
Fault Tolerance and Resilience in Cloud Computing Environments
Ravi Jhawar and Vincenzo Piuri, Universita’ degli Studi di Milano
The increasing demand for flexibility and scalability in dynamically obtaining and releasing computing resources in a cost-effective and device-independent manner, and easiness in hosting applications without the burden of installation and maintenance, has resulted in a wide adoption of the cloud computing paradigm. While the benefits are immense, this computing paradigm is still vulnerable to a large number of system failures; as a consequence, users have become increasingly concerned about the reliability and availability of cloud computing services. Fault tolerance and resilience serve as an effective means to address users’ reliability and availability concerns. In this chapter, we focus on characterizing the recurrent failures in a typical cloud computing environment, analyzing the effects of failures on users’ applications and surveying fault tolerance solutions corresponding to each class of failures. We also discuss the perspective of offering fault tolerance as a service to users’ applications as one of the effective means of addressing users’ reliability and availability concerns.
Keywords
cloud computing; fault model; architecture; servers; network; fault tolerance; crash failures; byzantine failures; checking; monitoring
1 Introduction
Cloud computing is gaining an increasing popularity over traditional information processing systems. Service providers have been building massive data centers that are distributed over several geographical regions to efficiently meet the demand for their Cloud-based services [1–3]. In general, these data centers are built using hundreds of thousands of commodity servers, and virtualization technology is used to provision computing resources (by delivering Virtual Machines—VMs—with a given amount of CPU, memory, and storage capacity) over the Internet by following the pay-per-use business model [4]. Leveraging the economies of scale, a single physical host is often used as a set of several virtual hosts by the service provider, and benefits such as the semblance of an inexhaustible set of available computing resources are provided to the users. As a consequence, an increasing number of users are moving to cloud-based services for realizing their applications and business processes.
The use of commodity components, however, exposes the hardware to conditions for which it was not originally designed [5,6]. Moreover, due to the highly complex nature of the underlying infrastructure, even carefully engineered data centers are subject to a large number of failures [7]. These failures evidently reduce the overall reliability and availability of the cloud computing service. As a result, fault tolerance becomes of paramount importance to the users as well as the service providers to ensure correct and continuous system operation even in the presence of an unknown and unpredictable number of failures.
The dimension of risks in the user’s applications deployed in the virtual machine instances in a cloud has also changed since the failures in data centers are normally outside the scope of the user’s organization. Moreover, traditional ways of achieving fault tolerance require users to have an in-depth knowledge of the underlying mechanisms, whereas, due to the abstraction layers and business model of cloud computing, a system’s architectural details are not widely available to the users. This implies that traditional methods of introducing fault tolerance may not be very effective in the cloud computing context, and there is an increasing need to address users’ reliability and availability concerns.
The goal of this chapter is to develop an understanding of the nature, numbers, and kind of faults that appear in typical cloud computing infrastructures, how these faults impact users’ applications, and how faults can be handled in an efficient and cost-effective manner. To this aim, we first describe the fault model of typical cloud computing environments on the basis of system architecture, failure characteristics of widely used server and network components, and analytical models. An overall understanding of the fault model may help researchers and developers to build more reliable cloud computing services. In this chapter, we also introduce some basic and general concepts on fault tolerance and summarize the parameters that must be taken into account when building a fault tolerant system. This discussion is followed by a scheme in which different levels of fault tolerance can be achieved by users’ applications by exploiting the properties of the cloud computing architecture.
In this chapter, we discuss a solution that can function in users’ applications in a general and transparent manner to tolerate one of the two most frequent classes of faults that appear in the cloud computing environment. We also present a scheme that can tolerate the other class of frequent faults while reducing the overall resource costs by half when compared to existing solutions in the literature. These two techniques, along with the concept of different fault tolerance levels, are used as the basis for developing a methodology and framework that offers fault tolerance as an additional service to the user’s applications. We believe that the notion of offering fault tolerance as a service may serve as an efficient alternative to traditional approaches in addressing user’s reliability and availability concerns.
2 Cloud Computing Fault Model
In general, a failure represents the condition in which the system deviates from fulfilling its intended functionality or the expected behavior. A failure happens due to an error, that is, due to reaching an invalid system state. The hypothesized cause for an error is a fault, which represents a fundamental impairment in the system. The notion of faults, errors, and failures can be represented using the following chain [8,9]:
![]()
Fault tolerance is the ability of the system to perform its function even in the presence of failures. This implies that it is utmost important to clearly understand and define what constitutes the correct system behavior so that specifications on its failure characteristics can be provided and consequently a fault tolerant system can be developed. In this section, we discuss the fault model of typical cloud computing environments to develop an understanding of the numbers as well as the causes behind recurrent system failures. In order to analyze the distribution and impact of faults, we first describe the generic cloud computing architecture.
Cloud Computing Architecture
Cloud computing architecture comprises four distinct layers as illustrated in Figure 1.1 [10]. Physical resources (blade servers and network switches) are considered the lowest-layer in the stack, on top of which virtualization and system management tools are embedded to form the infrastructure-as-a-service (IaaS) layer. Note that the infrastructure supporting large-scale cloud deployments is typically the data centers, and virtualization technology is used to maximize the use of physical resources, application isolation, and quality of service. Services offered by IaaS are normally accessed through a set of user-level middleware services that provide an environment to simplify application development and deployment (Web 2.0 or higher interfaces, libraries, and programming languages). The layer above the IaaS that binds all user-level middleware tools is referred to as platform-as-a-service (PaaS). User-level applications (social networks and scientific models) that are built and hosted on top of the PaaS layer comprise the software-as-a-service (SaaS) layer.
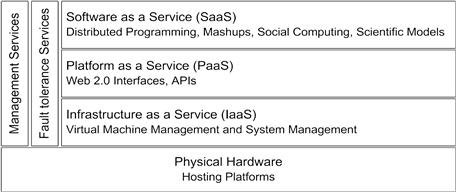
Failure in a given layer normally has an impact on the services offered by the layers above it. For example, failure in a user-level middleware (PaaS) may produce errors in the software services built on top of it (SaaS applications). Similarly, failures in the physical hardware or the IaaS layer will have an impact on most PaaS and SaaS services. This implies that the impact of failures in the IaaS layer or the physical hardware is significantly high; hence, it is important to characterize typical hardware faults and develop corresponding fault tolerance techniques.
We describe the failure behavior of various server components based on the statistical information obtained from large-scale studies on data center failures using data mining techniques [6,11] and analyze the impact of component failures on users’ applications by means of analytical models such as fault trees and Markov chains [12]. Similar to server components, we also present the failure behavior of network component failures.
Failure Behavior of Servers
Each server in the data center typically contains multiple processors, storage disks, memory modules, and network interfaces. The study about server failure and hardware repair behavior is to be performed using a large collection of servers (approximately 100,000 servers) and corresponding data on part replacement such as details about server configuration, when a hard disk was issued a ticked for replacement, and when it was actually replaced. Such a data repository, which included server collection spanning multiple data centers distributed across different countries, is gathered [6]. Key observations derived from this study are as follows:
• 92 percent of the machines do not see any repair events, but the average number of repairs for the remaining 8 percent is 2 per machine (20 repair/replacement events contained in nine machines were identified over a 14-month period). The annual failure rate (AFR) is therefore around 8 percent.
