
Chapter 6. DI refactorings
- Mapping runtime value to ABSTRACTIONS
- Working with short-lived DEPENDENCIES
- Resolving cyclic DEPENDENCIES
- Dealing with Constructor Over-injection
- Monitoring coupling
You may have noticed that I have a fascination with sauce béarnaise, or sauce hollandaise in general. One reason is that it tastes so good; another is that it’s a bit tricky to make. In addition to the challenge of production, sauce hollandaise presents an entirely different problem: it must be served immediately (or so I thought).
This used to be less than ideal when I was having guests. Instead of being able to casually greet my guests and make them feel welcome and relaxed, I was frantically whipping the sauce in the kitchen, leaving them to entertain themselves.
After a couple of repeat performances, my very sociable wife decided to take matters into her own hands. We live just across the street from a restaurant, so one day she chatted up the cooks to find out whether there is a trick that would enable me to prepare a genuine sauce hollandaise well in advance. It turns out that there is, so now I can serve a delicious sauce for my guests without first subjecting them to an atmosphere of stress and frenzy.
Each craft has its own tricks of the trade. This is also true for software development in general and DI in particular. There are challenges that just keep on popping up, and in many cases there are well-known ways to deal with them.
Over the years, I’ve seen people struggle when learning DI, and it occurred to me that many of the issues were similar in structure. In this chapter, we’ll look at the most common challenges that appear when we apply DI to a code base, and how we can resolve them. When we’re finished, you should be able to better recognize and handle these situations when they occur.
Similar to the two previous chapters in this part of the book, this chapter is organized as a catalog—this time of problems and solutions (or, if you will, refactorings). Figure 6.1 shows the structure of the chapter.
Figure 6.1. The structure of this chapter is a catalog of refactorings or solutions to common DI issues. Each of the sections can be read independently.

In each section, I’ll present a common issue and how you can address it, including an example. You can read each section independently or in sequence, as you prefer. The purpose of each section is to familiarize you with a solution to a commonly occurring problem so that you’ll be better equipped to deal with it if it occurs.
6.1. Mapping runtime values to Abstractions
When you start applying DI, one of the first difficulties you’re likely to encounter is when ABSTRACTIONS depend on runtime values. For example, an online map site may offer to calculate a route between two locations. It may give you a choice of how you want the route calculated: Do you want the shortest route? The fastest route based on known traffic patterns? The most scenic route?
Each option represents a different algorithm, and the application may treat each routing algorithm as an ABSTRACTION so it can treat them all equally. To calculate a route, the application needs a routing algorithm, but it doesn’t care which one. We must tell it which algorithm it should use, but we don’t know this until runtime, because it’s based on the user’s choice.
This section discusses how we can deal with this type of issue. Before turning to an example, we’ll briefly talk about the general problem. When we’re finished, your knee-jerk reaction to this challenge should be to introduce an Abstract Factory.
6.1.1. Abstractions with runtime Dependencies
When we use CONSTRUCTOR INJECTION, we implicitly state that we expect the DEPENDENCY to be unambiguous at runtime. Consider a constructor signature like this one:

This is never going to work if, at runtime, it’s unclear which implementation of DiscountRepository should be used. At design-time, we can treat the DEPENDENCY as an ABSTRACTION and follow the LISKOV SUBSTITUTION PRINCIPLE; but at runtime, a decision about which DiscountRepository to use must be made before the RepositoryBasketDiscountPolicy can be created. Because the DEPENDENCY is requested through the constructor, we can’t defer the decision past this point.
This only means that, as far as the RepositoryBasketDiscountPolicy class goes, there can be no ambiguity concerning DiscountRepository. Other consumers may also request DiscountRepository instances, and whether they all get the same or different instances is of less importance. Such DEPENDENCIES often represent Services[1] instead of Domain Objects. Conceptually, there is only one instance of a given Service.
1 Eric Evans, Domain-Driven Design: Tackling Complexity in the Heart of Software (New York: Addison-Wesley, 2004), 104.
Note
As you’ll see in chapter 9, there may be several implementations of the same ABSTRACTION in play at the same time. However, from the consumer’s perspective, there is only one.
Services belong to a common group of DEPENDENCIES, but at times a DEPENDENCY represent a proper Domain Object. This is particularly true when it comes to behavior-changing ABSTRACTIONS such as Strategies.[2] The previous route-calculation algorithm is one such example. Another may be a graphics editor’s collection of bitmap effects: each effect performs a transformation of a bitmap, but they may all be exposed to the application as ABSTRACTIONS—this is also an architecture that allows add-ins to be supported.
2 Erich Gamma et al, Design Patterns: Elements of Reusable Object-Oriented Software (New York: Addison-Wesley, 1994), 315.
In such cases, we can’t request the DEPENDENCY through the constructor, because a COMPOSER won’t know which implementation to pick. There may be zero, one, or many instances in play at different times through an application’s lifetime. The DEPENDENCY is ambiguous at design-time.
As always in software design, the solution is another level of indirection: this time, the Abstract Factory design pattern.
The Abstract Factory[3] design pattern addresses the problem when we need to be able to request an instance of an ABSTRACTION at will. It offers a bridge between ABSTRACTIONS and concrete runtime values, allowing us to translate a runtime value to a DEPENDENCY.
3 Ibid., 87.
The following figure illustrates how it works by introducing a new ABSTRACTION that creates instances of the originally required ABSTRACTION.

If we need to be able to create IFoo instances on request, we need a way to do that. An ABSTRACT FACTORY is another ABSTRACTION that we can use to create such instances as necessary.
An Abstract Factory is itself an ABSTRACTION whose only purpose is to create instances of the originally required ABSTRACTION. If we need to be able to create IFoo instances from concrete Bar instances, the corresponding Abstract Factory might look like this:
public interface IFooFactory
{
IFoo Create(Bar bar);
}
In this case, Bar is a concrete class. IFooFactory allows us to translate a concrete Bar instance to an abstract IFoo instance. The IFoo implementation may contain the bar instance or use the input as guidance to pick a particular IFoo instance.
In the degenerate case, an Abstract Factory may take no input parameters:
public interface IFooFactory
{
IFoo Create();
}
In that case, the Abstract Factory becomes a pure factory, whereas the translation aspect disappears.
Abstract Factory is one of the most useful design patterns. Keep it in mind, because it can be used to solve many issues with DI.
Tip
When one or more of the arguments supplied to an Abstract Factory is in itself an ABSTRACTION, this technique also becomes an example of METHOD INJECTION.
An Abstract Factory is the universal solution when we need to create DEPENDENCIES from runtime values.
Design considerations
As useful as Abstract Factory can be, we must take care to apply it with discrimination. The DEPENDENCIES created by an Abstract Factory should conceptually require a runtime value. The translation from a runtime value into an ABSTRACTION should make sense on the conceptual level. If you feel the urge to introduce an Abstract Factory to be able to create instances of a concrete implementation, you may have a LEAKY ABSTRACTION at hand.
Just as Test-Driven Development (TDD) ensures TESTABILITY, it’s safest to define interfaces first and then subsequently program against them. Even so, there are cases where we already have a concrete type and now wish to extract an interface.
When we do this, we must take care that the underlying implementation doesn’t leak through. One way this can happen is if we only extract an interface from a given concrete type, but all the parameter and return types are still concrete types defined in the same library.
If we need to extract an interface, we need to do it in a recursive manner, ensuring that all types exposed by the root interface are themselves interfaces. I call this Deep Extraction and the result Deep Interfaces.
ASP.NET MVC has some examples of Deep Interface extraction. For example, HttpContextBase has a Request property of type HttpRequestBase, and so on. This ABSTRACTION was recursively extracted from System.Web.HttpContext.
Always consider whether a given ABSTRACTION makes sense for other implementations than the one you have in mind. If it doesn’t, you should reconsider your design.
Abstract Factories come in many shapes and forms, and it may not always be apparent that you have one.
Note
Any ABSTRACTION that creates instances of other ABSTRACTIONS is an Abstract Factory. It doesn’t need to have a name that ends with Factory.
Let’s look at a couple of examples: first a simple, idiomatic example and subsequently a more complex example where the Abstract Factory is hidden under a different name.
6.1.2. Example: selecting a routing algorithm
The introduction to this section briefly discussed an online map site where the user can choose from different route-calculation algorithms. In this section, we’ll walk through how to apply an Abstract Factory to address this requirement.
In a web application, you can only transfer primitive types[4] from the browser to the server, so when the user selects a routing algorithm from a drop-down box, you must represent this by a number or a string. An enum is really just a number, so on the server you can represent the selection using this RouteType:
4 To be pedantic, we can only transfer strings, but most web frameworks support type conversion for primitive types.
public enum RouteType
{
Shortest = 0,
Fastest,
Scenic
}
However, what you need is an instance of IRouteAlgorithm that can calculate the route for you. To translate from the runtime RouteType value to IRouteAlgorithm, you can define an Abstract Factory:
public interface IRouteAlgorithmFactory
{
IRouteAlgorithm CreateAlgorithm(RouteType routeType);
}
This enables you to implement a GetRoute method for a RouteController by injecting the IRouteAlgorithmFactory and using it to translate the runtime value to the DEPENDENCY you need: IRouteAlgorithm. The following listing demonstrates the interaction.
Listing 6.1. Using an IRouteAlgorithmFactory

