
CHAPTER 4
Securing a Corporate Network
In this chapter you will learn:
• Penetration testing
• Reverse engineering
• Training and exercises
• Risk evaluation
Trust, but verify.
—Russian proverb
The title of this chapter might seem a bit misleading because we won’t address the entirety of the effort of securing a corporate network. It would take a very long book to do so. In this chapter, we focus on the specific aspects of this effort that would fall in the purview of a cybersecurity analyst. Apart from your daily job in the trenches looking for the telltale signs of nefarious actors in your systems, you will likely be involved in risk evaluations, penetration tests, training, and exercises. You should also be at least familiar with reverse engineering, because it is usually required in the more sophisticated incidents with which you will be involved. Let’s start with our favorite: penetration testing.
Penetration Testing
Penetration testing, also known as pen testing, is the process of simulating attacks on a network and its systems at the request of the owner, senior management. It uses a set of procedures and tools designed to test and possibly bypass the security controls of a system. Its goal is to measure an organization’s level of resistance to an attack and to uncover any weaknesses within the environment. A penetration test emulates the same methods attackers would use, so penetration attacks should align with the hacking tactics, techniques, and procedures (TTPs) of likely adversaries.
The type of penetration test that should be used depends on the organization, its security objectives, and the leadership’s goals. Some corporations perform periodic penetration tests on themselves using different types of tools, or they use scanning devices that continually examine the environment for new vulnerabilities in an automated fashion. Other corporations ask a third party to perform the vulnerability and penetration tests to provide a more objective view.
Penetration tests can evaluate web servers, Domain Name System (DNS) servers, router configurations, workstation vulnerabilities, access to sensitive information, remote dial-in access, open ports, and the properties of available services that a real attacker might use to compromise the company’s overall security. Some tests can be quite intrusive and disruptive. The timeframe for the tests should be agreed upon so productivity is not affected and personnel can bring systems back online if necessary.
NOTE Penetration tests are not necessarily restricted to information technology, but may include physical security as well as personnel security. Ultimately, the purpose is to compromise one or more controls, and these could be technical, physical, or operational.
The result of a penetration test is a report given to management that describes the vulnerabilities identified and the severity of those vulnerabilities, along with suggestions on how to deal with them properly. From there, it is up to management to determine how the vulnerabilities are actually dealt with and what countermeasures are implemented.
When performing a penetration test, the team goes through a four-step process called the kill chain:
1. Reconnaissance Footprinting and gathering information about the target
2. Exploitation Compromising a security control or otherwise gaining illicit access
3. Lateral movement Compromising additional systems from the breached one
4. Report to management Delivering to management documentation of test findings along with suggested countermeasures
The penetration testing team can have varying degrees of knowledge about the penetration target before the tests are actually carried out:
• Zero knowledge The team does not have any knowledge of the target and must start from ground zero. This is also known as black-box pen testing.
• Partial knowledge The team has some information about the target. This is also known as gray-box pen testing.
• Full knowledge The team has intimate knowledge of the target. This is also known as white-box pen testing.
Rules of Engagement
Robert Frost is famously quoted as saying “good fences make good neighbors.” This could not be truer in penetration testing. Many of the tasks involved in this activity are illegal in most countries, absent the consent of the system owner. Even if all legal precautions are in place, the risk of costly disruptions to critical business processes requires careful consideration. Finally, if the penetration testers focus their attention on the wrong targets, the value to the organization may be lessened. For all these reasons, it is absolutely critical to carefully define the timing, scope, authorizations, exploitation techniques, and communication mechanisms before the first cyber shot is fired.
Timing
Penetration tests can be expensive and risky, so it is important to consider timing issues. First of all, the scope of the exercise typically dictates the minimum required duration. Testing the software development subnet on a regional bank can be done a lot quicker than testing a multinational corporation. Part of the responsibility of the project champion is to balance the number of risk areas being tested against the number of days (and concomitant cost) that would be required to thoroughly assess them.
Another timing consideration is during which hours the pen testers will be active. If the test takes place during normal business hours, extra care must be taken to ensure no production systems are adversely affected in a way that could jeopardize real business. This schedule also allows defenders to better react to any detected attacks. Conversely, conducting the test after work hours mitigates the risk against business processes, but may lessen the training value for the defenders. When deciding which approach to use, it may be helpful to consider the time zone in which likely attackers would be operating. If attacks typically come at night or on weekends, then it may be best to allow the pen testing team to operate during those hours as well.
Scope
There is a common misconception that the penetration testers should try to be as realistic as possible and should therefore choose the networks and systems they target. There are many problems with this approach, not the least of which is that the testers must receive assurances that their targets are actually owned by whomever is telling them to attack them. It is not uncommon for organizations to outsource portions of their information infrastructure. Absent a very specific scope for the test, the evaluators run the risk of targeting systems owned by other parties that have not consented to the event.