• For an 8 percent AFR, repair costs that amounted to $2.5 million are approximately spent for 100,000 servers.
• About 78 percent of total faults/replacements were detected on hard disks, 5 percent on RAID controllers, and 3 percent due to memory failures. Thirteen percent of replacements were due to a collection of components (not particularly dominated by a single component failure). Hard disks are clearly the most failure-prone hardware components and the most significant reason behind server failures.
• About 5 percent of servers experience a disk failure in less than one year from the date when it is commissioned (young servers), 12 percent when the machines are one year old, and 25 percent when they are two years old.
• Interestingly, based on the chi-squared automatic interaction detector methodology, none of the following factors—age of the server, its configuration, location within the rack, and workload run on the machine—were found to be a significant indicator for failures.
• Comparison between the number of repairs per machine (RPM) to the number of disks per server in a group of servers (clusters) indicates that (i) there is a relationship in the failure characteristics of servers that have already experienced a failure, and (ii) the number of RPM has a correspondence to the total number of disks on that machine.
Based on these statistics, it can be inferred that robust fault tolerance mechanisms must be applied to improve the reliability of hard disks (assuming independent component failures) to substantially reduce the number of failures. Furthermore, to meet the high availability and reliability requirements, applications must reduce utilization of hard disks that have already experienced a failure (since the probability of seeing another failure on that hard disk is higher).
The failure behavior of servers can also be analyzed based on the models defined using fault trees and Markov chains [12,13]. The rationale behind the modeling is twofold: (1) to capture the user’s perspective on component failures, that is, to understand the behavior of users’ applications that are deployed in the VM instances under server component failures and (2) to define the correlation between individual component failures and the boundaries on the impact of each failure. An application may have an impact when there is a failure/error either in the processor, memory modules, storage disks, power supply (see Figure 1.2b) or network interfaces of the server, or the hypervisor, or the VM instance itself. Figure 1.2a illustrates this behavior as a fault tree where the top-event represents a failure in the user’s application. The reliability and availability of each server component must be derived using Markov models that are populated using long-term failure behavior information [6].
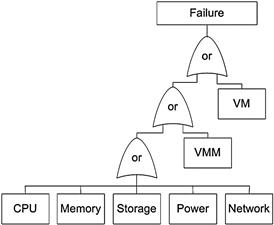
Figure 1.2a Fault tree characterizing server failures [12].
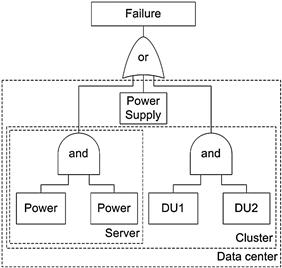
Figure 1.2b Fault tree characterizing power failures [12].
Failure Behavior of the Network
It is important to understand the overall network topology and various network components involved in constructing a data center so as to characterize the network failure behavior (see Figure 1.3b). Figure 1.3a illustrates an example of partial data center network architecture [11,14]. Servers are connected using a set of network switches and routers. In particular, all rack-mounted servers are first connected via a 1 Gbps link to a top-of-rack switch (ToR), which is in turn connected to two (primary and backup) aggregation switches (AggS). An AggS connects tens of switches (ToR) to redundant access routers (AccR). This implies that each AccR handles traffic from thousands of servers and routes it to core routers that connect different data centers to the Internet [11,12]. All links in the data centers commonly use Ethernet as the link layer protocol, and redundancy is applied to all network components at each layer in the network topology (except for ToRs). In addition, redundant pairs of load balancers (LBs) are connected to each AggS, and mapping between static IP address presented to the users and dynamic IP addresses of internal servers that process user’s requests is performed. Similar to the study on failure behavior of servers, a large-scale study on network failures in data centers is performed [11]. A link failure happens when the connection between two devices on a specific interface is down, and a device failure happens when the device is not routing/forwarding packets correctly (due to power outage or hardware crash). Key observations derived from this study are as follows:
• Among all the network devices, load balancers are least reliable (with failure probability of 1 in 5) and ToRs are most reliable (with a failure rate of less than 5 percent). The root causes for failures in LBs are mainly the software bugs and configuration errors (as opposed to the hardware errors for other devices). Moreover, LBs tend to experience short but frequent failures. This observation indicates that low-cost commodity switches (ToRs and AggS) provide sufficient reliability.
• The links forwarding traffic from LBs have the highest failure rates; links higher in the topology (connecting AccRs) and links connecting redundant devices have the second highest failure rates.
• The estimated median number of packets lost during a failure is 59 K, and the median number of bytes is 25 MB (the average size of lost packets is 423 Bytes). Based on prior measurement studies (that observe packet sizes to be bimodal with modes around 200 Bytes and 1400 Bytes), it is estimated that most lost packets belong to the lower part (ping messages or ACKs).
• Network redundancy reduces the median impact of failures (in terms of number of lost bytes) by only 40 percent. This observation is against the common belief that network redundancy completely masks failures from applications.
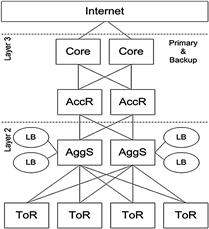
Figure 1.3a Partial network architecture of a data center [11].

Figure 1.3b Fault tree characterizing network failures [12].
Therefore, the overall data center network reliability is about 99.99 percent for 80 percent of the links and 60 percent of the devices. Similar to servers, Figure 1.3b represents the fault tree for the user’s application failure with respect to network failures in the data center. A failure occurs when there is an error in all redundant switches ToRs, AggS, AccR, or core routers, or the network links connecting physical hosts. Since the model is designed in the user’s perspective, a failure in this context implies that the application is not connected to the rest of the network or gives errors during data transmission. Through use of this modeling technique, the boundaries on the impact of each network failure can be represented (using server, cluster, and data center level blocks) and can further be used to increase the fault tolerance of the user’s application (by placing replicas of an application in different failure zones).
3 Basic Concepts on Fault Tolerance
In general, the faults we analyzed in the last section can be classified in different ways depending on the nature of the system. Since, in this chapter, we are interested in typical cloud computing environment faults that appear as failures to the end users, we classify the faults into two types similarly to other distributed systems:
• Crash faults that cause the system components to completely stop functioning or remain inactive during failures (power outage, hard disk crash).
• Byzantine faults that lead the system components to behave arbitrarily or maliciously during failure, causing the system to behave unpredictably incorrect.
As observed previously, fault tolerance is the ability of the system to perform its function even in the presence of failures. It serves as one of the means to improve the overall system’s dependability. In particular, it contributes significantly to increasing the system’s reliability and availability.
The most widely adopted methods to achieve fault tolerance against crash faults and byzantine faults are as follows:
• Checking and monitoring: The system is constantly monitored at runtime to validate, verify, and ensure that correct system specifications are being met. This technique, though very simple, plays a key role in failure detection and subsequent reconfiguration.
• Checkpoint and restart: The system state is captured and saved based on predefined parameters (after every 1024 instructions or every 60 seconds). When the system undergoes a failure, it is restored to the previously known correct state using the latest checkpoint information (instead of restarting the system from start).
