
"Perfect behavior is born of complete indifference."
Often one finds that certain types of logic are repeated throughout a program. Many separate parts of an application share similar concerns such as logging, security, or transactions. These are known as crosscutting concerns.
Rather than address these concerns in each individual class (as one would do normally), it's easier to address them all at once from a central location. Not only does this reduce repetitive boilerplate code, but it also makes maintenance of existing code less complicated.
Let's look at an example. Brokerage is a class that places an order for stock inside a database transaction. Traditionally, we would write code for starting and ending a transaction around each business method:
public class Brokerage {
private final TransactionManager txn;
public void placeOrder(Order order) {
txn.beginTransaction();
try {
...
} catch(DataException e) {
txn.rollback();
} finally {
if(!txn.rolledBack())
txn.commit();
}
}
}This transaction logic uses a TransactionManager to start and end a transaction, rolling back on an exception or committing as appropriate. This would be repeated in every method that needed to be transactional.
Now let's look at this if transactions were described declaratively:
public class Brokerage {
@Transactional
public void placeOrder(Order order) {
...
}
}This is much simpler. By declaring method placeOrder() as @Transactional, we're able to strip out most of the boilerplate code to wrap an order inside a transaction. Moreover, it removes Brokerage's dependency on a TransactionManager, making it simpler to code and test. Also, now all transaction-specific logic is centralized in one place.
@Transactional is a piece of metadata that allowed us to declare a transaction around placeOrder(). What really happened underneath was that placeOrder() was intercepted and wrapped inside a transaction before proceeding normally. This is done via a technique known as aspect-oriented programming (AOP) and is the focus of this chapter. In this chapter we'll look at how to apply this technique to intercept methods on objects that are created by dependency injection and how to insert new behavior around each method. We'll start by examining how method interception is achieved.
Methods can be intercepted in a number of different ways, depending on the AOP library:
At compile time, via a specialized compiler
At load time, by altering class definitions directly
At runtime, via dynamic proxying
This process is known as weaving, as in weaving in the new behavior. The introduced behavior is called advice.
Since we are concerned with dependency injection, we'll focus on the runtime flavor of weaving, which is done by the use of dynamic proxies.[29] Since DI libraries are responsible for creating objects, they are also able to intercede with proxies for intercepting behavior. This is transparent to any client, since the proxies are merely subclasses of the original types.
Proxying is a powerful technique. We can use it to replace almost any object created by an injector. Since a proxy possesses all the methods of the original type, it can alter the behavior of any of them.
Let's look at one such scenario where we intercept methods to add logging functionality using Guice.
What we want to do here is trace the execution of every method on a certain class, by printing something to the console. We want to do this using interception rather than adding print statements to each method. Guice lets us do this by binding an interceptor (a utility class containing the advice):
import org.aopalliance.intercept.MethodInterceptor;
import org.aopalliance.intercept.MethodInvocation;
public class TracingInterceptor implements MethodInterceptor {
public Object invoke(MethodInvocation mi) throws Throwable {
System.out.println("enter " + mi.getMethod().getName());
try {
return mi.proceed();
} finally {
System.out.println("exit " + mi.getMethod().getName());
}
}
}This class is pretty simple; it contains one method—invoke()—which is called every time an interception occurs. This method then does the following:
The last bit is done inside a finally block so that any exception thrown by the intercepted method does not subvert the exit trace.
Applying this interceptor is done via Guice's binding API inside any Module class, as shown in listing 8.1:
Example 8.1. A module that applies TracingInterceptor to all methods
import static com.google.inject.matcher.Matchers.*;
public class MyModule extends AbstractModule {
@Override
protected void configure() {
...
bindInterceptor(any(), any(), new TracingInterceptor());
}
}Tip
The import static statement at the top of this class makes it possible to omit the class name, Matchers, where the any() method is defined for convenience. It's a more readable shorthand for writing Matchers.any().
The interesting part about this listing is how the interceptor is bound:
bindInterceptor(any(), any(), new TracingInterceptor());The first two parameters are passed any(), which represents any class and any method, respectively. Guice uses these matchers to test for classes and methods to intercept. It comes with several such matchers out of the box, or you can write your own.
Now when we call any methods from objects wired by our injector, the methods will be traced on the console. Let's say Chef is one such class:
public class Chef {
public void cook() {
...
}
public void clean() {
...
}
}Now calling Chef's methods
Chef chef = Guice.createInjector(new MyModule())
.getInstance(Chef.class);
chef.cook();
chef.clean();produces the following output:
enter cook exit cook enter clean exit clean
Chef still has no knowledge of how to print to console. Furthermore, inside a unit test, methods are not intercepted, and your test code can focus purely on asserting the relevant business logic.
In the next section, we'll look at how to write the same tracing interceptor using a different framework. This will help you see the differences between the two major popular techniques.
Spring uses a different AOP library (although it also supports the AopAlliance) but works under similar principles. Spring's library is AspectJ, which can itself be used independently to provide a whole host of AOP features beyond method interception. For our purposes we'll focus on its Spring incarnation. We'll use the same class Chef, but this time we'll intercept it with Spring and AspectJ, as shown in listing 8.2.
Example 8.2. A tracing interceptor created as an aspect with Spring and AspectJ
import org.aspectj.lang.ProceedingJoinPoint;
public class TracingInterceptor {
public Object trace(ProceedingJoinPoint call) throws Throwable {
System.out.println("enter " + call.toShortString());
try {
return call.proceed();
} finally {
System.out.println("exit " + call.toShortString());
}
}
}It looks almost the same as our TracingInterceptor from Guice. The primary difference is that we do not implement any interface; rather we will tell the injector directly about method trace(). This is achieved as shown in listing 8.3.
