
So you're an expert on dependency injection (DI); you know it and use it every day. It's like your morning commute—you sleepwalk through it, making all the right left turns (and the occasional wrong right turns before quickly correcting) until you're comfortably sitting behind your desk at work. Or you've heard of DI and Inversion of Control (IoC) and read the occasional article, in which case this is your first commute to work on a new job and you're waiting at the station, with a strong suspicion you are about to get on the wrong train and an even stronger suspicion you're on the wrong platform.
Or you're somewhere in between; you're feeling your way through the idea, not yet fully convinced about DI, planning out that morning commute and looking for the best route to work, MapQuesting it. Or you have your own home-brew setup that works just fine, thank you very much. You've no need of a DI technology: You bike to work, get a lot of exercise on the way, and are carbon efficient.
Stop! Take a good, long breath. Dependency injection is the art of making work come home to you.
Most software today is written to automate some real-world process, whether it be writing a letter, purchasing the new album from your favorite band, or placing an order to sell some stock. In object-oriented programming (OOP), these are objects and their interactions are methods.
Objects represent their real-world counterparts. An Airplane represents a 747 and a Car represents a Toyota; a PurchaseOrder represents you buying this book; and so on.
Of particular interest is the interaction between objects: An airplane flies, while a car can be driven and a book can be opened and read. This is where the value of the automation is realized and where it is valuable in simplifying our lives.
Take the familiar activity of writing an email; you compose the message using an email application (like Mozilla Thunderbird or Gmail) and you send it across the internet to one or more recipients, as in figure 1.1. This entire activity can be modeled as the interaction of various objects.

Figure 1.1. Email is composed locally, delivered across an internet relay, and received by an inbox.<br></br>
This highlights an important precept in this book: the idea of an object acting as a service. In the example, email acts as a message composition service, internet relays are delivery agents, and my correspondent's inbox is a receiving service.
The process of emailing a correspondent can be reduced to the composing, delivering, and receiving of email by each responsible object, namely the Emailer, InternetRelay, and RecipientInbox. Each object is a client of the next.
Emailer uses the InternetRelay as a service to send email, and in turn, the InternetRelay uses the RecipientInbox as a service to deliver sent mail.
The act of composing an email can be reduced to more granular tasks:
Writing the message
Checking spelling
Looking up a recipient's address
And so on. Each is a fairly specialized task and is modeled as a specific service. For example, "writing the message" falls into the domain of editing text, so choosing a TextEditor is appropriate. Modeling the TextEditor in this fashion has many advantages over extending Emailer to write text messages itself: We know exactly where to look if we want to find out what the logic looks like for editing text.
Our
Emaileris not cluttered with distracting code meant for text manipulation.We can reuse the
TextEditorcomponent in other scenarios (say, a calendar or note-taking application) without much additional coding.If someone else has written a general-purpose text-editing component, we can make use of it rather than writing one from scratch.
Similarly, "checking spelling" is done by a SpellChecker. If we wanted to check spelling in a different language, it would not be difficult to swap out the English SpellChecker in favor of a French one. Emailer itself would not need to worry about checking spelling—French, English, or otherwise.
So now we've seen the value of decomposing our services into objects. This principle is important because it highlights the relationship between one object and others it uses to perform a service: An object depends on its services to perform a function.
In our example, the Emailer depends on a SpellChecker, a TextEditor, and an AddressBook. This relationship is called a dependency. In other words, Emailer is a client of its dependencies.
Composition also applies transitively; an object may depend on other objects that themselves have dependencies, and so on. In our case, SpellChecker may depend on a Parser to recognize words and a Dictionary of valid words. Parser and Dictionary may themselves depend on other objects.
This composite system of dependencies is commonly called an object graph. This object graph, though composed of many dependencies, is functionally a single unit.
Let's sum up what we have so far:
Service—An object that performs a well-defined function when called upon
Client—Any consumer of a service; an object that calls upon a service to perform a well-understood function
The service-client relationship implies a clear contract between the objects in the role of performing a specific function that is formally understood by both entities. You will also hear them referred to as:
Not only can you describe an object graph as a system of discrete services and clients, but you also begin to see that a client cannot function without its services. In other words, an object cannot function properly without its dependencies.
