
This chapter examines the use of Azure Data Lake Analytics (ADLA), which is Microsoft’s new “Big Data” toolset that runs on top of Azure Data Lake.
The ADLA tools and capabilities help make it easier and more efficient to solve today’s modern business analysis and reporting problems than with traditional, on-premise solutions. It is more efficient because it offers virtually unlimited storage, with immediate access to that storage for running analytical operations directly on top of it. There is no need for additional provisioning or acquisition; the resources are immediately available on-demand.
Data Lake offers the ability to persist the raw data in its native form and then run transformational and analytical jobs to create new analyses, summarizations, and predictions—across structured and un-structured data—all based on the original data. All this adds up to a “faster time-to-value” for a modern business seeking to maximize its true potential.
The key advantage is that you do not need to perform any ETL (Extract-Transform-Load) operations on the data in Azure Data Lake to run the analytical operations. This offers a huge advantage when dealing with large amounts of data, particularly when historical and regression analysis requirements come into play.
The ADLA service can handle jobs of virtually any scale instantly; you simply specify how much compute power you need when you submit your job. You can specify both the job’s priority and the number of Analytical Units (AU) for your job. AU’sallow you to specify how many computational resources your job can use. A single AU is roughly equivalent to two CPU cores and 6 GB of RAM. You only pay for your job while it is running, making it more cost-effective than with traditional on-premise approaches, where you must pay for the infrastructure whether it is utilized or not.
In this chapter, we begin by providing a wide-angle view of the features and capabilities of ADLA. We then apply this knowledge to the reference implementation and put all the pieces together as we walk through building the complete working solution. Figure 7-1 illustrates the role that ADLA plays in the reference implementation.

Figure 7-1. Azure Data Lake Analytics in the reference implementation architecture
We draw upon our key lessons from Chapter 5 (Stream Analytics) and Chapter 6 (Data Factory) to continue with the data movement activities in this chapter.
Specifically, we process the data that was moved to Azure Data Lake from Azure Blob storage (via Data Factory); that data represents the incoming IoT streaming data. We then join this raw, IoT data with the results of the Azure Machine Learning Web Service calls that were made “real-time” during the Stream Analytics ingestion job and then persist the data to Azure storage. Let’s get started with a brief technical overview of Azure ADLA capabilities and features.
Azure Data Lake Analytics
ADLA is a recent new Microsoft Azure distributed analytics service built on top of Apache YARN. YARN stands for “Yet Another Resource Negotiator” and is a cluster management technology for Apache Hadoop. ADLA was built with the primary goal of making Big Data analytics easy and more efficient. ADLA lets you focus on writing, running, and managing analytical jobs, rather than operating distributed computing infrastructure.
Some of the core capabilit ies of the ADLA service include the following:
Dynamic Scaling: ADLA has been architected at its core for cloud scale and performance. ADLA can dynamically provision resources and will allow you do analytics on extremely large datasets, such as terabytes or even exabytes of data. When a job completes, it winds down resources automatically, and you pay only for the processing power used for your job run. As you increase or decrease the size of data stored or the amount of compute used, you don’t have to rewrite any code. This lets you focus on your business logic only and not on how you process and store large datasets.
U-SQL: ADLA includes U-SQL, a query language that combines a familiar SQL-like declarative language with the extensibility and programmability provided by C#, for creating custom processors and reducers. U-SQL also provides the ability to query and combine data from a variety of data sources, including Azure Data Lake Storage, Azure Blob Storage, Azure SQL DB, Azure SQL Data Warehouse, and SQL Server instances running in Azure Virtual Machines.
Develop, Debug, and Optimize Faster Using Visual Studio: ADLA has deep integration with Visual Studio, so that you can use familiar tools to run, debug, and tune your analytics job code. Additionally, ADLA provides handy visualizations of your U-SQL jobs. These visualizations allow you to examine how your code runs at scale, which makes it easier to identify performance bottlenecks early and thereby optimize performance (and costs).
Big Data Analytics for the Masses: ADLA provides the tooling and framework so that even new developers can easily develop and run massively parallel data transformation and processing programs in U-SQL, R, Python, and .Net over petabytes of data. All your data can be analyzed with ADLA and U-SQL including unstructured, semi-structured, and structured data.
Integration with Existing IT Investments: ADLA can use your existing IT investments for identity, management, security, and data warehousing. ADLA is integrated with Azure Active Directory for user management and permissions. It also comes with built-in monitoring and auditing capabilities.
Cost Effective: ADLA becomes a very cost-effective solution for running Big Data workloads when you look at the details of how it is priced and scaled. With ADLA, you pay on a “per-job” basis only when your data is processed. The system automatically scales up or down as the job starts and completes, so you never pay for more than what you need. No additional hardware, licenses, or service-specific support agreements are required.
Optimized for Data Lake: It should be noted that ADLA is specifically designed and optimized to work together with Azure Data Lake Store to provide the highest levels of performance, throughput, and parallelization for your most demanding Big Data workloads.
Simplified Management and Administration: ADLA can be easily managed via the Azure Portal. Additionally, PowerShell can be used to automate analytics jobs and perform related ADLA tasks. The Azure Portal blades for ADLA also offer the ability to secure your analytics environment with Role-Based Access Control (RBAC) tools that are integrated with Azure Active Directory. Monitoring and alerting capabilities are also built into the Azure Portal for fulfilling operations and administration requirements.
Getting Started with Azure Data Lake Analytics
It is easy to get started with ADLA. There is a three-step process to get up and running:
Create an ADLA account in your Azure Subscription/Resource group. This is a one-time setup and allows you to start exploring your data along with running analytics jobs on that data.
Write and submit an ADLA job with U-SQL. You can create, submit, and monitor jobs from many different sources, such as the Azure Portal, Visual Studio, and PowerShell commands.
Examine the job results. At their core, ADLA jobs basically read and write data from storage in a highly distributed and massively parallel manner. For easy access, the storage sources can be from many various locations such as Data Lake Store, Azure blob storage, or data from other SQL servers on other platforms or services. And all the data can be analyzed “in-place” without any delay for extraction, preparation, or loading.
Next, we walk through these steps in more detail so that you can see how easy it is to get started with processing Big Data using ADLA.
Create an ADLA Account
To get started, in the Azure Portal navigate to the resource group for your deployment. Click on the + Add button and search for Data Lake Analytics, as shown in Figure 7-2.
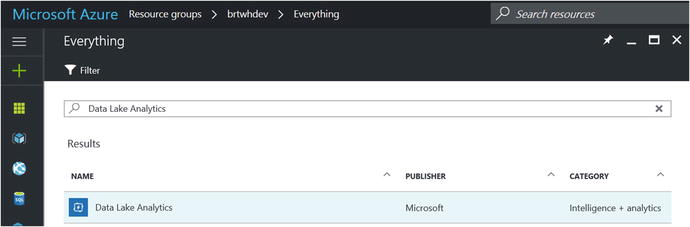
Figure 7-2. Adding Data Lake Analytics to a resource group
After selecting the option for Data Lake Analytics, click on the next screen to create the new Data Lake Analytics account, as shown in Figure 7-3.

Figure 7-3. Creating a new Azure Data Lake Analytics account
The next screen allows you to enter the specific parameters for creating a new ADLA account, as shown in Figure 7-4.

