
Chapter
11
Backup and Recovery
TOPICS COVERED IN THIS CHAPTER:
- Why we back up
- Backup methods
- Backup types
- Backup targets
- Backup to the cloud
- Backup retention
- Archiving
 In this chapter, you'll learn about server and application backups and restores. Although you'll be focusing mainly on server and application backup and recovery, many of the same principles apply to backing up devices such as laptops and tablets.
In this chapter, you'll learn about server and application backups and restores. Although you'll be focusing mainly on server and application backup and recovery, many of the same principles apply to backing up devices such as laptops and tablets.
The major lesson in this chapter is that backup is all about recovery. This point can't be stressed enough! Burn this fact into your head and make sure you never forget it. If you back up your data every day but can't restore data from those backups, your backups are useless and you're wasting your time.
You'll also learn about backup methods, such as hot backups and LAN-free backups, as well as the impact they have on both networks and application performance and recoverability. You'll learn about the types of backups, such as full backups, incremental backups, differential backups, and synthetic full backups, and how each impacts restore, application, and network performance. This chapter also covers backup devices such as tapes, tape drives, virtual tape libraries, and even other less-common backup media types such as Blu-ray Discs.
You'll see how capacity optimization technologies affect backup performance, cost, and potentially performance of the restore.
The chapter also covers archiving and how it differs from but also complements backup. And then there's the impact of ever-increasing legislation and regulatory audit requirements that govern so much of data archiving in the modern world. You'll learn about technologies that are great for archiving, such as content addressable storage and write once, read many technologies.
But again, the major lesson from this chapter is that backup is all about being able to recover lost or corrupt data—and recovering it in a timely and efficient, although not necessarily super fast, manner.
Why We Back Up
Backups aren't sexy. They cost money. They can be cumbersome to manage. And they can impact application performance. So why do we do them? Well, for starters, backups can save your data and potentially your job and your company—and that's no understatement. Basically, no data equals no business!
It's also no secret that data can be corrupted or accidentally deleted. When this happens, backups suddenly become the most important things in the world, and everyone sits around nervously chewing their fingernails in the hope that the data was recently backed up and can be restored.
The following are true statements that relate to the importance of backups:
- If the business can't go backward after a disaster, it can't go forward.
- If it's not backed up, it doesn't exist.
- If it doesn't exist in at least two places, it isn't backed up.
These statements form some of the fundamental principles of backup.
Now let's talk about the role of backup in disaster recovery and business continuity planning, as well as defining some terminology fundamental to backup and recovery.
Backups and Business Continuity
One of the major roles of backup and recovery is functioning as part of a business continuity plan (BCP). In a BCP, backups sit alongside other storage-related technologies such as replication and snapshots, though we should note that replicating data is absolutely not the same as backing up, and snapshots in and of themselves do not constitute backups. Anyway, backups should form a part of just about every business continuity plan.
Recovery Point Objectives
A recovery point objective (RPO) is the point in time to which a service can be restored/recovered. So, if you have an RPO of 24 hours, you will be able to recover a service or application to the state it was in no more than 24 hours ago. For example, a backup schedule that backs up a database every day at 2 a.m. can recover that database to the state it was in at 2 a.m. every day. At any given point in time, you will have a valid backup of the database that is no more than 24 hours old—within your stated RPO of 24 hours.
RPOs form part of a wider service-level agreement (SLA) between IT and the business. In the context of IT, an SLA is a form of contract outlining the levels of service that IT will provide to a customer. The customer is usually the business, or a business unit, if you're an internal IT department. For example, an SLA might define that all data will be backed up daily, and be recoverable within 6 hours of a request. Almost all SLAs will contain recovery point objectives.
When it comes to backups, recovery point objectives are a major consideration. If the business requires an RPO of 5 minutes for a certain application, then a daily backup of that system will not meet that RPO, and you will need to use different technologies such as snapshots.
With traditional tape-based backups, the normal minimum RPO is one day (24 hours), because it's usually not realistic to make traditional backups to tape more frequently than once per day. This is for two major reasons:
- Many backup methods impact the performance of the system being backed up. So making frequent traditional backups to tape could negatively impact the performance of the system being backed up.
- Many corporate backup systems (media servers, tape drives, backup networks) are already very busy taking just a single backup per day.
In these situations, if more-granular RPOs are required, traditional backups can be augmented with technologies such as snapshots. These snapshots could be taken, for example, every 15 minutes but kept for only one day. Then each full traditional backup to tape could be taken once per day and kept for 12 months. This configuration will allow for a recovery of the application to any 15-minute point within the last 24 hours.
Interestingly, within the context of backups, there is also the concept of retention. For example, if you take daily backups of your corporate database server, keep those backups for 12 months, and then expire (purge) them as soon as they are older than 12 months, you will not be able to recover the corporate database system to a state it was in more than 12 months ago. In this example, the retention period for backups of the corporate database system will be 12 months (365 days). And while this might not seem like a problem, legislation and regulatory requirements might state that data from a given system must be available to restore from the last 25 years.
Recovery Time Objectives
A recovery time objective (RTO) is significantly different from a recovery point objective. Whereas a recovery point objective says that you can recover a system or application to how it was within a certain given time window, a recovery time objective states how long it will take you to do that. For example, it might take you 8 hours to recover a system to the state it was in 24 hours ago.
And when defining and deciding RTOs, make sure you factor in things like these:
- The time it takes to recall tapes from off-site storage
- The time it takes to rally staff and get logged on and working on the recovery
For example, if you have no staff working on a Saturday morning, and all tapes are off-site in a secure storage facility, you will need to factor both of those facts into the RTO to handle the possibility of a user logging a request at 6 a.m. on a Saturday morning to restore some data. It's not as simple as saying that you can restore x GB per minute, so to restore y GB will take z minutes. There are other significant factors to consider.
Exercise 11.1 shows you how to create a simple scheduled backup.
EXERCISE 11.1
Creating a Simple Scheduled Backup
This step-by-step activity will walk you through the process of creating an hourly scheduled backup of a research folder to a SAN disk that is mounted locally as the F: drive on a Windows server. The schedule will take a backup of the c: esearch folder of the server every hour between 7 a.m. and 7 p.m.
- From the Windows desktop, click Start
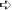 Administrative Tools Windows Server Backup.
Administrative Tools Windows Server Backup. - From within the Windows Server Backup tool, choose Action Backup Schedule.
- On the Getting Started screen, click Next.
- On the Select Backup Configuration screen, select Custom.
- On the Select Items for Backup screen, click the Add Files button.
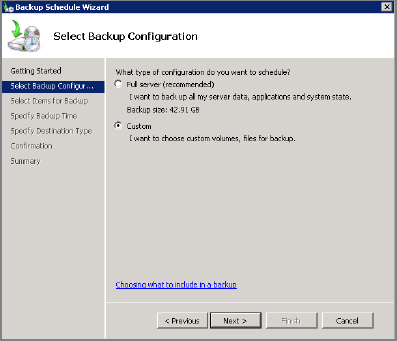
- On the resulting Select Items screen, select the folders that you want to back up, and click OK. In the following image below, the Research folder is selected.
- Verify that the correct items are selected for backup on the Select Items for Backup screen, and click Next.
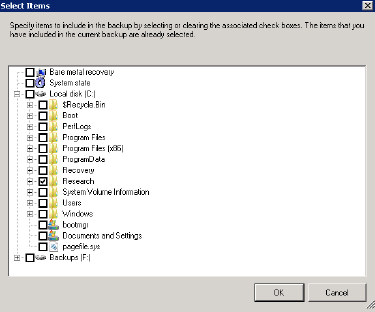
- On the Specify Backup Time screen, select the More Than Once A Day radio button and then select the times of day that you want to perform the backups. The following screenshot shows hourly backups selected between 7 a.m. and 8 p.m.
