
9.7 Code Optimization
An optimizing compiler tries to generate the target code which a good assembly language programmer, intimately knowledgeable about the target processor, would have written. In this process, the optimizer replaces some naïve programming constructs used by the High Level language programmer, by more efficient target code sequences, at the same time maintaining the semantics of the source code. Then what is the real issue? The point is: an optimizing compiler will also provide a similar optimization across the different processor architectures. We want portability and optimized code at the same time . If a good assembly language programmer had to write a similar code for different processor architectures, he/she will have to put in considerable effort in learning the assembly languages, its idioms and applying them to the task at hand.
Two goals of optimization are:
Execution time reduction: Try to reduce the execution time of the compiled code.
Memory space reduction: Try to reduce the memory space requirement of the compiled code.
There are two levels at which optimization is generally attempted:
Machine-independent optimization: Consider the following code segment:
for(i = 0; i < 10000; i++){
c = 5;
a = d[i] + c;
}
In this code segment, the statement c = 5; does something which is independent of the progress of the loop and its value is not changed during the loop. It can be executed only once outside the loop and still the semantics of the code segment is preserved while execution time is reduced.
c = 5;
for(i = 0; i < 10000; i++){
a = d[i] + c;
}
This kind of code adjustment and reduction of execution time and/or memory space is valid for any processor, as they are essentially independent of the processor characteristics. They are generally attempted before Code Generation takes place. However, we shall discuss them in Chapter 10. Some of the readers may feel that “I would have done the same thing myself if I had written the code”. Yes, most of the machine-independent optimization counteracts carelessness, laziness, lack of knowledge or available time to think on part of the programmer. However, the second type of optimization takes actions which are not expected from an average high level language programmer.
Machine-dependent optimization: For example, store some of the intermediate results in the computation in the processor register, rather than in the memory. The processor registers typically provide 80 times faster access compared to the main memory and thus it will lead to a more efficient program if most of the computation can be done in the processor registers. On the other hand, processor registers are costliest of memories. Some sophisticated hardware arrangements are made to deal with the large gap in the speed and cost of registers and memory. High-speed cache’ memories, generally known as Level-1 and Level-2 cache’, are introduced between the CPU and the main memory. Refer to Fig. 9.9, where we have shown the memory hierarchy as obtained in a modern general-purpose computer. We can safely say that a major part of the machine-dependent optimization effort is related to the issue of how to get maximum performance out of the memory hierarchy, keeping in mind the way the whole arrangement works.
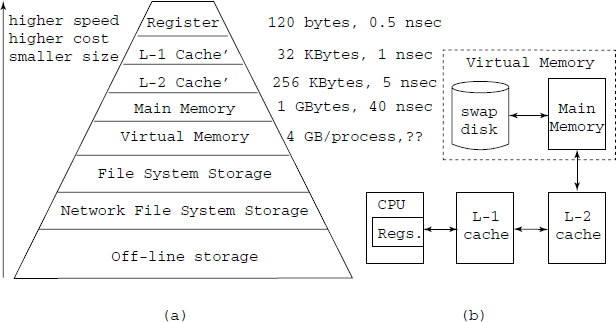
Fig. 9.9 (a) Memory hierarchy. The typical sizes and access speeds are noted on the side of each type of storage of our interest in code optimization. (b) The information flow in the top layers of the memory hierarchy. Registers store immediately needed (within a few instructions) information, L-1 cache stores about a kilobyte of immediately needed data and instructions of the most active processes, L-2 cache provides very roughly one active page (4 kb) per active process
The behaviour of the memory hierarchy can be roughly summarized as follows:
- Depending upon the instruction being executed, the CPU tries to access data in register/s or a memory address. If a register is being accessed, the data is available very quickly, say 0.5 nsec. The instruction can be completed at full processor speed.
- If a memory access is done, then if the address falls within the range of addresses whose data is held within L-1 cache, it is also available very fast, e.g. 1 nsec. Due to the small size of L-1 cache’, only limited data can be held there. If the data requested is not in the L-1 cache’, then the cache’ has to be loaded from L-2 cache’. There are two situations in which this can arise: first, if in the currently executing program there is a jump instruction, whose jump target falls outside the range held in L-1 cache’, second, the CPU starts another process – due to multi-tasking or an interrupt. The problem is that L-1 cache’ just does not load only the required data, it loads data from L-2 cache’ in chunks of say 128-bytes. This takes time, known as the latency of L-1 cache’. A very important aspect of all semiconductor memories, including cache’, is latency. All memory storages have a certain latency, which means that a certain number of clock cycles must pass between two operations, like reads. L-1 cache’ has lesser latency than L-2, typically 2 clock cycles or about 1 nsec, which is why it is so efficient.
- The L-2 cache’ is normally much bigger, such as 256, 512 or 1024 Kb. The purpose of the L-2 cache’ is to constantly read in slightly larger quantities of data from the main memory, so that the information is available to the L-1 cache’. The latency of L-2 cache’ is 6 clock cycles or 3 nsec. Note that when L-1 is to be reloaded, it is the latency of L-2 which is applicable.
- The comments about reloading of the L-1 cache’ from L-2 also apply to loading of L-2 cache’ from the main memory and the same issues of code replacement apply, but now with 3 times the penalty time.
- The reloading of -2 cache’ involves a memory read and will take about 40 nsec per 8-bytes (usual memory data bus width).
In summary, from machine-dependent code optimization viewpoint, use as much of registers as possible, avoid jumps – and especially conditional jumps as much as possible, avoid memory access wherever you can and, to utilize the speed-up made possible by pipelined instruction execution, reorder instructions.
In the remaining part of this chapter and in the next chapter, we shall discuss various strategies for optimization. We shall label each method by the following labels to denote their basic characteristics:
MD: Machine-dependent optimization method
MI: Machine-independent optimization method
TR: The method may give reduction of execution time
SR: The method may lead to reduction of memory space requirements
There are three categories of optimization:
Front-end optimization: Where the optimization actions are generally implemented in the front-end of the compiler, but some of them may be done during code generation [MD, MI, TR, SR]. They are discussed in Chapter 10 in more detail. Replacing a simple function by in-line code is an example of this kind of optimization, which can be considered both MD and MI.
Peep-hole (Linear) optimization: Actions are done on the IR, but some of them are done on the raw target code also [MD, MI, TR, SR].
Structural optimization: Examines the total program or a substantial part of it. Usually done at IR level, but takes a more global view of the code [MI, TR, SR].