The RouteController class’s responsibility is to handle web requests. The GetRoute method receives the user’s specification of origin and destination, as well as a selected RouteType. You need an ABSTRACT FACTORY to map the runtime RouteType value to an IRouteAlgorithm instance, so you request an instance of IRouteAlgorithmFactory using standard CONSTRUCTOR INJECTION.
In the GetRoute method, you can use the factory to map the routeType variable to an IRouteAlgorithm ![]() . When you have that, you can use it to calculate the route
. When you have that, you can use it to calculate the route ![]() and return the result.
and return the result.
Note
For the sake of conciseness, I omitted a Guard Clause in the GetRoute method. However, the supplied RouteSpecification may be null, so a more robust implementation should check for that.
The most obvious implementation of IRouteAlgorithmFactory would involve a simple switch statement and return three different implementations of IRouteAlgorithm based on the input. However, I’ll leave this as an exercise for the reader.
This example demonstrated mapping from runtime value to DEPENDENCY using an Abstract Factory in its purest form. The next example shows a more complex variation where at first glance you may not even realize that Abstract Factories are being used.
6.1.3. Example: using a CurrencyProvider
In most of chapter 4, you saw how to implement currency conversion in an ASP.NET MVC Controller. The Currency type is an abstract class, reproduced here so that you won’t have to flip back to section 4.1.4:
public abstract partial class Currency
{
public abstract string Code { get; }
public abstract decimal GetExchangeRateFor(
string currencyCode);
}
At first glance it seems a little weird to treat a concept like currency as an ABSTRACTION, because it sounds more like a Value Object.[5] However, notice that the GetExchangeRateFor method enables us to query it about a virtually unbounded set of conversion rates. If we assume 100 conversion rates, each Currency instance would consume more than 2 KB of memory. That doesn’t sound like a lot, but it may warrant an optimization like use of the Flyweight[6] design pattern.
5 Evans, Domain-Driven Design, 97.
6 Gamma, Design Patterns, 195.
Another issue that quickly arises with currency conversion regards the currency (sic!) of the currency: in other words, how up-to-date it is. Applications such as trader software for monetary markets require exchange rates to be updated several times a second, whereas an international commerce site is likely to get by with few updates for stable currencies. Such applications may also include markup or rounding strategies, adding to the potential complexity of implementing a Currency type. In that light, an abstract Currency class begins to sound reasonable.
When a consumer like an ASP.NET MVC Controller needs to convert prices, it requires a Currency as a DEPENDENCY to perform the conversion. In the sample commerce application used in this book, the Money class used to represent prices has this conversion method:
public Money ConvertTo(Currency currency)
A consumer such as a Controller can supply a Currency instance to all prices to convert them, but the question now arises, which Currency instance?
The choice of target Currency relies on a runtime value: the user’s preferred currency. This means we can’t request a single Currency object through CONSTRUCTOR INJECTION, because a COMPOSER is unable to know which Currency to use.
As you saw in section 4.1.1, the solution is to inject a CurrencyProvider instead of a single Currency:
public abstract class CurrencyProvider
{
public abstract Currency GetCurrency(string currencyCode);
}
Figure 6.2 illustrates how a Controller typically retrieves the user’s preferred currency code from the profile and uses the injected CurrencyProvider to create the appropriate Currency instance.
Figure 6.2. The injected CurrencyProvider is used to map a primitive runtime value (the currency code string) to a runtime DEPENDENCY (the Currency instance).

Although it has a different name, CurrencyProvider is an Abstract Factory that helps us bridge the gap between a runtime value and a runtime DEPENDENCY. A Currency conceptually depends on a currency code, so we can rest assured that we haven’t introduced a LEAKY ABSTRACTION by introducing the CurrencyProvider.
Another example from chapter 4 shows the degenerate case where there is no initial input parameter. In section 4.2.4, you saw how an abstract CurrencyProfileService has a GetCurrencyCode method that will return the user’s current currency code:
public abstract string GetCurrencyCode();
Although the GetCurrencyCode method returns a string instead of an ABSTRACTION, you can still view CurrencyProfileService as an Abstract Factory variant.
In the HomeController, you combine both variations to figure out the user’s preferred Currency:
var currencyCode = this.CurrencyProfileService.GetCurrencyCode(); var currency = this.currencyProvider.GetCurrency(currencyCode);
Both CurrencyProfileService and currencyProvider are injected Abstract Factories that are available to any member of the HomeController class. Sections 4.1.4 and 4.2.4 show how they’re injected.
Whenever we need to produce a runtime value and we want to be able to vary the means by which we produce this value independently of the consumer, we can inject an Abstract Factory. It’s typically a stateless service, so it fits better with how we normally treat DEPENDENCIES, and we can use CONSTRUCTOR INJECTION or PROPERTY INJECTION to supply the consumer with the factory.
There is another, different type of scenario where Abstract Factory also provides a good solution. This happens when we need to deal with short-lived DEPENDENCIES.
6.2. Working with short-lived Dependencies
Some DEPENDENCIES seem to be conceptually short-lived. These typically represent connections to external resources such as databases or web services. Such connections must be closed, or resource leaks will occur. In this section, we look at the best way to address such concerns.
Similar to the previous section, we’ll start by studying the general case and then proceed to look at an example. When we’re finished, you should understand two things:
- You can model such interactions with an Abstract Factory that produces disposable instances.
- You should strive to hide this pattern behind a stateless ABSTRACTION.
Before we turn to an example, let’s see what would cause me to say that.
6.2.1. Closing connections through Abstractions
The whole point of loose coupling and the LISKOV SUBSTITUTION PRINCIPLE is that a DEPENDENCY can be implemented in any number of ways. Even when you have a particular implementation in mind, a radically different implementation may potentially come along in the future.
Even so, some DEPENDENCIES represent access to external resources, and these tend to drag along issues related to resource usage. I am, of course, talking about connections in many shapes and forms.
Most .NET developers know that they should open an ADO.NET connection just before using it, and close it again as soon as the work is finished. Modern APIs like LINQ to SQL or LINQ to Entities automatically do this for us so we don’t have to explicitly deal with it.
Although the correct usage pattern concerning ADO.NET connections should be common knowledge, it’s far less known that the same is true for WCF clients. They should be closed as soon as we’re finished with a particular set of operations on a service, because they may otherwise leave orphaned resources on the server side.
A fundamental rule of service orientation is that services should be stateless. If we follow this rule, surely a WCF client should keep no resources alive on the server side, right?
Surprisingly, this may not be true. Even if we design a service to be completely stateless, WCF may not be. It depends on the binding.
One example among many relates to security. Message-based security tends to impact performance. This is true because asymmetric keys are computationally intensive, but it’s even more true for Federated security because multiple message exchanges are involved in establishing a security context. WCF’s default behavior is to establish a secure conversation based on the asymmetric key exchange. The service and client use the asymmetric security handshake to exchange an ad hoc symmetric key that is used to secure all future messages that are part of that session.
However, that behavior requires that both sides keep the shared secret in memory. The client must sign off with the service when it finishes the session, or it will orphan the symmetric key at the server. It will eventually be cleaned up after a timeout, but it takes up memory until then. To save resources on the server, the client should explicitly close the “connection” when it’s finished.
Although this isn’t true for all WCF bindings, it’s true for so many that we need to ensure that our WCF clients are good citizens.
How can we reconcile the need to close a WCF connection with the desire to avoid a LEAKY ABSTRACTION? This issue can be addressed on two levels:
- Hiding the entire connection management logic behind an ABSTRACTION
- Mimicking opening and closing connections on a more detailed level
The first option is preferred, but sometimes the second is required as well. Both options can be combined to get the best of both worlds.
Hiding connection management behind an Abstraction
DI is no excuse for writing applications with memory leaks, so we must be able to explicitly close connections as soon as possible. On the other hand, any DEPENDENCY may or may not represent out-of-process communication, so it would be a LEAKY ABSTRACTION if we were to model an ABSTRACTION to include a Close method.
Some people resort to letting their DEPENDENCIES derive from IDisposable. However, the Dispose method is just a Close method with another name, so that approach doesn’t solve the underlying problem.
Fortunately, database access technologies such as LINQ to SQL and LINQ to Entities show the way. In both cases, we access data through a context that contains a connection. Whenever we communicate with the database, the context automatically opens and closes the connection as necessary, entirely freeing us from the burden of dealing with this.
Our first reaction should be to do the same. Figure 6.3 shows how to define the ABSTRACTION at a level that is sufficiently coarse-grained that the implementation can open and close connections as necessary.
Figure 6.3. We can design an interface so that it’s sufficiently coarse-grained that each method encapsulates all interactions with an external resource in a single batch. The Consumer invokes a method on the IResource interface. An implementation of that method could open a connection and invoke several methods against the external resource before closing the connection and returning a result to the consumer.