- On the Select Destination Type screen, choose the destination for your backup data to be stored and click Next.
- On the Select Destination Disk screen, select the disk you want your backups to be copied to and click Next. This may result in a warning telling you that all of the selected disk will be formatted. This means all existing data on the disk will be deleted), so make sure that you select the correct disk as the backup target.
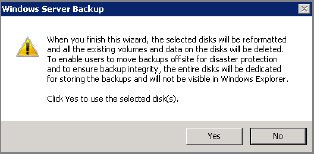
- On the confirmation screen, verify that all options are correct and click Finish.
This completes the steps required to schedule regular daily backups of a custom set of data on a Windows server when using the Windows Server Backup tool. It's worth noting that this tool provides only simple scheduling and doesn't allow you to specify different schedules for different days of the week such as weekends.
The Backup Window
The backup window is another item that relates to backup and business continuity. A backup window is a period of time—with a start and stop time—during which data can be backed up. For example, a backup window might include all noncore business hours for a certain business, such as 11 p.m. until 9 a.m. If that's the case, all backups have to start and complete within that window of time. However, many businesses have different backup windows for different applications, depending on core business hours for those applications.
A major reason for the backup window is that backups often negatively impact the performance of the system being backed up, so backing up a critical system during the core business day is usually not a good idea. It's important to get input from people close to the business when determining backup windows.
It's All about Recovery
Nobody cares about backups; people care only about restores. Backups are commonly considered the least sexy area of IT. Nobody thinks about backups when they're factoring things in for their applications, and nobody wants to dip their hands in their pockets to pay for backup infrastructure such as tapes and the like. However, everybody wants their data to be backed up, and everybody hits the roof if there aren't any backups when they need a restore operation! And believe me, if a business user needs data restored but there are no backups of that data, you will be in a world of hurt.
Backups are for the express purpose of being able to restore data after things such as user error/deletion, device failure, logical corruption, and so on. With that in mind, it's absolutely vital to be able to restore the data you're backing up. Backing up data, if you can't restore it, is pointless and will make you look incompetent in the eyes of your customers. As such, regular rehearsing of restoring data is vital. You should regularly test your capability to restore data that you have backed up.
The Importance of Testing Restore Operations
A company that I worked with was happily backing up its Microsoft Exchange environment until one day a restore of a crucial Exchange-related configuration file was requested. When an attempt was made to restore the file from the previous night's backup, the file was not found in the backup. This was assumed to be a missed file in that particular backup job, and an attempt was made to restore the file from the backup made the night before the previous night. Again the file was missing. This process was repeated, attempting to restore the file from week-end and month-end backup jobs; each time the file was missing. As a result, the file could not be restored, and the Exchange server had to be rebuilt.
It turned out that the Exchange server backups at this organization were being performed as standard filesystem backups and not with the Microsoft Exchange backup agents that work in conjunction with Microsoft Exchange to ensure application-consistent backups. This was immediately rectified, but it was too late to help with this specific restore request.
The takeaway point from this experience is that this company had never tested a restore of Exchange from their backups. When the time came that the company needed to rely on the backups, they were useless! So practice your restore operations!

In addition to the importance of being able to recover backed-up data, there are some applications, such as databases, that need to be backed up frequently in order to be able to truncate log files. If you don't back these systems up regularly, the log files can fill up and force the database to stop.
Backup Architecture
The most common backup architectures are based on the tried and tested client-server architecture. Most backup architectures are composed of the following four components:
- Backup servers
- Backup clients
- Media servers
- Backup targets
The backup server, which sometimes goes by names such as master server or cell manager, is the brains of the backup environment. This server holds all the job definitions, the job schedule, the backup database and catalog, and all other metadata relating to the backup environment.
Backup clients are software agents that are installed on servers being backed up, and are responsible for getting the data off the client machine being backed up, and onto the storage medium. Application-specific backup agents such as Microsoft Exchange or Microsoft SQL Server also coordinate application consistency of backups, but more on that later.
People in other departments of the company might not realize that the backup client agent is actually on the server, not the client. For most purposes, the distinction is negligible, but occasionally you might need to clarify this to your colleagues to avoid confusion.
Media servers connect to the backup target, and make it available to backup clients so that they can send data to the backup target. For example, a media server might be connected to a pool of storage over an FC network and make that storage available to backup clients over an IP LAN.
Backup targets range from tape drives and DVDs all the way up to large pools of disk-based storage or large tape libraries. Traditional approaches to backups primarily used tape as a backup target. More-modern approaches tend to favor disk-based mediums, including disk pools shared over LAN-based protocols such as SMB/CIFS and NFS, or even specialized disk arrays that imitate tape libraries, referred to as virtual tape libraries.
Figure 11.1 shows a typical backup environment with a single backup server, two backup clients, a single media server, and a disk pool.
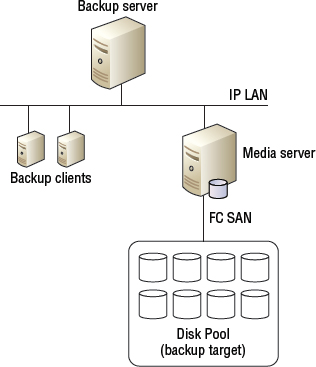
As you look at Figure 11.1, the high-level backup process would be as follows:
- The backup server monitors the backup schedule.
- When the schedule indicates that a particular client needs backing up, the backup server instructs the agent software on the backup client to execute a backup. As part of this instruction, the backup server tells the agent what data to back up and where to back it up to.
- The backup server sends the data over the IP to the media server.
- The media server channels the incoming backup data to the backup target over the FC SAN that it is connected to.
Backup Methods
The backup is a real industry old-timer. In fact, it's so old that it grew up with mainframe computers, and the two technologies are still close friends. Until recently, backup methods and technologies have resisted change. In fact, in many respects, backups still look the same as they did nearly 50 years ago. However, backup methods are finally succumbing to change, and there are an increasing number of methods for backing up servers and applications. This section presents some of the more popular methods and approaches.
Hot Backups
In the modern IT world, almost all backups are hot backups. Hot backups—sometimes called online backups—are taken while the application and server being backed up remain online and servicing users.
Hot backups are ideal for today's demands on IT resources, where servers and applications are expected to remain up and online at all times. Hot backups also help reduce administrative overhead and allow backup environments to scale because they don't require administrative stops and restarts of applications to be coordinated and managed just to cater to backups.
Most modern applications, such as Oracle Database and most of the Microsoft server products (Microsoft SQL Server, Microsoft Exchange Server, Microsoft SharePoint Server, and so on) all support hot backups. To provide this hot-backup feature, most applications place themselves into a hot-backup mode and utilize some form of point-in-time (PIT) technology that creates a frozen image of application data. This frozen image is then used for the backup. Quite often, snapshot technologies, including array-based snapshot technologies, are utilized as part of the PIT frozen image creation process.
Another matter of extreme importance in the world of hot backups is the ability to perform integrity checks against backups. Fortunately, most good applications that support hot backups have robust facilities to perform checksums, application-based integrity checks, and verifications of backup images. Doing this helps ensure that the backup is a good backup and will be useful as an image to restore from.
Offline Backups
Offline backups are the opposite of online hot backups, and hopefully they're a thing of the past. Offline backups require applications and databases to be taken offline for the duration of the backup. Obviously, this is far from ideal in the modern world, where businesses often operate 24/7 and cannot afford downtime of applications and services while performing regular backups.
LAN-Based Backups
LAN-based backups have been around for years and are perceived as cheap and convenient, but often low performance with a risk of impacting other traffic on the network.
