
Chapter 7. Building Evolvable Architectures
Until now, we’ve addressed the two primary aspects of evolutionary architecture—mechanics and structure—separately. Now we have enough context to tie them together.
Many of the concepts we discussed aren’t new ideas but rather old ideas viewed through a new lens. For example, testing has existed for years, but not with the fitness function emphasis on architectural verification. Continuous Delivery defined the idea of deployment pipelines. Evolutionary architecture shows architects how to add governance to that automation.
Many organizations pursue Continuous Delivery practices as a way to increase engineering efficiency for software development, a worthy goal in itself. However, we’re taking the next step, using those capabilities to create something more sophisticated—architectures that evolve with the real world.
So how can developers take advantage of these techniques on projects, both existing and new?
Principles of Evolutionary Architecture
Overarching both mechanics and structure in evolutionary architecture are five general principles. Let’s look at them now.
Last Responsible Moment
The agile development world has long extolled the virtues of last responsible moment: delaying decisions as long as you can, but no longer. Making decisions too early tends toward overengineering, and too late leads to failure to meet architectural goals.
The goal isn’t to unnecessarily delay. Rather, if an architect can find the correct inflection point in decision-making, they maximize the amount of information available. This helps because, ultimately, the architect’s job lies with trade-off analysis, and the more information they have, the more trade-off criteria are available.
When making decisions too early, architects naturally want to keep options open, tending toward picking more general solutions. However, this can overcomplicate specific implementations without providing teams the benefits of generality.
Decide early what the objective drivers are and prioritize decisions accordingly.
Architect and Develop for Evolvability
Architects should treat evolvability as a first-class concern in architecture. That implies thinking about objective measures when analyzing architecture characteristics. It also implies thinking about appropriate coupling and how to avoid brittleness in your architecture.
As we discussed in Chapter 6, architects must think of data and other external integration points (static coupling for the architecture quantum) as first-class design considerations. For example, data teams should integrate database changes continuously just like code, and architects should consider data dependencies as equal to code dependencies.
Like many holistic parts of architecture, this principle applies to software development process and tooling as well. Choose both to support the least friction and highest degree of feedback.
Postel’s Law
Be conservative in what you do, be liberal in what you accept from others.
Jon Postel
An important principle we can add to the discussion around contracts in “Contracts” is Postel’s Law, a general principle that tries to soften coupling points as much as possible. When applied to contracts and communication, it offers a useful guideline for enabling evolution:
- Be conservative in what you send
-
Don’t send more information than necessary—if a collaborating service needs only a phone number, don’t send a larger data structure. The more information in a contract, the more often other coupling points will take advantage of it, tightening a contract that could otherwise be looser.
- Be liberal in what you accept from others
-
You can accept more information than you consume. You don’t need to consume more information than necessary, even if there is additional data available. If you only want a phone number, don’t build a protocol for the entire address, only validate the phone number. This decouples a service from information/coupling points that it doesn’t need.
- Use versioning when breaking a contract
-
Architects must honor contracts in integration architecture (automated via consumer-driven contracts), which means paying attention to the evolution of service functionality.
Much has been written in the architecture space about Postel’s Law, for good reason—it offers good advice for decoupling, which in turn favors evolutionary architecture.
Architect for Testability
Many architects complain that their architecture has difficult areas to test, which isn’t surprising when testability often isn’t a priority when designing the architecture. Conversely, if architects design their architecture with testing in mind, they build easier ways to test parts of the architecture in isolation. For example, a lot of research and tools exist in the microservices ecosystem to facilitate testing, contributing to its general evolvability. In general, a correlation exists between a hard-to-test system and one that is hard to maintain and enhance.
A good example of architecture for testability also illustrates the single responsibility principle: every part of a system should have a single responsibility. For example, consider the formerly common antipattern of mixing business logic with messaging infrastructure via tools like Enterprise Service Bus. We realized that mixing concerns makes it difficult to test either behavior in isolation.
Conway’s Law
Surprising coupling points happen in sometimes surprising parts of software development. Paying attention to team structure and what impact it has on architecture is a key to evolutionary architecture; we cover Conway’s Law in “Don’t Fight Conway’s Law”).
Mechanics
Architects can operationalize the techniques for building an evolutionary architecture in three steps.
Step 1: Identify Dimensions Affected by Evolution
First, architects must identify which dimensions of the architecture they want to protect as it evolves. This always includes technical architecture, and usually things like data design, security, scalability, and the other “-ilities” architects have deemed important. This must involve other interested teams within the organization, including business, operations, security, and other affected parties. The Inverse Conway Maneuver (described in “Don’t Fight Conway’s Law”) is helpful here because it encourages multirole teams. Basically, this is the common behavior of architects at the onset of projects when identifying the architectural characteristics they want to support.
Step 2: Define Fitness Function(s) for Each Dimension
A single dimension often contains numerous fitness functions. For example, architects commonly wire a collection of code metrics into the deployment pipeline to ensure architectural characteristics of the codebase, such as preventing component dependency cycles. Architects document decisions about which dimensions deserve ongoing attention in a lightweight format such as a wiki. Then, for each dimension, they decide what parts may exhibit undesirable behavior when evolving, eventually defining fitness functions. Fitness functions may be automated or manual, and ingenuity will be necessary in some cases.
Step 3: Use Deployment Pipelines to Automate Fitness Functions
Lastly, architects must encourage incremental change on the project, defining stages in a deployment pipeline to apply fitness functions and managing deployment practices like machine provisioning, testing, and other DevOps concerns. Incremental change is the engine of evolutionary architecture, allowing aggressive verification of fitness functions via deployment pipelines and a high degree of automation to make mundane tasks like deployment invisible. Cycle time is the Continuous Delivery measure of engineering efficiency. Part of the responsibility of developers on projects that support evolutionary architecture is to maintain good cycle time. Cycle time is an important aspect of incremental change because many other metrics derive from it. For example, the velocity of new generations appearing in an architecture is proportional to its cycle time. In other words, if a project’s cycle time lengthens, it slows down how fast the project can deliver new generations, which affects evolvability.
