
10
Generative Adversarial Networks: A Comprehensive Review
Jyoti Arora1*, Meena Tushir2, Pooja Kherwa3 and Sonia Rathee3
1Department of Information Technology, Maharaja Surajmal Institute of Technology, GGSIPU, New Delhi, India
2Department of Electronics and Electrical Engineering, Maharaja Surajmal Institute of Technology, GGSIPU, New Delhi, India
3Department of Computer Science and Engineering, Maharaja Surajmal Institute of Technology, GGSIPU, New Delhi, India
Abstract
Generative Adversarial Networks (GANs) have gained immense popularity since their introduction in 2014. It is one of the most popular research area right now in the field of computer science. GANs are arguably one of the newest yet most powerful deep learning techniques with applications in several fields. GANs can be applied to areas ranging from image generation to synthetic drug synthesis. They also find use in video generation, music generation, as well as production of novel works of art. In this chapter, we attempt to present detail study about the GAN and make the topic understandable to the readers of this work. This chapter presents an extensive review of GANs, their anatomy, types, and several applications. We have also discussed the shortcomings of GANs.
Keywords: Generative adversarial networks, learning process, computer vision, deep learning, machine learning
List of Abbreviations
| Abbreviation | Full Form |
| GAN | Generative Adversarial Network |
| DBM | Deep Boltzmann Machine |
| DBN | Deep Belief Network |
| VAE | Variational Autoencoder |
| DCGAN | Deep Convolutional GAN |
| cGAN | conditional GAN |
| WGAN | Wasserstein GAN |
| LSGAN | Least Square GAN |
| INFOGAN | Information Maximizing Generative Adversarial Network |
| ReLU | Rectified Linear Unit |
| GPU | Graphics Processing Unit |
10.1 Introductıon
Generative Adversarial Networks (GANs) are an emerging topic of interest among today’s researchers. A large proportion of research is being done on GANs as can be seen from the number of research articles on GANs on Google Scholar. The term “Generative Adversarial Networks” yielded more than 3200 search results for the year 2021 alone (upto 20 March 2021). GANs have also been termed as the most interesting innovation in the field of Machine Learning since past 10 years by Yan LeCun who has a major contribution in the area of Deep Learning networks. The major applications of GANs lie in computer vision [1–5]. GANs are extensively used in the generation of images from text [6, 7], translation of image to image [8, 9], image completion [10, 11].
Ian Goodfellow et al. in their research paper “Generative Adversarial Nets” [12] introduced the cocept of GANs. In simplest words GANs are machine learning systems made up of the discriminator, the generator and two neural networks, that generate realistic looking images, video, etc. The generator generates new content which is then evaluated by the discriminator network. In a typical GAN the objective of the generator network is to successively “fool” the discriminator by producing new content that cannot be term as “synthesized” by the discriminator. Such a network can be thought of as analogous to a two player game (zero-sum game i.e the total gain of two players is zero [13]) where the players contest to win. GANs are an adversarial game setting where the generator is pitted against the discriminator [14]. In case of GANs the optimisation process is a minimax game and the goal is to reach Nash equilibrium [15].
Nowedays, GANs are one of the most commonly used deep learning networks. They fall into the class of deep generative networks which also include Deep Belief Network (DBN), Deep Boltzmann Machine (DBM) and Variational Autoencoder (VAE) [16]. Recently GANs and VAE have become popular techniques for unsupervised learning. Though originally intended for unsupervised learning [17–19]. GANs offer several advantages over other deep generative networks like VAE such as the ability of GANs to handle missing data and to model high dimensional data. GANs also have the ability to deliver multimodal outputs (Multiple feasible answers) [20]. In general, GANs are known to generate fine grained and realistic data whereas images generated by VAE tend to be blurred. Even though GANs offer several advantages they have some shortcomings as well. Two of the major limitations of GANs are that they are difficult to train and not easy to evaluate. It is difficult for the generator and the discriminator to attain the Nash equilibrium at the time of training [21] and difficult for the generator to learn the distribution of full datasets completely (leads to mode collapse). The term, mode collapse defines a condition wherein the limited amounts of samples are generated by the generator regardless of the input.
In this paper, we have extensively reviewed Generative Adversarial Networks and have discussed about the anatomy of GANs, types of GANs, areas of applications as well as the shortcomings of GANs.
10.2 Background
To understand GANs it is important to have some background of supervised and unsupervised learning. It is also required to understand generative modelling and how it differs from discriminative modelling. In this section, we attempt to discuss these.
10.2.1 Supervised vs Unsupervised Learning
A supervised learning process is carried by training of a model using a training dataset which consists of several samples with input as well as output labels corresponding to those input values. The model is trained using these samples and the end goal is that the model is able to predict the output label for an unseen input [22]. The objective is basically to train a model in order to generate a mapping capability between inputs, x and outputs, y given multiple labeled input-output pairs [23].
Another type of learning is where a data is given only with input variables (x). This problem does not have labeling of data [23]. The model is built by extracting patterns in the input data. Since the model in question here does not predict anything, no corrections take place here as in case of supervised learning. Generative modelling is a notable unsupervised learning problem. GANs are an example of unsupervised learning algorithms [12].
10.2.2 Generative Modeling vs Discriminative Modeling
Deep Learning models can be characterised into two types—generative models and discriminative models. Discriminative modelling is the same as classification in which we focus on evolving a model to forecast a class label, given a set of input-output pairs (supervised learning). The motive for this particular terminology is to design a model that must discriminate the inputs across classes and make a decision of which class the given input belongs to. Alternatively generative models are unsupervised models that summarise the distributions of inputs and generate new examples [24]. Really good generative models are able to make samples that are not only accurate but also not able to differentiate from the real examples supplied to the model.
In past few years, generative models have seen a significant rise in popularity, specially Generative Adversarial Networks (GANs) which have rendered very realistic results (Figure 10.1). The major difference between generative and discriminative models is that the aim in case of discriminative models is to learn the conditional probability distribution (P(y|x)) whereas, a generative model aims to learn the joint probability distribution (P(x,y)) [25]. In contrary to discriminative models, generative models can use this joint probability distribution to generate likely (x,y) samples. One might assume that there is no need of generating new data samples, owing to the abundance of data already available. However, in reality generative modelling has several important uses. Generative models can be used for text to image translation [6, 7] as well as for applications like generating a text sample in a particular handwriting fed to the system. Generative models, specifically GANs can also be used in reinforcement learning to generate artificial environments [26].

Figure 10.1 Increasingly realistic faces generated by GANs [27].
