
Getting to know Web applications
Conferring with the client
Working with Web servers
When I first started writing about World Wide Web applications, I had to describe the Web first. There were still a significant number of programmers who didn't know what it was, or thought it was CompuServe.
I don't really have that problem anymore.
The World Wide Web is now ubiquitous. Programmers of all stripes use the Web for research and communication. Providers use it for product updates and documentation. It is everywhere.
All the more reason to know how to code in the Web environment. Problem is that there are so many so-called frameworks for development that it is nearly impossible to decide which to use with a reasonable methodology. You almost have the draw straws.
If you are working in a Microsoft environment, and if you are writing a non-exceptional program, I recommend that you use plain, vanilla ASP.NET. Why? Sempf's Fourth Law: Simplicity above all. ASP.NET is a straightforward platform for Web creation.
ASP.NET has its share of problems, most of which involve writing Google (or some other really big complicated program). You probably aren't writing Google, so don't worry about it. If your site gets famous, you can get some venture capital and rewrite it into some custom framework. For now, just get your site written.
That's what ASP.NET enables you to do — get the job done. With ASP.NET, you can write a good Web site quickly, one that can be hosted just about anywhere. No one can ask for much more than that.
This chapter delves into the details of using ASP.NET with C#.
A Web application is a computer program that uses a very light client interface communicating with a server over the Internet in a stateless manner. Stateless means that the computer browsing the site and the server providing the site don't maintain a connection. You can see this process at a high level in Figure 1-1.
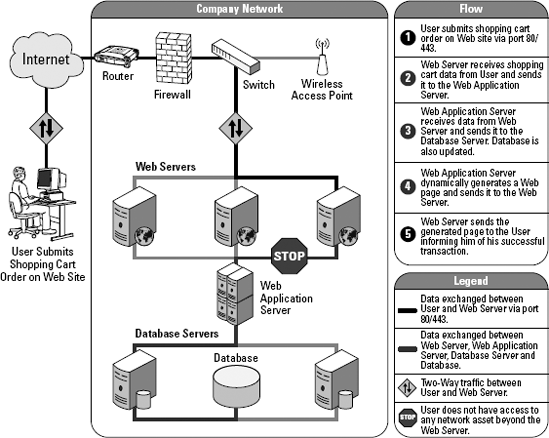
The client requests a document from the server, and the server sends the document when it gets around to it. The document, usually a combination of Hypertext Markup Language (HTML), Cascading Style Sheets (CSS), and JavaScript, contains standardized elements which make up the interface of the application.
Why do we need this? If there is just a set of documents on the server and the client is just requesting one after another, what's the point of that? Of course, getting a document is a good thing, but where does the application part come in?
The answer is within Web applications. Web applications are powerful because the server can construct the document on the fly whenever it receives a request. This server process is what makes Web applications work. (See Figure 1-2.)
Don't get me wrong, the light client interface — called the Web browser or just the browser — provides some important functionality. It handles the user interface and can do things independently of the server.
The server is largely where it's at, though. Because the server can remember things from moment to moment, and because it is assumed that the client forgets everything from page to page, the server is where the long-running communications all reside.
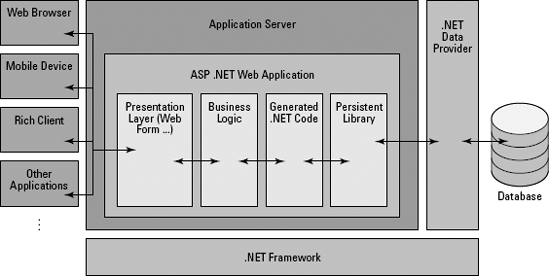
ASP.NET is a library of controls and processing logic that makes constructing the server side of things much easier. You construct "server pages," but they end up transformed into the documents that the client uses to show you the user interface. ASP.NET is classified as a Web Application Framework, not a programming language.
The programming language, for our purposes, is C#. However, you can code for ASP.NET in any .NET language — it is just another set of tools in the framework.
C# is the language that you use to tell the server how to organize the ASP.NET pieces and send them to the client. The clients will never see any C# code; they won't even know that you coded it in C#.
Note
This gets into the same discussion that we have several times throughout the book regarding the difference between the library and the language. ASP.NET is a library of tools, and that library is language independent. You orchestrate the functionality of the parts of the library using the language.