LAN-based backups work by sending backup data over the LAN, and this LAN can be your main production network or a network dedicated to backup traffic. Dedicated networks can be virtual LANs (VLANs), where a dedicated L2 broadcast domain is created for the backup traffic, or it can be a physically dedicated network with its own network cards in hosts and network switches. This latter option obviously costs more money than a simple VLAN, but it offers the best and most predictable performance, as well as being the simplest to troubleshoot and the least likely to negatively impact other non-backup-related network traffic.
In a typical LAN-based backup configuration, the backup client will send data from the host being backed up, over the LAN, to the media server or directly to the storage media. The important point is that backup data is always sent over the LAN.
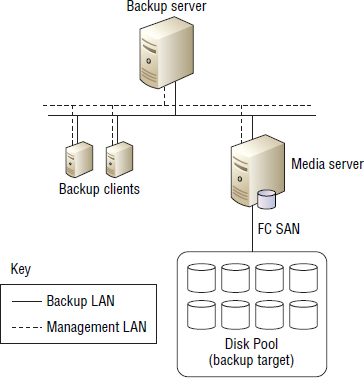
Figure 11.2 shows data being sent from a client over a dedicated backup LAN to a media server. The media server is then connected to the backup target via a Fibre Channel storage area network (FC SAN). In Figure 11.2, each server is connected to two LANs:
- Management LAN
- Backup LAN (dedicated to backup traffic)
LAN-Free Backups (SAN Based)
A LAN-free backup architecture, as the name hopefully suggests, backs up data without crossing the LAN. Quite often, the data is passed from the backup client to the storage medium over the SAN.
Sometimes LAN-free backups are referred to as SAN backups because they tend to back up data over the SAN rather than the LAN. They are also often referred to as block-based backups because they often don't understand, or care about, files. They simply back up all the blocks they're instructed to back up. This can be extremely fast when you are trying to back up millions of small files. However, it has an inherent downside. Block-based backups don't normally provide a smooth and simple way to restore individual files. If you want an individual file back, you may be required to restore the entire backup to a temporary area and then locate the required file and copy it back to its original location.
In comparison to LAN-based backups, LAN-free backups tend to offer higher performance and reliability, but at a higher cost. This is a real example of getting what you pay for. However, with the advent of 10G networking technologies, LAN-based backups can also be high performance, as well as high cost.
Being able to back data up at higher speeds can be important in environments where the backup window is a concern. If you are struggling to complete all of your backups within the allotted backup window, you may want to consider LAN-free backups or maybe even LAN-based backups over 10G Ethernet networks.
Figure 11.3 shows a LAN-free backup configuration in which the client being backed up has direct connectivity to a SAN-based tape library. In order to do this, the client being backed up usually must have either backup agent software that can talk directly to a tape library or an installation of the backup media server software.
In Figure 11.3, the backup server tells the agent software on the backup client to perform a backup to the tape library backup target. The backup data is then sent directly to the tape library over the SAN rather than the LAN. This lightens the load on the LAN and may enable organizations with existing investments in FC SAN technology to deploy a robust high-performance backup environment without having to deploy a dedicated backup LAN.
Serverless Backups
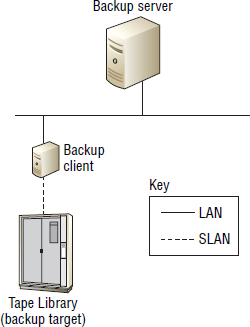
Serverless backups are a form of LAN-free backup, but they take the concept to the next step. They are not only LAN free, meaning they don't use the LAN to transport backup data, but also server free, meaning they don't utilize server resources either. Figure 11.4 shows this concept.
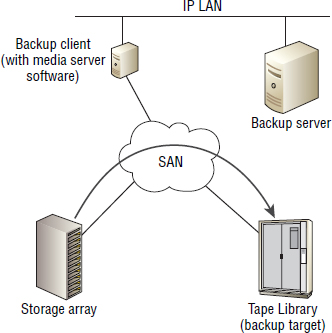
Under the hood, serverless backups use the SCSI-based EXTENDED COPY command, which allows data to be copied directly from a source LUN to a destination LUN. And the important word here is directly. In serverless backup configurations, data is sent from the source LUN directly to the target LUN over the SAN, but without passing through the server that owns the data.
Because serverless backups work with SAN-based LUNs, and tape devices on a SAN are presented as LUNs, the target LUNs in a serverless backup configuration often are tape based.
The EXTENDED COPY command doesn't have to copy an entire LUN to another LUN. It copies specified ranges of blocks from the source LUN to the target LUN. Those ranges are the blocks containing the data that is being backed up.
Figure 11.4 shows a typical serverless backup configuration with the path that the backup data copy takes being highlighted by the thick line from the storage array through the SAN to the tape library. The process works roughly as follows:
- The backup server tells the backup agent software on the backup client machine to initiate a serverless backup with the tape library specified as the target.
- A SCSI EXTENDED COPY command is utilized to copy the data directly from the storage array to the tape library via the SAN. At no point does any backup data pass through the backup client.
- Metadata about the job is passed over the IP LAN to the backup server. This metadata includes job details such as start time, completion time, completion code, and so on.
Although the data being backed up isn't sent over the LAN, the metadata concerning the backup is still sent over the LAN to the backup server and the backup client/agent. This is so that metadata such as job completion code, start time, end time, and so on can be stored on the backup server.
The advantages of serverless backups are the same as the advantages of LAN-free backups—high performance and high reliability, though at a potentially higher cost than LAN-based backups—with the added advantages of reducing the negative performance impact imposed on the server being backed up. After all, they're called serverless backups, so it's only to be expected that they don't touch or impact the server.
NDMP
Network Data Management Protocol (NDMP) is a protocol designed for standards-based efficient NAS backups. NDMP is similar to serverless backups in that backup data can be sent directly from the NAS device to the backup device without having to pass through a backup media server. Without NDMP, NAS-based file shares would have to be mounted on a backup media server to be able to be backed up. This configuration would drag data across the network (LAN) from the NAS to the backup media server and then possibly back over the network again to the backup device. With NDMP, there is no need to mount the NAS-based network share on the media server. Instead, data can be sent directly from the NAS device to the backup device, touching the network only once. This reduces the amount of load placed on the network.
Non-NAS-related network file servers, such as Windows and Linux servers, don't necessarily need NDMP because they can have backup agent software installed on them to enable them to back up directly to network-based backup devices. However, NAS arrays run custom operating systems that can't normally have backup agent software installed on them, and they therefore need a protocol such as NDMP.
An important feature of NDMP backup configurations is direct-access restore (DAR). Direct-access restore enables the following:
- Selective file restore (including individual file restore)
- Faster recovery
However, there is no free lunch! A side effect of the faster and more granular restore capabilities provided by DAR is that backups take longer. This is because as each file is backed up, its location within the backup is recorded. This prevents you from having to read or restore the entire backup image to locate individual files or directories that you want to restore.
Figure 11.5 shows a simple NDMP configuration.
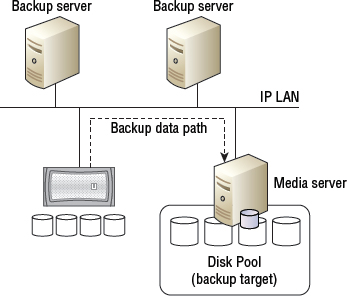
In Figure 11.5, the backup data is sent directly from the NAS device to the backup target disk pool over the LAN, as shown by the dotted line.
Backing up lots of small files can be a real killer–and not just for NDMP. For example, it will take a lot longer to back up 1,000,000 1 KB files than it will to back up a single 1,000,000 KB file (about 100 MB). A lot longer! One of the reasons is that each individual file has to be catalogued, and in some backup solutions, verified. It's similar to the difference between painting a single, large flat wall vs. painting the same surface area but on lots of smaller walls. With the large wall, you have only one set of corners and edges to paint, whereas painting lots of smaller walls massively increases the number of corners and edges you have to paint. If you have large filesystems with millions or billions of files and a small backup window that you are struggling to fit your backups into, then a block-based backup solution such as serverless backup might be a better option. However, block-based backups tend not to allow you to easily restore individual files.
