
Chapter
7
Files, NAS, and Objects
TOPICS COVERED IN THIS CHAPTER:
- NAS protocols including NFS and SMB/CIFS
- Traditional NAS arrays
- Unified storage arrays
- Scale-out NAS
- Object storage devices
- Content-aware storage
- Compliance archiving
 In this chapter, you'll look closely at the major protocols involved with NAS, file-serving, and object storage environments. You'll start out by looking at traditional file-serving and NAS environments, before moving on to more-modern and far more interesting scale-out NAS technologies. You'll then move on to the modern and extremely interesting world of object storage.
In this chapter, you'll look closely at the major protocols involved with NAS, file-serving, and object storage environments. You'll start out by looking at traditional file-serving and NAS environments, before moving on to more-modern and far more interesting scale-out NAS technologies. You'll then move on to the modern and extremely interesting world of object storage.
This chapter covers NFS and SMB/CIFS file-serving protocols, including the differences between the two and some of the features available in the various versions of each. You will then compare and contrast the use of NAS appliances with traditional general-purpose file servers. Finally, you will examine object storage and object storage devices, including how they compare to traditional file services and how they play well with Big Data and cloud storage.
What Files, NAS, and Objects Are
In the storage world, there have traditionally been two types of storage:
- Block storage
- File storage
Block storage shares raw devices and can be thought of as working with bits and bytes, whereas file storage operates at a higher level, and as the name suggests, works with files and folders.
If you install a new disk drive in your PC, it will appear to the operating system as a raw block device that you will need to format with a filesystem before you can start using it. If your grandmother needed a second disk drive installed in her PC, you would probably have to do it for her. File storage is different and a lot simpler. If somebody shares a folder with you over the network, once you are connected to the network, the shared folder is ready to use. There is no need to mess around formatting it or doing anything technical like that.
Shared file storage is often referred to as network-attached storage (NAS) and uses protocols such as NFS and SMB/CIFS to share storage. Generally speaking, NAS storage is often used for unstructured data storage such as shared folders and document repositories. A notable exception is using a NAS array to provide NFS datastores for VMware.
SAN and NAS have been around for years. SAN shares storage at the block level, and NAS shares storage at the file level. Between them they rule the roost in most corporate data centers, and probably will for a lot of years to come. However, they are not best suited to the kind of scale demanded by the cloud and Web 2.0–type media such as the large image and video files that are exponentially growing in the social media space.
This is where a relatively new type of storage, known as object storage, comes into play. Object storage is the new kid on the block and is still finding its place in the world. So far, it has been a massive success in the public cloud arena, but less so in the traditional corporate data center (although it is seeing more and more use cases and demand in the corporate data center).
File/NAS storage and object storage are covered in greater detail throughout the chapter.
Network-Attached Storage
As established in the introduction to the chapter, NAS is not SAN. It might use the same three letters for its acronym, but the two are not the same! SAN works at the block level, whereas NAS works at the file level. As this chapter concentrates on file-level storage, we will talk only of files, and then later we will talk about objects.
As already stated, NAS is an acronym for network-attached storage. In the corporate data center, most people think of NetApp when they think of NAS. True, NetApp can do block and file storage, but it is mainly known for doing file storage. However, NetApp is not the only vendor of NAS storage technology out there.
Files are a higher level of abstraction than blocks. Although NAS clients talk to NAS filers in terms of files, the filer itself still has to communicate with the disk drives on its backend via block-based protocols. Figure 7.1 shows a simple NAS setup with the client mounting a filesystem exported from the front-end of the NAS appliance, while on the backend the NAS performs the required block storage I/O. Effectively, the NAS hides the block-level complexity from the clients.
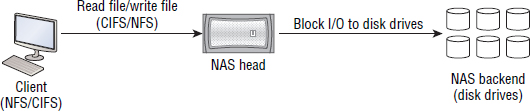
The most common examples of NAS storage in the corporate data center are user home directories and team drives. In the Microsoft Windows world, these NAS drives are referred to as shares, network shares, or CIFS shares. In the UNIX world, they are usually referred to as exports or NFS exports. You will explore CIFS and NFS further shortly.
In the Microsoft Windows world, it is most common to mount a share to the root directory of a drive letter. For example, your user home directory might be mounted to H:, and your department's team drive might be mounted to the root of F:. Windows also supports mount points, technically called reparse points, that allow external filesystems to be mapped to arbitrary locations within an existing filesystem—kind of like how it works in the Linux/UNIX world.
In the UNIX world, NFS exports are usually mounted to a mount point within the root (/) filesystem rather than a drive letter. For example, your team drive might be mounted to a directory called tech in the /mnt directory.

A mount point is a directory in a local filesystem, where a new external filesystem is made accessible. The directory that is used as the mount point should be kept empty. For example, your Linux server might have a /teams directory on its local hard drive but use this directory as a mount point for accessing an external filesystem that is accessed over the network.
In the Microsoft Windows world, the process of mounting a network drive is referred to as mapping a drive.
In both the Microsoft Windows and UNIX worlds, once a remote filesystem is mounted into the local namespace (either a drive letter in the Windows world or a mount point in the UNIX world), you read and write files to them as if the files and folders were local to your machine.
Although NAS might work at a higher level than SAN (block), it is by no means simple. NAS has to deal with the following concerns that SAN does not have to deal with:
- File-level locking
- User and group permissions
- Authentication
- Antivirus software
Now let's take a closer look at the most common NAS and file-sharing protocols.
NAS Protocols
Within the scope of NAS storage, there are several protocols. However, the most prominent and important—and the ones that you need to know the most about for the CompTIA Storage+ exam—are Network File System and Server Message Block.
NFS
It's only right that we start with Network File System (NFS). When Sun Microsystems invented NFS, it pretty much invented network file sharing as we know it today.
NFS is a client-server protocol that operates natively over TCP/IP networks and is deeply rooted (pun intended) in UNIX. However, it is also implemented in Microsoft Windows environments, albeit far less frequently than in UNIX environments.
There are two major versions of NFS in use today:
- NFSv3
- NFSv4 (including 4.1 and 4.2)
At the time of writing this book, deployment of NFSv3 still far outstrips deployment of NFSv4, even though NFSv3 was standardized in the mid-1990s and NFSv4 in the early 2000s.
The major components in an NFS configuration are the NFS server and the NFS client. The NFS server exports specific directories to specific clients over the network. The NFS client mounts the NFS exports in order to read and write from them. NFS servers can be either general-purpose UNIX/Linux servers, or can be NAS devices running an NFS service.
NFSv3 Overview
NFSv3 is a stateless protocol that operates over UDP or TCP and is based on the Open Network Computing (ONC) Remote Procedure Call (RPC) protocol.
NFSv3 is pretty awful at security. Basically, the standards for NFSv3 stipulate security as optional, resulting in hardly anybody implementing any of the recommended security features. Therefore, some organizations, especially financial institutions, try to avoid NFSv3.
NFSv3 is also tricky to configure behind and connect to through a firewall. This is because it utilizes the port mapper service to determine which network ports to listen and connect on. Basically, when an NFS server starts up, it tells the port mapper service which TCP/IP port numbers it is listening on for particular RPC numbers. This means that NFS clients have to ask the port mapper service on the NFS server which TCP or UDP port number to contact the NFS server on for a given RPC number. This mapping can change if the NFS daemon is restarted. This can get a bit messy in firewalled environments.
Despite these deficiencies, NFSv3 is still a highly functional and popular file-serving protocol, so long as you can overlook the gaping security holes.
