
TROILUS: This is the monstruosity in love, lady; thatthe will is infinite and the execution confin'd; thatthe desire is boundless and the act a slave to limit. | ||
| --Troilus and Cressida III, ii, 82–84. | ||
When a program executes, it interacts with its environment. The security policy allows some interactions and disallows others. The confinement problem deals with prevention of processes from taking disallowed actions. Beginning with Lampson's characterization of this problem, this chapter continues with a discussion of methods for confinement such as virtual machines and sandboxes. It concludes with a discussion of covert channels. This chapter focuses on confinement. Chapter 22, “Malicious Logic,” discusses tools and techniques used to breach confinement.
Consider a client and a server. When the client issues a request to the server, the client sends the server some data. The server then uses the data to perform some function and returns a result (or no result) to the client. Access control affects the function of the server in two ways.
The server must ensure that the resources it accesses on behalf of the client include only those resources that the client is authorized to access.
The server must ensure that it does not reveal the client's data to any other entity not authorized to see the client's data.
The first requirement represents the goal of the service provider. That goal is to prevent the client from sending messages to the server that cause it to access, alter, transmit, or consume resources that the client is not authorized to access, alter, transmit, or consume. The second requirement represents the goal of the service user. That goal is to prevent the server from transmitting confidential information to the service provider. In both cases, the server must be confined to accessing only a specific set of resources.
Lampson [609] calls this the confinement problem.
Definition 17–1. The confinement problem is the problem of preventing a server from leaking information that the user of the service considers confidential.
One characteristic of processes that do not leak information comes from the observation that a process must store data for later retrieval (the leaking). A process that does not store information cannot leak it. However, in the extreme, such processes also cannot perform any computations, because an analyst could observe the flow of control (or state of the process) and from that flow deduce information about the inputs. This leads to the observation that a process that cannot be observed and cannot communicate with other processes cannot leak information. Lampson calls this total isolation.
In practice, achieving total isolation is difficult. The processes to be confined usually share resources such as CPUs, networks, and disk storage with other, unconfined processes. The unconfined processes can transmit information over those shared resources.
Definition 17–2. A covert channel is a path of communication that was not designed to be used for communication.
Confinement is transitive. Assume that a process p is confined to prevent leakage. If it invokes a second process q, then q must be similarly confined or q could leak the information that p passes.
Definition 17–3. The rule of transitive confinement states that if a confined process invokes a second process, the second process must be as confined as the caller.
Confinement is a mechanism for enforcing the principle of least privilege (see Section 13.2.1). A properly confined process cannot transmit data to a second process unless the transmission is needed to complete their task. The problem is that the confined process needs access to the data to be transmitted and so the confinement must be on the transmission, not on the data access. To complicate matters, the process may have to transmit some information to the second process. In this case, the confinement mechanism must distinguish between transmission of authorized data and transmission of unauthorized data.
The combination of these problems illustrates the difficulty of preventing leakage. The dilemma is that modern computers are designed to share resources, and yet by the act of sharing they create channels of communication along which information can be leaked.
Lipner [635] examines the problem from a policy and modeling aspect. He considers two types of covert channels. The first involves the use of storage to transmit information. If a model correctly describes all ways in which information can be stored and read, then the model abstracts both legitimate and covert channels along which information can flow. The model constrains all accesses to storage. The only accesses allowed are those authorized by the policy, so the flows of information are legitimate. However, if the model does not capture all such flows, then unauthorized flows, or covert channels, arise.
Lipner then notes that all processes can obtain at least a rough idea of time. This makes time a communication channel. A program can “read” time by checking the system clock or (alternatively) by counting the number of instructions it has executed during a period of wall clock time. A program can “write” time by executing a set number of instructions and stopping, allowing another process to execute. This shared channel cannot be made exclusive unless a process does not share the computer with another process, which suggests isolation as a remedy.
Kocher's timing attacks on cryptosystems illustrate this problem [586]. Kocher notes that the instructions executed by implementations of cryptosystems depend on the setting of bits in the key. For example, the algorithm in Figure 17-1 implements a fast modular exponentiation function. If a bit is 1, two multiplications occur; otherwise, one multiplication occurs. The extra multiplication takes extra time. Kocher determines bits of the confidential exponent by measuring computation time.
Example 17-1. A fast modular exponentiation routine. This routine computes x = az mod n. The bits of z are zk–1, . . . ,z0.
x := 1; atmp := a; for i := 0 to k-1 do begin if zi = 1 then x := (x * atmp) mod n; atmp := (atmp * atmp) mod n; end; result := x;
We explore the mechanism of isolation first. Then we examine covert channels in more detail and discuss other approaches to analyzing them, including techniques for identifying covert channels and isolating them.
Systems isolate processes in two ways. In the first, the process is presented with an environment that appears to be a computer running only that process or those processes to be isolated. In the second, an environment is provided in which process actions are analyzed to determine if they leak information. The first type of environment prevents the process from accessing the underlying computer system and any processes or resources that are not part of that environment. The second type of environment does not emulate a computer. It merely alters the interface between the existing computer and the process(es).
The first type of environment is called a virtual machine.
Definition 17–4. A virtual machine is a program that simulates the hardware of a (possibly abstract) computer system.
A virtual machine uses a special operating system called a virtual machine monitor to provide a virtual machine on which conventional operating systems can run. Chapter 33 discusses virtual machines in more detail.