Example 8.3. A tracing interceptor configuration with myAspect.xml
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:aop="http://www.springframework.org/schema/aop"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans-2.5.xsd
http://www.springframework.org/schema/aop
http://www.springframework.org/schema/aop/spring-aop-2.5.xsd">
<bean id="chef" class="example.Chef"/>
<bean id="tracer" class="example.TracingInterceptor"/>
<aop:config>
<aop:aspect ref="tracer">
<aop:pointcut id="pointcuts.anyMethod"
expression="execution(* example.*.*(..))" />
<aop:around pointcut-ref="pointcuts.anyMethod" method="trace"/>
</aop:aspect>
</aop:config>
</beans>This looks like a complex bit of mumbo-jumbo, but it's quite simple. First we declare our TracingInterceptor in a <bean> tag, naming it "tracer":
<bean id="tracer" class="example.TracingInterceptor"/>Then we declare a pointcut using the <aop:pointcut> tag provided by Spring:
<aop:pointcut id="pointcuts.anyMethod"
expression="execution(* example.*.*(..))" />The expression "execution(* example.*.*(..))" is written in the AspectJ pointcut language and tells Spring to intercept the execution of any method with any visibility, name, or arguments from the example package. This pointcut expression is the equivalent in AspectJ of a matcher in Guice. Recall the binding expression for matching any method from listing 8.1:
bindInterceptor(any(), any(), new TracingInterceptor());AspectJ's pointcut language also allows you to declare matchers of your choosing. Since it is a dedicated language, it doesn't come with any matchers out of the box.
The other tag worth mentioning in listing 8.3 is <aop:aspect ref="tracer">. This is the declaration of an aspect, which is essentially a binding between a matcher (or pointcut) and an interceptor (advice). It is the semantic equivalent of method bindInterceptor() shown earlier. Now running the example
BeanFactory injector = new FileSystemXmlApplicationContext("myAspect.xml");
Chef chef = (Chef) injector.getBean("chef");
chef.cook();
chef.clean();produces the expected trace:
enter execution(cook) exit execution(cook) enter execution(clean) exit execution(clean)
Now that you've seen how to apply method interception at a high level, let's examine how its internals work, by looking at how to work with dynamic proxies and their semantics.
We said earlier that a dynamic proxy is a subclass that is generated at runtime. The fact that it is of the same type means we can transparently replace the original implementation with a proxy and decorate its behavior as we please. Proxying is a tricky subject. The best way to think of it is to imagine a handwritten subclass where all the methods invoke an interceptor instead of doing any real work. The interceptor then decides whether to proceed with the real invocation or effect some alternate behavior instead.
Listing 8.4 shows how such a proxy might look for Chef.
Example 8.4. A static (handwritten) proxy for Chef
public class ChefProxy extends Chef {
private final MethodInterceptor interceptor;
private final Chef chef;
public ChefProxy(MethodInterceptor interceptor, Chef chef) {
this.interceptor = interceptor;
this.chef = chef;
}
public void cook() {
interceptor.invoke(new MethodInvocation() { ... });
}
public void clean() {
interceptor.invoke(new MethodInvocation() { ... });
}
}Rather than delegate calls directly to the intercepted instance chef, this proxy calls the interceptor with a control object, MethodInvocation. This control object can be used by MethodInterceptor to decide when and how to pass through calls to the original chef. These libraries are also able to generate the bytecode for ChefProxy on the fly. Let's look one such proxying mechanism.
PROXYING INTERFACES WITH JAVA PROXIES
The Java core library provides tools for dynamically generating proxies. It implements the same design pattern we just saw with a proxy and interceptor pair and is provided as part of the reflection toolset in java.lang.reflect. It's limited to proxying interfaces, but this turns out to be sufficient for the majority of use cases. If we imagined that Chef was an interface rather than a class,
public interface Chef {
public void cook();
public void clean();
}we could create a dynamic subclass of Chef the following way:
import java.lang.reflect.Proxy;
...
Chef proxy = (Chef) Proxy.newProxyInstance(Chef.class.getClassLoader(),
new Class[] { Chef.class },
invocationHandler);The first argument to Proxy.newProxyInstance() is the classloader in which to define the new proxy:
Proxy.newProxyInstance(Chef.class.getClassLoader(), ...)Remember that this is not just a new object we're creating but an entirely new class. This can generally be the same as the default (context) classloader or, as in our example, the classloader to which the original interface belongs. It is sometimes useful to customize this, but for most cases you won't need to. You'll see more on this later in the chapter.
The second argument is an array of Class objects representing all the interfaces you want this proxy to intercept. In our example, this is just the one interface, Chef:
Proxy.newProxyInstance(..., new Class[] { Chef.class }, ...);And finally, the last argument is the invocation handler we want the proxy to use:
Proxy.newProxyInstance(..., invocationHandler);It must be an object that implements interface InvocationHandler from the java.lang.reflect package. As you can see, it is very similar to the AopAlliance's MethodInterceptor:
public interface InvocationHandler {
Object invoke(Object proxy, Method method, Object[] args);
}Here's a reimagining of the method-tracing interceptor from earlier in this chapter, using JDK Proxy and InvocationHandler with Chef:
public class TracingInterceptor implements InvocationHandler {
private final Chef chef;
public TracingInterceptor(Chef originalChef) {
this.chef = originalChef;
}
public Object invoke(Object proxy, Method method, Object[] args)
throws Throwable {
System.out.println("enter " + method.getName());
try {
return method.invoke(chef, args);} finally {
System.out.println("exit " + method.getName());
}
}
}To run it, we use the proxy obtained from Proxy.newProxyInstance():
import java.lang.reflect.Proxy;
...