NFSv4 Overview
NFSv4 is a massive step forward for the NFS protocol, bringing it up to par with other network file-sharing protocols such as SMB/CIFS. However, despite being ratified as a standard in the early 2000s, not many vendors have implemented it and even fewer customers have deployed it. That aside, NFSv4 offers some good features and it is gaining in popularity. Some of the major improvements include the following:
- Access control lists that are similar to Windows ACLs
- Mandated strong security
- Compound RPCs
- Delegations and client-side caching
- Operation over well-known TCP port 2049
- NFSv4.1 also brought parallel NFS (pNFS)
Let's look at some of these aspects in more detail.
NFSv4 Compound RPCs
NFSv3 was a chatty protocol—not the worst, but not great either. Basically, all actions in NFSv3 were short, sharp RPC exchanges through which the NFS client and NFS server would ping-pong lots of RPCs to each other. Figure 7.2 shows a typical conversation between a client and server using NFSv3.
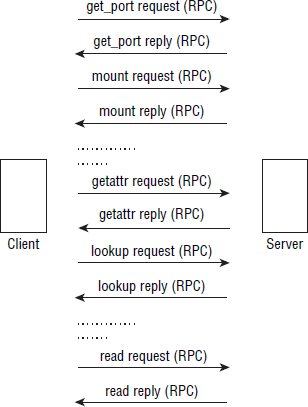
It was typical for a simple mount of an export and subsequent read of a file on the exported filesystem to require 20 or more exchanges between the NFS client and server. That is not ideal on a LAN, and it is a nightmare over a WAN because of the high latency common in WANs. Compound RPCs in NSv4 fix this. The principle is simple. NFS clients batch operations and send them to the NFS server as fewer RPCs. Responses from the server get batched too. This results in a far less chatty protocol that is better suited for WANs as well as LANs.
Defining WAN, LAN, and MAN
A wide area network (WAN) is a network that covers a large geographic distance. It doesn't matter whether that network is privately owned or is linked over the Internet. For example, the London and New York offices of a company may be connected over a dedicated private circuit, while the New York and Cayman Islands offices may use a VPN tunnel over the Internet. Both can be termed WANs.
A local area network (LAN) is the opposite of a WAN. A LAN is usually restricted to a single building or very short distances (approximately 100 meters or so). In a LAN you can have high data rates such as 40 GB and higher and still have relatively low latency.
A metropolitan area network (MAN) fits somewhere in between a LAN and a WAN and generally operates over moderate distances such as a city/metropolitan area.
NFSv4 Security
NFSv4 does a much better job at security than NFSv3. Although NFSv3 supports strong security, people (including vendors) often failed to implement it. NFSv4 changes the game by mandating strong security.
One of the major security enhancements is the use of Kerberos v5 for the usual cryptographic services:
- Authentication
- Integrity
- Privacy (encryption)
Both UNIX and Windows-based Kerberos Key Distribution Centers (KDCs) are supported.
Figure 7.3 shows an example NFSv4 configuration with a Kerberos KDC.
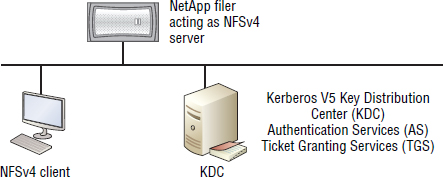
Mounting an NFSv4 export on a Linux host using Kerberos requires the mount options shown here:
mount -t nfs4 uber-netapp01:/vol/nfs4_test_vol /mnt/nfs4 -o sec=krb5
NFSv4 Access Control Lists and Permissions
With NFSv3, mount requests were allowed or denied based on the IP address of the client making the mount request. No thought was given to the user who was making the mount request. NFSv4 turns this on its head. In NFSv4, it is all about authenticating the user who makes the mount request.
NFSv4 has also caught up with SMB/CIFS with its use of proper access control lists (ACLs) that are based on the NTFS model. This is good because the NTFS security model is far superior to the traditional POSIX-based read/write/execute permissions common in the UNIX world.
ACLs in the NFSv4 world are populated with access control entries (ACEs). The model is a deny-unless-specifically-granted model, and because of this you should not have to explicitly deny access to files and directories. Abiding by this principle—not explicitly denying access—can keep troubleshooting ACL issues far simpler than if you do use explicit denies.
Putting It All Together
Now that you have explored the principles of NFS, let's go through an exercise of creating, exporting, and mounting an NFSv3 directory. See Exercise 7.1.
EXERCISE 7.1
Exporting and Mounting an NFS Share
On UNIX and Linux servers, the /etc/exports file contains the list of all NFS exported filesystems. If this file is present and configured, when a UNIX/Linux server starts up, the nfsd daemon will start and will export the filesystems listed. Naturally, I am using directory and client names that are on my system, and you will need to substitute names native to your system if you want to actively try this.
- Logged on to your Linux server, LegendaryLinux01, use the exportfs command to export the /home/npoulton/test_export directory to a Linux client called uberlinux01:
# exportfs uberlinux01:/home/npoulton/test_export/
- The previous command makes an entry in the /etc/exportfs file. Verify this with the exportfs command:
# exportfs :/home/npoulton/test_export/uberlinux01
- Now that your directory is exported to your Linux host called uberlinux01, let's switch to your legendarylinux01 client and mount the export to a mount point of /mnt/test:
# mount legendarylinux01:/home/npoulton/test_export/ /mnt/test
- Change the directory to /mnt/test and see whether you can see any files:
# cd /mnt/test # ls -l -rw-r--r-- 1 npoulton is 11 May 9 10:58 uber_file
- Unmount the export with the umount command:
# cd / # umount /mnt/test
- Switch back to your Linux export server (legendarylinux01) and unexport the directory. To do this, use the -u switch on with the exportfs command:
# exportfs -u uberlinux01:/home/npoulton/test_export/

It is highly recommended to use root squashing when exporting resources via NFS. Root squashing sets the user ID of anyone accessing NFS exports from the user context of the root user on their local machine (the NFS client) to a value of the NFS server's nfsnobody account. This effectively ensures they don't get root privilege to the NFS export. Don't turn this behavior off unless you are absolutely certain you know what you are doing.
SMB/CIFS
First, let's get the lingo right. This is a tricky one, though. Technically speaking, the protocol is SMB, an acronym for Server Message Block. However, just about everybody refers to it as Common Internet File System (CIFS, pronounced sifs). It was originally called CIFS, but is now formally called SMB. Boring, I know! At the end of the day, few people care, but you're usually safe going with the flow, and the flow is calling it CIFS.
Also on the topic of terminology, you will often hear people refer to things like CIFS shares, CIFS clients, and CIFS servers. A CIFS share is any folder that is shared on the network using the SMB/CIFS protocol. This generally is anything you connect to using a UNC path such as this:
\legendaryserversybex-book
UNC is an acronym for Universal Naming Convention, or Uniform Naming Convention. It is the syntax used to address CIFS shares over a network. The format for UNC paths is \servernamesharename. Because UNC is used to address CIFS shares, it is predominant in Microsoft Windows environments.
CIFS is a client-server-based protocol. A CIFS server is any file server dishing out CIFS shares. This could be a Windows server that is sharing some of its local directories, or it could refer to an instance of a file server on a NAS array. A CIFS client is any device that accesses a CIFS share over the network. All Microsoft Windows machines have a CIFS client, and no additional software is required. Linux servers require a Samba client installed in order to access CIFS shares.
The Strengths of SMB/CIFS
CIFS is the de facto file-serving protocol in the Microsoft Windows world. It's been around for years and has been tuned and tweaked into what is now a best-of-breed file-serving protocol. CIFS operates natively over TCP/IP networks on TCP port 445.