Backup Types
In the modern world, there are many types of backups—full backups, incremental backups, differential backups, synthetic backups—all of which can work together to cater most business backup needs. Application awareness is another factor that needs to be considered when choosing a backup method. Let's take a look at them in more detail.
Full Backups
As the name suggests, full backups back up everything. They start at the top and don't finish until they get all the way to the bottom. The Storage Network Industry Association (SNIA) defines full backups as “a backup in which all of a defined set of data objects are copied, regardless of whether they have been modified since the last backup.”
Like all things, full backups have their pros and cons.
On the positive side, they offer the best in terms of restore speed and restore simplicity. For example, if we back up an entire home drive with 250 GB of data on it every night and we want to recover the contents of our home drive from six days ago, we will probably need only one tape to perform the recovery. The process will require identifying the tape, loading it into the tape drive, and then restoring the data from the tape.
On the downside, full backups consume the most backup space on the backup target device, as well as the most network bandwidth and server resources. And they take the most time. Using the previous example of backing up our home drive every night, this means that every night we pull 250 GB of backup data across the network and store it to our backup device. Although that might not sound like a lot of data, it can quickly become a lot of data when you realize your organization has 100, 500, or over 1,000 home drives to back up each night. It also requires our entire home directory to be read as part of the backup process, placing additional read workload on the host and storage array hosting the home drive. So it's not all goodness when it comes to full backups.
Watch Out for What “Incremental” Means!
In common usage, and according to just about every commercial backup tool, an incremental backup is defined as a job that backs up files that have hanged since the last backup… and that “last backup” could be an incremental backup or a full backup. This means that a full recovery requires the most recent full backup plus all incremental backups since the full backup.
Sadly, at the time of writing, the SNIA defines incremental backups differently. According to the SNIA Storage Dictionary, a cumulative incremental backup (as opposed to a differential incremental backup) is a “backup in which all data objects modified since the last full backup are copied” (note the use of the word full). Because this book maps to the CompTIA Storage+ Powered by SNIA exam, the book uses the SNIA definition, especially in the next couple of sections. But don't be misled by that definition when you encounter “incremental backup” in non-SNIA, real-world contexts!
Cumulative Incremental Backups
A cumulative incremental backup-that's the SNIA term for what is commonly called a differential backup-is different from, but work in conjunction with, a full backup. The major difference between full and cumulative incremental backups is that cumulative incremental backups only back up data that has changed since the last full backup. So, in the first place, you need a full backup, and from there on, you can take cumulative incremental backups.
Most cumulative incremental backup solutions will back up an entire file even if only a single byte of the file has changed since the last backup. Let's look at an example based on our 250 GB home drive. Assume that we have a backup schedule that performs a full backup of our home drive every Friday evening, and then performs cumulative incremental backups every other day of the week. On Friday, we'll drag 250 GB over the network and store it on our backup device. Then on Saturday, we'll drag over the network and store to our backup device only files that have been updated since Friday night's full backup-probably not very much data at all. The same goes for every other backup prior to the next Friday night full backup; each cumulative incremental backup backs up only data that has changed since the previous Friday's full backup. And unless we change a lot of data in our home drive on a daily basis, this combination of full and cumulative incremental backups will save us a ton on backup storage space and network bandwidth.
That's great, but there's a downside too. Let's say it is Thursday, and we've deleted the entire contents of our home drive and need to restore it from the latest backup. The latest backup was Wednesday night, but Wednesday night's backup was only a cumulative incremental backup, so it contains only data that has changed since the full backup last Friday. So, in order to recover the entire contents of our home directory, we need the tapes from the Friday night full backup as well as the tape from Wednesday night's cumulative incremental backup. Our backup software then needs to coordinate the process so that what gets restored is an image of our home drive as it was Wednesday night.
It is slightly more complicated than taking a full backup every night, but when it comes to filesystem backups, most organizations decide that the benefits of using cumulative incremental backups during the week far outweigh the drawbacks.
Differential Incremental Backups
A differential incremental backup-again, that's the SNIA term-is a form of incremental backup. Like cumulative incremental backups, differential incremental backups work in conjunction with full backups. But instead of backing up all data that has changed since the last full backup, differential incremental backups back up only changed data since the last differential incremental. These are excellent at space efficiency, as each differential incremental backup will need to send even less data across the network to our backup device than a cumulative incremental backup. However, they have a downside. Differential incremental backups are the slowest and most complex when it comes to restore operations.
Let's take a look at how it works with our home drive example from the previous section. Let's say it is Thursday again, and we've deleted the entire contents of our home drive again, and need to restore it from the latest backup. The latest backup was Wednesday night. But this time Wednesday night's backup was a differential incremental backup, meaning it contains only data that has changed since the differential incremental backup the previous night (Tuesday night). And Tuesday night's backup was also a differential incremental backup, meaning it contains only data that has changed since Monday night's backup. And Monday night's backup was also a differential incremental backup. Hopefully, you get the picture. The net result is that in order to restore the entire contents of our home directory, we need the tapes from Friday night's full backup, as well all tapes from every subsequent differential incremental backup-Saturday, Sunday, Monday, Tuesday, and Wednesday! And again, the backup software then needs to coordinate the process so that what gets restored is an image of our home drive as it was Wednesday night.
This is way more complicated than even full and cumulative incremental backups. However, it is more space efficient and less of a burden on the network and host.
Synthetic Full Backups
A more recent form of backup—when compared to standard full, incremental, and differential backups—is the synthetic full backup. At a high level, a synthetic full backup works by taking a one-time full backup and then from that point on taking only incremental or differential backups. And for this reason, you may hear synthetic full backups referred to as a form of incremental forever backup system. But it's a little cleverer than this description might suggest. Instead of just taking incremental backups forever and always having to go back to the original full backup plus the latest differential incremental, periodically the synthetic full backup is created. And the synthetic full backup looks, feels, and works exactly like a normal full backup, only it isn't created by trawling every file in our home drive, hauling each one over the network again, and storing each one to our backup device again.
Let's look at our home drive example again. Let's assume we've decided to deploy a synthetic full approach to backing up our home directory. On the first Friday, we perform a traditional full backup. We read all 250 GB of data, pull it over the network, and store it as a single full backup image on our backup device. Great. Every subsequent night, we perform an incremental backup so that we pull only changed data over the network and store it to our backup device. Then, when the next Friday comes along, instead of performing another traditional full backup, with all of its associated overhead, we take last Friday's full backup image, take an up-to-date incremental, and then combine the previous full backup with the incremental backup we've just taken. And what we end up with is a backup image that is exactly what a traditional full backup image would look like, only we haven't had to read every file from our home drive and pull it over the network. And significantly, this synthetic full backup can then be used as the base for another week of incremental backups.
However, the way in which synthetic full backups are created can place additional stresses on the backup device, because the backup software has to read the entire contents of the last full backup from the backup device, while at the same time the backup device is writing out the new synthetic full backup image. This reading and writing can be a lot of hard work for a backup device.
Application-Aware Backups
Application-aware backups—sometimes called application-consistent backups—are a form of hot backup and are vital if you want to be able to restore your applications from your backups.
It's one thing to back up standard filesystem data, such as home drives and file shares, as flat files. But if you try to back up databases or applications such as Microsoft Exchange as flat files without coordinating the backup with the application, you almost certainly won't be able to recover your application from your backups!
Application-aware backups usually require installing special agent software on the application server, such as installing an Exchange Server agent on the Exchange server. This agent does the usual job of communicating with the backup server and sending data to the backup device, but it also provides the intelligence required to back up the application in a consistent state.
