
"A common mistake that people make when trying to design something completely foolproof is to underestimate the ingenuity of complete fools."
As you've just seen in chapter 5, scope is a very powerful tool for managing object state. In particular, it is a tool for making your objects and services agnostic of state management. In other words, you allow the injector to worry about the details of state and context, and you keep your objects lean. This has advantages in both productivity and design elegance.
In this chapter we'll look at how to apply these same principles to any stateful context and to broaden the applicability of scoping as a tool in dependency injection. Most libraries provide some manner of extending the available scoping functionality. We'll look at how to leverage this in Guice and Spring, in particular.
Closely related are the perils of scoping. While it is extremely powerful as a tool for reversing responsibility, state management can get very tricky to design and build around. We'll look at common pitfalls and some very hairy corner cases, which one would do well to respect. We'll also see how good design can ameliorate or completely avoid these cases and how it can also facilitate good testing.
Finally, I present some ideas for using scope in unusual and potentially interesting ways for very large applications that require enormous scalability. But first, let's lay the groundwork and explore how to customize scope.
We've had a long look at web scopes. HTTP request and HTTP session scopes provide a useful set of tools for working with context in web applications, particularly for dealing with user interactivity. Most applications (including web apps) are built around some form of data manipulation. In general this data is stored in a relational database like Oracle or PostgreSQL. In object-oriented languages, the same data is modeled as interrelating classes of objects and then mapped to database tables. Objects are marshaled to their counterpart tables, then retrieved as required in future interactions. This is often called object (or data) persistence.
The process of moving data between application memory (in the form of objects) and database storage (in the form of relational tables) occurs in series of tasks called transactions. Let's look at how to treat transactions as a context and define a custom scope around them.
A transaction is a form of interaction with a data store that is atomic, consistent, isolated, and durable. Such transactions are sometimes referred to as ACID transactions. This is what they imply:
Atomicity—All of the tasks inside a transaction are successful or none are.
Consistency—Data modified by a transaction does not violate prior constraints.
Isolation—Other transactions can never see data in a partial state as it is being transacted.
Durability—This refers to the ability to recover from failures while inside a transaction and leave data consistent.
These transactions extend to your application logic, meaning many different, unrelated components can all participate within a single transaction in order to perform a logical operation on data. Rather than pushing each task through in isolated fashion, it makes sense to combine them as a logical unit under an overall purpose. They are said to be coarse grained. When creating an employee record in the database, a transaction may include logic to create annual leave blocks, stock option grants, and other related records. If any one of these tasks fails (for instance, stock could not be assigned because of a shortage), the entire transaction is rolled back and no employee is created. This prevents the creation of a partial, invalid employee record and keeps the database in a consistent state. A new attempt must be made, once the stock shortage is corrected, in a separate transaction.
Like singletons or HTTP sessions, a transaction is also a specific context within an application. An injector can take advantage of this to reduce the passing around of ancillary data and placeholder objects and generally improve the maintainability of code by moving transactional concerns into transaction-scoped dependencies.
Before defining your own scope, it helps to ask a few questions:
Is the context that this scope represents clearly defined?
Objects must live for the entire life of this scope; does this work for all scoped instances? You should never have two life spans for a key within a scope.
Is there going to be more than one thread accessing objects in this scope?
Transaction scope has well-understood start and end points (see figure 6.1). A transaction is also generally confined to one thread of execution. While it's by no means impossible to consider scopes that may be accessed by multiple threads, it is certainly preferable to design scopes that are confined to a single thread. These scopes are inherently simpler and easier to test and reason about. Classes that are bound under thread-confined scopes also don't need to worry about thread-safety, and they are therefore easy to design and test.
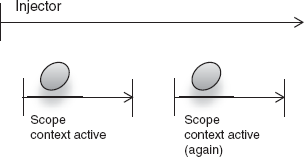
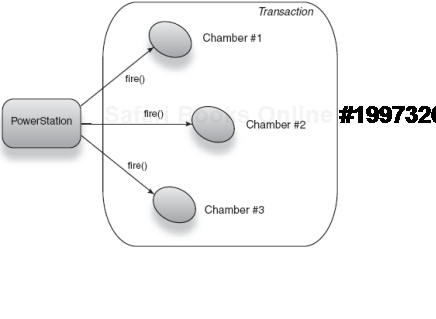
So it looks like we're on good ground. Before scoping, let's define a use case. A nuclear power station needs software written to start the reactors and begin the flow of power to an electrical grid. The restriction is that there are three chambers to activate, and they must either all activate or none should. If the chambers are too hot, none must activate. We'll model this as a transaction with a common logical goal, that being the startup of the power station. Listing 6.1 imagines this transactional power station.
Example 6.1. Three energy chambers activated in concert under a transaction
public class PowerStation {
...
public void start() {
transaction.begin();
chamber1.fire();
chamber2.fire();
chamber3.fire();
transaction.commit();
}
}We won't worry too much about the transaction architecture. The important thing is the context that it provides. In PowerStation's case, that context exists for the duration of method start(), finishing when it returns (figure 6.2 shows a model of this transaction). The call to transaction.commit() implies a successful completion of the transaction.
Now let's introduce the failure scenario, where one of the chambers may fail to start by throwing an exception:
public void start() {
transaction.begin();
boolean failed = false;
try {
chamber1.fire();
chamber2.fire();
chamber3.fire();
} catch (StartFailedException e) {
failed = true;
} finally {
if (failed)
transaction.rollback();
else
transaction.commit();
}
}In this modified version, start() expects that one of the chambers may fail, catches the relevant exception (StartFailedException), and proceeds to discard the changes to the transaction by rolling it back. The following lines ensure that a failure to start aborts the entire transaction:
if (failed)
transaction.rollback();
else
transaction.commit();Now let's look at the code in each chamber that may cause the abortive fault:
public class Chamber {
private final Gauge gauge;...
public void fire() {
gauge.measure();
if (gauge.temperature() > 100)
throw new StartFailedException();
...