CIFS is also widely deployed by many third-party NAS vendors, thanks to it being a publicly documented protocol despite the fact that it is Microsoft proprietary. Beware, though: not all third-party implementations implement all features.
CIFS is a pretty rich file-serving protocol. It supports all of the following, plus a lot more:
- Authentication
- Encryption
- Quotas
- Branch caching
- Advanced permissions
- Request compounding
- Request pipelining
SMB/CIFS can be used to share and access devices other than files and folders. It can also share printers and be used for inter-process communication (IPC) between servers.
SMB/CIFS originally had a shocking reputation. It was extremely chatty and had a checkered history that didn't embrace TCP/IP. Then with the introduction of Windows 2000, Microsoft suddenly embraced TCP/IP as if it had invented it. However, although it was ugly in its early stages, it is much better looking now!
SMB 2.0 was a massive revision that really upped the ante. Major improvements included vastly reducing network-related chatter, reducing the overall number of commands in the protocol suite, introducing command compounding, and adding pipelining of commands.
Command compounding allows commands to be batched up and sent as fewer commands. The same goes for responses. Pipelining takes things a little further by allowing multiple compounded commands to be sent before an ACK is received. It also supports TCP window scaling. The net result is a superior, less chatty protocol that is more suited to WAN use cases, including the Internet.
Be careful if using SMB/CIFS over the Internet, as there are many ways to exploit the protocol. You need to take care by making sure your servers and NAS devices are patched to the latest levels, and if possible you may want to utilize authentication and encryption using Kerberos.
SMB 3.0, introduced with Windows Server 2012, improved on the already excellent SMB 2.0 by adding various other improvements as well as introducing an interesting feature Microsoft calls SMB Direct. SMB Direct allows SMB traffic to be sent over high-performance, low-latency remote direct memory access (RDMA) technologies like InfiniBand.
On the security front, CIFS utilizes Kerberos for cryptographic services such as authentication and encryption, and it's pretty simple to set up. However, not all implementations of SMB/CIFS by NAS vendors implement Kerberos-based cryptographic services. Be sure to check before you buy.
All in all, modern versions of the SMB/CIFS protocol are solid. Microsoft is driving it hard, whereas many NFS shops—customers and vendors—have been very slow to implement and deploy many of the newer features that have been available in NFSv4 for over 10 years now.
A testament to the quality of recent versions of SMB/CIFS is that Microsoft now supports SQL Server 2012 database files to be stored on SMB/CIFS shares. This would not be supported if the protocol was not reliable and high performance.
Mapping a remote CIFS share is significant yet easy. See Exercise 7.2.
EXERCISE 7.2
Mounting a Remote CIFS Share
Here, you'll look at mapping and then checking the contents of a CIFS share. Obviously, if you follow these steps, you'll need to substitute the names of your own share and server.
- Use the net use command to map a remote CIFS share on a server to a mount point using the UNC naming convention. Here, I am mapping TeamDrive on server W2012-01 to a mount point of Z:, but you can use whatever remote CIFS share, server, and mount point you prefer.
net use Z: \w2012-01 eamdrive
- Now that the CIFS share is successfully mounted on the PC, run a dir command to list the contents of the share:
C:>cd z: Z:>dir Volume in drive Z is 143. Volume Serial Number is D2B5-52F Directory of Z: 21/09/2011 07:18 <DIR> Users
As you can see from the dir output, the CIFS share contains a single directory called Users.
SMB/CIFS Permissions
SMB/CIFS file and folder security is based on access control lists that allow extremely granular control of file and folder permissions.
There are a few things to be aware of when working with permissions on CIFS shares. First, CIFS shares have two distinct sets of permissions:
- Share permissions
- NTFS permissions
Share permissions can be applied only at the root of the share, not to subfolders or individual files. Share permissions also apply only to connections over the network, meaning that anyone logged on locally (including Terminal Services) automatically bypasses any share permissions. NTFS permissions, on the other hand, can be applied to any file or folder, and apply equally over the network or for locally logged-on users. NTFS permissions are way more flexible and granular than share permissions, and most of the permissions work you do will be with NTFS permissions.
As every CIFS share has to have both types of permissions, how can they work effectively together? One very common approach is to configure share permissions to grant full control to the Everyone group, and then to start locking things down with NTFS permissions. This effectively bypasses share permissions.
There are a couple of important points that are common to both share and NTFS permissions:
- Both work on an implicit deny model. If access is not specifically granted, it will be denied.
- The most restrictive permission applies.
The second point basically means that deny permissions trump allow permissions. For example, consider a scenario where the user npoulton is a member of the IT-All security group and also a member of the IT-Contractors security group. If the IT-All group is allowed access to a particular folder but the ITContractors group is denied access, the security principal npoulton will not be allowed to access the folder.
However, it is not quite as simple as that. Explicit permissions trump inherited permissions, even inherited deny permissions. This means that if a folder inherits a deny permission from its parent folder for the IT-All group, but that same group is explicitly granted access to the folder, the explicitly granted access will override the inherited deny permission.
This works slightly differently when enumerating share and NTFS permissions. If share permissions allow user npoulton full control of a share, but then the NTFS permissions allow the same user only read-only access, the effective permissions for the npoulton user will be read-only access.
Make sure you count to 10 and really think about what you are doing before granting NTFS full-control permission, as this permission allows the user to take ownership of the folder and its contents. Once a user has ownership of something, they are free to mess about with that object to their heart's content.
Clients and servers running different versions of the SMB protocol are said to be speaking different SMB dialects. When a client and server initiate communication, they negotiate the highest supported dialect.
FTP
FTP is an acronym for File Transfer Protocol. FTP is a client-server- based protocol that operates natively over TCP/IP networks. FTP is commonly used to transfer large files over the Internet, and as the name suggests, FTP actually transfers (moves) files between the client and the server. This differs from NFS and SMB, which allow files to remain on the server while they are being accessed and updated. Most web browsers support FTP, and there are also a wide variety of FTP clients available.
Vanilla FTP is weak on the security front and sends passwords as cleartext. If authentication and other security features are required, either FTP with SSL (FTPS) or Secure Shell FTP (SFTP) should be used.
In addition to the security weaknesses, FTP is a fairly primitive protocol when compared with the latest versions of NFS and SMB/CIFS. Consequently, FTP is losing popularity to protocols such as BitTorrent.
NAS Arrays
NAS arrays are specialized computer systems that act as file servers. They come in all shapes and sizes, starting with small home use systems and ranging all the way up to massively scalable, scale-out NAS systems. Most organizations run their businesses on mid- to high-end systems. These are often specialized, custom-built computers that pool and share large numbers of drives. Some NAS arrays have specialized custom hardware such as ASICs and FPGAs, although these are becoming less and less popular, and most are now built using commodity hardware. On the software side, things are different. Most NAS arrays run proprietary software that is stripped down to the bare bones and highly tuned specifically for file serving.
Running small, specialized NAS operating systems has several advantages, including these:
- High performance
- Small attack surface
- Simple upgrades and patch management
- Fewer bugs
High performance comes from the fact that the NAS OS does not have to cater to other general-purpose server requirements and can be tuned specifically for file serving. This also makes upgrading and patching significantly easier because you have fewer moving parts, so to speak. The small attack surface comes from the fact that the NAS OS runs only code specific to file serving and is therefore not at risk of hacks aimed at vulnerabilities in code that have nothing to do with file serving.
