
Chapter 5. Infrastructure Engineering
Let’s begin the process of actualizing our database clusters for consumption by applications and analysts. Previously, we’ve discussed a lot of the preparatory work: service-level expectations, risk analysis, and, of course, operational visibility. In the next two chapters, we discuss the techniques and patterns for designing and building the environments.
In this chapter, we discuss the various hosts a datastore can run on, including serverless or Database as a Service options. We discuss the various storage options available to those datastores.
Hosts
As discussed previously, your datastores do not exist in a vacuum. They must always run as processes on some host. Traditionally, database hosts were physical servers. Over the past decade, our options have grown, including virtual hosts, containers, and even abstracted services. Let’s look at each in turn, discuss the pros and cons of using them for databases, and examine some specific implementation details.
Physical Servers
In this context, a physical server is a host that has an operating system and is 100% dedicated to running services directly from that operating system. In immature environments, a physical server might run many services on it while traffic is low and resources are abundant. One of the first steps a database reliability engineer (DBRE) will take is to separate datastores to their own servers. The workloads required by a datastore are generally quite intensive on CPU, RAM, and Storage/IO. Some applications will be more CPU-bound or IO-bound, but you don’t want them competing with other applications for resources. Tuning these workloads is also quite specific and thus requires isolation to properly accomplish.
When you run a database on a dedicated physical host, your database will be interacting with and consuming a large number of components that we will discuss briefly in just a moment. For the purposes of this discussion, we will assume that you are running a Linux or Unix system. Even though much of this can be applied to Windows, the differences are significant enough that we will not be using them as examples.
We’ve tried to break out a significant chunk of the best practices here to show the depth of operating system (OS) and hardware knowledge that a DBRE can utilize to solve problems that can dramatically increase availability and performance of databases. As we go upward in abstractions to virtual hosts and containers, we will add in relevant information where appropriate.
Operating a System and Kernel
As the DBRE, you should collaborate directly with software reliability engineers (SREs) to define appropriate kernel configurations for your database hosts. These should become gold standards that automatically deploy along with database binaries and other configurations. Most database management systems (DBMS’s) will come with vendor-specific requirements and recommendations that should be reviewed and applied where possible. Interestingly, there can be very different approaches to this depending on the type of database you are using. So, we will go through a few high-level categories and discuss them.
I/O scheduler
Input/Output (I/O) scheduling is the method that operating systems use to decide the order in which block level I/O operations will be submitted to storage volumes. By default, these schedulers often assume they are working with spinning disks that have high seek latency. Thus, the default is usually an elevator algorithm that attempts to order requests by location and to minimize seek times. In Linux, you might see the following options available:
wtf@host:~$ cat /sys/block/sda/queue/scheduler [noop] anticipatory deadline cfq
The noop scheduler is the proper choice when the target block device is an array of SSDs with a controller that performs I/O optimization. Every I/O request is treated equally because seek times on solid-state drives (SSDs) are relatively stable. The deadline scheduler will optimize by seeking to minimize I/O latency by imposing deadlines to prevent starvation and by prioritizing reads over writes. The Deadline Scheduler has shown to be more performant in highly concurrent multithreaded environments, such as database loads.
Memory allocation and fragmentation
No one can deny that databases are some of the most memory-hungry applications a server can run. Understanding how memory is allocated and managed is critical to utilizing it as effectively as possible. Database binaries are compiled using a variety of memory allocation libraries. Here are some examples:
MySQL’s InnoDB, as of version 5.5, uses a custom library that wraps
glibc’smalloc. GitHub claims to have saved 30% latency by switching totcmalloc, whereas Facebook usesjemalloc.PostgreSQL also uses its own custom allocation library, with
mallocbehind it. Unlike most other datastores, PostgreSQL allocates memory in very large chunks, calledmemory contexts.As of version 2.1, Apache Cassandra off-heap allocation supports
jemallocover native.MongoDB’s version 3.2 implementation uses malloc by default but can be configured with
tcmallocorjemalloc.
jemalloc and tcmalloc have both proven to provide significant improvements in concurrency for most database workloads, performing significantly better than glibc’s native malloc while also reducing fragmentation.