Chef proxy = (Chef) Proxy.newProxyInstance(Chef.class.getClassLoader(),
new Class[] { Chef.class },
new TracingInterceptor(originalChef));
proxy.cook();
proxy.clean();This produces the expected trace:
enter cook exit cook enter clean exit clean
By constructing TracingInterceptor with a constructor argument, originalChef, we make it possible for the interceptor to proceed onto legitimate calls against the intercepted instance should it need to. In our invoke() interception handler, this is illustrated by the reflective method invocation:
Object invoke(Object proxy, Method method, Object[] args)
throws Throwable {
System.out.println("enter " + method.getName());
try {
return method.invoke(chef, args);
} finally {
System.out.println("exit " + method.getName());
}
}This is akin to the AopAlliance's MethodInvocation.proceed() and AspectJ's ProceedingJoinPoint.proceed().
Although Java provides a fairly powerful API for proxying interfaces, it provides no mechanism for proxying classes, abstract or otherwise. This is where third-party bytecode manipulation tools come in handy.
A couple of useful libraries provide tools for proxying. Guice and Spring both use a popular library called CGLib[30] to generate proxies under the hood. CGLib fills in nicely where Java's proxy mechanism falls short. It's able to generate the bytecode that would dynamically extend an existing class and override all of its methods, dispatching them to an interceptor instead.
If we had a concrete class FrenchChef, we would generate a proxy for it as follows:
import net.sf.cglib.proxy.Enhancer;
...
Chef chef = (Chef) Enhancer.create(FrenchChef.class,
new TracingInterceptor());The corresponding TracingInterceptor follows the design pattern we're intimately familiar with by now:
public class TracingInterceptor implements MethodInterceptor {
public Object intercept(Object proxy, Method method, Object[] args,
MethodProxy methodProxy) throws Throwable {
System.out.println("enter " + method.getName());
try {
return methodProxy.invokeSuper(proxy, args);
} finally {
System.out.println("exit " + method.getName());
}
}
}The interesting part is that we no longer have to hold onto the original chef; CGLib allows us to invoke the corresponding method directly on its superclass:
return methodProxy.invokeSuper(proxy, args);Class proxying can be very powerful if used correctly. It's best used inside dependency injectors (or similar tools) that need to enhance a class's behavior. The consequences of intercepting class methods can be tricky. We'll look at some later in this chapter. It's always generally advisable to use interface proxying where possible, unless you're convinced of the need and its implications.
Of course, there are other problems with interception. One can be too eager to apply this technique. In the next section we'll look at how this can lead to problems.
As in real life, you can run into trouble when you listen to too much advice. One of the important things to consider is that for each interception, you will incur the overhead of advising methods running before and after the original method. This is generally not an issue if you apply a few interceptors to a few methods. But when the chain gets longer, and it crosscuts critical paths in the application, it can degrade performance.
More important, the order of interception can play spoiler to program semantics. Here is a simple case:
public class Template {
private final String template = "Hello, :name!";
public String process(String name) {
return template.replaceAll(":name", name);
}
}Class Template converts a dynamically provided name into a string containing a greeting. The following code
new Template() .process("Josh");returns a greeting to Josh:
Hello, Josh!
Now, using method interception, we can enhance this greeting by decorating it in bold (let's use HTML <b> tags for familiarity):
import org.aopalliance.intercept.MethodInterceptor;
public class BoldDecoratingInterceptor implements MethodInterceptor {
public Object invoke(MethodInvocation mi) throws Throwable {
String processed = (String)mi.proceed();
return "<b>" + processed + "</b>";
}
}We bind this in using a simple matcher:
import static com.google.inject.matcher.Matchers.*;
...
bindInterceptor(subclassesOf(Template.class), any(), new
BoldDecoratingInterceptor());Now when a client processes anything from a template, it will be decorated in bold:
Guice.createInjector(...)
.getInstance(Template.class)
.process("Bob");This prints the following:
<b>Hello, Bob!</b>
So far, so good. Now let's say we want to wrap this whole thing in HTML so it can be rendered in a website. If we had several such templates, another interceptor would save a lot of time and boilerplate code:
import org.aopalliance.intercept.MethodInterceptor;
public class HtmlDecoratingInterceptor implements MethodInterceptor {
public Object invoke(MethodInvocation mi) throws Throwable {
String processed = (String) mi.proceed();
return "<html><body>" + processed + "</body></html>";
}
}Now we have two bits of advice. If you were to naïvely bind in this interceptor at any arbitrary point, it could lead to very unexpected behavior:
import static com.google.inject.matcher.Matchers.*; ...
bindInterceptor(subclassesOf(Template.class), any(), new
BoldDecoratingInterceptor());
bindInterceptor(subclassesOf(Template.class), any(),
new HtmlDecoratingInterceptor());This would print the following:
<b><html><body>Hello, Bob!</body></html></b>
Obviously, the order of interception matters. In this trivial example, it's easy for us to see where the problem is and correct it:
import static com.google.inject.matcherMatchers.*; ... bindInterceptor(subclassesOf(Template.class), any(),newHtmlDecoratingInterceptor());bindInterceptor(subclassesOf(Template.class), any(), new BoldDecoratingInterceptor());
Now processing the interceptor chain renders our desired HTML correctly:
<html><body><b>Hello, Bob!</b></body></html>
This highlights a serious problem that would have gone undetected if we had assumed unit tests were sufficient verification of application behavior. In our example, all interceptors were in the same spot, and it was easy to identify and fix the problem. In more complex codebases, it may not be so straightforward. You should exercise caution when using AOP. In our example, the bold decorator could probably have been written without an interceptor. It probably would have worked better if we had folded it into the template itself.