Figure 7-4. Creating a new Azure Data Lake Analytics account
Fill in your choices for the corresponding parameter values :
Name: Enter a unique name for your new ADLA account. Note that the name of the ADLA must be globally unique.
Subscription: The Azure subscription to use for this job.
Resource Group: The Azure Resource Group to create this service in.
Location: The Azure Data Center location.
Data Lake Store: The Azure Data Lake Store that will be the primary location for analyzing your data. Note that each ADLA account has a dependent Data Lake Store account. The ADLA account and the dependent Data Lake Store account must be located in the same Azure data center.
Once you are done, click on the Create button at the bottom of the screen. Your input will then be validated and the new Azure Data Lake account will be created after a brief period of time (typically less than one minute).
After your new ADLA account has been provisioned, navigate to the account via the Azure Portal. Your ADLA screen should appear similar to Figure 7-5.

Figure 7-5. Azure Data Lake Analytics web page blade
When working with ADLA via the Azure Portal, note that you will primarily use two of the navigation options shown at the top of the screen in Figure 7-5:
+ New Job: Allows you to create, submit, and monitor your ADLA jobs. This option allows you to create, upload, and download U-SQL scripts. When you are ready, you can submit them to run and monitor their progress.
Data Explorer: Allows you to quickly and easily navigate your data in both Data Lake Storage and ADLA database structures that contain tables and schemas.
Sample Scripts: Create, Submit, and Monitor Jobs
One of the best ways to quickly get acquainted with ADLA is to run through the sample scripts that you see in the Azure Portal after you create an analytics account.
The first time that you first provision a new Data Lake Store along with a new Data Lake Analytics account, you will be presented with an option to install the sample data. It is highly recommended that you do so, especially since the sample scripts have a dependency on the sample data being present on your system.
After you click on the Sample Scripts icon in the top navigation bar, a new blade will appear similar to Figure 7-6.

Figure 7-6. Sample script options
Click on the Query a TSV File option, as shown in Figure 7-6, and the New U-SQL Job window will appear, as shown in Figure 7-7.

Figure 7-7. Sample U-SQL script to read and write TSV files
From this initial sample script, you can identify several key aspects of the U-SQL language and operations:
U-SQL queries can be expressed in familiar SQL syntax.
Extractors and outputters are the keys to working with semi-structured and unstructured data.
U-SQL can easily extract tab-separated-value data from one flat file and then write it out to another flat file.
Values read from flat files can be assigned to different variable types.
Click on the Submit Job icon, as shown in the top-left side of Figure 7-7. Next, you will see a Job Summary screen similar to one shown in Figure 7-8.

Figure 7-8. Azure Data Lake Analytics: sample job results
This screen provides information as the job goes through the four stages of ADLA job execution : Preparing, Queued, Running, and Finalizing. Note that you can (and often will) use the Refresh command to manually refresh the screen to see an updated status of your job real-time in the dashboard.
Note that you can also browse both the input and the output files related to the analytics job execution, as shown on the left side of Figure 7-8.
The right side of the screen provides information pertaining to the execution details of the job. Figure 7-8 illustrates graphs that are provided to help visualize the job’s execution information: Progress, Data Read, Data Written, Execution Time, Average Execution Time per Node, Input Throughput, and Output Throughput.
By leveraging this rich job execution information, you can tune and tweak your Big Data analytical queries to optimize both your results and your costs. Note that you can also click on Replay (arrow icon) in the top navigation bar to visually replay your job (logically without actually running the job) and see how it consumes resources as it runs. See Figure 7-9 for the Replay button.

Figure 7-9. The Azure Data Lake Analytics Replay button helps you visualize your job after it runs
Close this blade and you will return to the job submission blade, where you can click on the Data Explorer option in the top navigation bar (see Figure 7-10).
Figure 7-10. Data Explorer icon
Next, you will see a view of the Data Explorer screen similar to the one shown in Figure 7-11.

Figure 7-11. The Data Lake Analytics Data Explorer view
A few items are noteworthy in Figure 7-11:
Top-left of the screen: You will see that you have a view into the contents of your Azure Data Lake Store. The contents appear as a file system with folders and files. This is the location where you will primarily work with any kind of unstructured data or “flat files”.
Bottom-Left of the screen: Includes the “Catalog” which represents a “structured” view of your data in ADLA, similar to a SQL Server database store. This catalog is used to hold structured data and code so that they can both be shared by U-SQL scripts. Each catalog can contain one or more additional databases.
A U-SQL database contains the following:
Assemblies: Share .NET code among U-SQL scripts.
Table-Values functions: Share U-SQL code among U-SQL scripts.
Tables: Share data among U-SQL scripts.
Schemas: Share table schemas among U-SQL scripts.
The next sample script explores this concept further, as you will create a database and a table in U-SQL script.
Navigate back to the Sample Scripts blade in the Azure Portal and select the second option, called Create Database and Table, as shown in Figure 7-12.

Figure 7-12. Data Lake sample scripts create database and table
Here, you see familiar SQL-like syntax statements that allow you to easily declare a new ADLA database and corresponding table. Additionally, we have declared a clustered index partitioned by a hash on the region. This could potentially provide a huge performance boost when dealing with large numbers of records.
Another observation is that the ADLA environment allows for an optimized mixture of storage and SQL commands that summarize, aggregate, transform, extract, and output meaningful business data at scale.
Click on the Submit Job icon in the top navigation bar and your job will be placed in the queue to eventually create a new database and table.
By now, it should be clear that there are many similarities in ADLA to the manner in which older generation “legacy” computer systems were designed to run. Batch environments have always been most efficient at dividing up computational workloads, running the workloads on distributed nodes, monitoring and gathering the results, and finally producing an output.
This next section demonstrates the U-SQL capabilities in action as you populate the sample database using the sample CSV input file.
Navigate back to the Sample Scripts blade and select the third option to populate the table, as shown in Figure 7-13.

Figure 7-13. Sample script to populate SQL table
This SQL script will read from the (semi-structured) .TSV file named SearchLog.tsv as the input source. It will then output the results into a new SQL table that you created with the previous script. Click on Submit Job and run the job to populate the new SQL table.
The last sample script step allows you to verify the results of the previous script by outputting the data from the SQL table you just populated back into a .TSV file.
Navigate back to the Sample Scripts blade and select the fourth and last option called Query Table, as shown in Figure 7-14.
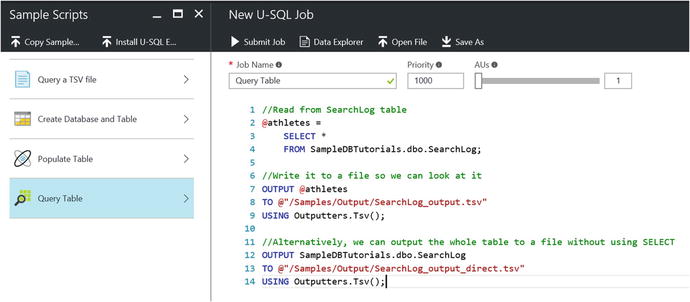
Figure 7-14. Sample script to query a SQL table and output results to a .TSV file
Click on Submit Job to run this job, which will query the new SQL table and then output the results to a .TSV file. As you have seen previously, after submitting the job you can easily monitor and view its progress through the stages of execution.
To verify the results of the Query Table script from the Data Lake Storage point of view, click on the Data Explorer icon in the top navigation bar and traverse the file folders to the folder Samples/Output, as illustrated in Figure 7-15.

