
This chapter examines the use of Azure Data Factory and Azure Data Lake, including where, why, and how these technologies fit in the capabilities of a modern business running at Internet speed. It first covers the basic technical aspects and capabilities of Azure Data Factory and Azure Data Lake. Following that, the chapter implements three major pieces of functionality for the reference implementation:
Update reference data that we used for the Azure Stream Analytics job. As you may recall, we used the reference data in an ASA SQL JOIN query for gathering extended team member health data.
Re-train the Azure Machine Learning Model for predicting team member health and exhaustion levels. This data will be based on updated medical stress tests that are administered to team members on a periodic basis.
Move data from Azure blob storage to Azure Data Lake. This step prepares the reference implementation Data Lake analytics, which is the topic of Chapter 7.
Azure Data Factory Overview
Azure Data Factory fulfills a critical need in any modern Big Data processing environment. It can be seen as the backbone of any data operation, as Data Factory provides the critical core capabilities required to perform enterprise data transformation functions . This includes:
Data Ingestion and Preparation: From multiple sources; any combination of on-premise and cloud-based data sources.
Transformation and Analysis: Schedule, orchestrate, and manage the data transformation and analysis processes.
Publish and Consumption: Ability to transform raw data into finished data that is ready for consumption by BI tools or mobile applications.
Monitoring and Management: Visualize, monitor, and manage data movement and processing pipelines to quickly identify issues and take intelligent action. Alert capabilities to monitor overall data processing service health.
Efficient Resource Management: Saves you time and money by automating data transformation pipelines with on-demand cloud resources and management.
Azure Data Factory is a cloud-based data integration service that orchestrates and automates the movement and transformation of data. You can create data integration solutions using Azure Data Factory that can ingest data from various data stores (handles both on-premise and cloud-based), transform and process the data, and then publish the processing results to various output data stores.
The Azure Data Factory service is a fully managed cloud-based service that allows you to create data processing “pipelines” that can move and transform data. Data Factory has the capability to perform highly advanced and customizable ETL (Extract-Transform-Load ) functions on the data as it moves through the various stages in a processing pipeline.
These data processing “pipelines” can then be run either on a specified schedule (such as hourly, daily, weekly, etc.) or on-demand to provide a rich batch processing capability for data movement and analytics at enterprise scale.
Azure Data Factory also provides rich visualizations to display the history, versions, and dependencies between your data pipelines, as well as monitor all your data pipelines from a single unified view. This allows you to easily detect and pinpoint any processing issues and set up appropriate monitoring alerts.
Figure 6-1 provides an illustration of the various data processing operations performed by Azure Data Factory, such as data ingestion, preparation, transformation, analysis, and finally publication. This data can be easily consumed by the key users of the data.
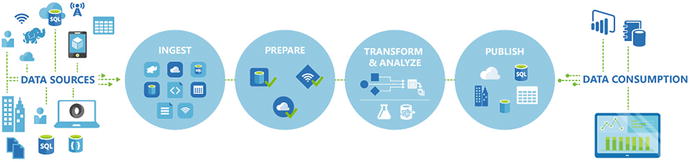
Figure 6-1. Azure Data Factory can ingest data from various data sources
Pipelines and Activities
In a normal Azure Data Factory solution, one or more data processing pipelines are typically utilized. A Data Factory pipeline is a logical grouping of activities. It’s used to group activities into a unit that together performs a single task.
Activities
Azure Data Factory activities define the actions to perform on your data. For example, you may use a copy activity to copy data from one data store to another. Similarly, you may use a hive activity, which runs a hive query on an Azure HDInsight cluster to transform or analyze your data. Data Factory supports two types of activities:
Data Movement Activities: This includes the copy activity, which copies data from a source data store to a sink data store. Data Factory supports the following data stores:
Azure:
Azure blob storage
Azure Data Lake Store
Azure SQL database
Azure SQL data warehouse
Azure table storage
Azure DocumentDB
Azure Search Index
Databases :
SQL Server*
Oracle*
MySQL*
DB2*
Teradata*
PostgreSQL*
Sybase*
Cassandra*
MongoDB*
Amazon Redshift
File Systems:
File System*
HDFS*
Amazon S3
FTP
Other Systems:
Salesforce
Generic ODBC*
Generic OData
Web Table (table from HTML)
GE Historian*
Note: Data stores denoted with a * can exist either on-premises or on an Azure Virtual Machine (IaaS). This option requires that you install the Data Management Gateway on either an on-premises or Azure Virtual Machine.
Note See the following link for more information on the Data Management Gateway.
Move data between on-premises sources and the cloud with Data Management Gateway: https://docs.microsoft.com/en-us/azure/data-factory/data-factory-move-data-between-onprem-and-cloud .
Data Transformation Activities: Azure Data Factory supports the following transformation activities that either can be added to pipelines individually or chained together with another activity.
Data Transformation Activity Environment | Compute Environment |
Hive | HDInsight [Hadoop] |
Pig | HDInsight [Hadoop] |
MapReduce | HDInsight [Hadoop] |
Hadoop Streaming | HDInsight [Hadoop] |
Machine Learning activities | Azure VM |
Stored Procedure | Azure SQL, Azure SQL Data Warehouse, or SQL Server in VM |
Data Lake Analytics U-SQL | Azure Data Lake Analytics |
Dot Net | HDInsight [Hadoop] or Azure Batch |
If you need to move data to or from a data store that the Azure Data Factory Copy Activity doesn’t support, or you need to transform data using custom logic, you can always create a custom .NET activity.
Note
For details on creating and using a custom activity, see the “Use custom activities in an Azure Data Factory pipeline” link at https://docs.microsoft.com/en-us/azure/data-factory/data-factory-use-custom-activities .
Linked Services
Linked services define the information needed for Azure Data Factory to connect to external data resources (for example: on-premises SQL Server, Azure Storage, and HDInsight running in Azure). Linked services are used for two primary purposes in Azure Data Factory:
To represent a data store: Such as an on-premise SQL Server, Oracle database, file share, or an Azure blob storage account.
To represent a compute resource: One that can host the execution of an activity. As an example, the HDInsight hive activity runs on an HDInsight Hadoop cluster and can be used to perform data transformations.
Datasets
In the larger scheme of things, linked services link the data stores to an Azure Data Factory job. Datasets represent data structures within those data stores.
As an example, an “Azure SQL linked service” might provide connection information for an Azure SQL database. An Azure SQL dataset would then specify the specific table that would contain the data for Azure Data Factory to process.
Additionally, an “Azure storage linked service” would provide connection information for Azure Data Factory to be able to connect to an Azure Storage account. From there, an Azure blob dataset would specify the container for the blob and the folder in the Azure Storage account from which the pipeline should read the incoming data.
Pipelines
An Azure Data Factory pipeline is a grouping of logically related activities. A pipeline is used to group activities into a logical unit that performs a task.
Activities define the specific actions to perform on the data. Each pipeline activity can take zero or more datasets as an input and can produce one or more datasets as output.
For example, a copy activity can be used to copy data from one Azure data store to another data store. Alternatively, one could use an HDInsight hive activity to run a hive query on an Azure HDInsight cluster in order to transform the data stream.
Azure Data Factory provides a wide range of data ingestion, movement, and transformation activities. Developers also have the freedom to choose to create a custom .NET activity to run their own custom code in an Azure Data Factory pipeline.
Scheduling and Execution
At this point, we have examined what Data Factory pipelines and activities are and how they are composed to create holistic data processing work streams in Azure Data Factory. We will now examine the scheduling and execution engine in Azure Data Factory.
It is important to note that an Azure Data Factory pipeline is active only between its start time and end time. Consequently, it is not executed before the start time or after the end time. If the pipeline is in the “paused” state, it will not get executed at all, no matter how the start and end times are set.
Note that it is not the pipeline that gets actually gets executed. Rather, it is the set of activities within the Data Factory pipeline that actually get executed. However, they do so in the overall context of the Data Factory pipeline.
The Azure Data Factory service allows you to create data pipelines that move and transform data, and then run those pipelines on a specified operational schedule (hourly, daily, weekly, etc.).
Data Factory also provides rich visualizations to display the history, version, and dependencies between data pipelines, and allows you to monitor all your data pipelines from a single unified view. This provides an easy management tool to help pinpoint issues and set up monitoring alerts.
Pipeline Copy Activity End-to-End Scenario
In this section, we examine a complete end-to-end example of creating an Azure Data Factory pipeline to copy data from Azure blob storage to an Azure SQL database. Along the way, we emphasize the major features and capabilities that you can exploit to make the most out of Azure Data Factory for your requirements.
Note
See this link for detailed steps to accomplish this Data Factory scenario :
Copy data from blob storage to SQL database using Data Factory: https://docs.microsoft.com/en-us/azure/data-factory/data-factory-copy-data-from-azure-blob-storage-to-sql-database
Scenario Prerequisites
Before you can create an Azure Data Factory pipeline or activities, you need the following:
Azure Subscription : If you don’t already have a subscription, you can start for free at https://azure.microsoft.com/en-us/free/?b=16.46 .
Azure Storage Account: You use the blob storage as a “source” data store in this scenario.
Azure SQL Database : You use an Azure SQL database as a destination data store in this tutorial.
SQL Server Management Studio or Visual Studio : You use these tools to create a sample database and destination table, and to view the resultant data in the database table.
JSON Definition
If you have walked through the Azure Data Factory link to “Copy Data from Blob Storage to SQL Database Using Data Factory,” you may have noticed that there are a variety of tools that you can use to define an Azure Data Factory pipeline or activity:
Copy Wizard
Azure Portal
Visual Studio
PowerShell
Azure Resource Manager template
ReST API
.NET API
No matter what the tool is used to create the initial Azure Data Factory job, ultimately, Azure Data Factory utilizes JavaScript Object Notation (JSON) to define and persist the definitions that you create via the tools.
JSON is a lightweight data-interchange format that makes it easy for humans to read and write as well as easy for machines to parse and generate. One distinct advantage of this approach is that the specific JSON configuration parameters can be finely tweaked and tuned for the scenario at hand in order to provide complete control over the configuration and run options for the Data Factory job.
To get started, navigate (via the Azure Portal) to your Azure Data Factory job created in the link and click on the Author and Deploy option, as shown in Figure 6-2.

Figure 6-2. Azure Portal Data Factory: Author and Deploy options
Once you have clicked on the Author and Deploy option, you will see a screen similar to the one in Figure 6-3, where you can navigate thru each step of a Data Factory pipeline job that was created and see the corresponding JSON for each step of the process.
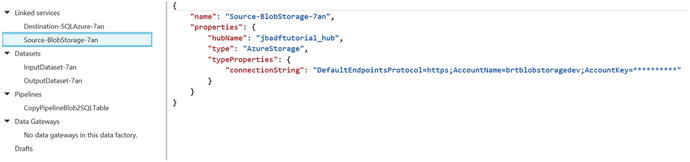
Figure 6-3. Data Factory: Author and Deploy JSON options
Let’s take a look at the JSON that was generated for the sample Copy Activity workflow for the Copy link. The starting point is to define the incoming and outgoing data sources for the job. In this case, we are using Azure blob storage for the input in the form of a file named EmpData.txt, which is a comma-separated value (CSV) formatted input file.