The primary advantage of a virtual machine is that existing operating systems do not need to be modified. They run on the virtual machine monitor. The virtual machine monitor enforces the desired security policy. This is transparent to the user. The virtual machine monitor functions as a security kernel.
In terms of policy, the virtual machine monitor deals with subjects (the subjects being the virtual machines). Even if one virtual machine is running hundreds of processes, the virtual machine monitor knows only about the virtual machine. Thus, it can apply security checks to its subjects, and those controls apply to the processes that those subjects are running. This satisfies the rule of transitive confinement.
Because virtual machines provide the same interface for communication with other virtual machines that computers provide, those channels of communication can be controlled or severed. As mentioned earlier, if a single host runs multiple virtual machines, those virtual machines share the physical resources of the host on which they run. (They may also share logical resources, depending on how the virtualizing kernel is implemented.) This provides a fertile ground for covert channels, a subject explored in Section 17.3.
A playground sandbox provides a safe environment for children to stay in. If the children leave the sandbox without supervision, they may do things they are not supposed to do. The computer sandbox is similar. It provides a safe environment for programs to execute in. If the programs “leave” the sandbox, they may do things that they are not supposed to do. Both types of sandboxes restrict the actions of their occupants.
Definition 17–5. A sandbox is an environment in which the actions of a process are restricted according to a security policy.
Systems may enforce restrictions in two ways. First, the sandbox can limit the execution environment as needed. This is usually done by adding extra security-checking mechanisms to the libraries or kernel. The program itself is not modified. For example, the VMM kernel discussed earlier is a sandbox because it constrains the accesses of the (unmodified) operating systems that run on it. The Java virtual machine is a sandbox because its security manager limits access of downloaded programs to system resources as dictated by a security policy [170].
The second enforcement method is to modify the program (or process) to be executed. Dynamic debuggers [8, 326, 442, 962] and some profilers [108] use this technique by adding breakpoints to the code and, when the trap occurs, analyzing the state of the running process. A variant, known as software fault isolation [934, 1028], adds instructions that perform memory access checks or other checks as the program runs, so any attempt to violate the security policy causes an error.
Like a virtual machine monitor, a sandbox forms part of the trusted computing base. If the sandbox fails, it provides less protection than it is believed to provide. Hence, ensuring that the sandbox correctly implements a desired security policy is critical to the security of the system.
Covert channels use shared resources as paths of communication. This requires sharing of space or sharing of time.
Definition 17–6. A covert storage channel uses an attribute of the shared resource. A covert timing channel uses a temporal or ordering relationship among accesses to a shared resource.
A covert timing channel is usually defined in terms of a real-time clock or a timer, but temporal relationships sometimes use neither. An ordering of events implies a time-based relationship that involves neither a real-time clock nor a timer.
A second property distinguishes between a covert channel that only the sender and receiver have access to and a covert channel that others have access to as well.
Definition 17–7. A noiseless covert channel is a covert channel that uses a resource available to the sender and receiver only. A noisy covert channel is a covert channel that uses a resource available to subjects other than the sender and receiver, as well as to the sender and receiver.
The difference between these two types of channels lies in the need to filter out extraneous information. Any information that the receiver obtains from a noiseless channel comes from the sender. However, in a noisy channel, the sender's information is mixed with meaningless information, or noise, from other entities using the resource. A noisy covert channel requires a protocol to minimize this interference.
The key properties of covert channels are existence and bandwidth. Existence tells us that there is a channel along which information can be transmitted. Bandwidth tells us how rapidly information can be sent. Covert channel analysis establishes both properties. Then the channels can be eliminated or their bandwidths can be reduced.
Covert channels require sharing. The manner in which the resource is shared controls which subjects can send and receive information using that shared resource. Detection methods begin with this observation.
Models such as the Bell-LaPadula Model represent information transfer using read and write operations and develop controls to restrict their use. Viewing “information transfer” more broadly, one can consider any operation that a second process can detect as being a write command. This immediately leads to the use of an interference model to detect these covert channels. If a subject can interfere with another subject in some way, there is a covert channel, and the nature of the interference identifies the channel.
Theorem 17–1. Let Σ be the set of states of the system. A specification is noninterference-secure if, for each subject s at security level l(s), there exists an equivalence relation ≡: Σ × Σ such that
for σ1, σ2 ∊ Σ, when σ1 ≡ σ2, σ1.v(s) = σ2.v(s)
for σ1, σ2 ∊ Σ and any instruction i, when σ1 ≡ σ2, A(i, σ1) ≡ A(i, σ2)
for σ ∊ Σ and instruction i, if π(i, l(s)) is empty, A(π(i, l(s)), σ).v(s) = σ.v(s).
Intuitively, this theorem states that the system is noninterference-secure if equivalent states have the same view for each subject, the view remains the same when any instruction is executed, and instructions from higher-level subjects do not affect the state from the viewpoint of lower-level subjects.
The designers looked at several parts of the SAT specification. The relevant parts were for the object creation instruction and the readable object set.
Let s be a subject with security level l(s), and let o be an object with security level l(o) and type τ(o). Let σ be the current state. The set of existing objects is listed in a global object table T(σ). Then the object creation specification object_create is as follows.
Specification 17–1.
[σ' = object_create(s, o, l(o), τ(o), σ) ∧ σ' ≠ σ' ⇔ [o ∉ T(σ) ∧ l(s) ≤ l(o)]
The object is created if it does not exist and if the subject's clearance is sufficient to permit the creation of an object at the desired level.