10.3 Anatomy of a GAN
A GAN is a bipartite model consist of two neural networks; (i) generator and (ii) a discriminator (Figure 10.2). The task of the generator network is to produce a set of synthetic data when fed with a random noise vector. This fixed-length vector is created randomly from a Gaussian distribution and is used to start the generative process. Following the training, the vector contains points that form a compressed representation of the original data distribution. The generator model acts on these points and applies meaning to them.
The task of the discriminator model is to classify the real data from the one generated by the generator. For doing this, it takes two inputs, an instance from the real domain and another one that comes from the set of examples generated by the generator and then labels them as fake or real i.e. 0 or 1 respectively.
These two networks are trained together with the generator generating a collection of samples. Further, these samples are fed to the discriminator along with real examples which classifies them as real or synthetic. With every successful classification, the discriminator is rewarded while the generator is penalized which it uses to tweak its weights. On the other hand, when the discriminator fails to predict, the generator is rewarded and parameters are not changed while the discriminator is penalized and the parameters of the model are revised. This process continues until the generator becomes skilled enough of synthesizing data which can fool the discriminator or the confidence of correct classification done by the discriminator drops to 50%.
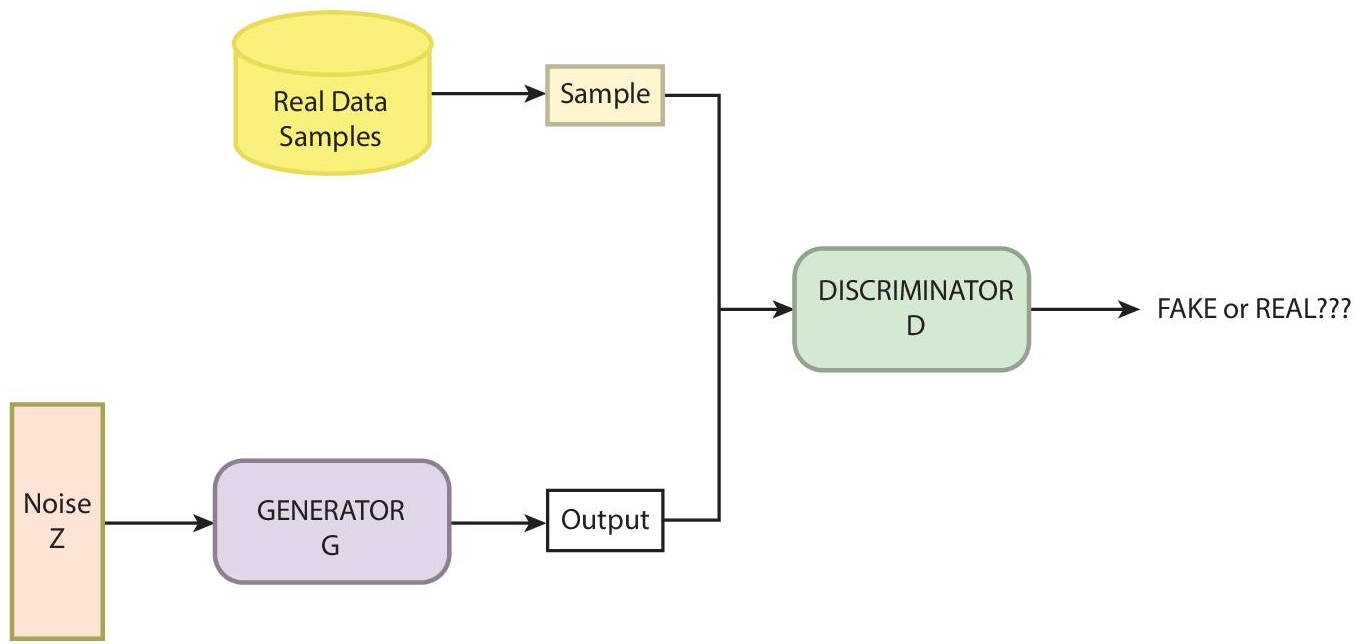
Figure 10.2 Architecture of GAN.
This adversarial training of the two networks makes the generative adversarial network interesting with the discriminator keen on maximizing the loss function while the generator trying to minimize it. The loss function is given below:
where, D(x) is the discriminator’s confidence, Ex is the expected value over all real data samples, G(z) is the sample generated by the generator when fed with noise z, D(G(z)) is the discriminator’s confidence as probability that fake data sample is real and, Ez is the estimated value over all generated fake instances G(z).
10.4 Types of GANs
In this section several types of GANs have been discussed. There are many types of GANs that have been proposed till date. These include Deep Convolutional GANs (DCGAN), conditional GANs (cGAN), InfoGANs, StackGANs, Wasserstein GANs (WGAN), Discover Cross Domain Relations with GANs (DiscoGAN), CycleGANs, Least Square GANs (LSGAN), etc.
10.4.1 Conditional GAN (CGAN)
CGANs or Conditional GANs was developed by Mirza et al. [28] with a thought that the plain GANs can be extended to a conditional network by feeding some supplementary information to the generator as well as the discriminator as an additional input layer as shown in Figure 10.3 anything from class labels to data from other modalities. These class labels control the generation of data of a particular class type. Furthermore, the input data with correlated information allows for improved GAN’s training. In the generator, the conditional information Y is fed along with the random noise Z merged in a hidden representation while in the discriminator this information is provided along with data instances.
