
"We shape our buildings, thereafter they shape us."
In chapter 1, we saw that dependency injection offers a unique and concise solution to the problem of constructing object graphs, with a strong emphasis on unit testing. The crux of this solution is the fact that all your code is freed from constructing dependencies. Code written with DI in mind is behaviorally focused and without distracting clutter. Why is this important?
While the answer may seem self-evident (hard to argue with the less and more precise), it is well worth spelling out:
Behaviorally focused—Presumably, you set out to write code toward a specific purpose, and that purpose is not to construct more objects! Whether writing an email system, a game, or an enterprise messaging system, your primary focus is the behavior of the system. When architectural concerns (such as constructing and locating services) impinge on this logic, it unnecessarily distracts from the original purpose.
Modular—Code designed in discrete, modular units is not only easy to maintain, but it is reusable and easy to package. Individual units are structurally simple to work with. Understanding whether code meets specified requirements is often a difficult proposition for developers. Modular code is focused on small functional subsets (for instance, a spellchecker) and thus is easier to develop.
Testable—Since modules are easy to test for general, purposed behavior without specific awareness of the overall system, it follows that they provide for more robust code. While nominal testability is a benefit in itself, there is much more that concise, loosely coupled code purports. The ability to swap out dependencies with mock counterparts is crucial when testing objects that make use of expensive resources like database connections.
In this chapter, we're going to work with dependency injectors, using various libraries. We'll look at how to identify dependencies, distinguish them from one another, and tell the injector what to do with them. This chapter also examines best practices in configuring dependency injectors and in choosing identifiers (keys) for objects. Let's begin with bootstrapping the injector.
The dependency injector is itself a service like any other. And like any service, it must be constructed and prepared before it can be used. This bootstrap of the injector occurs before any object in the application can benefit from DI. When and how the injector is bootstrapped is often specific to the kind of application in question. It may be done in the following situations:
In the init lifecycle stage of a web application, upon being deployed (figure 2.1)
On startup of a desktop program (figure 2.2)
On demand, every time it is needed (for instance, on remote invocations [figure 2.3])
Lazily, when it is first needed (figure 2.4)

Each option conforms to a different architectural scenario. None is the correct choice for all environments. It is typical to find that injector startup coincides with application startup. Once the injector has been bootstrapped, we can obtain an object from it for use.
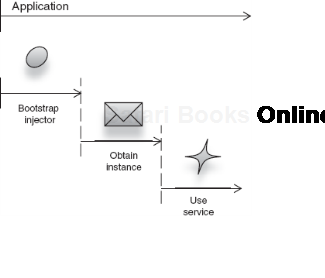
Let's look at one such scenario with a dependency injector named Guice. In this example, we will let Guice create and assemble an Emailer for us and provide it with dependencies (an English spellchecker). See figure 2.5.
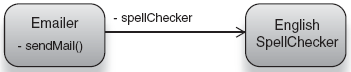
Guice.createInjector().getInstance(Emailer.class).send("Hello");Notice that we created the injector and obtained the emailer from it, all in one line—this is an example of the on-demand bootstrapping of injectors. In the example, we have done three things worth talking about:
Created the injector.
Obtained an instance of
Emailerfrom the injector.Signaled the
Emailerto send an email message.
Figure 2.6 illustrates this sequence.
Let's break down this example in code. The first invocation is a simple static method that asks Guice for a new injector:
Guice.createInjector()
We can think of Guice as a factory class for dependency injectors (recall the Factory pattern from chapter 1). This is fairly straightforward. The second invocation is of greater interest; it asks the injector for an instance of Emailer:
Guice.createInjector() .getInstance(Emailer.class)The Emailer obtained from our injector is properly wired with its dependencies, so when it needs to send a message it can call on its SpellChecker to do the spelling verification—all very tidy with a single-use injector:
Guice.createInjector() .getInstance(Emailer.class).send("Hello!");This, of course, is functionally identical to the more verbose form:
Injector injector = Guice.createInjector();
Emailer emailer = injector.getInstance(Emailer.class);
emailer.send("Hello!");This is reasonable at first glance and seems to have brought us some kind of compelling result. However, upon closer inspection it evokes a sense of déjà vu. Remember this?
Emailer emailer = (Emailer) new ServiceLocator().get("Emailer");Comparing this to obtaining an emailer from the injector yields more than a suspicious similarity:
It looks as though injector is performing the role of a Service Locator pattern and that I've used Emailer.class as a key that identifies emailers. As we've already noted, keys need not be strings, so it seems I have indeed used a Service Locator. That can't be right, can it? Well, yes, because an injector can itself be used as a Service Locator.
So what is the hype really about? In a sense the injector is an automated, all-purpose service locator prepackaged for convenience. This is a fair characterization, but with three important differences, and the hype is really about these three things:
Client code (the
Emailer) is not invoking the injector, unlike with service locators. Rather, it is the application bootstrapper that invokes the injector. The key difference here is that the latter does not participate in the behavior of the program.Only a root object is obtained from the injector. This object is generally the entry point of an application and is typically requested only once. This means that no matter how many client-service systems exist within the application, their creation, injection, and usage cascades from the root object. For example, an HTTP servlet is a root object, with data-source dependencies injected into it.
The injector obtains instances within the current execution context. In other words, the instance returned may or may not be different depending on the state of the application and the current context. This is known as scoping and is a very powerful feature of dependency injection—one that essentially separates it from Service Location. See chapter 5 for more on scopes.
In most real-world applications the act of obtaining and running objects is typically done for you by integration layers, such as the guice-servlet[7] extension does with HTTP servlets and Guice. Many DI libraries provide such integration layers out of the box.
This introduces us to the notion that a single unit is an entry point into a program, like a starting line from which other objects (dependencies) stem. The "offspring" of the root object are built and wired as required. In turn, each object may construct and call several of its own dependencies, and so on down the tree of dependencies. This cascading creation of objects is called viral injection.
Unlike traditional Service Location patterns this means your code is not explicitly dependent on a service (the dependency injector). Of course, apart from this is the not-insignificant fact that you don't have to write, test, or maintain the injector itself.
