
In the previous chapter, we looked at trees. Trees are important to understanding some complex topics in computer science, and we will use them going forward. In this chapter, we will look at a data structure that is equally important to the tree. This type of data structure is the hash table. Hash tables utilize hash functions to operate. In computer security in particular, cryptography and checksums rely heavily on hashing. In this chapter, we will look at the basics of hashes, hash functions, and hash tables.
Hashes and Hash Functions
Before we delve into hash data structures, we must look at what hashes are. When we are talking about a hash, what we mean is that there is some black box we call a function that converts one value to another. In Chapter 1 we talked about functions, so you may refer to that chapter for a further description.
While this may seem basic, that’s all a hash is—a function that converts one value to another. To understand a hash function, it may be easier to look at how it works in a step-by-step manner. We will start our discussion by looking at the function.
Let’s imagine we have a function in the form of a box; let’s call it a function box. Now imagine we take our function box, and we input the letter A. Don’t worry about how the box functions; just follow along with the logic.
Now within our box we have some special gizmos; every time we input the letter A, we get the number 1 as an output. We can see what such a setup looks like in Figure 4-1. For all its complexity, this is what the hash function does; we input data and get an output called a hash value
.
Figure 4-1.
Our function box
We’ll take this a step further. In Figure 4-2, we replace our function box with a hash function. The function is like before; we input the letter A and get an output. However, when we input data into the hash function instead of getting the number 1 as an output, the output is a hexadecimal sequence. This is how the most commonly encountered hash functions work.
Figure 4-2.
A hash function
The hash function is special in that it does not matter if the data being input is a single character, a string of characters, or even symbols. The hash value will always have the same fixed size.
Hash functions differ from regular functions. For a regular mathematical function, an element in the domain is mapped to exactly one element in the range. However, in a hash function, there is a small probability that two differing inputs may produce the same hash value. When this occurs, we get a hash collision. However, this is rare because even a change of one of the input bits to the hash function can result in a drastically different output of the hash function.
Good hash functions will have a value that is easy to compute and will avoid collisions. In the real world, there are many hash functions you will encounter, and many of them will have been designed for you.
Hash Table
Now that we understand how hashes function, we can understand the hash table data structure. Hash tables, like their name implies, utilize hashing, and the hash function is a fundamental part of the hash table data structure.
Hash tables, for all their complexity, can be simplified into this one-line description:
- At its core a hash table is a key-value lookup system.
That’s it. That’s all a hash table is, and we will keep this in mind going forward.
When we say that the hash table is a key-value lookup system, this means that in the hash table, every key has a value associated with it. This arrangement of data drastically increases the speed we perform lookups.
Since each key has a value associated with it, once we know the key, we can find the value instantly. This means that hash tables will have a time complexity when searching for an element of O(1).
This is advantageous because when we want to retrieve a value from, let’s say a database table, it can happen in most cases instantly, which the program end user will greatly appreciate.
The hash table utilizes hash functions
to perform the lookup. The key, which is usually a string, has a hash function applied to it; this then generates the hash value that is mapped to an index in the data structure (an array in a basic hash table) that’s used for storage. This means we can use the generated hash value to calculate the index in the array that we want to find or add to the table.
This might seem a little confusing, so an illustration of what I am saying will help; see Figure 4-3. Let’s imagine we have three strings, from STR0 to STR2. The hash function will take each string and have it mapped to an index in an array thanks to our hash function.
Figure 4-3.
Hash function
In the end, after each string has a hash function applied to it and generates an index for each string, our hash table will look like Figure 4-4.
Figure 4-4.
Hash table
While this method is efficient, there is a major drawback. Using an array, due to the underlying implementation of hash values and array sizes (that, honestly, we don’t need to understand how to use hash tables), can lead to a hash collision.
To solve this problem of a hash collision, the hash table implements what is known chaining to prevent this from happening.
Chaining is an innovative idea
that rather than storing elements in a simple array of elements, the hash table will store it as an array of elements that are linked lists.