While the identification of dimensions and fitness functions occurs at the beginning of a new project, it is also an ongoing activity for both new and existing projects. Software suffers from the unknown unknowns problem: developers cannot anticipate everything. During construction, some part of the architecture often shows troubling signs, and building fitness functions can prevent this dysfunction from growing. While some fitness functions will naturally come to light at the beginning of a project, many won’t reveal themselves until an architectural stress point appears. Architects must vigilantly watch for situations where nonfunctional requirements break and retrofit the architecture with fitness functions to prevent future problems.
Greenfield Projects
Building evolvability into new projects is much easier than retrofitting existing ones. First, developers have the opportunity to utilize incremental change right away, building a deployment pipeline at project inception. Fitness functions are easier to identify and plan before any code exists, making it easier to accommodate complex fitness functions because scaffolding has existed since inception. Second, architects don’t have to untangle any undesirable coupling points that creep into existing projects. The architect can also put metrics and other verifications in place to ensure architectural integrity as the project changes.
Building new projects that handle unexpected change is easier if a developer chooses the correct architectural patterns and engineering practices to facilitate evolutionary architecture. For example, microservices architectures offer extremely low coupling and a high degree of incremental change, making that style an obvious candidate (and another contributing factor to its popularity).
Retrofitting Existing Architectures
Adding evolvability to existing architectures depends on three factors: component coupling, engineering practice maturity, and developer ease in crafting fitness functions.
Appropriate Coupling and Cohesion
Component coupling largely determines the evolvability of the technical architecture. Yet the best possible evolvable technical architecture is doomed if the data schema is rigid and fossilized. Cleanly decoupled systems make evolution easy; nests of exuberant coupling harm it. To build truly evolvable systems, architects must consider all affected dimensions of an architecture.
Beyond the technical aspects of coupling, architects must also consider and defend the functional cohesion of the components of their system. When migrating from one architecture to another, the functional cohesion determines the ultimate granularity of restructured components. That doesn’t mean architects can’t decompose components to a ridiculous level, but rather that components should have an appropriate size based on the problem context. For example, some business problems are more coupled than others, such as in the case of heavily transactional systems. Trying to build an extremely decoupled architecture that is counter to the problem is unproductive.
Engineering practices matter when defining how evolvable an architecture can be. While Continuous Delivery practices don’t guarantee evolutionary architecture, it is almost impossible without them. Many teams embark on improved engineering practices for the sake of efficiency. However, once those practices cement, they become building blocks for advanced capabilities such as evolutionary architecture. Thus, the ability to build an evolutionary architecture is an incentive to improving efficiency.
Many companies reside in the transition zone between older practices and new. They may have solved low-hanging fruit like continuous integration but still have largely manual testing. While it slows cycle time, it is important to include manual stages in deployment pipelines. First, it treats each stage of an application’s build the same—as a stage in the pipeline. Second, as teams slowly automate more pieces of deployment, manual stages may become automated ones with no disruption. Third, elucidating each stage brings awareness about the mechanical parts of the build, creating a better feedback loop and encouraging improvements.
The biggest single common impediment to building evolutionary architecture is intractable operations. If developers cannot easily deploy changes, all parts of the feedback cycle are hampered.
We encourage architects to start thinking of all kinds of architectural verification mechanisms as fitness functions, including things they have previously considered in an ad hoc manner. For example, many architectures have a service-level agreement around scalability and corresponding tests. They also have rules around security requirements, with accompanying verification mechanisms. Architects often think of these as separate categories, but both intents are the same: verify some feature of the architecture. By thinking of all architectural verification as fitness functions, there is more consistency when automation and other beneficial synergistic interactions are defined.
COTS Implications
In many organizations, developers don’t own all the parts that make up their ecosystem. COTS (commercial off-the-shelf) and package software is prevalent in large companies, creating challenges for architects building evolvable systems.
COTS systems must evolve alongside other applications within an enterprise. Unfortunately, these systems don’t support evolution well. Here are aspects of evolutionary architecture that are generally poorly supported by COTS systems:
- Incremental change
-
Most commercial software falls woefully short of industry standards for automation and testing. Architects and developers must often build logical barriers between integration points and build whatever testing is possible, frequently treating the entire system as a black box. Enforcing agility in terms of deployment pipelines, DevOps, and other modern practices offers challenges to development teams.
- Appropriate coupling
-
Package software often commits the worst sins in terms of coupling. Generally, the system is opaque, with a defined API developers use to integrate. Inevitably, that API suffers from the problem described in “Antipattern: Last 10% Trap and Low Code/No Code”, allowing almost (but not quite) enough flexibility for developers to get useful work done.
- Fitness functions
-
Adding fitness functions to package software is perhaps the biggest hurdle to enable evolvability. Generally, tools of this ilk don’t expose enough internals to allow unit or component testing, making behavioral integration testing the last resort. These tests are less desirable because they are necessarily coarse grained, must run in a complex environment, and must test a large swath of behavior of the system.
Tip
Work diligently to hold integration points to your level of maturity. If that isn’t possible, realize that some parts of the system will be easier for developers to evolve than others.
Another worrisome coupling point introduced by many package software vendors is opaque database ecosystems. In the best-case scenarios, the package software manages the state of the database entirely, exposing selected appropriate values via integration points. In the worst case, the vendor database is the integration point to the rest of the system, vastly complicating changes on either side of the API. In this case, architects and DBAs must wrestle control of the database away from the package software for any hope of evolvability.
