
MACBETH: I pull in resolution and beginTo doubt th' equivocation of the fiendThat lies like truth: “Fear not, till Birnam woodDo come to Dunsinane,” and now a woodComes toward Dunsinane. Arm, arm, and out! | ||
| --The Tragedy of Macbeth, V, v, 42–46. | ||
Vulnerabilities arise from computer system design, implementation, maintenance, and operation. This chapter presents a general technique for testing for vulnerabilities in all these areas and discusses several models of vulnerabilities.
A “computer system” is more than hardware and software; it includes the policies, procedures, and organization under which that hardware and software is used. Lapses in security can arise from any of these areas or from any combination of these areas. Thus, it makes little sense to restrict the study of vulnerabilities to hardware and software problems.
When someone breaks into a computer system, that person takes advantage of lapses in procedures, technology, or management (or some combination of these factors), allowing unauthorized access or actions. The specific failure of the controls is called a vulnerability or security flaw; using that failure to violate the site security policy is called exploiting the vulnerability. One who attempts to exploit the vulnerability is called an attacker.
For example, many systems have special administrative users who are authorized to create new accounts. Suppose a user who is not an administrative user can add a new entry to the database of users, thereby creating a new account. This operation is forbidden to the nonadministrative user. However, such a user has taken advantage of an inconsistency in the way data in the database is accessed. The inconsistency is the vulnerability; the sequence of steps that adds the new user is the exploitation. A secure system should have no such problems. In practice, computer systems are so complex that exploitable vulnerabilities (such as the one described above) exist; they arise from faulty system design, implementation, operation, or maintenance.
Formal verification and property-based testing are techniques for detecting vulnerabilities. Both are based on the design and/or implementation of the computer system, but a “computer system” includes policies, procedures, and an operating environment, and these external factors can be difficult to express in a form amenable to formal verification or property-based testing. Yet these factors determine whether or not a computer system implements the site security policy to an acceptable degree.
One can generalize the notion of formal verification to a more informal approach (see Figure 23-1). Suppose a tester believes there to be flaws in a system. Given the hypothesis (specifically, where the tester believes the flaw to be, the nature of the flaw, and so forth), the tester determines the state in which the vulnerability will arise. This is the precondition. The tester puts the system into that state and analyzes the system (possibly attempting to exploit the vulnerability). After the analysis, the tester will have information about the resulting state of the system (the postconditions) that can be compared with the site security policy. If the security policy and the postconditions are inconsistent, the hypothesis (that a vulnerability exists) is correct.

Figure 23-1. A comparison between formal verification and penetration testing. In formal verification, the “preconditions” place constraints on the state of the system when the program (or system) is run, and the “postconditions” state the effect of running the program. In penetration testing, the “preconditions” describe the state of the system in which the hypothesized security flaw can be exploited, and the “postconditions” are the result of the testing. In both verification and testing, the postconditions must conform to the security policy of the system.
Penetration testing is a testing technique, not a proof technique. It can never prove the absence of security flaws; it can only prove their presence. In theory, formal verification can prove the absence of vulnerabilities. However, to be meaningful, a formal verification proof must include all external factors. Hence, formal verification proves the absence of flaws within a particular program or design and not the absence of flaws within the computer system as a whole. Incorrect configuration, maintenance, or operation of the program or system may introduce flaws that formal verification will not detect.
A penetration study is a test for evaluating the strengths of all security controls on the computer system. The goal of the study is to violate the site security policy. A penetration study (also called a tiger team attack or red team attack) is not a replacement for careful design and implementation with structured testing. It provides a methodology for testing the system in toto, once it is in place. Unlike other testing and verification technologies, it examines procedural and operational controls as well as technological controls.
A penetration test is an authorized attempt to violate specific constraints stated in the form of a security or integrity policy. This formulation implies a metric for determining whether the study has succeeded. It also provides a framework in which to examine those aspects of procedural, operational, and technological security mechanisms relevant to protecting the particular aspect of system security in question. Should goals be nebulous, interpretation of the results will also be nebulous, and the test will be less useful than if the goals were stated precisely. Example goals of penetration studies are gaining of read or write access to specific objects, files, or accounts; gaining of specific privileges; and disruption or denial of the availability of objects.
A second type of study does not have a specific target; instead, the goal is to find some number of vulnerabilities or to find vulnerabilities within a set period of time. The strength of such a test depends on the proper interpretation of results. Briefly, if the vulnerabilities are categorized and studied, and if conclusions are drawn as to the nature of the flaws, then the analysts can draw conclusions about the care taken in the design and implementation. But a simple list of vulnerabilities, although helpful in closing those specific holes, contributes far less to the security of a system.
In practice, other constraints affect the penetration study; the most notable are constraints on resources (such as money) and constraints on time. If these constraints arise as aspects of policy, they improve the test because they make it more realistic.
A penetration test is designed to characterize the effectiveness of security mechanisms and controls to attackers. To this end, these studies are conducted from an attacker's point of view, and the environment in which the tests are conducted is that in which a putative attacker would function. Different attackers, however, have different environments; for example, insiders have access to the system, whereas outsiders need to acquire that access. This suggests a layering model for a penetration study.
External attacker with no knowledge of the system. At this level, the testers know that the target system exists and have enough information to identify it once they reach it. They must then determine how to access the system themselves. This layer is usually an exercise in social engineering and/or persistence because the testers try to trick the information out of the company or simply dial telephone numbers or search network address spaces until they stumble onto the system. This layer is normally skipped in penetration testing because it tells little about the security of the system itself.
External attacker with access to the system. At this level, the testers have access to the system and can proceed to log in or to invoke network services available to all hosts on the network (such as electronic mail). They must then launch their attack. Typically, this step involves accessing an account from which the testers can achieve their goal or using a network service that can give them access to the system or (if possible) directly achieve their goal. Common forms of attack at this stage are guessing passwords, looking for unprotected accounts, and attacking network servers. Implementation flaws in servers often provide the desired access.
Internal attacker with access to the system. At this level, the testers have an account on the system and can act as authorized users of the system. The test typically involves gaining unauthorized privileges or information and, from that, reaching the goal. At this stage, the testers acquire (or have) a good knowledge of the target system, its design, and its operation. Attacks are developed on the basis of this knowledge and access.
In some cases, information about specific layers is irrelevant and that layer can be skipped. For example, penetration tests during design and development skip layer 1 because that layer analyzes site security. A penetration test of a system with a guest account (which anyone can access) will usually skip layer 2 because users already have access to the system. Ultimately, the testers (and not the developers) must decide which layers are appropriate.
The penetration testing methodology springs from the Flaw Hypothesis Methodology. The usefulness of a penetration study comes from the documentation and conclusions drawn from the study and not from the success or failure of the attempted penetration. Many people misunderstand this, thinking that a successful penetration means that the system is poorly protected. Such a conclusion can only be drawn once the study is complete and when the study shows poor design, poor implementation, or poor procedural and management controls. Also important is the degree of penetration. If an attack obtains information about one user's data, it may be deemed less successful than one that obtains system privileges because the latter attack can compromise many user accounts and damage the integrity of the system.
The Flaw Hypothesis Methodology was developed at System Development Corporation and provides a framework for penetration studies [632, 1038, 1039]. It consists of four steps.
Information gathering. In this step, the testers become familiar with the system's functioning. They examine the system's design, its implementation, its operating procedures, and its use. The testers become as familiar with the system as possible.
Flaw hypothesis. Drawing on the knowledge gained in the first step, and on knowledge of vulnerabilities in other systems, the testers hypothesize flaws of the system under study.
Flaw testing. The testers test their hypothesized flaws. If a flaw does not exist (or cannot be exploited), the testers go back to step 2. If the flaw is exploited, they proceed to the next step.
Flaw generalization. Once a flaw has been successfully exploited, the testers attempt to generalize the vulnerability and find others similar to it. They feed their new understanding (or new hypothesis) back into step 2 and iterate until the test is concluded.
A fifth step is often added [1038, 1039]:
Flaw elimination. The testers suggest ways to eliminate the flaw or to use procedural controls to ameliorate it.
The following sections examine each aspect of this methodology and show how it is used in practice.
In the steps of the Flaw Hypothesis Methodology, the design of the system is scrutinized, with particular attention to discrepancies in the components. The testers devise a model of the system, or of its components, and then explore each aspect of the designs for internal consistency, incorrect assumptions, and potential flaws. They then consider the interfaces between the components and the ways in which the components work together. At this stage, some of the testers must be very knowledgeable about the system (or acquire expertise quickly) to ensure that the model or models of the system represent the implementation adequately. If the testers have access to design documents and manuals, they can often find parts of the specification that are imprecise or incomplete. These parts will be very good places to begin, especially if different designers worked on parts of the system that used the unclear specification. (Occasionally, a single designer may interpret an unclear specification differently during the design of two separate components.) If a privileged user (such as root on UNIX systems or administrator on Windows systems) is present, the way the system manages that user may reveal flaws.
The testers also examine the policies and procedures used to maintain the system. Although the design may not reveal any weak points, badly run or incorrectly installed systems will have vulnerabilities as a result of these errors. In particular, any departure from design assumptions, requirements, or models will usually indicate a vulnerability, as will sloppy administrative procedures and unnecessary use of privileges. Sharing of accounts, for example, often enables an attacker to plant Trojan horses, as does sharing of libraries, programs, and data.
Implementation problems also lead to security flaws. Models of vulnerabilities offer many clues to where the flaws may lie. One strategy is for the testers to look in the manuals describing the programs and the system, especially any manuals describing their underlying implementation, assumptions, and security-related properties [106]. Wherever the manuals suggest a limit or restriction, the testers try to violate it; wherever the manuals describe a sequence of steps to perform an action involving privileged data or programs, the testers omit some steps. More often than not, this strategy will reveal security flaws.
Critical to this step is the identification of the structures and mechanisms that control the system. These structures and mechanisms are the programs (including the operating system) that will enable an attacker to take control of (parts of) the system, such as the security-related controllers. The environment in which these programs have been designed and implemented, as well as the tools (compilers, debuggers, and so on) used to build them, may introduce errors, and knowledge of that environment helps the testers hypothesize security flaws.