Note the two JSON code segments in Listing 6-1 that describe the Azure blob storage connection and the corresponding dataset definition for the input source .
Listing 6-1. JSON Description of INPUT Data Source for Copy Activity Definition
JSON - BLOB Storage Input Definition{"name": "Source-BlobStorage-7an","properties": {"hubName": "jbadftutorial_hub","type": "AzureStorage","typeProperties": {"connectionString": "DefaultEndpointsProtocol=https;AccountName=brtblobstoragedev;AccountKey=**********"}}}JSON - Data Definition:{"name": "InputDataset-7an","properties": {"structure": [{"name": "Column0","type": "String"},{"name": "Column1","type": "String"}],"published": false,"type": "AzureBlob","linkedServiceName": "Source-BlobStorage-7an","typeProperties": {"fileName": "EmpData.txt","folderPath": "adftutorial","format": {"type": "TextFormat","columnDelimiter": ","}},"availability": {"frequency": "Day","interval": 1},"external": true,"policy": {}}}
Note in the two JSON code segments that these two definitions completely describe the data input source even down to the field definitions within the CSV text file in Azure blob storage. This interface in the Azure Portal also allows you to easily override the standard parameters by simply editing the JSON directly.
Listing 6-2 shows sample JSON output for a Data Factory Copy Operation.
Listing 6-2. Data Factory Copy Operation JSON Parameters
Data Factory - JSON Copy Pipeline Operations{"name": "CopyPipelineBlob2SQLTable","properties": {"description": "CopyPipelineBlob2SQLTable","activities": [{"type": "Copy","typeProperties": {"source": {"type": "BlobSource","recursive": false},"sink": {"type": "SqlSink","writeBatchSize": 0,"writeBatchTimeout": "00:00:00"},"translator": {"type": "TabularTranslator","columnMappings": "Column0:FirstName,Column1:LastName"}},"inputs": [{"name": "InputDataset-7an"}],"outputs": [{"name": "OutputDataset-7an"}],"policy": {"timeout": "1.00:00:00","concurrency": 1,"executionPriorityOrder": "NewestFirst","style": "StartOfInterval","retry": 3,"longRetry": 0,"longRetryInterval": "00:00:00"},"scheduler": {"frequency": "Day","interval": 1},"name": "Blobpathadftutorial->dbo_emp"}],"start": "2016-11-22T15:06:22.806Z","end": "2099-12-31T05:00:00Z","isPaused": false,"hubName": "jbadftutorial_hub","pipelineMode": "Scheduled"}}
The JSON definition in Listing 6-2 allows you to have full control over the parameters, the mapping between the CSV file and the SQL table, and run behavior of this pipeline Copy job.
Additionally, note that within the scheduler section of the activity JSON code sample, you can specify a recurring schedule for a pipeline activity. For example, you can schedule a Data Factory pipeline copy activity to run every hour by modifying the JSON as follows:
JSON Code Fragment - Scheduler"scheduler": {"frequency": "Hour","interval": 1},
Note
See the following link for a complete overview of the JSON options for a Data Factory pipeline Copy operation:
Move data to and from Azure blob using Azure Data Factory: https://docs.microsoft.com/en-us/azure/data-factory/data-factory-azure-blob-connector#azure-storage-linked-service .
As can be seen from the composable architecture that the JSON definitions provided, Azure Data Factory is an extremely powerful and flexible tool to help manage all the critical aspects of managing Big Data in the cloud. Aspects such as data ingestion (either on-premise or in Azure), preparation, transformation, movement, and scheduling are all required features for running an enterprise-grade data management platform.
Monitoring and Managing Data Factory Pipelines
The Azure Data Factory service provides a rich monitoring dashboard capability that helps to perform the following tasks:
Assess pipeline health data from end-to-end
Identify and fix any pipeline processing issues
Track the history and ancestry of your data
View relationships between data sources
View full historical accounting of job execution, system health, and job dependencies
You can easily monitor the state of an Azure Data Factory pipeline job by navigating to your Data Factory job in the Azure Portal and then clicking on the Diagram option, as shown in Figure 6-4.
Figure 6-4. Azure Portal: Data Factory job, diagram view
Next, you will see a visual diagram of your Data Factory pipeline job, as shown in Figure 6-5. By clicking on either one of the Input or Output definitions, you can see the history and status of each “slice” of data that was created, along with what is scheduled to occur next.
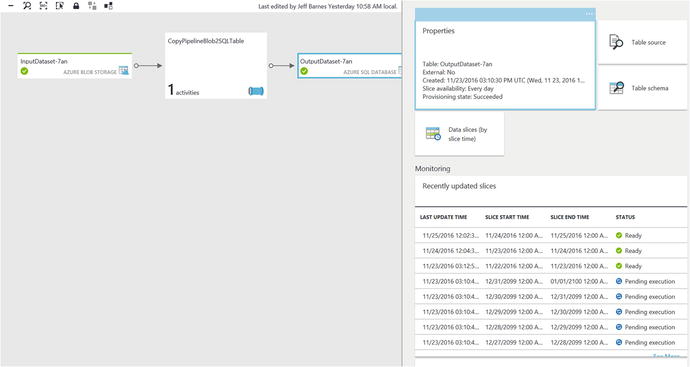
Figure 6-5. Monitoring an Azure Data Factory job by viewing the output segment history
Note that the status for each pipeline activity in Azure Data Factory can cycle among many potential execution states, as follows:
Skip
Waiting
In-Progress
In-Progress (Validating)
Ready
Failed
Figure 6-6 represents the various states of execution that can occur when an Azure Data Factory pipeline job is active.
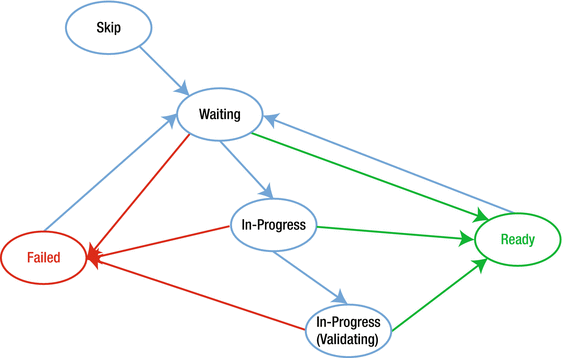
Figure 6-6. Data Factory pipeline job state transition flow
Azure Data Factory “slices” are the intervals in which the pipeline job is executed within the period defined in the start and end properties of the pipeline. For example, if you set the start time and end time to occur in a single day, and you set the frequency to be one hour, then the activity will be executed 24 times. In this case, you will have 24 slices, all using the same data source.
Normally, in Azure Data Factory , the data slices start in a Waiting state for pre-conditions to be met before executing. Then, the activity starts executing and the slice goes into the In-Progress state. The activity execution may succeed or fail. The slice is marked as Ready or Failed based on the result of the execution.
You can reset the slice to go back from Ready or Failed state to a Waiting state. You can also mark the slice state to Skip, which prevents the activity from executing and will not process the slice.
Note
See this link for more information: “Monitor and Manage Azure Data Factory Pipelines”: https://docs.microsoft.com/en-us/azure/data-factory/data-factory-monitor-manage-pipelines .
Data Factory Activity and Performance Tuning
Another key set of factors to consider when choosing a cloud data analytics processing system is performance and scalability . Azure Data Factory provides a secure, reliable, and high-performance, data ingestion, and transformation platform that can run at massive scale. Azure Data Factory can enable enterprise scenarios where multiple terabytes of data are moved and transformed across a rich variety of data stores, both on-premise and in Azure.
The Azure Data Factory copy activity offers a highly optimized data loading experience that is easy to install and configure. Within just a single pipeline copy activity, you can achieve load speeds similar to the following:
Load data into Azure SQL data warehouse at 1.2 GB per second.
Load data into Azure blob storage at 1.0 GB per second.
Load data into Azure Data Lake Store at 1.0 GB per second.
Parallel Copy
Azure Data Factory also has the ability to run copy activities from a source or write data to a destination in parallel operations executed in a Copy Activity run. This feature can have a dramatic impact on the throughput of a copy operation and can also reduce the time it takes to perform data transformation and movement functions.
You can use the JSON “parallel copies ” property to indicate the parallelism that you want copy activity to use. You can think of this property as the maximum number of threads in the copy activity that can read from your source or write to your sink data stores in parallel.
Listing 6-3. JSON Snippet of Pipeline Copy Activity Showing the parallelCopies Property
JSON Pipeline Copy Activity - "parallelCopies" Property"activities":[{"name": "Sample copy activity","description": "","type": "Copy","inputs": [{ "name": "InputDataset" }],"outputs": [{ "name": "OutputDataset" }],"typeProperties": {"source": {"type": "BlobSource",},"sink": {"type": "AzureDataLakeStoreSink"},"parallelCopies": 8}}]
For each copy activity run, Azure Data Factory determines the number of parallel copies to utilize to copy data from the source data store to the destination data store. The default number of parallel copies that are used is dependent on the type of data source and the data sink that is used.
Cloud Data Movement Units (DMUs)
A Cloud data Movement Unit (DMU) is a Data Factory measurement that represents the relative power (a combination of CPU, memory, and network resource allocation) of a single unit in Azure Data Factory. A DMU might be used in a cloud-to-cloud copy operation, but not in a hybrid copy from an on-premise data store.
By default, Azure Data Factory uses a cloud DMU to perform a single pipeline copy activity execution. To override the default, specify a value for the cloudDataMovementUnits property, as shown in the code segment in Listing 6-4.
Listing 6-4. Sample JSON snippet showing the cloudDataMovementUnits Property
Data Factory - JSON Property for "cloudDataMovementUnits""activities":[{"name": "Sample copy activity","description": "","type": "Copy","inputs": [{ "name": "InputDataset" }],"outputs": [{ "name": "OutputDataset" }],"typeProperties": {"source": {"type": "BlobSource",},"sink": {"type": "AzureDataLakeStoreSink"},"cloudDataMovementUnits": 4}}]
Note that you can achieve higher throughput by leveraging more data movement units (DMUs) than the default maximum DMUs, which is eight for a cloud-to-cloud copy activity run. As an example, you can copy data from Azure blob to Azure Data Lake Store at the rate of 1 gigabyte per second if you are set to use (100) DMUs. In order to request more DMUs than the default of eight for your subscription, you need to submit a support request via the Azure Portal.
Note
For more detailed information concerning performance and tuning for Azure Data Factory jobs, visit the “Copy Activity Performance and Tuning Guide” at https://docs.microsoft.com/en-us/azure/data-factory/data-factory-copy-activity-performance .