Typically, a penetration test is scoped in at least two ways: what is definitely in scope and what is surely out of scope. For instance, the organization may provide the testers with specific IP subnets within which any and all nodes are fair game, except for those on a specific list. Apart from business reasons for excluding systems, it is possible that there are regulatory considerations that would forbid probing them. Protected personal healthcare information (PHI) is a notable example of this. If the pen testers successfully compromised a host and extracted PHI, this could be in violation of federal law in the United States.
Having been given a list of “go” and “no-go” systems, the test team will sometimes come across nodes that are not on either list. It is important to define beforehand how these situations will be handled. If an ambiguous node needs to be manually verified, it could consume valuable test time. Some organizations, therefore, either whitelist or blacklist systems for the penetration testers, with whitelisting being the preferred approach.
Authorization
It is critical that senior management be aware of any risks involved in performing a penetration test before it gives the authorization for one. In rare instances, a system or application may be taken down inadvertently using the tools and techniques employed during the test. As expected, the goal of penetration testing is to identify vulnerabilities, estimate the true protection the security mechanisms within the environment are providing, and see how suspicious activity is reported. However, accidents can and do happen.
Security professionals should obtain an authorization letter that includes the extent of the testing authorized, and this letter or memo should be available to members of the team during the testing activity. This type of letter is commonly referred to as a “Get Out of Jail Free Card.” Contact information for key personnel should also be available, along with a call tree in the event something does not go as planned and a system must be recovered.
NOTE A “Get Out of Jail Free Card” is a document you can present to someone who thinks you are up to something malicious, when in fact you are carrying out an approved test. There have been many situations in which an individual (or a team) was carrying out a penetration test and was approached by a security guard or someone who thought this person was in the wrong place at the wrong time.
Exploitation
Exploitation is the act of using a vulnerability in a computer system in order to cause an unintended, unanticipated, or unauthorized behavior to occur in that system. Typically, exploitation involves a compromise to the confidentiality, integrity, or availability of the target. It is the very purpose of conducting a penetration test: to demonstrate that vulnerabilities are actually exploitable and to show how.
Exploitation often involves the use of specially crafted software, data, or commands called exploits that trigger the vulnerability and cause the desired behavior. These exploits are not all created equal; some are innocuous while others can cause temporary or even permanent damage to the target. It is because of the latter possibility that the methods of exploitation must be carefully discussed as part of the rules of engagement. It may be acceptable to cause the occasional blue screen of death on a workstation, but the same is typically not true of a production server.
Communication
When things go wrong in a penetration test (which is not all that unusual), the test team must have a clear communication mechanism that has been pre-coordinated. You don’t want to wait until you knock over a production server on a Friday evening to start figuring out whom you should call. Along the same lines, how bad do things have to get before the CEO gets a call in the middle of the night? We all hope it never gets to that, but many of us have found ourselves in crisis situations before. It is best to have thought about all possibilities (particularly the really bad ones).
There is another communication consideration during a penetration test: who knows what and when? There are some tests in which the defenders (apart from key leaders) are not aware that a pen testing team is attacking them. This is called a double-blind test when neither the penetration testers nor the defenders are given information about each other. The attackers are probing the network (initially) blindly, while the defenders are unaware that the attack is not a real one. Carefully planned communications processes become indispensable when this is the approach to testing.
Reporting
Once the penetration test is over and the interpretation and prioritization are done, the team will provide a detailed report showing many of the ways the company could be successfully attacked. This report usually provides a step-by-step methodology that was shown to be successful as well as recommended ways to mitigate the risk of real attackers doing the same thing. This is the input to the next cycle in what should be a continuous risk management process. All organizations have limited resources, so only a portion of the total risk can be mitigated. Balancing the risks and risk appetite of the company against the costs of possible mitigations and the value gained from each is part of what a cybersecurity analyst must be able to do. An oversight program is required to ensure that the mitigations work as expected and that the estimated cost of each mitigation action is closely tracked by the actual cost of implementation.
Reverse Engineering
Reverse engineering is the process of deconstructing something in order to discover its features and constituents. The features tell us what the system is capable of doing. They tell us what a thing can do. The constituents or parts tell us how it was put together to do what it does. Reverse engineering is necessary whenever we don’t have full documentation for a system but still have to ensure we understand what it does and how.
Hardware
There is a belief that hardware is immutable. That may have once been true, but we are increasingly seeing a move towards software-defined “things” such as radios and networks that used to be implemented almost exclusively in hardware. Increasingly, the use of custom electronics is yielding to an approach by which more generalized hardware platforms are running custom software. This makes both business and technical sense, because it is easier, faster, and cheaper to update software than it is to replace hardware. Still, at some point, we need hardware to run the software, and that software has to be trusted.
Source Authenticity
In 2012, there were multiple reports in the media of counterfeit networking products finding their way into critical networks in both industry and government. By one account, some of these fakes were even found in sensitive military networks. Source authenticity, or the assurance that a product was sourced from an authentic manufacturer, is important for all of us, but particularly so if we handle sensitive information. Two particular problems with fake products affect a cybersecurity analyst: malicious features and lower quality.