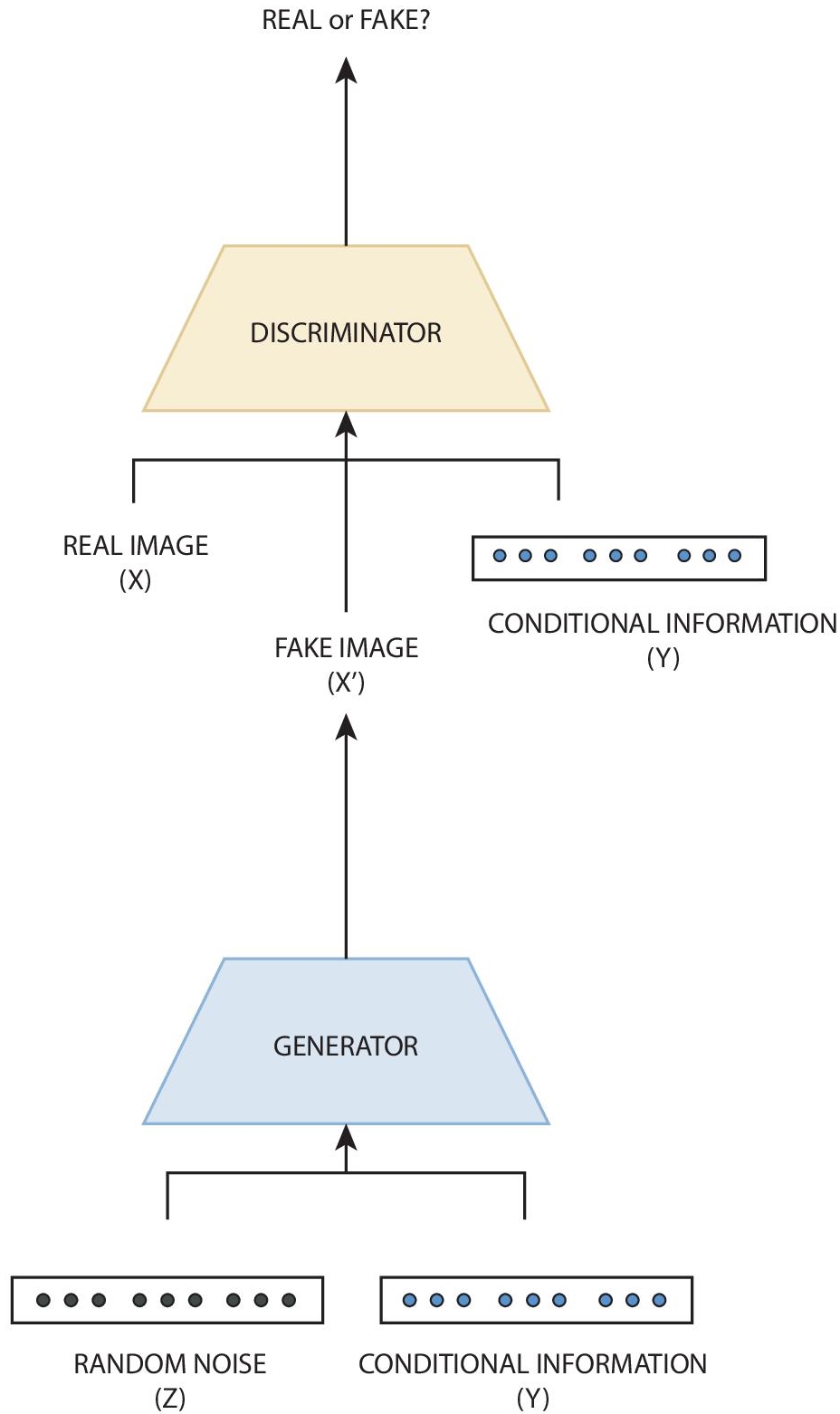
Figure 10.3 Architecture of cGAN.
The authors then trained the network on the MNIST dataset [29] where class labels were conditioned, encoded as one-hot vectors. Building on this, the authors then demonstrated automated image tagging with the predictions using multilabels, the conditional adversarial network to define a set of tag vectors conditioned on image features. A convolutional model inspired from [30] where full Imagenet dataset was pretrained for the image features and for word representation a corpus of text was acquired from the YFCC100M [31] dataset metadata to which proper preprocessing was applied. Finally, the model was then trained on the MIR Flickr dataset [32] to generate automated image tags (refer Figure 10.3).
10.4.2 Deep Convolutional GAN (DCGAN)
These were introduced by Radford et al. [33] in late 2015 as a strong contender for practicing unsupervised learning using CNNs in computer vision tasks. The authors of DCGAN mention three major ideas that helped them come up with a class of architectures that wins over the problems faced by prior efforts of building CNN based GANs which lead to training instability when working with high-resolution data (refer Figure 10.4).
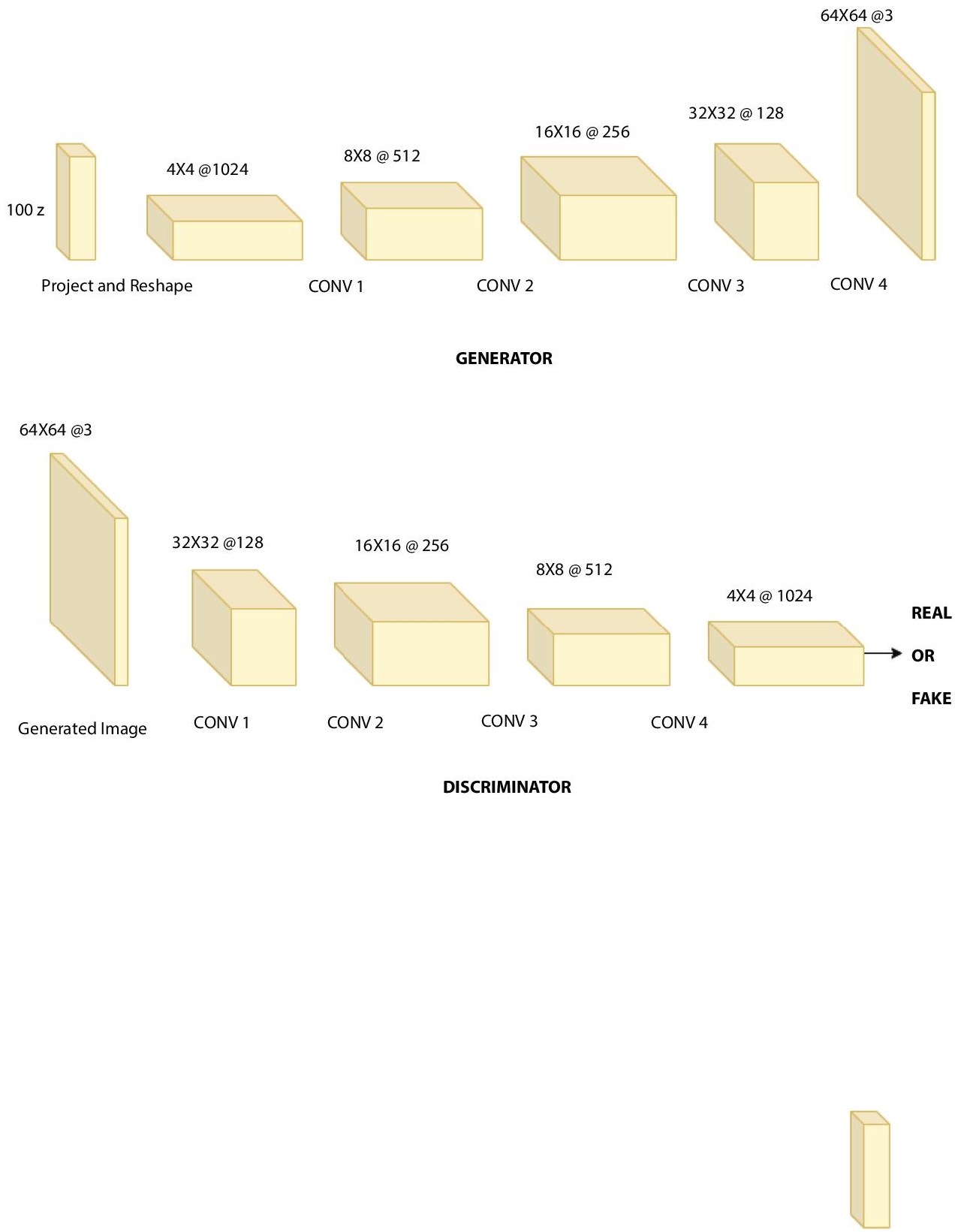
Figure 10.4 DCGAN architecture.
