
"The effort to understand the universe is one of the very few things that lifts human life a little above the level of farce and gives it some of the grace of tragedy."
It's often a puzzle to programmers who are new to dependency injection about when to apply it. When it wasn't widely understood, even experienced practitioners applied it too much or too sparingly. The immature state of libraries contributed to this fuzzy application too, giving one the tools but not the discretion of its applicability.
A more fundamental set of confusion arises from the best practices of the language itself. Are these distinct from the patterns relevant to DI? Are they superseded? Or can they coexist (figure 9.1)?
It turns out that such questions are based on the wrong premise entirely. The best practices portended by a language and its engineering fundamentals are the same as those proffered by dependency injection (figure 9.2).
In other words, design well for the language and problem domain, and you will have designed well for the principles of testing, succinctness, and flexibility.
One of the core problems in multithreaded object-oriented languages is that of visibility. We showed in earlier chapters that altering the state of an object in one thread did not necessarily mean altering its state for all threads. This was particularly relevant with the problem of scope widening discussed in chapters 5 and 6. A more subtle incarnation of this problem occurs during (and immediately after) the construction of an object. Unless carefully designed, its fields may not be properly visible to all threads using it. This is a problem sometimes known as unsafe publication, and it's discussed in the following section on object visibility.
In chapter 3 we said that a constructor is a special method that runs once immediately after memory allocation of an object, in order to perform initialization work. As such, the object allocated is generally not visible to any other threads of execution than the one creating it. I say "generally," as there are some special circumstances under which objects can be visible.
One of the best ways to understand visibility is to investigate a hashtable. A hashtable is a flexible data structure, sometimes called an associative array, that's used to store key-value pairs. Hashtables are ideal for us because they give us a scenario where one thread may come in and change values that are being read by other threads simultaneously, introducing problems of ordering and visibility. Consider a hashtable that stores email addresses by name (we'll use Java's java.util.HashMap):
Map<String, Email> emails = new HashMap<String, Email>();
emails.put("Dhanji", new Email("[email protected]")); //yes, this is my
//real email =)
emails.put("Josh", new Email("[email protected]"));System.out.println("Dhanji's email address really is "
+ emails.get("Dhanji"));Reading from this map is fairly straightforward, since there's only one thread of execution through this program (the main thread). We can confidently say that email address values are placed in the map before they're read. This is satisfied by simple lexical ordering. In other words, the put() method is called before the get(). The values are said to be safely published to the reader.
We can elaborate on this example by introducing a second thread:
public class UnsafePublication {
private Map<String, Email> emails = new HashMap<String, Email>();
public void putEmails() {
emails.put("Dhanji", new Email("[email protected]"));
emails.put("Josh", new Email("[email protected]"));
}
public void read() {
System.out.println("Dhanji's email address really is "
+ emails.get("Dhanji"));
}
}If method putEmails() is called by Thread A and method read() is called by Thread B, there's a danger that the values read() is looking for may not yet be available. This problem cannot be solved by lexical ordering either (see listing 9.1).

In listing 9.1, two threads are started up in order. Thread A has the task of writing emails into the hashtable, while Thread B calls read(), which prints them. Now, even though it appears there is a lexical ordering, there's no guarantee that Thread A will run before Thread B. Several factors are at play. It may be that CPU scheduling preempts the start of Thread A. Or it may be that the compiler believes reordering instructions will lead to better throughput. The point is, once you introduce multiple threads accessing a shared resource, lexical guarantees are no longer valid.
There's a further subtlety with regard to unsafe publication. Even if Thread A did execute on the CPU before Thread B, which we could presumably tell by adding the following print statement,
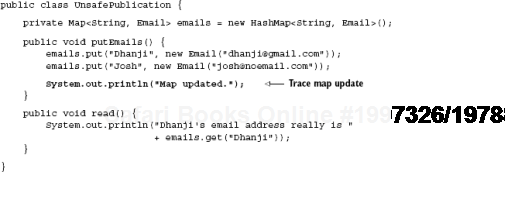
there's no guarantee that the program will behave properly. The following program's output is equally likely to happen:
Map updated. Dhanji's email address really is null
What's going on? The "Map updated." signal was printed in Thread A before the read. We should quite certainly have my email address in the hashtable! We can further confound the issue as shown in listing 9.2.
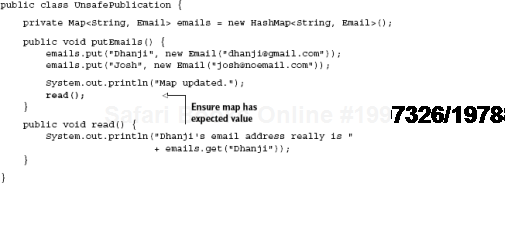
What will this program print? Can it possibly print something as absurd as this?