}
}If the chamber's gauge reads above 100, fire() will abort by throwing a StartFailed-Exception, causing the transaction to abort too. This works, but it does not ensure that the cumulative temperature is under control. All three chambers together must have a temperature less than 100, which the code fails to ensure. We need a change to how fire() performs its temperature check. As things stand, Gauge measures the heat level from each chamber independently. In other words, each Chamber has its own Gauge (that is, Gauge is bound under the no scope). To fix the problem, we need to share the gauges among all three chambers. Singleton scoping is not quite right since this would mean all dependents of Gauge would share the same instance (perhaps a backup Chamber on the other side of the station or perhaps some component that's not a Chamber at all).
The context for this heat measurement is the starting up of the PowerStation (its start() method). Therefore, the transaction scope is an apt fit:
@TransactionScoped
public class Gauge { .. }It's shown in figure 6.3 as a class model.

Now when each chamber is fired and consequently measures its heat level, the Gauge correctly reports a cumulative measure of heat from all three chambers. There need be no further changes to PowerStation, Chamber, or any of their methods.
@TransactionScoped is something we just made up (there is certainly no library for it). So how would we go about creating this scope in an injector? The following section answers this question using Guice.
A scope in Guice is represented by the Scope interface. Scope is as follows:
public interface Scope {
<T> Provider<T> scope(Key<T> key, Provider<T> unscoped);
}A custom scope is required to implement only one method, scope(), which returns a scoped instance Provider. Recall the Provider pattern from chapter 4. This is the same, except that instead of being used against the reinjection problem, here it's used for providing scoped instances. The two arguments to scope() manage the particular object in its context:
Key<T> key—The combinatorial key to be scopedProvider<T> unscoped—A provider that creates new instances of the bound key (in other words, it is a no-scope provider)
Use provider unscoped when a new context comes to life and new instances need to be provided. When the scope context completes, you simply discard all scoped instances, obtaining new ones from provider unscoped instead (see figure 6.4).
Listing 6.2 shows how this is done with the transaction scope.


Figure 6.4. The injector obtains instances from a Scope provider, which itself may use the no-scope provider.<br></br>
In listing 6.2, class TransactionScope exposes the Guice interface Scope. The implemented method scope() returns a scoped provider that acts as a bridge between the injector and its default no-scope provider. The no-scope provider unscoped is used to create new instances as required.
A scoped provider is returned for each key requested in method scope(). The provider checks a thread-local hash table, returning cached instances for the current thread:
public T get() {
Map<Key<?>, Object> map = instances.get();
if (!map.containsKey(key)) {
map.put(key, unscoped.get());
}
return (T) map.get(key);
}If an instance is not already present in the hash table, it is created and cached:
if (!map.containsKey(key)) {
map.put(key, unscoped.get());
}Otherwise, the instance mapped to the given key is returned normally:
return (T) map.get(key);
This ensures objects that don't yet exist in the current context are created when needed. Method beginScope() sets up a context for the current transaction by creating a new hash table to cache objects for the life of the scope (transaction):
public void beginScope() {
instances.set(new HashMap<Key<?>, Object>());
}The hash table maps Guice Keys to their scoped instances. Its complement, method endScope(), is called by the transaction framework when a transaction completes (either by a successful commit or an abortive rollback), disposing of the cached instances:
public void endScope() {
instances.remove();
}The entire context of the transaction, its scope, and scoped instances are confined to a single thread by using the ThreadLocal construct:
public class TransactionScope implements Scope {
private final ThreadLocal<Map<Key<?>, Object>> instances
= new ThreadLocal<Map<Key<?>, Object>>();
...
}ThreadLocals are utilities that allow stored objects to be available only to the storing thread and none other. Because a transaction runs entirely in a single thread, we can be sure that its context will only ever need to be accessed by that thread, and simultaneous transactions are separated from one another by confinement to their respective threads.
Now when a transaction-scoped object (such as Gauge from the previous section) is wired to any other object, it is done so inside an active transaction in the current thread. When a transaction completes, this instance is lost and any new transactions will see a new instance created. This also applies to concurrent transactions; they are kept walled apart by thread confinement.
Cool! What about when no transaction is active and a key is sought? Well, this is a serious problem, and it likely represents an error on the programmer's part. Either she did not start the transaction where it was meant to start or she configured the injector incorrectly. You should add a safety check that reports the error quickly and clearly in such cases:
public <T> Provider<T> scope(
final Key<T> key, final Provider<T> unscoped) {
return new Provider<T>() {
public T get() {
Map<Key<?>, Object> map = instances.get();
if (null == map) {
throw new
OutOfScopeException("no transaction was active");
}
if (!map.containsKey(key)) {
map.put(key, unscoped.get());
}
return (T) map.get(key);
}
};
}This is our sanity check that ensures a proper exception is raised (OutOfScopeException) if a transaction-scoped object is sought outside a transaction.
Registering a custom scope in Guice is simple:
public class TransactionModule extends AbstractModule {
@Override
protected void configure() {
bindScope(TransactionScoped.class, new TransactionScope());
...
}
}The scoping annotation @TransactionScoped is declared as follows:
@Retention(RetentionPolicy.RUNTIME)
@ScopeAnnotation
public @interface TransactionScoped { }This is a standard bit of boilerplate that needs to be used when declaring any Guice scope annotation. Notice that @ScopeAnnotation is a meta-annotation (an annotation on an annotation), which tells the injector that this is a scoping annotation. Now say that three times fast!
The same principles of context, instance longevity, and thread-safety apply to all injectors, and Spring is no different. The particular interfaces to expose for scoping, however, are slightly different. Spring also has a Scope interface that your scope implementation must expose. But it looks a bit different from Guice's Scope. It is shown in listing 6.3.
Example 6.3. Spring's custom scope interface
package org.springframework.beans.factory.config;
public interface Scope {
Object get(String key, ObjectFactory unscopedProvider);
Object remove(String key);
String getConversationId();
void registerDestructionCallback(String key,
Runnable destructionCallback);
}Let's take a look at this interface and see how it relates to what we saw in the previous section. First, the scoping provider method:
Object get(String key, ObjectFactory unscoped);
This is almost identical to Guice's scope() method, except that instead of returning a scoped provider, get() returns the scoped instance itself. Instead of taking a combinatorial key, it takes a string key. You can think of get() as being the provider itself. The second argument, ObjectFactory, is an implementation of the Provider pattern (similar to Guice's unscoped Provider). It provides no-scoped instances of the given key.