The first idea was to replace any pooling layers with strided convolutional layers in both the discriminator and the generator, taking motivation from the all convolutional network [34]. This allows the network to learn its spatial downsampling. The second was to remove the deeper architectures with fully connected layers and finally, the third idea was to use the concept of Batch Normalization [35] which transforms each input unit to have zero mean and unit variance and stabilizes the learning process by allowing the gradient to flow to deeper models. The technique, however, is not applied to the output layer of the generator and the input layer of the discriminator as its direct application to all the layers leads to training instability and sample oscillations. Additionally, ReLU [36] activation function is used in the generator saving the TanH activation function for the output layer. While the discriminator employs leaky rectified activation [37, 38] which works well with higher resolution images.
DCGAN was trained on three datasets: Large Scale Scene Understanding (LSUN) [39], Imagenet-1k [40] and a then newly assembled faces dataset having 3M images of 10K people. The main idea behind training DCGAN is to use the features realized by the model’s discriminator as a feature extractor for the classification model. Radford et al. in particular used the concept combined with a L2+SVM classifier which is when tested against the CIFAR-10 dataset leads an 82.8% accuracy.
10.4.3 Wasserstein GAN (WGAN)
They were introduced in 2017 by Martin Arjovsky et al. [41] as an alternate to the traditional GAN training methods that had proven to be quite delicate and unstable. WGAN is an impressive extension to GANs that improves stability while the model is being trained as well as helps in analysing the quality of the images generated by associating them with a loss function. The characteristic feature of this model is that it replaces the basic discriminator model with a critic that can be trained to optimality because of the Wasserstein distance [42] which is continuous and differentiable. Wasserstein distance is better than Kullback-Leibler [43] or Jensen-Shannon [44] divergences as it seeks to provide the minimum distance with a smooth and meaningful representation between two data distribution probabilities even when they are located in lower dimensional manifolds without overlaps.
The most compelling feature of WGAN is the drastic reduction of mode dropping phenomenon that is mostly found in GANs. A loss metric is correlated with the generator’s convergence. It is backed up by a strong mathematical motivation and theoretical argument. In simpler terms, a reliable gradient of Wasserstein GAN can be obtained by extensively training the critic. However, it might become unstable with the use of momentum-based optimiser (on critic), such as Adam optimizer [45]. Moreover, when the training of the algorithm is done by the generator without constant number of filters and batch normalization, WGAN produces samples while standard GAN fails to learn. WGAN does not show mode collapse when trained with an MLP generator with 4 layers and 512 units with ReLU nonlinearities while it can be significantly seen in standard GAN. The benefit of WGAN is that while being less sensitive to model architecture, it can still learn when the critic performs well. WGAN promises better convergence and training stability while generating high quality images.
10.4.4 Stack GAN
Stacked Generative Adversarial Networks (StackGANs) with Conditional Augmentation [46] for synthesizing 256*256 photorealistic images conditioned on text descriptions was introduced by Han Zhang et al. [46]. Generating high-quality images from text is of immense importance in applications like computer-aided design or photo-editing. However, a simple addition of unsampling layers in the current state-of-the-art GAN results in training instability. Several techniques such as energy-based GAN [47] or super-resolution methods [48, 49] may provide stability but limited details are added to the images with the low resolution like 64*64 images generated by Reed et al. [50].
StackGANs overcame this challenge by decomposing the text-to-image synthesis into a two-stage problem. Stage I GAN sketches follow the primitive shape and basic colour constrained to the given text description and yields a image with the low-resolution. Stage II GAN rectifies the faults in resulting in Stage I by reading the description of the text again and supplements the image by addition of compelling details. A new augmentation technique with proper conditioning encourages the stabilized training of conditional GAN. Images with the more photo realistic details and the diversities are generated using STACK GAN.
10.4.5 Least Square GAN (LSGANs)
Least Square GANs (LSGANs) was given by Xudong Mao, et al. in 2016 [51]. LSGANs have been developed with an idea of using the least square loss function which provides a nonsaturating gradient in the discriminator contrary to the sigmoid cross entropy function used by Regular GANS. The loss function based on least squares penalizes the fake samples and pulls them close to the decision boundary. The penalization caused by the least square loss function results to generate the samples by the generator closer to the decision boundary and hence they resemble the real data. This happens even when the samples are correctly seperated by the decision boundary. The convergence of the LSGANs shows a relatively good performance even without batch normalization [6].
Various quantitative and qualitative results have proved the stability of LSGANs along with their power to generate realistic images [52]. Recent studies [53] have shown that Gradient penalty has improved stability of GAN training. LSGANs with Gradient Penalty (LSGANs-GP) have been successfully trained over difficult architectures including 101-layered ResNet using complex datasets such as ImageNet [40].
10.4.6 Information Maximizing GAN (INFOGAN)
Information Maximizing GANs (InfoGAN) was introduced by Xi Chen et al. [54] as an extension with the information-theory concept to the regular GANs with an ability to learn disentangled representations in an unsupervised manner.
InfoGAN provides a disentangled representation that represents the salient attributes of a data instance which are helpful for tasks like face and object recognition. Mutual information is a simple and effective modification to traditional GANs. The concept core to InfoGAN is that a single unstructured noise vector is decomposed into two parts, as a source of incompressible noise(z) and latent code(c). In order to discover highly semantic and meaningful representations the common facts between generated samples and latent code is maximised with the use of variational lower bound. Although there have been previous works to learn disentangled representations like bilinear models [55], multiview perception [56], disBM [57] but they all rely on supervised grouping of data. InfoGAN does not require supervision of any kind and it can disentangle both discrete and continuous latent factors unlike hossRBM [58] which can be useful only for discrete latent variables with an exponentially increasing computational cost.
InfoGAN can successfully disentangle writing styles from the shapes of digits on the MNIST dataset. The latent codes(c) are modelled with one categorical code (c1) that switches between digits and models discontinuous variation in data. The continuous codes (c2 and c3) model rotation of digits and control the width respectively. The details like stroke style and thickness are adjusted in such a way that the resulting images are natural looking and a meaningful generalisation can be obtained.