![]() Real World Scenario
Real World Scenario
Make Sure You Test before You Make Changes
One company had experienced significant growth and was looking for options to reduce the network bandwidth consumed by backup traffic. Because they had started out as a small company, their LAN-based backup design didn't have a dedicated backup LAN. They looked to implement synthetic full backups.
However, their backup target devices were disk-based deduplication appliances. During the testing phase, before rolling out synthetic full backups, they noticed that backup performance was significantly impacted in a negative way when creating the synthetic full images. Upon closer inspection, it was realized that the way in which synthetic full backup images were created was generating a workload pattern that the deduplication backup appliances couldn't deal with; intensive reading and writing at the same time is bad enough for a disk-based storage system, but is compounded when deduplication is thrown into the mix. This is because when data is read back from a deduplication appliance, it has to be rehydrated (un-deduplicated), adding significantly to the disk thrashing that was already taking place. The end result in this case was reverting back to traditional full backups and looking at implementing a backup LAN.
Many applications provide a mechanism to back themselves up both hot and in a consistent state. In the Microsoft world, the Volume Shadow Copy Service (VSS) is a technology that allows Microsoft applications to be backed up in that hot and consistent state. Similar options exist for some non-Microsoft options, such as RMAN for Oracle. However, as VSS is so popular and well-known, let's take a quick look at how it works.
It is technically possible for any Windows application to plug into and leverage the VSS framework for application-aware backups. For example, Oracle running on Windows can use VSS for application-aware backups.
Microsoft Volume Shadow Copy Service
In the Microsoft VSS space, the backup software—which is known as a requestor in VSS parlance—instructs the VSS service running on a server that it wants to back up an application on that server. For example, if the intent is to back up Microsoft SQL Server, the backup software (VSS requestor) will tell VSS on the machine that is running SQL Server that it wants to back up SQL Server. VSS then tells the application (SQL Server) to prepare itself for a hot backup. The application does this by completing in-flight I/O, flushing local buffers, applying logs, and setting any application flags required for smooth recovery. The application then reports its status back to VSS. VSS then instructs the application to quiesce (freeze application I/O) while the snapshot is created. Once the snapshot is taken, VSS instructs the application (SQL Server) to resume operations. All application I/O that was frozen during the quiesce is completed, and normal operations resume. The backup is then taken based on the snapshot created by VSS. But it's important to understand that even during the quiesce period, while the application remains up and running and serving user requests, the application I/O that is frozen is still occurring but not being committed to disk until the quiesce period ends. The quiesce period usually lasts for only a few seconds while the snapshot is taken.
The end result is an application-consistent backup—one that is guaranteed to be viable as a recovery option—that was taken while the application was online and working. No users or clients of the application will be aware that the application was just placed in hot backup mode and a backup was taken.
Backup Targets and Devices
All backups need to be stored somewhere. Technically speaking, we refer to the destination of backups as backup targets, though sometimes we use the term backup device.
In the past, backup targets were almost always tape based, using technologies such as tape drives and tape libraries. Nowadays, though, there are all kinds of options, including, but not limited to, the following:
- Tape devices
- Virtual tape libraries
- Disk pools
- Cloud services
Let's take a closer look at each.
Backup-to-Tape
Backup-to-tape—sometimes referred to by the SNIA as B2T—is probably the oldest and most common form of backup.
Advantages of Tape
Backup-to-tape consists of backing data up to linear tape devices. Although tape might seem very much like an ancient technology, modern tape drives and tape libraries have many positive features, including these:
- High capacity
- High sequential performance
- Low power
On the performance front, the nature of tape is almost perfectly suited to back up performance requirements. The typical workload of a backup job is streaming sequential data, and tapes thrive on sequential workloads. However, tapes suck at random performance. But random performance isn't the top requirement in most backup solutions.
Disadvantages of Tape
There are also some drawbacks to tape as a backup medium:
- Media degradation
- Technology refresh
- Awkward for some restore types
As a form of magnetic storage medium, tapes are subject to degradation over time, especially if they aren't stored in optimal conditions—heat controlled, humidity controlled, and so on. Storing tapes in such ideal conditions costs money. Secure off-site storage of tapes, sometimes referred to as vaulting, can be even more costly.
There's also the concern that when you come to restore data from tapes in 10 years' time, even though you've stored the tapes in optimal conditions, you no longer have any tape drives or software that can read them.
In addition, tapes are great at restoring data from full backups, but if you have to perform restores based on differential backups, they can be cumbersome. For example, loading and unloading multiple tapes is awkward, as is fast-forwarding and rewinding back and forth through the tape reel in order to locate the right place on the reel where the data you want is stored.
Because of these concerns, as well as the drop in the cost of spinning disk media, many people are starting to move away from tape for backups. That said, it is still popular, and there is still a market for tape.
LTO Technology
All kinds of tape technologies are available, each requiring a specific type of tape drive and sometimes library. However, the most popular tape format in the open-systems space is the Linear Tape-Open (LTO) format.
Within the LTO standards, there are various versions of LTO tapes, each designated by a number. Current LTO versions include LTO-1, LTO-2, LTO-3, LTO-4, LTO-5, and LTO-6. According to the LTO standards, they have the performance, capacity specifications, and other features shown in Table 11.1.
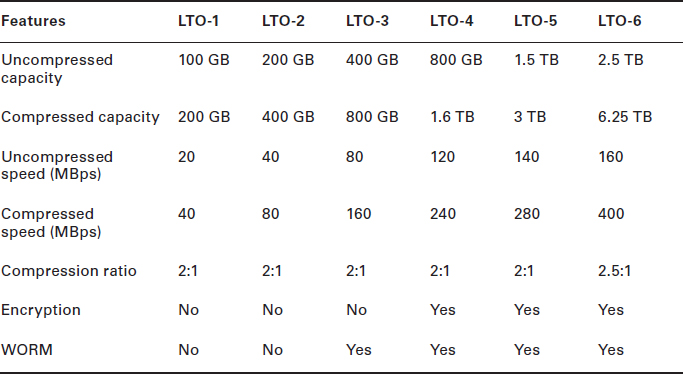
The LTO standards also mandate the following backward compatibility between drives and media:
- An LTO drive will be able to read data from tapes in its own generation, plus the two previous generations.
- An LTO drive will be able to write data to tapes in its own generation, plus the generation immediately preceding it.
Shoe-Shining
Shoe-shining is a phenomenon in the tape backup world that occurs when the speed at which data being sent to the tape drive doesn't match the speed that the tape drive is running at. When this occurs, the tape drive has to occasionally either slow down or momentarily stop while the data coming in from the media server builds up again. This starting and stopping of the tape reel, or slowing down and then speeding up of the tape, looks a bit like the back-and-forth action of shining shoes with a cloth. While occasional shoe-shining will slow down backup jobs, excessive shoe-shining can cause early wear and tear on the tape cartridge and the heads and motor of the tape drive.
Multiplexing
Multiplexing sends data from multiple backup jobs to a single tape drive. The objective is to increase the speed at which data is sent to a tape drive, allowing the tape drive to operate at maximum speed. This is great at helping to avoid shoe-shining.
However, multiplexing can affect restore performance. This is because the multiple streams of data that were multiplexed to the same tape drive are all interleaved next to each other. When you come to restore the data from one of the jobs (one of the streams), all of the data from all of the multiplexed jobs has to be read, and the data from the jobs that you're not restoring from has to be discarded, reducing the overall performance of the drive and the restore operation.
As a general rule of thumb, multiplexing enables faster backups but slower restores. When considering deploying multiplexing, you need to weigh the drawback of slower restores against the benefit of performing multiple backup jobs.