Map updated. Dhanji's email address really is[email protected]Dhanji's email address really isnull
Surely, not! In fact, it turns out this is quite possible because a guarantee of order alone is insufficient for safe publication. This is another manifestation of the visibility problems. There are several reasons why Thread B may see a null value, even though as far as Thread A is concerned, the map has been updated. We encountered one of these in an earlier chapter when looking at memory coherency. Without sufficient synchronization, the JVM makes no guarantees about visibility of fields between threads. This is a deliberate choice made by the language designers to allow for maximum flexibility in optimizations on various platforms. Thread A's updates to the hashtable may not yet be synchronized with main memory. Thus, they're not published to other threads. So while a thread can see its own updates, there's no assurance that others will. Now let's look at how to correctly publish to all threads.
It's easy to see how this problem can creep into DI as well. Unless properly published, objects may appear incompletely constructed to participating threads, with unavailable or partially constructed dependencies. Consider the equivalent of the hashtable we just saw:

MoreUnsafePublication is a simple variant of the hashtable that reads an email address using its dependency EmailDatabase. This time the issue of publication is not with the hashtable values but with the EmailDatabase dependency itself. Threads that call method read() cannot rely on the fact that the dependency is available. Without sufficient synchronization, the thread creating the object does not safely publish its fields to other threads. The following could easily result in a NullPointerException:
public void read() {
System.out.println("Dhanji's email address really is "
+ service.get("Dhanji"));
}Or worse, it could result in further corruption of the object graph. A very simple solution to this problem is to declare the field as final.[33] Final fields are given the guarantee of safe visibility to all threads concerned. Because these fields are generally always set in the constructor, they'll be visible to all threads once the constructor completes.
public class SafePublication {
private final EmailDatabase service;
public SafePublication(EmailDatabase service) {
this.service = service;
}
public void read() {
System.out.println("Dhanji's email address really is "
+ service.get("Dhanji"));
}
}In SafePublication, threads may call read() and expect dependency EmailDatabase to be set correctly. This holds for any thread, even those that did not construct the instance. This is a very simple but powerful solution that's an ideal choice for the vast majority of multithreading problems. It's good practice to declare fields final even if you believe the instance will only ever participate in one thread, as this gives a clear indication of intent.
As we've stated in earlier chapters, thread-safety is a concept very relevant to dependency injection. In the following section, we'll look at exactly what these semantics imply for wiring objects with dependencies.
We've just seen how we can run into visibility problems between threads. One typically encounters these problems only with singletons. This is because, in general, only singletons are shared by two (or more) threads. Final fields are a safe solution to this problem if you can guarantee that a reference to the object does not escape during construction (we'll look at what escaping means shortly). Many dependency injectors can also help by providing extra synchronization during the construction of singletons. For instance, PicoContainer can be put into a locking mode, which ensures object creation happens in a synchronized state:
MutablePicoContainer injector = new DefaultPicoContainer();
injector.as(LOCK, CACHE).addComponent(MyObject.class);
MyObject obj1 = injector.getComponent(MyObject.class);
MyObject obj2 = injector.getComponent(MyObject.class);Instances obj1 and obj2 are created in a synchronized fashion, so the dangers of visibility are safely mitigated. The characteristics LOCK and CACHE instruct PicoContainer to use locking and to create singletons. This would be equivalent to the following:
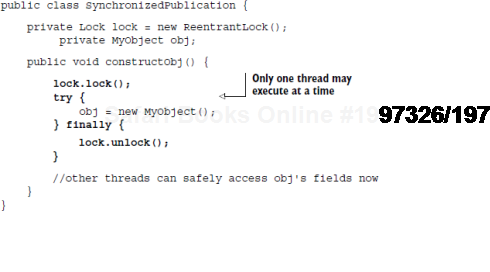
Now, fields of MyObject are correctly set and visible to all threads regardless of whether or not they are declared final:

Guice also provides a similar guarantee for all of its singletons. However, despite these niceties, one should not rely on the injector to do the work of safe wiring. If you design your classes to be well behaved in threaded environments, they will be safe regardless of whether or not you receive help from libraries. This is especially significant if you want to reuse code in different environments. It's also important when designing objects for concurrency. Furthermore, it's an implicit declaration of intent. When someone comes across your code and the final class members, it's very clear that they weren't meant to be changed. Even if you accidentally try to reassign field values after construction, you can't run afoul of mutability since the compiler alerts you to the problem. Recall that any attempt to modify a final field after construction,

results in a clear, fast failure of compilation:
Information:Compilation completed with 1 error and 0 warnings
Information:1 error
Information:0 warnings
EarlyWarning.java
Error:Error:line (9)cannot assign a value to final variable depThe documenting thread-safety annotations, @Immutable, @ThreadSafe, @NotThreadSafe, and @GuardedBy that we've used in earlier chapters are an additional clarification of behavioral intent. While the injector can help in minor ways, it's ultimately up to you to create code that's both safe and efficient.