It is not hard to imagine organizations or governments that would want to insert their own fake or modified version of a popular router into a variety of networks. Apart from a source of intelligence or data theft, it could also provide them with remote “kill” switches that could be leveraged for blackmail or in case of hostilities. The problem, of course, is that detecting these hidden features in hardware is often well beyond the means of most organizations. Ensuring your devices are legitimate and came directly from the vendor can greatly decrease this risk.
Another problem with counterfeit hardware is that, even if there is no malicious design, it is probably not built to the same standard as the genuine hardware. It makes no sense for a counterfeiter to invest the same amount of resources into quality assurance and quality control as the genuine manufacturer. Doing so would increase their footprint (and chance of detection) as well as drive their costs up and profit margins down. For most of us, the greatest risk in using counterfeits is that they will fail at a higher rate and in more unexpected ways than the originals. And when they do fail, you won’t be able to get support from the legitimate manufacturer.
Trusted Foundry
In their novel Ghost Fleet, authors P.W. Singer and August Cole describe a string of battles that go terribly wrong for the U.S. The cause, unbeknownst to the hapless Americans, is a sophisticated program to insert undetectable backdoors into the computer chips that run everything from missiles to ships. Although their account is fictional, there have been multiple reports in the open media about counterfeit products introducing vulnerabilities into networks, including some in the military.
The threat is real. In 2004, the U.S. Department of Defense (DoD) instituted the Trusted Foundry Program. The goal is to ensure that mission-critical military and government systems can be developed and fielded using a supply chain that is hardened against external threats. A trusted foundry is an organization capable of developing prototype or production-grade microelectronics in a manner that ensures the integrity of their products. The trust is ensured by the National Security Agency through a special review process. At the time of this writing, 77 vendors were rated as trusted foundries and available to U.S. DoD customers.
OEM Documentation
Original equipment manufacturers (OEMs) almost always provide detailed documentation on the features of their products. They also sometimes provide detailed performance parameters and characteristics that can be used to verify that the product you have is performing as intended. Though OEM documentation is of limited use in reverse engineering hardware, it can be helpful in some cases if you are trying to ensure that your products are genuine.
Reversing Hardware
In the previous sections, we discussed a variety of reasons why you should be suspicious of some hardware devices. If you really want to discover what a device does, and perhaps how, you will need to break it apart to find out. Although the topic of reversing hardware is worthy of its own book, there are some general approaches that can help point you in the right direction for future research.
NOTE The hardware reverse engineering techniques we discuss in this section will likely void your warranty and could even violate laws in some jurisdictions. Be sure to read your end user license and any legal warnings that apply to your product. If in doubt, check with your legal team before proceeding.
The easiest approach is to simply open the enclosure and take a peek inside. The chips on the boards and their very layout will give you a good starting point. You may be able to search online for photos that others have taken of the product, which would alert you to any suspicious components. Apart from that, you will be able to inventory many of the component chips, because these are almost always distinctly labeled. Chip manufacturers publish technical datasheets with detailed information about their products. These not only tell you what the chip does, but they also provide very specific information about every input and output pin on the chip. Figure 4-1 shows the block diagram for an Analog Devices analog-to-digital (A/D) converter, with detailed pin information.

Figure 4-1 Functional block diagram from a technical datasheet
Firmware is software that is permanently (or semi-permanently) programmed into read-only memory (ROM) on a hardware component. If you really want to know what a device does, you will probably have to extract the firmware and analyze it. You will likely need a general-purpose ROM programmer because these have the ability to read the software (for the purpose of verifying the write operation). You may need a chip-specific tool you could obtain from the manufacturer. Either way, you will end up with binary code, which you will have to reverse engineer too. We’ll get to software reversing in the next section.
Another approach to reverse engineering hardware is to capture the signals at its interfaces and analyze them. This can be done at the device level using a packet analyzer, which will give you a high-level view of the communications patterns. You can also look at the raw voltage level fluctuations using an oscilloscope or logic analyzer. These tools tend to be expensive, but they tell you exactly what is happening at the physical layer. With these tools, you can also monitor individual chip component behaviors and even inject your own inputs to see if there are any hidden features.
Software/Malware
As interesting and important as hardware reverse engineering is, most of us are likelier to be involved in efforts to reverse software and, in particular, malware. The process requires in-depth understanding of the architecture of the processors on which the software is intended to run. Reversing binaries is significantly different for ARM processors compared to x86 processors. The principles are the same, but the devil, as they say, is in the details.
Fingerprinting/Hashing
Sometimes we can save ourselves a lot of trouble by simply fingerprinting or hashing known-good or known-bad binary executable files. Just like fingerprints have an astronomically small probability of not being unique among humans, the result of running a file through a secure hashing function is extremely unlikely to be the same for any two files. The net result is that, when you compute the SHA-256 value of a known-good file like a Windows Dynamically Linked Library (DLL), the probability of an adversary modifying that file in any way (even by changing a single bit) and having it produce the same hash value is remote. But we are getting ahead of ourselves here.