The readable object set contains the set of existing objects that the subject could read in at the current, or at least at a future, state. We ignore discretionary controls for this predicate. Let s be a subject and o an object. Let l and T be as before, and let can_read(s, o, σ) be true if, in state σ, o is of a type to which s can apply the read operation (ignoring permissions). Then:
Specification 17–2.
o ∉ readable(s, σ) ⇔ [o ∉ T(σ) ∨ ¬(l(o) ≤ l(s)) ∨ ¬(can_read(s, o, σ))]
An object is not in the set if it does not exist, if the subject's security level does not dominate the object's security level, or if the subject is of the wrong type to read the object (or vice versa).
Because the SAT system model was tranquil, adding an object to the readable set requires a new object to be created. Let s' be the subject that creates it. Then:
Specification 17–3.
[o ∉ readable(s, σ) ∧ o ∊ readable(s, σ')] ⇔
[σ' = object_create(s', o, l(o), τ(o), σ) ∧ o ∉ T(σ) ∧
l(s') ≤ l(o) ≤ l(s) ∧ can_read(s, o, σ')]
For an object to be added to a subject's readable set, it initially cannot exist, it must first be created, and then its levels and discretionary access controls must be set appropriately.
Consider two states σ1 and σ2. These states differ only in that an object o exists in state σ2 and not in σ1 and that in state σ2, l(s) does not dominate l(o). By Specification 17–2, o ∉ readable(s, σ1) (because o does not exist) and o ∉ readable(s, σ2) (because ¬(l(o) ≤ l(s))). Thus, σ1 ≡ σ2. Now, s issues a command to create o with l(o) = l(s) and of a type that it can read (that is, can_read(s, o, σ1') is true, where σ1' is the state after object_create(s, o, σ1)). By Specification 17–1, σ1' differs from σ1 by the addition of o to the table T(σ1). This new entry would satisfy can_read(s, o, σ1' ) and l(s') ≤ l(o) ≤ l(s), where s' is the subject that created the object.
Next, because o exists in σ1, σ2' = object_create(s', o, σ2) = σ2. So, σ1 ≡ σ2 is true, but A(object_create(s', o, σ1), σ1) ≡ A(object_create(s', o, σ2), σ2) is false. This means that condition 2 in Theorem 17–1 is false. Thus, Theorem 17–1 does not apply.
Exploiting this covert channel is straightforward. To send a 1, the subject at a high level creates an object at a high level. The recipient (a second subject) tries to create the same object but at a low level. The creation fails, but no indication of the failure is given. The second subject then gives a different subject type permission to read and write the object. It writes a 1 to the object and reads the object. The read returns nothing. To send a 0, the subject at the high level creates nothing, but the subject at the low level follows the same steps. In this case, the read returns a 1.
Because noninterference techniques reason in terms of security levels and not in terms of time, these techniques are most useful for analyzing covert storage channels.
Kemmerer introduced a methodology for identifying shared channels and determining in what ways they are shared [557, 558]. First, the analyst identifies all shared resources and the attributes of those resources that are visible to subjects. These attributes make up the rows of the matrix. Next, the analyst determines the operations that either reference (read) or modify (alter) the attributes. These operations make up the columns of the matrix. The contents of each element of the matrix indicate whether the operation references, modifies, or both references and modifies the attribute.
The next step is to determine whether any of these shared resources provide covert channels. The following properties must hold for a covert storage channel to exist.
Both the sending and receiving processes must have access to the same attribute of a shared object.
The sending process must be able to modify that attribute of the shared object.
The receiving process must be able to reference that attribute of the shared object.
A mechanism for initiating both processes, and properly sequencing their respective accesses to the shared resource, must exist.
Hence, we need to consider only those attributes with both “R” and “M” in their rows.
The requirements for covert timing channels are similar to those for covert storage channels.
Both the sending and receiving processes must have access to the same attribute of a shared object.
Both the sending and receiving processes must have access to a time reference, such as a real-time clock, a timer, or the ordering of events.
The sending process must be able to control the timing of the detection of a change in the attribute by the receiving process.
A mechanism for initiating both processes, and properly sequencing their respective accesses to the shared resource, must exist.
As with covert storage channels, we need to consider only those attributes with both “R” and “M” in their rows.
Kemmerer demonstrates the use of the shared resource matrix (SRM) methodology at various stages of the software life cycle ranging from English requirements and formal specifications to implementation code. Its flexibility is one of its strengths.
The SRM methodology was used to analyze the Secure Ada Target [435, 436]. The participants constructed the matrix manually from a flow analysis of the model. From the transitive closure of the elements of the matrix, two potential covert channels were found, one using the assigned level attribute of an object and the other using the assigned type attribute.
The SRM methodology is comprehensive but incomplete. In particular, it does not address the problem of determining what the shared resources are and what the primitives used to access them are. In some ways, this is appropriate, because the techniques used differ at the different steps of the software life cycle. The generality of the SRM method makes it suitable for use throughout the life cycle. However, the absence of detail makes its application sensitive to the analysis of the particular stage of development: specification, design, or implementation. The next approach looks at these issues at the implementation, or source code, level.
The methods of Denning and Denning and of Reitman and Andrews discussed in Sections 16.3.3 and 16.3.4 can uncover covert channels. When an exception occurring depends on the value of a variable, a covert channel exists because information leaks about the value in that variable. Synchronization and interprocess communication primitives also cause problems because one process can control when it sends a message or blocks to receive a message, something the second process can typically detect. This differs from shared variables, which are legitimate channels of information flow. The covert channel occurs because of timing considerations or shared resources (such as a file system).