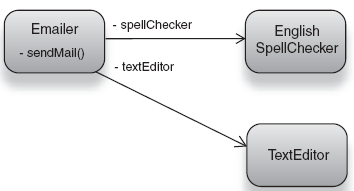
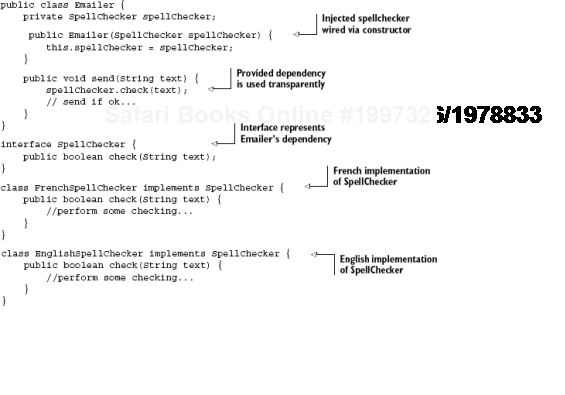
So what do our Emailer (client) and its SpellChecker (dependency) look like? Listing 2.1 has one version.
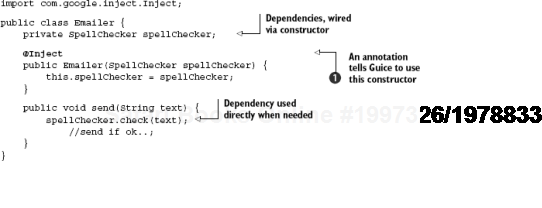
Notice the @Inject[8] annotation
Note
Annotations are a feature of Java that allow classes and programs to be enhanced with extra information. Tools, libraries, or even humans can use them to glean additional meaning or intent about the program. Annotations do not manipulate program semantics directly but instead provide a standard way of enhancing them along with appropriate tools.
When send() is called, Emailer has been wired with a SpellChecker and can be called on to check() spelling.
In the popular Spring Framework, the same thing is achieved with slightly different annotations:
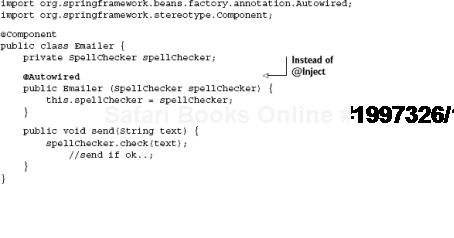
What we see here is one way of passing an injector some information via program metadata. In the next section, we'll see how injectors are configured in different ways.
Annotations and custom attributes are an elegant and unintrusive form of metadata that helps indicate some information about your code to an injector, namely, which constructor to use (and consequently what its dependencies are).
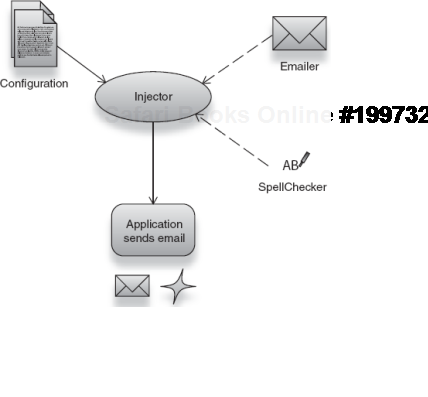
In essence, what I did was to use the @Inject annotation to configure the injector (@Autowired and @Component for Spring), providing it with the appropriate information it needed to construct the Emailer. DI libraries provide a number of mechanisms for configuring the injector (as shown in figure 2.7):
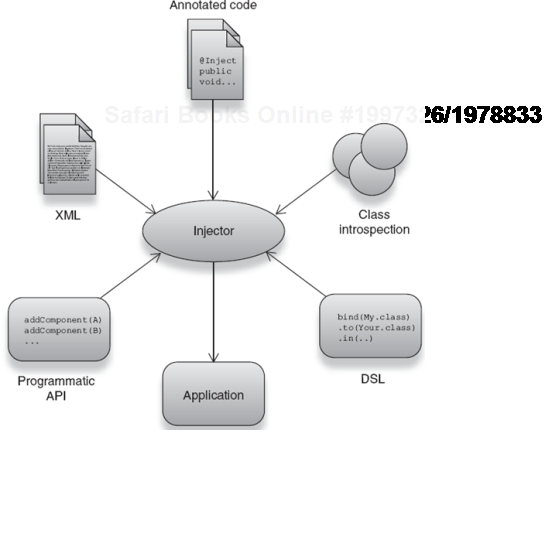
Or some combination of mechanisms.
That's certainly a lot of options. And choosing among them doesn't always come down to taste. Before judging the effectiveness of each option, let's take our emailer out for a spin with a couple of available options.
Spring's primary mode of configuration is an XML file. Though Spring offers many alternatives (we saw one with @Autowired), the XML configuration is its most easily identified and common configuration mechanism. Recall our three wonted steps:
Creating the injector
Obtaining a component instance from it
Using the instance to send mail (spamming away!)
In Guice this was written as:
Guice.createInjector().getInstance(Emailer.class).send("Hello!");Translating to Spring yields the following:
BeanFactory injector = new FileSystemApplicationContext("email.xml");
Emailer emailer = (Emailer) injector.getBean("emailer");
emailer.send("Hello!");Here, BeanFactory refers to the Spring dependency injector. The call to getBean() is analogous to the original call to getInstance(). Both return an instance of Emailer. One interesting difference is that we use a string key to identify emailers (and are therefore required to downcast[9] it into the variable emailer):
Emailer emailer = (Emailer) injector.getBean("emailer");Notice that sending an email remains exactly the same in both DI libraries:
emailer.send("Hello!");This is an important point, because it means that using code for its original, intended purpose remains exactly the same regardless of what library you choose. And it underlines the fact that dependency injection is not an invasive technique.
Note also how an injector is created. Rather than using a Factory, I've used construction by hand to create a FileSystemApplicationContext and assigned it to a variable of type BeanFactory. Both BeanFactory and FileSystemApplicationContext refer to Spring's injector. The latter is a specific kind of BeanFactory (just like an EnglishSpellChecker is a specific kind of SpellChecker).
The file email.xml contains the configuration required for Spring's injector to provide us with an emailer correctly wired with its dependencies. Listing 2.2 shows what email.xml looks like, and figure 2.8 shows how this works.

