
Chapter 9: Hash of Hashes – Looping Through SAS Hash Objects
9.2 Creating a Hash of Hashes (HoH) Table – Simple Example
9.3 Calculating Percentiles, Mode, Mean, and More
9.3.3 Percentiles, Mode, Median, and More
9.5.2 Multiple Split Calculations
9.1 Overview
Both our business users and their IT support staff have expressed appreciation for the examples provided so far that allow for parameterization and code generation. They commented positively on being exposed to the macro language and the capabilities of the SQL procedure.
However, they have expressed concern about having to write code for each hash table to be created, even given the overview of what could be done with the macro language and the SQL procedure. They plan on collecting more data that they would like to produce metrics on. For example, pitch speed, hit speed, run speed, and the list goes on. And they don’t want to have to add new code as they introduce new data fields and metrics.
They have also expressed surprise that we have not provided any examples of looping through multiple hash objects to address this requirement. Specifically, they were surprised that it was not possible to define a DATA step array of hash objects and loop through the hash objects. The IT support staff felt that such looping would be both simpler and clearer than using the macro language or the LINK statement to reuse the same/similar code.
We explained that such looping was possible by creating a hash object with the data portion containing non-scalar variables whose values point to other hash objects (note that the key portion cannot include such non-scalar variables).We also reminded them that this effort is a Proof of Concept and was never intended to be an implementation of their complete set of requirements.
In this chapter we provide an overview of creating a hash object whose items contain pointer values to other hash objects as their data – a Hash of Hashes which we abbreviate as HoH.
9.2 Creating a Hash of Hashes (HoH) Table – Simple Example
In section 8.2.3.1 “Calculating Multiple Medians,” we showed the following error message generated by the Program 8.6 Chapter 8 Multiple Medians Array Error.sas:
670 array _hashes(*) single double triple homerun;
ERROR: Cannot create an array of objects.
ERROR: DATA STEP Component Object failure.
Aborted during the COMPILATION phase.
NOTE: The SAS System stopped processing this step
because of errors.
As discussed in section 8.2.3.1, this error message is due to the fact that the PDV host variable that contains the pointer or identifier for a hash object is neither a numeric nor character field. As the ERROR message implies, it is an object; SAS considers numeric and character DATA step variables to be scalars, and the programming statements to deal with scalars can’t properly handle objects.
As we have already seen, a hash table entry can have scalar variables for which the hash items contain numeric or character values as data. However, the data portion of the table can also include non-scalar variables, particularly of type hash object. For any such hash variable (named H, say), the corresponding data values represent pointers to - or, if you will, identifiers of - the instances of other hash objects. The Retrieve operation (either by key or via enumeration) can be used to extract these pointer values from the HoH table into PDV host variable H, also of hash object type. After a pointer value has been retrieved into H, any hash method or operator call referencing H will now be executed against the hash table instance identified by the pointer value H currently contains. So just like an array can be used to loop through multiple numeric or character variables to perform the same operations, a hash object can be used to loop through multiple other hash objects to perform the same operations on each of those hash tables. The program below creates two hash tables and uses the DATASET argument tag to load the AtBats data sets into one of them and the Pitches data set into the second one. It then loops through those hash objects to produce notes in the log to demonstrate that we accessed two different hash tables.
Program 9.1 Chapter 9 Simple HoH.sas
data _null_;
length Table $41;
dcl hash HoH(); ❶
HoH.defineKey ("Table");
HoH.defineData("H","Table");
HoH.defineDone();
dcl hash h(); ❷
Table = "DW.AtBats"; ❸
h = _new_ hash(dataset:Table);
h.defineKey("Game_SK","Inning","Top_Bot","AB_Number");
h.defineData("Result");
h.defineDone();
HoH.add();
Table = "DW.Pitches"; ❹
h = _new_ hash(dataset:Table);
h.defineKey("Game_SK","Inning","Top_Bot","AB_Number","Pitch_Number");
h.defineData("Result");
h.defineDone();
HoH.add();
dcl hiter i_HoH("HoH"); ❺
do while (i_HoH.next() = 0); ❻
Rows = h.num_items; ❼
put (Table Rows)(=);
end;
stop; ➑
set dw.pitches(keep = Game_SK Inning Top_Bot AB_Number Pitch_Number Result); ➒
run;
❶ Define a hash object named HoH. The data portion variables in its hash table will be: (a) the non-scalar identifier H whose values point to other hash object instances; and (b) the scalar (character) variable Table. Note that though in this example we are not going to search table HoH by key, its key portion must contain at least one scalar variable; so we used variable Table, as the PDV host variable with this name already exists.
❷ Define a hash object named H. At the same time, the statement defines a non-scalar PDV variable H of type hash object. Its purpose is two-fold. First, it is to contain a pointer whose value identifies a particular instance of hash object H (similar to the field h_pointer discussed in 8.3 “Creating Multi-Way Aggregates”). Second, it is to serve as the PDV host variable for hash variable H defined in the data portion of table HoH.
❸ Create an instance of hash object H for the AtBats data and use the DATASET argument tag to load the data into its table. Now that the instance has been created, use the Insert operation to add a new item to table HoH. The value of Table forms its key portion; and the pointer to the instance of H (the current value of PDV variable H), along with the value of scalar variable Table, form its data portion. This value of H just loaded to the HoH hash table points to the hash table containing the AtBats data. (Note the use of the _NEW_ operator to create the instance of hash object H and assign the value of the identifier for this instance to the non-scalar PDV host variable H. We don’t use the DECLARE HASH statement here for instantiation, as it would require a different variable name for each hash object instance. Since we are going to insert the pointer values identifying different instances of the same hash object H into our HoH table, we want to reuse the same name.)
❹ Do the same for the AtBats data as we did for the Pitches data. Namely, first create a new instance of hash object H with the DATASET argument tag valued so as to load the data from Pitches. This value of H points to the hash table containing the Pitches data. Then use the pointer to this new instance as the value of hash variable H in another new item added to table HoH. We now have two entries in the hash table HoH with a value for H: one points to the hash table containing the AtBats data; one points to the hash table containing the Pitches data.
❺ Define a hash iterator for our Hash of Hashes (HoH) table. It enables the Enumerate All operation, so that we can illustrate looping through the HoH table sequentially one item at a time.
❻ Loop through our Hash of Hashes object (HOH) using the iterator, so that we can illustrate how to retrieve the pointer to each individual instance of hash object H using the same code. As we iterate through the HoH, for each item we access in the loop the PDV host values for H and Table are updated with the values from the corresponding HOH data portion hash variables.
❼ Get the number of items in the hash object instance whose identifier value, having just been retrieved from HoH, is currently stored in host variable H and assign it to variable Rows. Use the PUT statement to write the values of Rows to the log. Its point is to confirm that in each iteration through the loop, another pointer value that is stored in hash variable H is extracted into its PDV host variable H; and so each time operator H.NUM_ITEMS references hash object H, it accesses another instance of it identified by the pointer value retrieved in the current iteration.
❽ A STOP statement is used since the data is loaded into the hash tables using the DATASET argument tag. There is no need to execute the DATA step more than once.
❾ A SET statement (after the STOP statement) is used to define the needed PDV host variables. As mentioned in earlier programs, since that PDV host variables are not referenced in our DATA step program, the SET statement can appear anywhere; it does not need to be at the top of the DATA step. We needed only to reference the Pitches data set since it contains all the variables that need to be defined to the PDV. We could have just as easily referenced just the AtBats data set.
The SAS log notes and the PUT statement output are shown below.
NOTE: There were 287304 observations read from the data set DW.ATBATS.
NOTE: There were 875764 observations read from the data set DW.PITCHES.
Table=DW.AtBats Rows=287304
Table=DW.Pitches Rows=875764
We will provide a number of examples in the rest of this chapter that use the Hash of Hashes approach to parameterize and generalize a number of the examples discussed earlier in this book. These examples will illustrate that:
● Both scalar and non-scalar hash variables can coexist in the data portion of a hash table.
● The non-scalar variables of type hash object are pointers identifying hash object instances.
● The non-scalar variables of type hash iterator object can also be pointers identifying hash iterator object instances.
9.3 Calculating Percentiles, Mode, Mean, and More
Our first set of examples illustrating the Hash of Hashes approach is the reworking of section 8.2.3 “Calculating Medians, Percentiles the Mode, and More.”
We emphasized to both our business and IT users that we will be building up to the full capabilities of the Hash of Hashes approach by slowly building on the examples. As we revisit each of the examples from the previous chapter we will highlight additional functionality.
9.3.1 Percentiles
The first example is calculating percentiles. It illustrates iterating through the Hash of Hashes objects as well as each hash object item it contains. We are still hard-coding our list of variables; we will illustrate eliminating such hard coding shortly.
The following program does this calculation.
Program 9.2 Chapter 9 HoH Percentiles.sas
data Percentiles;
keep Variable Percentile Value;
length Variable $32;
format Percentile percent5. Value Best.;
dcl hash HoH(ordered:"A"); ❶
HoH.defineKey ("Variable");
HoH.defineData ("H","ITER","Variable"); ❷
HoH.defineDone();
dcl hash h();
dcl hiter iter; ❸
h = _new_ hash(dataset:"dw.AtBats(where=(Value) rename=(Distance=Value))" ❹
,multidata:"Y",ordered:"A");
h.defineKey("Value");
h.defineDone();
iter = _new_ hiter("H"); ❺
Variable = "Distance";
HoH.add(); ❻
h = _new_ hash(dataset:"dw.AtBats(where=(Value) rename=(Direction=Value))" ❼
,multidata:"Y",ordered:"A");
h.defineKey("Value");
h.defineDone();
iter = _new_ hiter("H");
Variable = "Direction";
HoH.add();
array _ptiles(6) _temporary_ (.05 .1 .25 .5 .75 .95);
call sortn(of _ptiles(*));
dcl hiter HoH_Iter("HoH"); ➑
do while (HoH_Iter.next() = 0); ➒
Counter = 0;
num_items = h.num_items;
do i = 1 to dim(_ptiles); ➓
Percentile = _ptiles(i);
do while (Counter lt Percentile*num_items);
Counter + 1;
iter.next();
end;
/* could add logic here to read next value to interpolate */
output;
end;
end;
stop;
Value = 0;
run;
❶ Define our Hash of Hashes table HoH. Since we want the output data ordered by the variable name, we use the ORDERED argument tag.
❷ Our percentile calculation requires us to iterate through our hash table objects that contain the data- i.e., we need an iterator object to do that. We can define a non-scalar field to be part of the data portion whose value is the pointer for that iterator object.
❸ Just as we saw above, we can define a non-scalar PDV variable Iter of type hash iterator. It will contain a pointer whose value identifies a particular instance of hash object iterator.
❹ Use the _NEW_ method to create an instance of the hash object H and load it with the Distance values from the AtBats data set. Note that in the argument to the DATASET argument, we renamed the Distance variable since we need to process multiple different variables. Our output data set will contain a column whose value is the variable's name (Variable) and another column whose value is the variable's value (Value).
❺ Use the _NEW_ method to create an instance of the hash iterator object Iter.
❻ The ADD method is used to add our hash object containing the data for the variable Distance to our Hash of Hashes object H.
❼ Repeat steps 4 through 6 for the variable Direction. Once the ADD method is executed, our Hash of Hashes table contains two items.
❽ In order to loop (i.e., enumerate) through our Hash of Hashes object HoH, we need an iterator object.
❾ We use the NEXT method to loop through all the items in our hash object HoH. Note that the first call to the NEXT method will point to the first item in HoH.
❿ The percentile calculation uses the same logic that we used in 8.2.3.2 “Calculating Additional Percentiles,” except we are now calculating percentiles for more than one variable in our input data set.
Running the above program creates the following output. Note that the percentile values for the variable Distance are the same as what we saw in Output 8.6.
Output 9.1 Direction Percentiles