The consumer is never aware that some implementations may be opening and closing connections on its behalf.
Whenever possible, we should strive to design a consumer’s DEPENDENCIES so that we never need to explicitly deal with the lifetime of the DEPENDENCY at this level. There are, however, instances where we can’t do that.
Opening and closing Dependencies
The problem with coarse-grained APIs is that they may not be flexible enough. Sometimes we simply need an ABSTRACTION that lets us explicitly model the lifecycle of DEPENDENCIES that otherwise will cause memory leaks.
Warning
Stopping one leak creates another. We exchange memory leaks for LEAKY ABSTRACTIONS.
The most common lifecycle we need to model is shown in figure 6.4.
Figure 6.4. The most common lifecycle for a connection is that we create it, use it, and close it when we’re finished with it. This is the lifecycle that we should model if we must model such things.

In section 6.1, you saw how to use an Abstract Factory to create DEPENDENCIES at will, so we need to find a coding idiom that fits with closing a connection. As figure 6.4 hints, we can use the IDisposable pattern to dispose of connection-using DEPENDENCIES.
Warning
Disposable DEPENDENCIES are design smells. Use them only when there is no other option. Read more in section 8.2.
In other words, we can model just about any interaction that fits the lifecycle from figure 6.4 with an Abstract Factory that creates disposable DEPENDENCIES (see figure 6.5).
Figure 6.5. We can model connection management and similar lifecycles by taking a DEPENDENCY on an Abstract Factory such as the IFooFactory shown here. Each time the consumer needs an instance of IFoo, it’s created by IFooFactory, but the consumer must remember to dispose of it appropriately.
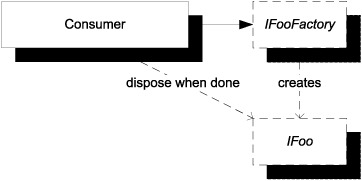
The usage pattern shown in figure 6.5 is often best implemented by using the C# using keyword (or a similar construct in other languages).
As the following example will show, it makes sense to combine both of the approaches just discussed. The resource access is modeled as a coarse-grained ABSTRACTION that shields the consumer from explicitly dealing with lifecycle management, whereas the implementation uses the described combination of Abstract Factory and disposable DEPENDENCIES. Let’s see how that works.
6.2.2. Example: invoking a product-management service
Imagine a Windows Presentation Foundation (WPF) application that provides a rich user interface for managing a product catalog. Such an application could communicate with the backend via a WCF service that exposes the necessary product catalog management operations.
Figure 6.6 shows how an implementation combines both techniques from the previous section.
Figure 6.6. The MainWindowViewModel class consumes the IProductManagementAgent interface. This is a coarse-grained interface that exposes appropriate methods for the consumer to call. From MainWindowViewModel’s perspective, no connection management is taking place. When the application is running, the WcfProductManagementAgent class provides the implementation of the coarse-grained interface. It does this by consuming the Abstract Factory IProductChannelFactory that creates disposable instances. The IProductManagementServiceChannel interface derives from IDisposable, which enables WcfProductManagementAgent to dispose of the WCF client when the operations have been successfully invoked.

Note
We’ll return to this WPF application in sections 6.3.2 and 7.4.2.
The consumer is shielded from connection management, which is an implementation detail of WcfProductManagementAgent.
Whenever the MainWindowViewModel class wants to invoke a service operation, it invokes its IProductManagementAgent DEPENDENCY. This is a completely normal DEPENDENCY injected via CONSTRUCTOR INJECTION. This, for example, shows how to delete a product:
this.agent.DeleteProduct(productId);
In this case, this.agent is the injected IProductManagementAgent DEPENDENCY. As you can see, no explicit connection management is taking place here; but if you look at the implementation in WcfProductManagementAgent, you see how Abstract Factory is used in combination with a disposable DEPENDENCY:
using (var channel = this.factory.CreateChannel())
{
channel.DeleteProduct(productId);
}
You don’t have an injected WCF client you can use to invoke the service operation because you need to close the client as soon as you’re finished with it, and it isn’t possible to reuse WCF channels. Instead, you have an injected Abstract Factory that you use to create a new channel. Because the operation is enclosed in a using scope, leaving the scope disposes the channel.
The factory DEPENDENCY is an instance of the IProductChannelFactory interface. This is a custom interface created for the occasion:
public interface IProductChannelFactory
{
IProductManagementServiceChannel CreateChannel();
}
However, the IProductManagementServiceChannel interface is an auto-generated interface created together with all the other WCF proxy types. Every time we create a service reference in Visual Studio or use svcutil.exe, such an interface is created along with the other types. The attractive feature of this auto-generated interface is that it implements IDisposable along with all the service operations.
This type is understood by WCF, making the implementation of IProductChannelFactory trivial because we can use System.ServiceModel.ChannelFactory<TChannel> to create the instances.
As a dominant principle, I prefer a stateless and coarse-grained interface like IProductManagementAgent to shield the implementation details from consumers. Although we must view disposable DEPENDENCIES as LEAKY ABSTRACTIONS, a leak can be contained within a particular implementation; and by doing that we gain TESTABILITY without compromising the overall design.
Abstract Factory is an extremely useful design pattern. It helps resolve runtime DEPENDENCIES and short-lived DEPENDENCIES. We can also include it in an effort to resolve cyclic DEPENDENCIES, but it doesn’t play a central role in that context.
6.3. Resolving cyclic Dependencies
Occasionally, DEPENDENCY implementations turn out to be cyclic. An implementation requires another DEPENDENCY whose implementation requires the first ABSTRACTION. Such a dependency graph can’t be satisfied.
It’s important to realize that the ABSTRACTIONS themselves can be perfectly acyclic, while particular implementation can introduce a cycle. Figure 6.7 shows how this could happen.
Figure 6.7. Cycles in the dependency graph can occur even if the ABSTRACTIONS have no relations to each other. In this example, each implementation implements a separate interface but also requires a DEPENDENCY. Because ConcreteC requires IA, but the only implementation of IA is ConcreteA with its DEPENDENCY on IB and so forth, we have a cycle that can’t be resolved as is.

