
5.3. Engineering new services
Developments in technology are changing the way we interact with computer systems. This section will look at some of the technologies that enable us to interact with computers in natural ways, as well as at the changes in interfaces that will enable new services.
5.3.1. Advanced dialogs
In 5.1.4, “Automatic speech recognition systems,” on page 371 we looked at how ASR systems perform word and phrase recognition. Here we look at systems that understand meaning based on context. Instead of using word grammars to define the domain of acceptable phrases, we use task models to describe the acceptable tasks that can be performed. The acceptable tasks will change depending on the state a dialog has taken.
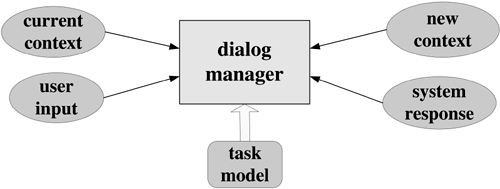
To date, language processing has successfully provided understanding, though often constrained to the grammars defined. As a result, most current systems use a loosely-coupled, unidirectional interface, such as grammars within VoiceXML or n-best words, with natural language constraints applied as a post-process for filtering the recognizer output. Context provides a level of discourse that places significant constraints on what people can talk about and how things can be referred to. In other words, knowing the context will narrow down what the speaker is trying to say. Dialog systems, as shown in Figure 5-8, use the current context, user input, and task model to determine the system response and the new context.
To achieve reasonable coverage of meaning, language-processing research has developed techniques based on “partial analysis” - the ability to find meaning-bearing phrases in the input and to construct meaning representations out of them, without requiring a complete analysis of the entire string.[5]
[5] W. Ward, "Understanding Spontaneous Speech: The Phoenix System," in: Proceedings of ICASSP 1991.
Natural dialogs imply a certain level of “understanding” through a form of knowledge representation and processing. The task of understanding is within context. At any time there is a finite number of possible outcomes that can be inferred. This finite number of outcomes is a function of the different ways in which we can express a result. Presenting the user with a set of options or choices based on context, representing a finite number of possible dialogs that are acceptable, is an integral part of Natural Language Processing (NLP).
Figure 5-9 shows a NLP system. It has some similarities to the ASR Linguistic Model we saw in Figure 5-3. The difference is that the input is words, not speech, and the output, instead of being recognized words or phrases, is an ordered list of possible meanings.
Figure 5-9. A Natural Language Processor and its components

Let's briefly look at the tasks each of the components performs:
Lexical processor
The lexical processor uses a dictionary to help transform the input words into a structure with more meaning.
This syntactic processor uses language grammars to add more meaning.
The domain of understandable concepts is also referred to as the “task model.”
This semantic processor uses semantic interpretation rules and a domain model of concepts and relationships that define the domain that the system can understand.
This is a context model that specifies the user's goals and the portions of those goals that have been achieved by previous inputs. This can be represented by a context tree with branches marked for the achieved parts of the dialog, where the nodes represent predefined categories. The NLP problem is complex because meaning relies on context and that context could have been stated in a previous input.
Action and Response
These represent the actions that the system can take for different events. This includes giving the appropriate response and asking questions to get more information for disambiguation.
Earlier (see 2.9, “Grammars,” on page 106) we looked at grammars and how grammars can be described using markup languages, such as GRXML. These grammars can recognize complex language structures. Natural dialogs are a progression of analyzing speaker responses to a prompt and building complex grammars. Taking into account that certain words or phrase fragments are more likely to occur and have a greater expectation of occurring, these expectations can be used for classifying phrase fragments into context categories.[6] The W3C working draft on Natural Language Semantic Markup Language (NLSML) attempts to formalize the results of semantic interpreters. It is intended that semantic interpreters will generate NLSML documents extracted from the user's utterances and machine determined meaning.
[6] S. Abdou, M. Scordilis, "Improved Speech Understanding Using Dialogue Expectations in Sentence Parsing," in: Proceedings of ICSLP2000.
Testing and evaluating such highly interdependent and adaptive systems is a challenge. Each of the subsystems, shown in Figure 5-8, can contribute to poor overall results. Ultimately actual real-world tests need to be carried out that closely monitor intermediate results. These results can further be used to tweak performance. Using a markup such as NLSML provides consistency of results and facilitates testing of different vendors' systems. Natural dialogs offer great promises for human-machine interaction as research is applied to new emerging voice services. Performance evaluation of dialog systems is an active area of research and many evaluation metrics have been proposed.[7]
[7] C. Kamm, M. Walker, D. Litman, "Evaluating Spoken Language Systems," in: Proceedings of ICASSP 1998.
5.3.2. Human factors engineering
Human factors engineering is a discipline which studies human interaction with systems. It considers the types of users that interact with the system and attempts to develop the best ways to interact with them.