Let's look at this in some detail. For clarity, we will omit the boilerplate XML schema declaration[10] at the top of the file
<bean id="emailer" class="Emailer">Recall that in Guice the key served as both identifier as well as the binding to the Emailer class and was implicit. In Spring's XML, this binding takes the form of an explicit declaration in a <bean> element. Dependencies of Emailer are similarly declared in their own <bean> tags, in this case a SpellChecker:
<bean id="spellChecker" class="SpellChecker">
Now turn your attention back to the first <bean> tag
<bean id="emailer" class="Emailer">
<constructor-arg ref="spellChecker"/>
</bean>The <constructor-arg> tag tells Spring to use constructor wiring. It also indicates that Emailer instances should be wired with objects identified by a string key, "spellChecker". SpellChecker itself is declared
<beans ...>
<bean id="emailer" class="Emailer">
<constructor-arg><bean class="SpellChecker"/></constructor-arg>
</bean>
</beans>In this case, I've nested the declaration of SpellChecker inside Emailer's constructorargument tag and omitted its identifier altogether. This is nicer for a couple of reasons:
The description of
SpellCheckeris available right inside that ofEmailer.SpellCheckeris not exposed via its own identifier. Therefore it can be obtained only within the context of aEmailer.
Both these ideas provide us with a neat encapsulation of Emailer and its dependencies. Dependency encapsulation means you can't accidentally wire a SpellChecker meant for an Emailer to some other object (a Klingon editor, for example).
This concept of encapsulation is roughly analogous to class member encapsulation, which you should be familiar with in Java code. Listing 2.3 revisits our original Emailer's source code for Spring.

There is no change—except that now I no longer need Guice's annotations and can safely remove them, leaving me with a pristine, shiny Emailer.
Both Spring and Guice provide the notion of explicit configuration (in Spring, as you saw, via XML). The advantage to this approach is that you have a central directory of all the services and dependencies used in a particular application. In a large project with many developers working on the same source code, such a directory is especially useful. In Guice this file is called a Module.
Guice modules are regular Java classes that implement the com.google.inject. Module interface (shown in listing 2.4).
Example 2.4. A typical Guice module
import com.google.inject.Binder;
import com.google.inject.Module;
public class MyModule implements Module {
public void configure(Binder binder) {
...
}
}Services are registered by using the given binder and making a sequence of calls that configure Guice accordingly. This is similar to the XML <bean> tags you saw in the previous section. Listing 2.5 shows how to declare an emailer's bindings explicitly.

This is pretty simple.
Tip
To save yourself some typing, extend the AbstractModule class, which is a convenience provided by Guice. This marginally neater version with exactly the same semantics is shown in listing 2.6.

Listings 2.5 and 2.6 are pretty close to Spring's XML configuration. You should be able to see the similarity quite easily:
<beans ...>
<bean id="emailer" class="Emailer">
<constructor-arg ref="spellChecker"/>
</bean>
<bean id="spellChecker" class="SpellChecker"/>
</beans>Before we look at keys and bindings (tying keys to their services) in greater detail, let's look at a few more cool DI libraries.
Guice configures the injector with annotations and optionally via inference; similarly Spring provides an XML facility for explicit injector configuration. Yet another alternative is provided by PicoContainer—this is similar to inference but takes the form of a programmatic API.

First, create the injector. Then grab an emailer from it, and dispatch those endearing greeting emails.
MutablePicoContainer injector = new DefaultPicoContainer();
injector.addComponent(Emailer.class);
injector.addComponent(SpellChecker.class);
injector.getComponent(Emailer.class).send("Hello!");This is much closer to the original Guice version with the only real difference being that we use construction by hand to create the injector itself, namely, a DefaultPicoContainer. The method getComponent() is exactly like getInstance() in Guice (and getBean() in Spring), taking Emailer.class as an identifier.
Note
Unless you are using PicoContainer 2.0, you will need to downcast the returned instance to type Emailer. In this example (and for the rest of this book), I've preferred PicoContainer 2.0, as it takes advantage of Java 5 and generics to add a measure of type safety.
What's this line doing here?
injector.addComponent(Emailer.class);That appears to be a bit more than the three sweet steps of our wonted familiarity. In fact, what we have done is combine bootstrap and configuration in the same sequence of method calls. The source code for Emailer itself does not change. So how does the injector know about Emailer's dependencies? There has been no explicit description of SpellCheckers and whether or not to use constructor wiring. Nor have we annotated the class itself with @Inject or anything like it.
By default, PicoContainer prefers constructor wiring and greedily looks for available constructors. Greedy, in this sense, refers to the widest set of arguments that it can successfully provide to a class's constructor.
This can seem somewhat counterintuitive, but let's explore an example. For consistency (and because it is cool), I will stick with the emailer. If we imagine that the emailer now requires an editor to write messages in (listing 2.7 and figure 2.10), this can be modeled as a second dependency.

Method send() now calls editor.getText()

This code works because PicoContainer greedily picks the second constructor (the one with a greater number of arguments). This default behavior is confusing but fortunately can be changed to suit your preference. We've now seen a couple of forms of configuration that tell a dependency injector how to construct objects. Next we'll use a different idiom: showing the injector how to construct objects.
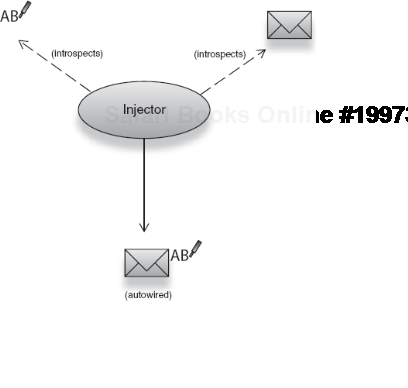
I mentioned in several places that Spring also supports other configuration styles, including the inference style of Guice. One compelling style it offers that you will come across very often is autowiring. Autowiring, as the name suggests, is a mode where Spring automatically resolves dependencies by inference on class structure. Back to our email scenario, if this is the structure of the object I want to build with autowiring:
public class Emailer {
private SpellChecker spellChecker;
public Emailer(SpellChecker spellChecker) {
this.spellChecker = spellChecker;
}
public void send(String text) {
spellChecker.check(text);
// send if ok...
}
}then I can have Spring wire Emailer's SpellChecker dependency without explicitly specifying it:
<beans ...>
<bean id="spellChecker" class="SpellChecker"/>
<bean id="emailer" class="Emailer" autowire="constructor"/>
</beans>Attribute autowire="constructor" informs the injector to guess dependencies by introspecting on Emailer's constructor. While we still had to register all the available dependency classes in the XML file, there was no need to specify how the graph is wired. Now when an instance of Emailer is constructed, it is automatically wired with a SpellChecker (see figure 2.11):
BeanFactory injector = new FileSystemXmlApplicationContext("email.xml");
Emailer emailer = (Emailer) injector.getBean("emailer");And the sending of emails can continue unfettered!
emailer.send("Hello!");Constructor autowiring can save you a lot of typing in XML, though it does force you to look in two places to understand your object graph. It is especially useful if most of your dependencies are of unique types, that is, without many variants. And it is particularly useful if you can enforce the convention of only one constructor per class.