Output 9.2 Distance Percentiles

9.3.2 Multiple Medians
We previously showed how to calculate medians using the hash object, including calculating medians for subgroups of the data – each type of hit. That required a separate hash object for each type of hit (similar to what many SAS users recognize as functionality that can be implemented using the BY statement) for each variable for which the median is required. As either the number of values or variables increases, the hard-coding is problematic.
This example uses parameter files and a Hash of Hashes object to provide functionality similar to what can be done with the BY statement. We need to calculate medians for both Distance and Direction for each value of the Result variable. Our first step is to create a parameter file that contains all the values of Result that have non-missing values for Distance and Direction.
While we could easily create a hash table with all the distinct values, we decided to use an SQL step to create the data we need. This approach reinforces combining the use of hash object techniques with other SAS functionality. We decided to take this approach for two reasons: to reinforce to the IT users the breadth of SAS tools; and to allow this example to focus on the Hash of Hashes approach. In response to a request from several of the IT users, we did agree to provide a variation of this program that just uses hash objects. They were curious about performance issues of this approach vs. an approach that uses only hash objects. You can access the blog entry that describes this program from the author page at http://support.sas.com/authors. Select either “Paul Dorfman” or “Don Henderson.” Then look for the cover thumbnail of this book, and select “Blog Entries.”
Program 9.3 Chapter 9 HoH Multiple Medians.sas (Part 1)
proc sql;
create table HoH_List as
select distinct "Distance " as Field
,Result
from dw.Atbats
where Distance is not null
outer union corr
select distinct "Direction" as Field
,Result
from dw.Atbats
where Distance is not null
;
quit;
The above SQL step creates the data set that specifies the 12 medians to be calculated.
Output 9.3 Medians to Be Calculated