A hashing function is a one-way function that takes a variable-length sequence of data such as a file and produces a fixed-length result called a “hash value.” For example, if you want to ensure a given file does not get altered in an unauthorized fashion, you would calculate a hash value for the file and store it in a secure location. When you want to ensure the integrity of that file, you would perform the same hashing function and then compare the new result with the hash value you previously stored. If the two values are the same, you can be sure the file was not altered. If the two values are different, you would know the file was modified, either maliciously or otherwise, so you would then investigate the event.
We can also apply hashes to malware detection. We discussed full packet captures in Chapter 2, and one of the benefits of doing this is that you can assemble binaries that are transported across the network. Having those, you can take a hash of the suspicious file and compare it to a knowledge base of known-bad hashes. One of the indispensable tools in any analyst’s toolkit is VirusTotal.com, a website owned and operated by Google that allows you to upload the hashes (or entire files) and see if anyone else has reported them as malicious or suspicious before. Figure 4-2 shows the results of submitting a hash for a suspicious file that has been reported as malicious by 40 out of 40 respondents.

Figure 4-2 VirusTotal showing the given hash corresponds to a malicious file
NOTE Uploading binaries to VirusTotal will allow the entire worldwide community, potentially including the malware authors, to see that someone is suspicious about these files. There are many documented cases of threat actors modifying their code as soon as it shows up on VirusTotal.
Decomposition
We can tell you from personal experience that not every suspicious file is tracked by VirusTotal. Sometimes, you have to dig into the code yourself to see what it does. In these situations, it is important to consider that computers and people understand completely different languages. The language of a computer, which is dictated by the architecture of its hardware, consists of patterns of ones and zeroes. People, on the other hand, use words that are put together according to syntactical rules. In order for people to tell computers what to do, which is what we call “programming,” there must be some mechanism that translates the words that humans use into the binary digits that computers use. This is the job of the compiler and the assembler. As Figure 4-3 shows, a human programmer writes code in a high-level language like C, which is compiled to assembly language, which is in turn assembled into a binary executable.

Figure 4-3 Source code being compiled and then assembled
Binary executables are specific to an operating system and processor family, which means that you cannot run a Linux program on a Windows machine. Windows programs are packaged in what is known as the Portable Executable (PE) format, in which every file starts with the 2-byte sequence 5A 4D (or 4D 5A, depending on which operating system you are using to inspect the file). By contrast, Linux executables are in what is known as the Executable and Linkable Format (ELF), in which every file starts with the 4-byte sequence 7F 45 4C 46. These starting sequences, or “magic numbers,” allow you to quickly determine which operating system is targeted by a given malware sample.
When we are analyzing malware, it is a rare thing to have access to the source code. Instead, all we usually get is a machine language binary file. In order to reverse engineer this program, we need a disassembler, such as IDA Pro. The disassembler converts the machine language back into assembly language, which can then be analyzed by a reverse engineer. Some decompilers also exist, but those are more “hit or miss” because there are many possible programs that would compile to a given assembly language file. This means that, on average, decompilers are not worth the effort.
Isolation/Sandboxing
We already touched on isolation techniques and sandboxing in Chapter 3 in the context of endpoint protection. Now we return to it for the purpose of more deliberate assessments of what hardware and software are actually doing. Sometimes we are unable or unwilling to invest the effort into reverse engineering a binary executable, but still want to find out what it does. This is where an isolation environment or sandbox comes in handy. Unlike endpoint protection sandboxes, this variety of tools is usually instrumented to assist the security analyst in understanding what a running executable is doing.
Cuckoo Sandbox is a popular open source isolation environment for malware analysis. It uses either VirtualBox or VMware Workstation to create a virtual computer on which to safely run the suspicious binary. Unlike other environments, Cuckoo is just as capable in Windows, Linux, Mac OS, or Android virtual devices. Another tool with which you may want to experiment is REMnux, which is a Linux distribution loaded with malware reverse engineering tools.
Training and Exercises
General George Patton is famously quoted as having said “you fight like you train,” but this idea, in various forms, has spread to a multitude of groups beyond the Army. It speaks to the fact that each of us has two mental systems: the first is a fast and reflexive one, and the second is slow and analytical. Periodic, realistic training develops and maintains the “muscle memory” of the first system, ensuring that reflexive actions are good ones. In the thick of a fight, bombarded by environmental information in the form of sights, sounds, smells, and pain, soldiers don’t have the luxury of processing it all, and must almost instantly make the right calls. So do we when we are responding to security incidents on our networks.
Admittedly, the decision times in combat and incident response are orders of magnitude apart, but you cannot afford to learn or rediscover the standard operating procedures when you are faced with a real incident. We have worked with organizations in which seconds can literally mean the loss of millions of dollars. The goal of your programs for training and exercises should then be to ensure that all team members have the muscle memory to quickly handle the predictable issues and, in so doing, create the time to be deliberate and analytical about the others.