Throughout all this, the testers draw on their past experience with the system, with penetrating systems in general, and on flaws that have been found in other systems. Later sections of this chapter present several models and frameworks of vulnerabilities and analyze them with respect to their ability to model system vulnerabilities. The classification of flaws often leads to the discovery of new flaws, and this analysis is part of the flaw hypothesis stage.
Once the testers have hypothesized a set of flaws, they determine the order in which to test the flaws. The priority is a function of the goals of the test. For example, if the testing is to uncover major design or implementation flaws, hypothetical flaws that involve design problems or flaws in system-critical code will be given a very high priority. If the testing is to uncover the vulnerability of the system to outsider attack, flaws related to external access protocols and programs will be given a very high priority and flaws affecting only internal use will be given a low priority. Assigning priorities is a matter of informed judgment, which emphasizes the need for testers to be familiar with the environment and the system.
Once the priorities have been determined, the testers study the hypothetical flaws. If a flaw can be demonstrated from the analysis, so much the better; this commonly occurs when a flaw arises from faulty specifications, designs, or operations. If the flaw cannot be demonstrated in this way, the tester must understand exactly why the flaw might arise and how to test for it in the least intrusive manner. The goal is to demonstrate that the flaw exists and can cause system compromise, but to minimize the impact of that demonstration.
When a system must be tested, it should be backed up and all users should be removed from it. This precautionary measure saves grief should the testing go awry. The tester then verifies that the system is configured as needed for the test and takes notes (or helps an observer take notes) of the requirements for detecting the flaw. The tester then verifies the existence of the flaw. In many cases, this can be done without exploiting the flaw; in some cases, it cannot. The latter cases are often political, in which the system developers or managers refuse to believe that the flaw exists until it is demonstrated. The test should be as simple as possible but must demonstrate that the exploitation succeeded; for example, a test might copy a protected file to a second protected file or change the date of modification of a system file by 1 second (unless the precise time of modification is critical). The tester's goal is to demonstrate what a hostile exploiter of the flaw could do, not to be that hostile exploiter. The notes of the test must be complete enough to enable another tester to duplicate the test or the exploitation on request; thus, precise notes are essential.
As testers successfully penetrate the system (either through analysis or through analysis followed by testing), classes of flaws begin to emerge. The testers must confer enough to make each other aware of the nature of the flaws, and often two different flaws can be combined for a devastating attack. As an example, one flaw may enable a tester to gain access to an unprivileged account on a Windows NT system, and a second flaw may enable an ordinary user to gain administrator privileges. Separately, the impact of these flaws depends on the site policy and security concerns. Together, they allow anyone who can connect to the system to become supervisor.
As a second example, some privileged programs on the UNIX system read input into a buffer on the user stack and fail to check the length. By supplying an appropriate input, the attacker can overwrite the return address and make it invoke code in the input stream. Similarly, many programs place a copy of command-line arguments onto the stack. Generalizing the former flaw suggests that programs that do the latter are equally vulnerable to compromise in a similar fashion (but the string is supplied as a command-line argument rather than as input).
The flaw elimination step is often omitted because correction of flaws is not part of the penetration. However, the flaws uncovered by the test must be corrected. For example, the TCSEC [285] requires that any flaws uncovered by penetration testing be corrected.
Proper correction of a flaw requires an understanding of the context of the flaw as well as of the details of both the flaw and its exploitation. This implies that the environment in which the system functions is relevant to correction of the flaw. For example, if a design flaw is uncovered during development as part of the testing cycle, the developers can correct the design problem and reimplement those portions of the system that are affected by the flaw. In this case, knowledge of how to exploit that flaw is not critical. If, however, a design flaw is uncovered at a production site, that site (and the vendor) may not be able to correct the flaw quickly enough to prevent attackers from exploiting it. In this case, understanding how the flaw can be exploited becomes critical because all the site can do is to try to block those paths of exploitation or to detect any attacker who tries to exploit the flaw. This justifies the extensive analysis during the flaw hypothesis and generalization phase. Understanding the origins of the flaw, its context, and its affect on the system leads to proper corrective measures based on the system and the environment in which it functions.
As an exercise, a graduate computer science class at the University of Michigan launched a penetration test against the Michigan Terminal System, a general-purpose operating system that ran on the University of Michigan's IBM 360 and 370 computer systems [457]. Their goal was to acquire access to the terminal control structures. The students had the approval and support of the computer center staff. They began by assuming that the attackers had access to an authorized account (step 3 on page 648).
The first step was to learn the details of the system's control flow and supervisor. When an individual user ran a program, memory was split into segments. Segments 0 to 4 contained the supervisor, system programs, and system state and were protected by hardware mechanisms. Segment 5 was a system work area, recording process-specific information such as privilege level, accounting information, and so forth. The process should not have been able to alter any of this information. Segments numbered 6 and higher contained user process information, and the process could alter them.
Segment 5 was protected by a virtual memory protection system. The virtual system had two states. In “system” mode, the process could access or alter its segment 5 and could issue calls to the supervisor. In “user” mode, segment 5 was not present in the address space of the process and so could not be modified. The process would run in user mode whenever user-supplied code would be executed. If the user code needed a system service, it would issue a system call; that code could in turn issue a supervisor call, in which case the supervisor would perform the needed function. The system code had to check parameters to ensure that the system (or supervisor) would access authorized locations only. Complicating this check was the way in which parameters were passed. A list of addresses (one per parameter) was constructed in user segments, and the address of this list was given to the system call in a register; hence, checking of parameters required following of two levels of indirection. All such addresses, of course, had to be in user segments numbered 6 (or higher).
The testing now entered the flaw hypothesis stage. The observation that many security problems arise at interfaces suggested focusing on the switch from user to system mode because system mode required supervisor privileges. The study focused on parameter checking, and it was discovered that an element of the parameter list could point to a location within the parameter list (see Figure 23-2). In other words, one could cause the system or supervisor procedure to alter a parameter's address after the validity of the old address had been verified.
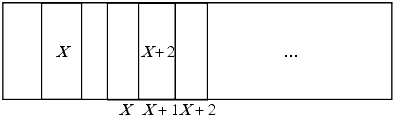
Figure 23-2. An example of the parameter passing conventions. Here, X is the address of the parameter list, and locations X, X + 1, and X + 2 contain addresses of the actual parameters. Note that location X + 1 contains the address X + 2, meaning that the last address in the parameter list is itself the location of a parameter (as well as containing the address of another parameter).
In order to exploit this flaw, the testers had to find a system routine that used this calling convention, took two parameters, altered at least one, and could be made to change the parameter to any of a specific set of values (which lay in the system segment). Several such routines were found; the one that was exploited was the line input routine, which returned the line number and length of the line as well as the line itself. The testers set up the parameter list so that the address for storing the line number was the location of the address of the line length. When called, the system routine validated the parameter list (all addresses were indeed in user segments), and it then read the input line. The line number was stored in the parameter list itself and was set to be an address within the system segment. The line length corresponded to the desired value of that location in the system segment. Thus, the testers were able to alter data in segment 5. However, they could not alter anything in the supervisor segments because those segments were protected by hardware.
During the flaw generalization stage, the testers realized the full implications of this flaw. The privilege level in segment 5 controlled the ability of the process to issue supervisor calls (as opposed to system calls). One of these calls turned off the hardware protection for segments 0 to 4. This enabled the process to alter any data or instructions in those segments and thus effectively control the computer completely.
During the test, the testers found numerous flaws that allowed them to acquire sufficient privileges to meet their goal. The penetration study was a success because it demonstrated how an attacker could obtain control of the terminal control structures.
The penetration study of a Burroughs B6700 system [1047] is particularly interesting because of the architecture of that system. Again as a class project, a graduate computer systems class at the University of Canterbury attempted to penetrate a Burroughs B6700 computer system running the 3.0 P.R.#1 release. The goal was to obtain the status of a privileged user and thus be able to alter privileged programs. The group explored four aspects of the system, in all cases beginning with an authorized account on the system (step 3 on page 648); we will discuss the only part that focused on file security.
The Burroughs B6700 system security is based on strict file typing. There are four relevant entities: ordinary users, privileged users, privileged programs, and operating system tasks. Ordinary users are tightly restricted; the other three classes can access file data without restriction but are still constrained from compromising integrity. Furthermore, the Burroughs system provides no assemblers; its compilers all take high-level languages as input and produce executable code. The B6700 distinguishes between data files and executable files by the type of the file. Only compilers can produce executable files. Moreover, if any user tries to write into a file or into a file's attributes, that file's type is immediately set to data, even if the file was previously an executable.
The group hypothesized that the system would not be able to detect a file that was altered offline. To test this hypothesis, the members of the group wrote and compiled a program to change the type of any file. It could not be run successfully yet because it would have to alter the file's attributes. Because it was not a recognized compiler, the file so altered would immediately become a data file. They then copied the machine code version of this program to tape. The tape utility created a header record indicating the file type. A second tape was mounted, and the contents of the first tape were copied to the second. During the transfer, the copying program altered the file type of the machine code to be a compiler. They then copied the file from the second tape to disk, and the file was installed as a compiler. The testers wrote a second subroutine, compiled it using the regular compiler, altered the machine code to give privileges to any user calling it, and used the bogus compiler to change the type of the altered file to executable. They then wrote a program to call that routine. It succeeded, and the user became privileged. This gave the user complete control of the system, achieving the goal.
A procedural corrective measure was to prevent unprivileged users from loading executables off tape. The testers noted the impracticality of this measure in many environments, such as academic and development sites.
This study [1052] is instructive because it began at step 1 of the list on page 648 and looked only at gathering nontechnical information needed to breach the computer system. It shows the importance of proper operations and organizational procedures in securing a system. Although the specific example is an amalgamation of techniques used in several real penetrations, the techniques are very effective and have repeatedly succeeded. Specifics are disguised to protect the corporations so penetrated.