Semantic variations like pose from lighting in 3D images, absence or presence of glasses, hairstyles and emotions can also be successfully disentangled with the help of InfoGAN. Without any supervision, a high level of visual understanding is demonstrated by them. Hence, InfoGAN can learn complex representations on complex datasets with superior image quality as compared to previous unsupervised approaches. Moreover, the use of latent code adds up only negligible computational cost on top of a regular GAN without any training difficulty.
The idea to use mutual information can be further applied to other methods like VAE [59], semisupervised learning with better codes [60] and InfoGAN is used as a tool for high dimensional data discovery.
10.5 Shortcomings of GANs
As captivating training a generative adversarial network may sound, it also has its own share of shortcomings when it comes to practicality, with the most significant ones being as follows:
A frequently encountered problem one faces while training a GAN is the enormous computational cost it requires. While a GAN might run for hours, on a single GPU and on a CPU, on the other hand, it may continue to run beyond even a day! Various researchers have come forward with different strategies to minimize this problem, one such being the idea of a building an architecture with effecient memory utilization. Shuanglong Liu et al. centered around architecture based on a parameters deconvolution, an FPGA-friendly method [61-63]. Based on a similar approach, A. Yazdanbakhsh et al. devised FlexiGan [64], an end-to-end solution, which produces FPGA based accelerator which is highly optimized from a high-level GAN specification.
The output of the discriminator calculates the loss function therefore the parameters are updated fastly. As a result, the convergence of discriminator is faster and this affects the functioning of the generator due to which parameters are not updated. Furthermore, the generator does not converges and thus generative adversarial networks suffers the problem of partial or total mode collapse, a state where in the generator is generating almost indistinguishable outputs for different latent encodings. To address this Srivastava et al. suggested VEEGAN [65] which contains a reconstructor network, which maps the data to noise by reversing the action of the generator.. Elsewhere, Kanglin Liu et al. proposed a spectral regularization technique (SR-GAN) [66] which balances the spectral distributions of the weight matrices saving them from getting collapse which consequently prevents mode collapsing in GANs.
Another difficulty experienced while developing a generative adversarial network is the inherent instability caused by training both the generator and the discriminator concurrently. Sometimes the parameters oscillate or destabilize, and never seem to converge. Through their work, Mescheder et al. [67] presented how training a GAN for absolutely continuous data and generator distributions show local convergence while performing unregularized training over a realistic case of distributions which are not absolutely continuous is not always convergent. Furthermore, by describing some of the regularization techniques put forward they analyze that GAN training with an instance or zero-centered gradient penalties leads to convergence. Another technique that can fix the instability problems of GANs is Spectral Normalization, a particular kind of normalization applied to the convolutional kernels which can greatly improve the training dynamics as shown by Zhang et al. through their model SAGAN [68].
An important point to consider is the influence that a dataset may have on the GAN which is being trained on it. Through their work, Ilya Kamenshchikov and Matthias Krauledat [69] demonstrate that how datasets also play a key role in the successful training of a GAN by taking into notice the influence of datasets like Fashion MNIST [70], CIFAR-10 [71] and ImageNet [40]. Also, building a GAN model requires a large training dataset otherwise its progress in the semantic domain is hampered.
Adding further to the list is the problem of the vanishing gradient that crops up during the training if the discriminator is highly accurate thereby, not providing enough information for the generator to make progress. To solve this problem a new loss function Wasserstein loss was proposed in the model W-GAN [41] by Arjovsky et al. where loss is updated by a GAN method and the instances are not actually classified by the discriminator. For each sample, a number is received as output. The value of the number need not necessarily be less than one or greater than 0, thus to decide whether the sample is real or fake, the value of threshold value is not 0.5. The training of the discriminator tries to make the output bigger for real instances as compare to fake instances. Working for a similar cause Salimans et al. in 2016 [72] proposed a set of heuristics to solve the problem of vanishing gradient and mode collapse among others by introducing the concept of feature matching. Other efforts worth highlighting include improving the WGAN [42] by Gulrajani et al. addressing the problems arising due to weight clipping, Fisher GAN [73] suggested by Mroueh and Sercu introduced a constraint dependent on the data to maintain the capacity of the critic to ensure the stability of training, and Improving Training of WGANs [74] by Wei et al.
10.6 Areas of Application
Known for revolutionizing the realm of machine learning ever since their introduction, GANs find their way in a plethora of applications ranging from image synthesis to synthetic drug discovery. This section brings to the fore some of the most important areas of application of GANs with each being discussed in detail as below:
10.6.1 Image
Perhaps, some of the most glorious exploits of GANs have surfaced in the field of image synthesis or manipulation. A major advancement in the field of image synthesis came in late 2015 with the introduction of DCGANs by Radford et al. [33] capable of generating random images from scratch. In the year 2017, Liqian Ma et al. [75] proposed a GANs based architecture that when supplied with an input image, could generate its variants with each having different postures of the element in the input image. Some other notable applications of GANs in the domain of image synthesis and manipulation include Recycle GAN [76], an approach based on data-driven methodology. It is used for transferring the content of one video or photo to another; ObjGAN [77], a novel GAN architecture developed by a team of scientists at Microsoft understands sketch layouts, captions, and based on the wording details are refined; StyleGAN [78], a model Nvidia developed, is capable of synthesizing high-resolution images of fictional people by learning attributes like facial pose, freckles, and hair.
10.6.2 Video
With a video being described as a series of images in motion, the involvement of various state-of-the-art GAN approaches in the domain of video synthesis is no surprise. With DeepMind’s proposal of DVDGAN [79], the generation of realistic-looking videos by a model when fed with a custom-tailored dataset is a matter of just a few lines of code and patience. Another noteworthy contribution of GANs in this sector is DeepRay, a Cambridge Consultants’ creation. It helps to generate images which are less distorted and more sharper from pictures that have been damaged or had obscured elements. This can be used to get rid of noise in videos too.
10.6.3 Artwork
GANs have the ability to generate more then images and video footage. They are capable of producing novel works of art provided they are supplied with the right dataset. Art-GAN [80], a conditional GAN based network generates images with abstract information like images with a certain art style after being trained on the Wikiart dataset. GauGAN [81] developed by the company can turn rough doodles into photorealistic masterpieces with breathtaking ease and NVIDIA Research has investigated AI-based arts as a deep learning model.
10.6.4 Music
After giving astonishing results when applied to images or videos, GANs are being involved in the field of music generation too. MidiNet [82], a CNN inspired GAN model developed by DeepMind is one such attempt that aims at producing realistic melody from random noise as input. Conditional-LSTM GAN [83] presented by the researchers based at the National Institute of Informatics in Tokyo which learns the latent relationship between the different lyrics and their corresponding melodies and then applies it to generate lyrics conditioned melodies is another effort worth mentioning.