Application-specific integrated circuits (ASICs) and field-programmable gate arrays (FPGAs) are effectively custom silicon—specialized processing hardware designed for a fairly specific task. There are a few minor differences between the two, but as far as we are concerned, they are custom hardware and are the antithesis to commodity hardware such as Intel x86 and x64 CPUs. There is a big move in the industry to get away from custom hardware and deploy as much as possible on commodity hardware, implementing the intelligence in software. This software-everything approach boasts lower costs and faster development cycles and is just about the only way to go for cloud-based technologies and software-defined technologies such as software-defined networking (SDN) and software-defined storage (SDS). There is still a small amount of custom hardware, ASICs, and FPGAs going into more-traditional storage technologies such as SAN and NAS disk arrays.
The primary goal of a NAS array is to pool storage and make it available to other systems as files and folders over an IP network. More often than not, the protocols used to share files are NFS and SMB/CIFS. Other protocols such as File Transfer Protocol (FTP) and Secure Copy (SCP) are sometimes included. Quite often, though, the protocol suites on NAS arrays lag behind the published standards and do not implement all features of a given protocol. For example, it is common for CIFS on a NAS device to lag behind the latest SMB/CIFS implementation on Microsoft Windows servers. This is due to several reasons. First, the NAS vendor will always lag behind Microsoft, as Microsoft owns and develops the protocol. The NAS vendors effectively copy its behavior. Second, not all NAS customers require all features, and vendors will implement only the features that their customers are asking for and the features for which they can justify the expense of development.
Although most NAS arrays are built on top of a commodity Intel architecture and often run a version of the Linux kernel, you cannot run your own software on them. The common exception is that some vendors allow you to run specialized NAS versions of antivirus software.
Figure 7.4 shows a logical block diagram of a typical NAS array.
The backend disk drives of a NAS array can be a part of the packaged NAS solution, or they can be LUNs from an external storage array. The latter is referred to as a NAS gateway, which is covered later in the chapter.
NAS arrays are also discussed throughout Chapter 3, “Storage Arrays.”
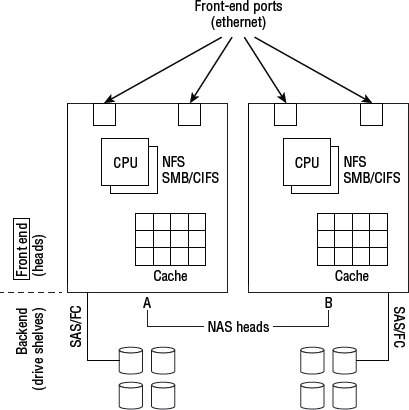
NAS Array vs. a General-Purpose File Server
NAS arrays are popular in modern data centers as consolidation points for file shares and storage for unstructured data.
The term structured data refers to data that is highly organized in a known fashion, such as databases. On the other hand, unstructured data refers to most other types of data such as document repositories and rich media files like pictures and video. NAS can be used for both, but is more commonly used for unstructured data storage.
As mentioned earlier, a standard Windows or Linux server can be configured as a file server and perform the same functions as a NAS array. In fact, sometimes Windows and Linux servers support more features such as Microsoft branch caching and some of the advanced features of Microsoft Distributed File System (DFS). So why would you spend the money on a specialized NAS array?
NAS Pros
On the plus side, NAS arrays tend to provide benefits in four key areas:
- Simplified management
- Increased performance
- Increased data availability
- Advanced features
On the topic of simplifying management, NAS arrays usually have specialized GUIs and CLIs that make managing filesystems, network connections, and advanced features a lot simpler. It is common for multiple general-purpose file servers to be consolidated to a single NAS array, dramatically reducing the number of management points in an environment. Also, patching and code upgrades can be hugely simplified and usually done without taking the system offline, not to mention that hardware upgrades are usually simple and very expandable.
From a performance perspective, NAS arrays tend to pool lots of drives together on the backend. This leads to increased-performance and reduced-performance hot spots. NAS arrays can also come with large DRAM and flash caches to increase performance.
Most NAS arrays support multiple controllers—sometimes referred to as heads—that provide increased performance as well as data availability. These heads are often configured in an n+1 configuration, where a single head can fail but the NAS system can remain up and operating.
Some of the advanced features NAS arrays support include advanced RAID protection, snapshots, remote replication, deduplication, compression, and hypervisor integration.
NAS Cons
On the downside, NAS arrays do not always support all features of a given protocol. For example, not all NAS arrays support NFSv4. Also, not all NAS arrays support all features of SMB/CIFS. Commonly, features such as branch cache and certain aspects of DFS are often not supported.
![]() Real World Scenario
Real World Scenario
Consolidating to a NAS array
A small/medium-sized business in the retail sector had an untidy sprawling file server estate built around an old version of Windows (Windows Server 2003) that was becoming more and more difficult to manage. The file server estate had started out using local disks in the physical file servers, but was starting to grow out of the locally attached disks and needed SAN storage presenting to the file servers in order to cope with growth in the file server estate. This SAN storage was not a cheap option, but there were no more slots for new disks in the file servers for more locally attached disk. It was decided to migrate the file server estate to NetApp Filers (NAS arrays). In the end, all eight of the company's physical file servers were migrated and consolidated to a single NetApp Filer. This Filer was a single point of management, had the capability to easily increase in capacity, and utilized replication and snapshot technologies to drastically improve the backup solution for the file server estate. Migrating file servers to the NetApp Filer was a huge success and the estate went from being out of control and sprawling, to under control with room for growth and major improvements to management, availability, and backup.
NAS vs. DAS
When comparing NAS to direct-attached storage (DAS), it is important to remember that DAS provides block storage, whereas NAS provides file storage—so it's not an apples-to-apples comparison.
Assuming you aren't concerned about the differences between block or file storage, the key benefits of NAS tend to be scalability and advanced features such as snapshots, remote replication, deduplication, and so on. However, NAS has higher latency and higher $/TB costs than DAS.
Sometimes NAS will be what you want, especially if you are looking for consolidated file serving, whereas for other requirements such as cheap dumb storage, DAS may be the better option.
NAS vs. SAN
This is more of an apples-to-apples comparison, although there is still the difference between file and block protocols.
Technically speaking, the differences boil down to the following. SAN storage shares only raw capacity over a dedicated network, whereas NAS also provides a network-aware filesystem (permissions, file locking, and so on). Each of those has pros and cons. SAN storage needs to be managed at the host by a volume manager layer and have a filesystem written to it, but shares from a NAS do not.
In the real world, NAS is sometimes seen as a bit of a dumping ground for office documents and rich media files. Although true, this does a huge disservice to NAS. It is probably fairer to say that NAS lends itself naturally to being shared storage for unstructured data, with structured data sets being more commonly deployed on SAN-based block storage.
Traditional NAS Arrays
Traditional NAS arrays like the original NetApp filers and EMC VNX devices are getting quite long in the tooth and are struggling to cope with many of today's unstructured data requirements. They tend not to be very scalable and can easily become a management headache in large environments, where it is not uncommon for medium-sized organizations to have 10 or more filers, and for larger organizations to have several hundred filers on your data center floor, each needing to be managed separately.
That aside, they do a good-enough job on a small scale and provide the usual NFS and SMB/CIFS protocols. They also provide features such as remote replication, snapshots, deduplication, and compression.
Unified NAS Arrays
Unified NAS arrays combine traditional NAS arrays with block SAN arrays in a single system. These hybrid arrays are sometimes called multi-protocol arrays because they support both file and block protocols. To some people, they are Frankenstorage, whereas for other people they are just what the doctor ordered. Generally speaking, they work for small and sometimes medium-sized organizations that have a requirement for block and file storage but cannot justify making two separate purchases. More often than not, these unified storage arrays maintain separate drive pools for block and file storage in order to keep the I/O of the two protocol types from walking all over each other and dragging performance down.
