
Chapter 4
Domain 3: Security Engineering (Engineering and Management of Security)
Abstract
Domain 3: Security Engineering, represents a large and complex technical domain. The chapter presents key cryptographic concepts of authentication and non-repudiation in addition to confidentiality and integrity, which are concepts presented in many of the domains. Beyond the foundational operations such as substitution and permutation and types of cryptosystems, symmetric, asymmetric, and hashing, this chapter also introduces key modes of operation for symmetric cryptosystems, Electronic Code Book (ECB), Cipher Block Chaining (CBC), Cipher Feedback (CFB), Output Feedback (OFB), and Counter Mode (CTR). The goal of the domain’s final section is to ensure that the safety of personnel is a key consideration when considering physical and environmental security. To ensure this safety requires an understanding of common issues that could negatively impact personnel’s safety, such as fire, smoke, flood, and toxins, with particular emphasis on smoke and fire detection and suppression. Physical security is the other main focus of this chapter and attention is given to physical access control matters including fences, gates, lights, cameras, locks, mantraps, and guards.
Keywords
Asymmetric Encryption
Hash Function
Hypervisor
Mantrap
Tailgating
Trusted Computer System Evaluation Criteria
Symmetric Encryption
Exam objectives in this chapter
• Security Models
• Evaluation Methods, Certification and Accreditation
• Secure System Design Concepts
• Secure Hardware Architecture
• Secure Operating System and Software Architecture
• Virtualization and Distributed Computing
• System Vulnerabilities, Threats and Countermeasures
• Cornerstone Cryptographic Concepts
• History of Cryptography
• Types of Cryptography
• Cryptographic Attacks
• Implementing Cryptography
• Perimeter Defenses
• Site Selection, Design, and Configuration
• System Defenses
• Environmental Controls
Unique Terms and Definitions
• Asymmetric Encryption—encryption that uses two keys: if you encrypt with one you may decrypt with the other
• Hash Function—one-way encryption using an algorithm and no key
• Hypervisor—Allows multiple virtual operating system guests to run on one host
• Mantrap—A preventive physical control with two doors. Each door requires a separate form of authentication to open
• Tailgating—Following an authorized person into a building without providing credentials
• TCSEC—Trusted Computer System Evaluation Criteria, also known as the Orange Book
• Symmetric Encryption—encryption that uses one key to encrypt and decrypt
Introduction
The Security Engineering domain is an example of the 2015 exam’s reordering and combining concepts from the 10 domains of the old exam to the current 8 domains. This domain contains large swaths of three formerly separate domains: Security Architecture, Cryptography, and Physical Security. As a result: this domain is quite large, and bursting with content.
As mentioned in Chapter 1, Introduction: the new order doesn’t always flow logically, but that is not important for exam success. In the end you will face 250 questions from all 8 domains, and questions will not overtly reference their domain of origin.
This domain begins with security architecture concepts, including security models, as well as secure system components in hardware and software. Next comes cryptography, including core concepts of symmetric encryption, asymmetric encryption, and hash functions. Finally, we will discuss physical security, where we will learn that safety of personnel is paramount.
Security Models
Security models provide “rules of the road” for securely operating systems. The canonical example is Bell-LaPadula, which includes “No Read Up” (NRU), also known as the Simple Security Property. This is the rule that forbids a secret-cleared subject from reading a top secret object. While Bell-LaPadula is focused on protecting confidentiality, other models, such as Biba, are focused on integrity.
Reading Down and Writing Up
The concepts of reading down and writing up apply to Mandatory Access Control models such as Bell-LaPadula. Reading down occurs when a subject reads an object at a lower sensitivity level, such as a top secret subject reading a secret object. Figure 4.1 shows this action.
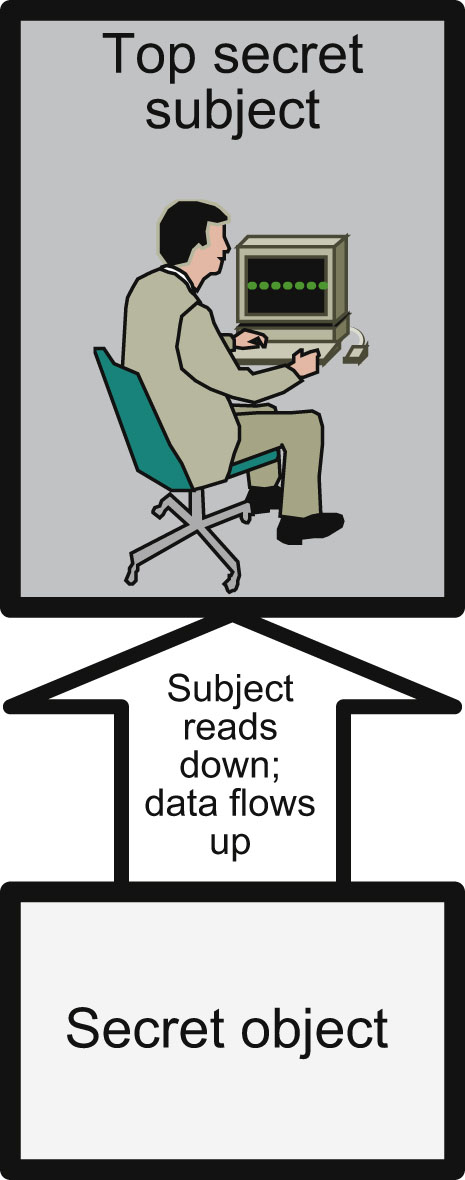
Figure 4.1 Reading Down
There are instances when a subject has information and passes that information up to an object, which has higher sensitivity than the subject has permission to access. This is called “writing up” because the subject does not see any other information contained within the object.
Writing up may seem counterintuitive. As we will see shortly, these rules protect confidentiality, often at the expense of integrity. Imagine a secret-cleared agent in the field uncovers a terrorist plot. The agent writes a report, which contains information that risks exceptionally grave damage to national security. The agent therefore labels the report top secret (writes up). Figure 4.2 shows this action. The only difference between reading up and writing down is the direction that information is being passed. It is a subtle but important distinction for the CISSP® exam.
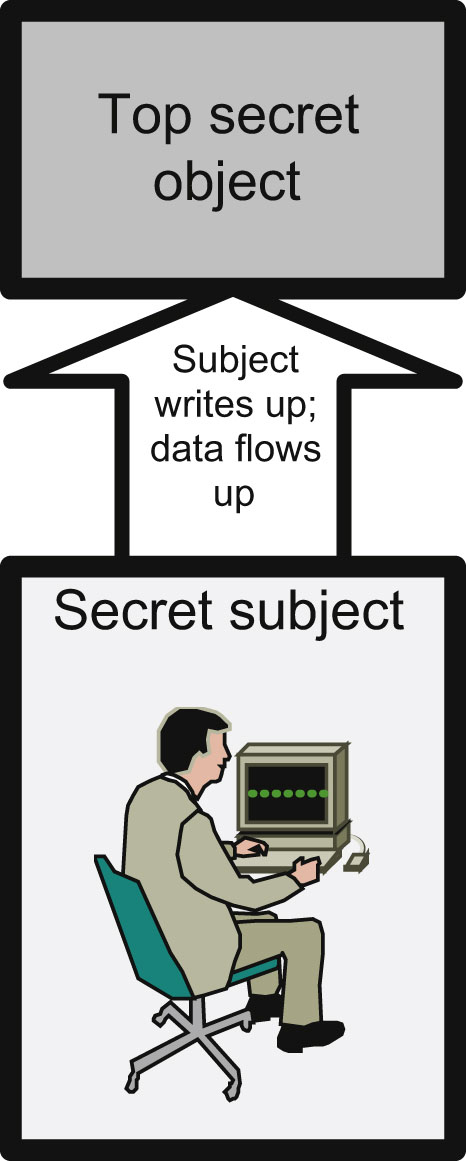
Figure 4.2 Writing Up
State Machine Model
A state machine model is a mathematical model that groups all possible system occurrences, called states. Every possible state of a system is evaluated, showing all possible interactions between subjects and objects. If every state is proven to be secure, the system is proven to be secure.
State machines are used to model real-world software when the identified state must be documented along with how it transitions from one state to another. For example, in object-oriented programming, a state machine model may be used to model and test how an object moves from an inactive state to an active state readily accepting input and providing output.
Bell-LaPadula Model
The Bell-LaPadula model was originally developed for the U.S. Department of Defense. It is focused on maintaining the confidentiality of objects. Protecting confidentiality means not allowing users at a lower security level to access objects at a higher security level. Bell-LaPadula operates by observing two rules: the Simple Security Property and the * Security Property.
Simple Security Property
The Simple security property states that there is “no read up:” a subject at a specific classification level cannot read an object at a higher classification level. Subjects with a Secret clearance cannot access Top Secret objects, for example.
* Security Property (Star Security Property)
The * Security Property is “no write down:” a subject at a higher classification level cannot write to a lower classification level. For example: subjects who are logged into a Top Secret system cannot send emails to a Secret system.
Strong and Weak Tranquility Property
Within the Bell-LaPadula access control model, there are two properties that dictate how the system will issue security labels for objects. The Strong Tranquility Property states that security labels will not change while the system is operating. The Weak Tranquility Property states that security labels will not change in a way that conflicts with defined security properties.
Lattice-Based Access Controls
Lattice-based access control allows security controls for complex environments. For every relationship between a subject and an object, there are defined upper and lower access limits implemented by the system. This lattice, which allows reaching higher and lower data classification, depends on the need of the subject, the label of the object, and the role the subject has been assigned. Subjects have a Least Upper Bound (LUB) and Greatest Lower Bound (GLB) of access to the objects based on their lattice position. Figure 4.3 shows an example of a lattice-based access control model. At the highest level of access is the box labeled, “{Alpha, Beta, Gamma}.” A subject at this level has access to all objects in the lattice.
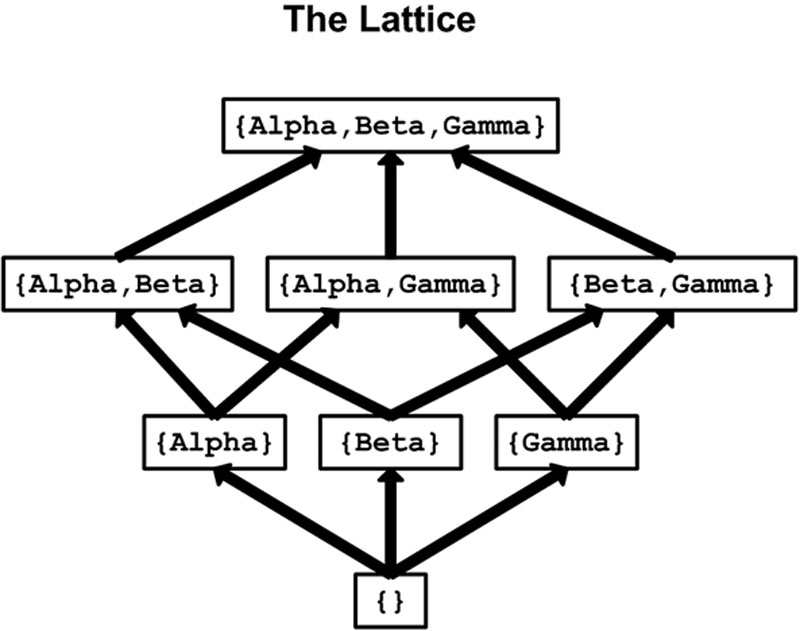
Figure 4.3 Lattice-Based Access Control
At the second tier of the lattice, we see that each object has a distinct upper and lower allowable limit. For example, assume a subject has “{Alpha, Gamma}” access. The only viewable objects in the lattice would be the “Alpha” and “Gamma” objects. Both represent the greatest lower boundary. The subject would not be able to view object Beta.
Integrity Models
Models such as Bell-LaPadula focus on confidentiality, sometimes at the expense of integrity. The Bell-LaPadula “No Write Down” rule means subjects can write up: a Secret subject can write to a Top Secret object. What if the Secret subject writes erroneous information to a Top Secret object? Integrity models such as Biba address this issue.
Biba Model
While many governments are primarily concerned with confidentiality, most businesses desire to ensure that the integrity of the information is protected at the highest level. Biba is the model of choice when integrity protection is vital. The Biba model, named after Kenneth J. Biba, has two primary rules: the Simple Integrity Axiom and the * Integrity Axiom.
Simple Integrity Axiom
The Simple Integrity Axiom is “no read down:” a subject at a specific classification level cannot read data at a lower classification. This prevents subjects from accessing information at a lower integrity level. This protects integrity by preventing bad information from moving up from lower integrity levels.
* Integrity Axiom
The * Integrity Axiom is “no write up:” a subject at a specific classification level cannot write to data at a higher classification. This prevents subjects from passing information up to a higher integrity level than they have clearance to change. This protects integrity by preventing bad information from moving up to higher integrity levels.
Clark-Wilson
Clark-Wilson is a real-world integrity model that protects integrity by requiring subjects to access objects via programs. Because the programs have specific limitations to what they can and cannot do to objects, Clark-Wilson effectively limits the capabilities of the subject. Clark-Wilson uses two primary concepts to ensure that security policy is enforced: well-formed transactions and Separation of Duties.
Well-Formed Transactions
Well-Formed Transactions describe the Clark-Wilson ability to enforce control over applications. This process is comprised of the “access control triple:” user, transformation procedure, and constrained data item.
A transformation procedure (TP) is a well-formed transaction, and a constrained data item (CDI) is data that requires integrity. Unconstrained data items (UDI) are data that do not require integrity. Assurance is based upon integrity verification procedures (IVPs) that ensure that data are kept in a valid state.
For each TP, an audit record is made and entered into the access control system. This provides both detective and recovery controls in case integrity is lost.
Certification, Enforcement and Separation of Duties
Within Clark-Wilson, certification monitors integrity, and enforcement preserves integrity. All relations must meet the requirements imposed by the separation of duty. All TPs must record enough information to reconstruct the data transaction to ensure integrity.
The purpose of separation of duties within the Clark-Wilson model is to ensure that authorized users do not change data in an inappropriate way. One example is a school’s bursar office. One department collects money and another department issues payments. Both the money collection and payment departments are not authorized to initiate purchase orders. By keeping all three roles separate, the school is assured that no one person can fraudulently collect, order, or spend the school’s money. The school depends on the honesty and competency of each person in the chain to report any improper modification of an order, payment, or collection. It would take a conspiracy among all parties to conduct a fraudulent act.
Information Flow Model
The Information Flow Model describes how information may flow in a secure system. Both Bell-LaPadula and Biba use the information flow model. Bell-LaPadula states “no read up” and “no write down.” Information flow describes how unclassified data may be read up to secret, for example, and then written up to top secret. Biba reverses the information flow path to protect integrity.
Chinese Wall Model
The Chinese Wall model is designed to avoid conflicts of interest by prohibiting one person, such as a consultant, from accessing multiple conflict of interest categories (CoIs). It is also called Brewer-Nash, named after model creators Dr. David Brewer and Dr. Michael Nash, and was initially designed to address the risks inherent with employing consultants working within banking and financial institutions.[1]
Conflicts of interest pertain to accessing company-sensitive information from different companies that are in direct competition with one another. If a consultant had access to competing banks’ profit margins, he or she could use that information for personal gain. The Chinese Wall model requires that CoIs be identified so that once a consultant gains access to one CoI, they cannot read or write to an opposing CoI. [2]
Noninterference
The noninterference model ensures that data at different security domains remain separate from one another. By implementing this model, the organization can be assured that covert channel communication does not occur because the information cannot cross security boundaries. Each data access attempt is independent and has no connection with any other data access attempt.
A covert channel is policy-violating communication that is hidden from the owner or users of a data system. There are unused fields within the TCP/IP headers, for example, which may be used for covert channels. These fields can also carry covert traffic, along with encrypting payload data within the packet. Many kinds of malware use these fields as covert channels for communicating back to malware command and control networks.
Take-Grant
The Take-Grant Protection Model contains rules that govern the interactions between subjects and objects, and permissions subjects can grant to other subjects. Rules include: take, grant, create, and remove. The rules are depicted as a protection graph that governs allowable actions. [3] Each subject and object would be represented on the graph. Figure 4.4 details a take-grant relationship between the users, Alice, Bob, and Carol with regards to each subject’s access to the object, “secret documents.” Subject Alice, who is placed in the middle of the graph, can create and remove (c, r) any privileges for the secret documents. Alice can also grant (g) user Carol any of these same privileges. User Bob can take (t) any of user Alice’s privileges.