Tsai, Gligor, and Chandersekaran [1002] have developed a method for identifying covert storage channels in source code. The method asserts that covert (storage) channels arise when processes can view or alter kernel variables. It focuses on identifying variables that processes can refer to directly or that processes can view or alter indirectly (through system calls).
The first step is to identify the kernel functions and processes for analysis. The processes involved are those that function at the highest level of privilege and perform actions on behalf of ordinary users. Processes executing on behalf of administrators are ignored because administrators have sufficient privilege to leak information directly; they do not need to use covert channels. System calls available only to the administrator are ignored for the same reason.
The second step identifies the kernel variables that user processes can read and/or alter. The process must be able to control how the variable is altered and be able to detect that the variable has been altered. For example, if a system call assigns the fixed value 7 to a particular variable whenever that system call is made, the process cannot control how that variable is altered. Similarly, error conditions affect visibility. For example, if the variable count being zero causes an error, the state of count can be determined from the setting of the error indicator: if it is set on exit, count is 0; otherwise, it is nonzero. The specific criteria are as follows.
The value of a variable is obtained from a system call.
A calling process can detect at least two different states of that variable.
The detection of such variables requires that the data flow through the kernel be analyzed to ensure that all dependencies (both data and functional) are detected. If the variable is a record or structure, the analysis process must consider changes in its attributes. If the variable is an array of records, changes both in the attributes of each element and in the array as a whole affect the analysis. Finally, the analysis must consider pointers to the variables in question.
Example 17-2. Visibility of variables. The code fragments represent the body of system calls. The return value is the value returned by the system call. At the left, x is visible directly. The value of y at the right is not directly visible, but its state can be deduced from the returned value.
x := func(abc, def); y := func(abc, def); if x = 0 then if y = 0 then x := x + 10; z := 1; return x; else z := 0; return z;
The third step is to analyze these shared variables, looking for covert channels. The analysis here is similar to the analysis in the SRM method. The results are given in terms of the primitives that alter or view the shared variables. Primitives associated with variables that can only be altered or only be viewed are discarded. Complicating this process is the observation that many variables may be associated with a single covert channel, or one variable with many covert channels.
The resulting primitives are then compared with the model of nondiscretionary access control under the assumption that the recipient's security clearance does not dominate the sender's.
An analysis of the Secure Xenix kernel using this method found two kernel variables involved in covert channels. Four classes of generic covert channels were identified, including an unexploitable class that could be exploited only when the system failed (one such channel caused a reboot) and a noiseless channel that could not be eliminated without discarding the semantics of regular Xenix. The analysts also used the SRM method to analyze the top-level specification of Secure Xenix and noted that it failed to detect several covert channels. (This was expected, because the top-level specifications did not specify the data structures in which the covert channels were found.)
Tsai, Gligor, and Chandersekaran conclude that the shared variables could have been detected by informal code analysis but claim it unlikely that informal analysis would make all the associations of those variables with system calls. Hence, informal analysis would have missed several covert channels that their methodology found.
Porras and Kemmerer have devised an approach to representing security violations that spring from the application of fault trees [812]. They model the flow of information through shared resources with a tree. The paths of flow are identified in this structure. The analyst determines whether each flow is legitimate or covert.
A covert flow tree is a tree-structured representation of the sequence of operations that move information from one process to another. It consists of five types of nodes.
Goal symbols specify states that must exist for the information to flow. There are several such states:
A modification goal is reached when an attribute is modified.
A recognition goal is reached when a modification of an attribute is detected.
A direct recognition goal is reached when a subject can detect the modification of an attribute by referencing it directly or calling a function that returns it.
An inferred recognition goal is reached when a subject can detect the modification of an attribute without referencing it directly and without calling a function that references the attribute directly. For example, the subject may call a function that performs one of two computations depending on the value of the attribute in question.
An inferred-via goal is reached when information is passed from one attribute to other attributes using a specified primitive operation (such as a system call).
A recognize-new-state goal is reached when an attribute that was modified when information was passed using it is specified by an inferred-via goal. The value need not be determined, but the fact that the attribute has been modified must be determined.
An operation symbol is a symbol that represents a primitive operation. The operation symbols may vary among systems if they have different primitive operations.
A failure symbol indicates that information cannot be sent along the path on which it lies. It means that the goal to which it is attached cannot be met.
An and symbol is a goal that is reached when both of the following hold for all children:
If the child is a goal, then the goal is reached.
The child is an operation.
An or symbol is a goal that is reached when either of the following holds for any children:
If the child is a goal, then the goal is reached.
The child is an operation.
Constructing the tree is a three-step process. To make the steps concrete, we present a simple set of operations and then ask if they can create a covert channel.
Assuming that processes are not allowed to communicate with one another, the reader is invited to try to find a covert storage channel.
The first step in constructing a covert flow tree is to determine what attributes (if any) the primitive operations reference, modify, and return.
The second step begins with the goal of locating a covert storage channel that uses some attribute. The analyst constructs the covert flow tree. The type of goal controls the construction, as follows.
The topmost goal requires that the attribute be modified and that the modification be recognized. Hence, it has one child (an and symbol), which in turn has two children (a modification goal symbol and a recognition goal symbol).
A modification goal requires some primitive operation to modify the attribute. Hence, it has one or child, which has one child operation symbol per operation for all operations that modify the attribute.
