
1.1 Languages
If you think a little about how our world operates, you will realize that animate and inanimate objects interact by sending messages to one another. These messages take various forms. For example, a honeybee communicates the location of a source of juices to other honeybees by a kind of “dance”. We human beings “talk” with one another or send written or electronic messages. You “talk” to (as distinct from via) your mobile phone by pressing various buttons and reading the display. In that case, your pressing the phone buttons is called commands or requests, but still, in a general sense they are messages.
All messages are expressed in some language, and usually there is a protocol (rules of communicating) for any situation where such messages are exchanged. For example, when someone calls Siddhartha on his phone, protocol requires that he says, “Hello, Siddhartha speaking”.
Various races of human beings have developed a number of languages for communication over thousands of years, such as Sanskrit, Farasi, Chinese, English, French, Tamil, Telugu, Hindi, Eskimo, Swahili, etc., in fact a few thousands of them. These are all called Natural languages, as they were developed during the natural evolution of human races.
When the era of computers and computer-like devices started during 1940s, a need arose for communicating with the computing machines. Most of the communication was in the form of commands or requests to do some work or job. As the machines “understood” only very elementary commands (“add number x to number y and put the result in a store called z”) rather than jobs of even mild complexity (“solve the quadratic equation ax2 + bx + c, given a, b and c”), it was necessary to supply a complete sequence of elementary commands, specifying how a particular job was to be done. A sequence of commands is called a program. This necessitated developing and defining the so-called programming languages.
During the early days of computer evolution, the only language a computing machine could follow was its binary command language (as most, though not all, machines were built using binary logic elements – called gates and flip-flops). This binary language was extremely terse, difficult to use and error-prone. With development of technology, it was found that programming can be done in languages more approachable for humans, but this entailed a price. If we call the language understood directly by a machine as M and the language more desirable from human viewpoint for specification of a computing job as L, then there should be a method available to translate a code in L to a code in M. Who would do this work? In fact, in the old days of the computer era, we understand that in some countries like Russia, this work was done by human clerks, called (aptly) “translators”. In the computer field, there are several interesting adages, one of them is: Let the computer do the dirty work. So, why not make the computer do the translation from L to M? The question is how can a computer machine, which does not “understand” any language other than its own command or machine language, translate from L (a language it does not understand) to M (a language it understands)? If you do not know Chinese, but know English, can you translate from Chinese to English?
This seemingly impossible work is made possible by using certain properties of the programming languages. Unlike the natural languages, the programming languages have a very restricted structure. Almost “blind” (i.e. mechanical) replacement for various words or constructs in a human approachable programming language like L, by a corresponding construct in M, is possible. This mechanical work can be performed by a computing machine.
This is a very brief account of translation process. For slightly more details read the rest of this chapter, and a still fuller account is given in this whole book.
A systematic study of both programming and natural languages requires that mathematical or formal models of various types of languages be defined. The languages which define such models are called Formal languages. In order to capture the essence of a language and allow mathematical manipulations, these formal languages look somewhat different from our day-to-day sense of a language. Appendix A on “Theory of Automata and Formal Languages” gives a detailed discussion of this topic.
Some years back, pioneering linguistics researcher, Noam Chomsky, set upon the task of translating a document written in one natural language, say Japanese, into a corresponding document in another, say English. While trying to develop the algorithms to do this difficult job, he studied the nature of various types of languages. A summary of his main findings are given in Appendix A, as Chomsky's Hierarchy of languages.
In this book, we concentrate only on translation of programming languages, taking models from formal languages where required.
A computer professional may come across several types of programming languages. The following sections details majority of them.
1.1.1 Machine Language
The binary machine code is one which the computer hardware “understands” is able to interpret for execution. A machine language program consists of instructions in binary digits, i.e. bits 0 and 1.
The machine instructions of modern computers consist of one or more bytes – group of eight bits. For example, some typical binary instructions for 8086 CPU chip are:
binary code Mnemonic opcode instr length (bytes)
11111000 clc 1
00000000 11000001 add a1, c1 2
Obviously, if one has to program in such a language, it is going to be very tedious, time-consuming and error-prone. Another difficulty would be while loading such a binary program from our paper to the memory of the computer.
In the old days of computer technology, the initial boot program (IPL), which loads a operating system from some auxiliary memory to the main memory, was required to be keyed-in via console (binary) key switches. The operator would have to remember the binary code for the few instructions of the IPL and painstakingly key them in.
1.1.2 HexAbsoluteLoaderLanguage
The above difficulty was overcome to some extent, by writing a Hex loader program in machine language, which could read ASCII representation of the machine instructions in hexadecimal. For example, the above two instructions would look like: F8 and 00 C1, respectively. Generally, such a loader program accepted program to be loaded in the format:
<load address> <length> <bytes to be loaded> <check-sum>
000C200 50 4F34 ... ... ... 87E3
This was still a far cry from a human-friendly programming language.
1.1.3 Assembly Language
The earliest attempt at providing a somewhat human approachable programming environment was in the form of assembly language and its translator, called an assembler. An assembly language provided:
- mnemonic op-codes – the programmer need not remember binary or hex op-codes;
- symbolic operands – the programmer need not keep track of the absolute memory addresses where various quantities in his program resides;
- address arithmetic – programmer can express addresses as displacements with reference to some declared symbols;
- data declaration – predefined data (initialized data) can be declared;
- memory reservation – working memory areas can be reserved and named.
For many years, even major applications were written in assembly language, extended by the macro assembly language (Section 1.1.4). Even today it is used as a step in translating High Level languages and also where hardware-specific code is needed, for example, in operating systems. Because each family of CPU has different instruction set, there is an assembly language (and a corresponding assembler) for each such CPU family. Thus, an assembly language reflects the architecture and Instruction Set of the computer for which it is designed.