From Spring 2.5, you can even resolve the ambiguity between multiple constructors in a class by placing an @Autowired annotation on the particular constructor you are interested in. Recall this from earlier in the chapter where we used it in place of @Inject. For example:
@Componentpublic class Emailer { private SpellChecker spellChecker; public Emailer() { this.spellChecker = null; }@Autowiredpublic Emailer(SpellChecker spellChecker) { this.spellChecker = spellChecker; } public void send(String text) { spellChecker.check(text); } }
@Autowired performs the same role as Guice's @Inject (in addition to @Component annotation placed on the class itself). It instructs the injector to choose the annotated constructor when introspecting the class for injection. Remember that you still need to place a <bean> tag in XML to make Spring aware of autowired classes:
<beans ...>
<bean id="spellChecker" class="SpellChecker"/>
<bean id="emailer" class="Emailer"/>
</beans>Note the absence of any explicit wiring directive (<constructor-arg> or <property>) that we used in the pure XML configuration system. Note also the more conspicuous absence of the autowire="..." attribute, which is unnecessary now that we have @Autowired.
Like Guice, this method is both concise and exemplar. In other words, what you see in constructor code is what you get in the object graph. The next few sections examine this concept in detail.
We've already seen that a service generally has some kind of identity, whether an arbitrary string identifier, the class it belongs to, or some other combinatorial key. In this section we will briefly examine a few approaches and the benefits or drawbacks of each.
First, let's formally address what it means to identify components and dependencies. Recall our discussion of the construction and assembly of object graphs from chapter 1. Essentially, a dependency is some implementation of a service. It may only be a flat object with no dependencies of its own. Or it may be an object with a vast graph of interconnected dependencies, which themselves have dependencies, and so on.
To sum up:
A dependency is any particular permutation of objects in a graph that represents the original service; that is, all permutations obey the same contract.
Permutations of the same service may be thought of as variants (or implementations) of that service.
Recall the example of the French and English Emailers. They are two variants of the same service (formed by two different object graphs). As shown in listing 2.9, dependent Emailer is the same for either variant.
Were we to construct them by hand, there would be two possible paths to take. First, for the English email service (the one with the English spellchecker):
Emailer emailer = new Emailer(new EnglishSpellChecker());
emailer.send("Hello!");Second, the version with French spelling:
Emailer emailer = new Emailer(new FrenchSpellChecker());
emailer.send("Bonjour!");In both these cases, we want an Emailer but with different dependencies set. Using a simple string identifier such as emailer or a class identifier like Emailer.class is clearly insufficient. As an alternative we might try these approaches:
Use a more specific string identifier, for example
"englishEmailer"or"frenchEmailer"Use the class identifier
Emailer.classtogether with a discriminator, for example, the ordered pair[Emailer.class, "english"]
Existing DI libraries use various methods to solve this problem, usually by falling into one of the two aforementioned paths. Both these options give us an abstract identity over a particular service implementation. Once its object graph has been described, a service implementation is easily identified by this abstract identity (which we refer to as its key).
If you wanted to use one particular implementation instead of another, you'd only need to point the dependent to its key. Keys are also essential when we want to leverage other features of dependency injectors, such as:
Interception—Modifying an object's behavior
Scope—Managing an object's state
Lifecycle—Notifying an object of significant events
Keys provide a binding between a label and the object graph that implements the service it identifies. The rest of this chapter will focus primarily on the merits and demerits of approaches to keys and bindings.
A key that explicitly spells out the identity of the service implementation should generally have three properties:
It is unique among the set of keys known to an injector; a key must identify only one object graph.
It is arbitrary; it must be able to identify particular, arbitrary service implementations that a user has cooked up. In other words, it has to be more flexible than the service name alone.[12]
It is explicit; it must clearly identify the object graph, preferably to the letter of its function.
While these are not hard-and-fast rules, they are good principles to follow. Too often, people dismiss the worth of clear and descriptive keys. Let's look at real-world examples:
A Set in Java is a data structure that has many implementations. Among other things, the contract of Set disallows duplicate entries. The core Java library ships with the following implementations of Set:
How should we choose keys for these variants? The names of these implementations give us a good starting point—nominally, "binaryTreeSet" and "hashTableSet". This certainly isn't rocket science! These keys are explicit, sufficiently different from one another to be unique, and they clearly identify the behavior of the implementation (either binary-tree or hash-table behavior). While this may seem fairly obvious, it is not often the case. You'd be surprised at how many real-world projects are obfuscated with unclear, overlapping keys that say little if anything about an object graph. It is as much for your benefit as the developer and maintainer of an application as it is for the dependency injector itself that you follow these guidelines. Lucid, articulate keys are easily identified and self-documenting, and they go a long way toward preventing accidental misuse, which can be a real nuisance in big projects.
I also strongly encourage use of namespaces, for example, "set.BinaryTree" and "set.HashTable", which are nicer to read and comprehend than "binaryTreeSet" and "hashTableSet". Namespaces are a more elegant and natural nomenclature for your key space and are eminently more readable than strings of grouped capitalized words. An email service with a French bent might be "emailer.French," and its counterparts might be "emailer.English, "emailer.Japanese," and so forth.
I am especially fond of namespaces in dependency injection. Their value was immediately apparent to me the first time I was on a project with a very large number of XML configuration files. They allowed my team and me to clearly separate services by areas of function and avert the risk of abuse or misapprehension. For instance, data services were prefixed with dao (for Data Access Object) and business services with biz. Helper objects that sat at the periphery of the core business purpose were confined to a util. namespace. I can't emphasize enough how useful this was for us. Consider some of the changes we made in a vast system of objects and dependencies identified solely by string keys (also see figure 2.12):
UserDetailsServicebecamedao.User.UserDataUtilsbecameutil.Users.DateDataUtilsbecameutil.Dates.UserServicebecamebiz.Users.
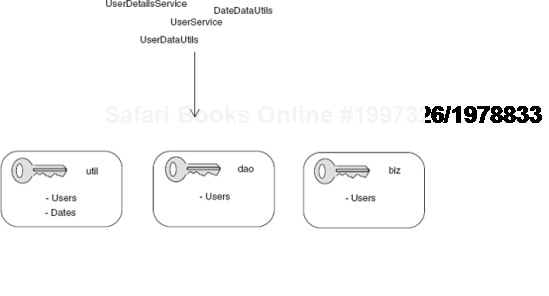
The astute reader will appreciate how much clearer—and more succinct—the latter form is. Of course, there is nothing new or innovative about the concept of namespaces, though one rarely sees it preached in documentation.