In fact, it's a good principle to design without the injector in mind for all threading cases. DI is meant to help your code become more flexible and testable in design, but it doesn't relieve you of the burden of engineering good code. Or should I say joy?
Another interesting but higher-level consideration is deciding when to use a dependency injector and when not to. This can often be quite tricky, as simplistic as it sounds. Ahead, we'll look at rules of thumb that help in making this decision.
The question of which classes of objects to manage using dependency injection is often a tricky one. Especially for programmers new to the technique, it can be quite a double-edged sword. Some are overeager to apply it, creating everything with the injector. Some are too careful and use DI sparingly, almost like a Factory or Service Locator. Neither of these extremes is particularly prudent. And both are especially counterproductive in large and complex codebases.
Most of the time, it's quite easy to determine what objects ought to be created and managed by dependency injection. A rule of thumb is to leave anything that's a service or action component to the purview of the injector and any class that models data to traditional, by-hand usage. Now let's see that principle in practice, in dealing with a specific example that uses data and service objects.
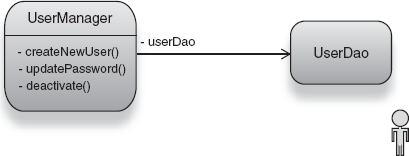
Let's take the case of an imaginary online auction house. Here you have several objects for managing users, bids, list items, reconciliation, and so forth. These are couched as three primary services, as shown in figure 9.3:
AuctionManager—Manages bids and auction statusItemManager—Manages list items and descriptionsUserManager—Manages user accounts and history
These three services are classes with several dependencies of their own. For example, UserManager needs a DAO to read and write user details to a data store:
public class UserManager {
private final UserDao userDao;
public UserManager(UserDao userDao) {
this.userDao = userDao;
}
//operations on user...
}
UserDao, in the example, is our interface to the data store. UserManager uses it to create new users, update details such as name and password, and in rare cases mark the account as inactive. Listing 9.3 shows the same class in some detail (also see figure 9.4).

In listing 9.3, we have three methods that perform some kind of manipulation of the User data object. createNewUser() registers a new user (represented by an instance of the User object) by saving it to a data store:
public void createNewUser(User user) {
validate(user);
userDao.save(user);
}This method also validates the instance of user, ensuring that all the data going in is correct. We don't deal with reporting validation errors at this juncture, since it is already assumed this has been done at the presentation layer (that is, the website). This validation step is purely a safeguard against programmer error. Once we're sure the data is valid, it's passed to UserDao to be saved.
Similarly, method updatePassword() performs data manipulation on User, but this time it's of an instance that already exists. The specific user is identified by a numeric userId, and it's the job of UserDao to locate and retrieve the relevant instance from the data store:
public void updatePassword(long userId, String password) {
User user = userDao.read(userId);
user.setPassword(password);
validate(user);
userDao.save(user);
}We then set the new password on this instance, signaling a change of password, and resave the details in the same fashion.
The third method in our set of operations deactivates a user account (presumably due to inactivity or violation of terms of use). Aptly named, method deactivate() takes in the numeric userId, deactivates it, and saves the relevant instance:
public void deactivate(long userId) {
User user = userDao.read(userId);
user.deactivate();
userDao.save(user);
}We don't need to validate the User this time since we aren't modifying any data in it with untrusted data received from actual user input.
One thing that's clear to us from these three operations is that UserDao and UserManager are services. The common thread that runs through them is that they perform operations on instances of the User class, which is data. Clearly, UserDao and UserManager are appropriate to be constructed and tested with DI. Class User, on the other hand, is constructed often at the presentation layer and has no dependencies. Listing 9.4 describes this data model class (also shown in figure 9.5).
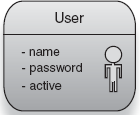
Example 9.4. The User data model class
public class User {
private long userId;
private String name;
private String password;
private boolean active = true;
public User(long userId, String name) {
this.userId = userId;
this.name = name;
}
public long getUserId() {return userId;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getPassword() {
return password;
}
public void setPassword(String password) {
this.password = password;
}
public boolean isActive() {
return active;
}
public void deactivate() {
this.active = false;
}
}In listing 9.4, all four fields are scalar data types. In other words, they are fields of type String, boolean, or long. And each datum has no real domain semantics. There's nothing special about Strings, booleans, or longs insofar as an auction house is concerned. Consider this in contrast to User, which is itself a data type, but one that's specific to the problem domain we're concerned with. It also captures specific operations around that domain (for example, deactivating user accounts).
Apart from having no real dependency structure, another interesting point about the User class is that almost all of its fields are mutable. Setter methods exist for name, password, and the active flag. This is because User models the real-world state of a user's account. Several instances of this class exist, and the specific values of each instance may change gradually over time, that is, when someone changes his password or has his account deactivated.