Later in this chapter we'll show how to protect against the "too much advice" problem with integration tests. For now, let it suffice to say that you should apply interception only in valid use cases. In the next section we'll look at these use cases as applicable to enterprise applications.
The tracing example was fun, but it's quite a trivial use case. The real advantage of interception comes to light in enterprise use cases, particularly with transactions and security. These may be database transactions or logical groupings of any kind of task. And likewise with security—it may be about authorization to perform a particular action or simply about barring users who aren't logged in.
By far, the most prolific and useful case of interception is to wrap database transactions and reduce the overall level of boilerplate code in business logic methods. There are several ways to go about this; both Guice and Spring provide modules that allow you to use declarative transactions. It's even possible to roll your own, but there are a few edge cases that should lead you to use the library-provided ones, which are thoroughly tested. So let's look at how to achieve transactions with the warp-persist module for Guice.
Like guice-servlet, which we encountered in chapter 5, warp-persist is a thin module library for Guice that provides support for persistence and transactions. Warp-persist provides integration with the following popular persistence engines:
Hibernate and JPA both provide a mapping layer between Java objects and relational database tables (stored in an RDBMS like PostgreSQL). And Db4objects is a lightweight object database, which can store and retrieve native objects directly.
Warp-persist sits between the Guice injector and these frameworks, and it reduces the burden on you to wrap and integrate them. It also provides an abstraction over their particular transaction architectures and lets you use matchers to model transactional methods declaratively. Let's take the simple example of storing a new car in a database inventory:
import javax.persistence.EntityManager;
import com.wideplay.warp.persist.Transactional;
public class CarInventory {
private final EntityManager em;
public CarInventory(EntityManager em) {
this.em = em;
}
@Transactional
public void newCar(Car car) {
em.persist(car);
}
}When a new car arrives, its details are entered into a Car object, and it's passed to method newCar(), which stores it using the EntityManager. The EntityManager is an interface provided by JPA that represents a session to the database. Entities (data) may be stored, retrieved, or removed via the EntityManager from within transactional methods.
The other important part of CarInventory is method newCar(), which is annotated @Transactional. This is an annotation provided by warp-persist that is used to demarcate a method as being transactional. If we didn't have the declarative approach with @Transactional, we would have to write the transaction behavior by hand:
public void newCar(Car car) {
EntityTransaction txn = em.getTransaction();
txn.begin();
boolean succeed = true;
try {
em.persist(car);
} catch (RuntimeException e) {
txn.rollback();succeed = false;} finally {if (succeed)txn.commit();}}
All of this code is required to correctly determine whether to roll back a transaction and close it properly when finished. This is only a trivial case, since we aren't considering the beginning and closing of the EntityManager itself. A session to the database may also need to be opened and closed around transactions.
In listing 8.5, the caught exception is being swallowed after a transaction rollback without any significant action being taken. So, apart from saving yourself a world of repetitive boilerplate, declarative transactions also give you semantic control over the transactional state.
Let's look at how to tell the Guice injector that we're going to use warp-persist (see listing 8.5).
Example 8.5. A module that configures warp-persist and @Transactional
import com.wideplay.warp.persist.PersistenceService;
import com.wideplay.warp.persist.jpa.JpaUnit;
public class CarModule extends AbstractModule {
@Override
protected void configure() {
...
install(PersistenceService.usingJpa()
.buildModule());
bindConstant().annotatedWith(JpaUnit.class).to("carDB");
}
}The method install() is a way of telling Guice to add another module to the current one. It is exactly equivalent to passing in each module to the createInjector() method individually:
Guice.createInjector(new CarModule(), PersistenceService.usingJpa()
.buildModule());The other important piece of configuration is the constant bound to "carDB":
bindConstant().annotatedWith(JpaUnit.class).to("carDB");This constant is used by warp-persist to determine which persistence unit to connect against. Persistence units are specified in the accompanying persistence.xml configuration file for JPA, which is typically placed in the META-INF/ directory. Here's what it might look like in our imaginary car inventory:
<?xml version="1.0" encoding="UTF-8" ?>
<persistence xmlns="http://java.sun.com/xml/ns/persistence"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://java.sun.com/xml/ns/persistence
http://java.sun.com/xml/ns/persistence/persistence_1_0.xsd"
version="1.0">
<!-- A JPA Persistence Unit -->
<persistence-unit name="carDB" transaction-type="RESOURCE_LOCAL">
<provider>org.hibernate.ejb.HibernatePersistence</provider>
<!-- JPA entities must be registered here -->
<class>example.Car</class>
<properties>
<!-- vendor-specific properties go here -->
</properties>
</persistence-unit>
</persistence>Note that along with the name of the persistence unit, all the persistent classes are listed here. These are classes mapped with JPA annotations, which tell the persistence engine how to map an object to a row in the database. example.Car might look something like this:
@Entity
public class Car {
@Id @GeneratedValue
private Integer id;
private String name;
private String model;
//get + set methods
}When you run this application and call the newCar() method with a populated Car object,
@Inject CarInventory inventory;
...
Car car = new Car("BMW", "325Ci");
inventory.newCar(car);a transaction is automatically started and committed around the call to newCar(). This ensures that the EntityManager enters the provided Car object into its corresponding database table.
Another interesting enterprise use case is that of security. Since interception can be applied from one spot, many parts of an application can be secured with a single, central step. In the following section, we'll explore how to secure groups of methods using Spring AOP and the Spring Security Framework.