1.1.4 Macro Assembly Language
With some experience of programming in an assembly language, programmers found that most of the time they are using repetition of basically same or similar code sequences. For example, summing up an array of numbers may be required as a commonly used operation. In a macro language, such sequences can be defined as a macro and be given an identifier. Once this is done, wherever in the remaining code one wants to insert the code, only the macro name need be specified.
Macro assembly language largely removed drudgery from programming. IBM “Autocoder” was once a much used such macro language.
1.1.5 Intermediate or ByteCode
ByteCode represents the “machine language” of a phantom or virtual computing machine. It is used as an intermediate representation of a program, keeping only the most essential features of the program. For example, compiler translates your myprog.java source code into myprog.class file which contain bytecodes.
1.1.6 High Level Language
A High Level language (HLL) looks more like a natural language than a machine or assembly language. An HLL is characterized by the following:
- It consists of statements, which specify steps of computation, in contrast to machine instructions in assembly languages.
- Statements are made up of language atoms – numbers, characters, text strings, function calls, etc.
- Usually, four types of statements are available:
Declarative: declares existence of certain entities having specified properties;
Definition: gives definitions of user-defined entities;
Imperative: specifies commands to be passed on to the execution agent (usually a CPU) – one very common imperative being an assignment;
Assignment: specifies some computation to be done and assignment of resulting value to an entity;
Control: determines the order in which statements are executed, generally by checking the current state of some entities;
- Structured programming and modularity are generally emphasized.
- Libraries of precompiled and tested modules are available for computation over diverse fields.
- Designed for easy debugging, code modification and code extension.
C, C++, Java and Ada are examples of HLL.
1.1.7 Very High Level Language
As advantages of HLL languages were realized (see Section 1.1.8), very High Level language (VHLL) was developed, especially for some specific application areas or computational needs. Apart from carrying forward the facilities generally available in a typical HLL, additional language facilities are seen in such languages. For example,
- PROLOG is a language for computation based on formal logic and specifically Horn clause. It is a declarative language for logic programming as opposed to procedural languages such as C or Java. It declares the data elements and relationships between them. Its basic action is to automatically search for a combination of values of specified entities to satisfy some logic expression. It does not depend upon step-by-step algorithms as we normally encounter.
- The programming languages for simulation package like MATLAB or statistical package like R are VHLL. They are object-oriented languages.
- Haskell is a Functional programming language.
- Perl and Python can also be called VHLL, as they use higher level objects such as lists, array and dictionaries directly. For example, a simple statement in Perl,
@evens = map {$_ if $_ % 2 == 0} (0...100);will assign a list consisting of all the even values between 0 and 100 to array @even. The iteration over an array of integers 0 to 100 is handled automatically as a part of the map function. - The METAFONT language developed by Prof. Donald Knuth, as a part of his TEXsystem to design fonts, is a VHLL. It automatically solves simultaneous equations to obtain co-ordinate values from known points.
1.1.8 Why High Level Language?
- Readability: An HLL will allow programs to be written that look similar to a text description of the underlying algorithms. If some care is taken, the program can become self-documenting.
- Portability: Though an ideal only partially achieved, HLL, being mostly machine independent, can be used for developing portable software. The same source code can be used on different families of machines, only thing needed is that the code has to be compiled on each type of machine separately.
- Productivity: Due to the brevity of expression in HLL for a given algorithm, the programmer's productivity increases. A rule of thumb used in software industry is that a programmer is expected to deliver 50 lines/day of tested and debugged code in any implementation language. Processing specified by 50 lines of code in C will be much higher compared to 50 lines of assembly code. Naturally, the higher the level of the language of the code, higher will be the programmer's productivity.
- Debugging ease: As the statements implementing the algorithms have logical meaning, finding and removing errors (debugging) are much more easier. Structured control constructs, if used in a proper way, also helps in debugging. Some HLL provide object-oriented programming facilities which further enhances debugging ease, modularity and code reuse.
- Modularity: The complete application development work can be divided into modules. This aids team work and also leads to code reuse, which saves considerable effort in code development.
- Optimization: Most of the good compilers provide, as option, optimized code. This executable code is comparable to what a human expert would deliver if he is using an assembly language.
- Generality: An HLL generally allows writing of code for a wide variety of applications, thus obviating a need for the programmer of becoming expert in many different languages.
- Error detection: An HLL compiler can detect several types of programmer errors, e.g. using a real variable as an integer, or not passing enough number of call arguments to a function. Also, a good compiler can give warnings for doubtful but syntactically correct code. Such warnings many times lead to detection of logical errors in the code, which a compiler is normally not expected to detect.
The HLL was developed during the 1950s to till today. Many of the HLLs are related to some others, and this relationship is called the genealogy of the programming languages (see Fig. 1.1).
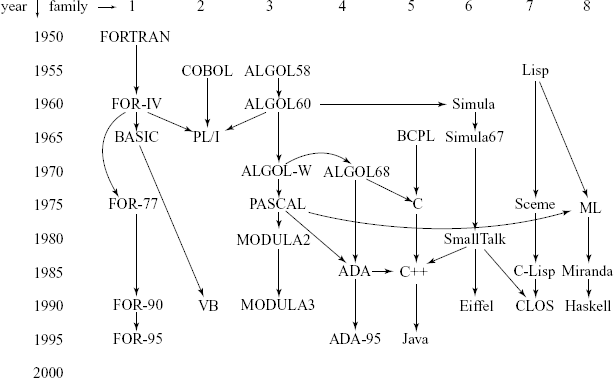
Note: The vertical axis in years is approximate only. Even though a language may be related or derived from some others, it does not mean that their run-time environments are comparable.