If trapped with necessary package software, architects should build as robust a set of fitness functions as possible and automate their running at every possible opportunity. Lack of access to internals relegates testing to less desirable techniques.
Migrating Architectures
Many companies end up migrating from one architectural style to another. For example, architects choose simple-to-understand architecture patterns at the beginning of a company’s IT history, often layered architecture monoliths. As the company grows, the architecture comes under stress. One of the most common paths of migration is from monolith to some kind of service-based architecture, for reasons of the general domain-centric shift in architectural thinking, covered in “Case Study: Microservices as an Evolutionary Architecture”. Many architects are tempted by the highly evolutionary microservices architecture as a target for migration, but this is often quite difficult, primarily because of existing coupling.
When architects think of migrating architecture, they typically think of the coupling characteristics of classes and components, but they ignore many other dimensions affected by evolution, such as data. Transactional coupling is as real as coupling between classes and just as insidious to eliminate when restructuring architecture. These extra-class coupling points become a huge burden when trying to break the existing modules into too-small pieces.
Many senior developers build the same types of applications year after year and become bored with the monotony. Most developers would rather write a framework than use a framework to create something useful: Metawork is more interesting than work. Work is boring, mundane, and repetitive, whereas building new stuff is exciting.
This manifests in two ways. First, many senior developers start writing the infrastructure that other developers use, rather than using existing (often open source) software. We once worked with a client who had been on the cutting edge of technology. They built their own application server, web framework in Java, and just about every other bit of infrastructure. At one point, we asked if they had built their own operating system too, and when they said, “No,” we asked, “Why not?!? You built everything else from scratch!”
Upon reflection, the company needed capabilities that weren’t available. However, when open source tools became available, they already owned their lovingly hand-crafted infrastructure. Rather than cut over to the more standard stack, they opted to keep their own because of minor differences in approach. A decade later, their best developers worked in full-time maintenance mode, fixing their application server, adding features to their web framework, and performing other mundane chores. Rather than applying innovation on building better applications, they permanently slaved away on plumbing.
Architects aren’t immune to building things just because it sounds like fun or will improve their resume. In general, building important things like frameworks and libraries is more enjoyable than slogging through a mundane business problem—but that’s the job!
Warning
Metawork is more interesting than work.
Don’t fall into the trap of implementing something just for the sake of implementing it. Make sure you have considered and measured all the trade-offs before committing to an irrevocable path.
Migration Steps
Many architects find themselves faced with the challenge of migrating an outdated monolithic application to a more modern service-based approach. Experienced architects realize that a host of coupling points exist in applications, and one of the first tasks when untangling a codebase is understanding how things are joined. When decomposing a monolith, the architect must take coupling and cohesion into account to find the appropriate balance. For example, one of the most stringent constraints of the microservices architectural style is the insistence that the database reside inside the service’s bounded context. When decomposing a monolith, even if it is possible to break the classes into small enough pieces, breaking the transactional contexts into similar pieces may present an insurmountable hurdle.
Many architects end up migrating from monolithic applications to service-based architectures. Consider the starting point architecture shown in Figure 7-1.

Figure 7-1. A monolith architecture as the starting point for migration, a “share everything” architecture
Building extremely granular services is easier in new projects but difficult in existing migrations. So how can we migrate the architecture in Figure 7-1 to the service-based architecture shown in Figure 7-2?
Performing the kind of migration shown in Figures 7-1 and 7-2 comes with a host of challenges: service granularity, transactional boundaries, database issues, and issues like how to handle shared libraries. Architects must understand why they want to perform this migration, and it must be a better reason than “it’s the current trend.” Splitting the architecture into domains, along with better team structure and operational isolation, allows for easier incremental change, one of the building blocks of evolutionary architecture, because the focus of work matches the physical work artifacts.

Figure 7-2. The service-based, “share as little as possible” end result of the migration
When decomposing a monolithic architecture, finding the correct service granularity is key. Creating large services alleviates problems like transactional contexts and orchestration but does little to break the monolith into smaller pieces. Too-fine-grained components lead to too much orchestration, communication overhead, and interdependency between components.
For the first step in migrating architecture, developers identify new service boundaries. Teams may decide to break monoliths into services via a variety of partitions as follows:
- Business functionality groups
-
A business may have clear partitions that mirror IT capabilities directly. Building software that mimics the existing business communication hierarchy falls distinctly into an applicable use of Conway’s Law (see “Don’t Fight Conway’s Law”).
- Transactional boundaries
-
Many businesses have extensive transactional boundaries they must adhere to. When decomposing a monolith, architects often find that transactional coupling is the hardest to break apart, as discussed in “Two-Phase Commit Transactions”.
- Deployment goals
-
Incremental change allows developers to selectively release code on different schedules. For example, the marketing department might want a much higher cadence of updates than inventory. Partitioning services around operational concerns like speed to release makes sense if that criterion is highly important. Similarly, a portion of the system may have extreme operational characteristics (like scalability). Partitioning services around operational goals allows developers to track (via fitness functions) health and other operational metrics of the service.
Coarser service granularity means many of the coordination problems inherent in microservices go away because more of the business context resides inside a single service. However, the larger the service, the more operational difficulties tend to escalate (another architectural trade-off).
Evolving Module Interactions
Migrating shared modules (including components) is another common challenge faced by developers. Consider the structure shown in Figure 7-3.

Figure 7-3. Modules with efferent and afferent coupling
In Figure 7-3, all three modules share the same library. However, the architect needs to split these modules into separate services. How can she maintain this dependency?