Figure 4.4 The Take-Grant Model
Take-Grant models can be very complex as relationships between subjects and objects are usually much more complex than the one shown here.
Access Control Matrix
An access control matrix is a table that defines access permissions between specific subjects and objects. A matrix is a data structure that acts as a table lookup for the operating system. For example, Table 4.1 is a matrix that has specific access permissions defined by user and detailing what actions they can enact. User rdeckard has read/write access to the data file as well as access to the data creation application. User etyrell can read the data file and still has access to the application. User rbatty has no access within this data access matrix.
Table 4.1
User Access Permissions
| Users | Data Access File # 1 | Data Creation Application |
| rdeckard | Read/Write | Execute |
| etyrell | Read | Execute |
| rbatty | None | None |
Zachman Framework for Enterprise Architecture
The Zachman Framework for Enterprise Architecture provides six frameworks for providing information security, asking what, how, where, who, when, and why, and mapping those frameworks across rules including planner, owner, designer, builder, programmer, and user. These frameworks and roles are mapped to a matrix, as shown in Figure 4.5 [39].
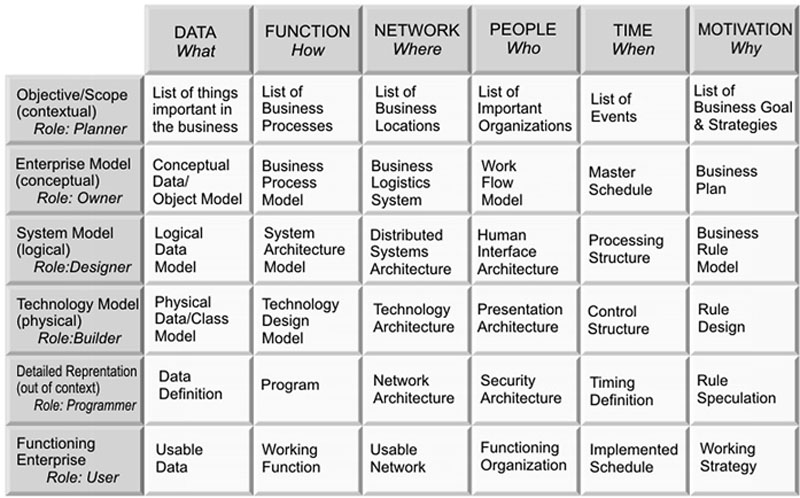
Figure 4.5 Zachman Framework
Graham-Denning Model
The Graham-Denning Model has three parts: objects, subjects, and rules. It provides a more granular approach for interaction between subjects and objects. There are eight rules:
• R1: Transfer Access
• R2: Grant Access
• R3: Delete Access
• R4: Read Object
• R5: Create Object
• R6: Destroy Object
• R7: Create Subject
• R8: Destroy Subject [4]
Harrison-Ruzzo-Ullman Model
The Harrison-Ruzzo-Ullman (HRU) Model maps subjects, objects, and access rights to an access matrix. It is considered a variation to the Graham-Denning Model. HRU has six primitive operations:
• Create object
• Create subject
• Destroy subject
• Destroy object
• Enter right into access matrix
• Delete right from access matrix [5]
In addition to HRU’s different operations, it also differs from Graham-Denning because it considers subjects to be also objects.
Modes of Operation
Defining the Mode of Operation necessary for an IT system will greatly assist in identifying the access control and technical requirements that system must have. Depending on the Mode of Operation, it may use a discretionary access control implementation or a mandatory access control implementation.
There are four Modes of Operation:
1. Dedicated
2. System High
3. Compartmented
4. Multilevel
Dedicated
Dedicated mode of operation means that the system contains objects of one classification label (e.g., secret) only. All subjects must possess a clearance equal to or greater than the label of the objects (a secret or higher clearance, using the previous example). Each subject must have the appropriate clearance, formal access approval, and need to know for all the information stored and processed on the system.
System High
In a system high mode of operation, the system contains objects of mixed labels (e.g., confidential, secret, and top secret). All subjects must possess a clearance equal to the system’s highest object (top secret, using the previous example).
Compartmented
In a compartmented mode of operation system, all subjects accessing the system have the necessary clearance but do not have the appropriate formal access approval, nor need to know for all the information found on the system. Objects are placed into “compartments,” and require a formal (system-enforced) need to know to access. Compartmented mode systems use technical controls to enforce need to know (as opposed to a policy-based need to know).
Multilevel
Multilevel mode of operation stores objects of differing sensitivity labels, and allows system access by subjects with differing clearances. The reference monitor mediates access between subjects and objects: if a top secret subject (with a need to know) accesses a top secret object, access is granted. If a secret subject attempts to access a top secret object, access is denied.
Evaluation Methods, Certification and Accreditation
Evaluation methods and criteria are designed to gauge the real-world security of systems and products. The Trusted Computer System Evaluation Criteria (TCSEC, aka the Orange Book) is the granddaddy of evaluation models, developed by the U.S. Department of Defense in the 1980s. Other international models have followed, including ITSEC and the Common Criteria.
When choosing security products, how do you know which is best? How can a security professional know that the act of choosing and using a specific vendor’s software will not introduce malicious code? How can a security professional know how well the software was tested and what the results were? TCSEC, ITSEC, and the Common Criteria were designed to answer those questions.
The Orange Book
The National Computer Security Center (NCSC), part of the National Institute of Standards and Technology (NIST), with help from the National Security Agency (NSA) developed the Trusted Computer System Evaluation Criteria (TCSEC) in 1983. This publication is also known as the “Orange Book” due to the fact that when it was first published, it had a bright orange cover. It was one of the first security standards implemented, and major portions of those standards are still used today in the form of U.S. Government Protection Profiles within the International Common Criteria framework.
TCSEC may be downloaded from http://csrc.nist.gov/publications/history/dod85.pdf. Division D is the lowest form of security, and A is the highest. The TCSEC divisions (denoted with a single letter, like “C”) and classes (denoted with a letter and number, like “B2”) are:
• D: Minimal Protection
• C: Discretionary Protection
• C1: Discretionary Security Protection
• C2: Controlled Access Protection
• B: Mandatory Protection
• B1: Labeled Security Protection
• B2: Structured Protection
• B3: Security Domains
• A: Verified Protection
• A1: Verified Design [6]
The Orange Book was the first significant attempt to define differing levels of security and access control implementation within an IT system. This publication was the inspiration for the Rainbow Series, a series of NCSC publications detailing specific security standards for various communications systems. It was called the Rainbow Series because each publication had a different color cover page. There are over 35 different security standards within the Rainbow series and they range widely in topic.
The TCSEC Divisions
TCSEC Division D is Minimal Protection. This division describes TCSEC-evaluated systems that do not meet the requirements of higher divisions (C through A).
TCSEC Division C is Discretionary Protection. “Discretionary” means Discretionary Access Control systems (DAC). Division C includes classes C1 (Discretionary Security Protection) and C2 (Controlled Access Protection).
TCSEC Division B is Mandatory Protection. “Mandatory” means Mandatory Access Control systems (MAC). Division B includes classes B1 (Labeled Security Protection), B2 (Structured Protection) and B3 (Security Domains). Higher numbers are more secure: B3 is more secure than B1.
TCSEC Division A is Verified Protection, with a single class A1 (Verified Design). A1 contains everything class B3, plus additional controls.
TNI/Red Book
The Trusted Network Interpretation (TNI) brings TCSEC concepts to network systems. It is often called the “red book,” due to the color of its cover. Note that TCSEC (orange book) does not address network issues.
ITSEC
The European Information Technology Security Evaluation Criteria (ITSEC) was the first successful international evaluation model. It refers to TCSEC Orange Book levels, separating functionality (F, how well a system works) from assurance (the ability to evaluate the security of a system). There are two types of assurance: effectiveness (Q) and correctness (E).[7]
Assurance correctness ratings range from E0 (inadequate) to E6 (formal model of security policy); Functionality ratings range include TCSEC equivalent ratings (F-C1, F-C2, etc.). The equivalent ITSEC/TCSEC ratings are:
• E0: D
• F-C1,E1: C1
• F-C2,E2: C2
• F-B1,E3: B1
• F-B2,E4: B2
• F-B3,E5: B3
• F-B3,E6: A1
Additional functionality ratings include:
• F-IN: High integrity requirements
• AV: High availability requirements
• DI: High integrity requirements for networks
• DC: High confidentiality requirements for networks
• DX: High integrity and confidentiality requirements for networks
See: http://www.ssi.gouv.fr/site_documents/ITSEC/ITSEC-uk.pdf for more information about ITSEC.
The International Common Criteria
The International Common Criteria is an internationally agreed upon standard for describing and testing the security of IT products. It is designed to avoid requirements beyond current state of the art and presents a hierarchy of requirements for a range of classifications and systems. The Common Criteria is the second major international information security criteria effort, following ITSEC. The Common Criteria uses ITSEC terms such as Target of Evaluation and Security Target.
The Common Criteria was developed with the intent to evaluate commercially available as well as government-designed and built IA and IA-enabled IT products. A primary objective of the Common Criteria is to eliminate known vulnerabilities of the target for testing.
Common Criteria Terms
The Common Criteria uses specific terms when defining specific portions of the testing process.
• Target of Evaluation (ToE): the system or product that is being evaluated
• Security Target (ST): the documentation describing the TOE, including the security requirements and operational environment
• Protection Profile (PP): an independent set of security requirements and objectives for a specific category of products or systems, such as firewalls or intrusion detection systems
• Evaluation Assurance Level (EAL): the evaluation score of the tested product or system
Levels of Evaluation
Within the Common Criteria, there are seven EALs; each builds on the level of in-depth review of the preceding level. [8] For example, EAL 3-rated products can be expected to meet or exceed the requirements of products rated EAL1 or EAL2.
The EAL levels are described in “Common Criteria for Information Technology Security Evaluation, Part 3: Security assurance components.” (July 2009, Version 3.1, Revision 3, Final, available at: http://www.commoncriteriaportal.org/files/ccfiles/CCPART3V3.1R3.pdf). The levels are:
• EAL1: Functionally tested
• EAL2: Structurally tested
• EAL3: Methodically tested and checked
• EAL4: Methodically designed, tested, and reviewed
• EAL5: Semi-formally designed, and tested
• EAL6: Semi-formally verified, designed, and tested
• EAL7: Formally verified, designed, and tested [9]
Secure System Design Concepts
Secure system design transcends specific hardware and software implementations and represents universal best practices.
Layering
Layering separates hardware and software functionality into modular tiers. The complexity of an issue such as reading a sector from a disk drive is contained to one layer (the hardware layer in this case). One layer (such as the application layer) is not directly affected by a change to another. Changing from an IDE (Integrated Drive Electronics) disk drive to a SCSI (Small Computer System Interface) drive has no effect on an application that saves a file. Those details are contained within one layer, and may affect the adjoining layer only.
The OSI model (which we will discuss in Chapter 5, Domain 4: Communication and Network Security) is an example of network layering. Unlike the OSI model, the layers of security architecture do not have standard names that are universal across all architectures. A generic list of security architecture layers is as follows:
1. Hardware
2. Kernel and device drivers
3. Operating System
4. Applications
In our previous IDE → SCSI drive example, the disk drive in the hardware layer has changed from IDE to SCSI. The device drivers in the adjacent layer will also change. Other layers, such as the applications layer, remain unchanged.
Abstraction
Abstraction hides unnecessary details from the user. Complexity is the enemy of security: the more complex a process is, the less secure it is. That said: computers are tremendously complex machines. Abstraction provides a way to manage that complexity.
A user double-clicks on an MP3 file containing music, and the music plays via the computer speakers. Behind the scenes, tremendously complex actions are taking place: the operating system opens the MP3 file, looks up the application associated with it, and sends the bits to a media player. The bits are decoded by a media player, which converts the information into a digital stream, and sends the stream to the computer’s sound card. The sound card converts the stream into sound, sent to the speaker output device. Finally, the speakers play sound. Millions of calculations are occurring as the sound plays, while low-level devices are accessed.
Abstraction means the user simply presses play and hears music.
Security Domains
A security domain is the list of objects a subject is allowed to access. More broadly defined, domains are groups of subjects and objects with similar security requirements. Confidential, Secret, and Top Secret are three security domains used by the U.S. Department of Defense (DoD), for example. With respect to kernels, two domains are user mode and kernel mode.
Kernel mode (also known as supervisor mode) is where the kernel lives, allowing low-level access to memory, CPU, disk, etc. It is the most trusted and powerful part of the system. User mode is where user accounts and their processes live. The two domains are separated: an error or security lapse in user mode should not affect the kernel. Most modern operating systems use both modes; some simpler (such as embedded) and older (such as Microsoft DOS) operating systems run entirely in kernel mode.
The Ring Model
The ring model is a form of CPU hardware layering that separates and protects domains (such as kernel mode and user mode) from each other. Many CPUs, such as the Intel ×86 family, have four rings, ranging from ring 0 (kernel) to ring 3 (user), shown in Figure 4.6. The innermost ring is the most trusted, and each successive outer ring is less trusted.
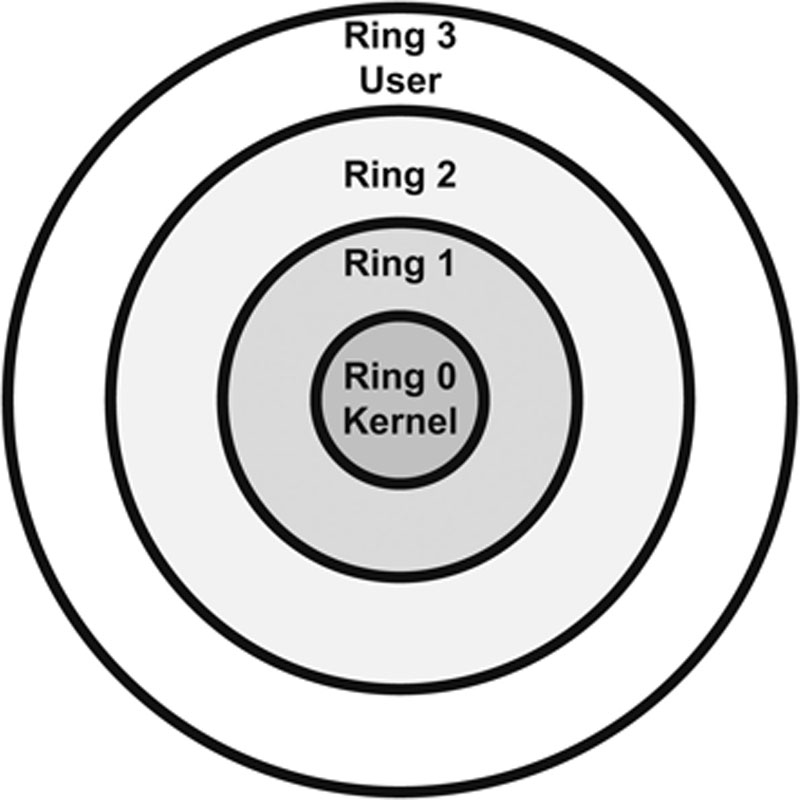
Figure 4.6 The Ring Model
The rings are (theoretically) used as follows:
• Ring 0: Kernel
• Ring 1: Other OS components that do not fit into Ring 0
• Ring 2: Device drivers
• Ring 3: User applications
Processes communicate between the rings via system calls, which allow processes to communicate with the kernel and provide a window between the rings. A user running a word processor in ring 3 presses “save”: a system call is made into ring 0, asking the kernel to save the file. The kernel does so, and reports the file is saved. System calls are slow (compared to performing work within one ring), but provide security. The ring model also provides abstraction: the nitty-gritty details of saving the file are hidden from the user, who simply presses the “save file” button.
While ×86 CPUs have four rings and can be used as described above, this usage is considered theoretical because most ×86 operating systems, including Linux and Windows, use rings 0 and 3 only. Using our “save file” example with four rings, a call would be made from ring 3 to ring 2, then from ring 2 to ring 1, and finally from ring 1 to ring 0. This is secure, but complex and slow, so most modern operating systems opt for simplicity and speed.
A new mode called hypervisor mode (and informally called “ring -1”) allows virtual guests to operate in ring 0, controlled by the hypervisor one ring “below.” The Intel VT (Intel Virtualization Technology, aka “Vanderpool”) and AMD-V (AMD Virtualization, aka “Pacifica”) CPUs support a hypervisor.
Open and Closed Systems
An open system uses open hardware and standards, using standard components from a variety of vendors. An IBM-compatible PC is an open system, using a standard motherboard, memory, BIOS, CPU, etc. You may build an IBM-compatible PC by purchasing components from a multitude of vendors. A closed system uses proprietary hardware or software.
Secure Hardware Architecture
Secure Hardware Architecture focuses on the physical computer hardware required to have a secure system. The hardware must provide confidentiality, integrity, and availability for processes, data, and users.
The System Unit and Motherboard
The system unit is the computer’s case: it contains all of the internal electronic computer components, including motherboard, internal disk drives, power supply, etc. The motherboard contains hardware including the CPU, memory slots, firmware, and peripheral slots such as PCI (Peripheral Component Interconnect) slots. The keyboard unit is the external keyboard.
The Computer Bus
A computer bus, shown in Figure 4.7, is the primary communication channel on a computer system. Communication between the CPU, memory, and input/output devices such as keyboard, mouse, display, etc., occur via the bus.
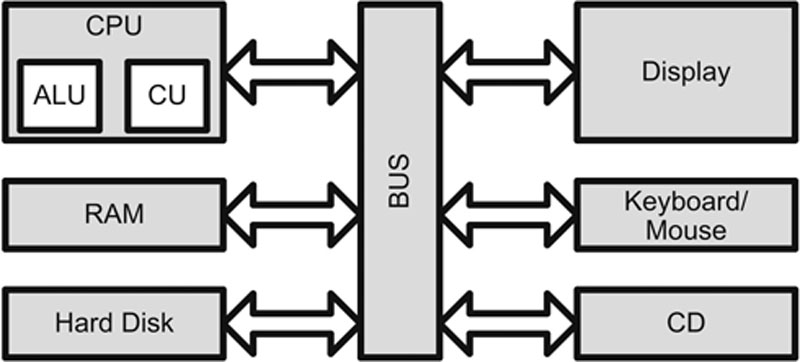
Figure 4.7 Simplified Computer Bus
Northbridge and Southbridge
Some computer designs use two buses: a northbridge and southbridge. The names derive from the visual design, usually shown with the northbridge on top, and the southbridge on the bottom, as shown in Figure 4.8. The northbridge, also called the Memory Controller Hub (MCH), connects the CPU to RAM and video memory. The southbridge, also called the I/O Controller Hub (ICH), connects input/output (I/O) devices, such as disk, keyboard, mouse, CD drive, USB ports, etc. The northbridge is directly connected to the CPU, and is faster than the southbridge.
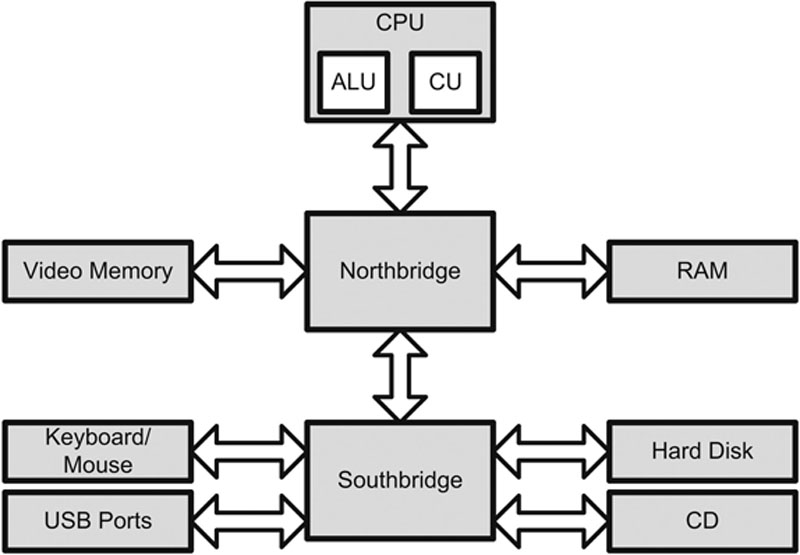
Figure 4.8 Northbridge and Southbridge Design
The CPU
The Central Processing Unit (CPU) is the “brains” of the computer, capable of controlling and performing mathematical calculations. Ultimately, everything a computer does is mathematical: adding numbers (which can be extended to subtraction, multiplication, division, etc.), performing logical operations, accessing memory locations by address, etc. CPUs are rated by the number of clock cycles per second. A 2.4 GHz Pentium 4 CPU has 2.4 billion clock cycles per second.
Arithmetic Logic Unit and Control Unit
The arithmetic logic unit (ALU) performs mathematical calculations: it “computes.” It is fed instructions by the control unit, which acts as a traffic cop, sending instructions to the ALU.
Fetch & Execute
CPUs fetch machine language instructions (such as “add 1 + 1”) and execute them (add the numbers, for answer of “2”). The “fetch and execute” (also called “Fetch, Decode, Execute,” or FDX) process actually takes four steps:
1. Fetch Instruction 1
2. Decode Instruction 1
3. Execute Instruction 1
4. Write (save) result 1
These four steps take one clock cycle to complete.
Pipelining
Pipelining combines multiple steps into one combined process, allowing simultaneous fetch, decode, execute, and write steps for different instructions. Each part is called a pipeline stage; the pipeline depth is the number of simultaneous stages that may be completed at once.
Given our previous fetch and execute example of adding 1 + 1, a CPU without pipelining would have to wait an entire cycle before performing another computation. A four-stage pipeline can combine the stages of four other instructions:
1. Fetch Instruction 1
2. Fetch Instruction 2, Decode Instruction 1
3. Fetch Instruction 3, Decode Instruction 2, Execute Instruction 1
4. Fetch Instruction 4, Decode Instruction 3, Execute Instruction 2, Write (save) result 1
5. Fetch Instruction 5, Decode Instruction 4, Execute Instruction 3, Write (save) result 2, etc.
Pipelining is like an automobile assembly line: instead of building one car at a time, from start to finish, lots of cars enter the assembly pipeline, and discrete phases (like installing the tires) occur on one car after another. This increases the throughput.
Interrupts
An interrupt indicates that an asynchronous event has occurred. CPU interrupts are a form of hardware interrupt that cause the CPU to stop processing its current task, save the state, and begin processing a new request. When the new task is complete, the CPU will complete the prior task.
Processes and Threads
A process is an executable program and its associated data loaded and running in memory. A “heavy weight process” (HWP) is also called a task. A parent process may spawn additional child processes called threads. A thread is a lightweight process (LWP). Threads are able to share memory, resulting in lower overhead compared to heavy weight processes.
Processes may exist in multiple states:
• New: a process being created
• Ready: process waiting to be executed by the CPU
• Running: process being executed by the CPU
• Blocked: waiting for I/O
• Terminate: a completed process
Another process type is “zombie,” a child process whose parent is terminated.
Multitasking and Multiprocessing
Applications run as processes in memory, comprised of executable code and data. Multitasking allows multiple tasks (heavy weight processes) to run simultaneously on one CPU. Older and simpler operating systems, such as MS-DOS, are non-multitasking: they run one process at a time. Most modern operating systems, such as Linux, Windows 10, and OS X support multitasking.
Multiprocessing has a fundamental difference from multitasking: it runs multiple processes on multiple CPUs. Two types of multiprocessing are Symmetric Multiprocessing (SMP) and Asymmetric Multiprocessing (AMP, some sources use ASMP). SMP systems have one operating system to manage all CPUs. AMP systems have one operating system image per CPU, essentially acting as independent systems.
Watchdog Timers
A watchdog timer is designed to recover a system by rebooting after critical processes hang or crash. The watchdog timer reboots the system when it reaches zero; critical operating system processes continually reset the timer, so it never reaches zero as long as they are running. If a critical process hangs or crashes, they no longer reset the watchdog timer, which reaches zero, and the system reboots.
CISC and RISC
CISC (Complex Instruction Set Computer) and RISC (Reduced Instruction Set Computer) are two forms of CPU design. CISC uses a large set of complex machine language instructions, while RISC uses a reduced set of simpler instructions.
The “best” way to design a CPU has been a subject of debate: should the low-level commands be longer and powerful, using less individual instructions to perform a complex task (CISC), or should the commands be shorter and simpler, requiring more individual instructions to perform a complex task (RISC), but allowing less cycles per instruction and more efficient code? There is no “correct” answer: both approaches have pros and cons. ×86 CPUs (among many others) are CISC; ARM (used in many cell phones and PDAs), PowerPC, Sparc, and others are RISC.
Memory Addressing
Values may be stored in multiple locations in memory, including CPU registers and in general RAM. These values may be addressed directly (“add the value stored here”) or indirectly (“add the value stored in memory location referenced here”). Indirect addressing is like a pointer. Addressing modes are CPU-dependent; commonly supported modes include direct, indirect, register direct, and register indirect.
Direct mode says “Add X to the value stored in memory location #YYYY.” That location stores the number 7, so the CPU adds X + 7. Indirect starts the same way: “Add X to the value stored in memory location #YYYY.” The difference is #YYYY stores another memory location (#ZZZZ). The CPU follows to pointer to #ZZZZ, which holds the value 7, and adds X + 7.
Register direct addressing is the same as direct addressing, except it references a CPU cache register, such as Register 1. Register indirect is also the same as indirect, except the pointer is stored in a register. Figure 4.9 summarizes these four modes of addressing.

