
Chapter 12. A Data Architecture Sampler
Now that we’ve gone over storage engines and individual datastores, let’s broaden our view to look at how those datastores can fit within multisystem architectures. Rare is the architecture that only involves one datastore. The reality is that there will be multiple ways to save data, multiple consumers of that data, and multiple producers of data. In this chapter, we present you a delightful little sampler of architectural components that are often used to enable our datastores followed by a few data-driven architectures that are found in the wild and the problems they attempt to solve.
Although this will be no where close to comprehensive, it should give you an excellent overview of the ecosystem and what to look for. This chapter will help you understand the effective uses for these components as well as the ways in which they can affect your data services, both positively and negatively.
Architectural Components
Each of these components falls within the purview of the day-to-day duties of the database reliability engineer (DBRE). Gone are the days when we can ignore all of the components around the data ecosystem. Each of these components has a definitive impact on overall data service availability, data integrity, and consistency. There is no way to ignore them when designing services and operational processes.
Frontend Datastores
The frontend database is the bread and butter of much of what we have been discussing throughout this book. Users of your applications typically query, insert, and modify data in these datastores through the data access layer. Historically, many applications are designed to function as if these databases were always available. This means that anytime these frontend datastores are down or so busy that they are slow enough to affect customer experience, the applications become unusable.
Historically, these systems have been referred to as OnLine Transactional Processing (OLTP) systems. They were characterized by a lot of quick transactions, and thus they were designed for very fast queries, data integrity in high concurrency, and scale based on the number of transactions they can handle concurrently. All data is expected to be real time with all of the necessary details to support the services using them. Each user or transaction is seeking a small subset of the data. This means query patterns tend to focus on finding and accessing a small, specific dataset within a large set. Effective indexing, isolation, and concurrency are critical for this, which is why it tends to be fulfilled by relational systems.
A frontend datastore is also characterized by the fact that its data is primarily populated by the users themselves. There are also user-facing datastores that are predominantly for analytics, often historically referred to as OnLine Analytics Processing (OLAP). These are discussed in the downstream analytics section.
We have already discussed the various attributes that most of these datastores employ: storage structure, data model, ACID/BASE paradigms, and trade-offs between availability, consistency, and latency. Additionally, we must consider overall operability and how they integrate with the rest of the ecosystem. Typical attributes required include the following:
Low-latency writes and queries
High availability
Low Mean Time to Recover (MTTR)
Ability to scale with application traffic
Easy integration with application and operational services
As you might imagine, this is a pretty steep bar for any architecture all by itself. These requirements can rarely be met without help from other components in the infrastructure, which we will review.
Data Access Layer
An application is often broken into presentation and business logic tiers. Within the business logic tier is what is known as the data access layer (DAL). This layer provides a simplified access to the persistent datastores used for the read and write components of the application. This often exhibits as a set of objects with attributes and methods that refer to stored procedures or queries. This abstraction hides datastore complexity from software engineers (SWEs).
An example of a DAL is the use of data access objects (DAO). DAOs provide interfaces to the database by mapping application calls to database. By keeping this persistence logic in it own place, SWEs can test data access discretely. Similarly, you can provide stubs instead of databases, and the application can still be tested. The common thought regarding this approach is that it requires a lot more coding in Java Database Connectivity (JDBC) or other equivalents. Still, by staying closer to the database, it gives you the ability to code effectively when performance must be achieved via specific methods. The other negative often given is that it requires the developer to have a greater understanding of the schema. We happen to think that this is a positive thing and that the more developers understand the schema, the better for everyone involved.
Another example of a DAL is the Object-Relational Mapper (ORM). As we’ve made clear, we don’t like ORMs for any number of reasons. There are some benefits, however. The ORM can provide a lot of features, including caching and auditing. It is critical to understand what your SWE teams are using, and what flexibility or constraints are introduced in data access coding and optimization.
Database Proxies
The database proxy layer sits between the application servers and the frontend datastores. Some proxies sit on Layer 4 (L4) of the networking transport layer and use the information available at that layer to decide how to distribute requests from application servers to the database servers. This includes the source and destination IP addresses and ports in the packet header. L4 functionality allows you to distribute traffic according to a specific algorithm but cannot take other factors like load or replication lag into account.
Layer 4 and 7
When we discuss layers, we are discussing layers of the Open Systems Interconnection (OSI) model. This model defines the standard for networking.