Frankenstorage refers to storage technologies that appear to be crudely bolted together. Examples include unified storage arrays that have simply taken a block storage array and a filer head and bolted them together to look like a single unified system, whereas under the covers they are two separate systems.
Scale-Out NAS Arrays
Anyone who knows anything about traditional NAS arrays will tell you that they do not scale. If you have large NAS requirements, you are forced to deploy multiple discrete NAS arrays, each of which is individually managed. This results in what is commonly referred to as NAS sprawl.
Scale-out-NAS goes all-out to bring scalability to NAS. And it does this while riding the Big Data wave, where companies are looking to mine and make use of vast quantities of unstructured data.
While having a lot in common with traditional NAS—such as supporting NFS and SMB/CIFS protocols over Ethernet networks—there are a couple of key principles that define scale-out NAS. These are as follows:
- Horizontal scalability
- Single global namespace
Horizontal Scalability
Horizontal scalability is just a fancy term for scale-out. Let's quickly define the term. Consider an application that runs on a server. Adding more memory, more storage, or more CPU to the server that the application runs on is called scale-up¸ or vertical scaling. Adding more servers, each with CPU, memory, and storage, to the application is scaling out, or horizontal scaling.
The principle in the NAS world is the same. A NAS system that supports scale-up will allow you to add more memory and storage to it, which is different from scale-out, whereby more nodes/heads/controllers can be added. On the other hand, a scale-out NAS system will allow you to add more nodes to it, with each node bringing its own CPU, memory, and storage to the NAS system. These scale-out NAS systems are often referred to as clusters or NAS clusters.
A good way to think of horizontal scaling is spreading the workload over more nodes.
Scale-out NAS clusters support multiple nodes that can be dynamically added to the cluster. Each node has its own CPU, memory, and storage that contribute to the overall NAS cluster. A high-speed, low-latency, backend network is usually required so that read access to data stored on drives attached to different nodes isn't slow. 10 GB Ethernet and InfiniBand are popular backend interconnect technologies.
Writing software and filesystems that support scale-out is a tricky business, which is why not all NAS systems are scale-out.
Single Global Namespace
Typically, a scale-out NAS cluster will boast a single infinitely scalable filesystem. A filesystem is sometimes referred to as a namespace. All nodes in the scale-out NAS cluster run the filesystem and have full read/write access to it.
Because there is only one filesystem (namespace) and it is accessed by all nodes in the cluster, it can be referred to as a single global namespace. Having a single global namespace like this leads naturally to evenly balanced data placement on the backend, not only leading to massively parallel I/O operations, but also reducing drive and node hot spots.
Aside from being massive and global, these filesystems are designed to allow nodes to be seamlessly added and removed from the cluster. This can help immensely when addressing technology refresh, such as when replacing old hardware with new. For example, new nodes running newer hardware can be admitted to the cluster, and nodes running old versions of hardware can be evicted, all seamlessly, making hardware technology refresh way simpler than it has been with traditional NAS arrays.
Scale-out filesystems like these are often described as distributed and cluster-aware. Typically, when data is written to the scale-out NAS system, the data will be distributed across the entire backend.
Anyone who has managed large traditional NAS arrays with multiple filesystems that are locked to just two nodes knows what a management pain in the neck that is. A single global namespace goes a long, long way to simplifying management as well as scalability. Figure 7.5 shows a traditional two-head NAS with multiple filesystems on the backend, each accessible primarily by its owning/connected node. Figure 7.6 shows a small, five-node scale-out NAS with a single filesystem (global namespace) on the backend that is equally accessible by all nodes in the cluster.
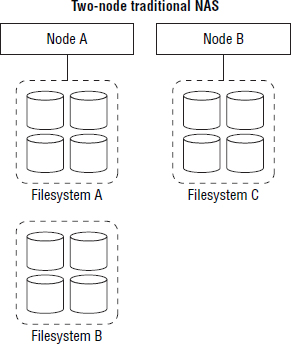
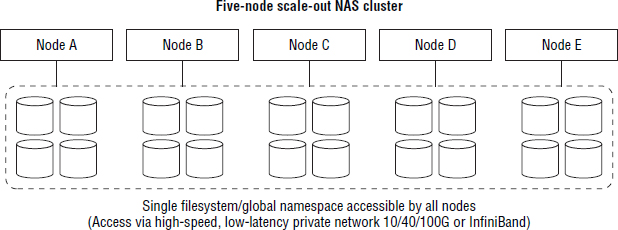
Generally speaking, scale-out architectures are preferred for large environments, as they prevent NAS sprawl. Instead of having to deploy many traditional NAS arrays, each with multiple filesystems that have to be managed separately, you can deploy a single scale-out NAS cluster running a single multi-petabyte-scale filesystem.
Other Scale-Out NAS Considerations
A couple of other matters are usually common to scale-out NAS. More often than not, scale-out NAS is built on top of commodity hardware. It is rare to see a scale-out NAS running ASICs and FPGAs. Also, scale-out NAS architectures often offer flexible protection schemes that work at the file level. For instance, individual files can be assigned different protection levels. For example, you might want to keep two copies of some files and three copies of some other files. Copies of files are usually kept on separate nodes in the cluster. Sometimes this is referred to as a form of network-level RAID or RAIN.
Redundant Array of Independent Nodes
RAIN is an acronym for redundant array of independent nodes, sometimes referred to as reliable array of independent nodes. If you've already read Chapter 4, “RAID: Keeping Your Data Safe,” you know that RAID provides protection at the drive level. RAIN is very similar to RAID but provides protection at the node level. Basically, in a RAIN-protected system, you can lose an entire node in the cluster without losing data.
RAIN architectures usually provide protection via parity, error-correction code such as Reed-Solomon codes, or by simply making extra copies of files and objects.
RAIN is extremely popular in distributed computing and cloud-scale storage, including major object storage services such as Amazon S3 and the like. It is also a technology that allows you to build highly resilient solutions on top of commodity hardware.
Scale-out NAS clusters also commonly support more-exotic protocols such as parallel NFS (pNFS).
Gateway NAS Appliances
A NAS gateway is a traditional NAS front-end without its own native drives on the backend. Basically, a NAS gateway is the NAS heads (nodes/controllers) that run the NAS operating systems and file-sharing protocols, but without any of its own capacity on the backend. Instead of having its own drives, a NAS gateway connects to an external FC storage array for its capacity. This is shown in Figure 7.7.
The external storage can be third-party storage, and it can be either dedicated to the NAS gateway or shared with other devices. However, if the external storage is shared with other systems, it is common to dedicate specific drives to the NAS gateway, as shown in Figure 7.8.
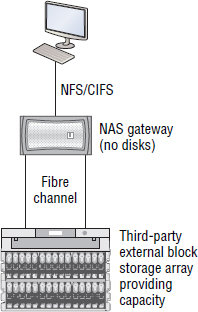
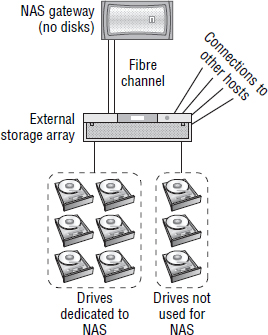
Beware of complexities in NAS gateway configurations, and make sure that you stick to your vendors' supported guidelines so that if things go wrong and you need to rely on the vendors, they will support you.
Obviously, a NAS client has no idea whether it is talking to a traditional NAS with its own captive storage backend, or whether it is talking to a NAS gateway.