Sometimes the library may be split cleanly, preserving the separate functionality each module needs. Consider the situation shown in Figure 7-4.
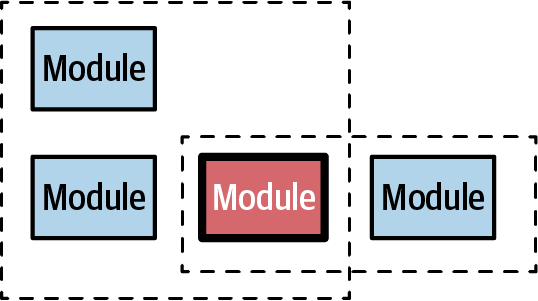
Figure 7-4. Modules with a common dependency
In Figure 7-4, both modules need the conflicting one shown in red (bold border). If developers are lucky, the functionality may be cleanly split down the middle, partitioning the shared library into the relevant parts needed by each dependent, as shown in Figure 7-5.

Figure 7-5. Splitting the shared dependency
Architects don’t have many useful code-level metrics, but here is a rare handy one. The Chidamber & Kemerer metrics suite includes useful metrics for determining whether a module is a good candidate to split or whether architects should use an approach called LCOM (Lack of Cohesion in Methods). LCOM measures structural cohesion in classes or components and exists in several different variants (LCOM1, LCOM2, etc.) to measure slightly different things. However, at its core, this metric measures lack of cohesion. Consider the three cases in Figure 7-6.

Figure 7-6. Three classes with differing cohesion levels
In Figure 7-6, M represents a method and V represents a field within the class. In this example, A represents a class with higher cohesion—more of the methods use fields—than B, which lacks cohesion. In fact, B could be split into three separate classes without difficulty.
LCOM measures the failed opportunities to take advantage of coupling points—in the example, B would score higher in LCOM than A or C, both of which have mixed cohesion.
This metric is available for any platform that supports the CK metrics suite; for example, a common open source Java implementation is ckjm.
LCOM is useful to an architect performing an architectural migration because a common part of that process deals with shared classes or components. When decomposing a monolith, architects can pretty easily determine how to partition the major parts of the problem domain. However, what about ancillary classes and other components—just how coupled are they? For example, when building a monolith, if a need arises in several places for some concept like Address, the team will share a single Address class, which makes sense. However, when it comes time to break up the monolith, what should they do with the Address class? The LCOM metric helps architects determine whether the class never should have been a single class in the first place—if this metric scores high, it isn’t cohesive. However, if LCOM scores low, architects must choose a different approach.
Two options remain: first, developers can extract the module into a shared library (such as a JAR, DLL, gem, or some other component mechanism) and use it from both locations, as shown in Figure 7-7.

Figure 7-7. Sharing a dependency via a JAR file
Sharing is a form of coupling, which is highly discouraged in architectures like microservices. An alternative to sharing a library is replication, as illustrated in Figure 7-8.

Figure 7-8. Duplicating a shared library to eliminate a coupling point
In a distributed environment, developers may achieve the same kind of sharing using messaging or service invocation.
When developers have identified the correct service partitioning, the next step is separation of the business layers from the UI. Even in microservices architectures, the UIs often resolve back to a monolith—after all, developers must show a unified UI at some point. Thus, developers commonly separate the UIs early in the migration, creating a mapping proxy layer between UI components and the backend services they call. Separating the UI also creates an anticorruption layer, insulating UI changes from architecture changes.
The next step is service discovery, allowing services to find and call one another. Eventually, the architecture will consist of services that must coordinate. By building the discovery mechanism early, developers can slowly migrate parts of the system that are ready to change. Developers often implement service discovery as a simple proxy layer: each component calls the proxy, which in turn maps to the specific implementation.
All problems in computer science can be solved by another level of indirection, except of course for the problem of too many indirections.
Dave Wheeler and Kevlin Henney
Of course, the more levels of indirection developers add, the more confusing navigating the services becomes.
When migrating an application from a monolithic application architecture to a more services-based one, the architect must pay close attention to how modules are connected in the existing application. Naïve partitioning introduces serious performance problems. The connection points in the application become integration architecture connections, with the attendant latency, availability, and other concerns. Rather than tackle the entire migration at once, a more pragmatic approach is to gradually decompose the monolithic architecture into services, looking at factors like transaction boundaries, structural coupling, and other inherent characteristics to create several restructuring iterations. First, break the monolith into a few large “portions of the application” chunks, fix up the integration points, and rinse and repeat. Gradual migration is preferred in the microservices world.
When migrating from a monolith, build a small number of larger services first.
Sam Newman, Building Microservices
Next, developers choose and detach the service from the monolith, fixing any calling points. Fitness functions play a critical role here—developers should build fitness functions, make sure the newly introduced integration points don’t change, and add consumer-driven contracts.
Guidelines for Building Evolutionary Architectures
We’ve used a few biology metaphors throughout the course of the book, and here is another. Our brains did not evolve in a nice, pristine environment where each capability was carefully built. Instead, each layer is based on primeval layers beneath. Much of our core autonomic behavior (like breathing, eating, etc.) resides in parts of our brain not very different from reptilian brains. Instead of wholesale replacement of core mechanisms, evolution builds new layers on top.
Software architecture in large enterprises follows a similar pattern. Rather than rebuild each capability anew, most companies try to adapt whatever is present. As much as we like to talk about architecture in pristine, idealized settings, the real world often exhibits a contrary mess of technical debt, conflicting priorities, and limited budgets. Architecture in large companies is built like the human brain: lower-level systems still handle critical plumbing details but have some old baggage. Companies hate to decommission something that works, leading to escalating integration architecture challenges.