Clearly, User objects are not ideal to be instantiated by DI. There's no gain to be had from interception or lifecycle for Users. Scope also doesn't quite fit in this scenario, since all Users are no scoped, but at the same time it can persist forever in a data store. Furthermore, there isn't anything significant to test in User code. Most methods are dumb setters or accessors, so it's appropriate to create and manage them by hand, like any other scalar object. Listing 9.5 is an example of doing just that from a new-user registration page.
@RequestScoped
public class NewUserPage {
private final UserManager userManager;
@Injectpublic NewUserPage(UserManager userManager) {
this.userManager = userManager;
}
public HTML registerNewUser(String name) {
userManager.createNewUser(new User(nextUserId(), name));
...
}
}NewUserPage represents a web page on the auction website where new users sign up to list and bid on items (see figure 9.6).

It is HTTP request scoped as is marked by the @RequestScoped annotation (recall guice-servlet and web scopes from chapter 5):
@RequestScoped
public class NewUserPage {
private final UserManager userManager;
...
}NewUserPage also takes data coming in from browser data entry and converts it into a created user by passing it on to the UserManager:
public HTML registerNewUser(String name) {
userManager.createNewUser(new User(nextUserId(), name));
...
}UserManager is a singleton service that's shared by all instances of the NewUserPage and is called at various data points for purposes like creating users, deactivating their accounts, or changing their details.
The other services, AuctionManager and ItemManager, also model actions on data model objects relating to auctions, list items, and so forth. Here too, the data model objects can be separated from their operations along simple lines (see figure 9.7).
Auctions, Items, ShoppingCarts, Money, and Users are all data classes that are operated on by the aforementioned singleton services and web pages. We can thus make an easy distinction between these classes and those that can benefit from dependency injection.
Another important design principle is encapsulation, sometimes called information hiding. In the following section, we'll look at how this applies to DI and techniques for taking advantage of it.
One of the core principles of OOP is encapsulation, that is, the hiding of any information within a component that is relevant only to that component. In classes, this takes the form of marking members as private. Not only does this make sense in terms of hiding information that's irrelevant to anyone else, it also ensures against accidental leaking of semantics.
Leaking of private member fields can be very dangerous since it can lead to tight coupling between components. A class making use of a specific kind of messaging service (say, email messaging) should not expose its implementation details to the outside world. If other classes mistakenly begin using its dependencies, this can lead to tight coupling. Let's take the case of a Messager service represented by the following interface
public interface Messager {
void send(Message msg);
}and its email-backed implementation:
public class Emailer implements Messager {
public void send(Message msg) {
//send message via email...
}
}Emailer converts the incoming generic message into an email and sends it away to recipients. So far so good. Now let's see what happens if we accidentally leak this abstraction:
public interface Messager {
void send(EmailMessage msg);
}
public class Emailer implements Messager {
public void send(EmailMessage msg) {//send message via email...
}
}Now, both Messaging and Emailer send EmailMessages in method sendMessage(). While this may seem okay at first glance, a closer examination reveals otherwise. Say you wrote a new kind of messaging service that used the popular Jabber instant messaging protocol to send messages:

Because of the leaked abstraction, method send() in JabberMessager does not actually implement send() from the Messager interface. Fortunately, this code will fail on compilation, complaining that the Messager interface is not fully implemented. But we're still stuck with the problem of not being able to change the messaging service's transport—stuck with email, that is. This highlights what is an extremely poor abstraction that has pretty much destroyed our encapsulation. We have effectively exposed the internals of the Emailer class directly and rendered the Messager interface irrelevant.
Of course, this is easily fixed in our case by reverting to the original implementation:

This version of Emailer correctly converts the incoming implementation-neutral Message object into an EmailMessage, which can be sent over email. Now it's easy for us to create and swap in a JabberMessager system with little difficulty and no impact to client code:

JabberMessager now successfully compiles, and the system behaves as expected.
We can take the idea of encapsulation a step further. It isn't always possible to make implementation details private—sometimes implementation classes need to share functionality among themselves. For example, a JabberMessager interface may depend on a JabberMessageConverter and a JabberTransport in order to convert and send the message:

These are dependencies that exist as public classes. And therefore they can be accessed, subclassed, and used by anyone, leading to a potential horde of tight coupling. In Java, there's an extra layer of visibility that we can take advantage of to prevent anyone outside a package (namespace) from knowing or using classes. This is sometimes called package-privacy or package-local access. Package-local access has no special keyword and is denoted by the lack of an access specifier. Dependency injectors allow us to take advantage of this special visibility by exposing only service interfaces and configuration from each package, hiding any implementation details within. Let's apply this to the Jabber example with Guice; see listing 9.5.