Spring and its XML configuration mechanism benefit heavily from this approach. If we were to declare the variant implementations of a Set, they may look something like this:
<beans ...>
<bean id="set.HashTable" class="java.util.HashSet"/>
<bean id="set.BinaryTree" class="java.util.TreeSet"/>
</beans>And obtaining these objects from the injector accords to their keys:
BeanFactory injector =
new FileSystemXmlApplicationContext("treesAndHashes.xml");
Set<?> items = (HashSet<?>) injector.getBean("set.HashTable");For a more complete scenario, consider this pattern for the email service and its two variant spellcheckers (listing 2.10).
Example 2.10. Variants of an email service using namespaces
<beans>
<bean id="spelling.English" class="EnglishSpellChecker"/>
<bean id="emailer.English" class="Emailer"><constructor-arg ref="spelling.English"/> </bean><bean id="spelling.French" class="FrenchSpellChecker"/><bean id="emailer.French " class="Emailer"> <constructor-arg ref="spelling.French"/> </bean> </beans>
Better yet, listing 2.11 is a more compact, encapsulated version of the same.
Example 2.11. A compact form of listing 2.10
<beans ...>
<bean id="emailer.English" class="Emailer">
<constructor-arg><bean class="EnglishSpellChecker"/></constructor-arg>
</bean>
<bean id="emailer.French" class="Emailer">
<constructor-arg><bean class="FrenchSpellChecker"/></constructor-arg>
</bean>
<bean id="emailer.Japanese" class="Emailer">
<constructor-arg><bean class="JapaneseSpellChecker"/></constructor-arg>
</bean>
</beans>By now, you should be starting to appreciate the value of namespaces, encapsulation, and well-chosen keys. Remember, a well-chosen key is unique, arbitrary, and explicit. When you must use string keys, choose them wisely. And use namespaces.
To drive the point home, look at the following two setups in pseudocode: one that uses poorly chosen keys and a flat keyspace and a second that conforms to our principles of good key behavior. Listing 2.12 shows an injector configuration with bad keys and no namespaces. Ugly! Wouldn't you agree?
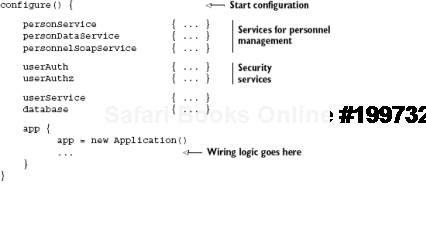
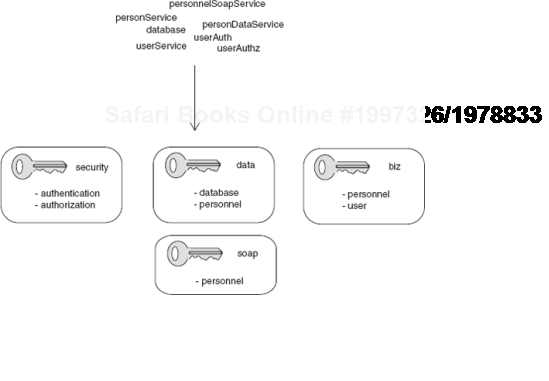
Now compare this with listing 2.13 (and figure 2.13), which presents an improved version of the same configuration. Much better!

String keys are flexible, and if chosen well they work well. But well chosen or not, string keys have limitations that can be confounding and rather, well, limiting! Let's talk about some of them.
String keys are inherently problematic when one factors human error into the equation. We have all been there. Take the possible ways to spell a common name, for example:
Alan
Allan
Alain
Allen
Allun (an Irish variant)
This is a short name (two syllables) and it does not incur the distractions of case and multiple-word capitalization.[15] Yet we can barely agree on a spelling even in the Englishspeaking world. Mistyping and misreading exacerbates the problem. It is not a stretch to imagine how things can get out of hand very quickly with a large number of services identified by many similar-looking (and sounding) keys. A misspelled key that maps to no valid service can be difficult to detect until well into the runtime of the program.
Furthermore, if you are working with a statically typed language like Java, this is a poor sacrifice to have to make. These languages are supposed to offer guarantees around type validity at compile time. Ideally, one should not have to wait until runtime to detect problems in key bindings.
Sometimes tools like IDEs or build agents can help do this extra level of checking for you, during or before compilation. IntelliJ IDEA[17] provides plug-ins for Spring for just this purpose. Naturally, it is difficult for any tool to guarantee the correct resolution of dependencies into dependents without bootstrapping the injector and walking across every bound object (or just about every one). As a result, this problem can arise often in injectors that use string keys.
In your injector configuration there is no way to determine the type of a binding if all you have is a string key. Without starting up the injector and inspecting the specific instance for a key, it is hard to determine what type the key is bound to. Take the following example of a game console (the Nintendo Wii) and a game to be played on it:
<beans>
<bean id="nintendo.wii" class="com.nintendo.Wii">
<constructor-arg ref="game.HalfLife"/>
</bean>
<bean id="game.HalfLife" class="com.valve.HalfLifeGame"/>
</beans>Here our keys appear reasonably well chosen: they are unique, arbitrary, and explicit (and they use namespaces). I've followed every tenet of good key behavior but something is horribly wrong with this injector configuration. The program crashes when I try to run it. To understand why, delve into the code behind these bindings:

The Nintendo game system takes an argument of type WiiGame via its constructor. This dependency represents a game I want to play (I enjoy Half-Life so let's go with that) and is loaded by the game system when play() is called. This is the game Half-Life:
package com.valve;
public class HalfLife implements PCGame {
public void load() { .. }
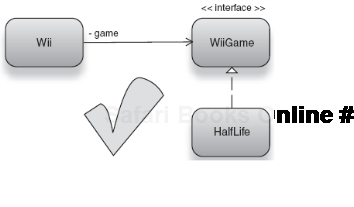
}Oh, no! Half-Life is a game for the PC, not the Wii! It is not an instance of Wii-Game and therefore cannot be wired into Wii's constructor (see figure 2.14).
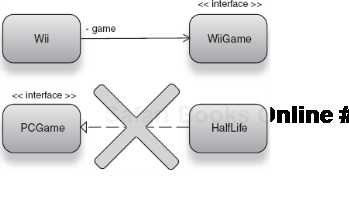
In Java, executing this program and requesting an instance by key nintendo. wii will result in an UnsatisfiedDependencyException being thrown. This indicates that the configured binding is of the wrong type for Wii's dependency, and it cannot be converted to the right type. More significant for us, however, is the fact that what appeared to be a perfectly well-written injector configuration turned out to be fatally flawed. Worse, there was no way to detect this until the offending object graph was constructed and used. This highlights a serious limitation of string keys.