Figure 7-15. Verify SQL-to-File job output files using the Data Explorer
You can click on each file to see the contents and verify that they originated from the file that you used to populate the Data Lake SQL table in Sample Script #3 (Populate Table).
Note that there is currently no way to interactively query or view the results of ADLA SQL query. That is due to the fact that ADLA is primarily based on a batch processing architecture.
To account for this reality, the easiest way to verify the contents of SQL queries is to declare an output file and write to that destination, as shown in Figure 7-14. Then you can use the Data Explorer to verify the results.
By running through the sample U-SQL scripts that come with ADLA, you have explored some of the more commonly used capabilities and features of the service. Although everything you accomplished in this quick tour of the samples was via the Azure Portal, Microsoft also provides additional tools for working with U-SQL in Visual Studio.
Tip
When developing ADLA scripts in the Azure Portal, it is often a good idea to have multiple browser tabs or windows open. One window would normally contain the Data Explorer view, and the other window would be used for editing scripts and submitting analytics jobs.
Azure Data Lake Tools for Visual Studio
Azure Data Lake Tools for Visual Studio is a free plug-in that works with Visual Studio (2015/2017) to enable easy authoring, debugging, and tuning of ADLA U-SQL scripts and queries.
In addition to handling all the basic operations available via the Azure Portal such as authoring, submitting, and monitoring ADLA jobs, there are many additional tools , utilities, and functionality you can leverage with Azure Data Lake Tools for Visual Studio, such as:
Unit Tests: Visual Studio Tools includes a new project template for creating U-SQL unit test scripts. This is invaluable for being able to run automated testing and regression scenarios.
IntelliSense: For help with prompting for Data Lake catalog entities such as databases, schemas, tables, User Defined Objects (UDOs), etc. Since you can only have one master catalog per ADLA account, the entities are all related to your specific compute account.
Auto-Formatting: When creating ADLA jobs, Visual Studio makes it easier to visual your U-SQL code and thereby improve readability and maintain-ability. All the formatting rules are configurable under Tools ➤ Options ➤ Text Editor ➤ SIP ➤ Formatting.
Go-To Definition and Find All References: These help you pinpoint code segments and determine code paths.
Heat Map: The VS Data Lake Tools provide user-selectable, color overlays on the job view to indicate: Progress, Data I/O, Execution time, and I/O throughput of each stage. This feature allows users to determine potential issues and distribution of job properties visually and intuitively.
Run U-SQL Locally: This capability alone with Data Lake Tools for Visual Studio can provide a U-SQL developer a huge boost in productivity. These tools allow developers to take advantage of all of the following rich development capabilities, all locally:
Run U-SQL scripts, along with C# assemblies.
Debug scripts and C# assemblies. Create/delete/view local databases, assemblies, schemas, and tables in Server Explorer, in exactly the same manner as you would do for an ADLA service.
The combination of the Visual Studio tools and tooling on top of the Azure Data Lake Store and Analytics provides a rich and powerful environment to develop, run, and mange a Big Data analytics environment.
A deeper detailed discussion of the features and capabilities of Data Lake Tools for Visual Studio is beyond the scope of this book. You are strongly advised to refer to the following links and resources for additional information.
Note
Download Azure Data Lake Tools for Visual Studio: https://www.microsoft.com/en-us/download/details.aspx?id=49504 .
Tip
Develop U-SQL scripts using Data Lake Tools for Visual Studio: https://docs.microsoft.com/en-us/azure/data-lake-analytics/data-lake-analytics-data-lake-tools-get-started .
ADLA U-SQL Features and Benefits
Regardless of whether you are creating U-SQL jobs using the Azure Portal or using the Data Lake Tools for Visual Studio, there are some huge benefits in leveraging this service for your Big Data processing needs.
U-SQL is a new language from Microsoft for processing Big Data jobs in Azure. U-SQL combines the familiar syntax of SQL with the expressiveness of custom code written in C#, on top of a scale-out runtime that can handle virtually any size of data. Some of the many features and benefits of leveraging U-SQL include the following:
Handles all types of data: unstructured, semi-structured, and structured.
Allows you to declare and use domain-specific, user-defined types using C#.
You can run U-SQL queries over Data Lake Store and Azure blobs.
You can also run federated queries over operational and data warehouse SQL stores, reducing the complexity of ETL operations.
Allows developers to leverage their existing skills with SQL and .NET. U-SQL developers are productive from day one.
Easy to scale and performance tune without the need to manually configure the environment.
Easy to use built-in connectors for common data formats.
Simple and rich extensibility model for adding customer–specific data transformations.
No limits on scale. Scales on-demand with no changes required to the code.
Automatically parallelizes U-SQL queries and custom code.
Designed to process petabytes of data.
Built-in aggregation functions that can be extended with custom C# aggregation functions.
Uses built-in extractors to read CSV and TSV files or create custom extractors for different data file formats.
Enterprise grade tools and execution environment.
Includes tools for managing, securing, sharing, and discovery of familiar data and code objects (tables, functions etc.)
Provides role-based authorization of catalogs and storage accounts using Azure Active Directory (AAD) security.
Provides auditing for catalog objects such as databases, tables, etc.
Sample SQL Table DDL (Data Definition Language) commands:
CREATE TABLE
CREATE CLUSTERED INDEX
CREATE TABLE w/ CLUSTERED INDEX
INSERT
TRUNCATE
DROP
Tables are registered in the metadata catalog and are discoverable by others via the catalog/metadata APIs.
Note
You can insert data into a table only if it has a clustered index.
Types of U-SQL User-Defined Operators
The U-SQL language allows for the following User-Defined Operators (UDOs ) that can be extended:
Extractors (called with Extract syntax)
Processors (called with Process syntax)
Appliers (called with Apply syntax)
Combiners (called with Combine syntax)
Reducers (called with Reduce syntax)
Outputters (called with Output syntax)
See the following link for more detailed information:
U-SQL programmability guide: https://docs.microsoft.com/en-us/azure/data-lake-analytics/data-lake-analytics-u-sql-programmability-guide#use-user-defined-extractors .
As of this writing, ADLA comes out-of-the-box with three extractors:
Comma-Separated-Value (CSV) delimited text
Tab-Separated-Value (TSV) delimited text
General-purpose extractor for delimited text
See the following link for U-SQL samples, libraries, and tools for extending U-SQL.
Note
The U-SQL GitHub Repository is found at https://github.com/Azure/usql .
See the following link for a more detailed walkthrough of using Azure Data Analytics from the Azure Portal.
Tip
Get started with Azure Data Lake Analytics using Azure Portal: https://docs.microsoft.com/en-us/azure/data-lake-analytics/data-lake-analytics-get-started-portal .
U-SQL Windowing Functions
U-SQL contains a powerful construct called “windowing functions ,” which are defined by the use of the OVER clause and represent those values that are computed from multiple rows instead of just the current row. U-SQL adopts a subset of the ANSI Standard SQL Window functions that were introduced into the language in 2003.
The window functions are categorized into the following general areas:
Reporting Aggregation Functions: Includes SUM and AVG.
Ranking Functions: Includes DENSE_RANK, ROW_NUMBER, NTILE, and RANK.
Analytic Functions: Includes cumulative distribution or percentiles and accessing data from a previous row (in the same result set) without using a self-join.
As you learned in Chapter 5, these types of aggregates can be especially crucial to the analysis of real-time streaming data over a period of time. In addition to the obvious benefits of gathering aggregates in real-time over fast moving data streams, there can also be value in performing these same types of aggregate analysis over historical datasets for “what-if” analyses and regression testing scenarios.
Figure 7-16 presents a sample U-SQL script that demonstrates the use of the OVER keyword with the PARTITION BY clause to refine the “window” to list all the employees, the department, and the total salary for the department. Note that the PARTITION BY clause is added to the OVER clause to create this summarization effect.

