
About
This section briefly introduces the authors, what this book covers, the technical skills you'll need to get started, and the hardware and software requirements required to complete all of the included activities and exercises.
About the Book
Data Science with Python begins by introducing you to data science and then teaches you to install the packages you need to create a data science coding environment. You will learn three major techniques in machine learning: unsupervised learning, supervised learning, and reinforcement learning. You will also explore basic classification and regression techniques, such as support vector machines, decision trees, and logistic regression.
As you make your way through chapters, you will study the basic functions, data structures, and syntax of the Python language that are used to handle large datasets with ease. You will learn about NumPy and pandas libraries for matrix calculations and data manipulation, study how to use Matplotlib to create highly customizable visualizations, and apply the boosting algorithm XGBoost to make predictions. In the concluding chapters, you will explore convolutional neural networks (CNNs), deep learning algorithms used to predict what is in an image. You will also understand how to feed human sentences to a neural network, make the model process contextual information, and create human language processing systems to predict the outcome.
By the end of this book, you will be able to understand and implement any new data science algorithm and have the confidence to experiment with tools or libraries other than those covered in the book.
About the Authors
Rohan Chopra graduated from Vellore Institute of Technology with a bachelor's degree in Computer Science. Rohan has experience of more than 2 years in designing, implementing, and optimizing end-to-end deep neural network systems. His research is centered around using deep learning to solve computer vision-related problems and has hands-on experience of working on self-driving cars. He is a data scientist at Absolutdata.
Acknowledgements:
"This book was written by me, Rohan Chopra, and co-authored by Aaron England and Mohamed Noordeen Alaudeen. Big thanks to my mentor, Sanjiban Sekhar Roy, for his support; also, thanks to all the team at Packt."
Aaron England earned a PhD from the University of Utah in Exercise and Sports Science with a cognate in Biostatistics. Currently, he resides in Scottsdale, Arizona, where he works as a data scientist at Natural Partners Fullscript.
Mohamed Noordeen Alaudeen is a lead data scientist at Logitech. Noordeen has more than 7 years of experience in building and developing end-toend big data and deep neural network systems. It all started when he decided to engage in data science for the rest of his life.
He is seasoned data science and big data trainer with both Imarticus Learning and Great Learning, which are two of the renowned data science institutes in India. Apart from his teaching, he does contribute his work to open-source. He has over 90+ repositories on GitHub, which have open-sourced his technical work and data science material. He is an active influencer( with over 22,000+ connections) on Linkedin, helping the data science community.
Learning Objectives
- Pre-process data to make it ready to use for machine learning
- Create data visualizations with Matplotlib
- Use scikit-learn to perform dimension reduction using principal component analysis (PCA)
- Solve classification and regression problems
- Get predictions using the XGBoost library
- Process images and create machine learning models to decode them
- Process human language for prediction and classification
- Use TensorBoard to monitor training metrics in real time
- Find the best hyperparameters for your model with AutoML
Audience
Data Science with Python is designed for data analysts, data scientists, database engineers, and business analysts who want to move towards using Python and machine learning techniques to analyze data and predict outcomes. Basic knowledge of Python and data analytics will help you to understand the various concepts explained in this book.
Approach
Data Science with Python takes a practical approach to equip beginners and experienced data scientists with the most essential tools required to master data science and machine learning techniques. It contains multiple activities that use real-life business scenarios for you to practice and apply your new skills in a highly relevant context.
Minimum Hardware Requirements
For an optimal student experience, we recommend the following hardware configuration:
- Intel Core i5 processor or equivalent
- 4 GB RAM (8 GB preferred)
- 15 GB available hard disk space
- Internet connection
Software Requirements
You'll also need the following software installed in advance:
- OS: Windows 7 SP1 64-bit, Windows 8.1 64-bit or Windows 10 64-bit, Ubuntu Linux, or the latest version of OS X
- Browser: Google Chrome/Mozilla Firefox latest version
- Notepad++/Sublime Text as IDE (optional, as you can practice everything using Jupyter Notebook in your browser)
- Python 3.4+ (the latest version is Python 3.7) installed (https://python.org)
- Anaconda (https://www.anaconda.com/distribution/)
- Git (https://git-scm.com/)
Installation and Setup
Open Anaconda Prompt and follow these steps to get your system ready for data science. We will create a new environment on Anaconda in which we will install all the required libraries and run our code:
- To create a new environment and install all the libraries, download the environment file from https://github.com/TrainingByPackt/Data-Science-with-Python/blob/master/environment.yml and run the following command:
conda env create -f environment.yml
- To activate the environment, run this command:
conda activate DataScience
For this book, whenever you are asked to open a terminal, you need to open Anaconda Prompt, activate the environment, and then proceed.
- Jupyter Notebook allows us to run code and experiment in code blocks. To start Jupyter Notebook run the following inside the DataScience environment:
jupyter notebook
A new browser window will open with the Jupyter interface. You can then navigate to the project location and run the Jupyter Notebooks.
Using Kaggle for Faster Experimentation
The Kaggle kernel platform provides free access to GPUs, which speeds up the training of machine learning by around 10x. GPUs are specialized chips that perform matrix calculations very quickly, much faster than a CPU. In this section, we will learn how we can make use of this free service to train our models more quickly:
- Open https://www.kaggle.com/kernels in your browser and sign in.
