
Chapter 1: PyTorch Lightning Adventure
Welcome to the world of PyTorch Lightning!!
We are witnessing what is popularly referred to as the Fourth Industrial Revolution, driven by Artificial Intelligence (AI). Since the creation of the steam engine some 350 years ago, which set humanity on the path to industrialization we saw another two industrial revolutions. We saw electricity bringing a sea change roughly 100 years ago, followed by the digital age some 50 years later revolutionizing the way we live our lives today. There is an equally transformative power in AI. Everything that we know about the world is changing fast and will continue to change at a pace that no one imagined before and certainly no one planned for. We are seeing transformational changes in how we contact customer services, with the advent of AI-powered chatbots; in how we watch movies/videos, with AI recommending what we should watch; in how we shop, using algorithms optimized for supply chains; in how cars are driven, using self-driving technology; in how new drugs are developed, by applying AI to complex problems such as protein folding; in how medical diagnoses are being carried out, by finding hidden patterns in massive amounts of data. Underpinning each of the preceding technologies is the power of AI. The impact of AI on our world is more than just the technology that we use; rather, it is much more transformational in terms of how we interact with society, how we work, and how we live. As many have said, AI is the new electricity, powering the engine of the 21st century.
And this monumental impact of AI on our lives and psyche is the result of a recent breakthrough in the field of Deep Learning (DL). It had long been the dream of scientists to create something that mimics the brain. The brain is a fascinating natural evolutionary phenomenon. A human brain has more Synapses than stars in the universe, and it is those neural connections that make us intelligent and allow us to do things such as think, analyze, recognize objects, reason with logic, and describe our understanding. While Artificial Neural Networks (ANNs) do not really work in the same way as biological neurons, they do serve as inspiration.
In the evolution of species, the earliest creatures were unicellular (such as amoeba), first appearing around 4 billion years ago, followed by small multi-cellular species that navigated blindly with no sense of direction for about 3.5 billion years. When everyone around you is blind, the first species that developed vision had a significant advantage over all other species by becoming the most intelligent species, and in evolutionary biology, this step (which happened some 500 million years ago) is known as the Cambrian explosion. This single event led to remarkable growth in the evolution of species, resulting in everything that we currently see on earth today. In other words, though Earth is about 4.5 billion years old, all the complex forms of life, including human brains, evolved in just the last 500 million years (which is in just 10% of Earth's lifetime), led by that single evolutionary event, which in turn led to the ability of organisms to "see" things.
In fact in humans as much 1/3 of our brain is linked to visual cortex; which is far more than any other senses. Perhaps explaining how our brain evolved to be most intelligence by first mastering "vision" ability.
With DL models of image recognition, we can finally make machines "see" things (Fei Fei Li has described this as the Cambrian explosion of Machine Learning (ML)), an event that will put AI on a different trajectory altogether, where one day it may really be comparable to human intelligence.
In 2012, a DL model achieved near-human accuracy in image recognition, and since then, numerous frameworks have been created to make it easy for data scientists to train complex models. Creating Feature Engineering (FE) steps, complex transformations, training feedback loops, and optimization requires a lot of manual coding. Frameworks help to abstract certain modules and make coding easier as well standardized. PyTorch Lightning is not just the newest framework, but it is also arguably the best framework that strikes the perfect balance between the right levels of abstraction and power to perform complex research. It is an ideal framework for a beginner in DL, as well as for professional data scientists looking to productionalize a model. In this chapter, we will see why that is the case and how we can harness the power of PyTorch Lightning to build impactful AI applications quickly and easily.
In this chapter, we will cover the following topics:
- What makes PyTorch Lightning so special?
- <pip install>—My Lightning adventure
- Understanding the key components of PyTorch Lightning
- Crafting AI applications using PyTorch Lightning
What makes PyTorch Lightning so special?
So, if you are a novice data scientist, the question on your mind would be this: Which DL framework should I start with? And if you are curious about PyTorch Lightning, then you may well be asking yourself: Why should I learn this rather than something else? On the other hand, if you are an expert data scientist who has been building DL models for some time, then you will already be familiar with other popular frameworks such as TensorFlow, Keras, and PyTorch. The question then becomes: If you are already working in this area, why switch to a new framework? Is it worth making the effort to learn something different when you already know another tool? These are fair questions, and we will try to answer all of them in this section.