• Replication: Critical system components are duplicated using additional hardware, software, and network resources in such a way that a copy of the critical components is available even after a failure happens. Replication mechanisms are mainly used in two formats: active and passive. In active replication, all the replicas are simultaneously invoked and each replica processes the same request at the same time. This implies that all the replicas have the same system state at any given point of time (unless designed to function in an asynchronous manner) and it can continue to deliver its service even in case of a single replica failure. In passive replication, only one processing unit (the primary replica) processes the requests, while the backup replicas only save the system state during normal execution periods. Backup replicas take over the execution process only when the primary replica fails.
Variants of traditional replication mechanisms (active and passive) are often applied on modern distributed systems. For example, the semiactive replication technique is derived from traditional approaches wherein primary and backup replicas execute all the instructions but only the output generated by the primary replica is made available to the user. Output generated by the backup replicas is logged and suppressed within the system so that it can readily resume the execution process when the primary replica failure happens. Figure 1.4a depicts the Markov model of a system that uses an active/semiactive replication scheme with two replicas [12]. This model serves as an effective means of deriving the reliability and availability of the system because the failure behavior of both replicas can be taken into account. Moreover, as described earlier, the results of the Markov model analysis can be used to support the fault trees in characterizing the impact of failures in the system. Each state in the model is represented by a pair (x, y) where x=1 denotes that the primary replica is working and x=0 implies that it failed. Similarly, y represents the working condition of the backup replica. The system starts and remains in state (1,1) during normal execution, that is, when both the replicas are available and working correctly. A failure either in the primary or the backup replica moves the system to state (0,1) or (1,0) where the other replica takes over the execution process. A single state is sufficient to represent this condition in the model since both replicas are consistent with each other. The system typically initiates its recovery mechanism in state (0,1) or (1,0), and moves to state (1,1) if the recovery of the failed replica is successful; otherwise it transits to state (0,0) and becomes completely unavailable. Similarly, Figure 1.4b illustrates the Markov model of the system for which a passive replication scheme is applied. λ denotes the failure rate, μ denotes the recovery rate, and k is a constant.
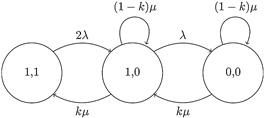
Figure 1.4a Markov model of a system with two replicas in active/semiactive replication scheme [12].

Figure 1.4b Markov model of a system with two replicas in passive replication scheme [12].
Fault tolerance mechanisms are varyingly successful in tolerating faults [15]. For example, a passively replicated system can tolerate only crash faults, whereas actively replicated system using 3f+1 replicas are capable of tolerating byzantine faults. In general, mechanisms that handle failures at a finer granularity, offering higher performance guarantees, also consume higher amounts of resources [16]. Therefore, the design of fault tolerance mechanisms must take into account a number of factors such as implementation complexity, resource costs, resilience, and performance metrics, and achieve a fine balance of the following parameters:
• Fault tolerance model: Measures the strength of the fault tolerance mechanism in terms of the granularity at which it can handle errors and failures in the system. This factor is characterized by the robustness of failure detection protocols, state synchronization methods, and strength of the fail-over granularity.
• Resource consumption: Measures the amount and cost of resources that are required to realize a fault tolerance mechanism. This factor is normally inherent with the granularity of the failure detection and recovery mechanisms in terms of CPU, memory, bandwidth, I/O, and so on.
• Performance: Deals with the impact of the fault tolerance procedure on the end-to-end quality of service (QoS) both during failure and failure-free periods. This impact is often characterized using fault detection latency, replica launch latency, failure recovery latency, and other application-dependent metrics such as bandwidth, latency, and loss rate.
We build on the basic concepts discussed in this section to analyze the fault tolerance properties of various schemes designed for cloud computing environment.
4 Different Levels of Fault Tolerance in Cloud Computing
As discussed earlier, server components in a cloud computing environment are subject to failures, affecting users’ applications, and each failure has an impact within a given boundary in the system. For example, a crash in the pair of aggregate switches may result in the loss of communication among all the servers in a cluster; in this context, the boundary of failure is the cluster since applications in other clusters can continue functioning normally. Therefore, while applying a fault tolerance mechanism such as a replication scheme, at least one replica of the application must be placed in a different cluster to ensure that aggregate switch failure does not result in a complete failure of the application. Furthermore, this implies that deployment scenarios (location of each replica) are critical to correctly realize the fault tolerance mechanisms. In this section, we discuss possible deployment scenarios in a cloud computing infrastructure, and the advantages and limitations of each scenario.
Based on the architecture of the cloud computing infrastructure, different levels of failure independence can be derived for cloud computing services [17,18]. Moreover, assuming that the failures in individual resource components are independent of each other, fault tolerance and resource costs of an application can be balanced based on the location of its replicas. Possible deployment scenarios and their properties are as follows.
• Multiple machines within the same cluster. Two replicas of an application can be placed on the hosts that are connected by a ToR switch (within a LAN). Replicas deployed in this configuration can benefit in terms of low latency and high bandwidth but obtain very limited failure independence. A single switch or power distribution failure may result in an outage of the entire application, and both replicas cannot communicate to complete the fault tolerance protocol. Cluster- level blocks in the fault trees of each resource component (network failures as shown in Figure 1.3b) must be combined using a logical AND operator to analyze the overall impact of failures in the system. Note that reliability and availability values for each fault tolerance mechanism with respect to server faults must be calculated using a Markov model.
• Multiple clusters within a data center. Two replicas of an application can be placed on the hosts belonging to different clusters in the same data center (on the hosts that are connected via a ToR switch and AggS). Failure independence of the application in this deployment context remains moderate since the replicas are not bound to an outage with a single power distribution or switch failure. The overall availability of an application can be calculated using cluster-level blocks from fault trees combined with a logical OR operator in conjunction with power and network using AND operator.
• Multiple data centers. Two replicas of an application can be placed on the hosts belonging to different data centers (connected via a switch), AggS and AccR. This deployment has a drawback with respect to high latency and low bandwidth, but offers a very high level of failure independence. A single power failure has the least effect on the availability of the application. The data center level blocks from the fault trees may be connected with a logical OR operator in conjunction with the network in the AND logic.
As an example [13,19], the overall availability of each representative replication scheme with respect to different deployment levels is obtained as shown in Table 1.1. Availability of the system is highest when the replicas are placed in two different data centers. The value declines when replicas are placed in two different clusters within the same data center, and it is lowest when replicas are placed inside the same LAN. The overall availability obtained by semiactive replication is higher than semipassive replication and lowest for the simple passive replication scheme.
Table 1.1
Availability Values (normalized to 1) for Replication Techniques at Different Deployment Scenarios [12].

As described earlier, effective implementation of fault tolerance mechanisms requires consideration of the strength of the fault tolerance model, resource costs, and performance. While traditional fault tolerance methods require tailoring of each application having an in-depth knowledge of the underlying infrastructure, in the cloud computing scenario, it would also be beneficial to develop methodologies that can generically function on users’ applications so that a large number of applications can be protected using the same protocol. In addition to generality, agility in managing replicas and checkpoints to improve the performance, and reduction in the resource consumption costs while not limiting the strength of fault tolerance mechanisms are required.