Once the problem is identified, we can fix it by selecting the correct implementation of Half-Life. Listing 2.14 shows this fix, illustrated in figure 2.15.

This time, the game is of the appropriate type and everything works as expected.
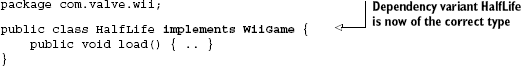
In large applications with many hundreds of object graphs, string identifiers incur many of these problems. No matter what language or injector you decide on, poorly chosen keys are a recipe for disaster. Oh, and use namespaces. Seriously!
We have seen how services are identified by a type. Recall some of the examples I've used so far in this book:
SpellChecker.classidentifiesEnglishSpellCheckerorFrenchSpellChecker.Emailer.classidentifies itself.WiiGame.classidentifiesHalfLife.Wii.classidentifies itself.
Unlike strings, referring to a type is not quite the same in all languages, but the essential semantic is the same. Java uses type literals that are analogous to string literals and essentially identify the type directly in code:
Set.classSpellChecker.classAirplane.class
Identifying by type is a natural and idiomatic way of referring to a dependency. It is self-descriptive and can be inferred by introspection tools automatically. This has additional advantages in a statically typed language where types are checked at compile time and any errors in types are revealed early.
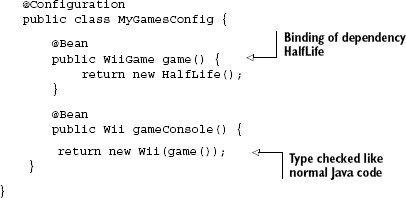
Look at how identifying by type helps prevent the very error we just saw with string keys and the incorrect wiring of dependencies. Listing 2.15 revisits the broken dependency where the wrong version of the game HalfLife is used in the game console.

This time, instead of XML configuration and Spring, I use Guice and its Module binding:

This injector configuration
Clearly, identifying by type is a winner when compared to plain string keys. PicoContainer also offers identifying by type in a similar fashion to what we've just seen with Guice. However, identifying by type does have serious limitations. In the next sections we'll explore what these are and how they may be overcome.
I'll wager you're already familiar with some of the limitations of type (or class literal keys). We saw the primary one at the beginning of this section—the inability to distinguish between different implementations of a service. The type key Car.class can refer either to BmwZ4s or to ToyotaCamrys, as shown in figure 2.16.
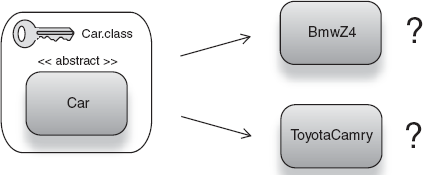
And the injector is none the wiser as to which one to select and wire to clients of Car. This is irksome if we wanted to plug in a variety of alternative implementations by just changing keys.
You can refer to a specific implementation directly (like BmwZ4.class instead of Car.class), but this is a poor solution and incurs the same problem of the one default implementation (can't replace it with a ToyotaCamry). Worse, it is difficult to test and tightly couples client code to dependencies, which is undesirable.
Identifying by type can be restrictive in other ways. Recall the three holy tenets of well-chosen keys that helped make them lucid and maintainable. Keys must be unique, arbitrary, and explicit. How does identifying by type fare under these tenets?
Not unique—Variant implementations of a service are indistinguishable by type key alone (
BMWZ4s andToyotaCamrys both have type keyCar.class).Not arbitrary—A key bears only the label of the service (that is, the dependency). There is no room to describe arbitrary variants. The game console accepts a
WiiGame, notHalfLifeorSuperMarioBrothers. Try getting your kid to spend his money on a nondescript, gray disc over a shiny new copy of Half-Life.May or may not be explicit—One could argue that there is no better explanation of the service's function than its contract. However, were a service contract to leave some details up to its implementations, or likely to other dependencies, we would lose all explicit enunciation, as in an
Emailerwith English spellchecking rather than French (both identified byEmailer.class).
It does not fare very well at all: one or possibly none out of three important requisites of good key behavior! Type keys are safer in the context of detecting errors early on, particularly in statically typed languages like Java and C#, but they are rigid and don't offer the breadth of abstraction that string keys do. String keys, on the other hand, are dangerous through misspelling and can be abstruse and opaque if improperly chosen. To summarize: type keys are safe but inflexible, and string keys are flexible but unsafe and potentially confusing.
It would be ideal if there were a key strategy that was both type and contract safe—and was flexible enough to wire dependents with many implementations that we could identify easily. Fortunately for us, combinatorial keys provide the best of both worlds.
Earlier, I described a sample combinatorial key for an English variant of our favorite email service; it looked like this:
[Emailer.class, "english"]
The ordered pair [Emailer.class, "english"] is one case of a combinatorial key consisting of a type key and a string key. The type key identifies the service that dependents rely on, in a safe and consistent manner. Its counterpart, the string key, identifies the specific variant that the key is bound to but does so in an abstract manner. Comparing this combinatorial key with a plain string key, the latter clearly has the advantage of type safety. Its second part (the string key) provides a clear advantage over plain type keys because it is able to distinguish between implementations. Let's examine this with a couple of examples:
Key 1: [Emailer.class, "english"] Key 2: [Emailer.class, "french"] Key X: [Book.class, "dependencyInjection"] Key Y: [Book.class, "harryPotter"]
Keys 1 and 2 identify object graphs of an email service with English and French spellchecking, respectively. Keys X and Y identify two different books.
Another example we've used before is an emailer that depends on a SpellChecker:
[Emailer.class, "withSpellChecker"]Consider a more complex take on this example, where our emailer depends on a SpellChecker, which itself depends on a dictionary to resolve word corrections (as figure 2.17 models).
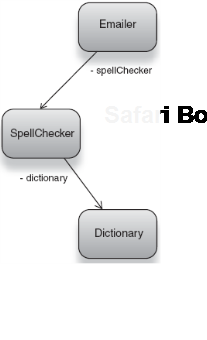
The combinatorial key identifying this object graph might look something like:
[Emailer.class, "withSpellCheckerAndDictionary"]
Even complex object graphs with many permutations are identified easily with combinatorial keys. They also comply with our rules for good key behavior:
Keys are unique. The second part to the ordered pair ensures that two implementations are identified uniquely.