10.6.5 Medicine
Owing to the ability to synthesize images with an unmatched degree of realism and the adversarial training, GANs are a boon for the medical industry. They are frequently used in image analysis, anomaly detection or even for the discovery of new drugs. More recently, the Imperial College London, University of Augsburg, and the Technical University of Munich The model dubbed Snore-GAN [84] is used to synthesize data to fill in gaps in real data. Meanwhile, Schlegl et al. suggested an unsupervised approach to detect anomalies relevant for disease progression and treatment monitoring through their discovery AnoGAN [85]. On the drug synthesis side of the equation, LatentGAN [86] an effort by Prykhodko et al. integerates a generative adversarial neural network with an autoencoder for de novo molecular design. It can be used with many other applications [89, 90].
10.6.6 Security
With GANs being applied to various domains, it seems the field of security has a lot to gain from them as well. A recently developed machine learning approach to password cracking PassGAN [87] generates password guesses by training a GAN on a list of leaked passwords. Keeping their potential to synthesize plausible instances of data, GANs are being used to make the existing deep learning networks used in cybersecurity more robust by manufacturing more fake data and training the existing deep learning techniques on them. In a similar vein, Haichao et al. have come up with SSGAN [88], a new strategy that generates more suitable and secure covers for steganography with an adversarial learning scheme.
10.7 Conclusıon
This paper provides a comprehensive review of generative adversarial networks. We have discussed the basic anatomy of GANs and the various kinds of GANs that have been widely used nowadays. This papers also discusses the various application areas of GANs. Despite the extensive potential, GANs have several shortcomings which have also been discussed. This review of generative adversarial networks extensively covers the basic fundamentals about GANs and will help the readers to gain a good understanding of this famous deep learning network, which has gained immense populatrity recently.
References
- 1. Regmi, K. and Borji, A., Cross-view image synthesis using conditional GANs. 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 3501–3510, 2018.
- 2. Wang, T., Liu, M., Zhu, J., Tao, A., Kautz, J., Catanzaro, B., High-resolution image synthesis and semantic manipulation with conditional GANs. 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8798–8807, 2017.
- 3. Odena, A., Olah, C., Shlens, J., Conditional image synthesis with auxiliary classifier gans, in: Proceedings of the 34th International Conference on Machine Learning, JMLR, vol. 70, pp. 2642–2651, 2017.
- 4. Vondrick, C., Pirsiavash, H., Torralba, A., Generating videos with scene dynamics, in: Advances in Neural Information Processing Systems, pp. 613– 621, 2016.
- 5. Zhu, J.-Y., Krähenbühl, P., Shechtman, E., Efros, A.A., Generative visual manipulation on the natural image manifold, in: European Conference on Computer Vision, Springer, pp. 597–613, 2016.
- 6. Reed, S.E., Akata, Z., Yan, X., Logeswaran, L., Schiele, B., Lee, H., Generative adversarial text to image synthesis. Proc. 33rd Int. Conf. Mach. Learning, PMLR, 48, 1060–1069, 2016.
- 7. Xu, T., Zhang, P., Huang, Q., Zhang, H., Gan, Z., Huang, X., He, X., AttnGAN: Fine-grained text to image generation with attentional generative adversarial networks. IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 1316–1324, 2017.
- 8. Lin, J., Xia, Y., Qin, T., Chen, Z., Liu, T., Conditional image-to-image translation. 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 5524–5532, 2018.
- 9. Choi, Y., Choi, M., Kim, M., Ha, J., Kim, S., Choo, J., StarGAN: Unified generative adversarial networks for multi-domain image-to-image translation. 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 8789–8797, 2017.
- 10. Akimoto, N., Kasai, S., Hayashi, M., Aoki, Y., 360-degree image completion by two-stage conditional GANS. IEEE International Conference on Image Processing (ICIP), Taipei, Taiwan, pp. 4704–4708, 2019.
- 11. Chen, Z., Nie, S., Wu, T., Healey, C.G., Generative adversarial networks in computer vision: A survey and taxonomy. 2018, arXiv preprint arXiv:1801.07632, 2018.
- 12. Goodfellow, I., Pouget-Abadie, J., Mirza, M., Xu, B., Warde-Farley, D., Ozair, S., Courville, A., Bengio, Y., Generative Adversarial Networks(PDF). Proceedings of the International Conference on Neural Information Processing Systems (NIPS 2014), pp. 2672–2680, 2014.
- 13. Wang, K., Gou, C., Duan, Y., Lin, Y., Zheng, X., Wang, F., Generative adversarial networks: Introduction and outlook. IEEE/CAA J. Autom. Sin., 4, 588– 598, 2017.
- 14. Grnarova, P., Levy, K.Y., Lucchi, A., Hofmann, T., Krause, A., An online learning approach to generative adversarial networks, 2017, ArXiv, abs/1706.03269.
- 15. Ratliff, L.J., Burden, S.A., Sastry, S.S., Characterization and computation of local Nash equilibria in continuous games, in: Proc. 51st Annu. Allerton Conf. Communication, Control, and Computing (Allerton), Monticello, IL, USA, pp. 917–924, 2013.
- 16. Pouyanfar, S., Sadiq, S., Yan, Y., Tian, H., Tao, Y., Reyes, M.E., Shyu, M., Chen, S., Iyengar, S.S., A survey on deep learning: Algorithms, techniques, and applications. ACM Comput. Surv., 51, 92, 1–92:36, 2018.
- 17. Kumar, A., Sattigeri, P., Fletcher, P.T., Improved semi-supervised llearning with GANs using manifold invariances, NIPS, 2017, ArXiv, abs/1705.08850.
- 18. Odena, A., Semi-supervised learning with generative adversarial networks, 2016, ArXiv, abs/1606.01583.
- 19. Lecouat, B., Foo, C.S., Zenati, H., Chandrasekhar, V.R., Semi-supervised learning with GANs: Revisiting manifold regularization. 2018. ArXiv, abs/1805.08957.
- 20. Goodfellow, I., Nips (2016) tutorial: Generative adversarial networks, p. 215, NIPS, arXiv preprint arXiv:1701.00160.
- 21. Farnia, F. and Ozdaglar, A.E., GANs may have no nash equilibria, 2020, ArXiv, abs/2002.09124.
- 22. Akinsola, J.E.T., Supervised machine learning algorithms: Classification and comparison. Int. J. Comput. Trends Technol. (IJCTT), 48, 128 – 138, 2017. 10.14445/22312803/IJCTT-V48P126.