Memory is allocated in pages that are 4 KB in size by default. Thus, 1 GB of memory is the equivalent of 262,144 pages. CPUs use a page table that contains a list of these pages, with each page referenced through a page table entry. A translation lookaside buffer (TLB) is a memory cache that stores recent translations of virtual memory to physical addresses for faster retrieval. A TLB miss is where the virtual-to-physical page translation is not in a TLB. A TLB miss is slower than a hit, and can require a page walk, requiring several loads. With large amounts of memory, and thus pages, TLB misses can create thrashing.
Transparent Huge Pages (THP) is a Linux memory management system that reduces the overhead of TLB lookups on machines with large amounts of memory by using larger memory pages, thus reducing the number of entries required. THPs are blocks of memory that come in 2 MB and 1 GB sizes. Tables used for 2 MB pages are suitable for gigabytes of memory, whereas 1 GB pages are best for terabytes. However, defragmentation of these large page sizes can cause significant CPU thrashing, which has been seen on Hadoop, Cassandra, Oracle, and MySQL workloads, among others. To mitigate this, you might need to deal with disabling defragmentation and losing up to 10% of your memory because of it.
Linux is not particularly optimized for database loads requiring low latency and high concurrency. The kernel is not predictable when it goes into reclaim mode, and one of the best recommendations we can give is to simply ensure that you never fully use your physical memory by reserving it to avoid stalls and significant latency impacts. You can reserve this memory by not allocating it in configuration.
Swapping
In Linux/UNIX systems, swapping is the process of storing and retrieving data that no longer fits in memory and needs to be saved to disk to alleviate pressure for memory resources. This is a very slow operation by orders of magnitude compared to memory access, and thus should be considered a last resort.
It is generally accepted that databases should avoid swapping because it can immediately increase latency beyond acceptable levels. That being said, if swap is disabled, the operating system “Out of Memory Killer” (OOM Killer) will shut down the database process.
There are two schools of thought here. The first, and more traditional, approach is that keeping a database up and slow is better than the database not being available at all. The second approach, and the one that aligns more closely with the DBRE philosophy, is that latency impacts are as bad as performance impacts; thus, swapping in from disk should not be tolerated at all.
Database configurations will typically have a realistic memory usage high watermark as well as a theoretical one. Fixed memory structures like buffer pools and caches will consume fixed amounts, making them predictable. At the connection layer, however, things can get messier. There is a theoretical limit based on the maximum number of connections and the maximum size of all per-connection memory structures, such as sort buffers and thread stacks. Using connection pools and some sane assumptions, you should be able to predict a reasonably safe memory threshold by which you can avoid swapping.
This process does allow for anomalies such as misconfigurations, runaway processes, and other pear-shaped events to push you past your memory bounds, which would shut down your server in an OOM event. This is a good thing, though! If you have effective visibility, capacity, and failover strategies in place, you have effectively shut out a potential Service-Level Objective (SLO) violation on latency.
Disabling Swap
You should do this only if you have rock-solid failover processes. Otherwise, you will absolutely find yourself affecting availability to your applications.
Should you choose to allow swapping in your environment, you can reduce the operating system’s chance of swapping out your database memory for file cache, which is generally not helpful. You can also adjust the OOM scores for your database processes to reduce the chance that your kernel memory profiler will kill your database process for memory needs elsewhere.
Non-Uniform memory access
Early implementations of multiple processors used an architecture called Symmetric Multiprocessing (SMP) to provide equal access to memory for each CPU via a shared bus between the CPUs and the memory banks. Modern multiprocessor systems utilize Non-Uniform Memory Access or NUMA, which provides a local bank of memory to each processor. Access to memory banked to other processors is still done over a shared bus. Thus, some memory access has much lower latency (local) versus others (remote).