Example 9.5. Package encapsulation of the Jabber services
package example.messaging;
public interface Messager {
void send(Message msg);
}
class JabberMessager implements Messager {
private final JabberTransport transport;
private final JabberMessageConverter converter;
public void send(Message msg) {
...
}
}
class JabberTransport {
...
}
class JabberMessageConverter {
...
}In listing 9.5, all of the implementation classes are declared package-local. They can't be seen from outside the example.messaging package by any classes. Moreover, all communication and use of Jabber services must occur through the Messager interface. This allows us a degree of control over the contract and behavior of our messaging module. It's also easy to specify API behavior to clients, and the documentation for this module is ridiculously simple (nothing more than the single-method Messager interface).
All we need to do to expose Jabber messaging to clients is place a single Guice module in the package, which contains all the nitty-gritty binding details:
public class MessagingModule extends AbstractModule {
@Override
protected void configure() {
bind(Messager.class).to(JabberMessager.class);
}
}The messaging module does nothing more than instruct the injector to use JabberMessager wherever Messaging services are needed. Here's such a user of Jabber messaging:
public class MessageClient {
private final Messager messager;
public MessageClient(Messager messager) {
this.messager = messager;
}
public void go() {
messager.send(new Message("Dhanji", "Hi there!"));
}
}This ensures loose coupling between client code and the messaging module, since clients need only attach to the Messaging interface. We can even use multiple implementations this way and distinguish between them using binding annotations:
public class MessagingModule extends AbstractModule {
@Override
protected void configure() {
bind(Messager.class).annotated-
With(Im.class).to(JabberMessager.class);
bind(Messager.class).annotatedWith(Mail.class).to(Emailer.class);
}
}Now clients can choose which implementation to use without coupling to any internals:
public class MessageClient {
private final Messager mailMessager;
private final Messager imMessager;
public MessageClient(@Im Messager imMessager, @Mail Messager
mailMessager) {
this.imMessager = imMessager;
this.mailMessager = mailMessager;
}
public void go() {Message msg = new Message("Dhanji", "Hi there!");
imMessager.send(msg);
mailMessager.send(msg);
}
}And all is well with the world.
A good example of this kind of encapsulation can be found in the warp-persist integration library we explored in chapter 8. Figure 9.8 is a screenshot of warp-persist's package tree. Notice the classes with a hollow bullet point to the left of them—these are package-local. Public components are restricted to hardly any public classes at all, thus vastly reducing the potential for tight coupling and abstraction leaking.
This is directly reflected in the API documentation for warp-persist. Look at the resulting streamlined and simple Javadoc frame in figure 9.9.
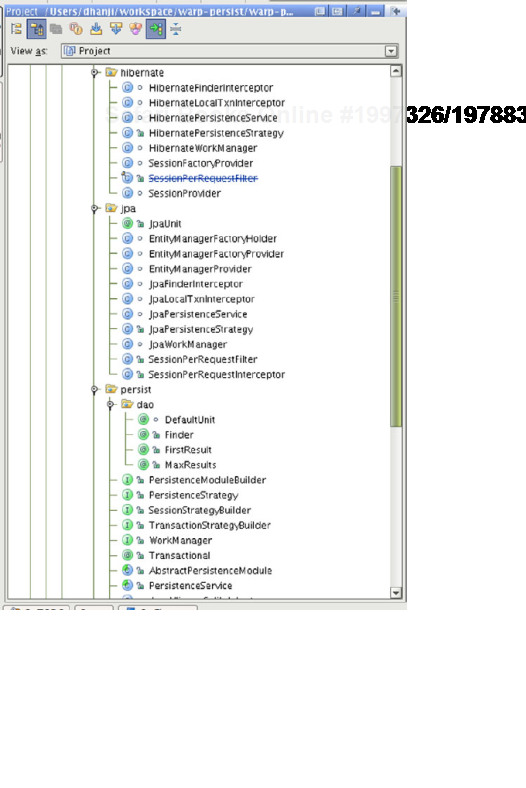
Figure 9.8. Screenshot of warp-persist's package tree (hollow bullets are packageprivate classes)<br></br>
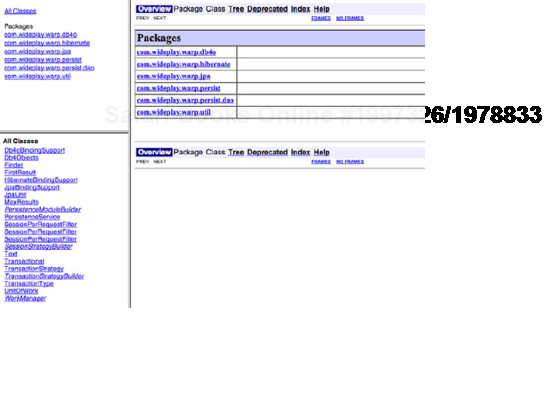
Figure 9.9. Javadoc of warp-persist's main package consisting of only enums, annotations, interfaces, and abstract classes<br></br>
Neat! A good rule of thumb is to apply package privacy to anything that's not an interface, enum, annotation, or abstract class because these types have very low potential for leaking abstraction logic. You can apply these principles and take advantage of dependency injection to get better encapsulation at the package and module levels.