Note
DI as a subject is primarily concerned with reliably and efficiently building such object graphs and the strategies, patterns, and best practices therein.
Let's look at ways of building object graphs before we take on DI.
Figure 1.2 shows a simple relationship between an object and its dependency.
Were you asked to code such a class without any other restrictions, you might attempt something like this:
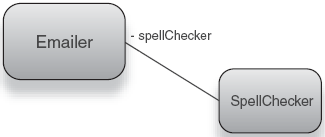
public class Emailer {
private SpellChecker spellChecker;
public Emailer() {
this.spellChecker = new SpellChecker();
}
public void send(String text) { .. }
}Then constructing a working Emailer (one with a SpellChecker) is as simple as constructing an Emailer itself:
Emailer emailer = new Emailer();
No doubt you have written code like this at some point. I certainly have. Now, let's say you want to write a unit test for the send() method to ensure that it is checking spelling before sending any message. How would you do it? You might create a mock SpellChecker and give that to the Emailer. Something like:

Of course, we can't use this mock because we are unable to substitute the internal spellchecker that an Emailer has. This effectively makes your class untestable, which is a showstopper for this approach.
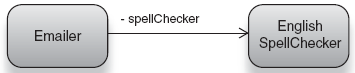
This approach also prevents us from creating objects of the same class with different behaviors. See listing 1.1 and figure 1.3.
Example 1.1. An email service that checks spelling in English
public class Emailer {
private SpellChecker spellChecker;public Emailer() {
this.spellChecker = new EnglishSpellChecker();
}
...
}In this example, the Emailer has an EnglishSpellChecker. Can we create an Emailer with a FrenchSpellChecker? We cannot! Emailer encapsulates the creation of its dependencies.
What we need is a more flexible solution: construction by hand (sometimes called manual dependency injection), where instead of a dependent creating its own dependencies, it has them provided externally.
Naturally, the solution is not to encapsulate the creation of dependencies, but what does this mean and to whom do we offload this burden? Several techniques can solve this problem. In the earlier section, we used the object's constructor to create its dependencies. With a slight modification, we can keep the structure of the object graph but offload the burden of creating dependencies. Here is such a modification (see figure 1.4):
public class Emailer {
private SpellChecker spellChecker;
public void setSpellChecker(SpellChecker spellChecker) {
this.spellChecker = spellChecker;
}
...
}Notice that I've replaced the constructor that created its own SpellChecker with a method that accepts a SpellChecker. Now we can construct an Emailer and substitute a mock SpellChecker:

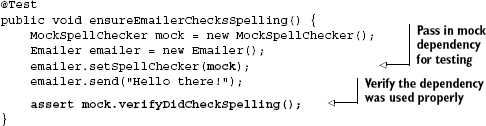
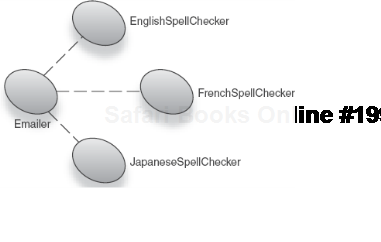
Similarly, it is easy to construct Emailers with various behaviors. Here's one for French spelling:
Emailer service = new Emailer();
service.setSpellChecker(new FrenchSpellChecker());Emailer service = new Emailer();
service.setSpellChecker(new JapaneseSpellChecker());Cool! At the time of creating the Emailer, it's up to you to provide its dependencies. This allows you to choose particular flavors of its services that suit your needs (French, Japanese, and so on) as shown in figure 1.5.
Since you end up connecting the pipes yourself at the time of construction, this technique is referred to as construction by hand. In the previous example we used a setter method (a method that accepts a value and sets it as a dependency). You can also pass in the dependency via a constructor, as per the following example:
public class Emailer {
private SpellChecker spellChecker;
public Emailer(SpellChecker spellChecker) {
this.spellChecker = spellChecker;
}
...