Although several fault tolerance approaches are being proposed for cloud computing services, most solutions that achieve at least one of the required properties described above are based on virtualization technology. By using virtualization-based approaches, it is also possible to deal with both classes of faults. In particular, in a later section of this chapter we present a virtualization-based solution that provides fault tolerance against crash failures using a checkpointing mechanism. We discuss this solution because it offers two additional, significantly useful, properties: (1) Fault tolerance is induced independent to the applications and hardware on which it runs. In other words, an increased level of generality is achieved since any application can be protected using the same protocol as long as it is deployed in a VM, and (2) mechanisms such as replication, failure detection, and recovery are applied transparently—not modifying the OS or application’s source code. Then, we present a virtualization-based solution that uses typical properties of a cloud computing environment to tolerate byzantine faults using a combination of replication and checkpointing techniques. We discuss this solution because it reduces the resource consumption costs incurred by typical byzantine fault tolerance schemes during fail-free periods nearly by half.
5 Fault Tolerance against Crash Failures in Cloud Computing
A scheme that leverages the virtualization technology to tolerate crash faults in the cloud in a transparent manner is discussed in this section. The system or user application that must be protected from failures is first encapsulated in a VM (say active VM or the primary), and operations are performed at the VM level (in contrast to the traditional approach of operating at the application level) to obtain paired servers that run in active–passive configuration. Since the protocol is applied at the VM level, this scheme can be used independent of the application and underlying hardware, offering an increased level of generality. In particular, we discuss the design of Remus as an example system that offers the preceding mentioned properties [20]. Remus aims to provide high availability to the applications, and to achieve this, it works in four phases:
1. Checkpoint the changed memory state at the primary, and continue to the next epoch of network and disk request streams.
2. Replicate system state on the backup.
3. Send checkpoint acknowledgment from the backup when complete memory checkpoint and corresponding disk requests have been received.
4. Release outbound network packets queued during the previous epoch upon receiving the acknowledgment.
Remus achieves high availability by frequently checkpointing and transmitting the state of the active VM on to a backup physical host. The VM image on the backup is resident in the memory and may begin execution immediately after a failure in the active VM is detected. The backup only acts like a receptor since the VM in the backup host is not actually executed during fail-free periods. This allows the backup to concurrently receive checkpoints from VMs running on multiple physical hosts (in an N-to-1 style configuration), providing a higher degree of freedom in balancing resource costs due to redundancy.
In addition to generality and transparency, seamless failure recovery can be achieved; that is, no externally visible state is lost in the event of a single host failure and recovery happens rapidly enough that it appears only like a temporary packet loss. Since the backup is only periodically consistent with the primary replica using the checkpoint-transmission procedure, all network output is buffered until a consistent image of the host is received by the backup, and the buffer is released only when the backup is completely synchronized with the primary. Unlike network traffic, the disk state is not externally visible, but it has to be transmitted to the backup as part of a complete cycle. To address this issue, Remus asynchronously sends the disk state to the backup where it is initially buffered in the RAM. When the corresponding memory state is received, complete checkpoint is acknowledged, output is made visible to the user, and buffered disk state is applied to the backup disk.
Remus is built on Xen hypervisor’s live migration machinery [21]. Live migration is a technique through which a complete VM can be relocated onto another physical host in the network (typically a LAN) with a minor interruption to the VM. Xen provides an ability to track guest writes to memory using a technique called shadow page tables. During live migration, memory of the VM is copied to the new location while the VM continues to run normally at the old location. The writes to the memory are then tracked, and the dirtied pages are transferred to the new location periodically. After a sufficient number of iterations, or when no progress in copying the memory is being made (i.e., when the VM is writing to the memory as fast as the migration process), the guest VM is suspended, remaining dirtied memory along with the CPU state is copied, and the VM image in the new location is activated. The total migration time depends on the amount of dirtied memory during guest execution, and total downtime depends on the amount of memory remaining to be copied when the guest is suspended. The protocol design of the system, particularly each checkpoint, can be viewed as the final stop-and-copy phase of live migration. The guest memory in live migration is iteratively copied, incurring several minutes of execution time. The singular stop-and-copy (the final step) operation incurs a very limited overhead—typically in the order of a few milliseconds.
While Remus provides an efficient replication mechanism, it employs a simple failure detection technique that is directly integrated within the checkpoint stream. A timeout of the backup in responding to commit requests made by the primary will result in the primary suspecting a failure (crash and disabled protection) in the backup. Similarly, a timeout of the new checkpoints being transmitted from the primary will result in the backup assuming a failure in the primary. At this point, the backup begins execution from the latest checkpoint. The protocol is evaluated (i) to understand whether or not the overall approach is practically deployable and (ii) to analyze the kind of workloads that are most amenable to this approach.
Correctness evaluation is performed by deliberatively injecting network failures at each phase of the protocol. The application (or the protected system) runs a kernel compilation process to generate CPU, memory, and disk load, and a graphics-intensive client (glxgears) attached to X11 server is simultaneously executed to generate the network traffic. Checkpoint frequency is configured to 25 milliseconds, and each test is performed two times. It is reported that the backup successfully took over the execution for each failure with a network delay of about 1 second when the backup detected the failure and activated the replicated system. The kernel compilation task continued to completion, and glxgears client resumed after a brief pause. The disk image showed no inconsistencies when the VM was gracefully shut down.
Performance evaluation is performed using the SPECweb benchmark that is composed of a Web server, an application server, and one or more Web client simulators. Each tier (server) was deployed in a different VM. The observed scores decrease up to five times the native score (305) when the checkpointing system is active. This behavior is mainly due to network buffering; the observed scores are much higher when network buffering is disabled. Furthermore, it is reported that at configuration rates of 10, 20, 30, and 40 checkpoints per second, the average checkpoint rates achieved are 9.98, 16.38, 20.25, and 23.34, respectively. This behavior can be explained with SPECweb’s very fast memory dirtying, resulting in slower checkpoints than desired. The realistic workload therefore illustrates that the amount of network traffic generated by the checkpointing protocol is very large, and as a consequence, this system is not well suited for applications that are very sensitive to network latencies. Therefore, virtualization technology can largely be exploited to develop general-purpose fault tolerance schemes that can be applied to handle crash faults in a transparent manner.
6 Fault Tolerance against Byzantine Failures in Cloud Computing
Byzantine fault tolerance (BFT) protocols are powerful approaches to obtain highly reliable and available systems. Despite numerous efforts, most BFT systems have been too expensive for practical use; so far, no commercial data centers have employed BFT techniques. For example, the BFT algorithm [22] for asynchronous, distributed, client-server systems requires at least 3f+1 replica (one primary and remaining backup) to execute a three-phase protocol that can tolerate f byzantine faults. Note that, as described earlier, systems that tolerate faults at a finer granularity such as the byzantine faults also consume very high amounts of resources, and as already noted, it is critical to consider the resource costs while implementing a fault tolerance solution.