- Click on the New Kernel button and select Notebook in the popup. The screen that is loaded, which is where you can run your code, looks like this:
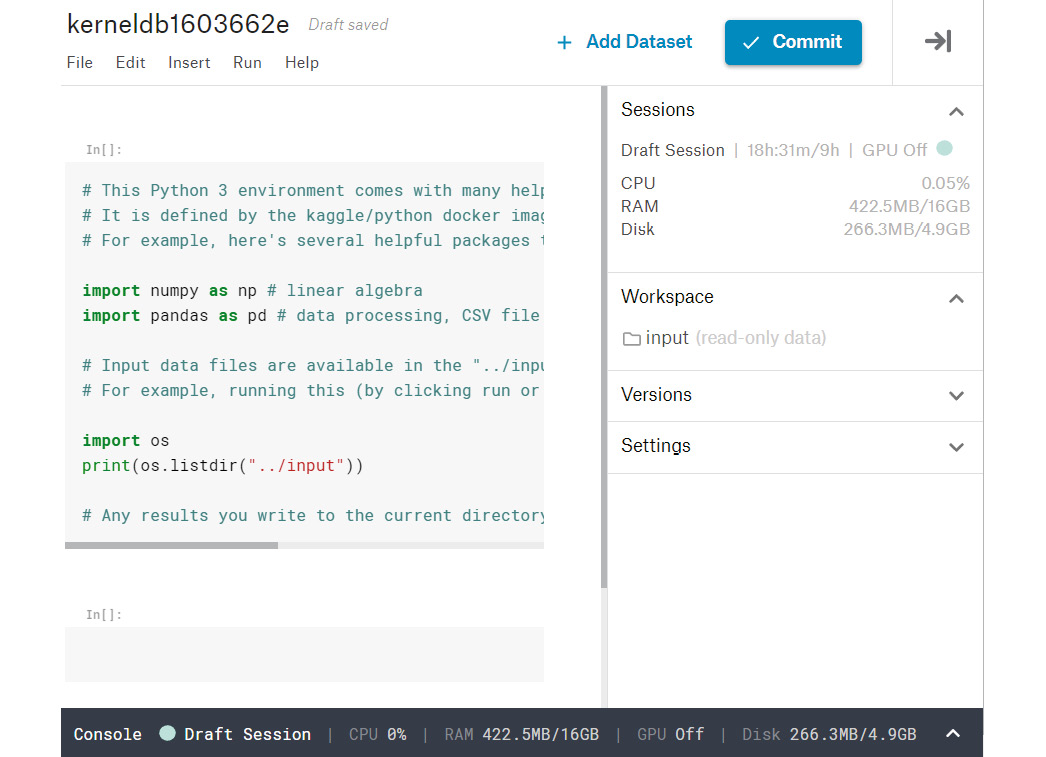
Figure 0.1: Notebook screen
In the top-left corner is the name of the notebook, which you can change.
- Click on Settings and activate the GPU on this notebook. To use the internet through the notebook, you will have to authenticate with your mobile phone:
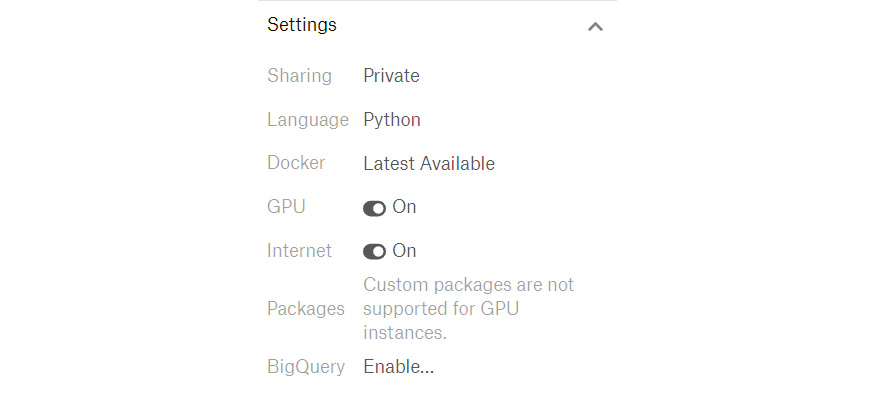
Figure 0.2: Settings screen
- To upload a Jupyter notebook to Kaggle, click on File and then Upload notebook. To load a dataset for this notebook, click on the Add Dataset button in the top-right corner. From here, you can add any dataset hosted on Kaggle or upload your own dataset. You can access your uploaded dataset from the following path:
../input/
- To download this notebook with the results after you are done running the code, click on File and select Download notebook. To save this notebook and its results in your Kaggle account, click the Commit button in the top-right corner.
You can make use of this Kaggle environment whenever you feel that your machine learning models are taking a lot of time to train.
This book uses datasets from UCI Machine Learning Repository [http://archive.ics.uci.edu/ml]. Irvine, CA: University of California, School of Information and Computer Science.
Conventions
Code words in text, database table names, folder names, filenames, file extensions, pathnames, dummy URLs, user input, and Twitter handles are shown as follows: "To read CSV data, you can use the read_csv() function by passing filename.csv as an argument."
A block of code is set as follows:
model.fit(x_train, y_train, validation_data = (x_test, y_test),
epochs=10, batch_size=512)
New terms and important words are shown in bold. Words that you see on the screen, for example, in menus or dialog boxes, appear in the text like this: "There are some cells that have either NA or are just empty."
Installing the Code Bundle
The code bundle for this book is hosted on GitHub at https://github.com/TrainingByPackt/Data-Science-with-Python.
We also have other code bundles from our rich catalog of books and videos available at https://github.com/PacktPublishing/. Check them out!