
Chapter 6. Infrastructure Management
In Chapter 5, we looked at the various infrastructure components and paradigms on which you might run your datastores. In this chapter, we discuss how to manage those environments at scale. We begin with the smallest unit, the individual host’s configuration and definition. From this point, we zoom out to the deployment of hosts and orchestration between components. After this, we zoom out even further to the dynamic discovery of the current state of infrastructure, and the publishing of that data—aka service discovery. Finally, we will go to the development stack, discussing how to create development environments that are similar to these large production stacks.
Gone are the days of one or two boxes that can be manually managed with ease and relative stability. Today, we must be prepared to support large, complex infrastructures with only a few sets of hands. Automation is critical in ensuring that we can deploy datastores repeatably and reliably. Application stability and availability, and the speed at which new features can be deployed, relies on this. Our goals must be to eliminate processes that are repetitive and/or manual and to create easily reproducible infrastructures via standardized processes and automation.
What are good opportunities for this?
Software installations, including operating system (OS), database, and associated packages and utilities
Configuring software and the OS for desired behaviors and workloads
Bootstrapping data into new databases
Installing associated tools such as monitoring agents, backup utilities, and operator toolkits
Testing of infrastructure for appropriate setup and behaviors
Static and dynamic compliance testing
If we were to boil all of this down, our goals are to ensure that we can consistently build and/or reproduce any component of our database infrastructures, and that we can know the current and previous state of any of these components as we carry out troubleshooting and testing.
Admittedly, this is a fairly high-level overview. Should you want to deep-dive, we’d suggest Infrastructure as Code, by Kief Morris (O’Reilly). The goal for this chapter is to explain the various components of infrastructure management via code that you will be asked to contribute to, and point out the ways in which they can make your life as a database reliability engineer (DBRE) easier.
Version Control
To achieve these goals, we must use version control for all components required in the process. This includes the following:
Source code and scripts
Libraries and packages that function as dependencies
Configuration files and information
Versions of OS images and database binaries
A version control system (VCS) is the core of any software engineering workflow. The database and systems engineers working with software engineers (SWEs) to build, deploy, and manage applications and infrastructures work together within the VCS. Traditionally, this was the case. The systems and database engineers would often not use any VCS. If they did happen to use one, it would be separate from the SWE team’s VCS, leading to an inability to map infrastructure versions to code versions.
Some examples of popular VCS platforms include:
GitHub
Bitbucket
Git
Microsoft Team Foundation Server
Subversion
The VCS must be the source of truth for everything in the infrastructure. This includes scripts, configuration files, and the definition files you will use to define a database cluster. When you want to introduce something new, you check it into the VCS. When you want to modify something, you check it out, perform your changes, and commit the changes back into the VCS. After commits are in place, review, testing, and ultimately deployment can occur. It is worth noting that passwords should be masked in someway before being stored in the VCS.
Configuration Definition
To define how your database cluster should be configured and built, you will be utilizing a series of components. Your configuration management application will use a domain-specific language (DSL), though you might also find yourself working with scripts in Windows PowerShell, Python, Shell Scripts, Perl, or other languages. Following are some popular configuration management applications:
Chef
Puppet
Ansible
SaltStack
CFEngine
By defining configuration, rather than scripting it, you create easily readable components which you reuse across your infrastructure. This creates consistency, and often reduces the amount of work needed to add a new component to configuration management.
These applications have primitives, which are called recipes in Chef or manifests in Puppet. These are rolled up into cookbooks or playbooks. These rollups incorporate the recipes with attributes that can be used to override defaults for different needs such as test versus production, file distribution schemes, and extensions such as libraries and templating. The end result of a playbook is code to generate a specific component of your infrastructure such as installing MySQL or Network Time Protocol (NTP).
These files can become quite complex in and of themselves and should share certain attributes. They should be parameterized so that you can run the same definition across different environments, such as dev, test, and production based on your inputs. The actions taken from these definitions and their application also need to be idempotent.