The goal of the study was to determine whether corporate security measures were effective in keeping external attackers from accessing the system. The corporation had a variety of policies and procedures (both technical and nontechnical) that were believed to protect the system.
The testers began by gathering information about the site. They searched the Internet and obtained information on the corporation, including the names of some employees and officials. They obtained the telephone number of a local branch of the company and from that branch got a copy of the annual report. From the report and the other data, the testers were able to construct much of the company's organization, as well a list of some of the projects on which individuals were working.
The testers determined that a corporate telephone directory would provide them with needed information about the corporate structure. One impersonated a new employee, and through judicious telephone calls found out that two numbers were required to have something delivered off-site: the number of the employee requesting the shipment and a Cost Center number. A tester promptly called the secretary of the executive about whom the testers knew the most; by impersonating another employee, the caller obtained the executive's employee number. A second tester impersonated an auditor and obtained that executive's Cost Center number. The testers used these numbers to have a corporate directory sent to a “subcontractor.”
At this point, the testers decided to contact newly hired personnel and try to obtain their passwords. They impersonated the secretary of a very senior executive of the company, called the appropriate office, and claimed that the senior executive was very upset that he had not been given the names of the employees hired that week. The information was promptly provided.
The testers then began calling the newly hired people. They claimed to be with the corporate computing center and provided a “Computer Security Awareness Briefing” over the telephone. In the process of this briefing, the testers learned the types of computer systems used, the employees' numbers, their logins, and their passwords. A call to the computing center provided modem numbers; the modems bypassed a critical security system. At this point, the testers had compromised the system sufficiently that the penetration study was deemed successful.
In this example, the first goal is to gain access to the system. Our target is a system connected to the Internet.
We begin by scanning the network ports on the target system. Figure 23-3 shows some of these ports, together with a list of protocols that servers listening on those ports may use. Note that protocols are running on ports 79, 111, 512, 513, 514, and 540; these ports are typically used on UNIX systems. Let us make this assumption.
Many UNIX systems use sendmail as their SMTP server. This large program has had many security problems [214, 218, 219, 220, 221, 468, 922, 983]. By connecting to the port, we determine that the target is using sendmail Version 3.1. Drawing on previous experience and widely known information [104], we hypothesize that the SMTP agent will recognize the command shell and give us a root-owned shell on the system. To do this, we need to execute the wiz command first. We are successful, as Figure 23-4 shows. On this particular system, we have obtained root privileges.
The key to this attack is an understanding of how most UNIX systems are configured and a knowledge of known vulnerabilities. Most UNIX systems use some variant of sendmail as their SMTP agent, and that program prints version information when a connection is made. The information enabled the testers to determine what set of attacks would be likely to be fruitful. Given the wide variation in sendmails (owing to differences in vendors' patches), the flaw had to be tested for. The test succeeded.
Example 23-3. The output of the UNIX port scan. These are the ports that provide network services.
ftp 21/tcp File Transfer telnet 23/tcp Telnet smtp 25/tcp Simple Mail Transfer finger 79/tcp Finger sunrpc 111/tcp SUN Remote Procedure Call exec 512/tcp remote process execution (rexecd) login 513/tcp remote login (rlogind) shell 514/tcp rlogin style exec (rshd) printer 515/tcp spooler (lpd) uucp 540/tcp uucpd nfs 2049/tcp networked file system xterm 6000/tcp x-windows server
Example 23-4. A successful accessing of a UNIX system.
220 zzz.com sendmail 3.1/zzz.3.9, Dallas, Texas, ready at Wed,
2 Apr 97 22:07:31 CST
helo xxx
250 zzz.com Hello xxx.org, pleased to meet you
wiz
250 Enter, O mighty wizard!
shell
#
Now assume we are at step 3 of the list on page 648. We have an unprivileged account on the system. We determine that this system has a dynamically loaded kernel; the program used to add modules to the kernel is loadmodule. Because such a program must be privileged (or else it could not update the kernel tables), an unprivileged user can execute a privileged process. As indicated before, this suggests that the program does some sort of validation or authorization check. Our vulnerabilities models (see Section 23.4) indicate that this is a source of many problems. Let us examine this program more closely.
The program loadmodule validates the module as being a dynamically loadable module and then invokes the dynamic loader ld.so to perform the actual load. It also needs to determine the architecture of the system, and it uses the program arch to obtain this information. A logical question is how it executes these programs. The simplest way is to use a library function system. This function does not reset any part of the environment. Hence, if the system call is used, the environment in which we execute loadmodule is passed to the subprocesses, and these subprocesses are run as root. In this case, we can set our environment to look for programs in our local directory first, and then in system directories (by setting the PATH variable to have “.” as the first directory).
We accept this as a working hypothesis, and we set out to verify that this flaw exists. We write a small program that prints its effective UID, name it ld.so, and move it to the current working directory. We then reset our PATH variable as indicated above and run loadmodule. Unfortunately, our program does not execute; nothing is printed.
Why not? Once we understand this, we may be able to figure out a way to bypass this check, and our understanding of the system will increase. We scan the executable looking for ASCII strings, to see exactly how their dynamic loader invokes those subprograms. We see that the invocations are “/bin/arch” and “/bin/ld.so”. So our attempt to change the search path (PATH environment variable) was irrelevant; the system never looked at that variable because full path names were given.
Rereading the manual page for the library function system, we notice that it invokes the command interpreter sh. Looking at sh's manual page, we learn that the IFS environment variable has as its value characters used to separate words in commands that sh executes. Given that loadmodule invokes “/bin/arch”, if the character “/” were in the value of the environment variable IFS, sh would treat this command as “bin arch”. Then we could use the idea that just failed, but call the program bin rather than ld.so.
We could verify this idea without a test, but it would require disassemby of the loadmodule executable unless we had source code (we would look for anything that reset the environment within loadmodule). Assuming that we do not have source code, we change the value of IFS to include “/”, reset PATH and IFS as described above, change the name of our small program from ld.so to bin, and run loadmodule. The process prints that its effective UID is 0 (root). Our test has succeeded. (Chapter 29, “Program Security,” discusses corrective measures for problems of this type. The vendor fixed the problem [216].)
Incidentally, this example leads to a simple flaw generalization. The problem of subprocesses inheriting environment variables and their values suggests that the privileged program did not adequately sanitize the (untrusted) environment in which that program executes before invoking subprograms that are to be trusted. Hence, any privileged program may have this flaw. One could even hypothesize that a standard library routine or system call is invoked. So, a general class of flaws would involve failure to sanitize the environment, and the indicator of such a flaw might be one or more specific function calls. At this point, the testers would look in the programmers' manuals to see if such routines existed; if so, they would analyze programs to see which privileged programs called them. This could lead to a large number of other vulnerabilities.
This penetration test required more study than the first and demonstrates how failure can lead to success. When a test fails, the testers may have not understood the system completely and so need to study why the test failed. In this example, the failure led to a reexamination of the relevant library function, which led to a review of one of the system command interpreters. During this review, one of the testers noticed an obscure but documented control over the way the command interpreter interpreted commands. This led to a successful test. Patience is often said to be a virtue, and this is certainly true in penetration testing.
As in the preceding example, we begin at step 2 of the list on page 648, and all we know is that the system is connected to the Internet. We begin as before, by probing network ports, and from the results (see Figure 23-5)—especially the service running on port 139—we conclude that the system is a Windows NT server.
We first probe for easy-to-guess passwords. We discover that the system administrator has chosen the password Admin, and we obtain access to the system. At this point, we have administrator privilege on the local system. We would like to obtain rights to other systems in the domain.
Example 23-5. The output of the Windows NT port scan. These are the ports that provide network service.
qotd 17/tcp Quote of the Day ftp 21/tcp File Transfer [Control] loc-srv 135/tcp Location Service netbios-ssn 139/tcp NETBIOS Session Service [JBP]
We examine the local system and discover that the domain administrator has installed a service that is running with the privileges of a domain administrator. We then obtain a program that will dump the local security authority database, and load it onto the system. After executing it, we obtain the service account password. Using this password, we acquire domain administrator privileges and can now access any system in the domain.
This penetration test uncovered a serious administrative problem. For some reason, a sensitive account had a password that was easy to guess. This indicates a procedural problem within the company. Perhaps the system administrators were too busy, or forgot, to choose a good password. Two generalizations are appropriate. First, other systems should be checked for weak passwords. Second, the company's security policies should be reviewed, as should its education of its system administrators and its mechanisms for publicizing the policies.
Considerable debate has arisen about the validity of penetration studies for testing system security. At one end of the spectrum are some vendors who report that “after 1 year of our system being on the Internet, no one has successfully penetrated the system,” implying (and in some cases stating) that this shows that their product is quite secure. At the other end is the claim that penetration testing has no validity, and only rigorous design, implementation, and validation comprise an adequate test of security.
The resolution lies somewhere between two these extremes. Penetration testing is no substitute for good, thorough specification, rigorous design, careful and correct implementation, and meticulous testing. It is, however, a very valuable component of the final stage, “testing”; it is simply a form of a posteriori testing. Ideally, it should be unnecessary; but human beings are fallible and make mistakes, and computer systems are so complex that no single individual, or group, understands all aspects of the hardware's construction, the software's design, implementation, and the computer system's interactions with users and environment. Hence, errors will be introduced. Properly done, penetration tests examine the design and implementation of security mechanisms from the point of view of an attacker. The knowledge and understanding gleaned from such a viewpoint is invaluable.
Penetration testing is a very informal, nonrigorous technique for checking the security of a system. Two problems with the Flaw Hypothesis Methodology described in Section 23.2.4 are its dependence on the caliber of the testers and its lack of systematic examination of the system. High-caliber testers will examine the design systematically, but all too often the testing degenerates into a more scattered analysis.
In an attempt to make the process more systematic, and less dependent on the knowledge of the individuals conducting the test, testers often look at flaws that exist on other systems and decide which ones could translate into the tested system's model. Classification schemes can help in this regard; they group similar vulnerabilities together and enable the analyst to extract common features. Hence, such schemes are important in the flaw hypothesis step and are worth exploring.