Let's start with a brief history of DL frameworks to establish where PyTorch Lightning fits in this context.
The first one….
The first DL model was executed in 1993 in Massachusetts Institute of Technology (MIT) labs by the godfather of DL, Yann LeCun. This was written in Lisp and, believe it or not, it even contained convolutional layers, just as with modern Convolutional Neural Network (CNN) models. The network shown in this demo is described in his Neural Information Processing Systems (NIPS) 1989 paper entitled Handwritten digit recognition with a backpropagation network.
The following screenshot shows an extract from this demo:

Figure 1.1 – MIT demo of handwritten digit recognition by Yann LeCun in 1993
Yann LeCun himself described in detail what this first model is in his blog post and this is shown in the following video: https://www.youtube.com/watch?v=FwFduRA_L6Q.
As you might have guessed, writing entire CNNs in C wasn't very easy. It took their team years of manual coding effort to achieve this.
The next big breakthrough in DL came in 2012, with the creation of AlexNet, which won the ImageNet competition. The AlexNet paper by Geoffrey Hinton et al. is considered the most influential paper, with the largest ever number of citations in the community. AlexNet set a precedent in terms of accuracy, made neural networks cool again, and was a massive network trained on optimized Graphics Processing Units (GPUs). They also introduced numerous kickass things, like BatchNorm, MaxPool, Dropout, SoftMax, and ReLU, which we will see later in our journey. With network architectures so complicated and massive, there was soon a requirement for a dedicated framework to train them.
So many frameworks?
Theano, Caffe, and Torch can be described as the first wave of DL frameworks that helped data scientists create DL models. While Lua was the preferred option for some as a programming language (Torch was first written in Lua as LuaTorch), many others were C++-based and could help train a model on distributed hardware such as GPUs and manage the optimization process. It was mostly used by ML researchers (typically post-doc) in academia when the field itself was new and unstable. A data scientist was expected to know how to write optimization functions with gradient descent code and make it run on specific hardware while also manipulating memory. Clearly, it was not something that someone in the industry could easily use to train models and take them into production.
Some examples of model-training frameworks are shown here:
Figure 1.2 – Model-training frameworks
TensorFlow, by Google, became a game-changer in this space by reverting to a Python-based, abstract function-driven framework that a non-researcher could use to experiment with while shielding them from the complexities around running DL code on hardware. Its success was followed by Keras, which simplified DL even further so that anyone with a little knowledge could train a DL model in just four lines of code.
But arguably, TensorFlow didn't parallelize well. It was also harder for it to train effectively in distributed GPU environments, hence the community felt a need for a new framework—something that combined the power of a research-based framework with the ease of Python. And PyTorch was born! This framework has taken the ML world by storm since its debut.
PyTorch versus TensorFlow
Looking on Google Trends at the competition between PyTorch and TensorFlow, you could say that PyTorch has taken over from TensorFlow in recent years and has almost surpassed it.
An extract from Google Trends can be seen here:
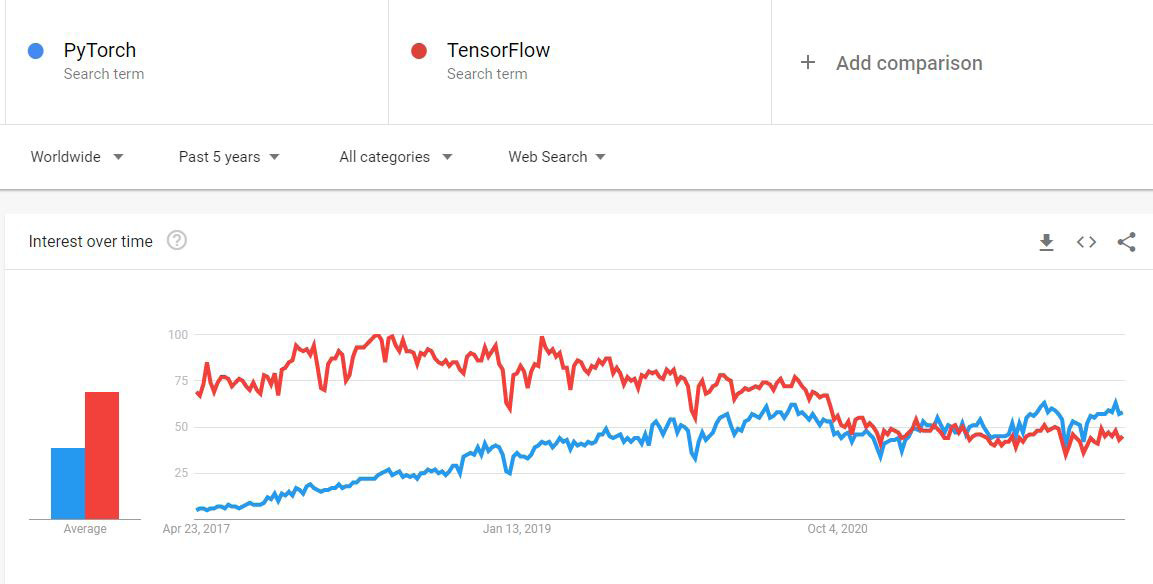
Figure 1.3 – Changes in community interest in PyTorch versus TensorFlow in Google Trends
While some may say that Google Trends is not the most scientific way to judge the pulse of the ML community, you can also look at many influential AI players with massive workloads—such as Facebook, Tesla, and Uber—defaulting to the PyTorch framework to manage their DL workloads and finding significant savings in compute and memory.