A recognition goal requires that a subject either directly recognize or infer a change in an attribute. It has an or symbol as its child. The or symbol has two children, one a direct recognition goal symbol and the other an inferred recognition goal symbol.
A direct recognition goal requires that an operation access the attribute. Like the modification goal, it has one or child, and that child in turn has one child operation symbol for each operation that returns the attribute. If no operation returns the attribute, a failure symbol is attached.
An inferred recognition goal requires that the modification be inferred on the basis of one or more other attributes. Hence, it has one child, an or symbol, which has one child inferred-via symbol for each operation that references an attribute and that modifies some attribute (possibly the same one that was referenced).
An inferred-via goal requires that the value of the attribute be inferred via some operation and a recognition of the new state of the attribute resulting from that operation. Hence, it has one child (an and symbol), which has two children (an operation symbol representing the primitive operation used to draw the inference and a recognize-new-state goal symbol).
A recognize-new-state goal requires that the value of the attribute be inferred via some operation and a recognition of the new state of the attribute resulting from that operation. The latter requires a recognition goal for the attribute. So, the child node of the recognize-new-state goal symbol is an or symbol, and for each attribute enabling the inference of the modification of the attribute in question, the or symbol has a recognition goal symbol child.
Tree construction ends when all paths through the tree terminate in either an operation symbol or a failure symbol. Because the construction is recursive, the analyst may encounter a loop in the tree construction. Should this happen, a parameter called repeat defines the number of times that the path may be traversed. This places an upper bound on the size of the tree.
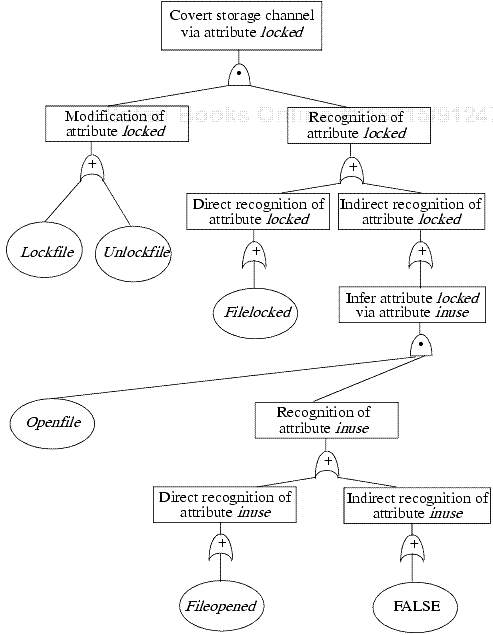
EXAMPLE: We build the covert flow tree for the attribute locked in our previous two examples. The goal state is “covert storage channel via attribute locked.” The and node beneath it has two children, “modification of attribute locked” and “recognition of attribute locked.” At this point, the tree looks like this:
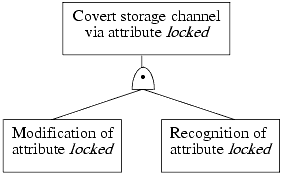
From the table in the preceding example, the operations Lockfile and Unlockfile modify the attribute locked. So that branch of the tree becomes:
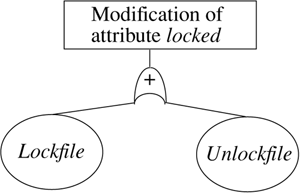
The recognition branch expands into direct recognition and inferred recognition branches. The direct recognition branch has an and with one child, Filelocked, because Filelocked returns the value of the locked attribute. The inferred recognition branch has an or child with one child, an “inferred-via” node that infers locked from inuse. This branch comes from comparing the “reference” row of the table in the preceding example with the “modify” row. If an operation references the locked attribute and modifies another attribute, inference is possible (assuming that the modification can be detected). At this point, the recognition branch looks like this:
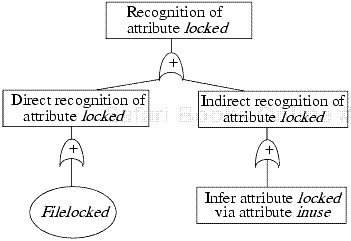
Inferring that the attribute locked has changed from the attribute inuse requires the operation Openfile. After that operation, the recognize-new-state goal represents the change in the attribute inuse:
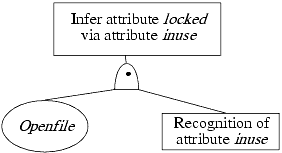
This in turn requires the recognition of modification of the attribute inuse (hence, a recognition state). The operation Fileopened recognizes this change directly; nothing recognizes it indirectly. The result is:
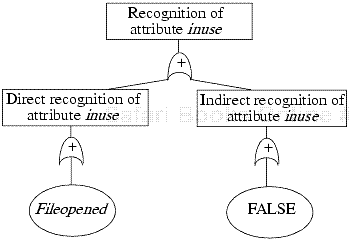
Figure 17-3 shows the full covert flow tree.
The analyst now constructs two lists. The first list contains sequences of operations that modify the attribute, and the second list contains sequences of operations that recognize modifications in the attribute. A sequence from the first list followed by a sequence from the second list is a channel along which information can flow. The analyst examines these channels to determine which are covert.
The shared resource matrix model and covert flow trees spring from the idea of examining shared resources for modification and reference operations, and both can be used at any point within the software development life cycle. One advantage of covert flow trees over the SRM model is that the former identifies explicit sequences of operations that cause information to flow from one process to another. The latter identifies channels rather than sequences of operations. In comparisons involving file system access operations and the Secure Ada Target, the covert flow tree method identified sequences of operations corresponding to the covert storage channels found by the SRM method and the noninterference method, as well as one not found by the other two.