The process of human factors engineering can often be divided into the following stages:
collecting and analyzing human-to-human dialogs
Before designing automated dialogs it is important to understand the way humans interact with other humans. Often these interactions are recorded to be later analyzed and categorized.
identifying elements that could be confusing or sound unnatural
Once the dialogs are created, they need to be tested to determine if users experience any confusion with them.
conducting the "Wizard of Oz" test
This is where a human tester, instead of the automated system, determines what tasks to present to the user.
developing prototype
An automated system is designed and implemented.
conducting usability studies
The prototype is tested by test users. Their interaction with the system is monitored to identify parts of the dialog with which the test users had difficulties. These trouble spots could include difficult-to-understand instructions, ambiguous questions, speech recognition errors, and grammar problems. Additionally, “softdata” is collected from the test users on whether they enjoyed using the system.
final implementation
All trouble spots are fixed in the design and the implementation is tested for correctness.
The goal of this process is to produce a voice application that meets needs of the users. This often entails additional research to understand the type of people using the system and to make sure the system fits within the rest of the company's marketing and branding. Therefore, aspects of the voice application, such as how prompts are phrased and what voice-talent is used for recorded audio, are all part of human factors engineering.
While human factors engineering is a discipline in its own right, the following guidelines may prove useful when developing voice applications:
Indicate with a short prompt that the system is automated.
Callers actually do mistake automated systems for humans sometimes.
Provide the option for context-sensitive help at anytime.
This is helpful for a caller who “got lost” in your application.
Consider different user levels of experience (mixed initiative).
There will be novice, intermediate, and advanced users, so the interaction and responses for each group will vary.
Set user expectations.
Prompts should cue the user, for example by notifying that there will be a delay (e.g. when transferring a call).
Use confirmations to reassure the caller.
Confirmations verify correct recognition of speech and allow the user to correct any misrecognized words. They can be implemented explicitly or implicitly. An implicit implementation would be: “Which account would you like to transfer money from?” “Checking.” “OK. Savings.” “No! Checking!” “OK. Checking [pause] OK. Let's continue.” Explicit is “Which account would you like to transfer money from?” “Checking.” “Did you say Savings?” “No. Checking.” “Did you say Checking?” “Yes.” “OK. Let's continue.” The former is shorter but can also be more dangerous.
Allow users to barge-in on prompts.
Listening to long prompts is sometimes unnecessary, so you should allow the user to interrupt the prompt.
Use examples or metaphors in prompts to express there sponse format expected.
Instead of using “Please say your birth date, the month, day, and year” it would be better to use “Please say your birth date, the month, day, and year. For example, January first nineteen ninety.”
Avoid infinite loops.
If the user can't answer a question, either move on or escalate the call to a human.
Avoid having recognition enabled during idle periods.
This may cause misrecognition and confuse the user as to where he or she is in the dialog.
Use different dialog strategies in different situations.
For example, in noisy or unreliable speech environments, DTMF is a good alternative to speech. Another strategy to consider is using prompts that are either open, such as "How may I help you?", or closed, such as "Please choose from options one, two, etc."
Avoid having long delays between prompts.
The user needs to know if the system is still active.
Avoid having too many entries in a menu.
Long menus make remembering all options difficult.
5.3.3. Multi-device interfaces
With the proliferation of many new devices (PDAs, mobile phones, desktop PCs, pagers, etc.) it is becoming important that an application can support more than one device. It is critical to accomplish this efficiently without re-writing the application for each new device type, otherwise maintaining such applications will become a programmer's nightmare.
One point worth clarifying is the separation between generating XML documents and interpreting XML documents. There are commercially available products that claim to be VoiceXML enabled, but in fact only generate VoiceXML. Such products provide either GUI-based development tools for generating VoiceXML or template-based tools for generating dynamic VoiceXML. Once XML documents are generated, they will need to be rendered. For example, to render VoiceXML documents, a VoiceXML interpreter will be required, such as the one we saw in Figure 5-2.
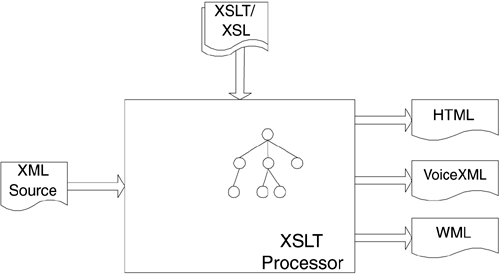
Shown in Figure 5-10 is a flexible approach to generating dynamic VoiceXML, HTML, or other markup language. In this approach the data model and the presentation of data are separated. The data model is shown as the XML source on the left and the template, written in XSL (shown in the topmost box of the figure), describes how to build the presentation model. XSLT takes the source XML document and, using different XSL templates, generates HTML, VoiceXML, WML, or other document types. Once generated, these documents can be rendered by the appropriate browser. In the case of HTML, the HTML document will be served through a Web server to the client's browser where the actual rendering of the Web page takes place. For VoiceXML documents, a VoiceXML interpreter is used that will render the document to the client telephone.
Figure 5-10. Generating VoiceXML and other markup language documents
So, generating VoiceXML documents does not require any special hardware. Existing Web applications can be extended to the phone or other devices using this approach. Adopting such an architecture reduces the cost and complexity of developing present and future multi-device applications. We saw an example application using XSLT in 4.3, “The Auto Attendant: generating VoiceXML using XSLT and ASP.NET,” on page 345.