Confused? Well, maybe some illustrations will clear it up. In a regular array-based linked list, each key element has a value associated with it. It would look something like Figure 4-5.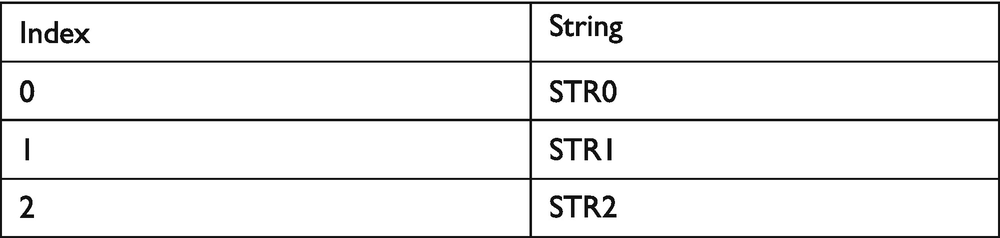
Figure 4-5.
Regular array linked list structure
The chaining method will have each element in the array as a liked list, as in Figure 4-6.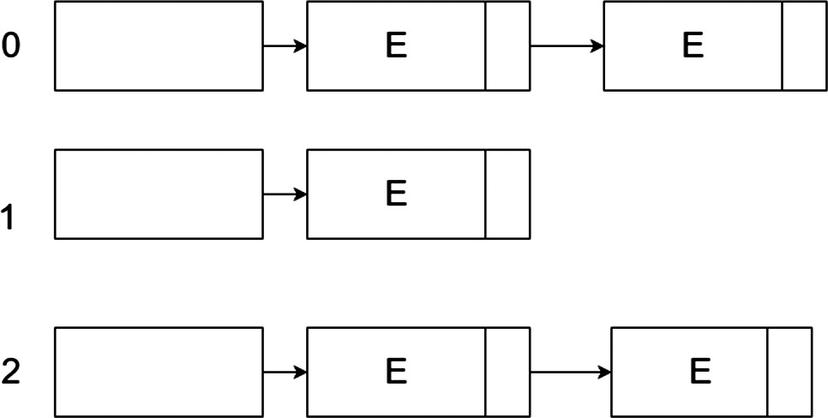
Figure 4-6.
Chaining method
As shown in the figure, instead of each element in the table simply having a value assigned to it, each element is a linked list that has items labeled as E, as in the figure. While this may not seem to have any added benefit, it helps with collision resolution.
The chain method resolves collisions by a simple method. If the hash function returns the same hash value for multiple elements, we simply “chain” those elements together with the same hash values at the same index in the hash table.
At index 0 and index 2, you see multiple items in a list associated with an element, which is because of the collision resolution ability of the hash table.
While this solves the problem of a hash collision
, as the chain length increases, the time complexity of the hash table lookup can worsen.
Computer Security Basics
Most commonly you will encounter hashing in computer security applications. However, before you understand exactly where hashing fits within this realm, it is important to have a basic understanding of computer security, which I will briefly cover in this section.
Computer networking is an essential part of computing as it allows computers to share resources. Exchanging data and information has allowed us to have a globalized society. Through the Internet, e-mail, and the Web people can work, study, and even form relationships with people all over the globe.
However, when sharing information, sometimes we do not want the information to fall into undesirable hands. Take, for example, Internet banking. When we do Internet banking, for example, we do not want our account information and passwords to be intercepted by a third party.
When sharing information, sometimes a third party can pretend to be someone they are not. Within computer security, when someone tries to identify themselves as someone else, this is called spoofing. To prevent spoofing and other compromises of the information exchange, we use encryption. The major way we avoid data being compromised is by using digital signatures.
Before we get into digital signatures, we will look at the cryptosystems that form an essential part of computer security.
Cryptosystems
Within the context of computer security, a cryptosystem is a set of algorithms that convert the input to the encryption process called plaintext into the output of the cryptosystem called ciphertext. When you convert plaintext into ciphertext, this is called encryption, and the conversion of ciphertext into plaintext is called decryption.
Cryptosystems use something called a key to aid the algorithm for the encryption process. A shared key cryptosystem uses the same key for encryption and decryption. How it works is that the person who wants to send data to someone else encrypts the data using a key. This key will convert the data into ciphertext. The receiver uses the key to decrypt the ciphertext and reobtain the original data.
While the shared key method seems secure, there are problems with this method. If a third party intercepts the encrypted message, since they do not have the key, they will not be able to decrypt the message. A problem arises if the key is sent over a network from one party to another, then the third party can intercept it, obtain the key, and decrypt the message.