The general purpose of a training event is to develop or maintain a specific set of skills, knowledge, or attributes that allow individuals or groups to do their jobs effectively or better. An exercise is an event in which individuals or groups apply relevant skills, knowledge, or attributes in a particular scenario. Although it could seem that training is a prerequisite for exercises (and, indeed, many organizations take this approach), it is also possible for exercises to be training events in their own right.
All training events and exercises should start with a set of goals or outcomes, as well as a way to assess whether or not those were achieved. This makes sense on at least two levels: at an operational level, it tells you whether you were successful in your endeavor or need to do it again (perhaps in a different way), and at a managerial level it tells decision makers whether or not the investment of resources is worth the results. Training and exercises tend to be resource intensive and should be applied with prudence.
Types of Exercises
Though cybersecurity exercises can have a large number of potential goals, they tend to be focused on testing tactics, techniques, and procedures (TTPs) for dealing with incidents and/or assessing the effectiveness of defensive teams in dealing with incidents. Either way, a key to success is to choose scenarios that facilitate the assessment process. The two major types of cybersecurity exercises are tabletop and live-fire.
Tabletop Exercises
Tabletop exercises (TTXs) may or may not happen at a tabletop, but they do not involve a technical control infrastructure. TTXs can happen at the executive level (for example, CEO, CIO, or CFO), at the team level (for example, security operations center or SOC), or anywhere in between. The idea is usually to test out procedures and ensure they actually do what they’re intended to and that everyone knows their role in responding to an event. TTXs require relatively few resources apart from deliberate planning by qualified individuals and the undisturbed time and attention of the participants.
After determining the goals of the exercise and vetting them with the senior leadership of the organization, the planning team develops a scenario that touches on the important aspects of the response plan. The idea is normally not to cover every contingency, but to ensure the team is able to respond to the likeliest and/or most dangerous scenarios. As they develop the exercise, the planning team will consider branches and sequels at every point in the scenario. A branch is a point at which the participants may choose one of multiple approaches to the response. If the branches are not carefully managed and controlled, the TTX could wander into uncharted and unproductive directions. Conversely, a sequel is a follow-on to a given action in the response. For instance, as part of the response, the strategic communications team may issue statements to the news media. A sequel to that could involve a media outlet challenging the statement, which in turn would require a response by the team. Like branches, sequels must be carefully used in order to keep the exercise on course. Senior leadership support and good scenario development are critical ingredients to attract and engage the right participants. Like any contest, a TTX is only as good as the folks who show up to play.
Live-Fire Exercises
A live-fire exercise (LFX) is one in which the participants are defending real or simulated information systems against real (though friendly) attackers. There are many challenges in organizing one of these events, but the major ones are developing an infrastructure that is representative of the real systems, getting a good red (adversary) team, and getting the right blue (defending) team members in the room for the duration of the exercise. Any one of these, by itself, is a costly proposition. However, you need all three for a successful event.
On the surface, getting a good cyber range does not seem like a major challenge. After all, many or our systems are virtualized to begin with, so cloning several boxes should be easy. The main problem is that you cannot use production boxes for a cyber exercise because you would compromise the confidentiality, integrity, and perhaps availability of real-world information and systems. Manually creating a replica of even one of your subnets takes time and resources, but is doable given the right level of support. Still, you won’t have any pattern-of-life (POL) traffic on the network. POL is what makes networks realistic. It’s the usual chatter of users visiting myriads of websites, exchanging e-mail messages, and interacting with data stores. Absent POL traffic, every packet on the network can be assumed to come from the red team.
A possible solution would be to have a separate team of individuals who simply provide this by simulating real-world work for the duration of the event. Unless you have a bunch of interns with nothing better to do, this gets cost-prohibitive really fast. A reasonable compromise is to have a limited number of individuals logged into many accounts, thus multiplying the effect. Another approach is to invest in a traffic generator that automatically injects packets. Your mileage will vary, but these solutions are not very realistic and will be revealed as fake by even a cursory examination. A promising area of research is in the creation of autonomous agents that interact with the various nodes on the network and simulate real users. Through the use of artificial intelligence, the state of the art is improving, but we are not there just yet.
Red Team
A red team is a group that acts as adversaries during an exercise. The red team need not be “hands on keyboard” because red-teaming extends to TTXs as well as LFXs. These individuals need to be very skilled at whatever area they are trying to disrupt. If they are part of a TTX and trying to commit fraud, they need to know fraud and anti-fraud activities at least as well as the exercise participants. If the defenders (or blue team members) as a group are more skilled than the red team, the exercise will not be effective or well-received.