Idempotency
An idempotent action is one that can be run repeatedly with the same outcomes. An idempotent operation takes a desired state and does whatever is necessary to bring the component to that state regardless of its current state. For instance, if you are updating a configuration file to set the size of your buffer cache, you can assume the entry exists, which is naive and error prone. Instead, you can insert the line into the file. If you insert this line automatically, but it already exists, you will duplicate it. Thus, the action is not idempotent.
Instead, you can have the script look to see if the entry exists. Then, if the line does exist, you can modify it. If the line is nonexistent, you can insert it. This is an idempotent approach.
We can break up into sections an example of the configuration definition required by a distributed system such as Cassandra as follows:
Core Attributes
Installation method, location, hashes
Cluster name and version
Group and user permissions
Heap sizing
JVM tuning and configuration
Directory layout
Service configuration
JMX setup
Virtual nodes
JBOD setup and layout
Garbage collection behavior
Seed discovery
Configuration of the YAML config file
OS resource configs
External services
PRIAM
JAMM (Java metrics)
Logging
OpsCenter
Data center and rack layout
In addition to idempotency and parameterization, each of these components should have appropriate pre and post tests and integration into monitoring and logging for error management and continuous improvement.
Pre and post tests will include validation that state starts and ends up where expected. Additional tests can focus on using features that might be enabled or disabled by the change to see if functional behavior is expected. We assume that operational, performance, capacity, and scale tests are done prior to determine if these changes are even necessary. This means that testing will focus on validation that the implementation worked and desired behaviors are occurring. You’ll find an example of a real-world case study with idempotency on the Salesforce Developers blog.
Building from Configuration
After you have your server specifications, acceptance tests, and modules for automation and building defined, you have everything in source code you need to build your databases. There are two approaches regarding how this should be done, and they are called baking and frying. Baking, frying, recipes, chefs...getting hungry yet? Check out John Willis’s presentation on DevOps and Immutable Delivery.
Frying involves dynamic configuration at host deployment time. Hosts are provisioned, operating systems are deployed, and then configuration occurs. All of the configuration management applications mentioned in the previous section have the ability to build and deploy infrastructure via frying.
For instance, if you are frying up a MySQL Galera Cluster, you might see the following:
Server hardware provisioned (three nodes)
Operating systems installed
Chef client and knife (CLI) installed, cookbooks uploaded
Cookbooks for OS permissions and configuration applied
Cookbooks for default package installations applied
Databag created/uploaded for /clusternode level attributes to be used (IP, init node, package names)
Node roles applied (Galera Node)
MySQL/Galera binaries installed
MySQL utility packages and scripts installed
Basic configuration set up
Tests run
Services started and shut down
Cluster created/primary node set up
Remaining nodes setup
Tests run
Register cluster with infrastructure services
Baking involves taking a base image and configuring that base image at build time. This creates a “golden image,"which becomes the standard template for all hosts built for the same role. This is then snapshotted and stored for future use. Amazon AMIs or virtual machine (VM) images are examples of the artifacts output from this baking process. In this scenario, nothing is dynamic.
Packer is a tool from Hashicorp that creates images. The interesting thing about Packer is that it can create images for different environments (such as Amazon EC2 or VMWare images) from the same configuration. Most configuration management utilities can create baked images as well.
Maintaining Configuration
In an ideal world, use of configuration management will help you mitigate and potentially eliminate configuration drift. Configuration drift is what happens after a server is deployed after frying or baking. Although all instances of this component might start identical, people will inevitably log in, tweak something, install something, or run a few experiments and leave some trace behind.
An immutable infrastructure is one that is not allowed to mutate, or change, after it has been deployed. If there are changes that must happen, they are done to the version controlled configuration definition, and the service is redeployed. Immutable infrastructures are attractive, because they provide the following:
- Simplicity
By not allowing mutations, the permutations of state in your infrastructure are dramatically limited.
- Predictability
State is always known. This means that investigations and discovery are much faster, and everything is easily reproducible during troubleshooting.
- Recoverability
State can easily be reintroduced by redeploying the golden image. This reduces mean time to recover (MTTR) significantly. These images are known, tested, and ready to deploy at any time.
That being said, immutable infrastructures can have fairly dramatic overhead. For instance, if you have a 20-node MySQL Cluster and you want to modify a parameter, you must then redeploy every single node of this cluster in order to apply the change after it is checked in.