Azure Data Lake Store
Azure Data Lake Store is a hyper-scale repository and processing environment for today’s modern Big Data analytical workloads.
Azure Data Lake enables you to persist data of any size, data type, and ingestion speed, in a single location, for use in operational and data analytics research.
Hadoop Access
Azure Data Lake Store can be accessed from Hadoop and Azure HDInsight using the WebHDFS-compatible ReST APIs. The hadoop-azure-datalake module provides support for integration with the Azure Data Lake Store. The JAR file is named azure-datalake-store.jar.
Note
For Hadoop Azure Data Lake Support, visit https://hadoop.apache.org/docs/r3.0.0-alpha1/hadoop-azure-datalake/index.html .
Note that there is a distinction to be made around the meaning of the term Azure Data Lake. There are potentially two different meanings in Microsoft Azure. It is typically used to refer to a storage subsystem in Azure more commonly referred to as “Azure Data Lake Store” or “ADLS”.
The other variation of the term is “Azure Data Lake Analytics” or “ADLA,” which is an Azure-based analytics service where you can easily develop and run massively parallel data transformation and processing programs in a variety of languages such as U-SQL, R, Python, and .NET. Azure Data Lake Analytics are covered in detail in Chapter 7. For now, we will cover the basics of Azure Data Lake Store.
ADLS is specifically designed to enable analytics on the data stored in Azure Data Lake. The Data Lake storage subsystem is fine-tuned specifically for high performance for data analytics scenarios.
As a completely managed service offering from Microsoft, Azure Data Lake Store includes all the enterprise-grade capabilities one would expect from a cloud-based repository with massive scalability. The key “abilities ” provided by Azure Data Lake Store include: security, manageability, scalability, reliability, and availability. All of the characteristics are essential for real-world enterprise use cases.
With Azure Data Lake Store, you can now explore and harvest value from all your unstructured, semi-structured, and structured enterprise data by running massively parallel analytics over literally any amount of data. Azure Data Lake Store has no artificial constraints on the amount of data, number of files, or the size of individual files that can be stored. At the time of this writing, ADLS can store individual files that can be as large as petabytes in size, which is at least 200x larger than any other cloud storage service available today.
Security Layers
Azure Data Lake Store has security features that are “built-in” from the ground up. As can be seen in Figure 6-7, Azure Data Lake Store has a number of Azure security features and capabilities layered in to help provide the highest confidence in the security of the data, whether the data is at rest or in transit.
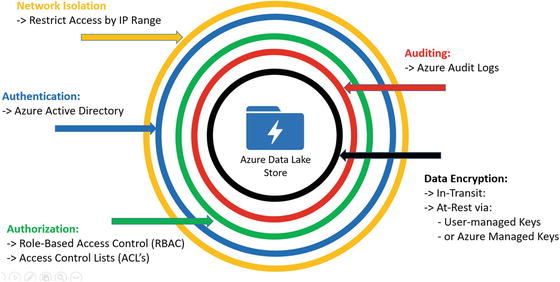
Figure 6-7. Layered security in Azure Data Lake Store
Figure 6-7 illustrates the various security layers involved in protecting your data in the Azure Data Lake Store. Here is a quick re-cap of these “built-in” security features:
Network Isolation: Azure Data Lake Store allows you to establish firewalls and define an IP address range for your trusted clients. With an IP address range, only clients that have an IP in the defined range can connect to Azure Data Lake Store.
Authentication: Azure Data Lake Store has Azure Active Directory (AAD) natively integrated to help manage users and group access and permissions. AAD also provides full lifecycle management for millions of identities, integration with on-premise Active Directory, single sign-on support, multi-factor authentication, and support for industry standard open authentication protocols such as OAuth.
Authorization: Azure Data Lake Store (ADLS) provides Role-Based Access Control (RBAC) capabilities via Access Control Lists (ACLs) for managing access to the data files in the Data Lake store. These capabilities provide fine-grained control over file access and permissions (at scale) to all data stored in an Azure Data Lake.
Auditing: Azure Data Lake Store provides rich auditing capabilities to help meet today’s modern security and regulatory compliance requirements. Auditing is turned on by default for all account management and data access activities. Audit logs from Azure Data Lake Store can be easily parsed as they are persisted in JSON format. Additionally, since the audit logs are in an easy-to-consume format such as JSON, you can you a wide variety of Business Intelligence (BI) tools to help analyze and report on ADLS activities.
Encryption: Azure Data Lake Store provides built-in encryption for both “at-rest” and “in-transit” scenarios. For data at-rest scenarios, Azure administrators can specify whether to let Azure to manage your Master Encryption Keys (MEKs) or you can use bring-your-own MEKs. In either case, the MEKs will be stored and managed securely in Azure Key Vault, which can utilize FIPS 140-2 Level 2 validated HSMs (Hardware Security Modules). For data in-transit scenarios, the Azure Data Lake Store data is always encrypted, by using the HTTPS (HTTP over Secure Sockets Layer) protocol.
Note that in Azure Data Lake Store, you can choose to have your data encrypted or have no encryption at all. If you choose encryption, all data stored in the Azure Data Lake Store is encrypted prior to persisting the data in the store. Alternately, ADLS will decrypt the data prior to retrieval by the client. From a client perspective, the encryption is transparent and seamless. Consequently, there are no code changes required on the client side to view or encrypt/decrypt the data.
ADLS Encryption Key Management
For encryption key management, Azure Data Lake Store provides two modes for managing your Master Encryption Keys (MEKs) . These keys are required for encrypting and decrypting any data that is stored in the Azure Data Lake Store.
You can either let Data Lake Store manage the master encryption keys for you or choose to retain ownership of the MEKs using your Azure Key Vault account. You can specify the mode of key management while creating a new Azure Data Lake Store account.
Tip
Get started with Azure Data Lake Analytics using the Azure Portal: https://docs.microsoft.com/en-us/azure/data-lake-analytics/data-lake-analytics-get-started-portal .
Implementing Data Factory and Data Lake Store in the Reference Implementation
Now that you have a solid background of the features and capabilities in Azure Data Factory and Azure Data Lake Store , you will put your knowledge to use by implementing a few more key pieces of the reference implementation in the remainder of this chapter. As a quick refresher, you will implement the following three pieces of functionality that are required for the reference implementation:
Update Reference data that you used for the Azure Stream Analytics job. You will use an Azure Data Factory copy job to copy team members’ profile data from Azure DocumentDB to a text-based CSV file in Azure Blob storage. As you may recall, you used this reference data in an ASA SQL JOIN query for gathering extended team member health data. We want to make sure that this reference data is updated periodically via a scheduled copy job.
Re-train the Azure Machine Learning model for predicting team member health and exhaustion levels. We implemented a function in Chapter 5 (StreamAnalytics) to call an Azure Machine Learning Web Service. We want to update the predictive model that runs behind this service using updated medical stress data from tests that are administered to team members on a periodic basis.
Move data from Azure blob storage to Azure Data Lake. This job will copy the data that originally came from the IoT Hub and was saved into Azure blob storage by the Azure Stream Analytics job in Chapter 5. We want to move this data from Azure blob Storage to Azure Data Lake Store.
Update Reference Data Input File for Azure Stream Analytics Jobs
In this section, we walk through the steps necessary to create an Azure Data Factory copy pipeline job that will copy data from an Azure DocumentDB “NoSQL” database to a text-based CSV file that is persisted in Azure blob storage.
Note that the CSV file will implement a specific file naming convention so that the Azure Stream Analytics job knows to utilize the latest version of the file for use in stream analytics jobs that require this reference data. Figure 6-8 illustrates the INPUT REFERENCE DATA parameter for the Azure Stream Analytics job that describes the file naming convention.

Figure 6-8. Stream Analytics reference data file naming convention
By utilizing this file naming convention, the reference data used as input in Azure Stream Analytics job will always reflect the most recent version of the data. Another advantage of using this approach is that future reference data updates can be easily made without adversely impacting any stream analytics jobs currently in process.
The next job that runs simply locates and ingests the latest reference data file that exists in Azure blob storage, based on the file naming convention. In this simple, but very effective, way, the stream analytics job will always use the latest version of the reference data at runtime.
Create Azure Data Factory Job
To get started, navigate to the resource group for your deployment via the Azure Portal. Click on the + Add button and search for Data Factory, as shown in Figure 6-9.
Figure 6-9. Searching and adding a Data Factory job to a resource group
After selecting Azure Data Factory, click on the next screen to create the new job, as shown in Figure 6-10.
Figure 6-10. Create Data Factory job
The next screen allows you to enter the specific parameters for creating a new Azure Data Factory job, as shown in Figure 6-11.
Figure 6-11. Data Factory create job parameters
Fill in your choices for the corresponding parameter values:
Name: Enter a unique name for your new Data Factory. Note that the name of the Azure Data Factory must be globally unique.
Subscription: The Azure subscription to use for this job.
Resource Group: The Azure Resource Group to create this service in.
Location: The Azure Data Center location.
Once you are done, click on the Create button at the bottom of the screen. Your input will then be validated and the new Azure Data Factory job will be created after a brief period of time. It should take less than one minute via the Azure Portal.
After your job has been provisioned, navigate to the new Data Factory via the Azure Portal and select the Copy Data (PREVIEW) option, as shown in Figure 6-12.
Figure 6-12. Data Factory: Copy Data Wizard
This will invoke the Azure Data Factory Copy Data Wizard to launch and will walk you through the steps necessary to create a basic copy pipeline. Behind the scenes, Azure Data Factory is generating JSON files to reflect your choices in the Copy Wizard.
Figure 6-13 depicts the first screen of the Copy Data Wizard and allows you to specify the properties for the copy job.
Figure 6-13. Data Factory Copy Data Wizard: specify properties
For this example, enter a task name of CopyReferenceData and keep the remaining defaults for the schedule, stat, and end dates. Click Next to advance to the next step.
Figure 6-14 depicts the Source Data screen, where you select Azure DocumentDB for the reference implementation scenario.
Figure 6-14. Data Factory Copy Data Wizard: specify source data store of Azure DocumentDB
After selecting Azure DocumentDB, you will then see a detailed screen similar to Figure 6-15, where you can specify the parameters for your DocumentDB instance to pull the reference data from.
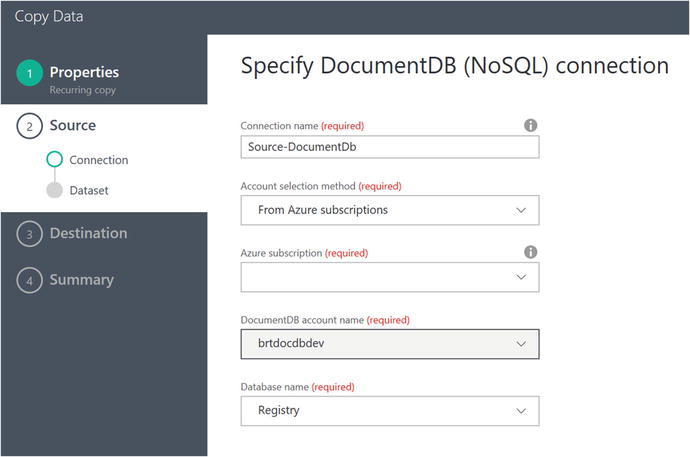
Figure 6-15. Data Factory Copy Data Wizard: specify Azure DocumentDB parameters
Click the Next button after entering the DocumentDB parameters. You will see a screen similar to Figure 6-16.