Vulnerability classification frameworks describe security flaws from various perspectives. Some frameworks describe vulnerabilities by classifying the techniques used to exploit them. Others characterize vulnerabilities in terms of the software and hardware components and interfaces that make up the vulnerability. Still others classify vulnerabilities by their nature, in hopes of discovering techniques for finding previously unknown vulnerabilities.
The goal of vulnerability analysis is to develop methodologies that provide the following abilities.
The ability to specify, design, and implement a computer system without vulnerabilities.
The ability to analyze a computer system to detect vulnerabilities (which feeds into the Flaw Hypothesis Methodology step of penetration testing).
The ability to address any vulnerabilities introduced during the operation of the computer system (possibly leading to a redesign or reimplementation of the flawed components).
The ability to detect attempted exploitatons of vulnerabilities.
Ideally, one can generalize information about security flaws. From these generalizations, one then looks for underlying principles that lead toward the desired goals. Because the abstraction's purpose is tied to the classifiers' understanding of the goal, and of how best to reach that goal, both of these factors influence the classification system developed. Hence, the vulnerability frameworks covering design often differ from those covering the detection of exploitation of vulnerabilities. Before we present several different frameworks, however, a discussion of two security flaws will provide a basis for understanding several of the problems of these frameworks.
This section presents two widely known security vulnerabilities in some versions of the UNIX operating system. We will use these vulnerabilities as examples when comparing and contrasting the various frameworks.
The program xterm is a program that emulates a terminal under the X11 window system. For reasons not relevant to this discussion, it must run as the omnipotent user root on UNIX systems. It enables the user to log all input and output to a log file. If the file does not exist, xterm creates it and assigns ownership to the user; if the file already exists, xterm checks that the user can write to it before opening the file. Because any root process can write to any file in the system, the extra check is necessary to prevent a user from directing xterm to append log output to (say) the system password file and gaining privileges by altering that file.
Suppose the user wishes to log to an existing file. The following code fragment opens the file for writing.
if (access("/usr/tom/X", W_OK) == 0){
if ((fd = open("/usr/tom/X", O_WRONLY|O_APPEND) )< 0){
/* handle error: cannot open file */
}
}
The semantics of the UNIX operating system cause the name of the file to be loosely bound to the data object it represents, and the binding is asserted each time the name is used. If the data object corresponding to /usr/tom/X changes after the access but before the open, the open will not open the file checked by access. So if, during that interval, an attacker deletes the file and links a system file (such as the password file) to the name of the deleted file, xterm appends logging output to the password file. At this point, the user can create a root account without a password and gain root privileges. Figure 23-6 shows this graphically.
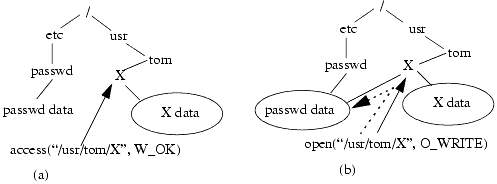
Figure 23-6. (a) The state of the system at the time of the access system call; the solid arrow indicates that the access refers to /usr/tom/X. Both /usr/tom/X and /etc/passwd name distinct objects. However, before the process makes its open system call, /usr/tom/X is deleted and a direct alias (hard link) for /etc/passwd is created and is named /usr/tom/X. Then the open accesses the data associated with /etc/passwd when it opens /usr/tom/X because /usr/tom/X and /etc/passwd now refer to the same file. This is shown in (b); with the dashed arrow indicating which data is actually read and the solid arrow indicating the name given to open.
The Internet worm of 1988 [322, 432, 845, 953] publicized our second flaw. It continues to recur—for example, in implementations of various network servers [224, 226, 227]. The finger protocol [1072] obtains information about the users of a remote system. The client program, called finger, contacts a server, called fingerd, on the remote system and sends a name of at most 512 characters. The server reads the name and returns the relevant information, but the server does not check the length of the name that finger sends. The storage space for the name is allocated on the stack, directly above the return address for the I/O routine. The attacker writes a small program (in machine code) to obtain a command interpreter and pads it to 512 bytes. She then sets the next 24 bytes to return to the input buffer instead of to the rightful caller (the main routine, in this case). The entire 536-byte buffer is sent to the daemon. The first 512 bytes go into the input storage array, and the excess 24 bytes overwrite the stack locations in which the caller's return address and status word are stored. The input routine returns to the code to spawn the command interpreter. The attacker now has access to the system. Figure 23-7 shows the changes in the user stack.
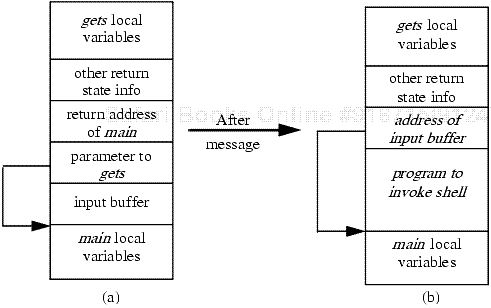
Figure 23-7. (a) The stack frame of fingerd when input is to be read. The arrow indicates the location to which the parameter to gets refers (it is past the address of the input buffer). (b) The same stack after the bogus input is stored. The input string overwrites the input buffer and parameter to gets, allowing a return to the contents of the input buffer. The arrow shows that the return address of main was overwritten with the address of the input buffer. When gets returns, it will pop its return address (now the address of the input buffer) and resume execution at that address.
The goals of a framework dictate the framework's structure. For example, if the framework is to guide the development of an attack detection tool, the focus of the framework will be on the steps needed to exploit vulnerabilities. If the framework is intended to aid the software development process, it will emphasize programming and design errors that cause vulnerabilities. Each of the following classification schemes was designed with a specific goal in mind.
Each of the following frameworks classifies a vulnerability as an n-tuple, the elements of the n-tuple being the specific classes into which the vulnerability falls. Some have a single set of categories; others are multidimensional (n > 1) because they are examining multiple characteristics of the vulnerabilities.
The RISOS (Research Into Secure Operating Systems) study [3] was prepared to aid computer and system managers and information processing specialists in understanding security issues in operating systems and to help them determine the level of effort required to enhance their system security. The investigators classified flaws into seven general classes.
Incomplete parameter validation
Inconsistent parameter validation
Implicit sharing of privileged/confidential data
Asynchronous validation/inadequate serialization
Inadequate identification/authentication/authorization
Violable prohibition/limit
Exploitable logic error
The investigators discussed techniques for avoiding, or ameliorating, the flaws in each class. They also attempted to develop methodologies and software for detecting incomplete parameter validation flaws. The survey examined several operating systems (MULTICS, BBN's TENEX, DEC's TOPS-10, Honeywell's GECOS, IBM's OS/MVT, SDS's SDS-940, and UNIVAC's EXEC-8) but noted that the flaw classes applied to other systems as well.
Incomplete parameter validation occurs when a parameter is not checked before use. The buffer overflows discussed earlier are the classic example of this type of flaw. Another example is a flaw in one computer's software emulator for integer division [212]. The caller provided two addresses as parameters, one for the quotient and one for the remainder. The quotient address was checked to ensure that it lay within the user's protection domain, but the remainder address was not similarly checked. By passing the address of the user identification number for the remainder, the programmer was able to acquire system privileges. Parameters need to be checked for type (and possibly format), ranges of values, access rights, and presence (or absence).
Inconsistent parameter validation is a design flaw in which each individual routine using data checks that the data is in the proper format for that routine, but the routines require different formats. Basically, the inconsistency across interfaces causes this flaw. An example occurs in a database in which each record is one line, with colons separating the fields. If one program accepts colons and newlines as part of data but other programs read the colons so accepted as field separators and the newlines so accepted as record separators, the inconsistency can cause bogus records to be entered into the database.
When an operating system fails to isolate processes and users properly, an implicit sharing of privileged/confidential data flaw occurs. The ability to recover a file's password in TENEX is an example of this type of flaw [989]. TENEX allowed the user to determine when paging occurred. Furthermore, when a file access required a password, the password was checked character by character, and the checking stopped at the first incorrect character. So, an attacker would position a guess for the password so that a page boundary lay between the first and second characters. He would then try to access the file. If paging occurred, the first character of the password was correct; if not, it was incorrect. Continuing in this fashion, the attacker could quickly recover the password needed to access the file. Kocher's timing attack against RSA, in which small variations in the speed of encipherment enable an attacker to deduce the private key (see Section 17.1), is another example of this type of flaw [586].
Race conditions and time-of-check to time-of-use flaws such as that shown in Figure 23-6 are members of the asynchronous validation/inadequate serialization class of flaws.
Inadequate identification/authorization/authentication flaws arise when a system allows a user to be erroneously identified, when one user can assume another's privilege, or when a user can trick the system (or another user) into executing a program without authorization. Trojan horses are examples of this type of flaw, as are accounts without passwords, because any user can access them freely. The UNIVAC 1100 provides an example related to file naming [3]. On that system, access to the system file SYS$*DLOC$ meant that the process was privileged. The system checked this by seeing if the process could access any file with the first three characters of the qualifier name SYS and the first three characters of the file name DLO. So, any process that could access the file SYSA*DLOC$, which was an ordinary (nonsystem) file, was also privileged and could access any file without the file access key.
Violable prohibition/limit flaws arise when system designers fail to handle bounds conditions properly. For example, early versions of TENEX kept the operating system in low memory and gave the user process access to all memory cells with addresses above a fixed value (marking the last memory location of the operating system). The limit of memory addressing was the address of the highest memory location; but when a user addressed a location beyond the end of memory, it was reduced modulo the memory size and so accessed a word in the operating system's area. Because the address was a large number, however, it was treated as being in user space—and hence could be altered [989].