This key distribution problem highlights the major flaws of the shared key cryptosystem. To aid with this problem, the public key cryptosystem was developed.
Public-Key Cryptosystem
In the public-key cryptosystem, different keys are used for encryption and decryption. We call the key that is used for encryption a public key and the key that is used for decryption a secret key. If the sender transmits the public key along with the data, there is no problem as the public key can only encrypt data and not decrypt it.
Hashing vs. Encryption
With all this talk about computer security and cryptosystems, you may be wondering how hashing fits into all this. It is important to make the distinction between hashing and encryption.
Encryption
is the name given to the process of making information unreadable by muddling it so that only someone with a key can use it. Within the encryption process we use an encryption algorithm called a cipher. Encryption assumes that we will use the cipher to encrypt and decrypt information, which is to say we expect to recover the information that we originally encrypted.
Hashing, on the other hand, takes data as an input and produces a fixed-length output without the intention of obtaining the original data. Whereas encryption is a two-way process, hashing is a one-way process.
As simple as it seems, it is important to keep this in mind and not to confuse hashing with encryption.
Role of Hashes in Computer Security
Within computer security, hashes have several uses including digital signatures and user authentication, which we will discuss in this section.
The first prominent role you will encounter for hashes is in digital signatures. Digital signatures are used to validate the legitimacy of digital data. In other words, it is a way of verifying the data received came from who it was supposed to come from. To do this, the data must be signed by the holder of the private key.
Two commonly encountered digital signature methods are Rivest-Shamir-Adleman (RSA) and Digital Signature Algorithm (DSA). These digital signature methods are similar with the exception that DSA can be used only for creation and verification of signatures but cannot be used for encryption. RSA, on the other hand, can be used for both digital signatures and encryption.
Within both methods, hashes are employed to aid with ensuring the signatures are secure. Within the RSA signature method, the process of signing involves using a hash function on the data before it is encrypted. The DSA method uses a cryptographic hash function based on the Secure Hash Algorithm (SHA) to aid in the process.
Hashes also find uses in user authentication methods such as in password applications. Since hashes are one-way and 1:1 functions, this makes them ideal for using with password security.
When we input a password into a login form, for example, it is verified with a password that is stored in a database that is linked to the application. If security is breached and someone gains access to the database, if the password is stored as plain text, then a malicious hacker can see all the passwords.
Now, if the password is hashed, then even if security is compromised, the passwords remain secure. From the time the user creates the password, we will be able to store it securely without knowing what it is. This is because the output of the hash will be stored and not the plain text. This hash is consistent, so it can be stored and compared without knowing exactly what it is.
There are other uses of hashes within the computer security realm including random number generation, message authentication code (MAC), one-way functions, and any other application the cryptographic engineer may fathom.
Hashes and Cyclic Redundancy Check
With the advent of the Internet of Things, you might encounter some embedded system that may have a microcontroller within it. One of the modules you may encounter on a microcontroller system is one used for the cyclic redundancy check (CRC), which uses hashing for operation.
A cyclic redundancy check is a method of detecting errors in digital data. To do this, a hash function is used to verify the authenticity of data. The CRC works by taking a checksum, which is a fixed number of bits and attaching it to the message being transmitted using the hash function. On the receiving end, the data is checked for errors by finding the remainder of the polynomial division of the contents transmitted.
If the data is checked and the CRC does not match the sent CRC, then the data is most likely corrupted. The application designer can then choose to have the data ignored or re-sent by the sender.
The CRC module finds extensive use in embedded systems for transmitting digital data via Ethernet and WiFi, for example.
Other Hash Uses
Some applications such as search engines, compilers, and databases must perform a lot of complex lookup operations. These lookup operations are time intensive and time critical, and regular data structures like linked lists may not be able to keep up.
As such, we need some operation that will perform in constant time, and as we stated earlier, hash tables typically have a time complexity of O(1). This fast constant time is ideal for such applications. This is where hashes shine and are used in such applications.
Conclusion
In this chapter, we examined the basics of hashing, hash functions, and hash tables. In the next chapter, we will look at graphs, which are an important concept in artificial intelligence that utilize graphs and graph searching algorithms for problem-solving. Should you need more information on the topics in this chapter, especially if your interest in computer security has been awakened, the book I personally recommend is Practical Information Security Management by Tony Campbell (Apress, 2016). You can also check several web sources on the topic.