}Then creating the Emailer is even more concise:
Emailer service = new Emailer(new JapaneseSpellChecker());This technique is called constructor injection and has the advantage of being explicit about its contract—you can never create an Emailer and forget to set its dependencies, as is possible in the earlier example if you forget to call the setSpellChecker() method. This concept is obviously very useful in OOP. We'll study it in greater detail in the coming chapters.
Note
The idea of connecting the pipes together, or giving a client its dependency, is sometimes also referred to as "injecting" objects into one another and other times as "wiring" the objects together.
While construction by hand definitely helps with testing, it has some problems, the most obvious one being the burden of knowing how to construct object graphs being placed on the client of a service. If I use the same object in many places, I must repeat code for wiring objects in all of those places. Construction by hand, as the name suggests, is really tedious! If you alter the dependency graph or any of its parts, you may be forced to go through and alter all of its clients as well. Fixing even a small bug can mean changing vast amounts of code.
Another grave problem is the fact that users need to know how object graphs are wired internally. This violates the principle of encapsulation and becomes problematic when dealing with code that is used by many clients, who really shouldn't have to care about the internals of their dependencies in order to use them. There are also potent arguments against construction by hand that we will encounter in other forms in the coming chapters. So how can we offload the burden of dependency creation and not shoot ourselves in the foot doing so? One answer is the Factory pattern.
Another time-honored method of constructing object graphs is the Factory design pattern (also known as the Abstract Factory[1] pattern). The idea behind the Factory pattern is to offload the burden of creating dependencies to a third-party object called a factory (shown in figure 1.6). Just as an automotive factory creates and assembles cars, so too does a Factory pattern create and assemble object graphs.
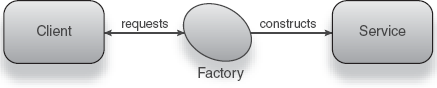
Let's apply the Factory pattern to our Emailer. The Emailer's code remains the same (as shown in listing 1.2).
Example 1.2. An email service whose spellchecker is set via constructor
public class Emailer {
private SpellChecker spellChecker;
public Emailer(SpellChecker spellChecker) {
this.spellChecker = spellChecker;
}
...
}Instead of constructing the object graph by hand, we do it inside another class called a factory (listing 1.3).
Example 1.3. A "French" email service Factory pattern
public class EmailerFactory {
public Emailer newFrenchEmailer() {
return new Emailer(new FrenchSpellChecker());
}
}Notice that the Factory pattern is very explicit about what kind of Emailer it is going to produce; newFrenchEmailer() creates one with a French spellchecker. Any code that uses French email services is now fairly straightforward:
Emailer service = new EmailerFactory().newFrenchEmailer();
The most important thing to notice here is that the client code has no reference to spellchecking, address books, or any of the other internals of Emailer. By adding a level of abstraction (the Factory pattern), we have separated the code using the Emailer from the code that creates the Emailer. This leaves client code clean and concise.
The value of this becomes more apparent as we deal with richer and more complex object graphs. Listing 1.4 shows a Factory that constructs our Emailer with many more dependencies (also see figure 1.4).
Example 1.4. A Factory that constructs a Japanese emailer
public class EmailerFactory {
public Emailer newJapaneseEmailer() {
Emailer service = new Emailer();
service.setSpellChecker(new JapaneseSpellChecker());
service.setAddressBook(new EmailBook());
service.setTextEditor(new SimpleJapaneseTextEditor());
return service;
}
}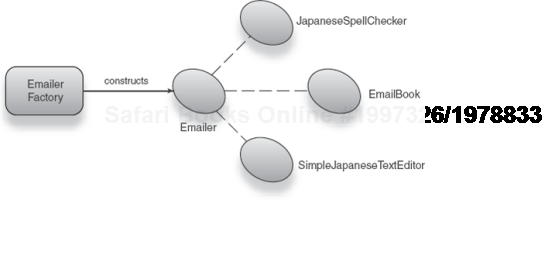
Figure 1.7. EmailerFactory constructs and assembles a Japanese Emailer with various dependencies.<br></br>
Code that uses such an Emailer is as simple and readable as we could wish:
Emailer emailer = new EmailerFactory().newJapaneseEmailer();
The beauty of this approach is that client code only needs to know which Factory to use to obtain a dependency (and none of its internals).