This data set is used in the following program to create the Hash of Hashes object that contains the 12 hash objects needed to calculate the desired medians.
Program 9.3 Chapter 9 HoH Multiple Medians.sas (Part 2)
data Medians;
if 0 then set dw.AtBats(keep=Result);
length Median 8;
keep Result Field Median;
dcl hash HoH(ordered:"A"); ❶
HoH.defineKey ("Result","Field");
HoH.defineData ("Result","Field","h","iter");
HoH.defineDone();
dcl hash h();
dcl hiter iter;
do until(lr); ❷
set HoH_List end = lr;
h = _new_ hash(dataset:cats("dw.AtBats"
|| "(where=(Result='" ❸
,Result
,"')"
,"rename=("
,field
,"=Median))")
,multidata:"Y",ordered:"A");
h.defineKey("Median");
h.defineDone();
iter = _new_ hiter("h");
HoH.add();
end;
dcl hiter HoH_Iter("HoH"); ❹
do while (HoH_Iter.next() = 0); ❺
Count = h.num_items;
iter.first();
do i = 1 to .5*Count - 1;
iter.next();
end;
/* could add logic here to interpolate if needed */
output;
end;
stop;
run;
❶ Just as in our previous examples, define our Hash of Hashes table and use the ORDERED argument tag since we want the output sorted by the values of the Result variable and the variable name.
❷ Read all the observations in the parameter file to create all the needed hash objects.
❸ Use the _NEW_ method to create an instance of the hash object H and load it with the values from the AtBats data for the subject variables using the DATASET argument. The CATS function is used to create a character expression that filters the data using a WHERE clause and renames our variable to Median. We did this so the variable name in the output data set is the same for each of the variables. For the first row in our HoH_List data set, the CATS function returns the following character string:
dw.AtBats(where=(Result='Double') rename=(Distance=Median))
❹ In order to loop (i.e., enumerate) through our Hash of Hashes object HoH, the hash iterator object HoH_Iter is created.
❺ Loop (enumerate) through the hash objects for each desired median and calculate the medians using the same logic used in section 8.2.3.1 “Calculating Multiple Medians.”
Running the above program creates the following output.
Output 9.4 Calculated Medians