This requirement for a highly skilled red team is problematic for a number of reasons. First of all, skills and pay tend to go hand-in-hand, which means these individuals will be expensive. Because their skills are so sought after, they may not even be available for the event. Additionally, some organizations may not be willing or able to bring in external personnel to exploit flaws in their systems even if they have signed a nondisclosure agreement (NDA). These challenges sometimes cause organizations to use their own staff for the red team. If your organization has people whose full-time job is to red team or pen test, then this is probably fine. However, few organizations have such individuals on their staff, which means that using internal assets may be less expensive but will probably reduce the value of the event. In the end, you get what you pay for.
Blue Team
The blue team is the group of participants who are the focus of an exercise. They perform the same tasks during a notional event as they would perform in their real jobs if the scenario was real. Though others will probably also benefit from the exercise, it is the blue team that is tested and/or trained the most. The team’s composition depends on the scope of the event. However, because responding to events and incidents typically requires coordinated actions by multiple groups within an organization, it is important to ensure that each of these groups is represented in the blue team.
The biggest challenge in assembling the blue team is that they will not be available to perform their daily duties for the duration of the exercise as well as for any pre- or post-event activities. For some organizations, this is too high of a cost and they end up sending the people they can afford to be without, rather than those who really should be participating. If this happens, the exercise might be of great training value for these participants, but may not allow the organization as a whole to assess its level of readiness. Senior or executive leadership involvement and support will be critical to keep this from happening.
White Team
The white team consists of anyone who will plan, document, assess, or moderate the exercise. Although it is tempting to think of the members of the white team as the referees, they do a lot more than that. These are the individuals who come up with the scenario, working in concert with business unit leads and other key advisors. They structure the schedule so that the goals of the exercise are accomplished and every participant is gainfully employed. During the conduct of the event, the white team documents the actions of the participants and interferes as necessary to ensure they don’t stray from the flow of the exercise. They may also delay some participants’ actions to maintain synchronization. Finally, the white team is normally in charge of conducting an after-action review by documenting and sharing their observations (and, potentially, assessments) with key personnel.
Risk Evaluation
Risk is the possibility of damage to or loss of any information system asset, as well as the ramifications should this occur. It is common to think of risk as the product of its impact on the organization and the likelihood of this risk materializing. For example, if you are considering the risk of a ransomware infection, the value of the assets could be measured by either the expected ransom (assuming you decide to pay it) or the cost to restore all the systems from backup (assuming you have those backups in the first place) or the cost to your business of never getting that information back.
Clearly, not all risks are equal. If you use the formula of value times probability, the result could give you an idea of the risks you ought to address first. Presumably, you would focus on the greatest risks first, since they have a higher value or probability (or both) than other risks on your list. There is another advantage to using this quantitative approach: it helps you determine whether the cost of mitigating the risk is appropriate. Suppose that a given risk has a value of $10,000 and can be mitigated by a control that costs only $1,000. Implementing that control would make perfect sense and would probably not be difficult for you to get support from your leadership.
Risk evaluation is the process of ranking risks, categorizing them, and determining which controls can mitigate them to an acceptable business value. There is no such thing as a 100 percent secure environment, which means that the risks will always have a value greater than zero. The main purpose of a risk evaluation is to help us balance the value of a risk with the cost of a control that mitigates it.
Impact and Likelihood
The two approaches to quantifying impacts and likelihood are quantitative and qualitative. A quantitative analysis is used to assign numeric (for example, monetary) values to all assets that could be impacted by a given risk. Each element within the analysis (for example, asset value, threat frequency, severity of vulnerability, impact damage, safeguard costs, safeguard effectiveness, uncertainty, and probability items) is quantified and entered into equations to determine total and residual risks. It is more of a scientific or mathematical approach to risk evaluation compared to qualitative. A qualitative analysis uses a “softer” approach to the data elements of a risk evaluation. It does not quantify that data, which means that it does not assign numeric values to the data so that they can be used in equations. As an example, the results of a quantitative risk analysis could be that the organization is at risk of losing $100,000 if a buffer overflow is exploited on a web server, $25,000 if a database is compromised, and $10,000 if a file server is compromised. A qualitative analysis would not present these findings in monetary values, but would assign ratings to the risks such as high, medium, and low. A common technique for doing qualitative analysis that yields numeric values is to replace the “high” category with the number 3, “medium” would be 2, and “low” would be 1. We will focus on the qualitative analysis in this book.
Examples of qualitative techniques to gather data are brainstorming, storyboarding, focus groups, surveys, questionnaires, checklists, one-on-one meetings, and interviews. The team that is performing the risk evaluation gathers personnel who have experience and education on the threats being evaluated. When this group is presented with a scenario that describes risks and loss potential, each member responds with their gut feeling and experience on the likelihood of the threat and the extent of damage that may result.
The expert in the group who is most familiar with this type of risk should review the scenario to ensure it reflects how the risk would materialize. Safeguards that would diminish the damage of this risk are then evaluated, and the scenario is played out for each safeguard. The exposure possibility and loss possibility can be ranked as high, medium, or low on a scale of 1 to 5, or 1 to 10. A common qualitative risk matrix is shown in Figure 4-4. Keep in mind that this matrix is just an example. Your organization may prioritize risks differently.
