
4.1 Top-down and Bottom-up Parsing
Parsing of a given sentence can be done in one of the two ways shown in Fig. 4.1:
Top-down: Starting with the start symbol of the grammar, we apply various productions to ultimately obtain the required sentence.
Bottom-up: Starting with a handle in the given sentence, we construct a forest of trees by applying the reductions (i.e. productions in reverse) which will ultimately merge into one parse tree.
Consider a grammar:
G = <{I,D,L}, {a−z, 0−9}, I, P>, with productions
P = { I –> L | IL | ID
L –> a | b | … | z
D –> 0 | 1 | … | 9
}
and a sentence x2 to be parsed. First, we consider the Top-down parsing (Fig. 4.2).
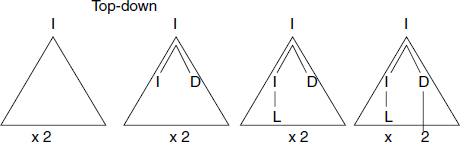
Fig. 4.2 Starting from I, and looking at “X2”, we derive a single tree, which ultimately results in “X2”
Note that in the second step we chose the production I –> ID. Instead, had we chosen I –> IL there, the parsing would have been unsuccessful. Thus in top-down parsing, we start with the start symbol and go on applying productions, but always “looking” at the sentence we want to generate.
Now consider Bottom-up parsing (Fig. 4.3). Again take x2 as the given sentence to be parsed. The sequence of reductions is

Consider, for example, grammar G given above the sentential form LDL:
- D is NOT a phrase.
- b is a simple phrase.
- L is a simple phrase.
- L is a handle, as it is the leftmost simple phrase.
The concept of a handle is important as it allows us to reduce it to an NT of that grammar.
We say that during Top-down parsing, we derive sentential forms and during Bottom-up parsing we reduce from sentential forms to the start symbol. It is necessary to give formal definitions of these concepts.
Definition 4.1.1 (Leftmost canonical Direct Derivation) If A → β is a production in the grammar and ![]() , then
, then ![]()
We say if ![]() , x right produces y.
, x right produces y.
Definition 4.1.2 (Rightmost canonical Direct Derivation) If A → β is a production in the grammar and ![]() , then
, then ![]()
We say if ![]() , x right produces y.
, x right produces y.
Leftmost derivation corresponds to left-to-right scan for Top-down parsing. Rightmost reduction (i.e. derivation in reverse) is used for Bottom-up parsing, while doing left-to-right scan.
Example – Derivation and Reduction
A unambiguous version for an arithmetic expression grammar, ![]()
![]() , and P is given by
, and P is given by
P = {
1. E → E + T | E − T | T
2. T → T * F | T/F | F
3. F → (E) | a
}
Consider the grammar ![]() and derive sentence “a + a * a” by left and right derivations.
and derive sentence “a + a * a” by left and right derivations.
Note that leftmost derivation corresponds to left-to-right scan while doing Top-down parsing. In case of Bottom-up parse, the problem of finding the correct sequence of productions ![]() for a given σ is approached by starting with σ and reducing the string to S; see the third column of Table 4.2.
for a given σ is approached by starting with σ and reducing the string to S; see the third column of Table 4.2.

Note: The third column shows left-to-right scan to catch a handle by rightmost derivation in reverse order (⇐) as reduction.
Further note that for the sentential form “E + T * a”, neither “E + T” nor “T” is a handle. Remember that a handle in a sentential form derived from the start symbol should be replaceable by a single NT. If we try that while reducing “E + T * a” as “E * a” it is not a sentential form derivable from E. Similarly, if the reduction as “E + E * a” it is not a sentential form derivable from E.
Reduced Grammars
There may be several forms of redundancies in a grammar. In a reduced grammar, which is free from such redundancies, the following are removed:
- redundant rules like A ⃗ A,
- redundant NT, which does not generate any Terminal string,
- unreachable NT.