Exploitable logic error flaws encompass problems not falling into any of the other classes; examples include incorrect error handling, unexpected side effects of instructions, and incorrect allocation of resources. One such flaw that occurred in early versions of TENEX requires an understanding of how the TENEX monitor implemented a return to the user's program. Basically, the monitor would execute a skip return to the address following the one stored in the user's program counter; the system would simply add 1 to the user's return word and return. On the PDP-10, the index field was a bit in the return word. If the return word was set to –1, the addition would overflow into the index field and change its semantics to refer to the contents of register 1, so the return would be to the location stored in that register. The attacker would load a bootstrap program into other registers, manipulate the contents of register 1 through a series of system calls so that it contained the address of the first bootstrap instruction, and then cause the monitor to execute a skip return. The bootstrap program would execute, loading the attacker's program and executing it with system privileges [614].
The RISOS project created a seminal study of vulnerabilities. It provided valuable insights into the nature of flaws, among them that security is a function of site requirements and threats, that there are a small number of fundamental flaws that recur in different contexts, and that operating system security is not a critical factor in the design of operating systems. It spurred research efforts into detection and/or repair of vulnerabilities in existing systems; the Protection Analysis study was the most influential of these efforts.
The Protection Analysis (PA) study [101] attempted to break the operating system protection problem into smaller, more manageable pieces. The investigators hoped that this would reduce the expertise required of individuals working on operating systems. The study aimed at development of techniques that would have an impact within 10 years. It developed a general strategy, called pattern-directed protection evaluation, and applied it to several operating systems. In one case, the investigators found previously unknown security vulnerabilities. From this approach grew a classification scheme for vulnerabilities. Neumann's presentation [772] of this study organizes the ten classes of flaws in order to show the connections among the major classes and subclasses of flaws (the italicized names in parentheses are the names used in the original study).
Improper protection domain initialization and enforcement
Improper choice of initial protection domain (domain)
Improper isolation of implementation detail (exposed representations)
Improper change (consistency of data over time)
Improper naming (naming)
Improper deallocation or deletion (residuals)
Improper validation (validation of operands, queue management dependencies)
Improper synchronization
Improper indivisibility (interrupted atomic operations)
Improper sequencing (serialization)
Improper choice of operand or operation (critical operator selection errors)
The investigators identified ten classes of errors and noted that a simple hierarchy could be built; however, the subclasses overlapped. Neumann's reorganization eliminated the overlap and is conceptually simpler than the original.
The first class is improper protection domain initialization and enforcement; it includes security flaws arising from initialization of the system or programs and enforcement of the security requirements. For example, when a system boots, the protection modes of the file containing the identifiers of all users logged in can be altered by any user. Under most security policies, the initial assignment of protections is incorrect, and hence a vulnerability exists. The subclass in which this particular flaw lies is improper choice of initial protection domain, which includes any flaw related to an initial incorrect assignment of privileges or of security and integrity classes, especially when that flaw allows untrusted users to manipulate security-critical data.
Improper protection flaws often arise when an abstraction is mapped into an implementation. The covert timing channel in the IBM KVM/370 system (see the example that begins on page 447) is an example of an improper isolation of implementation detail. This subclass also includes flaws that allow users to bypass the operating system and write directly to absolute I/O locations or to alter data structures in ways that are inconsistent with their functions (for example, altering the rights of a process by writing directly to memory).
Another example of an improper protection flaw can arise when a privileged program needs to open a file after checking that some particular condition holds. The goal of the adversary is to have the privileged program open another file for which the condition does not hold. The attack is an attempt to switch the binding of the name between the check and the open. Figure 23-6 shows an example for the UNIX system [116]. This is an instance of the subclass called improper change. Another instance of this subclass is when some object, such as a parameter, a file, or the binding of a process to a network port, changes unexpectedly.
If two different objects have the same name, a user may access or execute the wrong object. The classic example is the venerable Trojan horse (see Section 22.2): an attacker crafts a program that will copy data to a hidden location for later viewing and then invoke an editor, and gives it the same name as the widely used system editor. Now, a user invoking the editor may get the correct program or may get the bogus editor. Other examples of improper naming arise in networking. The best example occurs when two hosts have the same IP address. Messages intended for one of the hosts may be routed to the other, without any indication to the sender.
Failing to clear memory before it is reallocated, or to clear the disk blocks used in a file before they are assigned to a new file, causes improper deallocation or deletion errors. One example occurs when a program dumps core in a publicly readable file and the core dump contains sensitive information such as passwords.
The second major class of flaws is improper validation. These flaws arise from inadequate checking, such as fingerd's lack of bounds checking (with the results shown in Figure 23-7). A second example occurs in some versions of Secure NIS. By default, that protocol maps the root user into an untrusted user nobody on the theory that the server should not trust any claim to root privileges from remote systems unless the credentials asserting those privileges are cryptographic. If the Secure NIS server is misconfigured so that root has no private key, however, the remote client can claim to be root and supply credentials of the nobody user. The flawed system will determine that it cannot validate root's credentials and will promptly check for nobody's private key (because root is remapped when needed). Because the credentials will be validated, the remote client will be given root privileges [217].
Improper synchronization arises when processes fail to coordinate their activities. These flaws can occur when operations that should be uninterruptable are interrupted (the oxymoron “interrupting atomic operations” is often used to describe this phenomenon), or the flaws can arise when two processes are not synchronized properly. The flaw in the UNIX mkdir command in Version 7 is an example of the first case [989]. That command created directories by executing a privileged operation to create the directory and then giving it to the requester by changing the ownership of the directory. This should be done as a single operation, but in Version 7 UNIX systems two distinct system calls were needed.
mknod("xxx", directory)
chown("xxx", user, group)
If an attacker changed the binding of the name “xxx” to refer to the password file between these calls, the attacker would own that file and so could create and delete accounts with impunity. Thus, such a flaw is an example of improper indivisibility. The second subtype, improper sequencing, arises in at least one one-time password scheme. If the target system can run multiple copies of the server and two users attempt to access the same account, both may be granted access even though the password should be valid for at most one use. Essentially, accesses to the file need to be paired as a read followed by a write; but if multiple copies of the server run, nothing enforces this ordering of access types. This system suffers from improper sequencing.
The last category, improper choice of operand or operation, includes calling of inappropriate or erroneous functions. Examples include cryptographic key generation software calling pseudorandom number generation functions that produce predictable sequences of numbers or sequences of numbers with insufficient randomness. The Kerberos authentication system [306], as well as numerous other security-related programs, have suffered from this problem.
One of the goals of the PA project was to study the automated detection of instances of the aforementioned flaws in operating systems. The pattern-directed protection evaluation approach sprang from the observations that similar protection errors appear in different systems, and in different functional areas of the same system, and that the success of automated searching depends on the specificity with which the targets of the search are described. These observations, and the desire to develop widely applicable search techniques that nonexperts could use, led to the following procedure.
Collect descriptions of protection problems. The project gathered more than 100 security problems from six systems (EXEC-8, GECOS, MULTICS, OS/360, TENEX, and UNIX), not counting minor variations.
Convert these problems to a more formalized notation (called “raw error patterns”). This notation expressed a flaw as a set of conditions, possibly including relations among them. The set's membership was minimal, in that if any of the conditions was removed, the raw pattern no longer represented a security flaw. Complicating this process was a lack of a common vocabulary for describing the features of the system and of the flaw; furthermore, because the flaw depended on the security policy, a single error could produce multiple patterns.
Eliminate irrelevant features and abstract system-specific components into system-independent components. The goal of this step was to generalize the raw pattern so that it was independent of the specific system on which it arose. As an example, files, memory locations, and other data areas can be abstracted into a “memory cell” and the generalized raw patterns can refer to that cell.
Determine which features in the operating system code are relevant to the flaw, and abstract the relevant contexts of those features. These features are expressed independently of the system and are used to construct a pattern from which a search procedure can be derived.
Compare the combination of the relevant features in the operating system and their contexts with generic error patterns. This simply executes the search procedure derived in step 4.
The Protection Analysis project was the first project to explore automatic detection of security flaws in programs and systems. Its methods were not widely used, in part because of the inability to automate part of the procedure, in part because of its complexity, and in part because the procedure for reducing flaws to system-independent patterns was not complete. However, the efficacy of the idea was demonstrated, and the classification scheme of flaws greatly influenced the study of vulnerabilities. The PA project was a milestone in computer security research and was the last published vulnerability study for some time, because efforts were turned toward development of methods that were free of these errors.
In 1992, Landwehr, Bull, McDermott, and Choi [614] developed a taxonomy to help designers and operators of systems enforce security. They tried to answer three questions: how did the flaw enter the system, when did it enter the system, and where in the system is it manifest? They built three different classification systems, one to answer each of the three questions, and classified more than 50 vulnerabilities in these schemes.
The first classification scheme classified vulnerabilities by genesis. The class of inadvertent flaws was broken down using the RISOS categories (except that the incomplete and inconsistent validation classes were merged), and the class of intentional flaws was broken into malicious and nonmalicious flaws. Figure 23-8 summarizes these classes. The investigators felt that because most security flaws were inadvertent, better design and coding reviews could eliminate many of them; but if the flaws were intentional, measures such as hiring more trustworthy designers and programmers and doing more security-related testing would be more appropriate.
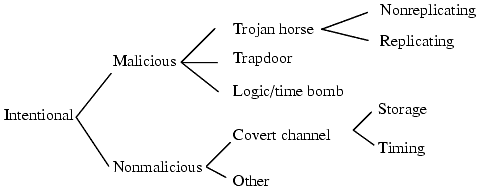
Figure 23-8. NRL taxonomy: flaws by genesis. This diagram shows only the Intentional portion of the taxonomy; the Unintentional portion is similar to the RISOS taxonomy except that the first two RISOS classes are merged.
The second scheme classified vulnerabilities by time of introduction; Figure 23-9 summarizes the subclasses. The investigators wanted to know if security errors were more likely to be introduced at any particular point in the software life cycle in order to determine if focusing efforts on security at any specific point would be helpful. They defined the development phase to be all activities up to the release of the initial version of the software, the maintenance phase to be all activities leading to changes in the software performed under configuration control, and the operation phase to be all activities involving patching of the software and not under configuration control (for example, installing a vendor patch).