Figure 7-16. Sample U-SQL script demonstrating the windowing capabilities of ADLA using OVER and PARTITION BY
Note that in Figure 7-16 the sample input data stream for employees was created entirely in code rather than read from a file or SQL table. Because we are working with a batch service, we still need to output our results to a CSV file (DepartSummary.csv) using the built-in CSV outputter format option. Figure 7-17 depicts that output.

Figure 7-17. Results of the sample U-SQL script demonstrating the windowing capabilities
Each row of the output results also contains the total salary for each department (the pre-aggregated sum of all salaries in that department) and is broken down by department.
Reporting Aggregation Functions
ADLA window functions support the following aggregates as part of the U-SQL language:
COUNT
SUM
MIN
MAX
AVG
STDEV
VAR
Ranking Functions
ADLA window functions support the following ranking functions as part of the U-SQL language:
RANK
DENSE_RANK
NTILE
ROW_ NUMBER
Analytical Functions
ADLA window functions support the following analytical functions as part of the U-SQL language:
CUME_DIST
PERCENT_RANK
PERCENTILE_CONT
PERCENTILE_DISC
See the following link for a more detailed walkthrough of using Azure Data Analytics window functions:
Note
Visit “Using U-SQL window functions for Azure Data Lake Analytics Jobs” at https://docs.microsoft.com/en-us/azure/data-lake-analytics/data-lake-analytics-use-window-functions .
ADLA Federated Queries: Querying the Data Where It Lives
One of the most powerful features of ADLA is that it allows you to easily query data residing in multiple Azure data stores, with the added benefit of not having to first move the data into a single data store before executing the query.
There are many additional benefits to the approach of querying the data from “where it lives”; here are just a few:
Avoids moving large amounts of data across the network between data stores. This can result in drastically reduced bandwidth and latency issues over the network.
Provides a single view of data without regard to the underlying physical location of the remote data store. Reference or master data can now live in its “natural habitat” where it normally resides.
Minimizes data proliferation issues caused by maintaining multiple copies. This was yesterday’s IT solution to handling the master data problem. It was usually accomplished by attempting to centralize the data stores, and that usually meant making multiple copies of the data.
Utilizes a single query language (U-SQL) for all data queries. In addition to being a “unifying” and “singular” programming language, it is also the most familiar to developers and therefore fastest to adopt and leverage based on existing skillsets. This can amount to a huge advantage in terms of developer productivity, code maintainability, and agility.
Each data store can maintain its own sovereignty. Because the data can reside in its original location, it can be queried “in-place” and with only a subset (the query results) returned over the network to the ADLA query results. This allows the data to always reside in its home location and thereby adhere to all the rules governing the domain and movement of the data.
There is one important point to make when it comes to the implementation of this feature. When you specify a U-SQL query to work with data from other external sources in Azure, such as Azure SQL database or SQL data warehouse, you will need to specify the following information as part of the query statement:
DATA SOURCE: Represents a remote data source such as Azure SQL Database. Requires that you specify all the details (connection string, credentials, etc.) required to connect and issue SQL statements.
EXTERNAL TABLE: A local ADLA SQL table, with columns defined as C# data types, that redirects queries issued against it to the remote table that it is based on. U-SQL handles the data type conversions automatically.
ADLA’s implementation of external tables allows you impose a specific schema against the remote data, which would help to shield you from remote schema changes. This capability allows you to issue queries that join external tables with local tables, allowing for some creative Big Data processing scenarios.
PASS THROUGH Queries: The U-SQL queries are issued directly against the remote data source in the syntax of the remote data source. An example would be that Transact SQL would be issued against the remote data source for Azure SQL database queries.
REMOTABLE_TYPES: For every external data source, you have to specify the list of “remoteable types”. This list constrains the types of queries that will be remoted. Ex: REMOTABLE_TYPES = (bool, byte, short, ushort, int, decimal).
LAZY METADATA LOADING: Here the remote data is schematized only when the query is actually issue to the remote data source. Your program must be able to deal with remote schema changes.
These implementation requirements result in a few key lessons that are worthy of a deeper technical walkthrough. This is necessary to fully demystify for the reader how this feature is implemented in Azure Data Lake Analytics.
Federated Queries: Overview of Steps Required to Query External Tables
It is important to note that there are several steps required to successfully implement an ADLA Federated query. We walk through each of the steps required starting with the prerequisites.
Confirm U-SQL Federated Query : Prerequisites Installed and Configured
Note that most of the prerequisites are required and will cause significant connectivity and access issues that can be difficult to diagnose.
Azure Subscription
Azure Data Lake Store (ADLS) account
Azure Data Lake Analytics (ADLA) account
Azure SQL Database or Azure SQL Data warehouse with SQL login/password credentials
Visual Studio 2015 (Optional). To create and execute U-SQL queries. U-SQL scripts can also be developed and deployed via the Azure Portal.
Azure Data Lake Tools for Visual Studio 2015. (Optional) works with Visual Studio 2015.
Azure PowerShell (Optional)
Download: http://aka.ms/webpi-azps
Verify “Read/Execute” Permissions on Your Azure Data Lake Store Account
This is required to create the catalog secret via a PowerShell command in a later step. To verify your permissions:
Navigate to your ADLS account in Azure Portal.
Click on the Data Explorer icon in the top navigation bar.
Click on the Access icon in the top navigation bar.
Validate you have Read/Execute permissions.
The screenshot in Figure 7-18 illustrates the proper permissions for an authorized user.