As long as the cycle remains, we can’t possibly satisfy all DEPENDENCIES, and our applications won’t be able to run. Clearly, something must be done, but what?
In this section, we look into the issue concerning cyclic DEPENDENCIES, including an example. When we’re finished, your first reaction should be to try to redesign your DEPENDENCIES. If that isn’t possible, you can break the cycle by refactoring from CONSTRUCTOR INJECTION to PROPERTY INJECTION. This represents a loosening of a class’s invariants, so it isn’t something you should do lightly.
6.3.1. Addressing Dependency cycles
Whenever I encounter a DEPENDENCY cycle, my first question is, “Where did I fail?”
Tip
A DEPENDENCY cycle is a design smell. If one appears, you should seriously reconsider your design.
A DEPENDENCY cycle should immediately trigger a thorough evaluation of the root cause of the cycle. It’s often based on either incorrect assumptions or a serious break of the rule of unidirectional DEPENDENCIES. In a layered application, classes should only talk to other classes in their own layer and the layer immediately below.
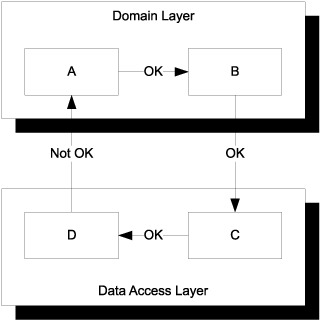
If the cycle traverses more than one layer, we know something is fundamentally wrong. As figure 6.8 shows, this would mean that some references go the wrong way.
Figure 6.8. When a cycle crosses one or more layer boundaries, at least one reference is architecturally illegal. In this case, the reference from D to A is the culprit. If a situation like this occurs, it should be addressed immediately.
It’s a little less clear what is going on if we have a cycle within a single layer. This may even be the result of valid considerations that just ended up as less-than-optimal implementations.
It’s imperative that we break a cycle in some way. As long as the cycle exists, the application won’t run.
Any cycle is a design smell, so our first reaction should be to redesign the involved part to prevent the cycle from happening in the first place. Table 6.1 shows some general directions we can take.
Table 6.1. Some redesign strategies for breaking DEPENDENCY cycles
|
Strategy |
Description |
|---|---|
| Events | You can often break a cycle by changing one of the ABSTRACTIONS to raise events instead of having to explicitly invoke a DEPENDENCY to inform the DEPENDENCY that something happened. Events are particularly appropriate if one side only invokes void methods on its DEPENDENCY. .NET events are an application of the Observer[7] design pattern, and you may occasionally consider implementing it explicitly. This is particularly true if you decide to use Domain Events[8] to break the cycle. This has the potential to enable true asynchronous one-way messaging. |
| PROPERTY INJECTION | If all else fails, we can break the cycle by refactoring one class from CONSTRUCTOR INJECTION to PROPERTY INJECTION. This should be a last-ditch effort because it only treats the symptoms. |
7 Ibid., 293.
8 Udi Dahan, “Domain Models: Employing the Domain Model Pattern” (MSDN Magazine, August 2009), http://msdn.microsoft.com/en-us/magazine/ee236415.aspx
I don’t intend to elaborate upon the first option because the existing literature already provides detailed treatment.
Tip
Attempt to address cycles by using events. If that fails, try an Observer. Only if you’re still unsuccessful should you consider breaking the cycle by using PROPERTY INJECTION.
Make no mistake: a DEPENDENCY cycle is a design smell. Our first priority should be to analyze the code to understand why the cycle appears. When we understand why, we should change the design.
Still, sometimes we can’t change the design. Even if we understand the root cause of the cycle, the offending API may be out of our control.
Breaking the cycle with Property Injection
In some cases, the design error is out of our control, but we still need to break the cycle. In such cases, we can break the cycle by using PROPERTY INJECTION.
Warning
You should only resort to solving cycles by using PROPERTY INJECTION as a last-ditch effort. It only treats the symptoms instead of curing the illness.
To break the cycle, we must analyze it to figure out where we can make a cut. Because using PROPERTY INJECTION suggests an optional rather than a required DEPENDENCY, it’s important that we closely inspect all DEPENDENCIES to determine where cutting hurts the least.
In figure 6.9, B requires an instance of IC (the interface that C implements). We can resolve the cycle by changing B’s DEPENDENCY from CONSTRUCTOR INJECTION to PROPERTY INJECTION. This means that we can create B first and inject it into A, and then subsequently assign C to B:
var b = new B(); var a = new A(b); b.C = new C(new D(a));
Figure 6.9. Given a cycle, we must first decide where to cut it. In this case, we decide to cut between B and C.

Using PROPERTY INJECTION this way adds extra complexity to B because it must now be able to deal with the case where its DEPENDENCY isn’t yet available.
Tip
Classes should never perform work involving DEPENDENCIES in their constructors because the injected DEPENDENCY may not yet be fully initialized.
If we don’t wish to loosen any of the original classes in this way, we can introduce a Virtual Proxy[9] that leaves B intact:
9 Gamma, Design Patterns, 208.
var lb = new LazyB(); var a = new A(lb); lb.B = new B(new C(new D(a)));
LazyB implements IB just like B does. However, it takes its IB DEPENDENCY through PROPERTY INJECTION instead of CONSTRUCTOR INJECTION, allowing us to break the cycle without violating the invariants of any of the original classes.
Although classes with the imaginative names A–D illustrate the structure of a solution, a more realistic example is warranted.
6.3.2. Example: composing a window
One of the most common situations where we can’t redesign our way out of a DEPENDENCY cycle is when we deal with external APIs. One such example is WPF.
In WPF, we can use the MVVM[10] pattern to implement separation of concerns by splitting the code into Views and underlying models. The models are assigned to the Views through a DataContext property. This is essentially PROPERTY INJECTION at work.
10 Josh Smith, “Patterns: WPF Apps With The Model-View-ViewModel Design Pattern” (MSDN Magazine, February 2009), http://msdn.microsoft.com/en-us/magazine/dd419663.aspx
Tip
You can read more about composing WPF applications with MVVM in section 7.4.
A DataContext serves as the Window’s DEPENDENCY, but the model plays a large part in controlling which Views are activated where. One of the actions a model must be able to perform is to pop up a dialog box. And one way to implement this is by injecting an ABSTRACTION like this into the model:
public interface IWindow
{
void Close();
IWindow CreateChild(object viewModel);
void Show();
bool? ShowDialog();
}
With an injected IWindow, any model can create new Windows and display them as modal or modeless windows. However, to implement this interface, we need a reference to the real Window to properly set the Owner property. The following listing shows the implementation of the CreateChild method.
Listing 6.2. Creating a child window
public virtual IWindow CreateChild(object viewModel)
{
var cw = new ContentWindow();
cw.Owner = this.wpfWindow;
cw.DataContext = viewModel;
WindowAdapter.ConfigureBehavior(cw);
return new WindowAdapter(cw);
}
ContentWindow is a WPF Window you can use to show a new window. It’s important to set the owner of a Window before showing it, because otherwise weird bugs can occur where a focused or modal window is hidden behind other windows. To prevent such bugs, you set the Owner property to the current Window. The wpfWindow field is another instance of System.Windows.Window.
You also assign the viewModel to the new Window’s DataContext before wrapping it in a new IWindow implementation and returning it.
The issue is that with this implementation, you have ViewModels that require IWindow, an IWindow implementation that requires a WPF Window, and WPF Windows that through their DataContext require a ViewModel to work. Figure 6.10 shows this cycle.
Figure 6.10. A WPF MVVM cycle. In MVVM, a Window depends on a ViewModel, which in turn depends on an IWindow instance. The proper implementation of IWindow is WindowAdapter, which depends on a WPF Window to be able to set the owner of each Window to avoid focus bugs.