Now how about testing this code? Are we able to mock Emailer's dependencies? Sure; our test can simply ignore the Factory and pass in mocks:

So far, so good. Now let's look at a slightly different angle: How can we test clients of Emailer? Listing 1.5 shows one way.

This client does not know anything about Emailer's internals; instead, it depends on a Factory. If we want to test that it correctly calls Emailer.send(), we need to use a mock. Rather than set the dependency directly, we must pass in the mock via the Factory, as in listing 1.6.

In this test, we pass in MockEmailer using the static method EmailerFactory.set(), which stores and uses the provided object rather than creating new ones (listing 1.7).
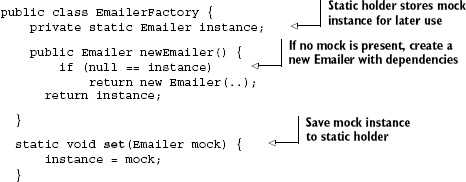
In listing 1.7, EmailerFactory has been heavily modified to support testing. A test can first set up a mock instance via the static set() method, then verify the behavior of any clients (as shown in listing 1.6).
Unfortunately, this is not the complete picture, since forgetting to clean up the mock can interfere with other Emailer-related tests that run later. So, we must reset the Factory at the end of every test:

We're not quite out of the woods yet. If an exception is thrown before the Factory is reset, it can still leave things in an erroneous state. So, a safer cleanup is required:

Much better. A lot of work to write a simple assertion, but worth it! Or is it? Even this careful approach is insufficient in broader cases where you may want to run tests in parallel. The static mock instance inside EmailerFactory can cause these tests to clobber each other from concurrent threads, rendering them useless.
Note
This is an essential problem with shared state, often portended by the Singleton pattern. Its effects and solutions are examined more closely in chapter 5.
While the Factory pattern solves many of the problems with construction by hand, it obviously still leaves us with significant hurdles to overcome. Apart from the testability problem, the fact that a Factory must accompany every service is troubling. Not only this, a Factory must accompany every variation of every service. This is a sizable amount of distracting clutter and adds a lot of peripheral code to be tested and maintained. Look at the example in listing 1.8, and you'll see what I mean.

If you wanted an English version of the Emailer, you would have to add yet another method to the Factory. And consider what happens when we replace EmailBook with a PhoneAndEmailBook. You are forced to make the following changes:
public class EmailerFactory {
public Emailer newJapaneseEmailer() { ...
service.setAddressBook(new PhoneAndEmailBook());
...
public Emailer newFrenchEmailer() { ...
service.setAddressBook(new PhoneAndEmailBook());
...
public Emailer newEnglishEmailer() { ...
service.setAddressBook(new PhoneAndEmailBook());
...
}All three of the changes are identical! It is clearly not a desirable scenario. Furthermore, any client code is at the mercy of available factories: You must create new factories for each additional object graph variation. All this spells reams of additional code to write, test, and maintain.
In the case of Emailer, following the idea to its inevitable extreme yields:

It is very difficult to test code like this. I have seen it ruin several projects. Clearly, the Factory pattern technique's drawbacks are serious, especially in larger and more complex code. What we need is a broader mitigation of the core problem.
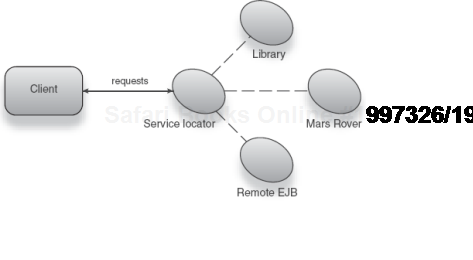
A Service Locator pattern is a kind of Factory. It is a third-party object responsible for producing a fully constructed object graph.
In the typical case, Service Locators are used to find services published by external sources; the service may be an API offered by a bank to transfer funds or a search interface from Google.