In a Linux system, a processor and its cores are considered a node. The operating system attaches memory banks to their local nodes and calculates cost between nodes based on distance. A process and its threads will be given a preferred node to utilize for memory. Schedulers can change this temporarily, but affinity will always go to the preferred node. On top of this, after memory is allocated, it will not be moved to another node.
What this means in an environment in which large memory structures are present, such as database buffer pools, is that memory will be allocated heavily to the preferred node. This imbalance will cause the preferred node to be filled, with no available memory on it. This means that even if you are utilizing less memory than physically available on the server, you will still see swapping.
At this point, for most DBMS requests, you set interleaving for NUMA in the kernel. Stories abound for PostgreSQL, Redis, Cassandra, MongoDB, MySQL, and ElasticSearch about the same issues.
Network
The assumption of this book is that all datastores are distributed. Network traffic is critical for the performance and availability of your databases, period. You can break up network traffic into the following categories:
Internode communications
Application traffic
Administrative traffic
Backup and recovery traffic
Internode communications include data replication, consensus and gossip protocols, and cluster management. This is the data that let’s the cluster know its own state and keeps data replicated in the amounts defined. Application traffic is the traffic that comes from application servers or proxies. This is what maintains application state and allows for the creation, mutation and deletion of data by applications.
Administrative traffic is the communication between management systems, operators, and the clusters. Administrative traffic is the communication between management systems, operators, and clusters. This includes starting and stopping services, deploying binaries, and making database and configuration changes. When things go badly elsewhere, this is the lifeline to systems that allows for manual and automated recovery. Backup and recovery traffic is just what it says. This is the traffic created when archiving and copying data, moving data between systems or recovering from backups.
Isolation of traffic is one of the first steps to proper networking for your databases. You can do this via physical network interface cards (NICs), or by partitioning one NIC. Modern server NICs generally come in 1 Gbps and 10 Gbps sizes, and you can bond them in a pair to allow for redundancy and load balancing. Although this redundancy will increase mean time between failures (MTBF), it is an example of creating robustness rather than resiliency.
Databases need a lean transport layer to manage their workloads. Frequent and fast connections, short round trips, and latency-sensitive queries all require a specific tuning effort. This can be broken down into three areas:
Tuning for large numbers of connections by expanding the amount of TCP/IP ports.
Reducing the time it takes to recycle sockets to avoid large amounts of connections sitting in
TIME_WAIT, and thus rendering it unusable.Maintaining a large TCP backlog so that saturation will not cause connections to be refused.
TCP/IP will become your best friend in troubleshooting latency and availability problems. We strongly suggest that you deep-dive into this. A good book to do so is Internetworking with TCP/IP, Vol 1 by Douglas E. Comer (Pearson). It is updated as of 2014 and is an excellent reference.
Storage
Storage for databases is a huge topic. You need to consider the individual disks, the grouped configuration of disks, controllers providing access to disks, volume management software, and the filesystems on top of this. It is quite possible to geek out on any single section of this for days, so we will try to stay focused on the big picture here.
In Figure 5-1, you can see the ways in which data is propagated to storage. When you read from a file, you go from user buffer, to page cache, to disk controller, to disk platter for retrieval, and then step back through that for delivery to the user.
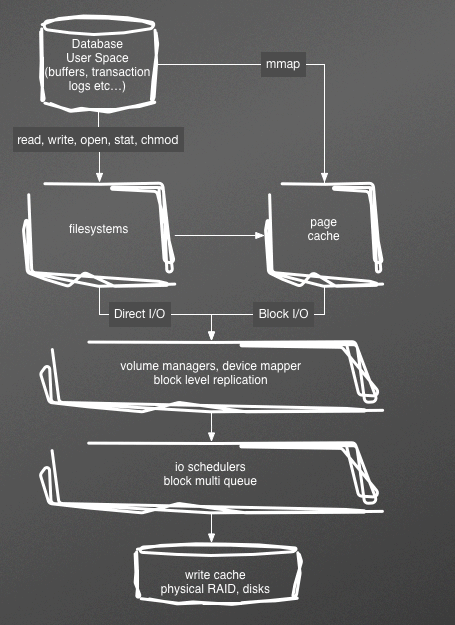
Figure 5-1. The linux storage stack
This elaborate cascade of buffers, schedulers, queues, and caches is used to mitigate the fact that disks are very slow compared to memory, with the difference being 100 nanoseconds versus 10 milliseconds.