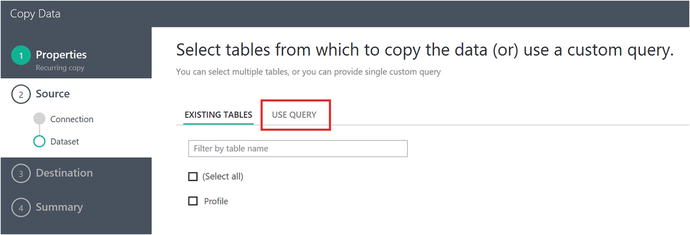
Figure 6-16. Data Factory Copy Data Wizard: specify copy from tables or query
Click on the option to Use Query instead of the existing tables. You want to dynamically select the fields you need from the DocumentDB table. You will see a screen similar to Figure 6-17.
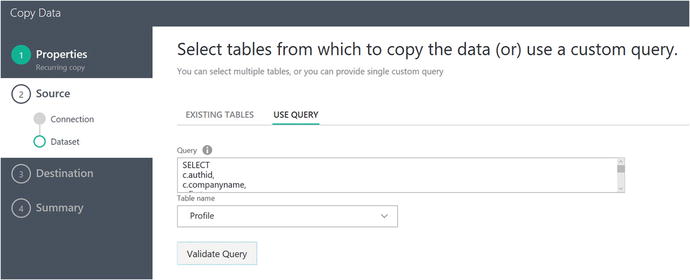
Figure 6-17. Data Factory Copy Data Wizard: specify query parameters
In the Query window, type in the following SQL statement:
SELECT
c.authid,
c.companyname,
c.firstname,
c.lastname,
c.username,
c.imageUrl,
c.type,
c.address.address1,
c.address.address2,
c.address.address3,
c.address.city,
c.address.state,
c.address.zip,
c.address.country,
c.social.phone,
c.social.email,
c.social.linkedin,
c.social.facebook,
c.social.twitter,
c.social.blog,
c.healthInformation.age,
c.healthInformation.height,
c.healthInformation.weight,
c.healthInformation.gender,
c.healthInformation.race,
c.location.longitude,
c.location.latitude,
c.id,
c.cachettl,
c._rid,
c._self,
c._etag,
c._attachments,
c._ts
FROM
c
WHERE
c.type <> 1For the table name, select Profile . Then click on Validate Query to test your SQL syntax. If there are no errors, the button will transition from Validating… back to Validate Query.
Click on the Next button to advance to the next screen where you will specify the destination data store, as shown in Figure 6-18.
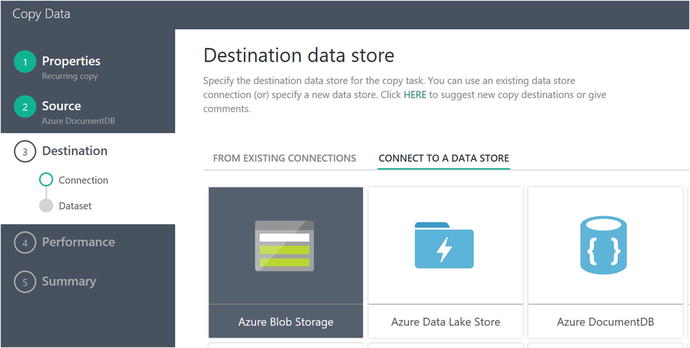
Figure 6-18. Data Factory Copy Data Wizard: specify destination data store
Select Azure Blob Storage and then click on the Next button to advance to the next screen. The next will ask for your Azure blob storage account specifics, as shown in Figure 6-19.

Figure 6-19. Data Factory Copy Data Wizard: specify Azure blob storage account properties
Enter your Azure blob storage account specifics and then click on the Next button to advance to the next screen, as shown in Figure 6-20. This is where you specify the folder and file names for the destination in Azure blob storage.
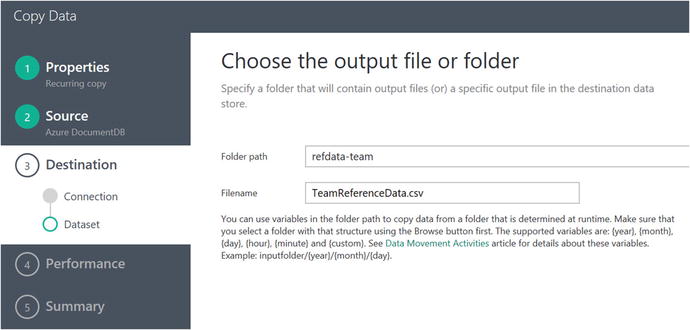
Figure 6-20. Data Factory Copy Data Wizard: specify output file or folder properties
Enter refdata-team as the folder path and TeamReferenceData.csv as the file name for the destination outputs. Then click on the Next button to advance to the next screen, as shown in Figure 6-21, where you will specify the file format settings.
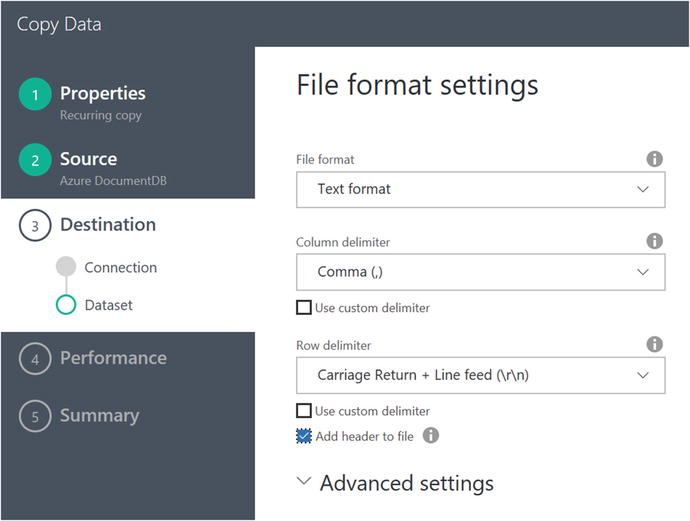
Figure 6-21. Data Factory Copy Data Wizard: specify file format settings
Keep the defaults for the file format settings options, but be sure to check the option for Add Header to File so that the column names are preserved.
Click on the Next button to advance to the next screen, performance settings, as shown in Figure 6-22.
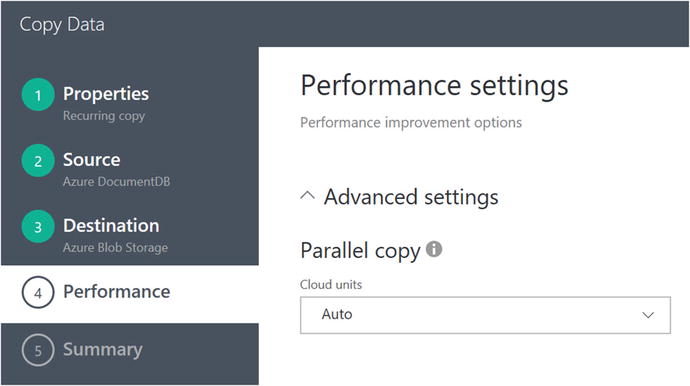
Figure 6-22. Data Factory Copy Data Wizard: specify performance settings
For the performance settings, keep the defaults and click the Next button. At this point, you will see a summary page that recaps all of the properties and settings you specified for this new copy job, as shown in Figure 6-23.
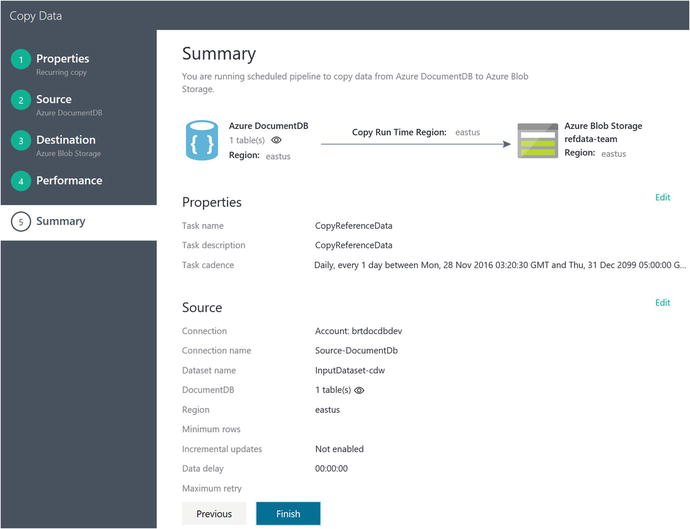
Figure 6-23. Data Factory Copy Data Wizard summary page
If all of the settings look good, click on the Finish button. The new Data Factory copy job will be validated and deployed. When that’s complete, you will see a screen similar to Figure 6-24.
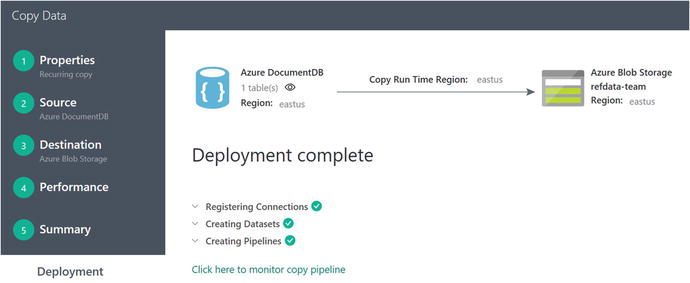
Figure 6-24. Data Factory Copy Data Wizard, deployment complete
Modify JSON Parameters for Copy Job
At this point, you have created the basic Azure Data Factory copy pipeline job for the reference implementation to refresh the reference data used in the Stream Analytics job in Chapter 5. This copy pipeline will select data from of the Azure DocumentDB database (via a SQL query statement) and then write it out to a CSV file in Azure blob storage.
The only minor change left is to tweak the JSON output parameters to create the output file name in Azure blob storage using a file naming convention pattern as the one shown:
TeamReferenceDatayyyy-MM-ddhh-mm.csv
Note the following the date/time naming format:
yyyy = Year
MM = Month
dd = Day
hh = Hour
mm = Minute
This naming convention change is crucial to ensure that you don’t try to update the file while it is in use and may be locked. It also allows you to build a historical inventory of the previous versions.
To make the change, you need to the JSON of the new Azure Data Factory pipeline job, navigate to the new pipeline job via the Azure Portal, and select the Author and Deploy option, as shown in Figure 6-25.