Tape Compression
Most tape drive technologies, including LTO, support native compression. The LTO specification uses a form of compression known as Streaming Lossless Data Compression (SLDC). Although SLDC is not the most efficient compression algorithm available, it is fast and recognized as a good balance between good compression and good performance.
Encrypted data doesn't compress well. Attempting to compress data that is encrypted can result in the data set being larger than it was before the compression attempt was made. Fortunately, most backup technologies that encrypt data before sending it to tape mark it as encrypted so that no attempt is made to compress it.
As you can see in Table 11.1, each version of the LTO standard lists its native compression ratio as a feature. This native tape compression is a feature that is always on.
Obviously, compression can significantly help reduce the number of tapes that you need to support your backup estate, helping bring costs down.
Tape Encryption
Over the last few years, there have been several significant losses of backup tapes that have been high profile enough to make the trade press and sometimes the national press. This has served to highlight the need to encrypt all data that will leave the confined walls of our corporate data centers. And tape backups are no exception. Make sure you encrypt your tapes!
The LTO standards define encryption-capable tape drives from LTO-4 and onward, but they don't mandate that all LTO-4 drives support encryption. So make sure you check the specifications of any new LTO tape drives you purchase if you're planning to use tape drive–based encryption.
The encryption algorithm used by LTO is a symmetric block cipher (256-bit AESGCM) that uses the same key to encrypt and decrypt the data. And with LTO drive based–encryption, a third-party key manager will be required for key management. Fortunately, most good backup applications will perform the task of key management.
On the performance front, most good drives will be able to perform encryption at full line-speed within the drive.
Because encrypted data can't be compressed, encryption should be performed after data is compressed, which is exactly what happens with LTO drive-based encryption.
Virtual Tape Library
The rise of the virtual tape library (VTL) was a major step forward for the backup industry. The VTL was the first major step away from tape-based backup targets to disk backup targets, and it has paved the way for more-native approaches to backing data up to disk-based targets.
At the time that VTL emerged, a lot of companies already had established practices, procedures, and policies around working with tape as the backup medium. In these cases, VTL technologies helped enable these companies to start using disk-based backup targets without having to change all of their existing processes and practices.
Today, nearly every backup application on the planet supports native backup to disk without the need for tape emulation (VTL). In fact, most modern backup applications have more-robust backup-to-disk options than they do backup-to-tape, with some backup apps not even supporting backup-to-tape!
At a high level, VTL technologies take disk-based storage arrays and carve them up to appear as tape libraries and tape drives—hence the name virtual tape library. The initial requirement for this virtualization is to enable existing backup software to back up to a disk-based backup target without having to be modified to understand disk pools—basically taking a disk-based backup target and making it look and feel exactly like a tape library so that existing backup software could talk to it.
Figure 11.6 shows a disk array being virtualized into a VTL configured with four virtual tape drives and a single robot.
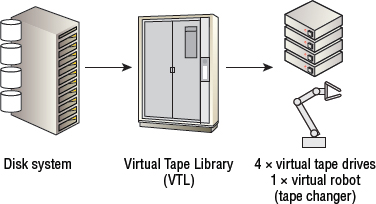
Strictly speaking, VTL technology is not a true backup-to-disk (B2D) technology. The major reason is that it takes a disk-based system and makes it look like an old-fashioned tape library. It is disk pretending to be tape, so doesn't strictly qualify as backup-to-disk.
One important technology that VTL solutions pioneered and pushed market acceptance of is data deduplication. Although not a feature restricted only to VTL technology, VTL solutions almost always perform native deduplication.
There are two major reason for this. First, backup workloads are ideally suited to deduplication. We back up the same data sets again and again, and often much of the data hasn't changed and so will deduplicate very well. Second, in order to be price competitive with traditional tape libraries, disk-based VTL systems needed a technology that allowed them to store more data on less tin.
For detailed coverage of deduplication technologies, see Chapter 10, “Capacity Optimization Technologies.”
Backup-to-Disk
Backup-to-disk (B2D)—sometimes called disk-to-disk (D2D)—is similar to backup-to-tape (B2T), but the target medium is disk rather than tape. Disk has a few advantages over tape:
- Superior random access
- Superior concurrent read and write operation
- Better reliability
Although random access isn't always seen as a crucial performance consideration with reference to backup (after all, a lot of backup workloads are heavily sequential), there can still be benefits to having good random performance. One such advantage is small file restores (which are one of the most common types of restore operation). With disk-based restores, the system can almost immediately locate the data required and begin the restore. With tape-based systems, it takes time to load the tape and then to fast-forward or rewind to the desired location.
Disk-based systems are also far superior at concurrent read and write operations. This can be helpful if creating synthetic full backups, where the system is both reading and writing during the creation of the synthetic full backup image (reading the last full backup and required incrementals, while at the same time writing out the synthetic full image).
Another place where it can help is concurrent backup (write) and restore (read) operations, though to be fair, it's uncommon to be both backing up and restoring from the same tape at the same time. However, if you don't have a lot of tape drives, you may well find yourself needing to unload a tape that you were backing up to in order to load a tape you need to restore from. Disk-based backup targets, with their superior concurrent read and write performance, will help you here.
Generally speaking, backup to disk can often offer faster restore times. For example, there is no waiting around for tapes to be loaded and spooled into position. Also, the native sequential performance of some tape drives can be hamstrung by multiplexed backups, meaning that tape-based restores aren't always as fast as they could be.
Disk-based backup targets offer a more reliable backup medium than tape does. This is based on the fact that, although disks and tapes are both susceptible to failure, disk arrays are almost always protected by RAID technologies. The net result is that when disks fail in a disk-based system, no data is lost. Tapes, on the other hand, are rarely, if ever, protected because backup jobs are rarely duplicated to multiple tapes to cater to failed tape scenarios.
An important consideration when performing backup to disk is that backup software needs to be able to understand disk-based backup targets such as disk pools, as they are significantly different from tape drives and tape cartridges. For one thing, there is no concept of tape cartridges, scratch pools, bar codes, and other tape-related aspects. However, all good modern backup applications have extensive support for disk-based backup targets.
Backup to disk is usually done over IP networks and provides a filesystem interface, such as NFS and SMB/CIFS, to the disk pool. It also allows multiple backup and restore operations to simultaneously access the disk pool.
In most environments, using backup-to-disk does not signal the end of tape. In actual fact, backup-to-disk is being used to augment existing tape-based backup solutions, improving them significantly. A common approach is to stage backups to disk and then eventually copy them off to tape, in a scheme often referred to as disk-to-disk-to-tape (D2D2T). Backups are made to disk targets and kept there up to a week or so. During this time, they are most likely to be required for restore operations, and because they're on disk, they can give excellent restore times. After this period, jobs are moved off to tape, where they are then taken off-site and stored for long-term retention. One downside to this approach is the need for an additional copy job to copy the backup images from the disk target to the tape target.
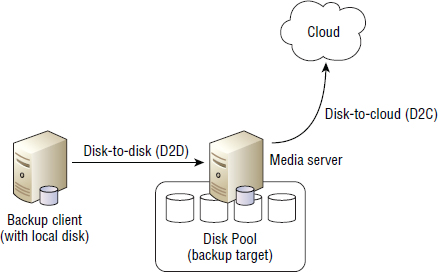
Backup to the Cloud
With all things in IT these days, the cloud is making inroads. The backup space is no exception.
With the cloud, you generally use services and pay based on how much you use the service. This commercial model is often referred to as a consumption model or consumption-based billing. You can also quickly and easily flex up or down the amount of a service you consume using the cloud.