In the interest of moderation and middle ground, there can be some mutations that are frequent, automated and predictable, and can be allowed in the environment. Manual changes are still prohibited, keeping a significant amount of the value of predictability and recoverability while minimizing operational overhead.
Enforcement of Configuration Definitions
How are these policies enforced?
Configuration synchronization
Many of the configuration management tools already discussed will provide synchronization. This means that any mutations occurring are overwritten on a schedule as the configuration is forcibly overwritten back to standard. This requires the synchronized state to be extraordinarily complete, however, or some areas will be missed, and thus allowed to drift.
Component redeploys
With appropriate tooling, you should be able to identify differences, and redeploy cleanly to eliminate them. Some environments might go so far as to constantly redeploy, or redeploy after any manual login/interaction has occurred on the component. This is generally more attractive in a baked solution, where the overhead of post-deployment configuration has been eliminated.
Using configuration definition and management can help ensure that your individual servers or instances are built correctly and stay that way. There is a higher level of abstraction in the deployment process, which is the definition of cross-service infrastructures and orchestration of those deployments.
Infrastructure Definition and Orchestration
Now that we’ve looked at the configuration and deployment of individual hosts, whether they be servers, VMs, or cloud instances, let’s zoom out to look at groups of hosts. After all, we will rarely be managing a single database instance in isolation. With the assumption that we are always working with a distributed datastore, we need to be able to build, deploy, and operate multiple systems at once.
Orchestration and management tools for provisioning infrastructures integrate with deployment (either frying or baking) applications to create full infrastructures, including services that might not use a host, such as virtual resources or platform as a service configurations. These tools will ideally create a solution for codifying the creation of an entire datacenter or service, giving developers and operations staff the ability to build, integrate, and launch infrastructures from end to end.
By abstracting infrastructure configurations into archivable, version-controlled code, these tools can integrate with configuration management applications to automate the provisioning of hosts and applications while handling all of the set up of underlying infrastructure resources and services required for automation tools to effectively do their jobs.
When discussing infrastructure definitions, we often use the term stack. You might have heard of a LAMP stack (Linux, Apache, MySQL, PHP), or a MEAN stack (MongoDB, Express.js, Angular.js, Node.js). These are generic solution stacks. A specific stack might be focused on a specific application or group of applications. A stack takes an even more specific meaning when you discuss the definition of infrastructures for the purpose of automation and orchestration via tooling. That is the definition we will be referring to here.
The structure of these stacks has a significant impact on how you meet your responsibilities as the DBRE on your team. Let’s discuss these permutations, and the impacts to the DBRE role.
Monolithic Infrastructure Definitions
In this stack, all of the applications and services that your organization owns are defined together in one large definition. In other words, all database clusters will be defined in the same files. In such an environment, any number of applications and services will typically be using one or more databases. You might find five different applications with their associated databases in the same definition.
There are really no pros to a monolithic infrastructure definition, but there are plenty of cons. From an overall orchestration/infrastructure as code point of view, the problems can be elaborated as follows:
If you want to make a change to the definition, you will need to test against the entire definition. This means that tests are slow and fragile. This will cause people to avoid making changes, creating a calcified and fragile infrastructure.
Changes are also more prone to break everything rather than being isolated to one component of the infrastructure.
Building a test or development environment means that you have to build everything together rather than a smaller section that is isolated that you can focus on.
Changes will often be restricted to small groups of individuals who are able to know the entire stack. This creates bottlenecks of changes, slowing velocity.
Teams can find themselves in a monolithically defined stack if they have introduced a new tool, like Terraform, and simply reverse engineered their entire infrastructure into it. When considering an infrastructure definition, you have horizontal considerations (various tiers within one stack) and vertical considerations (breaking up your stack functionally so that one service is in one stack, rather than putting all services in one).
Separating Vertically
By breaking out the definition to individual services per definition, as illustrated in Figure 6-1, you can reduce size and complexity. So, what once was one definition file can become two, one for each service. This reduces the failure domain during changes to one service only. It will also reduce testing by half, and the size of your development and test environments commensurately.