For database storage, you will have five major demands, or objectives:
capacity
throughput (or IO per second, aka IOPS)
latency
availability
durability
Storage capacity
Capacity is the amount of space available for the data and logs in your database. Storage can be via large disks, multiple disks striped together (RAID 0), or multiple disks functioning as individual mount points (known as JBOD, or just a bunch of disks). Each of these solutions has a different failure pattern. Single large disks are single points of failure, unless mirrored (RAID 1). RAID 0 will have its MTBF reduced by a factor of N, where N is the number of disks striped together. JBOD will have more frequent failures, but unlike RAID 0, the other N–1 disks will be available. Some databases can take advantage of this and stay functional, if degraded, while the replacement disk is acquired and installed.
Understanding a database’s total storage needs is only one piece of this picture though. If you have a 10 TB storage need, you can create a 10 TB stripe set, or mount ten 1 TB disks in JBOD and distribute data files across them. However, you now have a 10 TB database to back up at once, and if you have a failure, you will need to recover 10 TB, which takes a long time. During that time, you will have reduced capacity and availability for your overall system. Meanwhile, you must consider if your database software, the operating system, and the hardware can manage the concurrent workloads to read and write to this monolithic datastore. Breaking this system up into smaller databases will improve resiliency, capacity, and performance for applications, for backup/restores, and for copying the dataset.
Storage throughput
IOPS is the standard measure of input and output operations per second on a storage device. This includes reads and writes. When considering the needs, you must consider IOPS for the peak of a database’s workload rather than the average. When planning a new system, you will need to estimate the number of IOPS needed per transaction, and the peak transactions in order to plan appropriately. This will obviously vary tremendously depending on the application. An application that does constant inserts and single row reads can be expected to do four or five IOPs per transaction. Complex multiquery transactions can do 20 to 30 easily.
Database workloads tend to be mixed read/write, and random, rather than sequential. There are some exceptions, such as append-only write schemas (such as Cassandra’s SSTables), which will write sequentially. For hard disk drives (HDDs), random IOPs numbers are primarily dependent upon the storage device’s random seek time. For SSDs, random IOPs numbers are instead constrained by internal controller and memory interface speeds. This explains the significant improvement in IOPS seen by SSDs. Sequential IOPS indicate the maximum sustained bandwidth that the disk can produce. Often sequential IOPS are reported as megabytes per second (MBps), and are indicative of how a bulk load or sequential writes might perform.
When looking at SSDs, remember to consider the bus, as well. Consider installing a PCIe bus flash solution, such as FusionIO 6 GBps throughput with microsecond latency. As of this writing, 10 TB will cost you around $45,000, however.
Traditionally, IOPS was the constraining factor over storage capacity. This is particularly true for writes, which you could not optimize away via caching like reads. Adding disks via striping (RAID 0) or JBOD would add more IOPS capacity just like storage. RAID 0 will give you uniform latency and eliminate hot spots that might show up in JBOD, but at the expense of a reduced MTBF based on the number of disks in the stripe set.
Storage latency
Latency is the end-to-end client time of an I/O operation; in other words, the time elapsed between sending an I/O to storage and receiving an acknowledgement that the I/O read or write is complete. As with most resources, there are queues for pending requests, which can back up during saturation. Some level of queuing is not a bad thing, and, in fact, many controllers are designed to optimize queue depth. If your workload is not delivering enough I/O requests to fully use the performance available, your storage might not deliver the expected throughput.
Transactional database applications are sensitive to increased I/O latency and are good candidates for SSDs. You can maintain high IOPS while keeping latency down by maintaining a low queue length and a high number of IOPS available to the volume. Consistently driving more IOPS to a volume than it has available can cause increased I/O latency.