A Layer 7 (L7) proxy operates at the highest level of the networking transport layer. This is also known as the application, or in this case, the HTTP layer. At L7, the proxy has access to significantly more data from the TCP packet. L7 proxies can understand the database protocol and protocol routing and can be significantly customized.
Some of this functionality can include the following:
Health checking and redirection to healthy servers
Splitting of reads and writes to send reads to replicas
Query rewriting to optimize queries that cannot be tuned in code
Caching query results and returning them
Redirecting traffic to replicas that are not lagged
Generate metrics on queries
Perform firewall filtering on query types or hosts
All of this functionality does come at a cost, of course. The trade-off in this case is latency. So, deciding on an L4 proxy versus an L7 will depend on the needs of your team for functionality as well as latency. A proxy can help mitigate the effects of technical debt by fixing things at a different layer. But, this can also cause technical debt to be ignored for a longer amount of time, and it can make your application less portable toward other datastores as things evolve.
Availability
One major function of a proxy server is the ability to redirect traffic during the failure of a node. In the case of a node serving as a replica, a proxy can run a healthcheck and pull a node out of service. In the case of a primary or write failure, if there can be only one writer, the proxy can stop traffic to allow a safe failover to occur. Either way, the use of an effective proxy layer can dramatically reduce the MTTR of a failure. This assumes that you’ve set up your proxy layer to be tolerant. Otherwise, you’ve simply added a new failure point.
Data Integrity
If a proxy is simply directing traffic, there will be little impact to the data’s integrity. There are some opportunities for improving and affecting this, however. In an asynchronous repliction environment, an L7 proxy can pull any replicas out of service that are lagging behind in replication. This reduces the chance of stale data being returned to an application.
On the other hand, if the proxy is caching data to reduce latency and increase capacity on the database nodes, there can be a chance for stale data to be returned from that cache if it is not effectively invalidated after writes. We will discuss this and other caching issues in the caching section.
Scalability
A good proxy layer can dramatically improve scale. We’ve already discussed the scaling patterns, which include distributing reads across multiple replicas. Without a proxy, you can perform rudimentary load distribution, but it is not load or lag aware, and thus not as useful. But, using a proxy to distribute reads is a very effective approach for workloads that are heavy on reads. This assumes that the business makes enough money to pay for all of those replicas and that effective automation is put in place to manage them.
Another area for which a proxy layer can improve scalability is by load shedding. Many database servers suffer from a large number of concurrent connections. A proxy layer can act as a connection queue, holding a large number of connections while only allowing a certain number of those to do work in the database. While this might seem counterintuitive because of the increase in latency from concurrency, constraining connections and work can allow greater throughput.
Latency
Latency is a crucial consideration when adding another tier to the transaction flow. An L4 proxy adds minimal latency, but L7 adds significantly more. On the other hand, there are ways in which that can be amortized with latency improvements. These improvements include caching regularly executed queries, avoiding overly loaded servers, and rewriting ineffective queries. The trade-offs will vary dramatically across applications, and it will be up to you, the architects and engineers, to make those decisions. As with most trade-offs, we recommend simplicity over rich features unless they are absolutely needed. Simplicity and lower latency can be incredibly valuable to your organization.
Now that we’ve looked at the data access and proxy layers—the layers that help get an application to the database—let’s talk about the applications that function downstream from the database. These are the systems that consume, process, transform, and generally create value from those frontend datastores.
Event and Message Systems
Data does not exist in isolation. Because transactions occur in a primary datastore, there are any number of actions that must occur after a transaction is registered. In other words, these transactions function as events. Some examples of actions that might need to be taken after a transaction, include the following:
Data must be put into downstream analytics and warehouses
Orders must be fulfilled
Fraud detection must review a transaction
Data must be uploaded to caches or Content Delivery Networks (CDNs)
Personalization options must be recalibrated and published
Those were just a few examples of the possible actions that can be triggered after a transaction. Event and message systems are built to consume data from the datastores and publish those events for the downstream processes to act on them. Messaging and event software enables communication sharing between applications via asynchronous messages. These systems produce messages based on what they detect in the datastore. Those messages are then consumed by other applications that are subscribed to them.
There are a diverse group of applications that perform this function. The most popular as of this writing is Apache Kafka, which functions as a distributed log. Kafka allows for significant horizontal scale at the producer, consumer, and topic level. Other systems include RabbitMQ, Amazon Kinesis, and ActiveMQ. At its simplest, this can be an Extract, Transform, and Load (ETL) job or jobs that are constantly or periodically polling for new data in the datastore.