Next, the remove() method:
Object remove(String key);
remove evicts any instance stored for the given key in the scope's internal cache (the hash table in TransactionScope), and then another method retrieves the scope's identity:
String getConversationId();
This is an unusually named method. What it essentially points to is the unique identity of the particular scope context. If a transaction were active for the current thread, this method would return a string that uniquely identified this transaction. If we were implementing a session scope, we would return a session ID, unique to a user.
Finally, there's a lifecycle support method:
registerDestructionCallback() is intended to support lifecycle for specific keys when their instances go out of scope. We won't delve much into this now since lifecycle is coming up in the next chapter.
So what might TransactionScope look like with Spring? Listing 6.4 takes a stab at it.

Listing 6.4's TransactionScope is very similar to Guice's TransactionScope. The major difference is the three additional methods that Spring requires. For the conversation ID, I return the hash table itself (in String form). This is a simple hack for identifying a context. Depending on the kind of Map, this may or may not have good results. You will want to generate a more appropriate identifier in a production version. I also perform a sanity check every time scoping methods are called:
if (null == instances.get())
throw new IllegalStateException("no transaction is active");This is important because it fails fast with a clear and easily identifiable IllegalState-Exception. Countless hours have been wasted because failing code does not indicate exactly what was wrong and where.
Registering this scope with the injector is straightforward, and it involves a bit of simple cut-and-paste code in your injector configuration:

Then you are free to use it just like any other scope when declaring keys:
<bean id="gauge" class="nuclear.Gauge" scope="transaction">
...
</bean>Now your new scoped objects can be injected and used as needed. The next section switches around and looks at problems you can encounter when creating your own scopes. It is essential to understand these before you go off and create your own scopes.
Letting the injector manage the state of your objects is a wonderful thing when applied properly, but it also attracts danger. Scopes are extremely powerful because they invert the responsibility of managing state, and the injector takes care of passing it around to dependents. It keeps objects free of such concerns and makes them more focused and testable. However, this same power can lead to very grave pitfalls.
Many of these have to do with thread-safety. Some are about construction of object graphs that are striped with objects of different scopes. These pitfalls can lead to a range of unrelated problems that are not immediately apparent, for example, memory leaks, poor performance, or even erratic behavior. The counter to this latent peril is a thorough understanding of problem cases. With that said, let's start with scoping and thread-safety.
Singletons absolutely must be thread-safe—no exceptions. Any serious application has several threads of execution that are continually operating. They may be servicing different users, timers, remote clients, or any of a number of other purposes. A singleton-scoped key directly implies that only one shared instance of an object exists in the entire injector (and consequently the application). Multiple threads often end up accessing singleton instances and may even do so concurrently. Chapter 9 discusses the intricacies of threading and objects in detail (with a particular emphasis on Java's thread and memory model).
There are two ways in which you can create thread-safe classes. The simpler and more straightforward is to make them immutable, as shown in figure 6.5.
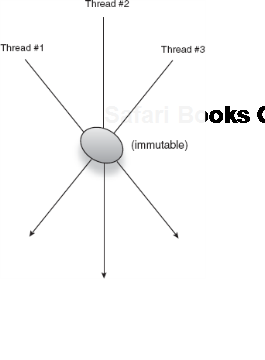
The fields of the following class are immutable (see how this might look for threads accessing it in figure 6.6):
import net.jcip.annotations.Immutable;
...
@Immutable @Singleton
public class MySafeObject{
private final Dependency dep1;
private final Dependency dep2;
@Inject
public MySafeObject(Dependency dep1, Dependency dep2) {
this.dep1 = dep1;
this.dep2 = dep2;
}
public Dependency getDep1() { return dep1; }
public Dependency getDep2() { return dep2; }
...
}Notice that MySafeObject has no setters and no methods that can alter or affect its dependencies' state. This is good immutable design. The marker annotation @Immutable is merely a tag that documents the behavior of MySafeObject (it has no effect in practice). Place it on classes that you have designed to be immutable. Don't be confused by its proximity to @Singleton; it is there only as documentation. It helps unfamiliar pairs of eyes read, understand, and reason about your classes. It also reduces confusion about intent. This is especially useful when you have bugs, since a colleague can spot the bug and know immediately that it violates design intent.
Tip
@Immutable and other thread-safety–related annotations are available from the Java Concurrency in Practice website. [27] They are downloadable at the site and provided under a flexible open source license. Neither Guice nor any other injector or production library reacts to the @Immutable annotation.
If their values never change, there is no risk of one thread modifying a value that's out of sync with its rivals. As figure 6.6 shows, mutable singletons, if not properly guarded, can get out of sync between threads.
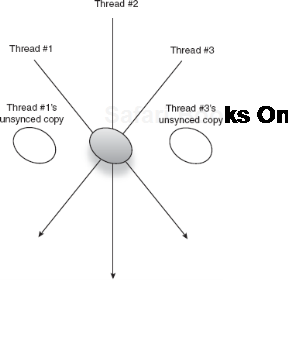
With immutable objects, the order of thread execution is irrelevant, so you have fewer problems to design for. Try very hard to make singleton objects immutable. This is by far the simplest and best approach.