In previous chapters, we looked at safe design with respect to multiple threads. This often meant correct synchronization. Earlier in this chapter we also looked at visibility. In the following section, we'll take a more performance-focused approach and look at the action of multiple threads concurrently.
Concurrency is increasingly a very important aspect of modern applications. As we scale to higher levels of traffic and demand, there's a greater need for multiple concurrent threads of execution. Thus, the role of objects managed by the dependency injector is extremely important. Singletons are a particularly significant example of this need.
In a large web application handling several hundreds of requests per minute, a poorly designed singleton can be a serious bottleneck. It introduces ceilings on concurrent performance and can even render the application unscalable under certain conditions.
Poor concurrent behavior is also more common than you might think. And since its effects are highlighted only during performance testing, it can be difficult to identify and mitigate, so it's quite relevant for us to study the effects of concurrency on singletons.
Mutability is an essential variable in this problem, so let's start with that.
Earlier in this chapter we explored the dangers of mutable objects as they manifested in visibility and publication problems. We also established that declaring fields final and making objects immutable was an efficient and robust solution to the thread-safety question. Now we'll explore exactly what it means to be immutable. Some pitfalls are contained within the idea of immutability too. To change things up, let's explore this as a series of puzzles.
IMMUTABLITY PUZZLE 1
Is the following class, Book, immutable?
public class Book {
private String title;
public String getTitle() {
return title;
}
public void setTitle(String title) {
this.title = title;
}
}ANSWER 1
This one's easy: no. The value of its title field can be changed arbitrarily by calling setTitle(), so it is clearly not immutable. We can make Book immutable by declaring title final:
public class ImmutableBook {
private final String title;
public ImmutableBook(String title) {
this.title = title;
}
public String getTitle() {
return title;
}
}Once set in the constructor, the value of title cannot change.
IMMUTABLITY PUZZLE 2
Is the following class, AddressBook, immutable?
public class AddressBook {
private final String[] names;
public AddressBook(String[] names) {
this.names = names;
}
public String[] getNames() {
return names;
}
}ANSWER 2
The value of the names field is set once in the constructor and is declared final. So AddressBook should be immutable, right? No! In fact, the subtle point is that since names is an array, only the reference to it is immutable by declaring it final. The following code is perfectly legal and can potentially lead to a world of hurt where multiple threads are concerned:
public class AddressBookMutator {
private final AddressBook book;
@Inject
public AddressBookMutator(AddressBook book) {
this.book = book;
}
public void mutate() {
String[] names = book.getNames();
for (int i = 0; i < names.length; i++)
names[i] = "Censored!";
for (int i = 0; i < names.length; i++)
System.out.println(book.getNames()[i]);
}
}Method mutate() destructively updates the array, even though field names is unchangeable. If you run the program, it prints "Censored!" for every name in the book. The only real solution to this problem is not to use arrays—or to use them very sparingly behind well-understood safeguards and documentation. Choose library collections (such as those found in java.util) classes where possible as these can be guarded by unmodifiable wrappers. See puzzle 3 for an illustration of using java.util.List instead of an array.
IMMUTABLITY PUZZLE 3
Is the following class, BetterAddressBook, immutable?
public class BetterAddressBook {
private final List<String> names;
public BetterAddressBook(List<String> names) {
this.names = Collections.unmodifiableList(names);
}
public List<String> getNames() {
return names;
}
}ANSWER 3
Thankfully, yes; BetterAddressBook is immutable. The wrapper provided by the Collections library ensures that no updates can be made to the list once it has been set. The following code, though it compiles, results in an exception at runtime:
BetterAddressBook book = new BetterAddressBook(Arrays.asList(
"Landau", "Weinberg", "Hawking"));
book.getNames().add(0, "Montana");This is a variant on puzzle 3. Take the same BetterAddressBook class we saw earlier. Is it at all possible to construct it in such a way that I can mutate it? You're not allowed to change the code of BetterAddressBook.