How dangerous is a covert channel? Policy and operational issues come into play, and we do not consider those issues here. We assume that whatever security policy is in force deems covert channels a serious problem. However, the amount of information that can be transmitted over a covert channel affects how serious a problem that channel presents. If the rate were one bit per hour, the channel would be harmless in most circumstances. If the rate were 1,000,000 bits per second, the channel would be dangerous. Following Millen [710], we examine the problem of measuring this bandwidth.
We begin by asking when the bandwidth is 0. Suppose Alice wants to send Bob information over a covert channel. Alice feeds her input into a machine that passes the output to Bob. We define the following random variables.
W represents the inputs to the machine.
A represents the inputs from Alice.
V represents the inputs to the machine from users other than Alice.
B represents all possible outputs to Bob.
Define I(A;B) as the amount of information transmitted over the covert channel. We are interested in the greatest amount of information that can be transmitted.
Definition 17–8. The covert channel capacity is maxA I(A;B).
This capacity is measured in bits. The rate is then established by dividing the capacity by the number of trials (or the amount of time) required to send the information.
We first establish that noninterference is sufficient to make the capacity of a covert channel 0.
Theorem 17–2. [710] If A and V are independent and A is noninterfering with B, then I(A;B) = 0.
Proof. It suffices to show that the conditions of the theorem mean that A and B are independent—that is, to prove that p(A = a, B = b) = p(A = a)p(B = b). Recall that
p(A = a, B = b) = ΣV p(A = a, B = b, V = v)
By Definition 8–4, A being noninterfering with B means that deleting that part of the input making up a will not change the output b. Thus, we need to consider only those values of B that can result from values of V. Hence,
p(A = a, B = b) = ΣV p(A = a, V = v)p(B = b | V = v)
By independence of A and V, this becomes
p(A = a, B = b) = ΣV p(A = a)p(V = v)p(B = b | V = v)
Standard manipulations yield
p(A = a, B = b)
=
p(A = a) (ΣV p(B = b | V = v)p(V = v))
=
P(A = a) p(B = b)
establishing independence and hence the desired result.
However, noninterference is not necessary [710]. To see this, consider a system with one bit of state; three inputs IA, IB, and IC; and one output OX. Each input flips the state, and the value of the state (0 or 1) is output. Let the system initially be in state 0, and let w be the sequence of inputs corresponding to the output x(w). Then the value x(w) depends on the length of the input; x(w) = length(w) mod 2. Clearly, IA is not noninterfering with OX because if the inputs from IA are deleted, the length of the input sequence is affected and so the value x(w) may also be affected. We consider two cases. In the following discussion, let W represent the random variable corresponding to the length of the input sequences, let A represent the random variable corresponding to the length of the components of the input subsequence contributed by input IA, let V represent the random variable corresponding to the length of the components of the input sequence not contributed by IA, and let X represent the random variable corresponding to the output state. Let A and V be independent and consider two distributions of V. (Without loss of generality, we restrict A and V to representing single bits.)
If V = 0, because W = (A + V) mod 2, then W = A. So A and W are not independent, and neither are A and X. Hence, if V = 0, I(A; X) ≠ 0.
Let inputs IB and IC produce inputs such that p(V = 0) = p(V = 1) = 0.5. Then,
p(X = x) = p(V = x, A = 0) + p(V = 1 – x, A = 1)
Because A and V are independent,
p(X = x) = p(V = x)p(A = 0) + p(V = 1 – x)p(A = 1)
This yields p(X = x) = 0.5. Moreover,
p(X = x | A = a) = p(X = (a + x) mod 2) = 0.5
Hence, A and X are independent, yielding I(A; X) = 0.
This means that even though A and X are not noninterfering, the channel capacity may be 0. In other words, the covert channel capacity will be 0 if either the input is noninterfering with the output or the input sequence is produced from independent sources and all possible values from at least one source are equiprobable. In the latter case, the distribution in effect “hides” the interference.
When an attacker uses a covert channel, he modulates the output by providing specific inputs. Suppose that, when no modulation occurs, the uncertainty in the output is eight bits. When modulation occurs, the uncertainty is reduced to five bits. Then the covert channel capacity is three bits, because the input “fixes” those bits. We formalize this idea as follows [710].
The capacity of the covert channel with inputs A and V, and output X, is the measure of the certainty in X given A. In terms of entropy, this means that we maximize
I(A; X) = H(X) – H(X | A)
with respect to A.
We now examine a model for bandwidth computation for a storage channel and a timing channel.
Costich and Moskowitz [236] examined the covert channel created by a multilevel secure database that used replication to ensure data availability. The database used the two-phase commit protocol to ensure atomicity of transactions. One coordinator process managed global execution; the other processes were participants.
The coordinator sends a message to each participant requesting whether to commit or abort the transaction. Each participant replies as it deems appropriate. If a participant replies to abort, it stops its process.
The coordinator gathers the replies from the participants. If all replies are to commit, the coordinator sends commit messages back to the participants. If any reply is to abort, the coordinator sends abort messages to the participants. Each participant that has sent a commit waits for the reply from the coordinator, and then acts accordingly.
In the database under discussion, if either the coordinator does not receive a reply from a participant or a participant does not receive a reply from the coordinator, the protocol times out and the parties act as though the transaction has been aborted.