Retrofitting evolvability into an existing architecture is challenging. If developers never built easy change into the architecture, it is unlikely to appear spontaneously. No architect, now matter how talented, can transform a Big Ball of Mud into a modern microservices architecture without immense effort. Fortunately, projects can receive benefits without changing their entire architecture by building some flexibility points into the existing one.
Remove Needless Variability
One of the goals of Continuous Delivery is stability—building on known good parts. A common manifestation of this goal is the modern DevOps perspective on building immutable infrastructure. We discussed the dynamic equilibrium of the software development ecosystem in Chapter 1—nowhere is that more apparent in how much the foundation shifts around software dependencies. Software systems undergo constant change, as developers update capabilities, issue service packs, and generally tweak their software. Operating systems are a great example, as they endure constant change.
Modern DevOps has solved the dynamic equilibrium problem locally by replacing snowflakes with immutable infrastructure. Snowflake infrastructure represents assets manually crafted by an operations person, and all future maintenance is done by hand. Chad Fowler coined the term immutable infrastructure in his blog post, “Trash Your Servers and Burn Your Code: Immutable Infrastructure and Disposable Components”. Immutable infastructure refers to systems defined entirely programmatically. All changes to the system must occur via the source code, not by modifying the running operating system. Thus, the entire system is immutable from an operational standpoint—once the system is bootstrapped, no other changes occur.
While immutability may sound like the opposite of evolvability, quite the opposite is true. Software systems are composed of thousands of moving parts, all interlocking in tight dependencies. Unfortunately, developers still struggle with unanticipated side effects of changes to one of those parts. By locking down the possibility of unanticipated change, we control more of the factors that make systems fragile. Developers strive to replace variables in code with constants to reduce vectors of change. DevOps introduced this concept to operations, making it more declarative.
Immutable infrastructure follows our advice to remove needless variables. Building software systems that evolve means controlling as many unknown factors as possible. It is virtually impossible to build fitness functions that can anticipate how the latest service pack of the operating system might affect the application. Instead, developers build the infrastructure anew each time the deployment pipeline executes, catching breaking changes as aggressively as possible. If developers can remove known foundational, changeable parts such as the operating system as a possibility, they have less ongoing testing burden to carry.
Architects can find all sorts of avenues to convert changeable things to constants. Many teams extend the immutable infrastructure advice to the development environment as well. How many times has some team member exclaimed, “But it works on my machine!”? By ensuring every developer has the exact same image, a host of needless variables disappear. For example, most development teams automate the update of development libraries through repositories, but what about updates to tools like IDEs? By capturing the development environment as immutable infrastructure, developers always work on the same foundation.
Building an immutable development environment also allows useful tools to spread throughout projects. Pair programming is a common practice in many agile engineering–focused development teams, including pair rotation, where each team member changes regularly, from every few hours to every few days. However, it’s frustrating when a tool appears on the computer a developer used yesterday that isn’t present today. Building a single source for developer systems makes it easy to add useful tools to all systems at once.
Make Decisions Reversible
Inevitably, systems that aggressively evolve will fail in unanticipated ways. When these failures occur, developers need to craft new fitness functions to prevent future occurrences. But how do you recover from a failure?
Many DevOps practices exist to allow reversible decisions—decisions that need to be undone. For example blue/green deployments, where operations have two identical (probably virtual) ecosystems—blue ones and green ones—are common in DevOps. If the current production system is running on blue, green is the staging area for the next release. When the green release is ready, it becomes the production system and blue temporarily shifts to backup status. If something goes awry with green, operations can go back to blue without too much pain. If green is fine, blue becomes the staging area for the next release.
Feature toggles are another common way developers make decisions reversible. By deploying changes underneath feature toggles, developers can release them to a small subset of users (called canary releasing) to vet the change. If a feature behaves unexpectedly, developers can switch the toggle back to the original and correct the fault before trying again. Make sure you remove the outdated ones!
Using feature toggles greatly reduces risk in these scenarios. Service routing—routing to a particular instance of a service based on request context—is another common method to canary-release in microservices ecosystems.
Prefer Evolvable over Predictable
…because as we know, there are known knowns; there are things we know we know. We also know there are known unknowns; that is to say we know there are some things we do not know. But there are also unknown unknowns—the ones we don’t know we don’t know.
Donald Rumsfeld, former US Secretary of Defense
Unknown unknowns are the nemesis of software systems. Many projects start with a list of known unknowns: things developers know they must learn about the domain and technology. However, projects also fall victim to unknown unknowns: things no one knew were going to crop up yet have appeared unexpectedly. This is why all Big Design Up Front software efforts suffer—architects cannot design for unknown unknowns.
All architectures become iterative because of unknown unknowns; agile just recognizes this and does it sooner.
Mark Richards
While no architecture can survive the unknown, we know that dynamic equilibrium renders predictability useless in software. Instead, we prefer to build evolvability into software: if projects can easily incorporate changes, architects don’t need a crystal ball. Architecture is not a solely up-front activity—projects constantly change in both explicit and unexpected ways throughout their life. One safeguard commonly used by developers to insulate themselves from change is an anticorruption layer.
Build Anticorruption Layers
Projects often need to couple themselves to libraries that provide incidental plumbing: message queues, search engines, and so on. The Abstraction Distraction antipattern describes the scenario where a project “wires” itself too much to an external library, either commercial or open source. Once it becomes time for developers to upgrade or switch the library, much of the application code utilizing the library has baked-in assumptions based on the previous library abstractions. Domain-driven design includes a safeguard against this phenomenon called an anticorruption layer. Here is an example.