When we reviewed this example with the IT staff, they noticed that the two loops seemed duplicative. They asked why not just calculate the medians inside the loop that read the data. We agreed that could be done and, in fact, would not need a Hash of Hashes object. We also reminded them again that this is a Proof of Concept and that we wanted to use this example to build upon the capabilities of the Hash of Hashes approach. We did agree to provide an example of such an approach (in addition to the alternative mentioned above that does not use the SQL procedure). You can access the blog entry that describes this program from the author page at http://support.sas.com/authors. Select either “Paul Dorfman” or “Don Henderson.” Then look for the cover thumbnail of this book, and select “Blog Entries.”
9.3.3 Percentiles, Mode, Median, and More
In 8.2.3.4 “Calculating Percentiles, Mode, Mean, and More in a Single DATA Step” we generated our percentiles and medians examples to illustrate using the hash object to, in one step, calculate percentages, and frequency distribution as well as the Mean, Median, Min, and Max.
This example demonstrates:
● More parameterization.
● The use of macro variables created using the SQL procedure.
● Using the ARRAY statement to define what Hash of Hashes objects are needed.
● Using an output data set for selected output metrics (the frequency distributions).
● Creating a hash object specifically to include the results of our calculations.
● Additional columns in the data portion of our Hash of Hashes object in order to facilitate the needed calculations.
The following DATA step program implements the Hash of Hashes approach to perform these calculations on multiple variables.
Program 9.4 Chapter 9 HoH MeanMedianMode.sas (Part 1)
data Ptiles; ❶
input Percentile;
Metric = put(Percentile,percent8.);
datalines;
.05
.1
.25
.5
.75
.95
;
data Variables; ❷
infile datalines;
length Variable $32;
input Variable $32.;
datalines;
Distance
Direction
;
proc sql noprint; ❸
select distinct Variable
into:Vars separated by ' '
from Variables;
quit;
❶ As we did previously, a data set is used to define the desired percentiles instead of an array. Note that we have both a numeric version (for use in performing the calculations) and character version (created by the PUT function for use in labeling the results) for each desired percentile value.
❷ A data set is used to list the variables to be analyzed. We pointed out to our users that, long term, this would be parameterized and not created in each program (again reminding them that this is just a Proof of Concept).
❸ The SQL procedure is then used to create a macro variable whose value is the list of variables (this approach also works if there is only one variable) to be analyzed.
The above code will likely be replaced in the followon implementation project. We wanted to separate the discussion of what this code does from the DATA step that implements the HoH approach which follows.
Program 9.4 Chapter 9 HoH MeanMedianMode.sas (Part 2)
data Distributions(keep=Variable Value Count Percent Cumulative Cum_Percent); ❶
length Variable $32 Value 8 Metric $8;
format Count Cumulative total comma12. Percent Cum_Percent percent7.2;
array _Variables(*) &Vars; ❷
dcl hash ptiles(dataset:"ptiles",ordered:"A"); ❸
ptiles.defineKey("Percentile");
ptiles.defineData("Percentile","Metric");
ptiles.defineDone();
dcl hiter iter_ptiles("ptiles");
dcl hash results(ordered:"A",multidata:"Y"); ❹
results.defineKey("Variable","Metric");
results.defineData("Variable","Metric","Value");
results.defineDone();
dcl hash HoH(ordered:"A"); ❺
HoH.defineKey ("I");
HoH.defineData ("H","ITER","Variable","Total","Sum","maxCount");
HoH.defineDone();
dcl hash h();
dcl hiter iter;
do I = 1 to dim(_Variables); ❻
h = _new_ hash(ordered:"A");
h.defineKey(vname(_Variables(i)));
h.defineData(vname(_Variables(i)),"Count");
h.defineDone();
iter = _new_ hiter("H");
Variable = vname(_Variables(i));
HoH.add();
end;
maxCount=0;
do Rows = 1 by 1 until(lr); ❼
set dw.AtBats end=lr;
do I = 1 to dim(_Variables); ❽
HoH.find(); ❾
if missing(_Variables(i)) then continue; ➓
if h.find() ne 0 then Count = 0;
Count + 1;
h.replace(); ![]()
Total + 1;
Sum + _Variables(I);
maxCount = max(Count,maxCount);
HoH.replace(); ![]()
end;
end;
do I = 1 to dim(_Variables); ![]()
_cum = 0;
HoH.find();
iter_ptiles.first();
last = .;
do j = 1 to h.num_items; ![]()
iter.next();
Percent = divide(Count,Total);
_Cum + Count;
Cumulative = _Cum;
Cum_Percent = divide(_Cum,Total);
Value = _Variables(I); /*vvalue(_Variables(I))*/
output; ![]()
if Count = maxCount
then results.add(Key:Variable
,Key:"Mode"
,Data:Variable
,Data:"Mode"
,Data:_Variables(I) /*vvalue(_Variables(I))*/ ![]()
);
if last le Percentile le Cum_Percent then
do; /* found the percentile */
if percentile ne 1 then results.add();
if iter_ptiles.next() ne 0 then percentile = 1;
end; /* found the percentile */
last = Cum_Percent;
end;
Value = divide(Sum,Total); ![]()
Metric = "Mean";
results.add();
iter.first(); ![]()
Value = _Variables(I); /*vvalue(_Variables(I))*/
Metric = "Min";
results.add();
iter.last(); ![]()
Value = _Variables(I); /*vvalue(_Variables(I))*/
Metric = "Max";
results.add();
end;
results.output(dataset:"Metrics"); ![]()
stop;
set ptiles;
run;
❶ Create an output data set for the frequency distributions.
❷ Define an array that contains the list of variables. The number of elements in this array defines how many hash object instances to create in our Hash of Hashes table.
❸ Define a hash object containing the desired percentile values similar to what was done previously. Note that this hash object does not contain the additional variables in the data portion for the results.
❹ Define a hash object that will contain the results (other than the frequency distribution). Note that both the Variable name and the Metric name are keys. The MULTIDATA argument tag is used to allow multiple items for the same key-values. This is needed because the Mode metric can have more than one value.
❺ Define our Hash of Hashes object. Note that it contains additional columns in the data portion that are used in performing our calculations. As we iterate (enumerate) through our hash object instances, these values will be updated and kept in synch with the PDV host variables.
❻ Loop through the elements of our array and create a hash object instance for each variable in the array. Note the use of the DIM function which prevents hard-coding of the number of variables as well as the VNAME function to insert the variable name into the Hash of Hashes table.
❼ Read all the AtBats data rows in an explicit (DoW) loop.
❽ As each row is read from the AtBats data set, loop through the items in the hash object HoH. Note that we do not use a hash iterator object; instead we can loop through the items as we loop through the array.
❾ Since the hash object HoH uses the array index variable I as its key, the FIND method retrieves the data portion values for the hash item corresponding to the variable in the array. This includes the running totals for the sum of the variable (Sum) and the total number of rows (Total), as well as the maximum frequency (maxCount).
❿ Skip rows that have a missing value for the subject variable.
![]() After the current frequency value (Count) has been incremented, update the instance of the hash object for the current variable.
After the current frequency value (Count) has been incremented, update the instance of the hash object for the current variable.
![]() After the running totals for the sum of the variable (Sum) and the total number of rows, (Total) as well as the maximum frequency (maxCount), update the data portion of the hash object HoH.
After the running totals for the sum of the variable (Sum) and the total number of rows, (Total) as well as the maximum frequency (maxCount), update the data portion of the hash object HoH.
![]() Once all the data has been read and summarized into our hash object, loop through the items in the hash object HoH to perform the needed calculations.
Once all the data has been read and summarized into our hash object, loop through the items in the hash object HoH to perform the needed calculations.
![]() The instances of the hash object H contain the frequency counts. Loop through the data to calculate the percent, cumulative count, and the cumulative percent.
The instances of the hash object H contain the frequency counts. Loop through the data to calculate the percent, cumulative count, and the cumulative percent.
![]() Output a row to the data set for the frequency distribution.
Output a row to the data set for the frequency distribution.
![]() If the value of Count is equal to the maximum (maxCount), add an item to the Results hash object for the Mode. Note that this assumes that all the variables to be analyzed are numeric. If both numeric and character variables are included, the PDV host variable Value can be defined as character and the VVALUE function can be used to provide the formatted value as a character expression.
If the value of Count is equal to the maximum (maxCount), add an item to the Results hash object for the Mode. Note that this assumes that all the variables to be analyzed are numeric. If both numeric and character variables are included, the PDV host variable Value can be defined as character and the VVALUE function can be used to provide the formatted value as a character expression.
![]() Calculate the Mean and call the ADD method to add an item to the hash object Results.
Calculate the Mean and call the ADD method to add an item to the hash object Results.
![]() Since the hash object H is in acending order, the first item is the minimum. Use the FIRST iterator object method to retrieve that value and call the ADD method to add an item to the hash object Results.
Since the hash object H is in acending order, the first item is the minimum. Use the FIRST iterator object method to retrieve that value and call the ADD method to add an item to the hash object Results.
![]() Likewise, the last item is the maximum. Use the LAST iterator object method to retrieve that value and call the ADD method to add an item to the hash object Results.
Likewise, the last item is the maximum. Use the LAST iterator object method to retrieve that value and call the ADD method to add an item to the hash object Results.
![]() Use the OUTPUT method to create a data set containing the calculated metrics to the data set Metrics.
Use the OUTPUT method to create a data set containing the calculated metrics to the data set Metrics.
The calculated metric values generated by the above program follow. Note that we have two Mode values for Distance. The metrics output for the Distance variable (Output 9.6) displays the same values as seen in Output 8.8 .
Output 9.5 Direction Metrics

Output 9.6 Distance Metrics
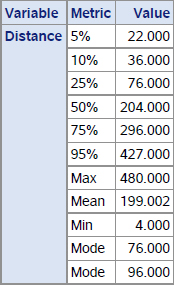
Output 9.7 First 10 Rows for the Direction Frequency Distribution