ANSWER 4
The answer is simple, if a bit confounding:
List<String> physicists = new ArrayList<String>();
physicists.addAll(Arrays.asList("Landau", "Weinberg", "Hawking"));
BetterAddressBook book = new BetterAddressBook(physicists);
physicists.add("Einstein");Now an iteration through BetterAddressBook's list of names
for (String name : book.getNames())
System.out.println(name);actually produces the mutated list:
Landau
Weinberg
Hawking
EinsteinSo, really, we must revise what we said in the answer to puzzle 3. BetterAddressBook is immutable only if its dependency list is not leaked anywhere else. Better yet, you can rewrite a completely safe version of it by copying the list at the time of its construction:
@Immutable
public class BestAddressBook {
private final List<String> names;
public BestAddressBook(List<String> names) {
this.names = Collections.unmodifiableList(
new ArrayList<String>(names));
}
public List<String> getNames() {
return names;
}
}Now you're free to leak and mutate the original list,
List<String> physicists = new ArrayList<String>();
physicists.addAll(Arrays.asList("Landau", "Weinberg", "Hawking"));
BetterAddressBook book = new BetterAddressBook(physicists);
physicists.clear();
physicists.add("Darwin");
physicists.add("Wallace");
physicists.add("Dawkins");
for (String name : book.getNames())
System.out.println(name);and BestAddressBook remains unaffected:
Landau Weinberg Hawking
While it may not always be necessary to take such a cautious approach, it's advisable to copy argument lists if you're at all unsure about them escaping into other uses subsequent to construction of the immutable object.
IMMUTABLITY PUZZLE 5
Is the following class, Library, immutable? (Recall Book from puzzle 1.)
public class Library {
private final List<Book> books;
public Library(List<Book> books) {
this.books = Collections.unmodifiableList(
new ArrayList<Book>(books));
}
public List<Book> getBooks() {
return books;
}
}ANSWER 5
Library depends on a list of Books, but it takes care to wrap the incoming list in an unmodifiable wrapper and copies it prior to doing so. Of course, its only field is final too. Everything looks right—or does it? It turns out that Library is mutable! While the collection of books is unchangeable, there's still the Book object itself, which, as you may recall from the first puzzle, allows its title to be set:
Book book = new Book();
book.setTitle("Dependency Injection");
Library library = new Library(Arrays.asList(book));
library.getBooks().get(0).setTitle("The Tempest"); //mutates LibraryThe golden rule with immutability and object graphs is that every dependency of an object must also be immutable. In the case of BestAddressBook, we got lucky, since Strings in Java are already immutable. Take care to ensure that every dependency you have is safely immutable before declaring an object as such. The @Immutable annotations mentioned in chapter 6 help a great deal in conveying and documenting this intent.
While immutability is a desirable goal, often you need to change state in order to do useful work. In the next section we'll look at how to do this and also keep our code performant.
Sometimes it just happens that you really need mutable objects. It isn't always possible to make everything immutable (though it would be nice!). This need usually arises when you have to maintain some kind of central state in a system that's shared between many or all threads. This is fairly common in large applications. You may need a counter to keep track of the number of requests to a particular resource, or you may be caching heavyweight data in application memory to avoid expensive trips to a database.
Generally, you want to isolate any such use cases and design them very carefully, giving yourself ample slack to test and reason about these multithreaded services. Essentially, such services need to synchronize the data between threads in such a way that the data remains coherent and that threads are not paused for long periods awaiting data. These are two very different problems, with quite different solutions. And they are classed under the headings of synchronization and concurrency, respectively.
THREAD-SAFE COUNTING
Consider a simple counter. Every time a message is received, it increments the count by one. There are several message handler threads, and they must all update the same counter. If they updated separate counters, there would be no thread-safety problem, but we'd be unable to tell what the total count was. So here's what such a counter might look like:
public class MessageCounter {
private int count;
public void messageReceived() {
count++;
}
}Method messageReceived() is called by each message-handling thread upon receiving a message to increment the count. Now, variable count is not final and is updated concurrently by more than one thread. So it is very possible that it will get out of sync and read an invalid or corrupt count. A simple solution is to synchronize the counter so that only one thread may increment the count at any given time:
public class MessageCounter {
private int count = 0;
public synchronized void messageReceived() {
count++;
}
}In this version, the singleton-scoped instance of MessageCounter itself acts as the lock. Each message-receiving thread must wait its turn in order to acquire the lock, increment the count, and release it. This solution works, and we are assured that the count never goes out of sync and that each increment is published safely to all threads.
For this very simple case, the synchronization solution is probably good enough. But think about what happens when there is an enormous number of threads going through the counter. Every one of them must wait to acquire and release the lock before it can proceed with handling the message. This can lead to a serious bottleneck. The problem gets even worse if additional work needs to be done before the counter can be incremented (say, looking up who sent the message from a hashtable). All threads must wait inexorably, until the one holding the lock can finish. This can lead to very poor throughput.
CONCURRENT COUNTING
Concurrent algorithms and data structures are designed with speed and scalability in mind. Multiple threads may liberally hit the critical code without suffering the single-file throughput problems of synchronization. This is accomplished in many ways, primarily by taking advantage of some special atomic operations provided by modern CPUs. Atomic operations execute in one go on the CPU and cannot be interrupted by another thread being prioritized while they're executing. Atomic operations are thus somewhat like a very small block of synchronized code that performs just one instruction.