In ML research community though, the choice between Tensorflow and PyTorch is quite clear. The winner is hands-down PyTorch!
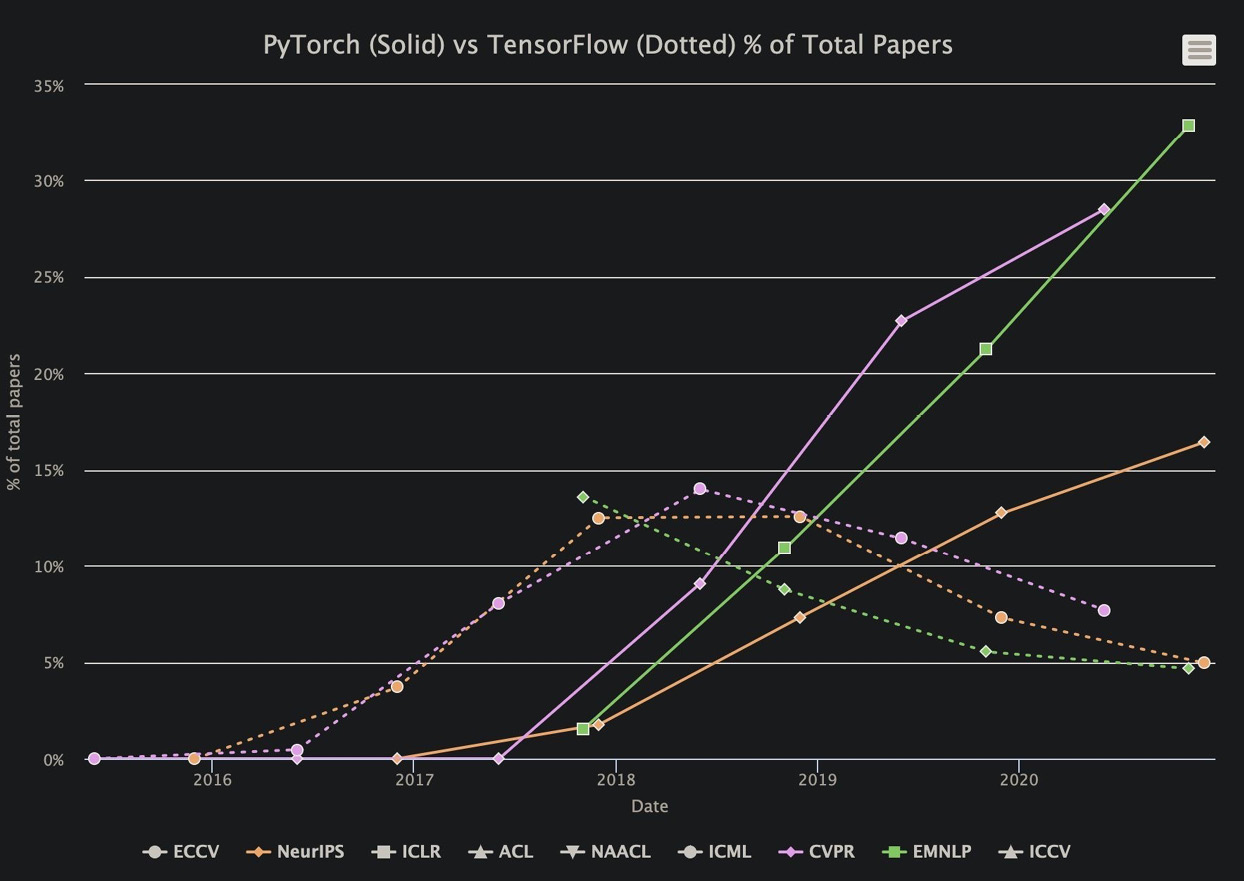
Figure 1.4 – TensorFlow vs PyTorch trends in top AI conferences for papers published
Both frameworks will have their die-hard fans, but PyTorch is reputed to be more efficient in distributed GPU environments given its inherent architecture. Here are a few other things that make PyTorch better than TensorFlow:
- Provides more stability.