Output 9.8 First 10 Rows for the Distance Frequency Distribution

9.4 Consecutive Events
This next example illustrates the use of arrays for scalar variables (i.e., numeric variables) whose values are needed to perform the needed calculations. In this case we are using a Hash of Hashes approach to count the same consecutive events as in the prior chapter. Four arrays are used to define:
● The variables which represent the event (the batter got a hit; the batter got on base).
● The calculated key for the hash object.
● The two fields (an array for each one) needed for each of the events.
The following code illustrates this approach. Note that while we could have also used parameter files for this, we have not done that in order to focus on the use of arrays. This program produces the same results as seen in section 8.2.3.5 “Determining the Distribution of Consecutive Events.”
Program 9.5 Chapter 9 HoH Count Consecutive Events.sas
data _null_;
format Consecutive_Hits Consecutive_OnBase 8.
Hits_Exact_Count Hits_Total_Count
OnBase_Exact_Count OnBase_Total_Count comma10.;
array _Is_A(*) Is_A_Hit Is_An_OnBase; ❶
array _Consecutive(*) Consecutive_Hits Consecutive_OnBase;
array _Exact(*) Hits_Exact_Count OnBase_Exact_Count;
array _Total(*) Hits_Total_Count OnBase_Total_Count;
if _n_ = 1 then
do; /* define the hash tables */
dcl hash HoH(ordered:"A"); ❷
HoH.defineKey ("I");
HoH.defineData ("H","ITER","Table");
HoH.defineDone();
dcl hash h();
dcl hiter iter;
h = _new_ hash(ordered:"D"); ❸
h.defineKey("Consecutive_Hits");
h.defineData("Consecutive_Hits","Hits_Total_Count","Hits_Exact_Count");
h.defineDone();
iter = _new_ hiter("H");
I = 1;
Table = vname(_Consecutive(I));
HoH.add();
h = _new_ hash(ordered:"D");
h.defineKey("Consecutive_OnBase");
h.defineData("Consecutive_OnBase","OnBase_Total_Count"
,"OnBase_Exact_Count");
h.defineDone();
iter = _new_ hiter("H");
I = 2;
Table = vname(_Consecutive(I));
HoH.add();;
end; /* define the hash table */
do I = 1 to dim(_Consecutive); ❹
_Consecutive(I) = 0;
end;
do until(last.Top_Bot); ❺
set dw.atbats(keep=Game_SK Inning Top_Bot Is_A_Hit Is_An_OnBase) end=lr;
by Game_SK Inning Top_Bot notsorted;
do I = 1 to dim(_Consecutive);
_Consecutive(I)=ifn(_Is_A(I),_Consecutive(I)+1,0); ❻
end;
do I = 1 to HoH.num_items; ❼
HoH.find();
if h.find() ne 0 then call missing(_Exact(I));
_Exact(I) + 1;
if _Is_A(I) then h.replace();
end;
end;
if lr; ❽
do I = 1 to dim(_Consecutive); ❾
HoH.find();
Cum = 0;
do consec = 1 to h.num_items;
rc = iter.next();
Cum + _Exact(I);
_Total(I) = Cum;
h.replace();
end;
h.output(dataset:Table); ➓
end;
run;
❶ Define the four arrays. Note that the dimension of the arrays (2) corresponds to the number of event types for which consecutive occurrences are to be calculated.
❷ Define our Hash of Hashes object. Note that the key portion is the index variable for the array. The ORDERED argument tag is used to ensure that the array elements are in sync with the instances in the Hash of Hashes object. One of the columns in the data portion is the variable name. That will be used to name the output data set.
❸ Create the hash object instances for each of the types of consecutive events. This could be parameterized (as mentioned above), but we chose not to do that in this Proof of Concept.
❹ Initialize the key portion of the hash values to 0 - in other words, no consecutive events at this point in processing the input data, just as what was done in the Program 8.13 example.
❺ Use a DoW loop to make each execution of the DATA step read the data for a single half inning, so that we can count consecutive events for each team separately. Note that we did not include the team identifier in our output data set. That could be easily done by using a hash object to look up the team details.
❻ Determine the key value for each event type just as in the Program 8.13 example (except we are using an array instead of a hard-coded variable name).
❼ Again, this is the same logic as was used in the prior example, except for the use of arrays to handle multiple event types.
❽ The remaining logic is executed only after we have read all the data.
❾ Use the array dimension to enumerate our Hash of Hashes objects and calculate the value that represents the “N or more” event counts by creating a cumulative count and adding it to the current exact count.
❿ Create an output data set for each event type.
Running the above program creates the following output. These are the same values as seen in Output 8.11. The only difference is that Output 8.11 showed one table and this output is one table for each type of consecutive event.
Output 9.9 Consecutive Hit Events

Output 9.10 Consecutive OnBase Events

9.5 Multiple Splits
Multiple splits is probably the ideal use case for the Hash of Hashes approach as there are almost a countably infinite set of splits that our users and the fans of Bizarro Ball are interested in. We included just a small sample in the previous example. There are many, many more splits that are almost a standard. For example, in addition to the ones included previously:
● Team vs. Team
● Batter vs. Team
● Pitcher vs. Team
● Batter vs. Pitcher
● Batter hits left/right/switch vs. Pitcher left/right
● Inning
● Home vs. Away
● Any combination of the above
● And so on, and so on
Given the number of different splits that may be requested, our example here leverages all the needed features that we illustrated earlier- most notably the use of parameter files to define the hash objects for both the lookup tables needed as well as for the splits calculations.
● Template.Chapter9LookupTables which are the lookup tables and which include a column that designates the name of the data set to be loaded using the DATASET argument tag. When this is implemented in the eventual application, we will likely create a parent-child table structure for this, as the variable datasetTag is not needed on every observation.
● Template.Chapter9Splits which lists the splits to be calculated. When this is implemented in the eventual application, we will likely also create a parent-child table structure for this to specify the values for the various argument tags (e.g., the ORDERED argument tag).
Output 9.11 All 20 Rows of Template.Chapter9LookupTables