Figure 4.9 Memory Addressing Summary
Memory Protection
Memory protection prevents one process from affecting the confidentiality, integrity, or availability of another. This is a requirement for secure multiuser (more than one user logged in simultaneously) and multitasking (more than one process running simultaneously) systems.
Process Isolation
Process isolation is a logical control that attempts to prevent one process from interfering with another. This is a common feature among multiuser operating systems such as Linux, UNIX, or recent Microsoft Windows operating systems. Older operating systems such as MS-DOS provide no process isolation. A lack of process isolation means a crash in any MS-DOS application could crash the entire system.
If you are shopping online and enter your credit card number to buy a book, that number will exist in plaintext in memory (for at least a short period of time). Process isolation means that another user’s process on the same computer cannot interfere with yours.
Interference includes attacks on the confidentiality (reading your credit card number), integrity (changing your credit card number), and availability (interfering or stopping the purchase of the book).
Techniques used to provide process isolation include virtual memory (discussed in the next section), object encapsulation, and time multiplexing. Object encapsulation treats a process as a “black box,” which we will discuss in Chapter 9, Domain 8: Software Development Security. Time multiplexing shares (multiplexes) system resources between multiple processes, each with a dedicated slice of time.
Hardware Segmentation
Hardware segmentation takes process isolation one step further by mapping processes to specific memory locations. This provides more security than (logical) process isolation alone.
Virtual Memory
Virtual memory provides virtual address mapping between applications and hardware memory. Virtual memory provides many functions, including multitasking (multiple tasks executing at once on one CPU), allowing multiple processes to access the same shared library in memory, swapping, and others.
Swapping and Paging
Swapping uses virtual memory to copy contents in primary memory (RAM) to or from secondary memory (not directly addressable by the CPU, on disk). Swap space is often a dedicated disk partition that is used to extend the amount of available memory. If the kernel attempts to access a page (a fixed-length block of memory) stored in swap space, a page fault occurs (an error that means the page is not located in RAM), and the page is “swapped” from disk to RAM.
Figure 4.10 shows the output of the Linux command “top,” which displays memory information about the top processes, as well as a summary of available remaining memory. It shows a system with 1,026,560 kb of RAM, and 915,664 kb of virtual memory (swap). The system has 1,942,224 kb total memory, but just over half may be directly accessed.

Figure 4.10 Linux “Top” Output
Most computers configured with virtual memory, as the system in Figure 4.10, will use only RAM until the RAM is nearly or fully filled. The system will then swap processes to virtual memory. It will attempt to find idle processes so that the impact of swapping will be minimal.
Eventually, as additional processes are started and memory continues to fill, both RAM and swap will fill. After the system runs out of idle processes to swap, it may be forced to swap active processes. The system may begin “thrashing,” spending large amounts of time copying data to and from swap space, seriously impacting availability.
Swap is designed as a protective measure to handle occasional bursts of memory usage. Systems should not routinely use large amounts of swap: in that case, physical memory should be added, or processes should be removed, moved to another system, or shortened.
BIOS
The IBM PC-compatible Basic Input Output System contains code in firmware that is executed when a PC is powered on. It first runs the Power-On Self-Test (POST), which performs basic tests, including verifying the integrity of the BIOS itself, testing the memory, identifying system devices, among other tasks. Once the POST process is complete and successful, it locates the boot sector (for systems that boot off disks), which contains the machine code for the operating system kernel. The kernel then loads and executes, and the operating system boots up.
WORM Storage
WORM (Write Once Read Many) Storage can be written to once, and read many times. It is often used to support records retention for legal or regulatory compliance. WORM storage helps assure the integrity of the data it contains: there is some assurance that it has not been (and cannot be) altered, short of destroying the media itself.
The most common type of WORM media is CD-R (Compact Disc Recordable) and DVD-R (Digital Versatile Disk Recordable). Note that CD-RW and DVD-RW (Read/Write) are not WORM media. Some Digital Linear Tape (DLT) drives and media support WORM.
Trusted Platform Module
Developed and updated by the Trusted Computing Group, a Trusted Platform Module (TPM) chip is a processor that can provide additional security capabilities at the hardware level. Not all computer manufacturers employ TPM chips, but the adoption has steadily increased. If included, a TPM chip is typically found on a system’s motherboard.
The TPM chip allows for hardware-based cryptographic operations. Security functions can leverage the TPM for random number generation, the use of symmetric, asymmetric, and hashing algorithms, and secure storage of cryptographic keys and message digests. The most commonly referenced use case for the TPM chip is ensuring boot integrity. By operating at the hardware level, the TPM chip can help ensure that kernel mode rootkits are less likely to be able to undermine operating system security. In addition to boot integrity, TPM is also commonly associated with some implementations of full disk encryption. With encryption, the TPM can be used to securely store the keys that can be used to decrypt the hard drive.
Given the storage of highly sensitive and valuable information, the TPM chip itself could be targeted by adversaries. With TPM being hardware-based, tampering with the TPM remotely from the operating system is made much less likely. The TPM chip also has aspects of tamper proofing to try to ensure that a physically compromised TPM chip does not allow for trivial bypass of the security functions offered.
Data Execution Prevention and Address Space Layout Randomization
One of the main goals when attempting to exploit software vulnerabilities is to achieve some form of code execution capability. Conceptually, the adversary would like to provide their own chosen instructions or supplied code to be executed by the compromised application. Intentionally corrupting the memory of a system via, for example a stack or heap-based buffer overflow condition, is a common means employed by the adversary.
The two most prominent protections against these types of memory corruption or overflow attacks are DEP (Data Execution Prevention) and ASLR (Address Space Location Randomization). DEP, which can be enabled within hardware and/or software, attempts to ensure that memory locations not pre-defined to contain executable content will not have the ability to have code executed. For example, an adversary exploits a buffer overflow condition in code that allows for adversary provided shellcode to end up in general data storage location within memory. With DEP, if that location had not been marked as expecting executable content, then successful exploitation might have been mitigated.
Another protection mechanism, ASLR, seeks to decrease the likelihood of successful exploitation by making memory addresses employed by the system less predictable. When developing exploits and building post-exploitation capabilities, the exploit code will leverage existing code loaded on a running system. If these components are consistently found at the same memory addresses, then the difficulty of exploitation is decreased. By randomizing the memory addresses used, the adversary is presented with a more difficult to exploit target. For an example of ASLR success, imagine an adversary developing a successful working exploit on their own test machine. When their code, which relies on particular operating system libraries and code being found at predictable memory addresses, is ported to a machine with ASLR enabled the exploit could be caused to fail.
The goal of these protection mechanisms is often suggested as preventing exploitation. However, that goal, while laudable, will never be achieved consistently. Rather the goal of these mitigation techniques is more appropriately thought of as trying to increase the cost of exploit development for the adversaries.
Secure Operating System and Software Architecture
Secure Operating System and Software Architecture builds upon the secure hardware described in the previous section, providing a secure interface between hardware and the applications (and users) that access the hardware. Operating systems provide memory, resource, and process management.
The Kernel
The kernel is the heart of the operating system, which usually runs in ring 0. It provides the interface between hardware and the rest of the operating system, including applications. As discussed previously, when an IBM-compatible PC is started or rebooted, the BIOS locates the boot sector of a storage device such as a hard drive. That boot sector contains the beginning of the software kernel machine code, which is then executed. Kernels have two basic designs: monolithic and microkernel.
A monolithic kernel is compiled into one static executable and the entire kernel runs in supervisor mode. All functionality required by a monolithic kernel must be precompiled in. If you have a monolithic kernel that does not support FireWire interfaces, for example, and insert a FireWire device into the system, the device will not operate. The kernel would need to be recompiled to support FireWire devices.
Microkernels are modular kernels. A microkernel is usually smaller and has less native functionality than a typical monolithic kernel (hence the term “micro”), but can add functionality via loadable kernel modules. Microkernels may also run kernel modules in user mode (usually ring 3), instead of supervisor mode. Using our previous example, a native microkernel does not support FireWire. You insert a FireWire device, the kernel loads the FireWire kernel module, and the device operates.
Reference Monitor
A core function of the kernel is running the reference monitor, which mediates all access between subjects and objects. It enforces the system’s security policy, such as preventing a normal user from writing to a restricted file, like the system password file. On a Mandatory Access Control (MAC) system, the reference monitor prevents a secret subject from reading a top secret object. The reference monitor is always enabled and cannot be bypassed. Secure systems can evaluate the security of the reference monitor.
Users and File Permissions
File permissions, such as read, write, and execute, control access to files. The types of permissions available depend on the file system being used.
Linux and UNIX permissions
Most Linux and UNIX file systems support the following file permissions:
• Read (“r”)
• Write (“w”)
• Execute (“x”)
Each of those permissions may be set separately to the owner, group, or world. Figure 4.11 shows the output of a Linux “ls –la /etc” (list all files in the /etc directory, long output) command.

Figure 4.11 Linux “ls -la” Command
The output in Figure 4.11 shows permissions, owner, group, size, date, and filename. Permissions beginning with “d” (such as “acpi”) are directories. Permissions beginning with “-” (such as at.deny) describe files. Figure 4.12 zooms in on files in /etc. highlighting the owner, group, and world permissions.
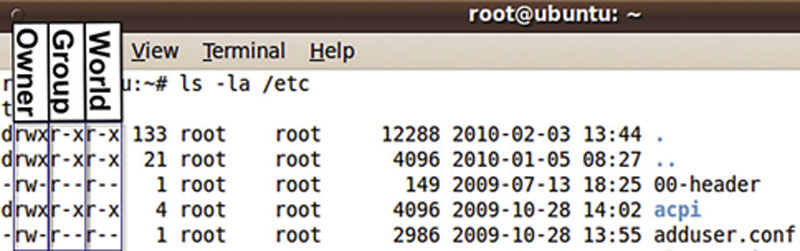
Figure 4.12 Linux /etc Permissions, Highlighting Owner, Group and World
The adduser.conf file in Figure 4.12 is owned by root and has “-rw-r--r--” permissions. This means adduser.conf is a file (permissions begin with “-”), has read and write (rw-) permissions for the owner (root), read (r--) for the group (also root), and read permissions (r--) for the world.
Microsoft NTFS Permissions
Microsoft NTFS (New Technology File System) has the following basic file permissions:
• Read
• Write
• Read and execute
• Modify
• Full control (read, write, execute, modify, and in addition the ability to change the permissions.)
NTFS has more types of permissions than most UNIX or Linux file systems. The NTFS file is controlled by the owner, who may grant permissions to other users. Figure 4.13 shows the permissions of a sample photo at C:UsersPublicPicturesSample PicturesPenguins.jpg.

Figure 4.13 NTFS Permissions
To see these permissions, right-click an NTFS file, choose “properties,” and then “security.”
Privileged Programs
On UNIX and Linux systems, a regular user cannot edit the password file (/etc/passwd) and shadow file (/etc/shadow), which store account information and encrypted passwords, respectively. But users need to be able to change their passwords (and thus those files). How can they change their passwords if they cannot (directly) change those files?
The answer is setuid (set user ID) programs. Setuid is a Linux and UNIX file permission that makes an executable run with the permissions of the file’s owner, and not as the running user. Setgid (set group ID) programs run with the permissions of the file’s group.
Figure 4.14 shows the permissions of the Linux command /usr/bin/passwd, used to set and change passwords. It is setuid root (the file is owned by the root user, and the owner’s execute bit is set to “s,” for setuid), meaning it runs with root (super user) permissions, regardless of the running user.

