
9.3 Data Structures
We now discuss how data structures, especially vectors, arrays and records or constructs like struct in C are handled by the code generator. Two aspects of these code constructs are to be considered – the layout of the structure in the memory and run-time access code generation.
9.3.1 Vectors and Arrays
These structures are characterized by having elements of exactly the same size and type, arranged in a linear sequence of consecutive memory addresses. That makes the code generation relatively simple. The elements in the vector or array could be of primitive data types like char, int, float, double, a pointer or it can be a user-defined data type, which may have any arbitrary size.
9.3.2 Vectors
A vector V of elements e of type T is stored in the memory as consecutive groups of sizeof(T) bytes. On some platforms, in order to increase the speed of memory access, sizeof(T) may be adjusted to the next higher multiple of 8- or 16-bytes, but we shall ignore that complication here. Figure 9.3 shows how a vector of integers is laid out and its access. From Fig. 9.3, we see that to access any element V[i] of a vector V, the address is base+i*s where s is the size of the elements in bytes. The total memory area to be assigned is n * s bytes, where n is the size of the vector. This can be easily generated as:
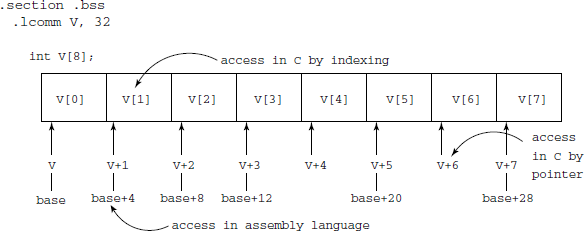
The access code is also simple, assuming that %esi contains the index (0 based) of the element we want:
movl V(,%esi,4), %eax
The value will be put in %eax.
In general to access A[i]:
base(A) + i * sizeof(A[1])
Depending on how A is declared, base(A) may be
- an offset from BP,
- an offset from some global label, or
- an arbitrary address.
The first two and sizeof(A[1]) are compile-time constants. For primitive data types, the sizeof(A[1]) is generally a power of 2 – 1 for char/byte, 2 for short, 4 for int, pointers and float and 8 for double and long. In x86 processors, the multiplication by the size is built into the instruction. On processors where this is not the case, it can be done by left-shift operations. For arrays consisting of elements of user-defined data types (usually structures), actual multiplication has to be used to generate the address. Even there, in case of x86 processors, leal instruction can be used to do the multiplication, as shown in Section 9.2.1.
9.3.3 Arrays
For the two-dimensional arrays, which are most common, how does the compiler handle A[i, j]? It depends upon the language specification about the array layout in the memory:
Row-major order: (most languages) Laid out as a sequence of consecutive rows. Rightmost subscript varies fastest, like: A[1,1], A[1,2], A[1,3], A[2,1], A[2,2], A[2,3]
Column-major order: (Fortran) Laid out as a sequence of columns. Leftmost subscript varies fastest, like: A[1,1], A[2,1], A[1,2], A[2,2], A[1,3], A[2,3]
Indirection vectors: (Java) Vector of pointers to pointers to … to vectors of elements. This layout takes much more space, trades indirection for arithmetic and is not amenable to analysis. This is also one of the methods used in scientific computations in C. (See, for example, “Numerical Recipes in C”.)
Figure 9.4 shows various layouts of an array.
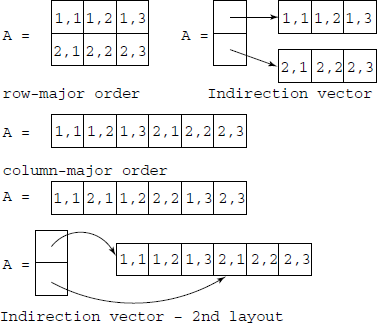
Fig. 9.4 Layout of an array in the memory. The indirection vector method has two variants, depending upon how individual rows are allocated space
Computing the array addresses: We illustrate the cases of two-dimensional arrays, A[rmax,cmax].
Row-major order: base(A) + (r*(cmax) + c)*sizeof(A[1])
Column-major order: base(A) + (c*(rmax) + r)*sizeof(A[1])
Indirection vectors: *(A[r])[c] where A[r] is a one-dimensional array reference, for example base(A) + r*sizeof(A[1])
Array references: To pass arrays as actual parameters to a function, a pointer to its first element and the size of each of the dimensions is given. In applications where a number of arrays are to be handled, it may be advisable to form a structure having these three values, which is traditionally known as dope-vector.
If the array being used in a function is a variable-sized array for example a local array dimensioned by actual parameters passed to the function, the array is to be allocated memory space at run-time.
Another aspect is array address calculations which is a major source of overhead in:
- Scientific applications make extensive use of arrays and array-like structures;
- Computational linear algebra, both dense and sparse;
- Non-scientific applications also use arrays – hash tables, adjacency matrices, tables, structures, etc.
The brighter side is that array calculations tend to iterate over arrays inside loops, and usually loops execute more often than code outside loops.
For example, consider the following code segment, where two conformal matrices are being handled.
for(j = 0; j < n; j++)
a[i][j] = a[i][j] + b[i][j];
A naïve approach would be to perform the address calculation twice:
for(j = 0; j < n; j++){
R1 = base(a) + (i * n + j) * (sizeof(A[1,1]))
R2 = base(b) + (i * n + j) * (sizeof(A[1,1]))
MEM(R1) = MEM(R1) + MEM(R2)
}
The inefficiency introduced is due to localized translation.
A more sophisticated way would be to move common calculations out of loop (see Chapter 10):
R1 = i * n * sizeof(A[1,1])
R2 = base(a) + R1
R3 = base(b) + R1
for(j = 0; j < n; j++){
a = j * sizeof(A[1,1])
R4 = R2 + a
R5 = R3 + a
MEM(R4) = MEM(R4) + MEM(R5)
}
An even more sophisticated method is to convert the multiplication to addition:
R1 = i * n * sizeof(A[1,1])
R2 = base(a) + R1
R3 = base(b) + R1
a = sizeof(A[1,1])
for(j = 0; j < n; j++){
R2 = R2 + a
R3 = R3 + a
MEM(R2) = MEM(R2) + MEM(R3)
}
Structures and Records
Structures and records have two complications:
- Each declared structure has a set of fields
- Size and offset
- Compute base + offset for field
- Use size to choose load width and register width
- Structures and records can have dimensions
- Arrays of structures
- Fields that are arrays or arrays of structures
- Use array address calculation techniques, as needed
Structures and records require compile-time support in the form of a table that maps field names to <offset,size> tuples.
Representing and Manipulating Strings
Character strings differ from scalars, arrays and structures in several ways. The basic unit is a character, whose typical sizes are 1- or 2-bytes. The target processor may or may not support character-size operations. Even then, the set of supported operations on strings is usually limited – assignment, length, concatenation and translation are usually available. On RISC processors, efficient string operations are complex.
Strings are represented usually by one of the two methods – explicit length field (as in PASCAL) and null termination (as in C). Strings’ length may also be fixed and varying. Each method has its advantages and disadvantages.