
3.1 Scanner
The job of a Scanner or lexical analyzer is identifying low-level language constructs – language atoms like identifiers, keywords, numbers, operators, string literals, etc. As these constructs can be represented as regular languages, a Scanner design is based on regular expressions and uses a finite-state machine as its implementation model.
The basic scanning process is a character-by-character examination of the input source code and identifying the tokens. A real Scanner will have to do several further jobs, first of which is to supply an internal representation of the atoms, called tokens, to the next phase – the parser. Consider a grammar for an arithmetic expression.
E −> E + T | T
T −> T * F | F
F −> ( E ) | i
This grammar is for syntax analysis and considers ‘i’ as a Terminal atom. To write the full grammar we would have to write the grammar to detect the identifier atom written as ‘i’:
I −> I | IL | ID
L −> a | b | … | z
D −> 0 | 1 | … | 9
This is the grammar for the lexical analysis or the Scanner, which will detect the identifier atoms in the source code and supply to the parser only a token ‘i’ whenever one ‘I’ is detected. It will also create a Symbol Table of the identifiers. There are two possible implementations for a Scanner:
- A separate pass: generates an intermediate file of uniform symbols (tokens), for the Parser.
- As a co-routine: (or sub-routine) it is called by the parser whenever a next token is needed.
The following are the advantages of the sub-routine method:
- The complete token list for the whole of the source code need not be stored.
- Multiple Scanners are possible, depending upon some detected syntax construct.
- Scanners can get feed-back from the parser to handle some difficult languages like FORTRAN. Consider two FORTRAN statements: DO11I=1.5 and DO11I = 1,5. Both are valid in FORTRAN, but the Scanner will have to identify DO 11 I as separate atoms in the second case.
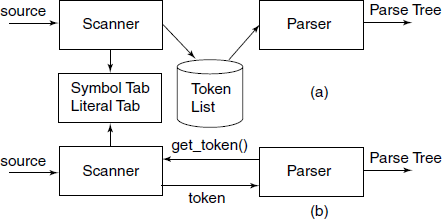
Fig. 3.2 Two ways in which a Scanner can interact with the parser: (a) Scanner creates an intermediate file of token-list; (b) Parser uses the Scanner as a procedure and calls it when a token is needed
Generally, in order to avoid the complexity introduced by the above-mentioned problem, most of the programming languages use a space character as a delimiter and restrict the use of the keywords severely.
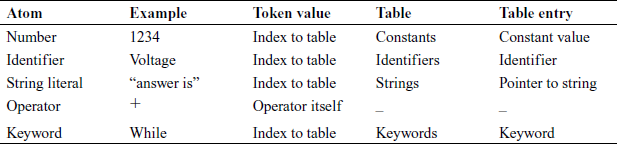
Whenever the Scanner identifies an atom, it returns a token which is a pair consisting of an integer denoting the type of token and generally an index into a table where the value of the atom is stored. These values are usually as shown in Table 3.2.
The token type is usually denoted by an integer, one specific value for each syntactic type. Following the convention used by yacc (see Section 3.3), the token type is assigned values greater than 256. This will allow the one character operators, which are most frequent, to be denoted by the token type itself. For example, consider statements
label1 : a = a + 5 ; goto label2;
and following illustrative assignments for syntactic types:
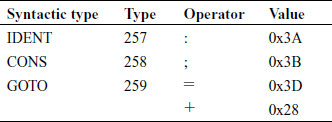
The Scanner will send out the following tokens to the parser.
A typical Scanner will have to do the following jobs:
- Detect and report the use of illegal characters as errors in the source code.
- Remove comments and white spaces (blanks, tabs, new lines).
- Differentiate between identifiers and the keywords.
- Prepare Symbol Table, Constant or Literal Table and convert the literals to internal representations (e.g. 123.45 is stored internally in IEEE standard format as 0x42f6e666).
- Send the token to the parser.
At this stage, it is suggested that you review the material in Appendix A, especially the topics regular languages, regular expressions and finite-state Automata.
3.1.1 Examples: RE, FSM and Implementation
We now discuss several examples of regular expressions, corresponding FSMs and their implementation in the form of algorithm or code.
Example: A decimal number
We want to detect unsigned decimal numbers of the form ![]()
The corresponding RE is R1 = d *.dd* where d is any digit 0 to 9.
The FSM is shown below.
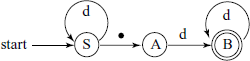
The corresponding Scanner code in C is
int main () {
char a;
S : a = getch();
if((a >= ′0′) && (a <= ′9′)) goto S;
if(a == ′.′) goto A;
else {
printf(″
Error″);
goto S;
}
A : a = getch();
if((a >= ′0′) && (a <= ′9′)) goto B;
else {
printf(″
Error″);
goto S;
}
B : a = getch();
if(a == ′#′){
printf(″
Accepted″);
goto S;
}
if((a >= ′0′) && (a <= ′9′)) goto B;
else {
printf(″
Error″);
goto S;
}
}
Note that we added an additional input character ‘#’ to indicate the end of input string. We could have used EOF character instead. We could have used a separate function get_d() to check if the input character is in the range ‘0’ to ‘9’. We have not included actions to be taken on acceptance of the input string. With a separate get_d() function, the implementation becomes:
int get_d() {
char a;
a = getch();
if((a >= ′0′) && (a <= ′9′)) return ′d′;
if(a == ′.′) return ′p′;
if(a == ′#′) return ′e′;
else {
printf(″
Error″);
return 0;
}
}
int main(){
char a;
S : if((a = get_d()) == ′d′) goto S;
if(a == ′p′) goto A;
else goto S;
A : if((a = get_d()) == ′d′) goto B;
else goto S;
B : if(get_d() == ′e′){
printf(″
Accepted″);
goto S;
}
if(get_d() == ′d′) goto B;
else goto S;
}
Note that get_d() has effectively become our Scanner's Scanner.