Figure 6-25. Data Factory, Author and Deploy option
After you select this option, you will see a screen similar to Figure 6-26. Here, you can click on each of the components of the pipeline and expand the parameters underneath each section .
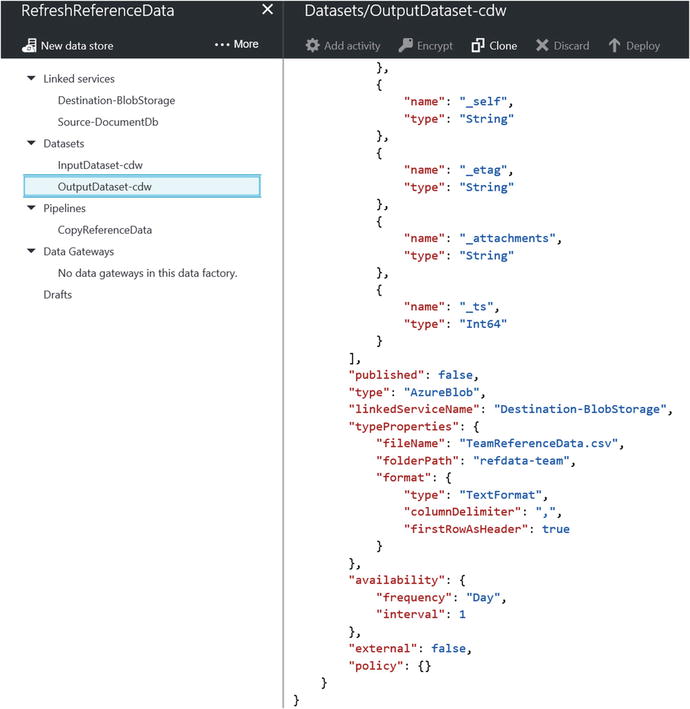
Figure 6-26. Data Factory, view data factory components
As you click on each section, you will see the corresponding JSON template and parameters on the right side of the Azure Portal web page.
Click on the OutputDataset-cdw under the Datasets section to see the corresponding JSON. Scroll all the way down to the bottom and you should see a section of code similar to Figure 6-27.

Figure 6-27. Data Factory: default output file naming in JSON
Note the fileName parameter, which is set to the value of TeamReferenceData.csv. This will be the section of JSON code you will modify to meet the file naming convention of TeamReferenceData" + "yyyy-MM-ddhh-mm.csv". To do this, find and replace the previous JSON code with the following JSON code:
"typeProperties": {
"fileName": "TeamReferenceData{slice}.csv",
"folderPath": "refdata-team",
"format": {
"type": "TextFormat",
"columnDelimiter": ",",
"firstRowAsHeader": true
},
"partitionedBy": [
{
"name": "slice",
"value": {
"type": "DateTime",
"date": "SliceStart",
"format": "yyyy-MM-ddhh-mm"
}
}
]
},Note that the JSON code you replaced will use a dynamic file naming convention based on the Date and Time attributes for the specific processing slice that is created from the Data Factory pipeline job.
After you make this update to the JSON, the Deploy option will become available, as shown in Figure 6-28.

Figure 6-28. Data Factory: deploy updated JSON
After selecting the option to deploy your updated pipeline JSON data to Azure, the JSON will be saved, validated, and then deployed to the Azure Data Factory service.
Run Data Factory Copy Job On-Demand and Check Results
To run this new Azure Data Factory pipeline job, navigate to the job via the Azure Portal and select the Monitor & Manage option, as shown in Figure 6-29.
Figure 6-29. Data Factory’s Monitor & Manage option
After selecting this option, a new tab will open in your browser. The Data Factory Resource Explorer App will open and display your Data Factory jobs and their corresponding pipeline definitions and activities, as shown in Figure 6-30.
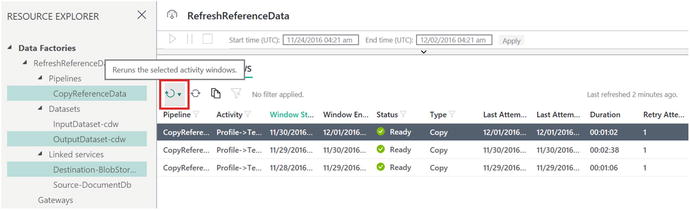
Figure 6-30. Data Factory, re-run job activity
To run this updated copy pipeline job “on demand,” do the following:
Select the latest pipeline activity.
Click on the Rerun icon, as highlighted in red in Figure 6-30.
Choose either Rerun or Rerun with Upstream Data.
Note When you select the Rerun with Upstream in Pipeline option, it reruns all upstream activity windows as well.
After a few minutes, the copy pipeline job will run to completion. At this point, you can check the Azure blob output destination container refdata-team and look for a file with a naming convention that follows TeamReferenceDatayyyy-MM-ddhh-mm.csv. The screenshot in Figure 6-31 displays successful output of several Team Reference Data CSV files over a period of three days using the Visual Studio Cloud Explorer tool to view the output blob container.
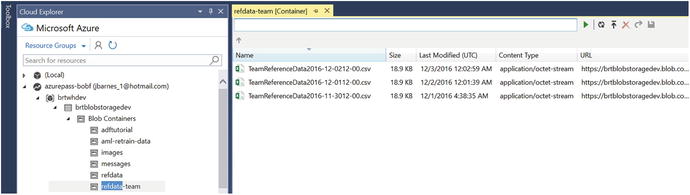
Figure 6-31. Data Factory: successful daily outputs of team reference data CSV output files
To summarize this exercise, you just walked through all the steps necessary to update the reference data that you used for the Azure Stream Analytics job in Chapter 5.
Implementing the Data Factory Azure Ml Update Resource Activity
In this next section, we tackle the second objective for the Azure Data Factory pipeline tasks, which is to re-train the Azure Machine Learning model via an Azure Data Factory pipeline job. The updates to the Azure Machine Learning model will come from the results of medical stress tests that are administered to team members on a periodic basis and then uploaded into Azure blob storage for re-training the model.
We cover the detailed specifics of implementing the Azure Machine Learning model and associated Web Services in Chapter 9.
For this exercise, we assume that the Azure ML predictive model has already been extended with an additional web service endpoint. The additional endpoint will allow for re-training the model (in batch mode) based on recently updated training data.
Data Factory AML Retraining: High-Level Design
At a high level, we are going to create a Data Factory pipeline job that will accomplish two objectives in order to fully re-train our Azure ML model :
Process the updated Machine Learning training data and produce an .iLearner ML output file. This file then becomes the input to the Update Resource activity in the next step.
Add a second Update Resource Activity to the pipeline to update the existing Azure ML Web Service with the updated trained model via the .iLearner ML output file .
Create Data Factory Job to Retrain Azure ML Model
To get started, navigate to the resource group for your deployment via the Azure Portal. Click on the + Add button and search for Data Factory, as shown in Figure 6-32.
Figure 6-32. Searching for and adding a Data Factory job to a resource group
After selecting Azure Data Factory, you will see a Data Lake overview screen. Click on the Create button to create the new Data Factory job.
The next screen allows you to enter the specific parameters for creating a new Azure Data Factory job, as shown in Figure 6-33.
Figure 6-33. Data Factory create job parameters
Fill in your choices for the corresponding parameter values:
Name: Enter a unique name for your new Data Factory. Note that the name of the Azure Data Factory must be globally unique. We use ReTrainMLModel.
Subscription: The Azure subscription to use for this job.
Resource Group: The Azure Resource Group to create this service in.
Location: The Azure Data Center location.
Once you are done, click on the Create button at the bottom of the screen. Your input will then be validated and the new Azure Data Factory job will be created after a brief period of time.
After your job has been provisioned, navigate to the new Data Factory via the Azure Portal and select the Author and Deploy option, as shown in Figure 6-34.
Figure 6-34. Data Factory Author and Deploy option
Next, you are going to build the Data Factory pipeline components using just JSON to define the individual elements of the Data Factory Azure ML re-training pipeline job.
Define Linked Service: Azure Storage
To define the Linked Service for Azure Storage, click on the New Data Store icon in the top navigation bar and then select Azure Storage, as shown in Figure 6-35.
Figure 6-35. Data Factory: add a new data store
After your new linked service has been created, replace the default JSON with the JSON code shown here. Note that you need to have your specific Azure blob storage credentials to fill in.
{
"name": "AzureStorageLinkedService",
"properties": {
"description": "",
"hubName": "retrainmlmodel_hub",
"type": "AzureStorage",
"typeProperties": {
"connectionString": "DefaultEndpointsProtocol=https;AccountName=<YourAccountName>;AccountKey=<YourAccountKey>"
}
}
}Next, click on the Deploy icon in the top navigation bar and your JSON will be uploaded, validated, and deployed.
Define Input Dataset: Updated Azure ML Training Data
To define a new dataset, click on the …More icon and then click on the New Dataset icon, as shown in Figure 6-36.
Figure 6-36. Data Factory: add new dataset, training data
Next, select the option for Azure Blob Storage, as shown in Figure 6-37.
Figure 6-37. Data Factory: add new dataset, Azure blob storage option
After your new dataset has been created, replace the default JSON with the JSON code shown here.
{
"name": "trainingData",
"properties": {
"published": false,
"type": "AzureBlob",
"linkedServiceName": "AzureStorageLinkedService",
"typeProperties": {
"fileName": "RETRAIN_Teammates_AML_Training_Data.csv",
"folderPath": "aml-retrain-data",
"format": {
"type": "TextFormat"
}
},
"availability": {
"frequency": "Week",
"interval": 1
},
"external": true,
"policy": {
"externalData": {
"retryInterval": "00:01:00",
"retryTimeout": "00:10:00",
"maximumRetry": 3
}
}
}
}Make sure the fileName and folderPath parameters are set for your environment. Note that the frequency will be once per week.
Next, click on the Deploy icon in the top navigation bar and your JSON will be uploaded, validated, and deployed to the Data Factory definition.
Define Output Dataset: Updated Azure ML Training Model
This dataset definition will represent the output .iLearner file from the Azure ML training web service. The Azure ML Batch Execution Activity produces this dataset. This dataset will also serve as the input file for the Azure ML Update Resource activity.
Create an additional dataset for our Data Factory job by following the same instructions to create a new dataset and summarized here:
Click on the …More icon and then click on the New Dataset icon.
Select the option for Azure Blob Storage.
After your new dataset has been created, replace the default JSON with the JSON code shown here.
{
"name": "trainedModelBlob",
"properties": {
"published": false,
"type": "AzureBlob",
"linkedServiceName": "AzureStorageLinkedService",
"typeProperties": {
"fileName": "model.ilearner",
"folderPath": "aml-retrain-data",
"format": {
"type": "TextFormat"
}
},
"availability": {
"frequency": "Week",
"interval": 1
}
}
}Make sure the folderPath parameter is set correctly for your environment.