In Java, these are modeled by the java.util.concurrent.atomic library and associated data structures found in the java.util.concurrent package. Using these we can rewrite the counter to be concurrent rather than sequential:
public class MessageCounter {
private final AtomicInteger count = new AtomicInteger(0);
public void messageReceived() {
count.incrementAndGet();
}
}The method incrementAndGet() executes atomically. This is opposed to count++, which is actually three operations masquerading as one:
Read value from
count.Increment value by one.
Write new value back to
count.
In the non-atomic situation, intervening threads can easily alter count concurrently and corrupt its value. With the atomic incrementAndGet() this cannot happen.
Furthermore, if a thread is slow in incrementing its count (due to additional work that it's doing, perhaps), this doesn't block other threads from making progress in the meantime as synchronization would. This leads to real concurrency of threads and a substantial increase in throughput.
The value of concurrent data structures becomes more readily apparent when dealing with more complex forms of data, such as those stored in hashtables. Consider the second use case we mentioned, where data is placed into a cache and then looked up by multiple threads to prevent expensive trips to a database. Using a traditional synchronized hashtable this would look as follows:
public class SimpleCache {
private final Map<String, Data> map =
Collections.synchronizedMap(new HashMap<String, Data>());
public void set(String key, Data val) {
map.put(key, val);
}public Data get(String key) {
return map.get(key);
}
}SimpleCache uses a synchronized wrapper around a simple hashtable. This wrapper has a single lock that is acquired on every get() and every put() operation. This is done to safely publish values (as we discussed early in this chapter) to all threads. However, SimpleCache is extremely slow since every thread must wait for the hashmap to perform a lookup operation and release the lock held by the current thread. put() operations can be even worse since they can involve resizing the underlying array when it becomes full. In any high-traffic environment, this is unacceptably underperformant. What we need is for threads to be able to look up values concurrently and perhaps wait only when there are many insertions going on. What we need is a concurrent hashtable:
import java.util.concurrent.ConcurrentHashMap;
public class ConcurrentCache {
private final Map<String, Data> map
= new ConcurrentHashMap<String, Data>();
public void set(String key, Data val) {
map.put(key, val);
}
public Data get(String key) {
return map.get(key);
}
}This is a special hashtable implementation because it doesn't use locking to read from the map at all! It allows multiple threads to make progress to the same values without requiring a coarse-grained lock as synchronized hashtables do. Instead it locks only on insertion operations but using more fine-grained locks distributed across the hashtable. The keys are partitioned along a configurable number of stripes. Each stripe is assigned a lock, and any concurrent insertions to keys in the same stripe must wait for sequential access (just like synchronization). Dividing the table into even a small number of stripes is several times more efficient than locking the entire table every time.
Opt for concurrent data structures wherever you can. And reason carefully about the semantics of making any object a singleton, because you will have to worry about thread safety and concurrency. Finally, conquer your problem by assessing it through the three cordons of immutability, safe publication, and concurrency.
This chapter was a thorough workout in best practices and concurrency. Architecturally, the best practices portended by a language and its design patterns are the same as those required by dependency injection. Where possible you should design with testability in mind but not rely on the behavior of an injector.
One of the primary problems to face with singletons and objects shared between threads is that of visibility. Dependencies set on an object need to be visible to all threads that use the object. This is known as safe publication. One way to guarantee proper visibility is to make objects immutable. This involves plenty more than merely declaring fields final, as you saw with a series of five puzzles on the topic. Immutability requires that every object in a graph be immutable and that no dependencies "escape" after construction.
Designing objects for better encapsulation is also very important. Dependency injectors like Guice allow you to hide implementation classes in package privacy and expose only interfaces to clients. This helps prevent tight coupling and the accidental leakage of internals. Another important design question is which objects to create and manage via the injector. A rule of thumb is to ask whether an object is a service component or whether it models data. If the latter, there's no benefit to be gained from dependency injection, lifecycle, scope, and so on, and you're better served working with them by hand.
Finally, we explored what it means to be thread-safe in mutable cases. This was especially tricky, since synchronization through locks is insufficient in all cases. In high-traffic environments, you cannot afford to let threads queue up, waiting to acquire a single global lock to a shared resource. The answer is to use concurrent data structures such as those provided by the java.util.concurrent library. These data structures purport atomic operations and more fine-grained locking, which allows for better throughput in systems that require a high level of concurrency.
This chapter gave you a solid, low-level grounding in designing code for safe, highly performant Java applications using dependency injection. Next we'll take a broader view and look at how to integrate an application with other libraries and utility frameworks.
[33] See this article on developerWorks for more information: http://www.ibm.com/developerworks/library/j-jtp03304/