Example: Identifier
We want to detect identifiers defined by an RE R2 = L(L | | D)*, where L represents letters ‘A to Z a to z’ and D represents digits ‘0 to 9’.
The FSM is:

int main () {
char a;
s : a = getch();
if(isalpha(a)) goto C;
else {
printf(″
Error″);
goto S;
}
C : a = getch();
if(isalpha(a) || isdigit(a)) goto C;
else {
printf(″
Error″);
goto S;
}
}
Example: A Scanner for C-like language
As a final example, we discuss a simplified Scanner for a C-like language. The simplification is mainly in ignoring the pre-processor statements, i.e. those starting with ‘#’.
One of the tricky issues is handling the comments; they are to be ignored, just like white space. So we begin by giving portion of the FSM which deals with white space and comments.
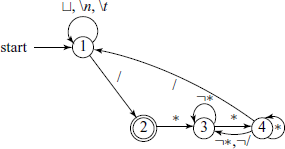
Note that the final state 2 accepts a ‘/’, but there is a transition out of it on a ‘*’. Such transitions will require look-ahead in our implementation. The blanks ‘![]() ’, new line and tab characters are just ignored, so the transition is back to state 1. When a ‘/’ is encountered, a look-ahead will check if the next character is a ‘*’, if so, then we are in a comment and go to state 3. We remain in state 3 till a ‘*’ is again encountered. Then possibly we are coming out of the comment and in anticipation of that, go to state 4. If the very next character is not a ‘/’ or a ‘*’ we go back to state 3, as the comment is not over yet. If it is a ‘*’, we remain in state 4. In state 4, if we get a ‘/’, the comment is over and we go back to state 1.
’, new line and tab characters are just ignored, so the transition is back to state 1. When a ‘/’ is encountered, a look-ahead will check if the next character is a ‘*’, if so, then we are in a comment and go to state 3. We remain in state 3 till a ‘*’ is again encountered. Then possibly we are coming out of the comment and in anticipation of that, go to state 4. If the very next character is not a ‘/’ or a ‘*’ we go back to state 3, as the comment is not over yet. If it is a ‘*’, we remain in state 4. In state 4, if we get a ‘/’, the comment is over and we go back to state 1.
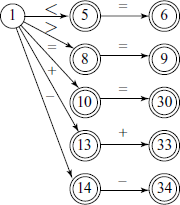
Other situations where we shall have to use look-ahead is when we encounter multi-character operators, such as ‘>=’ or ‘++’. The portion of FSM corresponding to them is shown below.
The other double-character operators in C, such as ‘!=’, ‘||’ and ‘&&’ will have similar state transitions.
Single-character operators such as ‘(’, ‘)’, ‘:’, ‘;’, etc. take the FSM to a state for each of them. We have already seen detection of numbers and identifiers in the previous two examples. A skeleton C language code is given below.
Scanner()
{
int c;
char *p;
L1: while((c = getchar()) == ′ ′ || c == ′ ′ || c == ′
′);
if(c == EOF)
return 0;
if(isalpha(c)){
Symbol *s;
char sbuf[100], *p = sbuf;
do{
*p++ = c;
}
while((c = getchar()) != EOF && isalnum(c));
ungetc(c, stdin);
*p = ′�′;
if((s = lookup(sbuf)) == 0){
s = install(sbuf, UNDEF, addrs);
addrs++;
}
lexval.sym = s;
return lexval.type = s–>type == UNDEF ? VAR : s–>type;
}
switch(c)
{
int c1;
case ′/′: c1 = lookahead(′*′, CSTART, DIV);
if(c1 == DIV) return DIV;
else {
L3: c1 = getchar();
while(c1 != ′*′) c1 = getchar();
while(c1 == ′*′) c1 = getchar();
if(c1 != ′/′) goto L3;
goto L1;
}
case ′>′:
return lookahead(′=′, GE, GT);
case ′<′:
return lookahead(′=′, LE, LT);
case ′=′:
return lookahead(′=′, EQ, ′=′);
case ′!′:
return lookahead(′=′, NE, NOT);
case ′|′:
return lookahead(′|′, OR, ′|′);
case ′&′:
return lookahead(′&′, AND, ′&′);
case ′
′:
lineno++;
return ′
′;
default:
return c;
}
}
if(c == ′.′ || isdigit(c))
{
double d;
ungetc(c, stdin);
scanf(″%lf″, &d);
yylval.sym = install(″″, NUMBER, d);
return NUMBER;
}
return c;
}
int lookahead(int check, int yes, int no)
{
int c = getchar();
if(c == check)
return yes;
ungetc(c, stdin);
return no;
}