Other NAS Array Goodness
As mentioned in Chapter 3, NAS arrays often provide important technologies, such as the following:
- Deduplication
- Compression
- Remote replication
- Snapshots
- Hypervisor integrations and offloads
NAS Performance
Aside from the usual storage culprits such as disk drive speed and cache sizing, there are a ton of other things that can significantly impact NAS performance. Let's take a minute to highlight some of these.
Network Impact on NAS Performance
As NAS technologies operate over IP networks, they are massively affected, positively and negatively, by the performance of the network. And as with all things storage related, latency is usually the most important performance characteristic. High latency causes irate users, and if it gets bad enough, applications can become useless to the point that they are considered down. So take this seriously!
Because of this, 10 GB Ethernet and dedicated LANs should be seriously considered. 10 GB Ethernet offers increased bandwidth, and dedicated networks remove congestion, which is a killer for latency. Also, if latency is a real concern and you cannot go with SAN or locally attached storage, you should seriously consider low-latency switches and at the very least keep the number of network hops to a minimum.
Jumbo frames can also improve performance. At a low level, communication between a client and a server occurs over Ethernet frames. And jumbo frames can reduce the number of frames sent between the client and server, improving overall network performance. When working with jumbo frames, make sure they are supported and enabled on all devices in the data path—NICs, switches, and NAS devices.
Link aggregation technologies, sometimes referred to as bonding, can also be helpful. Link aggregation can be applied at the host (client) in the form of NIC teaming, as well as in the network with technologies such as Link Aggregation Control Protocol (LACP). These technologies can help improve throughput as well as multipath failover.
Link aggregation is similar to ISL trunks/port channels in the FC world. The basic notion is combining multiple links between two switches into a single logical link with increased throughput and improved failover.
TCP window scaling can also impact performance, especially on a high-latency network such as a WAN. TCP window framing works by a server advertising how much unacknowledged data it can accept before it will stop accepting more data. A larger TCP window allows a server to accept more unacknowledged data, and this can significantly improve performance over high-latency networks such as WANs, where it can take a long time for data sent from one host to arrive at the destination. Think of the link between two hosts as a pipe; a larger TCP window allows you to fill up the pipe.
Non-Network-Related NAS Performance Influencers
Away from the network, NAS and file-based storage has a high-metadata overhead: the metadata-to-user data ratio is high. This means that waiting around for slow metadata operations to complete can drag NAS performance into the gutter. Therefore, some NAS designs, including scale-out NAS clusters, ensure that metadata is always stored on flash media for fast access.
Antivirus (AV) solutions can also impede NAS performance if the file-scanning overhead is too high. Make sure you follow your vendor's best practices when implementing AV solutions around a NAS deployment.
Implementing security in a NAS environment can also increase overhead and reduce performance. Early implementations of Kerberized NFSv4 in privacy mode (end-to-end encryption) added a significant CPU overhead to operations. However, modern, faster CPUs have vastly improved things in this area. You should still test the performance impact of things like this before implementing them.
Object Storage
Let's start out with a quick high-level overview and then get a little deeper. Object storage requires a bit of a mindset change for some people. Keep in mind that it is intended for cloud-scale and cloud-use cases as well as designed to be accessed via RESTful APIs. You will examine all of this more closely soon.
If we were to compare object storage to SAN or NAS storage, it would probably be fair to say that object storage has more in common with NAS than SAN. This is mainly because objects are more like files than they are blocks. In fact, it could be said that in many cases files are objects, and objects are files. However, there are several key differences between an object storage device (OSD) and a NAS system.
First, objects don't always have human-friendly names. They are often identified by hideously long (for example, 64-bit) unique identifiers that are derived from the content of the object plus some arbitrary hashing scheme.
Next, objects are stored in a single, large, flat namespace. Flat means that there is no hierarchy or tree structure as there is with a traditional filesystem. This flat namespace is a key factor in the massive scalability inherent in object storage systems. Even scale-out NAS systems, with the massive petabyte-scale filesystems, limit the number of files in either the filesystem or individual directories within the filesystem. Figure 7.9 shows a traditional hierarchical filesystem compared to the flat namespace of an object store.
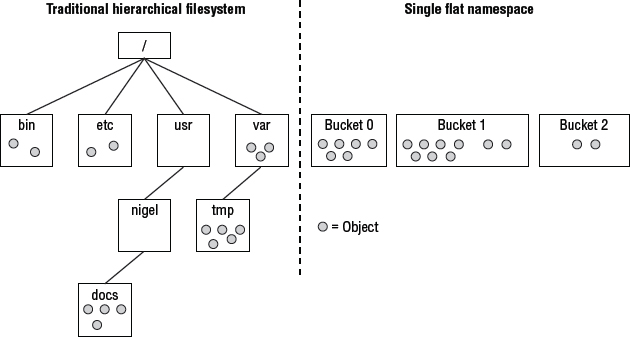
Another key difference between object storage and NAS is that object storage devices are not usually mounted over the network like a traditional NAS filesystem. Instead of being mounted and accessed via protocols such as NFS and SMB/CIFS, object storage devices are accessed via APIs such as REST, SOAP, and XAM. Quite often it will be an application that talks with the OSD rather than a human being.
The Storage Networking Industry Association (SNIA) developed the XAM API in an attempt to provide a standards-based interface for object stores and CAS systems, to avoid vendor lock-in. XAM is an acronym for eXtensible Access Method.
Let's take a moment to look at a really useful analogy comparing NAS with object storage. If NAS was compared to parking your car while out for a meal, you would have to personally drive your car into the parking garage, choose a level, and then choose a parking space. It would then be your responsibility to remember the level and space where you parked. Object storage is more like valet parking, where you drive your car up to the front of the restaurant, jump out, and exchange your car for a ticket, leaving the task of parking your car to the restaurant staff. While you're in the restaurant, you have no idea where your car is parked. All you care about is that when you're finished eating and socializing and want your car back, you can hand in your ticket, and your car will be returned exactly as you left it. With object storage, you (or your application) create some data and give it to the OSD in exchange for a unique object ID (OID). You (and your application) don't care where the object is stored, as long as it is protected and returned to you the next time you present your unique OID to the OSD. That should be pretty simple.
Object storage is not designed for high-performance and high-change requirements, nor is it designed for storage of structured data such as databases. This is because object storage often doesn't allow updates in place. It is also not necessarily the best choice for data that changes a lot. What it is great for is storage and retrieval of rich media and other Web 2.0 types of content such as photos, videos, audio, and other documents.
Now it is time to take a closer look at object storage.
Objects and Object IDs
Object storage devices are for storing objects. By objects we are really talking about files, and more often than not rich media files such as images, video, and audio files. Because they are usually rich media files, objects are often large, but they don't have to be. Although databases are also technically files, we wouldn't refer to database files as objects.
Every object stored in an object store is assigned its own unique object ID, known as an OID. The OID is usually a hideous 64-bit hash value that will mean nothing to you. However, it is absolutely vital.
Each object is stored in the object store, along with extensive metadata describing the object.
If we return to the valet parking analogy, we mentioned that we don't care where in the object store our objects are stored. Well, that is only true up to a point. You will want to consider policies that determine things such as what protection levels are applied to objects as well as what locations objects are available in. On a small scale, locations can refer to which nodes within the same data center an object is stored in; on a larger scale, it can refer to which country or continent a copy of an object is stored in. This is because object storage works at cloud scale, and object stores can, and do, span countries and continents. You may have nodes from the same object store in Australia, England, and the United States. Having copies of objects in each of these three locations leads naturally to protection (similar to RAID) as well as local access to data. If the nodes in Australia go down, you will still have copies of objects in England and the United States. Also, if you are based in the United States, accessing objects from the United States–based nodes will be faster than having to access remote copies in either Australia or England. That being said, object access will still not be fast compared to a SAN or NAS system.