These external sources may reside in the same application, machine, or local area network, or they may not. Consider an interface to the NASA Mars Rover several millions of miles away, a simple library for text processing, bundled within an application, or a Remote Enterprise Java Bean (EJB).[2] Look at figure 1.8 for a visual.
Let's look at what a service locator does:
Emailer emailer = (Emailer) new ServiceLocator().get("Emailer");Notice that we pass the Service Locator a key, in this case the word "Emailer." This tells our locator that we want an Emailer. This is significantly different from a Factory that produces only one kind of service. A Service Locator is, therefore, a Factory that can produce any kind of service.
Right away this helps reduce a huge amount of repetitive Factory code, in favor of the single Service Locator.
Let's apply the Service Locator pattern to the earlier example:
This code is simple and readable. The identity of a service (its key) is sufficient to obtain exactly the right service and configuration. Now altering the behavior of a service identified by a particular key or fixing bugs within it by changing its object graph will have no effect on dependent code and can be done transparently.
Unfortunately, being a kind of Factory, Service Locators suffer from the same problems of testability and shared state. The keys used to identify a service are opaque and can be confusing to work with, as anyone who has used JNDI can attest. If a key is bound improperly, the wrong type of object may be created, and this error is found out only at runtime. The practice of embedding information about the service within its identifier (namely, "JapaneseEmailerWithPhoneAndEmail") is also verbose and places too much emphasis on arbitrary conventions.
With DI, we take a completely different approach—one that emphasizes testability and concise code that is easy to read and maintain. That's only the beginning; as you will see soon, with DI we can do a great deal more.
With dependency injection, we take the best parts of the aforesaid pre-DI solutions and leave behind their drawbacks.
DI enables testability in the same way as construction by hand, via a setter method or constructor injection. DI removes the need for clients to know about their dependencies and how to create them, just as factories do. It leaves behind the problems of shared state and repetitive clutter, by moving construction responsibility to a library.
With DI, clients need know nothing about French or English Emailers, let alone French or English SpellCheckers and TextEditors, in order to use them. This idea of not explicitly knowing is central to DI. More accurately, not asking for dependencies and instead having them provided to you is an idea called the Hollywood Principle.
The Hollywood Principle is "Don't call us; we'll call you!" Just as Hollywood talent agents use this principle to arrange auditions for actors, so do DI libraries use this principle to provide objects with what they depend on.
This is similar to what we saw in construction by hand (sometimes referred to as manual dependency injection). There is one important difference: The task of creating, assembling, and wiring the dependencies into an object graph is performed by an external framework (or library) known as a dependency injection framework, or simply a dependency injector. Figure 1.9 illustrates this arrangement.
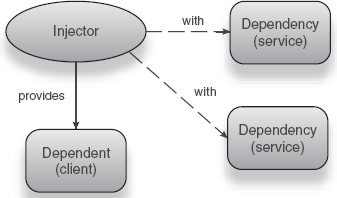
Control over the construction, wiring, and assembly of an object graph no longer resides with the clients or services themselves. The Hollywood Principle's reversal of responsibilities is sometimes also known as IoC.
Note
DI frameworks are sometimes referred to as IoC containers. Examples of such frameworks are PicoContainer (for Java), StructureMap (for C#), and Spring (for Java and C#).
Listing 1.9 shows the Hollywood Principle in action.

In this example, our dependent is SimpleEmailClient
In order to send mail, SimpleEmailClient does not need to expose anything about Emailer or how it works. Put another way, SimpleEmailClient encapsulates Emailer, and sending email is completely opaque to the user. Constructing and connecting dependencies is now performed by a dependency injector (see figure 1.10).
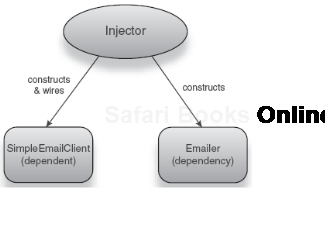
Figure 1.10. The injector constructs and wires SimpleEmailClient with a dependency (Emailer).<br></br>
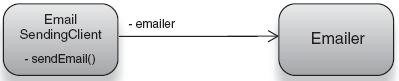
The dependency is shown as a class diagram in figure 1.11.