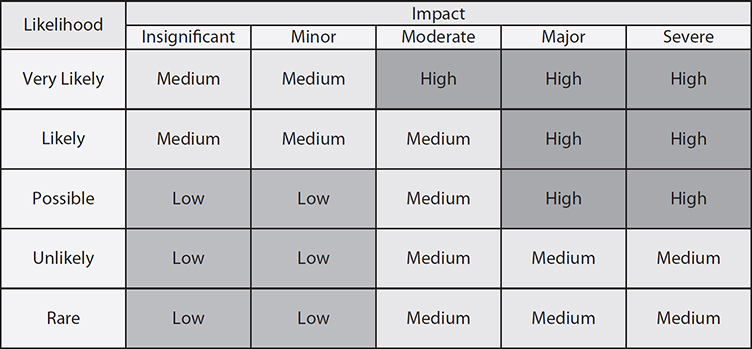
Figure 4-4 Qualitative analysis of likelihood versus impact

EXAM TIP You should be able to categorize impacts and likelihoods as being high, medium, or low for the exam. With those categories, you should then be able to evaluate the fitness of technical and operational controls.
Once the selected personnel rank the possibility of a threat happening, the loss potential, and the advantages of each safeguard, this information is compiled into a report and presented to management to help it make better decisions on how best to implement safeguards into the environment. The benefits of this type of analysis are that communication must happen among team members to rank the risks, safeguard strengths, and identify weaknesses, and the people who know these subjects the best provide their opinions to management.
Let’s look at a simple example of a qualitative risk analysis. The risk analysis team presents a scenario explaining the threat of a hacker accessing confidential information held on the five file servers within the company. The risk analysis team then distributes the scenario in a written format to a team of five people (the cybersecurity analyst, database administrator, application programmer, system operator, and operational manager), who are also given a sheet to rank the threat’s severity, loss potential, and each safeguard’s effectiveness, with a rating of 1 to 5, 1 being the least severe, effective, or probable. Table 4-1 shows the results.

Table 4-1 Example of a Qualitative Analysis
This data is compiled and inserted into a report and presented to management. When management is presented with this information, it will see that its staff (or a chosen set) feels that purchasing a network-based managed backup system will protect the company from this threat more than purchasing an intrusion prevention system or implementing user security awareness training. This is the result of looking at only one threat, and management will view the severity, probability, and loss potential of each risk so it knows which should be addressed first.
Technical Control Review
Technical controls (also called logical controls) are security controls implemented mainly through software or hardware components, as in firewalls, IDS, encryption, identification, and authentication mechanisms. A technical control review is a deliberate assessment of technical control choices and how they are implemented and managed. You may have decided during your risk evaluation that a firewall might be the best control against a particular risk, but several months later how do you know it is working as you intended it to? Apart from ensuring that it is still the best choice against a given risk, the review considers issues like the ones listed here:
• Is the control version up to date?
• Is it configured properly to handle the risk?
• Do the right people (and no others) have access to manage the control?
• Are licenses and/or support contracts current?
Even in organizations that practice strict configuration management, it is common to find hardware or software that were forgotten or that still have account access for individuals who are no longer in the organization. Additionally, the effectiveness of a technical control can be degraded or even annulled if the threat actor changes procedures. These are just some of the reasons why it makes sense to periodically review technical controls.
Operational Control Review
Operational controls (also called policy or administrative controls) are security controls implemented through business processes and codified in documents such as policy letters or standing operating procedures (SOPs). Examples of administrative controls are security documentation, risk management, personnel security, and training. Unlike technical controls, operational controls typically require no purchases.
Like technical controls, our policies can become outdated, Furthermore, it is possible that people are just not following them, or attempting to do so in the wrong way. An operational control review is a deliberate assessment of operational control choices and how they are implemented and managed. The review first validates that the controls are still the best choice against a given risk, and then considers issues like the ones listed here:
• Is the control consistent with all applicable laws, regulations, policies, and directives?
• Are all affected members of the organization aware of the control?
• Is the control part of newcomer or periodic refresher training for the affected personnel?
• Is the control being followed?
Operational controls, like technical ones, can become ineffective with time. Taking the time to review their effectiveness and completeness is an important part of any security program.
Chapter Review
This chapter was all about proactive steps you can take to ensure the security of your corporate environment. The implication of this discussion is that security is not something you architect once and then walk away from. It is a set of challenges and opportunities that needs to be revisited periodically and even frequently. You may have done a very through risk analysis and implemented appropriate controls, but six months later many of those may be moot. You wouldn’t know this to be the case unless you periodically (and formally) review your controls for continued effectiveness. It is also wise to conduct periodic penetration tests to ensure that the more analytical exercise of managing risks actually translates to practical results on the real systems. Control reviews and pen tests will validate that your security architecture is robust.