Of course, not every singleton can be made immutable. Sometimes you may need to alter the object's state (for example, in a counter or accumulator). If you decide to use setter injection to resolve circular dependencies or the in-construction problem (see chapter 3), you cannot make the class immutable. In these cases, you must carefully design the object and all of its dependencies to be thread-safe. Here I have the same class; it is no longer immutable but thread-safe insofar as it guarantees that all of its dependencies will be visible to all threads:
import net.jcip.annotations.ThreadSafe;@ThreadSafe@Singleton public class MySafeObject2{ privatevolatileDependency dep1; privatevolatileDependency dep2; @Inject public void set(Dependency dep1, Dependency dep2) { this.dep1 = dep1; this.dep2 = dep2; } public Dependency getDep1() { return dep1; } public Dependency getDep2() { return dep2; } ... }
@ThreadSafe, like @Immutable, is intended to convey information about the class's design, nothing more. Java's volatile keyword ensures that the value of a field is kept coherent with all threads. In other words, when MySafeObject2's dependencies are changed using the set() method, they are immediately visible to all threads. This is a very important point, and you will appreciate why when @ThreadSafe is contrasted with the following class:
import net.jcip.annotations.NotThreadSafe;
@NotThreadSafe @Singleton
public class MyUnsafeObject {
private Dependency dep1;
private Dependency dep2;
@Inject
public void set(Dependency dep1, Dependency dep2) {
this.dep1 = dep1;
this.dep2 = dep2;
}
public Dependency getDep1() { return dep1; }
public Dependency getDep2() { return dep2; }
...
}MyUnsafeObject is critically flawed, because the Java language makes no guarantees that any thread other than the one that set its dependencies will see the dependencies (without additional synchronization). In other words, the memory between threads in non-final, non-volatile fields may be incoherent. The subtle reason has to do with the way Java Virtual Machines (JVM) are designed to manage threads. Threads may keep local, cached copies of non-volatile fields that can quickly get out of sync with one another unless they are synchronized correctly. We'll study this problem and its solutions in greater detail in chapter 9.
Making a class thread-safe is often a difficult and involved process. No simple litmus test exists to say a class is completely thread-safe. Even the best of us can get tripped up when dealing with apparently simple threading and concurrency issues. Your best bet is to reason carefully about a class and its threading environment. Explore plenty of scenarios both common and atypical where a singleton may be used. Try to convince at least one other person of the safety of your code. Actively hunt for flaws; never assume they don't exist. Always validate your assumptions. Test! Test! And test again until you're satisfied.
Thread-safety problems can also present in other ways, particularly when dealing with dependencies that cross scoping boundaries. This is an especially tricky situation called scope widening, which we'll explore in detail in the next section.
I've mentioned a problem called scope-widening injection a few times so far in this book. It came up particularly when wider scoped objects depended on narrower scoped objects, such as a singleton that depends on a no-scoped or request-scoped object. When such a situation is encountered, you end up with a no-scoped (or request-scoped) object that is held by the singleton, and it no longer comes under the purview of its original scope. That means when the context ends, the instance continues to exist as a dependency of the singleton. As you can imagine, this causes a whole swathe of knotty problems that can go undetected. Worse, they won't necessarily cause errors or exceptions to be raised and may appear to be functioning correctly, when really they're opening up a whole bunch of unintended semantics and consequences.
Scope widening also applies to any scopes that are logically of different contexts—even those that may belong to the same scope but refer to separate contexts, such as two separate user sessions. While this kind of scope widening is less likely (due to the walling off between contexts by the injector), it can still occur if a singleton is used to bridge them. I should really say, if a singleton is abused as a bridge. Not only does it break the semantics of the scope as understood at the time of its definition, it also can lead to serious performance, maintenance, and correctness problems. Scope widening is tricky, since it cannot easily be addressed by testing either. The simplest kind of peril in scope widening is an object whose scope has ended. This gremlin is called an out-of-scope object.
BEWARE THE OUT-OF-SCOPE OBJECT!
Instances that are out of scope present the most serious difficulty of the scope-widening cases. This naïve singleton class depends on a no-scoped component:

TextReader is simple; its method scan() accepts a list of strings and prints the total number of words. Its dependency WordCounter counts the number of words it has received so far:

So far, so good. Let's try using the TextReader to count a few example string sets:
Injector injector = Guice.createInjector();
TextReader reader = injector.getInstance(TextReader.class);
reader.scan(Arrays.asList("Dependency injection is good!",
"Really, it is!"));This code correctly prints a total word count of 7.
Total words: 7
Now lets extend the example and give it more to do:
Injector injector = Guice.createInjector();
TextReader reader = injector.getInstance(TextReader.class);
reader.scan(Arrays.asList("Dependency injection is good!",
"Really, it is!"));
reader.scan(Arrays.asList("Dependency injection is terrific!",
"Use it more!"));What does the program print now?
Total words: 7
Total words: 14What went wrong? The second count should have been the same as the first. Double-check the words: There are only seven in both sets. We've been had by scope-widening injection. While you would normally expect the no-scoped WordCounter to be disposed of after the first call to scan() and a new instance to take its place subsequently, what really happened is that TextReader has held onto the original instance. This situation would not improve even if we were to obtain TextReader itself twice from the injector:
Injector injector = Guice.createInjector();
TextReader reader = injector.getInstance(TextReader.class);
reader.scan(Arrays.asList("Dependency injection is good!",
"Really, it is!"));
TextReader reader2 = injector.getInstance(TextReader.class);
reader2.scan(Arrays.asList("Dependency injection is terrific!",
"Use it more!"));This program still prints an incorrect result:
Total words: 7
Total words: 14The first run is okay, since at that time all instances (TextReader and WordCounter) are new ones. But the second run uses the old instance of WordCounter as well and so ends up accumulating the word count. If we added a third line this accumulation would continue (visualized in figure 6.7):
Injector injector = Guice.createInjector();
TextReader reader = injector.getInstance(TextReader.class);
reader.scan(Arrays.asList("Dependency injection is good!","Really, it is!"));
TextReader reader2 = injector.getInstance(TextReader.class);
reader2.scan(Arrays.asList("Dependency injection is terrific!",
"Use it more!"));
TextReader reader3 = injector.getInstance(TextReader.class);
reader3.scan(Arrays.asList("The quick brown fox", "is really annoying!"));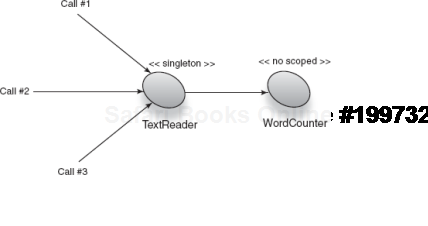
This should print three sets of 7, but instead it prints
Total words: 7
Total words: 14
Total words: 21There are a couple of really easy solutions. The simpler is to remove the discrepancy in scope between TextReader and WordCounter by choosing the narrowest scope for both, in other words, make TextReader no scoped:
public class TextReader { .. }Note the missing @Singleton annotation, implying no scope. This is shown in figure 6.8.