Authorization is another common use case for intercepted methods. The pattern is sometimes even applied to web applications where HTTP requests are intercepted by servlet Filters and processed against security restrictions.
Certain methods that provide privileged business functionality can come under the crosscutting banner of security. Like transactions, these methods must first verify that the user driving them has sufficient privileges to execute their functionality. This is a repetitive task that can be moved to the domain of interceptors, which have the rather elegant advantage of being able to suppress secured methods completely. They also allow for declarative management of security across a set of business objects, which is a useful model when applied in very large applications with similar, recurring security concerns.
Let's look at how this is done using Spring Security, an extension to Spring that provides many security features. First, Spring Security is meant primarily for web applications, so enabling it requires a HTTP filter to be present. This gives us a hook into Spring's security stack. Draw up a web.xml like the following:
<filter>
<filter-name>springSecurity</filter-name>
<filter-class>org.springframework.web.filter.DelegatingFilterProxy</
filter-class>
</filter>
<filter-mapping>
<filter-name>springSecurity</filter-name>
<url-pattern>/*</url-pattern>
</filter-mapping>Much like guice-servlet's GuiceFilter (from chapter 5), this filter mapping tells the servlet container to route all requests through Spring Security's DelegatingFilterProxy. This Spring-provided filter is able to call into Spring's injector and determine the correct set of security constraints to apply.
Here's a corresponding XML configuration for securing objects of an imaginary class PhoneService, managed by the Spring injector:
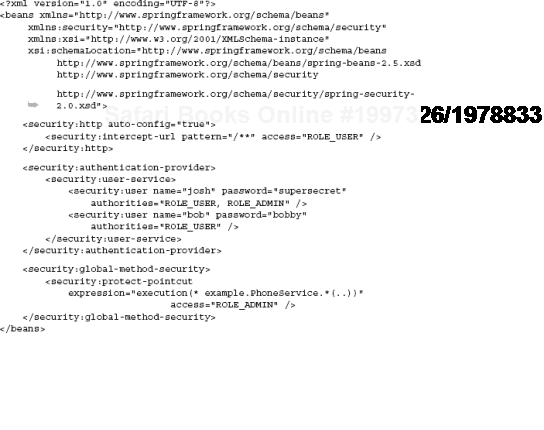
Wow, that's quite a lot of configuration! Let's look at what it all means. First, we set up automatic configuration to use a whole bunch of defaults for customizable services that Spring Security provides:
<security:http auto-config="true">
<security:intercept-url pattern="/**" access="ROLE_USER" />
</security:http>These are good for our purpose, where we only want to demonstrate security around methods via interception as it applies to dependency injection.
Here we've also asked Spring to intercept all requests coming in and allow access only to users with the privilege ROLE_USER:
<security:http auto-config="true">
<security:intercept-url pattern="/**" access="ROLE_USER" />
</security:http>The path matcher pattern="/**" used by Spring Security[31] is slightly different from the conventional servlet pattern and is equivalent to a URL mapping of "/*" in servlet parlance.
Next, we set up two users, josh and bob, and gave them both ROLE_USER access:
<security:authentication-provider>
<security:user-service>
<security:user name="josh" password="supersecret"
authorities="ROLE_USER, ROLE_ADMIN" />
<security:user name="bob" password="bobby"
authorities="ROLE_USER" />
</security:user-service>
</security:authentication-provider>This means they will be able to access any page in the web application by default.
Finally, we applied a method security constraint via a pointcut. Recall pointcuts from the section early in this chapter on Spring AOP with AspectJ. This pointcut expression matches any method in an imaginary class PhoneService:
<security:global-method-security>
<security:protect-pointcut
expression="execution(* example.PhoneService.*(..))"
access="ROLE_ADMIN" />
</security:global-method-security>This security pointcut prevents access to methods in PhoneService from anyone but ROLE_ADMIN users. In our case only josh had this role:
<security:user name="josh" password="supersecret"
authorities="ROLE_USER, ROLE_ADMIN" />
<security:user name="bob" password="bobby" authorities="ROLE_USER" />Let's imagine PhoneService to look something like this:
public class PhoneService {
public Response call(String number) {
...
}
public void hangUp() {
...
}
}Now if any client code tries to access methods from this class via the Spring injector
<bean class="example.PhoneCaller">
<constructor-arg><bean class="example.PhoneService"/></constructor-arg>
</bean>and the corresponding class,
public class PhoneCaller {
private final PhoneService phone;
public PhoneCaller(PhoneService phone) {
this.phone = phone;
}
public void doAction() {
Response response = phone.call("555-1212");
if (response.notBusy())phone.hangUp();
}
}when a user triggers this action (by, for example, clicking a button to call a recipient), Spring Security intercepts calls to PhoneService.call() and PhoneService.hangUp() and ensures that the user has the appropriate role. If not, an exception is raised and the user is shown an authorization failure message. In this scenario, the target methods are never executed.
This example requires a lot of delving into ancillary topics, such as Spring's web integration layer and related concerns. We've taken only the most cursory glance at this security system, focusing instead on the method interception use case. For a more thorough examination, consult the source code accompanying this chapter and visit http://www.springsource.org for the Spring Security documentation.
In the rest of this chapter, we'll change gears and look at the flip side of all this interception and how basic assumptions in design may need to change depending on how you use AOP.
As you saw earlier, proxying is an advanced topic and can involve some pretty low-level semantics dealing with the internals of Java. Thus there are several pitfalls and mistaken assumptions that can lead you astray when working with proxied classes or interfaces. Ideally, a proxy should behave identically to its replaced counterpart. However, this is not always the case.