There are also issues that go beyond the architecture. Regardless of how well you secure your environment, sooner or later you will face a suspicious hardware device or executable file that needs to be analyzed. Though having the in-house skills to reverse engineer hardware or software is not within the reach of every organization, as an analyst you need to be aware of what the issues are and where to find those who can help.
Finally, the human component of your information systems must also be considered. Training is absolutely essential both to maintain skills and to update awareness to current issues of concern. However, simply putting the right information into the heads of your colleagues is not necessarily enough. It is best to test their performance under conditions that are as realistic as possible in either table-top or live-fire exercises. This is where you will best be able to tell whether the people are as prepared as the devices and software to combat the ever-changing threats to your organization.
Questions
1. The practice of moving, or pivoting, from a compromised machine to another machine on the network is referred to as what?
A. Exploitation
B. Trusted foundry
C. Decomposition
D. Lateral movement
2. Which is not a consideration to take during a penetration test?
A. None, the goal is to be as realistic as possible.
B. Personal healthcare information.
C. Time limitations.
D. Effects on production services.
3. Who is the ultimate giver of consent for a penetration test?
A. The penetration tester or analyst
B. The security company
C. The system owner
D. The FBI
4. In an exercise, which type of team is the focus of the exercise, performing their duties as they would normally in day-to-day operations?
A. Blue team
B. Red team
C. Gray team
D. White team
5. Which of the following addresses the vulnerabilities associated with component supply chains?
A. Exploitation bank
B. Partial knowledge
C. Reporting chain
D. Trusted foundry
Refer to the following illustration for Questions 6 and 7:

6. You are analyzing a suspicious executable you suspect to be malware. In what language is this file being viewed?
A. Natural language
B. High-level language
C. Assembly language
D. Machine language
7. Which operating system is this program designed for?
A. Linux
B. Windows
C. Mac OS
D. iOS
8. What two factors are considered in making a quantitative assessment on risk?
A. Expected value and probability of occurrence
B. Expected value and probability of vulnerability
C. Potential loss and probability of occurrence
D. Potential loss and expected value
Use the following scenario to answer Questions 9–12:
Your company was hired to perform a penetration test on a small financial services company. The company has no in-house expertise in security assessments and is relying on your team to help them addresses their challenges. The Chief Information Officer invites you to review the network with his network engineer. Since they are a small company, the engineer tells you that they haven’t been targeted for many attacks. Additionally, most of the production systems see the most traffic during local business hours of 9 A.M. to 5 P.M., and they cannot, under any circumstances, be disrupted.
9. Based on the meeting with the CIO, what kind of penetration test will you be conducting?
A. Partial knowledge
B. Red box
C. Total recall
D. Zero knowledge
10. Before leaving the office, you ask the CIO to provide which formal document authorizing you to perform certain activities on the network?
A. Syslogs
B. Network flows
C. Certificate Authority
D. Authorization memo
11. Considering the scope of this test, what is your recommendation for the best times to conduct the test?
A. Any time during normal business hours
B. Beginning at 7 P.M.
C. Over lunchtime
D. Exactly at 9 A.M.
12. You complete the pen test and are preparing the final report. Which areas should you normally not include in the deliverables?
A. Information that could be gleaned about the company from open sources
B. Specific exploitable technical features of the network
C. Audit of the existing physical infrastructure
D. Full packet captures
Answers
1. D. Lateral movement is the act of compromising additional systems from the initially breached one.
2. A. A successful penetration requires lots of preparation, which includes defining the scope, objectives, off-limit areas, timing, and duration of the test.
3. C. Consent of the system owner is critical for a penetration test because many of the tasks involved in this activity are illegal in most countries.
4. A. The blue team is the group of participants who are the focus of an exercise and will be tested the most while performing the same tasks in a notional event as they would perform in their real jobs.
5. D. A trusted foundry is an organization capable of developing prototype or production-grade microelectronics in a manner that ensures the integrity of their products.
6. D. Machine language is represented as a series of ones and zeroes, or sometimes (as in the illustration) in hexadecimal.
7. B. Windows executables always start with the byte sequence 5A4D or 4D5A, depending on which operating system you are using to inspect the file. They also typically include the string “This program cannot be run in DOS mode” for backward compatibility.
8. C. Quantitative risk assessment is calculated using the amount of the potential loss and the probability that the loss will occur.
9. A. Because the CIO and network engineer provided you with upfront information about the target, you have partial knowledge about this system.
10. D. An authorization memo includes the extent of the testing authorized, and should be made available to team members during the testing period.
11. B. Because the CIO prioritizes uptime of critical production systems, it’s best to avoid performing the pen test during those hours.
12. D. Penetration testing isn’t restricted to technology only. The report should cover all discovered vulnerabilities in physical and information security, including the successful use of social engineering. You would normally not want to include full packet captures because, absent specific authorizations, this could lead to privacy or regulatory problems.