When finished, click on the Deploy icon in the top navigation bar and your JSON will be uploaded, validated , and deployed to the Data Factory definition.
Define Linked Service: Azure ML Training Endpoint
Next, you will create a linked service that points to the default endpoint of the Azure ML training web service.
To get started, click on the …More icon and then click on the New Compute icon. Then select the Azure ML option, as shown in Figure 6-38.
Figure 6-38. Data Factory: add new compute Azure blob storage option
After your new linked service has been created, replace the default JSON with the JSON code shown here. Note that you will need to have your specific Azure ML URL endpoint and API key to fill in the parameters:
{
"name": "trainingEndpoint",
"properties": {
"hubName": "retrainmlmodel_hub",
"type": "AzureML",
"typeProperties": {
"mlEndpoint": "<YourEndPointURL>",
"apiKey": "<YourAPIKey>"
}
}
} }
}Next, click on the Deploy icon in the top navigation bar and your JSON will be uploaded, validated , and deployed.
Define Linked Service: Azure ML Updatable Scoring Endpoint
Next, you will create a linked service that defines an Azure Machine Learning linked service that points to the non-default updatable endpoint of the scoring Azure ML Web Service.
Note Before creating and deploying an Azure ML linked service, follow the steps in this link to create a second (non-default and updatable) endpoint for the Azure ML Scoring Web Service.
https://docs.microsoft.com/en-us/azure/machine-learning/machine-learning-create-endpoint .
To get started, click on the …More icon and then click on the New Compute icon. Then select the Azure ML option, as shown in Figure 6-38.
After your new linked service has been created, replace the default JSON with the JSON code shown here. Note that you will need to have your specific Azure ML URL endpoint and API key to fill in the parameters:
{
"name": "updatableScoringEndpoint2",
"properties": {
"hubName": "retrainmlmodel_hub",
"type": "AzureML",
"typeProperties": {
"mlEndpoint": "<YourMLRetrainingEndpoint>",
"apiKey": "<YourMLRetrainingAPIKey>",
"updateResourceEndpoint": "<YourMLRetrainingURLEndpoint>"
}
}
}Next, click on the Deploy icon in the top navigation bar and your JSON will be uploaded, validated, and deployed.
Define Output Dataset: Dummy Azure Blob Output
At the time of this writing, when you include an Azure ML Update resource activity in a Data Factory pipeline job, it does not generate any output.
However, Azure Data Factory requires an output dataset in order to drive the schedule of a pipeline. Therefore, we will implement a dummy/placeholder Azure blob dataset to handle this use case.
To define a new Dataset, click on the …More icon and then click on the New Dataset icon, as shown in Figure 6-39.
Figure 6-39. Data Factory: add new dataset, dummy output data
Next, select the option for Azure Blob Storage, as shown in Figure 6-40.
Figure 6-40. Data Factory: add new dataset, Azure blob storage option
After your new dataset has been created, replace the default JSON with the JSON code shown here.
{
"name": "DummyPlaceholderBlob",
"properties": {
"published": false,
"type": "AzureBlob",
"linkedServiceName": "AzureStorageLinkedService",
"typeProperties": {
"fileName": "dummyfile.csv",
"folderPath": "aml-retrain-data",
"format": {
"type": "TextFormat"
}
},
"availability": {
"frequency": "Week",
"interval": 1
}
}
}Make sure the fileName and folderPath parameters are set for your environment. Note that the frequency will be once per week.
Next, click on the Deploy icon in the top navigation bar and your JSON will be uploaded, validated, and deployed to the Data Factory definition.
Define Data Factory Pipeline Job with Two Activities
Now, you will combine all the previously defined linked services and dataset definitions as you define a new Data Factory pipeline job.
The new Data Factory pipeline job will have two activities defined:
AzureMLBatchExecution: The Azure ML Batch Execution activity takes the updated team health training data from Azure blob storage as input, and then produces an .iLearner file as an output.
AzureMLUpdateResource: This activity takes the .iLearner file as input and then sends it to the Azure ML Training web service to update the ML model.
Note: The placeholderBlob is just a dummy output dataset that is required by the Azure Data Factory service to run the pipeline.
To define the new pipeline, right-click on the Pipelines section of the left navigation bar of the Authoring pane and then select New Pipeline, as shown in Figure 6-41.
Figure 6-41. Data Factory: add new pipeline
After your new pipeline has been created, replace the default JSON with the JSON code shown here.
{
"name": "retrainmlpipeline",
"properties": {
"activities": [
{
"type": "AzureMLBatchExecution",
"typeProperties": {
"webServiceInput": "trainingData",
"webServiceOutputs": {
"output1": "trainedModelBlob"
},
"webServiceInputs": {},
"globalParameters": {}
},
"inputs": [
{
"name": "trainingData"
}
],
"outputs": [
{
"name": "trainedModelBlob"
}
],
"policy": {
"timeout": "02:00:00",
"concurrency": 1,
"executionPriorityOrder": "NewestFirst",
"retry": 1
},
"scheduler": {
"frequency": "Week",
"interval": 1
},
"name": "retraining",
"linkedServiceName": "trainingEndpoint"
},
{
"type": "AzureMLUpdateResource",
"typeProperties": {
"trainedModelDatasetName": "trainedModelBlob",
"trainedModelName": "Training Exp for ADF ML [trained model]"
},
"inputs": [
{
"name": "trainedModelBlob"
}
],
"outputs": [
{
"name": "DummyplaceholderBlob"
}
],
"policy": {
"timeout": "01:00:00",
"concurrency": 1,
"retry": 3
},
"scheduler": {
"frequency": "Week",
"interval": 1
},
"name": "AzureML Update Resource",
"linkedServiceName": "updatableScoringEndpoint2"
}
],
"start": "2016-02-13T00:00:00Z",
"end": "2016-02-14T00:00:00Z",
"isPaused": false,
"hubName": "retrainmlmodel_hub",
"pipelineMode": "Scheduled"
}
}Make sure the fileName and folderPath parameters are set for your environment. Note that the frequency will be once per week.
Next, click on the Deploy icon in the top navigation bar and your JSON will be uploaded, validated, and deployed to the Data Factory definition.
At this point, you have manually created a complete Data Factory pipeline job (described via JSON) to update the Azure ML training service.
The Data Factory pipeline is composed of the following components , as shown in Figure 6-42.
Three linked services
Three datasets
One pipeline
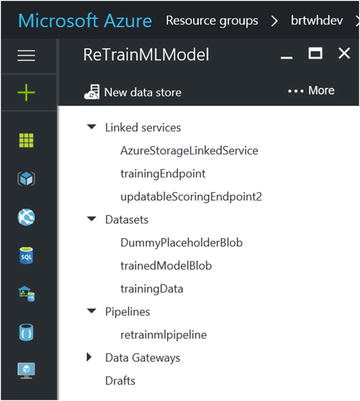
Figure 6-42. Data Factory pipeline components
In order to get a visual representation of the Azure Data Factory and components you have created, navigate to your Data Factory job in the Azure Portal and select the Diagram option, as shown in Figure 6-43.
Figure 6-43. Data Factory Diagram view
After clicking on the Diagram icon, you will see a representation of your Data Factory pipeline, as shown in Figure 6-44.
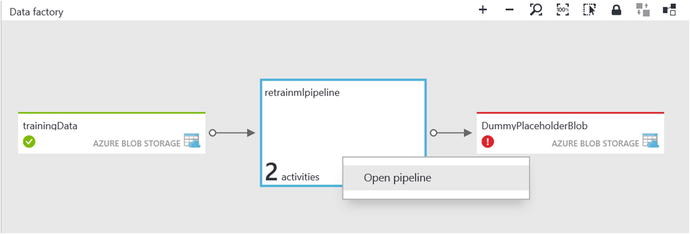
Figure 6-44. Data Factory diagram, open pipeline option
However, you will notice that this view is still collapsed, as the pipeline icon states it has two activities. To expand the pipeline, right-click on the pipeline icon and select Open Pipeline, as shown in Figure 6-44.
When you click on the Open Pipeline option, the screen will expand to auto-fit the viewing window in order to reveal the entire pipeline. Figure 6-45 illustrates the new view.

Figure 6-45. Data Factory diagram, open pipeline view
Note that this view is extremely helpful when assembling multi-step pipeline jobs using Azure Data Factory. You can also adjust the zoom levels and drill down into individual components.
To summarize, in this section, you created a new Data Factory pipeline job to automatically update the Machine Learning Web Service using the following JSON definitions :
Linked Service: Azure Storage
Linked Service: Azure ML Training Endpoint
Linked Service: Azure ML Updatable Scoring Endpoint
Input Dataset: Updated Azure ML Training Data
Output Dataset: Updated Azure ML Training Model
Output Dataset: Dummy Azure Blob Output
Data Factory Pipeline Job: With two Activities
This piece of the reference implementation provides a completely automated method of retraining the Azure Machine Learning Web Service.
The updates are based on updated team health data that is generated from periodic stress test results administered to team members. This creates a “full lifecycle” solution to maintaining an updated Azure ML training models based on physical data updates.
Note See the following link for more details about configuring an Azure Data Factory pipeline job to retain an Azure ML Web Service:
Move Data From Blob Storage to Data Lake
The third and last Data Factory job we will implement in this chapter focuses on moving data from Azure blob storage to Azure Data Lake.
This Data Factory will prepare the reference implementation data for the next subject covered in Chapter 7.
As a refresher, the data in Azure blob storage that you will move to Azure Data Lake was created as an output result of the Azure Stream analytics job created in Chapter 5.
You will move this data to Azure Data Lake for several reasons, including the following:
Data Archival: Keep the data in its original form as when it was received from the IoT Hub.
Deep Analytics: Azure Data Lake is both a powerful storage and powerful analytics platform, as we will explore more in Chapter 7.
Regression Analysis: Oftentimes, there is value in being able to re-run Big Data analysis over historical data to evaluate alternative outcomes or make other make other (historical) improvements.
Create Azure Data Lake Store Account
Before you can copy your data from Azure blob storage to Azure Data Lake, you need to create an Azure Data Lake Store account.
To get started, navigate to the resource group for your deployment via the Azure Portal. Click on the + Add button and search for Data Lake, as shown in Figure 6-46.
Figure 6-46. Searching for and adding a Data Lake Store to a resource group
Next, you will see an overview page about Azure Data Lake Store. Click on the Create button to advance to the next screen.
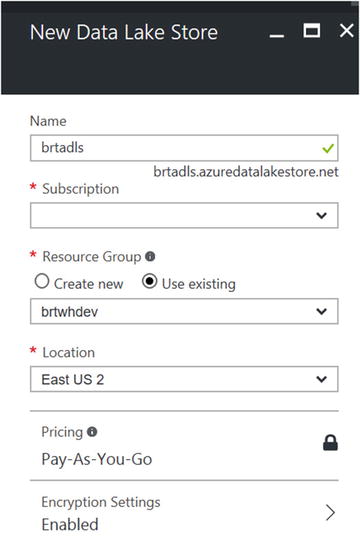
Figure 6-47. Parameters for creating a new Data Lake Store
Fill in your choices for the corresponding parameter values:
Name: Enter a unique name for your new Data Lake Store.