There is no reasonable kind of redesign you can apply to get out of the circular DEPENDENCY. The relationship between Window and ViewModel is fixed because System.Windows.Window is an external API (defined in the Base Class Library [BCL]). Likewise, WindowAdapter depends on a Window to avoid focus bugs, so this relationship is also externally given.
The only relationship you can change is between a ViewModel and its IWindow. Technically, you could redesign this to use events, but that would lead to a rather counter-intuitive API. To show a dialog box, you would have to raise an event and hope someone subscribes by showing a modal window. Furthermore, you would have to return the result of the dialog box by reference via the original event arguments. Raising the event would be a blocking call. This would be technically possible, but strange, so we’ll rule that out.
It seems we can’t redesign our way out of the cycle, so how do we break it?
Breaking the cycle
We need to find a relationship where we can cut the cycle to introduce PROPERTY INJECTION. In this case it’s easy, because the relationship between a WPF Window and a ViewModel already uses PROPERTY INJECTION. This is where we’ll cut.
The simplest solution is to wire up anything else and set the DataContext property on the MainWindow as the last thing before showing it. This is possible but not particularly DI CONTAINER–friendly, because it would require us to explicitly assign a DEPENDENCY after composition has been performed.
As an alternative, we can encapsulate this deferred assignment in a lazy-loading adapter. This enables us to wire up everything properly with a DI CONTAINER.
Note
The following example draws on the same project that is also described in section 7.4.2. You can see all the code in the code download for the book.
Let’s see how to encapsulate creation of an IWindow implementation that correctly bootstraps a MainWindowViewModel and assigns it to a WPF MainWindow instance. To help do that, you introduce this Abstract Factory:
public interface IMainWindowViewModelFactory
{
MainWindowViewModel Create(IWindow window);
}
The MainWindowViewModel class has more than one DEPENDENCY, but all the DEPENDENCIES other than IWindow can be satisfied immediately, so you don’t need to supply them as a parameter to the Create method. Instead, you can inject them into the concrete implementation of IMainWindowViewModelFactory.
You use IMainWindowViewModelFactory as a DEPENDENCY in an implementation of IWindow derived from the WindowAdapter glimpsed in listing 6.2. This enables you to defer initialization of the IWindow implementation until the first method is invoked. Here you see how the CreateChild method from listing 6.2 is overridden:
public override IWindow CreateChild(object viewModel)
{
this.EnsureInitialized();
return base.CreateChild(viewModel);
}
Before performing any real work, you must make sure that all DEPENDENCIES are fully initialized. When they are, you can safely invoke the base implementation.
The next listing shows how the EnsureInitialized method is implemented using the injected IMainWindowViewModelFactory.
Listing 6.3. Deferred initialization of DEPENDENCIES

When initializing the MainWindowAdapter, you first invoke the injected Abstract Factory to produce the desired ViewModel ![]() . This is possible at this point because the MainWindowAdapter instance is already created; and because it implements IWindow, you can pass the instance to the Create method.
. This is possible at this point because the MainWindowAdapter instance is already created; and because it implements IWindow, you can pass the instance to the Create method.
When you have the ViewModel, you can assign it to the DataContext of the encapsulated WPF Window ![]() . With a bit of further setup, the Window is now fully initialized and ready for use.
. With a bit of further setup, the Window is now fully initialized and ready for use.
In the application’s COMPOSITION ROOT, you can wire it all up like this:
IMainWindowViewModelFactory vmFactory =
new MainWindowViewModelFactory(agent);
Window mainWindow = new MainWindow();
IWindow w =
new MainWindowAdapter(mainWindow, vmFactory);
The mainWindow variable becomes the WpfWindow property in listing 6.3, and vmFactory matches the field of the same name. When you invoke the Show or ShowDialog method on the resulting IWindow, the EnsureInitialize method is invoked and all DEPENDENCIES are satisfied.
This combination of a deferred initialization with the help of an Abstract Factory can be a nice extra touch, but it’s the presence of PROPERTY INJECTION that enables you to break the cycle in the first place. In this case you were “lucky” because a WPF Window already uses PROPERTY INJECTION through its DataContext property.
Always keep in mind that the best way to address a cycle is to redesign the API so that the cycle disappears. However, in the rare cases where this is impossible or highly undesirable, we must break the cycle by using PROPERTY INJECTION in at least one place. This enables us to compose the rest of the object graph apart from the DEPENDENCY associated with the property. When the rest of the object graph is fully populated, we can inject the appropriate instance via the property. As an optional extra touch, we can encapsulate this property-assignment logic in a class and use an Abstract Factory to assign the property value at the last possible moment.
PROPERTY INJECTION signals that a DEPENDENCY is optional, so we shouldn’t make the change lightly. CONSTRUCTOR INJECTION is much preferred in most cases, but it may make some people uneasy. Let’s see why.
6.4. Dealing with Constructor Over-injection
Unless you have special requirements, CONSTRUCTOR INJECTION should be your preferred injection pattern. However, some people become uncomfortable when the number of DEPENDENCIES grows. They don’t like a constructor with too many parameters.
In this section, we’ll look at the apparent problem of a growing number of constructor parameters and why this is a good thing rather than a bad thing. As you’ll see, it doesn’t mean we should accept long parameter lists in constructors, so we’ll also review what we can do about too many constructor arguments. An example rounds off the section.
6.4.1. Recognizing and addressing Constructor Over-injection
When a constructor’s parameter list grows too large, we call the phenomenon Constructor Over-injection[11] and consider it a code smell. It’s a general code smell unrelated to, but magnified by, DI. Although our initial reaction might be that we don’t like CONSTRUCTOR INJECTION because of Constructor Over-injection, we should be thankful that a general design issue is revealed to us.
11 Jeffrey Palermo, “Constructor over-injection smell—follow up,” 2010, http://jeffreypalermo.com/blog/constructor-over-injection-smell-ndash-follow-up/
In this section, we’ll first take a moment to appreciate how Constructor Over-injection makes our lives a little easier, and then consider appropriate reactions.
Constructor Over-injection as a signal
Although CONSTRUCTOR INJECTION is easy to implement and use, it makes people uncomfortable when their constructors start looking like this:
public MyClass(IUnitOfWorkFactory uowFactory,
CurrencyProvider currencyProvider,
IFooPolicy fooPolicy,
IBarService barService,
ICoffeeMaker coffeeMaker,
IKitchenSink kitchenSink)
I can’t say I blame anyone for disliking such a constructor, but don’t blame CONSTRUCTOR INJECTION. We can agree that a constructor with six parameters is a code smell, but it indicates a violation of the SINGLE RESPONSIBILITY PRINCIPLE rather than a problem related to DI.
Tip
CONSTRUCTOR INJECTION makes it easy to spot SINGLE RESPONSIBILITY PRINCIPLE violations.
Instead of feeling uneasy about Constructor Over-injection, we should embrace it as a fortunate side effect of CONSTRUCTOR INJECTION. It’s a signal that alerts us whenever a class takes on too much responsibility.
My personal threshold lies at four constructor arguments. Whenever I add a third argument, I begin considering whether I could design things differently, but I can live with four arguments for a few classes. Your limit may be different, but when you cross it, it’s time to refactor.
How we refactor a particular class that has grown too big depends on the particular circumstances: the object model already in place, the domain, business logic, and so on. Splitting up a budding God Class[12] into smaller, more focused classes according to well-known design patterns is always a good move.
12 William J. Brown, et al., AntiPatterns: Refactoring Software, Architectures, and Projects in Crisis (New York: Wiley Computer Publishing, 1998), 73.
Still, there are cases where business requirements oblige us to do a lot of different things at the same time. This is often the case at the boundary of an application. Think about a coarse-grained web service operation that triggers many business events. One way to model such operations is by hiding the myriad DEPENDENCIES behind Facade Services.
Refactoring to Facade Services
There are many ways we can design and implement collaborators so that they don’t violate the SINGLE RESPONSIBILITY PRINCIPLE. In chapter 9, we’ll discuss how the Decorator[13] design pattern can help us stack CROSS-CUTTING CONCERNS instead of injecting them into consumers as services. This can eliminate a lot of constructor arguments.
13 Gamma, Design Patterns, 175.
Still, in some scenarios a single entry point needs to orchestrate many DEPENDENCIES. One example is a web service operation that triggers a complex interaction of many different services. The entry point of a scheduled batch job may face the same issue.
Figure 6.11 shows how we can refactor key relationships into Facade Services.
Figure 6.11. In the top diagram, the consumer has five DEPENDENCIES, which is a strong indication that it violates the SINGLE RESPONSIBILITY PRINCIPLE. Still, if the role of the consumer is to orchestrate those five DEPENDENCIES, we can’t throw any away. Instead, we can introduce Facade Services that orchestrate parts of the relationship. In the bottom diagram, the consumer has only two DEPENDENCIES, and the Facades have two and three DEPENDENCIES.