There are a few little caveats to Web development, however. The client — which doesn't care a whit that you are coding in C# — needs some care and feeding. There is no state in Web applications, so you need to think a little differently. The client does a lot automatically for you in Web development. The server has some security concerns.
Before we dig into the details of using C# with ASP.NET, I'd like to take a tour through the details of Web development and point out some things you need to keep in mind. So here we go.
When you are writing a Windows Form, WPF, or console application, your platform for the client is a Windows computer. When you are writing a Web application, you have no idea what the platform for your client is. It could be a Mac, any one of 12 Windows operating systems, or Linux. It could be a phone, a tablet, or a netbook. It could be a television, a gaming device, or a refrigerator (really: see Figure 1-3).

The point is that you don't know what you are writing for, so you have a very different development experience for a Web browser than you do for a Windows client. You don't know what size the screen is, you don't know what language the machine is set to, you don't know how fast the connection to the Internet is. You know nothing about your client.
You have to question the client. You can't assume much about the browser, so you have to make certain design decisions differently than you usually would.
You can depend on the browser to do some things for you that you might be used to having to do for yourself. The programming details are explained in Chapter 4, but it is important to get a good overview now.
First, the client browser has a built-in scripting system called ECMAScript. Second, the browser can tell you some subset of details about itself, its host machine, and the user that is using it.
By now you get the idea that communication with the browser occurs via the network, and that the client and browser are disconnected. Although that is true, the client isn't completely out in the fog when it comes to interacting with the user.
You can send a script along with your HTML document. This script references objects on the screen — just like your C# code would — and makes things happen for the user.
Usually this script is in the JavaScript language. Why not C#? Well, C# isn't a scripting language. C# needs to be compiled, and JavaScript isn't compiled. It just sits there, in text, waiting for the browser to run it.
Note
The fact that it is in text means you have to be careful not to put secure information in a script. Right-click on any Web page in your browser and click View Source to see that page's script code.
A lot of the script that your pages need will be generated by ASP.NET. This book is about C#, not JavaScript, so we focus on the server features, not the client features. For now, you should just know that "things are happening" on the client side, however.
When a browser makes a request to a server, a lot of useful information about the client gets sent along with the page name that is requested. You can reference this in the backwardly named ServerVariables collection.
This is about as good as learning about the client gets. These details will, however, help you get the most out of your communication with the client. Here some examples of the values available:
AUTH_USER:The logged-in user.REMOTE_USER:The same as AUTH_USER.CONTENT_LENGTH:Size of the request. This is useful if a file is uploaded.HTTP_USER_AGENT:Which browser the client is using.REMOTE_ADDR:The IP number of the client computer.QUERY_STRING:All the stuff after the question mark in the request. Check out the Address bar of a browser in many Web applications to see what I mean.ALL_HTTP:Every header variable (request details made available to the server) sent by the client.
In total, there are usually 63 variables in the header. The most commonly accessed of them are in the System.Web.HttpRequest class. You'll also find the collection of ServerVariables there. More on getting to that class in Chapter 4. Search MSDN for ServerVariables to get the complete list.
As you can imagine, there are a few weaknesses to the browser-as-client model. At this point in the book, you should know that the more layers you stack on, the more problems you are going to encounter. Not even letting the programmer know what computer the user has is another.
Here are a few of these weaknesses:
Changing window sizes: The most basic difficulty in using a browser as a client is changing window sizes. In a Windows program, you have at least some control over how large the window is — if it gets too small, you can change it programmatically. In a Web application, however, you have very little control over the window size. For all you know, the user could be using a cellphone, right? That's a small window!
Because of this, every form you develop using ASP.NET has to be size-agnostic to the best of your ability. Especially when your form is destined for the public Internet — you just can't make assumptions about the size of the user's screen.
Sporadic communication: When the client wants something from the server, the client requests it from the server. It is the server's responsibility to get the client what it wants, and then wait. And wait. And wait some more.
Even if the server wants an acknowledgement from the client, it might never get one. The user might have closed the browser.
Communication from the client to the server is sporadic. Secure transactions are nearly impossible because the server can't be sure that the client will communicate any information back. Because of the loosely coupled nature of the Internet, you just can't make any assumptions about communication time.
Distrusted input: Browser documents are sent as a package of text and images (and sounds and fonts and Flash movies, if needed) to the client from the server. The requests are sent back to the server from the client in a similar way — text.