Output 9.12 First 20 Rows of Template.Chapter9Splits

The following program calculates these splits.
Program 9.6 HoH Chapter 9 Multiple Splits.sas
data _null_;
dcl hash HoH(ordered:"A"); ❶
HoH.defineKey("hashTable");
HoH.defineData("hashTable","H","ITER","CalcAndOutput");
HoH.defineDone();
dcl hiter HoH_Iter("HoH");
dcl hash h();
dcl hiter iter;
/* define the lookup hash object tables */
do while(lr=0); ❷
set template.chapter9lookuptables
template.chapter9splits(in = CalcAndOutput)
end=lr;
by hashTable;
if first.hashTable then ❸
do; /* create the hash object instance */
if datasetTag ne ' ' then h = _new_ hash(dataset:datasetTag
,multidata:"Y");
else h = _new_ hash(multidata:"Y");
end; /* create the hash object instance */
if Is_A_key then h.DefineKey(Column); ❹
h.DefineData(Column); ❺
if last.hashTable then ❻
do; /* close the definition and add it to our HoH hash table */
h.defineDone();
HoH.add();
end; /* close the definition and add it to our HoH hash table */
end;
/* create non-scalar fields for the needed lookup tables */
HoH.find(key:"GAMES"); ❼
dcl hash games;
games = h;
HoH.find(key:"PLAYERS");
dcl hash players;
players = h;
HoH.find(key:"TEAMS");
dcl hash teams;
teams = h;
if 0 then set dw.players
dw.teams
dw.games;
format PAs AtBats Hits comma6. BA OBP SLG OPS 5.3;
lr = 0;
do until(lr); ❽
set dw.AtBats(rename=(batter_id=player_id)) end = lr;
call missing(Team_SK,Last_Name,First_Name,Team_Name,Date,Month,DayOfWeek);
games.find();
players_rc = players.find();
do while(players_rc = 0);
if (Start_Date le Date le End_Date) then leave;
players_rc = players.find_next();
end;
if players_rc ne 0 then call missing(Team_SK,First_Name,Last_Name);
teams.find();
do while (HoH_Iter.next() = 0); ❾
if not calcAndOutput then continue;
call missing(PAs,AtBats,Hits,_Bases,_Reached_Base);
rc = h.find();
PAs + 1;
AtBats + Is_An_AB;
Hits + Is_A_Hit;
_Bases + Bases;
_Reached_Base + Is_An_OnBase;
BA = divide(Hits,AtBats);
OBP = divide(_Reached_Base,PAs);
SLG = divide(_Bases,AtBats);
OPS = sum(OBP,SLG);
h.replace();
end;
end;
do while (HoH_Iter.next() = 0); ➓
if not calcAndOutput then continue;
h.output(dataset:hashTable||"(drop=_:)");
end;
stop;
run;
❶ As in our previous example, define our Hash of Hashes table. The key for our hash table is the name of our hash table. We have two different uses of the hash object instances added to this hash table: used as a lookup table vs. as a table to contain our split calculations. We include the column calcAndOutput in the data portion to distinguish between these.
❷ Read the parameter files that define the hash tables to be created. An IN variable is used to provide the value for the calcAndOutput PDV host variable that is included in the data portion of our Hash of Hashes tables. That allows us to identify those items which contain instances that are to contain calculations and are used to create output data sets vs. those that create the needed lookup tables.
❸ Use the _NEW_ operator to create an instance of the hash object H and if the instance is a lookup table, load the data into it. Note that the MULTIDATA argument tag is set to allow multiples for the lookup tables. Eventually that should be parameterized so the setting can be specific to each lookup table. We need to allow for multiple items with the same key value since the PLAYERS lookup table is the Type 2 Slowly Changing Dimension table created in section 7.4, “Creating a Bizarro Ball Star Schema Data Warehouse.”
❹ If the current column is part of the key portion, define it as a key.
❺ Regardless, add the column to the data portion of the hash object. For now we are assuming that every column is added to the data portion of the hash object. Eventually this can be parameterized so that a column can be included in just the key portion, just the data portion, of both portions of the hash object.
❻ Finalize the creation of the hash table instance.
❼ In order to perform the table lookups (search-and-retrieve) needed, we need a non-scalar variable of type hash object for each lookup table. We use the FIND method to populate non-scalar variables whose values point to the instances of the lookup table hash objects for Games, Players, and Teams.
❽ Read the AtBats data in a loop and perform the table lookups (search-and-retrieve) for the needed fields from the Games, Players, and Teams lookup tables just as was done previously. The only change made here is that we have decided to use Player_ID as the key to the lookup table.
❾ Loop (enumerate) the hash object and, for every instance that is a hash that contains calculated splits, perform the calculations. Note that this looping eliminates the need for multiple assignments and LINK statements.
❿ Loop (enumerate) the hash object and for every instance that is a hash table that contains calculated splits use the OUTPUT method to create an output data set containing the results for this split.
This program calculates the same metrics as seen in Output 8.12-8.16. The output data sets are not ordered (i.e., sorted) by the key values, as the ORDERED data set tag was not used as was used for the data sets listed in Output 8.12-8.16. Because of that, the data rows shown here may be different given that only the first 5 rows are shown. We told the business users that additional metadata options could certainly be implement to specify and control the ordering of the output data sets. We also told them that those details would be determined should they decide to proceed to a full implementation after the completion of the Proof of Concept.
Output 9.13 First 5 Rows of byDayOfWeek Split Results