Throughput-intensive applications like large MapReduce queries are less sensitive to increased I/O latency and are well-suited for HDD volumes. You can maintain high throughput to HDD-backed volumes by maintaining a high queue length when performing large, sequential I/O.
The Linux page cache is another bottleneck to latency. By using direct IO (O_DIRECT), you can avoid multimillisecond latency impacts by bypassing the page cache.
Storage availability
Performance and capacity are critical factors, but unreliable storage must be accounted for. Google did an extensive study on HDD failure rates in 2007 titled "Failure Trends in a Large Disk Drive Population" (see Figure 5-2). From this, you can expect about 3 out of 100 drives to fail in their first three months of service. Of disks that make it through the first six months, you will find approximately 1 in 50 fail between six months and one year in service. This doesn’t seem like a lot, but if you have six database servers with eight drives each, you can expect to have a disk failure during that period.

Figure 5-2. HDD failure rates, according to Google
This is why engineers began mirroring drives, à la RAID 1, and enhancing stripe sets with a parity drive. We don’t talk much about the parity variants (e.g., RAID 5) because their write penalty is so large. Modern storage subsystems will typically find disks in JBOD or grouped in stripes (RAID 0), mirrors (RAID 1), or mirrors that are striped (RAID10). With that in mind, it is easy to extrapolate that RAID 1 and RAID 10 are most tolerant of single-disk failures, whereas RAID 0 is most prone to complete service loss (and greater chances the more disks in the stripe). JBOD shows the ability to tolerate failures while still serving the rest of the storage.
Availability is not just the MTBF of your volumes. It is also the time it would take to rebuild after a failure, or the mean time to recover (MTTR). The choice of RAID 10 versus RAID 0 is dependent on the ability to easily deploy replacement database hosts during a failure. It can be tempting to stay with RAID 0 for performance reasons. RAID 1 or 10 requires double the IOPS for writes, and if you are using high-end drives, the duplication of hardware can become expensive. RAID 0 is performant and predictable, but somewhat fragile. After all, a five-drive stripe set of HDDs can be expected to have about a 10% failure rate in the first year. With four hosts, you can reasonably expect a failure every year or two.
With a mirror, you can replace the disk without the need to rebuild the database. If you are running a 2 TB database with fairly fast-spinning disks, database backup copy time is measured in hours, and you will likely need more hours for database replication to sync the delta from the last backup. To be comfortable with this, you will need to consider if you have enough capacity to support peak traffic with one, or even two, failed nodes while this recovery is going on. In a sharded environment, where one dataset is only a percentage of users, this might be perfectly acceptable, meriting more fragile data volumes for the benefits of cost and/or write latency.
Durability
Finally, there is durability. When your database goes to commit data to physical disk with guarantees of durability, it issues an operating system call known as fsync() rather than relying on page cache flushing. An example of this is when a redo log or write-ahead log is being generated and must be truly written to disk to ensure recoverability of the database. To maintain write performance, many disks and controllers utilize an in-memory cache. fsync instructs the storage subsystem that these caches must be flushed to disk. If your write cache is backed by a battery, and can survive a power loss, it is much more performant to not flush this cache. It is important to validate that your particular setup does truly flush data to stable storage, whether that is a non-volatile RAM (NVRAM), write cache or the disk platters themselves. You can do this via a utility such as diskchecker.pl by Brad Fitzpatrick.
Filesystem operations can also cause corruption and inconsistency during failure events, such as crashes. Journaling filesystems like XFS and EXT4 significantly reduce the possibility of such events, however.
Storage Area Networks
In opposition to direct storage, you can use a storage area network (SAN) with an external interface, typically Fibre Channel. SANs are significantly more expensive than direct attached, and by centralizing storage, you reduced management expense and allow a significant amount of flexibility.
With top-of-the-line SANs, you get significantly more cache. Additionally, there are a lot of features that can be useful for large datasets. Being able to take snapshots for backups and data copies is incredibly useful. Realistically, data snapshots and movement are some of the nicest features in modern infrastructures, where SSDs provide better IO than traditional SANs.