For backup and recovery, the cloud is interesting as a backup target. In one sense it's almost ideal, as you don't need fast or frequent access to your backups after they're stored to the cloud. However, the big question is how you get your backed-up data to the cloud. A common approach is to deploy a disk-to-disk-to-cloud (D2D2C) architecture. This is similar to disk-to-disk-to-tape (D2D2T), with the tape being replaced by the cloud. In this architecture, the disk-to-disk portion still occurs within your data center, utilizes deduplication technology, and transfers only deduplicated data to the cloud for long-term retention, where it's not expected to be required for restore operations as often as the data that is on premise on the intermediary disk backup platform. Deduplication technology and synthetic full backups, or other incremental forever approaches, also help here. It should also be noted in this D2D2C architecture that only a portion of the backup estate exists in the cloud.
D2D2C architecture is shown in Figure 11.7. The process is broken into two steps:
- Backing up data from disk to disk
- Copying the same data from disk to the cloud
The two steps are combined for the complete D2D2C model. There will usually be a few days between step 1 and step 2, during which time the backup image is kept on site and on disk for fast restore. After a small period of time, such as a week or so, the backup images can be moved out to the cloud.
However, even with local disk-based backup targets and deduplication, if the amount of data you back up each month is too much, utilizing the cloud as a backup target just isn't going to work for you. It will simply take too long for you to get your data up to the cloud. In addition, you have to consider how long it will take to get it back if you need to perform a large-scale restore. Obviously, it depends on your deduplication ratios and network connection to your cloud backup provider (Internet links usually won't cut it), but if you're backing up about 10 TB or more each month, using the cloud as a backup target might prove challenging.
Even with all of these considerations, Gartner expects that 40 percent of the $30 billion + backup market will move to the cloud by 2016. In late 2013, Amazon Web Services (the largest public cloud provider on the planet) introduced a VTL gateway to its cloud storage platforms, hugely simplifying the road to incorporating cloud storage into corporate backup environments.
If you decide to go with the cloud as a backup target, you need to make sure you encrypt all data that you send to the cloud and that you own the encryption keys and keep them outside that cloud service. You will also want a clearly defined exit plan that allows you to get your data back in the event that you are not happy with the service.
Backup Retention Policies
Backup environments require backup retention policies. These policies dictate how long backup images are kept. For example, you may want to keep a weekly full backup image for 365 days, but keep daily incremental images for only 28 days.
The most popular retention scheme in use is the Grandfather-Father-Son (GFS) scheme. The GFS scheme is based on three generations of backups, as follows:
Grandfather: Monthly backups
Father: Weekly backups
Son: Daily backups
GFS schemes also apply retention policies against each generation of backup. Probably to best understand how this works, you should walk through the steps of creating such a policy. Exercise 11.2 shows how you can set up a basic backup retention policy.
EXERCISE 11.2
Creating a Backup Retention Policy
In this exercise, you will set up a basic backup retention policy. You'll use the popular GFS scheme.
- Determine the three generations of backups that you will use. Go ahead and use this scheme, which is fairly practical for many circumstances:
- Grandfather: Monthly backups
- Father: Weekly backups
- Son: Daily backups
- Determine your GFS retention policy to apply to each generation of backup. Make these your retention policies for your backups:
- Monthly backups: Keep for 60 months (5 years)
- Weekly backups: Keep for 52 weeks (1 year)
- Daily backups: Keep for 28 days
- Design a backup policy based on this particular retention scheme. Here is a basic approach you can use:
- Take full backups every Friday night and class each one as a weekly backup.
- Designate the first weekly backup of each calendar month as a monthly backup. Each of these will be expired based on the preceding policy (expire weekly backups after 52 weeks and monthly backups after 60 months).
- On Saturday through Thursday, incremental backups are taken and expired after 28 days.
- If you're using tape as your backup media, you can add into the mix the requirement to store weekly and monthly full backups off-site, but keep daily incremental backups on site.
This is the basis of a simple but powerful backup retention policy that we could publish to our users as part of a service-level agreement as follows:
- All data from the last 28 days can be restored from the previous night's backup (RPO), and can be restored within one working day (RTO).
- All data between 28 and 365 days old can be restored to the nearest Friday night backup of the data (RPO), and can be restored within two working days (RTO).
- All data between 1 year and 5 years old can be restored to the nearest first Friday of the month (RPO), and can be restored within two working days (RTO).
In this example SLA, we highlight references to RPOs and RTOs. For example, in the first item we state that the point in time that we can recover data from the last 28 days is the previous night, giving us an RPO of no greater than 24 hours. We also state it will take us no longer than one business day to get this data back, giving us an RTO of one business day.
Obviously, this backup retention policy won't fit all scenarios, but it is a good starting point that is easy to adjust.
When relying on incremental and differential backups, make sure that you keep the full backups that these rely on (the last full backup before the incremental or differential). In a GFS-based system like the one described in Exercise 11.2, this will always be the case, as we keep weekly fully backups for one year and monthly full backups for five years.
Defining SLAs should be done in consultation with the business or IT personnel designated as the liaison with the business. The agreements should also be published to both IT and the business and should be regularly reviewed.
Archiving
First, and foremost, archiving and backups are not the same! It's like saying cars and airplanes are the same, because they both transport people from one place to another. But try taking a plane to the grocery store, or using your car to take a trip to somewhere on the other side of the world. You could do both, but neither are ideal. The same goes for backups and archiving technologies and their use cases.
Backups and Archiving Comparison
Let's quickly compare and contrast backups and archiving.
For the most part¸ backups are intended to protect data that is currently or recently in use. Backups provide medium to fast recovery of this data, usually in the event that it's lost, deleted, or corrupted. It is kind of like an insurance policy in case you lose your data and need it back quickly in order to keep running the business.
Backups deal with operational recovery of files, folders, applications, and services. The typical use cases include the following:
- User-requested restores
- Disaster recovery (DR) and business continuity (BC)
On the topic of user-requested restores of backups, we've probably all been there. A user calls up or logs a ticket with the help desk, asking for a specific file or folder to be restored, usually because they've just deleted it. Previous backups of the deleted file or folder are then used to restore the lost data. We all cross our fingers, hoping that there's a valid backup to restore from.
Using backups for DR is different. As a last resort—after attempting potentially quicker methods of DR such as replication—backups can be used to recover entire systems, either at the local or a remote site.
Archiving is used to efficiently store data that is no longer used, or only very infrequently used, but needs keeping. In the case of email archiving, copies of emails are made as they are sent and received, so they can't be tampered with before entering the archive. The most common reason for archiving and retrieving data is legal compliance requirements. Most data stored in an archive needs to be tamper proof so it can be guaranteed to be unchanged from the time it was stored.
When comparing backups with archives, it's helpful to think of backups as being used to put lost data back to its original location so it can be used for its original purpose. Objects that are backed up are indexed according to their location. Archives, on the other hand, are used to locate data based on its content, and usually to copy the data to a new location where it can be used for a different purpose—often corporate or legal compliance. Archives are usually full-text indexed so you can locate items based on their content rather than their location.
Archive systems that provide tamper-proof storage of data are said to provide content assurance or content authenticity. The term nonrepudiation is also used in reference to archive systems that provide content authenticity, indicating that you cannot deny the authenticity of the data.
Even though backups and archives are not the same, they do complement each other. One example is that archived data generally doesn't need to be backed up like nonarchived data does. This is because data in the archive doesn't change. As long as it's backed up and then stored on a reliable archive platform, it may never need backing up again. This means that moving old, unused data to an archiving solution can help trim back the amount of data that you're backing up each month.
Compliance
Regulatory compliance is no doubt the single-largest driving factor behind the uptake of archiving solutions. Most developed countries have legal requirements around the storage, retrieval, and eventual deletion of data, especially data of a personal or business-sensitive nature. In the United States, the Sarbanes-Oxley Act of 2002 (SOX) is one of the more well-known examples. Others include Payment Card Industry Data Security Standard (PCI DSS), and various data protection laws that are legal in different countries and territories across the world. If your business is a global business, you will likely need to incorporate and comply with multiple compliance regulations.