The high resource consumption cost (see Table 1.2) in BFT protocols is most likely due to the way faults are normally handled. BFT approaches typically replicate the server (state machine replication—SMR), and each replica is forced to execute the same request in the same order. This enforcement requirement demands that the server replicas reach an agreement on the ordering of a given set of requests even in the presence of byzantine faulty servers and clients. For this purpose, an agreement protocol that is referred to as the Byzantine Agreement is used. When an agreement on the ordering is reached, service execution is performed, and majority voting scheme is devised to choose the correct output (and to detect the faulty server). This implies that two clusters of replicas are necessary to realize BFT protocols.
Table 1.2
Resource Consumption Costs Incurred by Well-Known Byzantine Fault Tolerance Protocols [23].

When realistic data center services implement BFT protocols, the dominant costs are due to the hardware performing service execution and not due to running the agreement protocol [23]. For instance, a toy application running null requests with the Zyzzyva BFT approach [24] exhibits a peak throughput of 80 K requests/second, while a database service running the same protocol on comparable hardware exhibits almost three times lower throughput. Based on this observation, ZZ, an execution approach that can be integrated with existing BFT SMR and agreement protocols, is presented [23]. The prototype of ZZ is built on the BASE implementation [22] and guarantees BFT, while significantly reducing resource consumption costs during fail-free periods. Table 1.2 compares the resource costs of well-known BFT techniques. Since ZZ provides an effective balance between resource consumption costs and the fault tolerance model, later in this section we discuss its system design in detail.
The design of ZZ is based on the virtualization technology and is targeted to tolerate byzantine faults while reducing the resource provisioning costs incurred by BFT protocols during fail-free periods. The cost reduction benefits of ZZ can be obtained only when BFT is used in the data center running multiple applications, so that sleeping replicas can be distributed across the pool of servers and higher peak throughput can be achieved when execution dominates the request processing cost and resources are constrained. These assumptions make ZZ a suitable scheme to be applied in a cloud computing environment. The system model of ZZ makes the following assumptions similar to most existing BFT systems:
• The service is either deterministic, or nondeterministic operations in the service can be transformed to deterministic ones using an agreement protocol (ZZ assumes a SMR-based BFT system).
• The system involves two kinds of replicas: (1) agreement replicas that assign an order to the client’s requests and (2) execution replicas that execute each client’s request in the same order and maintain the application state.
• Each replica fails independently and exhibits byzantine behavior (faulty replicas and clients may behave arbitrarily).
• An adversary can coordinate faulty nodes in an arbitrary manner, but it cannot circumvent standard cryptographic measures (collision-resistant hash functions, encryption scheme, and digital signatures).
An upper bound g on a number of faulty agreement replicas and f execution replicas is assumed for a given window of vulnerability.
• The system can ensure safety in an asynchronous network, but liveness is guaranteed only during periods of synchrony.
Since the system runs replicas inside virtual machines, to maintain failure independence, it requires that a physical host can deploy at most one agreement and one execution replicas of the service simultaneously. The novelty in the system model is that it considers a byzantine hypervisor. Note that, as a consequence of the above replica placement constraint, a malicious hypervisor can be treated by simply considering a single fault in all the replicas deployed on that physical host. Similarly, an upper bound f on the number of faulty hypervisors is assumed. The BFT execution protocol reduces the replication cost from 2f+1 to f+1 based on the following principle:
• A system that is designed to function correctly in an asynchronous environment will provide correct results even if some of the replicas are outdated.
• A system that is designed to function correctly in the presence of f byzantine faults will, during a fault-free period, remain unaffected even if up to f replicas are turned off.
The second observation is used to commission only an f+1 replica to actively execute requests. The system is in a correct state if the response obtained from all f+1 replicas is the same. In case of failure (when responses do not match), the first observation is used to continue system operation as if the f standby replicas were slow but correct replicas.
To correctly realize this design, the system requires an agile replica wake-up mechanism. To achieve this mechanism, the system exploits virtualization technology by maintaining additional replicas (VMs) in a “dormant” state, which are either pre-spawned but paused VMs or the VM that is hibernated to a disk. There is a trade-off in adopting either method. Pre-spawned VM can resume execution in a very short span (in the order of few milliseconds) but consumes higher memory resources, whereas VMs hibernated to disks incur greater recovery times but occupy only storage space. This design also raises several interesting challenges such as how can a restored replica obtain the necessary application state that is required to execute the current request? How can the replication cost be made robust to faulty replica or client behavior? Does the transfer of an entire application state take an unacceptably long time?
The system builds on the BFT protocol that uses independent agreement and execution clusters [25]). Let A represent the set of replicas in the agreement cluster, |A|=2g+1, that runs the three-phase agreement protocol [22]. When a client c sends its request Q to the agreement cluster to process an operation o with timestamp t, the agreement cluster assigns a sequence number n to the request. The timestamp is used to ensure that each client request is executed only once and a faulty client behavior does not affect other clients’ requests. When an agreement replica j learns of the sequence number n committed to Q, it sends a commit message C to all execution replicas.
Let E represent the set of replicas in the execution cluster where |E|=f+1 during fail-free periods. When an execution replica i receives 2g+1 valid and matching commit messages from A, in the form of a commit certificate {Ci}, i ε A|2g+1, and if it has already processed all the requests with lower sequence than n, it produces a reply R and sends it to the client. The execution cluster also generates an execution report ER for the agreement cluster.
During normal execution, the response certificate {Ri}, i ε E|f+1 obtained by the client matches replies from all f+1 execution nodes. To avoid unnecessary wake-ups due to a partially faulty execution replica that replies correctly to the agreement cluster but delivers a wrong response to the client, ZZ introduces an additional check as follows: When the replies are not matching, the client resends the same request to the agreement cluster. The agreement cluster sends a reply affirmation RA to the client if it has f+1 valid responses for the retransmitted request. In this context, the client accepts the reply if it receives g+1 messages containing a response digest ![]() that matches one of the replies already received. Finally, if the agreement cluster does not generate an affirmation for the client, additional nodes are started.
that matches one of the replies already received. Finally, if the agreement cluster does not generate an affirmation for the client, additional nodes are started.
ZZ uses periodic checkpoints to update the state of newly commissioned replicas and to perform garbage collection on a replica’s logs. Execution nodes create checkpoints of the application state and reply logs, generate a checkpoint proof CP, and send it all execution and agreement nodes. The checkpoint proof is in the form of a digest that allows recovering nodes in identifying the checkpoint data they obtain from potentially faulty nodes, and the checkpoint certificate {CPi}, i ε E|f+1 is a set of f+1 CP messages with matching digests.
Fault detection in the execution replicas is based on timeouts. Both lower and higher values of timeouts may impact the system’s performance. The lower may falsely detect failures, and the higher may provide a window to the faulty replicas to degrade the system’s performance. To set appropriate timeouts, ZZ suggests the following procedure: The agreement replica sets the timeout τn to Kt1 upon receiving the first response to the request with sequence number n; t1 is the response time and K is a preconfigured variance bound. Based on this trivial theory, ZZ proves that a replica faulty with a given probability p can inflate average response time by a factor of:

where:
![]()
![]()
P(m) represents the probability of m simultaneous failures, and I(m) is the response time inflation that m faulty nodes can inflict. Assuming identically distributed response times for a given distribution, E[MINf+1−m] is the expected minimum time for a set of f+1−m replicas, and E[MAXf+1] is the expected maximum response time of all f+1 replicas [23]. Replication costs vary from f+1 to 2f+1, depending on the probability of replicas being faulty p and the likelihood of false timeouts π1. Formally, the expected replication cost is less than (1+r)f+1, where r=1−(1−p)f+1+(1−p)f+1π1. Therefore, virtualization technology can be effectively used to realize byzantine fault tolerance mechanisms at a significantly lower resource consumption costs.