Notice that SimpleEmailClient knows nothing about what kind of Emailer it needs or is using to send a message. All it knows is that it accepts some kind of Emailer, and this dependency is used when needed. Also notice that the client code is now starting to resemble service code; both are free of logic to create or locate dependencies. DI facilitates this streamlining, stripping code of distracting clutter and infrastructure logic, leaving purposed, elementary logic behind.
We have not yet seen how the wiring is done, as this differs from injector to injector, but what we've seen is still very instructive because it highlights the separation of infrastructure code (meant for wiring and construction) from application code (the core purpose of a service). The next couple of sections explore this idea, before we jump into the specifics of working with dependency injectors.
Worthy as they are of a heavyweight bout, these two terms are not really opposed to one another as the heading suggests. You will come across the term IoC quite often, both in the context of dependency injection and outside it. The phrase Inversion of Control is rather vague and connotes a general reversal of responsibilities, which is nonspecific and could equally mean any of the following:
A module inside a Java EE application server
An object wired by a dependency injector
A test method automatically invoked by a framework
An event handler called on clicking a mouse button
Pedantic users of the term suggest that all of these cases are consistent with its definition and that DI itself is simply one instance of IoC.
In common use, dependency injectors are frequently referred to as IoC containers.
In the interest of clarity, for the rest of this book I will abandon the term IoC (and its evil cousin IoC container) in favor of the following, more precise terms:
Early frameworks differed by the forms of wiring that they proffered and promoted. Over the years, the efficacy of setter and constructor wiring overtook that of other forms of wiring, and more flexible solutions that emphasized the safety of contracts and the reduction of repetitive code emerged. With the rise of related paradigms such as aspectoriented programming (AOP), these features continued to improve. Applications built with DI became streamlined and tolerant to rapid structural and behavioral change.
The modes of configuring a dependency injector also evolved from verbose sets of contracts and configuration files to more concise forms, using new language constructs such as annotations and generics. Dependency injectors also took better advantage of class manipulation tools like reflection and proxying and began to exploit design patterns such as Decorator [4] and Builder,[5] as well as Domain Specific Languages (DSL).
A growing emphasis on unit testing continues to be a natural catalyst to the growth of DI popularity. This made for agile programs, which are easily broken down into discrete, modular units that are simple to test and swap out with alternative behaviors. Consequently, loose coupling is a core driver in the evolution of DI.
We will explore the best approaches to solving problems with DI and look in detail at bad practices, pitfalls, and corner cases to watch out for, as well as the safety, rigor, and power of DI, properly applied. And most of all we'll see how DI can make your code lean, clean, and something mean.
We have now looked at several possible solutions and hinted at a cool alternative called DI. We've also taken an evening stroll down History Lane, turning at the corner of Terminology Boulevard (and somehow visited Hollywood on the way!). Before we proceed to the nuts and bolts of dependency injection, let's survey the landscape to learn what libraries are available, how they work and how they originated.
This is by no means a comparison or evaluation of frameworks; it's a brief introduction. Neither is it meant to be a comprehensive list of options. I will only touch on relatively well-known and widely used DI libraries in Java—and only those that are open source and freely available. Not all of them are purely DI-focused, and very few support the full gamut of DI design patterns described in this book. Nevertheless, each is worth a look.
Java is the birthplace of dependency injection and sports the broadest and most mature set of DI libraries among all platforms. Since many of the problems DI evolved to address are fundamental to Java, DI's effectiveness and prevalence are especially clear in this platform. We'll look at five such libraries ranging from the earliest incarnations of DI in Apache Avalon, through mature, widely adopted libraries like Spring and PicoContainer, to the cutting-edge, modern incarnation in Google, Guice.
Apache Avalon
Apache Avalon is possibly the earliest DI library in the Java world, and it's perhaps the first library that really focused on dependency injection as a core competency. Avalon styled itself as a complete application container, in the days before Java EE and application servers were predominant. Its primary mode of wiring was via custom interfaces, not setter methods or constructors. Avalon also supported myriad lifecycle and event-management interfaces and was popular with many Apache projects. The Apache James mail server (a pure Java SMTP, POP3, and IMAP email server) is built on Avalon.