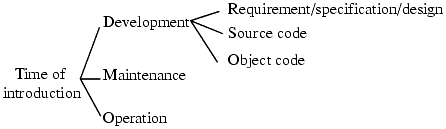
The third scheme classified by location of the flaw; Figure 23-10 summarizes the classes. The intent is to capture where the flaw manifests itself and to determine if any one location is more likely to be flawed than any other. If so, focusing resources on that location would improve security.
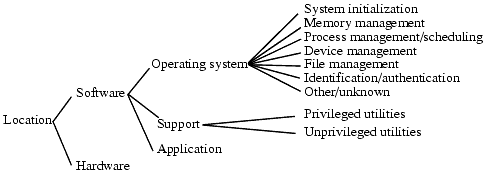
The investigators noted that their sample size (50 flaws) was too small to draw any statistically sound conclusions. However, by plotting the classes against one another on scatter plots, they concluded that with a large enough sample size, an analyst could study the relationships between location and genesis, genesis and time of introduction, and location and time of introduction. The knowledge gained from such a study would help developers concentrate on the most likely places, times, and causes of security flaws.
Landwehr's taxonomy differs from the others in that it focuses on social processes as well as technical details of flaws. In order to classify a security flaw correctly on the time of introduction and genesis axes, either the precise history of the particular flaw must be known or the classifier must make assumptions. This ambiguity is unsettling, because this information is not always available. However, when available, this information is quite useful, and the study was the first to approach the problem of reducing vulnerabilities by studying the environments in which they were introduced.
Aslam [43] developed a classification scheme for security flaws that categorized faults and grouped similar faults together. It differed from both the PA and RISOS studies in that it drew on software fault studies to develop its categories, and it focused specifically on implementation flaws in the UNIX system. Moreover, the categories and classes in both PA and RISOS had considerable overlap; Aslam presented a decision procedure for classifying faults unambiguously. This made it useful for organizing vulnerability data in a database, one of the goals of his study.
Aslam distinguished between coding faults, which were introduced during software development, and emergent faults, which resulted from incorrect initialization, use, or application. For example, a program that fails to check the length of an input string before storing it in an array has a coding fault, but allowing a message transfer agent to forward mail to an arbitrary file on the system is an emergent fault. The mail agent is performing exactly according to specification, but the results produce a dangerous security hole.
The class of coding faults is subdivided into synchronization errors and condition validation errors. Synchronization errors arise when a timing window between two operations allows a fault to be exploited or when operations are improperly serialized. For example, the xterm flaw discussed previously is a classic synchronization error. Condition validation errors arise when bounds are not checked, access rights are ignored, input is not validated, or authentication and identification fails. The finger flaw is an example of this.
Emergent faults are either configuration errors or environment faults. The former arise from installing a program in the wrong place, with the wrong initialization or configuration information, or with the wrong permissions. For example, if the tftp daemon is installed so that any file in the system can be accessed, the installer has caused a configuration error. Environment faults are those faults introduced by the environment as opposed to those from the code or from the configuration. On older UNIX systems, for example, any shell whose name began with “-” was interactive; so an attacker could link a setuid shell script to the name “-gotcha” and execute it, thereby getting a setuid to root shell [103].
Aslam's decision procedure [42] consisted of a set of questions for each class of flaws, the questions being ordered so that each flaw had exactly one classification.
The contribution of Aslam's taxonomy was to tie security flaws to software faults and to introduce a precise classification scheme. In this scheme, each vulnerability belonged to exactly one class of security flaws. Furthermore, the decision procedure was well-defined and unambiguous, leading to a simple mechanism for representing similar flaws in a database.
Consider the flaws described in Section 23.3.1. Both depend on the interaction of two processes: the trusted process (xterm or fingerd) and a second process (the attacker). For the xterm flaw, the attacker deletes the existing log file and inserts a link to the password file; for the fingerd flaw, the attacker writes a name the length of which exceeds the buffer size. Furthermore, the processes use operating system services to communicate. So, three processes are involved: the flawed process, the attacker process, and the operating system service routines. The view of the flaw when considered from the perspective of any of these processes may differ from the view when considered from the perspective of the other two. For example, from the point of view of the flawed process, the flaw may be an incomplete validation of a parameter because the process does not adequately check the parameter it passes to the operating system by means of a system call. From the point of view of the operating system, however, the flaw may be a violable prohibition/limit, because the parameter may refer to an address outside the space of the process. Which classification is appropriate?
Levels of abstraction muddy this issue even more. At the lowest level, the flaw may be, say, an inconsistent parameter validation because successive system calls do not check that the argument refers to the same object. At a higher level, this may be characterized as a race condition or an asynchronous validation/inadequate serialization problem. At an even higher level, it may be seen as an exploitable logic error because a resource (object) can be deleted while in use.
The levels of abstraction are defined differently for every system, and this contributes to the ambiguity. In the following discussion, the “higher” the level, the more abstract it is, without implying precisely where in the abstraction hierarchy either level occurs. Only the relationship, not the distance, of the levels is important in this context.
We now expand on these questions using our two sample flaws.
We begin with the PA taxonomy. From the point of view of the xterm process, the flaw is clearly an improper change flaw because the problem is that between the time of check (access) and the time of use (open), the referent of the name changes. However, with respect to the attacker process, the flaw is an improper deallocation or deletion flaw because something (in this case, the binding between the name and the referent) is being deleted improperly. And from the operating system's point of view, the flaw is an improper indivisibility flaw because the opening of the file should atomically check that the access is allowed.
Reconsider the problem at a higher level of abstraction from the point of view of the operating system. At this level, a directory object is seen simply as an object; deletion and creation of files in the directory are semantically equivalent to writing in the directory, and obtaining file status and opening a file require that the directory be read. In this case, the flaw may be seen as a violation of the Bernstein conditions [84] (requiring no reading during writing, and a single writer), which means that the flaw is one of improper sequencing.
At the abstraction level corresponding to design, the attacking process should not be able to write into the directory in the first place, leading to a characterization of the flaw as one of improper choice of initial protection domain. This is not a valid characterization at the implementation level because both the attacking process and the xterm are being executed by the same user and the semantics of the implementation of the UNIX operating system require that both processes be able to access the same objects in the same way.
At the implementation level, with respect to the xterm process and the RISOS taxonomy, the xterm flaw is clearly an asynchronous validation/inadequate serialization flaw because the file access is checked and then opened nonatomically. From the point of view of the attacker, the ability to delete the file makes the flaw an exploitable logic error as well as a violable prohibition/limit flaw because the attacker is manipulating a binding in the system's domain. And from the operating system's point of view, the flaw is an inconsistent parameter validation flaw because the access check and open use the same parameters, but the objects they refer to are different, and this is not checked.
Interestingly, moving up in the hierarchy of abstractions, the flaw may once again be characterized as a violation of the Bernstein conditions, or the nonatomicity of an operation that should be atomic; in either case, it is an asynchronous validation/inadequate serialization flaw. So the process view prevails.
At the design level, a write being allowed where it should not be is an inadequate identification/authentication/authorization flaw because the resource (the containing directory) is not adequately protected. Again, owing to the nature of the protection model of the UNIX operating system, this would not be a valid characterization at the implementation level.
Hence, this single flaw has several different characterizations. At the implementation level, depending on the classifier's point of view, the xterm flaw can be classified in three different ways. Trying to abstract the underlying principles under one taxonomy places the flaw in a fourth class, and under the other taxonomy, one view (the xterm process view) prevails. Moving up to the design level, a completely different classification is needed. Clearly, the ambiguity in the PA and RISOS classifications makes it difficult to classify flaws with precision.
The classification under the NRL taxonomy depends on whether this flaw was intentional or not; the history is unclear. If it was intentional, at the lowest level, it is an inadvertent flaw of serialization/aliasing; if it was unintentional (because on earlier systems xterm need not be privileged), it is a nonmalicious: other flaw. In either case, at higher levels of abstraction, the classification would parallel that of the RISOS scheme. Given the history, the time of introduction is clearly during development, and the location is in the class support: privileged utilities. So, this taxonomy classifies this particular flaw unambiguously on two axes. However, the third classification is ambiguous even when points of view and levels of abstraction are ignored.
The selection criteria for fault classification in Aslam's taxonomy places the flaw in the object installed with incorrect permissions class from the point of view of the attacking program (because the attacking program can delete the file), in the access rights validation error class from the point of view of the xterm program (because xterm does not properly validate the file at the time of access), and in the improper or inadequate serialization error class from the point of view of the operating system (because the deletion and creation should not be interspersed between the access and open). As an aside, in the absence of the explicit decision procedure, the flaw could also have been placed in a fourth class, race conditions. So, although this taxonomy classifies flaws into specific classes, the class into which a flaw is placed is a function of the decision procedure as well as the nature of the flaw itself. The fact that this ambiguity of classification is not a unique characteristic of one flaw is apparent when we study the second flaw—the fingerd flaw.
With respect to the fingerd process and the PA taxonomy, the buffer overflow flaw is clearly an improper validation flaw because the problem is failure to check parameters, leading to addressing of memory not in its memory space by referencing through an out-of-bounds pointer value. However, with respect to the attacker process (the finger program), the flaw is one of improper choice of operand or operation because an operand (the data written onto the connection) is improper (specifically, too long, and arguably not what fingerd is to be given). And from the operating system's point of view, the flaw is an improper isolation of implementation detail flaw because the user is allowed to write directly into what should be in the space of the process (the return address) and to execute what should be treated as data only.
Moving still higher in the layers of abstraction, the storage space of the return address is a variable or an object. From the operating system's point of view, this makes the flaw an improper change flaw because a parameter—specifically, the return address—changes unexpectedly. From the fingerd point of view, however, the more abstract issue is the execution of data (the input); this is improper validation—specifically, failure to validate the type of the instructions being executed. So, again, the flaw is an improper validation flaw.
At the highest level, the system is changing a security-related value in memory and is executing data that should not be executable. Hence, this is again an improper choice of initial protection domain flaw. But this is not a valid characterization at the implementation level because the architectural design of the system requires the return address to be stored on the stack, just as the input buffer is allocated on the stack, and, because the hardware supporting most versions of the UNIX operating system cannot protect specific words in memory (instead, protection is provided for all words on a page or segment), the system requires that the process be able to write to, and read from, its stack.