Keys are arbitrary. While the dependency is identified by the first part, any specific behavior exhibited by a custom variant is easily described by the second part of the key.
Keys are explicit. More so than with pure string keys, combinatorial keys are able to identify both the service contract they exhibit and any specific variation to the letter of its function.
So, combinatorial keys are safe, explicit, and able to identify any service variants clearly and precisely. They solve the problems of type-safety that pure string keys can't, and they ease the rigidity of pure type keys. And they do so in an elegant manner. The only drawback is that we have a string part that incurs the problems of misspelling and misuse identified earlier. For example, it is quite easy to see how the following combinatorial keys, relatively safe though they are, can still end up problematic:
[Emailer.class, "englihs"] [Emailer.class, "English"] [Emailer.class, "francais"] [Emailer.class, "withFaser"] [Emailer.class, "with.SpellChecker"] [Emailer.class, "With.SpellChecker"]
Each of these keys will result in an erroneous injector configuration that won't be detected until runtime. While there are certainly far fewer possible total errors with this approach, there are nonetheless the same perils and pitfalls so long as we rely on a string key in any consistent and foundational manner. How then can we fix this problem?
It turns out we can still keep all the benefits of combinatorial keys and eliminate the problems that the string part of the key presents. By using an annotation in place of the string part of the combinatorial key, we get the benefit of a safe key and the flexibility of an arbitrary and explicit string key.
Consider the following combinatorial keys that are composed of a type and an annotation type:
[Emailer.class, English.class] [Emailer.class, WithSpellChecker.class] [Database.class, FileBased.class]
Misspelling the annotation name results in a compiler error, which is an early and clear indication of the problem. This is exactly what we were after. What we have done is effectively replace the string key with a second type key. In combination with the service's type key, this retains the qualities of good behavior in well-chosen keys but also eliminates the problems posed by arbitrary, abstract strings. This is quite a comprehensive and elegant solution. The fact that annotations can be reused also makes them good for more than the one service:
[Emailer.class, English.class] [Dictionary.class, English.class] [SpellChecker.class, English.class]
We use the @English annotation to distinguish variant implementations of not only the Emailer but also the Dictionary and TextEditor services. These keys are selfdocumenting and still give us the flexibility of a string key. Since annotations are cheap to create (hardly a couple of lines of code) and reuse, this approach scales nicely too.
Guice embodies the use of type/annotation combinatorial keys and was probably the first library to use this strategy. Listing 2.16 and figure 2.18 show what the injector configuration might look like for the spellchecking service I presented in the previous example.
Example 2.16. Guice module binding services to combinatorial keys
public class SpellingModule extends AbstractModule {
@Override
protected void configure() {
bind(SpellChecker.class)
.annotatedWith(English.class)
.to(EnglishSpellChecker.class);
bind(SpellChecker.class)
.annotatedWith(French.class)
.to(FrenchSpellChecker.class);
}
}Then using either of these services in a client is as simple as using the appropriate annotation:
Guice.createInjector(new SpellingModule())
.getInstance(Key.get(SpellChecker.class, English.class))
.check("Hello!");When this code is executed, Guice obtains the SpellChecker instance bound to the combinatorial key represented by [SpellChecker.class, English.class]. Invoking the check() method on it runs the service method on the correct (that is, English) implementation.
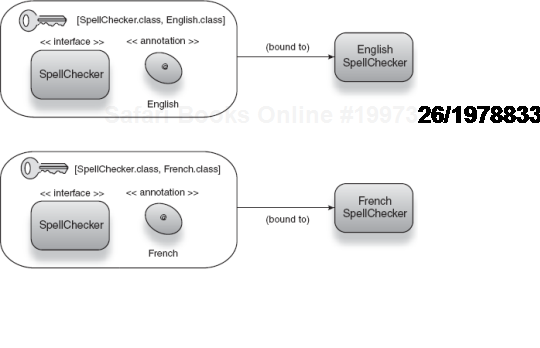
Figure 2.18. Combinatorial type keys use annotations to identify variant implementations of an interface.<br></br>
This is also easily done in any client of SpellChecker via the use of @English annotation near the injection point of the dependency. Here's one such example:
public class SpellCheckerClient {
@Inject
public SpellCheckerClient(@English SpellChecker spellChecker) {
//use provided spellChecker
}
}This might strike you as odd—while the client does not depend directly on a specific implementation, it seems to couple via the use of @English annotation. Doesn't this mean SpellCheckerClient is tightly coupled to English spellcheckers? The answer is a surprising no. To understand why, consider the following altered injector configuration:
public class SpellingModule extends AbstractModule {
@Override
protected void configure() {
bind(SpellChecker.class)
.annotatedWith(English.class)
.to(FrenchSpellChecker.class);
}
}In this example, I've changed the service implementation bound to the combinatorial key [SpellChecker.class, English.class] so that any dependent referring to an @English annotated SpellChecker will actually receive an implementation of type FrenchSpellChecker. There are no errors, and SpellCheckerClient is unaware of any change and more importantly unaffected by any change. So they aren't really tightly coupled.
No client code needs to change, and we were able to alter configuration transparently.
Similarly, you can build such combinatorial bindings in Spring JavaConfig using types and method names:
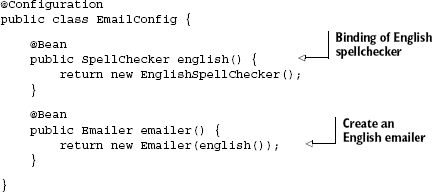
Here, the combinatorial key is [SpellChecker, english()], the latter being the name of the method. It performs a very similar function to the @English annotation we saw just now, though the two approaches differ slightly.
Now let's look at how to take this practice a step further and separate code by area of concern.
You have seen how object graphs that represent various services may be created, assembled, and referenced. You have also seen the steps to creating and using dependency injectors and ultimately the objects that they manage for an application. DI libraries differ slightly in the manner in which these steps are achieved and the rigor with which they are performed, but ultimately they all follow the same principles.
Together, these properties make for lean and focused components with code only to deal with their primary business purpose, be it:
Rendering a web page
Sending email
Purchasing stock
Checking bad spelling
Logic geared toward such purposes is termed application logic. Everything else is meant only to support and enhance it. Logic for constructing and assembling object graphs, obtaining connections to databases, setting up network sockets, or crunching text through spellcheckers is all peripheral to the core purpose of the application.