You can understand and avoid many of the pitfalls if you keep in mind that a proxy is simply a subclass of the original type. Let's look at some of these cases.
If you have a reference to an object, never rely on the sameness (==) test to assert that it's the object you're expecting. An object created by the injector may have been proxied, and though it appears to be the same as the original object, it isn't. This is true even in the case of singletons. Here's such a scenario:
final Painting picasso = new Painting("Picasso");
Injector injector = Guice.createInjector(new AbstractModule() {
protected void configure() {
bind(Painting.class).toInstance(picasso);
bindInterceptor(any(), any(), new TracingInterceptor());
}
});
assert picasso == injector.getInstance(Painting.class); //will failIn this case, we create an instance outside the injector and bind it via the bind().toInstance() directive:
final Painting picasso = new Painting("Picasso");
Injector injector = Guice.createInjector(...
bind(Painting.class).toInstance(picasso);
...This is an implicit singleton-scoped binding (since we've hand-created the only instance).
Next, we bound in a TracingInterceptor like the ones we've seen throughout this chapter. This runs on all classes and all methods:
bindInterceptor(any(), any(), new TracingInterceptor());Now, we obtain the bound instance of Painting (picasso) from the injector and compare it using a sameness assertion to the instance we already know about:
assert picasso == injector.getInstance(Painting.class); //will failThis assertion fails because even though we're semantically talking about the same instance, the physical instances are different. One has been proxied by the injector and the other is a direct reference to the original instance.
A related but much more common anti-pattern is to assume that the class of an available object is the same as the one it is bound to. For example, many logging frameworks publish log messages under the class of an object. Many people naively make the following mistake:
import java.util.logging.*;
public class ANoisyService {
public final Logger log = Logger.getLogger(getClass().getName());
...
}This is a dangerous assumption because while it appears as though method getClass() will return Class<ANoisyService>, in reality it may return the class of the dynamically generated proxy! So instead of logging under ANoisyLogger, your log statements may be printing under some unintelligible, generated class name.
Worse than this, if you use getClass() to make decisions on application logic, you can find some very erratic and unexpected behavior. Here's an example of a naïve equals() method implementation that mistakenly precludes a proxied object from an equality test:
public class EqualToNone {
@Override
public boolean equals(Object object) {
if (object == null || object.getClass() != EqualsToNone.class)
return false;
...
}
}This equals() method makes the assumption that subclass instances cannot be semantically equivalent to superclass instances. This is a wrong assumption when any proxied objects are involved. It's not only dependency injectors that need to proxy objects for dynamic behavior modification. Many web frameworks and persistence libraries also employ this design pattern to provide dynamic behavior.
To fix this problem, you should always assume that an object can be proxied and program accordingly:
public class EqualToNone {
@Override
public boolean equals(Object object) {
if (!(object instanceof EqualToNone))
return false;
...
}
}This is a much better implementation that's safe to proxying behavior. Similarly, you should always be explicit about your sameness semantic:
import java.util.logging.*;
public class ANoisyService {
public final Logger log = Logger.getLogger(ANoisySer-
vice.class.getName());
...
}Now, ANoisyService will always publish under the correct logging category regardless of whether or not it has been proxied. Another problem that arises from this situation is the inability to intercept static methods.
Since proxies are merely subclasses and Java doesn't support overriding static methods, it follows that proxies cannot intercept static methods. However, something more subtle is at work. If you try the following example,
public class Super {
public static void babble() {
System.out.println("yakity yak");
}
}
public class Sub extends Super {
public static void babble() {
System.out.println("eternal quiet");
}
public static void main(String...args) {
babble();
}
}and run class Sub from the command line, what do you think it will print? Will the program even compile?
Yes, it will compile! And it prints
eternal quiet
which appears to all eyes like an overridden static method. We declared a static method babble() in Super and another static method babble() in Sub. When we ran babble() from Sub, it used the subclass's version. This looks very much like overriding instance methods in subclasses. Fortunately there's an explanation: What's really happening is that there are two static methods named babble() and the one in Sub is hiding the one in Super via its lexical context. In other words, if you were to run this from anywhere outside Sub or Super, you'd have to specify which method you were talking about:
import staticSuper.*; ...babble();
This version correctly prints "yakity yak" as expected. So any code that statically depends on Sub or Super must always be explicit about which one it is talking about, meaning that there is no way to substitute a proxied subtype (even were it possible) without the client itself doing so. When you want dynamic behavior, don't place logic in static methods.
Private methods also face the same problem because they cannot be overridden. Although they have access to dynamic state, they cannot be proxied.
In Java, methods can have private visibility. A method that is private can't be called from anywhere outside its owning class. This applies to subclasses too, which means that dynamic proxies (which are just subclasses) cannot intercept private methods. If we go back to our FrenchChef and alter the visibility of method clean() as follows,
public class FrenchChef {
public void cook() {
...
}
private void clean() {
...
}
}and then run it by adding a main() method to its body,

it will produce the following output
enter cook exit cook
with no mention of clean(). This was not because clean did not run; we called it from main(), after all. Rather it was because proxying doesn't permit private methods to be intercepted before they're dispatched. A good solution to this problem is to elevate the class's visibility slightly:
public class FrenchChef {
public void cook() {
...
}
protected void clean() {
...