Now, the program can remain as is:
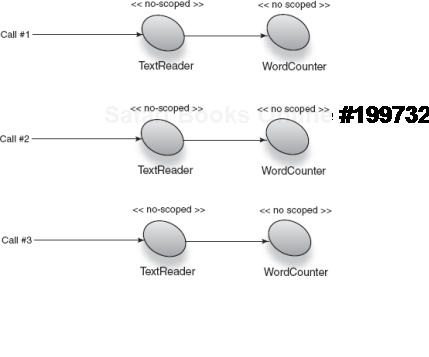
Figure 6.8. Both TextReader and its dependent have the same scope and are safe from scope widening.<br></br>
Injector injector = Guice.createInjector();
TextReader reader = injector.getInstance(TextReader.class);
reader.scan(Arrays.asList("Dependency injection is good!",
"Really, it is!"));
TextReader reader2 = injector.getInstance(TextReader.class);
reader2.scan(Arrays.asList("Dependency injection is terrific!",
"Use it more!"));
TextReader reader3 = injector.getInstance(TextReader.class);
reader3.scan(Arrays.asList("The quick brown fox", "is really annoying!"));And it correctly prints the three independent word counts:
Total words: 7 Total words: 7 Total words: 7
This is an example of scope-widening injection that could not be caught with a unit test. Any test of WordCounter would pass, since it does correctly count the number of words in a string. Any test of TextReader would also pass, since a mocked WordCounter would only assert that correct calls were made to it around its behavior rather than around its state.
Well, this solution works, but by making TextReader no scoped rather than fixing the problem of scope widening, you might say I've sidestepped it. While this is a legitimate solution, there are times when this doesn't work. You need a singleton, and it depends on a no-scoped instance, or, more generally, a wider-scoped object depends on a narrower-scoped object.
Scope widening viewed in this light is a form of the reinjection problem (see chapter 3). We can use the same solution to mitigate scope widening. By replacing the narrower-scoped dependency with a provider (and fetching it each time), we allow the injector to intervene when new instances are required:
@Singleton
public class TextReader {
private final Provider<WordCounter> counterProvider;
@Inject
public TextReader(Provider<WordCounter> counterProvider) {
this. counterProvider = counterProvider;
}
public void scan(List<String> strings) {
WordCounter counter = counterProvider.get();
for(String string : strings)
counter.count(string);
System.out.println("Total words: " + counter.words());
}
}TextReader can now go back to being a singleton but continue depending on a no-scoped object without any scope-widening effects. Figure 6.9 imagines how this might work.
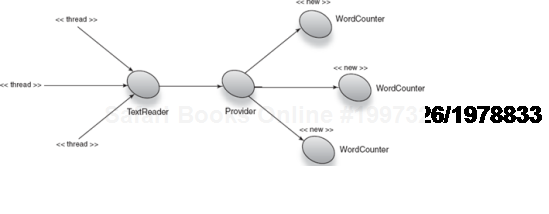
Running the program yields the correct word counts:
Total words: 7 Total words: 7 Total words: 7
One subtle thing to note is that in the new TextReader's scan() method we retrieve WordCounter once per method rather than once per use. If we had done this instead:
public void scan(List<String> strings) {
for(String string : strings)
counterProvider.get().count(string);
System.out.println("Total words: " +
counterProvider.get().words());
}we would have ended up with a very different (and rather obnoxious) result:
Total words: 0 Total words: 0 Total words: 0
There's nothing wrong with the coding of WordCounter or its logic, and that's fine. It's just that the statement that prints the count uses a new instance of WordCounter, discarding the one that has just run a count. This is one of the perils of stateful behavior. It would probably have had you looking everywhere except where the fault was (that is, in the scoping).
NO, REALLY: BEWARE THE OUT-OF-SCOPE OBJECT!
Out-of-scope objects can also cause bugs in other areas. One common version is the use of an out-of-scope object between (or before) scope contexts (see figure 6.10).
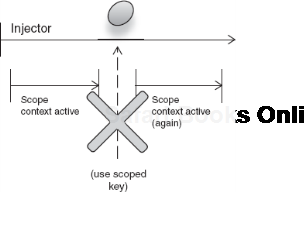
This is a common problem that users of guice-servlet and Guice post about on the community mailing lists. Consider a servlet managed by guice-servlet:
import com.google.inject.servlet.RequestScoped;@RequestScopedpublic class HelloServlet extends HttpServlet { public voidinit(ServletConfig config) { .. } ... }
and its injector configuration:
Guice.createInjector(new ServletModule() {
protected void configureServlets() {
serve("/hello").with(HelloServlet.class);
}
});Now there is one method of note in HelloServlet: init(), which is called by the guice-servlet on startup of the web application. What's interesting is that HelloServlet is itself request scoped. The servlet lifecycle methods are fired when the web application starts and there are no active requests at the time. The injector (via request scope) immediately detects that there is no active request, so it aborts with an OutOfScopeException (as shown in figure 6.11). This happens at the earliest point of the application's life, so it fails to load the entire web app.