Figure 7-18. Azure Data Lake Store: user permissions view via the Azure Portal
Configure Access to the Remote Azure SQL Database: Allow IP Range in the SQL Server Firewall for the ADLA Services That Execute the U-SQL Queries
This step grants access to the ADLA service to access your Azure SQL Server and its related Azure SQL databases.
Navigate to the targeted Azure SQL Database Server instance via the Azure Portal:
Click on the SQL Server icon to get to the settings page.
Click on the Firewall icon on the left navigation blade.
Create a new rule with range 25.66.0.0 to 25.66.255.255.
Click on the Save icon on the top navigation bar to save these changes.
The screenshot in Figure 7-19 depicts the Azure SQL Server Firewall configuration screen and a new firewall rule added for ADLA access.
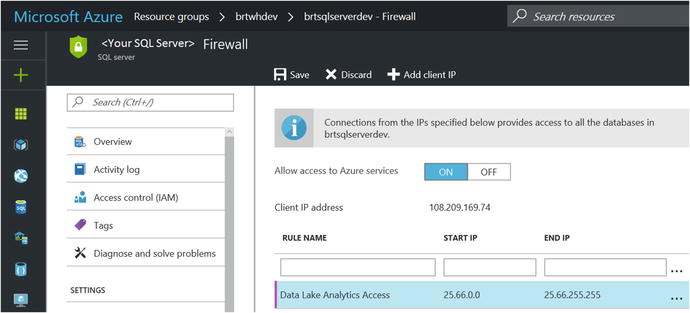
Figure 7-19. Adding a new SQL Server firewall rule for allowing remote access via the Azure Data Lake Analytics service
Create a New ADLA SQL Database and SQL table via U-SQL Query
The next step is to create an ADLA SQL Database and SQL table. To do this, navigate to your ADLA account via the Azure Portal and then select the +New Job icon to submit a new U-SQL job. Enter this U-SQL code to create an ADLA SQL database and table:
//Create TableCREATE DATABASE IF NOT EXISTS SearchMaster;//Create TableCREATE TABLE IF NOT EXISTS SearchMaster.dbo.SearchLog(//Define schema of tableUserId int,Start DateTime,Region string,Query string,Duration int,Urls string,ClickedUrls string,INDEX idx1 //Name of indexCLUSTERED (Region ASC) //Column to cluster byPARTITIONED BY HASH (Region) //Column to partition by);
Use PowerShell to Create a New Catalog Secret in the ADLA Database
This secret contains the password for the SQL login and connection string for the Azure SQL database.:
#Login (Microsoft Azure Login screen will appear):Login-AzureRmAccount#Show your available Azure Subscriptions:Get-AzureRmSubscription#Connect to Azure Subscription that contains the ADLA Database:Set-AzureRMContext -SubscriptionId 00000000-0000-0000-0000-000000000000New-AzureRmDataLakeAnalyticsCatalogCredential -AccountName "ContosoADLAAccount" `-DatabaseName "ContosoADLADB" `-CredentialName "ContosoAzureSQLDB_Secret" `-Credential (Get-Credential) `-DatabaseHost "ContosoSQLSVR.database.windows.net" -Port 1433
You can verify that these PowerShell commands created a new credential object in your ADLA SQL database by navigating to your SQL database using the ADLA Data Explorer. Start by expanding the node for your database and then expanding the Credentials node, as shown in Figure 7-20.
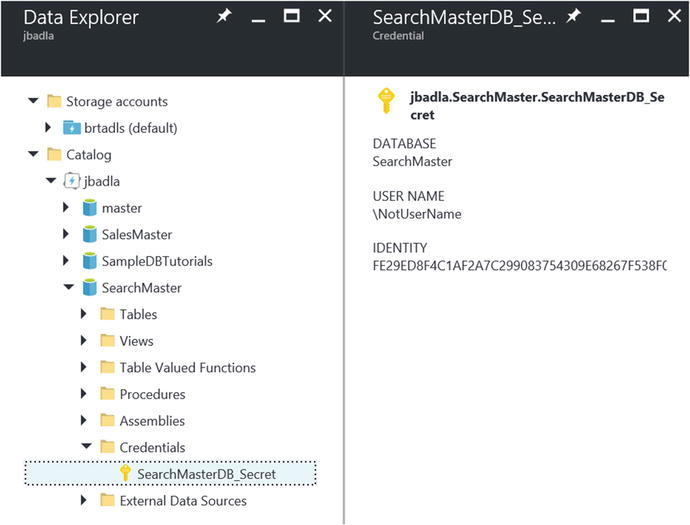
Figure 7-20. Viewing the Azure Data Lake Analytics SQL database credentials created by PowerShell
Create a CREDENTIAL with an IDENTITY that matches the AzureRmDataLakeAnalyticsCatalogCredential Name
This is used in the PowerShell script (ContosoAzureSQLDB_Secret) in the ADLA Database using this U-SQL query:
//Connect to ADLA DatabaseUSE DATABASE YourADLADatabaseName;//Create CREDENTIAL//IDENTITY: ADLA SQL Catalog Secret, MUST MATCH name chosen in prior PowerShell script -> "ContosoAzureSQLDB_Secret"CREATE CREDENTIAL IF NOT EXISTS [ContosoAzureSQLDB_Secret] WITH USER_NAME = " YourAzureSQLDB_Username ", IDENTITY = " YourAzureSQLDB_Secret";
Create Data Source in ADLA Database with a Reference to the Azure SQL Database
Use this U-SQL query:
// Create External Data Source on ADLA SQL DBCREATE DATA SOURCE IF NOT EXISTS [ASQL_YOURDB]FROM AZURESQLDBWITH (PROVIDER_STRING = "Initial Catalog= YourASQLDB;Trusted_Connection=False;Encrypt=True",CREDENTIAL = [ContosoAzureSQLDB_Secret],REMOTABLE_TYPES = (bool, byte, sbyte, short, ushort, int, uint, long, ulong, decimal, float, double, string, DateTime));
Create an External Table in ADLA SQL Database Based on the Remote Data Source
Use this U-SQL query. Note that the ADLA SQL table schema needs to match the remote table schema with corresponding field types .
// CREATE EXTERNAL TABLE in ADLA SQL database to represent the remote database table.CREATE EXTERNAL TABLE DailySales (OrderID int?,SalesDate DateTime?,Customer string,Street string,City string,Region string,State string,Zip string,SubTotal decimal?,SalesTax decimal?,SalesTotal decimal?) FROM [ASQL_YOURDB] LOCATION "dbo.DailySales";
Query the New Federated External Azure SQL Database Table
Output the results to a text (.CSV) file using this U-SQL query statement:
@query = SELECT * FROM DailySales;OUTPUT @queryTO "/Output/TestFederatedfile.csv"USING Outputters.Csv();
At this point, you have successfully configured your environment according to the setup procedures and prerequisites. You should now be able to issue U-SQL job queries against the remote external data store (an Azure SQL database in this case) .
The ADLA Federated Query capability offers a huge advantage in productivity as it allows you to query and compute remote data that lives virtually anywhere and then join that data with multiple additional cloud sources.
At the time of this writing, the following external data sources are allowed in an ADLA Federated Query:
AZURESQLDB: Specifies that the external source is a Microsoft Azure SQL Database instance.
AZURESQLDW: Specifies that the external source is a Microsoft Azure SQL Data warehouse instance.
SQLSERVER: Specifies that the external source is a Microsoft SQL Server instance running in an accessible Microsoft Azure VM. Only SQL Server 2012 and newer versions are supported.
Combining Row Sets
The Azure Data Lake U-SQL language provides a number of operators to combine row sets from various data sources. Here are the current operators supported in the ADLA U-SQL programming language:
LEFT OUTER JOIN
LEFT INNER JOIN
RIGHT INNER JOIN
RIGHT OUTER JOIN
FULL OUTER JOIN
CROSS JOIN
LEFT SEMI JOIN
RIGHT SEMI JOIN
EXCEPT ALL
EXCEPT DISTINCT
INTERSECT ALL
INTERSECT DISTINCT
UNION ALL
UNION DISTINCT
Azure Portal Integration
As you have seen in this brief overview of ADLA, there are many tasks that can be accomplished right in the Azure Portal. For example, you can accomplish all of these tasks right from the Azure Portal in order to be (immediately) highly productive:
Create a New ADLA account.
Author U-SQL scripts. Open/Save.
Submit U-SQL jobs.
Cancel running jobs.
Provision users who can submit ADLA jobs.
Visualize usage statistics (compute hours).
Visualize job management charts.
These tasks comprise the full lifecycle of U-SQL job execution from creation, to submission, to monitoring, and finally to analyzing job results.
Of course, for the hard-core ADLA developers, Visual Studio and the Data Lake Tools for Visual Studio may be a better fit. To get an idea of the capabilities of the Data Lake Tools for Visual Studio, take a look at the following link.
Note
Develop U-SQL scripts using Data Lake Tools for Visual Studio at this link: https://docs.microsoft.com/en-us/azure/data-lake-analytics/data-lake-analytics-data-lake-tools-get-started
Big Data Jobs: Simplified Management and Administration
In addition to the web-based management capabilities available in the Azure Portal, there are additional management and monitoring capabilities available for Azure Data Lake Store and Analytics.
Task Automation via PowerShell Scripts: They enable you to create a highly automated, Big Data data processing environment.
Role-Based Access Control (RBAC) with Azure Active Directory (AAD): Provides seamless user authentication and authorization integration services.
Monitoring for Service Operations and Activity
Job Management: The total number of jobs submitted as well as the number that succeeded, failed, or were cancelled
Job Compute Usage: The number of compute hours consumed by the jobs
U-SQL: Optimization Is Built- In
The ADLA U-SQL language is truly unique in that it has the following powerful optimization capabilities built-in:
Automatic “in-lining” of U-SQL expressions, which means that the whole U-SQL script leads to a single execution model.
Execution plan that is optimized “out-of-the-box” and without any user intervention required.
Automatic per-job and user-driven parallelization optimizations.
Detailed visibility into the U-SQL job execution steps, for debugging and optimization purposes.
Heat map functionality to help identify performance bottlenecks.
Implementing ADLA in the Reference Implementation
Now that you have a solid background of the features and capabilities of ADLA and the U-SQL programming language, you will put this knowledge to use by implementing a few more key pieces of the reference implementation.
As a quick refresher, Figure 7-21 illustrates the “big picture” when it comes to the reference implementation and the role that ADLA plays in the implementation of this architecture.