Figure 4.14 Linux Setuid Root Program /usr/bin/passwd
The “passwd” program runs as root, allowing any user to change their password, and thus the contents of /etc/passwd and /etc/shadow. Setuid programs must be carefully scrutinized for security holes: attackers may attempt to trick the passwd command to alter other files. The integrity of all setuid and setgid programs on a system should be closely monitored.
Virtualization and Distributed Computing
Virtualization and distributed computing have revolutionized the computing world, bringing wholesale changes to applications, services, systems data, and data centers. Yesterday’s best practices may no longer apply. Where is the DMZ when your data is in the cloud? Can your NIDS monitor data sent from one guest to another in a single host? Does your physical firewall matter?
Virtualization
Virtualization adds a software layer between an operating system and the underlying computer hardware. This allows multiple “guest” operating systems to run simultaneously on one physical “host” computer. Popular transparent virtualization products include VMware, QEMU, and Xen.
There are two basic virtualization types: transparent virtualization (sometimes called full virtualization) and paravirtualization. Transparent virtualization runs stock operating systems, such as Windows 10 or Ubuntu Linux 15.04, as virtual guests. No changes to the guest OS are required. Paravirtualization runs specially modified operating systems, with modified kernel system calls. Paravirtualization can be more efficient, but requires changing the guest operating systems. This may not be possible for closed operating systems such as the Microsoft Windows family.
Hypervisor
The key to virtualization security is the hypervisor, which controls access between virtual guests and host hardware. A Type 1 hypervisor (also called bare metal) is part of an operating system that runs directly on host hardware. A Type 2 hypervisor runs as an application on a normal operating system, such as Windows 10. For example: VMware ESX is a Type 1 hypervisor and VMware Workstation is Type 2.
Many virtualization exploits target the hypervisor, including hypervisor-controlled resources shared between host and guests, or guest and guest. These include cut-and-paste, shared drives and shared network connections.
Virtualization Benefits
Virtualization offers many benefits, including lower overall hardware costs, hardware consolidation, and lower power and cooling needs. Snapshots allow administrators to create operating system images that can be restored with a click of a mouse, making backup and recovery simple and fast. Testing new operating systems, applications, and patches can be quite simple. Clustering virtual guests can be far simpler than clustering operating systems that run directly in hardware.
Virtualization Security Issues
Virtualization software is complex and relatively new. As discussed previously, complexity is the enemy of security: the sheer complexity of virtualization software may cause security problems.
Combining multiple guests onto one host may also raise security issues. Virtualization is no replacement for a firewall: never combine guests with different security requirements (such as DMZ and internal) onto one host. The risk of virtualization escape (called VMEscape, where an attacker exploits the host OS or a guest from another guest) is a topic of recent research. Trend Micro reports: “Core Security Technologies has very recently reported of a bug that allows malicious users to escape the virtual environment to actually penetrate the host system running it. The bug exists in the shared folder feature of the Windows client-based virtualization software.”[10] Known virtualization escape bugs have been patched, but new issues may arise.
Many network-based security tools, such as network intrusion detection systems, can be blinded by virtualization. A traditional NIDS connected to a physical SPAN port or tap cannot see traffic passing from one guest to another on the same host. NIDS vendors are beginning to offer virtual IDS products, running in software on the host, and capable of inspecting host-guest and guest-guest traffic. A similar physical to virtual shift is occurring with firewalls.
Cloud Computing
Public cloud computing outsources IT infrastructure, storage, or applications to a 3rd party provider. A cloud also implies geographic diversity of computer resources. The goal of cloud computing is to allow large providers to leverage their economies of scale to provide computing resources to other companies that typically pay for these services based on their usage.
Three commonly available levels of service provided by cloud providers are Infrastructure as a Service (IaaS), Platform as a Service (PaaS) and Software as a Service (SaaS). Infrastructure as a Service provides an entire virtualized operating system, which the customer configures from the OS on up. Platform as a Service provides a pre-configured operating system, and the customer configures the applications. Finally, Software as a Service is completely configured, from the operating system to applications, and the customer simply uses the application. In all three cases the cloud provider manages hardware, virtualization software, network, backups, etc. See Table 4.2 for typical examples of each.
Table 4.2
Example Cloud Service Levels
| Type | Example |
| Infrastructure as a Service (IaaS) | Linux server hosting |
| Platform as a Service (PaaS) | Web service hosting |
| Software as a Service (SaaS) | Web mail |
Private clouds house data for a single organization, and may be operated by a 3rd party, or by the organization itself. Government clouds are designed to keep data and resources geographically contained within the borders of one country, designed for the government of the respective country.
Benefits of cloud computing include reduced upfront capital expenditure, reduced maintenance costs, robust levels of service, and overall operational cost-savings.
From a security perspective, taking advantage of public cloud computing services requires strict service level agreements and an understanding of new sources of risk. One concern is multiple organizations’ guests running on the same host. The compromise of one cloud customer could lead to compromise of other customers.
Also, many cloud providers offer pre-configured system images, which may introduce risks via insecure configuration. For example, imagine a blog service image, with the operating system, web service and blogging software all pre-configured. Any vulnerability associated with the pre-configured image can introduce risk to every organization that uses the image.
Organizations should also negotiate specific rights before signing a contract with a cloud computing provider. These rights include the right to audit, the right to conduct a vulnerability assessment, and the right to conduct a penetration test (both electronic and physical) of data and systems placed in the cloud.
Finally, do you know where your data is? Public clouds may potentially move data to any country, potentially beyond the jurisdiction of the organization’s home country. For example: US-based laws such as HIPAA (Health Insurance Portability and Accountability Act) or GLBA (Gramm-Leach-Bliley Act) have no effect outside of the United States. Private or government clouds should be considered in these cases.
Grid Computing
Grid computing represents a distributed computing approach that attempts to achieve high computational performance by a non-traditional means. Rather than achieving high performance computational needs by having large clusters of similar computing resources or a single high performance system, such as a supercomputer, grid computing attempts to harness the computational resources of a large number of dissimilar devices.
Grid computing typically leverages the spare CPU cycles of devices that are not currently needed for a system’s own needs, and then focus them on the particular goal of the grid computing resources. While these few spare cycles from each individual computer might not mean much to the overall task, in aggregate, the cycles are significant.
Large-Scale Parallel Data Systems
The primary purpose of large-scale parallel systems is to allow for increased performance through economies of scale. One of the key security concerns with parallel systems is ensuring data integrity is maintained throughout the processing. Often parallel systems will leverage some degree of shared memory on which they operate. This shared memory, if not appropriately managed, can expose potential race conditions that introduce integrity challenges.
Peer to Peer
Peer to peer (P2P) networks alter the classic client/server computer model. Any system may act as a client, a server, or both, depending on the data needs. Like most technology, most P2P networks were designed to be neutral with regards to intellectual property rights. That being said, P2P networks are frequently used to download commercial music and movies, often in violation of the intellectual property owner’s rights. Decentralized peer-to-peer networks are resilient: there are no central servers that can be taken offline.
One of the first P2P systems was the original Napster, which debuted in 1999. It was designed to allow music sharing and was partially peer-to-peer: downloads occurred in P2P fashion, but the central index servers (where users could search for specific songs, albums and artists) were classic client/server design.
This design provided an Achilles heel for lawyers representing the music industry: if the central index servers were taken down, users would be unable to locate music. This is exactly what happened in 2001. Many P2P protocols designed during and since that time, including Gnutella and BitTorrent, are decentralized. If you have a Gnutella network with 10,000 systems and any 1,000 go offline, you now have a Gnutella network of 9,000 systems.
Beyond intellectual property issues, integrity is a key P2P concern. With no central repository of data, what assurance do users have of receiving legitimate data? Cryptographic hashes are a critical control, and should be used to verify the integrity of data downloaded from a P2P network.
Thin Clients
Thin clients are simpler than normal computer systems, with hard drives, full operating systems, locally installed applications, etc. They rely on central servers, which serve applications and store the associated data. Thin clients allow centralization of applications and their data, as well as the associated security costs of upgrades, patching, data storage, etc. Thin clients may be hardware-based (such as diskless workstations) or software-based (such as thin client applications).
Diskless Workstations
A diskless workstation (also called diskless node) contains CPU, memory, and firmware, but no hard drive. Diskless devices include PCs, routers, embedded devices, and others. The kernel and operating system are typically loaded via the network. Hardware UNIX X-Terminals are an example of diskless workstations.
A diskless workstation’s BIOS begins the normal POST procedure, loads the TCP/IP stack, and then downloads the kernel and operating system using protocols such as the Bootstrap Protocol (BOOTP) or the Dynamic Host Configuration Protocol (DHCP). BOOTP was used historically for UNIX diskless workstations. DHCP, which we will discuss in Chapter 5, Domain 4: Communication and Network Security, has more features than BOOTP, providing additional configuration information such as the default gateway, DNS servers, etc.
Thin Client Applications
Thin client applications normally run on a system with a full operating system, but use a Web browser as a universal client, providing access to robust applications that are downloaded from the thin client server and run in the client’s browser. This is in contrast to “fat” applications, which are stored locally, often with locally stored data, and with sometimes complex network requirements.
Thin clients can simplify client/server and network architecture and design, improve performance, and lower costs. All data is typically stored on thin client servers. Network traffic typically uses HTTP (TCP port 80) and HTTPS (TCP port 443). The client must patch the browser and operating system to maintain security, but thin client applications are patched at the server. Citrix ICA, 2X ThinClientServer and OpenThinClient are examples of thin client applications.
The Internet of Things (IoT)
The Internet of Things (IoT) refers to small internet connected devices, such as baby monitors, thermostats, cash registers, appliances, light bulbs, smart meters, fitness monitors, cars, etc., etc. Many of these devices are often directly accessible via the internet.
You may think of your “Smart” TV as a television (which it is), but it is probably also running a server operating system such as Linux. These devices can pose significant security risks: default credentials are common, enterprise management tools are usually lacking, and straightforward issues such as patching can be difficult (if not impossible). Vendors often release base operating system patches quite slowly, and commonly end support for devices that are still in widespread use.
Here is the (condensed) nmap network mapper output for a Samsung Smart TV, showing it is most likely running Linux:

System Vulnerabilities, Threats and Countermeasures
System Threats, Vulnerabilities, and Countermeasures describe security architecture and design vulnerabilities, and the corresponding exploits that may compromise system security. We will also discuss countermeasures, or mitigating actions that reduce the associated risk.
Emanations
Emanations are energy that escapes an electronic system, which may be remotely monitored under certain circumstances. Energy includes electromagnetic interference, discussed later in this chapter.
Wired Magazine discussed the discovery of electronic emanations in the article “Declassified NSA Document Reveals the Secret History of TEMPEST”: “It was 1943, and an engineer with Bell Telephone was working on one of the U.S. government’s most sensitive and important pieces of wartime machinery, a Bell Telephone model 131-B2… Then he noticed something odd. Far across the lab, a freestanding oscilloscope had developed a habit of spiking every time the teletype encrypted a letter. Upon closer inspection, the spikes could actually be translated into the plain message the machine was processing. Though he likely did not know it at the time, the engineer had just discovered that all information processing machines send their secrets into the electromagnetic ether.”[13]
As a result of this discovery, TEMPEST (not an acronym, but a codename by the United States National Security Agency) was developed as a standard for shielding electromagnetic emanations from computer equipment.
Covert Channels
A covert channel is any communication that violates security policy. The communication channel used by malware installed on a system that locates Personally Identifiable Information (PII) such as credit card information and sends it to a malicious server is an example of a covert channel. Two specific types of covert channels are storage channels and timing channels.
The opposite of a covert channel is an overt channel: authorized communication that complies with security policy.
Covert Storage Channels
A storage channel example uses shared storage, such as a temporary directory, to allow two subjects to signal each other. Imagine Alice is a subject with a top secret clearance, and Bob is a secret-cleared subject. Alice has access to top secret information that she wishes to share with Bob, but the mandatory access control (MAC) system will prevent her from doing so.
Bob can see the size of Alice’s temporary files, but not the contents. They develop a code: a megabyte file means war is imminent (data labeled top secret), and a 0-byte file means “all clear.” Alice maintains a 0-byte file in the temporary directory until war is imminent, changing it to a 1-megabyte file, signaling Bob in violation of the system’s MAC policy.
Covert Timing Channels
A covert timing channel relies on the system clock to infer sensitive information. An example of a covert timing channel is an insecure login system. The system is configured to say “bad username or password,” if a user types a good username with a bad password, or a bad username and a bad password. This is done to prevent outside attackers from inferring real usernames.
Our insecure system prints “bad username or password” immediately when a user types a bad username/bad password, but there is a small delay (due to the time required to check the cryptographic hash) when a user types a good username with a bad password. This timing delay allows attackers to infer which usernames are good or bad, in violation of the system’s security design.
Backdoors
A backdoor is a shortcut in a system that allows a user to bypass security checks (such as username/password authentication) to log in. Attackers will often install a backdoor after compromising a system. For example, an attacker gains shell access to a system by exploiting a vulnerability caused by a missing patch. The attacker wants to maintain access (even if the system is patched), so she installs a backdoor to allow future access.
Maintenance hooks are a type of backdoor; they are shortcuts installed by system designers and programmers to allow developers to bypass normal system checks during development, such as requiring users to authenticate. Maintenance hooks become a security issue if they are left in production systems.
Malicious Code (Malware)
Malicious Code or Malware is the generic term for any type of software that attacks an application or system. There are many types of malicious code; viruses, worms, trojans, and logic bombs can cause damage to targeted systems.
Zero-day exploits are malicious code (a threat) for which there is no vendor-supplied patch (meaning there is an unpatched vulnerability).
Computer Viruses
Computer viruses are malware that does not spread automatically: they require a carrier (usually a human). They frequently spread via floppy disk, and (more recently) portable USB (Universal Serial Bus) memory. These devices may be physically carried and inserted into multiple computers.
Types of viruses include:
• Macro virus: virus written in macro language (such as Microsoft Office or Microsoft Excel macros)
• Boot sector virus: virus that infects the boot sector of a PC, which ensures that the virus loads upon system startup
• Stealth virus: a virus that hides itself from the OS and other protective software, such as antivirus software
• Polymorphic virus: a virus that changes its signature upon infection of a new system, attempting to evade signature-based antivirus software
• Multipartite virus: a virus that spreads via multiple vectors. Also called multipart virus.
Worms
Worms are malware that self-propagates (spreads independently). The term “worm” was coined by John Brunner in 1975 in the science fiction story The Shockwave Rider. Worms typically cause damage two ways: first by the malicious code they carry; the second type of damage is loss of network availability due to aggressive self-propagation. Worms have caused some of the most devastating network attacks.
The first widespread worm was the Morris worm of 1988, written by Robert Tappan Morris, Jr. Many Internet worms have followed since, including the Blaster worm of 2003, the Sasser worm of 2004, the Conficker worm of 2008 + , and many others.
Trojans
A trojan (also called a Trojan horse) is malware that performs two functions: one benign (such as a game), and one malicious. The term derives from the Trojan horse described in Virgil’s poem The Aeneid.
Rootkits
A rootkit is malware that replaces portions of the kernel and/or operating system. A user-mode rootkit operates in ring 3 on most systems, replacing operating system components in “userland.” Commonly rootkitted binaries include the ls or ps commands on Linux/UNIX systems, or dir or tasklist on Microsoft Windows systems.
A kernel-mode rootkit replaces the kernel, or loads malicious loadable kernel modules. Kernel-mode rootkits operate in ring 0 on most operating systems.
Packers
Packers provide runtime compression of executables. The original exe is compressed, and a small executable decompresser is prepended to the exe. Upon execution, the decompresser unpacks the compressed executable machine code and runs it.
Packers are a neutral technology that is used to shrink the size of executables. Many types of malware use packers, which can be used to evade signature-based malware detection. A common packer is UPX (Ultimate Packer for eXecutables), available at http://upx.sourceforge.net/.
Logic Bombs
A logic bomb is a malicious program that is triggered when a logical condition is met, such as after a number of transactions have been processed, or on a specific date (also called a time bomb). Malware such as worms often contain logic bombs, behaving in one manner, and then changing tactics on a specific date and time.
Roger Duronio of UBS PaineWebber successfully deployed a logic bomb against his employer after becoming disgruntled due to a dispute over his annual bonus. He installed a logic bomb on 2000 UBS PaineWebber systems, triggered by the date and time of March 4, 2002 at 9:30 AM: “This was the day when 2000 of the company’s servers went down, leaving about 17,000 brokers across the country unable to make trades. Nearly 400 branch offices were affected. Files were deleted. Backups went down within minutes of being run.”[14]
Duronio’s code ran the command “/usr/sbin/mrm –r / &” (a UNIX shell command that recursively deletes the root partition, including all files and subdirectories). He was convicted, and sentenced to 8 years and 1 month in federal prison.
Antivirus Software
Antivirus software is designed to prevent and detect malware infections. Signature-based antivirus uses static signatures of known malware. Heuristic-based antivirus uses anomaly-based detection to attempt to identify behavioral characteristics of malware, such as altering the boot sector.
Server-Side Attacks
Server-side attacks (also called service-side attacks) are launched directly from an attacker (the client) to a listening service. The “Conficker” worm of 2008+ spread via a number of methods, including a server-side attack on TCP port 445, exploiting a weakness in the RPC service. Windows systems that lacked the MS08-067 patch (and were not otherwise protected or hardened) were vulnerable to this attack. More details on Conficker are available at: http://mtc.sri.com/Conficker.
The attack is shown in Figure 4.15, where evil.example.com launches an attack on bank.example.com, listening on TCP port 445.

Figure 4.15 Server-Side Attack
Patching, system hardening, firewalls, and other forms of defense-in-depth mitigate server-side attacks. Organizations should not allow direct access to server ports from untrusted networks such as the Internet, unless the systems are hardened and placed on DMZ networks, which we will discuss in Chapter 5, Domain 4: Communication and Network Security.
Client-Side Attacks
Client-side attacks occur when a user downloads malicious content. The flow of data is reversed compared to server-side attacks: client-side attacks initiate from the victim who downloads content from the attacker, as shown in Figure 4.16.

Figure 4.16 Client-Side Attack
Client-side attacks are difficult to mitigate for organizations that allow Internet access. Clients include word processing software, spreadsheets, media players, Web browsers, etc. Browsers such as Internet Explorer and Firefox are actually a collection of software: the browser itself, plus third-party software such as Adobe Acrobat Reader, Adobe Flash, iTunes, QuickTime, RealPlayer, etc. All are potentially vulnerable to client-side attacks. All client-side software must be patched, a challenge many organizations struggle with.
Most firewalls are far more restrictive inbound compared to outbound: they were designed to “keep the bad guys out,” and mitigate server-side attacks originating from untrusted networks. They often fail to prevent client-side attacks.
Web Architecture and Attacks
The World Wide Web of 10 years ago was a simpler Web: most Web pages were static, rendered in HTML. The advent of “Web 2.0,” with dynamic content, multimedia, and user-created data has increased the attack surface of the Web: creating more attack vectors. Dynamic Web languages such as PHP (a “recursive acronym” that stands for PHP: Hypertext Preprocessor) make Web pages far more powerful and dynamic, but also more susceptible to security attacks.
An example PHP attack is the “remote file inclusion” attack. A URL (Universal Resource Locator) such as “http://good.example.com/index.php?file=readme.txt” references a PHP script called index.php. That script dynamically loads the file referenced after the “?,” readme.txt, which displays in the user’s Web browser.
An attacker hosts a malicious PHP file called “evil.php” on the Web server evil.example.com, and then manipulates the URL, entering:

If good.example.com is poorly configured, it will download evil.php, and execute it locally, allowing the attacker to steal information, create a backdoor, and perform other malicious tasks.
Applets
Applets are small pieces of mobile code that are embedded in other software such as Web browsers. Unlike HTML (Hyper Text Markup Language), which provides a way to display content, applets are executables. The primary security concern is that applets are downloaded from servers, and then run locally. Malicious applets may be able to compromise the security of the client.
Applets can be written in a variety of programming languages; two prominent applet languages are Java (by Oracle/Sun Microsystems) and ActiveX (by Microsoft). The term “applet” is used for Java, and “control” for ActiveX, though they are functionally similar.
Java
Java is an object-oriented language used not only to write applets, but also as a general-purpose programming language. Java bytecode is platform-independent: it is interpreted by the Java Virtual Machine (JVM). The JVM is available for a variety of operating systems, including Linux, FreeBSD, and Microsoft Windows.
Java applets run in a sandbox, which segregates the code from the operating system. The sandbox is designed to prevent an attacker who is able to compromise a java applet from accessing system files, such as the password file. Code that runs in the sandbox must be self-sufficient: it cannot rely on operating system files that exist outside the sandbox. A trusted shell is a statically compiled shell (it does not use operating system shared libraries), which can be used in sandboxes.
ActiveX
ActiveX controls are the functional equivalent of Java applets. They use digital certificates instead of a sandbox to provide security. ActiveX controls are tied more closely to the operating system, allowing functionality such as installing patches via Windows Update. Unlike Java, ActiveX is a Microsoft technology that works on Microsoft Windows operating systems only.
OWASP
The Open Web Application Security Project (OWASP, see: http://www.owasp.org) represents one of the best application security resources. OWASP provides a tremendous number of free resources dedicated to improving organizations’ application security posture. One of their best-known projects is the OWASP Top 10 project, which provides consensus guidance on what are considered to be the ten most significant application security risks. The OWASP Top 10 is available at https://www.owasp.org/index.php/Category:OWASP_Top_Ten_Project.
In addition to the wealth of information about application security threats, vulnerabilities, and defenses, OWASP also maintains a number of security tools available for free download including a leading interception proxy: ZAP, the Zed Attack Proxy.
XML
XML (Extensible Markup Language) is a markup language designed as a standard way to encode documents and data. XML is similar to, but more universal than, HTML. XML is used on the Web, but is not tied to it: XML can be used to store application configuration, output from auditing tools, and many other uses. Extensible means users may use XML to define their own data formats.
Service Oriented Architecture (SOA)
Service Oriented Architecture (SOA) attempts to reduce application architecture down to a functional unit of a service. SOA is intended to allow multiple heterogeneous applications to be consumers of services. The service can be used and reused throughout an organization rather than built within each individual application that needs the functionality offered by the service.
Services are expected to be platform independent and able to be called in a generic way not dependent upon a particular programming language. The intent is that any application may leverage the service simply by using standard means available within their programming language of choice. Services are typically published in some form of a directory that provides details about how the service can be used, and what the service provides.
Though Web Services are not the only example they are the most common example provided for the SOA model. XML or JSON (JavaScript Object Notation) is commonly used for the underlying data structures of web services, SOAP (originally an acronym for ‘Simple Object Access Protocol,’ but now simply ‘SOAP’) or REST (Representational State Transfer) provides the connectivity, and the WSDL (Web Services Description Language) provides details about how the Web Services are to be invoked.
Database Security
Databases present unique security challenges. The sheer amount of data that may be housed in a database requires special security consideration. As we will see shortly in the “Inference and Aggregation” section, the logical connections database users may make by creating, viewing, and comparing records may lead to inference and aggregation attacks, requiring database security precautions such as inference controls and polyinstantiation.
Polyinstantiation
Polyinstantiation allows two different objects to have the same name. The name is based on the Latin roots for multiple (poly) and instances (instantiation). Database polyinstantiation means two rows may have the same primary key, but different data.
Imagine you have a multilevel secure database table. Each tuple (a tuple is a row, or an entry in a relational database) contains data with a security label of confidential, secret, or top secret. Subjects with the same three clearances can access the table. The system follows mandatory access control rules, including “no read up:” a secret subject cannot read an entry labeled top secret.
A manager with a secret clearance is preparing to lay off some staff, opens the “layoffs” table, and attempts to create an entry for employee John Doe, with a primary key of 123-45-6789. The secret subject does not know that an entry already exists for John Doe with the same primary key, labeled top secret. In fact entries labeled top secret exist for the entire department, including the manager: the entire department is going to be laid off. This information is labeled top secret: the manager cannot read it.
Databases normally require that all rows in a table contain a unique primary key, so a normal database would generate an error like “duplicate entry” when the manager attempts to insert the new entry. The multilevel secure database cannot do that without allowing the manager to infer top secret information.
Polyinstantiation means the database will create two entries with the same primary key: one labeled secret, and one labeled top secret.
Inference and Aggregation
Inference and aggregation occur when a user is able to use lower level access to learn restricted information. These issues occur in multiple realms, including database security.
Inference requires deduction: there is a mystery to be solved, and lower level details provide the clues. Aggregation is a mathematical process: a user asks every question, receives every answer, and derives restricted information.
Inference requires deduction: clues are available, and a user makes a logical deduction. It is like a detective solving a crime: “Why are there so many pizza delivery cars in the Pentagon parking lot? A lot of people must be working all night…I wonder why?” In our database example, polyinstantiation is required to prevent the manager from inferring that a layoff is already planned for John Doe.
Aggregation is similar to inference, but there is a key difference: no deduction is required. Aggregation asks every question, receives every answer, and the user assembles restricted information.
Imagine you have an online phone database. Regular users can resolve a name, like Jane Doe, to a number, like 555-1234. They may also perform a reverse lookup, resolving 555-1234 to Jane Doe. Normal users cannot download the entire database: only phone administrators can do so. This is done to prevent salespeople from downloading the entire phone database and cold calling everyone in the organization.
Aggregation allows a normal user to download the entire database, and receive information normally restricted to the phone administrators. The aggregation attack is launched when a normal user performs a reverse lookup for 555-0000, then 555-0001, then 555-0002, etc., until 555-9999. The user asks every question (reverse lookup for every number in a phone exchange), receives every answer, and aggregates the entire phone database.
Inference and Aggregation Controls
Databases may require inference and aggregation controls. A real-world inference control based on the previous “Pentagon Pizza” learn by example would be food service vendors with contracts under NDA, required to securely deliver flexible amounts of food on short notice.
An example of a database inference control is polyinstantiation. Database aggregation controls may include restricting normal users to a limited amount of queries.
Data Mining
Data mining searches large amounts of data to determine patterns that would otherwise get “lost in the noise.” Credit card issuers have become experts in data mining, searching millions of credit card transactions stored in their databases to discover signs of fraud. Simple data mining rules, such as “X or more purchases, in Y time, in Z places” can be used to discover credit cards that have been stolen and used fraudulently.
Data mining raises privacy concerns: imagine if life insurance companies used data mining to track purchases such as cigarettes and alcohol, and denied claims based on those purchases.
Data Analytics
Data analytics can play a role in database security by allowing the organization to better understand the typical use cases and a baseline of what constitutes typical or normal interaction with the database. Understanding what normal operations looks like can potentially allow the organization to more proactively identify abuse from insider threats or compromised accounts. Given the rather high likelihood that significant and/or sensitive data is housed within a database, any tools that can improve the organization’s facility for detecting misuse could be a significant boon to security.
Countermeasures
The primary countermeasure to mitigate the attacks described in the previous section is defense in depth: multiple overlapping controls spanning across multiple domains, which enhance and support each other. Any one control may fail; defense in depth (also called layered defense) mitigates this issue.
Technical countermeasures are discussed in Chapter 5, Domain 4: Communication and Network Security. They include routers and switches, firewalls, system hardening including removing unnecessary services and patching, virtual private networks, and others.
Administrative countermeasures are discussed in Chapter 2, Domain 1: Security and Risk Management. They include policies, procedures, guidelines, standards, and related documents.
Physical countermeasures are discussed later in this chapter. They include building and office security, locks, security guards, mobile device encryption, and others.
Mobile Device Attacks
A recent information security challenge is mobile devices ranging from USB flash drives to laptops that are infected with malware outside of a security perimeter, and then carried into an organization. Traditional network-based protection, such as firewalls and intrusion detection systems, are powerless to prevent the initial attack.
Infected mobile computers such as laptops may begin attacking other systems once plugged into a network. USB flash drives can infect hosts systems via the Microsoft Windows “autorun” capability, where the “autorun.inf” file is automatically executed when the device is inserted into a system. Some types of malware create or edit autorun.inf in order to spread to other systems upon insertion of the USB flash drive.
Mobile Device Defenses
Defenses include administrative controls such as restricting the use of mobile devices via policy. The U.S. Department of Defense instituted such a policy in 2008 after an alleged outbreak of the USB-borne SillyFDC worm. Wired.com reports: “The Defense Department’s geeks are spooked by a rapidly spreading worm crawling across their networks. So they have suspended the use of so-called thumb drives, CDs, flash media cards, and all other removable data storage devices from their nets, to try to keep the worm from multiplying any further.”[16]
Technical controls to mitigate infected flash drives include disabling the “autorun” capability on Windows operating systems. This may be done locally on each system, or via Windows Active Directory group policy.
Technical controls to mitigate infected mobile computers include requiring authentication at OSI model layer 2 via 802.1X, which we will discuss in Chapter 5, Domain 4: Communication and Network Security. 802.1X authentication may be bundled with additional security functionality, such as verification of current patches and antivirus signatures. Two technologies that do this are Network Access Control (NAC) and Network Access Protection (NAP). NAC is a network device-based solution supported by vendors including Cisco Systems. NAP is a computer operating system-based solution by Microsoft.
Another mobile device security concern is the loss or theft of a mobile device, which threatens confidentiality, integrity and availability of the device and the data that resides on it. Backups can assure the availability and integrity of mobile data.
Full disk encryption (also known as whole disk encryption) should be used to ensure the confidentiality of mobile device data. This may be done in hardware or software, and is superior to partially-encrypted solutions such as encrypted files, directories or partitions.
Remote wipe capability is another critical control, which describes the ability to erase (and sometimes disable) a mobile device that is lost or stolen.
Cornerstone Cryptographic Concepts
Cryptography is secret writing: secure communication that may be understood by the intended recipient only. While the fact that data is being transmitted may be known, the content of that data should remain unknown to third parties. Data in motion (moving on a network) and at rest (stored on a device such as a disk) may be encrypted.
The use of cryptography dates back thousands of years, but is very much a part of our modern world. Mathematics and computers play a critical role in modern cryptography. Fundamental cryptographic concepts are embodied by strong encryption, and must be understood before learning about specific implementations.
Key Terms
Cryptology is the science of secure communications. Cryptography creates messages whose meaning is hidden; cryptanalysis is the science of breaking encrypted messages (recovering their meaning). Many use the term cryptography in place of cryptology: it is important to remember that cryptology encompasses both cryptography and cryptanalysis.
A cipher is a cryptographic algorithm. A plaintext is an unencrypted message. Encryption converts a plaintext to a ciphertext. Decryption turns a ciphertext back into a plaintext.
Confidentiality, Integrity, Authentication and Non-Repudiation
Cryptography can provide confidentiality (secrets remain secret) and integrity (data is not altered in an unauthorized manner): it is important to note that it does not directly provide availability. Cryptography can also provide authentication (proving an identity claim).
Additionally, cryptography can provide nonrepudiation, which is an assurance that a specific user performed a specific transaction and that the transaction did not change. The two must be tied together. Proving that you signed a contract to buy a car is not useful if the car dealer can increase the cost after you signed the contract. Nonrepudiation means the individual who performed a transaction, such as authenticating to a system and viewing personally identifiable information (PII), cannot repudiate (or deny) having done so afterward.
Confusion, Diffusion, Substitution and Permutation
Diffusion means the order of the plaintext should be “diffused” (or dispersed) in the ciphertext. Confusion means that the relationship between the plaintext and ciphertext should be as confused (or random) as possible. Claude Shannon, the father of information security, in his paper Communication Theory of Secrecy Systems, first defined these terms in 1949.[17]
Cryptographic substitution replaces one character for another; this provides confusion. Permutation (also called transposition) provides diffusion by rearranging the characters of the plaintext, anagram-style. “ATTACKATDAWN” can be rearranged to “CAAKDTANTATW,” for example. Substitution and permutation are often combined. While these techniques were used historically (the Caesar Cipher is a substitution cipher), they are still used in combination in modern ciphers such as the Advanced Encryption Standard (AES).
Strong encryption destroys patterns. If a single bit of plaintext changes, the odds of every bit of resulting ciphertext changing should be 50/50. Any signs of non-randomness may be used as clues to a cryptanalyst, hinting at the underlying order of the original plaintext or key.
Cryptographic Strength
Good encryption is strong: for key-based encryption, it should be very difficult (and ideally impossible) to convert a ciphertext back to a plaintext without the key. The work factor describes how long it will take to break a cryptosystem (decrypt a ciphertext without the key).
Secrecy of the cryptographic algorithm does not provide strength: secret algorithms are often proven quite weak. Strong crypto relies on math, not secrecy, to provide strength. Ciphers that have stood the test of time are public algorithms, such as the Triple Data Encryption Standard (TDES) and the Advanced Encryption Standard (AES).
Monoalphabetic and Polyalphabetic Ciphers
A monoalphabetic cipher uses one alphabet: a specific letter (like “E”) is substituted for another (like “X”). A polyalphabetic cipher uses multiple alphabets: “E” may be substituted for “X” one round, and then “S” the next round.
Monoalphabetic ciphers are susceptible to frequency analysis. Figure 4.17 shows the frequency of English letters in text. A monoalphabetic cipher that substituted “X” for “E,” “C” for “T,” etc., would be quickly broken using frequency analysis. Polyalphabetic ciphers attempt to address this issue via the use of multiple alphabets.

Figure 4.17 Frequency of English Letters
Modular Math
Modular math lies behind much of cryptography: simply put, modular math shows you what remains (the remainder) after division. It is sometimes called “clock math” because we use it to tell time: assuming a 12-hour clock, 6 hours past 9:00 PM is 3:00 AM. In other words, 9 + 6 is 15, divided by 12 leaves a remainder of 3.
As we will see later, methods like the running-key cipher use modular math. There are 26 letters in the English alphabet; adding the letter “Y” (the 25th letter) to “C” (the third letter) equals “B” (the 2nd letter). In other words, 25 + 3 equals 28. 28 divided by 26 leaves a remainder of 2. It is like moving in a circle (such as a clock face): once you hit the letter “Z,” you wrap around back to “A.”
Exclusive Or (XOR)
Exclusive Or (XOR) is the “secret sauce” behind modern encryption. Combining a key with a plaintext via XOR creates a ciphertext. XOR-ing the same key to the ciphertext restores the original plaintext. XOR math is fast and simple, so simple that it can be implemented with phone relay switches (as we will see with the Vernam Cipher).
Two bits are true (or 1) if one or the other (exclusively, not both) is 1. In other words: if two bits are different the answer is 1 (true). If two bits are the same the answer is 0 (false). XOR uses a truth table, shown in Table 4.3. This dictates how to combine the bits of a key and plaintext.
Table 4.3
XOR Truth Table

If you were to encrypt the plaintext “ATTACK AT DAWN” with a key of “UNICORN,” you would XOR the bits of each letter together, letter by letter. We will encrypt and then decrypt the first letter to demonstrate XOR math. “A” is binary 01000001 and “U” is binary 01010101. We then XOR each bit of the plaintext to the key, using the truth table in Table 4.3. This results in a Ciphertext of 00010100, shown in Table 4.4.
Table 4.4
01000001 XORed to 01010101
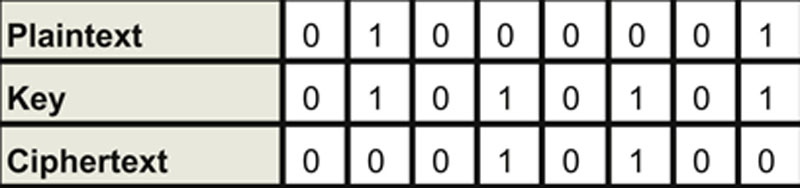
Now let us decrypt the ciphertext 00010100 with a key of “U” (binary 01010101). We XOR each bit of the key (01010101) with the ciphertext (00010100), again using the truth table in Table 4.3. We recover our original plaintext of 01000001 (ASCII “A”), as shown in Table 4.5.
Table 4.5
00010100 XORed to 01010101
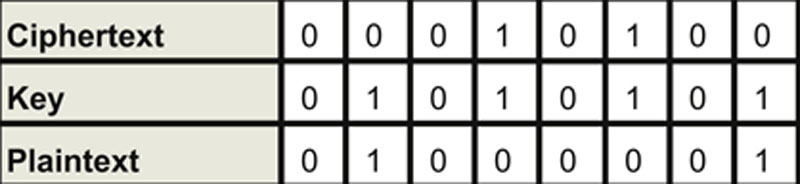
Data at Rest and Data in Motion
Cryptography is able to protect both data at rest and data in motion (AKA data in transit). Full disk encryption (also called whole disk encryption) of a magnetic disk drive using software such as TrueCrypt or PGP Whole Disk Encryption is an example of encrypting data at rest. An SSL or IPsec VPN is an example of encrypting data in motion.
Protocol Governance
Cryptographic Protocol Governance describes the process of selecting the right method (cipher) and implementation for the right job, typically at an organization-wide scale. For example: as we will learn later in this chapter, a digital signature provides authentication and integrity, but not confidentiality. Symmetric ciphers are primarily used for confidentiality, and AES is preferable over DES due to strength and performance reasons (which we will also discuss later).
Organizations must understand the requirements of a specific control, select the proper cryptographic solution, and ensure factors such as speed, strength, cost, complexity (and others) are properly weighed.
History of Cryptography
Cryptography is the oldest domain in the Common Body of Knowledge: stretching back thousands of years to the days of the Pharos in Egypt. Cryptography has changed the course of human history, playing a role in world wars and political intrigue.
Egyptian Hieroglyphics
Hieroglyphics are stylized pictorial writing used in ancient Egypt. Some hieroglyphics contained small puzzles, meant to attract the attention of the reader, who would solve the simple pictorial challenge. One type of puzzle featured a serpent-like symbol in place of a letter such as “S.” This form of writing was popular from roughly 2000 to 1000 B.C.
The meaning was hidden, albeit weakly, and this became the first known example of secret writing, or cryptography.
Spartan Scytale
The Scytale was used in ancient Sparta around 400 B.C. A strip of parchment was wrapped around a rod (like the tape on a baseball or cricket bat). The plaintext was encrypted by writing lengthwise down the rod (across the wrapped strip). The message was then unwound and sent. When unwound, the words appeared as a meaningless jumble.
The receiver, possessing a rod of the same diameter, wrapped the parchment across the rod, reassembling the message.
Caesar Cipher and other Rotation Ciphers
The Caesar Cipher is a monoalphabetic rotation cipher used by Gaius Julius Caesar. Caesar rotated each letter of the plaintext forward three times to encrypt, so that A became D, B became E, etc., as shown in Table 4.6.
Table 4.6
Caesar (Rot-3) Cipher

Table 4.7 shows how “ATTACK AT DAWN” encrypts to “DWWDFN DW GDZQ” using the Caesar Cipher. Note that rotating three letters is arbitrary; any number of letters (other than 26, assuming an English alphabet) may be rotated for the same effect.
Table 4.7
Encrypting “ATTACK AT DAWN” with the Caesar Cipher

Another common rotation cipher is Rot-13, frequently used to conceal information on bulletin board systems such as Usenet. For example, details that could “spoil” a movie for someone who had not seen it would be encoded in Rot-13: “Qrpxneq vf n ercyvpnag!” Many Usenet readers had a Rot-13 function to quickly decode any such messages.
Rot-13 rotates 13 characters, so that “A” becomes “N,” “B” becomes “O,” etc. A nice feature of Rot-13 is one application encrypts (albeit weakly); a second application decrypts (the equivalent of Rot-26, where “A” becomes “A” again).
Vigenère Cipher
The Vigenère cipher is a polyalphabetic cipher named after Blaise de Vigenère, a French cryptographer who lived in the 16th century. The alphabet is repeated 26 times to form a matrix, called the Vigenère Square. Assume a plaintext of “ATTACKATDAWN.” A key (such as “NEXUS”) is selected and repeated (“NEXUSNEXUS…”). The plaintext is then encrypted with the key via lookups to the Vigenère Square. Plaintext “A” becomes ciphertext “N,” and Figure 4.18 shows how plaintext “T” becomes ciphertext “X.” The full ciphertext is “NXQUUXEQXSJR.”