- 23. Murphy, K.P., Machine Learning: A Probabilistic Approach, p. 216, The MIT Press, 2012.
- 24. Bishop, C.M., Pattern Recognition and Machine Learning, p. 216, Springer, 2011.
- 25. Liu, B. and Webb, G.I., Generative and discriminative learning, in: Encyclopedia of machine learning, C. Sammut and G.I. Webb (Eds.), Springer, Boston, MA, 2011.
- 26. Kasgari, A.T., Saad, W., Mozaffari, M., Poor, H.V., Experienced deep reinforcement learning with generative adversarial networks (GANs) for model-free ultra reliable low latency communication, 2019, ArXiv, abs/1911.03264.
- 27. Brundage, M., Avin, S., Clark, J., Toner, H., Eckersley, P., Garfinkel, B., Dafoe, A., Scharre, P., Zeitzoff, T., Filar, B., Anderson, H.S., Roff, H., Allen, G.C., Steinhardt, J., Flynn, C., Beard, S., Belfield, H., Farquhar, S., Lyle, C., Crootof, R., Evans, O., Page, M., Bryson, J., Yampolskiy, R., Amodei, D., The malicious use of artificial intelligence: Forecasting, prevention, and mitigation, 2018, ArXiv, abs/1802.07228.
- 28. Mirza, M. and Osindero, S., Conditional generative adversarial nets, 2014, ArXiv, abs/1411.1784.
- 29. Chen, F., Chen, N., Mao, H., Hu, H., Assessing four neural networks on handwritten digit recognition dataset (MNIST), 2018, ArXiv, abs/1811.08278.
- 30. Krizhevsky, A., Sutskever, I., Hinton, G.E., Imagenet classification with deep convolutional neural networks. NIPS, 2012.
- 31. Yahoo flickr creative common 100m, p. 219, Dataset, http://webscope.sand-box.yahoo.com/catalog.php?datatype=i&did=67.
- 32. Huiskes, M.J. and Lew, M.S., The mir flickr retrieval evaluation, in: MIR ‘08: Proceedings of the 2008 ACM International Conference on Multimedia Information Retrieval, New York, NY, USA, ACM, 2008.
- 33. Radford, A., Metz, L., Chintala, S., Unsupervised representation learning with deep convolutional generative adversarial Networks, 2015, CoRR, abs/1511.06434.
- 34. Springenberg, J.T., Dosovitskiy, A., Brox, T., Riedmiller, M.A., Striving for simplicity: The all convolutional net, 2014, CoRR, abs/1412.6806.
- 35. Ioffe, S. and Szegedy, C., Batch normalization: Accelerating deep network training by reducing internal covariate shift, 2015, ArXiv, abs/1502.03167.
- 36. Nair, V. and Hinton, G.E., Rectified linear units improve restricted Boltzmann machines. ICML, 2010.
- 37. Maas, A.L., Rectifier nonlinearities improve neural network acoustic models, 2013.
- 38. Xu, B., Wang, N., Chen, T., Li, M., Empirical evaluation of rectified activations in convolutional network, 2015. ArXiv, abs/1505.00853.
- 39. Yu, F., Zhang, Y., Song, S., Seff, A., Xiao, J., LSUN: Construction of a large-scale image dataset using deep learning with humans in the loop, 2015, ArXiv, abs/1506.03365.
- 40. Deng, J., Dong, W., Socher, R., Li, L., Li, K., Li, F., ImageNet: A large-scale hierarchical image database. 2009 IEEE Conference on Computer Vision and Pattern Recognition, pp. 248–255, 2009.
- 41. Arjovsky, M., Chintala, S., Bottou, L., Wasserstein GAN, 2017, ArXiv, abs/1701.07875.
- 42. Gulrajani, I., Ahmed, F., Arjovsky, M., Dumoulin, V., Courville, A.C., Improved training of Wasserstein GANs. NIPS, 2017.
- 43. Ponti, M., Kittler, J., Riva, M., Campos, T.E., Zor, C., A decision cognizant Kullback-Leibler divergence. Pattern Recognit., 61, 470–478, 2017.
- 44. Nielsen, F., On a generalization of the Jensen-Shannon divergence and the JS-symmetrization of distances relying on abstract means, 2019, ArXiv, abs/1912.00610.
- 45. Kingma, D.P. and Ba, J., Adam: A method for stochastic optimization, 2014. CoRR, abs/1412.6980, https://arxiv.org/pdf/1412.6980.pdf.
- 46. Zhang, H., Xu, T., Li, H., StackGAN: Text to photo-realistic image synthesis with stacked generative adversarial networks. 2017 IEEE International Conference on Computer Vision (ICCV), pp. 5908–5916, 2016.
- 47. Zhao, J.J., Mathieu, M., LeCun, Y., Energy-based generative adversarial network, 2016, ArXiv, abs/1609.03126.
- 48. Sønderby, C.K., Caballero, J., Theis, L., Shi, W., Huszár, F., Amortised MAP inference for image super-resolution, 2016, ArXiv, abs/1610.04490.
- 49. Ledig, C., Theis, L., Huszár, F., Caballero, J.A., Aitken, A., Tejani, A., Totz, J., Wang, Z., Shi, W., Photo-realistic Single image super-resolution using a generative adversarial network. 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 105–114, 2016.
- 50. Reed, Z.A., Yan, X., Logeswaran, L., Schiele, B., Lee, H., Generative adversarial text-to-image synthesis, 2016. arXiv:1609.04802.
- 51. Mao, X., Li, Q., Xie, H., Lau, R.Y., Wang, Z., Smolley, S.P., Least squares generative adversarial networks. 2017 IEEE International Conference on Computer Vision (ICCV), pp. 2813–2821, 2016.
- 52. Mao, X., Li, Q., Xie, H., Lau, R.Y., Wang, Z., Smolley, S.P., On the effectiveness of least squares generative adversarial networks. IEEE Trans. Pattern Anal. Mach. Intell., 41, 2947–2960, 2019.
- 53. Kodali, N., Hays, J., Abernethy, J.D., Kira, Z., On convergence and stability of GANs. Artif. Intell., 2018. arXiv. https://arxiv.org/pdf/1705.07215.pdf.
- 54. Chen, X., Duan, Y., Houthooft, R., Schulman, J., Sutskever, I., Abbeel, P., InfoGAN: Interpretable representation learning by information maximizing generative adversarial nets. NIPS, 2016.
- 55. Tenenbaum, J.B. and Freeman, W.T., Separating style and content with bilinear models. Neural Comput., 12, 1247–1283, 2000.
- 56. Zhu, Z., Luo, P., Wang, X., Tang, X., Deep learning multi-view representation for face recognition, 2014. ArXiv, abs/1406.6947.