With all this text, you would think that someone would find a way to fake a request. Oh wait, they have. Lots of them. And it is easy, and free.
Take a look at Fiddler, a free tool that lets you completely alter the requests sent from a browser. (See Figure 1-4.) Fiddler gives you the capability to view a request — including the results from a form (even a login form) — alter the text directly, then send it on its merry way.
Security risk? You betcha. You need to distrust every character sent to you from the client. Validate everything in the server code. We look at this in Chapters 2 and 3.
Random implementations: When you are writing a WPF application in C#, you know the application will be running on Windows. You might not know which edition, but you have a good idea about how it will work. When you write an ASP.NET system, on the other hand, you know that the client might or might not follow a set of standards, but that's about it. You don't know how the browser will behave.
The more significant impact of this is in positioning, as it turns out. The technology that specified most of the positioning and styling in browsers, called Cascading Style Sheets (CSS), is rife with misimplementation.
That means that not only do you not know how your application will behave out there, but also that it might not look right, either! Yea for the Web! Seriously, scripting is another piece of the puzzle that isn't the same across browsers. ECMAScript is another standard, and it is implemented differently by different browser companies.
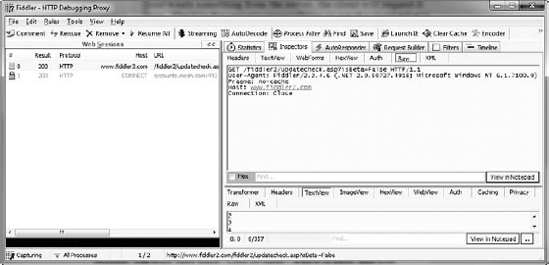
The only way around all of this is to test, test, test. If all else fails, take the simplest road. And don't get tremendously picky about a pixel here and there.
The other side of this client/server equation is the server. For those of us writing in ASP.NET, the server will be Internet Information Server fully 99.5 percent of the time. Other servers implement ASP.NET in one fashion or another, but you almost never see them.
The role of the Web server is to accept requests from clients, do whatever processing is required, and then pass back a browser-viewable page. This means that the ASP.NET code we write will be turned into HTML and JavaScript by the Web server. You have less control over what is happening than you might think.
A PostBack isn't a returned package from the post office. It is how ASP.NET handles communication between the client and the server so you don't have to.
The first time users request a page in ASP.NET in a given session, they usually type the URL into the address bar, or click a link like www.csharpfordummies.com. The next page loaded, however, is a carefully controlled communication with the server, called a PostBack.
A PostBack is a JavaScript function used in place of the built-in POST function to send information about the data on the page back to the server. It looks like this to the client:
javascript:WebForm_DoPostBackWithOptions(new WebForm_PostBackOptions("ctl
00$cphAdmin$btnSave", "", true, "", "",
false, false))Quite a change from a URL, huh? To make what I mean more clear, let's go back in time.
Back in the day, Web servers supported GETs and POSTs. What's more, they still support GETs and POSTs.
A GET is a request for a page, using just the URL. You can send data in the URI (after a question mark in the link of text) but that's all you are sending — nothing from the page itself goes back. A GET request looks like this:
GET /fiddler2/updatecheck.asp?isBeta=False HTTP/1.1
User-Agent: Fiddler/2.2.4.6 (.NET 2.0.50727.4918; Microsoft Windows NT
6.1.7100.0)
Pragma: no-cache
Host: www.fiddler2.com
Connection: CloseA POST sends values from a form on the page. The form can be invisible, but it has to be there. POSTs are a lot bigger than GETs and have a set format that is hard to navigate at times. Here is an example POST:
POST /feedbackAction.asp HTTP/1.1
Accept: application/x-ms-application, image/jpeg, application/xaml+xml, image/
gif, image/pjpeg, application/x-ms-xbap, application/vnd.ms-excel,
application/vnd.ms-powerpoint, application/msword, application/x-shockwave-
flash, */*
Referer: http://www.grovecity.com/feedback.asp
Accept-Language: en-US
User-Agent: Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.1; WOW64;
Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET
CLR 3.0.30729; Media Center PC 6.0; .NET CLR 1.1.4322; InfoPath.2;
OfficeLiveConnector.1.3; OfficeLivePatch.0.0)
Content-Type: application/x-www-form-urlencoded
Accept-Encoding: gzip, deflate
Host: www.grovecity.com
Content-Length: 69
Connection: Keep-Alive
Pragma: no-cache
Cookie: ASPSESSIONIDAATQCRCA=MJEFOIFACGPONMOBADPIDLKH
user=Bill&[email protected]&subject=Test&comment=This+is+a+POST%21All the header variables are there, and then the contents of the form are all linked together at the end of the request.