When defining object protection policies, the more copies you keep, the better protected your objects are, but at the expense of space. If you don't stipulate exactly where additional copies of an object will be kept, the OSD will make sure that copies are kept in locations that provide the highest levels of availability. For instance, the OSD will not keep three copies on the same disks attached to the same node, as this would make the node and its disks a single point of failure.
Another consideration is the number and size of objects. Theoretically, some object storage devices support almost unlimited numbers of objects and unlimited sizes of objects. In reality, object stores with billions of objects are common. On the topic of object size, this depends on your choice of object storage technology, but objects can be very big. We're talking terabytes!
Metadata
If you thought metadata was important in NAS, wait until you see object storage. Extensive metadata is a hallmark of object-based storage.
Forget trying to remember in which directory, within a directory, within a directory, that you can't remember the name of anymore, you saved that file six weeks ago. Object storage is all about searching and indexing based on metadata. A common example is medical images such as X-ray and MRI images. These can be tagged with powerful metadata including things such as name of patient, age of patient, gender, ethnic background, height, weight, smoker, drinker, prescribed medication, existing medical conditions, and so on. All of these things can be searched and utilized. Another common example is traffic management and surveillance systems, where saved video images can be tagged with extensive metadata such as road type, time of day, time of year, weather, visibility, congestion metric, thumbnail view, and so on.
Metadata is stored with the object in standard key-value pairs. And generally speaking, an OSD will tag every object with basic metadata such as size, creation time, last modified time, and so on. After that, you or your application can define almost limitless custom metadata. The OSD will probably not understand this user-defined custom metadata, but this is not important. All that is important is that it exists and can be searched on and utilized by your applications.
Once the metadata is added to the object, the data payload and metadata are then stored together within the OSD, although the OSD may well chunk the object up for more-efficient storage on the backend.
API Access
As mentioned earlier, not all OSDs provide a NAS interface. Access to the OSD is often just via APIs such as RESTful HTTP, SOAP, or sometimes language-specific libraries and APIs such as Python, PHP, Java, and so on. This means that object storage is absolutely not a direct replacement for NAS.
A RESTful HTTP API means very simple PUT/GET/POST/DELETE operations that are common to HTTP and the Web. Examples of GET and PUT commands are shown next. The GET will list all containers in the npoulton account, whereas the PUT will create a new container called uber_container:
GET http://swift.nigelpoulton.com/v1/npoulton/ PUT http://swift.nigelpoulton.com/v1/npoulton/uber_container
These examples are a little oversimplified because requests should always require an authentication token. Therefore, the PUT command to create the container would probably look more like this:
curl -X PUT -H ‘X-Auth-Token: AUTH_tk3…bc8c’ http://swift.nigelpoulton.com/v1/ AUTH_admin/uber_container
Because objects in an object store can be manipulated by lightweight HTTP web services, each object can, and usually is, given its own unique URL by which it can be accessed. For example:
http://swift.nigelpoulton.com/v1/npoulton/uber_container/lily_in_a_tree.eps
Some object stores do provide a NAS interface, allowing them to be mounted over the network and accessed via the likes of NFS and CIFS.
Architecture
Object storage is designed with the cloud in mind, including factors such as massive scalability, ultra-low cost, and relatively low performance. It is also designed to work with standard web APIs such as REST.
For a more detailed discussion and explanation of private, public, and hybrid cloud models, see Chapter 15, “Cloud Storage.”
Architecturally speaking, object storage devices are pretty simple. They have a front end and a backend. The front end is where the clever stuff happens. It is effectively the broker between the clients that speak REST and SOAP APIs, and the backend that speaks lower-level block storage protocols. The front-end usually deals with the extensive metadata, too, and works over Ethernet networks running TCP/IP. There is also a backend private network used for node-to-node communication. Figure 7.10 shows a simple object storage architecture.
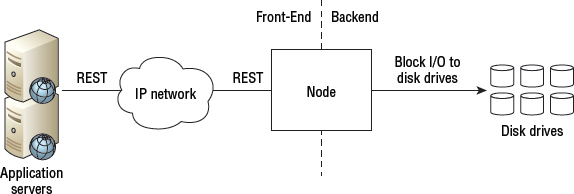
Unlike scale-out NAS technologies that run their backend over high-speed 10 GB and 40 GB Ethernet, or sometimes InfiniBand, the private networks in object stores are not high speed or low latency. In fact, they often have to traverse WANs and the Internet—so rather than high speed and low latency, they often operate over low-speed, high-latency links.
While the namespace can be carved into partitions, sometimes called containers or buckets, these containers and buckets cannot be nested. This is a major difference from traditional filesystems, where directories are nested within directories. Object store namespaces are flat. The namespace of an object store is also fully distributed, even in object stores that span the globe.
Public or Private Cloud
Object storage is relatively new and designed with the cloud in mind. Rather than building their own in-house object storage systems, many companies are opting to utilize cloud-based object storage services such as Amazon S3, Windows Azure, and Rackspace Cloud Files. These cloud-based storage services—known as public cloud—usually operate on a pay-as-you-go pricing model that allows companies to avoid the up-front capital costs involved in purchasing your own hardware and software, thus lowering the initial costs involved with deploying object-based storage.
With cloud-based models, you create an account with a provider, ship them your data—either via the Internet or by physically shipping them USB hard drives with your data on them—and then you start using the service. From that point on, you typically pay monthly, depending on how much capacity and bandwidth you use. You can access and manage your data via the APIs that your cloud storage provider supports, or via a control-panel–type tool they provide for you. Some cloud storage providers also provide, or partner with, content delivery network (CDN) providers to offer faster access to your data. CDNs speed up access to your data by placing web-based servers in strategic locations around the world that cache your data. For example, if your cloud storage provider has data centers in the United States and the United Kingdom, but you are operating out of Hong Kong, a CDN placed near Hong Kong that caches your data set will vastly improve your overall cloud storage experience.
The major alternative to public cloud is private cloud, and a popular private cloud option is OpenStack. OpenStack is a suite of cloud platforms that includes compute, network, storage, and management functionality. The major OpenStack storage offering is OpenStack Object Storage, commonly referred to by its code name OpenStack Swift. OpenStack software was initially a joint venture between Rackspace and NASA that was designed to reduce the costs of operating IT infrastructure by running infrastructure services as software that sits on top of cheap commodity servers, networking, and storage hardware. OpenStack is now backed by many of the traditional big IT companies such as HP, IBM, Dell, Red Hat, and Cisco and is gaining a lot of traction with companies looking to move away from purchasing expensive storage technologies from the traditional storage vendors.
OpenStack Swift is the technology that powers Rackspace Cloud Files and also underpins many of the other public cloud services available. It has extensive API access and offers all the major features of object storage, including authentication, containers, varying levels of redundancy, encryption, and more.
Security
As with all things that touch an IP network, especially the Internet, security is of paramount importance. For this reason, you will want to ensure that any object storage solution you choose to utilize mandates that all operations include a valid authorization token from your authorization subsystem. Fortunately, most do.
Object Store Options
There are tons of examples of object stores out there. Some are public cloud, some are private cloud, and some offer hybrid models. Let's take a brief look at some of them.
Amazon S3
If you thought Amazon.com was a book-selling company, you're still living in the ’90s and are way behind the times. Amazon is a technology company and a massive, cloud-based, data storage company. Amazon Simple Storage Service (S3) is probably the biggest and best-known object storage system in the world. There are trillions of objects stored in Amazon S3. Yes, trillions! This means there are more objects in Amazon S3 than we think there are stars in our Milky Way galaxy. That being said, S3 still has a long way to go until it stores more objects than there are grains of sand on the earth!