Figure 4.18 Vigenère Square Encrypting Plaintext “T” with a Key of “E”
Cipher Disk
Cipher disks have two concentric disks, each with an alphabet around the periphery. They allow both monoalphabetic and polyalphabetic encryption. For monoalphabetic encryption, two parties agree on a fixed offset: “Set ‘S’ to ‘D’.” For polyalphabetic encryption, the parties agree on a fixed starting offset, and then turn the wheel once every X characters: “Set ‘S’ to ‘D,’ and then turn the inner disk 1 character to the right after every 10 characters of encryption.” Figure 4.19 shows a modern cipher disk.
Figure 4.19 A Modern Cipher Disk from the National Cryptologic Museum Courtesy of the National Security Agency
Leon Battista Alberti, an Italian architect and Renaissance man, invented the cipher disk in 1466 or 1467. The disks were made of copper, with two concentric alphabets. In addition to inventing the cipher disk, Alberti is considered the inventor of the polyalphabetic cipher: he began with a static offset, but turned the disks after each few words were encrypted.
Cipher disks were used for hundreds of years; they were commonly used through the time of the U.S. Civil war. Figure 4.20 shows original brass cipher disks used by the Confederate States of America.

Figure 4.20 Confederate States of America Cipher Disks Courtesy of the National Security Agency
Jefferson Disks
Thomas Jefferson created Jefferson Disks in the 1790s. Jefferson called his invention the “Wheel Cypher;” it had 36 wooden disks, each with 26 letters in random order (“jumbled and without order,” according to Jefferson [18]) along the edge, like the ridges of a coin. The device, shown in Figure 4.21, was used briefly and then forgotten. Cipher wheels were later independently invented. Jefferson’s papers describing his “cypher” were rediscovered in 1922.

Figure 4.21 Jefferson Disks Courtesy of the National Security Agency
To encrypt a message with Jefferson Disks, you must first create an identical set of disks and securely send one to the party you wish to communicate with. Then arrange the first 36 letters of plaintext along one line of letters on the disks. Then pick any other line of “jumbled” letters: this is the ciphertext. Continue this process for each 36 letters of plaintext.
To decrypt, the recipient arranges the ciphertext along one line of the disks. Then the recipient scans the other 25 lines, looking for one that makes sense (the rest will be a jumble of letters, in all likelihood).
David Kahn, in his seminal history of cryptography called The Codebreakers, stated that the Jefferson Disk was the most advanced cryptographic device of its time and called Thomas Jefferson “the Father of American Cryptography.”[19]
Book Cipher and Running-Key Cipher
The book cipher and running-key cipher both use well-known texts as the basis for keys.
A book cipher uses whole words from a well-known text such as a dictionary. To encode, agree on a text source, and note the page number, line, and word offset of each word you would like to encode. Benedict Arnold used a book cipher to communicate with British conspirators.
Arnold and British army officer John André agreed to use Nathan Bailey’s Universal Etymological English Dictionary to encode and decode messages. Here is a sample of ciphertext sent from Arnold to André on July 12, 1780: “As 158.9.25 and 115.9.12 are 226.9.3′d by./236.8.20ing 131.9.21, 163.9.6…” The ciphertext means “As <word on page 158, column 9, offset 25> and <word on page 115, column 9, offset 12 > …” etc. This translates into “As Life and fortune are risked by serving His Majesty…”[20]
Running-key ciphers also use well-known texts as the basis for their keys: instead of using whole words, they use modulus math to “add” letters to each other. Assume a conspirator wishes to send the message “ATTACK AT DAWN” to a fellow conspirator. They have agreed to use the Preamble of the United States Constitution (“We the People of the United States, in Order to form a more perfect Union…”) as their running key. Table 4.8 shows the resulting ciphertext.
Table 4.8
Running Key Ciphertext of “ATTACK AT DAWN”
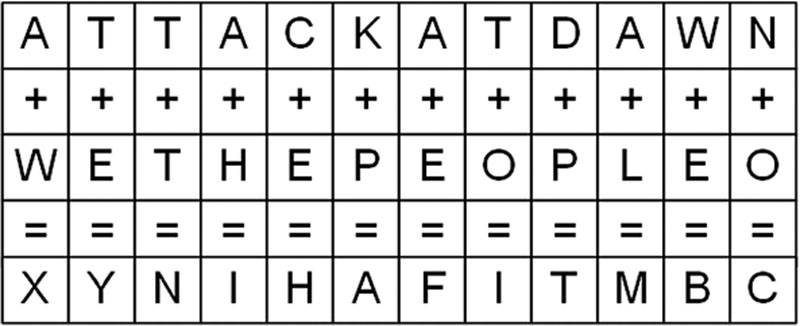
Codebooks
Codebooks assign a code word for important people, locations, and terms. One example is the Cipher for Telegraphic Correspondence, which was used by Union General Joseph Hooker during the United States Civil War. Each word in the codebook has two codenames. As shown in Figure 4.22, the president was “Adam” or “Asia,” the Secretary of State was “Abel” or “Austria,” etc.

Figure 4.22 Cipher for Telegraphic Correspondence Courtesy of the National Security Agency
One-Time Pad
A one-time pad uses identical paired pads of random characters, with a set amount of characters per page. Assume a pair of identical 100-page one-time pads with 1000 random characters per page. Once the identical pair of pads is created, they are securely given to two groups or individuals who wish to communicate securely.
Once the pads are securely distributed, either side may communicate by using the first page of the pad to encrypt up to 1000 characters of plaintext. The encryption is done with modular addition (as we saw previously, “Y” + “C” = “B”). The message is then sent to the receiver, who references the same page of the pad to decrypt via modular subtraction (“B” − “C” = “Y”). Once a page of the pad is used, it is discarded and never used again.
The one-time pad is the only encryption method that is mathematically proven to be secure, if the following three conditions are met: the characters on the pad are truly random, the pads are kept secure, and no page is ever reused.
Vernam Cipher
The first known use of a one-time pad was the Vernam Cipher, named after Gilbert Vernam, an employee of AT&T Bell Laboratories. In 1917 he invented a teletypewriter (capable of transmitting teletypes via phone lines) that encrypted and decrypted using paper rolls of tape containing the encryption key. Originally the keys were reused; the system began using a one-time pad (pairs of identical tapes with random keys that were never reused) in the 1920s.
The Vernam cipher used bits (before the dawn of computers, as other teletypes also did). The one-time pad bits were XORed to the plaintext bits.
Project VENONA
VENONA was the project undertaken by United States and United Kingdom cryptanalysts to break the KGB’s (the Soviet Union’s national security agency) encryption in the 1940s.
The KGB used one-time pads for sensitive transmissions, which should have rendered the ciphertext unbreakable. The KGB violated one of the three rules of one-time pads: they reused the pads. This allowed the U.S. and U.K. cryptanalysts to break many of the transmissions, providing critical intelligence. Many famous names were decrypted, including details on the nuclear espionage committed by Ethel and Julius Rosenberg.
Hebern Machines and Purple
Hebern Machines are a class of cryptographic devices known as rotor machines, named after Edward Hebern. Figure 4.23 shows an original Hebern Electric Code Machine. They look like large manual typewriters, electrified with rotors (rotating motors). These devices were used after World War I, through World War II, and in some cases into the 1950s.

Figure 4.23 Hebern Electric Code Machine Courtesy of the National Security Agency
Enigma
Enigma was used by German Axis powers during World War II. The initial cryptanalysis of Enigma was performed by French and Polish cryptanalysts; the British, led by Alan Turing in Bletchley Park, England, continued the work. The intelligence provided by the cryptanalysis of Enigma (called Ultra) proved critical in the European theater of World War II. British cryptanalyst Sir Harry Hinsley said, “the war, instead of finishing in 1945, would have ended in 1948 had the Government Code and Cypher School not been able to read the Enigma ciphers and produce the Ultra intelligence.”[21]
Enigma, shown in Figure 4.24, looks like a large typewriter with lamps and finger wheels added. The military version of Enigma (commercial versions also existed) had three finger wheels that could be set to any number from 1 to 26 (the finger wheels provide the key). As you type on the keyboard, the finger wheels turn, and a lamp for the corresponding ciphertext illuminates. To decrypt, set the finger wheels back to their original position, and type the ciphertext into the keyboard. The lamps illuminate to show the corresponding plaintext.

Figure 4.24 A Young Cryptographer using Enigma at the National Cryptologic Museum Courtesy of the National Security Agency
SIGABA
SIGABA was a rotor machine used by the United States through World War II into the 1950s. While similar to other rotor machines such as Enigma, it was more complex, based on analysis of weaknesses in Enigma by American cryptanalysts including William Friedman. SIGABA was also called ECM (Electronic Code Machine) Mark II.
SIGABA, shown in Figure 4.25, was large, complex, and heavy: far heavier and cumbersome than Enigma. As a result, it saw limited field use. SIGABA was never known to be broken.

Figure 4.25 SIGABA Courtesy of the National Security Agency
Purple
Purple is the Allied name for the encryption device used by Japanese Axis powers during World War II. While many sources describe Purple as a rotor machine from the same era, such as Enigma and American SIGABA, it is actually a stepping-switch device, primarily built with phone switch hardware. Other models included Red and Jade. Figure 4.26 shows a fragment of a Purple machine recovered from the Japanese Embassy in Berlin at the end of World War II.

Figure 4.26 Fragment of Japanese Purple Machine Courtesy of the National Security Agency
While Alan Turing led the British cryptanalysis of Enigma, senior cryptanalyst William Friedman led the United States effort against Purple. The Japanese Axis powers took Japanese plaintext, added code words, and then encrypted with Purple. The U.S. challenge was threefold: decrypt, translate the code words, and then translate Japanese to English.
In 1942, the Allies decoded Purple transmissions referencing a planned sneak attack on “AF.” The Allies believed AF was a code word for Midway Island, but they wanted to be sure. They sent a bogus message, weakly encoded, stating there was a water problem on Midway Island. Two days later the Allies decrypted a Purple transmission stating there was a water problem on AF.
The Allies knew where and when the “sneak” attack would be launched, and they were ready. The Battle of Midway Island provided a decisive victory for the Allies, turning the tide of war in the Pacific theater.
Cryptography Laws
The importance of cryptography was not lost on many governments, especially the United States. Intelligence derived from cryptanalysis was arguably as powerful as any bomb. This lead to attempts to control cryptography through the same laws used to control bombs: munitions laws.
COCOM
COCOM is the Coordinating Committee for Multilateral Export Controls, which was in effect from 1947 to 1994. It was designed to control the export of critical technologies (including cryptography) to “Iron Curtain” countries during the cold war.
Charter COCOM members included the United States and a number of European countries. Later Japan, Australia, Turkey, and much of the rest of the non-Soviet-controlled countries in Europe joined. Export of encryption by members to non-COCOM countries was heavily restricted.
Wassenaar Arrangement
After COCOM ended, the Wassenaar Arrangement was created in 1996. It features many more countries, including former Soviet Union countries such as Estonia, the Russian Federation, Ukraine, and others. The Wassenaar Arrangement also relaxed many of the restrictions on exporting cryptography.
Types of Cryptography
There are three primary types of modern encryption: symmetric, asymmetric, and hashing. Symmetric encryption uses one key: the same key encrypts and decrypts. Asymmetric cryptography uses two keys: if you encrypt with one key, you may decrypt with the other. Hashing is a one-way cryptographic transformation using an algorithm (and no key).
Symmetric Encryption
Symmetric encryption uses one key to encrypt and decrypt. If you encrypt a zip file, and then decrypt with the same key, you are using symmetric encryption. Symmetric encryption is also called “Secret key” encryption: the key must be kept secret from third parties. Strengths include speed and cryptographic strength per bit of key. The major weakness is that the key must be securely shared before two parties may communicate securely. Symmetric keys are often shared via an out-of-band method, such as via face-to-face discussion.
The key is usually converted into a subkey, which changes for each block of data that is encrypted.
Stream and Block Ciphers
Symmetric encryption may have stream and block modes. Stream mode means each bit is independently encrypted in a “stream.” Block mode ciphers encrypt blocks of data each round: 64 bits for the Data Encryption Standard (DES), and 128 bits for AES, for example. Some block ciphers can emulate stream ciphers by setting the block size to 1 bit; they are still considered block ciphers.
Initialization Vectors and Chaining
An initialization vector is used in some symmetric ciphers to ensure that the first encrypted block of data is random. This ensures that identical plaintexts encrypt to different ciphertexts. Also, as Bruce Schneier notes in Applied Cryptography, “Even worse, two messages that begin the same will encrypt the same way up to the first difference. Some messages have a common header: a letterhead, or a ‘From’ line, or whatever.”[22] Initialization vectors solve this problem.
Chaining (called feedback in stream modes) seeds the previous encrypted block into the next block to be encrypted. This destroys patterns in the resulting ciphertext. DES Electronic Code Book mode (see below) does not use an initialization vector or chaining and patterns can be clearly visible in the resulting ciphertext.
DES
DES is the Data Encryption Standard, which describes the Data Encryption Algorithm (DEA). DES was made a United States federal standard symmetric cipher in 1976. It was created due to a lack of cryptographic standards: vendors used proprietary ciphers of unknown strengths that did not interoperate with other vendor’s ciphers. IBM designed DES, based on their older Lucifer symmetric cipher. It uses a 64-bit block size (meaning it encrypts 64 bits each round) and a 56-bit key.
Modes of DES
DES can use five different modes to encrypt data. The modes’ primary difference is block versus (emulated) stream, the use of initialization vectors, and whether errors in encryption will propagate to subsequent blocks.
The five modes of DES are:
• Electronic Code Book (ECB)
• Cipher Block Chaining (CBC)
• Cipher Feedback (CFB)
• Output Feedback (OFB)
• Counter Mode (CTR)
ECB is the original mode of DES. CBC, CFB, and OFB were later added in FIPS Publication 81 (see http://www.itl.nist.gov/fipspubs/fip81.htm). CTR mode is the newest mode, described in NIST Special Publication 800-38a (see: http://csrc.nist.gov/publications/nistpubs/800-38a/sp800-38a.pdf).
Electronic Code Book (ECB)
Electronic Code Book (ECB) is the simplest and weakest form of DES. It uses no initialization vector or chaining. Identical plaintexts with identical keys encrypt to identical ciphertexts. Two plaintexts with partial identical portions (such as the header of a letter) encrypted with the same key will have partial identical ciphertext portions.
ECB may also leave plaintext patterns evident in the resulting ciphertext. Bitmap image data (see Figure 4.27a) encrypted with a key of “Kowalski” using 56-bit DES ECB mode (see Figure 4.27b) shows obvious patterns.

Figure 4.27 (a) Plaintext 8-bit Bitmap (BMP). Image (b) 56-bit DES ECB-Encrypted Ciphertext Bitmap Courtesy of the National Security Agency
Cipher Block Chaining (CBC)
Cipher Block Chaining (CBC) mode is a block mode of DES that XORs the previous encrypted block of ciphertext to the next block of plaintext to be encrypted. The first encrypted block is an initialization vector that contains random data. This “chaining” destroys patterns. One limitation of CBC mode is that encryption errors will propagate: an encryption error in one block will cascade through subsequent blocks due to the chaining, destroying their integrity.
Cipher Feedback (CFB)
Cipher Feedback (CFB) mode is very similar to CBC; the primary difference is CFB is a stream mode. It uses feedback (the name for chaining when used in stream modes) to destroy patterns. Like CBC, CFB uses an initialization vector and destroys patterns, and errors propagate.
Output Feedback (OFB)
Output Feedback (OFB) mode differs from CFB in the way feedback is accomplished. CFB uses the previous ciphertext for feedback. The previous ciphertext is the subkey XORed to the plaintext. OFB uses the subkey before it is XORed to the plaintext. Since the subkey is not affected by encryption errors, errors will not propagate.
Counter (CTR)
Counter (CTR) mode is like OFB; the difference again is the feedback: CTR mode uses a counter. This mode shares the same advantages as OFB (patterns are destroyed and errors do not propagate) with an additional advantage: since the feedback can be as simple as an ascending number, CTR mode encryption can be done in parallel. A simple example would be the first block is XORed to the number 1, the second to the number 2, etc. Any number of rounds can be combined in parallel this way.
Table 4.9 summarizes the five modes of DES.
Table 4.9
Modes of DES Summary
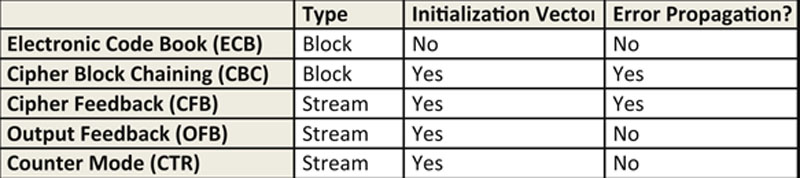
Single DES
Single DES is the original implementation of DES, encrypting 64-bit blocks of data with a 56-bit key, using 16 rounds of encryption. The work factor required to break DES was reasonable in 1976, but advances in CPU speed and parallel architecture have made DES weak to a brute-force key attack today, where every possible key is generated and attempted. Massively parallel computers such as COPACOBANA (Cost-Optimized Parallel COde Breaker, given as a non-testable example, see: http://www.copacobana.org for more information), which uses over 100 CPUs in parallel, can break 56-bit DES in a week or so (and faster with more CPUs), at a cost of under $10,000.
Triple DES
Triple DES applies single DES encryption three times per block. Formally called the “Triple Data Encryption Algorithm (TDEA) and commonly called TDES,” it became a recommended standard in 1999 by the United States Federal Information Processing Standard (FIPS) Publication 46-3 (see: http://csrc.nist.gov/publications/fips/fips46-3/fips46-3.pdf). FIPS 46-3 recommended single DES for legacy use only, due to the ever-lowering work factor required to break single DES.
Triple DES has held up well after years of cryptanalysis; the primary weakness is that it is slow and complex compared to newer symmetric algorithms such as AES or Twofish. Note that “double DES” (applying DES encryption twice using two keys) is not used due to a meet-in-the-middle attack: see the “Cryptographic Attacks” section for more information.
Triple DES Encryption Order and Keying Options
Triple DES applies DES encryption three times per block. FIPS 46-3 describes “Encrypt, Decrypt, Encrypt” (EDE) order using three keying options: one, two, or three unique keys (called 1TDES EDE, 2TDES EDE, and 3TDES EDE, respectively).
This order may seem confusing: why not encrypt, encrypt, encrypt, or EEE? And why use one through three keys? If you “decrypt” with a different key than the one used to encrypt, you are really encrypting further. Also, EDE with one key allows backwards compatibility with single DES.
Table 4.10 shows a single DES ECB encryption of “ATTACK AT DAWN” with the key “Hannibal” results in ciphertext of “•ÁGPÚ ¦qŸÝ«¦-” (this is the actual ciphertext; some bytes contain nonprintable characters).
Table 4.10
Single DES Encryption