Figure 7-21. Data Lake Analytics role in the reference implementation architecture
As can be seen in Figure 7-21, you’ll draw upon our key lessons from Chapter 6 (Data Factory) and Chapter 7 (Data Lake Analytics) to continue with the data movement and transformation activities for the reference application in this chapter.
Specifically, in this next section, you will be processing the data that was moved to the Azure Data Lake Store from Azure Blob storage (via an Azure Data Factory job), which represents the incoming IoT streaming data.
You will then join this raw, incoming, IoT data with the results of the Azure Machine Learning Web service calls that were made real-time during the Stream Analytics ingestion job and then persisted to Azure Blob storage. This is the persisted copy of the “hot” data path that checked the team member’s health. The “hot” output path destination defined in Chapter 5 was for Power BI; we also persisted the output to Azure blob Storage for a more permanent record of the real-time streaming results that were processed with Machine Learning Web Service calls.
Modify Azure Data Factory Job: “Copyfromblobtodatalake”
In this section, we walk through modifying the existing Data Factory pipeline named CopyFromBlobToDataLake.
Basically, we need to add two more copy activities to the pipeline in order to move these two files to Azure Data Lake:
Historical IoT Hub Streaming Data Machine Learning Web Service Call Results from “hot” path.
Team Member Reference Data Team Member Company Affiliation.
The easiest way to do this is to navigate to the existing Azure Data Factory Job, called CopyFromBlobToDataLake, and then select the option for Copy Data (PREVIEW) as shown in Figure 7-22.
Figure 7-22. Azure Data Factory Copy Data option
Selecting this option will allow you to easily add copy functionality to the existing Data Factory Pipeline Copy job.
Walk through the steps in the Azure data Factory Copy Data PREVIEW Wizard to create the copy job for the first additional file we need—the Historical IoT Hub Streaming Data Machine Learning Web Service Call Results. Here is a high-level outline of the input and outputs that are required to create this new copy pipeline.
New Copy Job: Historical IoT Hub Streaming Data Machine Learning Web Service Call Results:
INPUT Dataset (Blob):
These files will be found in a Blob container named streamingmldata and will be generated under a folder structure of Year/Month/Day/Hour.
OUTPUT Dataset (Data Lake):
Set the output data set to point to the file name of the form StreamingMLResultsDataFile{year}{month}{day}{hour}.csv.
Next, add another copy job to the existing Azure Data Factory Pipeline job to copy the second data file, the Team Member Reference Data .CSV file.
Again, we will use the Copy Data Wizard to make it fast and easy. Refer to the following input and output dataset guidance for locating and replicating your data according to the reference implementation.
Here is a high-level outline of the input and outputs that are required to create this new “copy” pipeline.
New Copy Job: Team Member Reference Data:
INPUT Dataset (Blob):
These files will be found in a Blob container named refdata-team and will be generated under a file named "TeamReferenceData" + "{year}{month}{day}{hour}"+ ".csv".
Note that the file generations will include the extension of {year}{month}{day}{hour} to the file name.
OUTPUT Dataset (Data Lake):
Set the output data set to point to the folder named streamingmldata. The file name will be "TeamReferenceData" + "{year}{month}{day}{hour}" + ".csv".
At this point, we have successfully modified our Azure Data Factory Pipeline job to copy two additional files into Azure Data Lake for building the master historical Machine Learning Analysis ADLA SQL table.
The last step is to run the updated Data Factory Copy jobs and actually move the data files from Azure Blob Storage to Azure Data Lake.
Create Azure Data Factory Job to Automatically Populate the Azure Sql Databases (By Business Entity) Using the Sql Query Extractions from the Azure Data Lake Database
This last step will complete the data analysis and reporting journey by exposing the historical IoT sensor data and associated Machine Learning Web Service call results for consumption by the business entities in the reference implementation scenario.
At this point, all the hard work has already been completed, and all you have to do is create an Azure Data Factory job to select the data out of the ADLA SQL database, filter the results by business entity, and then insert the data into the individual Azure SQL databases you created in the last step.
To get started via the Azure Portal, first navigate to your existing Azure resource group. Search for Data Factory and then add a new Data Factory job, as shown in Figure 7-23.
Figure 7-23. Adding a new Azure Data Factory job to a resource group
Next, complete the Azure Data Factory Job configuration parameters, as shown in Figure 7-24.

Figure 7-24. Azure Data Factory job parameters
Click on the Create icon, and then the new Data Factory job will be provisioned into your Azure Resource Group after a few minutes.
After the new Data Factory job has been provisioned into your environment, navigate to the new Data Factory job and select the Copy Data (PREVIEW) icon to launch the Copy Wizard.