Benefits of Physical Servers
Physical servers are the simplest approach to hosting databases. There are no abstractions that hide implementation and runtime details or add additional complexity. In most cases, you have as much control as is possible with your OS, and as much visibility. This can make operations fairly straightforward.
Cons of Physical Servers
Still, there can be some drawbacks to using physical servers. First among them is that you can find yourself wasting capacity that has been dedicated to specific servers. Additionally, deployment of these systems can take quite a lot of time, and it can be difficult to ensure that every server is identical from the hardware and software perspectives. With that in mind, let’s discuss virtualization.
Virtualization
In virtualization, software separates physical infrastructures to create various dedicated resources. This software makes it possible to run multiple operating systems that run multiple applications on the same server. With virtual machines (VMs), for example, you could alternately run four instances of Linux on one server, each with dedicated computing, memory, networking, and storage.
Virtualization allows an infrastructure’s resources, including compute, storage, and networking, to be combined to create pools that can be allocated to virtual servers. This is often referred to as cloud computing. This is what you work with if you are running on a public cloud infrastructure such as Amazon Web Services (AWS). This can also be done within your own data centers.
Essentially, whether in a public, private, or hybrid solution, you are able to define what your server resources and the related operating systems look like via code. This allows for consistent deployments for database systems, which means the DBREs users are empowered to build their own database clusters, which have been configured according to the standards set by the DBRE. These standards include the following:
OS
Database software version
OS and database configurations
Security and permissions
Software packages and libraries
Management scripts
This is all a wonderful thing, but adding an abstraction layer on top of physical resources does create its own set of complexities to manage. Let’s look at some of them.
Hypervisor
A hypervisor or virtual machine monitor (VMM) can be software, firmware, or hardware. The hypervisor creates and runs VMs. A computer on which a hypervisor runs one or more VMs is called a host machine, and each VM is called a guest machine. The hypervisor presents the guest operating systems with a virtual operating platform and manages the execution of the guest operating systems.
Storage
Storage durability and performance are not what you would expect in the virtualized world. Between the page cache of your VM and the physical controller lies a virtual controller, the hypervisor, and the host’s page cache. This means increased latency for I/O. For writes, hypervisors do not honor fsync calls in order to manage performance. This means that you cannot guarantee that your writes are flushed to disk when there is a crash.
Additionally, even though you can easily spin-up a VM in 10 minutes or less, that does not necessarily create the data that an existing database needs to be functional. For instance, if you are deploying a new replica, you will need to bootstrap the data for that replica from somewhere.
When looking at storage in virtualized environments, there are two major categories: local storage and persistent block storage. Local storage is ephemeral. Its data cannot survive the life of the VM. Persistent block storage can be attached to any VM and utilized. If the virtual machine is shut down, another VM can attach to that storage. This externalized, persistent storage is ideal for databases. This block storage often will allow snapshots for easy data movement, as well.
This block storage is much more network dependent than traditional physical disks, and congestion can quickly become a performance killer.
Use Cases
With all of these caveats, the DBRE must consider virtual and cloud resources carefully when planning to use them for database infrastructure. When designing for these infrastructures, you must consider all of the aforementioned factors, which we summarize here:
Relaxed durability means data loss must be considered an inevitability.
Instance instability means automation, failover, and recovery must be very reliable.
Horizontal scale requires automation to manage significant numbers of servers.
Applications must be able to tolerate latency instability.
Even with all of this in mind, there can be tremendous value to virtualized and cloud infrastructures for databases. The ability to create self-service platforms that your users can build on and work with is a force multiplier for DBRE resources. This allows dissemination of knowledge and best practices even with only a few DBREs on staff.
Rapid deployment also allows for extensive testing of applications and prototyping. This allows for development teams to be much more productive without bottlenecking on the DBRE for deployments and configuration. This also means developers are less likely to go off on their own when deploying new application persistence tiers.