Applying triple DES EDE with the same key each time results in the same ciphertext as single DES. Round 3 is identical to round 1, as shown in Table 4.11.
Table 4.11
Triple DES Encryption with One Key

2TDES EDE uses key 1 to encrypt, key 2 to “decrypt,” and key 1 to encrypt. This results in 112 bits of key length. It is commonly used for legacy hardware applications with limited memory.
3TDES EDE (three different keys) is the strongest form, with 168 bits of key length. The effective strength is 112 bits due to a partial meet-in-the-middle attack; see the Cryptographic Attacks section of this chapter for more information.
International Data Encryption Algorithm (IDEA)
The International Data Encryption Algorithm is a symmetric block cipher designed as an international replacement to DES. The IDEA algorithm is patented in many countries. It uses a 128-bit key and 64-bit block size. IDEA has held up to cryptanalysis; the primary drawbacks are patent encumbrance and its slow speed compared to newer symmetric ciphers such as AES.
Advanced Encryption Standard (AES)
The Advanced Encryption Standard is the current United States standard symmetric block cipher. It was published in Federal Information Processing Standard (FIPS) 197 (see: http://csrc.nist.gov/publications/fips/fips197/fips-197.pdf). AES uses 128-bit (with 10 rounds of encryption), 192-bit (12 rounds of encryption), or 256-bit (14 rounds of encryption) keys to encrypt 128-bit blocks of data. AES is an open algorithm, free to use, and free of any intellectual property restrictions.
AES was designed to replace DES. Two- and three-key TDES EDE remain a FIPS-approved standard until 2030, to allow transition to AES. Single DES is not a current standard, and not recommended.
Choosing AES
The United States National Institute of Standards and Technology (NIST) solicited input on a replacement for DES in the Federal Register in January 1997. They sought a public symmetric block cipher algorithm that was more secure than DES, open, and fast and efficient in both hardware and software. Fifteen AES candidates were announced in August 1998, and the list was reduced to five in August 1999. Table 4.12 lists the five AES finalists.
Table 4.12
Five AES Finalists

Rijndael was chosen and became AES. The name, pronounced “Rhine Dahl” in English, is a combination of the Belgian authors’ names: Vincent Rijmen and Joan Daemen. Rijndael was chosen “because it had the best combination of security, performance, efficiency, and flexibility.”[23]
Table 4.13 shows the “State,” which is the block of data that is being encrypted via AES. Each smaller box in the State is a byte (8 bits), and there are 16 bytes (128 bits) in each block. Data is encrypted and visualized in literal blocks. The algorithm that AES is based on was called “Square” for this reason.
Table 4.13
One 128-bit Block of AES Data, Called the State
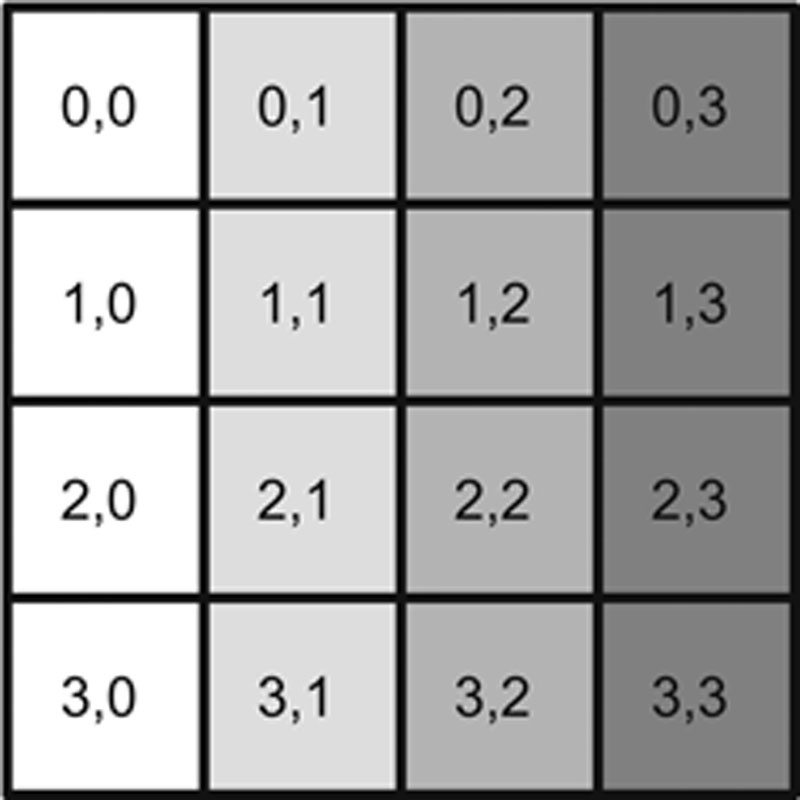
AES Functions
AES has four functions: SubBytes, ShiftRows, MixColumns, and AddRoundKey. These functions provide confusion, diffusion, and XOR encryption to the State.
ShiftRows
ShiftRows provides diffusion by shifting rows of the State. It treats each row like a row of blocks, shifting each a different amount:
• Row 0 is unchanged
• Row 1 is shifted 1 to the left
• Row 2 is shifted 2 to the left
• Row 3 is shifted 3 to the left.
Table 4.14 shows the transformation to the State.
Table 4.14
ShiftRows, Before and After

MixColumns
MixColumns also provides diffusion by “mixing” the columns of the State via finite field mathematics, as shown in Table 4.15.
Table 4.15
MixColumns

SubBytes
The SubBytes function provides confusion by substituting the bytes of the State. The bytes are substituted according to a substitution table (also called an S-Box).
To use the table, take the byte of the State to be substituted (assume the byte is the letter “T”). ASCII “T” is hexadecimal byte “53.” Look up 5 on the X row and 3 on the Y column, resulting in hexadecimal byte “ed;” this replaces “53” in the State. Figure 4.28 shows the AES substitution table directly from FIPS-197, with the byte 53 lookup overlaid on top:

AddRoundKey
AddRoundKey is the final function applied in each round. It XORs the State with the subkey. The subkey is derived from the key, and is different for each round of AES.
Blowfish and Twofish
Blowfish and Twofish are symmetric block ciphers created by teams led by Bruce Schneier, author of Applied Cryptography. Blowfish uses from 32 through 448 bit (the default is 128) keys to encrypt 64 bits of data. Twofish was an AES finalist, encrypting 128-bit blocks using 128 through 256 bit keys. Both are open algorithms, unpatented and freely available.
RC5 and RC6
RC5 and RC6 are symmetric block ciphers by RSA Laboratories. RC5 uses 32 (testing purposes), 64 (replacement for DES), or 128-bit blocks. The key size ranges from zero to 2040 bits.
RC6 was an AES finalist. It is based on RC5, altered to meet the AES requirements. It is also stronger than RC5, encrypting 128-bit blocks using 128-, 192-, or 256-bit keys.
Asymmetric Encryption
For thousands of years, cryptographic ciphers suffered from a chicken-and-egg problem: in order to securely communicate with someone, you had to first (securely) share a key or device. Asymmetric encryption was a mathematical breakthrough of the 1970s, finally solving the age-old challenge of pre-shared keys. Asymmetric pioneers include Whitfield Diffie and Martin Hellman, who created the Diffie-Hellman key exchange in 1976. The RSA algorithm was invented in 1977 (RSA stands for “Rivest, Shamir, and Adleman,” the authors’ names).
Asymmetric encryption uses two keys: if you encrypt with one key, you may decrypt with the other. One key may be made public (called the public key); asymmetric encryption is also called public key encryption for this reason. Anyone who wants to communicate with you may simply download your publicly posted public key and use it to encrypt their plaintext. Once encrypted, your public key cannot decrypt the plaintext: only your private key can do so. As the name implies, your private key must be kept private and secure.
Additionally, any message encrypted with the private key may be decrypted with the public key. This is typically used for digital signatures, as we will see shortly.
Asymmetric Methods
Math lies behind the asymmetric breakthrough. These methods use “one-way functions,” which are easy to compute “one way,” and difficult to compute in the reverse direction.
Factoring Prime Numbers
An example of a one-way function is factoring a composite number into its primes. A prime number is a number evenly divisible only by one and itself; a composite number is evenly divisible by numbers other than 1 and itself.
Multiplying the prime number 6269 by the prime number 7883 results in the composite number 49,418,527. That “way” is quite easy to compute, taking milliseconds on a calculator. Answering the question “which prime number times which prime number equals 49,418,527” is much more difficult. That problem is called factoring, and no shortcut has been found for hundreds of years. This is the basis of the RSA algorithm.
Factoring a large composite number (one thousands of bits long) is so difficult that the composite number can be safely publicly posted (this is the public key). The primes that are multiplied to create the public key must be kept private (they are the private key).
Discrete Logarithm
A logarithm is the opposite of exponentiation. Computing 7 to the 13th power (exponentiation) is easy on a modern calculator: 96,889,010,407. Asking the question “96,889,010,407 is 7 to what power” (finding the logarithm) is more difficult. Discrete logarithms apply logarithms to groups, which is a much harder problem to solve. This one-way function is the basis of the Diffie-Hellman and ElGamal asymmetric algorithms.
Diffie-Hellman Key Agreement Protocol
Key agreement allows two parties to securely agree on a symmetric key via a public channel, such as the Internet, with no prior key exchange. An attacker who is able to sniff the entire conversation is unable to derive the exchanged key. Whitfield Diffie and Martin Hellman created the Diffie-Hellman Key Agreement Protocol (also called the Diffie-Hellman Key Exchange) in 1976. Diffie-Hellman uses discrete logarithms to provide security.
Elliptic Curve Cryptography
ECC leverages a one-way function that uses discrete logarithms as applied to elliptic curves. Solving this problem is harder than solving discrete logarithms, so algorithms based on Elliptic Curve Cryptography (ECC) are much stronger per bit than systems using discrete logarithms (and also stronger than factoring prime numbers). ECC requires less computational resources because shorter keys can be used compared to other asymmetric methods. ECC is often used in lower power devices for this reason.
Asymmetric and Symmetric Tradeoffs
Asymmetric encryption is far slower than symmetric encryption, and is also weaker per bit of key length. The strength of asymmetric encryption is the ability to securely communicate without pre-sharing a key.
Table 4.16 compares symmetric and asymmetric algorithms based on key length. Note that systems based on discrete logarithms and factoring prime numbers are far weaker per bit of key length than symmetric systems such as Triple DES and AES. Elliptic Curve fares much better in comparison, but is still twice as weak per bit compared to AES.

Asymmetric and symmetric encryption are typically used together: use an asymmetric algorithm such as RSA to securely send someone an AES (symmetric) key. The symmetric key is called the session key; a new session key may be retransmitted periodically via RSA.
This approach leverages the strengths of both cryptosystems. Use the slower and weaker asymmetric system for the one part that symmetric encryption cannot do: securely pre-share keys. Once shared, leverage the fast and strong symmetric encryption to encrypt all further traffic.
Hash Functions
A hash function provides encryption using an algorithm and no key. They are called “one-way hash functions” because there is no way to reverse the encryption. A variable-length plaintext is “hashed” into a fixed-length hash value (often called a “message digest” or simply a “hash”). Hash functions are primarily used to provide integrity: if the hash of a plaintext changes, the plaintext itself has changed. Common older hash functions include Secure Hash Algorithm 1 (SHA-1), which creates a 160-bit hash and Message Digest 5 (MD5), which creates a 128-bit hash. Weaknesses have been found in both MD5 and SHA-1; newer alternatives such as SHA-2 are recommended.
Collisions
Hashes are not unique, because the number of possible plaintexts is far larger than the number of possible hashes. Assume you are hashing documents that are a megabit long with MD5. Think of the documents as strings 1,000,000 bits long, and the MD5 hash as a string 128 bits long. The universe of potential 1,000,000-bit strings is clearly larger than the universe of 128-bit strings. Therefore, more than one document could have the same hash: this is called a collision.
While collisions are always possible (assuming the plaintext is longer than the hash), they should be very difficult to find. Searching for a collision to match a specific plaintext should not be possible to accomplish in a reasonable amount of time.
MD5
MD5 is the Message Digest algorithm 5, created by Ronald Rivest. It is the most widely used of the MD family of hash algorithms. MD5 creates a 128-bit hash value based on any input length. MD5 has been quite popular over the years, but weaknesses have been discovered where collisions could be found in a practical amount of time. MD6 is the newest version of the MD family of hash algorithms, first published in 2008.
Secure Hash Algorithm
Secure Hash Algorithm is the name of a series of hash algorithms; SHA-1 was announced in 1993 in the United States Federal Information Processing Standard 180 (see http://www.itl.nist.gov/fipspubs/fip180-1.htm). SHA-1 creates a 160-bit hash value.
Like MD5, SHA-1 was also found to have weak collision avoidance. SHA-2 was announced in 2001 (see http://csrc.nist.gov/publications/fips/fips180-2/fips180-2.pdf). SHA-2 includes SHA-224, SHA-256, SHA-384, and SHA-512, named after the length of the message digest each creates.
While SHA-2 is recommended over SHA-1 or MD5, it is still less common due to its relative newness. The search for the next-generation hashing algorithm was announced in the Federal Register in 2007, similar to the AES competition. It was completed in October 2012, and SHA-3 was finalized in August 2015. Note that the finalization of SHA-3 is too new for the current exam, and is therefore not testable.
HAVAL
HAVAL (Hash of Variable Length) is a hash algorithm that creates message digests of 128, 160, 192, 224, or 256 bits in length, using 3, 4, or 5 rounds. HAVAL uses some of the design principles behind the MD family of hash algorithms, and is faster than MD5.
Cryptographic Attacks
Cryptographic attacks are used by cryptanalysts to recover the plaintext without the key. Please remember that recovering the key (sometimes called “steal the key”) is usually easier than breaking modern encryption. This is what law enforcement typically does when faced with a suspect using cryptography: they obtain a search warrant and attempt to recover the key.
Brute Force
A brute-force attack generates the entire key space, which is every possible key. Given enough time, the plaintext will be recovered. This is an effective attack against all key-based ciphers, except for the one-time pad. Since the key of a one-time pad is the same length as the plaintext, brute forcing every possible key will eventually recover the plaintext, but it will also produce vast quantities of other potential plaintexts, including all the works of Shakespeare. A cryptanalyst would have no way of knowing which potential plaintext is real. This is why the one-time pad is the only provably unbreakable form of crypto.
Social Engineering
Social engineering uses the human mind to bypass security controls. This technique may be used to recover a key by tricking the key holder into revealing the key. Techniques are varied, and include impersonating an authorized user when calling a help desk, and requesting a password reset. Information Security Europe tried a more direct route by asking users for their password in exchange for a treat: “More than one in five London office workers who talked to a stranger outside a busy train station were willing to trade a password for a chocolate bar.”[26]
Rainbow Tables
A Rainbow Table is a pre-computed compilation of plaintexts and matching ciphertexts (typically passwords and their matching hashes). Rainbow tables greatly speed up many types of password cracking attacks, often taking minutes to crack where other methods (such as dictionary, hybrid, and brute force password cracking attempts) may take much longer. We will discuss these methods of password cracking in Chapter 6, Domain 5: Identity and Access Management.
Many believe that rainbow tables are simply large databases of password/hash combinations. While this is how they appear to work (albeit at a typical speed of minutes and not seconds or less per lookup), this is not how rainbow tables work internally.
While pre-computation has obvious advantages, terabytes (or much more) would be required to store that much data using a typical database. All possible Microsoft LANMAN hashes and passwords would take roughly 48 terabytes of data to store; yet the Ophcrack rainbow table Linux live distribution (shown in Figure 4.29) can crack 99% of LANMAN hashes using only 388 megabytes for table storage. How is this possible?
Figure 4.29 Ophcrack Windows Rainbow Table Linux Live Distribution
Philippe Oechslin describes this challenge in his paper Making a Faster Cryptanalytic Time-Memory Trade-Off: “Cryptanalytic attacks based on exhaustive search need a lot of computing power or a lot of time to complete. When the same attack has to be carried out multiple times, it may be possible to execute the exhaustive search in advance and store all results in memory. Once this precomputation is done, the attack can be carried out almost instantly. Alas, this method is not practicable because of the large amount of memory needed.” [27]
Rainbow tables rely on a clever time/memory tradeoff. This technique was researched by Martin Hellman (of Diffie Hellman fame), and improved upon by Philippe Oechslin. Long chains of password-hash (plaintext-ciphertext) pairs are connected together. Thousands or millions of pairs may be connected into one chain (called a rainbow chain), and many chains may be formed, connected via a reduction function (which takes a hash and converts it into another possible password). At the end, everything in the chain may be removed, except the first and last entry. These chains may be rebuilt as needed, reconstituting all intermediate entries. This saves a large amount of storage, in exchange for some time and CPU cycles.
Known Plaintext
A known plaintext attack relies on recovering and analyzing a matching plaintext and ciphertext pair: the goal is to derive the key that was used. You may be wondering why you would need the key if you already have the plaintext: recovering the key would allow you to decrypt other ciphertexts encrypted with the same key.
Chosen Plaintext and Adaptive Chosen Plaintext
A cryptanalyst chooses the plaintext to be encrypted in a chosen plaintext attack; the goal is to derive the key. Encrypting without knowing the key is done via an “encryption oracle,” or a device that encrypts without revealing the key. This may sound far-fetched, but it is quite practical: a VPN concentrator encrypts plaintext to ciphertext without revealing the key (only users authorized to manage the device may see the key).
Adaptive-chosen plaintext begins with a chosen plaintext attack in round 1. The cryptanalyst then “adapts” further rounds of encryption based on the previous round.
Chosen Ciphertext and Adaptive Chosen Ciphertext
Chosen ciphertext attacks mirror chosen plaintext attacks: the difference is that the cryptanalyst chooses the ciphertext to be decrypted. This attack is usually launched against asymmetric cryptosystems, where the cryptanalyst may choose public documents to decrypt that are signed (encrypted) with a user’s public key.
Adaptive-chosen ciphertext also mirrors its plaintext cousin: it begins with a chosen ciphertext attack in round 1. The cryptanalyst then “adapts” further rounds of decryption based on the previous round.
Meet-in-the-Middle Attack
A meet-in-the-middle attack encrypts on one side, decrypts on the other side, and meets in the middle. The most common attack is against “double DES,” which encrypts with two keys in “encrypt, encrypt” order. The attack is a known plaintext attack: the attacker has a copy of a matching plaintext and ciphertext, and seeks to recover the two keys used to encrypt.
The attacker generates every possible value for key 1 and uses each to encrypt the plaintext, saving the intermediate (half-encrypted) ciphertext results. DES has a 56-bit key, so this will take 256 encryptions.
The attacker then generates every possible value for key 2, and uses each to decrypt the ciphertext. Once decrypted, the attacker looks up the intermediate ciphertext, looking for a match. If there is a match, the attacker has found both key 1 and key 2. The decryption step will take 256 attempts at most, for a total of 257 attempts (256 encryptions + up to 256 decryptions = 257).
In other words, despite 112 bits of key length, breaking double DES is only twice as hard as breaking 56-bit single DES. This is far too easy, so double DES is not recommended. 3TDES has a key length of 168 bits, but an effective strength of 112 bits due to the meet-in-the-middle attack: 3TDES has three keys and two “middles,” one can be used for a meet-in-the-middle attack, bypassing roughly one-third of the work.
Known Key
The term “known key attack” is misleading: if the cryptanalyst knows the key, the attack is over. Known key means the cryptanalyst knows something about the key, to reduce the efforts used to attack it. If the cryptanalyst knows that the key is an uppercase letter and a number only, other characters may be omitted in the attack.
Differential Cryptanalysis
Differential cryptanalysis seeks to find the “difference” between related plaintexts that are encrypted. The plaintexts may differ by a few bits. It is usually launched as an adaptive chosen plaintext attack: the attacker chooses the plaintext to be encrypted (but does not know the key), and then encrypts related plaintexts.
The cryptanalyst then uses statistical analysis to search for signs of non-randomness in the ciphertexts, zeroing in on areas where the plaintexts differed. Every bit of the related ciphertexts should have a 50/50 chance of flipping: the cryptanalyst searches for areas where this is not true. Any such underlying order is a clue to recover the key.
Linear Cryptanalysis
Linear cryptanalysis is a known plaintext attack where the cryptanalyst finds large amounts of plaintext/ciphertext pairs created with the same key. The pairs are studied to derive information about the key used to create them.
Both differential and linear analysis can be combined as differential linear analysis.
Side-Channel Attacks
Side-channel attacks use physical data to break a cryptosystem, such as monitoring CPU cycles or power consumption used while encrypting or decrypting. Some purists may claim this is breaking some type of rule, but as Bruce Schneier said, “Some researchers have claimed that this is cheating. True, but in real-world systems, attackers cheat. Their job is to recover the key, not to follow some rules of conduct. Prudent engineers of secure systems anticipate this and adapt to it.”[28]
Implementation Attacks
An implementation attack exploits a mistake (vulnerability) made while implementing an application, service or system. Bruce Schneier describes implementation attacks as follows: “Many systems fail because of mistakes in implementation. Some systems don’t ensure that plaintext is destroyed after it’s encrypted. Other systems use temporary files to protect against data loss during a system crash, or virtual memory to increase the available memory; these features can accidentally leave plaintext lying around on the hard drive. In extreme cases, the operating system can leave the keys on the hard drive. One product we’ve seen used a special window for password input. The password remained in the window’s memory even after it was closed. It didn’t matter how good that product’s cryptography was; it was broken by the user interface.” [29]
Birthday Attack
The birthday attack is named after the birthday paradox. The name is based on fact that in a room with 23 people or more, the odds are greater than 50% that two will share the same birthday. Many find this counterintuitive, and the birthday paradox illustrates why many people’s instinct on probability (and risk) is wrong. You are not trying to match a specific birthday (such as your’s); you are trying to match any birthday.
If you are in a room full of 23 people, you have a 1 in 365 chance of sharing a birthday with each of the 22 other people in the room, for a total of 22/365 chances. If you fail to match, you leave the room and Joe has a 21/365 chance of sharing a birthday with the remaining people. If Joe fails to match, he leaves the room and Morgan has a 20/365 chance, and so on. If you add 22/365 + 21/365 + 20/365 + 19/365 … + 1/365, you pass 50% probability.
The birthday attack is used to create hash collisions. Just as matching your birthday is difficult, finding a specific input with a hash that collides with another input is difficult. However, just like matching any birthday is easier, finding any input that creates a colliding hash with any other input is easier due to the birthday attack.
Key Clustering
A goal of any cryptographic cipher is that only one key can derive the plaintext from the ciphertext. Key Clustering occurs when two symmetric keys applied to the same plaintext produce the same ciphertext. This allows two different keys to decrypt the ciphertext.
Implementing Cryptography
Symmetric, asymmetric, and hash-based cryptography do not exist in a vacuum: they are applied in the real world, often in combination, to provide confidentiality, integrity, authentication, and nonrepudiation.
Digital Signatures
Digital signatures are used to cryptographically sign documents. Digital signatures provide nonrepudiation, which includes authentication of the identity of the signer, and proof of the document’s integrity (proving the document did not change). This means the sender cannot later deny (or repudiate) signing the document.
Roy wants to send a digitally signed email to Rick. Roy writes the email, which is the plaintext. He then uses the SHA-1 hash function to generate a hash value of the plaintext. He then creates the digital signature by encrypting the hash with his RSA private key. Figure 4.30 shows this process. Roy then attaches the signature to his plaintext email and hits send.