Agile architects prize the last responsible moment principle when making decisions, which is used to counter the common hazard in projects of buying complexity too early. We worked intermittently on a Ruby on Rails project for a client who managed wholesale car sales. After the application went live, an unexpected workflow arose. It turned out that used-car dealers tended to upload new cars to the auction site in large batches, both in number of cars and number of pictures per car. We realized that, as much as the general public doesn’t trust used-car dealers, dealers really don’t trust one another; thus, each car must include a photo covering essentially every molecule of the car. Users wanted a way to begin an upload, then either get progress via some UI mechanism like a progress bar, or check back later to see if the batch was done. Translated to technical terms, they wanted asynchronous upload.
A message queue is one traditional architectural solution to this problem, and the team discussed whether to add an open source queue to the architecture. A common trap at this juncture for many projects is the attitude of “We know we’ll need a message queue for lots of stuff eventually, so let’s get the fanciest one we can now and grow into it later.” The problem with this approach is technical debt: stuff that’s part of your project that isn’t supposed to be there and is in the way of stuff that is supposed to be there. Most developers treat crufty old code as the only form of technical debt, but projects can inadvertently buy technical debt as well via premature complexity.
For the project, the architect encouraged developers to find a simpler way. One developer discovered BackgrounDRb, an extraordinarily simple open source library that simulates a single message queue backed by a relational database. The architect knew this simple tool would probably never scale to other future problems, but she didn’t have other objections. Rather than try to predict future usage, she instead made it relatively easy to replace by placing it behind an API. In the last responsible moment, answer questions such as “Do I have to make this decision now?”, “Is there a way to safely defer this decision without slowing any work?”, and “What can I put in place now that will suffice but I can easily change later if needed?”
Around the one-year anniversary, a second request for asynchronicity appeared in the form of timed events around sales. The architect evaluated the situation and decided that a second instance of BackgrounDRb would suffice, put it in place, and moved on. At around the two-year anniversary, a third request appeared for constantly updating values like caches and summaries. The team realized that the current solution couldn’t handle the new workload. However, they now had a good idea about what kind of asynchronous behavior the application needed. At that point, the project switched over to Starling, a simple but more traditional message queue. Because the original solution was isolated behind an interface, it took one pair of developers less than one iteration (one week on that project) to complete the transition—without disrupting other developers’ work on the project.
Because the architect put an anticorruption layer in place with an interface, replacing one piece of functionality became a mechanical exercise. Building an anticorruption layer encourages the architect to think about the semantics of what they need from the library, not the syntax of the particular API. But this is not an excuse to abstract all the things! Some development communities love preemptive layers of abstraction to a distracting degree, but understanding suffers when you must call a Factory to get a proxy to a remote interface to a Thing. Fortunately, most modern languages and IDEs allow developers to be just in time when extracting interfaces. If a project finds itself bound to an out-of-date library in need of change, the IDE can extract an interface on behalf of the developer, making a Just In Time (JIT) anticorruption layer.
Tip
Build Just In Time anticorruption layers to insulate against library changes.
Controlling the coupling points in an application, especially to external resources, is one of an architect’s key responsibilities. Try to find the pragmatic time to add dependencies. As an architect, remember that dependencies provide benefits but also impose constraints. Make sure the benefits outweigh the cost in updates, dependency management, and so on.
Developers understand the benefits of everything and the trade-offs of nothing!
Rich Hickey, creator of Clojure
Architects must understand both benefits and trade-offs and build engineering practices accordingly.
Using anticorruption layers encourages evolvability. While architects can’t predict the future, we can at least lower the cost of change so that it doesn’t impact us so negatively.
Build Sacrificial Architectures
In his book Mythical Man Month, Fred Brooks says to “Plan to Throw One Away” when building a new software system.
The management question, therefore, is not whether to build a pilot system and throw it away. You will do that. […] Hence plan to throw one away; you will, anyhow.
Fred Brooks
His point was that once a team has built a system, they know all the unknown unknowns and proper architecture decisions that are never clear from the outset—the next version will profit from all those lessons. At an architectural level, developers struggle to anticipate radically changing requirements and characteristics. One way to learn enough to choose a correct architecture is to build a proof of concept. Martin Fowler defines a sacrificial architecture as an architecture designed to be thrown away if the concept proves successful. For example, eBay started as a set of Perl scripts in 1995, migrated to C++ in 1997, and then to Java in 2002. Obviously, eBay has been a resounding success in spite of rearchitecting the system several times. Twitter is another good example of successful utilization of this approach. When Twitter released, it was written in Ruby on Rails to achieve fast time to market. However, as Twitter became popular, the platform couldn’t support the scale, resulting in frequent crashes and limited availability. Many early users became all too familiar with Twitter’s failure beacon, shown in Figure 7-9.

Figure 7-9. Twitter’s famous Fail Whale
Thus, Twitter restructured its architecture to replace the backend with something more robust. However, it could be argued that this tactic is the reason the company survived. If the Twitter engineers had built the final, robust platform from the beginning, it would have delayed their entry into the market long enough for Snitter or some alternative short-form messaging service to beat them to market. Despite the growing pains, starting with a sacrificial architecture eventually paid off.
Cloud environments make sacrificial architecture more attractive. If developers have a project they want to test, building the initial version in the cloud greatly reduces the resources required to release the software. If the project is successful, architects can take the time to build a more suitable architecture. If developers are careful about anticorruption layers and other evolutionary architecture practices, they can mitigate some of the pains of the migration.
Many companies build a sacrificial architecture to achieve a minimum viable product to prove a market exists. While this is a good strategy, the team must eventually allocate time and resources to build a more robust architecture, hopefully less visibly than Twitter.