Subscription: The Azure subscription to use for this job.
Resource Group: The Azure Resource Group to provision this resource in.
Location: The Azure Data Center location.
Once you are done, click on the Create button at the bottom of the screen. Your input will then be validated and the new Azure Data Lake Store will be created in a few minutes at most.
Create Data Factory Job: Copy from Azure Blob to Data Lake
To get started, navigate to the resource group for your deployment via the Azure Portal. Click on the + Add button and search for Data Factory, as shown in Figure 6-48.
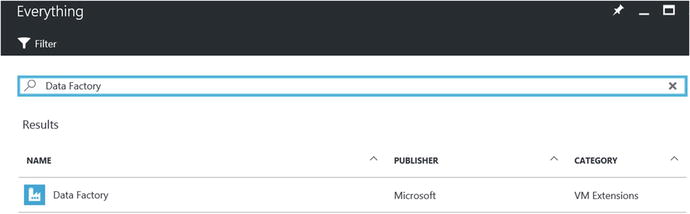
Figure 6-48. Searching for and adding a Data Factory job to a resource group
After selecting Azure Data Factory, click on the Create button to create the new job.
The next screen will allow you to enter the specific parameters for creating a new Azure Data Factory job, as shown in Figure 6-49.
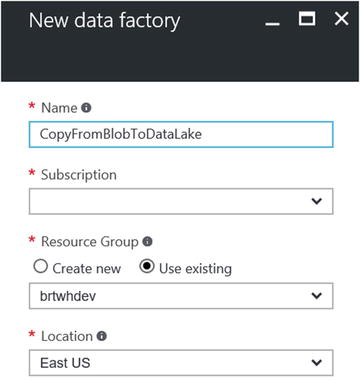
Figure 6-49. Data Factory create job parameters
Fill in your choices for the corresponding parameter values:
Name: Enter a unique name for your new Data Factory job. Note that the name of the Azure Data Factory must be globally unique.
Subscription: The Azure subscription to use for this job.
Resource Group: The Azure Resource Group to create this service in.
Location: The Azure Data Center location.
Once you are done, click on the Create button at the bottom of the screen. Your input will then be validated and the new Azure Data Factory job will be created after a brief period of time. It should take less than one minute via the Azure Portal.
After your job has been provisioned, navigate to the new Data Factory via the Azure Portal and select the Copy Data (PREVIEW) option, as shown in Figure 6-50.
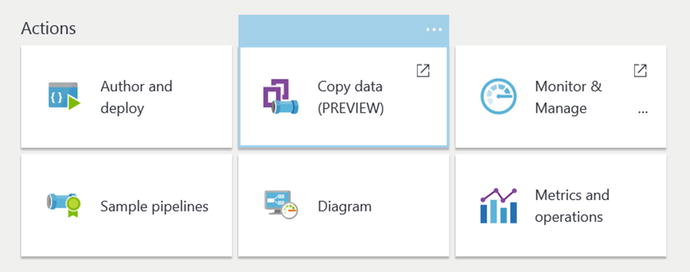
Figure 6-50. Data Factory Copy Data Wizard
This will invoke the Azure Data Factory Copy Data Wizard to launch and will walk you through the steps necessary to create a basic copy pipeline. Behind the scenes, Azure Data Factory is generating JSON files to reflect your choices in the Copy Wizard.
Figure 6-51 depicts the first screen of the Copy Data Wizard and allows you to specify the properties for the copy job.
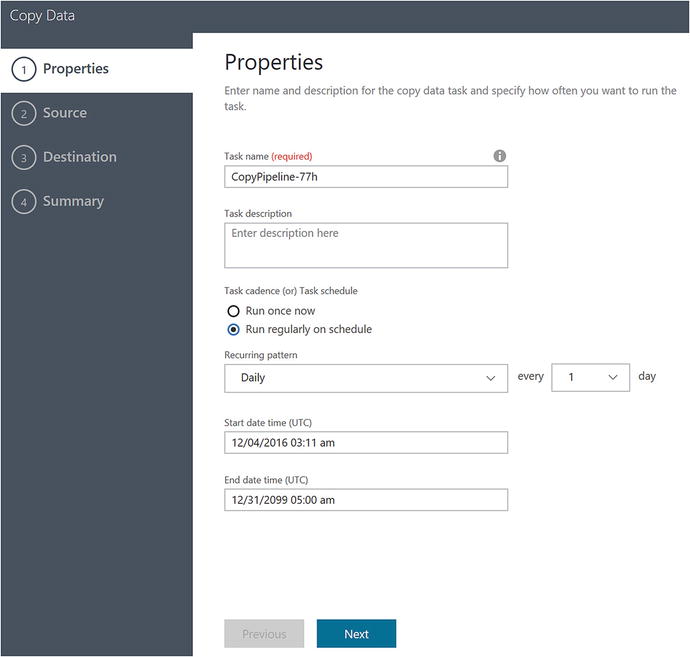
Figure 6-51. Data Factory Copy Data Wizard: specify properties
For this example, enter a task name of CopyBlobToDataLake and keep the remaining defaults for the schedule, stat, and end dates. Click Next to advance to the next step.
Figure 6-52 depicts the Source Data screen, where you should select Azure Blob Storage for the reference implementation scenario.
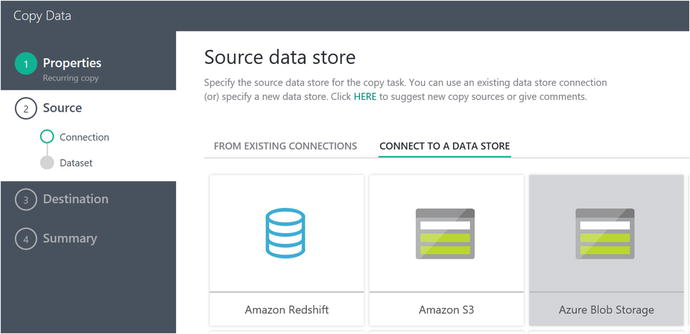
Figure 6-52. Data Factory Copy Data Wizard: specify source data store for Azure blob storage
Next, specify the Source Data Store properties for Azure blob storage, as shown in Figure 6-53.
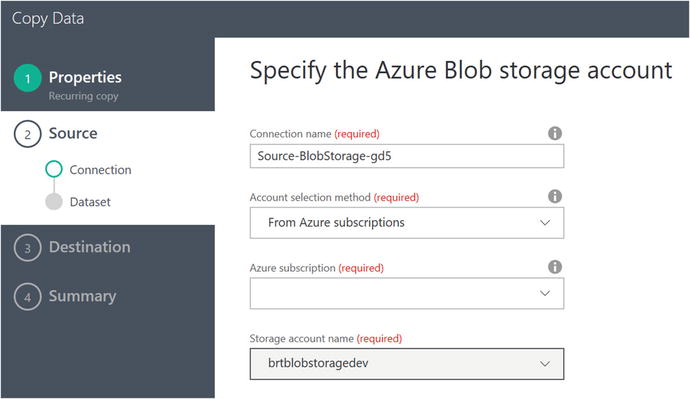
Figure 6-53. Data Factory Copy Data Wizard: specify source data store for Azure blob storage properties
Next, choose the folder in Azure blob storage that will contain the source dataset, as shown in Figure 6-54.
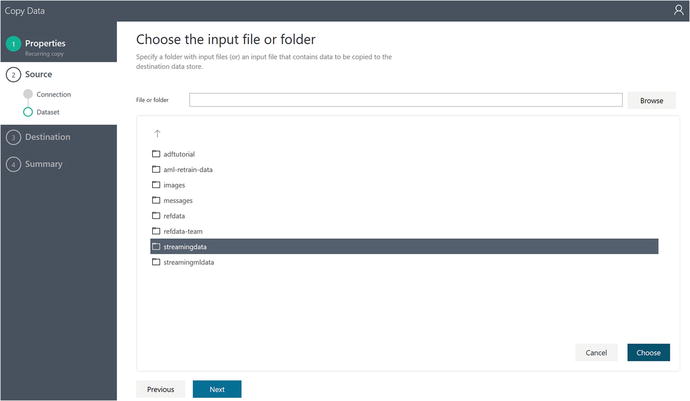
Figure 6-54. Data Factory Copy Data Wizard: specify a source folder in blob storage
After selecting the streamingdata folder and clicking on Choose, click on the Next button. You will see the screen in Figure 6-55.
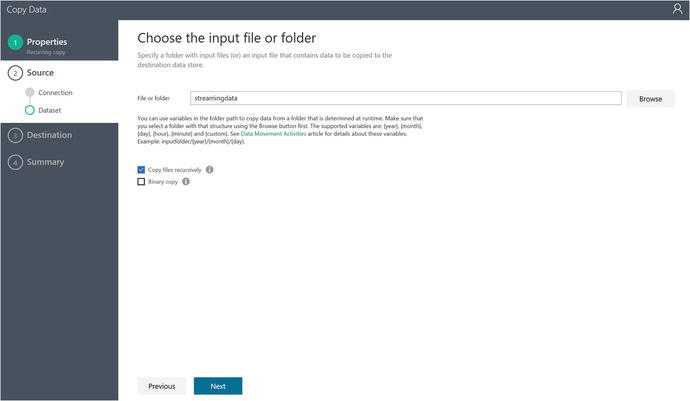
Figure 6-55. Data Factory Copy Data Wizard: specify a source folder and an option for copying files recursively
Select the option to Copy Files Recursively, as shown in Figure 6-55, then click on the Next button.
At this point, the Data Factory Copy Wizard will attempt to connect to the Azure blob storage folder and automatically detect the file format of the files in blob storage, as shown in Figure 6-56.
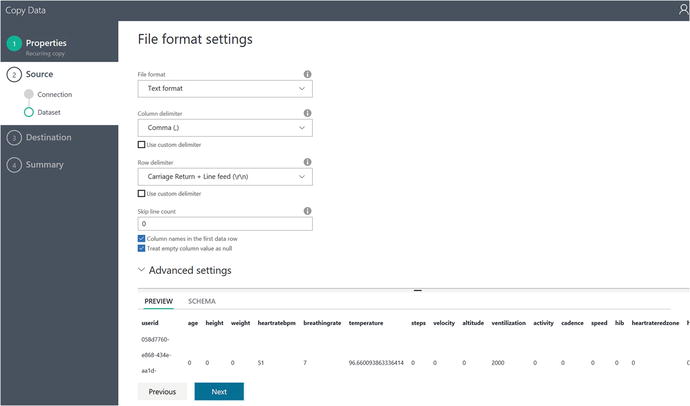
Figure 6-56. Data Factory Copy Data Wizard: file format settings
If the settings do not match, you may need to review the Azure blob storage output from the Stream Analytics job defined in Chapter 5.