Availability
An event system can positively affect the availability of a datastore. Specifically, by pushing the events and the processing of those events out of the datastore, we are eliminating one mode of activity from the datastore. This reduces resource utilization and concurrency, which could potentially affect availability of core services. It also means that event processing can occur even during peak activity periods because they do not need to worry about disturbing production.
Data integrity
One of the biggest risks when moving data across systems is the risk of data corruption and loss. In a distributed message bus with any number of data sources and consumers of that data, data validation is an incredible challenge. For data that cannot be lost, the consumer must write a copy of some sort or another back into the bus. An audit consumer can then read those messages and compare them to the original one. Just like the data validation pipeline we discussed in the recovery section, this is a lot of work in terms of coding and resources. But, it is absolutely necessary for data that you cannot afford to lose. Of course, this can be sampled for data that can tolerate some loss. If there is detected loss, there needs to be a way to notify downstream processes that they must reprocess a specific message. How that occurs will depend on the consumer.
Similarly, it is important to verify that the storage mechanism for events or messages is durable enough to maintain persistence for the life of the message. If there can be data loss, there is a data integrity issue. The inverse of this is duplication. If data can be duplicated, an event will be reprocessed. If you cannot guarantee that the processing is idempotent and thus can be rerun with the same results if the event is reprocessed, you might be better off using a datastore that can be indexed appropriately to manage duplicates.
Scalability
As just discussed in “Availability”, by pulling the events and their subsequent processing out of the frontend datastore, we are reducing the overall load on the database. This is workload partitioning, which we have discussed in scaling patterns as a step on the path to scale. By decoupling orthagonal workloads, we eliminate multimodal workload interference.
Latency
Pulling event processing out of the frontend datastores is an obvious win on reducing potential conflicts that can reduce frontend application latency. The time it takes to get the events from the frontend datastore to the event processing system is additional latency for the processing of those events, however. The asynchronous nature of this process means that applications must be built to tolerate a delay in processing.
So, now that we have reviewed how to get to the datastores and the glue to connect data between the frontend datastore and the downstream consumers, let’s look at some of those downstream consumers.
Caches and Memory Stores
We have already discussed how incredibly slow disk access is in comparison to memory. This is why we strive to get all datasets of our datastores to fit in memory structures like buffer caches rather than reading them from disk. That being said, for many environments, the budget to keep a dataset in memory just does not exist. For data that that is too large for your datastore’s cache, consideration of caching systems and in-memory datastores is worth merit.
Caching systems and in-memory datastores are fairly similar in terms of the basics. They function to store data on RAM rather than disk, providing rapid access for reads. If your data is infrequently changed and you can tolerate the ephemeral nature of in-memory storage, this can prove to be an excellent option. Many in-memory datastores will offer persistence by copying data to disk via background processes that run asynchronously from the transaction. But, that introduces a high risk of data being lost in a crash before it can be saved.
In-memory datastores often have additional features, such as advanced datatypes, replication, and failover. Newer in-memory stores are also optimized for in-memory access, which can prove faster than even a dataset in a relational system that fits fully in the database cache. Database caches still must do validation on the freshness of their stores and manage concurrency and ACID requirements. Thus, an in-memory datastore might prove the best fit for systems requiring the fastest latency.
There are three approaches to populating caches. The first approach is putting data in cache after it has been written to a persistent datastore like a relational database. The second approach is writing to cache and persistence at the same time in a doublewrite. This approach is fragile due to the opportunity for one of the two writes to fail. Expensive mechanisms for guarantees, including post-write validation or two-phase commit, are required to make this work. The final approach is writing to cache first and then letting that persist to disk asynchronously. This is also called a write-through approach. Let’s discuss how each of these approaches can affect your database ecosystem.
Availability
Use of a cache can positively affect availability by allowing reads to continue even in the case of a datastore failure. For read-heavy applications, this can be very valuable. On the other hand, if a caching system provides improved capacity and/or latency, or if the caching systems fails, the persistence data behind it might prove to be inadequate for the traffic load sent back to it. Maintaining availability at the caching layer becomes just as critical as availability at the datastore, meaning that you have twice the complexity to manage.