Refactoring to Facade Services is more than just a party trick to get rid of too many DEPENDENCIES. The key is to identify natural clusters of interaction. In figure 6.11, it turns out that DEPENDENCIES A–C form a natural cluster of interaction, and so do D and E.
A beneficial side effect is that discovering these natural clusters draws previously undiscovered relations and domain concepts out in the open. In the process, we turn implicit concepts into explicit concepts.[14] Each Facade becomes a service that captures this interaction on a higher level, and the consumer’s single responsibility becomes to orchestrate these high-level services.
14 Evans, Domain-Driven Design, 206-223.
Note
Facade Services are abstract Facades[15]—hence the name.
15 Gamma, Design Patterns, 185.
Facade Services are related to Parameter Objects,[16] but instead of combining and exposing components, a Facade Service exposes only the encapsulated behavior, while hiding the constituents.
16 Martin Fowler et al., Refactoring: Improving the Design of Existing Code (New York: Addison-Wesley, 1999), 295.
Obviously, we can repeat this refactoring if we have such a complex application that the consumer ends up with too many DEPENDENCIES on Facade Services. Creating a Facade for Facade Services is a perfectly sensible thing to do.
Close to the boundary of our application (such as the UI or a web service), we can operate with a set of rather coarse-grained ABSTRACTIONS. As we examine the implementations of DEPENDENCIES, we see that behind coarse-grained services are finer-grained services, which are combinations of even finer-grained services. This enables us to quickly get an overview at the entry level while ensuring that each final implementation adheres to the SINGLE RESPONSIBILITY PRINCIPLE.
Let’s look at an example.
6.4.2. Example: refactoring order reception
The sample commerce application that we look at from time to time needs to be able to receive orders. This is often best done by a separate application or subsystem because at that point the semantics of the transaction change.
As long as you’re looking at a shopping basket, you can dynamically calculate unit prices, exchange rates, and discounts; but when a customer places an order, all those values must be captured and frozen as they were presented when the customer approved the order. Table 6.2 provides an overview of the order-reception process.
Table 6.2. When the order subsystem receives a new order, it must perform a number of different actions.
|
Action |
Required DEPENDENCIES |
|---|---|
| Save the order | OrderRepository |
| Send a receipt email to the customer | IMessageService |
| Notify the accounting system about the invoice amount | IBillingSystem |
| Select the best warehouses to pick and ship the order based on the items in the order and proximity to the shipping address | ILocationService, IInventoryManagement |
| Ask the selected warehouses to pick and ship the entire order or parts of it | IInventoryManagement |
Five different DEPENDENCIES are required just to receive an order. Imagine which other DEPENDENCIES you would need to handle other order-related operations!
Let’s first review how this would look if the consuming OrderService class directly imported all these DEPENDENCIES; subsequently, you’ll see how you can refactor the functionality by using Facade Services.
Too many fine-grained Dependencies
If you let OrderService directly consume all five DEPENDENCIES, the structure is as shown in figure 6.12.
Figure 6.12. OrderService has five direct DEPENDENCIES, indicating that it violates the SINGLE RESPONSIBILITY PRINCIPLE.

If you use CONSTRUCTOR INJECTION for the OrderService class (which you should), you have a constructor with five parameters. This is too many and indicates that the OrderService has too many responsibilities. On the other hand, all these DEPENDENCIES are required because the OrderService class must implement all of the desired functionality when it receives a new order.
You can address this issue by redesigning OrderService.
Refactoring to Facade Services
The first thing you need to do is to look for natural clusters of interaction to identify potential Facade Services. The interaction between ILocationService and IInventoryManagement should immediately draw your attention, because you use them to find the closest warehouses that can fulfill the order. This could potentially be a complex algorithm, but after you’ve selected the warehouses you need to notify them about the order.
If you think about this a little further, ILocationService is an implementation detail of notifying the appropriate warehouses about the order. The entire interaction can be hidden behind an IOrderFulfillment interface, as shown in figure 6.13. Interestingly, order fulfillment sounds a lot like a domain concept in its own right; chances are that you just discovered an implicit domain concept and made it explicit.
Figure 6.13. The interaction between IInventoryManagement and ILocationService is implemented in the LocationOrderFulfillment class, which implements the IOrderFulfillment interface. Consumers of the IOrderFulfillment interface have no idea that the implementation has two DEPENDENCIES.
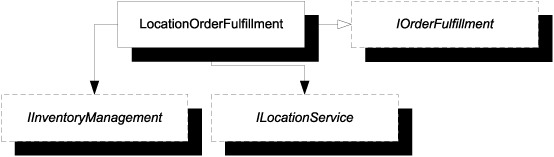
The default implementation of IOrderFulfillment consumes the two original DEPENDENCIES, so it has a constructor with two parameters, which is fine. As a further benefit, you’ve encapsulated the algorithm for finding the best warehouse for a given order into a reusable component.
This refactoring collapses two DEPENDENCIES into one but leaves you with four DEPENDENCIES of the OrderService class. You need to look for other opportunities to aggregate DEPENDENCIES into a Facade.
The next thing you may notice is that all the requirements involve notifying other systems about the order. This suggests that you can define a common ABSTRACTION that models notifications—perhaps something like this following code snippet:
public interface INotificationService
{
void OrderAdded(Order order);
}
Tip
The Domain Event design pattern is another good alternative in this scenario.
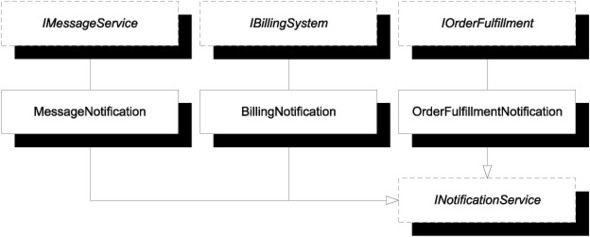
Each notification to an external system can be implemented using this interface. You can even consider wrapping OrderRepository in INotificationService, but it’s likely that the OrderService class will need access to other methods on OrderRepository to implement other functionality. Figure 6.14 shows how you implement the other notifications using INotificationService.
Figure 6.14. Every notification to an external system can be hidden behind the INotificationService—even the new IOrderFulfillment interface you just introduced.
You may wonder how this helps, because you’ve wrapped each DEPENDENCY in a new interface. The number of DEPENDENCIES didn’t decrease, so did you gain anything?
Yes. Because all three notifications implement the same interface, you can wrap them in a Composite.[17] This is another implementation of INotificationService that decorates a collection of INotificationService instances and invokes the OrderAdded method on them all.
17 Gamma, Design Patterns, 163.
From a conceptual perspective, this also makes sense because from a high-level view you don’t care about the details of how OrderService notifies other systems. However, you do care that it does. Figure 6.15 shows the final DEPENDENCIES of OrderService.
Figure 6.15. The final OrderService with refactored DEPENDENCIES. You keep OrderRepository as a separate DEPENDENCY because you need its additional methods to implement other functionality of OrderService. All the other notifications are hidden behind the INotificationService interface. At runtime, you use a CompositeNotificationService that contains the remaining three notifications.