Avalon is defunct, though Apache James is still going strong. Some of the ideas from Avalon have passed on to another project, Apache Excalibur, whose DI container is named Fortress. Neither Avalon nor Excalibur/Fortress is in common use today.
Spring Framework is a groundbreaking and cornerstone dependency injection library of the Java world. It is largely responsible for the popularity and evolution of the DI idiom and for a long time was almost synonymous with dependency injection. Spring was created by Rod Johnson and others and was initially meant to solve specific pains in enterprise projects. It was established as an open source project in 2003 and grew rapidly in scope and adoption. Spring provides a vast set of abstractions, modules, and points of integration for enterprise, open source, and commercial libraries. It consists of much more than dependency injection, though DI is its core competency. It primarily supports setter and constructor injection and has a variety of options for managing objects created by its dependency injector. For example, it provides support for both the AspectJ and AopAlliance AOP paradigms.
Spring adds functionality, features, and abstractions for popular third-party libraries at alarming rates. It is extremely well-documented in terms of published reference books as well as online documentation and continues to enjoy widespread growth and adoption.
PicoContainer and NanoContainer
PicoContainer was possibly the first DI library to offer constructor wiring. It was envisioned and built around certain philosophical principles, and many of the discussions found on its website are of a theoretical nature. It was built as a lightweight engine for wiring components together. In this sense it is well-suited to extensions and customization. This makes PicoContainer useful under the covers. PicoContainer supports both setter and constructor injection but clearly demonstrates a bias toward the latter. Due to its nuts-and-bolts nature, many people find PicoContainer difficult to use in applications directly. NanoContainer is a sister project of PicoContainer that attempts to bridge this gap by providing a simple configuration layer, with PicoContainer doing the DI work underneath. NanoContainer also provides other useful extensions.
Apache HiveMind was started by Howard Lewis Ship, the creator of Apache Tapestry, a popular component-oriented Java web framework. For a long time Tapestry used HiveMind as its internal dependency injector. Much of the development and popularity of HiveMind has stemmed from this link, though HiveMind and Tapestry have parted company in later releases. HiveMind originally began at a consulting project of Howard's that involved the development and interaction of several hundreds of services. It was primarily used in managing and organizing these services into common, reusable patterns.
HiveMind offers both setter and constructor injection and provides unusual and innovative DI features missing in other popular libraries. For example, HiveMind is able to create and manage pools of a service for multiple concurrent clients. Apache HiveMind is not as widely used as some other DI libraries discussed here; however, it has a staunch and loyal following.
Google Guice
Guice (pronounced "Juice") is a hot, new dependency injector created by Bob Lee and others at Google. Guice unabashedly embraces Java 5 language features and strongly emphasizes type and contract safety. It is lightweight and decries verbosity in favor of concise, type-safe, and rigorous configuration. Guice is used heavily at Google, particularly in the vast AdWords application, and a version of it is at the heart of the Struts2 web framework. It supports both setter and constructor injection along with interesting alternatives. Guice's approach to AOP and construction of object graphs is intuitive and simple. Guice is also available inside the Google Web Toolkit (GWT), via its cousin Gin.[6]
It is a new kid on the block, but its popularity is rising and its innovations have already prompted several followers and even some mainstays to emulate its ideas. Guice has a vibrant and thoughtful user community.
Several other DI libraries are also available. You could write a whole book on the subject! Some provide extra features, orthogonal to dependency injection, or are simply focused on a different problem space. JBoss Seam is one such framework; it offers complex state management for web applications and integration points for standardized services such as EJBs. It also offers a reasonably sophisticated subset of dependency injection.
As languages, C# and .NET are structurally similar to Java. They are both statically typed, object-oriented languages that need to be compiled. It is no surprise, then, that C# is found in the same problem space as Java and that dependency injectors are applied to equal effect in applications written in C#. However, the prevalence of DI is much lower in the C# world in general. While C# has ports of some Java libraries like Spring and PicoContainer, it also has some innovative DI of its own, particularly in Castle MicroKernel, which does a lot more than just DI. StructureMap, on the other hand, is a mainstay and a more traditional DI library.