Another major issue is that of the thundering herd. In a thundering herd, all of the cache servers have a very frequently accessed piece of data invalidated due to a write or due to a time-out. When this happens, a large number of servers then simultaneously send requests for reads to the persistence store so that they can refresh their cache. This can cause a concurrency backup that can overload the persistence datastore. When that happens it might prove impossible to serve the reads from the cache or the persistence tier.
You can manage thundering herds with multiple approaches. Ensuring that cache time-outs are offset from one another is a simple, if not very scalable approach. Adding a proxy cache layer that can limit direct access to the datastore is a more manageable approach. At this point, you have a persistence tier, a proxy cache tier, and a cache tier. As you can see, scaling can rapidly become quite complex.
Data integrity
Data integrity can be quite the sticky situation with caching systems. Due to the fact that your cached data is generally a somewhat static copy of potentially ever-changing data, you must make a trade-off between how frequently you allow for the refreshing of data and the inherent impact to your persistence store versus how much of a chance there is that you are showing stale data to anything querying the cache.
When putting data into cache after saving it, you must be prepared for the chance for stale data. This approach is best suited for relatively static data that rarely needs to be invalidated and recached. Examples would include lookup datasets such as geocodes, application metadata, and read-only content, such as news articles or user-generated content.
When putting data into persistence and cache at the same time, you are eliminating the opportunity for stale data. This does not eliminate the need for validation that the data is not stale, however. Directly after a write, and periodically thereafter, you must continue to run validation checks to ensure that you are providing the consumer with the correct data.
Finally, when writing data to your cache first, followed by a write to your persistence store, you must have a means of reconstructing the write in the event that your cache crashes before it can send the write forward to the persistence tier. Logging all writes and treating them as events that can trigger validation code is one approach to doing this. Of course, at this point, you are in many ways reproducing the complexity that many home-built datastores already provide. Thus, you must carefully consider whether the write through approach is worth the complexity required to validate and maintain integrity across datastores.
Scalability
One primary reason for using caches and in-memory databases is because you are scaling the read dimension of your workload. So, yes, by adding a caching tier you can effectively achieve greater degrees of scale at the cost of complexity in your environment. But, as we discussed in the availability section, you are now creating a dependency on this tier to successfully achieve your Service-Level Objectives (SLO). If your cache servers fail, or become invalidated or corrupted, you can no longer rely on your persistence store to maintain reads for your application.
Latency
Outside of scalability, the other reason to use a caching tier is to reduce latency for reads. This is a great use of cache or in-memory technology, but if your cache server fails, you no longer can directly observe what your persistence stores look like without the cache server in existence. It is worth scheduling and performing periodic tests with read traffic bypassing the cache in test environments to see how your persistence tier handles both write and read workloads simultaneously. If failing back to your persistence store is a valid contingency in production, you will want to test these failures in production as well as test.
Caching and in-memory datastores are tried-and-true components of many successful datadriven architectures. They play well with event-driven middleware and can truly level up your application’s scalability and performance. That being said, it is an additional tier to manage in terms of operational expense, risk of failures, and risk of data integrity. This cannot be overlooked, which often happens because many cache systems are just so darned easy to implement. It is your job as the DBRE to ensure that your organization takes the availability and integrity responsibilities of this subsystem seriously.
Each of these components plays a vital role in the availability, scalability, and enhanced functionality of your datastores. But, each one of these increases architectural complexity, operational dependencies, and risk of data loss and data integrity issues. Those trade-offs are crucial when making architectural decisions. Now that we have looked at some of the individual components, let’s look at some of the architectures used to push data through frontend production through the datastore and into any number of downstream services.
Data Architectures
The data architectures in this chapter are an example set of data-driven systems that are designed to accept, process, and deliver data. In each, we will discuss the basic principles, uses, and tradeoffs. Our goal in this is to give context to how the datastores and associated systems that we have been discussing throughout this book exist in the real world. It goes without saying that these are simply examples. Real-world application will always vary tremendously based on each organization’s needs.
Lambda and Kappa
Lambda is a real-time big data architecture that has gained a certain level of ubiquitousness in many organizations. Kappa is a response pattern that seeks to introduce simplicity and take advantage of newer software. Let’s go over the original architecture first and then discuss the permutation.
Lambda architecture
The Lambda architecture is designed to handle a significant volume of data that is processed rapidly to serve near-real-time requests, while also supporting long-running computation. Lambda consists of three layers: batch processing, real-time processing, and a query layer, as illustrated in Figure 12-1.