This reduces OrderService to only two DEPENDENCIES, which is a much more reasonable number. Functionality is unchanged, making this a true refactoring. On the other hand, the conceptual level of OrderService changed. Its responsibility is now to receive an order, save it, and notify other systems. The details of which systems are notified and how this is implemented have been pushed down to a more detailed level.
Even though you consistently use CONSTRUCTOR INJECTION throughout, no single class’s constructor ends up requiring more than two parameters (CompositeNotificationService takes an IEnumerable<INotificationService> as a single argument).
Constructor Over-injection isn’t a problem related to DI in general or CONSTRUCTOR INJECTION specifically. Rather, it’s a signal that the class in question has too many responsibilities. The code smell comes from the class, not CONSTRUCTOR INJECTION; and as always, we should regard the smell as an opportunity to improve the code.
There are many ways we can refactor to patterns, but one option is to introduce Facade Services that model concepts at a higher abstraction level. This addresses the violation of the SINGLE RESPONSIBILITY PRINCIPLE and often draws out previously undiscovered domain concepts in the process.
This is one of the many ways DI helps us write better code. Because loose coupling is so valuable, we want to make sure loosely coupled code stays loosely coupled. The next section discusses how to do that.
6.5. Monitoring coupling
Loose coupling is valuable, but it’s surprisingly easy to introduce tight coupling. All it takes is a novice developer and a moment of inattention, and a hard reference may be introduced. In Visual Studio, it’s easy to add new references to an existing project, but this is often what we want to avoid. Discipline must be observed to ensure that each module focuses on its own area of responsibility.
In this section, we’ll look at some techniques that can be useful when we want to make sure loosely coupled code stays loosely coupled. Perhaps we want to protect the code against our mistakes, or perhaps junior developers on the team need a bit of help.
Nothing beats human interaction when it comes to transferring knowledge. Pair programming is ideal, but it may still be a good idea to back up manual review with automated tooling. In the next sections, we’ll look at how automated testing can be helpful, along with a dedicated tool called NDepend.
6.5.1. Unit-testing coupling
If we have a unit-test suite that we run regularly, we can quickly add a few unit tests that examine DEPENDENCIES and fail if an unwarranted dependency is detected. Using the type system in .NET, we can easily write a unit test that loops through all of an assembly’s references and fails if it finds one that shouldn’t be there.[18]
18 This idea was presented in Glenn Block, “PrismShouldNotReferenceUnity,” 2008, http://blogs.msdn.com/b/gblock/archive/2008/05/05/prismshouldnotreferenceunity.aspx
The Commerce sample application already has unit tests in place, so you can easily add one more. The following listing shows a unit test that protects the Presentation Logic module from directly referencing the SQL Server–based Data Access module.
Listing 6.4. Enforcing loose coupling with a unit test
[Fact]
public void SutShouldNotReferenceSqlDataAccess()
{
// Fixture setup
Type sutRepresentative = typeof(HomeController);
var unwanted = "Ploeh.Samples.Commerce.Data.Sql";
// Exercise system
var references =
sutRepresentative.Assembly
.GetReferencedAssemblies();
// Verify outcome
Assert.False(
references.Any(a => a.Name == unwanted),
string.Format(
"{0} should not be referenced by SUT",
unwanted));
// Teardown
}
This test looks for DEPENDENCIES of the Presentation Logic module. To get the list of references, you need to query the assembly in question. You can get the assembly from any type contained within that assembly, so you can pick one. It’s often a good idea to choose a type you expect to stay around for the long haul, because otherwise you’ll have to rewrite the test if you ever delete the type you selected. This test chooses HomeController because the website will always have a front page.
You also need to identify the assembly you wish to prevent from being referenced. You could use the same technique and pick a representative type from that assembly, but that would mean you need to reference that assembly from the unit test. This isn’t quite as bad as referencing the unwanted assembly from the production code, but it would still create an artificial coupling between these two libraries—you could say they become guilty by association. Although type safety is desirable, loose coupling trumps in this case, so instead you identify the unwanted assembly with a string (but see the following discussion for alternatives).
Getting the referenced assemblies from the representative type is as easy as a single method call. You can now use a simple LINQ query to verify that none of the referenced assemblies have the unwanted name. In the assertion, you also print out a message to display if the assertion fails.
Tip
This assertion uses a simple LINQ query, but you can replace it with a foreach loop if you’re developing on .NET 3.0 or earlier versions.
Tip
You can also reverse the logic and write the test so that only specific references on a predefined list are allowed and all other references are considered illegal.
If you’re using Test-Driven Development (TDD) to implement your code, you’re used to the so-called Red/Green/Refactor development cycle where you first write a failing test, then make it pass, and finally modify the code to make it more maintainable.
It turns out that making a tight-coupling-preventing test fail is more difficult than you may think. Even if the targeted Visual Studio project has a reference to the undesirable DEPENDENCY, the compiler will only include the reference if it’s being used.
Thus, to make such a test fail, we must first add the reference we don’t want and then write a line of dummy code that uses a type from the unwanted DEPENDENCY. As soon as we’ve seen the test fail, we can then reverse the process to make it pass. This is obviously not a problem if the library under test already violates the coupling constraint.
The previous example adds the unit test to an existing unit-test suite that targets the Presentation Logic module. Figure 6.16 illustrates the references in action.
Figure 6.16. The PresentationLogicUnitTest library is a test suite that targets the PresentationLogic library. To do that, it needs a reference to its target as well as the shared ABSTRACTIONS that are defined in the Domain Model. Because PresentationLogicUnitTest doesn’t target the Domain Model, the DomainModel module is shown in gray.

Listing 6.4 identifies the unwanted assembly with a simple string, but it would have been more type-safe to identify it using a representative type. However, that would require you to add a reference to the SQL Server–based Data Access module to the unit test, as shown in figure 6.17.
Figure 6.17. If we want type safety by adding a representative type from the SqlDataAccess library to PresentationLogicUnitTest, we introduce a new DEPENDENCY to the unit-test suite for the sole reason that we want to make sure it’s never accidentally added to the PresentationLogic library. Ironic, isn’t it?

You may think that adding an extra reference to a unit-test project can’t be that bad, but doing so has more disadvantages than are immediately apparent.
A detailed treatment of why a unit-test project should only reference the project it targets is outside the scope of this book, but the overall problem is that it creates an indirect dependency between PresentationModel and SqlDataAccess. Although both of these projects can exist and compile without the other, the unit-test project ties them together.
This indirect dependency can only be broken by throwing away the unit test that originally caused the dependency to exist. However, unit tests are written to be executed, so this is far from desirable.
If we want to keep such tight-coupling-preventing unit tests within an existing unit-test project, the cost of adding a hard reference to all the unwanted assemblies is too great. The best option is to identify the unwelcome DEPENDENCIES using strings, as shown in listing 6.4.
The disadvantage is that if we change the name of the prohibited assembly, the test becomes worthless—or maybe even worse than worthless, because we may think we’re protected when we aren’t.
This isn’t a major issue if we have reason to believe that assembly names are stable. When this isn’t the case, we need a different strategy.
6.5.2. Integration-testing coupling
There are compelling reasons why unit-test projects should only reference their targets. Yet to stay robust in the face of changing assembly names, we may at times need type-safe references to all the undesirable DEPENDENCIES. These sound like contradictory requirements, but we can solve this conundrum by introducing a new integration-test project.
You can add a new test project to the Commerce solution and add all the references you need. Figure 6.18 shows this solution; and although it looks a lot like figure 6.17, the difference is that for the integration test, all the references are legal and equally valid.
Figure 6.18. The CommerceIntegrationTest project contains automated tests that verify that the relationships between modules are correct. Unlike unit tests, an integration-test suite can contain as many references as are necessary to perform the test.