}
}Protected methods are good candidates for proxying, since they're hidden from all external users except subclasses of the original type. Running the program again produces a more satisfying result:
enter cook exit cook enter clean exit clean
This is probably the best solution for the majority of cases although it may not always be ideal. While protected methods are hidden from classes outside the current hierarchy, they are still visible to nonproxy subclasses that may exist in different modules. If this is undesirable, Java has yet another visibility level: package-local visibility. This makes methods invisible to any code that's outside the owning class's package. Package-local[32]visibility is perfect for hiding methods from subclasses that may extend your class but for which you don't want certain methods shown. These methods can still be intercepted by proxies, because proxies are typically generated within the same package as the original class. Denote package-local visibility by omitting an access keyword:
public class FrenchChef {
public void cook() {
...
}
void clean() {
...
}
}Note
I say that proxies are typically generated within the same package, but there are some cases where this may not be true. This behavior is dependent on specific decisions made by the library you're using. Keep an eye out for such decisions. Most dependency injectors can be relied on to place proxies within the same package as their parent classes.
Another variant of this problem (the inability to override certain methods) presents itself when a method has specifically declared itself to be final.
Methods can be declared as final to prevent subclasses from overriding them. The final keyword is not a visibility modifier, since it can be applied on public, protected, or package-local methods:
public class FrenchChef {
public final void cook() {
...
}
void clean() {
...
}
}However, it does prevent a subclass from redefining the method by overriding it. The following code results in a compiler error:
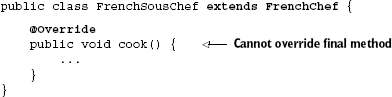
Naturally, this means a proxy can't override it either, and therefore a final method can't be intercepted for behavior modification. The solution in such cases is obviously to remove the final modifier. But if this can't be done for some reason (perhaps you don't have access to the source code), you can wrap the method in a pass-through delegator:

This class can now be proxied for interception. Method cook() is not final so it can be intercepted safely with a proxy. And the class FrenchChefDelegator implements Chef, so clients of Chef are not impacted by the change.
Tip
An even better solution would be to proxy the Chef interface directly and pass calls through to the specific implementation. For example, Spring's AOP mechanism allows you to choose interface proxying as the default method. This is also easily accomplished by hand.
The same principle applies to final classes. These are classes that cannot be extended. Not only can their methods not be intercepted, but you can't generate subclasses of them at all:
public final class FrenchChef implements Chef {
public void cook() {
...
}
public void clean() {
...
}
}The Delegator pattern also works well for this situation:
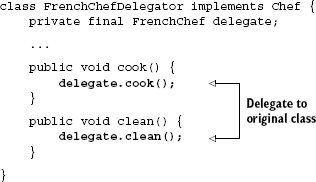
When in doubt always choose this method over inheritance—even simpler would be proxying the interface directly. Just as final classes and methods cannot be intercepted at runtime, neither can class member fields.
Certain flavors of AOP allow you to make deferred modifications to any parts of a codebase. The build-time weaving from AspectJ allows you to alter fields, interfaces implemented, and even static methods. However, neither Spring nor Guice provides this kind of weaving. Almost all use cases for interception can be fulfilled with the runtime weaving flavor that they do provide. However, it does mean that fields, any kind of fields, are off limits with regard to interception.
Let's say FrenchChefs have a dependency on a RecipeBook:
public class FrenchChef implements Chef {
private final RecipeBook recipes;
public void cook() {
...
}public void clean() {
...
}
}An interceptor can only advise behavior on methods cook() and clean() but cannot advise anything on recipes. Even if methods on recipes were called from cook() or clean(), an interceptor declared on FrenchChef would not be able to trap specific behavior:
private final RecipeBook recipes;
public void cook() {
recipes.read("ratatouille");
...
}And a tracing interceptor declared with the specific matcher
bindInterceptor(subclassesOf(Chef.class), any(),
new TracingInterceptor());will ignore method calls on RecipeBook and trace only methods cook() and clean(). Of course, expanding the matching strategy will allow you to intercept RecipeBook's methods. The following matcher is much better suited:
The general one we have used earlier in the chapter
bindInterceptor(any(), any(), new TracingInterceptor());will also work nicely:
enter cook enter read exit read exit cook enter clean exit clean
The limitation here is that any intercepted dependency must also have been provided by dependency injection. No dependency injector can intercept methods on objects it doesn't create. For example, the following class
public class FrenchChef implements Chef {
private final RecipeBook recipes = new RecipeBook();
public void cook() {
...
}
public void clean() {
...
}
}creates its own dependency (see construction by hand from chapter 1) and therefore subverts the interception mechanism. No matcher will be able to intercept method calls on RecipeBook now:
enter cook exit cook enter clean exit clean
Furthermore, any accesses to scalar fields like primitives or Strings are not open to interception whether or not they are injected by the dependency injector:
public class FrenchChef implements Chef {
private int dishesCooked;
private BigInteger potsWashed;
private String currently;
public void cook() {
dishesCooked++;
currently = "cooking";
}
public void clean() {
potsWashed = potsWashed.add(BigInteger.ONE);
currently = "cleaning";
}
}None of these accesses—whether via method calls or directly by assignment—are visible to interceptors. Typically this is not a problem, but it's something to keep in mind when you're designing services with scalar fields. Of course, not all dependencies will necessarily need interception.
One of the nice things about DI is that it doesn't affect the way you write tests. If we were to test a class with many complex dependencies, all we'd need to do would be replace them with mock or stub equivalents. This principle can become somewhat muddied when interception comes into play.