One other aspect of technical debt impacts many initially successful projects, elucidated again by Fred Brooks, when he refers to the second system syndrome—the tendency of small, elegant, and successful systems to evolve into giant, feature-laden monstrosities due to inflated expectations. Business people hate to throw away functioning code, so architecture tends toward always adding, never removing, or decommissioning.
Technical debt works effectively as a metaphor because it resonates with project experience and represents faults in design, regardless of the driving forces behind them. Technical debt aggravates inappropriate coupling on projects—poor design frequently manifests as pathological coupling and other antipatterns that make restructuring code difficult. As developers restructure architecture, their first step should be to remove the historical design compromises that manifest as technical debt.
Mitigate External Change
A common feature of every development platform is external dependencies: tools, frameworks, libraries, and other assets provided by and (more importantly) updated via the internet. Software development sits on a towering stack of abstractions, each built on the abstractions before. For example, operating systems are an external dependency outside the developer’s control. Unless companies want to write their own operating system and all other supporting code, they must rely on external dependencies.
Most projects rely on a dizzying array of third-party components, applied via build tools. Developers like dependencies because they provide benefits, but many developers ignore the fact that they come with a cost as well. When relying on code from a third party, developers must create their own safeguards against unexpected occurrences: breaking changes, unannounced removal, and so on. Managing these external parts of projects is critical to creating evolutionary architecture.
In “Go To Statement Considered Harmful,” Edsger Dijkstra’s March 1968 letter to the Editor of Communications of the ACM, the legendary figure in computer science famously punctured the existing best practice of unstructured coding, leading eventually to the structured programming revolution. Since that time, “considered harmful” has become a trope in software development.
Transitive dependency management is our “considered harmful” moment.
Chris Ford (no relation to Neal)
Chris’s point is that, until we recognize the severity of the problem, we cannot determine a solution. While we’re not offering a solution to the problem, we need to highlight it because it critically affects evolutionary architecture. Stability is one of the foundations of both Continuous Delivery and evolutionary architecture. Developers cannot build repeatable engineering practices atop uncertainty. Allowing third parties to make changes to core dependencies defies this principle.
We recommend that developers take a more proactive approach to dependency management. A good start on dependency management models external dependencies using a pull model. For example, set up an internal version-control repository to act as a third-party component store, and treat changes from the outside world as pull requests to that repository. If a beneficial change occurs, allow it into the ecosystem. However, if a core dependency disappears suddenly, reject that pull request as a destabilizing force.
Using a Continuous Delivery mindset, the third-party component repository utilizes its own deployment pipeline. When an update occurs, the deployment pipeline incorporates the change, then performs a build and smoke test on the affected applications. If successful, the change is allowed into the ecosystem. Thus, third-party dependencies use the same engineering practices and mechanisms of internal development, usefully blurring the lines across this often unimportant distinction between in-house written code and dependencies from third parties—at the end of the day, it’s all code in a project.
Updating Libraries Versus Frameworks
Architects make a common distinction between libraries and frameworks, with the colloquial definition of “a developer’s code calls a library whereas the framework calls a developer’s code.” Generally, developers subclass from frameworks (which in turn call those derived classes), thus the distinction that the framework calls code. Conversely, library code generally comes as a collection of related classes and/or functions developers call as needed. Because the framework calls the developer’s code, it creates a high degree of coupling to the framework. Contrast that with library code, which is generally more utilitarian code (like XML parsers, network libraries, etc.) and has a lower degree of coupling.
We prefer libraries because they introduce less coupling to your application, making them easier to swap out when the technical architecture needs to evolve.
Tip
Prefer libraries over frameworks where possible.
One reason to treat libraries and frameworks differently comes down to engineering practices. Frameworks include capabilities such as UI, object-relational mapper, scaffolding like model-view-controller, and so on. Because the framework forms the scaffolding for the remainder of the application, all the code in the application is subject to impact by changes to the framework. Many of us have felt this pain viscerally—any time a team allows a fundamental framework to become outdated by more than two major versions, the effort (and pain) to finally update it is excruciating.
Because frameworks are a fundamental part of applications, teams must be aggressive about pursuing updates. Libraries generally form less brittle coupling points than frameworks do, allowing teams to be more casual about upgrades. One informal governance model treats framework updates as push updates and library updates as pull updates. When a fundamental framework (one whose afferent/efferent coupling numbers are above a certain threshold) updates, teams should apply the update as soon as the new version is stable and they can allocate time for the change. Even though it will take time and effort, the time spent early is a fraction of the cost if the team perpetually procrastinates on the update.
Because most libraries provide utilitarian functionality, teams can afford to update them only when new desired functionality appears, using more of an “update when needed” model.
Tip
Update framework dependencies aggressively; update libraries passively.
Version Services Internally
In any integration architecture, developers inevitably must version service endpoints as the behavior evolves. Developers use two common patterns to version endpoints, Version Numbering or Internal Resolution. For version numbering, developers create a new endpoint name, often including the version number, when a breaking change occurs. This allows older integration points to call the legacy version while newer ones call the newer version. The alternative is internal resolution, where callers never change the endpoint—instead, developers build logic into the endpoint to determine the context of the caller, returning the correct version. The advantage of retaining the name forever is less coupling to specific version numbers in calling applications.
In either case, severely limit the number of supported versions. The more versions there are, the more testing and other engineering burdens there will be. Strive to support only two versions at a time, and only temporarily.
Case Study: Evolving PenultimateWidgets’ Ratings
PenultimateWidgets has a microservices architecture so the developers can make small changes. Let’s look more closely at the details of one of those changes, switching star ratings, as outlined in Chapter 3. Currently, PenultimateWidgets has a star rating service, whose parts are shown in Figure 7-10.