A final comment to consider is that the VoiceXML interpreter need not reside remotely, but could instead reside inside the client device, just as Web browsers reside within the client PC. This allows off-line voice application processing without being connected to a server. This could prove advantageous in transient cell phone connections where users can receive a small VoiceXML application listing their voice mail messages that is rendered locally by a VoiceXML interpreter residing on their cell phones. For example, they can listen to the list of received calls offline and only go back online when they desire to access those messages that are of interest to them.
5.3.4. Multimodal interfaces
In the previous section, we looked at multi-device interfaces. Sometimes a single device can have more than one interface. For example, a WAP enabled cell phone has audio and visual interfaces. Multimodal applications consider interaction with such devices using the best-suited interface for the media type being conveyed. For driving directions, a map is better suited than audio directions. For user interaction with an application, whether one device with multiple interfaces is used or several different devices are used doesn't really matter and the distinction between multi-device and multimodal becomes irrelevant.
5.3.4.1. What is multimodal?
Multimodal access enables users to interact with an application in a variety of ways; they can input data using speech, a keyboard, keypad, mouse, and/or stylus, and receive data as synthesized speech, audio, plain text, motion video, and/or graphics. Each of these modes can be used independently or concurrently.
Multimodality can go beyond the common modes to include handwriting detection, intelligent conversational avatars, eye-tracking devices, sensors, and many other things to come.
5.3.4.2. Why multimodality?
The use of multimodality holds promise to enhance human-computer interaction. Since human perception is based largely on multimodality, it is an important factor in the realization of human-friendly interfaces. One important reason for developing multimodal interfaces is the potential to greatly expand the accessibility of computing by offering interface options based on individual abilities and preferences. User accessibility can be increased to support native languages, users of different ages, skill levels, cognitive styles, sensory and motor impairments.
Multimodality also increases performance stability and robustness. For example, in a noisy environment a user can point at their choice instead of saying it to avoid possible incorrect recognition. In another scenario the user may point at one of several option lists and at the same time speak the specific option item. Here the results of both inputs can be combined to yield better performance and avoid errors.
Effective interfaces can be used for different tasks and constraints. A user could prefer to interface using voice rather than a stylus on a small mobile device. The user can bypass multiple layers of menus with speech. On the other hand, the sequential nature of speech may be a poor choice to output information when it can be efficiently displayed. For example, seeing a map is more efficient than listening to an audio description of a map.
5.3.4.3. Types of modality
Modality considers more than one input and output. The interaction can be sequential or synchronous for both inputs and outputs.
sequential input and output
By sequential multimodality we mean that only one of the different modalities is active at a given time. This applies both to input and output modes. For example, the user can have a bi-modal device with a visual and voice interface. At any time the device can accept, as input, either a button click or a spoken response. However, only the first input will be used for processing. For sequential modal output, again, only one mode is used for output at any time.
synchronous input
Here, more than one input mode will be accepted as input simultaneously. There is of course a finite window of time in which the application will be “listening” to the user's input. Disambiguation of inputs needs to be provided. If the user clicks on one item and verbally selects another, there must be a way to resolve this conflict, whether through markup or as part of the application logic.
synchronous output
Multimodal output refers to more than one modality being used as output simultaneously in a coordinated manner. There needs to be a mechanism to synchronize output. The Working Draft of the W3C -“Multimodal Requirements for Voice Markup Language” specifies SMIL for synchronization.
5.3.4.4. XHTML+Voice
The XHTML+Voice combination is intended for Web clients that support visual and spoken interaction. It uses XHTML and XML events to connect to the XML speech framework - VoiceXML, GRXML, and SSML. The submission includes voice modules that support speech synthesis, speech dialogs, command and control, speech grammars, and the ability to attach voice handlers for responding to specific Document Object Model (DOM) events.
The XML Events Specification provides XML applications with the ability to uniformly integrate event listeners and associated event handlers with DOM event interfaces. The XML event types supported by the XHTML+Voice profile include all event types defined for HTML 4.01 intrinsic events, plus the VoiceXML 2.0 events (noinput, nomatch, error, and help) as well as an additional filled event for field or form-level filled elements. An XHTML element associates one of the event types with an ID reference to the VoiceXML form that will handle these events.
5.3.4.5. SALT
Started in October 2001, SALT (Speech Application Language Tags) is still being developed by a Forum and has not been submitted to the W3C. SALT is similar to the XHTML+Voice Specification; it also leverages the event-based DOM execution model to integrate with specific interfaces. SALT defines "speech tags" that are extensions to HTML, enabling developers to add a spoken dialog interface to Web applications. Speech tags are a set of XML elements, not unlike VoiceXML, which provide dialog, speech interface, and call control services.
There are five main element types that SALT uses:
prompt
Configures the speech synthesizer and playing out prompts.
reco
Configures the speech recognizer, executing recognition and handling recognition events.
grammar
Specifies input grammar resources.
bind
Processes recognition results into the page.
dtmf
Configures and controls DTMF.