Having to handle the header had a lot of problems when it came to the sophisticated Web forms that ASP.NET provides, so Microsoft used JavaScript to short-circuit the process. They created a special method that would be on every page that ASP.NET generates.
This method formats the information in order to better manage the communication with the server. A PostBack looks like this:
POST /admin/Pages/Add_entry.aspx?id=e387aab8-1292-4c75-985f-5f8e5db3089a HTTP/1.1
Accept: application/x-ms-application, image/jpeg, application/xaml+xml, image/
gif, image/pjpeg, application/x-ms-xbap, application/vnd.ms-excel,
application/vnd.ms-powerpoint, application/msword, application/x-shockwave-
flash, */*
Referer: http://www.sempf.net/admin/Pages/Add_entry.aspx?id=e387ccb8-1292-4c75-
985f-5f8e5db3089a
Accept-Language: en-US
User-Agent: Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.1; WOW64;
Trident/4.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET
CLR 3.0.30729; Media Center PC 6.0; .NET CLR 1.1.4322; InfoPath.2;
OfficeLiveConnector.1.3; OfficeLivePatch.0.0)
Content-Type: multipart/form-data; boundary=---------------------------
7d922c323b0016
Accept-Encoding: gzip, deflate
Host: www.sempf.net
Content-Length: 9399
Connection: Keep-Alive
Pragma: no-cache
-----------------------------7d922c323b0016
Content-Disposition: form-data; name="__LASTFOCUS"
-----------------------------7d922c323b0016
Content-Disposition: form-data; name="ctl00$cphAdmin$txtTitle"
C# 4.0 at CONDG
-----------------------------7d922c323b0016
Content-Disposition: form-data; name="ctl00$cphAdmin$ddlAuthor"
Admin
-----------------------------7d922c323b0016
Content-Disposition: form-data; name="ctl00$cphAdmin$txtDate"
2009-09-08 22:21
-----------------------------7d922c323b0016
Content-Disposition: form-data; name="ctl00$cphAdmin$txtContent$TinyMCE1$txtCont
ent"
<p>I was very pleased to be able to give my C# 4.0 talk at the <a href="http://
www.condg.org/">Central Ohio .NET Developers Group</a> last month.</p>
-----------------------------7d922c323b0016
Content-Disposition: form-data; name="ctl00$cphAdmin$txtUploadImage"; filename=""
Content-Type: application/octet-stream
-----------------------------7d922c323b0016
Content-Disposition: form-data; name="ctl00$cphAdmin$txtUploadFile"; filename=""
Content-Type: application/octet-stream
-----------------------------7d922c323b0016
Content-Disposition: form-data; name="ctl00$cphAdmin$txtSlug"
C-40-at-CONDG
-----------------------------7d922c323b0016Notice the nice layout of the data, with the form field name, and the data and everything all nice to read? Fortunately, you don't have to worry about any of this. ASP.NET gets it for you.
When you create an event handler for an object — a button, for instance — a PostBack will be used for that communication. This is how ASP.NET changes your interface with the server and client. It makes Web programming look like Windows programming, at least as far as events are concerned.
The other major piece of the puzzle in Web server usage is state. No, I don't mean that field in the Address database. I mean that the server should know the state of the application at any given time.
Web servers don't do a very good job of remembering state because of one of the problems with Web browsers — inconsistency of communications. Because the server doesn't know if you are going to send anything from one minute to the next, they can't depend on getting it.
For this reason, the server tries to remember certain things about your session by putting values in the form that they can use later. The server uses a ViewState value for that. The ViewState is an encrypted string that the server can use to remember who you are from POST to POST.
Even with these values, maintaining session state has its problems. For instance, in a secure application you might need to maintain a transaction for a database function. This is nearly impossible in a Web application, because you can't be sure you will get the return acknowledgment. Because of this, nearly all the data processing happens on the server — I cover this in more detail in Chapter 5.