Figure 12-1. Lambda architecture
If data is written to a frontend datastore, you can use a distributed log such as Kafka to create a distributed and immutable log for the Lambda processing layers. Some data is written directly to log services rather than going through a datastore. The processing layers ingest this data.
Lambda has two processing layers, so it can support fast queries with a “good enough” rapid processing while also allowing for more comprehensive and accurate computations. The batch-processing layer is often done via Mapreduce queries, which have a latency that simply cannot be tolerated by real-time or near-real-time queries. A typical datastore for the batch layer is a distributed filesystem such as Apache Hadoop. Mapreduce then creates batch views from the master dataset.
The real-time processing layer processes the data streams as fast as they come in without requiring completeness or 100% accuracy. This is a trade-off on data quality for latency to present recent data to the application. This layer is the delta that fills in data that is lagging from the batch layer. After batch processing completes, the data from the real-time layer is replaced by the batch layer. This is usually accomplished with a streaming technology such as Apache Storm or Spark backed by a low-latency datastore such as Apache Cassandra.
Finally, we have the serving layer. The server layer is the layer that returns data to the application. It includes the batch views created from the batch layer and indexing to ensure low-latency queries. This layer is implemented by using HBase, Cassandra, Apache Druid, or another similar datastore.
In addition to the value of low-latency results from the real-time layer, there are other benefits to this architecture, not least of which is that the input data remains unchanged in the master dataset. This allows for reprocessing of the data when code and business rules change.
The most significant drawback to this architecture is that you need to maintain two separate code bases, one for the real time and one for the batch processing layers. This complexity comes with much higher maintenance costs and a risk of data integrity issues if the two code bases are not always synchronized. There are frameworks that have come about that can compile code to both the real-time and batch-processing layers. Additionally, there is the complexity of operating and maintaining both systems.
Another valid criticism of this architecture is that real-time processing has matured significantly since the Lambda architecture was introduced. With newer streaming systems, there is no reason that semantic guarantees cannot be as strong as batch processes without sacrificing latency.
Kappa architecture
The original concept of the Kappa architecture (Figure 12-2) was first described by Jay Kreps when he was at LinkedIn. In Lambda, you use a relational or NoSQL datastore to persist data. In a Kappa architecture, the datastore is an append-only immutable log such as Kafka. The real-time processing layer streams through a computational system and feeds into auxiliary stores for serving. Kappa architecture eliminates the batch processing system, with the expectation that the streaming system can handle all transformations and computations.
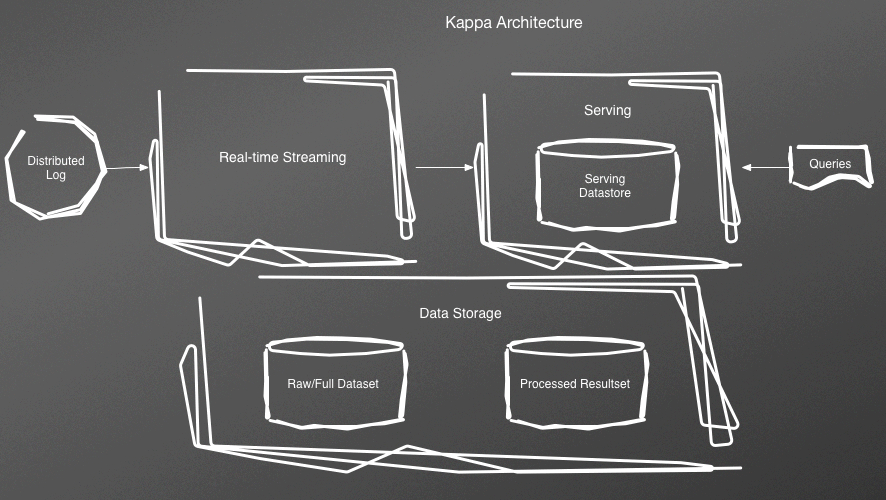
Figure 12-2. Kappa architecture
One of the biggest values to Kappa is the reduction in complexity and operational expense of Lambda by eliminating the batch processing layer. It also aims to reduce the pain of migrations and reorganizations. When you want to reprocess data, you can start a reprocessing, test it, and switch over to it.
Lambda and Kappa are examples of patterns that you can use to process and present large amounts of data in real time. Next, we look at some architectural patterns that are data driven and are built as alternatives to the traditional approach to applications that speak directly to their datastores.