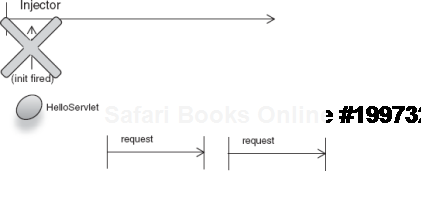
Figure 6.11. Request-scoped HelloServlet is used out of scope, that is, before any requests arrive.<br></br>
Session scoping a servlet will similarly fail because no user session can be found under which to bring the key into scope. These are all cases of objects being used out of scope and represent serious flaws in the design of a program. In other words, HelloServlet is unavailable for the application to start up. We can use one of the mitigants of the reinjection problem, the Adapter pattern, to solve this problem. Consider this rather plain but functional version of HelloServlet bound with an Adapter:

Also the modified injector configuration, using the Adapter instead:
Guice.createInjector(new ServletModule() {
protected void configureServlets() {
serve("/hello").with(HelloServletAdapter.class);
}
});HelloServletAdapter is a singleton wrapper around HelloServlet that acts as a go-between. It solves the out-of-scope problem (figure 6.12) by moving the logic for the portions that are outside the scope of HelloServlet into itself. Any calls to its service() method are delegated down to the request-scoped HelloServlet.
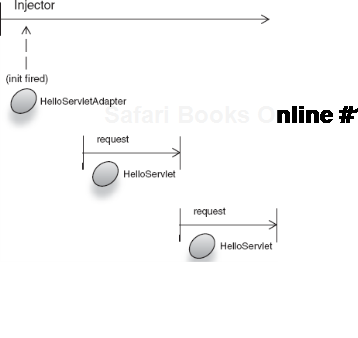
Since service() is called only during a request, we can rest assured that HelloServlet will always be inside a valid request. Now HelloServlet can keep its scope and still effectively function as expected. Now that we've seen all the domestic problems of scope widening, let's shift gears and look at the truly nasty pitfalls—ones that involve multiple threads and objects in widened scopes.
THREAD-SAFETY REVISITED
Scope widening can also lead to concurrency problems. Wiring any singleton with a narrower-scoped dependency means that it automatically becomes accessible to all the dependents of that singleton. If multiple threads access the singleton object, they are likely to modify its nonsingleton dependencies. If they are not immutable or thread-safe, you may see erratic and unpredictable behavior. Even if they are, they may be underperforming. Thread-safety is a particularly tough subject, since there are so many nuances to the concurrent modification (and access) of state. One of these is the issue of safe publication, which is dealt with in chapter 9.
You must take particular care to ensure that singletons never depend on objects that are not thread-safe, or if they do, that these dependencies are guarded properly. Here's an example of a class, scoped as a singleton, that depends on a counting service:
@Singleton
public class TextPrinter {
private final Counter counter;
public void print(String text) {
System.out.println(text);
counter.increment();
if (counter.getCount() == 100)
System.out.println("done!");
}
}TextPrinter has a thread unsafe dependency, Counter, which looks like this:
@NotThreadSafe
public class Counter {
private long count;
public void increment() {
count++;
}
public long getCount() {
return count;
}
}Because many threads hit TextPrinter's methods, print() and printCount(), they also increment and read Counter concurrently. When the number of lines printed hits 100, it prints "done!" Unfortunately, the way things stand this may never happen. The counter keeps incrementing, no matter how many threads hit it, so it is logical to assume that counter must reach 100 at some point (when a hundred lines are printed):
if (counter.getCount() == 100)
System.out.println("done!");So what's the problem? Right away there is the problem of memory coherency. Class Counter is not a singleton and so has been designed without thread-safety in mind. That would be fine were it used at any scope other than singleton (or more strictly, any scope that is confined to single threads). In practice, however, Counter has had its scope widened by being wired to TextPrinter, which is a singleton. One fix we can try is to make count volatile (as we did in a similar example not long ago):
//@ThreadSafe?
public class Counter {
private volatile long count;
public void increment() {
count++;
}
public long getCount() {
return count;
}
}Now, at last, all threads see the same value of count. However, this isn't quite enough. It is conceivable that two threads could run through the print() method at once—the first thread incrementing count to 100 and the second to 101. Then if either the first or second continues down the print() method, it will hit the statement testing whether count is 100. But the count has already hit 101, so the statement evaluates to false and keeps on going. Our base case is never reached, and the program never prints "done!"
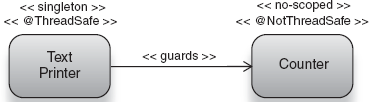
Clearly, concurrent access to the counter is not desirable—at least not willy-nilly. To fix this problem, we need to ensure that each thread sees not only the latest value of count but also the value that it has set. In other words, each thread must have access to the counter exclusively. This is known as mutual exclusion and is achieved as follows (also illustrated in figure 6.13):
@ThreadSafe@Singleton public class TextPrinter { private final Counter counter; publicsynchronizedvoid print(String text) { System.out.println(text); counter.increment(); if (counter.getCount() == 100) System.out.println("done!"); } }
The synchronized keyword ensures that no two threads execute method print() concurrently.
Threads queue up behind one another and execute print() one by one, ensuring that calls to getCount() always return the value set by the same thread in counter.increment() just above. Can we now call Counter thread-safe? It has proper visibility across threads, and it works in singletons that guarded it appropriately. But we can't quite go that far. As a dependency, it can still be used in a thread-unsafe manner. So we must leave it thus:
@NotThreadSafe
public class Counter {
private long count;
public void increment() {
count++;
}
public long getCount() {
return count;
}
}Thread-safety is an eternally difficult problem, and it's especially subtle in the case of scope widening since it is hard to detect. Good documentation and modular design will help you go a long way to avert its issues. Scope widening can also create nasty problems that don't involve threads, particularly with memory usage. In the next section we'll look at how this edge case can rear its ugly head and how to solve it.
SCOPE WIDENING AND MEMORY LEAKS
Scope-widening injection certainly has a lot of pitfalls! In Java, a garbage collector runs behind your programs, periodically checking for objects that are no longer in use, reclaiming the memory they occupy. Garbage collection is a wonderful feature of modern languages that frees you from having to worry about a large number of memory issues. Memory is automatically allocated to objects when they come into instance. When they're no longer in use, that memory is claimed for reuse.