Rick receives Roy’s email and generates his own SHA-1 hash value of the plaintext email. Rick then decrypts the digital signature with Roy’s RSA public key, recovering the SHA-1 hash Roy generated. Rick then compares his SHA-1 hash with Roy’s. Figure 4.31 shows this process.
Figure 4.31 Verifying a Digital Signature
If the two hashes match, Rick knows a number of things:
1. Roy must have sent the email (only Roy knows his private key). This authenticates Roy as the sender.
2. The email did not change. This proves the integrity of the email.
If the hashes match, Roy cannot later deny having signed the email. This is nonrepudiation. If the hashes do not match, Rick knows either Roy did not send it, or that the email’s integrity was violated.
Message Authenticate Code
A Message Authentication Code (MAC) is a hash function that uses a key. A common MAC implementation is Cipher Block Chaining Message Authentication Code (CBC-MAC), which uses CBC mode of a symmetric block cipher such as DES to create a MAC. Message Authentication Codes provide integrity and authenticity (proof that the sender possesses the shared key).
HMAC
A Hashed Message Authentication Code (HMAC) combines a shared key with hashing. IPsec uses HMACs (see below).
Two parties must pre-share a key. Once shared, the sender uses XOR to combine the plaintext with a shared key, and then hashes the output using an algorithm such as MD5 (called HMAC-MD5) or SHA-1 (called HMAC-SHA-1). That hash is then combined with the key again, creating an HMAC.
The receiver combines the same plaintext with the shared key locally, and then follows the same process described above, resulting in a local HMAC. The receiver compares that with sender’s HMAC. If the two HMACs match, the sender is authenticated (this proves the sender knows the shared key), and the message’s integrity is assured (the message has not changed).
Public Key Infrastructure
Public Key Infrastructure (PKI) leverages all three forms of encryption to provide and manage digital certificates. A digital certificate is a public key signed with a digital signature. Digital certificates may be server-based (used for SSL Web sites such as https://www.ebay.com, for example) or client-based (bound to a person). If the two are used together, they provide mutual authentication and encryption. The standard digital certificate format is X.509.
NIST Special Publication 800-15 describes five components of PKI:
• Certification Authorities (CAs) that issue and revoke certificates
• Organizational Registration Authorities (ORAs) that vouch for the binding between public keys and certificate holder identities and other attributes
• Certificate holders that are issued certificates and can sign digital documents
• Clients that validate digital signatures and their certification paths from a known public key of a trusted CA
• Repositories that store and make available certificates and Certificate Revocation Lists (CRLs) [31]
Certificate Authorities and Organizational Registration Authorities
Digital certificates are issued by Certificate Authorities (CAs). Organizational Registration Authorities (ORAs) authenticate the identity of a certificate holder before issuing a certificate to them. An organization may operate as a CA or ORA (or both).
CAs may be private (run internally) or public (such as VeriSign or Thawte). Anyone off the street cannot simply request and receive a certificate for www.ebay.com, for example; they must prove that they have the authority to do so. This authentication is done by the CA, and can include business records research, emails sent to domain contacts, and similar methods.
Certificate Revocation Lists
The Certification Authorities maintain Certificate Revocation Lists (CRL), which, as the name implies, list certificates that have been revoked. A certificate may be revoked if the private key has been stolen, an employee is terminated, etc. A CRL is a flat file, and does not scale well. The Online Certificate Status Protocol (OCSP) is a replacement for CRLs, and uses client-server design that scales better.
Key Management Issues
Certificate Authorities issue digital certificates and distribute them to certificate holders. The confidentiality and integrity of the holder’s private key must be assured during the distribution process.
Public/private key pairs used in PKI should be stored centrally (and securely). Users may lose their private key as easily as they may forget their password. A lost private key that is not securely stored means that anything encrypted with the matching public key will be lost (short of cryptanalysis described previously).
Note that key storage is different than key escrow. Key storage means the organization that issued the public/private key pairs retains a copy. Key escrow, as we will discuss shortly, means a copy is retained by a third-party organization (and sometimes multiple organizations), often for law enforcement purposes.
A retired key may not be used for new transactions, but may be used to decrypt previously encrypted plaintexts. A destroyed key no longer exists, and cannot be used for any purpose.
SSL and TLS
Secure Sockets Layer (SSL) brought the power of PKI to the Web. SSL authenticates and provides confidentiality to Web traffic. Transport Layer Security (TLS) is the successor to SSL. They are commonly used as part of HTTPS (Hypertext Transfer Protocol Secure).
When you connect to a Web site such as https://www.isc2.org/, the data is encrypted. This is true even if you have not pre-shared a key: the data is encrypted out of the gate. This is done via asymmetric encryption: your browser downloads the digital certificate of www.isc2.org, which includes the site’s public key, signed by the Certificate Authority’s private key. If your browser trusts the CA (such as VeriSign), then this signature authenticates the site: you know it’s isc2.org and not a rogue site. Your browser then uses that public key to securely exchange a symmetric session key. The private key is stored on the isc2.org Web server, which allows it to decrypt anything encrypted with the public key. The symmetric key is then used to encrypt the rest of the session.
The ciphers used for authentication, key exchange, and symmetric encryption are flexible: your browser will negotiate each with the server. Supported algorithms include (but are not limited to) RSA and Diffie-Hellman for key exchange, RSA and Digital Signature Algorithm (DSA) for authentication, and AES and triple DES for confidentiality.
SSL was developed for the Netscape Web browser in the 1990s. SSL 2.0 was the first released version; SSL 3.0 fixed a number of security issues with version 2. TLS was based on SSL 3.0. TLS is very similar to that version, with some security improvements. Although typically used for HTTPS to secure Web traffic, TLS may be used for other applications such as Internet chat and email client access.
IPsec
IPsec (Internet Protocol Security) is a suite of protocols that provide a cryptographic layer to both IPv4 and IPv6. It is one of the methods used to provide Virtual Private Networks (VPN), which allow you to send private data over an insecure network, such as the Internet (the data crosses a public network, but is “virtually private”). IPsec includes two primary protocols: Authentication Header (AH) and Encapsulating Security Payload (ESP). AH and ESP provide different, and sometimes overlapping functionality.
Supporting IPsec protocols include Internet Security Association and Key Management Protocol (ISAKMP) and Internet Key Exchange (IKE).
AH and ESP
Authentication Header provides authentication and integrity for each packet of network data. AH provides no confidentiality; it acts as a digital signature for the data. AH also protects against replay attacks, where data is sniffed off a network and resent, often in an attempt to fraudulently reuse encrypted authentication credentials.
Encapsulating Security Payload primarily provides confidentiality by encrypting packet data. It may also optionally provide authentication and integrity.
Security Association and ISAKMP
AH and ESP may be used separately or in combination. An IPsec Security Association (SA) is a simplex (one-way) connection that may be used to negotiate ESP or AH parameters. If two systems communicate via ESP, they use two SAs (one for each direction). If the systems leverage AH in addition to ESP, they use two more SAs, for a total of four. A unique 32-bit number called the Security Parameter Index (SPI) identifies each simplex SA connection. The Internet Security Association and Key Management Protocol (ISAKMP) manages the SA creation process.
Tunnel and Transport Mode
IPsec can be used in tunnel mode or transport mode. Tunnel mode is used by security gateways (which can provide point-to-point IPsec tunnels). ESP Tunnel mode encrypts the entire packet, including the original packet headers. ESP Transport mode only encrypts the data (and not the original headers); this is commonly used when the sending and receiving system can “speak” IPsec natively.
AH authenticates the original IP headers, so it is often used (along with ESP) in transport mode, because the original headers are not encrypted. Tunnel mode typically uses ESP alone (the original headers are encrypted, and thus protected, by ESP).
IKE
IPsec can use a variety of encryption algorithms, such as MD5 or SHA-1 for integrity, and triple DES or AES for confidentiality. The Internet Key Exchange negotiates the algorithm selection process. Two sides of an IPsec tunnel will typically use IKE to negotiate to the highest and fastest level of security, selecting AES over single DES for confidentiality if both sides support AES, for example.
PGP
Pretty Good Privacy (PGP) brought asymmetric encryption to the masses. Phil Zimmerman created a controversy when he released PGP in 1991. For the first time, an average computer user could easily leverage the power of asymmetric encryption, which allows strangers (including criminals) to securely communicate without pre-sharing a key.
Zimmerman was investigated for munitions export violations by the United States government after the PGP source code was posted to the Usenet bulletin board system in 1991. The prosecutors dropped the case in 1996. RSA complained to Zimmerman for including the (then) patented RSA algorithm in PGP. Zimmerman had encouraged users to pay RSA for a license if they used the algorithm. Zimmerman agreed to stop publishing PGP to address the patent issue (though copies were freely available from other sources).
PGP provides the modern suite of cryptography: confidentiality, integrity, authentication, and nonrepudiation. It can be used to encrypt emails, documents, or an entire disk drive. PGP uses a Web of trust model to authenticate digital certificates, instead of relying on a central certificate authority (CA). If you trust that my digital certificate authenticates my identity, the Web of trust means you trust all the digital certificates that I trust. In other words, if you trust me, you trust everyone I trust.
S/MIME
MIME (Multipurpose Internet Mail Extensions) provides a standard way to format email, including characters, sets, and attachments. S/MIME (Secure/MIME) leverages PKI to encrypt and authenticate MIME-encoded email. The client or client’s email server (called an S/MIME gateway) may perform the encryption.
Escrowed Encryption
Escrowed encryption means a third-party organization holds a copy of a public/private key pair. The private key is often divided into two or more parts, each held in escrow by different trusted third-party organizations, which will only release their portion of the key with proper authorization, such as a court order. This provides separation of duties.
One goal of escrowed encryption is to offer a balance between an individual’s privacy, and the needs of law enforcement. Another goal is to ensure that encrypted data is recoverable in the event of key loss or employee termination.
Clipper Chip
The Clipper Chip was the name of the technology used in the Escrowed Encryption Standard (EES), an effort announced in 1993 by the United States government to deploy escrowed encryption in telecommunications devices. The effort created a media firestorm, and was abandoned by 1996.
The Clipper Chip used the Skipjack algorithm, a symmetric cipher that uses an 80-bit key. The algorithm was originally classified as secret. The secrecy of the algorithm was another controversial issue: secrecy of an algorithm does not provide cryptographic strength, and secret ciphers are often found to be quite insecure. Skipjack was later declassified in 1998 (after the Clipper Chip effort had been abandoned).
Steganography
Steganography is the science of hidden communication. The name is based on the Greek words “steganos” and “graphein,” which mean covered and write, or concealed writing. Encryption may provide confidentiality to a radio transmission, for example, but the communication itself is not hidden; only the meaning is concealed. Steganography hides the fact that communication is taking place.
The ancient Greek historian Herodotus documented the first use of steganography in the Histories of Herodotus. Herodotus described shaving a slave’s head, tattooing instructions on it, waiting for the hair to grow back, and sending the slave across enemy lines. Another method hid a message inside a rabbit’s stomach.
Modern steganography hides information inside data files, such as images. An 8-bit bitmap has 256 colors, for example. Say two different white pixels (called W0 and W1) in the image appear identical to the naked eye. You may encode a message by treating W0 and W1 as a bit stream.
Assume the file has a sequence of pixels in this order: W1, W1, W1, W1, W0, W0, W0, W1. You would like to encode “10101010” in the image. Treat W0 as binary 0, and W1 as binary 1. Then flip the pixels accordingly, resulting in W1, W0, W1, W0, W1, W0, W1 and W0. Figure 4.32 shows the process. A white arrow means the pixel was unchanged; black arrows represent changed pixels.
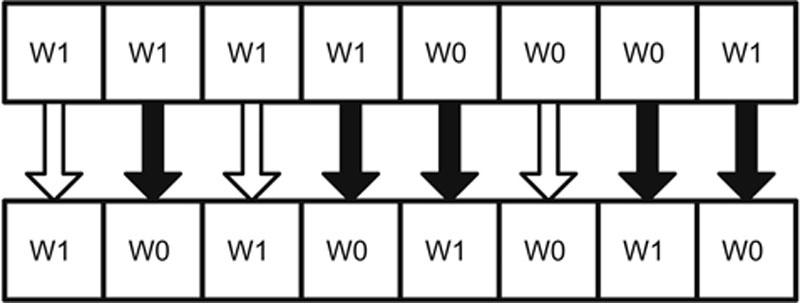
Figure 4.32 Steganographic Substitution of Bitmap Pixels
The image now contains the hidden message “10101010,” though it appears the same to the naked eye (and the size has not changed). The integrity of the image has changed. This method is called Substitution. Other methods include injection (add data to the file, creating a larger file) and new file creation. Substitution and Injection require a host file, new file creation creates a new file, as the name implies.
Messages that are hidden via steganography are often encrypted first, providing both confidentiality of the data and secrecy of the communication.
Digital Watermarks
Digital Watermarks encode data into a file. The watermark may be hidden, using steganography. Watermarks are often used to fingerprint files (tying a copy of a file to its owner).
..................Content has been hidden....................
You can't read the all page of ebook, please click here login for view all page.