Figure 7-25. Data Factory Copy Data Wizard
Next, walk through the Copy Data Wizard to create a Data Factory pipeline job that will copy the data from each individual .CSV file (one for each entity) to the appropriate Azure SQL database (which varies by business entity). The SQL table name and scheme in each database is the same across all databases.
Here are code fragments from a sample Azure Data Factory job to populate an Azure SQL Database for WigiTech, based on a .CSV file exported from the Azure Data Lake Store .
Linked Service: Source Azure Data Lake Store
{
"name": "Source-DataLakeStore-f0g",
"properties": {
"hubName": "populateazuresqldbs_hub",
"type": "AzureDataLakeStore",
"typeProperties": {
"dataLakeStoreUri": "https://brtadls.azuredatalakestore.net/webhdfs/v1",
"authorization": "**********",
"sessionId": "**********",
"subscriptionId": "<Your Subscription ID>",
"resourceGroupName": "brtwhdev"
}
}
}Linked Service: Destination: Azure SQL Database
{
"name": "Destination-SQLAzure-f0g",
"properties": {
"hubName": "populateazuresqldbs_hub",
"type": "AzureSqlDatabase",
"typeProperties": {
"connectionString": "Data Source=brtsqlserverdev.database.windows.net;Initial Catalog=IOTDataMLHistory-WigiTech;Integrated Security=False;User ID=<Your User ID>;Password=<Your Password>;Connect Timeout=30;Encrypt=True"
}
}
} Input Dataset : .CSV File in Azure Data Lake Store
{
"name": "InputDataset-f0g",
"properties": {
"structure": [
{
"name": "Column0",
"type": "String"
},
{
"name": "Column1",
"type": "Int64"
},
{
"name": "Column2",
"type": "Int64"
},
{
"name": "Column3",
"type": "Int64"
},
{
"name": "Column4",
"type": "Int64"
},
{
"name": "Column5",
"type": "Double"
},
{
"name": "Column6",
"type": "Double"
},
{
"name": "Column7",
"type": "Int64"
},
{
"name": "Column8",
"type": "Double"
},
{
"name": "Column9",
"type": "Int64"
},
{
"name": "Column10",
"type": "Double"
},
{
"name": "Column11",
"type": "Double"
},
{
"name": "Column12",
"type": "Int64"
},
{
"name": "Column13",
"type": "Int64"
},
{
"name": "Column14",
"type": "Int64"
},
{
"name": "Column15",
"type": "Int64"
},
{
"name": "Column16",
"type": "Int64"
},
{
"name": "Column17",
"type": "Int64"
},
{
"name": "Column18",
"type": "String"
},
{
"name": "Column19",
"type": "String"
},
{
"name": "Column20",
"type": "Int64"
},
{
"name": "Column21",
"type": "Double"
},
{
"name": "Column22",
"type": "Double"
},
{
"name": "Column23",
"type": "Datetime"
},
{
"name": "Column24",
"type": "Datetime"
},
{
"name": "Column25",
"type": "Int64"
},
{
"name": "Column26",
"type": "Datetime"
},
{
"name": "Column27",
"type": "String"
},
{
"name": "Column28",
"type": "String"
},
{
"name": "Column29",
"type": "String"
},
{
"name": "Column30",
"type": "Int64"
},
{
"name": "Column31",
"type": "Int64"
},
{
"name": "Column32",
"type": "String"
},
{
"name": "Column33",
"type": "Int64"
},
{
"name": "Column34",
"type": "String"
},
{
"name": "Column35",
"type": "Datetime"
},
{
"name": "Column36",
"type": "String"
},
{
"name": "Column37",
"type": "Double"
},
{
"name": "Column38",
"type": "Int64"
},
{
"name": "Column39",
"type": "String"
},
{
"name": "Column40",
"type": "String"
}
],
"published": false,
"type": "AzureDataLakeStore",
"linkedServiceName": "Source-DataLakeStore-f0g",
"typeProperties": {
"fileName": "StreamingDataMLHistory-WigiTech.Csv",
"folderPath": "output/",
"format": {
"type": "TextFormat",
"columnDelimiter": ",",
"quoteChar": """
}
},
"availability": {
"frequency": "Day",
"interval": 1
},
"external": true,
"policy": {}
}
}Output Dataset : Azure SQL Database Table
{
"name": "OutputDataset-f0g",
"properties": {
"structure": [
{
"name": "UserId",
"type": "String"
},
{
"name": "Age",
"type": "Double"
},
{
"name": "Height",
"type": "Double"
},
{
"name": "Weight",
"type": "Double"
},
{
"name": "HeartRateBPM",
"type": "Double"
},
{
"name": "BreathingRate",
"type": "Double"
},
{
"name": "Temperature",
"type": "Double"
},
{
"name": "Steps",
"type": "Double"
},
{
"name": "Velocity",
"type": "Double"
},
{
"name": "Altitude",
"type": "Double"
},
{
"name": "Ventilization",
"type": "Double"
},
{
"name": "Activity",
"type": "Double"
},
{
"name": "Cadence",
"type": "Double"
},
{
"name": "Speed",
"type": "Double"
},
{
"name": "HIB",
"type": "Double"
},
{
"name": "HeartRateRedZone",
"type": "Double"
},
{
"name": "HeartrateVariability",
"type": "Double"
},
{
"name": "Status",
"type": "Int32"
},
{
"name": "Id",
"type": "String"
},
{
"name": "DeviceId",
"type": "String"
},
{
"name": "MessageType",
"type": "Int32"
},
{
"name": "Longitude",
"type": "Double"
},
{
"name": "Latitude",
"type": "Double"
},
{
"name": "Timestamp",
"type": "Datetime"
},
{
"name": "EventProcessedUtcTime",
"type": "Datetime"
},
{
"name": "PartitionId",
"type": "Int32"
},
{
"name": "EventEnqueuedUtcTime",
"type": "Datetime"
},
{
"name": "FirstName",
"type": "String"
},
{
"name": "LastName",
"type": "String"
},
{
"name": "UserName",
"type": "String"
},
{
"name": "UType",
"type": "String"
},
{
"name": "Phone",
"type": "String"
},
{
"name": "Email",
"type": "String"
},
{
"name": "Gender",
"type": "String"
},
{
"name": "MLUserid",
"type": "String"
},
{
"name": "MLTimestamp",
"type": "String"
},
{
"name": "ScoredLabels",
"type": "String"
},
{
"name": "ScoredProb",
"type": "Double"
},
{
"name": "Race",
"type": "Int32"
},
{
"name": "CompanyName",
"type": "String"
},
{
"name": "Rid",
"type": "String"
}
],
"published": false,
"type": "AzureSqlTable",
"linkedServiceName": "Destination-SQLAzure-f0g",
"typeProperties": {
"tableName": "[dbo].[IOTDataMLHistory]"
},
"availability": {
"frequency": "Day",
"interval": 1
},
"external": false,
"policy": {}
}
}Pipeline : Copy CSV to Azure SQL Database
{
"name": "CopyPipeline-f0g",
"properties": {
"activities": [
{
"type": "Copy",
"typeProperties": {
"source": {
"type": "AzureDataLakeStoreSource",
"recursive": true
},
"sink": {
"type": "SqlSink",
"writeBatchSize": 0,
"writeBatchTimeout": "00:00:00"
},
"translator": {
"type": "TabularTranslator",
"columnMappings": "Column0:UserId,Column1:Age,Column2:Height,Column3:Weight,Column4:HeartRateBPM,Column5:BreathingRate,Column6:Temperature,Column7:Steps,Column8:Velocity,Column9:Altitude,Column10:Ventilization,Column11:Activity,Column12:Cadence,Column13:Speed,Column14:HIB,Column15:HeartRateRedZone,Column16:HeartrateVariability,Column17:Status,Column18:Id,Column19:DeviceId,Column20:MessageType,Column21:Longitude,Column22:Latitude,Column23:Timestamp,Column24:EventProcessedUtcTime,Column25:PartitionId,Column26:EventEnqueuedUtcTime,Column27:FirstName,Column28:LastName,Column29:UserName,Column30:UType,Column31:Phone,Column32:Email,Column33:Gender,Column34:MLUserid,Column35:MLTimestamp,Column36:ScoredLabels,Column37:ScoredProb,Column38:Race,Column39:CompanyName,Column40:Rid"
}
},
"inputs": [
{
"name": "InputDataset-f0g"
}
],
"outputs": [
{
"name": "OutputDataset-f0g"
}
],
"policy": {
"timeout": "1.00:00:00",
"concurrency": 1,
"executionPriorityOrder": "NewestFirst",
"style": "StartOfInterval",
"retry": 3,
"longRetry": 0,
"longRetryInterval": "00:00:00"
},
"scheduler": {
"frequency": "Day",
"interval": 1
},
"name": "Activity-0-Data lake path_ output_->[dbo]_[IOTDataMLHistory]"
}
],
"start": "2016-12-23T03:32:59.874Z",
"end": "2099-12-31T05:00:00Z",
"isPaused": false,
"hubName": "populateazuresqldbs_hub",
"pipelineMode": "Scheduled"
}
} Once you have finished creating the new Azure Data Factory job to copy the CSV file data into the Azure SQL databases, you can easily verify the output. Open SQL Server Management Studio or Visual Studio Server Explorer and run a SQL query over the newly populated SQL table. Figure 7-26 illustrates the results of a SQL query against the IOTDataMLHistory SQL table.