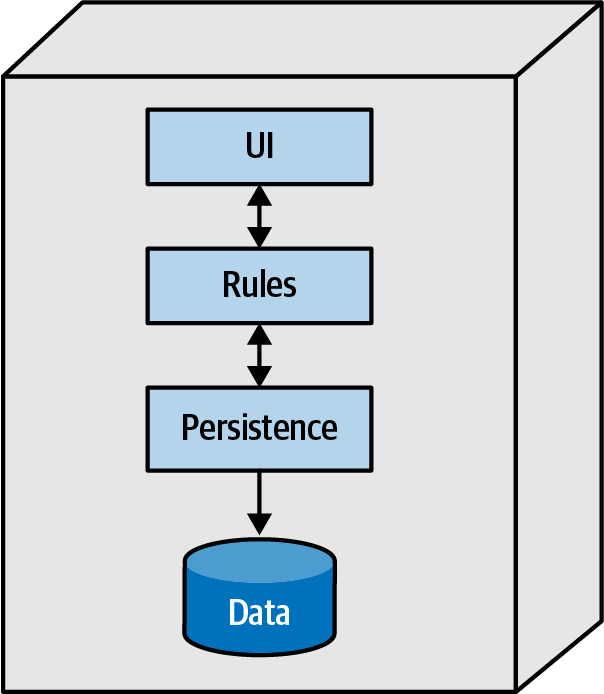
Figure 7-10. The internals of PenultimateWidgets’ StarRating service
As shown in Figure 7-10, the star rating service consists of a database and a layered architecture, with persistence, business rules, and a UI. Not all of PenultimateWidgets’ microservices include the UI. Some services are primarily informational, whereas others have UIs tightly coupled to the service’s behavior, as is the case with star ratings. The database is a traditional relational database that includes a column to track ratings for a particular item ID.
When the team decided to update the service to support half-star ratings, they modified the original service as shown in Figure 7-11.

Figure 7-11. The transitional phase, where StarRating supports both types
In Figure 7-11, they added a new column to the database to handle the additional data—whether a rating has an additional half-star. The architects also added a proxy component to the service to resolve the return differences at the service boundary. Rather than force calling services to “understand” the version numbers of this service, the star rating service resolves the request type, sending back whichever format is requested. This is an example of using routing as an evolutionary mechanism. The star rating service can exist in this state as long as some services still want star ratings.
Once the last dependent service has evolved away from whole-star ratings, developers can remove the old code path, as shown in Figure 7-12.
Developers can remove the old code path and perhaps remove the proxy layer to handle version differences (or perhaps leave it to support future evolution).

Figure 7-12. The ending state of StarRating, supporting only the new type of rating
In this case, PenultimateWidgets’ change wasn’t difficult from a data evolution standpoint because the developers were able to make an additive change, meaning they can add to the database schema rather than change it. What about the case where the database must change as well because of a new feature? Refer to the discussion on evolutionary data design in Chapter 6.
Fitness Function-Driven Architecture
A common practice in agile software development is test-driven development, where developers write unit tests before writing the corresponding functionality. A similar process can be used in architecture, particularly when the success of the application depends on meeting some stringent capabilities. Building a fitness function that governs that capability to help drive design ensures that it stays top of mind as the architect designs other parts.
The creators of the LMAX architecture famously utilized this approach. Because of changes to laws governing markets in a particular country, regular citizens could participate in the market online (buying and selling) without needing a special license. However, for this application to be successful, they had to be able to manage millions of transactions per second. For various reasons, the technology platform of choice was Java, which wasn’t known for scale at this level by default. Thus, the first thing they built was a fitness function that measured transaction speed, and they started experimenting with designs to achieve this high goal. They started with threads but couldn’t get even close to the desired goal. Next, they tried various implementations of the actor model but also couldn’t get near their goal. In measuring every part of the system, they realized that the business logic they were running was a tiny percentage of computation time—everything else was a context switch.
Armed with this knowledge, they designed an architecture approach known as input and output disruptors, which used a single thread and ring buffers to eventually achieve over six million transactions per second on a single thread. The architecture is described in detail at https://martinfowler.com/articles/lmax.html (and many parts are open source).
During this process, the team popularized the term mechanical sympathy in relation to hardware and software, based on one of the architects being a fan of Formula One racing. In that sport, commentators note that really great drivers have “mechanical sympathy” for their car—they understand how each part works and can “feel” when things are good or bad. In software, mechanical sympathy refers to understanding the layers underneath abstractions to fully understand what drives each piece of, for example, performance. When a request/response sequence occurs, exactly what takes time during that call, all the way down to the network layer, and how might a team optimize it?
Mechanical sympathy requires fitness functions both to define aspirational goals and to govern those strict requirements as changes occur. Once the LMAX team achieved their initial goal, they left the fitness functions in place as they built out the remainder of the solution, changing directions several time as approaches came into conflict with their fitness functions.
A number of software development teams have started adopting this approach of Fitness Function–Driven Architecture, particularly in situations like the above where meeting some aspirational architecture characteristic’s goal determines success. Just as in test-driven development, fitness function–driven architecture ensures that changes don’t impact success criteria.
Summary
Like all things in software architecture, the aspects of evolutionary architecture cannot be separated—fitness function and structure collaborate to help architects build evolvability.
It took many years for practices such as continuous integration and test-driven development to become standard parts of software engineering practices. Many architects use pieces of evolutionary architecture with monitors, ad hoc metrics, and other occasionally applied verifications but still use outdated governance such as architecture review boards, code reviews, and other proven ineffective practices.
Architects who want to build systems that can survive many changes in both domain and technology can build fitness functions and control coupling via contracts to build systems that provide high degrees of feedback about important things. As a few of the thousand things that make up our software change, architects need confidence that everything still works correctly, provided by the practices of evolutionary architecture.