- 57. Reed, S.E., Sohn, K., Zhang, Y., Lee, H., Learning to disentangle factors of variation with manifold interaction. ICML, 2014.
- 58. Desjardins, G., Courville, A.C., Bengio, Y., Disentangling factors of variation via generative entangling, 2012. ArXiv, abs/1210.5474.
- 59. Kingma, D.P. and Welling, M., Auto-Encoding Variational Bayes, 2013. CoRR, arXiv:1312.6114, abs/1312.6114.
- 60. Springenberg, J.T., Unsupervised and Semi-supervised Learning with Categorical Generative Adversarial Networks, 2015. CoRR, abs/1511.06390.
- 61. Liu, S., Zeng, C., Fan, H., Ng, H., Meng, J., Que, Z., Niu, X., Luk, W., Memory-efficient architecture for accelerating generative networks on FPGA. 2018 International Conference on Field-Programmable Technology (FPT), pp. 30–37, 2018.
- 62. Sulaiman, N., Obaid, Z., Marhaban, M.H., Hamidon, M.N., Design and implementation of FPGA-based systems -A Review. Aust. J. Basic Appl. Sci., 3, 224, 2009.
- 63. Shawahna, A., Sait, S.M., El-Maleh, A.H., FPGA-based accelerators of deep learning networks for learning and classification: A review. IEEE Access, 7, 7823–7859, 2019.
- 64. Yazdanbakhsh, A., Brzozowski, M., Khaleghi, B., Ghodrati, S., Samadi, K., Kim, N.S., Esmaeilzadeh, H., FlexiGAN: An end-to-end solution for FPGA acceleration of generative adversarial networks. 2018 IEEE 26th Annual International Symposium on Field-Programmable Custom Computing Machines (FCCM), pp. 65–72, 2018.
- 65. Srivastava, A., Valkov, L., Russell, C., Gutmann, M.U., Sutton, C.A., VEEGAN: Reducing mode collapse in GANs using implicit variational learning. NIPS, 2017.
- 66. Liu, K., Tang, W., Zhou, F., Qiu, G., Spectral regularization for combating mode collapse in GANs. 2019 IEEE/CVF International Conference on Computer Vision (ICCV), pp. 6381–6389, 2019.
- 67. Mescheder, L.M., Geiger, A., Nowozin, S., Which training methods for GANs do actually Converge? ICML, 2018.
- 68. Zhang, H., Goodfellow, I.J., Metaxas, D.N., Odena, A., Self-attention generative adversarial networks, 2019. ArXiv, abs/1805.08318.
- 69. Kamenshchikov, I. and Krauledat, M., Effects of dataset properties on the training of GANs, 2018. ArXiv, abs/1811.02850.
- 70. Xiao, H., Rasul, K., Vollgraf, R., Fashion-MNIST: A novel image dataset for benchmarking machine learning algorithms, 2017. ArXiv, abs/1708.07747.
- 71. Krizhevsky, A., Learning multiple layers of features from tiny images, 2009.
- 72. Salimans, T., Goodfellow, I.J., Zaremba, W., Cheung, V., Radford, A., Chen, X., Improved techniques for training GANs. NIPS, 2016.
- 73. Mroueh, Y. and Sercu, T., Fisher GAN. NIPS, 2017.
- 74. Wei, X., Gong, B., Liu, Z., Lu, W., Wang, L., Improving the improved training of Wasserstein GANs: A consistency term and its dual effect, 2018. ArXiv, abs/1803.01541.
- 75. Ma, L., Jia, X., Sun, Q., Schiele, B., Tuytelaars, T., Gool, L.V., Pose guided person image generation, 2017. ArXiv, abs/1705.09368.
- 76. Bansal, A., Ma, S., Ramanan, D., Sheikh, Y., Recycle-GAN: Unsupervised video retargeting. ECCV, 2018.
- 77. Li, W., Zhang, P., Zhang, L., Huang, Q., He, X., Lyu, S., Gao, J., Object-driven text-to-image synthesis via adversarial training. 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 12166–12174, 2019.
- 78. Karras, T., Laine, S., Aila, T., A style-based generator architecture for generative adversarial networks. 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 4396–4405, 2018.
- 79. Clark, A., Donahue, J., Simonyan, K., Efficient video generation on complex datasets, 2019. ArXiv, abs/1907.06571.
- 80. Tan, W.R., Chan, C.S., Aguirre, H.E., Tanaka, K., ArtGAN: Artwork synthesis with conditional categorical GANs. 2017 IEEE International Conference on Image Processing (ICIP), pp. 3760–3764, 2017.
- 81. Park, T., Liu, M., Wang, T., Zhu, J., Semantic image synthesis with spatially-adaptive normalization. 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 2332–2341, 2019.
- 82. Yang, L., Chou, S., Yang, Y., MidiNet: A convolutional generative adversarial network for symbolic-domain music generation, 2017. ArXiv, abs/1703.10847.
- 83. Yu, Y.B. and Canales, S., Conditional LSTM-GAN for melody generation from Lyrics, 2019. ArXiv, abs/1908.05551.
- 84. Zhang, Z., Han, J., Qian, K., Janott, C., Guo, Y., Schuller, B.W., Snore-GANs: Improving Automatic snore sound classification with synthesized data. IEEE J. Biomed. Health Inform., 24, 300–310, 2019.
- 85. Schlegl, T., Seeböck, P., Waldstein, S.M., Schmidt-Erfurth, U., Langs, G., Unsupervised anomaly detection with generative adversarial networks to guide marker discovery. IPMI, 2017.
- 86. Prykhodko, O., Johansson, S.V., Kotsias, P., Arús-Pous, J., Bjerrum, E.J., Engkvist, O., Chen, H., A de novo molecular generation method using latent vector based generative adversarial network. J. Cheminformatics, 11, 74, 2019.
- 87. Hitaj, B., Gasti, P., Ateniese, G., Pérez-Cruz, F., PassGAN: A deep learning approach for password guessing, 2019. ArXiv, abs/1709.00440.
- 88. Shi, H., Dong, J., Wang, W., Qian, Y., Zhang, X., SSGAN: Secure steganography based on generative adversarial networks, PCM, p. 228, 2017.
- 89. Hooda, S. and Mann, S., Examining the effectiveness of machine learning algorithms as classifiers for predicting disease severity in data warehouse environments. Rev. Argent. Clín. Psicol., 29, 233–251, 2020.
- 90. Arora, J., Grover, M., Aggarwal, K., Augmented reality model for the virtualisation of the mask. J. Multi Discip. Eng. Technol., 14, 2, 2021, 2021.
Note
- *Corresponding author: [email protected]