Across the world, though, most legal requirements call for data in an archive to meet the following standards:
- Be tamper proof
- Be deleted after a given time
- Provide an audit trail
In the storage world, various technologies can provide tamper-proof capability, and we often refer to them as write once, read many (WORM) technologies. Some, such as some DVD and Blu-ray Disc technologies, provide this feature natively. Others, such as disk-based solutions, need to either be designed in a specific way or have special firmware written for them that make the data they store tamper proof. One such technology in the ever popular disk-based compliance archiving space is content-addressable storage (CAS).
For an in-depth discussion of content addressable storage, see Chapter 7, “Files, NAS, and Objects.”
Archiving solutions are also often required to provide detailed audit logs showing who has access to data in the archive and who has accessed it.
Also, with some regulations, it's just as important to delete sensitive data after a certain amount of time as it is to keep it in the first place. Many regulations state that after a specified amount of time, data must be purged from the archive.
How long your company keeps copies of data will be dictated by legal and compliance people at the company. However, not keeping data for long enough can have negative side effects. For example, if you have a policy stating that backups of email will be kept for only 30 days, you obviously cannot restore emails from more than 30 days ago.
In the real world, an increasing number of companies are chomping at the bit to delete and purge data as soon as possible. There are two main reasons driving this behavior. First, deleting data frees up valuable space in the archive. Second, data kept in archives, for regulatory reasons, can be and often is used against the company in litigation and other situations that can impose fines and similar penalties on the company. For these two reasons, many companies are keen to get rid of data as soon as possible.
Discovery
Archives need to be indexed and quickly searchable. When a request is made to restore lost or deleted files from a previous night's backup, the user logging the call knows the filename and file location. In contrast, when a file or email is subpoenaed, the information provided will most likely not be as specific. For example, if a court subpoenas an email, it will most likely ask for something along the lines of “an email sent by XYZ executive between July and August 2010 regarding discounted pricing of XYZ product.” This is far more vague than a typical user requesting a restore of a file. Because of this, it's a top requirement of an archiving solution to be quickly and extensively searchable. If you can't locate and retrieve data that has been requested by a court within the time the regulations specify, your business will almost certainly be landed with a fine.
Archive Media
Disk is ideally suited as an archive medium. It provides large capacity, good random access, and reliability when deployed with RAID technologies. And it's getting cheaper all the time.
Because data that is stored in an archive is stored only once, it's vital that the medium that the archived data is stored on is reliable. If that media becomes corrupted or fails, you'll lose your only copy of that data in the archive, leaving you in a very tight place, especially if you have to respond to a legal request for that data. On the reliability front, disk-based archives are almost always protected by RAID-type technologies, making them extremely reliable, and significantly, more reliable than tape.
Disk-based archives are also a lot better than tape when it comes to technology refreshes. Although both tape and disk need refreshing every few years, tape technology refresh is particularly painful and labor-intensive. Nobody wants to do it. Consequently, tape refresh often gets overlooked until you find yourself with very old backups on very old tapes that you can no longer recover from. And as tapes usually get stored off-site, the truism out of sight, out of mind applies, and we often forget that we need to refresh them.
On the other hand, disk-based archives sit in the middle of your data center and suck power every single day, meaning you're less likely to forget about them. Also, the process of migrating data from a disk-based archive to a newer disk-based archive is far simpler and far less work than copying old tapes to new tapes.
On the topic of power consumption and associated operational expenditure costs, some disk-based archives support spin-down and massive array of idle disks (MAID) technologies, where unused disk drives are spun down (turned off or put into low-power mode) to reduce overall power consumption of the archive. When they are needed, they are spun back up. However, this extra time taken to spin them back up is negligible compared to the time required to recall tapes from off-site storage.
Optical media, such as DVD and Blu-ray, are options as archive media, although they are rarely seen in the real world. They're both removable, meaning they can be vaulted, and they both offer native WORM capability. They can also be cheap. However, archive solutions are very long-term investments, and you need to think extremely hard about how your archive solution will look in 10 years. This is one area in the real world where optical media is falling short. These are all valid questions that you need to seriously consider:
- How long will your chosen optical media be around for?
- How reliable will it be in 10 years?
- How long will the payers be around for?
Optical media also struggled with capacity and performance. Tapes and disks can store far more data and often provide faster access, and with disks, you don't waste time having to mount and unmount the media.
![]() Real World Scenario
Real World Scenario
The Dificulty of Using Backups as an Archive
A U.S.-based retail company was subpoenaed for some data relating to an investigation, but they didn't have a proper archiving solution in place. Instead, they had to rely on an old backup to recover the data. Because the data being requested was from several years ago, the backup tapes that the data was thought to be on were stored off-site with a third party and had to be recalled to site. There was a delay of an extra day in recalling the tapes because they were from so long ago. Then when the tapes arrived back at the site, they used an old format of tape (SDLT), and the company no longer had any tape drives at the data center that could read that format. Fortunately, a suitable tape drive was located, based in a branch office, and arrangements were made for it to be shipped to the data center ASAP–meaning local backups at the branch office had to be disabled until the SDLT drive was returned. When the drive arrived at the data center, a new media server had to be built to house the tape drive. Also, because the data was so old, each individual tape had to be read in order to index its contents. As several tapes had been recalled, this took another two to three days. In the end, the data was recovered and provided to the legal department.
On top of all of this overhead, there was an increased risk that the tapes would be unreadable because of media degradation. In this particular instance, this didn't happen, but there was a good chance that after all the efforts of the IT staff in recalling tapes, borrowing the tape drive, and building new servers, the tapes would have been unreadable.
Restoring the data also would have been made even more complicated had the company changed backup applications since the data had been backed up!
This kind of experience is in stark contrast to using a purpose-built archiving solution, where the data sits on reliable media that is maintained (disks are scrubbed and RAID protected), indexed, and searchable, and data is accessed over industry-standard protocols such as SMB/CIFS and NFS.
Summary
In this chapter we set the scene by discussing why we back up and why backups are so important, and defined some important terms such as recovery point objective, recovery time objective, and backup window. We then stressed the importance of being able to restore from backups. After that, we talked in detail about the major types of backup, including hot backups, LAN-based backups, LAN-free backups, serverless backups, and NDMP backups. We then discussed the differences between full backups, incremental backups, and differential backups, and how they can be effectively used as part of a backup retention scheme. We then moved on to discussing different backup target technologies such as tape, disk, and the cloud, and finished the chapter talking about archiving technologies and compliance archives.
Chapter Essentials
Backups and Business Continuity Backups are an important part of disaster recovery and business continuity plans. It's absolutely vital that backups are reliable and can be easily and reliably recovered from. Take the time to test your restore procedures so that you don't end up trying to recover data from a particular type of backup in the heat of an emergency.
Hot Backups Hot backups are application-consistent backups taken while a system remains online. No system downtime is required for backups, and the backup is guaranteed by the application to be consistent and therefore useful as a recovery point. Most popular applications and databases support a hot backup mode.
Synthetic Full Backups Synthetic full backups reduce the client and network load required to create full backup images. Rather than trawl the entire contents of the client being backed up and drag all the associated data across the network to the backup target, synthetic full backups work by taking a previous full backup image, already stored on the backup target, and joining it with a new incremental image. The resulting joined image is exactly what you would have achieved had you taken a new full backup. The difference is that this synthetic full backup was created by taking only an incremental backup of the client and having to pull that over the network.
Archiving Archiving is not the same as backing up your data. Archives usually take the form of compliance archives that adhere to regulatory requirements relating to authenticity of data and nonrepudiation. Archives need to be indexed and searchable, provide a secure and reliable audit trail for data, and built on top of reliable media that can be easily refreshed. Archives need to be planned with the very long-term in mind.