Output 9.14 First 5 Rows of byMonth Split Results

Output 9.15 First 5 Rows of byPlayer Split Results

Output 9.16 First 5 Rows of byPlayerMonth Split Results

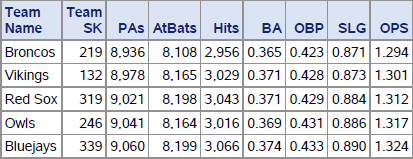
Output 9.17 First 5 Rows of byTeam Split Results
9.5.1 Adding a Unique Count
The users for our Proof of Concept have confirmed that they like this approach to deal with splits. However, they have expressed a couple of concerns. The functionality to calculate unique counts (e.g., games played) is absolutely required, and they need to see an example of doing that using the Hash of Hashes approach. We agreed to do that but qualified that to say that we would not attempt to parameterize that at this point. We assured them it could be parameterized and pointed out that just modifying the existing program using a hard-coded approach would likely do a better job of illustrating how this could be done. They agreed to that limitation and so the following program illustrates adding a unique count of Games. The changes to the program are shown in bold.
Program 9.7 Chapter 9 HoH Multiple Splits with Unique Count.sas
data _null_;
dcl hash HoH(ordered:"A");
HoH.defineKey("hashTable");
HoH.defineData("hashTable","H","ITER","calcAndOutput","U"); ❶
HoH.defineDone();
dcl hiter HoH_Iter("HoH");
dcl hash h();
dcl hash u(); ❷
dcl hiter iter;
/* define the lookup hash object tables */
do while(lr=0);
set template.chapter9lookuptables
template.chapter9splits(in = calcAndOutput)
end=lr;
by hashTable;
if first.hashTable then
do; /* create the hash object instance */
if datasetTag ne ' ' then ❸
do; /* create the lookup table hash object */
h = _new_ hash(dataset:datasetTag,multidata:"Y");
u = _new_ hash(); /* not used */
end; /* create the lookup table hash object */
else
do; /* create the two hash objects for the calculations */
h = _new_ hash();
u = _new_ hash();
end; /* create the two hash objects for the calculations */
end; /* create the hash object instance */
if Is_A_Key then
do; /* define the keys for the two hash objects for the calculations */
h.DefineKey(Column);
u.DefineKey(Column); ❹
if calcAndOutput then u.DefineKey("Game_SK");
end; /* define the keys for the two hash objects for the calculations */
h.DefineData(Column);
if last.hashTable then
do; /* close the definition and add it to our HoH hash table */
if calcAndOutput then h.DefineData("N_Games"); ❺
h.defineDone();
u.defineDone();
HoH.add();
end; /* close the definition and add it to our HoH hash table */
end;
/* create non-scalar fields for the needed lookup tables */
HoH.find(key:"GAMES");
dcl hash games;
games = h;
HoH.find(key:"PLAYERS");
dcl hash players;
players = h;
HoH.find(key:"TEAMS");
dcl hash teams;
teams = h;
if 0 then set dw.players
dw.teams
dw.games;
format PAs AtBats Hits comma6. BA OBP SLG OPS 5.3;
lr = 0;
do until(lr);
set dw.AtBats(rename=(batter_id=player_id)) end = lr;
call missing(Team_SK,Last_Name,First_Name,Team_Name,Date,Month,DayOfWeek);
games.find();
players_rc = players.find();
do while(players_rc = 0);
if (Start_Date le Date le End_Date) then leave;
players_rc = players.find_next();
end;
if players_rc ne 0 then call missing(Team_SK,First_Name,Last_Name);
teams.find();
do while (HoH_Iter.next() = 0);
if not calcAndOutput then continue;
call missing(N_Games,PAs,AtBats,Hits,_Bases,_Reached_Base); ❻
rc = h.find();
N_Games + (u.add() = 0); ❼
PAs + 1;
AtBats + Is_An_AB;
Hits + Is_A_Hit;
_Bases + Bases;
_Reached_Base + Is_An_OnBase;
BA = divide(Hits,AtBats);
OBP = divide(_Reached_Base,PAs);
SLG = divide(_Bases,AtBats);
OPS = sum(OBP,SLG);
h.replace();
end;
end;
do while (HoH_Iter.next() = 0);
if not calcAndOutput then continue;
h.output(dataset:hashTable||"(drop=_:)");
end;
stop;
run;
❶ Add a non-scalar field U (i.e., a hash pointer) to the data portion of our Hash of Hashes object HoH. The hash object instance identified by the value of U will be used to support the calculation of a distinct (or unique) count.
❷ Define a non-scalar PDV variable U of type hash.
❸ Create an instance of the hash object U in addition to the instances of the hash object H. Note that we don’t need a hash object instance of U for the lookup tables. However, as it is not clear that an existing non-scalar field can be set to null, we create a new one (which has virtually no impact on performance). This prevents the lookup table hash table items from having a value for U that points to an instance that was generated previously in the loop for a splits hash table.
❹ The hash object instance U is defined to have the same keys as the splits hash object as well as the variable (Game_SK) which is the unique key for each game.
❺ Add the field N_Games to the data portion of our splits hash objects.
❻ Add N_Games to the list of calculated fields that need to be set to null before the FIND method call.
❼ Add 1 to the current value of N_Games if the current key value for the split (plus Game_SK) is not found in the hash object instance pointed to by the value of U. If the key is not found, that means this is a new game and the unique count of games should be incremented. This is exactly the same logic as used in earlier examples.
This program produces the same results for all of the fields in the previous example along with the additional field N_Games. The following output shows two of the output tables created.
Output 9.18 First 5 Rows of byDayOfWeek

The value of N_Games is the same for all the rows due to the nature of the schedule of the games.
Output 9.19 First 5 Rows of byMonth

The above results are the same as what is shown in Output 9.13 and 9.14 with the exception of the additional column N_Games. Note that the results are not sorted by the key here as well. Also note that the number of games is different for each month since each month has a different number of games due to the fact that months don’t start on a week boundary and there are no games played on Thursday.
9.5.2 Multiple Split Calculations
The second concern our users expressed is how to deal with splits that either required different key values (e.g., pitching splits instead of or in addition to batting splits), or different calculations. For different calculations we pointed out that one approach (again, via parameterization) was separate programs or perhaps the use of the macro language. We did agree to augment our original multiple splits program to illustrate performing both batting and pitching splits. Shown below is a program that calculates metrics for how each batter does against all the pitchers he has faced while at the same time calculating metrics for how each pitcher does against all the batters he has faced.
Our first step is to augment our parameter file that defines the splits. Our users agreed to let us hard-code that update into our sample programs instead of building another parameter file once we pointed out that the changes would be clearer if we took that approach.
Program 9.8 Chapter 9 HoH Multiple Splits Batter and Pitcher.sas (Part 1)
data chapter9splits;
set template.chapter9splits
template.chapter9splits(in=asPitcher); ❶
by hashTable;
if asPitcher
then hashTable = catx("_",hashTable,"PITCHER"); ❷
else hashTable = catx("_",hashTable,"BATTER");
output;
if last.hashTable;
Column = "IP"; ❸
output;
Column = "ERA";
output;
Column = "WHIP";
output;
Column = "_Runs";
output;
Column = "_Outs";
output;
Column = "_Walks";
output;
run;
proc sort data = chapter9splits out = chapter9splits equals;
by hashTable;
run;
proc sql;
create table pitchers as ❹
select distinct game_sk, top_bot, ab_number, pitcher_id
from dw.pitches;
quit;
❶ Interleave the data set with itself and create a copy in the WORK library that has each split definition repeated – once for batter splits and once for pitcher splits.
❷ The hashTable field is updated to include either PITCHER or BATTER in the name. We will use that (hard-coded for now) to perform the needed calculations for each type of split.
❸ The pitching calculations included all the same calculations as done for batters, plus some additional ones:
◦ IP – Innings Pitched.
◦ ERA – Earned Run Average. Note that our sample data does not distinguish between earned and unearned runs.
◦ WHIP – Walks plus Hits per Inning Pitched.
◦ Runs, _Outs and _Walks. These are fields we need to aggregate in order to do the needed additional calculations. Note that their names begin with underscores (_) so they will be excluded from the output data set.
❹ In order to create split calculations we need to know who the pitcher was for each row in the AtBats data set. That field is not available in the AtBats data set. But we can look it up in the Pitches data set using the appropriate set of keys (Game_SK, Top_Bot, AB_Number). The following SQL procedure step creates the data needed for the lookup table.
The above code will likely be replaced in the followon implementation project. We wanted to separate the discussion of what this code does from the DATA step that implements the HoH approach which follows.
Output 9.20 Modified Chapter9Splits Data Set – First 26 Rows