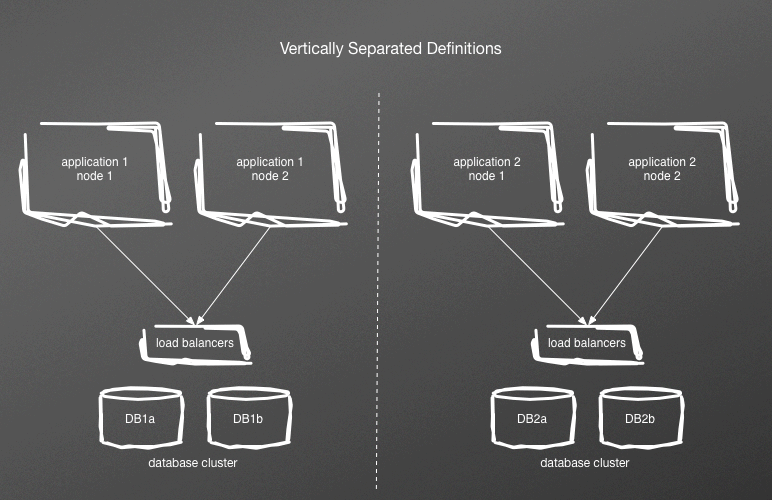
Figure 6-1. Separating vertically
If you have multiple applications using the same database tier, which is rather common, this will prove more challenging. At this point, you will need to create three definitions. One will be a shared database definition, and the other two will be the individual service definitions, excluding the database tier, as demonstrated in Figure 6-2.

Figure 6-2. Vertically separated service definitions, with shared database
Now your failure domain for changes to the definition file are reduced even further, because each definition is smaller and more focused. However, you still have two applications coupled to the database, which means that there will need to be integration testing to ensure that changes made to the database tier work effectively with the other application stacks. So, testing will still require all applications to be built and deployed. Having applications separated does mean that you have the flexibility to build and test applications serially or in parallel depending on your infrastructure constraints.
Separated Tiers (Horizontal Definitions)
If you take the application definitions that have been separated out, you can break definition files out by tiers, also called horizontally separating. So, a standard web app might have a web server stack, an application server stack, and a database stack. The primary advantage of breaking out your infrastructure definition in this matter is that you have now reduced your failure domain even further. In other words, if you need to change configuration to your database servers, you don’t need to worry about potentially breaking the build for web servers.
After you have separated tiers vertically and potentially horizontally, you find yourself dealing with new and interesting complexities. Specifically, you now have communication paths across stacks that require sharing of data. Your database load balancer virtual IPs must be shared with your application servers, but the stacks have their own definitions. This dynamic infrastructure requires a service catalog to ensure that any component of your infrastructure can effectively share its state to any other component for communication and integration.
Acceptance Testing and Compliance
Utilizing automation and infrastructure as code obviously gives us a lot of benefits. One more that we haven’t mentioned yet is acceptance testing and compliance. With images of infrastructure in place, you can utilize tools such as ServerSpec, which uses descriptive language to define tests for your infrastructure images. This brings test-driven development (TDD) to your infrastructure, which is a great opportunity to continue to align infrastructure and software engineering.
With a framework such as ServerSpec for automated testing, you can delve into compliance and security, which are ideal customers of this. Working with these teams you can create a test suite focused on database security and compliance. Inspec is a plug-in for ServerSpec that does this work quite well. You can find more information about it at the Chef blog.
Service Catalog
With dynamic environments being built, scaled, and destroyed automatically, there must be a source of truth for current state that all infrastructure components can use. Service discovery is an abstraction that maps specific designations and port numbers of your services and load balancers to semantic names. For instance, mysql-replicas is a semantic that can include any number of MySQL hosts replicating data from the primary write host. The utility of this is being able to refer to things by semantic names instead of IP address, or even hostnames. Information in the catalog can be accessed via HTTP or DNS.
The following are some of the most common service discovery tools available as of this writing:
Zookeeper
Consul.io
Etcd
Build your own!
There are numerous use cases for such a server catalog that the DBRE might encounter. Here are a few. (We discuss more in later chapters as we explore specific architectures.)