The Simple in S3 is the key to its popularity and widespread implementation. You can sign up and play with it today—as you can with other public cloud object stores. Because it is web based, you can access it and store and retrieve data from it wherever you are on the planet, as long as you have an Internet connection.
You can store and retrieve as much data as your Internet connection and bank balance will allow. S3 uses a utility-style billing system, which is common to most cloud services. You can also apply policies to your objects so that they are deleted or archived to a cheaper, slower object archive called Amazon Glacier.
S3 refers to unique OIDs as keys¸ and it stores objects in buckets. When you store an object to S3, it will be stored and protected over several Amazon facilities before you receive notification that it has been successfully stored. Network-based check summing is also performed when you store and retrieve objects, to ensure that no corruption has occurred over the network.
OpenStack Swift
Swift is OpenStack's object storage offering. Swift can be used to build public or private object stores. Swift is open source software that allows you to build your own horizontally scalable OSD on top of commodity hardware. It has an authenticated RESTful HTTP API interface. Like most object stores, Swift can be manipulated with the common Linux curl command. You can start small and scale your Swift OSD to hundreds or even thousands of nodes.
Despite being open source, Swift is a mature and feature-rich object storage system. These features include extensive API access via REST, with bindings for Python, PHP, Java, and more. It also offers bulk imports, authentication, encryption, and object replication.
OpenStack is being positioned as a major operating platform for the cloud and offers way more than just Swift. In the storage space, OpenStack also offers Cinder for block storage. Outside of storage there are components for computing, networking, automation, and more. Check out www.openstack.org for more information.
Compliance Archives and Content-Addressable Storage
Many organizations are subject to government- and industry-enforced regulations that require them to keep immutable copies of data. Immutable means that once the data is created, you must be able to guarantee that it cannot be changed. Another industry term associated with immutability of data is write once, read many (WORM). In WORM technologies, you can write an object once and read it as many times as you wish, but you cannot update or change the object. A common example of WORM is CD-ROM technologies.
A well-known example of a data-retention regulatory requirement is the Sarbanes-Oxley Act of 2002, known affectionately as SOX. Others include HIPAA and PCI.
A particular branch of object store, known as content-addressable storage (CAS), is popular as a compliance archive. In a CAS system, all objects are fingerprinted with a hash that determines the location of the object in the object store. The concept that the content of an object determines where it is located in the store could be a mindset change for many people, but it is at the very heart of how CAS works.
As an object is placed in the CAS object store, the contents of the object are read and then ran through a hashing system to generate a fingerprint that is assigned to the object. This fingerprint determines the location of the object in the CAS store. Here is the important part: if you change any part of that object, you change its fingerprint, which also changes its location in the store! When reading an object again in the future, its hash will be evaluated, and you will know whether the object has been changed.
For this reason, CAS is a real natural when it comes to compliance archiving, and many CAS systems are designed to enforce strict data immutability and guarantee that objects under a retention policy cannot be tampered with during their retention period.
This process of guaranteeing that an object has not changed since it was placed in the store—because its fingerprint and address have not changed—is known as assurance or sometimes content authenticity. Therefore, CAS systems are said to provide content assurance or content authenticity.
Another thing that CAS is a natural at is deduplication. If a new object is added to the store that is identical to an existing object, it will get an identical fingerprint and an identical location in the store. When this happens, a second copy of the object cannot be created and the object is naturally deduplicated. While this is a form of deduplication, it should be noted that it is more correctly referred to as file-level single instancing and is nowhere near as powerful as block-level deduplication. That said, it is still a nice side-benefit of CAS systems.
When considering a CAS system that uses hash functions, it is vital that strong hash functions, such as SHA-1, are used. If weak hashing functions are used, you increase the risk of collisions, which occur when two different objects return the same hash value. When this happens, the CAS system thinks the two objects are the same, and you lose data! This is because the CAS system thinks that it already has a copy of the new object and therefore doesn't need to store the new object being submitted to the store. The only ways to avoid this are to use strong hashing functions that negate the chance of collisions or to perform bit-for-bit comparisons each time a hash match is found. Both of these have an associated overhead. Stronger hash functions are computationally more intensive than weak hash functions, whereas bit-for-bit comparisons require backend storage operations to read the existing object. Bit-for-bit comparisons work by comparing every bit in the newly submitted object with every bit the object already stored. Fortunately, most modern CAS systems employ strong hashes such as SHA-1 that are extremely unlikely to generate collisions.
One thing that CAS is not great for is data that changes frequently. The overhead of continually changing the fingerprint and storage location for lots of objects that are frequently updated can be a real burden to CAS systems.
Object Storage Summary
Object storage is almost perfect for cloud-scale storage of data that doesn't change often and doesn't need particularly fast access. Storage of pictures and video files taken on mobile devices and uploaded to social networking sites and private cloud storage would be impossible with traditional storage technologies such as NAS and SAN. Object storage came marching to the rescue here!
Object stores also provide a neat solution to long-term data archives, especially compliance archives that have to store immutable copies of data.
Because they are inherently slow and not a good fit for data with a high rate of change, object stores won't completely take over the corporate data center. However, they already own the Internet. In corporate data centers, object stores will sit alongside NAS and SAN technologies for many years to come.
When looking at solutions for large amounts of unstructured data, object stores deserve close inspection. They also provide an opportunity to move away from traditional, vendor-based, prepackaged, off-the-shelf offerings and an opportunity to embrace commodity hardware with software-driven intelligence.
Chapter Essentials
NAS Arrays NAS arrays are purpose-built storage systems designed to provide shared file services over a shared IP network. They can be used to consolidate multiple general-purpose file servers such as Windows and Linux servers. They implement NFS and SMB/CIFS protocols and offer high performance, high availability, and advanced features such as snapshots and remote replication.
Traditional NAS Arrays Traditional NAS arrays are best suited for small and medium-sized businesses but struggle to meet the unstructured data demands of large businesses. They provide decent performance and advanced data services such as snapshots, remote replication, and data-efficiency technologies such as compression and deduplication. They do not scale well.
Scale-Out NAS Arrays Scale-out NAS arrays attempt to provide all that traditional NAS arrays provide, with the added benefit of massive scalability. They still use traditional file-serving protocols such as NFS and SMB/CIFS. They help avoid NAS sprawl in large environments and can be well suited for Big Data projects.
Object Storage Object storage is a new class of storage system designed for cloud-scale scalability. Objects are stored and retrieved from an object store via web-based APIs such as REST and SOAP. Each object can be tagged with extensive metadata that can be searched and indexed. Object storage is ideal for rich content data that does not change often and does not require high performance. It is popular in the public cloud model.
Content-Aware Storage Content-aware storage (CAS) is a form of object storage that is well suited as a compliance archive for providing data immutability to meet government and regulatory standards. In CAS systems, the content of an object determines its location within the object store, and any changes to the content of the object changes its location in the store. CAS in not well suited to data that changes frequently.
Summary
In this chapter we covered the topics of file storage and object storage. We started out by learning the major file serving protocols — SMB and NFS — and how they are used as well as what security features they have. We then learned about Network Attached Storage (NAS) arrays, compared them to local storage and SAN storage and explained some of the advanced and enterprise class features they often have. We also talked about some of the scalability limitations of traditional NAS arrays and how scale-out NAS solutions are addressing this limitation. Then we moved on to the exciting topic of object storage and explained how it differs from more traditional block and file storage solutions, and how these differences make it ideal for most cloud storage requirements. We talked about object storage architecture and how it is primarily accessed via APIs, as well as the importance of metadata in object storage.