7 Fault Tolerance as a Service in Cloud Computing
The drawback of the solutions discussed earlier is that the user must either tailor its application using a specific protocol (ZZ) by taking into account the system architecture details, or require the service provider to implement a solution for its applications (Remus). Note that the (i) fault tolerance properties of the application remain constant throughout its life cycle using this methodology and (ii) users may not have all the architectural details of the service provider’s system. However, the availability of a pool of fault tolerance mechanisms that provide transparency and generality can allow realization of the notion of fault tolerance as a service. The latter perspective on fault tolerance intuitively provides immense benefits.
As a motivating example, consider a user that offers a Web-based e-commerce service to its customers that allows them to pay their bills and manage fund transfers over the Internet. The user implements the e-commerce service as a multitier application that uses the storage service of the service provider to store and retrieve its customer data, and compute service to process its operations and respond to customer queries. In this context, a failure in the service provider’s system can impact the reliability and availability of the e-commerce service. The implications of storage server failure may be much higher than a failure in one of the compute nodes. This implies that each tier of the e-commerce application must possess different levels of fault tolerance, and the reliability and availability goals may change over time based on the business demands. Using traditional methods, fault tolerance properties of the e-commerce application remains constant throughout its life cycle, and hence, in the user’s perspective, it is complementary to engage with a third party (the fault tolerance service provider—ftSP), specify its requirements based on the business needs, and transparently possess desired fault tolerance properties without studying the low-level fault tolerance mechanisms.
The ftSP must realize a range of fault tolerance techniques as individual modules (separate agreement and execution protocols, and heartbeat-based fault detection technique as an independent module) to benefit from the economies of scale. For example, since the failure detection techniques in Remus and ZZ are based on the same principle, instead of integrating the liveness requests within the checkpointing stream, the heartbeat test module can be reused in both solutions. However, realization of this notion requires a technique for selecting appropriate fault tolerance mechanisms based on users’ requirements and a general-purpose framework that can integrate with the cloud computing environment. Without such a framework, individual applications must implement its own solution, resulting in a highly complex system environment. Further in this section, we present a solution that supports ftSP to realize its service effectively.
In order to abstract low-level system procedures from the users, a new dimension to fault tolerance is presented in [26] wherein applications deployed in the VM instances in a cloud computing environment can obtain desired fault tolerance properties from a third party as a service. The new dimension realizes a range of fault tolerance mechanisms that can transparently function on user’s applications as independent modules, and a set of metadata is associated with each module to characterize its fault tolerance properties. The metadata is used to select appropriate mechanisms based on users’ requirements. A complete fault tolerance solution is then composed using selected fault tolerance modules and delivered to the user’s application.
Consider ft_unit to be the fundamental module that applies a coherent fault tolerance mechanism, in a transparent manner, to a recurrent system failure at the granularity of a VM instance. An ft_unit handles the impact of hardware failures by applying fault tolerance mechanisms at the virtualization layer rather than the user’s application. Examples of ft_units include the replication scheme for the e-commerce application that uses a checkpointing technique such as Remus (ft_unit1), and the node failures detection technique using the heartbeat test (ft_sol2). Assuming that the ftSP realizes a range of fault tolerance mechanisms as ft_units, a two-stage delivery scheme that can deliver fault tolerance as a service is as follows:
The design stage starts when a user requests the ftSP to deliver a solution with a given set of fault tolerance properties to its application. Each ft_unit provides a unique set of properties; the ftSP banks on this observation and defines the fault tolerance property p corresponding to each ft_unit as ![]() , where u represents the ft_unit,
, where u represents the ft_unit, ![]() denotes the high-level abstract properties such as reliability and availability, and A denotes the set of functional, structural, and operational attributes that characterize the ft_unit u. The set A sufficiently refers to the granularity at which the ft_unit can handle failures, its limitations and advantages, resource consumption costs, and quality of service parameters. Each attribute a∈A takes a value v(a) from a domain Da, and a partial (or total) ordered relationship is defined on the domain Da. The values for the abstract properties are derived using the notion of fault trees and the Markov model as described for the availability property in Table 1.1. An example of fault tolerance property for the ft_unit u1 is p=(u1,
denotes the high-level abstract properties such as reliability and availability, and A denotes the set of functional, structural, and operational attributes that characterize the ft_unit u. The set A sufficiently refers to the granularity at which the ft_unit can handle failures, its limitations and advantages, resource consumption costs, and quality of service parameters. Each attribute a∈A takes a value v(a) from a domain Da, and a partial (or total) ordered relationship is defined on the domain Da. The values for the abstract properties are derived using the notion of fault trees and the Markov model as described for the availability property in Table 1.1. An example of fault tolerance property for the ft_unit u1 is p=(u1,![]() ={reliability =98.9%, availability=99.95%}, A={mechanism = semiactive_replication, fault_model = server_crashes, power_outage, number_of_replicas =4}).
={reliability =98.9%, availability=99.95%}, A={mechanism = semiactive_replication, fault_model = server_crashes, power_outage, number_of_replicas =4}).
Similar to the domain of attribute values, a hierarchy of fault tolerance properties ≤p is also defined: If P is the set of properties, and given two properties pi, pj∈P, pi≤ppj if pi·p=pj·p and for all a∈A, vi(a)≤vj(a). This hierarchy suggests that all ft_units that hold the property pj also satisfy the property pi. The fault tolerance requirements of the users are assumed to be specified as desired properties pc, and for each user request, the ftSP first generates a shortlisted set S of ft_units that match pc. Each ft_unit within the set S is then compared, and an ordered list based on user’s requirements is created. An example of the matching, comparison, and selection process is as follows:
As an example, assume that the ftSP realizes three ft_units with properties
p1=(u1, A={mechanism = heartbeat_test, timeout_period =50 ms, number_of_replicas=3, fault_model = node_crashes})
p2=(u2, A={mechanism = majority_voting, fault_model = programming_errors})
p3=(u3, A={mechanism = heartbeat_test, timeout_period = 25 ms, number_of_replicas =5, fault_model = node_crashes})
respectively. If the user requests fault tolerance support with a robust crash failure detection scheme, the set S=(u1, u3) is first generated (u2 is not included in the set because it doesn’t target server crash failures alone, and its attribute values that contribute to robustness are not defined) and finally after comparing each ft_unit within S, ftSP leverages u3 since it is more robust than u1.