Some platforms (or languages) make it harder to design dependency injectors because they lack features such as garbage collection and reflection. C++ is a prime example of such a language. However, it is still possible to write dependency injectors in these languages with other methods that substitute for these tools. For instance, some C++ libraries use precompilation and source code generation to enable DI.
Still other languages place different (and sometimes fewer) restrictions on types and expressions, allowing objects to take on a more dynamic role in constructing and using services. Python and Ruby are good examples of such duck-typed languages. Neither Python nor Ruby programs need to be compiled; their source code is directly interpreted, and type checking is done on the fly. Copland is a DI library for Ruby that was inspired by (and is analogous to) Apache HiveMind for Java. Copland uses many of the same terms and principles as HiveMind but is more flexible in certain regards because of the dynamic nature of Ruby.
This chapter was an exposition to the subject of building programs in units and has laid the groundwork for DI. Most software is about automating some process in the real world, such as sending a friend a message by email or processing a purchase order. Components in these processes are modeled as a system of objects and methods. When we have vast swaths of components and interactions to manage, constructing and connecting them becomes a tedious and complex task. Development time spent on maintenance, refactoring, and testing can explode without carefully designed architectures. We can reduce all of this to the rather simple-sounding problem of finding and constructing the dependencies, the requisite services of a component (client). However, as you've seen, this is nontrivial when dealing with objects that require different behaviors and does not often scale with typical solutions.
Prior to the use of dependency injectors, there were several solutions of varying effectiveness:
Construction by hand—This involves the client creating and wiring together all of its dependencies. This is a workable solution and certainly conducive to testing, but it scales very poorly as we've merely offloaded the burden of creating and wiring dependencies to clients. It also means clients must know about their dependencies and about their implementation details.
The Factory pattern—Clients request a service from an intermediary component known as a Factory. This offloads the burden to Factories and leaves clients relatively lean. Factories have been very successful over the years; however, they pose very real problems for testing and can introduce more with shared state. In very large projects they can cause an explosion of infrastructure code. Code using factories is difficult to test and can be a problem to maintain.
The Service Locator pattern—Essentially a type of Factory, it uses keys to identify services and their specific configurations. The Service Locator solves the explosion-of-factories problem by hiding the details of the service and its configuration from client code. Since it is a Factory, it is also prone to testability and shared state problems. Finally, it requires that a client explicitly request each of its dependencies by an arbitrary key, which can be unclear and abstruse.
Dependency injection offers an innovative alternative via the Hollywood Principle: "Don't call us; we'll call you!" meaning that a component need know nothing about its dependencies nor explicitly ask for them. A third-party library or framework known as the dependency injector is responsible for constructing, assembling, and wiring together clients with services.
DI solves the problem of object graph construction and assembly by applying the Hollywood Principle across components. However, this is just a small window into what is possible when an application is designed and built around DI. We will explore managing state and modifying the behavior and lifecycle of objects in broader contexts. We'll look at the nuances, pitfalls, and corner cases of various configurations and the subtle consequences of particular design choices. This book will equip you with the knowledge and careful understanding you need to design robust, testable, and easily maintainable applications for any purpose or platform. In the next chapter, you'll get a chance to get your hands dirty. We'll dive right in to using some of the DI libraries surveyed in this chapter and contrast their various approaches. Keep a bar of soap handy.
[1] Erich Gamma et al., Design Patterns: Elements of Reusable Object-Oriented Software (Addison-Wesley Professional Computing Series, 1994). Sometimes called the "Gang of Four" book.
[2] A Remote EJB is a type of service exposed by Java EE application servers across a network. For example, a brokerage may expose an order-placing service as a Remote EJB to various client banks.
[3] The article has been updated many times over the years. You can read the latest version at http://martinfowler.com/articles/injection.html.
[4] Erich Gamma et al, Design Patterns: "The Decorator Pattern."
[5] Ibid., "The Builder Pattern."
[6] Google Gin is a port of Guice for the GWT, a JavaScript web framework. Find out more at http://code.google.com/p/google-gin.