With respect to the fingerd process using the RISOS taxonomy, the buffer overflow flaw is clearly an incomplete parameter validation flaw because the problem is failure to check parameters, allowing the buffer to overflow. However, with respect to the fingerd process, the flaw is a violable prohibition/limit flaw because the limit on input data to be sent can be ignored (violated). And from the operating system's point of view, the flaw is an inadequate identification/authentication/authorization flaw because the user is allowed to write directly to what should be in the space of the process (the return address) and to execute what should be treated as data only.
Moving still higher, the storage space of the return address is a variable or an object. From the operating system's point of view, this makes the flaw one of asynchronous validation/inadequate serialization because a parameter—specifically, the return address—changes unexpectedly. From the fingerd point of view, however, the more abstract issue is the execution of data (the input); this is improper validation—specifically, failure to validate the type of the instructions being executed. So the flaw is an inadequate identification/authentication/authorization flaw.
At the highest level, this is again an inadequate identification/authentication/authorization flaw because the system is changing a security-related value in memory and is executing data that should not be executable. Again, owing to the nature of the protection model of the UNIX operating system, this would not be a valid characterization at the implementation level.
The NRL taxonomy suffers from similar problems in its classification by genesis, which—for inadvertent flaws, as this is—uses the RISOS taxonomy. In this case, the time of introduction is clearly during development, and the location is in the support: privileged utilities class. So, this taxonomy classifies this particular flaw unambiguously on two axes. Note that knowledge of the history of the program is needed to perform the classification. A rogue programmer could easily have inserted this vulnerability into a patch distributed to system administrators, in which case the genesis classification would be as a malicious flaw, falling in the trapdoor category, and the time of introduction would be in the operating class.
Finally, under Aslam's taxonomy, the flaw is a boundary condition error from the point of view of the attacking program (because the limit on input data can be ignored) and from the point of view of the xterm program (because the process writes beyond a valid address boundary) and an environment fault from the point of view of the operating system (because the error occurs when the program is executed on a particular machine—specifically, a stack-based machine). As an aside, in the absence of the explicit decision procedure, the flaw could also have been placed in the class of access rights validation errors because the code executed in the input buffer should be data only and because the return address is outside the protection domain of the process and yet is altered by it. So, again, this taxonomy satisfies the decision procedure criterion, but not the uniqueness criterion.
The RISOS classifications are somewhat more consistent among the levels of abstraction because the improper authorization classification runs through the layers of abstraction. However, point of view plays a role here because that classification applies to the operating system's point of view at two levels and to the process view between them. This, again, limits the usefulness of the classification scheme. Because Landwehr's work is based on RISOS, it has similar problems.
Flaw classification is not consistent among different levels of abstraction. Ideally, a flaw should be classified the same at all levels (possibly with more refinement at lower levels). This problem is ameliorated somewhat by the overlap of the flaw classifications because as one refines the flaws, the flaws may shift classes. However, the classes themselves should be distinct; they are not, leading to this problem.
The point of view is also a problem. The point of view should not affect the class into which a flaw falls, but, as the examples show, it clearly does. So, can we use this as a tool for classification—that is, identify flaws on the basis of the three classes into which they fall? The problem is that the classes are not partitions; they overlap, and so it is often not clear which class should be used for a component of the triple.
In short, the xterm and fingerd examples demonstrate weaknesses of the PA, RISOS, NRL, and Aslam classifications: either the classifications of some flaws are not well defined or they are arbitrary and vary with the levels of abstraction and points of view from which the flaws are considered.
Gupta and Gligor [428] developed a formal analysis technique arising from failure to perform adequate checks. This is not a vulnerabilities model, because it presupposes classification—that is, the vulnerabilities that their technique detects are asserted to be vulnerabilities arising from failure to perform adequate checks. As a scheme for classifying flaws, this obviously is not adequate. As a method for detecting previously undetected flaws of the designated class, it is very elegant. We present this model here because it is an excellent example of the use of a classification scheme.
Gupta and Gligor make two hypotheses.
Hypothesis of Penetration Patterns. “[S]ystem flaws that cause a large class of penetration patterns can be identified in system (i.e., TCB) source code as incorrect/absent condition checks or integrated flows that violate the intentions of the system designers.”[1]
If true, this hypothesis implies that an appropriate set of design and implementation principles would prevent vulnerabilities. This leads to the next hypothesis:
Hypothesis of Penetration-Resistant Systems. “[A] system (i.e., TCB) is largely resistant to penetration if it adheres to a specific set of design properties.”[2]
Gupta and Gligor select and formalize several properties, and from those properties derive checks to determine if the system correctly obeys them.
System isolation or tamperproofness, which states that users must not be able to tamper with the system. This encompasses parameter checking at the system boundary, separation of user and system addresses, and allowing entry to the system only at well-defined gates at which parameters and privileges can be validated.
System noncircumventability, which states that the system must check all references to objects.
Consistency of global objects belonging to the system, with respect to both timing and storage.
Elimination of undesirable system and user dependencies, which usually refers to prevention of denial-of-service attacks.
For modeling purposes, Gupta and Gligor focus on the consistency principle and set as their policy that accesses to system entities and functions were allowed only if the conditions for access were validated atomically.
Gupta and Gligor's model focuses on the flow of control during the validation of parameters. Consider the system function rmdir [429]. It takes a single parameter. When invoked, it allocates space for a copy of the parameter on the stack and copies that parameter into the allocated storage. Thus, control flows through three steps: the allocation of storage, the binding of the parameter with the formal argument, and the copying of the formal argument (parameter) to the storage. The failure to check the length of the parameter is the flaw.
The model represents the system as a sequence of states and state transitions. The abstract cell set C = { c1, …, cn } is the set of system entities that holds information. The system function set F = { f1, …, fx } is the set of all system functions that the user may invoke; those involving time delays (such as sleep and pause) are also in the set Z ⊆ F. The system condition set R = { r1, …, rm } is the set of all parameter checks. The information flow set is the set of all possible information flows between pairs of abstract cells and is represented as IF = C × C, where each (ci, cj) means that information flows from ci to cj. Similarly, the call relationship between system functions is denoted by SF = F × F, where each (fi, fj) means that fi calls fj or fi returns to fj. The latter two sets capture the flow of information and control throughout the system.
System-critical functions are functions that the analysts deem critical with respect to penetration; examples include functions that cause time delays (because this may allow a window during which checked parameters are changed) and functions that can cause the system to crash. These functions are represented by the set K = { k1, …, ks }. System entry points are the gates through which user processes invoke system functions; they are represented by the set E = { e1, …, et }.
EXAMPLE: Consider the rmdir function. Figure 23-11 shows the flow of control and information. fname points to a global entity and therefore is a member of C. rmdir is a system function and thus is in F; it is also an entry point and thus is in E. The parameter fname cannot be an illegal address, and the string it points to must be smaller than the space allocated to buf. This means that the predicates islegal(fname) and length(fname) < spacefor(buf) are in R. We deem strcpy to be a system-critical function because it does not check destination bounds or source addresses, so strcpy is in K. Because information flows from fname to buf, the tuple (fname, buf) ∊ IF, and because the rmdir function calls strcpy, (rmdir, strcpy) ∊ SF.
![The integrated flow path for the rmdir system function in one version of the UNIX operating system. From [429], Figure 11(a), p. 178.](http://imgdetail.ebookreading.net/software_development/21/0201440997/0201440997__computer-security-art__0201440997__graphics__23fig11.gif)
Figure 23-11. The integrated flow path for the rmdir system function in one version of the UNIX operating system. From [429], Figure 11(a), p. 178.
The alter set AC = { (c1, R1), … (cn, Rn), }, where Ri ⊆ R, is the set of abstract cells that can be altered and the conditions that must be validated first. The predicate Element(ci, Ri) means that the conditions in Ri must be checked before ci is viewed or altered. The view set VC = { (c1, R'1), … (cn, R'n), }, where R'i ⊆ R, is the set of abstract cells that can be viewed and the conditions that must be validated first. The critical function set KF = { (k1, R''1), … (ks, R''s) } and the entry point set EF = { (e1, R'"1), … (et, R'"t) } are defined analogously.
The model defines three functions for capturing the history of transitions. Each triple in the altered cells set ACS = { (c1, e1, pathcond1), …, } means that ci has been altered by invoking entry point ei, and pathcondi ⊆ IF ∪ SF ∪ R is the sequence (ordered set) of information flows, function flows, and conditions along the path. The viewed cells set VCS = { (c1, e1 , pathcond'1), …, } and the critical functions invoked set KFS = { (k1, e1, pathcond"1), …, } are defined analogously. The triplet (ACS, VCS, KFS) makes up the state of the system.
A state is said to be penetration-resistant if it meets the following three requirements.
For all states (c, e, p) ∊ ACS:
The conditions associated with the entry point e in EF are a subset of the conditions checked in p.
The conditions associated with the cell c ∊ AC are a subset of the conditions checked in p.
There is a subsequence of p that contains the last element of p, contains the conditions in part b, and does not contain any elements (f, g) ∊ SF with f ∊ Z or g ∊ Z.
Requirement 1, but for (c, e, p) ∊ VCS rather than ACS
Requirement 1, but for (k, e, p) ∊ KFS rather than (c, e, p) ∊ ACS
These requirements define a state invariant SI. Intuitively, SI says that if the system function checks all conditions on the global variables and parameters to be altered (requirement 1) or viewed (requirement 2), and all conditions on the system-critical functions (requirement 3), then the system cannot be penetrated using a technique that exploits a failure to check the conditions. Part (a) of each requirement requires checking of conditions on entry. Part (b) requires checking of conditions on the memory locations or system-critical functions. Part (c) requires checking of changes in previously checked parameters as a result of a time delay caused by a function.