Memory reclamation is a vital process that helps ensure programs run smoothly and that they can stay up for indefinite periods. Next to hardware failure, memory leaks are the greatest threat to this ability. Memory is said to leak when a programmer expects an object to be reclaimed but the garbage collector can't do so. Usually this is because of programmer oversights (like scope-widening injection). These unreclaimable zombie objects no longer serve any purpose, yet they cannot be claimed by the garbage collector because it cannot verify that they are not in use. Over time these objects can accumulate and consume all of a machine's memory, causing loss of performance and even program crashes.
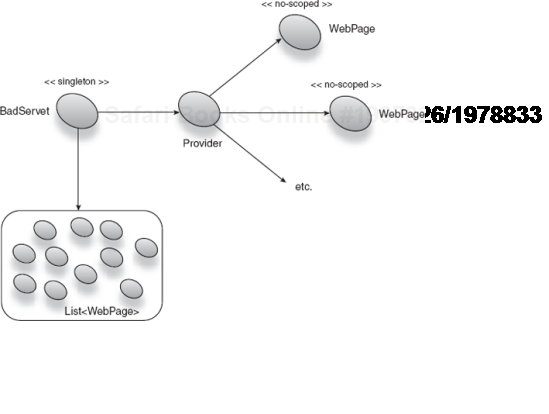
So how does scope widening feed this problem? Take the case of a singleton. A singleton is held by an injector forever, that is, for the injector's (and usually the application's) entire life span. Therefore, a singleton is never reclaimed during the life of an application. Singletons are generally reclaimed only on shutdown. If any nonsingletons are accidentally wired to a singleton through scope-widening injection, it follows that these objects are also (indirectly) held forever. Here's a naïve example of a servlet that holds onto no-scoped instances on every request:
@Singleton
public class BadServlet extends HttpServlet {
public final Provider<WebPage> page;
public final List<WebPage> pages = new ArrayList<WebPage>();
public void service(HttpServletRequest request,
HttpServletResponse response) {
pages.add(page.get());
pages.get(0).handle(request, response);
}
}BadServlet is a frivolous example, but it serves to illustrate how a no-scoped dependency (WebPage) can be scope widened and held by a singleton, as shown in figure 6.14.
If you continually refresh the URL served by this servlet, your web server will eventually run out of memory and die with an OutOfMemoryError.
A simple solution is to discard instances as soon as they are used:
@Singleton
public class GoodServlet extends HttpServlet {
public final Provider<WebPage> page;
public void service(HttpServletRequest request,
HttpServletResponse response) {
page.get().handle(request, response);
}
}The following method uses a no-scoped dependency but discards it immediately:

GoodServlet servlet is properly behaved and allows instances of WebPage to be reclaimed by the garbage collector, and all is well with the universe. Scope-widening injection contains many such dangers. Avoid it where possible and try to use simpler designs, either by using the narrowest scope available or by choosing the Provider and Adapter design patterns as we've seen.
If there's one feature of dependency injection that you can't do without (besides wiring), it would be scope. Scopes apply the Hollywood Principle to the state of objects. They are a powerful way of removing boilerplate and infrastructure logic from your code. The importance of this cannot be understated, since it means your code is easier to read and test. Scopes also reduce objects' dependence on one another and therefore simplify your object graphs.
While many DI libraries provide scopes out of the box, and some web frameworks round out the complement with advanced scopes (like flash and conversation), there's still plenty of room for innovation. We saw just how a custom transaction scope can help make components easier to code and test. By pulling the menial labor into behind-the-scenes code, you save yourself a tremendous amount of repetition, coupling, and extra testing. That being said, here are some ideas for leveraging the power of scope.
Objects that are expensive to create (or data that is expensive to retrieve from a store) are especially conducive to in-memory caching. Caching is the idea that an object is kept around after its initial fetch, so that additional requests for it can use the cached copy rather than go through the (potentially expensive) process of obtaining it again.
A cache, specifically a disk cache, is powerful in that it can maintain the state of certain important objects across multiple lives of an injector (and, indeed, an application). A particular state can be restored this way for continuing work. In a computer game you play through several difficult levels, then are called away to more mundane pursuits, and so have to close down the game. But you don't want to play through all those levels again. A disk cache can let the application save game state for later resumption. Figure 6.15 imagines how this might look.

This works in any scenario where long-lived data needs to be saved across injectors. A cache is also powerful for keeping a handle on data constants (such as a list of countries) that rarely change. As the application requests cached items by wiring them in as dependencies, the injector goes to an external store (or creates an instance) for the object. Any subsequent wiring is much faster using the cached copy.
A data grid is very much like a cache in that it is an in-memory store of frequently used data. However, it is a cache that is common across a large number of physical (or logical) machines. These individual machines share objects and act in concert as a grid. Grids are sometimes referred to as cluster caches. Some sophisticated grids (like Oracle Coherence) do much more than spread objects across a cluster, however. Coherence features querying and updating operations, very much like a database. Grids can also hold objects for very long periods of time, since they are able to distribute the storage load across many more machines than single-disk caches. As a result, they are also often faster and more flexible in clustered applications.
A grid scope that takes advantage of persisting instances in a data grid has no end of useful applications. Grid scoping allows you to transparently cluster a massive number of stateful services and data. This is done transparently so that the load is efficiently balanced across machines without tedious clustering logic and extra service programming. Figures 6.16 and 6.17 show how an instance can be injected in one node and transparently distributed across the grid, to be used by dependents anywhere.
The simplest use case is replication of user credentials across a cluster. A user logged into a single machine may have some relevant data stored in an HTTP session, but if the application is backed by several machines in a cluster, you need to ensure the credentials are also clustered correctly. Grid scoping is a compelling way of creating single-sign-on semantics across even different kinds of applications. Single sign-on is the idea that you log in once, on any application in a domain, and you are logged in to all applications on that domain. Here's how you might share a user's relevant information across a data grid:
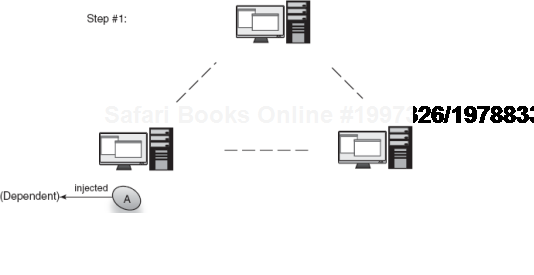
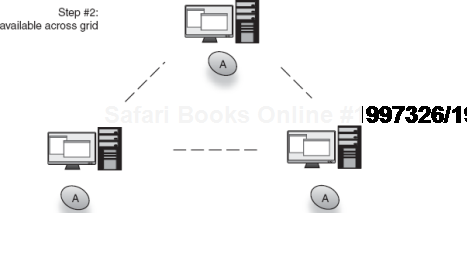
Figure 6.17. Now a grid-scoped instance of A is transparently available to the entire grid.<br></br>
@GridScoped @ThreadSafe
public class Users {
private final Map<String, UserContext> users;
...