- Easy-to-build extensions and wrappers.
- Much more comprehensive domain libraries.
- Static graph representations in TensorFlow weren't very helpful. It wasn't feasible to train networks easily.
- Dynamic Tensors in PyTorch were a game-changer that made it easy to train and scale.
A golden mean – PyTorch Lightning
Rarely do I come across something that I find as exciting as PyTorch Lightning! This framework is a brainchild of William Falcon whose PhD advisor is (guess who)..Yann LeCun! Here's what makes it stand out:
- It's not just cool to code, but it also allows you to do serious ML research (unlike Keras).
- It has better GPU utilization (compared with TensorFlow).
- It has 16-bit precision support (very useful for platforms that don't support Tensor Processing Units (TPUs), such as IBM Cloud).
- It also has a really good collection of state-of-the-art (SOTA) model repositories in the form of Lightning Flash.
- It is the first framework with native capability and Self-Supervised Learning (SSL).
In a nutshell, PyTorch Lightning makes it fun and cool to make DL models and to perform quick experiments, all while not dumbing down the core data science aspect by abstracting it from data scientists, and always leaving a door open to go deep into PyTorch whenever you want to!
I guess it strikes the perfect balance by allowing more capability to do Data Science while automating most of the "engineering" part. Is this the beginning of the end for TensorFlow? For the answer to that question, we will have to wait and see.
<pip install> – My Lightning adventure
Getting started with PyTorch Lightning is very easy. You can use the Anaconda distribution to set up your environment locally or use a cloud option such as Google Colaboratory (Google Colab), Amazon Web Services (AWS), Azure, or IBM Watson Studio to get started. (It is recommended that you use a cloud environment to run some of the more complex models.) Most of the code in this book is run on Google Collab or Anaconda using Python 3.6 with Mac OS. Please make appropriate changes to your env on other systems for installation.
PyTorch Lightning can be installed using pip in your Jupyter notebook environment, like this:
pip install pytorch-lightning
In addition to importing PyTorch Lightning (the first import statement can be seen in the following code snippet), the following import block shows statements that are usually part of the code:
import pytorch_lightning as pl
import torch
from torch import nn
import torch.nn.functional as F
from torchvision import transforms
The torch package is used for defining tensors and for performing mathematical operations on the tensors. The torch.nn package is used for constructing neural networks, which is what nn stands for. torch.nn.functional contains functions including activation and loss functions, whereas torchvision.transforms is a separate library that provides common image transformations. Once the PyTorch Lightning framework and all packages are installed, you should see the completion log, as illustrated in the following screenshot:
Figure 1.5 – Installation result for PyTorch Lightning
Once PyTorch Lightning is installed you can check the version for PyTorch and torch
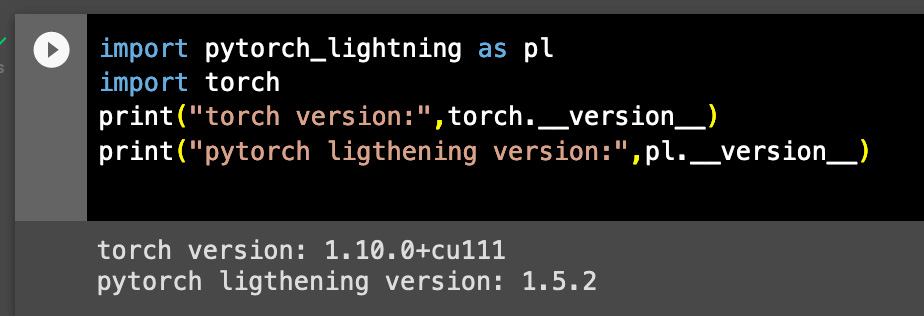
Figure 1.6 – Verifying the installation
That's it! Now, you are all set to begin your Lightning adventure!