While this infrastructure logic is essential to all applications, it is important to distinguish it from the application logic itself. This not only helps keep application logic clear and focused, but it also prevents tests from being polluted with distracting bugs and errors that may have nothing to do with the code's purpose. Dependency injection helps in this regard. Figure 2.19 describes the fundamental injector and object composition that forms the basis of modern architectures.
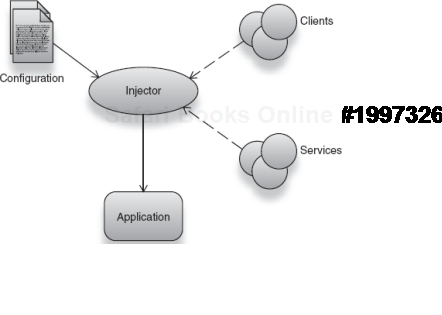
Figure 2.19. Injectors assemble clients and services as per configuration, into comprehensive applications.<br></br>
Good DI libraries enforce and exemplify this core ideology. They are as much about preventing abuse as they are about proffering best practices or flexibility. As such, a DI library that takes extra steps to prevent you from accidentally shooting yourself in the foot (by checking bindings at compile time, for instance) is preferable. On the other hand, DI libraries that offer a great deal of flexibility (and weak type safety) can draw even experienced developers into traps. This is where careful design is important. Don't be afraid to refactor and redesign your code when you discover violations of good design. A little bit of effort up front to ensure that infrastructure logic remains separate from application logic will go a long way toward keeping your code readable, maintainable, and robust throughout its life.
This chapter was a headfirst dive into dependency injectors, their configuration, and their use. You saw how injectors must be bootstrapped with specified configuration and then used to obtain and perform operations on components they build and wire. At first, the injector looks no different to a service locator, and this is roughly correct in the context of obtaining the first, or the root, component from which the rest of an object graph extends.
All services that are used as dependencies are labeled by a key, which the injector uses as a way of referring to them during configuration or service location. The coupling of a key to a particular object graph is called a binding. These bindings determine how components are provided with their dependencies and thus how object graphs are ultimately constructed and wired. There are several kinds of keys, the most common being simply string identifiers, which are common in XML-configured DI libraries such as Spring, StructureMap, and HiveMind. String keys are flexible and provide us with the freedom to describe arbitrary and various assemblies of object graphs that portend a service. Different object graphs that conform to the same set of rules, that are the same service, may be thought of as different implementations of that service. String keys allow easy identification of such dependency variants.
However, string keys have many limitations, and the fact that they are unrestricted character strings means that they are prone to human error and to misuse and poor design choices. This leads to the necessity of well-chosen string identifiers that portend good key behavior. We defined the characteristics of well-chosen keys as being unique, arbitrary, and explicit. Unique keys ensure that no two object graphs are identified by the same key accidentally and so ensure that there is no ambiguity when a dependency is sought. Arbitrary keys are useful in supporting a variety of custom variants of services, which a creative user may have cooked up. Finally, these keys must also be explicit if they are to exactly describe what a service implementation does as clearly and concisely as is possible. Well-chosen keys combined with the use of namespaces greatly improve readability and also reduce the probability of accidental misuse.
String keys satisfy all of these qualities, but they have serious drawbacks since they lack the knowledge of the type (or class) they represent. This can result in syntactically correct injector configuration that fails at runtime, sometimes even as late as the first use of a faultily configured object graph. In rare cases, it can even result in incorrect dependency wiring without any explicit errors, which is a very scary situation! In a statically typed language like Java, better solutions are imperative to these problems, especially in large projects that make use of agile software methods that require rapid, iterative execution of partial units.
An alternative is the use of type keys. These are keys that simply refer to the data type of the service. Type keys solve the misspelling and misuse problem of string keys but sacrifice a lot of flexibility and abstraction in doing so. PicoContainer is one DI library that supports the use of type keys. Their primary limitation is the inability to distinguish between various implementations without directly referring to them in client code. As a result, type keys violate almost all of the requirements of well-chosen keys, though they are safe and help catch errors early, at compile time.
One solution is to combine the two approaches and use type keys to narrow down the service's type and pair it with a string key that distinguishes the specific variant. These are called combinatorial keys, and they provide all of the flexibility of string keys and retain the rigor of type keys. PicoContainer also provides for these hybrid type/string combinatorial keys. However, the use of string identifiers at all still means that there is a risk of misspelling and accidental misuse. Guice provides a comprehensive solution: the use of custom annotation types in place of the string part of a combinatorial key. The combination of the type key referring to a service and an annotationtype key referring to an abstract identifier to distinguish between implementations provides for a compelling mitigation of the problems of even partial string keys.
Finally, whatever DI library you choose, dependency injectors are geared toward the same goals, that is, separate logic meant for constructing and assembling object graphs, managing external resources and connections, and so on from logic that is intended solely for the core purpose of the application. This is called the separation of infrastructure from application logic and is an important part of good design and architecture. The majority of the concepts presented in this book revolve around this core ideology and in many ways serve to emphasize or enhance the importance of this separation. A successful rendition of dependency injection gives you more time to focus effort on application logic and helps make your code testable, maintainable, and concise.
[7] Guice-servlet allows your HTTP servlets to be created and injected by Guice. A detailed example is provided in chapter 5. For more on guice-servlet, visit http://code.google.com/p/google-guice.
[8] The @Inject annotation ships with Guice's library distribution.
[9] Downcasting (or casting) is the checked process of converting an instance of a general type into that of a more specific type; this is typically done by assigning the instance to a variable of the target type. In the given case, the general type Object is cast into a more specific type Emailer.
[10] An XML schema is a formal description of the structure of an XML document toward a particular purpose. In this case, it describes the legal form and structure of a Spring configuration file.
[11] Read more of Eric's comic strips at http://stuffthathappens.com.
[12] Recall the example of SpellChecker (the service) being insufficient to distinguish between its English and French implementations.
[13] A binary tree is a data structure in which each stored item may have two successors (or children), starting at a single root item.
[14] A hash table is a data structure designed to store and look up entries in a single step using a calculated address known as a hash code.
[15] A phrase or set of words in a key is often delimited by capitalizing each first letter. For example, "Technicolor dream coat" would be written as TechnicolorDreamCoat or technicolorDreamCoat, which are two forms of the CamelCase convention.
[16] Do not confuse static and dynamic typing with strong and weak typing, or indeed with duck typing.
[17] IntelliJ IDEA is an advanced Java IDE developed by JetBrains. It is usually at the forefront of innovation in developer productivity. Find out more at http://www.jetbrains.com.