as illustrated in Figure 6-12.

Figure 6-12. Building a broader data context to preserve stored procedures
In Figure 6-12, rather than replace the triggers and stored procedures in code, the team opted for a bigger granularity of service. No generic advice is possible here; teams must evaluate on a case-by-case basis the trade-offs of their decisions.
Case Study: Evolving from Relational to Nonrelational
Many organizations like PenultimateWidgets start with monolithic applications for good strategic reasons: time to market, simplicity, market uncertainty, and a host of other reasons. These applications typically include a single relational database, the industry standard for decades.
When breaking apart the monolith, teams may rethink their persistence as well. For example, for cataloging and categorizing analytics, a graph database might be better. For some problem domains, name/value pair databases provide better options. One of the beneficial features of highly distributed architectures such as microservices lies with architects’ ability to choose different persistence mechanisms based on the problem rather than an arbitrary standard. A migration from a monolith to microservices might look like Figure 6-13.
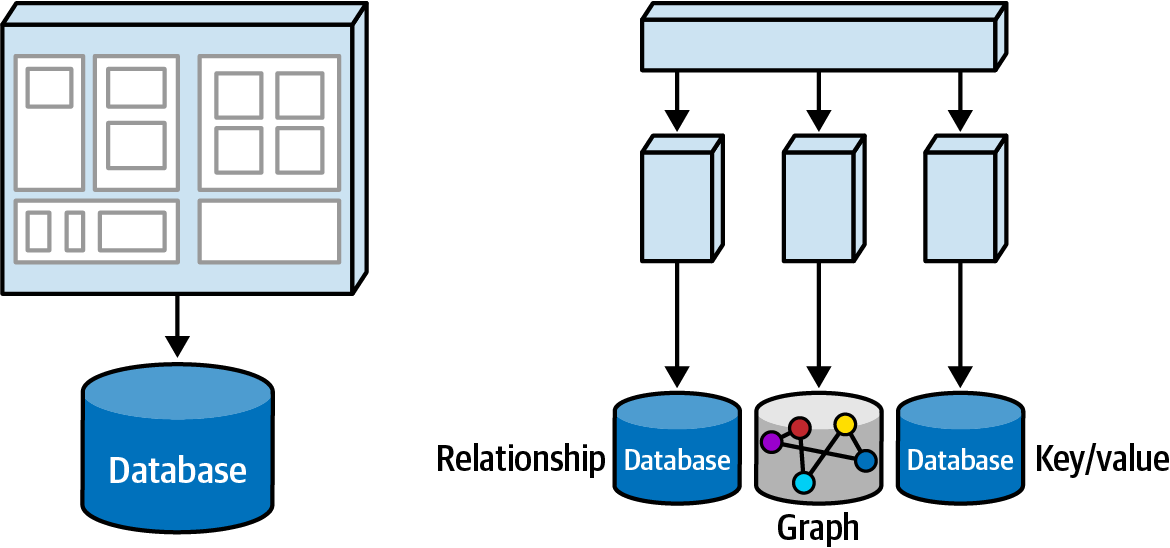
Figure 6-13. PenultimateWidgets’ migration from a monolith to a microservices architecture
In Figure 6-13, catalog, analytics (used for market forecasting and other business intelligence), and operational data (such as sales status, transactions, etc.) all reside in a single database, sometimes bending the way a relational database is used to accommodate the various uses. However, when moving to microservices, the teams have the chance to break the monolithic data into different, more representative types. For example, some data might be better suited for key/value pairs rather than for strictly relational databases. Similarly, some problems that data teams can solve in seconds with a graph database can take hours or days in a relational one.
However, moving from a single type of database to multiple databases (even of the same type) can cause issues; everything in software architecture is a trade-off. Architects may struggle convincing data teams of the architectural requirement from microservices to break persistence into multiple data stores, so architects should highlight the trade-offs inherent in each approach.
Summary
The last part of our definition of an evolutionary architecture includes across multiple dimensions, and data is the most common extra-architecture concern that impacts the evolution of software systems. The advent of modern distributed architectures such as microservices forced architects to take on problems that used to belong solely to data teams. Restructuring architectures around bounded contexts means partitioning data as well, which comes with its own set of trade-offs.
Architects must both think more diligently about the impacts of data on architecture and collaborate with data teams just as with developers.