Containers
Containers sit on top of a physical server and its host OS. Each container shares the host OS kernel, binaries, and libraries. These shared components are read-only, and each container can be written to through a unique mount. Containers are much lighter than VMs. In fact, they are only megabytes in size. Whereas a VM might take 10 minutes or so to spin up, a container can take seconds to start.
For datastores, however, the advantages of a quick spin up in Docker are often outweighed by the need to attach, bootstrap, and synchronize data. Additionally, kernel-level customizations, IO heavy workloads, and network congestion often make a shared OS/host model challenging. Docker is a great tool for rapidly spinning up deployments for tests and development environments, however, and DBREs will still find useful places for it in their toolkits.
Database as a Service
Increasingly, companies are looking to third-party solutions for their virtualization and cloud services. Taking the self-service model we discussed in Chapter 6 further, you end up with third-party-managed database platforms. All of the public cloud providers offer these, the most famous being Amazon’s Relational Database Service (RDS), which offers MySQL, PostgreSQL, Aurora, SQL Server, and Oracle. In these environments, you are given the opportunity to choose fully deployed database environments to place in your infrastructure.
Database as a Service (DBaaS) has gained significant adoption rates because of the idea that the automation of many of the more mundane aspects of operations frees up time from valuable engineering resources. Typical features can include:
Deployment
Master failover
Patches and upgrades
Backup and recovery
Exposure of metrics
High performance due to "special sauce,” such as Amazon’s Aurora
All of this does free up time, but also can lead software engineers (SWEs) to think that database specialists are not needed. This could not be further from the truth. Abstracted services add their own challenges, but more important, they allow you to focus where your specialized knowledge can create the most value.
Challenges of DBaaS
Lack of visibility is one of the biggest challenges. With no access to the OS, network devices, and hardware, you will be unable to diagnose many significant issues.
Although many monitoring systems are now gathering database SQL data at the TCP level to manage data gathering at scale, they must fall back to logs or internal snapshots such as MySQL’s performance schema for data. Additionally, time-tested tracing and monitoring tools like top, dtrace, and vmstat are unavailable.
Durability issues are similar to other virtualized environments, and implementation of important components such as replication and backups are often black boxes that rely on your vendor to do the right thing.
The DBRE and the DBaaS
In the world of marketing, DBaaS platforms are often sold as ways to eliminate the need for expensive and difficult-to-hire/retain database specialists. The DBaaS platform does allow for more rapid introduction of an operationally sound database infrastructure, which can delay the need for hiring or engaging a specialist. This is far from the elimination of the need for the specialist that is being sold however.
If anything, with the DBaaS abstracting away toil and easy-to-solve issues, you create risk that a difficult-to-solve issue will come up before you have the appropriate database specialists dialed into your environment. Additionally, there are key decisions to be made early that do require someone with depth in the database engine you have chosen. These decisions include the following:
Which database engine to use
How to model your data
An appropriate data access framework
Database security decisions
Data management and growth/capacity plans
So, even though software engineers may be more empowered by the DBaaS, you as the DBRE should work harder than ever to help them choose correctly and to ensure that they understand where your expertise can make the difference in success or failure of the DBaaS deployment.
DBaaS can be very attractive to an organization, particularly in its early days when every engineering minute is incredibly critical. As a DBRE in such an environment, it is strongly recommended that you consider a migration path and a disaster recovery path to your own infrastructure. Everything that your DBaaS solution can do you and your operations team can automate at the right time, giving you full control and visibility into your datastores for better or for worse.
Wrapping Up
In this chapter, we looked at the various combinations of hosts that you might find yourself working with—physical, virtual, containers, and services. We discussed the impact of processing, memory, network and storage resources, and the impacts that under-allocation and misconfiguration can cause.
In Chapter 6, we discuss how to manage these database infrastructures through appropriate tooling and process to scale and to manage risk and failure. We will cover configuration management, orchestration, automation and service discovery, and management.
1 “A brief update on NUMA and MySQL” and “The MySQL ’swap insanity’ problem and the effects of the NUMA architecture”, both available on his blog.