Note that each ft_unit serves only as a single fundamental fault tolerance module. This implies that the overall solution ft_sol that must be delivered to the user’s application can be obtained by combining a set of ft_units as per specific execution logic. For instance, a heartbeat test-based fault detection module must be applied only after performing replication, and the recovery mechanism must be applied after a failure is detected. In other words, ft_units must be used to realize a process that provides a complete fault tolerance solution, such as:
invoke:ft unit(VM-instances replication)
invoke:ft unit(failure detection)
execute(failure detection ft unit)
By composing ft_sol using a set of modules on the fly, the dimension and intensity of the fault tolerance support can be changed dynamically. For example, the more robust fault detection mechanism can be replaced with a less robust one in the ft_sol based on the user’s business demands. Similarly, by realizing each ft_unit as a configurable module, resource consumption costs can also be made limited. For example, a replication scheme using five replicas can be replaced with one having three replicas if desired by the user.
The runtime stage starts immediately after ft_sol is delivered to the user. This stage is essential to maintain a high level of service because the context of the cloud computing environment may change at runtime, resulting in mutable behavior of the attributes. To this aim, the ftSP defines a set of rules R over attributes a∈A and their values v(a) such that the validity of all the rules r∈R establishes that the property p is supported by ft_sol (violation of a rule indicates that the property is not satisfied). Therefore, in this stage, the attribute values of each ft_sol delivered to users’ applications is continuously monitored at runtime, and a corresponding set of rules are verified using a validation function f(s, R). The function returns true if all the rules are satisfied; otherwise, it returns false. The matching and comparison process defined for the design stage is used to generate a new ft_sol in case of a rule violation. By continuously monitoring and updating the attribute values, note that the fault tolerance service offers support that is valid throughout the life cycle of the application (both initially during design time and runtime).
As an example, for a comprehensive fault tolerance solution ft_sol s1 with property
p1= (s1, ![]() ={reliability =98.9%, availability=99.95%}, A={mechanism = active_replication, fault_detection = heartbeat_test, number_of_replicas =4, recovery_time =25 ms}), a set of rules R that can sufficiently test the validity of p1 can be defined as:
={reliability =98.9%, availability=99.95%}, A={mechanism = active_replication, fault_detection = heartbeat_test, number_of_replicas =4, recovery_time =25 ms}), a set of rules R that can sufficiently test the validity of p1 can be defined as:
These rules ensure that end reliability and availability are always greater than or equal to 98.9 percent and 99.95 percent, respectively.
A conceptual architectural framework, the Fault Tolerance Manager (FTM), provides the basis to realize the design stage and runtime stage of the delivery scheme, and serves as the basis for offering fault tolerance as a service (see Figure 1.5). FTM is inserted as a dedicated service layer between the physical hardware and user applications along the virtualization layer. FTM is built using the principles of service-oriented architectures, where each ft_unit is realized as an individual Web service and ft_sol is created by orchestrating a set of ft_units (Web services) using the business process execution language (BPEL) constructs. This allows the ftSP to satisfy its scalability and interoperability goals. The central computing component, denoted as the FTMKernel, has three main components:
• Service Directory: It is the registry of all ft_units realized by the service provider in the form of Web services that (i) describes its operations and input/output data structures (WSDL and WSCL), and(ii) allows other ft_units to coordinate and assemble with it. This component also registers the metadata representing the fault tolerance property of each ft_unit. Service Directory matches user’s preferences and generates the set S of ft_units that satisfy pc.
• Composition Engine: It receives an ordered set of ft_units from the service directory as input and generates a comprehensive fault tolerance solution ft_sol as output. In terms of service-oriented architectures, the composition engine is a Web service orchestration engine that exploits BPEL constructs to build a fault tolerance solution.
• Evaluation Unit: It monitors the composed fault tolerance solutions at runtime using the validation function and the set of rules defined corresponding to each ft_sol. The interface exposed by Web services (WSDL and WSCL) allows the evaluation unit to validate the rules. If a violation is detected, the evaluation unit updates the present attribute values in the metadata; otherwise, the service continues uninterrupted.

Finally, let’s take a brief look at a set of components that provide complementary support to fault tolerance mechanisms that are included in the FTM. These components affect the quality of service and support ftSP in satisfying user’s requirements and constraints (see checklist: “An Agenda for Action for Satisfying Users’ Requirements and Constraints Activities”).
For example, consider that at the start of the service, the resource manager generates a profile of all computing resources in the cloud and identifies five processing nodes {n1, … ,n5}∈N with the network topology represented in Figure 1.6a. Further, consider that the FTMKernel, upon gathering the user’s requirements from the Client Interface, chooses a passive replication mechanism for the e-commerce service. Based on the chosen fault tolerance mechanism (the set of ft_units that realize the envisioned passive replication scheme), FTMKernel requires that the following conditions be satisfied: (i) the replica group must contain one primary and two backup nodes, (ii) the node on which the primary replica executes must not be shared with any other VM instances, (iii) all the replicas must be located on different nodes at all times, and (iv) node n5 must not allow any user-level VM instance (rather, it should be used only to run system-level services such as monitoring unit). An overview of the activities performed by each supporting component in the FTM is as follows:
• The replication manager (RM) selects the node n1 for the primary replica and nodes n3 and n4, respectively, for two backup replicas so that a replica group can be formed (see Figure 1.6b). Assume that the replication manager synchronizes the state between the replicas by frequently checkpointing the primary and updating the state of backup replicas.
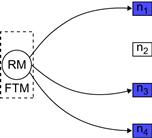
• The messaging manager establishes the infrastructure required for carrying out the checkpointing protocol and forms the replica group for the e-commerce service (see Figure 1.6c).

• Assume that the service directory selects a proactive fault tolerance mechanism. As a consequence, the failure detection/prediction manager continuously gathers the state information of nodes n1, n3, and n4, and verifies if all system parameter values satisfy threshold values (physical memory usage of a node allocated to a VM instance must be less than 70 percent of its total capacity).
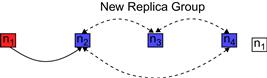
• When the failure detection/prediction manager predicts a failure in node n1 (see Figure 1.6d), it invokes the fault masking ft_unit that performs a live migration of the VM instance. The entire OS at node n1 is moved to another location (node n2) so that e-commerce customers do not experience any impact of the failure.

• Although the high availability goals are satisfied using the fault masking manager (see Figure 1.6e), the IaaS may be affected since the system now consists of four working nodes only. Therefore, FTM applies robust recovery mechanisms at node n1 to resume it to a normal working state, increasing the system’s overall lifetime (see Figure 1.6f).

Within the FTM framework, the notion of providing fault tolerance as a service can therefore be effectively realized for the cloud computing environment. Based on FTM’s delivery scheme, users can achieve high levels of reliability and availability for their applications without having any knowledge about the low-level mechanisms, and dynamically change the fault tolerance properties of its applications (based on the business needs) at runtime.
8 Summary
Fault tolerance and resilience in cloud computing are critical to ensure correct and continuous system operation. We discussed the failure characteristics of typical cloud-based services and analyzed the impact of each failure type on user’s applications. Since failures in the cloud computing environment arise mainly due to crash faults and byzantine faults, we discussed two fault tolerance solutions, each corresponding to one of these two classes of faults. The choice of the fault tolerance solutions was also driven by the large set of additional properties that they offer (generality, agility, transparency, and reduced resource consumption costs).