If the file format settings match your expected inputs, click on the Next button to select the destination data store, as shown in Figure 6-57.
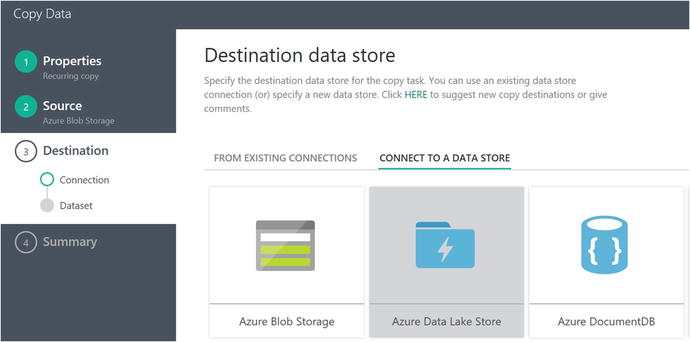
Figure 6-57. Data Factory Copy Data Wizard: select Data Lake destination
Click on the Azure Data Lake Store icon and then click on the Next button to select Data Lake as the output destination.
The next option you’ll define in the Copy Activity Wizard is for the destination Azure Data Lake Store account, as shown in Figure 6-58.
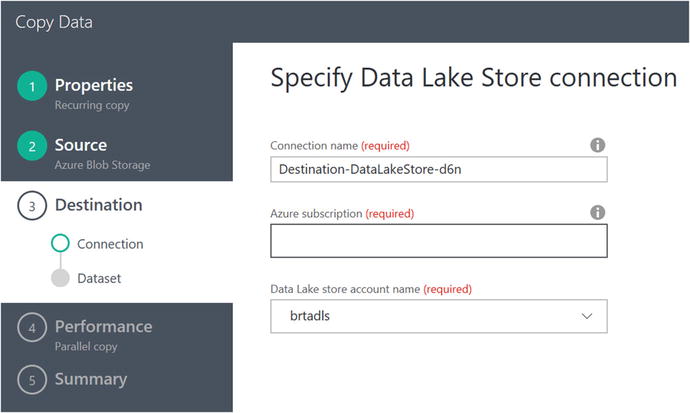
Figure 6-58. Data Factory Copy Data Wizard: select Data Lake destination
Select your Azure subscription and Azure Data Lake Store Name and then click on the Next button.
The next screen in the Copy Wizard will allow you to select the output destination folder and file path for the destination data in Azure Data Lake.
Set the Filename parameter to the value of inputfolder/{year}/{month}/{day}, as shown in Figure 6-59.
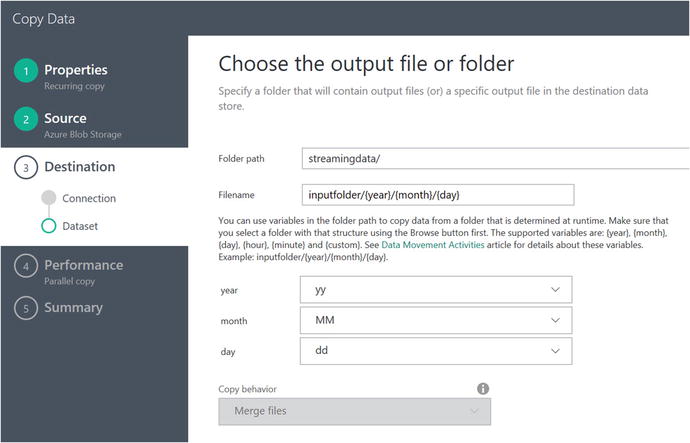
Figure 6-59. Data Factory Copy Data Wizard: select a Data Lake Destination folder and file name values
Click on the Next button to advance to the next screen in the Copy Wizard. Here, you will see options for specifying the file format settings. Select the option for Add Header to File, as shown in Figure 6-60.
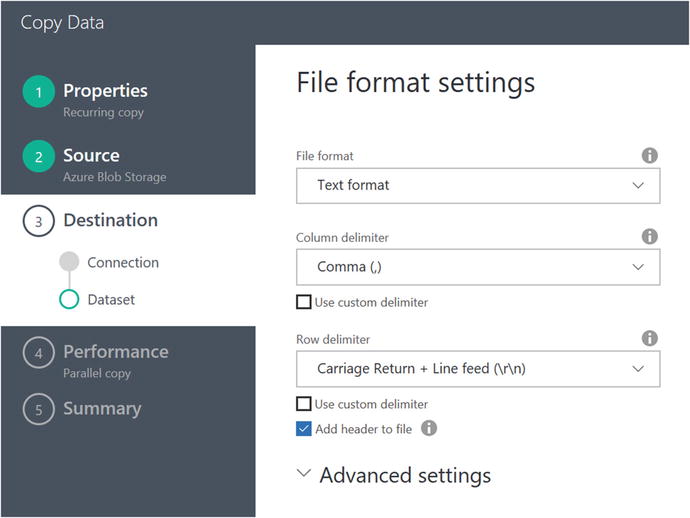
Figure 6-60. Data Factory Copy Data Wizard: specify Data Lake destination file format values
Next, you will see a screen where you can adjust the performance settings for the copy job. Accept the default values of Auto for Cloud Units and Parallel Copies and click on the Next icon, as shown in Figure 6-61.
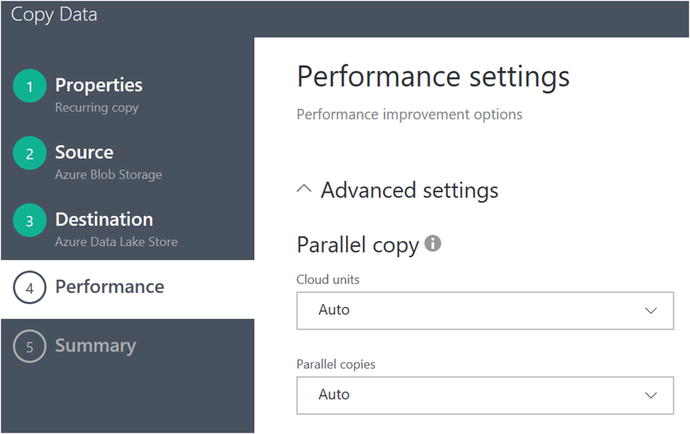
Figure 6-61. Data Factory Copy Data Wizard: specify Data Lake destination file format values
The last screen in the Copy Wizard is the summary screen, as shown in Figure 6-62.
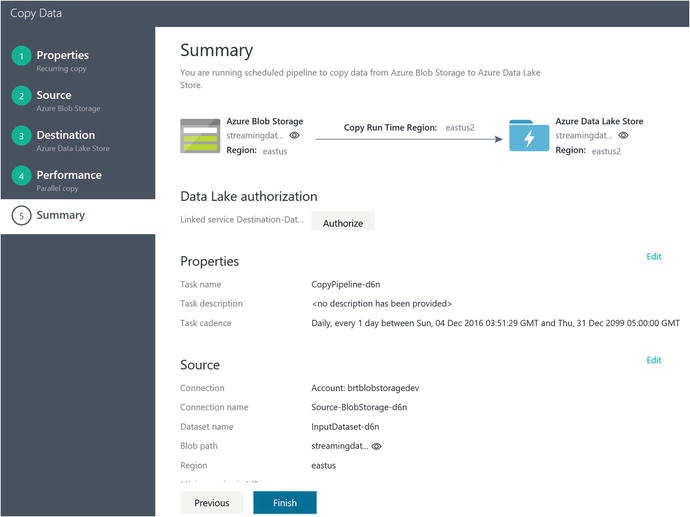
Figure 6-62. Summary screen of the Data Factory Copy Data Wizard
First, click on the Authorize button, as shown in Figure 6-62 so that you can sign in to the Azure subscription again and the copy job can capture the credentials.
Finally, click on the Finish button to create the new Data Factory pipeline job.
After a brief period of time, the new Data Factory copy job will be registered and deployed, as shown in Figure 6-63.
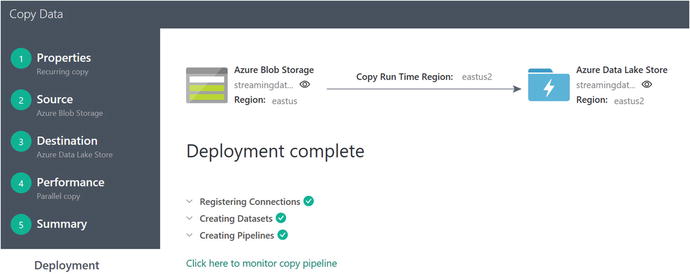
Figure 6-63. Deployment complete
After your new pipeline job has been deployed, it will run and you can check for the output in your destination Azure Data Lake Store.
Figure 6-64 depicts an example of the updated Data Lake Store copy results using the Visual Studio Cloud Explorer to view the destination output in the Data Lake Store folder.
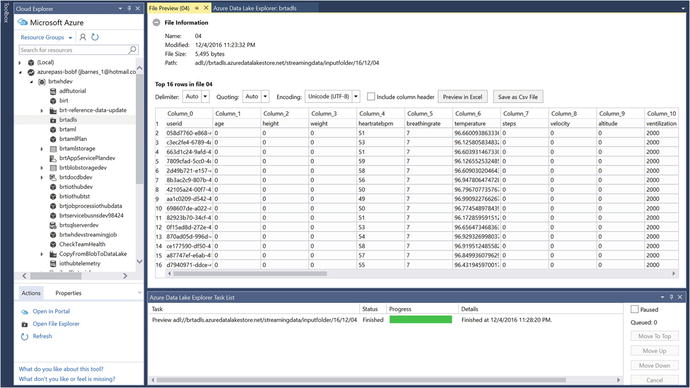
Figure 6-64. Visual Studio Cloud Explorer: view Data Lake Store
At this point, you have now completed the third and final Data Factory use case scenario for the reference implementation.
Note See the following link for more detailed information.
“Move Data to and from Azure Data Lake Store Using Azure Data Factory”: https://docs.microsoft.com/en-us/azure/data-factory/data-factory-azure-datalake-connector .
Summary
This chapter provided a high-level overview of Azure Data Factory and Azure Data Lake Store. You implemented three Data Factory jobs to accomplish the corresponding use case scenarios for the reference implementation:
Update reference data
Re-train the Azure Machine Learning model
Move data from Azure blob storage to Azure Data Lake Store
It should now be very apparent that Azure Data Factory is the primary tool for accomplishing what is known in the Business Intelligence field as ETL (Extract, Transform, and Load) operations in Azure.
You also saw how Data Factory jobs can be edited using pure JSON to gain fine control over the execution aspects of a Data Factory job. You used parameters in Data Factory to create scheduled jobs to automate the data movement operations on a recurring, weekly, basis.
Data Lake Store is a robust and virtually limitless data store that we will explore more fully in the next chapter when we examine Data Lake analytics.