While the imperative behavior of a class is the same in both test and application, its semantic behavior can change advice introduced by AOP. For example, a theme park's ticket-purchase system collects money and dispenses a ticket:
public class TicketBooth {
public Ticket purchase(Money money) {
if (money.equals(Money.inDollars("200")))
return new Ticket();
return Ticket.INSUFFICIENT_FUNDS;
}
}We can write a unit test for this class quite easily:
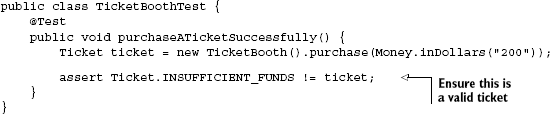
If you decided to modify this behavior by printing a discount coupon for every 100th customer (via an interceptor), the original class's semantic has changed:

The immediate solution that comes to mind is simply to write another unit test, this time around the interceptor:

But this is not where the difficulty lies. As you saw in "Too much advice can be dangerous!" the combination of two behavioral units can affect total semantic behavior and belie the assertions of individual unit tests. One effective solution is to write an integration test that brings the relevant units together and tests them as they might behave in the eventual application environment.
This is different from a full acceptance test or QA pass, since we're interested in only a particular combination of behaviors and can restrict our attention to the classes we expect to be intercepted:
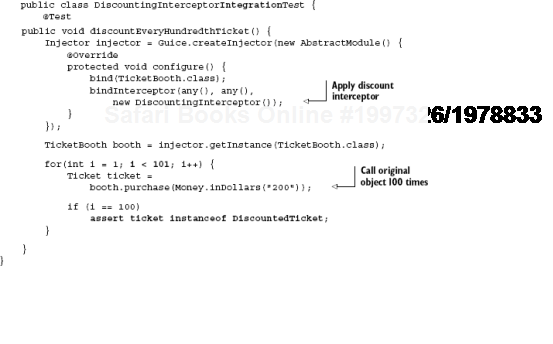
This test looks very similar to the unit test on the interceptor, but it gives us more confidence about how these units come together. Notice that we call the TicketBooth.purchase() method just as clients would in the real application. And its behavior is decorated with interceptors that would also be present in the real app. Where this gets really useful is if we add a second or a third interceptor (as we did in "Too much advice can be dangerous!"); then the confidence that the integration test provides is far greater than the sum of individual unit tests.
When you have any sort of services in your program that rely on side effects like these, it's important to write vertical integration tests to give yourself some assurance on their combined behavior. This will generally be in addition to any unit tests that exist on individual classes. Neither is enough alone, but together they give us sufficient breadth for verifying correct behavior.
In this chapter we encountered certain concerns that are global to a program. In traditional approaches, these are addressed individually with repetitive and boilerplate code. A technique known as AOP allows us to centralize this code in one location and apply it many times using a matcher (or pointcut). Matchers allow us to introduce additional behavior before and after business methods execute in a dynamic and declarative fashion. This introduced behavior is known as advice and is typically applied in the form of interceptors.
Interceptors trap the normal behavior of a method and decorate it with the provided advice. They are applied via the use of dynamic proxies, which are generated subclasses of the original class that reroute method calls through an interceptor. The Java core library provides a simple proxying mechanism for generating subclasses of interfaces on the fly. More sophisticated proxy libraries are available for proxying concrete classes too (CGLib is one example).
Because dependency injectors create the services used by an application, they are able to intercede with a proxy that intercepts behavior when applicable. These interceptors can be turned on or off with simple configuration options in both Spring and Guice.
Intercepting methods is a powerful technique for adding dynamic behavior that crosscuts a problem domain. Concerns like security, logging, and transactions are typical use cases for interception. However, it's fraught with pitfalls and requires a thorough understanding if it's to be applied properly, and it has unintended consequences. One pitfall is the order of interception: An interceptor that replaces the returned value of methods (or their arguments) can unintentionally disrupt the behavior of other interceptors yet to run. An integration test that puts together the expected set of interceptors can be a good confidence booster in such cases.
Warp-persist is an integration layer for Guice that allows you to apply transactions declaratively to Hibernate-, JPA-, and Db4objects-driven applications. It provides an @Transactional annotation that can be applied to introduce transactionality around any method in an application. Of course, it supports interception without annotations too.
Similarly Spring Security is an AOP-based security framework for Spring applications. Spring Security allows you to declare users and roles and attach them to methods via the use of a pointcut (a matching expression). When a user who is logged into the system executes these methods, an interceptor verifies that he has sufficient privileges, blowing up with an exception if not.
Other things to watch out for with proxies are sameness tests. The == operator tests whether references are equal; it can lead you astray if you test a reference against its intercepted equivalent, since the latter is a dynamically generated proxy. Semantically they refer to the same instance underneath. Equality testing should be applied in such cases. The same also applies to comparing classes of objects directly with the getClass() reflective method.
There are several parts of a class and its behaviors that simply cannot be intercepted with runtime proxies. For example, static methods are not attached to any instance, so they cannot be intercepted. Similarly, fields and methods on objects belonging to these fields are off-limits (unless they too have been injected). Methods having private visibility or a final modifier are also ineligible for proxying and thus behavior modification through interception.
With all these corner cases and pitfalls in mind, you can still apply this technique to great effect in your code. Reducing boilerplate and introducing behavior modification to services late in the game can be a powerful tool. Use interception wisely.
In the next chapter we'll look at some more general design issues specific to very large sets of applications that interact with one another, and we'll show how to use dependency injection in these environments.
[30] CGLib stands for Code Generation Library. Find out more about CGLib at http://cglib.sourceforge.net.
[31] If you're familiar with Ant, note that Spring Security uses Ant-style paths to match against URIs. Ant is a popular build-scripting tool for Java from Apache: http://ant.apache.org/.
[32] Package-local visibility is sometimes also called package-private or default visibility.