
A.3 Grammars
A correct specification of a programming language requires:
- Specification of a set of symbols, called Terminals;
- The set of all syntactically correct programs;
- The “meaning” of such programs.
Possible methods in which we can specify a language:
- Exhaustive listing of each and every sentence in that language.
- Use a Generative method: give rules by which correct sentences can be formed. The set of such rules, which must be finite, is called a Grammar.
For certain restricted class of languages, known as Regular Languages, a simpler generative method, known as Regular Expression, which is a kind of formula, is generally used (see Section A.4).
- Use a machine or Acceptor which, when fed with any string s ∈ V*, will tell us “Accepted” or “Rejected”, depending upon whether s ∈ L (see Fig. A.4).

The rules in a grammar are called Production rules or simply Productions.
Meta-language: It is a system or language used to describe precisely another language. Indian grammarian Panini was the first inventor of such a language.
In the present era, grammars were studied extensively by Noam Chomsky and others, while Indian Sanskrit grammarian Panini gave a highly systematic grammar some 2500 years back in his book Ashtadhyayi. The method used by him to specify the grammar – a meta-language – was quite similar to what we use (Backus Normal Form) today.
The three-way relationship between a Language, its Grammar and corresponding Acceptor is shown in Fig. A .5.
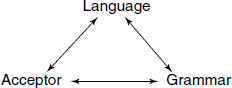
A grammar can be used in two ways:
- Generate a sentence, e.g. a programmer uses the grammar of a programming language while writing her programs to ensure that they strictly belong to the language.
- Design the Acceptor, i.e. a device to check sentences in the language, a Compiler.
We shall mainly study two kinds of Formal Languages – Regular Expressions and Context-free Languages – in terms of their grammars, with an intention of finding algorithms to design the Acceptors for them. As it is shown in Chapters 3 and 4 on the front-end of compilers, we can utilize those algorithms to design the corresponding phases of a compiler.
A typical programming language is a three-layered language:
- At lexical level, the constructs can be expressed in terms of regular expressions.
- At expression level and nested control structure level, the constructs can be expressed in terms of CFL.
- Simple control structures themselves can be expressed in terms of regular expressions.
Example
Consider a grammar:
GO :
I –> L
I –> IL
I –> ID
L –> a
L –> b
…
D –> 0
D –> 1
...
This grammar generates sentences which are identifiers in a typical programming language, like abc, asl34, xc56d, etc. In other words, it specifies and generates a language of identifiers.
The right arrow symbol denotes a production or replacement. It means that the symbol on the LHS can be replaced by the string on the RHS. Apart from the right arrow, there are two kinds of symbols used – the capital letters denote non-terminals or meta-symbols and the small letters and digits denote Terminals or final-symbols.
Generally, the symbol on the LHS of the first rule is called the starting symbol. When we wish to generate a sentence in our language, we start with a string which contains only the starting symbol. We then successively use various applicable rules in the grammar (in any order we choose) to replace all the non-terminals (NT) with Terminals (T). We stop when no more replacement can take place by use of any of the grammar rules.
For example, we can generate a sentence ‘abl23d’ like this:
Note that we had to think a bit about which of the rules we shall apply at each stage of the production. Had we chosen a rule wrongly, we would not have got the required sentence.
Note that the above grammar is defined in a Recursive way. This is fundamental to definition of infinite languages.
Formal Grammars
A formal grammar is defined as:
where
VN = set of non-Terminals,
VT = set of Terminals,
S = the starting symbol, S ∈ VN P = productions, a set of rules. P has the general form:
Note that VN is a set of Terminal symbols in the meta-laneuage in which the grammar is written.
Direct Derivative
Let G be a grammar and s, t ∈ V*, where V = VN ∪ VT.
s is called a direct derivative of t, written as t ⇒ s, if there are strings s1 and s2 in V*, such that t = s1 α s2, s = s1 β s2, and α → β is a production (rule) in P.
s is called derivative, t ⇒ + s, if there are strings s0, s1, s2, s3, … in V*, such that t = s0, s0 ⇒ s1, s1 ⇒ s2, etc. and sn = s.
Then, a language ![]()
A.3.1 Methods of Grammar Specification
Ways of specifying a grammar:
- Backus Normal Form (BNF) and modified or extended BNF;
- syntax or “Railroad” diagrams;
- syntax trees.
Note that a Chomsky type-3 language (Regular Language) can also be specified by a formula known as Regular Expressions, see Sections A.3.2 and A.4.