We also presented an innovative delivery scheme that leverages existing solutions and their properties to deliver high levels of fault tolerance based on a given set of desired properties. The delivery scheme was supported by a conceptual framework, which realized the notion of offering fault tolerance as a service to user’s applications. Due to the complex nature of cloud computing architecture and difficulties in realizing fault tolerance using traditional methods, we advocate fault tolerance as a service to be an effective alternative to address users’ reliability and availability concerns.
Finally, let’s move on to the real interactive part of this chapter: review questions/exercises, hands-on projects, case projects, and optional team case project. The answers and/or solutions by chapter can be found in the Online Instructor’s Solutions Manual.
Chapter Review Questions/Exercises
True/False
1. True or False? Crash faults do not cause the system components to completely stop functioning or remain inactive during failures (power outage, hard disk crash).
2. True or False? Byzantine faults do not lead the system components to behave arbitrarily or maliciously during failure, causing the system to behave unpredictably incorrect.
3. True or False? The system is rarely monitored at runtime to validate, verify, and ensure that correct system specifications are being met.
4. True or False? The system state is captured and saved based on undefined parameters (after every 1024 instructions or every 60 seconds).
5. True or False? Critical system components are duplicated using additional hardware, software, and network resources in such a way that a copy of the critical components is available even before a failure happens.
Multiple Choice
1. What measures the strength of the fault tolerance mechanism in terms of the granularity at which it can handle errors and failures in the system:
D. Multiple machines within the same cluster
2. What factor deals with the impact of the fault tolerance procedure on the end-to-end quality of service (QoS) both during failure and failure-free periods?
D. Multiple machines within the same cluster
3. How many replicas of an application can be placed on the hosts that are connected by a ToR switch (within a LAN)?
4. How many replicas of an application can be placed on the hosts belonging to different clusters in the same data center (on the hosts that are connected via a ToR switch and AggS)?
5. How many replicas of an application can be placed on the hosts belonging to different data centers (connected via a switch), AggS and AccR?
Exercise
Hands-On Projects
Project
What components go into a cloud architecture?
Case Projects
Problem
How does cloud architecture scale?
Optional Team Case Project
Problem
How do you achieve fault tolerance in a cloud?
Acknowledgments
This work was supported in part by the Italian Ministry of Research within the PRIN 2008 project “PEPPER” (2008SY2PH4).
References
1. Amazon Elastic Compute Cloud, © 2012, Amazon Web Services, Inc. or its affiliates. All rights reserved. <http://aws.amazon.com/ec2>, 2012.
2. Azure, © 2012 Microsoft. <http://www.windowsazure.com/en-us/>, 2012.
3. Build your business on Google Cloud Platform. <https://cloud.google.com/>, 2012.
4. Amazon Elastic Compute Cloud, © 2012, Amazon Web Services, Inc. or its affiliates. All rights reserved. <http://aws.amazon.com/ec2>, 2012.
5. E. Feller, L. Rilling, C. Morin, Snooze: a scalable and autonomic virtual machine management framework for private clouds, in: Proc. of CCGrid’12, Ottawa, Canada, 2012, pp. 482–489.
6. K. Vishwanath, N. Nagappan, Characterizing cloud computing hardware reliability, in: Proc. of SoCC’10, Indianapolis, IN, USA, 2010, pp. 193–204.
7. Helzle U, Barroso LA. The Datacenter as a Computer: An Introduction to the Design of Warehouse-Scale Machines first ed. Morgan and Claypool Publishers 2009.
8. B. Selic, Fault tolerance techniques for distributed systems, <http://www.ibm.com/developerworks/rational/library/114.html>, 2012.
9. A. Heddaya, A. Helal, Reliability, Availability, Dependability and Performability: A User-Centered View, Boston, MA, USA, Tech. Rep., 1997.
10. Armbrust M, Fox A, Griffith R, et al. Tech. Rep. UCB/EECS-2009-28 Above the Clouds: A Berkeley View of Cloud Computing Berkeley: EECS Department, University of California; 2009.
11. Gill P, Jain N, Nagappan N. Understanding network failures in data centers: measurement, analysis and implications. ACM Comp Commun Rev. 2011;41(4):350–361.
12. R. Jhawar, V. Piuri, Fault tolerance management in IaaS clouds, in: Proc. of ESTEL’12, Rome, Italy, October 20, 2012.
13. Smith WE, Trivedi KS, Tomek LA, Ackaret J. Availability analysis of blade server systems. IBM Syst J. 2008;47(4):621–640.
14. Load Balancing Data Center Services SRND: Solutions Reference Nework Design, Cisco Systems, Inc., 170 West Tasman Drive, San Jose, CA 95134-1706, Copyright © 2004, Cisco Systems, Inc. All rights reserved. <https://learningnetwork.cisco.com/servlet/JiveServlet/previewBody/3438-102-1-9467/cdccont_0900aecd800eb95a.pdf> March 2004.
15. Ayari N, Barbaron D, Lefevre L, Primet P. Fault tolerance for highly available internet services: concepts, approaches and issues. IEEE Commun Surv Tutor. 2008;10(2):34–46.
16. R. Jhawar, V. Piuri, M. Santambrogio, A comprehensive conceptual system-level approach to fault tolerance in cloud computing, in: Proc. of IEEE SysCon’12, Vancouver, BA, Canada, 2012, pp. 1–5.
17. R. Guerraoui, M. Yabandeh, Independent faults in the cloud, in: Proc. of LADIS’10, Zurich, Switzerland, 2010, pp. 12–17.
18. A. Undheim, A. Chilwan, P. Heegaard, Differentiated availability in cloud computing SLAs, in: Proc. of Grid’11, Lyon, France, 2011, pp. 129–136.
19. S. Kim, F. Machinda, K. Trivedi, Availability modeling and analysis of virtualized system, in: Proc. of PRDC’09, Shanghai, China, 2009, pp. 365–371.
20. B. Cully, G. Lefebvre, D. Meyer, M. Feeley, N. Hutchinson, A. Warfield, Remus: high availability via asynchronous virtual machine replication, in: Proc. of NSDI’08, San Francisco, CA, USA, pp. 161–174.
21. C. Clark, K. Fraser, S. Hand, J.G. Hansen, E. Jul, C. Limpach, et al., Live migration of virtual machines, in: Proc. NSDI’05, Boston, MA, USA, pp. 273–286.
22. M. Castro, B. Liskov, Practical byzantine fault tolerance, in: Proc. of OSDI’99, New Orleans, LA, USA, 1999, pp. 173–186.
23. T. Wood, R. Singh, A. Venkataramani, P. Shenoy, E. Cecchet, ZZ and the art of practical BFT execution, in: Proc. of EuroSys’11, Salzburg, Austria, 2011, pp. 123–138.
24. Kotla R, Alvisi L, Dahlin M, Clement A, Wong E. Zyzzyva: speculative byzantine fault tolerance. ACM Trans Comput Syst. 2009;27(4):7.1–7.39.
25. J. Yin, J.P. Martin, A. Venkataramani, L. Alvisi, M. Dahlin, Separating agreement from execution for byzantine fault tolerant services, in: Proc. of SOSP’03, New York, NY, USA, 2003, pp. 253–267.
26. Jhawar R, Piuri V, Santambrogio M. Fault tolerance management in cloud computing: a system-level perspective. IEEE Syst J. 2012.