Suppose the replicated database consists of two types of components—one at a Low security level and another at a High security level. If a Low component begins the two-phase commit, both Low and High components must cooperate in the two-phase commit protocol. A High component can transmit information to a Low component by selectively aborting transactions (either by sending abort messages or simply by not sending anything, causing a time-out). This is a covert channel [519].
This channel is noisy because transactions may abort for reasons other than the sending of information. The analysis must take this into account.
Covert channels convey information by varying the use of shared resources. An obvious way to eliminate all covert channels is to require processes to state what resources they need before execution and provide these resources in such a manner that only the process can access them. This includes runtime, and when the stated runtime is reached, the process is terminated and the resources are released. The resources remain allocated for the full runtime even if the process terminates earlier. Otherwise, a second process could infer information from the timing of the release of the resources (including access to the CPU). This strategy effectively implements Lampson's idea of total isolation, but it is usually unworkable in practice.
An alternative approach is to obscure the amount of resources that a process uses. A receiving process cannot determine what amount of resource usage is attributable to the sender and what amount is attributable to the obfuscation. This can be done in two ways.
First, the resources devoted to each process can be made uniform. This is a variant of isolation, because each process gets the same amount of resources and cannot tell whether a second process is accessing the resource by measuring the timing or amount of resources available. In essence, the system eliminates meaningful irregularities in resource allocation and use.
Second, a system can inject randomness into the allocation and use of resources. The goal is to make the covert channel a noisy one and to have the noise dominate the channel. This does not close the covert channel (because it still exists) but renders it useless.
Both these techniques affect efficiency. Assigning fixed allocations and constraining use waste resources. Fixing the time slices on the KVM system means that the CPU will be unused (or will execute an idle process) when another virtual machine could run a non-idle process. Increasing the probability of aborts in the multilevel secure database system will abort some transactions that would normally commit, increasing the expected number of tries to update the database. Whether the closing of the covert channel or the limiting of the bandwidth compensates adequately for the loss in efficiency is a policy decision.
A device known as a pump is the basis of several techniques for defeating covert channels.
EXAMPLE: The pump [546] is a (hardware or software) tool for controlling a communication path between a High process and a Low process. It consists of a buffer for messages to and from the High process, a buffer for messages to and from the Low process, and a communications buffer of length n that is connected to both of the other buffers (see Figure 17-4). We assume that messages are numbered and that the communications buffer preserves messages if the pump crashes. Under these assumptions, the processes can recover (so that either the messages in the pump are delivered or the sender detects that they are lost and resends the message; see Exercise 9).
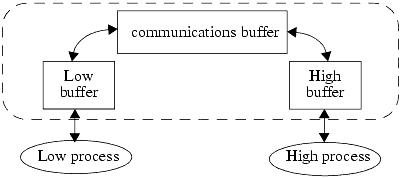
Figure 17-4. The pump. Messages going between the High and Low processes enter the pump (represented by the dashed oval). The pump controls the rate at which the messages flow between the two processes. The pump acknowledges each message as it is moved from the process buffer to the communications buffer.
A covert timing channel occurs when the High process can control the rate at which the pump passes messages to it. The Low process fills the communications buffer by sending messages to the pump until it fails to receive an acknowledgment. At that point, the High and Low processes begin their trials. At the beginning of each trial, if the High process wants to send a 1, it allows the pump to send it one of the queued messages. If the High process wants to send a 0, it does not accept any messages from the pump. If the Low process receives an acknowledgment, it means that a message has moved from the Low buffer to the communications buffer. This can happen only if a space in the communications buffer opens. This occurs when the High process reads a message. Hence, if the Low process gets an acknowledgment, the High process is signaling a 1. By a similar argument, if the Low process does not get an acknowledgment, the High process is signaling a 0. Following the trial, if the Low process has received an acknowledgment, it must send another message to the pump to enter the state required for the next trial.
In what follows, we assume that the Low process and the pump can process messages more quickly than the High process. Let Li be the random variable corresponding to the time from the Low process' sending a message to the pump to the Low process' receiving an acknowledgment. Let Hi be the random variable corresponding to the average time required for the High process to acknowledge each of the last n messages. Three cases arise.
E(Li) > Hi. This means that the High process can process messages in less time than it takes for the Low process to get the acknowledgment. Because this contradicts our assumption above, the pump must be artificially delaying acknowledgments. This means that the Low process will wait for an acknowledgment regardless of whether the communications buffer is full or not. Although this closes the covert timing channel, it is not optimal because the processes may wait even when they do not need to.
E(Li) < Hi. This means that the Low process is sending messages into the pump faster than the High process can remove them. Although it maximizes performance, it opens the covert channel.
E(Li) = Hi. This means that the pump and the processes handle messages at the same rate. It balances security and performance by decreasing the bandwidth of the covert channel (with respect to time) and increases performance. The covert channel is open, however, and performance is not optimal.
Kang and Moskowitz [546] showed that adding noise to the channel in such a way as to approximate the third case reduced the covert channel capacity to at most 1/nr, where r is the time between the Low process' sending a message to the pump and its receiving an acknowledgment when the communications buffer is not full. They concluded that the pump substantially reduces the capacity of covert channels between High and Low processes when compared with direct connection of those processes.
The confinement problem is the problem of preventing a process from illicitly leaking information. Its solutions lie in some form of separation or isolation. Virtual machines provide a basis for these mechanisms, as do less restrictive sandbox environments. Virtual machines and sandboxes limit the transfer of information by controlling expected paths used to send (or receive) data.