Backus Normal Form
The grammar G0 in the above example can be expressed in BNF as:
<identifier> ::= <letter> | <identifier> <letter> |
<identifier> <digit>
<letter> ::= a|b|c|d|e|f|g|h|i|j|k|l|m|n|o|p|q|r|s|t|u|v|w|x|y|z
<digit> ::= 0|1|2|3|4|5|6|7|8|9
Extended BNF
The BNF is extended by additional constructs:
[e] – 0 or 1 occurrence of e,
{e} – 0 or more occurrences of e,
{e}m, n – minimum m and maximum n occurrences of e,
‘c’ – Terminal symbol c.
Railroad Diagrams
Railroad diagrams are pictorial means for specifying a grammar and are most useful to a programmer as a reference for the syntax of the programming language he plans to use (see Fig. A.6). The arrows show direction in which the expansion or replacement takes place. Expansion starts from the LHS and proceeds generally towards RHS.
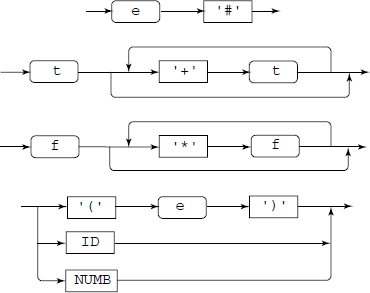
Fig. A.6 Railroad diagrams: for top – a statement, a simple expression using only addition of terms, a term and a factor in an arithmetic expression. Compare with corresponding grammar
Syntax Trees
A grammar can also be represented by an abstract syntax tree. For example, the example grammar of an arithmetic expression is shown in Fig. A.7.
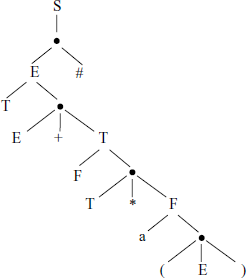
In this tree, a node is either a NT symbol, a bullet (•) or a T symbol. The interpretation of the tree is as follows:
NT The branches denote alternative productions; if it is a leaf-node, then it is subject to further replacements by the sub-tree under it.
• Denotes concatenation operation of its branches.
T The Terminal symbol stands for itself in the productions.
A.3.2 Chomsky Classification
During his study or languages, Noam Chomsky classified languages – Natural, programming and Formal – into four classes, as shown in Table A.2.
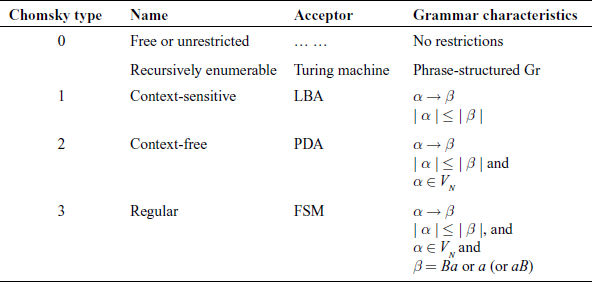
Note: LBA – Linear Bounded Automata, PDA – Push-down Automata, FSM – Finite-state Machine (Finite Automata)
Examples and Exercises
- L = {anbncn | n ≥ 1}
P = { 1. S –> aSBC 2. S –> abC 3. bB –> bb4. bC –> be 5. CB –> BC 6. cC –> cc }Confirm that the grammar does generate the language specified. - L = {anbcn | n ≥ 1}
P = { 1. S –> a C c 2. C –> a C c 3. C –> b }Confirm that the grammar does generate the language specified. - Grammar G1:
P = { 1. E –> E + T 2. E –> T 3. T –> T * F 4. T –> F 5. F –> (E) 6. F –> a }What language does the grammar generate? -
P = { 1. S –> aS 2. S –> aB 3. B –> bC 4. C –> aC 5. C –> a }What language does the grammar generate? - Grammar G2:
P = { 1. ∨ –> N 2. V –> +N 3. V –> −N 4. N –> 0 | 1 | ... |9 5. N –> ON | IN | ... | 9N }What language does the grammar generate? -
P = { 1. S –> iEtS 2. S –> iEtSeS 3. S –> a 4. E –> b }What language does the grammar generate? What kind of language is it? - Grammar G3 = < {V, S, R, N}, {+, ‒, ., d, #}, V, P >
P = { 1. ∨ –> SR# 2. S –> + 3. S –> ‒ 4. S –> e 5. R –> .dN 6. R –> dN.N 7. N –> dN 8. N –> e }What language does the grammar generate? What kind of language is it?