Figure 7-26. Verify import Azure SQL database using a SQL query in SQL Server Management Studio
At this point, you have completed all the tasks necessary to implement the Azure architecture for the reference implementation, as illustrated in Figure 7-27.
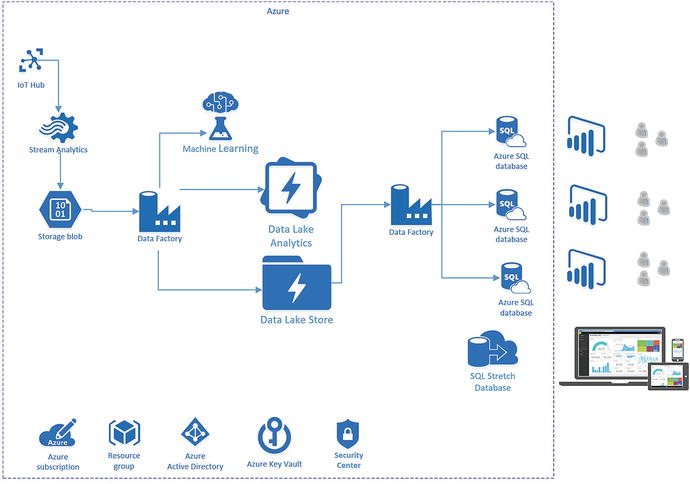
Figure 7-27. Azure architecture for the reference implementation
A final step in this process for a full production implementation would be to “lock down” the security aspects of this solution by restricting users and user access to the Azure Data Lake Store and Azure SQL databases via the Azure Portal.
Note
See this link for more information: Security in Azure Data Lake Store: https://docs.microsoft.com/en-us/azure/data-lake-store/data-lake-store-security-overview .
Reference Implementation Summary
At this point in the construction of the reference implementation, we have successfully introduced the use of Azure Data Lake and ADLA to provide additional large-scale, batch data processing and analysis capabilities.
One of the more unique and enabling aspects of ADLA applications, built as truly cloud-based solutions, is that you only pay for the resources you consume. It is a pure “consumption-model” approach. In the case of the reference implementation, the incremental Azure billing costs amount to just the costs for the Data Lake Storage (storage consumed) and the ADLA (per job run) costs. This means you can just focus on building and refining the data applications at hand and leave all the infrastructure provisioning, job scheduling, deployment, scaling, and monitoring tasks to Microsoft Azure.
To summarize the progress so far, we provided data capture, analysis, and reporting capabilities by business entity to help achieve the following goals:
Provided a historical team health monitoring archival and analysis solution using Azure Data Lake.
Established a comprehensive, historical Machine Learning analysis dataset for creating and refining team health predictions based upon actual or simulated real-time sensor data.
Enabled full regression analysis scenarios for analyzing and “re-playing” historical events.
Created the ability to repeat and fine-tune Machine Learning algorithms over the historical data.
Provided secure, individualized, “self-serve business intelligence” capabilities to each business entity to connect, view, and extract their data. Power BI makes it easy to automatically publish to the web or any mobile device. Chapter 9 explores this topic further.
Summary
This chapter provided a high-level overview of Azure Data Lake Store (ADLS) and Azure Data Lake Analytics (ADLA) and explored the rich set of complementary capabilities offered by both services.
The primary focus of these two cloud services is clearly handling Big Data at scale. One of the more interesting aspects is the flexible and open-ended architecture that enables ingesting all types of data via custom or out-of-the-box data extractors and output formatters.
Some of the key value propositions are discussed in the following sections.
Handles Virtually All Types of Data
U-SQL is the language of choice for creating ADLA and it can handle virtually all data ingestion scenarios.
Unstructured, semi-structured, or structured data.
Domain-specific user defined types using C#.
U-SQL queries over Data Lake and Azure blobs.
Federated Queries over Operational SQL stores and SQL DW, removing the complexity and processing time requirements of traditional Extract-Transform-Load (ETL) operations.
Productive from Day One
The combination of Azure Data Lake Store, ADLA, and U-SQL make it super easy to become instantly productive in the environment.
Provides effortless scale and performance without the need to manually tune or configure the environment.
Provides one of best developer experiences throughout the development lifecycle for both novices and experts.
Allows developers to easily leverage existing skill sets with SQL and .NET.
ADLA provides easy and powerful data extraction, preparation, and reporting capabilities.
Easy to use, built-in, text-based connectors for ingesting the most common data formats like tab and comma-delimited text files.
Simple and rich extensibility model for adding customer–specific data transformations.
No Limits to Scale
Azure Data Lake Store offers virtually limitless storage capacity and the ADLA environment was built from the ground up to handle some of the largest and complex distributed data processing scenarios in the industry today.
Scales on demand with no code changes required.
Automatically parallelizes U-SQL and custom code jobs.
Designed to process literally petabytes of data.
Enterprise Grade
Microsoft Azure leverages other common cloud services such as Azure Active Directory (AAD) to help create a secure, integrated, and easily manageable Big Data cloud environment.
Azure Data Lake Store offers virtually limitless storage capacity and the Azure Managing, securing, sharing, and discovery of familiar data and code objects (tables, functions, etc.)
Role-based Authorization capabilities for ADLA SQL catalogs and storage accounts using Azure Active Directory (AAD) integrated security.
Auditing capabilities are exposed for monitoring of ADLA Catalog objects (databases, tables, etc.).
Reference Implementation
This chapter demonstrates how easy it is to provision, prepare, develop, and publish large datasets that were generated by IoT front-end applications.
You saw how most tasks are accomplished via simple Azure service “configuration activities” vs. the legacy method of doing things, which usually required a dedicated hardware environment, along with all of the additional costs, maintenance, and overhead.
Just Scratching the Surface
It is important to note that we have really only just scratched the surface in terms of the coverage of ADLA features and capabilities. There are many deeper additional topics to explore concerning the functionality and features that are built-in and extensible to the U-SQL programming language and surrounding ADLA services.
Suffice it to say that there are many use case scenarios can easily be implemented via the constructs provided by this set of services for truly handling Big Data in the Azure cloud.