However, shared resources provide unexpected paths for transmission of information. Detecting and analyzing these covert channels require deduction of the common resources, which processes can manipulate (alter) the resources, which processes can access (read) the resources, and how much information per trial the channel can transmit. Several methods, among them a matrix methodology and tree analysis methodology, provide systematic ways to analyze systems for such channels.
Information flow and noninterference techniques focus on how information moves about the system. Information flow considers exceptions resulting from flows that are disallowed. The exception itself leads to a covert channel. Noninterference techniques work similarly and also provide a basis for measuring channel capacity. Statistical techniques are useful also.
Covert channels are difficult to eliminate. Countermeasures focus on making the channel less useful by decreasing its capacity, usually through the addition of randomness to obscure the regularity that sending and receiving requires.
Research into the confinement problem and its solutions includes research into malicious logic as well as covert channels.
Policy determines what information is to be confined. Policy representation is critical to a correct implementation of these requirements. So is a mechanism for translating these representations into effective, reliable security mechanisms. This is a fruitful area for research not only because of the technical issues, such as power of expression and constraint representation, but also because of the human interface issues.
Balancing security and functionality raises issues of controlling the channels through which systems communicate, as well as shared channels. A sandbox isolates some aspects of processes while providing access to system resources. Preventing other information from leaking requires development of precise mechanisms and is also an area of active research, particularly in mobile code. Sandboxes often reduce performance and efficiency of processes. Minimizing this impact makes such security constraints more acceptable.
Covert channel research focuses on detection, measurement, and mitigation. Techniques for detecting covert channels require effort by a human analyst. Simplifying and reducing the effort required would aid the discovery of these channels. Techniques for discovering these channels at all levels of the software life cycle are still in their infancy.
The balance between minimizing the bandwidths of covert channels (or closing them entirely) and providing acceptable performance is delicate. Techniques for optimizing both simultaneously are primitive and rarely yield mechanisms that provide optimality. This is another active research area.
Confinement mechanisms are used to limit the actions of downloaded or untrusted programs [24, 58, 180, 242, 655, 694]. McLean [685] raises questions about the effectiveness of sandboxes. Dean, Felten, and Wallach examine the Java security model [262]. Nieh and Leonard [776] discuss VMware, a virtual machine system implemented for Intel hardware, and Sugerman, Venkitachalam, and Lim [980] consider its performance.
Millen [712] provides a retrospective of covert channel research, including an amusing view of the disk-arm covert channel. Gold, Linde, and Cudney [400] review the successes and failures of KVM/370. Karger and Wray [553] discuss covert storage channels in disk accesses. Hu [499] discusses a countermeasure against covert channels arising from process scheduling. Kocher, Jaffe, and Jun [587] extend the timing analysis work to analysis of power consumption to obtain cryptographic keys, with remarkable success.
Several studies describe the relationship between noise and the capacity of timing channels [732, 733, 734, 1061]. Gray [421] suggests alternating between secure and nonsecure modes to limit bandwidth. Tsai and Gligor [1003] examine a Markov model for bandwidth computation in covert storage channels. Browne [153] examines state transitions to place upper bounds on covert channels. Meadows [688] discusses covert channels in integrity lock architectures, in which a trusted component mediates access to databases. Venkatraman and Newman-Wolfe [1013] examine the capacity of a covert channel on a network. The “light pink book” [289] looks at covert channels in the context of government security requirements.
Variations of the pump extend its concept to other arenas, including the network [547, 548] and a nozzle for limiting the effectiveness of denial of service attacks [977].
1: | Implement the transmission protocol in the example that follows Definition 17–2. Measure how much information is sent over a 10-minute period. |
2: | Two UNIX processes wish to communicate but cannot use standard IPC mechanisms. However, both can run ps(1) as a subprocess.
|
3: | Consider the rule of transitive confinement. Suppose a process needs to execute a subprocess in such a way that the child can access exactly two files, one only for reading and one only for writing.
|
4: | A company wishes to market a secure version of the Swiss Cheese Operating System (SCOS), known as much for its advanced user and database management features as for its security vulnerabilities. The company plans to build a virtual machine to run SCOS and run that virtual machine on a second system, the Somewhat Secure Operating System (SSOS). The marketing literature claims that the VM running SCOS provides total isolation, thereby eliminating any potential security problems.
|
5: | In the Janus system, when the framework disallows a system call, the error code EINTR (interrupted system call) is returned.
|
6: | The following system call adds read permission for a process (for_ pid) if the caller (call_ pid) owns the file, and does nothing otherwise. (The operating system supplies call_ pid; the caller supplies the two latter parameters.) function addread(call_pid, for_pid : process_id; fid: file_id):integer; begin if (call_pid = filelist[fid].owner) then addright(filelist[fid].access_control_list, for_pid, "r"); addread := (call_pid = filelist[fid].owner); end.
|
7: | In the covert flow tree technique, it is possible for some part of the tree to enter a loop in which recognition of attribute a depends on recognition of attribute b, which in turn is possible when attribute a is recognized.
|
8: | Section 17.3.2.3 derives a formula for I(A; X). Prove that this formula is a maximum with respect to p when p = M / (Mm + 1), with M and m as defined in that section. |
9: | Prove that if the pump crashes, either every message in the pump has been delivered or the sender detects that a message has been lost and resends it. |