State transition rules control the updating of information as the system changes. If τ is a state transition function and Σ = (ACS, VCS, KFS) is the current state, then τ(Σ) = Σ' = (ACS', VCS', KFS'). In this model, τ is alter_cell, view_cell, or invoke_crit_func.
The function alter_cell(c, e, p) checks that c ∊ C, e ∊ E, and p ⊆ IF ∪ SF ∪ R and that requirement 1 holds. If so, ACS' = ACS ∪ { (c, e, p) }, VCS' = VCS, and KFS' = KFS. If not, the function has attempted to move the system into a state that is not penetration-resistant.
The function view_cell(c, e, p) checks that c ∊ C, e ∊ E, and p ⊆ IF ∪ SF ∪ R, and that requirement 2 holds. If so, ACS' = ACS, VCS' = VCS ∪ { (c, e, p) }, and KFS' = KFS. If not, the function has attempted to move the system into a state that is not penetration-resistant.
Finally, the function invoke_crit_func(k, e, p) checks that k∊ K, e ∊ E, and p ⊆ IF ∪ SF ∪ R and that requirement 3 holds. If so, ACS' = ACS, VCS' = VCS, and KFS' = KFS ∪ { (f, e, p) }. If not, the function has attempted to move the system into a state that is not penetration-resistant.
Theorem 23–1. Let the system be in a state V that satisfies the state invariant SI. Then, if a state transition function is applied to V, the resulting state V' will also satisfy SI.
Gupta and Gligor designed and implemented an automated penetration analysis (APA) tool that performed this testing. The primitive flow generator reduces C statements to Prolog facts recording data and control flow information, condition statements, and sequencing information. Two other modules, the information flow integrator and the function flow integrator, integrate execution paths derived from the primitive flow statements to show pertinent flows of information, flows of control among functions, and how the conditions affect the execution paths. The condition set consistency prover analyzes conditions along an execution path and reports inconsistencies. Finally, the flaw detection module applies the Hypothesis of Penetration Patterns by determining whether the conditions for each entry point conform to penetration-resistant specifications.
The Gupta-Gligor theory presents a formalization of one of the classes of vulnerabilities—specifically, inconsistent and incomplete parameter validation (possibly combined with improper change). The formalization builds preconditions for executing system functions; the APA tool verifies that these preconditions hold (or determines that they do not).
Whether or not this technique can be generalized to other classes of flaws is an open question. In particular, the technique is extremely sensitive to the level of detail at which the system is analyzed and to the quality of the specifications describing the policy. This work is best seen as a foundation on which future automation of penetration analysis may build and a reinforcement of the idea that automated tools can aid an analyst in uncovering system vulnerabilities.
Could the theory be generalized to classify vulnerabilities? The model assumes an existing classification scheme (specifically, improper or inadequate checks) and describes a technique and a tool for detecting vulnerabilities of this class. Were the purpose of the model to classify vulnerabilities (rather than to detect them), basing classification on the nature of the tools that detect them is tautological and a single vulnerability could fall into several classes depending on how the tool was crafted. Hence, such an (inverted) application of the Gupta-Gligor approach would suffer from the same flaws that plague the other classification schemes. However, the purpose of the model is to detect, not to classify, vulnerabilities of one specific type.
As the Internet has grown, so has connectivity, enabling attackers to break into an increasing number of systems. Often very inexperienced attackers appear to have used extremely sophisticated techniques to break into systems, but on investigation it can be seen that they have used attack tools. Indeed, attack tools are becoming very widespread, and most systems cannot resist a determined attack.
In the past, attention was focused on building secure systems. Because of the large number of nonsecure systems in use today, it is unrealistic to expect that new, secure systems will be deployed widely enough to protect the companies and individuals connected to the Internet. Instead, existing systems will be made more secure, and as vulnerabilities are found they will be eliminated or monitored. The vulnerability models discussed in this chapter guide us in improving the software engineering cycle and in reducing the risk of introducing new vulnerabilities, and penetration analyses enable us to test admittedly nonsecure systems to determine whether or not they are sufficiently secure for the uses to which they are put.
Research in the area of vulnerability analysis focuses on discovery of previously unknown vulnerabilities and quantification of the security of systems according to some metric. All agree that the security of existing systems is poor—but how poor is another matter.
Adaptive security springs from fault-tolerant methods. When a system is under attack, security mechanisms limit the actions of suspect processes. When a system is not under attack, less stringent controls are applied. Under what conditions should one begin adapting in order to minimize the impact of the attack while still maximizing openness? Do the attack-detecting sensors themselves introduce vulnerabilities? Minimizing false alarms (and thus unnecessary impact on system performance) is a difficult problem.
The best test of a model is how well it describes real-world phenomena. Ideally, a vulnerability model can describe all the security holes in a system and can provide guidance on how to verify or refute the existence of those holes. Most vulnerability models are based on formal methods. Those methods are adapted to systems in which security policies cannot be rigorously defined. One research issue is how to retain enough formalism to prove that a model works and yet eliminate any formalism that is not relevant to the existing system.
Vulnerability databases add to this question. They provide much of the historical basis for the first step in the Flaw Hypothesis Methodology. The databases support research on characterization of vulnerabilities. The data collected about the vulnerabilities varies depending on the purpose of the database. Sharing data raises problems of trust and interpretation. Two workshops on sharing information from vulnerability databases concluded that a central database is impractical and emphasized the need to share data. One interesting aspect of such sharing is the provision of a common numbering scheme. Each database uses its own scheme but also includes the number from the common enumeration scheme. Researchers at MITRE have pioneered a numbering scheme called Common Vulnerabilities and Exposures (CVE), which provides each vulnerability with a unique number. Vendors and vulnerability databases can use these numbers to correlate vulnerabilities. What constitutes a “vulnerability” for the purposes of this scheme is vague. Currently, an editorial board determines whether a proposed vulnerability is one vulnerability, many vulnerabilities, a repeat of a vulnerability that has already been numbered, or not a vulnerability.
Finally, the precise definitions of “attack” and “vulnerability” are under study. Although the current definitions have much in common, the various nuances of each paper and study color its precise meaning. Rigorous definitions of these two terms would lead to a clearer understanding of how and why systems fail.
Descriptions of vulnerabilities usually are anecdotal or are found through informal sources (such as the Internet). Papers describing security incident handling, security incident response, and security tools [192, 737, 860, 973] often describe both successful and unsuccessful attacks. Some books and papers [13, 458, 784] describe attack tools in detail. Others [576, 847] describe techniques for attacking systems. Parker [799] outlines several techniques that unsuccessful criminals have used.
Several papers discuss analyses of programs and systems for vulnerabilities. One paper [117] describes a syntactic approach to finding potential race conditions. Others [241, 716, 1026] discuss buffer overflows. The use of fault injection to find potential vulnerabilities has also been discussed [390, 1020].
The Common Vulnerabilities and Exposures list is discussed in two papers [195, 657]
1: | Classify the following vulnerabilities using the RISOS model. Assume that the classification is for the implementation level. Justify your answer.
|
2: | Classify the vulnerabilities in Exercise 1 using the PA model. Assume that the classification is for the implementation level. Justify your answer. |
3: | The C shell does not treat the IFS variable as a special variable. (That is, the C shell separates arguments to commands by white spaces; this behavior is built in and cannot be changed.) How might this affect the loadmodule exploitation? |
4: | A common error on UNIX systems occurs during the configuration of bind, a directory name server. The time-to-expire field is set at 0.5 because the administrator believes that this field's unit is minutes (and wishes to set the time to 30 seconds). However, bind expects the field to be in seconds and reads the value as 0—meaning that no data is ever expired.
|
5: | Can the UNIX Bourne shell variable HOME, which identifies the home directory of a user to programs that read start-up files from the user's home directory, be used to compromise a system? If so, how? |
6: | An attacker breaks into a Web server running on a Windows 2000–based system. Because of the ease with which he broke in, he concludes that Windows 2000 is an operating system with very poor security features. Is his conclusion reasonable? Why or why not? |
7: | Generalize the vulnerability described in Section 23.2.6 in order to suggest other ways in which the system could be penetrated. |
8: | Generalize the example in Section 23.2.7 in order to describe other weaknesses that the security of the computer system might have. |
9: | Why might an analyst care how similar two vulnerabilities are? |
10: | One expert noted that the PA model and the RISOS model are isomorphic. Show that the PA vulnerability classifications correspond to the RISOS vulnerability classes and vice versa. |
11: | The NRL classification scheme has three axes: genesis, time of introduction, and location. Name two other axes that would be of interest to an analyst. Justify your answer. |
12: | In the NRL classification scheme for the “time of introduction” axis, must the development phase precede the maintenance and operation phases, and must the maintenance phase precede the operation phase? Justify your answer. |
13: | In the NRL classification scheme for the “genesis” axis, how might one determine whether a vulnerability is “malicious” or “nonmalicious”? |
14: | In the NRL classification scheme for the “genesis” axis, can the classes “Trojan horse” and “covert channel” overlap? Justify your answer. If your answer is yes, describe a Trojan horse that is also a covert channel or vice versa. |
15: | Aslam's classification scheme classifies each vulnerability into a single category based on a decision tree that requires “yes” or “no” answers to questions about the vulnerability. A researcher has suggested replacing the tree with a vector, the components of which correspond to questions about the vulnerability. A “1” in the vector corresponds to a “yes” answer to the question; a “0” corresponds to a “no” answer. Compare and contrast the two approaches. |
16: | For the fingerd security hole to be exploited, certain conditions must hold. Based on the discussion in Section 23.3.1, enumerate these conditions. |
17: | For the xterm security hole to be exploited, certain conditions must hold. Based on the discussion in Section 23.3.1, enumerate these conditions. |
18: | Use Gupta and Gligor's technique to analyze a UNIX kernel for security flaws in the open system call. Check for problems with the first argument, which is a character string. |
19: | Generalize Gupta and Gligor's technique to extend to integer values. You should check for overflow (both negative and positive).
|
20: | Perform a penetration test on a system after you obtain authorization to do so. Apply the Flaw Hypothesis Methodology to obtain a meaningful assessment of the system's security. |