Understanding the key components of PyTorch Lightning
Before we jump into building DL models, let's revise a typical pipeline that a Deep Learning project follows.
DL pipeline
Let's revise a typical ML pipeline for a DL network architecture. This is what it looks like:
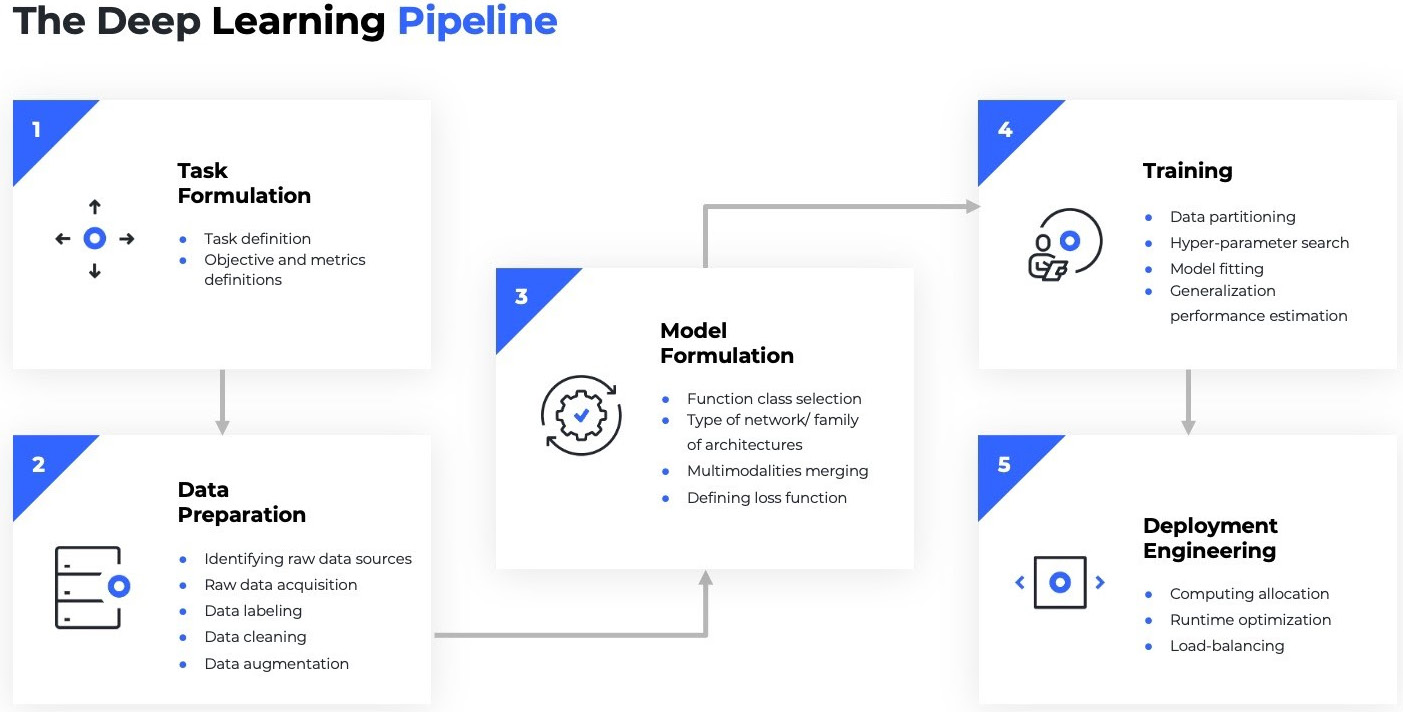
Figure 1.7 – DL pipeline
A DL pipeline typically involves the following steps. We will continue to see them throughout the book, utilizing them for each aspect of problem-solving:
- Defining the problem:
- Set a clear task and objective of what is expected.
- Data preparation:
- This step involves finding the right dataset to solve this problem, ingest it, and clean it. For most DL projects, this involves the data engineer working in images, videos, or text corpora to acquire datasets (sometimes by scraping the web), and then cataloging them into sizes.