}
@NotThreadSafe
public class UserContext {
private String username;
private boolean isActive;
private Preferences prefs;
...
}Thereafter, servlets, EJBs, service objects, mail components, and many others can all share a user's information by simply injecting the Users object. Of all the powerful applications of scope, grid scope is perhaps the most interesting since it offers so much potential for horizontally scaling applications.
The possibilities for client applications to scale and grow are endless, with SOA and enterprise systems cleverly using dependency injection's wonderful design patterns. We've seen the modularity and separation of responsibilities that this can bring. We've also seen how this can help us scale by moving applications off to dedicated hardware. And we've seen the flexibility it can bring in terms of accommodating new business processes and even interbusiness collaboration.
There are a few more exciting possibilities. The kind of scaling we've seen thus far, adding stronger hardware to individual layers of an application, is known as vertical scaling or tiering. You will often hear architectures referred to as an n-tiered or vertically tiered system. This kind of scaling has its advantages, but it can get expensive very quickly. And for very large amounts of traffic, it can even become untenable. An increasingly popular alternative system is known as horizontal scaling.
Horizontal scaling refers to an architecture that increases its processing capacity by the addition of any number of homogenous nodes, each capable of performing the same function as any other. Incoming traffic is evenly distributed across several of these worker machines from a few strong-load distributors. This kind of hardware is both cheap and easily replaceable. And as it turns out, it is extremely powerful when scaling to very large loads.
Apache's Hadoop project is an example of one such homogenous cluster-computing system. It consists of a master machine that distributes a single, computationally expensive task across a number of worker slaves. Then it gathers results from each one and recombines (or reduces) them into an expected total order. This is incredibly useful for searching across large datasets and performing expensive computations that can be broken down into simpler ones.
One possible use of DI would be to apply a similar abstraction over the grid computing network, where one interface and one method call are orchestrated across several machines using a grid service proxy, in much the same way as we used a remote proxy in the SOA case. There are early attempts at performing this sort of orchestration, but most of the effort has been focused on transparent slicing and distribution of tasks around the cluster rather than architectural design patterns for clients of such services. A library like that combined with a thin integration layer for clients could really make dependency injection shine.
Injectors are extensible via the definition of custom scopes. These are scopes that match some particular context of a problem domain that would benefit from the application of the Hollywood Principle. Database transaction scope is one such example. Keys bound within this scope return the same instance while a transaction is active in the current thread but return new instances in other transactions (either subsequent or concurrent). Be careful when crafting your own scopes, and adhere to the following principles:
Define the context of a scope clearly and succinctly.
Try to keep contexts confined to a single thread.
Assess whether your scope improves testability of components. If not, stay away! There is no end to the pain that can be caused by a presumed performance or development improvement that ends up not being easy to test.
Custom scopes really require a lot of thought and planning. Objects wired across scoping boundaries can cause serious problems that can go undetected even with comprehensive unit testing.
The problem of "crossing" a scoping boundary is very serious indeed—wiring a narrow-scoped object (that is, a no-scoped one) to a wider-scoped object (a singleton) entirely changes the assumptions about that narrower scope. The instance becomes held by the singleton and effectively lives for the same amount of time. You should try to design an architecture so this scope-widening injection is rare. Binding all keys in the object graph under the narrowest scope is one simple mitigation. However, this doesn't work for all cases; sometimes you need a singleton that depends on a no-scoped (or narrower-scoped) object. You can solve problems in this case by applying the Provider design pattern from chapter 3.
Another issue with scope widening is objects that are out of scope. An out-of-scope object is one for which a key is requested when its bound scope is not active, for example, a request-scoped key wired outside an HTTP request (say, during application startup). Such problems represent design flaws. Rethink the architecture of your long-lived components and their collaborators. If you must, solve the problem with the Adapter pattern, as shown in chapter 3.
A third issue that arises from scope-widening injection is thread-safety. Keys of narrower scope, when wired to a singleton, are susceptible to the action of multiple concurrent threads. It is not enough to secure the singleton component alone; you must guard access to its narrower-scoped dependencies or ensure that they are immutable. This problem often goes undetected and can lead to erratic, unpredictable behavior (without any specific errors being raised), which can be a nightmare to debug. There is no easy way to detect thread-safety issues in scope-widened cases, since unit tests (and even integration tests) are not reliable in this regard. Think about your object graphs and convince yourself (and preferably an educated colleague) that they are thread-safe. Better yet, avoid scope-widening injection altogether.
Finally, scope-widening injection can cause memory leaks if the wider-scoped object holds onto its narrower-scoped dependencies. Memory leaking is impossibly hard to detect and results in arbitrary application crashes, which can be disastrous in production environments.
Although scopes have many pitfalls that may scare you off writing your own, you shouldn't be afraid. These are some positive features of scope:
Reduction of boilerplate
Reduction of interdependent code
Reduction (or removal) of dependence on infrastructure
Logical use of the Hollywood Principle to create focused, concise code
Improved testability
The benefits vastly outweigh any perils. Consider the careful use of scopes, and design them according to your problem domain. Scopes can make the use of caches, clusters, and data grids transparent to vastly increase an application's scalability and give it powerful features such as stateful replication.
We've spent two chapters studying the problems and benefits of scope. In the next chapter let's change the theme slightly and look at a broader topic, applicable to all kinds of applications, object lifecycle.