Note that the first 10 rows in the above table are the same except for the _BATTER suffix as seen in Output 9.12. The next 10 are also the same except for the _PITCHER suffix. The next 6 rows are the additional Pitcher split metrics to be calculated.
Program 9.8 Chapter 9 HoH Multiple Splits Batter and Pitcher.sas (Part 2)
data _null_;
dcl hash HoH(ordered:"A");
HoH.defineKey ("hashTable");
HoH.defineData ("hashTable","H","ITER","CalcAndOutput");
HoH.defineDone();
dcl hiter HoH_Iter("HoH");
dcl hash h();
dcl hiter iter;
/* define the lookup hash object tables */
do while(lr=0);
set template.chapter9lookuptables
chapter9splits(in=CalcAndOutput) ❶
end=lr;
by hashTable;
if first.hashTable then
do; /* create the hash object instance */
if datasetTag ne ' ' then h = _new_ hash(dataset:datasetTag
,multidata:"Y");
else h = _new_ hash(multidata:"Y");
end; /* create the hash object instance */
if Is_A_key then h.DefineKey(Column);
h.DefineData(Column);
if last.hashTable then
do; /* close the definition and add it to our HoH hash table */
h.defineDone();
HoH.add();
end; /* close the definition and add it to our HoH hash table */
end;
/* create non-scalar fields for the needed lookup tables */
HoH.find(key:"GAMES");
dcl hash games;
games = h;
HoH.find(key:"PLAYERS");
dcl hash players;
players = h;
HoH.find(key:"TEAMS");
dcl hash teams;
teams = h;
dcl hash pitchers(dataset:"Pitchers"); ❷
pitchers.defineKey("game_sk","top_bot","ab_number");
pitchers.defineData("pitcher_id");
pitchers.defineDone();
if 0 then set dw.players
dw.teams
dw.games
dw.pitches; ❸
format PAs AtBats Hits comma6.
BA OBP SLG OPS 5.3
IP comma6. ERA WHIP 6.3; ❹
lr = 0;
do until(lr);
set dw.AtBats end = lr; ❺
call missing(Team_SK,Last_Name,First_Name,Team_Name,Date,Month,DayOfWeek);
games.find();
pitchers.find(); ❻
do while (HoH_Iter.next() = 0);
if not calcAndOutput then continue;
call missing(PAs,AtBats,Hits,_Bases,_Reached_Base,_Outs,_Runs); ❼
if upcase(scan(hashTable,-1,"_")) = "BATTER" then player_id = batter_id; ❽
else player_id = pitcher_id;
players_rc = players.find();
do while(players_rc = 0);
if (Start_Date le Date le End_Date) then leave;
players_rc = players.find_next();
end;
if players_rc ne 0 then call missing(Team_SK,First_Name,Last_Name);
teams.find();
rc = h.find();
PAs + 1;
AtBats + Is_An_AB;
Hits + Is_A_Hit;
_Bases + Bases;
_Reached_Base + Is_An_OnBase;
_Outs + Is_An_Out; ❾
_Runs + Runs;
_Walks + (Result = "Walk");
BA = divide(Hits,AtBats);
OBP = divide(_Reached_Base,PAs);
SLG = divide(_Bases,AtBats);
OPS = sum(OBP,SLG);
if _Outs then ➓
do; /* calculate pitcher metrics suppressing missing value note */
IP = _Outs/3;
ERA = divide(_Runs*9,IP);
WHIP = divide(sum(_Walks,Hits),IP);
end; /* calculate pitcher metrics suppressing missing value note */
h.replace();
end;
end;
do while (HoH_Iter.next() = 0);
if not calcAndOutput then continue;
h.output(dataset:hashTable||"(drop=_:)");
end;
stop;
run;
❶ Use our modified parameter file instead of the original one in the template library.
❷ Create the hash table needed to look up the pitcher details for each row in the AtBats data set.
❸ Add the Pitchers data to define the variables to the PDV.
❹ Add formats for our new calculations.
❺ We are not renaming Batter_ID to Player_ID as we need to use both Batter_ID and Pitcher_ID to look up the player information.
❻ Call the FIND method to find and retrieve the Pitcher_ID value for the current row in the AtBats data set.
❼ Call the MISSING call routine to set the additional fields used in the calculations to null.
❽ The value used for Player_ID needs to be the value of Batter_ID for batter split calculations and Pitcher_ID for pitcher split calculations. Because we are changing this value as we loop through the hash object instances, the player and team detail lookups are now done inside the loop.
❾ Add the counts/sums needed for the additional pitching splits calculations.
❿ Calculate the values for the additional pitching metrics.
This program creates 5 output data sets of batting splits and 5 of pitching splits. The first 5 rows of the team splits for batters and pitches are shown below.
Output 9.21 First 5 Rows of Batter Splits

Comparing this output with the byPlayer splits seen in Output 9.15 above confirms that the results are the same. This is as we expected since the point of this example was to leave the batter metrics unchanged while calculating additional metrics for each pitcher.
Output 9.22 First 5 Rows of Pitcher Splits with Additional Metrics

This is a new output result table, as it summarized the data based on who the pitcher was instead of the batter. It also includes the additional metrics (IP, ERA, and WHIP) that our business users were interested in calculating for the pitchers. The business users were also particularly pleased that the standard batting metrics could be so easily calculated for how pitchers performed against all the batters that they have faced.
9.6 Summary
Both the business users and their IT staff were very positive about the flexibility offered by the Hash of Hashes approach. They recognized that it added some complexity. But the ability to add split calculations as well as define different metrics for different splits using a metadata (i.e., parameter file) was something they really liked. In response to questions from both the business and IT users, we confirmed that many of their additional requirements could likely be addressed by an approach that used a metadata-driven Hash of Hashes approach.