Event Sourcing
Event Sourcing is an architectural pattern that completely changes how you retrieve and insert stored data. In this case, data storage’s abstraction layer is taken lower, which creates flexibility in the creation and reconstruction of data views.
In the event-sourcing architectural pattern, changes to entities are saved as a sequence of state changes. When state changes, a new event is appended to the log. In a traditional datastore, changes are destructive, replacing the previous state with the current. In this model, with all mutations recorded, the application can reconstruct current state by replaying the events from the log. This datastore is called an event store.
This is more than just a new log for mutations. Event sourcing and distributed logs are a new data modeling pattern. Event sourcing complements traditional storage such as relational or key–value stores by exposing a lower level of data storage that functions as events rather than stateful values that can be overwritten.
The event store also functions not only as a distributed log of events and database of record, but also as a message system, as we reviewed earlier in the chapter. Downstream processes and workflows can subscribe to them. When a service saves an event in the event store, it is delivered to all interested subscribers. You can implement the event store in relational or NoSQL datastores or in a distributed log such as Kafka. There is even an event store called EventStore, an open source project that stores immutable, append-only records. The choice will depend a lot on the rate of change and the length of time in which all events must be stored prior to snapshotting and compaction.
Event sourcing offers a number of benefits. Unlike the world of destructive mutations, it is quite simple to audit the life cycle of an entity. It also makes debugging and testing much easier. With event stores, even if someone accidentally removes a table or a chunk of data, you have the distributed log to recreate tables wholesale or on the fly based on a specific entity that is missing. There are challenges, however. Not least of which is managing schema evolutions of the entities because the change can invalidate previous events that have been stored. External dependencies can also be challenging to recreate when replaying an event stream.
With the benefits of event sourcing, many shops might find use for implementing it even if their many applications still use the more traditional datastores instead of the event store. Over time, giving full historical access via API for auditing, reconstruction, and different transformations can provide significant benefits.
CQRS
There is a natural evolution from using an event store as an ancillary storage abstraction to using an event store as the core data storage layer. This is command-query-responsibility segregation (CQRS). The driver for CQRS is the idea that the same data can be represented for consumption using multiple models or views. This need for different models comes from the idea that different domains have different goals, and those goals require different contexts, languages, and ultimately views of the data.
You can accomplish this by using event sourcing. With a distributed log of event state changes, worker processes that subscribe to those events can build effective views to be consumed. CQRS can also enable some other very useful behaviors. Instead of just building new views, you can build views of that data in different datastores that are optimized for the query patterns that consume them. For instance, if the data is text that you want to search, putting it into a search store like ElasticSearch for one view can create an optimized view for the search application. You are also creating independent scaling patterns for each aggregate. By using read optimized data stores for queries and an append-only log that is optimized for writes, you are effectively using CQRS to distribute and optimize your workloads.
There is a great potential for unnecessary complexity in this architecture, however. It is entirely possible to segregate data that needs only one view or over-segregate to more views than are absolutely necessary. Focusing only on the data that actually requires the multimodel approach is important to keep complexity down.
Ensuring that writes or commands return enough data to effectively find the new version numbers of their models can go a long way in helping reduce complexity within the application as well. If commands return success/failure, errors, and a version number that can be used to get the resulting model version will help with this. You can even return data from the affected model as part of a command, which might not be exactly according to the theory of CQRS but can make everyone’s life much easier.
You do not need to couple CQRS with event sourcing. Event sourcing as the core data storage mechanism is quite complicated. It is important to make sure that only the data that has functions as a series of state changes is represented in that manner. You can perform CQRS using views, database flags, and external logic or any number of other ways that are less complex than event sourcing itself.
This was just a sampling of data-driven architectures that you might find yourself working with or designing. The key in each is recognizing the life cycle of the data, and finding effective storage and transport to get that data to each component of the system. Data can be presented in any number of ways, and most of today’s organizations will eventually need to be able to accomplish multiple presentation models while maintaining the integrity of the core dataset.
Wrapping Up
With this sampler, we hope you see some of the opportunities to create even more functionality, availability, scale, and performance within your datastores. There are plenty of opportunities to lock yourself into complex architectures that cost a tremendous amount to maintain. The worst case, of course, is the loss of data integrity, which should be a real concern throughout your career.
With this chapter, we are coming to the conclusion of our book. In the final chapter, we will bring this all back together with some guidance on how you can continue to develop your own career and the culture of database reliability within your organizations.