- Most DL models require huge amounts of data, while models also need to be resilient to minor changes in images such as cropping. For this purpose, engineers augment the dataset by creating crops of original images or black and white (B/W) versions, or invert them, and so on.
- Modeling:
- This would first involve FE and defining what kind of network architecture we want to build.
- For example, in the case of a data scientist creating new image recognition models, this would involve defining a CNN architecture with three layers of convolution, a step size, slide window, gradient descent optimization, a loss function, and suchlike can be defined.
- For ML researchers, this step could involve defining new loss functions that measure accuracy in a more useful way or perform some magic by making a model train with a less dense network that gives the same accuracy, or defining a new gradient optimization that distributes well or converges faster.
- Training:
- Now comes the fun step. After data scientists have defined all the configurations for a DL network architecture, they need to train a model and keep tweaking it until it achieves convergence.
- For massive datasets (which are the norm in DL), this can be a nightmarish exercise. A data scientist must double up as an ML engineer by writing code to distribute it to the underlying GPU or central processing unit (CPU) or TPU, manage memory and epochs, and keep iterating the code that fully utilizes compute power. A lower 16-bit precision may help train the model faster, and so data scientists may attempt this.
- Alternatively, a distributed downpour gradient descent can be used to optimize faster. If you are finding yourself out of breath with some of these terms, then don't worry. Many data scientists experience this, as it has less to do with statistics and more to do with engineering (and this is where we will see how PyTorch Lightning comes to the rescue).
- Another major challenge in distributed computing is being able to fully utilize all the hardware and accurately compute losses that are distributed in various GPUs. It's not simple either to do data parallelism, (distribute data to different GPUs in batches) or do model parallelism (distribute models to different GPUs).
- Deployment engineering:
- After the model has been trained, we need to take it to production. ML operations (MLOps) engineers work by creating deployment-ready format files that can work in their environment.
- This step also involves creating an Application Programming Interface (API) to be integrated with the end application for consumption. Occasionally, it can also involve creating infrastructure to score models for incoming traffic sizes if the model is expected to have a massive workload.
PyTorch Lightning abstraction layers
PyTorch Lightning frameworks make it easy to construct entire DL models to aid data scientists. Here's how this is achieved:
- The LightningModule class is used to define the model structure, inference logic, optimizer and scheduler details, training and validation logic, and so on.
- A Lightning Trainer abstracts the logic needed for loops, hardware interactions, fitting and evaluating the model, and so on.
- You can pass a PyTorch DataLoader to the trainer directly, or you can choose to define a LightningDataModule for improved shareability and reuse.
Crafting AI applications using PyTorch Lightning
In this book, you will see how we can build various types of AI models effortlessly and efficiently using PyTorch Lightning. With hands-on examples that have industry-wide applications and practical benefits, you will get trained not just in PyTorch Lightning but in the whole gamut of different DL families.
Image recognition models
We will begin our journey by creating our first DL model in the form of an image recognition model in Chapter 2, Getting off the Ground with the First Deep Learning Model. Image recognition is the quintessential identity of a DL framework and, by using PyTorch Lightning, we will see how to build an image classification model using CNN..
Transfer learning
DL models are notorious for requiring training over a huge number of epochs before they can converge, thereby consuming tremendous amounts of GPU compute power in the process. In Chapter 3, Transfer Learning Using Pre-Trained Models, you will learn a technique known as Transfer learning (TL), which makes it possible to get good results without much hard work, by transferring knowledge from large pre-trained architectures like ResNet-50 for image classification or BERT for text classification..
NLP Transformer models
We will also look at Natural Language Processing (NLP) models and see how DL can make text classification possible over gargantuan amounts of text data. You will learn how the famous pre-trained NLP models, including Transformer, can be used in Chapter 3, Transfer Learning Using Pre-Trained Models, and adapt to your business needs effortlessly.
Lightning Flash
The creation of DL models also involves a process of fairly complex feature engineering pipelines with equally tedious training and optimization steps. Most data scientists start their journey by adopting SOTA models that have won Kaggle competitions or influential research papers. In Chapter 4, Ready-to-Cook Models from Lightning Flash, you will learn how an out-of-the-box utility such as Lightning Flash improves productivity by providing a repository of standard network architecturesfor standard tasks like object detection or classification for text, audio or video. We will build the model for video classification and automatic speech detection for audio files in a jiffy.