- Database failovers
By registering Write IPs to the catalog, you can create templates for load balancers. When IP is switched, load balancer configurations rebuild and reload.
- Sharding
Share information about writeable shards to application hosts.
- Cassandra Seed Nodes
A service catalog can be very simple, storing service data to integrates services, or it can include numerous additional facilities, including health checks to ensure that data in the catalog provides working resources. You can also store key–value pairs in many of these catalogs.
Bringing It All Together
That was a lot of information, and a lot of it high-level. Let’s discuss a day in the life of a DBRE using these concepts for MySQL. Hopefully, this will add some valuable context. For simplicity, we will assume that this environment runs in Amazon’s EC2 environment. You’ve been tasked with bringing up a new MySQL cluster for your primary user database, which is sharded and requires more capacity. Here are the tools you’ve been given:
MySQL Community, 5.6
MySQL MHA for replication management and failover
Consul for cluster state database
The Terraform files and the Chef Cookbooks for MySQL shards for the user database are checked into GitHub, of course. There should be no manual changes that need to occur in order to build this. You grumble about the fact that you should probably automate capacity analysis and deployment of new shards, but this is only your third month and you just haven’t had the time yet.
Checking your deployment logs, you see the last time a MySQL shard was deployed, and you compare that to the current versions of the terraform and chef code to validate that nothing has changed since then. Everything checks out, so you should be good to go. First, you run terraform with the plan option, to show the execution path and verify nothing untoward will happen. Assuming that is good, you go ahead and run the terraform commands to build the shard.
Terraform executes a chef provisioner that queries Consul for the latest shard_id, and increments it by one. Using that shard_id, it runs its way through a series of steps that include the following:
Launch three EC2 instances in two availability zones (AZs) using the appropriate Amazon Machine Images (AMIs) for MySQL Shard Hosts
Configuring MySQL on these hosts and bringing the service up
Register each node into consul, under the
shard_idnamespaceFirst one will register as master, the following will register as failovers
Start replication using this data
Launch two EC2 instances in two AZs using the appropriate AMIs for MySQL MHA Manager Hosts
Register Master High Availability (MHA) manager to consul, under the
shard_idnamespaceConfigure MHA using node data from consul
Start MHA replication manager
Run through a series of failover tests
At this point, you have an MHA managed MySQL cluster that is registered in Consul. Some things will happen automatically from here, including the following:
Backups start snapshotting from the master automatically, as scripts use Consul.
Monitoring agents are in the AMIs, and automatically begin sending metrics and logs to the operational visibility stack.
Finally, when you are satisfied, you mark the shard as active in Consul. At this point, proxy servers begin adding it to their templates and reloading. Application servers identify it as available, and start sending data to it as appropriate.
Development Environments
Testing locally in a development environment or sandbox is crucial to this workflow. You should feel confident in the impacts of your changes before committing it to the VCS. One of our goals with everything we’ve discussed in this chapter is repeatability. This means that the sandbox must be as close as possible in software and configuration as your actual infrastructure. This means the same OS, the same configuration management, orchestration, and even service catalogs.
When discussing deployment, we mentioned Packer. To reiterate, Packer allows you to create multiple images from the same configuration. This includes images for virtual machines on your workstation. Using a tool like Vagrant on your workstation allows you to download the latest images, build the VMs, and even run through a standard test suite to verify that everything works as expected.
After you’ve done your changes, tested them, brought down any new changes from your VCS and tested again, you can commit this right back into the team VCS in preparation for integration and deployment.
Wrapping Up
Using infrastructure as code, automation, and version control are crucial skillsets for any reliability engineer, and the DBRE is no exception. With the tools and techniques discussed in this chapter, you can begin eliminating toil, reducing mistakes, and creating self-service deployments for your engineering teams.
In Chapter 7, we begin digging deeper into a crucial component of infrastructure: backup and recovery. One key difference in the database tiers is the importance of persistence and availability of data. Although most other environments can be built as artifacts and deployed fast and easily, databases require large working sets of data to be attached and maintained safely. There is a broad toolkit available to do this, which is what we will go over next.