An integration test is another type of automated test at the API level. The difference between a unit test and an integration test is that a unit test deals with the unit in isolation, whereas integration tests focus on verifying that several units (often across different libraries) integrate with each other as intended.
Per definition, an integration-test project can reference all the DEPENDENCIES it needs to do its job, so it’s well suited to containing tests that enforce architectural constraints.
An integration-test suite is tightly coupled to a particular constellation of modules, so it’s much less reusable. It must be constrained to only contain the tests that absolutely only can be defined as integration tests, and tests that protect against unwanted coupling may belong in this category. Listing 6.5 shows a type-safe equivalent to the test in listing 6.4. It follows the same blueprint but varies when it comes to identifying the unwanted DEPENDENCY.
Listing 6.5. Enforcing loose coupling with an integration test

Now that you have references to all necessary DEPENDENCIES, you can pick a type from each module that you can use to represent their assemblies. In contrast with the previous example, you can identify both in a type-safe way.
Just as you did before, you retrieve a list of all the assemblies the PresentationLogic library references ![]() . Using the AssemblyName of each assembly
. Using the AssemblyName of each assembly ![]() , you then verify that the references don’t contain the SQL Server–based assembly
, you then verify that the references don’t contain the SQL Server–based assembly ![]() . The builtin static ReferenceMatchesDefinition method compares AssemblyNames.
. The builtin static ReferenceMatchesDefinition method compares AssemblyNames.
You may have noticed that the tests in listings 6.4 and 6.5 are similar. You could write new tests like the one in listing 6.5 by varying the two representative types and keep everything else constant.
The next logical step would be to extract the common part of the test into a Parameterized Test.[19] This would allow you to write a simple list of almost declarative tests that define what is and isn’t allowed in this particular constellation of modules.
19 Gerard Meszaros, xUnit Test Patterns: Refactoring Test Code (New York: Addison-Wesley, 2007), 607.
Unit tests and integration tests are great options if you’re already using automated API-level tests. If not, you should start doing so today, but there are also other alternatives.
6.5.3. Using NDepend to monitor coupling
If for some unfathomable reason you don’t wish to use unit tests, you can use a tool called NDepend (http://ndepend.com) to warn you if you or your team members introduce unwanted coupling.
NDepend is a commercial software tool that analyzes projects or solutions and reports a lot of statistics about the code. As an example, it can generate dependency graphs not unlike the ones you’ve seen throughout this book. If we analyze Mary’s original commerce solution from chapter 2, we get the graph shown in figure 6.19.
Figure 6.19. Dependency graph generated by NDepend for Mary’s commerce solution. By default, NDepend includes all DEPENDENCIES, including modules from the BCL. The size of the boxes reflects the number of code lines in each module, and the thickness of the arrows reflects the number of members used across the references.
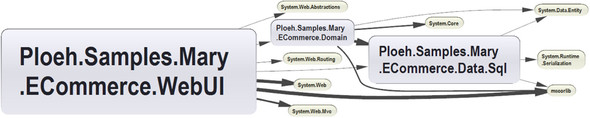
This looks complicated, but we can hide the BCL modules and rearrange the view to arrive at figure 6.20.
Figure 6.20. Modified NDepend graph for Mary’s commerce solution. In this graph, I’ve manually removed all BCL modules and made the boxes and arrows the same size.
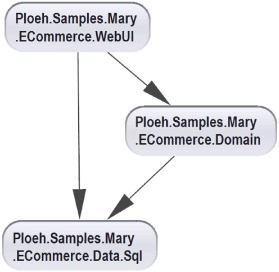
Does figure 6.20 look familiar? If you have eidetic memory, you may recall figure 2.10; but otherwise you can flip back to it. Notice how they share the same structure and illustrate the same relationship.
NDepend can do much more than draw pretty graphs. One of its most powerful features is the Code Query Language (CQL), which lets us query our code about a wide range of information with syntax reminiscent of SQL.
If Mary had written a CQL check before developing her solution, she would have been warned before much damage had been done. Here is a query that could have saved her a lot of trouble:
WARN IF Count > 0 IN SELECT ASSEMBLIES WHERE IsDirectlyUsing "ASSEMBLY:Ploeh.Samples.Mary.ECommerce.Data.Sql" AND NameIs "Ploeh.Samples.Mary.ECommerce.Domain"
When executed, this CQL query issues a warning if the Domain module directly references the SQL Server DataAccess module. In Mary’s solution, this query indeed issues a warning.
We can write as many CQL queries for a solution as we like and either run them using a visual editor or automate the process using a command-line tool. In both cases, XML files with analysis results are generated, so we can write our own automation tools that take appropriate action if we want to include such a step in an automated build process.
Note
I’ve only scratched the surface of NDepend’s features. It can do many other things, but I wanted to focus on its ability to keep an eye on coupling.
NDepend and automated tests are two ways to automatically monitor code to ensure that illegal DEPENDENCIES don’t sneak in by accident. We can use one or both of these methods as part of an automated Build Verification Test (BVT) or Continuous Integration (CI) effort.
In large code bases maintained by big teams, this can protect us from considerable grief. Although we can’t keep an eye on everything that goes on and perform manual code reviews of every check-in, automated tools can alert us when suspect things happen.
Warning
Some tools may produce false positives, so don’t blindly believe them when they tell you that you have a problem. Always use your experience and knowledge to evaluate warnings. Discard them if you don’t agree.
Review each incident with the appropriate amount of care, and take personal action if it represents a real issue.
Consider using automated tools to monitor coupling in large code bases. Doing so can prevent inadvertent tight coupling from messing up your code base while you concentrate on the other challenges described in this chapter.
6.6. Summary
DI isn’t particularly difficult when you understand a few basic principles, but as you learn, you’re guaranteed to run into issues that may leave you stumped for a while. This chapter attempts to address some of the most common issues people encounter.
One of the most versatile and useful design patterns related to DI is Abstract Factory. We can use it to translate primitive runtime values such as strings or numbers entered by users to instances of complex ABSTRACTIONS. We can also use Abstract Factories in combination with the IDisposable interface to mimic short-lived DEPENDENCIES such as connections to external resources.
Tip
Translate runtime values to DEPENDENCIES with Abstract Factories.
Tip
Mimic connections with ABSTRACT FACTORIES that create disposable DEPENDENCIES.
A problem that sometimes arises is DEPENDENCY cycles. These tend to occur because of APIs that are too demanding. The more APIs are designed around a query paradigm, the more likely cycles become. We can avoid cycles by observing the Hollywood Principle (tell, don’t ask). Methods with void signatures can be redesigned as events, which can often be used to break cycles. If a redesign is impossible, we can break a cycle by changing a single CONSTRUCTOR INJECTION to PROPERTY INJECTION. However, this shouldn’t be done lightly, because it changes the semantics of the consumer.
Tip
Break cycles with PROPERTY INJECTION.
CONSTRUCTOR INJECTION should be your preferred DI pattern; an additional benefit is that it becomes glaringly obvious every time you violate the SINGLE RESPONSIBILITY PRINCIPLE. When a single class has too many DEPENDENCIES, it’s a signal that we should redesign it in some way. Perhaps we can split it into several smaller classes, but occasionally we need to keep all the functionality within a single class.
Tip
Resolve Constructor Over-injection by refactoring to Facade Services.
In those cases, we can raise the abstraction level by inserting a layer of Facade Services between the consumer and the original DEPENDENCIES. Performing such a refactoring often results in the positive side effect that some of these Facade Services turn out to be previously undiscovered implicit domain concepts. Drawing implicit concepts out in the open and making them explicit is an improvement of the domain model.
While we perform these nitty-gritty refactorings, we must not lose sight of the big picture. Automated tests or tools can help us monitor whether tight coupling reappears in parts of the code base.
If we write a lot of unit tests (and particularly if we use Test-Driven Development), tight coupling will quickly manifest itself in complex and brittle test code. Or perhaps it’s impossible to unit-test large pieces of an application.
Tip
Write automated tests to enforce loose coupling.
If we don’t write unit tests, tight coupling may be overlooked, but we may experience many of its symptoms: as the code base evolves, it becomes more and more difficult to maintain. The nice clean design we originally intended slowly erodes into Spaghetti Code.[20] Adding a new feature requires us to touch the code base in many seemingly unrelated areas.
20 Brown, AntiPatterns, 119.
This chapter described solutions for issues commonly encountered with DI. Together with the two preceding chapters, it forms a catalog of patterns, anti-patterns, and refactorings. This catalog constitutes part 2 of the book. In part 3, we’ll turn toward the three dimensions of DI: OBJECT COMPOSITION, LIFETIME MANAGEMENT, and INTERCEPTION.