Time series models with LSTM
Forecasting and predicting the next event in a time series is an evergreen challenge within the industry. In Chapter 5, Time Series Models, you will learn how we can build time series models in PyTorch Lightning using Reccurent Neural Networks (RNN) with Long Short Term Memory (LSTM) network architecture.
Generative Adversarial Networks with Autoencoders
Generative Adversarial Network (GAN) models are one of the most fascinating aspects of DL applications and can create realistic-looking images of people or places or objects that simply don't exist in real life. In Chapter 6, Deep Generative Models, you will learn how, by using PyTorch Lightning, you can easily craft GAN models to create realistic looking fake images of animals, food items, or people.
Self-Supervised models combining CNN and RNN
The application of DL models is not limited to just creating fancy fake images using GANs. We can even ask a machine to describe a scene in a movie or ask informative questions regarding the content of an image (such as who is in the picture or what they are doing). This model architecture is known as a semi-supervised model and, in Chapter 7, Semi-Supervised Learning, you will learn a hybrid of CNN-RNN architecture (where RNN stands for Recurrent Neural Network) that can be utilized to teach a machine how to write situational poetry. In the same chapter, we will also see how to train a model from scratch and speed it up using 16-bit precision and other operational hacks to ensure smooth training.
Self-Supervised models for contrastive learning
If machines can create realistic images or write human-like descriptions, can't they teach themselves? Self-supervised models aim to make machines learn how to perform complex tasks with low or no labels at all, thereby revolutionizing everything that we could do with AI. In Chapter 8, Self-Supervised Learning, you will learn how PyTorch Lightning has native support for self-supervised models. You will learn how to teach a machine to perform Contrastive Learning (CL), which can distinguish images without any labels purely by means of representation learning.
Deploying and scoring models
Every DL model that can ever be trained dreams of one day being productionalized and used for online predictions. This piece of ML engineering requires data scientists to familiarize themselves with various model file formats. In Chapter 9, Deploying and Scoring Models, you will learn how to deploy and score models in inter-portable models that can be language-independent and hardware-agnostic in production environments with the help of the Pickle and Open Neural Network Exchange (ONNX) formats.
Scaling models and productivity tips
Finally, the capabilities of PyTorch Lightning are not just limited to creating new models on defined architectures, but also advance the SOTA using new research. In Chapter 10, Scaling and Managing Training, we will see some capabilities that make such new research possible, as well as how to improve productivity by providing troubleshooting tricks and quick tips. We will also focus on various ways to scale the model training.
Further reading
Here are some links for PyTorch Lightning that you will find very useful through the course of this book:
- Official documentation: https://pytorch-lightning.readthedocs.io/en/latest/?_ga=2.177043429.1358501839.1635911225-879695765.1625671009.
- GitHub source: https://github.com/PyTorchLightning/pytorch-lightning.
- If you face any issues in the code, you can seek help by raising an issue on GitHub. The Pytorch Lightning team is normally very responsive: https://github.com/PyTorchLightning/lightning-flash/issues.
- You can seek out help on PL community channels. The PyTorch Lightning community is fast growing and very active.
Summary
You may be a beginner exploring the field of DL to see whether it's the right career for you. You may be a student of an advanced degree trying to do your research in ML to complete your thesis or get papers published. Or, you may be an expert data scientist with years of experience in training DL models and taking them to production. PyTorch Lightning has something for everyone to do almost anything in DL.
It combines the raw power of PyTorch, which offers efficiency and rigor, with the simplicity of Python, by providing a wrapper over complexity. You can always go as deep as you want in doing some innovative work (as you will see later in this book), while you can also get numerous out-of-the-box neural network architectures that save you from having to reinvent the wheel (which you will also learn about later). It is fully compatible with PyTorch, and code can easily be refactored. It is also perhaps the first framework that is designed for the persona of Data Scientist as opposed to other roles, such as ML researcher, ML-Ops engineer, or data engineer.
We will begin our journey with a simple DL model and will keep expanding our scope to more advanced and complex models with each chapter. You will find that it covers all the famous models, leaving you empowered with Deep Learning skills to make an impact in your organization. So, let's get things moving in our next chapter with your first DL model.